最优匹配(KUHN MUNKRAS算法)
最大化指派问题匈牙利算法

最大化指派问题匈牙利算法匈牙利算法,也称为Kuhn-Munkres算法,是用于解决最大化指派问题(Maximum Bipartite Matching Problem)的经典算法。
最大化指派问题是在一个二分图中,找到一个匹配(即边的集合),使得匹配的边权重之和最大。
下面我将从多个角度全面地介绍匈牙利算法。
1. 算法原理:匈牙利算法基于增广路径的思想,通过不断寻找增广路径来逐步扩展匹配集合,直到无法找到增广路径为止。
算法的基本步骤如下:初始化,将所有顶点的标记值设为0,将匹配集合初始化为空。
寻找增广路径,从未匹配的顶点开始,依次尝试匹配与其相邻的未匹配顶点。
如果找到增广路径,则更新匹配集合;如果无法找到增广路径,则进行下一步。
修改标记值,如果无法找到增广路径,则通过修改标记值的方式,使得下次寻找增广路径时能够扩大匹配集合。
重复步骤2和步骤3,直到无法找到增广路径为止。
2. 算法优势:匈牙利算法具有以下优势:时间复杂度较低,匈牙利算法的时间复杂度为O(V^3),其中V是顶点的数量。
相比于其他解决最大化指派问题的算法,如线性规划算法,匈牙利算法具有更低的时间复杂度。
可以处理大规模问题,由于时间复杂度较低,匈牙利算法可以处理大规模的最大化指派问题,而不会因为问题规模的增加而导致计算时间大幅增加。
3. 算法应用:匈牙利算法在实际中有广泛的应用,例如:任务分配,在人力资源管理中,可以使用匈牙利算法将任务分配给员工,使得任务与员工之间的匹配最优。
项目分配,在项目管理中,可以使用匈牙利算法将项目分配给团队成员,以最大程度地提高团队成员与项目之间的匹配度。
资源调度,在物流调度中,可以使用匈牙利算法将货物分配给合适的运输车辆,使得货物与运输车辆之间的匹配最优。
4. 算法扩展:匈牙利算法也可以扩展到解决带权的最大化指派问题,即在二分图的边上赋予权重。
在这种情况下,匈牙利算法会寻找一个最优的匹配,使得匹配边的权重之和最大。
Kuhn-Munkres算法

Kuhn-Munkres算法KmKuhn-Munkres算法⼀种⽤于进⾏⼆分图完全匹配的算法前pre技能匈⽛利算法及增⼴路标顶对于图G(U∪V,E)。
对于x∈U,定义Lx i。
对于i∈V。
定义Ly i。
这个玩意叫做标顶,是⼀种⼈为构造的数值。
⽤于进⾏⼆分图完全匹配可⾏标顶对于所有的边,假设权值是W,⽅向是x→y,则是算法执⾏中,恒定满⾜Lx x+Ly y≥W相等⼦图相等⼦图包括U∪V,但只包括满⾜W=Lx x+Ly y的边若相等⼦图有完全匹配,则原图有完全匹配实现概括通过更改标顶,找出相等⼦图。
实现具体扩⼤相等⼦图假设当前相等⼦图⽆法进⾏完全匹配,则⾄少有⼀个点u,从其出发⽆法找到增⼴路则我们需要修改标顶,使更多的边参与进来。
假设我们现在已经知道了⼀个M,这个M是使其他边增加到相等⼦图的最⼩标顶修改量然后我们令所有的Lx i减去M,所有的Ly i加上M正确性?假设我们现在在相等⼦图中在U中已经被匹配的点x,则我们规定x∈A,否则x∈A′相似的,对于x∈V,若x已经被匹配上,则x∈B,否则x∈B′对于⼀条边(x→y,权值(代价)是W)若x∈A,y∈B,仍满⾜Lx x+Ly y=W若x∈A′,y∈B′,则为Lx x+Ly y≥W,即是原本就不在交替路中的的依旧不在若x∈A′,y∈B,则Lx x+Ly y增加,不会被添加进⼊若x∈A,y∈B′,则Lx x+Ly y有所减少,可能会被添加其他关于若x∈A′,y∈B,则Lx x+Ly y增加,不会被添加进⼊若x∈A,y∈B′,则Lx x+Ly y有所减少,可能会被添加对于上边这句,是为了保证在将⼀个点x,x∈U进⾏匹配时,只会相应的引⼊y,y∈V,⽽不会引⼊U中的点。
M如何计算?M的⼤⼩取决于没有被加到相等⼦图中的最⼤边的⼤⼩,即是Lx x+Ly y−W⽽这个我们在寻找增⼴路的时候就可以顺带更新。
其他M的贪⼼选取保证了最⼤权。
个⼈理解是损失最⼩的代价,使其可以加⼊到相等⼦图代码using std::max;using std::min;const int maxn=500;const int inf=0x7fffffff;int M[maxn][maxn];int m[maxn][maxn];int lx[maxn],ly[maxn],mins[maxn],pat[maxn];int S[maxn],T[maxn],tot;int vis[maxn];int n;bool find(int x){S[x]=1;for(int i=1;i<=n;i++){if(T[i]) continue;int s=lx[x]+ly[i]-m[x][i];if(!s){T[i]=1;if(!pat[i]||find(pat[i])){pat[i]=x;return true;}}elsemins[i]=min(mins[i],s);}return false;}int KM(){for(int i=1;i<=n;i++) lx[i]=-inf;for(int i=1;i<=n;i++)for(int j=1;j<=n;j++)lx[i]=max(lx[i],m[i][j]),ly[i]=0;memset(pat,0,sizeof(pat));for(int i=1;i<=n;i++){for(int j=1;j<=n;j++)mins[j]=inf;while(1){memset(T,0,sizeof(T));memset(S,0,sizeof(S)); if(find(i)) break;int Min=inf;for(int j=1;j<=n;j++) Min=min(Min,mins[j]);for(int j=1;j<=n;j++){if(S[j]) lx[j]-=Min;if(T[j]) ly[j]+=Min;}}}int ans=0;for(int i=1;i<=n;i++)ans+=m[pat[i]][i];return ans;}Processing math: 100%。
kuhntucker定理

kuhntucker定理Kuhn-Tucker定理是最优化理论中的一个重要定理,用于描述在约束条件下的极值问题。
该定理给出了一组必要条件,使得一个非线性规划问题的解可以被判定为最优解。
以下是Kuhn-Tucker定理的主要内容:设给定一个非线性规划问题,目标函数为f(x),约束条件为g_i(x) ≤0,h_i(x) = 0,其中x 是决策变量,g_i(x) 和h_i(x) 是约束函数。
Kuhn-Tucker定理的主要结论是:如果x* 是一个可行解,并且满足一定条件(Kuhn-Tucker条件),那么x* 就是一个最优解。
Kuhn-Tucker条件包括以下几个方面:1. 约束条件的可行性:所有的约束条件必须满足,即g_i(x*) ≤0 和h_i(x*) = 0。
2. 梯度条件:目标函数的梯度和约束条件的梯度的线性组合必须为零,即存在拉格朗日乘子λ_i 和μ_i,使得满足以下条件:∇f(x*) + ∑[λ_i∇g_i(x*)] + ∑[μ_i∇h_i(x*)] = 03. 非负性条件:拉格朗日乘子λ_i 和μ_i 必须非负,即λ_i ≥0 和μ_i ≥0。
4. 互补松弛条件:拉格朗日乘子与约束条件的乘积为零,即λ_i * g_i(x*) = 0 和μ_i * h_i(x*) = 0。
这意味着当某个约束条件不活跃(对应的λ_i 为零)时,该约束条件的梯度应为零;当某个等式约束条件不是活跃约束(对应的μ_i 为零)时,该等式约束条件的梯度应为零。
通过满足上述Kuhn-Tucker条件,可以验证一个解是否为非线性规划问题的最优解。
需要注意的是,Kuhn-Tucker定理是一个必要条件定理,即如果一个解不满足Kuhn-Tucker条件,则它不一定是最优解。
因此,在应用Kuhn-Tucker定理时,还需要进一步考虑其他可能的情况和条件,以确保找到真正的最优解。
最优匹配
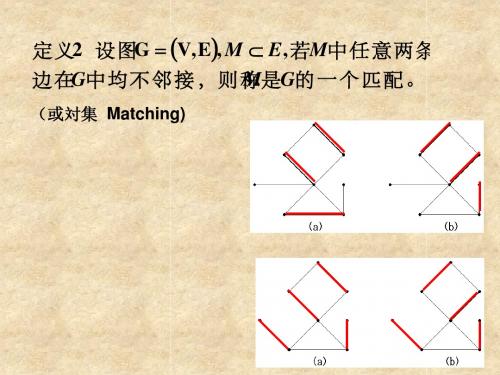
④ 对与xi邻接且尚未给标号的yj都给定标号i. 若所有的 yj 都是M的饱和点,则转向⑤,否则 逆向返回. 即由其中M的任一个非饱和点 yj 的标 号i 找到xi ,再由 xi 的标号k 找到 yk ,…,最后由 yt 的标号s找到标号为0的xs时结束,获得M-增广路 xs yt … xi yj , 记E(P) ={xs yt , … , xi yj },重新记M 为M⊕E(P),将所有标记标号清空,转向①.
二部图的最佳匹配算法: 可行顶点标号法(Kuhn-Munkres算法):
算法基本思想:通过点标记将赋权图转化为非赋权 图,再用匈牙利算法求最大匹配
求完备二部赋权图G = (X, Y, E, F )的最佳匹 配算法迭代步骤: 设G =(X, Y, E, F)为完备的二部赋权图,L是 其一个初始可行点标记,通常取 L(x) = max {F (x y) | y∈Y}, x∈X, L(y) = 0, y∈Y.
二部图赋权矩阵
Y:
y1
y2
邻接矩阵
二部图的匹配及其应用
Hall定理 设G = ( X, Y, E )为二部图, 则① G存在 饱和X的每个点的匹配的充要条件是 对任意S X ,有 | N (S ) | ≥ | S | . 其中, N (S ) = {v | u∈S, v与u相邻}. ② G存在完美匹配的充要条件是 对任意S X 或S Y 有 | N (S ) | ≥ | S | .
解 ① 取初始匹配M={x2 y2 , x3 y3 , x5 y5} ② 给X中M的两个非饱和点x1,x4都给以标号0和标 记* (如下图所示).
二部图的匹配及其应用
例18:求下图的最大匹配。 *0 *2 *3
匈亚利算法:
*0
km匹配算法流程

km匹配算法流程The KM matching algorithm, also known as the Kuhn-Munkres algorithm, is a classic method for solving the assignment problem in operations research. It aims to find the optimal assignment of a set of tasks to a set of agents, minimizing the total cost of the assignments. The algorithm is based on the concept of a cost matrix, where each element represents the cost of assigning a particular task to a particular agent.KM匹配算法,也称为Kuhn-Munkres算法,是运筹学中解决分配问题的经典方法。
其目标是为一系列任务找到一系列代理的最优分配,以最小化分配的总成本。
该算法基于成本矩阵的概念,其中每个元素表示将特定任务分配给特定代理的成本。
The KM algorithm proceeds in several steps. Firstly, it initializes the cost matrix and introduces slack variables to represent the difference between the cost of a particular assignment and the minimum cost row or column. Then, it searches for zero-cost assignments, which represent optimal matches between tasks and agents. If no zero-cost assignments are found, the algorithm proceeds to the next step.KM算法包括几个步骤。
最大权匹配KM算法

最大权匹配KM算法
KM算法(Kuhn–Munkres算法,也称为匈牙利算法)是由Kuhn于
1955年和Munkres于1957年分别提出的,用于解决二分图最大匹配问题。
该算法的核心思想是基于匈牙利算法的增广路径,通过构建一个增广路径
来不断更新匹配,直到无法找到增广路径为止。
算法流程如下:
2.从G的每个未匹配顶点开始,通过增广路径将其标记为可增广点;
3.当存在增广路径时,将匹配的边进行反向操作,直到不存在增广路径;
4. 利用增广路径的反向操作可以修改lx和ly的值,使其满足特定
约束条件;
5.通过相等子图的扩展来实现增广路径的;
6.重复步骤3-5,直到不存在更多的增广路径;
7.返回找到的最大匹配。
具体实现时,对于增广路径的可以利用DFS或BFS等方法进行,当找
到一个增广路径时,通过反向操作修改匹配情况,并更新lx和ly的值。
同时,算法还可以使用增广路径来调整优化标号,以减少匹配时间。
KM算法是一种高效的解决最大权匹配问题的方法,其时间复杂度为
O(V^3),其中V为图的顶点数。
算法的核心思想是利用二分图中的相等子
图来查找增广路径,并通过修改顶点的标号来实现最大匹配。
总之,最大权匹配KM算法是一个解决带权无向二分图最大匹配问题
的高效算法,通过不断寻找增广路径并调整顶点的标号来实现最大权匹配。
它的思想简单而有效,可以广泛应用于各种实际问题中。
匈牙利匹配算法的原理

匈牙利匹配算法的原理匈牙利匹配算法(也被称为二分图匹配算法或者Kuhn-Munkres算法)是用于解决二分图最大匹配问题的经典算法。
该算法由匈牙利数学家Dénes Kőnig于1931年提出,并由James Munkres在1957年进行改进。
该算法的时间复杂度为O(V^3),其中V是图的顶点数。
匹配问题定义:给定一个二分图G=(X,Y,E),X和Y分别代表两个不相交的顶点集合,E表示连接X和Y的边集合。
图中的匹配是指一个边的集合M,其中任意两条边没有公共的顶点。
匹配的相关概念:1.可增广路径:在一个匹配中找到一条没有被占用的边,通过这条边可以将匹配中的边个数增加一个,即将不在匹配中的边添加进去。
2. 增广路径:一个可增广路径是一个交替序列P=v0e1v1e2v2...ekvk,其中v0属于X且不在匹配中,v1v2...vk属于Y且在匹配中,e1e2...ek在原图中的边。
3.增广轨:一个交替序列形如V0E1V1E2...EkVk,其中V0属于X且不在匹配中,V1V2...Vk属于Y且在匹配中,E1E2...Ek在原图中的边。
增广轨是一条路径的特例,它是一条从X到Y的交替序列。
1.初始时,所有的边都不在匹配中。
2.在X中选择一个点v0,如果v0已经在匹配中,则找到与v0相连的在Y中的顶点v1、如果v1不在匹配中,则(v0,v1)是可增广路径的第一条边。
3. 如果v1在匹配中,则找到与v1相连的在X中的顶点v2,判断v2是否在匹配中。
依此类推,直到找到一个不在匹配中的点vn。
4.此时,如果n是奇数,则(n-1)条边在匹配中,这意味着我们找到了一条增广路径。
如果n是偶数,则(n-1)条边在匹配中,需要进行进一步的处理。
5.如果n是偶数,则将匹配中的边和非匹配中的边进行颠倒,得到一个新的匹配。
6.对于颠倒后的匹配,我们再次从第2步开始,继续寻找增广路径。
7.重复步骤2到步骤6,直到找不到可增广路径为止,此时我们得到了最大匹配。
Ku二分图最大权匹配(KM算法)hn

Kuhn-Munkres 算法Maigo 的 KM 算法讲解(的确精彩)KM 算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转 化为求完备匹配的问题的。
设顶点 Xi 的顶标为 A[i],顶点 Yi 的顶标为 B[i],顶点 Xi 与 Yj 之间的边权为 w[i,j]。
在算法执行过程中 的任一时刻,对于任一条边(i,j), A[i]+B[j]>=w[i,j]始终成立。
KM 算法的正确 性基于以下定理: * 若由二分图中所有满足 A[i]+B[j]=w[i,j]的边(i,j)构成的子图 (称做相等子 图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
这个定理是显然的。
因为对于二分图的任意一个匹配,如果它包含于相 等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相 等子图,那么它的边权和小于所有顶点的顶标和。
所以相等子图的完备匹配 一定是二分图的最大权匹配。
初始时为了使 A[i]+B[j]>=w[i,j]恒成立,令 A[i]为所有与顶点 Xi 关联的边 的最大权,B[j]=0。
如果当前的相等子图没有完备匹配,就按下面的方法修改 顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个 X 顶点,我们 找不到一条从它出发的交错路。
这时我们获得了一棵交错树,它的叶子结点 全部是 X 顶点。
现在我们把交错树中 X 顶点的顶标全都减小某个值 d,Y 顶 点的顶标全都增加同一个值 d,那么我们会发现:两端都在交错树中的边(i,j),A[i]+B[j]的值没有变化。
也就是说,它原来属于 相等子图,现在仍属于相等子图。
两端都不在交错树中的边(i,j),A[i]和 B[j]都没有变化。
也就是说,它原来属于 (或不属于)相等子图,现在仍属于(或不属于)相等子图。
X 端不在交错树中,Y 端在交错树中的边(i,j),它的 A[i]+B[j]的值有所增大。
二分图匹配算法及其应用【文献综述】

二分图匹配算法及其应用【文献综述】文献综述数学与应用数学二分图匹配算法及其应用图的匹配理论简单的说就是使得图G 中每两个点之间都有联系. 匹配理论是图论中的一个重要内容, 它在运筹学、系统工程中都有着广泛的应用, 近几十年来, 随着组合数学的迅速发展, 匹配理论成为许多重要理论的基础和源泉. 二分图的最大匹配算法是匹配理论研究的热点之一. KM 算法是求最大匹配的经典算法, 它是在匈牙利算法的进一步提高, 它是解决数学中一类存在性问题的基本工具, 广泛应用于社会、经济、科技、自然等各个领域中. 本文主要研究KM 算法的具体原理, 步骤, 以及它一些实际问题中的应用.图的匹配问题起源于1935年霍尔的“婚姻问题”. KM 算法是Kuhn 和Munkras 分别于1955年和1957年独立提出来的, 他们在研究图论中最大权匹配问题时很巧妙运用KM 算法去解决问题.定义1 图G 有三部分所组成(1) 非空集合)(G V , 称为G 的结点集, 其成员称为结点或顶点.(2) 集合)(G E , 称为G 的边集, 其成员称为边.(3) 函数))(),(()(:G V G V G E G →ψ,称为边和顶点的关联映射. 这里))(),((G V G V 称为)(G V 的偶对集, 其成员偶对形如),(v u , u ,v 为结点, 它们未必不同. 当),()(v u e G =ψ时, 称边e 关联端点u ,v . 当),(v u 用作序偶时)()())(),((G V G V G V G V ?=,e 称为有向边, e 以u 为起点, 以v 为终点, 图G 称为有向图; 当),(v u 用作无序偶对时, ),(),(u v v u =, 称e 为无向边(或边), 图G 称为无向图(或图). 定义2 无向图?ψ?=,,E V G 称为二分图, 如果有非空集合X ,Y 使V Y X =Y ,X Y =?I ,且对每一E e ∈, ),()(y x e =ψ, X x ∈,Y y ∈. 此时常用?ψ?,,E V 表示二分图G . 若对X 中任一x 及Y 中的任一y 恰有一边E e ∈, 使),()(y x e =ψ, 则称G 为完全二分图. 当m X =, n Y =时, 完全二分图G 记为n m K ,.定义3 图G 的顶点1v 到顶点l v 的拟路径是指如下顶点与边的序列:l l l v e v v e v e v ,,,,,,,1132211--Λ其中l l v v v v v ,,,,,1321-Λ为G 的顶点, 121,,,-l e e e Λ为G 的边, 且)1,,2,1(-=l i e i Λ以i v 及1+i v 为端点(对有向图G , i e 以i v 为起点, 以1+i v 为终点). 当)1,,2,1(-=l i e i Λ各不相同时, 该拟路径称为路径.定义4 若M 是二分图),(E V G =的一个匹配. 设从图G 中的一个顶点到另一个顶点存在一条路径, 这条路是由属于M 的边和不属于M 的边P 交替出现组成的, 则称这条路为增广路(或称交互树或交错树). 如果增广路的首尾两个顶点不属于M , 则称这条路为可增广路.定义 5 设?ψ?=,,E V G 为二分图, 当给G 赋予映射W V f →:或W E g →:, W 为任意集合、常用实数集及其子集, 此时G 为赋权图, 常用?ψ?f E V ,,,或?ψ?g E V ,,,或?ψ?g f E V ,,,,表示之. )(v f 称为结点v 的权, )(e g 称为e 的权.定义6 设??=Y E X G ,,为二分图, E M ?. 称M 为G 的一个匹配, 如果M 中任何两条边都没有公共端点. G 的所有匹配中边数最多的匹配称为最大匹配, 其边数称为匹配数. 如果X (Y )中任一顶点均为匹配M 中边的端点, 那么称M 为X (Y )—完全匹配. 若M 既是X —完全匹配又是Y —完全匹配, 则称M 为G 的完全匹配.定义7 设二分图??=Y E X G ,,, 其中X =Y =匹配数, E 中每条边),(j i Y X 有权0,≥j i W , 若能找到一个匹配M (M =匹配数), 满足所有匹配的边权和最大(或最小), 则称M 为G 的一个最大(或最小)权匹配.定义8 称图中顶点u 到v 是可达的, 如果v u =, 或者有一条u 到v 的路径. 如果G 的任何两个顶点都是互相可达的, 称无向图G 是连通的. 如果G '是G 的子图,G '是连通的, 并且不存在G 的真子图G '', 使G ''是连通的, 且G ''以G '为真子图, 则图G '称为图G 的连通分支.定理1(霍尔定理) 设图??=Y E X G ,,. G 有X —完全匹配的充分必要条件是: 对每一X S ?, 其中)(S N 为S 的邻域, 即Y S v ii v N S N ∈=)()(, 则有S S N ≥)(.定理2(Tutte 定理) 一个图G 有完全匹配当且仅当对图G 的任意顶点子集S 有图S G -的奇分支数不大于S 中的顶点数, 其中S G -表示从图G 中删去顶点集S 及其关联的边所得的图, 图的奇分支是指奇数个顶点的连通分支.定理3 若由二分图中所有满足j i j i W Y X ,=+的边(,)i j 构成的子图(称做相等子图)有完全匹配, 那么这个完全匹配就是二分图的最大权匹配.Kuhn -Munkras 算法(即KM 算法)流程(1) 初始化可行顶标的值;(2) 用匈牙利算法寻找完备匹配;(3) 若未找到完全匹配则修改可行顶标的值;(4) 重复(2)(3)直到找到相等子图的完全匹配为止.KM 算法是通过给每个顶点一个标号(我们有时称之为顶标)来把求最大权匹配的问题转化为不断地寻找增广路以使二分图的匹配数达到最大的完全匹配的问题. 我们令二分图中X 部的节点的顶标为i X . Y 部的节点的顶标为j Y . X 部与Y 部节点之间的权值为j i W ,. 要求在算法执行过程中的任一时刻,对于任一条边(,)i j , 使得j i j i W Y X ,≥+始终成立. 在初始时, 令i X 为所有与顶点i X 关联的边的权值的最大值, 令0=i Y . 如果当前的相等子图没有完全匹配, 就需要修改顶标以使扩大相等子图, 直到相等子图具有完全匹配为止(这样就可以求出最大权匹配).如果当前相等子图找不到完全匹配, 那么是因为对于某个X 顶点, 我们找不到一条从它出发的增广路. 这时为了获得了一条增广路, 现在我们把增广路中X 的顶点的顶标全都减小某个值d , Y 的顶点的顶标全都增加d , 就可以使得至少有一条新边进入相等子图. 那么我们会发现:(1) 两端都在增广路中的边(,)i j , j i Y X +的值没有变化. 也就是说, 它原来属于相等子图, 现在仍属于相等子图.(2) 两端都不在增广路中的边(,)i j , i X 和j Y 都没有变化. 也就是说, 它原来属于(或不属于)相等子图, 现在仍属于(或不属于)相等子图.(3) X 端不在增广路中, Y 端在增广路中的边(,)i j , 它的j i Y X +的值有所增大. 它原来不属于相等子图, 现在仍不属于相等子图.(4) X 端在增广路中, Y 端不在增广路中的边(,)i j , 它的j i Y X +的值有所减小. 也就说, 它原来不属于相等子图, 现在可能进入了相等子图, 因而使相等子图得到了扩大.现在的问题就是求d 值了. 为了使j i j i W Y X ,≥+始终成立, 且至少有一条边进入相等子图, 则}min{,j i j i W Y X d -+=, 而且i X 在增广路中, j Y 不在增广路中.刘桂真[1]对二分图最大权匹配开讨论, 介绍了二分图最大权匹配并将匹配问题从“婚姻问题”推广到工作分派问题.耿素云[2]通过对二分图的匹配及带权图的应用进行了讨论也将其运用到实际中, 并以此解决了最短路径的问题、关键路径问题以及中国邮递员问题.杨胜超、张瑞军[3]在介绍毕业论文选题系统的系统用例、功能模块、和流程图的基础上, 针对学生选题不均衡这一突出问题, 引出了二分图最大权匹配的经典算法—KM 算法, 该算法能够根据学生的题目预选、自命题、未定题等多种情况, 完成题目与学生的智能匹配, 使最终题目的整体满意度最高, 从而提高学生毕业论文选题质量. 该系统在武汉科技大学管理学院04级毕业论文选题中实施.谢政、程浩光[4]利用赋双权的二分图中求关于第一个权最大的限制下、第二个权最小的完美匹配的网络模型, 给出了这一模型的有效性, 并用此算法解决了企业的优化组合分工中的挖潜问题.彭宇新, Ngo Chong-Wah, 肖建国[5]利用尝试将二分图的最大权匹配用于镜头检索. 把两个镜头的相似度度量建模为一个带权的二分图: 镜头中的每一帧看成二分图的一个结点, 两个镜头之间任意帧的相似值作为边的权值. 在一一对应的前提下, 利用最大权匹配的KM 算法求出该二分图的最大权, 以此作为两个镜头的相似度. 考虑到检索的速度的问题, 提出了两个改进算法.对于二分图最大权匹配的算法有不少, 如: 顶点标记法等. 但KM 算法是求解二分图最大权匹配的经典算法. 本文主要研究用KM 算法解决二分图最大权匹配的步骤过程及二分图最大权匹配算法的应用. 特别是在解决工作分派问题上以及其他实际问题中的应用.。
匈牙利算法——精选推荐

二分图最优匹配:对于二分图的每条边都有一个权(非负),要求一种完备匹配方案,使得所有匹配边的权和最大,记做最优完备匹配。
(特殊的,当所有边的权为1时,就是最大完备匹配问题)解二分图最优匹配问题可用穷举的方法,但穷举的效率=n!,所以我们需要更加优秀的算法。
先说一个定理:设M是一个带权完全二分图G的一个完备匹配,给每个顶点一个可行顶标(第i个x顶点的可行标用lx[i]表示,第j个y顶点的可行标用ly[j]表示),如果对所有的边(i,j) in G,都有lx[i]+ly[j]>=w[i,j]成立(w[i,j]表示边的权),且对所有的边(i,j) in M,都有lx[i]+ly[j]=w[i,j]成立,则M是图G的一个最优匹配。
Kuhn-Munkras算法(即KM算法)流程:v(1)初始化可行顶标的值v(2)用匈牙利算法寻找完备匹配v(3)若未找到完备匹配则修改可行顶标的值v(4)重复(2)(3)直到找到相等子图的完备匹配为止KM算法主要就是控制怎样修改可行顶标的策略使得最终可以达到一个完美匹配,首先任意设置可行顶标(如每个X节点的可行顶标设为它出发的所有弧的最大权,Y节点的可行顶标设为0),然后在相等子图中寻找增广路,找到增广路就沿着增广路增广。
而如果没有找到增广路呢,那么就考虑所有现在在匈牙利树中的X节点(记为S集合),所有现在在匈牙利树中的Y节点(记为T 集合),考察所有一段在S集合,一段在not T集合中的弧,取delta = min {l(xi)+l(yj)-w(xi,yj) , | xi in S, yj in not T} 。
明显的,当我们把所有S集合中的l(xi)减少delta之后,一定会有至少一条属于(S, not T)的边进入相等子图,进而可以继续扩展匈牙利树,为了保证原来属于(S,T )的边不退出相等子图,把所有在T 集合中的点的可行顶标增加delta。
随后匈牙利树继续扩展,如果新加入匈牙利树的Y节点是未盖点,那么找到增广路,否则把该节点的对应的X匹配点加入匈牙利树继续尝试增广。
匹配问题及算法

265
95
290
350
453
190
340
202 98 176 196 230 128 196
101
49
88
98 115 64
98
4. 令圈0元素对应位置的Xij=1,其余元素为0,得 最优分配,对应位置处权和为最低消耗。
【匈牙利算法的Matlab实现】
见Word文档。三个文件 fc01.m fc02.m fc03.m
四、最优分配问题
最优分派问题是在人员分派问题中把工人对各 种工作的效率考虑进去,以便工人的总效率达 到最大,此问题称为最优分派问题。
2. 圈0元素。在C’中未被直线通过的含0元素最少 的行(列)中圈出0元素,通过这个0元素作一 条竖(或横)线。重复此步,若能圈出不同行 列的n个0元素,转4,否则转3
3. 调整耗费矩阵,在C’中没有被直线穿过的数集 D中,找出最小数d,D中所有数据都减去d, 相交处元素加d。新的耗费矩阵依旧记作D.
F(n)=(n-1)[f(n-1)+f(n-2)], F(2)=1
二、较大基数匹配算法
【算法思想】
1. 任意取得图中一边,将其存入匹配M中; 2. 从该图中将与匹配M中的每一条边相邻的边
删除;
3. 只到所剩子图全为孤立点,算法结束,否则 转1.
function J=matgraf(W) n=size(W,1); J=zeros(n,n); while sum(sum(W))~=0
进一步,若G中每个顶点都是M-饱和点,即匹 配M将G中所有顶点都匹配成功,则称M为G的完 美匹配;而若在图G中不存在另一个匹配M2,使得 |M2|>|M|,则称M为最大匹配,其中|M|称为G的匹 配数。
Kuhn-Munkres算法

Kuhn-Munkres算法(二分图最大权匹配)二分图最佳匹配(kuhn munkras 算法 O(m*m*n)).邻接矩阵形式。
返回最佳匹配值,传入二分图大小m,n邻接矩阵 mat ,表示权,match1,match2返回一个最佳匹配,为匹配顶点的match值为-1,一定注意m<=n,否则循环无法终止,最小权匹配可将全职取相反数。
初始化: for(i=0;i<MAXN;i++)for(j=0;j<MAXN;j++) mat[i][j]=-inf;对于存在的边:mat[i][j]=val;//注意不能负值********************************************************/#include<string.h>#define MAXN 310#define inf 1000000000 #define _clr(x) memset(x,-1,sizeof(int)*MAXN)int KM(int m,int n,int mat[][MAXN],int*match1,int *match2){int s[MAXN],t[MAXN],l1[MAXN],l2[MAXN];int p,q,i,j,k,ret=0;for(i=0;i<m;i++){l1[i]=-inf;for(j=0;j<n;j++)l1[i]=mat[i][j]>l1[i]?mat[i][j]:l1[i];if(l1[i]==-inf) return -1;}for(i=0;i<n;i++)l2[i]=0;_clr(match1);_clr(match2);for(i=0;i<m;i++){_clr(t);p=0;q=0;for(s[0]=i;p<=q&&match1[i]<0;p++){for(k=s[p],j=0;j<n&&match1[i]<0;j++){if(l1[k]+l2[j]==mat[k][j]&&t[j]<0){s[++q]=match2[j];t[j]=k;if(s[q]<0){for(p=j;p>=0;j=p){match2[j]=k=t[j];p=match1[k];match1[k]=j;}}}}}if(match1[i]<0){i--;p=inf;for(k=0;k<=q;k++){for(j=0;j<n;j++){if(t[j]<0&&l1[s[k]]+l2[j]-mat[s[k]][j]<p)p=l1[s[k]]+l2[j]-mat[s[k]][j];}}for(j=0;j<n;j++)l2[j]+=t[j]<0?0:p;for(k=0;k<=q;k++)l1[s[k]]-=p;}}for(i=0;i<m;i++)ret+=mat[i][match1[i]];return ret;}下面是从网上的博客摘抄的一些零散的总结。
数学建模y04研究生录取中的最佳匹配问题D题

3
D 题-张雄明,晏小波,褚瑞-一等奖
S
T
(1, 2)
1
1
(2, 2)
(1, 1)
2
2
图 2 一个不稳定匹配对的实例, 边上的权用二元组表示。 如(1, 2)表示,从左到右的权为 1,从右到左的权为 2
如图 2 所示,假设(S1, T1)、(S2, T2)为二部图最大权匹配的两条边,但 S1 对 T1 的满意 度为 1,S1 对 T2 的满意度为 2;而 T2 对 S1 的满意度为 2,T2 对 S2 的满意度为 1,这样,相 对于 T1, S1 更倾向于选 T2 做导师,T2 也更倾向于选 S1 做考生,这样的匹配对(S1, T1)和(S2, T2)就是一对不稳定匹配对。含有不稳定匹配对的匹配方案也称之为不稳定的。
导师 j 的学术水平有 4 个指标,其归一化值分别为 λ j,l (l = 1, 2, 3, 4) 。则导师 j 的学术
水平可表述为:
4
∑ bj = k11λ j,1 + k21λ j,2 + k31λ j,3 + k41λ j,4 ( kl1 = 1 , kl1 >0, l=1, 2, 3 ,4) l =1
sgn(
x)
=
⎧1,
⎨ ⎩
−
1,
x>0 x≤0
floor(x) :x 向下取整函数 ;
问题的分析
1. 将考生录取转化为二分图的匹配问题 本文需要解决的问题是在特定的约束条件下,导师和考生之间建立一种匹配关系(即:
考生被某个导师录取),使得导师和考生双方的总满意度最大。可以把导师集合 T 和考生集 合 S 看成某个二部图顶点集的两个子集,连接 S 与 T 的边表征了某考生对某导师可能的申 报关系,该边上的权表征了申报该导师使得该考生所能获取的满意度;连接 T 到 S 的边表 征了导师对考生可能的录取关系,其上的权表征了录取该考生使得该导师所能获取的满意 度。该二部图具有以下特点:
最优性条件(非线性规划)kuhn-tucker条件

ㄡ ▽h(ㄡ )
最优性条件即:
▽h(x*)
f ( x*) *h j ( x*) j
j 1
h
二、不等式约束问题的Kuhn-Tucker条件: 考虑问题 min f(x) (fg) s.t. gi(x) ≤0 i=1,2, …,m 设 x*∈S={x|gi(x) ≤0 i=1,2, …,m} 令 I={i| gi(x*) =0 i=1,2, …,m} 称I为 x*点处的起作用集(紧约束集)。 如果x*是l.opt. ,对每一个约束函数来说,只有当它是起作用约 束时,才产生影响,如:
二、不等式约束问题的Kuhn-Tucker条件: (续) 定理(最优性必要条件): (K-T条件) 问题(fg), 设S={x|gi(x) ≤0},x*∈S,I为x*点处的起作用集,设f, gi(x) ,i ∈I在x*点可微, gi(x) ,i I在x*点连续。 向量组{▽gi(x*), i ∈I}线性无关。 如果x*----l.opt. 那么, u*i≥0, i ∈I使
Байду номын сангаас
问题
min f(x) (fgh) s.t. g(x) ≤0 h(x)=0 约束集 S={x|g(x) ≤0 , h(x)=0}
一、等式约束问题的最优性条件: 考虑 min f(x) (fh) s.t. h(x)=0 回顾高等数学中所学的条件极值: 问题 求z=f(x,y)极值 min f(x,y) 即 在ф(x,y)=0的条件下。 S.t. ф(x,y)=0 引入Lagrange乘子:λ Lagrange函数 L(x,y;λ)= f(x,y)+ λ ф(x,y)
一、等式约束性问题的最优性条件: (续) 若(x*,y*)是条件极值,则存在λ* ,使 fx(x*,y*)+ λ* фx (x*,y*) =0 fy(x*,y*)+ λ* фy(x*,y*) =0 Ф (x*,y*)=0 推广到多元情况,可得到对于(fh)的情况: min f(x) 分量形式: s.t. hj(x)=0 j=1,2, …,l 若x*是(fh)的l.opt. ,则存在υ*∈ Rl使
二分图匹配匈牙利算法和KM算法简介

❖
end else
匈牙利算法
❖ begin
❖ j := queue[st];
❖
while true do
❖
begin
❖
t := match1[j];
❖
match1[j] := i;
❖
match2[i] := j;
❖
if t = 0 then break;
❖
i := t; j := father[t];
1 2
3 4
例题1 Place the Robots(ZOJ)
小结
比较前面的两个模型:模型一过于简单,没有给问 题的求解带来任何便利;模型二则充分抓住了问题的内 在联系,巧妙地建立了二部图模型。为什么会产生这种 截然不同的结果呢?其一是由于对问题分析的角度不同: 模型一以空地为点,模型二以空地为边;其二是由于对 原型中要素的选取有差异:模型一对要素的选取不充分, 模型二则保留了原型中“棋盘”这个重要的性质。由此 可见,对要素的选取,是图论建模中至关重要的一步。
例题3 打猎
❖ 猎人要在n*n的格子里打鸟,他可以在某一行 中打一枪,这样此行中的所有鸟都被打掉, 也可以在某一列中打,这样此列中的所有鸟 都打掉。问至少打几枪,才能打光所有的鸟?
❖ 建图:二分图的X部为每一行,Y部为每一列, 如果(i,j)有一只鸟,那么连接X部的i与Y部的j。
❖ 该二分图的最大匹配数则是最少要打的枪数。
匈牙利算法
❖ for i:=1 to n do
❖ if (father[i]=0)and(a[queue[st],i]=1) then
❖ begin
❖ if match2[i]<>0 then
❖
km(kuhn-munkres)算法的具体表达

km(kuhn-munkres)算法的具体表达KM算法,即Kuhn-Munkres算法(又称为匈牙利算法),是一种用于求解二分图最大权匹配问题的经典算法。
它由Eugene L. Lawler于1960年首次提出,后来由James Munkres在1957年独立发表,因此常称为Kuhn-Munkres算法。
二分图最大权匹配问题是指给定一个带权二分图,要求在图中选取权重之和最大的边集合,使得任意两条边不属于同一个顶点。
其中,带权二分图是指图的每条边都带有一个非负权重。
KM算法使用了两个关键的概念:交错树和相等子图。
交错树是指一个T=(S,P)的有向树,其中S是原二分图的所有顶点的集合,P是树中的边集合。
相等子图是指原二分图的一个子图,其中T中所有入树边的权重之和等于所有出树边的权重之和。
KM算法具体的步骤如下:1.初始化:将图中所有边的权重初始化为0,构建了一个初始的交错树T=(X,Y)(其中X,Y分别表示两个顶点集合)。
2.判断相等子图:对于T中的每个顶点x,如果存在一条满足lx+ly=W(其中lx是x在T中所有入树边的权重之和,ly是x在T中所有出树边的权重之和,W是x在原图G中的权重),则把x加入到相等子图中。
3.寻找未匹配节点:在相等子图中寻找未匹配节点,并标记为未父节点。
4.寻找增广路:如果存在未匹配节点,则从中选择一个起始节点,寻找一条与之交替出现的边构成的路径,使路径的最后一个边是一条与未匹配节点关联的边。
这样的路径称为增广路。
5.修改标号:对于相等子图中的每个顶点x,从已匹配节点中选择一个与之关联的顶点y,并计算d=min(lx+ly-w)(其中w是x和y之间的边的权重),为了使增广路更优,将T中所有x节点的入树边的权重减去d,将T中所有y节点的出树边的权重加上d。
6.更新交错树:将增广路中的所有边和T中的所有非树边进行调整,得到新的交错树。
7.重复步骤3-6,直到没有未匹配节点为止。
从匈牙利算法到Kuhn-Munkres算法

从匈⽛利算法到Kuhn-Munkres算法匈⽛利算法要解决的是这样的问题,⽐如⼀群男⽣⼥⽣,男⽣是否有缘可以跟⾃⼰喜欢的⼈在⼀起。
当然我们简化成集合符号A和B, A和B的⼤⼩可以不同,我们只想知道最后按照喜欢的⼈在⼀起的话,最多有⼏对。
匈⽛利算法从0开始构建匹配的可能性。
如果男⽣Ai喜欢⼥⽣Bj⽽且⼥⽣Bj未匹配,那么她当然可以跟男⽣Ai在⼀起了。
但是不要慌,后⾯的情况还可能变化,Ai可能Bj+1在⼀起,但是我们保证结果是每次都⽐原来的成功数要⼤的。
匈⽛利算法当然是解决图论的问题,这⾥不⽤A,B了——X和Y两个从X开始,每次找到⼀个未配对的点u抽象的说,是我们在X这边保存了已经访问过的点S,在Y这边类似有T,从u点开始S和T都不断增⼤,每次只增⼤1,增⼤的规则是u的邻接点y如果已经匹配z,就把y加到T,z加到S,下⼀步的操作,是换个u, 再将T中没有访问过的点再次考查⼀遍。
如果y没有匹配,那正好,根据你的访问规则,这个时候u和y肯定可以配对的,这样就可以增加配对了。
我们的⼯作是为了让配对的个数越来越多,直到最后不能再配对。
不能配对的判定就是Hall定理,S的邻接点刚好是T。
由于这个问题实在太过常见,以⾄于很多⼈还是像我10分钟前想的例⼦⼀样⽼掉⽛。
我们还是想个其他的抽象吧。
可能有⼈会希望说我们可以改成公司⾯试应聘者,多个公司跟多个应聘者匹配啊。
对哦,前提是你们不要拿了offer就跑掉了。
对了你有没有想到前⾯说的是男⽣喜欢⼥⽣?如果是这样的话说明什么?我们忽略了⽅向。
如果只有男⽣喜欢⼥⽣,那这个也是⼀厢情愿的,单向的连接的说。
那怎么解决呢? 好了另外⼀个例⼦,如果东南亚n国希望出⼝椰⼦岛中国各y省,但是⼀个省只能跟⼀国签约(现实中没有的)。
这个也是⼀种问题。
那好的,我们现在定个价格,让总的价格最⼤(喂喂喂),这不是对我们来说的,是对东南亚各国来说的。
这个就是可以抽象成Kuhn-Munkres算法了。
二分图及匹配算法

Chapter 3
二分图最佳匹配
-二分图最佳匹配-
定义:图G中权值和最大的完全匹配。
Kuhn-Munkras算法:该算法是通过给每个顶点一个标号(叫做顶标) 来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点Xi的顶标 为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。在算法 执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。 KM算法的正确性基于以下定理: 若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等 子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 KM算法流程: (1)初始化可行顶标的值; (2)用匈牙利算法寻找完备匹配; 这样做是O(n^4)的
-稳定婚姻问题-
Байду номын сангаас
求婚拒绝算法(Gale-Shapley算法/延迟认可算法): 先对所有男生进行单身标记,称其为单身狗男。当存在单身狗男时,进行 以下操作:
①选择一位单身狗男在所有尚未拒绝她的女生中选择一位被他排名最优先 的女神;
②女神将正在追求她的单身狗男与其现任进行比较,选择其中排名优先的 男生作为其男友,即若单身狗男优于现任,则现任被抛弃为前任;否则保 留其男友,拒绝单身狗男。 ③若某男生被其女友抛弃,则重新变成单身狗男,至①重复。
Chapter 5
稳定婚姻问题
-稳定婚姻问题-
你们班上有n位男生和n位女生,每个人对异性都有一个排序,表示对他们 的爱恋程度。现在你的任务是使他们凑成CP,使他们的爱情坚不可摧! 满足一下条件的爱情不是坚不可摧的: 男生u和女生v不是CP,但他们爱恋对方的程度都大于爱恋现任 的程度。 因为这样男生u和女生v会抛下已经是CP的那个她/他,另外组成一对。于 是乎多出了两位前任,这样就会让人再也无法相信爱情了! 怎么能避免悲剧的发生呢?
最优匹配(Kuhn_Munkras算法)

最优匹配(Kuhn_Munkras算法)最优匹配(Kuhn_Munkras算法)// ** Start of PerfectMatch *******************************// Name: PerfectMatch by Kuhn_Munkras O(n^3)// Description: w is the adjacency matrix, nx,ny are the size of x and y, // lx, ly are the lables of x and y, fx[i], fy[i] is used for marking// whether the i-th node is visited, matx[x] means x match matx[x],// maty[y] means y match maty[y], actually, matx[x] is useless, // all the arrays are start at 1int nx,ny,w[MAXN][MAXN],lx[MAXN],ly[MAXN];int fx[MAXN],fy[MAXN],matx[MAXN],maty[MAXN];int path(int u){int v;fx[u]=1;for(v=1;v<=ny;v++)if((lx[u]+ly[v]==w[u][v])&&(fy[v]<0)) {fy[v]=1;if((maty[v]<0)||(path(maty[v]))) {matx[u]=v;maty[v]=u;return(1);} // end of if((maty[v]...} // end of if((lx[u]...return(0);} // end of int path()int PerfectMatch(){int ret=0,i,j,k,p;memset(ly,0,sizeof(ly));for(i=1;i<=nx;i++) {lx[i]=-INF;for(j=1;j<=ny;j++)if(w[i][j]>lx[i])lx[i]=w[i][j];} // end of for(i...memset(matx,-1,sizeof(matx));memset(maty,-1,sizeof(maty));for(i=1;i<=nx;i++) {memset(fx,-1,sizeof(fx));memset(fy,-1,sizeof(fy));if(!path(i)) {i--;p=INF;for(k=1;k<=nx;k++)if(fx[k]>0)for(j=1;j<=ny;j++)if((fy[j]<0)&&(lx[k]+ly[j]-w[k][j]<p))< p="">p=lx[k]+ly[j]-w[k][j];for(j=1;j<=ny;j++) ly[j]+=(fy[j]<0?0:p);for(k=1;k<=nx;k++) lx[k]-=(fx[k]<0?0:p);} // end of if(!path(i))} // end of for(i...for(i=1;i<=ny;i++) ret+=w[maty[i]][i];return ret;} // end of int PerfectMatch()// ** End of PerfectMatch *********************************</p))<>。
二分图最佳匹配,求最大权匹配或最小权匹配

⼆分图最佳匹配,求最⼤权匹配或最⼩权匹配Beloved Sons题意:国王有N个⼉⼦,现在每个⼉⼦结婚都能够获得⼀定的喜悦值,王⼦编号为1-N,有N个⼥孩的编号同样为1-N,每个王⼦⼼中都有⼼仪的⼥孩,现在问如果安排,能够使得题中给定的式⼦和最⼤。
分析:其实题⽬中那个开根号是个烟雾弹,只要关⼼喜悦值的平⽅即可。
那么对王⼦和⼥孩之间构边,边权为喜悦值的平⽅,对于每⼀个王⼦虚拟出⼀个⼥孩边权为0,这样是为了所有的王⼦都能够有⼥孩可以配对,以便算法能够正确的执⾏。
求⼆分图最佳匹配,要求权值最⼤,lmatch返回⼀个最佳匹配。
1 #include<cstdio>2 #include<cstring>3#define mt(a,b) memset(a,b,sizeof(a))4const int inf=0x3f3f3f3f;5class Kuhn_Munkras { ///⼆分图最佳匹配O(ln*ln*rn)邻接阵6 typedef int typec;///边权的类型7static const int MV=1024;///点的个数8int ln,rn,s[MV],t[MV],ll[MV],rr[MV],p,q,i,j,k;9 typec mat[MV][MV];10public:11int lmatch[MV],rmatch[MV];12void init(int tln,int trn) { ///传⼊ln左部点数,rn右部点数,要求ln<=rn,下标0开始13 ln=tln;14 rn=trn;15for(i=0; i<ln; i++)16for(j=0; j<rn; j++)17 mat[i][j]=-inf;18 }19void add(int u,int v,typec w) {///最⼩权匹配可将权值取相反数20 mat[u][v]=w;21 }22 typec solve() {///返回最佳匹配值,-1表⽰⽆法匹配23 typec ret=0;24for (i=0; i<ln; i++) {25for (ll[i]=-inf,j=0; j<rn; j++)26 ll[i]=mat[i][j]>ll[i]?mat[i][j]:ll[i];27if( ll[i] == -inf ) return -1;// ⽆法匹配!28 }29for (i=0; i<rn; rr[i++]=0);30 mt(lmatch,-1);31 mt(rmatch,-1);32for (i=0; i<ln; i++) {33 mt(t,-1);34for (s[p=q=0]=i; p<=q&&lmatch[i]<0; p++)35for (k=s[p],j=0; j<rn&&lmatch[i]<0; j++)36if (ll[k]+rr[j]==mat[k][j]&&t[j]<0) {37 s[++q]=rmatch[j],t[j]=k;38if (s[q]<0)39for (p=j; p>=0; j=p)40 rmatch[j]=k=t[j],p=lmatch[k],lmatch[k]=j;41 }42if (lmatch[i]<0) {43for (i--,p=inf,k=0; k<=q; k++)44for (j=0; j<rn; j++)45if(t[j]<0&&ll[s[k]]+rr[j]-mat[s[k]][j]<p)46 p=ll[s[k]]+rr[j]-mat[s[k]][j];47for (j=0; j<rn; rr[j]+=t[j]<0?0:p,j++);48for (k=0; k<=q; ll[s[k++]]-=p);49 }50 }51for (i=0; i<ln; i++) {52if( lmatch[i] < 0 ) return -1;53if( mat[i][lmatch[i]] <= -inf ) return -1;54 ret+=mat[i][lmatch[i]];55 }56return ret;57 }58 } gx;59int a[512];60int main() {61int t,n,m;62while(~scanf("%d",&t)) {63while(t--) {64 scanf("%d",&n);65for(int i=0; i<n; i++) {66 scanf("%d",&a[i]);67 a[i]*=a[i];68 }69 gx.init(n,n<<1);70for(int i=0,j; i<n; i++) { 71 scanf("%d",&m);72while(m--) {73 scanf("%d",&j);74 gx.add(i,j-1,a[i]);75 }76 gx.add(i,i+n,0);77 }78int flag=gx.solve();79for(int i=0; i<n; i++) {80int ans=0;81if(gx.lmatch[i]<n) {82 ans=gx.lmatch[i]+1;83 }84 printf("%d ",ans);85 }86 puts("");87 }88 }89return0;90 }View Codeend。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
最优匹配(Kuhn_Munkras算法)
//**Start of PerfectMatch*******************************
//Name:PerfectMatch by Kuhn_Munkras O(n^3)
//Description:w is the adjacency matrix,nx,ny are the size of x and y, //lx,ly are the lables of x and y,fx[i],fy[i]is used for marking
//whether the i-th node is visited,matx[x]means x match matx[x], //maty[y]means y match maty[y],actually,matx[x]is useless,
//all the arrays are start at1
int nx,ny,w[MAXN][MAXN],lx[MAXN],ly[MAXN];
int fx[MAXN],fy[MAXN],matx[MAXN],maty[MAXN];
int path(int u)
{
int v;
fx[u]=1;
for(v=1;v<=ny;v++)
if((lx[u]+ly[v]==w[u][v])&&(fy[v]<0)){
fy[v]=1;
if((maty[v]<0)||(path(maty[v]))){
matx[u]=v;
maty[v]=u;
return(1);
}//end of if((maty[v]...
}//end of if((lx[u]...
return(0);
}//end of int path()
int PerfectMatch()
{
int ret=0,i,j,k,p;
memset(ly,0,sizeof(ly));
for(i=1;i<=nx;i++){
lx[i]=-INF;
for(j=1;j<=ny;j++)
if(w[i][j]>lx[i])
lx[i]=w[i][j];
}//end of for(i...
memset(matx,-1,sizeof(matx));
memset(maty,-1,sizeof(maty));
for(i=1;i<=nx;i++){
memset(fx,-1,sizeof(fx));
memset(fy,-1,sizeof(fy));
if(!path(i)){
i--;
p=INF;
for(k=1;k<=nx;k++)
if(fx[k]>0)
for(j=1;j<=ny;j++)
if((fy[j]<0)&&(lx[k]+ly[j]-w[k][j]<p))
p=lx[k]+ly[j]-w[k][j];
for(j=1;j<=ny;j++)ly[j]+=(fy[j]<0?0:p);
for(k=1;k<=nx;k++)lx[k]-=(fx[k]<0?0:p);
}//end of if(!path(i))
}//end of for(i...
for(i=1;i<=ny;i++)ret+=w[maty[i]][i];
return ret;
}//end of int PerfectMatch()
//**End of PerfectMatch*********************************。