一种基于并行计算熵迁移策略的多分辨DOM数据生成算法
一种基于条件熵的决策表属性约简算法

ce y. inc
Ke wo d y rs
De i o a l A t b ts r d c in C n i o a n r p cs n t b e i t u e e u t o d t n le to y i r o i
0 引 言
知识库 中的知识 ( 属性 ) 并不是 同等重要 的 , 中某些 知识 其 是冗余 的, 这不利于有 效地作 出正确 简 洁的决 策。所谓 属性 约 简 , 是在保持知识库分类 能力不变的条件下 , 就 删除其 中不相关
Ab ta t sr c T i p p rpo oe n ag r h o tiue e u t no e iintbeb sdo o dt n le t p ntebsso l s e- hs a e rp ssa lo tm fat b tsrd ci fd cso a l ae nc n io a nr yo ai f a i a i r o i o h cs f i
( ,)∈ , bEB }显然 ID B 是一个等价关 系。 ] 表 xY V 。 N () [ 。 示包含元素 的 ID )的 等价类 。 N ( 定 义 3 决策表 DT对于每个 子集 U和不 可分辨关 系 B 的下近似集可 以定义为 : , B X)= { I ∈ U A [ X} ( ] () 1
信息 函数 ( 没 有 缺省值 时 , ) 称决 策 表是 完备 的 , 否则 是 不 完备 的 ; 一个决 策表 的决 策属性是 唯一的 , 若 称为单 一决策表 ; 若是不 唯一 的 , 称为 多决策表 。而对 于具有 多个决策 属性 的决
相对熵最小化算法-概念解析以及定义

相对熵最小化算法-概述说明以及解释1.引言1.1 概述概述部分的内容应该介绍相对熵最小化算法的背景和基本概念。
以下是一个可能的编写示例:引言相对熵最小化算法是一种在信息论中使用的重要方法。
在许多实际问题中,尤其是在模式识别、机器学习和数据压缩等领域,我们需要评估两个概率分布之间的相似性。
而相对熵最小化算法提供了一种有效的方式来度量这种相似性。
在本文中,我们将详细探讨相对熵最小化算法的原理、应用和优势,并对未来的研究进行展望。
文章结构本文主要分为引言、正文和结论三个部分。
在引言部分,我们将首先对相对熵最小化算法进行简要的概述,介绍其在信息论中的重要性和应用领域。
然后我们将给出文章的目的和结构。
在正文部分,我们将详细介绍相对熵的概念,包括其定义和基本性质。
随后,我们将解释相对熵最小化算法的原理,并提供一些实例来说明其应用。
在结论部分,我们将总结相对熵最小化算法的优势,并对未来相关研究的发展进行展望。
最后,我们将给出本文的结论。
目的本文的目的在于全面介绍相对熵最小化算法,深入探讨其原理和应用,并展望未来相关研究的方向。
通过本文的阅读,读者将能够更好地理解和应用相对熵最小化算法。
总结相对熵最小化算法是一种在信息论中使用的重要方法,用于度量两个概率分布之间的相似性。
本文将详细介绍其概念、原理和应用,并探讨其优势和未来的研究方向。
通过对相对熵最小化算法的深入理解,我们可以更好地应用于实际问题中,并推动相关研究的发展。
1.2文章结构文章结构部分的内容可以包括以下方面的描述:在本文中,我们将按照以下结构组织内容,以便读者更好地理解相对熵最小化算法的原理、应用以及其在未来的研究方向。
本文包括以下几个主要部分:第一部分是引言,其中将概述相对熵最小化算法的背景和重要性,以及本文的目的和总结。
第二部分是正文,我们将详细介绍相对熵的概念,包括其定义、特点和在信息论中的应用。
然后,我们将阐述相对熵最小化算法的原理,包括其数学表达式和求解方法。
智能视觉工程基础知识单选题100道及答案解析

智能视觉工程基础知识单选题100道及答案解析1. 智能视觉工程中,图像的分辨率主要取决于()A. 像素数量B. 颜色深度C. 图像格式D. 压缩比答案:A解析:图像分辨率是指图像中像素的数量,像素数量越多,分辨率越高。
2. 以下哪种图像格式常用于智能视觉中的深度学习模型训练()A. JPEGB. PNGC. BMPD. TIFF答案:B解析:PNG 格式支持无损压缩,保留更多图像细节,常用于深度学习模型训练。
3. 在智能视觉中,边缘检测常用的算法是()A. 中值滤波B. 均值滤波C. Sobel 算子D. 高斯滤波答案:C解析:Sobel 算子是一种常用的边缘检测算法。
4. 智能视觉系统中,用于消除图像噪声的方法是()A. 直方图均衡化B. 图像锐化C. 图像平滑D. 图像分割答案:C解析:图像平滑可以消除噪声。
5. 以下哪个不是智能视觉中的目标检测算法()A. R-CNNB. YOLOC. K-MeansD. SSD答案:C解析:K-Means 是聚类算法,不是目标检测算法。
6. 智能视觉工程中,图像的灰度级通常用()表示A. 二进制B. 十进制C. 十六进制D. 八进制答案:A解析:图像灰度级常用二进制表示。
7. 对于智能视觉中的图像分类任务,常用的损失函数是()A. 均方误差B. 交叉熵C. 绝对值误差D. 对数损失答案:B解析:交叉熵常用于图像分类任务的损失计算。
8. 智能视觉系统中的特征提取方法不包括()A. SIFTB. HOGC. LBPD. DCT答案:D解析:DCT 主要用于图像压缩,不是特征提取方法。
9. 以下哪种深度学习框架在智能视觉中应用广泛()A. TensorFlowB. Scikit-learnC. OpenCVD. Matplotlib答案:A解析:TensorFlow 是广泛应用于深度学习,包括智能视觉的框架。
10. 智能视觉中,用于图像增强的直方图操作是()A. 直方图规定化B. 直方图拉伸C. 直方图均衡D. 以上都是答案:D解析:直方图规定化、拉伸、均衡都可用于图像增强。
【计算机研究与发展】_整合_期刊发文热词逐年推荐_20140727
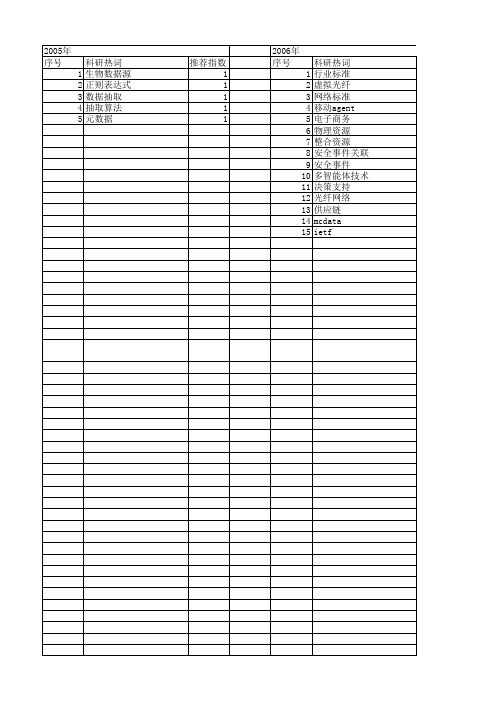
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
科研热词 频繁项目集 预测分析 重排 运动补偿 软数据 磁盘存储 硬数据 数据挖掘 插值 并行化 带宽优化 子任务 多核系统 同步 协同序贯高斯模拟 分布式文件系统 关联规则 个性监测 sdram markov模型 h.264/avc fp-tree fp-growth算法 dtrfp-growth算法 2dcache
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2007年 序号 1 2 3 4 5 6 7
科研热词 迭代优化 聚类 网格 结构鲁棒性 有效性 数据管理服务 chinagrid
推荐指数 1 1 1 1 1 1 1
2008年 序号 1 2 3 4 5
2008年 科研热词 最大熵模型 局部特征 命名实体识别 启发式知识 全局特征 推荐指数 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12
科研热词 重构 重复记录 编辑距离 管理策略 生产系统 深层网 无线网络 搜索算法 家庭网络 备份系统 便携式存储 个人存储
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
高性能计算中的并行计算模型与算法

高性能计算中的并行计算模型与算法前言在当今信息时代,高性能计算已经成为各个领域研究与应用的重要工具。
而在高性能计算中,实现并行计算是提高计算效率的重要手段之一。
本文将探讨高性能计算中的并行计算模型与算法,以期对该领域的研究与应用有一定的了解与启发。
一、并行计算模型1.1 SPMD模型(Single Program Multiple Data)SPMD模型是一种常用的并行计算模型,它将计算任务划分为多个子任务,每个子任务独立执行相同的程序代码,但操作不同的数据。
这种模型适用于问题的规模较大,而且子任务之间不需要进行过多的通信与同步的场景。
1.2 SIMD模型(Single Instruction Multiple Data)SIMD模型是一种特殊的并行计算模型,它同样将计算任务划分为多个子任务,但是每个子任务执行的是相同的指令,且操作相同的数据。
这种模型适用于需要大量重复计算的场景,如图像处理和视频编码等。
1.3 MIMD模型(Multiple Instruction Multiple Data)MIMD模型是一种更加灵活的并行计算模型,它将计算任务划分为多个子任务,每个子任务可以执行不同的指令,操作不同的数据。
这种模型适用于需要更细粒度的任务划分和复杂的并行计算场景,如科学计算和大规模数据分析等。
二、并行计算算法2.1 分而治之算法分而治之算法(Divide and Conquer)是一种常用的并行计算算法。
它将原始问题划分为多个子问题,并通过递归地解决子问题来得到最终的结果。
在并行计算中,每个子问题可以由一个独立的处理器来处理,从而加快问题的求解速度。
2.2 并行排序算法并行排序算法是一类重要的并行计算算法,它通过将原始数据划分为多个子集,每个子集在独立的处理器上进行排序,最后通过合并操作来得到全局有序的结果。
这种算法适用于需要对大规模数据进行排序的场景,如数据挖掘和搜索引擎等。
2.3 并行搜索算法并行搜索算法是一种解决搜索问题的并行计算算法。
混合专家模型 (MoE) 详解

混合专家模型 (MoE) 详解随着 Mixtral 8x7B (announcement, model card) 的推出,一种称为混合专家模型 (Mixed Expert Models,简称 MoEs) 的 Transformer 模型在开源人工智能社区引起了广泛关注。
在本篇博文中,我们将深入探讨MoEs 的核心组件、训练方法,以及在推理过程中需要考量的各种因素。
简短总结混合专家模型 (MoEs):●与稠密模型相比,预训练速度更快●与具有相同参数数量的模型相比,具有更快的推理速度●需要大量显存,因为所有专家系统都需要加载到内存中●在微调方面存在诸多挑战,但近期的研究表明,对混合专家模型进行指令调优具有很大的潜力。
什么是混合专家模型?模型规模是提升模型性能的关键因素之一。
在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
混合专家模型(MoE) 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。
这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。
特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
那么,究竟什么是一个混合专家模型(MoE) 呢?作为一种基于Transformer 架构的模型,混合专家模型主要由两个关键部分组成:●稀疏MoE 层: 这些层代替了传统Transformer 模型中的前馈网络(FFN) 层。
MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。
在实际应用中,这些专家通常是前馈网络(FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
●门控网络或路由: 这个部分用于决定哪些令牌(token) 被发送到哪个专家。
例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。
高空间分辨率遥感影像多尺度分割优化组合算法

高空间分辨率遥感影像多尺度分割优化组合算法许飞;曹鑫;陈学泓;崔喜红【摘要】高空间分辨率遥感影像能够充分地描述地表覆盖空间异质性,可用于提取地面目标物.然而高空间分辨率在像元尺度的目标提取时易产生“椒盐效应”问题,面向对象的小尺度影像分割也受此效应影响;而大尺度的影像分割造成较小目标的遗漏.本文提出了一种针对高空间分辨率遥感影像的多尺度分割优化组合算法MOCA (Multi-scale-segmentation Optimal Composition Algorithm),基于后验概率信息熵指标选择影像中每个地面目标的最优分割尺度并集成组合,获得高空间分辨率遥感影像的多尺度分割优化组合结果.本文使用F指标和BCI (Bidirectional Consistency Index)两种指标评估地面目标物提取精度,并将MOCA与同类多尺度分割方法进行比较.实验结果表明,本文提出的MOCA算法可实现多个分割尺度的最优组合,并获得较高的地面目标物提取精度.%High spatial resolution remote sensing imagery can fully delineate the heterogeneity of land covers and has been widely used for extracting surfaceobjects.However,pixel-based object extraction from high spatial resolution images may bring in'salt-and-pepper effect',and this effect also occurs when segmentation scale is small using object based analysis.Choosing a big segmentation scale will omit small surface objects.In this research,a Multi-scalesegmentation Optimal Composition Algorithm (MOCA) for object-based extraction with high spatial resolution imagery are proposed.MOCA selects optimal segmentation scale for each surface object based on entropy of posterior probabilities of land covers,and combines different scales to produce the suitable scales composition.F-measure and Bidirectional Consistency Index (BCI) are used to evaluate the accuracy of surface object extraction and compared with the existing multi-scale-segmentation method.Results show that MOCA can achieve the optimal composition of multiple scales and obtain a high accuracy of object extraction.【期刊名称】《地理信息世界》【年(卷),期】2017(024)003【总页数】5页(P1-5)【关键词】高空间分辨率;面向对象;多尺度分割;后验概率;信息熵【作者】许飞;曹鑫;陈学泓;崔喜红【作者单位】北京师范大学地表过程与资源生态国家重点实验室,北京100875;北京师范大学地表过程与资源生态国家重点实验室,北京100875;北京师范大学地理科学学部遥感科学与工程研究院,北京100875;北京师范大学地表过程与资源生态国家重点实验室,北京100875;北京师范大学地理科学学部遥感科学与工程研究院,北京100875;北京师范大学地表过程与资源生态国家重点实验室,北京100875;北京师范大学地理科学学部遥感科学与工程研究院,北京100875【正文语种】中文【中图分类】P2370 引言高空间分辨率遥感影像提高了遥感技术监测地面信息的精细程度,被广泛应用于城市规划、土地资源调查等领域。
深度学习及其应用_复旦大学中国大学mooc课后章节答案期末考试题库2023年

深度学习及其应用_复旦大学中国大学mooc课后章节答案期末考试题库2023年1.GAN中的Mode Collapse问题是指什么?答案:生成器只生成少数几种样本2.有关循环神经网络(RNN)变种的说法哪些是正确的?答案:RNN的变种增加了网络的复杂性,训练过程难度一般会大一些。
_RNN的变种可以在某些方面改进RNN的不足,例如减少梯度消失、输入句子词汇上文文语义获取等_这些RNN的变种结构都有一定的调整,但大多都可以处理时序数据的分类或预测问题。
3.以下说法错误的有哪些?答案:类似VGG、GoogLeNet等网络,AlexNet采用了卷积块的结构。
_为了获得不同尺度的特征,GoogLeNet采用了1X1,3X3,7X7等不同尺度的卷积核。
_ResNet卷积神经网络使用了批量标准化(BN)增加了网络的训练稳定性,并像VGG算法利用了skip链接减少信息的损失。
4.循环神经网络一般可以有效处理以下哪些序列数据?答案:随时间变化的数值型参数_声音_文本数据5.循环神经网络的损失函数是所有时刻的输出误差之和。
答案:正确6.长短期记忆网络(LSTM)通过遗忘门减少一般循环神经网络(RNN)的短期记忆不足,但增加算法的计算复杂度。
答案:正确7.循环神经网络的深度是由RNN cell的时刻数量,或者是隐层的数量确定的,2种说法都有一定的道理。
答案:正确8.循环神经网络(RNN)每一个时间步之间的迁移中使用了共享参数(权重等),与前馈神经网络比较更不容易引起梯度消失问题答案:错误9.以下有关生成对抗网络的说法哪个是错误的?答案:生成器和判别器的代价函数在训练过程中是同时优化的10.有关生成对抗网络(GAN)的代价函数,下面哪个说法是错误的?答案:一般来说,GAN通过训练总能达到代价函数的极小值11.在目标检测算法中,IoU(Intersection over Union)主要用于?答案:度量检测框和真实框的重叠程度12.下面哪种情况可能不能使用生成对抗网络实现?答案:机器人取名字13.对于生成对抗网络(GAN)的训练,下面哪个说法是正确的?答案:如果判别器发生了过拟合,那么生成器可能会生成一起很奇怪的样本14.在DCGAN中,判别器的激活函数可以使用Leaky ReLU,而不采用Sigmoid的原因是以下哪个?答案:防止判别器在训练过程中发生梯度消失,降低鉴别器的能力15.有关生成器和判别器的代价函数,以下哪个说法是错误的?答案:通过一同调整生成器和判别器的权重等参数,达到两者总的代价函数平衡16.有关生成器和判别器的交叉熵代价函数,以下哪个说法是错误的?答案:当训练生成器时,希望判别器的输出越逼近0越好17.有关获得较高质量生成样本的隐向量z的说法,下面说法错误的是哪个?答案:可以随机取值18.与卷积神经网络不同,循环神经网络因为固有的时序性,很难在GPU上做并行训练。
迁移学习10大经典算法

迁移学习10大经典算法在机器研究领域中,迁移研究是一种利用已学到的知识来解决新问题的方法。
迁移研究算法可以帮助我们将一个或多个已经训练好的模型的知识迁移到新的任务上,从而加快研究过程并提高性能。
以下是迁移研究领域中的10大经典算法:1. 预训练模型方法(Pre-trained models):通过在大规模数据集上进行预训练,然后将模型迁移到新任务上进行微调。
2. 领域自适应方法(Domain adaptation):通过将源领域的知识应用到目标领域上,解决领域差异导致的问题。
3. 迁移特征选择方法(Transfer feature selection):选择和目标任务相关的有效特征,减少特征维度,提高模型性能。
4. 迁移度量研究方法(Transfer metric learning):通过研究一个度量空间,使得源领域和目标领域之间的距离保持一致,从而实现知识迁移。
5. 多任务研究方法(Multi-task learning):通过同时研究多个相关任务的知识,提高模型的泛化能力。
6. 迁移深度卷积神经网络方法(Transfer deep convolutional neural networks):使用深度卷积神经网络进行特征提取,并迁移到新任务上进行训练。
7. 迁移增强研究方法(Transfer reinforcement learning):将已有的增强研究知识应用到新任务上,优化智能体的决策策略。
8. 迁移聚类方法(Transfer clustering):通过将已有的聚类信息应用到新数据上,实现对未标记数据的聚类。
9. 迁移样本选择方法(Transfer sample selection):通过选择源领域样本和目标领域样本的子集,减少迁移研究中的负迁移影响。
10. 迁移异构研究方法(Transfer heterogeneous learning):处理源领域和目标领域数据类型不一致的问题,例如将文本数据和图像数据进行迁移研究。
基于信息熵的特征选择算法研究

基于信息熵的特征选择算法研究在机器学习和数据挖掘领域,特征选择是极其重要的一个环节。
通过去除冗余和无关的特征,特征选择可以帮助提高模型的性能和效率。
基于信息熵的特征选择算法是一种常见的特征选择方法,其基本思想是通过计算每个特征的信息熵来评估其重要性。
信息熵的概念源于信息论,它用于度量一个随机变量的不确定性。
在特征选择中,信息熵可以用于衡量一个特征对于分类或预测任务的贡献程度。
具体来说,信息熵低的特征意味着该特征对于分类或预测任务更有价值,因为这些特征能够提供更多的确定性。
基于信息熵的特征选择算法主要有两种:基于互信息的特征选择算法和基于单变量特征选择算法。
互信息是一种非线性的信息度量方法,它可以用于衡量两个随机变量之间的相关性。
在特征选择中,基于互信息的特征选择算法通过计算每个特征与目标变量之间的互信息来评估特征的重要性。
具体来说,互信息大的特征意味着该特征与目标变量有较强的相关性,因此对于分类或预测任务更有价值。
对于每个特征,计算其与目标变量之间的互信息。
单变量特征选择算法是一种更为简单的特征选择方法,它主要用于去除冗余和无关的特征。
该方法通过计算每个特征的信息熵来评估其重要性,并只选择信息熵低的特征。
可以使用一些启发式方法(如递归)进一步优化选择的特征。
需要注意的是,基于单变量特征选择算法虽然简单,但是它只能考虑每个特征单独的信息熵,而无法考虑特征之间的相关性。
因此,在某些情况下,它可能会漏选一些对于分类或预测任务有用的特征。
基于信息熵的特征选择算法是一种有效的特征选择方法,它通过计算每个特征的信息熵来评估其重要性。
基于互信息的特征选择算法可以用于衡量特征与目标变量之间的相关性,而基于单变量特征选择算法则主要用于去除冗余和无关的特征。
在实际应用中,可以根据具体的需求和场景选择合适的算法来进行特征选择。
随着大数据时代的到来,数据挖掘技术在众多领域得到了广泛应用。
特征加权与特征选择作为数据挖掘算法的关键步骤,对于挖掘出数据中的隐含信息和提高算法性能具有重要意义。
基于深度学习模型的芯片迁移算法研究

基于深度学习模型的芯片迁移算法研究引言在现今数字化时代,计算机科技应用广泛,人工智能技术应用日益突出。
随着芯片制造技术不断革新,芯片的性能不断提升,由于芯片性能提升,导致一些设备的芯片需要更新迭代。
芯片迁移算法有着广泛的研究和应用价值,能够对芯片设计和制造提供帮助。
正文一、芯片迁移算法介绍芯片迁移算法是指将设计好的芯片在不同芯片制造技术下转换为能够被制造的芯片。
芯片迁移算法的研究和实践应用可以提高芯片的设计和制造效率。
芯片迁移算法的主要目的是通过更高效的算法设计,在保障芯片质量前提下提高芯片设计和制造效率。
同时,芯片迁移算法也是为了在芯片制造过程中发现设计问题并完成芯片纠错和优化的。
二、芯片迁移算法实现芯片迁移算法有很多方法可以实现,其中最为广泛的应用方法是深度学习算法。
1. 深度学习算法深度学习算法是一种基于多层神经网络的机器学习算法,可以通过多层非线性变换完成高复杂度模式识别。
深度学习算法在芯片设计过程中的应用可以优化芯片设计效果,提高芯片制造的一致性和可靠性。
深度学习算法在芯片迁移算法中的具体应用包括以下步骤:(1)芯片数据预处理:芯片中所有的电路都需要被编码成数字信号。
(2)深度学习模型训练:通过深度神经网络训练模型,根据数据集学习其中的结构和特征。
(3)特征选择和预处理:选择深度学习模型最优特征进行预处理。
(4)迁移学习:通过对深度学习模型进行预测和分类等任务,获取更好的芯片数据,实现芯片设计的迁移。
2. 其他算法除了深度学习算法,还有其他方法可以实现芯片迁移算法,如核函数算法、迁移学习和决策树等算法。
其中,迁移学习算法可以通过在已有的数据集上进行学习来解决新数据集的问题,并将新学习的知识应用在干扰或缺失情况下的设计中。
决策树算法则可以通过将芯片设计分为多个子问题,使用树形结构来解决复杂的芯片设计问题。
三、芯片迁移算法应用芯片迁移算法可以应用于芯片设计和芯片制造过程中的各个领域。
1. 芯片设计芯片设计是实现芯片定制化的关键步骤。
基于注意力掩码与特征提取的人脸伪造主动防御

基于注意力掩码与特征提取的人脸伪造主动防御1. 内容综述随着社交媒体和在线平台的普及,人脸伪造技术逐渐成为一种严重的安全威胁。
这种技术利用深度学习算法对人脸图像进行篡改,以达到欺骗、欺诈或其他恶意目的。
为了应对这一挑战,研究人员提出了许多基于注意力掩码与特征提取的人脸伪造主动防御方法。
这些方法旨在通过检测和阻止人脸伪造攻击,保护用户隐私和数据安全。
1.1 研究背景在当今信息化社会中,人脸伪造技术日益成熟,给个人隐私保护和信息安全带来了巨大挑战。
随着深度学习技术的快速发展,基于注意力掩码与特征提取的人脸伪造主动防御方法应运而生。
这种方法通过在人脸伪造过程中引入注意力机制和特征提取技术,有效地提高了对人脸伪造行为的识别和防御能力。
传统的人脸伪造检测方法主要依赖于人工设计的特征提取器和分类器,这些方法在面对复杂的人脸伪造场景时,往往表现出较低的准确性和鲁棒性。
而基于注意力掩码与特征提取的人脸伪造主动防御方法则能够自动地从原始图像中提取关键信息,同时忽略无关的信息,从而提高对人脸伪造行为的识别准确率。
研究者们已经在这一领域取得了一系列重要成果,一些研究成果表明,利用注意力机制可以有效地识别出人脸伪造样本中的微小变化;另外,结合深度学习和卷积神经网络(CNN)等先进技术,可以实现对人脸伪造行为的高效、准确识别。
尽管目前的研究取得了一定的进展,但仍然面临着许多挑战。
如何进一步提高模型的泛化能力和鲁棒性,以及如何在实际应用中实现对大规模数据的有效处理等问题尚待进一步研究。
本研究旨在探讨基于注意力掩码与特征提取的人脸伪造主动防御方法,以期为解决这一问题提供新的思路和技术支持。
1.2 研究意义随着互联网的普及和社交媒体的发展,人脸伪造技术逐渐成为了一种新型的攻击手段。
这种攻击手段可以通过伪造他人的人脸图像来达到欺骗、敲诈等目的,给个人隐私和信息安全带来极大的威胁。
研究如何有效地防御人脸伪造攻击具有重要的理论价值和实际应用意义。
stablediffusion原理vae

stablediffusion原理vae稳定扩散(Stable Diffusion)是一种使用变分自动编码器(Variational Autoencoder, VAE)进行概率编码和解码的机器学习方法。
VAE 是一种生成模型,其目标是通过学习输入数据的概率分布来生成新的数据样本。
稳定扩散的实现基于以下原理:1.VAE模型:VAE由两个主要部分组成,即编码器和解码器。
编码器将输入数据映射到一个低维的潜在空间(也称为隐空间),解码器则将潜在空间的向量转换为可重构的原始输入数据。
2. 变分自动编码器(Variational Autoencoder):VAE 使用变分推断来训练模型。
它引入了一个随机潜在变量(latent variable),并假设该变量服从一个已知的概率分布(常用的是高斯分布)。
推断过程包括利用编码器将输入数据映射到潜在空间,并使用解码器从潜在空间中重建输入数据。
3.算法步骤:稳定扩散通过以下步骤实现:a. 首先,使用 VAE 训练编码器和解码器。
训练时,利用输入数据和重构的数据之间的差异来计算重建损失(reconstruction loss)和 KL散度损失(KL divergence loss)。
b.在训练完成后,选择两个不同的样本,分别作为起点和终点。
将这两个样本通过编码器,获得它们在隐空间的表示。
c.通过插值法在隐空间中,构建一系列平滑过渡的潜在向量。
d.输入每个插值点的潜在向量到解码器,并生成对应的样本。
e.通过反向传播,优化生成的样本,使其更加贴近插值点所要表达的特征。
f.重复步骤c-e,直到获得满意的结果。
5.优势:与其他插值方法相比,稳定扩散能够产生更加真实和平滑的结果,很好地利用了VAE的特性。
它不仅可以用于图像生成,还可以用于其他类型的数据,如文本和音频。
一种基于变分模态分解和样本熵的MEMS陀螺去噪方法

Keywords:MEMS gyroscope; denoising algorithm; variational mode decomposition; signal reconstruction; interval threshold de⁃
noising;sample entropy
0 引言
πt k
cherel 傅里叶等距变换交替迭代得到子问题的解为:
1 基本原理与分析
示,此时重新定义 IMF 为一个调频调幅信号。
k=1
(1) 初始化 u^ 1k 、ω 1k 和拉格朗日乘数 λ 1 ,并设定最
(2) 根据式(4) 和式(5) 更新 u^ k 、ω k 。
^
(3) 根据式(6) 更新 λ。
用于非平稳随机误差的去噪算法具有重要意义。 目
前许多学者都致力于解决相关问题,提出了采用例如
号的统计特性下分别建立状态方程和量测方程,结构
较弱。 基于 WT 的时频分析方法需要事先选定一个小
波基,特定的小波基在全局可能是最佳的,但针对信
号的某些局部特征却很难分离出来,即小波基的选取
对整个分析的结果影响很大,缺乏灵活性的同时也存
声混合 IMFs 和高频噪声 IMFs。 舍弃高频噪声 IMFs,并利用软区间阈值降噪方法实现对混合分量的进
一步处理,最后通过重构得到最终的信号。 对一组真实的 MEMS 陀螺静态漂移输出数据进行实验分
析,比较结果表明该算法的去噪性能优于同为模态分解的 EMD 去噪方法。
关键词:MEMS 陀螺仪;去噪算法;变分模态分解;信号重构;区间阈值降噪;样本熵
(1) 对 u k 作 Hlibert 变换求解其分析信号以获得
(4)
ω k 可通过式( 5) 进行更新。 拉格朗日乘数可通
基于多种群的自适应迁移PSO算法

基于多种群的自适应迁移PSO算法邓先礼;魏波;曾辉;桂凌;夏学文【期刊名称】《电子学报》【年(卷),期】2018(046)008【摘要】针对标准PSO中单一社会学习模式造成的算法容易陷入局部最优和后期收敛速度慢等问题,提出了一种基于多种群的自适应迁移PSO算法(Multi-population based self-adaptive migration PSO,MSMPSO).通过融合两种常用的邻居拓扑结构,赋予个体更多的信息来源;在多个子种群并行进化的基础上,利用不同加速因子的组合赋予各子种群不同的搜索特性,进而通过周期性对子种群的历史性能进行评估,以此为基础指导个体的迁移操作,实现子种群间的协作与计算资源的合理分配,并最终提升算法的综合性能.对CEC2013测试函数的优化结果表明,MSMPSO在求解精度、收敛速度等方面均表现出较好的性能.【总页数】8页(P1858-1865)【作者】邓先礼;魏波;曾辉;桂凌;夏学文【作者单位】华东交通大学软件学院,江西南昌330013;华东交通大学软件学院,江西南昌330013;新疆工程学院计算机工程系,新疆乌鲁木齐830023;华东交通大学经济管理学院,江西南昌330013;华东交通大学软件学院,江西南昌330013【正文语种】中文【中图分类】TP301【相关文献】1.基于自适应多种群的粒子群优化算法 [J], 曾辉;王倩;夏学文;方霞2.基于混沌知识迁移的的多种群粒子群文化算法 [J], 郭一楠;程健;曹媛媛;刘丹丹3.基于混沌迁移策略的多种群差分进化算法 [J], 付晓刚;俞金寿4.一种基于多种群协作进化的自适应差分进化算法研究 [J], 周頔5.基于改进多种群PSO算法的火炮随动系统调节器参数优化 [J], 韩超;段纬然;贾长治;闫媛媛因版权原因,仅展示原文概要,查看原文内容请购买。
基于信息熵的网络流异常监测和三维可视方法

基于信息熵的网络流异常监测和三维可视方法陈鹏;司健;于子桓;王蔚旻【摘要】Through the analysis of network traffic, the network condition reflecting, abnormal behavior mining, network security situation awareness are enabled. Large scale network flow has mass data and wide range dimensions. Aiming at these features, in order to monitor network running situation and abnormity and improve the users’awareness experience, this paper puts forward a kind of quasi real time flow reporting mechanism, designs a flow monitoring system based on 3D visualization, and combines with the flow abnormity mining method based on information entropy, through manual monitor and data mining, realizes abnormal flow visualization monitoring. It presents the monitoring system design scheme and implementation results, resolves the hard problem of network flow visualization, puts forward a kind of traffic situa-tion scheme which is more intuitive, improves the users’network situation awareness capability.%通过分析网络流量可以反映网络运行情况,挖掘异常行为,感知网络安全态势。
图像处理中的机器学习与深度学习考试

图像处理中的机器学习与深度学习考试(答案见尾页)一、选择题1. 在图像处理中,以下哪个因素对机器学习算法的性能影响最大?A. 数据集的大小B. 计算资源C. 算法的复杂性D. 所需处理的图像类型2. 以下哪种深度学习架构被广泛用于图像分类任务?A. 卷积神经网络(CNN)B. 循环神经网络(RNN)C. 长短期记忆网络(LSTM)D. 生成对抗网络(GAN)3. 在训练深度学习模型时,哪种技术可以减少过拟合?A. 正则化B. 交叉验证C. 权重共享D. 数据增强4. 在图像处理中,以下哪个步骤不是特征提取的一部分?A. 特征选择B. 特征转换C. 特征规范化D. 特征计算5. 在使用机器学习进行图像处理时,以下哪种类型的数据对模型的性能影响最大?A. 二维图像B. 三维体积数据C. 时间序列数据D. 高维数据6. 在深度学习中,以下哪种类型的损失函数通常用于图像分类任务?A. 均方误差(MSE)B.交叉熵损失C. Hinge lossD. Kullback-Leibler散度(KL散度)7. 在图像处理中,以下哪个操作不属于图像增强技术?A. 滤波B. 深度学习C. 图像缩放D. 色彩调整8. 在训练机器学习模型时,以下哪种技术可以提高模型的泛化能力?A. 数据清洗B. 特征选择C. 正则化D. 数据集划分9. 在图像处理中,以下哪种类型的变换可以提高特征的表达能力?A. 维度不变性变换B. 仿射变换C. 直角坐标变换D. 非线性变换10. 在深度学习中,以下哪种优化算法通常用于提高模型的训练速度和性能?A. 随机梯度下降(SGD)B. 动量法C. Adam优化器D. Nesterov加速SGD11. 在图像处理中,以下哪个因素对机器学习算法的性能影响最大?A. 数据集的大小B. 计算资源C. 算法的复杂性D. 图像的分辨率12. 以下哪种深度学习架构被广泛用于图像分类任务?A. 卷积神经网络(CNN)B. 循环神经网络(RNN)C. 长短期记忆网络(LSTM)D. 生成对抗网络(GAN)13. 在图像处理中,以下哪个步骤不是特征提取的一部分?A. 图像标准化B. 特征选择C. 特征转换D. 特征编码14. 在深度学习中,以下哪个术语描述了网络的输出层?A. 激活函数B. 全连接层C. 卷积层D. 输出层15. 在图像处理中,以下哪种技术可以用于减少图像的噪声?A. 图像平滑B. 图像锐化C. 图像增强D. 图像分割16. 在机器学习中,以下哪个概念用于描述模型预测和实际结果之间的差异?A. 偏差B. 方差C. 标准差D. 总体标准差17. 在深度学习中,以下哪种类型的损失函数通常用于图像分类任务?A. 对数损失B. 梯度下降C. 莫尔积分D.交叉熵18. 在图像处理中,以下哪个步骤不属于图像预处理阶段?A. 图像去噪B. 图像缩放C. 图像增强D. 图像编码19. 在机器学习中,以下哪个术语用于描述模型的不确定性?A. 权重B. 贝叶斯估计C. 模型复杂度D. 支持向量机20. 在深度学习中,以下哪个操作用于调整网络的输出大小以适应后续任务?A. 层归一化B. 批归一化C. 卷积层D. 池化层21. 图像处理中,以下哪个不是机器学习算法?A. K-均值聚类B. 支持向量机(SVM)C. 随机森林D. 神经网络22. 在图像识别中,以下哪个神经网络结构最常用于卷积神经网络(CNN)?B. VGGNetC. ResNetD. MobileNet23. 机器学习中的交叉验证方法中,以下哪个不是常见的评估指标?A. 准确率B. 精确率C. 召回率D. F1分数24. 在深度学习中,以下哪个操作通常不是在卷积层完成的?A. 卷积B. 激活C. 池化D. 全连接25. 以下哪个不是深度学习中的优化算法?A. 随机梯度下降(SGD)B. AdamC. RpropD. Adagrad26. 在图像处理中,以下哪个技术可以用于减少图像的噪声?A. 特征匹配B. 图像融合C. 非局部均值去噪D. 直方图均衡化27. 在卷积神经网络中,以下哪个操作可以用于调整特征图的大小?A. 池化B. 扩张C. 折叠28. 以下哪个不是机器学习中常用的评估指标?A. R平方B. AUC-ROC曲线C. 对数损失D. 均方误差(MSE)29. 在图像处理中,以下哪个技术可以用于图像增强?A. 图像缩放B. 图像旋转C. 图像滤波D. 图像锐化30. 以下哪个不是深度学习中的损失函数类型?A. 对数损失B. Hinge损失C. 指数损失D. 平方损失31. 以下哪个选项是卷积神经网络(CNN)的核心组件?A. 卷积层B. 池化层C. 全连接层32. 以下哪种技术可以用于图像去噪?A. 主成分分析(PCA)B. 高斯滤波33. 在深度学习中,哪种类型的神经网络通常用于图像分类任务?A. 循环神经网络(RNN)B. 生成对抗网络(GAN)34. 以下哪种技术可以用于图像超分辨率?A. 双线性插值B. 卷积神经网络(CNN)35. 以下哪种技术可以用于实现图像风格迁移?A. 变分自编码器(VAE)B. 深度卷积神经网络(DCNN)36. 以下哪种技术可以用于图像恢复?A. 合成孔径雷达(SAR)B. 高斯平滑滤波37. 什么是卷积神经网络(CNN)?A. 一种用于图像分类的神经网络B. 一种用于语音识别的神经网络C. 一种用于自然语言处理的神经网络D. 一种用于生成对抗网络(GANs)的神经网络38. 在图像处理中,哪种类型的特征提取通常不依赖于人工特征设计?A. 领域自适应特征(SAF)B. 卷积特征C. 局部感受野D.深度学习特征39. 以下哪种深度学习架构被广泛用于图像分类任务?A. 循环神经网络(RNN)B. 长短期记忆网络(LSTM)C. 卷积神经网络(CNN)D. 生成对抗网络(GAN)40. 在深度学习中,哪种类型的损失函数通常用于分类问题?A. 对数损失B. Hinge lossC. Cross-Entropy lossD. Mean Squared Error (MSE)41. 什么是迁移学习?A. 将预训练模型在特定任务上进行微调B. 使用无监督学习方法进行训练C. 使用少量标注数据进行训练D. 使用自监督学习方法进行训练42. 在图像处理中,哪种类型的算法通常用于物体检测和识别?A. 基于规则的方法B. 基于统计的方法C. 基于机器学习的方法D. 基于深度学习的方法43. 在深度学习中,哪种类型的优化算法被广泛使用?A. 随机梯度下降(SGD)B. 动量法C. Adam optimizerD. Adagrad44. 在图像处理中,哪种类型的滤波器通常用于去噪和边缘检测?A. 椭圆低通滤波器B. 基于梯度的滤波器C. 基于形态学的滤波器D. 基于傅里叶变换的滤波器45. 什么是生成对抗网络(GANs)?A. 一种用于生成新样本的神经网络B. 一种用于分类的神经网络C. 一种用于回归的神经网络D. 一种用于序列预测的神经网络46. 在深度学习中,哪种类型的架构被广泛用于自然语言处理任务?A. 循环神经网络(RNN)B. 长短期记忆网络(LSTM)C. 卷积神经网络(CNN)D. Transformer二、问答题1. 什么是机器学习和深度学习?它们在图像处理中的应用有哪些?2. 常见的图像处理算法有哪些?它们在机器学习和深度学习中如何实现?3. 什么是图像重建?它在医学影像等领域有什么应用?4. 什么是图像配准?它在多模态成像中有什么作用?5. 什么是图像加密?它在信息安全领域有什么应用?6. 什么是图像超分辨率?它在高清显示等领域有什么应用?7. 什么是图像风格迁移?它在艺术创作等领域有什么应用?8. 什么是图像分割?它在无人驾驶等领域有什么应用?参考答案选择题:1. C2. A3. A4. C5. D6. B7. B8. D9. D 10. C11. C.算法的复杂性 12. A.卷积神经网络(CNN) 13. A.图像标准化 14. D.输出层 15. A.图像平滑 16. A.偏差 17. D.交叉熵 18. D.图像编码 19. B.贝叶斯估计 20. D.池化层21. A 22. B 23. B 24. D 25. A 26. C 27. C 28. D 29. D 30. C31. A 32. B 33. A 34. B 35. A 36. A 37. A 38. D 39. C 40. C41. A 42. D 43. C 44. B 45. A 46. D问答题:1. 什么是机器学习和深度学习?它们在图像处理中的应用有哪些?机器学习是一种让计算机通过数据学习知识和技能的方法,而无需进行明确的编程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
万方数据
第12期一种基于并行计算熵迁移策略的多分辨I)OM数据生成算法1479
◇誊警謦攀誊篡繁誊
数字正射影像(digitalorthophotomap,DOM)是空间信息应用的基础数据,也是实现空间信息应用的重要前提[1].DOM数据的主要应用包括作为图层叠加的背景、作为地物提取源数据和三维可视化的纹理数据等.例如,城市景观的三维重建就可以将DOM数据以纹理映射技术贴到数字高程模型网格曲面上,以获得极具真实感的地形渲染.
由于DOM数据通常是海量的,通常利用多分辨数据组织方法[2 ̄4],也就是根据人和设备接收或显示信息带宽的实际限制,将海量数据按照信息的分辨率进行组织,达到减少数据传输量和计算量的目的.DOM数据以多分辨数据结构进行组织,各分辨率的数据层叠加起来,呈现像金字塔一样的四棱锥形状,形象地称其为金字塔形DOM多分辨数据结构或塔形DOM多分辨数据结构.
海量多分辨DOM数据的生成需要大量计算和大容量存储,普通计算机远远不能满足要求.由于塔形DOM多分辨数据结构具有很强的域分解性,因此可以将塔形多分辨DOM数据的生成算法架构在并行计算机上.如同一般并行程序一样,需要考虑如何调度任务及分配资源,以取得良好的性能Is].鬻;驾穗繁。
≮婚睡秧撼载警藏漆誊i誊。
|i|如图1所示,塔形多分辨DOM数据结构是由若干层从上到下尺度逐渐变大、逐渐清晰的图像构成,这些图层渐次接近于原始图像.在传输数据给用户时,可以从顶层(低分辨率)到底层(高分辨率)逐步地发送.因而,这种结构特别适用于图像的渐进传输.
图1塔形多分辨DOM数据结构
Hg.1Datastructureofmulti-resolution
通常以切片的方式保存多分辨DOM中的图像层数据.切片就是预定尺寸大小(如128×128)的图像块.各层图像都可划分为若干个大小相同的切片.这样,切片就成为组成金字塔的基本单元.多分辨DOM数据的生成也就是为多分辨塔中各图像层生成切片.用户浏览图像时,一般只需要局部图像,因此可以仅传输浏览点周围的切片.与传输整幅图像相比,这样的传输方式可大大减少响应时间.由此,可以把多分辨率DOM数据的生成分为图像压缩和图像切割两部分.其中,图像压缩是生成塔形DOM多分辨数据结构中的各图像层.通常最高分辨率图像层的分辨率和原始图像分辨率保持一致,最低分辨率图像层为一个切片的大小.相邻两层图像分辨率的比值叫压缩率,常用的压缩率为1/4.图像切割则是为塔形多分辨DOM数据结构中的各图像层生成切片.
在图像压缩时,一般可以对图像进行逐层压缩,即由多分辨DOM数据塔的底层向上压缩,每一层图像都是由下一层图像经压缩得到,直至图像为切片大小.压缩可以采用四邻域平均、小波等算法.而图像切割也可每次将一个图像块分为四个子图像块,直到切割为切片大小.
图2即是一个3层塔形DOM多分辨数据结构的生成示意图.A为原始图像,A经切割后生成D中的4个图像块;这4个图像块再分别经切割后生成F中的16个切片,F即为3层DOM多分辨数据塔的底层.A经压缩后生成B,B的大小为A的1/4,B经图像切割后生成E中的4个切片,E为塔形DOM多分辨数据结构的第2层.B再经压缩后生成C,C的大小为B的1/4,C即为多分辨DOM数据结构的顶层.
对于多分辨DOM数据的生成,我们可以定义两种变换和两种类型的生成任务.两种变换即切割变换S和压缩变换f,切割变换S得到输入图像块经切割后的左上、右上、左下、右下4个图像块;压缩变换c得到输入图像块经压缩后的图像块.两种类型的生成任务分别为生成切片任务G和生成多分辨DOM任务F.其中,前者为输入图像块生成其切片数据,后者为输入图像块生成多分辨DOM数据.假设原始图像为P,初始时只一个F型任务,设
为F(夕),即为原始图像块乡生成多分辨DOM数万方数据
万方数据
万方数据
万方数据。