T6数据库变慢的终极解决办法文库
T升级U工具使用说明
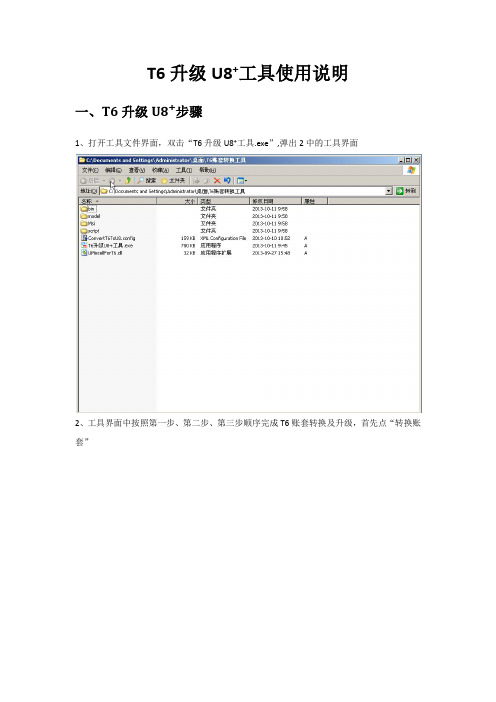
T6升级U8+工具使用说明一、T6升级U8+步骤1、打开工具文件界面,双击“T6升级U8+工具.exe”,弹出2中的工具界面2、工具界面中按照第一步、第二步、第三步顺序完成T6账套转换及升级,首先点“转换账套”3、选择需要升级的T6账套存放路径,弹出解压提示后点击“确定”4、选择解压后账套的存放路径并点击“确定”5、解压完会弹出“解压成功”提示,然后点击“确定”,然后点下一步6、进行数据库密码校验,输入正确的数据库密码后点击“下一步”7、选择转换完账套的存放路径,然后点击“下一步”后点开始转换8、转换过程中遇到T6账套科目编码长度超过15位的,会弹出安装MSI 工具包的提示,按照提示安装T6账套转换脚本.msi即可,然后点确定。
(科目编码长度不超过15位没有提示,不需要安装T6账套转换脚本.msi包);9、继上一步点击“确定”后弹出MSI包的安装文件10、双击“T6账套转换脚本.msi”后,弹出下面安装界面,点击“下一步”11、选择我接受“许可协议”的条款后,点击“下一步”12、点击“安装”13、MSI工具安装完成后,点击“完成”14、T6科目编码长度不超过15位,或执行安装T6账套转换脚本.msi包(系统回到T6账套转换界面),转化过程会有进度条提示15、转换完成后,点击“确定”T6账套转换完成16、返回首页后,点击“引入升级”按钮17、弹出“系统管理”(必须在U8+数据库服务器上才会弹出来)18、登陆“系统管理”,操作员选择admin19、打开需要升级账套的存放路径20、选择账套引入后的存放路径21、打开“系统--升级SQL server数据”选项22、选择需要升级的账套,直到升级完成23、升级U8+成功后,点击“调整数据”按钮24、打开需要调整的T6账套路径后,点击“下一步”25、选择“目标账套和目标年度”后点击“下一步”(默认全选)26、需要调整的功能列表,点击“下一步”27、在“开始升级数据”界面,点击“开始升级”按钮28、升级成功后,点击“确定”,升级完成二、升级到U8+后,部分模块需要单独处理1、出纳模块:升级到U8+后,首先到系统启用中把出纳启用,之后手工在系统管理给操作员赋予出纳的功能权限,然后打出纳的最新补丁包,最后按照T6出纳管理升级U8+方案.pdf进行出纳数据升级;2、财务分析:升级到U8+,需要手工到系统启用中启用财务分析模块或专家财务评估即可使用;3、UFO报表:升级到U8+后,需要用户手工赋予MR0151(报表登陆)权限,UFO系统才可以看到4、BS门户权限:T6升级到U8+V10.1版本及之前版本,需要手工到系统管理为操作员配置‘U8-ERP功能列表’权限(U8+V10.1之后版本不需要手工配置权限);5、物料清单:T6中的物料清单可以升级到U8+,升级成功后需要手工到系统启用中把物料清单模块启用,然后到系统管理中手工给操作员赋予物料清单的功能权限。
sybase数据库慢的请留意

sybase数据库慢的请留意数据库系统在当今的信息技术领域中发挥着重要作用,为各种应用程序的数据存储和管理提供支持。
然而,有时候我们可能会遇到Sybase数据库运行缓慢的问题。
本文将讨论一些可能导致Sybase数据库变慢的原因,并提供一些解决方案和优化策略。
一、索引设计不合理索引在数据库中起到加速查询操作的作用。
然而,当索引设计不合理时,可能会导致数据库查询变慢。
比如,过多的索引会增加数据库维护的负担,而过少的索引则会导致查询性能下降。
解决方案:对数据库进行分析,评估每个表的查询模式和频率,并根据这些信息,合理地设计索引。
避免创建过多冗余的索引,以免影响数据库性能。
二、存储空间不足Sybase数据库的存储空间管理对数据库的性能和稳定运行至关重要。
当存储空间不足时,数据库的读写操作会变慢。
此外,如果没有进行定期的空间清理,数据库中存储的日志文件会不断增长,进一步导致数据库性能下降。
解决方案:定期监控数据库的存储空间使用情况,合理规划并扩展存储空间。
同时,设置定期的空间清理任务,删除过期的日志文件等。
三、查询语句不优化编写高效的查询语句是提高数据库性能的关键。
当查询语句没有经过充分优化时,可能会导致数据库响应变慢。
解决方案:对于复杂的查询语句,使用Sybase提供的查询优化工具(如Explain Plan)进行分析,找出影响查询性能的因素,并进行优化。
避免使用不必要的子查询或者多次嵌套的查询操作。
四、硬件性能问题数据库的性能受到硬件的限制。
如果数据库运行在低配置的硬件环境下,可能会导致数据库响应变慢。
解决方案:评估数据库运行所在的硬件环境,确保硬件配置满足数据库的需要。
如果硬件配置有限,可以考虑升级硬件或者将数据库迁移到更高配置的服务器上。
五、数据库统计信息不准确数据库需要根据统计信息来优化查询执行计划。
如果数据库的统计信息不准确或者过期,会导致数据库查询慢。
解决方案:定期更新数据库的统计信息,以提高查询的准确性和效率。
处理数据量很大时超时的思路

处理数据量很大时超时的思路处理大量数据时,超时问题可能由于多种原因出现,例如系统资源不足、数据处理速度慢、网络延迟等。
针对这些问题,以下是一些可能的解决思路:
1. 优化数据处理算法和代码:检查和优化数据处理相关的算法和代码,提高代码的执行效率。
例如,使用更高效的算法,或者将复杂的操作分解为多个简单的操作并行处理。
2. 增加系统资源:通过增加系统资源来提升处理能力。
例如,增加内存、提高CPU性能、增加磁盘空间等。
3. 分批处理数据:将大量数据分成较小的批次进行处理,以减少单次处理的数据量。
同时,可以并行处理多个批次,以提高整体处理速度。
4. 优化数据库查询:如果超时问题与数据库查询有关,可以优化数据库查询语句,使用索引、分区等数据库技术来提高查询速度。
5. 使用缓存技术:对于重复性较高的数据处理任务,可以使用缓存技术来存储已经处理过的数据,避免重复处理。
6. 调整超时设置:根据实际情况调整超时时间的设置,使其更符合实际需求。
7. 使用分布式处理系统:对于非常大规模的数据处理任务,可以考虑使用分布式处理系统,将任务拆分成多个子任务在多台机器上并行处理。
这些思路需要根据具体的实际情况进行选择和实施,可能需要综合考虑技术、成本、资源等多个因素。
数据库慢查询优化的方法与技巧

数据库慢查询优化的方法与技巧数据库是现代应用程序中不可或缺的组成部分,它负责存储、管理和提供数据。
然而,随着数据量的增长和复杂查询的增加,数据库查询性能可能会变得缓慢。
在这篇文章中,我们将探讨一些常见的数据库慢查询优化方法和技巧,帮助您提高数据库查询的执行效率。
1.适当的索引策略索引是提高数据库查询速度的重要手段之一。
通过对经常被查询的列创建索引,可以减少数据库查询的扫描次数,从而提高查询性能。
然而,过多或不恰当的索引可能会导致性能下降。
因此,在进行索引优化时,在经常被查询的列上创建适当的索引,并避免索引重叠和冗余是非常重要的。
2.优化SQL查询语句良好的SQL查询语句可以显著提高数据库的执行效率。
首先,避免使用SELECT *语句,因为它会返回所有列的数据,而不仅仅是需要的数据。
其次,尽量避免使用复杂的子查询和嵌套查询,这些查询可能会导致性能下降。
此外,合理利用JOIN和WHERE子句来限制查询结果的数量,从而提高查询性能。
3.合理分配硬件资源数据库的性能不仅取决于软件层面的优化,还与硬件资源的分配有关。
确保数据库服务器具有足够的处理能力、内存和存储空间,可以提高数据库查询的执行效率。
此外,可以考虑使用更快的存储设备,如固态硬盘(SSD),以加快数据库的读写速度。
4.定期更新统计信息数据库在执行查询时,会根据统计信息生成查询执行计划。
因此,定期更新统计信息可以帮助数据库优化查询执行计划,从而提高查询性能。
可以使用数据库管理工具或定期脚本来更新统计信息,确保它们与数据库中的实际数据保持一致。
5.分区和分表技术在处理大型数据集时,分区和分表技术可以提高数据库查询的执行效率。
分区可以根据数据范围、哈希值或列表将数据划分为多个逻辑部分,并分别存储在不同的物理位置。
而分表是将大型表拆分成多个小表,每个小表包含部分数据。
这些技术可以减少查询的扫描范围,从而提高查询性能。
6.避免过多的数据库连接数据库连接是应用程序和数据库之间的通信通道。
数据库连接超时与连接池耗尽问题排查解决方法

数据库连接超时与连接池耗尽问题排查解决方法在企业应用开发中,数据库是至关重要的一部分,而连接池又是管理数据库连接的关键。
然而,在实际应用中,经常会遇到数据库连接超时与连接池耗尽等问题,影响系统的性能与可用性。
在本文中,我们将讨论如何排查与解决这些问题。
1. 问题描述数据库连接超时是指当应用程序获取数据库连接的时间超过了预设的超时时间,而连接池耗尽是指没有可用的数据库连接进行分配。
这两个问题都会导致应用程序无法正常访问数据库,从而影响系统的性能与可用性。
2. 排查步骤在排查数据库连接超时与连接池耗尽问题时,可以采取以下步骤:2.1 监控数据库连接池状态首先,需要检查数据库连接池的状态信息,包括当前活跃的连接数、空闲连接数以及最大连接数等参数。
这些参数可以通过数据库连接池的管理界面或监控工具得到。
如果活跃连接数持续增加,而且连接池无法为新的请求提供连接,那么很有可能是连接池耗尽的问题。
2.2 分析数据库连接超时日志连接超时问题一般会在数据库连接超时日志中有所体现。
通过分析这些日志,可以了解连接超时问题的具体表现,例如连接建立的时间、超时时间以及连接超时的原因等。
在此基础上,可以进一步排查与解决超时问题。
2.3 检查数据库服务器负载如果连接池无法满足新的连接请求,那么可能是因为数据库服务器负载过高而导致的。
在这种情况下,通过监控数据库服务器的CPU、内存和磁盘等指标,可以判断是否存在性能瓶颈。
如果数据库服务器负载过高,可以考虑优化数据库查询、增加硬件资源或者采用分布式数据库等解决方案。
2.4 优化数据库连接池配置连接池的配置参数对于性能和可用性非常关键。
其中,最大连接数、最小连接数、连接超时时间等参数需要根据具体的业务需求进行合理的配置。
如果连接池的配置参数不当,可能会导致连接池耗尽或连接超时的问题。
通过调整这些参数,可以缓解连接池问题带来的性能瓶颈。
3. 解决方法根据排查结果,可以针对数据库连接超时与连接池耗尽问题采取如下解决方法:3.1 增加连接池大小如果连接池无法满足新的连接请求,可以考虑增加连接池的大小。
数据库视图的性能问题与解决方法

数据库视图的性能问题与解决方法数据库视图是数据库中的逻辑表,通过将一些表的数据整合在一起,可以提供方便、快速的对数据进行查询操作。
然而,随着数据库中数据量的增加和查询复杂度的提升,数据库视图的性能问题也逐渐凸显出来。
本篇文章将探讨数据库视图常见的性能问题,并提出相应的解决方法。
1. 数据库视图性能问题的原因分析在理解数据库视图性能问题之前,首先需要了解数据库视图的基本概念。
数据库视图是基于一些表的查询结果构建的,它本身并不存储实际的数据,而是存储查询的逻辑过程。
因此,当对数据库视图进行查询时,实际上是对所涉及的表进行查询。
1.1 数据量过大造成的性能下降当数据库中的表记录数量达到一定规模时,数据库视图的查询性能会明显下降。
这是因为数据库引擎需要处理大量的数据,并进行复杂的关联操作,导致查询的效率较低。
1.2 多表关联导致的低效查询数据库视图通常由多个表的联合查询构建而成。
当涉及到多个表的关联操作时,查询的性能也会受到影响。
因为数据库引擎需要将多个表的数据进行关联,并进行排序、过滤等操作,导致查询效率低下。
1.3 视图索引缺失引起的性能问题数据库视图本身不具备物理存储结构,因此通常不会建立索引来提高查询性能。
然而,对于经常被查询的视图,缺乏索引会导致查询时的数据扫描操作变得更加耗时。
2. 数据库视图性能问题的解决方法针对数据库视图性能问题,可以采取以下一些解决方法来提高视图的查询性能。
2.1 数据库的优化配置对于数据库视图的性能问题,一个重要的解决方法是通过优化数据库的配置来提高查询效率。
可以考虑增加数据库的缓冲区大小,调整并发连接数等,以提高数据库的整体性能。
2.2 适当使用索引虽然数据库视图本身不存储数据,但可以使用索引来提高查询性能。
对于经常被查询的视图,可以考虑为视图相关的表增加合适的索引,以加快查询速度。
2.3 视图缓存视图缓存是一种将查询的结果缓存起来,以提高视图查询性能的技术。
当视图查询的结果被缓存后,下次执行相同的查询操作时,可以直接从缓存中获取结果,减少了对底层表重新计算的开销。
T6问题及解决方法汇编

T6维护问题及解决方法汇编第一篇、维护技巧在软件应用过程中,会遇到这样那样的报错现象,有些错误提示不是很明显,如结转供应链的时候提示“供应链结转失败”,其他无任何提示,这种错误现象通常让人摸不着头脑,不知如何解决。
那么只要掌握了下面这1个技巧,就可以帮助我们的维护人员来分析这些问题,并快速解决问题。
一、SQL SERVER事件探查器功能:监视SQL Server中的事件,可用于调试SQL语句和存储过程说明:维护过程中经常碰到错误提示,有操作引发的错误,可通过操作界面分析解决,也有数据出错引发的错误,此类错误提示有直接提示错误原因的,如:“无法将NULL值插入列‘iRefselect’,表Rpt_FltDEF;该列不允许空。
IRSERT失败”,“列名‘****’无效”,也有不是直接原因的提示,如:“存货系统结转失败”,此时我们可能跟据以往经验大致分析定位进数据库表查看出错数据,但更多情况无法判断时,可用事件探查器跟踪分析SQL语句,可解决大部分的数据问题。
打开方式:“开始”-->“程序”-->“Microsoft SQL Server”-->“事件探查器”案例分析年度结转时报结转失败,别的没有任何提示,这种错误除了用事件探查器跟踪找到原因,没有更好的解决方法,如下图所示。
1,打开事件探查器,建立跟踪模板2,选项SQL Server身份验证,登录名为SA,输入口令,默认为空,如下图所示。
3,跟踪属性选择事件,在选定事件类只选择TSQL和存储过程,点运行,如下图所示。
4,接下来我们看到跟踪界面,并且为运行状态,我们先按工具条的以停止运行,然后点以清空跟踪内容,等需要要跟踪时再运行,结果如下图所示。
5,进行年度结转,定为到出错前的界面,点跟踪界面工具条的按扭以运行跟踪,出现错误提示时点以停止运行,跟踪结果如下从上图可看到跟踪结果,一般出错的SQL位置往往是跟踪的最后位置,很多情况是Insert、Delete、update语句,从图中可观察确实有INSERT INTO PO_details的语句。
存储过程太慢

存储过程太慢1. 数据库设计问题:存储过程中的查询可能没有正确索引或使用了不适当的表结构。
确保你的表和索引是经过优化的,并且符合你的查询需求。
2. 复杂的逻辑:如果存储过程包含复杂的逻辑或大量的计算,可能会导致性能下降。
尝试简化存储过程的逻辑,或者将复杂的计算分解为多个步骤。
3. 大量的数据操作:如果存储过程涉及大量的数据插入、更新或删除操作,可能会影响性能。
考虑分批处理数据或使用更高效的方法来执行这些操作。
4. 数据库服务器性能:存储过程的性能也可能受到数据库服务器的硬件资源限制。
确保你的数据库服务器具有足够的内存、CPU 处理能力和磁盘I/O 性能。
5. 过时的统计信息:如果数据库的统计信息过时或不准确,查询优化器可能会做出不理想的执行计划。
定期更新统计信息以确保优化器有正确的数据来做出决策。
6. 外部因素:存储过程的性能还可能受到其他外部因素的影响,如网络延迟、磁盘性能问题或高并发负载。
检查这些方面是否存在问题。
为了优化存储过程的性能,可以采取以下一些常见的措施:1. 分析执行计划:使用数据库的执行计划工具来查看存储过程的执行计划,确定是否存在性能问题并找出优化的机会。
2. 优化查询语句:确保查询语句在存储过程中是高效的,使用适当的索引、避免全表扫描、减少连接操作等。
3. 使用参数化查询:如果存储过程接受参数,使用参数化查询可以避免SQL 注入攻击,并提高查询的性能。
4. 考虑重新设计:如果存储过程的性能仍然无法满足需求,可能需要重新审视你的设计和需求,考虑是否可以使用其他方式实现相同的功能。
5. 性能监控和调优:定期监控存储过程的性能,并根据实际情况进行调整和优化。
数据库连接超时问题的处理方法

数据库连接超时问题的处理方法在进行数据库操作时,经常会遇到数据库连接超时的问题。
这是一个常见的错误,可能会导致应用程序无法正常运行,甚至引发一系列的错误。
在本文中,我们将讨论数据库连接超时问题的处理方法,以帮助开发人员快速解决这个问题。
1. 理解数据库连接超时问题在开始寻找解决方法之前,我们首先需要了解数据库连接超时是什么问题。
数据库连接超时是指当一个数据库连接在规定的时间内没有得到响应时,连接就会被强制关闭。
这个时间段通常由数据库的配置参数决定。
数据库连接超时问题通常发生在以下几种情况下:- 网络问题:包括网络延迟、网络中断等;- 数据库性能问题:当数据库负载过大或执行的查询语句较复杂时,可能会导致连接超时;- 防火墙问题:防火墙可能会限制数据库的访问,并导致连接超时。
了解这些问题的原因对于解决连接超时问题非常重要。
2. 调整数据库连接超时时间一种常见的处理方法是调整数据库连接超时时间。
通过增加超时时间,可以给数据库服务器更多的时间来响应连接请求,从而避免连接超时问题。
不同的数据库系统可能有不同的方法来调整连接超时时间,以下是一些常见的数据库系统的调整方法:- MySQL:在MySQL中,可以通过修改`wait_timeout`参数来调整连接超时时间。
该参数表示连接在未活动状态下的最长时间(以秒为单位)。
可以通过在MySQL配置文件中修改该参数的值来调整连接超时时间。
- Oracle:对于Oracle数据库,可以通过在SQL*Net配置文件`sqlnet.ora`中修改`SQLNET.INBOUND_CONNECT_TIMEOUT`参数来调整连接超时时间。
- SQL Server:在SQL Server中,可以通过修改连接字符串中的`ConnectionTimeout`属性来调整连接超时时间。
3. 连接池管理使用连接池可以有效地管理数据库连接,提高应用程序的性能和稳定性。
连接池可以在应用程序启动时创建一定数量的连接,并在需要时重用这些连接,从而减少了频繁创建和销毁连接的开销。
T6【处理总账数据库表一则】

二、解决方法
在有了这个结果之后,决定加大查询的范围,对错误的记录范围进行确定。 将查询的记录数加大,发现查询范围扩大到1584条的时候,就会出现该错误, 而查询范围在前1583条之内都为正常,并看到第1583条记录的i_id号,开始单独对 1584号的i_id进行查询,发现出现错误提示,而顺序号再继续,则无错误内容,而 对该错误记录进行删除会出现一样的错误提示,故查询时将查询条件设为排除该 i_id进行查询,可正常输出结果。 之后将正常的结果(由于凭证每条分录是一条记录,所以将跟错误i_id号为同 一张凭证的记录排除在外)导入到临时表中,将gl_accvouch表删除重建,然后再 将所有数据倒回。 再将错误的凭证利用手工编号的方式进行补录。数据即正常,但由于该凭证 曾做过记账,则出现该凭证的数据已经计入GL_accsum表和GL_accass表,所以 对这两个表中涉及到的数据进行调整,账套数据就恢复正常了。
பைடு நூலகம்
三、总
结
三、总结
该问题为一日常问题,但是如果进行数据库表 的修复工作,则工作量可能较大,而且方法较难, 很不容易掌握。此方法虽为针对特殊问题的特殊方 法,但是为一些相关的数据错误提供了一个解决方 法的依据,希望通过这个方法能够起到一个抛砖引 玉的效果,让大家能够有更多的办法去面对数据库 错误,从而更快的解决类似的问题。 最后,祝大家工作愉快!
在确定了问题的原因的同时,发现SQL在查询的时候,结果集会有闪现,然 后才会提示这个SQL报错,那么怀疑该表只是部分数据出错。针对这个怀疑,我们 顺藤摸瓜进行进一步的验证。 如果是部分出错,那么对该数据库表的前一部分数据进行查询应该是允许的, 于是写语句select top 1 * from gl_accvouch 进行查询,发现确实可以查询出该表的 第一行记录。
用友T6数据库变慢的解决方法

用友T6数据库变慢的解决方法一些客户的数据库是巨量数据,特别是用到生产管理的模块,千万行甚至亿行记录都不足为奇。
如此情况下,数据库运行速度将受到严重影响,打开一个账表半小时甚至两小时,做一个计划要两天两夜,客户抱怨不断,服务人员焦头烂额,总不能叫客户都去买大型计算机吧。
其实是有办法可以大大提升数据库运行效率的,这要求我们的服务人员要学会数据库日常维护的高级技巧,而且是必须学会。
下面是数据库效率提升技巧的全面内容,建议所有服务人员自行练习并用在实际工作中,要求熟练掌握。
技巧一:重建索引效率提升指数:高特点:一二三买单,灰常的快,一下就弄完可以走人了。
案例:某超市T1商贸宝百万行级数据,原速度五秒,重建索引后两秒不到,速度提升近一倍。
不要小看这几秒,对超市来讲,那意味着不必要排长队。
由于数据库日常写操作频繁,索引的工作效率会越来越低,速度自然大受影响,很多客户会有这种感觉,前半年还非常快,后半年就受不了了。
刚刚到年底,正好是出报告、查资料的年关,偏偏软件慢得要命,服务人员也别想有好日子过,陪着加班吧,就算解决不了问题,也让人家心理舒服点。
这样的日子可以过去了。
命令1:DBCC DBREINDEX (表名称,”“,70) ---针对主要影响速度的表,一般如rdrecords、salebillvouchs、pp_mrpdetails、pp_rmrpdetails说明:只对主要表操作,影响速度的当然是这几个大表,速度解决问题,也不影响客户使用命令2:exec sp_msforeachtable “DBCC DBREINDEX(““?”“)” ---数据库所有表重建索引说明:不太建议,除非太咸了特别指出,重建索引前必须断网,以保证所有客户端无人在操作软件,你懂的技巧二:表分区效率提升指数:超高特点:慢工出快活。
硬盘越多,它就越快,所有硬盘一起转当然快;CPU越多,它就更快,sqlserver的引擎对这个有优化设计;设计得越合理,它就灰常滴快,例如历史数据按年存放,因为你一般不用嘛,那数据库只对你要操作的部分分区检索,自然飞快。
用友T6应用实施过程出现的若干技术问题及其处理办法

用友T6应用实施过程出现的若干技术问题及其处理办法同一帐套总帐和工资连用,总帐结帐时提示总帐无法结帐问题现象:用户在同一帐套总帐和工资连用。
年结后,反结帐上年,修改凭证,修改后,结帐时提示“工资未结帐”。
实际情况是工资在结转时已经结帐。
解决方法:由于年结后,工资模块的结帐标识没有反写回数据库中的gl_mend表中,所以取消上年12月结帐,在结帐时,提示工资模块没有结帐,只需要修改GL_mend表中,工资的结帐标识12月改为1,再登陆软件结帐。
建立年度帐过程中,列名‘cVenHelp’无效”原因:T3升级到T6,T3数据表vendor表中有列cVenHelp,T6没有解决方案:执行脚本alter table vendor drop column cVenHelp ,删除该列打开新年度入库调整单时候提示‘加载出错,稍后再试’问题分析:提示模版出错,怀疑是此单据模版记录出错,但是使用单据模版恢复工具还是不可以,跟踪语句执行发现:单据模版带小数位。
此列vt_id 是从justinvouch表vt_id列带过的。
查询justinvouch表中vt_id列为81.00解决方法:修改justinvouch表中vt_id列为81,然后看下justinvouch表的vt_id的类型,如果不是int型,要改成int型。
执行以上操作时注意备份!vt_id改成int型年结后,发货统计表上年结存数量和本年期初数量对不上问题分析:软件在年结时对于发货单的处理是:只要该发货单对应生成了相应的发票,并且发票数量大于等于发货单的数量,那么该发货单不论是否有出库单生成都不结转至下年。
相对的,只要发货单没有对应发票生成,不论有无生成出库单,只要该发货单不进行关闭都自动结转至下年。
解决方案:可将上年对应发票数量与该发货单对上却又不一一对应的发货单确保生成出库单后进行关闭,再进行年结。
数据就对上了。
普通权限操作员查不到新年度期初问题原因:主要是由于年结之后所有的期初帐的制单人都是auser而不是上年度的各个操作员,因为年结之后的账目都是一个综合的,会把各个同一属性的存货汇总在一起。
MySQL数据库慢查询的排查与优化方法

MySQL数据库慢查询的排查与优化方法概述:MySQL是目前互联网应用中最常用的关系型数据库之一,然而,在实际的应用过程中,我们经常会遇到数据库查询变慢的情况。
这不仅影响了应用的性能和用户体验,还可能导致系统崩溃。
因此,对于MySQL数据库慢查询的排查和优化方法是非常重要的。
本文将为大家详细介绍如何有效地排查慢查询问题,并提供相应的优化建议。
一、初步排查问题当我们发现数据库查询变慢时,首先应该进行初步的排查,确定是否是数据库本身存在性能问题。
以下是一些初步排查问题的方法:1. 确认问题的范围:通过监控工具或日志分析,找出出现慢查询的具体时间段或具体的SQL语句,确认问题的范围。
2. 查看系统性能指标:通过监控工具查看MySQL实例的CPU、内存、磁盘IO等系统性能指标,确认是否存在明显的资源瓶颈,例如CPU使用率过高或磁盘IO过于频繁。
3. 检查数据库配置:检查MySQL的配置文件f,确认是否存在一些不合理的配置项,比如缓冲区设置过小、并发连接数设置过高等。
二、分析慢查询日志如果初步排查确定是数据库查询问题,那么接下来我们需要分析MySQL的慢查询日志,以找出导致查询变慢的具体原因。
下面是一些常用的方法和工具:1. 启用慢查询日志:在MySQL配置文件中开启慢查询日志(slow_query_log),并设置slow_query_log_file参数来指定日志文件的位置。
通常,建议将慢查询时间阈值设置为较小的值,例如1秒。
2. 分析慢查询日志:使用pt-query-digest、Percona Toolkit等工具对慢查询日志进行分析,以确定慢查询的原因和性能瓶颈。
- 查询频繁的SQL语句:通过分析慢查询日志中的SQL语句,可以找出查询频次最高的语句。
这些语句可能存在性能问题,需要优化。
- 查询缓慢的索引:通过慢查询日志可以找出执行查询语句时耗时较长的索引。
这些索引可能需要进行优化或重新设计。
- 锁等待和死锁情况:慢查询日志还可以展示出锁等待和死锁的情况。
ORACLE数据库变得非常慢解决方案一例

ORACLE数据库变得非常慢解决方案一例数据库变得非常慢[/b][/b]接到客户报告最近数据库速度慢了好多,同样的应用慢了4,5倍.我做了个statspack,没发现什么问题,主要信息:Cache Sizes (end)~~~~~~~~~~~~~~~~~Buffer Cache: 3,104M Std Block Size:8KShared Pool Size: 400M Log Buffer:3,072KLoad Profile~~~~~~~~~~~~ Per Second Per Transaction--------------- ---------------Redo size: 394,918.91 68,578.62Logical reads: 40,718.26 7,070.82Block changes: 3,516.66 610.68Physical reads: 1,673.37 290.59Physical writes: 63.58 11.04User calls: 122.83 21.33Parses: 22.04 3.83Hard parses: 2.23 0.39Sorts: 10.36 1.80Logons: 0.38 0.07Executes: 54.35 9.44Transactions: 5.76% Blocks changed per Read: 8.64 Recursive Call %: 46.61Rollback per transaction %: 0.00 Rows per Sort: 1601.81Instance Efficiency Percentages (Target 100%)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 99.99 Redo NoWait %: 100.00Buffer Hit %: 95.91 In-memory Sort %: 99.99Library Hit %: 98.08 Soft Parse %: 89.90Execute to Parse %: 59.45 Latch Hit %: 99.88Parse CPU to Parse Elapsd %: % Non-Parse CPU:Shared Pool Statistics Begin EndMemory Usage %: 86.59 86.84% SQL with executions>1: 88.19 88.59% Memory for SQL w/exec>1: 94.34 94.96Top 5 Timed Events~~~~~~~~~~~~~~~~~~ % TotalEvent Waits Time (s) Ela Time-------------------------------------------- ------------ ----------- -------- db file scattered read 585,373 5,110 36.24latch free 38,146 3,331 23.63db file sequential read 328,881 2,096 14.87PX Deq: Txn Recovery Start 645 1,124 7.97db file parallel write 3,840 754 5.35****************************AIX系统:***********************************#iostat 5 5tty: tin tout avg-cpu: % user % sys % idle % iowait0.0 2.5 16.4 2.8 69.7 11.1Disks: % tm_act Kbps tps Kb_read Kb_wrtnhdisk0 20.9 141.9 33.0 1176852937 1037907344hdisk1 20.4 136.6 31.3 1136554209 996356546hdisk2 12.6 140.3 56.6 702195893 1487895240hdisk3 10.6 249.1 39.5 1887071251 2001871356cd0 0.0 0.0 0.0 0 0tty: tin tout avg-cpu: % user % sys % idle % iowait0.0 339.4 22.1 6.6 19.0 52.4Disks: % tm_act Kbps tps Kb_read Kb_wrtnhdisk0 95.6 615.2 152.0 2112 964hdisk1 96.0 612.0 150.8 2156 904hdisk2 83.0 2470.4 226.4 11524 828hdisk3 7.0 60.0 12.6 300 0cd0 0.0 0.0 0.0 0 0tty: tin tout avg-cpu: % user % sys % idle % iowait0.0 460.4 31.3 7.7 13.1 47.9Disks: % tm_act Kbps tps Kb_read Kb_wrtnhdisk0 95.4 648.0 158.4 1844 1396hdisk1 98.4 679.2 163.4 1896 1500hdisk2 89.6 2595.2 260.2 12088 888hdisk3 5.8 44.8 10.2 212 12cd0 0.0 0.0 0.0 0 0tty: tin tout avg-cpu: % user % sys % idle % iowait0.0 364.5 21.9 7.4 14.9 55.9Disks: % tm_act Kbps tps Kb_read Kb_wrtnhdisk0 96.6 750.9 177.9 1152 2604hdisk1 95.2 773.3 177.7 1176 2692hdisk2 70.2 2002.5 205.1 9740 276hdisk3 5.0 132.8 8.4 152 512cd0 0.0 0.0 0.0 0 0************FZYC1/#sar 5 5AIX FZYC1 3 4 000177DF4C00 06/06/0610:15:40 %usr %sys %wio %idle10:15:45 15 2 63 1910:15:50 19 3 56 2210:15:55 22 5 54 2010:16:00 20 10 51 2010:16:05 25 9 51 15Average 20 6 55 19******************FZYC1/#ps -ef |pgUID PID PPID C STIME TTY TIME CMDroot 1 0 0 Dec 07 - 29:33 /etc/initroot 4158 1 0 Dec 07 - 0:00 /usr/lib/methods/ssa_daemon -lssa0root 4446 11096 0 Dec 07 - 182:03 /usr/dt/bin/dtsessionroot 5014 1 0 Dec 07 - 1577:46 /usr/sbin/syncd 10root 5958 10322 0 Dec 07 - 24:57 /usr/lpp/X11/bin/X -x abx -x dbe -x GLX -D /usr/lib/X11//rgb -T -force :0 -auth /var/dt/A:0-aWkfiaroot 10322 1 0 Dec 07 - 0:01 /usr/dt/bin/dtlogin -daemonroot 10610 1 0 Dec 07 - 0:00 /usr/lib/errdemonroot 10926 4446 0 Dec 07 - 0:00 /usr/dt/bin/dttermroot 11096 10322 0 Dec 07 - 0:00 dtlogin -daemonroot 11364 17626 0 Dec 07 pts/0 0:00 /bin/kshroot 11620 1 0 Dec 07 - 0:00 imqsmdem imqsrv.ini /etc/IMNSearch/dbcshelp/...我发现iowait太高了,怀疑是这个系统同步进程root 5014 1 0 Dec 07 - 1577:46 /usr/sbin/syncd 10照成的,aix系统不怎么熟,会不会是这个照成数据库变慢呢? 要不要喀嚓掉它?我怀疑不是数据库的问题,因为应用没什么变化,定期维护也有做.问题情况简要叙述:客户报告数据库越来越慢,业务快无法进行了,近期并没有上什么新的应用和大的改变. 收集信息:statspack 发现top5等待首位为db scatter readaix topas 和iostat 发现iowait 严重,超过50% busy保持90%分析:查询top sql,v$sesstat+v$statname发现awms 应用进程db session logical reads等磁盘读写严重awms应用为实时查询(很频繁),查询sql的执行路径为,主要sql为对一些基表进行全表扫描.基表数据量不大(5-8w)左右,理论上查询io并不应该太髙.进一步查发现,该表dml较多,照成表不断扩大,碎片增多,对该表的full scan代价越来越大.仅仅凭112m的大小并不会照成太严重的io,但是该表被用于实查询,并且由于是full scan,在查询完成后会被至到LRU列表的least used 端.因此照成频繁的读写.内存不够用,引起了过多的swap.(这里为推测的原因,并不能肯定是正确的)解决:把表重建(truncate掉重插数据,或者move表然后重建索引),这些基表不大,并且频繁使用,由于这些特性,所以将其keep到buffer中--alter table table_namestorage (buffer_pool keep)观察了些时间,数据性能恢复了./archiver/tid-248860.html小记:不明原因的解决了ORACLE慢的问题近来发现ORACLE服务器超级慢,而且慢并不是由应用程序性能导致的,就连运行proc 预编译程序都很慢,可见问题还是出在ORACLE服务器本身。
TOA连接T6数据库不通过的解决方案
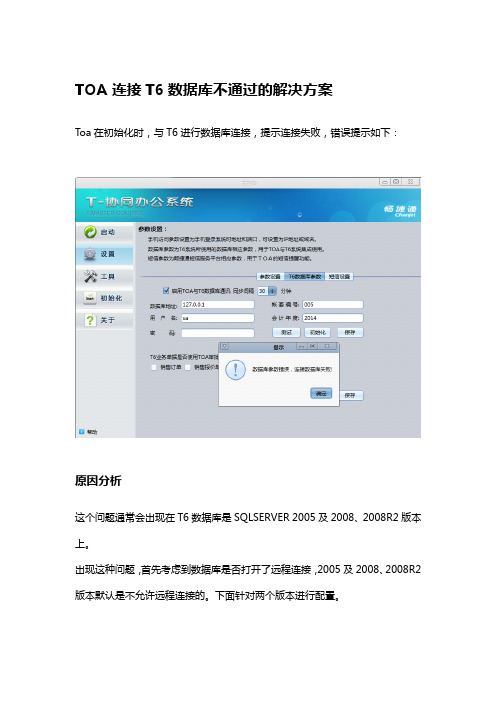
TOA连接T6数据库不通过的解决方案Toa在初始化时,与T6进行数据库连接,提示连接失败,错误提示如下:原因分析这个问题通常会出现在T6数据库是SQLSERVER 2005及2008、2008R2版本上。
出现这种问题,首先考虑到数据库是否打开了远程连接,2005及2008、2008R2版本默认是不允许远程连接的。
下面针对两个版本进行配置。
解决方案一、SQL Server 2005配置1、打开数据库的外围应用配置器2、打开服务和链接的外围应用配置器3、打开远程链接—把本地链接和远程链接设置为“同时使用TCP/IP和named pipes(B)”4、点击服务---停止---启动(重启数据库服务)二、SQL Server 2008/SQL Server 2008 R2配置1、打开sql2008,使用sa身份登录-2、登录后,右键选择“属性”。
左侧选择“连接”,勾选“允许远程连接此服务器”,然后点“确定”。
3、右键选择“方面”。
在右侧的下拉框中选择“服务器配置”;将“RemoteAccessEnable d”属性设为“True”,点“确定”4、退出SQL Server Management Studio Express,打开sql server配置管理器,确保SQLsever在运行5、在左侧选择SQL server网络配置节点下的sqlexpress的协议,在右侧的T CP/IP默认是“否”,右键启用或者双击打开设置面板将其修改为“是”6、选择“IP 地址”选项卡,设置TCP的端口为“1433”7、将"客户端协议"的"TCP/IP"也修改为“启用”(如果是英文版的,是Enabl ed)8、配置完成,重新启动SQL Server 2008。
此时应该可以使用了,但是还是要确认一下防火墙。
打开防火墙设置。
将SQLServr.exe(C:\Program Files\Mic rosoft SQL Server\MSSQL10.SQLEXPRESS\MSSQL\Binn\sqlservr.exe)添加到允许的列表中。
数据库性能优化解决方案文档

数据库性能优化解决方案数据库能优化方案是对用户提出的K3系统在使用过程中遇到的性能问题,从SQL Se rver调整,硬件调整这两方面提出了性能优化解决方案。
1SQLServer调整当用户使用K3系统一段时间以后,发现系统的响应时间越来越长.这种情形往往是由于账套数据库缺乏维护引起的。
缺乏维护的数据库会存在过多地碎片、过期的统计、隐含着可能的错误查询结果的数据库的逻辑和物理的不一致性,这些都会直接影响系统的性能。
这里介绍解决上述账套数据库性能问题常用的方法。
1.1使用DBCC语句发现和解决上述问题.DBCC:数据库一致性检查器。
◆信息DBCC SHOWCONTIG(表名[,索引名])在有大的改动的表,引入数据的表,或者引起低效查询的表上使用该语句.例:DBCCSHOWCONTIG(’T_ITEM’)◆DBCC DBREINDEX重建指定数据库中表的一个或多个索引.例1:重建某个索引ﻩﻩDBCCDBREINDEX(’T_ITEM',uk_item2, 80)例2:重建所有索引DBCC DBREINDEX ('T_ITEM’,’',80)◆DBCCSHOW_STATISTICS显示指定表上的指定目标(例如一个索引名称))的当前分布统计信息。
这些统计信息是被SQL Server查询优化器使用的DBCC SHOW_STATISTICS(表名,目标)例:DBCC SHOW_STATISTICs(’t_item','pk_item’)◆sp_updatestats &UPDATE STATISTICS 更新统计信息;sp_updatestats对当前数据库中所有用户定义的表运行UPDATESTATISTICS。
使用UPDATESTATISTICS语句的时机:在一个空表上创建一个索引,然后在以后应用它。
执行TRUNCA TETABLE语句,然后在以后重新应用该表.通过使用FULLSCAN或SAMPLE选项请求明细的索引统计信息.例1。
ORACLE数据库变得非常慢解决方案一例

ORACLE数据库变得非常慢解决方案一例最近在为一个项目做数据库优化,发现ORACLE数据库运行得特别慢,简直让人头大。
今天就来给大家分享一下我是如何一步步解决这个问题的,希望对你们有所帮助。
事情是这样的,那天老板突然过来,一脸焦虑地说:“小王,你看看这个数据库,查询速度怎么这么慢?客户都投诉了!”我二话不说,立刻开始分析原因。
我打开了数据库的监控工具,发现CPU和内存的使用率都很高,看来是数据库的压力确实很大。
然后,我开始查看慢查询日志,发现了很多执行时间很长的SQL语句。
这时,我意识到,问题的根源可能就在这些SQL语句上。
一、分析SQL语句1.对执行时间长的SQL语句进行优化。
我检查了这些SQL语句的写法,发现很多地方可以优化。
比如,有些地方使用了子查询,我尝试将其改为连接查询,以提高查询效率。
2.检查索引。
我发现有些表上没有合适的索引,导致查询速度变慢。
于是,我添加了合适的索引,以提高查询速度。
3.调整SQL语句的顺序。
有些SQL语句的执行顺序不当,导致查询速度变慢。
我调整了这些语句的顺序,使其更加合理。
二、调整数据库参数1.增加缓存。
我发现数据库的缓存设置比较低,导致查询时需要频繁读取磁盘。
我适当增加了缓存大小,以提高查询速度。
2.调整线程数。
我发现数据库的线程数设置较低,无法充分利用CPU资源。
我将线程数调整为合适的值,以提高数据库的处理能力。
3.优化数据库配置。
我对数据库的配置文件进行了调整,比如调整了日志文件的存储路径和大小,以及调整了数据库的备份策略等。
三、检查硬件资源1.检查CPU。
我查看了CPU的使用情况,发现CPU负载较高。
我建议公司采购更强大的CPU,以提高数据库的处理能力。
2.检查内存。
我发现内存的使用率也很高,于是建议公司增加内存容量。
3.检查磁盘。
我检查了磁盘的读写速度,发现磁盘的I/O性能较低。
我建议公司更换更快的磁盘,以提高数据库的读写速度。
四、定期维护1.定期清理数据库。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
其实是有办法可以大大提升数据库运行效率的,这要求我们的服务人员要学会数据库日常维护的高级技巧,而且是必须学会。
下面是数据库效率提升技巧的全面内容,建议所有服务人员自行练习并用在实际工作中,要求熟练掌握。
技巧一:重建索引
效率提升指数:高
特点:一二三买单,灰常的快,一下就弄完可以走人了。
命令1:DBCC DBREINDEX (表名称,"",70) ---针对主要影响速度的表,一般如rdrecords、salebillvouchs、pp_mrpdetails、pp_rmrpdetails
说明:只对主要表操作,影响速度的当然是这几个大表,速度reachtable "DBCC DBREINDEX(""?"")" ---数据库所有表重建索引
3.创建分区函数。这个函数是本文件组专有的,再建其它的文件组还得再搞一个。主要是设定,包括预设现有的数据从哪里开始水平分割,比如我们假设U8 10.0的上一年度最后一行rdrecords记录的Id是5000000,那么就可以设定这个值,这以内的记录会切割保存到第一个分区中。
CREATE PARTITION FUNCTION [函数名] (int) AS RANGE LEFT FOR VALUES (5000000,8274249,12000000)
此句表示,分三个区存放原先的数据
4.将分区函数绑定到分区架构上
CREATE PARTITION SCHEME [架构名]
AS PARTITION [函数名]
TO ([PRIMARY],[文件组名],[PRIMARY],[文件组名],[PRIMARY],[文件组名])
5.删除表的主键,必须删除,表担心,主键可以再建的
真的。
这个有点点难,因为要求有更多的数据库知识,不过初中生的水平也够用了,来吧。
1.为数据库建个文件组(可以建多个),最好是存放于不同磁盘上。这样效率得以最大化,想一想吧,我们查一个年度所有收发记录,三个硬盘一起转,是不是原来速度的三倍?
ALTER DATABASE 数据库名 ADD FILEGROUP 文件组名
ALTER TABLE 数据表名称 DROP CONSTRAINT [主键]
6.删除聚集索引,如果有的话,我还没找到命令,现在是手动删除的
7.开始做表分区
ALTER TABLE 数据表名称 add CONSTRAINT [主键] PRIMARY KEY CLUSTERED (主键字段名)
案例:某超市T1商贸宝 百万行级数据,原速度五秒,重建索引后两秒不到,速度提升近一倍。不要小看这几秒,对超市来讲,那意味着不必要排长队。
由于数据库日常写操作频繁,索引的工作效率会越来越低,速度自然大受影响,很多客户会有这种感觉,前半年还非常快,后半年就受不了了。刚刚到年底,正好是出报告、查资料的年关,偏偏软件慢得要命,服务人员也别想有好日子过,陪着加班吧,就算解决不了问题,也让人家心理舒服点。这样的日子可以过去了。
2.一个文件组可放置多个文件,下面,只为一个文件组分配一个文件,类推吧。
ALTER DATABASE 数据库名 ADD FILE (NAME = N"文件组名", FILENAME = N"存放路径",SIZE = 5MB , FILEGROWTH = 10% ) TO FILEGROUP 文件组名
还有,必须得是sql2005及以上版本,人家买的ERP你还装sql2000,去死吧。
案例:NC、U8 10.0,是的,它们用的就是表分区,所以数据越海,速度也越Hi
没有做表分区之前,客户是痛苦的,你也得痛苦,因为你不明白几万元的服务器怎么就玩不转一个T6,但NC这么海却可以在宽带上溜溜的跑?U8 10.0还不分年度裤呢,咱一个年度还用爬的?如果我说可以提升五倍甚至更高的速度,你信不信?反正我是信了。
建议以后不要给客户做收缩处理,没空间了买硬盘吧。
说明:不太建议,除非太咸了
特别指出,重建索引前必须断网,以保证所有客户端无人在操作软件,你懂的
技巧二:表分区
效率提升指数:超高
特点:慢工出快活。硬盘越多,它就越快,所有硬盘一起转当然快;CPU越多,它就更快,sqlserver的引擎对这个有优化设计;设计得越合理,它就灰常滴快,例如历史数据按年存放,因为你一般不用嘛,那数据库只对你要操作的部分分区检索,自然飞快。
ON [SHEME_rdrec](主键字段名)
你看,这不是恢复了主键吗
不过还是得手动恢复原来的聚集索引,这个我再查查语句吧
特别提出:
数据库收缩并不能提高数据库的读取效率,正相反,它反而更慢了。原因,是收缩后数据库内部的数据存储发生位移,也就是索引变得更低效。
这种情况下,必须再做一次索引重建,但我发现似乎只要收缩了以后,数据库都慢,重建索引也恢复不到原来的速度,一下想不明白道理,而且做的测试次数也有限给别人看;等到老了,才明白照片事拍给自己看的。当大部分的人都在关注你飞得高不高时,只有少部分人关心你飞得累不累,这就是友情!我们有一些客户的数据库是巨量数据,特别是用到生产管理的模块,千万行甚至亿行记录都不足为奇。如此情况下,数据库运行速度将受到严重影响,打开一个账表半小时甚至两小时,做一个计划要两天两夜,客户抱怨不断,服务人员焦头烂额,总不能叫客户都去买大型计算机吧。