云南大学软件学院数据结构实验七实验报告——哈希函数建表查表程序
哈希表的用法

哈希表的用法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表的主要用法包括:
1.插入元素:向哈希表中添加新的元素。
这通常涉及到使用哈希函数来计算元素的关键码值对应的存储位置,并将元素存储在该位置。
2.查找元素:在哈希表中查找特定的元素。
这同样需要使用哈希函数来计算元素的关键码值对应的存储位置,然后检查该位置是否有相应的元素。
3.删除元素:从哈希表中移除指定的元素。
这涉及到找到元素的存储位置,并将其从表中删除。
哈希表的时间复杂度通常是O(1),这意味着无论哈希表中有多少元素,插入、查找和删除操作都可以在常数时间内完成。
然而,这取决于哈希函数的选择和冲突解决策略。
如果哈希函数设
计得不好或者冲突解决策略不合适,可能会导致性能下降。
此外,哈希表还有一些其他的应用,例如用于实现关联数组、缓存系统、去重处理等等。
c语言中哈希表用法

c语言中哈希表用法在C语言中,哈希表(hash table)是一种数据结构,用于存储键值对(key-value pairs)。
它利用哈希函数(hash function)将键映射到一个特定的索引,然后将该索引用于在数组中存储或查找相应的值。
使用哈希表可以实现高效的数据查找和插入操作。
下面是哈希表的基本用法:1.定义哈希表的结构体:```ctypedef struct {int key;int value;} hash_table_entry;typedef struct {int size;hash_table_entry **buckets;} hash_table;```2.初始化哈希表:```chash_table *create_hash_table(int size) {hash_table *ht = (hash_table*)malloc(sizeof(hash_table));ht->size = size;ht->buckets = (hash_table_entry**)calloc(size,sizeof(hash_table_entry*));return ht;}```在初始化时,需要定义哈希表的大小(桶的数量)。
3.计算哈希值:```cint hash_function(int key, int size) {//根据具体需求实现哈希函数,例如对key取余操作return key % size;}```哈希函数将key映射到哈希表的索引位置。
4.插入键值对:```cvoid insert(hash_table *ht, int key, int value) { //计算哈希值int index = hash_function(key, ht->size);//创建新的哈希表节点hash_table_entry *entry =(hash_table_entry*)malloc(sizeof(hash_table_entry));entry->key = key;entry->value = value;//将节点插入到相应的桶中if (ht->buckets[index] == NULL) {ht->buckets[index] = entry;} else {//处理哈希冲突,例如使用链表或开放定址法解决冲突//这里使用链表来处理冲突hash_table_entry *current = ht->buckets[index];while (current->next != NULL) {current = current->next;current->next = entry;}}```5.查找值:```cint get(hash_table *ht, int key) {int index = hash_function(key, ht->size);hash_table_entry *current = ht->buckets[index]; //在相应的桶中查找相应的值while (current != NULL) {if (current->key == key) {return current->value;current = current->next;}return -1; //未找到对应的值}```哈希表的优点是它具有快速的查找和插入操作,平均情况下的查找和插入时间复杂度为O(1)。
云南大学数据库实验4:数据查询
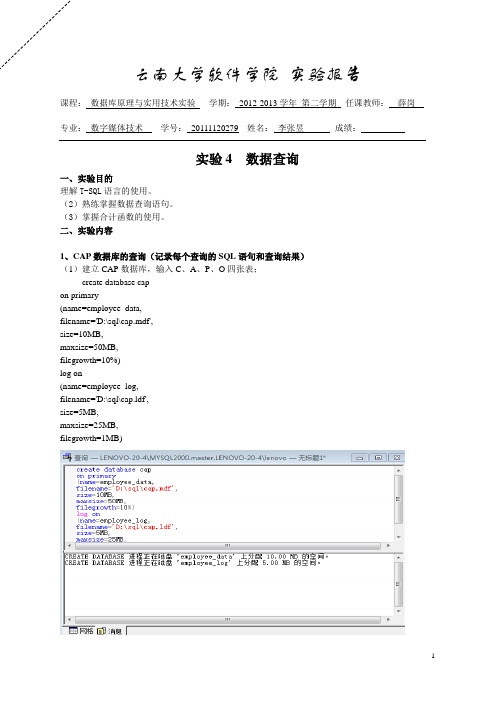
云南大学软件学院实验报告课程:数据库原理与实用技术实验学期:2012-2013学年第二学期任课教师:薛岗专业:数字媒体技术学号:20111120279 姓名:李张昱成绩:实验4 数据查询一、实验目的理解T-SQL语言的使用。
(2)熟练掌握数据查询语句。
(3)掌握合计函数的使用。
二、实验内容1、CAP数据库的查询(记录每个查询的SQL语句和查询结果)(1)建立CAP数据库,输入C、A、P、O四张表;create database capon primary(name=employee_data,filename='D:\sql\cap.mdf',size=10MB,maxsize=50MB,filegrowth=10%)log on(name=employee_log,filename='D:\sql\cap.ldf',size=5MB,maxsize=25MB,filegrowth=1MB)(2)完成课后习题[3.2]b、[3.5]、[3.8]a,b、[3.11]b,f,j,l [3.2]b:[3.5]【3.8】a【3.11】b2、Employee数据库的查询(记录每个查询的SQL语句和查询结果)(1)向表中插入数据。
(2)将职工编号为000006的员工3月份基本工资增加为3000,奖金增加到800。
(3)员工000009已经离开公司,将该员工的数据删除(4)简单条件查询✓查询person表中所有不重复的职称。
✓查询具有高级职称的女员工信息✓查询职工姓名为黎明的员工数据✓查询各部门的实发工资总数(5)复杂条件查询✓查询平均工资高于3000的部门名和对应的平均工资。
✓查询1月份实发工资比平均实发工资高的员工姓名和实发工资额。
✓查询2月份实发工资比一月高的员工姓名。
✓利用sql语句将1,2,3月累积的员工的实发工资按降序排序11。
数据结构课程设计--哈希表实验报告

福建工程学院课程设计课程:算法与数据结构题目:哈希表专业:网络工程班级:xxxxxx班座号:xxxxxxxxxxxx姓名:xxxxxxx2011年12 月31 日实验题目:哈希表一、要解决的问题针对同班同学信息设计一个通讯录,学生信息有姓名,学号,电话号码等。
以学生姓名为关键字设计哈希表,并完成相应的建表和查表程序。
基本要求:姓名以汉语拼音形式,待填入哈希表的人名约30个,自行设计哈希函数,用线性探测再散列法或链地址法处理冲突;在查找的过程中给出比较的次数。
完成按姓名查询的操作。
运行的环境:Microsoft Visual C++ 6.0二、算法基本思想描述设计一个哈希表(哈希表内的元素为自定义的结构体)用来存放待填入的30个人名,人名为中国姓名的汉语拼音形式,用除留余数法构造哈希函数,用线性探查法解决哈希冲突。
建立哈希表并且将其显示出来。
通过要查找的关键字用哈希函数计算出相应的地址来查找人名。
通过循环语句调用数组中保存的数据来显示哈希表。
三、设计1、数据结构的设计和说明(1)结构体的定义typedef struct //记录{NA name;NA xuehao;NA tel;}Record;录入信息结构体的定义,包含姓名,学号,电话号码。
typedef struct //哈希表{Record *elem[HASHSIZE]; //数据元素存储基址int count; //当前数据元素个数int size; //当前容量}HashTable;哈希表元素的定义,包含数据元素存储基址、数据元素个数、当前容量。
2、关键算法的设计(1)姓名的折叠处理long fold(NA s) //人名的折叠处理{char *p;long sum=0;NA ss;strcpy(ss,s); //复制字符串,不改变原字符串的大小写strupr(ss); //将字符串ss转换为大写形式p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}(2)建立哈希表1、用除留余数法构建哈希函数2、用线性探测再散列法处理冲突int Hash1(NA str) //哈希函数{long n;int m;n=fold(str); //先将用户名进行折叠处理m=n%HASHSIZE; //折叠处理后的数,用除留余数法构造哈希函数return m; //并返回模值}Status collision(int p,int c) //冲突处理函数,采用二次探测再散列法解决冲突{int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();}else printf("\n此人不存在,查找不成功!\n");benGetTime();}(4)显示哈希表void ShowInformation(Record* a) //显示输入的用户信息{int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}(5)主函数的设计void main(int argc, char* argv[]){Record a[MAXSIZE];int c,flag=1,i=0;HashTable *H;H=(HashTable*)malloc(LEN);for(i=0;i<HASHSIZE;i++){H->elem[i]=NULL;H->size=HASHSIZE;H->count=0;}while (1){ int num;printf("\n ");printf("\n 欢迎使用同学通讯录录入查找系统");printf("\n 哈希表的设计与实现");printf("\n 【1】. 添加用户信息");printf("\n 【2】. 读取所有用户信息");printf("\n 【3】. 以姓名建立哈希表(再哈希法解决冲突) ");printf("\n 【4】. 以电话号码建立哈希表(再哈希法解决冲突) ");printf("\n 【5】. 查找并显示给定用户名的记录");printf("\n 【6】. 查找并显示给定电话号码的记录");printf("\n 【7】. 清屏");printf("\n 【8】. 保存");printf("\n 【9】. 退出程序");printf("\n 温馨提示:");printf("\n Ⅰ.进行5操作前请先输出3 ");printf("\n Ⅱ.进行6操作前请先输出4 ");printf("\n");printf("请输入一个任务选项>>>");printf("\n");scanf("%d",&num);switch(num){case 1:getin(a);break;case 2:ShowInformation(a);break;case 3:CreateHash1(H,a); /* 以姓名建立哈希表*/break;case 4:CreateHash2(H,a); /* 以电话号码建立哈希表*/break;case 5:c=0;SearchHash1(H,c);break;case 6:c=0;SearchHash2(H,c);break;case 7:Cls(a);break;case 8:Save();break;case 9:return 0;break;default:printf("你输错了,请重新输入!");printf("\n");}}system("pause");return 0;3、模块结构图及各模块的功能:四、源程序清单:#include<stdio.h>#include<stdlib.h>#include<string.h>#include <windows.h>#define MAXSIZE 20 #define MAX_SIZE 20 #define HASHSIZE 53 #define SUCCESS 1#define UNSUCCESS -1#define LEN sizeof(HashTable)typedef int Status;typedef char NA[MAX_SIZE];typedef struct {NA name;NA xuehao;NA tel;}Record;typedef struct {Record *elem[HASHSIZE]; int count; int size; }HashTable;Status eq(NA x,NA y) {if(strcmp(x,y)==0)return SUCCESS;else return UNSUCCESS;}Status NUM_BER;void getin(Record* a) {int i;system("cls");printf("输入要添加的个数:\n");scanf("%d",&NUM_BER);for(i=0;i<NUM_BER;i++){printf("请输入第%d个记录的姓名:\n",i+1);scanf("%s",a[i].name);printf("请输入%d个记录的学号:\n",i+1);scanf("%s",a[i].xuehao);printf("请输入第%d个记录的电话号码:\n",i+1);scanf("%s",a[i].tel);}}void ShowInformation(Record* a){int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}void Cls(Record* a){printf("*");system("cls");}long fold(NA s){char *p;long sum=0;NA ss;strcpy(ss,s);strupr(ss);p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}int Hash1(NA str){int m;n=fold(str);m=n%HASHSIZE;return m;}int Hash2(NA str){long n;int m;n = atoi(str);m=n%HASHSIZE;return m;}Status collision(int p,int c){int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();void CreateHash1(HashTable* H,Record* a){ int i,p=-1,c,pp;system("cls"); benGetTime();for(i=0;i<NUM_BER;i++){p=Hash1(a[i].name);pp=p;while(H->elem[pp]!=NULL) {pp=collision(p,c);if(pp<0){printf("第%d记录无法解决冲突",i+1);continue;}}H->elem[pp]=&(a[i]);H->count++;printf("第%d个记录冲突次数为%d。
哈希实验报告

引言概述:本文旨在对哈希实验进行报告,重点介绍哈希实验的二次探测法、哈希函数、哈希表的查找、插入与删除操作,并分析实验结果。
通过本实验的开展,我们对哈希算法的原理、实现和性能有了更深入的理解,也增加了对数据结构的实践能力。
正文内容:一、二次探测法1.定义与原理2.步骤与流程3.优缺点分析4.实验过程与结果5.实验中的注意事项二、哈希函数1.哈希函数的设计原则2.常见的哈希函数算法3.哈希冲突与解决方法4.哈希函数的优化策略5.实验中的哈希函数选择与应用三、哈希表的查找操作1.哈希表的存储结构与基本操作2.直接定址法查找3.拉链法查找4.其他查找方法与比较5.实验结果与分析四、哈希表的插入与删除操作1.插入操作的实现思路2.插入操作的效率分析3.删除操作的实现思路4.删除操作的效率分析5.实验结果分析与对比五、实验结果与总结1.实验数据的统计与分析2.实验中的问题与解决方案3.实验结论与总结4.对哈希算法的进一步探讨与应用展望5.实验的意义与启示总结:通过对哈希实验的详细阐述,我们对二次探测法、哈希函数、哈希表的查找、插入与删除操作有了更深入的了解。
实验结果与分析表明,在哈希表的实现中,选择合适的哈希函数、解决哈希冲突以及优化插入与删除操作,对提高哈希表的性能至关重要。
哈希算法作为一种重要的数据结构应用,具有广泛的应用前景,在实际问题中具有重要的实践意义。
通过本次实验,我们不仅提升了对数据结构的理论理解,也增强了数据结构算法的实践能力,为今后的学习与研究打下了坚实的基础。
建立一个顺序表,表中元素为学生,每个学生信息包含姓名、学号和成绩三部分,对该表实现输出、插入、删除、

云南大学物理实验教学中心实验报告课程名称:计算机软件技术基础实验项目:实验二、线性表(顺序存储)及其应用学生姓名:学号:学院系级专业成绩指导教师:实验时间:年日时分至时分实验地点:实验类型:教学(演示□验证□综合█设计□)学生科研□课外开放□测试□其它□一、实验目的:掌握顺序表的建立及基本操作。
二、问题:建立一个顺序表,表中元素为学生,每个学生信息包含姓名、学号和成绩三部分,对该表实现:①输出、②插入、③删除、④查找功能,并计算出平均成绩和总成绩。
三、程序的编写与调试1、原程序:#include <iostream>using namespace std;typedef struct{ long double num; char name[10]; int score; } STUDENT; class sq_LList{ private:int mm;int nn;STUDENT *v;public:sq_LList(int);void prt_sq_LList();void ins_sq_LList(int, STUDENT);void del_sq_LList(int);void sea_num_sq_LList(int);voidvoid cal_sq_LList(int);};/*输出*/sq_LList ::sq_LList(int m){ mm=m;v=new STUDENT [mm];v[0].num=970156; strcpy(v[0].name,"张小明"); v[0].score=87; v[1].num=970157; strcpy(v[1].name,"李小青"); v[1].score=96;v[2].num=970158; strcpy(v[2].name,"刘华");v[2].score=85; v[3].num=970159; strcpy(v[3].name,"王伟");v[3].score=93; v[4].num=970160; strcpy(v[4].name,"李启明"); v[4].score=88;nn=5;}void sq_LList ::prt_sq_LList(){ int i;for(i=0; i<nn; i++){ cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}/*插入*/void sq_LList ::ins_sq_LList(int i, STUDENT b){ int k;if(nn==mm){cout<<"overflow"; return ;}if(i>nn) i=nn+1;if(i<1) i=1;for(k=nn; k>=i; k--)v[k]=v[k-1];v[i-1]=b; nn=nn+1;}/*删除*/void sq_LList ::del_sq_LList(int i){ int k;if(nn==0){cout<<"underflow"<<endl; return ;}if((i<1)||(i>nn)){cout<<"Not this element in the list!"<<endl; return ;}for(k=i; k<nn; k++)v[k-1]=v[k];nn=nn-1;}/*按学号查找*/void sq_LList ::sea_num_sq_LList(int i){ int k,t ;____t=0;for(i=0;i<nn;i++){ if(v[i].num==k){ t=t+1;cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}if(t==0)cout<<"No this student in the list!"<<endl;}/*按姓名查找*/void sq_LList ::sea_name_sq_LList(int i, char y[]){ int t;____t=0;for(i=0;i<nn;i++){ if(strcmp(y,v[i].name)=0){t=t+1cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}if(t==0) cout<<"No this student in the list!"<<endl }/*计算*/void sq_LList ::cal_sq_LList(int m){ int i;float sum,avr;{ sum=0;for(i=0;i<nn;i++){sum=sum+v[i].score;avr=sum/(i+1);}}cout<<"总分:"<<sum<<endl;cout<<"平均分:"<<avr<<endl;}int main(){ int mx; sq_LList s1(100);while (1){ cout<<"1.输出 2.插入 3.删除 4.查找 5.计算 0.退出\n";cout<<"输入0-5:";cin>>mx;switch(mx){ case 1: s1.prt_sq_LList(); break;case 2: int i; STUDENT b;cout<<"输入插入点位置和插入元素值:";cin>>i>>b.num>>>>b.score;s1.ins_sq_LList(i,b); s1.prt_sq_LList(); break; case 3: cout<<"请输入删除学生的位置:";cin>>i;s1.del_sq_LList(i);s1.prt_sq_LList(); break; case 4: int main(){ int mx;while (1){cout<<"1.按学号查找 2.按姓名查找 0.返"<<endl;cout<<"输入0-2:";cin>>mx;switch (mx){casecout<<"请输入要查找学生的学号:";s1.sea_num_sq_LList(i); break;casecout<<"请输入要查找学生的姓名:";s1.sea_name_sq_LList(); break;case 0: cout<<"返回"<<endl; return ;}}return 0;} break;case 5: s1.cal_sq_LList(); break;case 0: cout<<"程序结束"<<endl; return 0;}}return 0;2、正确程序:#include <iostream>using namespace std;typedef struct{ long double num; char name[10]; int score; } STUDENT; class sq_LList{ private:int mm;int nn;STUDENT *v;public:sq_LList(int);void prt_sq_LList();void ins_sq_LList(int, STUDENT);void del_sq_LList(int);void sea_num_sq_LList(int);void sea_name_sq_LList();void cal_sq_LList(int);/*输出*/sq_LList ::sq_LList(int m){ mm=m;v=new STUDENT [mm];v[0].num=970156; strcpy(v[0].name,"张小明"); v[0].score=87; v[1].num=970157; strcpy(v[1].name,"李小青"); v[1].score=96;v[2].num=970158; strcpy(v[2].name,"刘华");v[2].score=85; v[3].num=970159; strcpy(v[3].name,"王伟");v[3].score=93; v[4].num=970160; strcpy(v[4].name,"李启明"); v[4].score=88;nn=5;}void sq_LList ::prt_sq_LList(){ int i;for(i=0; i<nn; i++){ cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}/*插入*/void sq_LList ::ins_sq_LList(int i, STUDENT b){ int k;if(nn==mm){cout<<"overflow"; return ;}if(i>nn) i=nn+1;if(i<1) i=1;for(k=nn; k>=i; k--)v[k]=v[k-1];v[i-1]=b; nn=nn+1;}/*删除*/void sq_LList ::del_sq_LList(int i){ int k;if(nn==0){cout<<"underflow"<<endl; return ;}if((i<1)||(i>nn)){cout<<"Not this element in the list!"<<endl; return ;}for(k=i; k<nn; k++)v[k-1]=v[k];nn=nn-1;}/*按学号查找*/void sq_LList ::sea_num_sq_LList(int i){ int k,t ;cin>>k;t=0;for(i=0;i<nn;i++){ if(v[i].num==k){ t=t+1;cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}if(t==0)cout<<"No this student in the list!"<<endl;}/*按姓名查找*/void sq_LList ::sea_name_sq_LList(){ char y[10]; int i,t;cin>>y;t=0;for(i=0;i<nn;i++){ if(strcmp(y,v[i].name)==0){t=t+1;cout<<"学号: "<<v[i].num<<" 姓名: "<<v[i].name<<" "<<"分数: "<<v[i].score<<endl;}}if(t==0) cout<<"No this student in the list!"<<endl; }/*计算*/void sq_LList ::cal_sq_LList(int m){ int i;float sum,avr;{ sum=0;for(i=0;i<nn;i++){sum=sum+v[i].score;avr=sum/(i+1);}}cout<<"总分:"<<sum<<endl;cout<<"平均分:"<<avr<<endl;}int main(){ int mx; sq_LList s1(100);while (1){ cout<<"1.输出 2.插入 3.删除 4.查找 5.计算 0.退出\n";cout<<"输入0-5:";cin>>mx;switch(mx){ case 1: s1.prt_sq_LList(); break;case 2: int i; STUDENT b;cout<<"输入插入点位置和插入元素值:";cin>>i>>b.num>>>>b.score;s1.ins_sq_LList(i,b); s1.prt_sq_LList(); break; case 3: cout<<"请输入删除学生的位置:";cin>>i;s1.del_sq_LList(i);s1.prt_sq_LList(); break; case 4:{ int mx;while (1){cout<<"1.按学号查找 2.按姓名查找 0.返"<<endl;cout<<"输入0-2:";cin>>mx;switch (mx){case 1: cout<<"请输入要查找学生的学号:";s1.sea_num_sq_LList(i); break;case 2: cout<<"请输入要查找学生的姓名:";s1.sea_name_sq_LList(); break;case 0: cout<<"返回"<<endl; return 0;}}return 0;} break;case 5: s1.cal_sq_LList(i); break;case 0: cout<<"程序结束"<<endl; return 0;}}return 0;}四、实验总结通过此次试验,我对线性表(顺序存储)有了全面的认识,知道了什么是线性表,以及线性表有什么作用;并学会了如何根据要求建立一个实际的线性表,包括线性表的输出、插入、删除、查。
哈希表简单例子

哈希表简单例子哈希表是一种常用的数据结构,它可以用来存储键值对,并且能够以常数时间复杂度进行查找、插入和删除操作。
在这篇文章中,我将给大家列举一些哈希表的简单例子,希望能够帮助大家更好地理解和应用哈希表。
1. 学生信息管理系统:我们可以将学生的学号作为键,学生的姓名作为值,通过哈希表来管理学生的信息。
这样,我们就可以通过学生的学号快速地查找到对应的姓名,而不需要遍历整个数据集。
2. 图书馆借阅系统:我们可以将图书的编号作为键,借阅者的信息(如姓名、借书日期等)作为值,通过哈希表来管理图书的借阅情况。
这样,当有人借阅或归还图书时,我们可以快速地定位到对应的图书并更新借阅信息。
3. 联系人电话簿:我们可以将联系人的姓名作为键,电话号码作为值,通过哈希表来管理联系人的电话号码。
这样,当我们需要查找某个联系人的电话时,可以直接通过姓名进行查找,而不需要遍历整个电话簿。
4. 缓存系统:在计算机系统中,缓存用于存储经常访问的数据,以提高访问速度。
我们可以使用哈希表来实现缓存系统,将数据的关键字作为键,数据本身作为值。
这样,当需要访问某个数据时,可以首先在哈希表中查找,如果存在则直接返回,否则再从存储介质中读取数据。
5. 单词计数器:在文本处理中,我们经常需要统计某个单词在文本中出现的次数。
我们可以使用哈希表来实现一个简单的单词计数器,将单词作为键,出现的次数作为值。
这样,当需要统计某个单词的出现次数时,可以直接通过键进行查找。
6. 数组去重:在一组数据中,我们经常需要去除重复的元素。
我们可以使用哈希表来实现数组的去重功能,将数组中的元素作为键,出现的次数作为值。
这样,当需要判断某个元素是否重复时,可以直接通过键进行查找。
7. URL短链接:在互联网中,我们经常需要将较长的URL转换为较短的URL,以方便用户分享和记忆。
我们可以使用哈希表来实现URL 的短链接功能,将长URL作为键,短URL作为值。
这样,当用户访问短URL时,可以通过哈希表快速地定位到对应的长URL。
c实现的hash表-概述说明以及解释

c实现的hash表-概述说明以及解释1.引言1.1 概述在计算机科学中,哈希表(Hash Table),又被称为散列表,是一种常用的数据结构。
它能够以常数时间复杂度(O(1))来实现插入、删除和查找等操作,因此具有高效的特性。
哈希表通过哈希函数将键(key)映射到一个固定大小的数组(通常称为哈希表)。
通过这种映射关系,我们可以在数组中快速访问到对应的值(value)。
常见的应用场景包括缓存系统、数据库索引、编译器符号表等。
相对于其他数据结构,哈希表具有以下优点:1. 高效的插入、删除和查找操作:哈希表在插入、删除和查找数据时以常数时间复杂度进行操作,无论数据量大小,都能快速地完成操作。
2. 高效的存储和检索:通过哈希函数的映射关系,哈希表能够将键值对存储在数组中,可以通过键快速地找到对应的值。
3. 空间效率高:哈希表通过哈希函数将键映射到数组下标,能够充分利用存储空间,避免冗余的存储。
然而,哈希表也存在一些局限性:1. 冲突问题:由于哈希函数的映射关系是将多个键映射到同一个数组下标上,可能会导致冲突。
解决冲突问题的常见方法包括链地址法(Chaining)和开放定址法(Open Addressing)等。
2. 内存消耗:由于哈希表需要维护额外的空间来存储映射关系,所以相比于其他数据结构来说,可能会占用较多的内存。
本篇长文将重点介绍C语言实现哈希表的方法。
我们将首先讨论哈希表的定义和实现原理,然后详细介绍在C语言中如何实现一个高效的哈希表。
最后,我们将总结哈希表的优势,对比其他数据结构,并展望哈希表在未来的发展前景。
通过本文的学习,读者将能够深入理解哈希表的底层实现原理,并学会如何在C语言中利用哈希表解决实际问题。
1.2 文章结构本文将围绕C语言实现的hash表展开讨论,并按照以下结构进行组织。
引言部分将对hash表进行概述,介绍hash表的基本概念、作用以及其在实际应用中的重要性。
同时,引言部分还会阐述本文的目的,即通过C语言实现的hash表,来探讨其实现原理、方法以及与其他数据结构的对比。
数据结构的实验报告

一、实验目的本次实验旨在让学生掌握数据结构的基本概念、逻辑结构、存储结构以及各种基本操作,并通过实际编程操作,加深对数据结构理论知识的理解,提高编程能力和算法设计能力。
二、实验内容1. 线性表(1)顺序表1)初始化顺序表2)向顺序表插入元素3)从顺序表删除元素4)查找顺序表中的元素5)顺序表的逆序操作(2)链表1)创建链表2)在链表中插入元素3)在链表中删除元素4)查找链表中的元素5)链表的逆序操作2. 栈与队列(1)栈1)栈的初始化2)入栈操作3)出栈操作4)获取栈顶元素5)判断栈是否为空(2)队列1)队列的初始化2)入队操作3)出队操作4)获取队首元素5)判断队列是否为空3. 树与图(1)二叉树1)创建二叉树2)遍历二叉树(前序、中序、后序)3)求二叉树的深度4)求二叉树的宽度5)二叉树的镜像(2)图1)创建图2)图的深度优先遍历3)图的广度优先遍历4)最小生成树5)最短路径三、实验过程1. 线性表(1)顺序表1)初始化顺序表:创建一个长度为10的顺序表,初始化为空。
2)向顺序表插入元素:在顺序表的第i个位置插入元素x。
3)从顺序表删除元素:从顺序表中删除第i个位置的元素。
4)查找顺序表中的元素:在顺序表中查找元素x。
5)顺序表的逆序操作:将顺序表中的元素逆序排列。
(2)链表1)创建链表:创建一个带头结点的循环链表。
2)在链表中插入元素:在链表的第i个位置插入元素x。
3)在链表中删除元素:从链表中删除第i个位置的元素。
4)查找链表中的元素:在链表中查找元素x。
5)链表的逆序操作:将链表中的元素逆序排列。
2. 栈与队列(1)栈1)栈的初始化:创建一个栈,初始化为空。
2)入栈操作:将元素x压入栈中。
3)出栈操作:从栈中弹出元素。
4)获取栈顶元素:获取栈顶元素。
5)判断栈是否为空:判断栈是否为空。
(2)队列1)队列的初始化:创建一个队列,初始化为空。
2)入队操作:将元素x入队。
3)出队操作:从队列中出队元素。
数据结构查找实验报告

数据结构查找实验报告一、实验目的本次实验的主要目的是深入理解和掌握常见的数据结构查找算法,包括顺序查找、二分查找、哈希查找等,并通过实际编程实现和性能比较,分析它们在不同数据规模和分布情况下的效率和适用场景。
二、实验环境本次实验使用的编程语言为 Python 38,开发环境为 PyCharm。
实验中所使用的数据集生成工具为 numpy 库。
三、实验原理1、顺序查找顺序查找是一种最简单的查找算法,它从数据结构的开头依次逐个比较元素,直到找到目标元素或遍历完整个数据结构。
其平均时间复杂度为 O(n)。
2、二分查找二分查找要求数据结构是有序的。
通过不断将查找区间缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n)。
3、哈希查找哈希查找通过将元素映射到一个特定的哈希表中,利用哈希函数计算元素的存储位置,从而实现快速查找。
理想情况下,其平均时间复杂度为 O(1),但在存在哈希冲突时,性能可能会下降。
四、实验步骤1、数据集生成使用 numpy 库生成不同规模和分布的数据集,包括有序数据集、无序数据集和具有一定重复元素的数据集。
2、顺序查找实现编写顺序查找算法的函数,接受数据集和目标元素作为参数,返回查找结果(是否找到及查找次数)。
3、二分查找实现实现二分查找算法的函数,同样接受数据集和目标元素作为参数,并返回查找结果。
4、哈希查找实现构建哈希表并实现哈希查找函数,处理哈希冲突的情况。
5、性能比较对不同规模和类型的数据集,分别使用三种查找算法进行查找操作,并记录每种算法的查找时间和查找次数。
五、实验结果与分析1、顺序查找在无序数据集中,顺序查找的性能表现较为稳定,查找时间随着数据规模的增大线性增长。
但在有序数据集中,其性能没有优势。
2、二分查找二分查找在有序数据集中表现出色,查找时间随着数据规模的增大增长缓慢,体现了对数级别的时间复杂度优势。
然而,在无序数据集中无法使用。
数据结构实验报告(实验)

深 圳 大 学 实 验 报 告课程名称: 数据结构实验与课程设计 实验项目名称: 实验一:顺序表的应用 学院: 计算机与软件学院 专业: 指导教师: **报告人: 文成 学号: ********** 班级: 5 实验时间: 2012-9-17实验报告提交时间: 2012-9-24教务部制一、实验目的与要求:目的:1.掌握线性表的基本原理2.掌握线性表地基本结构3.掌握线性表地创建、插入、删除、查找的实现方法要求:1.熟悉C++语言编程2.熟练使用C++语言实现线性表地创建、插入、删除、查找的实现方法二、实验内容:Problem A: 数据结构——实验1——顺序表例程Description实现顺序表的创建、插入、删除、查找Input第一行输入顺序表的实际长度n第二行输入n个数据第三行输入要插入的新数据和插入位置第四行输入要删除的位置第五行输入要查找的位置Output第一行输出创建后,顺序表内的所有数据,数据之间用空格隔开第二行输出执行插入操作后,顺序表内的所有数据,数据之间用空格隔开第三行输出执行删除操作后,顺序表内的所有数据,数据之间用空格隔开第四行输出指定位置的数据Sample Input611 22 33 44 55 66888 352Sample Output11 22 33 44 55 6611 22 888 33 44 55 6611 22 888 33 55 6622HINT第i个位置是指从首个元素开始数起的第i个位置,对应数组内下标为i-1的位置Problem B: 数据结构——实验1——顺序表的数据交换Description实现顺序表内的元素交换操作Input第一行输入n表示顺序表包含的·n个数据第二行输入n个数据,数据是小于100的正整数第三行输入两个参数,表示要交换的两个位置第四行输入两个参数,表示要交换的两个位置Output第一行输出创建后,顺序表内的所有数据,数据之间用空格隔开第二行输出执行第一次交换操作后,顺序表内的所有数据,数据之间用空格隔开第三行输出执行第二次交换操作后,顺序表内的所有数据,数据之间用空格隔开注意加入交换位置的合法性检查,如果发现位置不合法,输出error。
数据结构课程设计实践报告

数据结构实验报告本文是范文,仅供参考写作,禁止抄袭本文内容上传提交,违者取消写作资格,成绩不合格!实验名称:排序算法比较提交文档学生姓名:提交文档学生学号:同组成员名单:指导教师姓名:排序算法比较一、实验目的和要求1、设计目的1.掌握各种排序的基本思想。
2.掌握各种排序方法的算法实现。
3.掌握各种排序方法的优劣分析及花费的时间的计算。
4.掌握各种排序方法所适应的不同场合。
2、设计内容和要求利用随机函数产生30000个随机整数,利用插入排序、起泡排序、选择排序、快速排序、堆排序、归并排序等排序方法进行排序,并统计每一种排序上机所花费的时间二、运行环境(软、硬件环境)软件环境:Vc6.0编程软件运行平台: Win32硬件:普通个人pc机三、算法设计的思想1、冒泡排序:bubbleSort()基本思想: 设待排序的文件为r[1..n]第1趟(遍):从r[1]开始,依次比较两个相邻记录的关键字r[i].key和r[i+1].key,若r[i].key>r[i+1].key,则交换记录r[i]和r[i+1]的位置;否则,不交换。
(i=1,2,...n-1)第1趟之后,n个关键字中最大的记录移到了r[n]的位置上。
第2趟:从r[1]开始,依次比较两个相邻记录的关键字r[i].key和r[i+1].key,若r[i].key>r[i+1].key,则交换记录r[i]和r[i+1]的位置;否则,不交换。
(i=1,2,...n-2)第2趟之后,前n-1个关键字中最大的记录移到了r[n-1]的位置上,作完n-1趟,或者不需再交换记录时为止。
2、选择排序:selSort()每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
选择排序不像冒泡排序算法那样先并不急于调换位置,第一轮(k=1)先从array[k]开始逐个检查,看哪个数最小就记下该数所在的位置于minlIndex中,等一轮扫描完毕,如果找到比array[k-1]更小的元素,则把array[minlIndex]和a[k-1]对调,这时array[k]到最后一个元素中最小的元素就换到了array[k-1]的位置。
2013年云南大学软件学院专业课试卷答案

2013年云南大学软件学院专业课试卷答案(仅供参考)考试科目:数据结构与程序设计;考试科目代码:904一、填空题(共10题,每题2分,共20分)1、数据结构在计算机存储器中的两种存储结构是:顺序存储结构,链式存储结构。
2、今有一空栈S,对下列待进栈的数据元素序列A、B、C、D、E、F依次进行进栈、进栈、出栈、进栈、进栈、出栈的操作,则此操作完成后,栈S的栈顶元素为C,栈底元素为A。
3、深度为K的二叉树至多有2k-1个结点,其中第i层上至多有2i-1个结点。
4、数据的逻辑结构有集合,线性结构,树形结构和图四种。
5、哈希表的平均查找长度不随表中结点数目增加而增加,而是随着负载因子(装填因子)的增大而增大。
6、假定在有序表A[1…20]上进行二分查找,则比较二次查找成功的结点数为2,比较四次查找成功的结点数为8。
7、队列和栈都是线性表,栈的操作特性是后进先出。
队列的操作特性是先进先出。
8、在一棵二叉树中,假定度为2的结点数为5个,度为1的结点数为6个,则叶子结点数为6个,总的结点数为17个。
9、快速排序在平均情况下的时间复杂度是O(nlogn),最坏情况下的时间复杂度是O(n2)。
10、哈希方法中,需要考虑的两个主要问题是:构造哈希函数和解决处理冲突方法。
二、单选题(共10题,每题2分,共20分)1、对广义表L=((a,b),(c,d),(e,f))执行操作Tail(Tail(L))的结果是AA、((e,f))B、(e,f)C、(f)D、( )2、若进栈序列为1,2,3,4,进栈过程中可以出栈,则C不可能是一个出栈序列。
A、3,4,2,1B、2,4,3,1C、1,4,2,3D、3,2,1,43、栈和队列都是BA、顺序存储的线性结构B、操作受限的线性结构C、链式存储的线性结构D、操作受限的非线性结构4、排序方法中,从未排序序列中依次取出元素与已排序序列(初始时为空)中的元素进行比较,将其放入已排序序列的正确位置上的方法,称为D。
数据结构实验报告顺序表

数据结构实验报告顺序表数据结构实验报告:顺序表一、引言数据结构是计算机科学的重要基础,它研究数据的组织方式和操作方法。
顺序表是一种常见的数据结构,它以数组的形式存储数据元素,具有随机访问和插入删除方便的特点。
本实验旨在深入理解顺序表的实现原理和操作方法,并通过实验验证其性能。
二、实验目的1. 掌握顺序表的基本概念和实现原理;2. 熟悉顺序表的插入、删除、查找等操作;3. 分析顺序表的时间复杂度,并进行性能测试。
三、实验过程1. 顺序表的定义和初始化顺序表是一种线性表,它以一组连续的存储单元来存储数据元素。
在实验中,我们使用数组来实现顺序表。
首先,定义一个结构体来表示顺序表,包括数据元素和当前长度等信息。
然后,通过动态分配内存来初始化顺序表。
2. 插入元素顺序表的插入操作是将一个新元素插入到指定位置,同时移动后面的元素。
在实验中,我们可以通过循环将后面的元素依次向后移动,然后将新元素放入指定位置。
3. 删除元素顺序表的删除操作是将指定位置的元素删除,并将后面的元素依次向前移动。
在实验中,我们可以通过循环将后面的元素依次向前移动,然后将最后一个元素置为空。
4. 查找元素顺序表的查找操作是根据指定的值查找元素所在的位置。
在实验中,我们可以通过循环遍历顺序表,逐个比较元素的值,找到匹配的位置。
五、实验结果与分析在实验中,我们通过插入、删除、查找等操作对顺序表进行了测试,并记录了操作所需的时间。
通过分析实验结果,我们可以得出以下结论:1. 顺序表的插入操作的时间复杂度为O(n),其中n为元素的个数。
因为插入操作需要移动后面的元素,所以时间复杂度与元素个数成正比。
2. 顺序表的删除操作的时间复杂度也为O(n),与插入操作相同,需要移动后面的元素。
3. 顺序表的查找操作的时间复杂度为O(n),需要逐个比较元素的值。
六、结论通过本次实验,我们深入理解了顺序表的实现原理和操作方法。
顺序表以数组的形式存储数据,具有随机访问和插入删除方便的特点。
哈希表简单例子

哈希表简单例子哈希表是一种以键-值对(key-value pair)形式存储数据的数据结构,它通过将键映射到一个位置来实现高效的数据访问。
哈希表的实现基于哈希函数,该函数将键转换为一个索引值,然后将该索引值用作数组的下标,将值存储在数组的对应位置上。
以下是关于哈希表的一些简单例子:1. 学生成绩记录:可以使用学生的学号作为键,将学生的成绩作为值存储在哈希表中。
这样,当需要查询某个学生的成绩时,只需要通过学号找到对应的值。
2. 博客文章的标签:在博客系统中,可以使用博客文章的标签作为键,将对应的文章标题作为值存储在哈希表中。
这样,当需要查找某个标签下的所有文章时,只需要通过标签找到对应的值。
3. 电话簿:可以使用人名作为键,将对应的电话号码作为值存储在哈希表中。
这样,当需要查找某个人的电话号码时,只需要通过人名找到对应的值。
4. 缓存管理:在计算机系统中,可以使用文件名作为键,将文件内容作为值存储在哈希表中。
这样,当需要读取某个文件时,可以先查找哈希表,如果文件已经在哈希表中,则可以直接从哈希表中读取文件内容,避免了磁盘IO操作,提高了读取速度。
5. 用户登录状态管理:在网站系统中,可以使用用户的登录名作为键,将用户的登录状态作为值存储在哈希表中。
这样,当用户进行登录操作时,可以通过用户的登录名找到对应的值,判断用户是否已经登录。
6. 单词计数器:在文本处理中,可以使用单词作为键,将对应的出现次数作为值存储在哈希表中。
这样,可以通过单词找到对应的值,统计单词在文本中的出现次数。
7. 账号密码管理:在用户系统中,可以使用用户的账号作为键,将用户的密码作为值存储在哈希表中。
这样,可以通过账号找到对应的密码,进行用户身份验证。
8. 文件校验和验证:在文件传输中,可以使用文件名作为键,将文件的校验和作为值存储在哈希表中。
这样,可以通过文件名找到对应的校验和,验证文件在传输过程中是否被修改。
9. URL路由映射:在Web开发中,可以使用URL作为键,将对应的处理函数作为值存储在哈希表中。
详解数据结构之散列(哈希)表
详解数据结构之散列(哈希)表1.散列表查找步骤散列表,最有用的基本数据结构之一。
是根据关键码的值直接进行访问的数据结构,散列表的实现常常叫做散列(hasing)。
散列是一种用于以常数平均时间执行插入、删除和查找的技术,下面我们来看一下散列过程。
我们的整个散列过程主要分为两步:1.通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
就好比麻辣鱼,我们就让它在川菜区,糖醋鱼,我们就让它在鲁菜区。
但是我们需要注意的是,无论什么记录我们都需要用同一个散列函数计算地址,然后再存储。
2.当我们查找时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。
因为我们存和取的时候用的都是一个散列函数,因此结果肯定相同。
刚才我们在散列过程中提到了散列函数,那么散列函数是什么呢?我们假设某个函数为f,使得存储位置= f (key) ,那样我们就能通过查找关键字不需要比较就可获得需要的记录的存储位置。
这种存储技术被称为散列技术。
散列技术是在通过记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使得每个关键字key 都对应一个存储位置f(key)。
见下图这里的 f 就是我们所说的散列函数(哈希)函数。
我们利用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间就是我们本文的主人公------散列(哈希)上图为我们描述了用散列函数将关键字映射到散列表。
但是大家有没有考虑到这种情况,那就是将关键字映射到同一个槽中的情况,即f(k4) = f(k3) 时。
这种情况我们将其称之为冲突,k3 和k4 则被称之为散列函数 f 的同义词,如果产生这种情况,则会让我们查找错误。
幸运的是我们能找到有效的方法解决冲突。
首先我们可以对哈希函数下手,我们可以精心设计哈希函数,让其尽可能少的产生冲突,所以我们创建哈希函数时应遵循以下规则:1.必须是一致的。
假设你输入辣子鸡丁时得到的是在看,那么每次输入辣子鸡丁时,得到的也必须为在看。
国家开放大学《数据结构》课程实验报告(实验6——查找)参考答案

/*按平均成绩进行折半查找并插入新记录,使表仍按平均成绩降序排列*/
int BinSort(Student *a,int n,Student x)
{
int low,high,mid;
int i,j;
/*折半查找*/
low=0;
high=n-1;
while(low<=high)
{
mid=(low+high)/2;
void main()
{
Student a[N]={{"Zhao",95},{"Qian",90},{"Sun",86},{"Li",75}},x;
int n=4; /*学生人数,即表长*/
printf("初始%d位学生的信息表如下:\n",n);
Display(a,n);
printf("\n\n");
《数据结构》课程实验报告
(实验6——查找)
学生姓名
学 号
班 级
指导老师
实验名称
实验成绩
实验报告
实
验
概
述
实验目的:
某班学生成绩信息表中,每个学生的记录已按平均成绩由高到低排好序,后来发现某个学生的成绩没有登记到信息表中,使用折半查找法把该同学的记录插入到信息表中,使信息表中的记录仍按平均成绩有序。
实验要求:
(1)建立现有学生信息表,平均成绩已有序。
(2)输入插入学生的记录信息。
(3)用折半查找找到插入位置,并插入记录。
设计思路:
(1)用结构数组存储成绩信息表。
(2)对记录中的平均成绩进行折半查找并插入。
实验内容源自程序代码:/*实验5.1折半查找*/
数据结构实验报告顺序表

数据结构实验报告顺序表数据结构实验报告:顺序表摘要:顺序表是一种基本的数据结构,它通过一组连续的存储单元来存储线性表中的数据元素。
在本次实验中,我们将通过实验来探索顺序表的基本操作和特性,包括插入、删除、查找等操作,以及顺序表的优缺点和应用场景。
一、实验目的1. 理解顺序表的概念和特点;2. 掌握顺序表的基本操作;3. 了解顺序表的优缺点及应用场景。
二、实验内容1. 实现顺序表的初始化操作;2. 实现顺序表的插入操作;3. 实现顺序表的删除操作;4. 实现顺序表的查找操作;5. 对比顺序表和链表的优缺点;6. 分析顺序表的应用场景。
三、实验步骤与结果1. 顺序表的初始化操作在实验中,我们首先定义了顺序表的结构体,并实现了初始化操作,即分配一定大小的存储空间,并将表的长度设为0,表示表中暂时没有元素。
2. 顺序表的插入操作接下来,我们实现了顺序表的插入操作。
通过将插入位置后的元素依次向后移动一位,然后将新元素插入到指定位置,来实现插入操作。
我们测试了在表中插入新元素的情况,并验证了插入操作的正确性。
3. 顺序表的删除操作然后,我们实现了顺序表的删除操作。
通过将删除位置后的元素依次向前移动一位,来实现删除操作。
我们测试了在表中删除元素的情况,并验证了删除操作的正确性。
4. 顺序表的查找操作最后,我们实现了顺序表的查找操作。
通过遍历表中的元素,来查找指定元素的位置。
我们测试了在表中查找元素的情况,并验证了查找操作的正确性。
四、实验总结通过本次实验,我们对顺序表的基本操作有了更深入的了解。
顺序表的插入、删除、查找等操作都是基于数组的操作,因此在插入和删除元素时,需要移动大量的元素,效率较低。
但是顺序表的优点是可以随机访问,查找效率较高。
在实际应用中,顺序表适合于元素数量不变或变化不大的情况,且需要频繁查找元素的场景。
综上所述,顺序表是一种基本的数据结构,我们通过本次实验对其有了更深入的了解,掌握了顺序表的基本操作,并了解了其优缺点及应用场景。
云南大学软件学院计算机网络原理实验六实验报告3
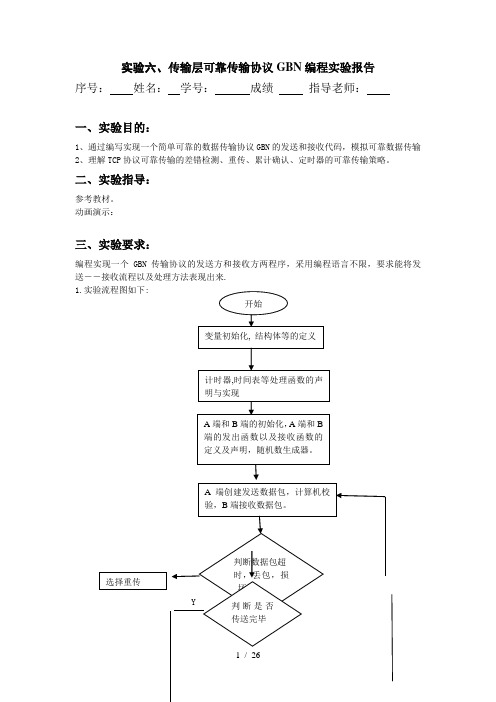
实验六、传输层可靠传输协议GBN编程实验报告序号:姓名:学号:成绩指导老师:一、实验目的:1、通过编写实现一个简单可靠的数据传输协议GBN的发送和接收代码,模拟可靠数据传输2、理解TCP协议可靠传输的差错检测、重传、累计确认、定时器的可靠传输策略。
二、实验指导:参考教材。
动画演示:三、实验要求:编程实现一个GBN传输协议的发送方和接收方两程序,采用编程语言不限,要求能将发送――接收流程以及处理方法表现出来.1.实验流程图如下:N2.实验截图与代码如下: 截图: 传送下一个数据包结束代码及注释:一、GBN.h#pragma once#include <stdio.h>//基础功能模块的数据结构声明#define BIDIRECTIONAL 1 /* change to 1 if you're doing extra credit andwrite a routine called B_output *//* a "msg" is the data unit passed from layer 5 (teachers code) to layer4 (students' code). It contains the data (characters) to be delivered tolayer 5 via the students transport level protocol entities. */struct msg{ char data[20];};/* a packet is the data unit passed from layer 4 (students code) to layer3 (teachers code). Note the pre-defined packet structure, which allstudents must follow. */struct pkt{int seqnum;int acknum;int checksum;char payload[20];};#define WINDOWSIZE 8#define MAXBUFSIZE 50#define RTT 15.0#define NOTUSED 0#define NACK -1#define TRUE 1#define FALSE 0#define A 0#define B 1//网络仿真部分数据结构声明***********************************************************struct event{float evtime; /* event time */int evtype; /* event type code */int eventity; /* entity where event occurs */struct pkt *pktptr; /* ptr to packet (if any) assoc w/ this event */ struct event *prev;struct event *next;};/* possible events: */#define TIMER_INTERRUPT 0#define FROM_LAYER5 1#define FROM_LAYER3 2#define OFF 0#define ON 1//基础功能模块的函数声明******************************************************************* void ComputeChecksum(struct pkt *packet);//计算校验和int CheckCorrupted(struct pkt packet);//检查数据是否出错void A_output( struct msg message);//A端向外发送数据void A_input(struct pkt packet);//A端接收数据void A_timerinterrupt();//A计时器超时void A_init();//A端初始化void B_output(struct msg message);void B_input(struct pkt packet);void B_timerinterrupt();void B_init();//网络仿真部分的函数声明**************************************************void init(); //初始化仿真器float jimsrand();//随机数发生器[0,1]//处理事件列表部分的函数声明*********************************************void generate_next_arrival();//产生下一个到达的分组void insertevent(struct event *p);//向事件列表中插入一条新的事件void printevlist();//打印事件列表//******************************************************************** //**********************计时器模块*********************************** void stoptimer(int);//停止计时器void starttimer(int,float);//启动计时器//******************************************************************** *//**************************网络各层之间传送模块***********************void tolayer3(int AorB,struct pkt packet);//向第3层发送信息void tolayer5(int AorB,char datasent[20]);//向第5层发送信息二、GBN.c#include "GBN.h"#include <stdio.h>#include <string.h>#include <stdlib.h>extern int TRACE = 1; /* for my debugging */为我的调试extern int nsim = 0; /* number of messages from 5 to 4 so far */目前为止信息的数字是从5到4extern int nsimmax = 0; /* number of msgs to generate, then stop */如果信息产生的数字为0,然后就停止extern float time = 0.000;float lossprob; /* probability that a packet is dropped */数据包可能会丢失float corruptprob; /* probability that one bit is packet is flipped*/这一点的数据包可能会被弹出去float lambda; /* arrival rate of messages from layer 5 */ 第五层到达的信息的次序int ntolayer3; /* number sent into layer 3 */被传送到第三层的数据static int nlost = 0; /* number lost in media */在媒介中数据丢失static int ncorrupt = 0; /* number co rrupted by media*/被媒介毁坏的数据static int expectedseqnum = 0; /* expected se quence number at receiver side */在接收者这边接收到预期的序列数据static int nextseqnum; /* next sequence number to use in sender side */下一个序列数据使用在发送者这边static int base; /* t he head of sender window */发送者的头窗口struct pkt winbuf[WINDOWSIZE]; /* window packets buffer */数据包缓冲区窗口static int winfront,winrear; /* front and rear points of wind ow buffer */窗口缓冲区的前方点和后方点static int pktnum; /* packet number of window buffer */窗口缓冲区的数据包个数struct msg buffer[MAXBUFSIZE]; /* sender message buffer */发送消息缓冲区int buffront,bufrear; /* front and rear pointers of buffer */缓冲区的前指针与后指针static int msgnum; /* message number of buffer */信息数量的缓冲int packet_lost =0;int packet_corrupt=0;int packet_sent =0;extern int packet_correct=0;extern int packet_resent =0;int packet_timeout=0;extern struct event *evlist = NULL; /* the event list *///计算校验和void ComputeChecksum( struct pkt *packet){int checksum;int i;checksum = packet->seqnum;checksum = checksum + packet->acknum;for ( i=0; i<20; i++ )checksum = checksum + (int)(packet->payload[i]);checksum = 0-checksum;packet->checksum = checksum;}//检查是否出错int CheckCorrupted(struct pkt packet){int checksum;int i;checksum = packet.seqnum;checksum = checksum + packet.acknum;for ( i=0; i<20; i++ )checksum = checksum + (int)(packet.payload[i]);if ( (packet.checksum+checksum) == 0 )return (FALSE);elsereturn (TRUE);}//A端向外发送数据/* called from layer 5, passed the data to be sent to other side */ void A_output(struct msg message){int i;struct pkt sendpkt;/* if window is not full */if ( nextseqnum < base+WINDOWSIZE ){printf("----A: New message arrives, send window is not full, send new messge to layer3!\n");/* create packet */sendpkt.seqnum = nextseqnum;sendpkt.acknum = NOTUSED;for ( i=0; i<20 ; i++ )sendpkt.payload[i] = message.data[i];/* computer checksum */ComputeChecksum (&sendpkt);/* send out packet */tolayer3 (A, sendpkt);/* copy the packet to window packet buffer */winrear = (winrear+1)%WINDOWSIZE;pktnum ++;winbuf[winrear] = sendpkt;for (i=0; i<20; i++)winbuf[winrear].payload[i]= sendpkt.payload[i];/* update state variables */nextseqnum = nextseqnum+1;starttimer(A,RTT);B_input(sendpkt);A_input(sendpkt);}/* if window is full */else{printf("----A: New message arrives, send window is full,");/* if buffer full, give up and exit*/if ( msgnum == MAXBUFSIZE){printf (" Error: Sender buffer is full! \n");exit (1);}/* otherwise, buffer the message */else{printf("buffer new message!\n");bufrear = (bufrear+1) % MAXBUFSIZE;for (i=0; i<20; i++)buffer[bufrear].data[i] = message.data[i];msgnum ++;}}}//B端向外发送数据/* called from layer 5, passed the data to be sent to other side */ void B_output(struct msg message){int i;struct pkt sendpkt;/* if window is not full */if ( nextseqnum < base+WINDOWSIZE ){printf("----A: New message arrives, send window is not full, send new messge to layer3!\n");/* create packet */sendpkt.seqnum = nextseqnum;sendpkt.acknum = NOTUSED;for ( i=0; i<20 ; i++ )sendpkt.payload[i] = message.data[i];/* computer checksum */ComputeChecksum (&sendpkt);/* send out packet */tolayer3 (A, sendpkt);A_input(sendpkt);/* copy the packet to window packet buffer */winrear = (winrear+1)%WINDOWSIZE;pktnum ++;winbuf[winrear] = sendpkt;for (i=0; i<20; i++)winbuf[winrear].payload[i]= sendpkt.payload[i];/* if it is the first packet in window, start timeout */ //if ( base == nextseqnum )//{//starttimer(A,RTT);//printf("----A: start a new timer!\n");// }/* update state variables */nextseqnum = nextseqnum+1;}/* if window is full */else{printf("----A: New message arrives, send window is full,");/* if buffer full, give up and exit*/if ( msgnum == MAXBUFSIZE){printf (" Error: Sender buffer is full! \n");exit (1);}/* otherwise, buffer the message */else{printf("buffer new message!\n");bufrear = (bufrear+1) % MAXBUFSIZE;for (i=0; i<20; i++)buffer[bufrear].data[i] = message.data[i];msgnum ++;}}}//A端接收数据void A_input(struct pkt packet){struct pkt sendpkt;int i;/* if received packet is not corrupted and ACK is received */if ( (CheckCorrupted(packet) == FALSE) && (packet.acknum != NACK) ) {printf("----A: ACK %d is correctly received,",packet.acknum);packet_correct++;/* delete the acked packets from window buffer */winfront = (winfront+(packet.acknum+1-base)) % WINDOWSIZE; pktnum = pktnum - (packet.acknum+1-base);/* move window base */base = packet.acknum+1;stoptimer(A);if ( base < nextseqnum){//starttimer(A,RTT);printf ("\n\n\nsend new packets!");}/* if buffer is not empty, send new packets */while ( (msgnum!=0) && (nextseqnum<base+WINDOWSIZE) ) {/* create packet */sendpkt.seqnum = nextseqnum;sendpkt.acknum = NOTUSED;buffront = (buffront+1) % MAXBUFSIZE;for ( i=0; i<20 ; i++ )sendpkt.payload[i] = buffer[buffront].data[i];/* computer checksum */ComputeChecksum (&sendpkt);/* if it is the first packet in window, start timeout */if ( base == nextseqnum ){//starttimer(A,RTT);printf ("send new packets!\n");}/* send out packet */tolayer3 (A, sendpkt);/* copy the packet to window packet buffer */winrear = (winrear+1)%WINDOWSIZE;winbuf[winrear] = sendpkt;pktnum ++;/* update state variables */nextseqnum = nextseqnum+1;/* delete message from buffer */msgnum --;}}elseprintf ("----A: NACK is received, do nothing!\n");}//B端接收数据*****************************************************一定要调用这个/* Note that with simplex transfer from a-to-B, there is no B_output() */ /* called from layer 3, when a packet arrives for layer 4 at B*/void B_input(struct pkt packet){struct pkt sendpkt;int i;/* if not corrupted and received packet is in order */if ( (CheckCorrupted(packet) == FALSE) && (packet.seqnum == expectedseqnum)){printf("\n----B: packet %d is correctly received, send ACK!\n",packet.seqnum);/* send an ACK for the received packet *//* create packet */sendpkt.seqnum = NOTUSED;sendpkt.acknum = expectedseqnum;for ( i=0; i<20 ; i++ )sendpkt.payload[i] = '0';/* computer checksum */ComputeChecksum (&sendpkt);/* send out packet *///tolayer3 (B, sendpkt);/* update state variables */expectedseqnum = expectedseqnum+1;printf("----B:expectedseqnum = %d\n",expectedseqnum);/* deliver received packet to layer 5 *///tolayer5(B,packet.payload);}/* otherwise, discard the packet and send a NACK */else{printf("----B: packet %d is corrupted or not I expects, send NACK!\n",packet.seqnum);/* create packet */sendpkt.seqnum = NOTUSED;sendpkt.acknum = NACK;for ( i=0; i<20 ; i++ )sendpkt.payload[i] = '0';/* computer checksum */ComputeChecksum (&sendpkt);/* send out packet */tolayer3 (B, sendpkt);}}//A计时器超时/* called when A's timer goes off */void A_timerinterrupt(){int i;printf("----A: time out,resend packets!\n");/* start timer */starttimer(A,RTT);/* resend all packets not acked */for ( i=1; i<=pktnum; i++ ){packet_resent++;tolayer3(A,winbuf[(winfront+i)%WINDOWSIZE]);}}//B计时器超时/* called when B's timer goes off */void B_timerinterrupt(){int i;printf("----B: time out,resend packets!\n");/* start timer */starttimer(B,RTT);/* resend all packets not acked */for ( i=1; i<=pktnum; i++ ){packet_resent++;tolayer3(B,winbuf[(winfront+i)%WINDOWSIZE]);}}//A端初始化/* entity A routines are called. You can use it to do any initialization */void A_init()base = 0;nextseqnum = 0;buffront = 0;bufrear = 0;msgnum = 0;winfront = 0;winrear = 0;pktnum = 0;}//B端初始化/* entity B routines are called. You can use it to do any initialization */void B_init(){expectedseqnum = 0;}//初始化仿真器void init() /* initialize the simulator */{int i;float sum, avg;float jimsrand();FILE *fp;fp = fopen ("parameter.txt","r");printf("----- Stop and Wait Network Simulator Version 1.1 -------- \n\n");printf("Enter the number of messages to simulate: ");//fscanf(fp,"%d",&nsimmax);scanf("%d",&nsimmax);printf("\nEnter packet loss probability [enter 0.0 for no loss]: "); //fscanf(fp, "%f",&lossprob);scanf("%f",&lossprob);printf("\nEnter packet corruption probability [0.0 for no corruption]: "); //fscanf(fp,"%f",&corruptprob);scanf("%f",&corruptprob);printf("\nEnter average time between messages from sender's layer5 [ > 0.0]: ");//fscanf(fp,"%f",&lambda);scanf("%f",&lambda);printf("\nEnter TRACE: ");//fscanf(fp,"%d",&TRACE);scanf("%d",&TRACE);printf("\n\n");srand(9999); /* init random number generator */sum = 0.0; /* test random number generator for students */for (i=0; i<1000; i++)sum=sum+jimsrand(); /* jimsrand() should be uniform in [0,1] */avg = sum/1000.0;/*if(avg < 0.25 || avg > 0.75){printf("It is likely that random number generation on your machine\n" ); printf("is different from what this emulator expects. Please take\n"); printf("a look at the routine jimsrand() in the emulator code. Sorry. \n");exit(0);}*/printf("%f",avg);ntolayer3 = 0;nlost = 0;ncorrupt = 0;time=0.0; /* initialize time to 0.0 */generate_next_arrival(); /* initialize event list */}//随机数发生器float jimsrand(){double mmm = 2147483647; /* largest int - MACHINE DEPENDENT */float x; /* individual students may need to change mmm */x = rand()/mmm; /* x should be uniform in [0,1] */return(x);}//**************************************************************************************//*******************************事件处理部分*******************************************void generate_next_arrival(){double x,log(),ceil();struct event *evptr;float ttime;int tempint;//if (TRACE>2)//printf("-----------------GENERATE NEXT ARRIVAL: creating new arrival\n");x = lambda*jimsrand()*2; /* x is uniform on [0,2*lambda] *//* having mean of lambda */evptr = (struct event *)malloc(sizeof(struct event));evptr->evtime = time + x;evptr->evtype = FROM_LAYER5;if (jimsrand()<0.5){evptr->eventity = A;}evptr->eventity = B;insertevent(evptr);}//向事件列表中插入一条新的事件void insertevent(struct event *p){struct event *q,*qold;if (TRACE>2){//printf(" INSERTEVENT: time is %lf\n",time);//printf(" INSERTEVENT: future time will be %lf\n",p->evtime);}q = evlist; /* q points to front of list in which p struct inserted */if (q==NULL)/* list is empty */{evlist=p;p->next=NULL;p->prev=NULL;}else{for (qold = q; q !=NULL && p->evtime > q->evtime; q=q->next) qold=q;if (q==NULL)/* end of list */{qold->next = p;p->prev = qold;p->next = NULL;}else if (q==evlist)/* front of list */p->next=evlist;p->prev=NULL;p->next->prev=p;evlist = p;}else /* middle of list */{p->next=q;p->prev=q->prev;q->prev->next=p;q->prev=p;}}}//打印事件列表void printevlist(){struct event *q;int i;printf("--------------\nEvent List Follows:\n");for(q = evlist; q!=NULL; q=q->next){printf("Event time: %f, type: %d entity: %d\n",q->evtime,q->evtype,q->eventity);}printf("--------------\n");}//启动计时器void starttimer(int AorB,float increment){struct event *q;struct event *evptr;if (TRACE>2)printf("\n----A: START TIMER: starting timer at %f\n",time);/* be nice: check to see if timer is already started, if so, then warn *//* for (q=evlist; q!=NULL && q->next!=NULL; q = q->next) */for (q=evlist; q!=NULL ; q = q->next)if ( (q->evtype==TIMER_INTERRUPT && q->eventity==AorB) ){//printf("Warning: attempt to start a timer that is already started\n");return;}/* create future event for when timer goes off */evptr = (struct event *)malloc(sizeof(struct event));evptr->evtime = time + increment;evptr->evtype = TIMER_INTERRUPT;evptr->eventity = AorB;insertevent(evptr);}//停止计时器/* called by students routine to cancel a previously-started timer */ void stoptimer(int AorB) /* A or B is trying to stop timer */{struct event *q,*qold;if (TRACE>2)printf("\n----A: STOP TIMER: stopping timer\n");/* for (q=evlist; q!=NULL && q->next!=NULL; q = q->next) */for (q=evlist; q!=NULL ; q = q->next)if ( (q->evtype==TIMER_INTERRUPT && q->eventity==AorB) )/* remove this event */{if (q->next==NULL && q->prev==NULL)evlist=NULL; /* remove first and only event on listelse if (q->next==NULL) /* end of list - there is one in front */ q->prev->next = NULL;else if (q==evlist) /* front of list - there must be event after */{q->next->prev=NULL;evlist = q->next;}else /* middle of list */{q->next->prev = q->prev;q->prev->next = q->next;}free(q);return;}//printf("Warning: unable to cancel your timer. It wasn't running.\n");}//向第三层发送信息/************************** TOLAYER3 ***************/void tolayer3(int AorB,struct pkt packet){struct pkt *mypktptr;struct event *evptr,*q;float lastime, x, jimsrand();int i;ntolayer3++;/* simulate losses: */if (jimsrand() < lossprob){nlost++;if (TRACE>0)printf(" TOLAYER3: packet being lost\n");return;}/* make a copy of the packet student just gave me since he/she may decide *//* to do something with the packet after we return back to him/her */ mypktptr = (struct pkt *)malloc(sizeof(struct pkt));mypktptr->seqnum = packet.seqnum;mypktptr->acknum = packet.acknum;mypktptr->checksum = packet.checksum;for (i=0; i<20; i++)mypktptr->payload[i] = packet.payload[i];if (TRACE>2){printf(" TOLAYER3: seq: %d, ack %d, check: %d ", mypktptr->seqnum,mypktptr->acknum, mypktptr->checksum);for (i=0; i<20; i++)printf("%c",mypktptr->payload[i]);printf("");}/* create future event for arrival of packet at the other side */evptr = (struct event *)malloc(sizeof(struct event));evptr->evtype = FROM_LAYER3; /* packet will pop out from layer3 */ evptr->eventity = (AorB) % 2; /* event occurs at other entity */evptr->pktptr = mypktptr; /* save ptr to my copy of packet *//* finally, compute the arrival time of packet at the other end. medium can not reorder, so make sure packet arrives between 1 and 10 time units after the latest arrival time of packetscurrently in the medium on their way to the destination */lastime = time;/* for (q=evlist; q!=NULL && q->next!=NULL; q = q->next) */for (q=evlist; q!=NULL ; q = q->next)if ( (q->evtype==FROM_LAYER3 && q->eventity==evptr->eventity) ) lastime = q->evtime;evptr->evtime = lastime + 1 + 9*jimsrand();/* simulate corruption: */if (jimsrand() < corruptprob){ncorrupt++;if ( (x = jimsrand()) < .75)mypktptr->payload[0]='Z'; /* corrupt payload */else if (x < .875)mypktptr->seqnum = 999999;elsemypktptr->acknum = 999999;if (TRACE>0)printf(" TOLAYER3: packet being corrupted\n");}//if (TRACE>2)//printf(" TOLAYER3: scheduling arrival on other side\n");insertevent(evptr);}//向第五层发送信息/************************** TOLAYER5 ***************/void tolayer5(int AorB,char datasent[20]){int i;if (TRACE>2){printf(" TOLAYER5: data received: ");for (i=0; i<20; i++)printf("%c",datasent[i]);printf("\n");}}三、GBN-CS.c#include "GBN.h"#include <stdio.h>#include <string.h>#include <stdlib.h>extern int TRACE ; /* for my debugging */extern int nsim ; /* number of messages from 5 to 4 so far */extern int nsimmax; /* number of msgs to generate, then stop */extern float time;extern int packet_correct;extern int packet_resent;extern struct event *evlist;int main(){struct event *eventptr;struct msg msg2give;struct pkt pkt2give;int i,j;char c;init();A_init();B_init();while (1){eventptr = evlist; /* get next event to simulate */ if (eventptr==NULL)goto terminate;evlist = evlist->next; /* remove this event from event list */if (evlist!=NULL)evlist->prev=NULL;if (TRACE >= 2){printf("\nEVENT time: %f,",eventptr->evtime);printf(" type: %d",eventptr->evtype);if (eventptr->evtype==0)printf(", timerinterrupt ");else if (eventptr->evtype==1)printf(", fromlayer5 ");elseprintf(", fromlayer3 ");printf(" entity: %d\n",eventptr->eventity);}time = eventptr->evtime; /* update time to next event time*/if (nsim==nsimmax)break; /* all done with simulation */if (eventptr->evtype == FROM_LAYER5 ){generate_next_arrival(); /* set up future arrival *//* fill in msg to give with string of same letter */j = nsim % 26;for (i=0; i<20; i++)msg2give.data[i] = 97 + j;if (TRACE>2){printf(" MAINLOOP: data given to student: ");for (i=0; i<20; i++)printf("%c", msg2give.data[i]);printf("\n");}nsim++;if (eventptr->eventity == A){A_output(msg2give);}else{B_output(msg2give);}}else if (eventptr->evtype == FROM_LAYER3){pkt2give.seqnum = eventptr->pktptr->seqnum;pkt2give.acknum = eventptr->pktptr->acknum;pkt2give.checksum = eventptr->pktptr->checksum;for (i=0; i<20; i++)pkt2give.payload[i] = eventptr->pktptr->payload[i];if (eventptr->eventity == A) /* deliver packet by calling */ A_input(pkt2give); /* appropriate entity */elseB_input(pkt2give);free(eventptr->pktptr); /* free the memory for packet */ }else if (eventptr->evtype == TIMER_INTERRUPT){if (eventptr->eventity == A)A_timerinterrupt();elseB_timerinterrupt();}else{printf("INTERNAL PANIC: unknown event type \n");}free(eventptr);}terminate:printf(" Simulator terminated at time %f\n after sending %d msgs from layer5\n",time,nsim);printf(" correctly sent pkts: %d \n", packet_correct);printf(" resent pkts: %d \n", packet_resent);system("pause");}附源代码及注释四. 实验小结通过本次试验了解了编程实现简单可靠的数据传输GBN协议,模拟了可靠数据传输理解了TCP协议可靠传输的差错检测、重传、累计确认、定时器的可靠传输策略。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
云南大学软件学院数据结构实验报告
(本实验项目方案受“教育部人才培养模式创新实验区(X3108005)”项目资助)实验难度: A □ B □ C □
学期:
任课教师:
实验题目: 实验七查找算法的设计与实现
小组长:
联系电话:
电子邮件:
完成提交时间:年月日
云南大学软件学院2010学年秋季学期
《数据结构实验》成绩考核表
学号:姓名:本人承担角色:课题分析,算法设计,程序编写,后期调试,完成实验报告
综合得分:(满分100分)
指导教师:年月日
(注:此表在难度为C时使用,每个成员一份。
)
(下面的内容由学生填写,格式统一为,字体: 楷体, 行距: 固定行距18,字号: 小
四,个人报告按下面每一项的百分比打分。
难度A满分70分,难度B满分90分)一、【实验构思(Conceive)】(10%)
(本部分应包括:描述实验实现的基本思路,包括所用到的离散数学、工程数学、程序设计、算法等相关知识)
1.数据结构算法的知识:
●表的定义。
●表项的表示。
●表的存储结构。
●哈希表的定义
●哈希函数的构造方法
●哈希表查找处理冲突的办法
2.面向对象的程序设计相关知识:
●C#基本语法知识。
●类的定义,实例化。
●对象的生成调用。
●变量的传递。
二、【实验设计(Design)】(20%)
(本部分应包括:抽象数据类型的功能规格说明、主程序模块、各子程序模块的伪码说明,主程序模块与各子程序模块间的调用关系)
本实验创建了一个类Form类,用于窗口的初始化,控制各控件的属性和动作,构造哈希表的表项,构造哈希表以及哈希表的各项操作
抽象数据类型的功能规格说明:
窗口初始化:private void Form1_Load(object sender, EventArgs e)
存储新的表项按钮:private void button1_Click(object sender, EventArgs e)
查找目标表项按钮:private void button2_Click(object sender, EventArgs e)
声明全局哈希查找表:public hashTableNode [] HSTable = new hashTableNode
[1000]; //最多能保存1000个同学的信息
定义结构体数组:public struct hashTableNode
{
public string name; //保存该同学的姓名
public int number; //保存该同学的学号
}
查找空余表项的函数:public int findEmpty(int hashCode)
//利用再哈希法
查找目标表项的函数:public int Search(int hashCode)
//也是利用再哈希法
主程序模块伪代码说明:
声明全局哈希查找表:public hashTableNode [] HSTable = new hashTableNode 退出程序:this.Close()
三、【实现描述(Implement)】(30%)
(本部分应包括:抽象数据类型具体实现的函数原型说明、关键操作实现的伪码算法、函数设计、函数间的调用关系,关键的程序流程图等,给出关键算法的时间复杂度分析。
)
①抽象数据类型具体实现的函数原型说明:
1、节点类型;
public struct hashTableNode
{
public string name;
public int number;
}
2、Hash算法
public int findEmpty(int hashCode)
{
int index = -1; //初始化索引变量
int divisor = 1000; //初始化取模的除数
while (index == -1) //循环条件
{
index = Math .Abs (hashCode % divisor ); //取模
if (HSTable[index].number != 0) //判断目标表项是否被占用
return index; //返回索引变量
divisor--; //取模除数自减
if (divisor <= 0) //满足除法性质
return -2; //返回错误信息
}
return index; //返回索引
}
②关键操作实现的伪码算法:
中序遍历查找伪代码:
先对已知的哈希值对1000取模,求得的索引搜索后判断目标是否可用,如果可用。
直接返回索引,算法结束。
如果不可用,取模除数自减1,再次进行如上操作,直至目标可用返回索引,或者直至取模除数减至0,提示找不到为止。
③关键的程序流程图:
四、【测试结果(Testing)】(10%)
(本部分应包括:对实验的测试结果,应具体列出每次测试所输入的数据以及输出的数据,并对测试结果进行分析总结)
测试过程:
1.打开程序主界面:
2. 输入数据,建立哈希查找表
假设我们以如下数据为例:
杨扬1120048
王同杰1120078
陈旭1120088
李文婷1120061
张旭阳1120016
马腾辉1120017
由于使用除留余数法生成哈希值,可见,数据之间还是分散的相当开的。
散列存储测试成功!
3.查找测试:
以搜索杨扬,查找杨扬的学号为例,在查找单元的被查找人姓名一栏中填入“杨扬”,点击确定
就会在查询结果中显示目标信息:
与以前输入的一样。
查找单元测试通过!
4. 健壮性测试:
如果在查询菜单里面输入一个未进入名单里的人名:(例:薛岗)
点击查找,返回错误信息
健壮性测试通过!
五、【实验总结】(10%)
(本部分应包括:自己在实验中完成的任务,注意组内的任意一位同学都必须独立完成至少一项接口的实现;对所完成实验的经验总结、心得)
杨扬(20091120048)部分:
工作:算法构思、设计、实现;编写代码、后期调试、完成试验报告。
总结:
①这次实验使我对Hash查找表、Hash搜索算法有了熟练的掌握。
②在设计程序时,摆在我面前有以下几个难题:
首先,如何用C#生成符合一定规则的HashTable?这个问题花了我不少时间,最后通过定义一个结构体数组来避免指针的缺失,解决了此问题。
其次,在生成HashTable之后,如何实现HashTable搜索算法呢?我觉得还是继续使用哈希法推算index,如果不符合要求则继续使用再哈希法,直至达到符合要求的表项或者条件出错退出。
利用哈希法选择index能够很有效的减少堆积,降低平均查找长度,实现快速存取的目的。
③本次试验,有些同学帮助我很多,一起讨论并解决了不少问题,使得程序更佳完善。
一个人不可能面面俱到,这时同学的帮助与合作尤为重要,一定要虚心求教,认真倾听别人的意见,不要认为自己做的东西才是最好的,只有这样才能进步。
六、【项目运作描述(Operate)】(10%)
(本部分应包括:项目的成本效益分析,应用效果等的分析。
)
1.用户使用手册:
操作过程:
1.打开程序主面板;
当用户需要输入某个同学的学号时:
对于用户需要新建的表项,可以在姓名栏中输入用户姓名,学号栏中输入用户学号,然后单击确定键完成一个表项的建立,此时,系统会返回给用户一个存储的索引。
这个索引就是该项在表中存储的逻辑位置。
当用户需要查找某个同学的学号时:
在查找单元格中输入被查找同学的姓名,然后单击确定,系统如果找到,就会在下列菜单中显示目标的详细信息,如果没找到,则会在弹出窗口里显示“找不到”。
综述:
本程序所占空间12 KB,运行所占内存10 MB,运行环境要求也比较低,windows98以上版本的系统就行。
实现此程序用了1个实验课时,以及课下大概3个课时的时间,所用时间也不算太多。
运行此程序可以实现了一个简单的Hash表的构建,新建表项,以及查找表项。
运行界面也比较友好的。
2.运作分析:
①在成本方面有:
培训相关设计营销人员成本。
人力资源的消耗(成员基本工资)。
软件售后服务支持:通信,交通费用。
②在效益方面有:
应用后大大地减少了编码空间的浪费,提高查找算法的运行效率。
有效减少内存堆积。
给我们提供难得的实践机会。
软件使用相关费用。
③应用效果:
可改写成服务器版本,提高服务器的使用效率。
为后续的编程实现奠定了算法基础。
3.用户反馈:
①李通(软件学院09级学生):程序总体上看来没有大的问题,能比较流畅的完
成我们需要的工作,性能较为稳定。
②刘雪峰(软件学院09级学生):程序所占用的内存比我想象的少很多,运行环
境要求不高,运行时几乎没有延迟,界面友好。
③江涛(软件学院09级学生):总体不错,不过也有一些需要注意的问题:打开
程序后若输入姓名或者学号内容为空也摁确定按钮,会导致程序崩溃。
(此BUG我会在后续版本中改进)。