Java数据结构与经典算法——高手必会
java 经典笔试算法题

java 经典笔试算法题一、排序算法1. 实现一个基于Java的快速排序算法。
答:快速排序是一种常用的排序算法,其核心思想是分治法。
首先选择一个基准元素,将数组分成两部分,一部分小于基准元素,一部分大于基准元素。
然后递归地对这两部分继续进行快速排序,直到整个数组有序。
2. 实现一个稳定的冒泡排序算法。
答:冒泡排序是一种简单的排序算法,通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
稳定的冒泡排序算法是指在排序过程中,相同元素的相对位置不会改变。
3. 实现一个选择排序算法。
答:选择排序是一种简单直观的排序算法。
其工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
二、字符串操作算法1. 实现一个函数,将一个字符串反转。
答:可以使用StringBuilder类的reverse()方法来实现字符串的反转。
2. 实现一个函数,将一个字符串中的所有大写字母转换为小写字母,其余字符保持不变。
答:可以使用String类的replaceAll()方法和toLowerCase()方法来实现。
3. 实现一个函数,将一个字符串按空格分割成单词数组,并删除空字符串和null字符串。
答:可以使用split()方法和Java 8的流来处理。
三、数据结构算法1. 实现一个单向链表,并实现插入、删除、查找和打印链表的功能。
答:单向链表是一种常见的数据结构,可以通过定义节点类和链表类来实现。
插入、删除、查找和打印链表的功能可以通过相应的方法来实现。
2. 实现一个二叉搜索树(BST),并实现插入、查找、删除节点的功能。
答:二叉搜索树是一种常见的数据结构,它具有唯一的高度特性。
插入、查找和删除节点的功能可以通过相应的方法来实现,如左旋、右旋、递归等。
3. 实现一个哈希表(HashMap),并实现插入、查找和删除键值对的功能。
答:HashMap是一种基于哈希表的映射数据结构,它通过哈希码的方式将键映射到对应的值上。
Java数据结构和算法

Java数据结构和算法一、数组于简单排序 (1)二、栈与队列 (4)三、链表 (7)四、递归 (22)五、哈希表 (25)六、高级排序 (25)七、二叉树 (25)八、红—黑树 (26)九、堆 (36)十、带权图 (39)一、数组于简单排序数组数组(array)是相同类型变量的集合,可以使用共同的名字引用它。
数组可被定义为任何类型,可以是一维或多维。
数组中的一个特别要素是通过下标来访问它。
数组提供了一种将有联系的信息分组的便利方法。
一维数组一维数组(one-dimensional array )实质上是相同类型变量列表。
要创建一个数组,你必须首先定义数组变量所需的类型。
通用的一维数组的声明格式是:type var-name[ ];获得一个数组需要2步。
第一步,你必须定义变量所需的类型。
第二步,你必须使用运算符new来为数组所要存储的数据分配内存,并把它们分配给数组变量。
这样Java 中的数组被动态地分配。
如果动态分配的概念对你陌生,别担心,它将在本书的后面详细讨论。
数组的初始化(array initializer )就是包括在花括号之内用逗号分开的表达式的列表。
逗号分开了数组元素的值。
Java 会自动地分配一个足够大的空间来保存你指定的初始化元素的个数,而不必使用运算符new。
Java 严格地检查以保证你不会意外地去存储或引用在数组范围以外的值。
Java 的运行系统会检查以确保所有的数组下标都在正确的范围以内(在这方面,Java 与C/C++ 从根本上不同,C/C++ 不提供运行边界检查)。
多维数组在Java 中,多维数组(multidimensional arrays )实际上是数组的数组。
你可能期望,这些数组形式上和行动上和一般的多维数组一样。
然而,你将看到,有一些微妙的差别。
定义多维数组变量要将每个维数放在它们各自的方括号中。
例如,下面语句定义了一个名为twoD 的二维数组变量。
int twoD[][] = new int[4][5];简单排序简单排序中包括了:冒泡排序、选择排序、插入排序;1.冒泡排序的思想:假设有N个数据需要排序,则从第0个数开始,依次比较第0和第1个数据,如果第0个大于第1个则两者交换,否则什么动作都不做,继续比较第1个第2个…,这样依次类推,直至所有数据都“冒泡”到数据顶上。
数据结构与算法分析java——散列

数据结构与算法分析java——散列1. 散列的概念 散列⽅法的主要思想是根据结点的关键码值来确定其存储地址:以关键码值K为⾃变量,通过⼀定的函数关系h(K)(称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存⼊到此存储单元中。
检索时,⽤同样的⽅法计算地址,然后到相应的单元⾥去取要找的结点。
通过散列⽅法可以对结点进⾏快速检索。
散列(hash,也称“哈希”)是⼀种重要的存储⽅式,也是⼀种常见的检索⽅法。
按散列存储⽅式构造的存储结构称为散列表(hash table)。
散列表中的⼀个位置称为槽(slot)。
散列技术的核⼼是散列函数(hash function)。
对任意给定的动态查找表DL,如果选定了某个“理想的”散列函数h及相应的散列表HT,则对DL中的每个数据元素X。
函数值h(X.key)就是X在散列表HT中的存储位置。
插⼊(或建表)时数据元素X将被安置在该位置上,并且检索X时也到该位置上去查找。
由散列函数决定的存储位置称为散列地址。
因此,散列的核⼼就是:由散列函数决定关键码值(X.key)与散列地址h(X.key)之间的对应关系,通过这种关系来实现组织存储并进⾏检索。
⼀般情况下,散列表的存储空间是⼀个⼀维数组HT[M],散列地址是数组的下标。
设计散列⽅法的⽬标,就是设计某个散列函数h,0<=h( K ) < M;对于关键码值K,得到HT[i] = K。
在⼀般情况下,散列表的空间必须⽐结点的集合⼤,此时虽然浪费了⼀定的空间,但换取的是检索效率。
设散列表的空间⼤⼩为M,填⼊表中的结点数为N,则称为散列表的负载因⼦(load factor,也有⼈翻译为“装填因⼦”)。
建⽴散列表时,若关键码与散列地址是⼀对⼀的关系,则在检索时只需根据散列函数对给定值进⾏某种运算,即可得到待查结点的存储位置。
但是,散列函数可能对于不相等的关键码计算出相同的散列地址,我们称该现象为冲突(collision),发⽣冲突的两个关键码称为该散列函数的同义词。
java算法总结

java算法总结一、排序1、冒泡排序:t冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
2、选择排序:t选择排序是一种简单直观的排序算法,无论什么数据进去都是O(n)的时间复杂度。
所以用到它的时候,数据规模越小越好。
唯一的好处可能就是不占用额外的内存空间了吧。
3、插入排序:t插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
4、希尔排序:t希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。
希尔排序是非稳定排序算法。
该方法的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
二、查找1、线性查找:t线性查找又称顺序查找,是一种最简单的查找算法。
从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则查找成功;若扫描结束仍没有找到关键字等于k的结点,则表示表中不存在关键字等于k的结点,查找失败。
2、二分查找:t二分查找又称折半查找,要求待查找的序列有序。
每次取中间位置的值与待查关键字比较,如果中间位置的值更大,则在前半部分循环这个查找的过程,如果中间位置的值更小,则在后半部分循环这个查找的过程。
3、二叉查找树:t二叉查找树(Binary Search Tree,简称BST),又被称为二叉搜索树、有序二叉树。
它是一棵空树或者是具有下列性质的二叉树:若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;任意节点的左、右子树也分别为二叉查找树;没有键值相等的节点三、字符串处理1、KMP算法:tKMP算法是由Donald E.Knuth、Vaughn R. Pratt和James H.Morris三人于1977年提出的一种改进的字符串匹配算法,它利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
java业务的常用算法,应用场景

java业务的常用算法,应用场景Java业务的常用算法及应用场景算法是计算机科学的基础,它可以解决各种计算问题。
在Java编程中,算法的应用非常广泛。
本文将介绍Java业务中常用的算法以及它们的应用场景。
一、排序算法排序算法是最基本、最常用的算法之一。
在Java业务中,需要对数据进行排序的场景非常多。
例如,对数组或集合中的元素按照某个属性进行排序,对数据库中的记录按照某个字段进行排序等等。
常用的排序算法有冒泡排序、选择排序、插入排序、快速排序等。
这些算法各有特点,可以根据排序需求的不同选择合适的算法。
二、查找算法查找算法用于在一组数据中查找目标元素。
在Java业务中,查找算法的应用场景也很多。
例如,根据关键字从数据库中查询记录,查找集合中满足条件的元素等等。
常用的查找算法有线性查找、二分查找等。
线性查找适用于无序数据,而二分查找适用于有序数据。
三、图算法图算法用于解决图结构相关的问题。
在Java业务中,图算法可以应用于各种场景。
例如,社交网络中的好友关系图分析,行程规划中的路径搜索等等。
常用的图算法有广度优先搜索、深度优先搜索、最短路径算法等。
这些算法可以帮助我们理解和分析复杂的图结构,解决实际问题。
四、贪心算法贪心算法是一种通过局部最优选择来达到全局最优的算法。
在Java业务中,贪心算法可以用于解决各种优化问题。
例如,资源分配中的任务调度,机票价格计算中的最优组合等等。
贪心算法的核心思想是不断做出局部最优选择,并且希望这些选择最终能够达到全局最优。
虽然贪心算法不一定能够得到最优解,但在许多实际问题中,它的效果是非常好的。
五、动态规划算法动态规划算法是一种将复杂问题分解成简单子问题的思想。
在Java业务中,动态规划算法可以用于解决各种优化问题。
例如,最短路径问题、背包问题、字符串匹配问题等等。
动态规划算法的基本思路是通过保存已计算过的结果,避免重复计算,从而大大提高算法效率。
它常常用于求解具有最优子结构的问题。
java面试题经典算法

java面试题经典算法经典算法在Java面试中经常被问及,因为它们可以展示面试者对基本数据结构和算法的理解程度。
以下是一些经典算法,我会逐个介绍它们。
1. 冒泡排序(Bubble Sort),这是一种简单的排序算法,它重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
时间复杂度为O(n^2)。
2. 快速排序(Quick Sort),快速排序使用分治法策略来把一个序列分为两个子序列。
它是一种分而治之的算法,时间复杂度为O(nlogn)。
3. 二分查找(Binary Search),二分查找是一种在有序数组中查找某一特定元素的搜索算法。
时间复杂度为O(logn)。
4. 递归算法(Recursion),递归是指在函数的定义中使用函数自身的方法。
递归算法通常用于解决可以被分解为相同问题的子问题的情况。
5. 动态规划(Dynamic Programming),动态规划是一种在数学、计算机科学和经济学中使用的一种方法。
它将问题分解为相互重叠的子问题,通过解决子问题的方式来解决原始问题。
6. 深度优先搜索(Depth-First Search)和广度优先搜索(Breadth-First Search),这两种搜索算法通常用于图的遍历和搜索。
深度优先搜索使用栈来实现,而广度优先搜索则使用队列来实现。
以上是一些常见的经典算法,当然还有很多其他的算法,如贪心算法、Dijkstra算法、KMP算法等等。
在面试中,除了了解这些算法的原理和实现方式之外,还需要能够分析算法的时间复杂度、空间复杂度以及适用场景等方面的知识。
希望这些信息能够帮助你在Java面试中更好地准备算法相关的问题。
Java常见的七种查找算法

Java常见的七种查找算法1. 基本查找也叫做顺序查找,说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。
从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
示例代码:public class A01_BasicSearchDemo1 {public static void main(String[] args){//基本查找/顺序查找//核心://从0索引开始挨个往后查找//需求:定义一个方法利用基本查找,查询某个元素是否存在//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}int[] arr ={131,127,147,81,103,23,7,79};int number =82;System.out.println(basicSearch(arr, number));}//参数://一:数组//二:要查找的元素//返回值://元素是否存在public static boolean basicSearch(int[] arr,int number){//利用基本查找来查找number在数组中是否存在for(int i =0; i < arr.length; i++){if(arr[i]== number){return true;}}return false;}}2. 二分查找也叫做折半查找,说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。
但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。
用给定值先与中间结点比较。
比较完之后有三种情况:•相等说明找到了•要查找的数据比中间节点小说明要查找的数字在中间节点左边•要查找的数据比中间节点大说明要查找的数字在中间节点右边代码示例:package com.itheima.search;public class A02_BinarySearchDemo1 {public static void main(String[] args){//二分查找/折半查找//核心://每次排除一半的查找范围//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}int[] arr ={7,23,79,81,103,127,131,147};System.out.println(binarySearch(arr,150));}public static int binarySearch(int[] arr,int number){//1.定义两个变量记录要查找的范围int min =0;int max = arr.length-1;//2.利用循环不断的去找要查找的数据while(true){if(min > max){return-1;}//3.找到min和max的中间位置int mid =(min + max)/2;//4.拿着mid指向的元素跟要查找的元素进行比较if(arr[mid]> number){//4.1 number在mid的左边//min不变,max = mid - 1;max = mid -1;}else if(arr[mid]< number){//4.2 number在mid的右边//max不变,min = mid + 1;min = mid +1;}else{//4.3 number跟mid指向的元素一样//找到了return mid;}}}}3. 插值查找在介绍插值查找之前,先考虑一个问题:为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?二分查找中查找点计算如下:mid=(low+high)/2, 即mid=low+1/2*(high-low);我们可以将查找的点改进为如下:mid=low+(key-a[low])/(a[high]-a[low])*(high-low),这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
Java核心数据结构(List、Map、Set)原理与使用技巧
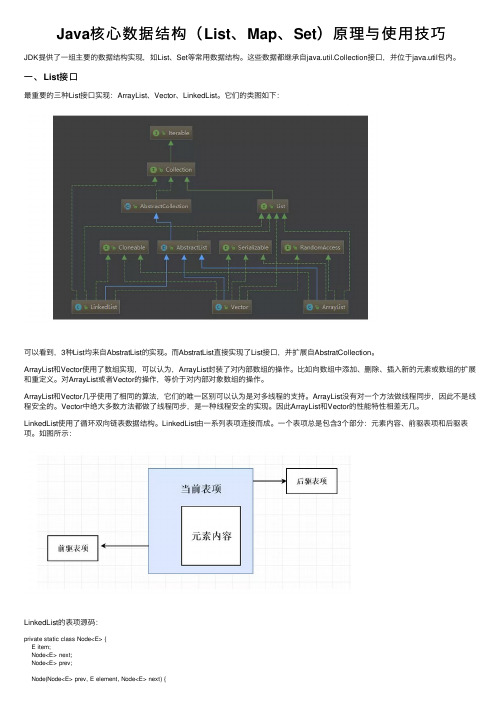
Java核⼼数据结构(List、Map、Set)原理与使⽤技巧JDK提供了⼀组主要的数据结构实现,如List、Set等常⽤数据结构。
这些数据都继承⾃java.util.Collection接⼝,并位于java.util包内。
⼀、List接⼝最重要的三种List接⼝实现:ArrayList、Vector、LinkedList。
它们的类图如下:可以看到,3种List均来⾃AbstratList的实现。
⽽AbstratList直接实现了List接⼝,并扩展⾃AbstratCollection。
ArrayList和Vector使⽤了数组实现,可以认为,ArrayList封装了对内部数组的操作。
⽐如向数组中添加、删除、插⼊新的元素或数组的扩展和重定义。
对ArrayList或者Vector的操作,等价于对内部对象数组的操作。
ArrayList和Vector⼏乎使⽤了相同的算法,它们的唯⼀区别可以认为是对多线程的⽀持。
ArrayList没有对⼀个⽅法做线程同步,因此不是线程安全的。
Vector中绝⼤多数⽅法都做了线程同步,是⼀种线程安全的实现。
因此ArrayList和Vector的性能特性相差⽆⼏。
LinkedList使⽤了循环双向链表数据结构。
LinkedList由⼀系列表项连接⽽成。
⼀个表项总是包含3个部分:元素内容、前驱表项和后驱表项。
如图所⽰:LinkedList的表项源码:private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}⽆论LinkedList是否为空,链表都有⼀个header表项,它既是链表的开始,也表⽰链表的结尾。
数据结构与算法分析java课后答案

数据结构与算法分析java课后答案【篇一:java程序设计各章习题及其答案】>1、 java程序是由什么组成的?一个程序中必须有public类吗?java源文件的命名规则是怎样的?答:一个java源程序是由若干个类组成。
一个java程序不一定需要有public类:如果源文件中有多个类时,则只能有一个类是public类;如果源文件中只有一个类,则不将该类写成public也将默认它为主类。
源文件命名时要求源文件主名应与主类(即用public修饰的类)的类名相同,扩展名为.java。
如果没有定义public类,则可以任何一个类名为主文件名,当然这是不主张的,因为它将无法进行被继承使用。
另外,对applet小应用程序来说,其主类必须为public,否则虽然在一些编译编译平台下可以通过(在bluej下无法通过)但运行时无法显示结果。
2、怎样区分应用程序和小应用程序?应用程序的主类和小应用程序的主类必须用public修饰吗?答:java application是完整的程序,需要独立的解释器来解释运行;而java applet则是嵌在html编写的web页面中的非独立运行程序,由web浏览器内部包含的java解释器来解释运行。
在源程序代码中两者的主要区别是:任何一个java application应用程序必须有且只有一个main方法,它是整个程序的入口方法;任何一个applet小应用程序要求程序中有且必须有一个类是系统类applet的子类,即该类头部分以extends applet结尾。
应用程序的主类当源文件中只有一个类时不必用public修饰,但当有多于一个类时则主类必须用public修饰。
小应用程序的主类在任何时候都需要用public来修饰。
3、开发与运行java程序需要经过哪些主要步骤和过程?答:主要有三个步骤(1)、用文字编辑器notepad(或在jcreator,gel, bulej,eclipse, jbuilder等)编写源文件;(2)、使用java编译器(如javac.exe)将.java源文件编译成字节码文件.class;(3)、运行java程序:对应用程序应通过java解释器(如java.exe)来运行,而对小应用程序应通过支持java标准的浏览器(如microsoft explorer)来解释运行。
java数据结构算法面试题

java数据结构算法面试题面试对于求职者来说是一个重要的环节,尤其是对于计算机专业的求职者来说,数据结构和算法是面试中经常涉及的重要话题。
掌握Java数据结构和算法面试题,对于成功通过面试至关重要。
本文将介绍一些常见的Java数据结构和算法面试题,并给出相应的解答。
一、数组1. 给定一个整数数组,如何找到其中的最大值和最小值?解答:可以使用遍历数组的方式比较每个元素与当前的最大值和最小值,更新最大值和最小值。
2. 给定一个整数数组,如何找到其中两个数的和等于指定的目标值?解答:可以使用两层循环遍历数组,对每对不同的数进行求和判断是否等于目标值。
二、链表1. 如何实现链表的反转?解答:可以创建一个新的链表,然后遍历原链表,将原链表的每个节点插入到新链表的头部即可。
2. 如何判断链表中是否存在环?解答:可以使用快慢指针的方式遍历链表,如果存在环,则快指针最终会追上慢指针。
三、栈和队列1. 如何使用栈实现队列?解答:可以使用两个栈,一个用于入队操作,另一个用于出队操作。
当进行出队操作时,如果出队的栈为空,则需要将入队的栈中的元素依次出栈并入队栈,然后再出队。
2. 如何使用队列实现栈?解答:可以使用两个队列,一个用于入栈操作,另一个用于出栈操作。
当进行出栈操作时,需要将入栈的队列中的元素依次出队并入出栈的队列,直到剩下一个元素,即为需要出栈的元素。
四、排序算法1. 如何实现快速排序算法?解答:快速排序算法是一种分治算法,基本思想是选择一个基准元素,将数组分成两个子数组,小于基准元素的放在左边,大于基准元素的放在右边,然后递归地对子数组进行排序。
2. 如何实现归并排序算法?解答:归并排序算法也是一种分治算法,基本思想是将数组递归地分成两个子数组,然后合并两个有序的子数组,最终得到一个有序的数组。
五、查找算法1. 如何实现二分查找算法?解答:二分查找算法是一种分而治之的思想,首先将数组按照中间元素划分为两个子数组,然后判断目标值与中间元素的大小关系,从而确定目标值在哪个子数组中,然后递归地进行查找。
Java数据结构和算法.(第二版)

2-3树 外部存储 小结 问题 实验 编程作业 第11章 哈希表 哈希化简介 开放地址法 链地址法 哈希函数 哈希化的效率 哈希化和外部存储 小结 问题 实验 编程作业 第12章 堆 堆的介绍 Heap专题applet 堆的Java代码 基于树的堆 堆排序 小结 问题 实验 编程作业 第13章 图 图简介 搜索 最小生成树 有向图的拓扑排序
问题 实验 编程作业 第6章 递归 三角数字 阶乘 变位字 递归的二分查找 汉诺(Hanoi)塔问题 归并排序 消除递归 一些有趣的递归应用 小结 问题 实验 编程作业 第7章 高级排序 希尔排序 划分 快速排序 基数排序 小结 问题 实验 编程作业 第8章 二叉树 为什么使用二叉树? 树的术语 一个类比 二叉搜索树如何工作 查找节点 插入一个节点
封面页 书名页 版权页 前言页 目录页 第1章 综述 数据结构和算法能起到什么作用? 数据结构的概述 算法的概述 一些定义 面向对象编程 软件工程 对于C++程序员的Java Java数据结构的类库 小结 问题 第2章 数组 Array专题Applet Java中数组的基础知识 将程序划分成类 类接口 Ordered专题applet 有序数组的Java代码 对数 存储对象 大O表示法 为什么不用数组表示一切? 小结 问题 实验 编程作业 第3章 简单排序
Java数据结构与算法

Java数据结构与算法一、引言Java 是一种强大、高效的编程语言,在现代软件开发领域中使用广泛。
作为一名 Java 开发人员,了解数据结构与算法的重要性不言而喻,因为数据结构和算法是计算机科学的核心。
本文将重点讨论 Java 数据结构与算法,它们的实现方式及其应用。
二、数据结构数据结构是一种在计算机中组织和存储数据的方式。
在软件开发过程中,开发人员需要选择合适的数据结构来存储和处理数据,以实现最好的性能和效率。
Java 提供了很多内置的数据结构,例如数组、链表、队列和栈等。
1. 数组数组是 Java 中最基本和最常用的数据结构之一。
它是一个固定大小的数据序列,其中的元素都具有相同的数据类型。
数组可以使用索引来访问和修改元素。
在 Java 中,可以使用内置的数组类型 int[]、double[]、char[]等,也可以使用泛型数组类型 ArrayList。
可以通过如下方式创建一个 Java 数组:int[] arr = new int[10];这会创建一个长度为 10 的 int 类型数组,其中的元素默认值为 0。
2. 链表链表是一个由节点组成的数据结构,其中每个节点都包含一个数据元素和一个指向下一个节点的指针。
链表的优点在于可以很容易地添加或删除元素,但是访问元素时需要遍历整个链表。
Java 中提供了多种链表类型,包括单向链表、双向链表和循环链表。
可以通过如下方式创建一个单向链表:public class Node {int val;Node next;Node(int x) { val = x; }}Node head = new Node(1);head.next = new Node(2);这会创建一个包含两个元素的单向链表,其值分别为 1 和 2。
3. 队列队列是一种先进先出(FIFO)的数据结构,在 Java 中可以使用内置的Queue 接口实现。
Queue 接口定义了许多方法,例如 add()、remove()、peek() 等,可以用于向队列中添加元素、删除元素和获取队列顶端的元素。
数据结构与算法的哪些知识点最容易考察

数据结构与算法的哪些知识点最容易考察在计算机科学领域,数据结构与算法是至关重要的基础知识。
无论是在学术研究还是实际的软件开发中,对于数据结构和算法的理解与掌握程度都有着很高的要求。
当我们面临各种考试或者技术面试时,了解哪些知识点最容易被考察,能够帮助我们更有针对性地进行学习和准备。
首先,链表(Linked List)是经常被考察的一个重要知识点。
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
对于链表的操作,如链表的创建、遍历、插入、删除节点等,都是常见的考察点。
特别是在处理链表的循环、链表的反转等问题时,需要我们对指针的操作有清晰的理解和熟练的运用能力。
栈(Stack)和队列(Queue)也是容易考察的内容。
栈遵循后进先出(Last In First Out,LIFO)的原则,而队列遵循先进先出(First In First Out,FIFO)的原则。
理解这两种数据结构的特点以及它们的基本操作,如入栈、出栈、入队、出队等,是很关键的。
此外,利用栈来解决表达式求值、括号匹配等问题,以及使用队列来实现广度优先搜索(BreadthFirst Search,BFS)等算法,也是常见的考察形式。
树(Tree)结构在数据结构与算法中占据着重要地位。
二叉树(Binary Tree)是其中的基础,包括二叉树的遍历(前序、中序、后序遍历)、二叉搜索树(Binary Search Tree)的特性和操作,以及平衡二叉树(如 AVL 树、红黑树)的概念和调整算法等,都是容易被考察的知识点。
此外,树的层次遍历、构建二叉树等问题也经常出现在考题中。
图(Graph)的相关知识也是考察的重点之一。
图的表示方法(邻接矩阵、邻接表)、图的遍历算法(深度优先搜索(DepthFirst Search,DFS)和广度优先搜索(BreadthFirst Search,BFS))、最短路径算法(如迪杰斯特拉算法(Dijkstra's Algorithm)和弗洛伊德算法(FloydWarshall Algorithm))以及最小生成树算法(如普里姆算法(Prim's Algorithm)和克鲁斯卡尔算法(Kruskal's Algorithm))等,都是需要我们熟练掌握的内容。
JAVA常用的数据结构和算法

JAVA基本数据结构和排序算法Email: ********************.cnQQ: 4480860061Java容器类1.1 容器作用和概念1.1.1数组数组是一种容器,以线性序列放置对象和基本类型数据,可快速访问数组元素,但不灵活,容量必须事先定义好,不能随着需求的变化而扩容。
基于此JAVA中提供容器类。
1.1.2容器的架构其层次如下图,都是从Object派生而来。
需要注意的是Set、List、Collcetion和Map都是接口,不是具体的类实现。
在Java中提供了Collection和Map接口。
其中List和Set继承了Collection接口;同时用Vector、ArrayList、LinkedList三个类实现List接口,HashSet、TreeSet实现Set接口。
直接有HashTable、HashMap、TreeMap实现Map接口。
List和set都是放单独的对象的,map则是方一个名值对,就是通过一个key找到一个value;list存放东西是有序的,set是没有顺序的;list允许重复存入,set不可以。
1.1.3List接口有序的Collection,此接口用户可以对列表中每个元素的插入位置进行精确地控制,用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素,与Set不同,列表通常允许重复的元素,更确切地讲,列表通常允许满足e1.equals(e2)的元素对e1和e2,并且如果列表本身允许null元素。
其方法主要包括://添加boolean add(E e);void add(int index, E element);boolean addAll(Collection<? extends E> c);boolean addAll(int index, Collection<? extends E> c);//删除boolean remove(Object o);E remove(int index);boolean removeAll(Collection<?> c);//获取某个元素E get(int index);//获取某个元素的索引int indexOf(Object o);int lastIndexOf(Object o);//是否相同boolean equals(Object o);//将某个元素指定添加到某个位置E set(int index, E element);//获取索引范围之内的元素List<E> subList(int fromIndex, int toIndex);//迭代器ListIterator<E> listIterator();ListIterator<E> listIterator(int index);(1)ArrayList底层用数组实现的List,特点,查询效率高,增删效率低,线程不安全。
常用的数据结构和算法

常用的数据结构和算法一、引言在计算机科学和编程中,数据结构和算法是非常基础而重要的概念。
数据结构是一种组织和存储数据的方式,而算法则是在这些数据上执行的操作和计算的方法。
掌握常用的数据结构和算法,对于解决复杂的计算问题和优化程序性能都有着重要的作用。
本文将介绍常用的数据结构和算法,包括线性结构、树形结构、图结构以及常见的排序算法、搜索算法等。
我们将从基础的概念和特点入手,逐步深入讨论每种数据结构和算法的原理、应用场景和优缺点。
二、线性结构2.1 数组数组是一种最简单的数据结构,它是一块连续的内存空间,用于存储一组相同类型的元素。
数组最重要的特点是随机访问,即可以通过索引快速定位和访问任意位置的元素。
但数组的大小是固定的,插入和删除操作比较低效。
2.2 链表链表是一种动态的数据结构,使用指针将一组节点串起来。
每个节点包含了数据和指向下一个节点的指针。
链表的插入和删除操作比较高效,但随机访问的效率较低。
2.3 栈栈是一种后进先出(LIFO)的数据结构,只能在一端进行插入和删除操作。
栈常用于括号匹配、逆波兰表达式求值等场景。
2.4 队列队列是一种先进先出(FIFO)的数据结构,只能在一端进行插入操作,另一端进行删除操作。
队列常用于任务调度、缓存管理等场景。
三、树形结构3.1 二叉树二叉树是一种每个节点最多有两个子节点的树形结构,它具有左子树和右子树之分。
二叉树的遍历方式包括前序遍历、中序遍历和后序遍历。
3.2 AVL树AVL树是一种自平衡二叉搜索树,它通过节点的平衡因子来维护树的平衡性。
AVL树的插入和删除操作会通过旋转操作来保持平衡。
3.3 B树B树是一种多路平衡查找树,它的每个节点可以拥有多个子节点。
B树广泛应用于磁盘和数据库的索引结构中,可以有效减少磁盘I/O次数。
3.4 Trie树Trie树,也称为字典树或前缀树,是一种专门用于处理字符串的树形结构。
Trie树的每个节点可以包含多个子节点,用于存储字符串的共同前缀。
java算法总结

java算法总结Java算法总结Java是一种广泛使用的编程语言,它具有高效、可靠、安全等特点,因此在算法领域也得到了广泛的应用。
本文将对Java算法进行总结,包括常用的算法类型、算法实现方法以及算法优化技巧等方面。
一、常用的算法类型1. 排序算法:包括冒泡排序、选择排序、插入排序、快速排序、归并排序等。
2. 查找算法:包括顺序查找、二分查找、哈希查找等。
3. 图论算法:包括最短路径算法、最小生成树算法、拓扑排序算法等。
4. 字符串算法:包括字符串匹配算法、字符串编辑距离算法等。
5. 动态规划算法:包括背包问题、最长公共子序列问题、最长递增子序列问题等。
二、算法实现方法1. 递归实现:递归是一种常用的算法实现方法,它可以将一个问题分解成多个子问题,然后逐步解决这些子问题,最终得到问题的解。
2. 迭代实现:迭代是一种循环实现方法,它可以通过循环来解决问题,通常比递归更高效。
3. 分治实现:分治是一种将问题分解成多个子问题,然后分别解决这些子问题,最终将子问题的解合并成原问题的解的方法。
4. 贪心实现:贪心是一种通过每一步的最优选择来得到全局最优解的方法。
三、算法优化技巧1. 时间复杂度优化:通过优化算法的时间复杂度来提高算法的效率,例如使用哈希表来优化查找算法的时间复杂度。
2. 空间复杂度优化:通过优化算法的空间复杂度来减少算法的内存占用,例如使用滚动数组来优化动态规划算法的空间复杂度。
3. 剪枝优化:通过剪枝来减少算法的搜索空间,例如使用剪枝来优化深度优先搜索算法的效率。
4. 并行优化:通过并行计算来提高算法的效率,例如使用多线程来优化排序算法的效率。
Java算法是一种非常重要的编程技能,它可以帮助我们解决各种复杂的问题。
通过学习常用的算法类型、算法实现方法以及算法优化技巧,我们可以更好地掌握Java算法,提高算法的效率和准确性。
Java常用排序算法程序员必须掌握的8大排序算法

分类:1)插入排序(直接插入排序、希尔排序)2)交换排序(冒泡排序、快速排序)3)选择排序(直接选择排序、堆排序)4)归并排序5)分配排序(基数排序)所需辅助空间最多:归并排序所需辅助空间最少:堆排序平均速度最快:快速排序不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:1.直接插入排序(1)基本思想:在要排序的一组数中,假设前面(n-1)[n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。
如此反复循环,直到全部排好顺序。
(2)实例(3)用java实现12345678911121314151617181920package com.njue;publicclass insertSort {public insertSort(){inta[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,56,17,18,23,34,15,35,2 5,53,51};int temp=0;for(int i=1;i<a.length;i++){int j=i-1;temp=a[i];for(;j>=0&&temp<a[j];j--){a[j+1]=a[j]; //将大于temp的值整体后移一个单位}a[j+1]=temp;}for(int i=0;i<a.length;i++){System.out.println(a[i]);}2. 希尔排序(最小增量排序)(1)基本思想:算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差 d.对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。
当增量减到1时,进行直接插入排序后,排序完成。
(2)实例:(3)用java实现123456789101112131415161718192122232425262728293031publicclass shellSort { publicshellSort(){int a[]={1,54,6,3,78,34,12,45,56,100}; double d1=a.length;int temp=0;while(true){d1= Math.ceil(d1/2);int d=(int) d1;for(int x=0;x<d;x++){for(int i=x+d;i<a.length;i+=d){int j=i-d;temp=a[i];for(;j>=0&&temp<a[j];j-=d){a[j+d]=a[j];}a[j+d]=temp;}}if(d==1){break;}for(int i=0;i<a.length;i++){System.out.println(a[i]);}}3.简单选择排序(1)基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
常用数据结构和算法

常用数据结构和算法在计算机科学领域,数据结构和算法是构建高效程序的基石。
无论是开发软件应用,还是进行系统优化,都离不开对数据结构和算法的研究和应用。
本文将介绍一些常用的数据结构和算法,并讨论它们的特点和应用场景。
一、数组(Array)数组是最基本的数据结构之一,它由一系列连续的内存空间组成,可以存储相同类型的数据。
数组的特点是随机存取,即可以通过索引直接访问指定位置的元素。
数组在存取数据时效率非常高,但插入和删除操作则比较低效。
它的应用场景包括存储一组有序的数据、快速查找等。
二、链表(Linked List)链表是一种非连续的数据结构,由多个节点组成,每个节点包含一个数据元素和指向下一个节点的指针。
链表的特点是插入和删除操作效率高,但查找操作则比较低效,需要遍历整个链表。
链表适用于频繁插入和删除元素的场景,比如实现队列、栈等。
三、栈(Stack)栈是一种特殊的数据结构,它遵循先入后出(LIFO)的原则。
栈可以用数组或链表来实现,常见的操作包括入栈(push)和出栈(pop)。
栈的应用场景很广,比如表达式求值、函数调用等。
四、队列(Queue)队列是一种遵循先入先出(FIFO)原则的数据结构。
队列可以用数组或链表来实现,常见的操作包括入队(enqueue)和出队(dequeue)。
队列的应用包括任务调度、消息传递等。
五、树(Tree)树是一种层次结构的数据结构,由节点和边组成。
树的结构使得在其中进行搜索、插入和删除等操作非常高效。
常见的树结构包括二叉树、二叉搜索树、平衡二叉树、红黑树等。
树的应用非常广泛,比如文件系统、数据库索引等。
六、图(Graph)图是一种由节点和边组成的非线性数据结构,它包括有向图和无向图。
图的表示方式有邻接矩阵和邻接表两种,它的应用场景包括网络拓扑分析、搜索算法等。
七、排序算法排序算法是数据处理中非常重要的一类算法,主要用于将一组无序的数据按照某种规则进行排序。
常见的排序算法包括冒泡排序、插入排序、选择排序、快速排序、归并排序等。
数据结构java语言描述

数据结构java语言描述数据结构是计算机科学中的一门重要课程,它研究如何组织和存储数据,以便于程序的操作和使用。
在现代计算机科学中,数据结构被广泛应用于算法设计、程序设计、数据库系统、网络通信等领域。
本文将以《数据结构Java语言描述》为标题,介绍数据结构的基本概念、分类、常用算法和Java语言实现。
一、基本概念数据结构是指数据元素之间的关系,包括数据元素的类型、组织方式和操作方法。
常见的数据结构有线性结构、树形结构和图形结构。
线性结构是指数据元素之间存在一个前驱和一个后继,例如数组、链表、栈和队列等;树形结构是指数据元素之间存在一个父子关系,例如二叉树、堆和哈夫曼树等;图形结构是指数据元素之间存在多种关系,例如有向图、无向图和带权图等。
数据结构的基本操作包括插入、删除、查找和遍历等。
插入操作是将一个新的数据元素插入到已有数据结构中,删除操作是将一个已有数据元素从数据结构中删除,查找操作是在数据结构中查找一个指定的数据元素,遍历操作是按照一定的方式遍历数据结构中的所有数据元素。
二、分类数据结构可以按照不同的方式进行分类,常见的分类方法包括线性结构、树形结构、图形结构、顺序存储结构和链式存储结构等。
1.线性结构线性结构是指数据元素之间存在一个前驱和一个后继,数据元素之间的关系具有线性的特点。
常见的线性结构包括数组、链表、栈和队列等。
数组是一种线性结构,它是由一组连续的存储单元组成的,每个存储单元存储一个数据元素。
数组的特点是支持随机访问,但插入和删除操作效率较低。
链表是一种线性结构,它是由一组不连续的存储单元组成的,每个存储单元存储一个数据元素和一个指向下一个存储单元的指针。
链表的特点是插入和删除操作效率较高,但访问操作效率较低。
栈是一种线性结构,它是一种后进先出(LIFO)的数据结构,支持插入和删除操作。
栈的应用包括表达式求值、函数调用和回溯算法等。
队列是一种线性结构,它是一种先进先出(FIFO)的数据结构,支持插入和删除操作。
数据结构与算法知识点必备

数据结构与算法知识点必备一、数据结构知识点1. 数组(Array)数组是一种线性数据结构,它由相同类型的元素组成,通过索引访问。
数组的特点是随机访问速度快,但插入和删除操作较慢。
常见的数组操作包括创建、访问、插入、删除和遍历。
2. 链表(Linked List)链表是一种动态数据结构,它由节点组成,每一个节点包含数据和指向下一个节点的指针。
链表的特点是插入和删除操作快,但访问速度较慢。
常见的链表类型包括单向链表、双向链表和循环链表。
3. 栈(Stack)栈是一种后进先出(LIFO)的数据结构,只能在栈顶进行插入和删除操作。
常见的栈操作包括入栈(push)和出栈(pop)。
4. 队列(Queue)队列是一种先进先出(FIFO)的数据结构,只能在队尾插入元素,在队头删除元素。
常见的队列操作包括入队(enqueue)和出队(dequeue)。
5. 树(Tree)树是一种非线性数据结构,由节点和边组成。
树的特点是层次结构、惟一根节点、每一个节点最多有一个父节点和多个子节点。
常见的树类型包括二叉树、二叉搜索树、平衡二叉树和堆。
6. 图(Graph)图是一种非线性数据结构,由节点和边组成。
图的特点是节点之间的关系可以是任意的,可以有环。
常见的图类型包括有向图、无向图、加权图和连通图。
7. 哈希表(Hash Table)哈希表是一种根据键(key)直接访问值(value)的数据结构,通过哈希函数将键映射到数组中的一个位置。
哈希表的特点是查找速度快,但内存消耗较大。
常见的哈希表操作包括插入、删除和查找。
二、算法知识点1. 排序算法(Sorting Algorithms)排序算法是将一组元素按照特定顺序罗列的算法。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序。
2. 查找算法(Search Algorithms)查找算法是在一组元素中寻觅特定元素的算法。
常见的查找算法包括线性查找、二分查找和哈希查找。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.大O表示法:粗略的量度方法即算法的速度是如何与数据项的个数相关的算法大O表示法表示的运行时间线性查找 O(N)二分查找 O(logN)无序数组的插入 O(1)有序数组的插入 O(N)无序数组的删除 O(N)有序数组的删除 O(N)O(1)是最优秀的,O(logN)良好,O(N)还可以,O(N2)稍差(在冒泡法中见到)2.排序public class JWzw {//插入排序public void insertArray(Integer []in){int tem = 0;int num = 0;int upnum = 0;for (int i = 0; i < in.length; i++) {for (int j = i - 1; j >= 0; j--) {num++;if (in[j+1] < in[j]) {tem = in[j+1];in[j+1] = in[j];in[j] = tem;upnum++;}else{break;}}}for (int i = 0; i < in.length; i++) {System.out.print(in[i]);if(i < in.length - 1){System.out.print(",");}}System.out.println();System.out.println("插入排序循环次数:" + num);System.out.println("移动次数:" + upnum);System.out.print("\n\n\n");}//选择排序public void chooseArray(Integer []in){int tem = 0;int num = 0;int upnum = 0;for(int i = 0;i < in.length;i++){for(int j = i;j < in.length - 1;j++){num++;if(in[j+1] < in[j]){tem = in[j+1];in[j + 1] = in[j];in[j] = tem;upnum++;}}}for (int i = 0; i < in.length; i++) {System.out.print(in[i]);if(i < in.length - 1){System.out.print(",");}}System.out.println();System.out.println("选择排序循环次数:" + num);System.out.println("移动次数:" + upnum);System.out.print("\n\n\n");}//冒泡排序public void efferArray(Integer []in){int tem = 0;int num = 0;int upnum = 0;for(int i = 0;i < in.length;i++){for(int j = i;j < in.length - 1;j++){num++;if(in[j+1] < in[i]){tem = in[j+1];in[j+1] = in[i];in[i] = tem;upnum++;}}}for (int i = 0; i < in.length; i++) {System.out.print(in[i]);if(i < in.length - 1){System.out.print(",");}}System.out.println();System.out.println("冒泡排序循环次数:" + num);System.out.println("移动次数:" + upnum);System.out.print("\n\n\n");}//打印乘法口诀public void printMulti(){for (int j = 1; j < 10; j++) {for (int i = 1; i <= j; i++) {System.out.print(i + " * " + j + " = " + j * i + "\t");}System.out.print("\t\n");}System.out.print("\n\n\n");}//打印N * 1 + N * 2 + N * 3 =num的所有组合public void printNumAssemble(int num){for (int i = 0; i < num + 1; i++) {for (int j = 0; j < num / 2 +1; j++) {for (int in = 0; in < num / 3 + 1; in++) {if (i * 1 + j * 2 + in * 3 == num) {System.out.println("小马" + i + ",\t中马" + j + ",\t大马" + in);}}}}}/*** @param args*/public static void main(String[] args) {JWzw jwzw = new JWzw();int num = 3;jwzw.printMulti();//打印乘法口诀jwzw.printNumAssemble(100);//打印N * 1 + N * 2 + N * 3 =num的所有组合Integer in[] = {8,89,5,84,3,45,12,33,77,98,456,878,654,213,897};jwzw.efferArray(in);//冒泡排序Integer in1[] = {8,89,5,84,3,45,12,33,77,98,456,878,654,213,897};jwzw.insertArray(in1);//插入排序Integer in2[] = {8,89,5,84,3,45,12,33,77,98,456,878,654,213,897};jwzw.chooseArray(in2);//选择排序//int i = num++;//System.out.println(i);System.out.println(1000>>2);}}3.优先级队列class PriorityQueue {private long[] a = null;private int nItems = 0;private int maxSize = 0;public PriorityQueue(int maxSize) {a = new long[maxSize];this.maxSize = maxSize;nItems = 0;}public void insert(long l) {//优先级队列的插入不是队尾,而是选择一个合适的按照某种顺序插入的//当队列长度为0时,如下//不为0时,将所有比要插入的数小的数据后移,这样大的数就在队列的头部了int i = 0;if(nItems == 0) {a[0] = l;} else {for(i=nItems-1; i>=0; i--) {if(l < a[i])a[i+1] = a[i];elsebreak;}a[i+1] = l;}nItems++;}public long remove() {//移出的是数组最上端的数,这样减少数组元素的移动return a[--nItems];}public boolean isEmpty() {return (nItems == 0);}public boolean isFull() {return (nItems == maxSize);}public int size() {return nItems;}}public class duilie {// 队列体类private duilie s;private String data;duilie(String data) {this.data = data;}public String getData() {return data;}public void setData(String data) {this.data = data;}public duilie getS() {return s;}public void setS(duilie s) {this.s = s;}}public class duiliecz {// 队列操作类/*** @param args*/private int i = 0;// 队列长private duilie top = new duilie("");// 队列头private duilie end = new duilie("");// 队列尾public void add(String s) {// 添加队列duilie m = new duilie(s);if (i != 0) {m.setS(top.getS());top.setS(m);} else {top.setS(m);end.setS(m);}i++;}4.队列public void del() {// 删除队尾if (i == 0) {return;} else if (i == 1) {top.setS(null);end.setS(null);} else {duilie top1 = new duilie("");// 队列底查找用缓存 top1.setS(top.getS());while (!top1.getS().getS().equals(end.getS())) { top1.setS(top1.getS().getS());}end.setS(top1.getS());}i--;}public static void main(String[] args) {// TODO Auto-generated method stubduiliecz m = new duiliecz();m.add("1");m.add("2");m.add("3");m.add("4");for (int n = 0; n < 4; n++) {m.del();}}public int getI() {return i;}public duilie getEnd() {return end;}public duilie getTop() {return top;}}5.栈public class Stack {int[] arr;int len = 0;public Stack() {arr = new int[100];}public Stack(int n) {arr = new int[n];}public int size() {return len + 1;}// 扩大数组public void resize() {int[] b = new int[arr.length * 2];System.arraycopy(arr, 0, b, 0, arr.length);arr = b;}public void show() {for (int i = 0; i < len; i++) {System.out.print(arr[i] + " ");}System.out.println();}// 进栈public void push(int a) {if (len >= arr.length)resize();arr[len] = a;len++;}// 出栈public int pop() {if (len == 0) {System.out.println();System.out.println("stack is empty!");return -1;}int a = arr[len - 1];arr[len - 1] = 0;len--;return a;}}6.链表class Node {Object data;Node next;public Node(Object data) {setData(data);}public void setData(Object data) {this.data = data;}public Object getData() {return data;}}class Link {Node head;int size = 0;public void add(Object data) {Node n = new Node(data);if (head == null) {head = n;} else {Node current = head;while (true) {if (current.next == null) {break;}current = current.next;}current.next = n;}size++;}public void show() {Node current = head;if (current != null) {while (true) {System.out.println(current);if (current == null) {break;}current = current.next;}} else {System.out.println("link is empty");}}public Object get(int index) {// ....}public int size() {return size;}}7.单链表class Node // 节点类,单链表上的节点{String data; // 数据域,存放String类的数据Node next; // 指向下一个节点Node(String data) {this.data = data; // 构造函数}String get() {return data; // 返回数据}}class MyLinkList // 链表类{Node first; // 头节点int size; // 链表长度MyLinkList(String arg[]) {// Node first = new Node("head");//生成头节点first = new Node("head"); // J.F. 这里不需要定义局部变量 first// 如果定义了局部变量,那成员变量 first 就一直没有用上// 所以,它一直为空size = 0;Node p = first;for (int i = 0; i < arg.length; i++) // 将arg数组中的元素分别放入链表中{Node q = new Node(arg[i]);q.next = p.next; // 每一个节点存放一个arg数组中的元素p.next = q;p = p.next;size++;}}MyLinkList() // 无参数构造函数{// Node first = new Node("head");first = new Node("head"); // J.F. 这里犯了和上一个构造方法同样的错误size = 0;}int size() // 返回链表长度{return size;}void insert(Node a, int index) // 将节点a 插入链表中的第index个位置{Node temp = first;for (int i = 0; i < index; i++) {temp = temp.next;// 找到插入节点的前一节点}a.next = temp.next; // 插入节点temp.next = a;size++;}Node del(int index) // 删除第index个节点,并返回该值{Node temp = first;for (int i = 0; i < index; i++) {temp = temp.next;// 找到被删除节点的前一节点}Node node = temp.next;temp.next = node.next;size--; // 删除该节点,链表长度减一return node;}void print() // 在屏幕上输出该链表(这段程序总是出错,不知道错在哪里){Node temp = first;for (int i = 1; i < size; i++) // 将各个节点分别在屏幕上输出{temp = temp.next;System.out.print(temp.get() + "->");}}void reverse() // 倒置该链表{for (int i = 0; i < size; i++) {insert(del(size - 1), 0); // 将最后一个节点插入到最前// J.F. 最后一个节点的 index 应该是 size - 1// 因为第一个节点的 index 是 0}}String get(int index) // 查找第index个节点,返回其值{if (index >= size) {return null;}Node temp = first;for (int i = 0; i < index; i++) {temp = temp.next;// 找到被查找节点的前一节点}return temp.next.get();}}class MyStack // 堆栈类,用单链表实现{MyLinkList tmp;Node temp;MyStack() {// MyLinkList tmp = new MyLinkList();tmp = new MyLinkList(); // J.F. 和 MyLinkList 构造方法同样的错误}void push(String a) // 压栈,即往链表首部插入一个节点{Node temp = new Node(a);tmp.insert(temp, 0);}String pop() // 出栈,将链表第一个节点删除{Node a = tmp.del(0);return a.get();}int size() {return tmp.size();}boolean empty() // 判断堆栈是否为空{if (tmp.size() == 0)return false;elsereturn true;}}public class MyLinkListTest // 测试程序部分{public static void main(String arg[]) // 程序入口{if ((arg.length == 0) || (arg.length > 10))System.out.println("长度超过限制或者缺少参数");else {MyLinkList ll = new MyLinkList(arg); // 创建一个链表ll.print(); // 先输出该链表(运行到这一步抛出异常)ll.reverse(); // 倒置该链表ll.print(); // 再输出倒置后的链表String data[] = new String[10];int i;for (i = 0; i < ll.size(); i++) {data[i] = ll.get(i); // 将链表中的数据放入数组}// sort(data);// 按升序排列data中的数据(有没有现成的排序函数?)for (i = 0; i < ll.size(); i++) {System.out.print(data[i] + ";"); // 输出数组中元素}System.out.println();MyStack s = new MyStack(); // 创建堆栈实例sfor (i = 0; i < ll.size(); i++) {s.push(data[i]); // 将数组元素压栈}while (!s.empty()) {System.out.print(s.pop() + ";"); // 再将堆栈里的元素弹出}}}}8.双端链表class Link {public int iData = 0;public Link next = null;public Link(int iData) {this.iData = iData;}public void display() {System.out.print(iData + " ");}}class FirstLastList {private Link first = null;private Link last = null;public FirstLastList() {first = null;last = null;}public void insertFirst(int key) {Link newLink = new Link(key);if (this.isEmpty())last = newLink;newLink.next = first;first = newLink;}public void insertLast(int key) {Link newLink = new Link(key);if (this.isEmpty())first = newLink;elselast.next = newLink;last = newLink;}public Link deleteFirst() {Link temp = first;if (first.next == null)last = null;first = first.next;return temp;}public boolean isEmpty() {return (first == null);}public void displayList() {System.out.print("List (first-->last): ");Link current = first;while (current != null) {current.display();current = current.next;}System.out.println("");}}class FirstLastListApp {public static void main(String[] args) {// TODO Auto-generated method stubFirstLastList theList = new FirstLastList();theList.insertFirst(22); // insert at fronttheList.insertFirst(44);theList.insertFirst(66);theList.insertLast(11); // insert at reartheList.insertLast(33);theList.insertLast(55);theList.displayList(); // display the listtheList.deleteFirst(); // delete first two itemstheList.deleteFirst();theList.displayList(); // display again }}9.有序链表package arithmetic;class Link {public int iData = 0;public Link next = null;public Link(int iData) {this.iData = iData;}public void display() {System.out.print(iData + " ");}}class SortedList {private Link first = null;public SortedList() {first = null;}public void insert(int key) {Link newLink = new Link(key);Link previous = null;Link current = first;// while的第一个条件是没有到达链表的尾端,第二个是按顺序找到一个合适的位置while (current != null && key > current.iData) {previous = current;current = current.next;}// 如果是空表或者要插入的元素最小,则在表头插入keyif (current == first)first = newLink;elseprevious.next = newLink;newLink.next = current;}/*** 删除表头的节点** @return要删除的节点*/public Link remove() {Link temp = first;first = first.next;return temp;}public boolean isEmpty() {return (first == null);}public void displayList() {System.out.print("List (first-->last): ");Link current = first; // start at beginning of listwhile (current != null) // until end of list,{current.display(); // print datacurrent = current.next; // move to next link}System.out.println("");}}class SortedListApp {public static void main(String[] args) { // create new listSortedList theSortedList = new SortedList();theSortedList.insert(20); // insert 2 itemstheSortedList.insert(40);theSortedList.displayList(); // display listtheSortedList.insert(10); // insert 3 more itemstheSortedList.insert(30);theSortedList.insert(50);theSortedList.displayList(); // display listtheSortedList.remove(); // remove an itemtheSortedList.displayList(); // display list }}10.双向链表class Link {// 双向链表,有两个指针,一个向前,一个向后public int iData = 0;public Link previous = null;public Link next = null;public Link(int iData) {this.iData = iData;}public void display() {System.out.print(iData + " ");}}class DoublyLinked {// 分别指向链表的表头和表尾private Link first = null;private Link last = null;public boolean isEmpty() {return first == null;}/*** 在表头插入数据** @param要插入的节点的数据*/public void insertFirst(int key) {Link newLink = new Link(key);// 如果开始链表为空,则插入第一个数据后,last也指向第一个数据if (this.isEmpty())last = newLink;else {// 表不为空的情况first.previous = newLink;newLink.next = first;}// 无论怎样,插入后都的让first重新指向第一个节点first = newLink;}public void insertLast(int key) {// 在尾端插入数据,同上Link newLink = new Link(key);if (this.isEmpty())first = newLink;else {last.next = newLink;newLink.previous = last;}last = newLink;}/*** 在指定的节点后插入数据** @param key* 指定的节点的值* @param iData* 要插入的数据* @return是否插入成功*/public boolean insertAfter(int key, int iData) {Link newLink = new Link(key);Link current = first;// 从first开始遍历,看能否找到以key为关键字的节点while (current.iData != key) {current = current.next;// 若能找到就跳出循环,否则返回false,插入失败if (current == null)return false;}// 如果插入点在last的位置if (current == last) {last = newLink;} else {// 非last位置,交换各个next和previous的指针newLink.next = current.next;current.next.previous = newLink;}current.next = newLink;newLink.previous = current;return true;}/*** 删除表头的节点** @return*/public Link deleteFirst() {Link temp = first;// 如果表中只有一个元素,删除后则为空表,所以last=nullif (first.next == null)last = null;else// 否则,让第二个元素的previous=nullfirst.next.previous = null;// 删除头指针,则first指向原来的secondfirst = first.next;return temp;}public Link deleteLast() {// 同上Link temp = last;if (last.previous == null)first = null;elselast.previous.next = null;last = last.previous;return temp;}public Link deleteKey(int key) {Link current = first;// 遍历整个链表查找对应的key,如果查到跳出循环,否则...while (current.iData != key) {current = current.next;// ...否则遍历到表尾,说明不存在此key,返回null,删除失败if (current == null)return null;}if (current == first)first = first.next;elsecurrent.previous.next = current.next;if (current == last)last = last.previous;elsecurrent.next.previous = current.previous;return current;}public void displayForward() {Link current = first;while (current != null) {current.display();current = current.next;}System.out.println();}public void displayBackward() {Link current = last;while (current != null) {current.display();current = current.previous;}System.out.println();}}class DoublyLinkedApp {public static void main(String[] args) { // make a new list DoublyLinked theList = new DoublyLinked();theList.insertFirst(22); // insert at fronttheList.insertFirst(44);theList.insertFirst(66);theList.insertLast(11); // insert at reartheList.insertLast(33);theList.insertLast(55);theList.displayForward(); // display list forwardtheList.displayBackward(); // display list backwardtheList.deleteFirst(); // delete first itemtheList.deleteLast(); // delete last itemtheList.deleteKey(11); // delete item with key 11theList.displayForward(); // display list forwardtheList.insertAfter(22, 77); // insert 77 after 22theList.insertAfter(33, 88); // insert 88 after 33theList.displayForward(); // display list forward}}11.实现二叉树前序遍历迭代器class TreeNode 这个类用来声明树的结点,其中有左子树、右子树和自身的内容。