java利用xml导出word(占位符替换)
java如何生成word文档_使用Java生成word文档(附源码)

java如何生成word文档_使用Java生成word文档(附源码)当我们使用Java生成word文档时,通常首先会想到iText和POI,这是因为我们习惯了使用这两种方法操作Excel,自然而然的也想使用这种生成word文档。
但是当我们需要动态生成word时,通常不仅要能够显示word中的内容,还要能够很好的保持word中的复杂样式。
这时如果再使用IText和POI去操作,就好比程序员去搬砖一样痛苦。
这时候,我们应该考虑使用FreeMarker的模板技术快速实现这个复杂的功能,让程序员在喝咖啡的过程中就把问题解决。
实现思路是这样的:先创建一个word文档,按照需求在word中填好一个模板,然后把对应的数据换成变量${},然后将文档保存为xml文档格式,使用文档编辑器打开这个xml格式的文档,去掉多余的xml符号,使用Freemarker读取这个文档然后替换掉变量,输出word文档即可。
具体过程如下:1.创建带有格式的word文档,将该需要动态展示的数据使用变量符替换。
2.将刚刚创建的word文档另存为xml格式。
3.编辑这个XMl文档去掉多余的xml标记,如图中蓝色部分4.从官网最新的开发包,将freemarker.jar拷贝到自己的开发项目中。
5.新建DocUtil类,实现根据Doc模板生成word文件的方法package com.favccxx.secret.util;import java.io.BufferedWriter;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import java.util.Map;import freemarker.template.Configuration;import freemarker.template.DefaultObjectWrapper;import freemarker.template.Template;import freemarker.template.TemplateExceptionHandler;public class DocUtil {privateConfiguration configure = null;publicDocUtil(){configure= new Configuration();configure.setDefaultEncoding("utf-8");}/*** 根据Doc模板生成word文件* @param dataMap Map 需要填入模板的数据* @param fileName 文件名称* @param savePath 保存路径*/publicvoid createDoc(Map dataMap, String downloadType, StringsavePath){try{//加载需要装填的模板Templatetemplate = null;//加载模板文件configure.setClassForTemplateLoading(this.getClass(),"/com /favccxx/secret/templates");//设置对象包装器configure.setObjectWrapper(newDefaultObjectWrapper());//设置异常处理器configure.setT emplateExceptionHandler(TemplateException Handler.IGNORE_HANDLER);//定义Template对象,注意模板类型名字与downloadType要一致template= configure.getTemplate(downloadType + ".xml");//输出文档FileoutFile = new File(savePath);Writerout = null;out= new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"utf-8"));template.process(dataMap,out);outFile.delete();}catch (Exception e) {e.printStackTrace();}}}6.用户根据自己的需要,调用使用getDataMap获取需要传递的变量,然后调用createDoc方法生成所需要的文档。
Java完美生成word的解决方案

POI读word文档还行,写文档实在不敢恭维,复杂的样式很难控制不提,想象一下一个20多页,嵌套很多表格和图像的word文档靠POI来写代码输出,对程序员来说比去山西挖煤还惨,况且文档格式还经常变化。
iText操作Excel还行。
对于复杂的大量的word也是噩梦。
直接通过JSP输出样式基本不达标,而且要打印出来就更是惨不忍睹。
Word从2003开始支持XML格式,用XML还做就很简单了。
大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。
经测试这样方式生成的word 文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office 中编辑文档完全一样。
看看实际效果:首先用office【版本要2003以上,以下的不支持xml格式】编辑文档的样式,图中红线的部分就是我要输出的部分:将编辑好的文档另存为XML再用Firstobject free XML editor【Firstobject free XML editor的使用见这里】将xml中我们需要填数据的地方打上FreeMarker标记【FreeMarker的语法见这里】最后生成的文档样式主要程序代码:view sourceprint?01 package com.havenliu.document;0203 import java.io.BufferedWriter;04 import java.io.File;05 import java.io.FileNotFoundException;06 import java.io.FileOutputStream;07 import java.io.IOException;08 import java.io.OutputStreamWriter;09 import java.io.Writer;10 import java.util.ArrayList;11 import java.util.HashMap;12 import java.util.List;13 import java.util.Map;1415 import freemarker.template.Configuration;16 import freemarker.template.Template;17 import freemarker.template.TemplateException;1819 public class DocumentHandler {20 private Configuration configuration = null;2122 public DocumentHandler() {23 configuration = new Configuration();24 configuration.setDefaultEncoding("utf-8");25 }2627 public void createDoc() {28 //要填入模本的数据文件29 Map dataMap=new HashMap();30 getData(dataMap);31 //设置模本装置方法和路径,FreeMarker支持多种模板装载方法。
java导出之导出word文档

java导出之导出word⽂档Springboot之word导出1.简介导出word实现⽤的⼯具是poi-tl,主要是通过预先设置word模板格式,通过数据填充来实现数据动态录⼊。
⽀持动态表格以及图。
使⽤步骤主要分为准备冰箱,准备象,把象装进冰箱。
2.准备环境(冰箱)包括两种,导包和模板预设置com.deepoove poi-tl 1.9.1 注意:poi-tl版本对阿帕奇的poi版本依赖有条件,低版本会报错,Tomcat会默认依赖低版本的jar包。
准备模板,模板可以设置⾏⾼,位置,固定宽度和最⼩⾼度,可以保证内容显⽰完全3.准备数据(⼤象)######Controller 层,返回值和两个⼊参public ResponseEntity<byte[]> exportJbZwJlxx(HttpServletRequest request, HttpServletResponse response) {//任免表⾥,需要基本信息,职务信息,部门⼈员信息,简历信息以及个⼈经历信息if(jbZwJlxxScCxDto.getDxbz()==null || "".equals(jbZwJlxxScCxDto.getDxbz()) ){log.error("档案薪酬判断标志不能为空");throw new RuntimeException("dxbz不能为空,或者为空字符串");}try {return jbZwJlxxService.getParams(jbZwJlxxScCxDto);} catch (Exception e) {log.error("导出失败",e);}return null;}######Service层获取数据,格式如下,和模板上对应即可Map<String, Object> params = new HashMap<>(100);params.put("jljj",!jlxxBean.getJljj().equals(CmGbglConstants.SPACE)? jlxxBean.getJljj() : "⽆");######动态表格的数据封装,通过**对象的属性赋值**int length = 7;// 返回数据超过七条if (res.size() > length) {length = res.size();// 封装查询回来的⼤于7的对象for (int i = 0; i < length; i++) {QtxxDto qtxxDto = new QtxxDto();qtxxDto = res.get(i);Map<String,Object> detailMap = new HashMap<String, Object>(7);detailMap.put("cw", qtxxDto.getCw());detailMap.put("name", qtxxDto.getName());qtxxDto.setCsny(getAge(qtxxDto.getCsny())+"");detailMap.put("csny", qtxxDto.getCsny());detailMap.put("zzmmmc",qtxxDto.getZzmmmc());detailMap.put("gzdwjzw",qtxxDto.getGzdwjzw());detailList.add(detailMap);qtxxDtos.add(qtxxDto);}} else {// 数据集长度⼩于七条for (int i = 0; i < res.size(); i++) {QtxxDto qtxxDto = new QtxxDto();qtxxDto = res.get(i);qtxxDto.setCsny(getAge(qtxxDto.getCsny())+"");qtxxDtos.add(qtxxDto);}for (int j = 0; j < (length - res.size()); j++) {QtxxDto qtxxDto = new QtxxDto();qtxxDtos.add(qtxxDto);}}}params.put("detailList", qtxxDtos);4.和模板建⽴关系try{//获得模板⽂件的输⼊流,这个是放在启动器的那个项⽬的resource下InputStream in = this.getClass().getResourceAsStream("/word/rmb.docx");//表格⾏循环插件HackLoopTableRenderPolicy policy = new HackLoopTableRenderPolicy();//绑定detailListConfigure config = Configure.builder().bind("detailList", policy).build();XWPFTemplate template = pile(in , config).render(params);String fileName = new String("rmb.docx".getBytes("UTF-8"), "iso-8859-1");ByteArrayOutputStream outputStream = new ByteArrayOutputStream();template.write(outputStream);template.close();HttpHeaders httpHeaders = new HttpHeaders();httpHeaders.add("content-disposition", "attachment;filename=" + fileName);httpHeaders.setContentType(MediaType.APPLICATION_OCTET_STREAM);ResponseEntity<byte[]> filebyte = new ResponseEntity<byte[]>(outputStream.toByteArray(), httpHeaders,HttpStatus.CREATED);outputStream.close();return filebyte;} catch (Exception e) {log.error("导出失败", e);throw e;}注意:模板放置的位置可以放在resource下,在本地编译的时候可以使⽤类加载器获取,但是打包到正式环境后就会找不到模板。
java导出数据为word文档(保持模板格式)

java导出数据为word⽂档(保持模板格式)导出数据到具体的word⽂档⾥⾯,word有⼀定的格式,需要保持不变这⾥使⽤freemarker来实现:①:设计好word⽂档格式,需要⽤数据填充的地⽅⽤便于识别的长字符串替换如 aaaaaaaaaaaaaaaa②:将word⽂档另存为 2003 xml格式③:找到需要替换的地⽅,如将 aaaaaaaaaaaa 修改为 ${userName}如果是list展⽰,注意按照如下⽅式修改:<#list list1 as list1Item>XXXXXXXXXXXXXXXXXX 原有格式代码如⼀⾏数据或者⼀个单元格</#list>④:替换完成后,将xml⽂件后缀修改为ftljava代码如下:package com.xiao;import java.io.UnsupportedEncodingException;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;public class Main {public static void main(String[] args) throws UnsupportedEncodingException {Map<String, Object> dataMap = new HashMap<String, Object>();dataMap.put("name", "肖昌伟");dataMap.put("depart", "云平台");dataMap.put("date", "2016年"); //列表数据封装List<String> list1 = new ArrayList<String>();list1.add("itema");list1.add("itemb");list1.add("itemc");dataMap.put("list1", list1);DocumentHandler mdoc = new DocumentHandler();mdoc.createDoc(dataMap, "E:/outFile2.doc");}}package com.xiao;import java.io.BufferedWriter;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStreamWriter;import java.io.UnsupportedEncodingException;import java.io.Writer;import java.util.Map;import freemarker.template.Configuration;import freemarker.template.Template;import freemarker.template.TemplateException;public class DocumentHandler {private Configuration configuration = null;public DocumentHandler() {configuration = new Configuration();configuration.setDefaultEncoding("utf-8");}public void createDoc(Map<String, Object> dataMap, String fileName) throws UnsupportedEncodingException {//需要导出模板的包路径configuration.setClassForTemplateLoading(this.getClass(), "/com/xiao");Template t = null;try {t = configuration.getTemplate("template.ftl");} catch (IOException e) {e.printStackTrace();}File outFile = new File(fileName);Writer out = null;FileOutputStream fos = null;try {fos = new FileOutputStream(outFile);OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");out = new BufferedWriter(oWriter);} catch (FileNotFoundException e1) {e1.printStackTrace();}try {t.process(dataMap, out);out.close();fos.close();} catch (TemplateException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}System.out.println("⽂档导出完成");}}这样就可以看到填充好了数据的word⽂档,格式和模板设置的保持⼀致。
java根据模板生成word文档,兼容富文本、图片

java根据模板⽣成word⽂档,兼容富⽂本、图⽚Java⾃动⽣成带图⽚、富⽂本、表格等的word⽂档使⽤技术 freemark+jsoup ⽣成mht格式的伪word⽂档,已经应⽤项⽬中,确实是可⾏的,⽆论是富⽂本中是图⽚还是表格,都能在word中展现出来使⽤jsoup解析富⽂本框,将其中的图⽚进⾏Base64位转码,使⽤freemark替换模板的占位符,将变量以及图⽚资源放⼊模板中在输出⽂件maven地址<!--freemarker--><!--<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.23</version></dependency><!--JavaHTMLParser--><!--<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version></dependency>制作word的freemark模板1. 先将wrod的格式内容定义好,如果需要插⼊参数的地⽅以${xxx}为表⽰,例:${product}模板例⼦: 2. 将模板另存为mht格式的⽂件,打开该⽂件检查每个变量(${product})是否完整,有可能在${}中出现其他代码,需要删除。
3. 将mht⽂件变更⽂件类型,改成ftl为结尾的⽂件,引⼊到项⽬中 4. 修改ftl模板⽂件,在⽂件中加上图⽚资源占位符${imagesBase64String},${imagesXmlHrefString}具体位置如下图所⽰: 5. ftl⽂件中由⼏个关键配置需要引⼊到代码中:docSrcParent = word.filesdocSrcLocationPrex =nextPartId = 01D2C8DD.BC13AF60上⾯三个参数,在模板⽂件中可以找到,需要进⾏配置,如果配置错误,图⽚⽂件将不会显⽰下⾯这三个参数固定,切换模板也不会改变shapeidPrex = _x56fe__x7247__x0020typeid = #_x0000_t75spidPrex = _x0000_i 6. 模板引⼊之后进⾏代码编辑源码地址为:下载源码后需要进⾏调整下内容:1. 录⼊步骤5中的6个参数2. 修改freemark获取模板⽅式下⾯这种⽅式能获取模板,但是在项⽬打包之后⽆法获取jar包内的⽂件Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));Template template=configuration.getTemplate("xxx.ftl");通过流的形式直接创建模板对象Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));InputStream inputStream=newFileInputStream(newFile(templatePath+"/"+templateName)); InputStreamReader inputStreamReader=newInputStreamReader(inputStream,StandardCharsets.UTF_8); Template template=newTemplate(templateName,inputStreamReader,configuration);。
Java使用模板导出word文档

Java使⽤模板导出word⽂档Java使⽤模板导出word⽂档需要导⼊freemark的jar包1. 使⽤word模板,在需要填值的地⽅使⽤字符串代替,是因为word转换为xml⽂件时查找不到要填⼊内容的位置。
尽量不要在写字符串的时候就加上${},xml⽂件会让它和字符串分离。
⽐如:姓名| name2. 填充完之后,把word⽂件另存为xml⽂件,然后使⽤notepad 等编辑软件打开,打开之后代码很多,也很乱,根本看不懂,其实也不⽤看懂哈,搜索找到你要替换的位置的字符串,⽐如name,然后加上${},变成${name}这样,然后就可以保存了,之后把保存的⽂件名后缀替换为.ftl。
模板就ok了。
3. 有个注意事项,这⾥的值⼀定不可以为空,否则会报错,freemark有判断为空的语句,这⾥⽰例⼀个,根据个⼈需求,意思是判断name是否为空,trim之后的lenth是否⼤于0:<#if name?default("")?trim?length gt 0><w:t>${name}</w:t></#if>4. 如果在本地的话可以直接下载下来,但是想要在通过前端下载的话那就需要先将⽂件下载到本地,当作临时⽂件,然后在下载⽂件。
接下来上代码,⽰例:public void downloadCharge(String name, HttpServletRequest request, HttpServletResponse response) {Map<String, Object> map = new HashMap<>();map.put("name", name);Configuration configuration = new Configuration();configuration.setDefaultEncoding("utf-8");try { //模板存放位置InputStream inputStream = this.getClass().getResourceAsStream("/template/report/XXX.ftl");Template t = new Template(null, new InputStreamReader(inputStream));String filePath = "tempFile/";//导出⽂件名String fileName = "XXX.doc";//⽂件名和路径不分开写的话createNewFile()会报错File outFile = new File(filePath + fileName);if (!outFile.getParentFile().exists()) {outFile.getParentFile().mkdirs();}if (!outFile.exists()) {outFile.createNewFile();}Writer out = null;FileOutputStream fos = null;fos = new FileOutputStream(outFile);OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");//这个地⽅对流的编码不可或缺,使⽤main()单独调⽤时,应该可以,但是如果是web请求导出时导出后word⽂档就会打不开,并且包XML⽂件错误。
Java将Word转为XML,XML转为Word的方法

2.XML转 Word
import com.spire.doc.*; public class XMLtoWord {
public static void main(String[] args) { //创建实例,加载xml测试文档 Document doc = new Document(); doc.loadFromFile("test.xml"); //保存为Docx格式 doc.saveToFile("toDocx.docx",FileFormat.Docx); //保存为Doc格式 doc.saveToFile("toDoc.doc",FileFormat.Doc);
网络错误400请刷新页面重试持续报错请尝试更换浏览器或网络环境
Java将 Word转为 XML, XML转为 Word的方法
本文介绍将Word和XML文档进行双向互转的方法。转换时,Word支持.docx/.doc等格式。
代码环境如下:
Word测试文档:.docx或.doc 编译环境:IntelliJ IDEA JDK版本:1.8.0 Word jar包:
} }
原创内容,转载请注明出处!程序代码:来自1.Word转 为 XML
import com.spire.doc.*; public class WordtoXML {
public static void main(String[] args) { //加载Word测试文档 Document doc = new Document(); doc.loadFromFile("input.docx");//支持doc格式 //调用方法转为xml文件 doc.saveToFile("toxml.xml.",FileFormat.Word_Xml); doc.dispose();
Java根据模板动态生成word文件

Java根据模板动态⽣成word⽂件最近项⽬中需要根据模板⽣成word⽂档,模板⽂件也是word⽂档。
当时思考⼀下想⽤POI API来做,但是觉得⽤起来相对复杂。
后来⼜找了⼀种⽅式,使⽤freemarker模板⽣成word⽂件,经过尝试觉得还是相对简单易⾏的。
使⽤freemarker模板⽣成word⽂档主要有这么⼏个步骤1、创建word模板:因为我项⽬中⽤到的模板本⾝是word,所以我就直接编辑word⽂档转成freemarker(.ftl)格式的。
2、将改word⽂件另存为xml格式,注意使⽤另存为,不是直接修改扩展名。
3、将xml⽂件的扩展名改为ftl4、编写java代码完成导出使⽤到的jar:freemarker.jar (2.3.28) ,其中Configuration对象不推荐直接new Configuration(),仔细看Configuration.class⽂件会发现,推荐的是 Configuration(Version incompatibleImprovements) 这个构造⽅法,具体这个构造⽅法⾥⾯传的就是Version版本类,⽽且版本号不能低于2.3.0闲⾔碎语不再讲,直接上代码1public static void exportDoc() {2 String picturePath = "D:/image.png";3 Map<String, Object> dataMap = new HashMap<String, Object>();4 dataMap.put("brand", "海尔");5 dataMap.put("store_name", "海尔天津");6 dataMap.put("user_name", "⼩明");78//经过编码后的图⽚路径9 String image = getWatermarkImage(picturePath);10 dataMap.put("image", image);1112//Configuration⽤于读取ftl⽂件13 Configuration configuration = new Configuration(new Version("2.3.0"));14 configuration.setDefaultEncoding("utf-8");1516 Writer out = null;17try {18//输出⽂档路径及名称19 File outFile = new File("D:/导出优惠证明.doc");20 out = new BufferedWriter(new OutputStreamWriter(new21 FileOutputStream(new File("outFile")), "utf-8"), 10240);22 } catch (UnsupportedEncodingException e) {23 e.printStackTrace();24 } catch (FileNotFoundException e) {25 e.printStackTrace();26 }27// 加载⽂档模板28 Template template = null;29try {30//指定路径,例如C:/a.ftl 注意:此处指定ftl⽂件所在⽬录的路径,⽽不是ftl⽂件的路径31 configuration.setDirectoryForTemplateLoading(new File("C:/"));32//以utf-8的编码格式读取⽂件33 template = configuration.getTemplate("导出优惠证明.ftl", "utf-8");34 } catch (IOException e) {35 e.printStackTrace();36throw new RuntimeException("⽂件模板加载失败!", e);37 }3839// 填充数据40try {41 template.process(dataMap, out);42 } catch (TemplateException e) {43 e.printStackTrace();44throw new RuntimeException("模板数据填充异常!", e);45 } catch (IOException e) {46 e.printStackTrace();47throw new RuntimeException("模板数据填充异常!", e);48 } finally {49if (null != out) {50try {51 out.close();52 } catch (IOException e) {53 e.printStackTrace();54throw new RuntimeException("⽂件输出流关闭异常!", e);55 }56 }57 }58 }View Code因为很多时候我们根据模板⽣成⽂件需要添加⽔印,也就是插⼊图⽚1/***2 * 处理图⽚3 * @param watermarkPath 图⽚路径 D:/image.png4 * @return5*/6private String getWatermarkImage(String watermarkPath) {7 InputStream in = null;8byte[] data = null;9try {10 in = new FileInputStream(watermarkPath);11 data = new byte[in.available()];12 in.read(data);13 in.close();14 } catch (Exception e) {15 e.printStackTrace();16 }17 BASE64Encoder encoder = new BASE64Encoder();18return encoder.encode(data);19 }View Code注意点:插⼊图⽚后的word转化为ftl模板⽂件(ps:⽔印图⽚可以在word上调整到⾃⼰想要的⼤⼩,然后在执⾏下⾯的步骤)1、先另存为xml2、将xml扩展名改为ftl3、打开ftl⽂件, 搜索w:binData 或者 png可以快速定位图⽚的位置,图⽚已经编码成0-Z的字符串了, 如下:5、将上述0-Z的字符串全部删掉,写上${image}(变量名随便写,跟dataMap⾥的key保持⼀致)后保存6、也是创建⼀个Map, 将数据存到map中,只不过我们要把图⽚⽤代码进⾏编码,将其也编成0-Z的字符串,代码请看上边⾄此⼀个简单的按照模板⽣成word并插⼊图⽚(⽔印)功能基本完成。
java导出word格式的文件

java导出word格式的⽂件1. 使⽤POI技术⽣成word格式的⽉报,实现功能根据⽇期进⾏预览,导出。
2. 使⽤template.docx作为word模板,参数使⽤特殊符号标识,封装数据(Map<String,String>); 通过IO读取模板替换参数,从⽽动态获取数据。
3. 预览的实现,由于web页⾯展⽰通过html或pdf来进⾏。
将word转为pdf后基本都会出现样式的不兼容问题,所以放弃。
最终我根据word的模板⼜⼿写了⼀个html对应的模板,参数使⽤的jsp的el表达式动态替换参数,从⽽动态获取数据。
暂时没有考虑word模板过多的情况。
4. 由于我做的系统的前端是easyui的框架,预览时的翻页使⽤了panel插件功能,批量导出使⽤的ZipEntry。
相关代码1 package com.bocsh.base.util;23 import java.io.ByteArrayOutputStream;4 import java.io.FileInputStream;5 import java.io.IOException;6 import java.util.List;7 import java.util.Map;8 import java.util.Map.Entry;9 import java.util.Set;101112//import org.apache.poi.POIXMLDocument;13 import ermodel.*;1415/**16 * 通过word模板⽣成新的word⼯具类17 *18 * @author zhiheng19 *20 *21 * XWPFDocument代表⼀个docx⽂档,其可以⽤来读docx⽂档,也可以⽤来写docx⽂档22 * XWPFParagraph代表⽂档、表格、标题等种的段落,由多个XWPFRun组成23 * XWPFRun代表具有同样风格的⼀段⽂本24 * XWPFTable代表⼀个表格25 * XWPFTableRow代表表格的⼀⾏26 * XWPFTableCell代表表格的⼀个单元格27 * XWPFChar 表⽰.docx⽂件中的图表28 * XWPFHyperlink 表⽰超链接29 * XWPFPicture 代表图⽚30 *31 *32 *33*/34public class WorderToNewWordUtils {3536/**37 * 判断表格是需要替换还是需要插⼊,判断逻辑有$为替换,表格⽆$为插⼊38 * @param inputUrl 模板存放地址39 * @param textMap 需要替换的信息集合40 * @param excelDataBytes ⽣成了新的数据流 word格式,存放容器41 * @return 成功返回true,失败返回false42*/43public static boolean changWord(String inputUrl,44 Map<String, String> textMap, Map<String,byte[]> excelDataBytes) {4546//模板转换默认成功47 boolean changeFlag = true;48 ByteArrayOutputStream writeToBytes = null;49try {50//获取docx解析对象51 XWPFDocument document = new XWPFDocument(new FileInputStream(inputUrl));52//解析替换⽂本段落对象53 WorderToNewWordUtils.changeText(document, textMap);54//解析替换表格对象55 WorderToNewWordUtils.changeTable(document, textMap);5657//⽣成了新的数据流 word 格式58 writeToBytes = new ByteArrayOutputStream();59 document.write(writeToBytes);60 excelDataBytes.put(textMap.get("year") + textMap.get("month"), writeToBytes.toByteArray());6162 } catch (IOException e) {63 e.printStackTrace();64 changeFlag = false;65 }finally{66try {67if(writeToBytes!=null)68 writeToBytes.close();69 } catch (IOException e) {70 e.printStackTrace();71 }72 }7374return changeFlag;7576 }777879/**80 * 替换段落⽂本81 * @param document docx解析对象82 * @param textMap 需要替换的信息集合83*/84public static void changeText(XWPFDocument document, Map<String, String> textMap){ 85//获取段落集合86 List<XWPFParagraph> paragraphs = document.getParagraphs();8788for (XWPFParagraph paragraph : paragraphs) {89//判断此段落时候需要进⾏替换90 String text = paragraph.getText();91if(checkText(text)){92 List<XWPFRun> runs = paragraph.getRuns();93for (XWPFRun run : runs) {94//替换模板原来位置95 run.setText(changeValue(run.toString(), textMap),0);96 }97 }98 }99100 }101102/**103 * 替换表格对象⽅法104 * @param document docx解析对象105 * @param textMap 需要替换的信息集合106*/107private static void changeTable(XWPFDocument document, Map<String, String> textMap){ 108//获取表格对象集合109 List<XWPFTable> tables = document.getTables();110for (int i = 0; i < tables.size(); i++) {111//只处理⾏数⼤于等于2的表格,且不循环表头112 XWPFTable table = tables.get(i);113if(table.getRows().size()>1){114//判断表格是需要替换还是需要插⼊,判断逻辑有$为替换,表格⽆$为插⼊115if(checkText(table.getText())){116 List<XWPFTableRow> rows = table.getRows();117//遍历表格,并替换模板118 eachTable(rows, textMap);119 }120 }121 }122123124 }125126127/**128 * 遍历表格129 * @param rows 表格⾏对象130 * @param textMap 需要替换的信息集合131*/132private static void eachTable(List<XWPFTableRow> rows ,Map<String, String> textMap){ 133for (XWPFTableRow row : rows) {134 List<XWPFTableCell> cells = row.getTableCells();135for (XWPFTableCell cell : cells) {136//判断单元格是否需要替换137if(checkText(cell.getText())){138 List<XWPFParagraph> paragraphs = cell.getParagraphs();139for (XWPFParagraph paragraph : paragraphs) {140 List<XWPFRun> runs = paragraph.getRuns();141for (XWPFRun run : runs) {142 run.setText(changeValue(run.toString(), textMap),0);143 }144 }145 }146 }147 }148 }149150151/**152 * 判断⽂本中时候包含$153 * @param text ⽂本154 * @return 包含返回true,不包含返回false155*/156private static boolean checkText(String text){157 boolean check = false;158if(text.indexOf("$")!= -1){159 check = true;160 }161return check;162163 }164165/**166 * 匹配传⼊信息集合与模板167 * @param value 模板需要替换的区域168 * @param textMap 传⼊信息集合169 * @return 模板需要替换区域信息集合对应值170*/171private static String changeValue(String value, Map<String, String> textMap){172 Set<Entry<String, String>> textSets = textMap.entrySet();173for (Entry<String, String> textSet : textSets) {174//匹配模板与替换值格式${key}175 String key = "${"+textSet.getKey()+"}";176if(value.indexOf(key)!= -1){177 value = textSet.getValue();178 }179 }180//模板未匹配到区域替换为空181if(checkText(value)){182 value = "0";183 }184return value;185 }186187188 }注意:1. html模板和word模板共⽤的数据模型2. 写这个功能前翻阅了⼤量的关于java导出word的博客,有⼤量的将word转为ftl格式再去操作,感觉不是很⽅便和直观。
JAVA操作WORD

JAVA操作WORDJava操作Word主要有两种方式:一种是使用Apache POI库进行操作,另一种是使用XML模板进行操作。
下面将详细介绍如何通过XML模板实现Java操作Word。
1.准备工作:2. 创建Word模板:首先,创建一个空的Word文档,将其保存为XML格式,作为Word的模板。
可以在Word中添加一些标记或占位符,用于后续替换。
3.导入POI和相关依赖:在Java项目中,导入以下依赖:```xml<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.xmlbeans</groupId><artifactId>xmlbeans</artifactId><version>3.1.0</version></dependency>```4.读取模板文件:使用POI库读取Word模板文件,将其转换为XML格式的字符串,并保存为`template.xml`文件中。
```javaimport ermodel.XWPFDocument;import java.io.FileOutputStream;public class WordTemplateReaderpublic static void main(String[] args) throws ExceptionXWPFDocument document = new XWPFDocument(new FileInputStream("template.docx"));FileOutputStream out = new FileOutputStream("template.xml");document.write(out);out.close(;document.close(;}}```5.数据替换:读取template.xml文件,使用Java中的字符串替换功能,将模板中的占位符替换为实际的数据。
java实现的导出word文档

java实现的导出word⽂档之前没有做过类似的功能,所以第⼀次接触的时候费了我⼀天的时间来完成这个功能。
先说⼀下原理,其实就是通过修改后缀来完成的。
需要先⽤office2013做⼀个word模板,就是你想要⽣成的word的模板,保存为xml格式。
然后在线格式化⼀下,这样⽣成的代码⽐较规范,然后将后缀修改为ftl,内容为⼀下格式:、我使⽤的⽅法是通过Action跳转的⽅法来进⾏调⽤的,Action⽅法如下,[java] view plain copy print?1. public String exportProWorkOrder(){2.3. /** 取出参数**/4.5. /** 输出审批 **/6. Template t=null;7. PrintWriter wt = null;8.9. try {10. /** 查询数据 **/11. ProjectWorkOrder pwo = consultingProjectBo.findPWOMessage(18);12.13. Map<String,Object> dataMap=new HashMap<String,Object>();14.15. //getData(dataMap);16. /** 放置数据 **/17. consultingProjectBo.makeExportProWorkOrderData(pwo,dataMap);18. String fn = makeFileName(pwo);19.20. //FTL⽂件所存在的位置21. t = freeMarkerConfiguration.getTemplate("export_proworkorder.ftl"); //⽂件名22.23.24. //配置 Response 参数25. getResponse().setContentType(26. "application/msword; charset=UTF-8");27. getResponse().setHeader(28. "Content-Disposition",29. "Attachment;filename= "30. + new String(fn.toString().getBytes(31. //"UTF-8"),"UTF-8"));32. "gb2312"), "ISO8859_1"));//20151030 改为UTF-8 需要兼容性测试33. wt = getResponse().getWriter();34. t.process(dataMap, wt);34. t.process(dataMap, wt);35.36. } catch (IOException e) {37. e.printStackTrace();38. } catch (Exception e) {39. e.printStackTrace();40. } finally {41. if(wt!=null){42. wt.flush();43. wt.close();44. }45. }46. return null;47. }48.49. protected String makeFileName(ProjectWorkOrder pwo) {50. if(pwo==null){51. return "⽂件不存在";52. }53.54. String filename = "";55. if(pwo.getProjectTitle()!=null){56. filename = pwo.getProjectTitle() + "⼯程造价咨询项⽬⼯作交办单" + ".doc";57. }else{58. filename = "⼯程造价咨询项⽬⼯作交办单"+".doc";59. }60.61. return filename;62. }跳转进⼊⽅法中,期中放置数据的⽅法如下,[java] view plain copy print?1. public ProjectWorkOrder findPWOMessage(Integer projectId){2. SimpleDateFormat sdf = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" );3. Project project = null;4. List<ProjectDepartment> list = null;5. ProjectEngineering pe = null;6. project = projectBo.findFull(projectId);7. list = projectDepartmentBo.findPDByProjectId(projectId);8. pe = projectEngineeringBo.findPEByProjectId(projectId);9. ProjectWorkOrder pwo = new ProjectWorkOrder();10. if(projectId != null){11. pwo.setProjectId(projectId);12. }13. if(project.getProject_title() != null){14. pwo.setProjectTitle(project.getProject_title());15. }16. if(project.getBegin_date() != null){17. pwo.setBeginDate(sdf.format(project.getBegin_date()));18. }19. if(project.getEnd_date() != null){20. pwo.setEndDate(sdf.format(project.getEnd_date()));21. }22. if(project.getProject_target() != null){23. pwo.setProjecTarget(project.getProject_target());24. }24. }25. if(project.getMember_id() != null){26. Member member = memberBo.getCacheMember(project.getMember_id());27. pwo.setMemberId(member.getMember_name());28. }29. if(pe.getPlan_no() != null){30. pwo.setPlanNu(pe.getPlan_no());31. }32. if(pe.getIncrement() != null){33. pwo.setInvestment(pe.getIncrement());34. }35. if(pe.getDo_item() != null){36. pwo.setDoItem(pe.getDo_item());37. }38. if(pe.getKey_point() != null){39. pwo.setKeyPoint(pe.getKey_point());40. }41. if(list != null){42. pwo.setChild(addtypePlus(list));43. }44. return pwo;45. }46. /**47. *将⼯程造价咨询项⽬⼯作交办单导出为word48. */49. @Override50. public void makeExportProWorkOrderData(ProjectWorkOrder pwo, Map<String, Object> dataMap) {51. if(pwo==null){52. return;53. }54. if(pwo.getProjectTitle() != null){55. dataMap.put("ptitle",pwo.getProjectTitle());//项⽬名称56. }else{57. dataMap.put("ptitle","⽆");58. }59. if(pwo.getProjectId() != null){60. dataMap.put("pid", pwo.getProjectId());//⼯程id61. }else{62. dataMap.put("pid", "0");63. }64. if(pwo.getBeginDate() != null){65. dataMap.put("begindate", pwo.getBeginDate());//项⽬开始时间66. }else{67. dataMap.put("begindate", "⽆");68. }69. if(pwo.getEndDate() != null){70. dataMap.put("endate", pwo.getEndDate());//结束⽇期71. }else{72. dataMap.put("endate", "⽆");73. }74. if(pwo.getProjecTarget() != null){75. dataMap.put("ptarget", pwo.getProjecTarget());//⽬标76. }else{77. dataMap.put("ptarget", "⽆");78. }79. if(pwo.getMemberId() != null){80. dataMap.put("pmemberid", pwo.getMemberId());//负责⼈81. }else{81. }else{82. dataMap.put("pmemberid", "⽆");83. }84. if(pwo.getPlanNu() != null){85. dataMap.put("plano", pwo.getPlanNu());//计划编号86. }else{87. dataMap.put("plano", "⽆");88. }if(pwo.getInvestment() != null){89. dataMap.put("investment", pwo.getInvestment());//总投资90. }else{91. dataMap.put("investment", "⽆");92. }93. if(pwo.getDoItem() != null){94. dataMap.put("doitem", pwo.getDoItem());//事项95. }else{96. dataMap.put("doitem", "⽆");97. }98. if(pwo.getKeyPoint() != null){99. dataMap.put("keypoint", pwo.getKeyPoint());//重点100. }else{101. dataMap.put("keypoint", "⽆");102. }103. if(pwo.getChild() != null){104. dataMap.put("list", pwo.getChild());//联系⼈列表105. }else{106. dataMap.put("list", "⽆");107. }108. SimpleDateFormat tempDate = new SimpleDateFormat("yyyy年MM⽉dd⽇"); 109. String datetime = tempDate.format(DateTimeUtil.getCurrDate());110. dataMap.put("datetime", datetime);111. }112. /**113. * 将单位类型数字转换为对应的字符114. */115. private List<ProjectDepartment> addtypePlus(List<ProjectDepartment> list){116. for (ProjectDepartment projectDepartment : list) {117. if(projectDepartment.getType() == 1){projectDepartment.setTypePlus("委托单位");} 118. if(projectDepartment.getType() == 2){projectDepartment.setTypePlus("建设单位");} 119. if(projectDepartment.getType() == 3){projectDepartment.setTypePlus("施⼯单位");} 120. if(projectDepartment.getType() == 4){projectDepartment.setTypePlus("监理单位");} 121. if(projectDepartment.getType() == 5){projectDepartment.setTypePlus("设计单位");} 122. if(projectDepartment.getType() == 6){projectDepartment.setTypePlus("编制单位");} 123. }124. return list;125. }配置⽂件的信息这⾥就不在多说了,同时需要修改ftl中的参数,修改⽅法如下,[html] view plain copy print?1. <w:r wsp:rsidRPr="002C3578">2. <w:rPr>3. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>4. <wx:font wx:val="宋体"/>5. <w:sz-cs w:val="21"/>6. </w:rPr>7. <w:t><![CDATA[${doitem}]]></w:t>7. <w:t><![CDATA[${doitem}]]></w:t>8. </w:r>与jsp中的⽅法基本⼀致,处理list,如果遇到循环的话,使⽤如下的⽅法,[html] view plain copy print?1. <#list list as bean><!-- Start 循环体 -->2. <w:tr wsp:rsidR="002C3578" wsp:rsidRPr="002C3578" wsp:rsidTr="002C3578">3. <w:trPr>4. <w:trHeight w:val="427"/>5. </w:trPr>6. <w:tc>7. <w:tcPr>8. <w:tcW w:w="534" w:type="dxa"/>9. <w:vmerge/>10. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>11. </w:tcPr>12. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">13. <w:pPr>14. <w:jc w:val="center"/>15. <w:rPr>16. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>17. <wx:font wx:val="宋体"/>18. <w:sz-cs w:val="21"/>19. </w:rPr>20. </w:pPr>21. </w:p>22. </w:tc>23. <w:tc>24. <w:tcPr>25. <w:tcW w:w="1596" w:type="dxa"/>26. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>27. </w:tcPr>28. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">29. <w:pPr>30. <w:spacing w:line="360" w:line-rule="auto"/>31. <w:jc w:val="center"/>32. <w:rPr>33. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>34. <wx:font wx:val="宋体"/>35. <w:sz-cs w:val="21"/>36. </w:rPr>37. </w:pPr>38. <w:r wsp:rsidRPr="002C3578">39. <w:rPr>40. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>41. <wx:font wx:val="宋体"/>42. <w:sz-cs w:val="21"/>43. </w:rPr>44. <w:t><![CDATA[${bean.typePlus}]]></w:t>45. </w:r>46. </w:p>47. </w:tc>48. <w:tc>48. <w:tc>49. <w:tcPr>50. <w:tcW w:w="2130" w:type="dxa"/>51. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>52. </w:tcPr>53. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">54. <w:pPr>55. <w:spacing w:line="360" w:line-rule="auto"/>56. <w:jc w:val="center"/>57. <w:rPr>58. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>59. <wx:font wx:val="宋体"/>60. <w:sz-cs w:val="21"/>61. </w:rPr>62. </w:pPr>63. <w:r wsp:rsidRPr="002C3578">64. <w:rPr>65. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>66. <wx:font wx:val="宋体"/>67. <w:sz-cs w:val="21"/>68. </w:rPr>69. <w:t><![CDATA[${bean.department_name}]]></w:t>70. </w:r>71. </w:p>72. </w:tc>73. <w:tc>74. <w:tcPr>75. <w:tcW w:w="2131" w:type="dxa"/>76. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>77. </w:tcPr>78. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">79. <w:pPr>80. <w:spacing w:line="360" w:line-rule="auto"/>81. <w:jc w:val="center"/>82. <w:rPr>83. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>84. <wx:font wx:val="宋体"/>85. <w:sz-cs w:val="21"/>86. </w:rPr>87. </w:pPr>88. <w:r wsp:rsidRPr="002C3578">89. <w:rPr>90. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>91. <wx:font wx:val="宋体"/>92. <w:sz-cs w:val="21"/>93. </w:rPr>94. <w:t><![CDATA[${bean.linkman}]]></w:t>95. </w:r>96. </w:p>97. </w:tc>98. <w:tc>99. <w:tcPr>100. <w:tcW w:w="2131" w:type="dxa"/>101. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>102. </w:tcPr>103. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578"> 104. <w:pPr>104. <w:pPr>105. <w:spacing w:line="360" w:line-rule="auto"/>106. <w:jc w:val="center"/>107. <w:rPr>108. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>109. <wx:font wx:val="宋体"/>110. <w:sz-cs w:val="21"/>111. </w:rPr>112. </w:pPr>113. <w:r wsp:rsidRPr="002C3578">114. <w:rPr>115. <w:rFonts w:ascii="宋体" w:h-ansi="宋体"/>116. <wx:font wx:val="宋体"/>117. <w:sz-cs w:val="21"/>118. </w:rPr>119. <w:t><![CDATA[${bean.phone}]]></w:t>120. </w:r>121. </w:p>122. </w:tc>123. </w:tr>124. </#list><!-- End 循环体 -->这样就能导出想要的word⽂档,⼀定要记住,使⽤office2013,我试着⽤WPS,但是⽣成内容让我很懵逼,全是xml代码。
Java学习之导出word文档
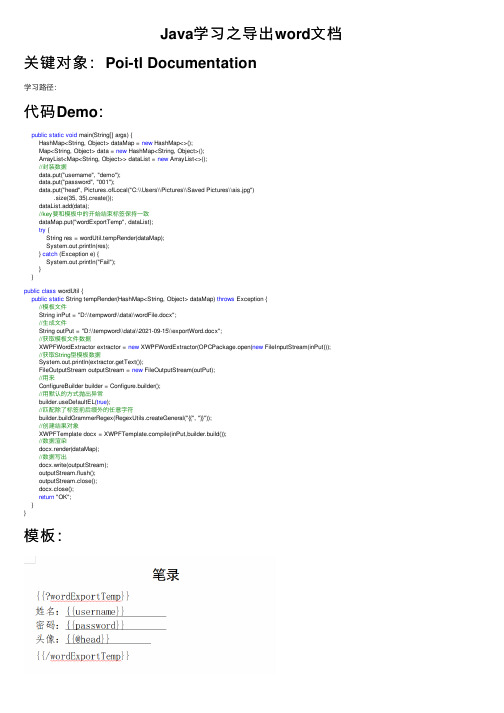
Java学习之导出word⽂档关键对象:Poi-tl Documentation学习路径:代码Demo:public static void main(String[] args) {HashMap<String, Object> dataMap = new HashMap<>();Map<String, Object> data = new HashMap<String, Object>();ArrayList<Map<String, Object>> dataList = new ArrayList<>();//封装数据data.put("username", "demo");data.put("password", "001");data.put("head", Pictures.ofLocal("C:\\Users\\Pictures\\Saved Pictures\\ais.jpg").size(35, 35).create());dataList.add(data);//key要和模板中的开始结束标签保持⼀致dataMap.put("wordExportTemp", dataList);try {String res = wordUtil.tempRender(dataMap);System.out.println(res);} catch (Exception e) {System.out.println("Fail");}}public class wordUtil {public static String tempRender(HashMap<String, Object> dataMap) throws Exception {//模板⽂件String inPut = "D:\\tempword\\data\\wordFile.docx";//⽣成⽂件String outPut = "D:\\tempword\\data\\2021-09-15\\exportWord.docx";//获取模板⽂件数据XWPFWordExtractor extractor = new XWPFWordExtractor(OPCPackage.open(new FileInputStream(inPut)));//获取String型模板数据System.out.println(extractor.getText());FileOutputStream outputStream = new FileOutputStream(outPut);//⽤来ConfigureBuilder builder = Configure.builder();//⽤默认的⽅式抛出异常eDefaultEL(true);//匹配除了标签前后缀外的任意字符builder.buildGrammerRegex(RegexUtils.createGeneral("{{", "}}"));//创建结果对象XWPFTemplate docx = pile(inPut,builder.build());//数据渲染docx.render(dataMap);//数据写出docx.write(outputStream);outputStream.flush();outputStream.close();docx.close();return "OK";}}模板:注意:{{?wordExportTemp}} 中的“wordExportTemp”要和封装数据Map的“key"保持⼀致!结果。
java根据word模板导出word文件

java根据word模板导出word⽂件1、word模板⽂件处理,如下图所⽰在word ⽂档中填值的地⽅写⼊占位变量2、将word⽂档另存为xml⽂件、编辑如下图,找到填写的占位,修改为${bcrxm}格式3、将⽂件后缀名改为.ftl⽂件4、java处理过程、引⼊frameMark jar 包5、java代码 ⼀、将需要填充的数据封装到map中、与模板中的占位对应、为什么⽤map 我也不知道。
⼆、创建configuration对象 三、设置编码 utf-8 四、获取模板 configuration.setDirectoryForTemplateLoading() ⽅法、configuration.getTemplate()⽅法 五、将模板和数据模型合并⽣成⽂件 template.process(map, out); //map为封装的数据、out为输出流对象6、完整代码、configuration.setClassForTemplateLoading ⽅法有不同的使⽤⽅式、可以根据⾃⼰的需要选择、具体使⽤⽅法、问度娘。
public static String createWord1(Map dataMap,String templateName,String filePath,String fileName,HttpServletRequest request,HttpServletResponse response){ String fileOnlyName=null;try {//创建配置实例Configuration configuration = new Configuration();//设置编码configuration.setDefaultEncoding("UTF-8");//ftl模板⽂件统⼀放⾄ template 包下⾯configuration.setClassForTemplateLoading(Util.class,"/template/");//获取模板Template template = configuration.getTemplate(templateName,"UTF-8");//重命名fileOnlyName = rename(fileName);//定义路径统⼀放到 webappo/hgjc/uploadRoot⽬录下String servicePath = request.getSession().getServletContext().getRealPath(File.separator);String basePath = ReadConfig.getConfigValue("uploadRoot")+File.separator+ReadConfig.getConfigValue(filePath)+File.separator+fileOnlyName;//输出⽂件File outFile = new File(servicePath+basePath);//如果输出⽬标⽂件夹不存在,则创建if (!outFile.getParentFile().exists() ){outFile.getParentFile().mkdirs();}//将模板和数据模型合并⽣成⽂件Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8"));//⽣成⽂件template.process(dataMap, out);//关闭流out.flush();out.close();} catch (Exception e) {e.printStackTrace();}return fileOnlyName;}。
Java导出Word文档案例

Java导出Word⽂档案例摘⾃:最近做的⼀个Flex项⽬中要把报表导出到Word⽂件中。
⽹上查了好多资料后最终在⽹友的帮助和⾃⼰的奋⽃下成功搞定。
现把代码贴出来供⼤家批评指正并⼀起学习。
package org.replace;import java.io.File;import java.io.FileInputStream;import java.io.FileWriter;import java.io.IOException;import java.io.InputStream;import java.io.PrintWriter;import java.util.Iterator;import java.util.Map;public class ReportWord {public String replaceStr(String content, String oldcontent,String newcontent) {String rc = encodeToUnicode(newcontent);String target = "";oldcontent = "$" + oldcontent + "$";target = content.replace(oldcontent, rc);return target;}public String encodeToUnicode(String str) {if (str == null)return "";StringBuilder sb = new StringBuilder(str.length() * 2);for (int i = 0; i < str.length(); i++) {sb.append(encodeToUnicode(str.charAt(i)));}return sb.toString();}public String encodeToUnicode(char character) {if (character > 255) {return "&#" + (character & 0xffff) + ";";} else {return String.valueOf(character);}}public void exportWordFile(String inputPath, String outPath,Map<String, String> data) {String sourname = inputPath;String sourcecontent = "";InputStream ins = null;try {ins = new FileInputStream(sourname);byte[] b = new byte[1638400];// 提⾼对⽂件的读取速度,特别是对于1M以上的⽂件if (!new File(sourname).isFile()) {System.out.println("源模板⽂件不存在");return;}int bytesRead = 0;while (true) {bytesRead = ins.read(b, 0, 1638400);if (bytesRead == -1) {System.out.println("读取模板⽂件结束");break;}sourcecontent += new String(b, 0, bytesRead);}} catch (Exception e) {e.printStackTrace();}String targetcontent = "";String oldText = "";Object newValue;try {Iterator<String> keys = data.keySet().iterator();int keysfirst = 0;while (keys.hasNext()) {oldText = (String) keys.next();newValue = data.get(oldText);String newText = (String) newValue;if (keysfirst == 0) {targetcontent = replaceStr(sourcecontent, oldText, newText); keysfirst = 1;} else {targetcontent = replaceStr(targetcontent, oldText, newText); keysfirst = 1;}}FileWriter fw = new FileWriter(outPath, true);PrintWriter out = new PrintWriter(fw);if (targetcontent.equals("") || targetcontent == "") {out.println(sourcecontent);} else {out.println(targetcontent);}out.close();fw.close();System.out.println(outPath + " ⽣成⽂件成功");} catch (IOException e) {e.printStackTrace();}}}测试代码为:package org.replace;import java.io.File;import java.util.HashMap;public class ExportFile {public static void main(String[] args) {ReportWord rw = new ReportWord();HashMap<String, String> map = new HashMap<String, String>(); map.put("1", "张三");map.put("2", "李四");map.put("3", "王五");map.put("4", "赵六");map.put("5", "彩笔");map.put("6", "张三");map.put("7", "李四");map.put("8", "王五");map.put("9", "赵六");map.put("10", "彩笔");map.put("11", "张三");map.put("12", "李四");map.put("13", "王五");map.put("14", "赵六");map.put("15", "彩笔");String inUrl = "D:" + File.separator + "itest.mht";String outUrl = "C:" + File.separator + "Users"+ File.separator + "Administrator" + File.separator + "Desktop"+ File.separator + "itest.doc";File fileOut = new File(outUrl);File fileIn = new File(inUrl);if(fileOut.exists()){fileOut.delete();System.out.println(inUrl + "⽂件已存在,已删除!"); }if(!fileIn.exists()){return;}rw.exportWordFile(inUrl, outUrl, map);}}使⽤的模板为.mht⽂件。
java利用xml导出word(占位符替换)

package cn.action;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.util.ArrayList;import java.util.Date;import java.util.HashMap;import java.util.Iterator;import java.util.List;import java.util.Map;import java.util.Set;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerFactory;import javax.xml.transform.dom.DOMSource;import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;import sun.misc.BASE64Encoder;public class XmlWord {private Map<String,String> dataMap = new HashMap<String,String>();public Map<String, String> getDataMap() {return dataMap;}public void setDataMap(Map<String, String> dataMap) {this.dataMap = dataMap;}/*** 设置标识值* @param tagList 标识* @param dataList 数据* @param dataMap*/public void setData(List<String> tagList,List<String> dataList){Iterator<String> it1 = tagList.iterator();Iterator<String> it2 = dataList.iterator();while(it1.hasNext()){this.dataMap.put(it1.next(), it2.next());}}/*** 载入一个xml文档* @param filename 文件路径* @return 成功返回Document对象,失败返回null*/public Document LoadXml(String filename){Document doc = null;try {DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();doc = (Document) builder.parse(new File(filename));System.out.println(doc);} catch (Exception e) {System.out.println("载入xml文件时出错");e.printStackTrace();}return doc;}/*** 图片转码* @return 返回图片base64字符串* @throws Exception*/public String getImageStr(String imgFile){InputStream in = null;BASE64Encoder encoder = null;byte[] data = null;try {in = new FileInputStream(imgFile);} catch (FileNotFoundException e) {System.out.println("文件没找到!");e.printStackTrace();}try {data = new byte[in.available()];in.read(data);in.close();} catch (IOException e) {e.printStackTrace();}encoder = new BASE64Encoder();return encoder.encode(data);}/*** doc2XmlFile* 将Document对象保存为一个xml文件* @return true:保存成功flase:失败* @param filename 保存的文件名* @param document 需要保存的document对象*/public boolean doc2XmlFile(Document document,String filename){boolean flag = true;try{TransformerFactory transFactory = TransformerFactory.newInstance();Transformer transformer = transFactory.newTransformer();DOMSource source=new DOMSource();source.setNode(document);StreamResult result=new StreamResult();FileOutputStream fileOutputStream = new FileOutputStream(filename);result.setOutputStream(fileOutputStream);transformer.transform(source, result);fileOutputStream.close();}catch(Exception ex){flag = false;ex.printStackTrace();}return flag;}/*** 替换标识内容:单个文本标记* @param element 要替换内容的节点* @param tag 标识名称* @param data 替换参数* @return 返回替换后的节点* @throws Exception*/public Element replaceTagContext(Object element,String tag,String data){Element xElement = null;xElement = (Element) element;NodeList tElements = xElement.getElementsByTagName("w:t");//w:t标签组for(int i=0; i<tElements.getLength(); i++){Element tElement = (Element)tElements.item(i);if(tElement.getTextContent().equals(tag)){tElement.setTextContent(data);}}return xElement;}/*** 替换标识内容:多个文本标记* @param element 要替换内容的节点* @return 返回替换后的节点* @throws Exception*/public Element replaceTagContext(Element element){Element xElement = element;NodeList tElements = xElement.getElementsByTagName("w:t");//w:t标签组Set<String> dataSet = this.dataMap.keySet();Iterator<String> it = dataSet.iterator();while(it.hasNext()){String tag = it.next();String data = dataMap.get(tag);for(int i=0; i<tElements.getLength(); i++){Element tElement = (Element)tElements.item(i);if(tElement.getTextContent().equals(tag)){tElement.setTextContent(data);}}}return xElement;}/*** 添加图片* @param element 需要替换内容的节点* @param tag 标识名称* @param imgName 图片名称,若word中有多张图,图片名必须唯一* @param imgStr 图片转码后的base64字符串* @return 返回替换后的节点*/public Element replacePic(Element element,String tag,String imgName,String imgFile){ Element xElement = element;NodeList tElements = xElement.getElementsByTagName("w:binData");//w:t标签组pkg:binaryDataString wName = "wordml://"+imgName;for(int i=0; i<tElements.getLength(); i++){Element picElement = (Element)tElements.item(i);if(picElement.getTextContent().equals(tag)){picElement.setTextContent(this.getImageStr(imgFile));/*图片编码*/picElement.setAttribute("w:name",wName);//设置名字Element imagedataElement = (Element) xElement.getElementsByTagName("v:imagedata").item(i);imagedataElement.setAttribute("src",wName);}}return xElement;}/*** 插入图片* @param parentElement 图片添加至何处* @param imgFile 图片路径* @param isnewLine 是否换行* @return 返回添加图片节点后的节点*/public Element addPic(Element parentElement,String imgFile,boolean isnewLine){ Document parent = parentElement.getOwnerDocument();Element p = null;Element pict = null;Element binData = null;Element shape = null;Element imagedata = null;String src = "wordml://" + new Date().getTime();if(isnewLine){p = parent.createElement("w:p");}pict = parent.createElement("w:pict");binData = parent.createElement("w:binData");binData.setAttribute("w:name", src);binData.setAttribute("xml:space", "preserve");binData.setTextContent(this.getImageStr(imgFile));shape = parent.createElement("v:shape");imagedata = parent.createElement("v:imagedata");imagedata.setAttribute("src", src);//构造图片节点shape.appendChild(imagedata);pict.appendChild(binData);pict.appendChild(shape);if(isnewLine){p.appendChild(pict);parentElement.appendChild(p);}else{parentElement.appendChild(pict);}return parentElement;}/*** 插入段落* @param parentElement 待添加段落的节点* @param data 待插入数据* @return*/public Element addParagraph(Element parentElement,String data){ Document parent = parentElement.getOwnerDocument();Element p = null;Element r = null;Element t = null;p = parent.createElement("w:p");r = parent.createElement("w:r");t = parent.createElement("w:t");t.setTextContent(data);//构造图片节点r.appendChild(t);p.appendChild(r);parentElement.appendChild(p);return parentElement;}}。
Freemarker+xml实现Java导出word
Freemarker+xml实现Java导出word前⾔最近做了⼀个调查问卷导出的功能,需求是将维护的题⽬,答案,导出成word,参考了⼏种⽅案之后,选择功能强⼤的freemarker+固定格式之后的wordxml实现导出功能。
导出word的代码是可以直接复⽤的,于是在此贴出,并进⾏总结,⽅便⼤家拿⾛。
实现过程概览先在word上,调整好⾃⼰想要的样⼦。
然后存为xml⽂件。
保存为freemarker模板,以ftl后缀结尾。
将需要替换的变量使⽤freemarker的语法进⾏替换。
最终将数据准备好,和模板进⾏渲染,⽣成⽂件并返回给浏览器流。
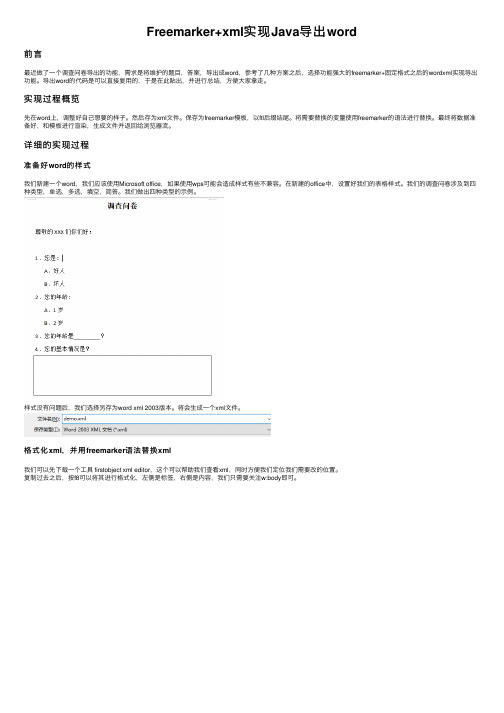
详细的实现过程准备好word的样式我们新建⼀个word,我们应该使⽤Microsoft office,如果使⽤wps可能会造成样式有些不兼容。
在新建的office中,设置好我们的表格样式。
我们的调查问卷涉及到四种类型,单选,多选,填空,简答。
我们做出四种类型的⽰例。
样式没有问题后,我们选择另存为word xml 2003版本。
将会⽣成⼀个xml⽂件。
格式化xml,并⽤freemarker语法替换xml我们可以先下载⼀个⼯具 firstobject xml editor,这个可以帮助我们查看xml,同时⽅便我们定位我们需要改的位置。
复制过去之后,按f8可以将其进⾏格式化,左侧是标签,右侧是内容,我们只需要关注w:body即可。
像右侧的调查问卷这个就是个标题,我们实际渲染的时候应该将其进⾏替换,⽐如我们的程序数据map中,有title属性,我们想要这⾥展⽰,我们就使⽤语法${title}即可。
freemarker的具体语法,可以参考freemarker的问题,在这⾥我给出⼏个简单的例⼦。
⽐如我们将所有的数据放置在dataList中,所以我们需要判断,dataList是不是空,是空,我们不应该进⾏下⾯的逻辑,不是空,我们应该先循环题⽬是必须的,答案是需要根据类型进⾏再次循环的。
Java导出Word文档

Java导出Word⽂档js 请求后端function exportWord(opId){location.href=ctx+'/maintainPro/downloadWord?opId='+opId+"&type=0";} java后端代码⽰例@RequestMapping(value = "/downloadWord")@AdminToolControllerLog(description = "word⽂档下载")public void downloadTemplate(HttpServletRequest req, HttpServletResponse resp,Long opId,String type) throws Exception {JsonMsg msg = new JsonMsg();MaintainPro maintainPro = maintainproService.findMaintainPro(opId);String classpath = this.getClass().getResource("/").getPath();String docRoot = classpath.replaceAll("WEB-INF/classes/", "");String wordDirUrl = "static/resources/word/";// String docRoot = classpath.replaceAll("classes/", "");// String wordDirUrl = "RePlan/static/resources/word/";String fileName="项⽬申报书.docx"; //word模板名称String filePath =docRoot+wordDirUrl+fileName;Map<String, Object> ini = getIniMap(maintainPro); //获取固定字段信息List<Map<String, Object>> list1 = getTableList(maintainPro,1L); //获取列表数据List<Map<String, Object>> list2 = getTableList(maintainPro,2L);List<Map<String, Object>> list3 = getTableList(maintainPro,3L);WordReporter wordReporter = new WordReporter();wordReporter.setTempLocalPath(filePath);wordReporter.init(ini); //固定字段赋值wordReporter.replaceTableParams(ini, 0); //对应表格固定字段信息赋值(0指word模板中第⼀个表格,依次类推)wordReporter.replaceTableParams(ini, 1);wordReporter.replaceTableParams(ini, 2);wordReporter.replaceTableParams(ini, 3);wordReporter.replaceTableParams(ini, 4);wordReporter.replaceTableParams(ini, 5);//遍历(设备、产品软件、应⽤软件)表格wordReporter.export(list1,6,1,1); //需要遍历的列表赋值(6指word模板中第7个表格,表格从第1⾏开始,以第1⾏作为创建⾏)wordReporter.export(list2,7,1,1);wordReporter.export(list3,8,1,1);int index = fileName.indexOf(".");String prefix = fileName.substring(0,index);fileName = fileName.replace(prefix, maintainPro.getPiName()+"申报书"); //导出⽂件重新命名buildWordheader(req, resp, fileName);//刷新缓冲resp.flushBuffer();OutputStream ouputStream = resp.getOutputStream();wordReporter.getXwpfDocument().write(ouputStream);if (ouputStream != null) {ouputStream.close();}msg.setSuccess(true);}//将对象中所需字段转mappublic Map<String,Object> getIniMap(MaintainPro maintainPro){Map<String, Object> map = maintainproService.findIniMapById(maintainPro.getOpId());if(map!=null) {if(map.get("PI_NAME")!=null) {//项⽬名称map.put("piName", map.get("PI_NAME").toString());}}return map;}public void buildWordheader(HttpServletRequest req, HttpServletResponse resp,String filename) throws UnsupportedEncodingException { resp.reset();String fileNameURL = URLEncoder.encode(filename, "UTF-8");resp.setCharacterEncoding("UTF-8");//response.setHeader("Content-disposition", "attachment;filename=" + fileName);resp.setHeader("Content-disposition", "attachment;filename=" + fileNameURL + ";" + "filename*=utf-8''" + fileNameURL);resp.setContentType("application/octet-stream");}package mon.util;import ng.StringUtils;import ermodel.*;import org.openxmlformats.schemas.wordprocessingml.x2006.main.*;import java.io.*;import java.util.Iterator;import java.util.List;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;/*** Created by lzx on 2018/8/12*/public class WordReporter {private String tempLocalPath;private XWPFDocument xwpfDocument = null;private FileInputStream inputStream = null;private OutputStream outputStream = null;public WordReporter(){}public WordReporter(String tempLocalPath){this.tempLocalPath = tempLocalPath;}/*** 设置模板路径* @param tempLocalPath*/public void setTempLocalPath(String tempLocalPath) {this.tempLocalPath = tempLocalPath;}/*** 初始化* @throws IOException*/public void init(Map<String,Object> params) throws IOException{inputStream = new FileInputStream(new File(this.tempLocalPath));xwpfDocument = new XWPFDocument(inputStream);replaceParams(xwpfDocument, params);}/*** 替换段落⾥⾯的变量** @param doc 要替换的⽂档* @param params 参数*/private static void replaceParams(XWPFDocument doc, Map<String, Object> params) {Iterator<XWPFParagraph> iterator = doc.getParagraphsIterator();XWPFParagraph paragraph;while (iterator.hasNext()) {paragraph = iterator.next();replaceParam(paragraph, params);}}/*** 替换段落⾥⾯的变量** @param paragraph 要替换的段落* @param params 参数*/private static void replaceParam(XWPFParagraph paragraph, Map<String, Object> params) {List<XWPFRun> runs;Matcher matcher;String runText = "";if (matcher(paragraph.getParagraphText()).find()) {runs = paragraph.getRuns();int j = runs.size();for (int i = 0; i < j; i++) {runText += runs.get(0).toString();//保留最后⼀个段落,在这段落中替换值,保留段落样式if (!((j - 1) == i)) {paragraph.removeRun(0);}}matcher = matcher(runText);if (matcher.find()) {while ((matcher = matcher(runText)).find()) {runText = matcher.replaceFirst(params.get(matcher.group(1))==null?"":params.get(matcher.group(1)).toString()); // runText = matcher.replaceFirst(String.valueOf(params.get(matcher.group(1))));}runs.get(0).setText(runText, 0);}}}/*** 正则匹配字符串** @param str* @return*/private static Matcher matcher(String str) {Pattern pattern = pile("\\$\\{(.+?)\\}", Pattern.CASE_INSENSITIVE);Matcher matcher = pattern.matcher(str);return matcher;}/*** @param doc docx解析对象* @param params 需要替换的信息集合* @param tableIndex 第⼏个表格* @param tableList 需要插⼊的表格信息集合*/public static void changeTable(XWPFDocument doc, Map<String, Object> params, int tableIndex, List<String[]> tableList) { //获取表格对象集合List<XWPFTable> tables = doc.getTables();//获取第⼀个表格根据实际模板情况决定去第⼏个word中的表格XWPFTable table = tables.get(tableIndex);//替换表格中的参数// replaceTableParams(params,0);//在表格中插⼊数据insertTable(table, tableList);}/*** 为表格插⼊⾏数,此处不处理表头,所以从第⼆⾏开始** @param table 需要插⼊数据的表格* @param tableList 插⼊数据集合*/private static void insertTable(XWPFTable table, List<String[]> tableList) {//创建与数据⼀致的⾏数for (int i = 0; i < tableList.size(); i++) {table.createRow();}int length = table.getRows().size();for (int i = 1; i < length; i++) {XWPFTableRow newRow = table.getRow(i);List<XWPFTableCell> cells = newRow.getTableCells();for (int j = 0; j < cells.size(); j++) {XWPFTableCell cell = cells.get(j);cell.setText(tableList.get(i - 1)[j]);}}}/*** 替换表格⾥⾯的变量** @param doc 要替换的⽂档* @param params 参数*/public void replaceTableParams( Map<String, Object> params,int tableIndex) {List<XWPFTable> tableList = xwpfDocument.getTables();XWPFTable table =tableList.get(tableIndex);;List<XWPFTableRow> rows;List<XWPFTableCell> cells;List<XWPFParagraph> paras;//判断表格是需要替换还是需要插⼊,判断逻辑有$为替换,表格⽆$为插⼊if (matcher(table.getText()).find()) {rows = table.getRows();for (XWPFTableRow row : rows) {cells = row.getTableCells();for (XWPFTableCell cell : cells) {paras = cell.getParagraphs();for (XWPFParagraph para : paras) {replaceParam(para, params);}}}}}/*** 导出⽅法* @param params* @param tableIndex word的表格索引* @param rownum 从第⼏⾏开始* @param createrowindex 以第⼏⾏作为创建⾏* @return* @throws Exception*/public boolean export(List<Map<String,Object>> params, int tableIndex,int rownum,int createrowindex) throws Exception{this.insertValueToTable(xwpfDocument,params,tableIndex,rownum,createrowindex);return true;}/*** 循环填充表格内容* @param xwpfDocument* @param params* @param tableIndex* @throws Exception*/private void insertValueToTable(XWPFDocument xwpfDocument, List<Map<String,Object>> params, int tableIndex,int rownum,int createrowindex) throws Exception { List<XWPFTable> tableList = xwpfDocument.getTables();if(tableList.size()<=tableIndex){throw new Exception("tableIndex对应的表格不存在");}XWPFTable table = tableList.get(tableIndex);List<XWPFTableRow> rows = table.getRows();if(rows.size()<2){throw new Exception("tableIndex对应表格应该为2⾏");}//模板的那⼀⾏XWPFTableRow tmpRow = rows.get(rownum);List<XWPFTableCell> tmpCells = null;List<XWPFTableCell> cells = null;XWPFTableCell tmpCell = null;tmpCells = tmpRow.getTableCells();table.getCTTbl();String cellText = null;String cellTextKey = null;Map<String,Object> totalMap = null;for (int i = 0, len = params.size(); i < len; i++) {Map<String,Object> map = params.get(i);// 创建新的⼀⾏// XWPFTableRow row = table.createRow();XWPFTableRow row = createRow(table.getCTTbl(),table,createrowindex);// 获取模板的⾏⾼设置为新⼀⾏的⾏⾼row.setHeight(tmpRow.getHeight());cells = row.getTableCells();for (int k = 0, klen = cells.size(); k < klen; k++) {tmpCell = tmpCells.get(k);XWPFTableCell cell = cells.get(k);cellText = tmpCell.getText();if (StringUtils.isNotBlank(cellText)) {//转换为mapkey对应的字段cellTextKey = cellText.replace("$", "").replace("{", "").replace("}", "").replaceAll("[^a-zA-Z0-9_\\u4E00-\\u9FA5]", "");if (map.containsKey(cellTextKey)) {// 填充内容并且复制模板⾏的属性setCellText(tmpCell,cell,map.get(cellTextKey)==null?"":map.get(cellTextKey).toString());}}}}// 删除模版⾏table.removeRow(rownum);}private XWPFTableRow createRow(CTTbl ctTbl,XWPFTable table,int i){int sizeCol = ctTbl.sizeOfTrArray() > 0 ? ctTbl.getTrArray(i).sizeOfTcArray() : 0;XWPFTableRow tabRow = new XWPFTableRow(ctTbl.addNewTr(), table);addColumn(tabRow, sizeCol);//tableRows.add(tabRow);return tabRow;}private void addColumn(XWPFTableRow tabRow, int sizeCol) {if (sizeCol > 0) {for (int i = 0; i < sizeCol; i++) {tabRow.createCell();}}}/*** 复制模板⾏的属性* @param tmpCell* @param cell* @param text* @throws Exception*/private void setCellText(XWPFTableCell tmpCell, XWPFTableCell cell,String text) throws Exception {CTTc cttc2 = tmpCell.getCTTc();CTTcPr ctPr2 = cttc2.getTcPr();CTTc cttc = cell.getCTTc();CTTcPr ctPr = cttc.addNewTcPr();if (ctPr2.getTcW() != null) {ctPr.addNewTcW().setW(ctPr2.getTcW().getW());}if (ctPr2.getVAlign() != null) {ctPr.addNewVAlign().setVal(ctPr2.getVAlign().getVal());}if (cttc2.getPList().size() > 0) {CTP ctp = cttc2.getPList().get(0);if (ctp.getPPr() != null) {if (ctp.getPPr().getJc() != null) {cttc.getPList().get(0).addNewPPr().addNewJc().setVal(ctp.getPPr().getJc().getVal());}}}if (ctPr2.getTcBorders() != null) {ctPr.setTcBorders(ctPr2.getTcBorders());}XWPFParagraph tmpP = tmpCell.getParagraphs().get(0);XWPFParagraph cellP = cell.getParagraphs().get(0);XWPFRun tmpR = null;if (tmpP.getRuns() != null && tmpP.getRuns().size() > 0) {tmpR = tmpP.getRuns().get(0);}XWPFRun cellR = cellP.createRun();cellR.setText(text);// 复制字体信息if (tmpR != null) {if(!cellR.isBold()){cellR.setBold(tmpR.isBold());}cellR.setItalic(tmpR.isItalic());cellR.setUnderline(tmpR.getUnderline());cellR.setColor(tmpR.getColor());cellR.setTextPosition(tmpR.getTextPosition());if (tmpR.getFontSize() != -1) {cellR.setFontSize(tmpR.getFontSize());}if (tmpR.getFontFamily() != null) {cellR.setFontFamily(tmpR.getFontFamily());}if (tmpR.getCTR() != null) {if (tmpR.getCTR().isSetRPr()) {CTRPr tmpRPr = tmpR.getCTR().getRPr();if (tmpRPr.isSetRFonts()) {CTFonts tmpFonts = tmpRPr.getRFonts();CTRPr cellRPr = cellR.getCTR().isSetRPr() ? cellR.getCTR().getRPr() : cellR.getCTR().addNewRPr();CTFonts cellFonts = cellRPr.isSetRFonts() ? cellRPr.getRFonts() : cellRPr.addNewRFonts();cellFonts.setAscii(tmpFonts.getAscii());cellFonts.setAsciiTheme(tmpFonts.getAsciiTheme());cellFonts.setCs(tmpFonts.getCs());cellFonts.setCstheme(tmpFonts.getCstheme());cellFonts.setEastAsia(tmpFonts.getEastAsia());cellFonts.setEastAsiaTheme(tmpFonts.getEastAsiaTheme());cellFonts.setHAnsi(tmpFonts.getHAnsi());cellFonts.setHAnsiTheme(tmpFonts.getHAnsiTheme());}}}}// 复制段落信息cellP.setAlignment(tmpP.getAlignment());cellP.setVerticalAlignment(tmpP.getVerticalAlignment());cellP.setBorderBetween(tmpP.getBorderBetween());cellP.setBorderBottom(tmpP.getBorderBottom());cellP.setBorderLeft(tmpP.getBorderLeft());cellP.setBorderRight(tmpP.getBorderRight());cellP.setBorderTop(tmpP.getBorderTop());cellP.setPageBreak(tmpP.isPageBreak());if (tmpP.getCTP() != null) {if (tmpP.getCTP().getPPr() != null) {CTPPr tmpPPr = tmpP.getCTP().getPPr();CTPPr cellPPr = cellP.getCTP().getPPr() != null ? cellP.getCTP().getPPr() : cellP.getCTP().addNewPPr();// 复制段落间距信息CTSpacing tmpSpacing = tmpPPr.getSpacing();if (tmpSpacing != null) {CTSpacing cellSpacing = cellPPr.getSpacing() != null ? cellPPr .getSpacing() : cellPPr.addNewSpacing();if (tmpSpacing.getAfter() != null) {cellSpacing.setAfter(tmpSpacing.getAfter());}if (tmpSpacing.getAfterAutospacing() != null) {cellSpacing.setAfterAutospacing(tmpSpacing.getAfterAutospacing());}if (tmpSpacing.getAfterLines() != null) {cellSpacing.setAfterLines(tmpSpacing.getAfterLines());}if (tmpSpacing.getBefore() != null) {cellSpacing.setBefore(tmpSpacing.getBefore());}if (tmpSpacing.getBeforeAutospacing() != null) {cellSpacing.setBeforeAutospacing(tmpSpacing.getBeforeAutospacing());}if (tmpSpacing.getBeforeLines() != null) {cellSpacing.setBeforeLines(tmpSpacing.getBeforeLines()); }if (tmpSpacing.getLine() != null) {cellSpacing.setLine(tmpSpacing.getLine());}if (tmpSpacing.getLineRule() != null) {cellSpacing.setLineRule(tmpSpacing.getLineRule());}}// 复制段落缩进信息CTInd tmpInd = tmpPPr.getInd();if (tmpInd != null) {CTInd cellInd = cellPPr.getInd() != null ? cellPPr.getInd(): cellPPr.addNewInd();if (tmpInd.getFirstLine() != null) {cellInd.setFirstLine(tmpInd.getFirstLine());}if (tmpInd.getFirstLineChars() != null) {cellInd.setFirstLineChars(tmpInd.getFirstLineChars());}if (tmpInd.getHanging() != null) {cellInd.setHanging(tmpInd.getHanging());}if (tmpInd.getHangingChars() != null) {cellInd.setHangingChars(tmpInd.getHangingChars());}if (tmpInd.getLeft() != null) {cellInd.setLeft(tmpInd.getLeft());}if (tmpInd.getLeftChars() != null) {cellInd.setLeftChars(tmpInd.getLeftChars());}if (tmpInd.getRight() != null) {cellInd.setRight(tmpInd.getRight());}if (tmpInd.getRightChars() != null) {cellInd.setRightChars(tmpInd.getRightChars());}}}}}/*** 收尾⽅法* @param outDocPath* @return* @throws IOException*/public boolean generate(String outDocPath) throws IOException{outputStream = new FileOutputStream(outDocPath);xwpfDocument.write(outputStream);this.close(outputStream);this.close(inputStream);return true;}/*** 关闭输⼊流* @param is*/private void close(InputStream is) {if (is != null) {try {is.close();} catch (IOException e) {e.printStackTrace();}}}/*** 关闭输出流* @param os*/private void close(OutputStream os) {if (os != null) {try {os.close();} catch (IOException e) {e.printStackTrace();}}}public XWPFDocument getXwpfDocument() {return xwpfDocument;}public OutputStream getOutputStream() {return outputStream;}}word模板⽰例:。
Java之word导出下载

Java之word导出下载前⾔最近遇到项⽬需求需要将数据库中的部分数据导出到 word 中,具体是在⼀个新闻列表中将选中的新闻导出到⼀个 word 中。
参考了⽹上⼀些教程,实现了该功能,在此记录下来。
导出结果如下:图中为导出的其中两条新闻。
搜索⽹上导出 word 的⽅式有很多种,但是很多都是⼀笔带过,有⽰例代码的只找到了 POI 导出,和通过 FreeMarker ⽅式导出,但是只是具有参考意义。
本⽂采取使⽤ FreeMark ⽅式。
实现步骤1. Maven ⼯程引⼊FreeMarker 的依赖,⾮ Maven ⼯程添加 jar 包<dependency><groupId>org.freemarker</groupId><artifactId>freemarker</artifactId><version>2.3.26-incubating</version></dependency>2. 创建 word 模板1. 新建 word 替换内容为占位符2. 另存模板为 XML ⽂件3. 使⽤ NotePad++ 打开 xml ⽂件4. 选中全部内容,到进⾏格式化5. 将原内容替换为格式化后的内容6. 因为我的 word 的内容是⼀个列表,所以需要添加⼀个 freemarer 标签标识7. 找到 <w:document>元素下⾯的<w:body>元素,添加 <#list newsList news>,并在</w:body>结束标签之前闭合</#list>,此处的newsList 为后台读取模板时需要需要渲染数据map集合的key,其所对应的是⼀个list集合。
8. 保存为 FreeMarker 的模板⽂件,后缀为 ftl 格式,拷贝到项⽬中3. 编写代码1. 从数据中查询数据集合放⼊Map中,调⽤⼯具⽅法,返回流Map<String, Object> root = new HashMap<String, Object>();root.put("newsList", newsList);//newsList为新闻对象集合String template = "/temp.ftl"; //模板⽂件的地址ByteArrayOutputStream outputStream = WordUtil.process(root, template);return outputStream;2. 调⽤下载⼯具类进⾏下载即可。
Java实现XML文档到word文档转换

Java实现XML文档到word文档转换
段红亮;司青燕
【期刊名称】《电脑开发与应用》
【年(卷),期】2008(21)8
【摘要】XML文档在当今的网络传输中使用越来越广泛。
用XML文档交换信息给人们带来很多好处,首先,XML文档简单且便于阅读,因为它使用的是人的语言而不是计算机语言;其次,XML与JAVA完全兼容,且完全可以移植;再次,XML的可扩展性强。
【总页数】2页(P73,76)
【作者】段红亮;司青燕
【作者单位】中南大学信息科学与工程学院;中南大学信息科学与工程学院
【正文语种】中文
【中图分类】TP3
【相关文献】
1.论XML文档数据库数据之间的转换原理及转换对象 [J], 刘刚
2.用JAVA实现MARC元数据向DC元数据的转换 [J], 石仙鹤;郑巧英
3.在Oracle中用Java实现身份证转换 [J], 孙璐
4.Word文档文件格式的转换以及利用文件格式转换挽求死机的文档 [J], 汤俊
5.Java实现Word文档到XML文档转换浅析 [J], 李文锋;段红亮
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
package cn.action;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.util.ArrayList;import java.util.Date;import java.util.HashMap;import java.util.Iterator;import java.util.List;import java.util.Map;import java.util.Set;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerFactory;import javax.xml.transform.dom.DOMSource;import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;import sun.misc.BASE64Encoder;public class XmlWord {private Map<String,String> dataMap = new HashMap<String,String>();public Map<String, String> getDataMap() {return dataMap;}public void setDataMap(Map<String, String> dataMap) {this.dataMap = dataMap;}/*** 设置标识值* @param tagList 标识* @param dataList 数据* @param dataMap*/public void setData(List<String> tagList,List<String> dataList){Iterator<String> it1 = tagList.iterator();Iterator<String> it2 = dataList.iterator();while(it1.hasNext()){this.dataMap.put(it1.next(), it2.next());}}/*** 载入一个xml文档* @param filename 文件路径* @return 成功返回Document对象,失败返回null*/public Document LoadXml(String filename){Document doc = null;try {DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();doc = (Document) builder.parse(new File(filename));System.out.println(doc);} catch (Exception e) {System.out.println("载入xml文件时出错");e.printStackTrace();}return doc;}/*** 图片转码* @return 返回图片base64字符串* @throws Exception*/public String getImageStr(String imgFile){InputStream in = null;BASE64Encoder encoder = null;byte[] data = null;try {in = new FileInputStream(imgFile);} catch (FileNotFoundException e) {System.out.println("文件没找到!");e.printStackTrace();}try {data = new byte[in.available()];in.read(data);in.close();} catch (IOException e) {e.printStackTrace();}encoder = new BASE64Encoder();return encoder.encode(data);}/*** doc2XmlFile* 将Document对象保存为一个xml文件* @return true:保存成功flase:失败* @param filename 保存的文件名* @param document 需要保存的document对象*/public boolean doc2XmlFile(Document document,String filename){boolean flag = true;try{TransformerFactory transFactory = TransformerFactory.newInstance();Transformer transformer = transFactory.newTransformer();DOMSource source=new DOMSource();source.setNode(document);StreamResult result=new StreamResult();FileOutputStream fileOutputStream = new FileOutputStream(filename);result.setOutputStream(fileOutputStream);transformer.transform(source, result);fileOutputStream.close();}catch(Exception ex){flag = false;ex.printStackTrace();}return flag;}/*** 替换标识内容:单个文本标记* @param element 要替换内容的节点* @param tag 标识名称* @param data 替换参数* @return 返回替换后的节点* @throws Exception*/public Element replaceTagContext(Object element,String tag,String data){Element xElement = null;xElement = (Element) element;NodeList tElements = xElement.getElementsByTagName("w:t");//w:t标签组for(int i=0; i<tElements.getLength(); i++){Element tElement = (Element)tElements.item(i);if(tElement.getTextContent().equals(tag)){tElement.setTextContent(data);}}return xElement;}/*** 替换标识内容:多个文本标记* @param element 要替换内容的节点* @return 返回替换后的节点* @throws Exception*/public Element replaceTagContext(Element element){Element xElement = element;NodeList tElements = xElement.getElementsByTagName("w:t");//w:t标签组Set<String> dataSet = this.dataMap.keySet();Iterator<String> it = dataSet.iterator();while(it.hasNext()){String tag = it.next();String data = dataMap.get(tag);for(int i=0; i<tElements.getLength(); i++){Element tElement = (Element)tElements.item(i);if(tElement.getTextContent().equals(tag)){tElement.setTextContent(data);}}}return xElement;}/*** 添加图片* @param element 需要替换内容的节点* @param tag 标识名称* @param imgName 图片名称,若word中有多张图,图片名必须唯一* @param imgStr 图片转码后的base64字符串* @return 返回替换后的节点*/public Element replacePic(Element element,String tag,String imgName,String imgFile){ Element xElement = element;NodeList tElements = xElement.getElementsByTagName("w:binData");//w:t标签组pkg:binaryDataString wName = "wordml://"+imgName;for(int i=0; i<tElements.getLength(); i++){Element picElement = (Element)tElements.item(i);if(picElement.getTextContent().equals(tag)){picElement.setTextContent(this.getImageStr(imgFile));/*图片编码*/picElement.setAttribute("w:name",wName);//设置名字Element imagedataElement = (Element) xElement.getElementsByTagName("v:imagedata").item(i);imagedataElement.setAttribute("src",wName);}}return xElement;}/*** 插入图片* @param parentElement 图片添加至何处* @param imgFile 图片路径* @param isnewLine 是否换行* @return 返回添加图片节点后的节点*/public Element addPic(Element parentElement,String imgFile,boolean isnewLine){ Document parent = parentElement.getOwnerDocument();Element p = null;Element pict = null;Element binData = null;Element shape = null;Element imagedata = null;String src = "wordml://" + new Date().getTime();if(isnewLine){p = parent.createElement("w:p");}pict = parent.createElement("w:pict");binData = parent.createElement("w:binData");binData.setAttribute("w:name", src);binData.setAttribute("xml:space", "preserve");binData.setTextContent(this.getImageStr(imgFile));shape = parent.createElement("v:shape");imagedata = parent.createElement("v:imagedata");imagedata.setAttribute("src", src);//构造图片节点shape.appendChild(imagedata);pict.appendChild(binData);pict.appendChild(shape);if(isnewLine){p.appendChild(pict);parentElement.appendChild(p);}else{parentElement.appendChild(pict);}return parentElement;}/*** 插入段落* @param parentElement 待添加段落的节点* @param data 待插入数据* @return*/public Element addParagraph(Element parentElement,String data){ Document parent = parentElement.getOwnerDocument();Element p = null;Element r = null;Element t = null;p = parent.createElement("w:p");r = parent.createElement("w:r");t = parent.createElement("w:t");t.setTextContent(data);//构造图片节点r.appendChild(t);p.appendChild(r);parentElement.appendChild(p);return parentElement;}}。