weka使用教程
WEKA教程完整版(新)

广东外语外贸大学 杜剑峰
WEKA教程
1. 2. 3.
4.
5. 6.
7.
8. 9.
WEKA简介 数据格式 数据准备 属性选择 可视化分析 分类预测 关联分析 聚类分析 扩展WEKA
课程的总体目标和要求: 熟悉WEKA的基本操作,了 解WEKA的各项功能 掌握数据挖掘实验的流程
2、数据格式(续)
字符串属性 字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘 中非常有用。 示例: @ATTRIBUTE LCC string 日期和时间属性 日期和时间属性统一用―date‖类型表示,它的格式是 @attribute <name> date [<date-format>] 其中<name>是这个属性的名称,<date-format>是一个字符串, 来规定该怎样解析和显示日期或时间的格式,默认的字符串是 ISO-8601所给的日期时间组合格式―yyyy-MM-ddTHH:mm:ss‖。 数据信息部分表达日期的字符串必须符合声明中规定的格式要求 (下文有例子)。
2、数据格式(续)
WEKA支持的<datatype>有四种
numeric <nominal-specification> string date [<date-format>]
数值型 标称(nominal)型 字符串型 日期和时间型
其中<nominal-specification> 和<date-format> 将在下 面说明。还可以使用两个类型―integer‖和―real‖,但是 WEKA把它们都当作―numeric‖看待。注意―integer‖, ―real‖,―numeric‖,―date‖,―string‖这些关键字是区分 大小写的,而―relation‖、“attribute ‖和―data‖则不区分。
weka使用-徐延昆
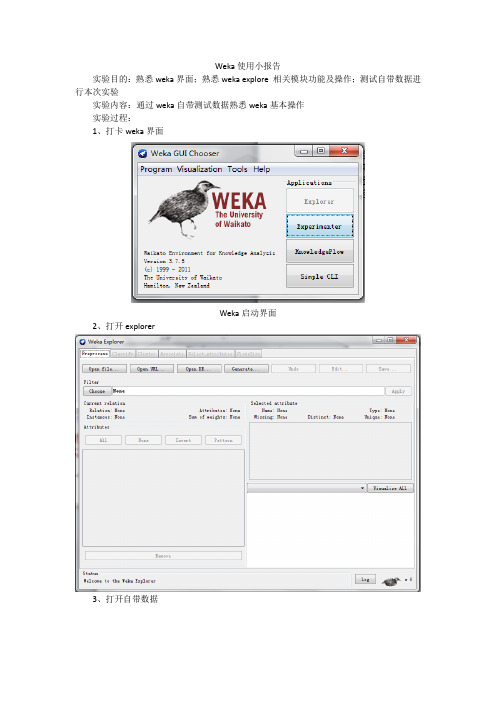
Weka使用小报告实验目的:熟悉weka界面;熟悉weka explore 相关模块功能及操作;测试自带数据进行本次实验实验内容:通过weka自带测试数据熟悉weka基本操作实验过程:1、打卡weka界面Weka启动界面2、打开explorer3、打开自带数据打开一个名为contact-lenses的arff数据文件,可以从基本界面发现这个数据里的一些特征:(1)数据关系名称:contact-lenses(2)数据实例个数:24(3)数据每个实例属性个数:5(4)总权重:243、观察基本数据信息红色标注的部分就是数据属性,可以看到这组数据共有五个属性:(1)Age(2)Spectacle-prescrip(3)Astigmatism(4)Tear-prod-rate(5)Contact-lenses这个标注的是所选属性的一些信息:属性名称:age属性取值个数:3丢失率:0单值个数:0属性类型:分类型表中是属性具体取值,比如说age:(1)年轻(2)接近老年(3)老年右下角的直方图就是具体属性中包含其他属性的图,比如说上图所选就是age属性,每个age里包括contact比例就是蓝、红、浅蓝的比例。
这些可以更换,只要class属性中选择其他的类。
上面这个直方图就可以完全显示各种类之间比例的关系。
4、使用过滤器5、使用分类器选择分类器为one-B 6选择完分类器选项之后可以选择测试方式,我使用了3种测试方法,对5个属性都进行了测试6、聚类操作7、关联分析8、可视化分析9、收获和问题:(1)熟悉了基本操作(2)对一些术语还不是很理解,分类聚类等(3)在进行一次聚类操作的时候出现了不能停止的情况(4)测试的数据个数太少,没有尝试使用一个大数据,导致最后可视化看不出什么关系。
电算化常用数据挖掘与机器学习工具操作指南

电算化常用数据挖掘与机器学习工具操作指南在当今数字化时代,数据的快速增长和复杂性使得传统的数据处理方式已无法满足实际需求。
因此,数据挖掘和机器学习成为了解决大规模数据处理的重要工具。
本文将介绍电算化常用的数据挖掘和机器学习工具的操作指南,帮助读者更好地理解和应用这些工具。
一、WEKA软件WEKA是一个十分常用的机器学习工具,其功能强大、易于使用。
以下是WEKA软件的操作指南:1. 安装WEKA软件下载WEKA安装文件并按照提示完成软件的安装。
2. 数据预处理在WEKA中,选择“预处理”选项,对数据进行清洗、去除噪声、处理缺失值等操作,以获得干净的数据集。
3. 特征选择通过选择合适的特征,提高模型的准确性和效率。
使用WEKA的“特征选择”功能,可以根据不同的特征选择算法来进行特征选择。
4. 模型构建与评估选择合适的机器学习算法,使用WEKA中的“分类”或“回归”功能,进行模型的构建与训练。
同时,可以使用WEKA提供的交叉验证、混淆矩阵等评估工具,评估模型的性能。
5. 模型应用与保存完成模型的构建和评估后,可以使用WEKA对新数据进行预测和分类。
同时,也可以将模型保存下来,以备将来使用。
二、Python编程语言与相关库Python是一种广泛应用于数据挖掘和机器学习领域的编程语言,其丰富的库使得数据处理和模型构建变得更为便捷。
以下是使用Python进行数据挖掘和机器学习的操作指南:1. 安装Python环境与相关库首先,安装Python编程环境,并通过pip命令安装相关库,如NumPy、Pandas、Scikit-learn等。
2. 数据加载与预处理使用Pandas库加载数据,并利用库中的函数进行数据清洗、去除异常值等预处理操作。
3. 特征工程在数据挖掘和机器学习中,特征工程是提取和选择合适的特征,以增加模型的准确性和泛化能力。
可以利用特征选择、特征提取、特征变换等方法进行特征工程。
利用Scikit-learn库中的各种机器学习算法,可以构建多种模型。
Weka数据挖掘软件使用指南

Weka数据挖掘软件使用指南Weka 数据挖掘软件使用指南1. Weka简介该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过得到。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。
在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2. Weka启动打开Weka主界面后会出现一个对话框,如图:主要使用右方的四个模块,说明如下:Explorer使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等;(本文主要总结这个部分的使用)Experimenter运行算法试验、管理算法方案之间的统计检验的环境;KnowledgeFlow这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。
它有一个优势,就是支持增量学习;SimpleCLI提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令;(某些情况下使用命令行功能更好一些)3.主要操作说明点击进入Explorer模块开始数据探索环境:3.1主界面进入Explorer模式后的主界面如下:3.1.1标签栏主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是:1. Preprocess. 选择和修改要处理的数据;2. Classify. 训练和测试关于分类或回归的学习方案;3. Cluster. 从数据中学习聚类;4. Associate.从数据中学习关联规则;5. Select attributes. 选择数据中最相关的属性;6. Visualize.查看数据的交互式二维图像。
3.1.2载入、编辑数据标签栏下方是载入数据栏,功能如下:1.Open file.打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat);2.Open URL.请求一个存有数据的URL 地址;3.Open DB.从数据库中读取数据;4.Generate.从一些数据生成器中生成人造数据。
weka使用

1)Explorer用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。
(An environment for exploring data with WEKA)2)Experimentor用来进行实验,对不同学习方案进行数据测试的环境。
(An environment for performing experiments and conducting statistical tests between learning schemes.)3)KnowledgeFlow功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。
另外,它支持增量学习。
(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)4)SimpleCLI简单的命令行界面。
(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)二、实验内容1.选用数据文件为:2.在WEKA中点击explorer 打开文件3.对数据整理分析4.将数据分类:单机classify ——在test options 中 选择第一项(Use training set )——点击classifier 下面的choose 按钮 选择trees 中的J48由上图可知该树有5个叶子是否出去游玩由天气晴朗(sunny)、天气预报(overcast)以及阴雨天(rainy)因素决定5.关联规则我们打算对前面的“bank-data”数据作关联规则的分析。
weka数据预处理标准化方法说明

weka数据预处理标准化方法说明Weka(Waikato Environment for Knowledge Analysis)是一套用于数据挖掘和机器学习的开源软件工具集,提供了丰富的功能,包括数据预处理、分类、回归、聚类等。
在Weka中,数据预处理是一个关键的步骤,其中标准化是一个常用的技术,有助于提高机器学习算法的性能。
下面是在Weka中进行数据标准化的一般步骤和方法说明:1. 打开Weka:启动Weka图形用户界面(GUI)或使用命令行界面。
2. 加载数据:选择“Explorer”选项卡,然后点击“Open file”按钮加载您的数据集。
3. 选择过滤器(Filter):在“Preprocess”选项卡中,选择“Filter”子选项卡,然后点击“Choose”按钮选择一个过滤器。
4. 选择标准化过滤器:在弹出的对话框中,找到并选择标准化过滤器。
常见的标准化过滤器包括:- Normalize:这个过滤器将数据标准化为给定的范围,通常是0到1。
- Standardize:使用这个过滤器可以将数据标准化为零均值和单位方差。
- AttributeRange:允许您手动指定每个属性的范围,以进行标准化。
5. 设置标准化选项:选择标准化过滤器后,您可能需要配置一些选项,例如范围、均值和方差等,具体取决于选择的过滤器。
6. 应用过滤器:配置完成后,点击“Apply”按钮,将标准化过滤器应用于数据。
7. 保存处理后的数据:如果需要,您可以将标准化后的数据保存到文件中。
8. 查看结果:在数据预处理完成后,您可以切换到“Classify”选项卡,选择一个分类器,并使用标准化后的数据进行模型训练和测试。
记住,具体的步骤和选项可能会因Weka版本的不同而有所差异,因此建议查阅Weka文档或在线资源以获取更具体的信息。
此外,标准化的适用性取决于您的数据和机器学习任务,因此在应用标准化之前,最好先了解您的数据的分布和特征。
weka使用教程

weka使用教程Weka是一个强大的开源机器学习软件,它提供了各种功能和算法来进行数据挖掘和预测分析。
以下是一个简单的Wea使用教程,帮助您了解如何使用它来进行数据分析和建模。
1. 安装Weka:首先,您需要下载并安装Weka软件。
您可以从官方网站上下载Weka的最新版本,并按照安装说明进行安装。
2. 打开Weka:安装完成后,打开Weka软件。
您将看到一个欢迎界面,上面列出了各种不同的选项和功能。
选择“Explorer”选项卡,这将帮助您导航和执行不同的任务。
3. 导入数据:在Explorer选项卡上,点击“Open file”按钮以导入您的数据集。
选择您要导入的数据文件,并确认数据文件的格式和结构。
4. 数据预处理:在导入数据之后,您可能需要对数据进行预处理,以清除噪声和处理缺失值。
在Weka中,您可以使用各种过滤器和转换器来处理数据。
点击“Preprocess”选项卡,然后选择适当的过滤器和转换器来定义您的预处理流程。
5. 数据探索:在数据预处理之后,您可以使用Weka的可视化工具来探索您的数据。
点击“Classify”选项卡,然后选择“Visualize”选项。
这将显示您的数据集的可视化图表和统计信息。
6. 建立模型:一旦您对数据进行了足够的探索,您可以使用Weka的各种机器学习算法建立模型。
在“Classify”选项卡上选择“Choose”按钮,并从下拉菜单中选择一个适当的分类算法。
然后,使用“Start”按钮训练模型并评估模型的性能。
7. 模型评估:一旦您建立了模型,您可以使用Weka提供的评估指标来评估模型的性能。
在“Classify”选项卡上,选择“Evaluate”选项,Weka将自动计算模型的准确性、精确度、召回率等指标。
8. 导出模型:最后,一旦您满意您的模型性能,您可以将模型导出到其他应用程序或格式中。
在Weka中,点击“Classify”选项卡,选择“Save model”选项,并指定模型的保存位置和格式。
weka配置教程

一、WEKA的安装在WEKA的安装文件中有weka-3-6-9.exe和weka-3-6-9jre.exe,这两个软件我们安装一个即可,这里主要介绍weka-3-6-9.exe的安装步骤1.安装Java运行环境下载jdk-7u21-windows-i586.exe(最新版)安装包,双击安装包进行安装,根据安装向导提示,点击下一步即可,安装完成以后可以通过命令提示符输入java–version 进行验证,若出现如下图所示,表示安装成功。
2.配置环境变量右击我的电脑,点击属性,出现如下界面:、选择高级——>环境变量,如图所示:出现环境变量配置界面:双击Path,然后出现编辑系统变量窗口:在变量值编辑框中,将光标移动至最后,添加一个分号“;”,然后将java的jdk安装路径追加到编辑框最后,我的系统中安装路径为:C:\ProgramFiles\Java\jdk1.7.0_21\bin,所以在编辑框最后写入:“; C:\ProgramFiles\Java\jdk1.7.0_21\bin”,即可完成环境变量的配置。
3.weka-3-6-9.exe双击此文件开始进行安装,在出现的窗口中点击Next,然后点击I Agree,再点击Next,此时出现如下窗口,Browse左边的区域是WEKA的默认安装路径,我们可以点击Browse选择我们想要安装WEKA的位置,然后点击窗口下方的NEXT,也可以不点击Browse直接将WEKA安装到默认的目录下,即直接点击窗口下方的NEXT,在新出现的窗口中点击Install开始安装,等待几秒种后点击Next,在新窗口中会有一个Start Weka单选框(默认情况下是选中的),如果我们想安装完成后就启动WEKA,那么我们就直接点击新窗口下方的FINISH 完成安装,如果我们不想立即启动WEKA可以单击Start Weka前面的单选框,然后点击FINISH即可完成安装,此时WEKA已经安装到我们的电脑中。
weka操作介绍讲解学习

标变量,直方图中的每个长方形
就会按照该变量的比例分成不同
颜色的段。默认地,分类或回归
任务的默认目标变量是数据集的
最后一个属性。要想换个分段的
依据,即目标变量,在区域7上 方的下拉框中选个不同的分类属
性就可以了。下拉框里选上
“No Class”或者一个数值属性会 变成黑白的直方图。
wekቤተ መጻሕፍቲ ባይዱ操作介绍
在KnowledgeFlow 窗口顶部有八个标签: DataSources--数据载入器 DataSinks--数据保存器 Filters--筛选器 Classifiers--分类器 Clusterers--聚类器 Associations—关联器 Evaluation—评估器 Visualization—可视化
关联运行结果
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好!谢谢
3 4
5 8
1 2
6 7
1.区域1的几个选项卡是用来切换不同的 挖掘任务面板。
Preprocess(数据预处理) Classify(分类) Cluster(聚类) Associate(关联分析) Select Attributes(选择属性) Visualize(可视化)
2. 区域2是一些常用按钮。包括打开数据, 保存及编辑功能。我们可以在这里把 “bank-data.csv”,另存为“bank-data.arff”
Cluster
主要算法包括: SimpleKMeans — 支持分类属性的K均值算法 DBScan — 支持分类属性的基于密度的算法 EM — 基于混合模型的聚类算法 FathestFirst — K中 心点算法 OPTICS — 基于密度的另一个算法 Cobweb — 概念聚类算法 sIB — 基于信息论的聚类算法,不支持分类属性 XMeans — 能自动确定簇个数的扩展K均值算法,不 支持分类属性
数据挖掘工具Weka API使用文档说明书

Evaluation
weka.classifiers.trees weka.associations
Business Intelligence Lab
Option handling
5
Either with get/set methods
Every action overwrites the previous ones
Weka Knowledge Flow documents the process, but …
it is time-consuming to experiment with many variants
(algs, params, inputs, …)
Split into x% training and (100-x)% test
Stratified sampling, where x range in [20-80]
For which x accuracy is maximized?
Business Intelligence Lab
BUSINESS INTELLIGENCE LABORATORY
Weka API
Salvatore Ruggieri
Computer Science Department, University of Pisa
Business Informatics Degree
Why API?
2
Weka Explorer does not keep track of experimental settings
E.g., selection of customers in marketing campaigns can be suggested to the marketer by a decision-support system which exploits data mining models
Weka使用文档(1)
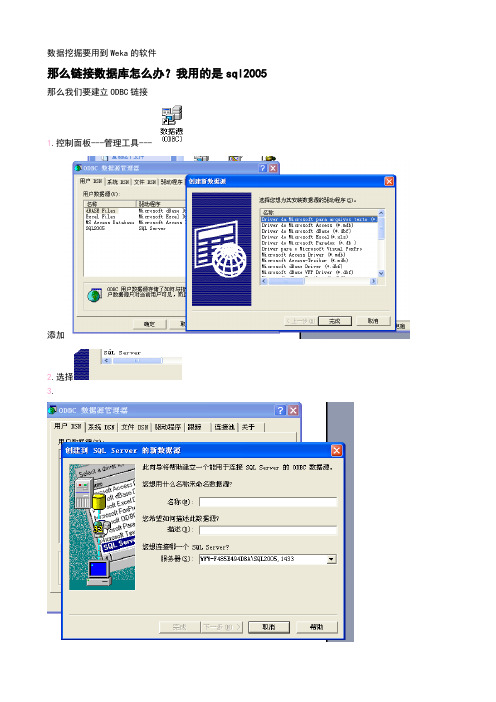
数据挖掘要用到Weka的软件那么链接数据库怎么办?我用的是sql2005 那么我们要建立ODBC链接1.控制面板---管理工具---添加2.选择3.1433是sql服务的端口4.下一步我们来进行安装文件。
在官网上/projects/weka/能够下载到最新版本。
我用的是3.6版本。
安装后请解压weka.jar文件,找到文件名DatabaseUtils.props一下是java数据类型Java type Java method Identifier Weka attribute type VersionString getString() 0 nominalboolean getBoolean() 1 nominaldouble getDouble() 2 numericbyte getByte() 3 numericshort getByte() 4 numericint getInteger() 5 numericlong getLong() 6 numericfloat getFloat() 7 numericdate getDate() 8 datetext getString() 9 string >3.5.5time getTime() 10 string >3.5.8In the props file one lists now the type names that the database returns and what Java type it represents (via the identifier), e.g.:CHAR=0VARCHAR=0CHAR and VARCHAR are both String types, hence they are interpreted as String (identifier 0)Note: in case database types have blanks, one needs to replace those blanks with an underscore, e.g., DOUBLE PRECISION must be listed like this:DOUBLE_PRECISION=2对应你的文件添加修改类型和他的值(注意大小写)修改文件DatabaseUtils.props.odbcjdbcURL=jdbc:odbc:SQL2005(SQL2005是建立连接池的名称)最后把修改后的文件添加到压缩文件中。
WEKA 5

图5. 5 Weka API文档
5.2.2
weka.core包
core(核心)包是Weka系统的核心,几乎所有的其他类 都访问核心包里的类。可以点击页面左上部的 weka.core超链接以了解包内包含什么内容。如图5. 6所 示,页面左下部显示核心包内的对象,按功能将其分为 Interfaces(接口)、Classes(类)、Enums(枚举) 和Exceptions(例外)四个部分。前两个部分比较重要, 其中,Classes部分列出了核心包里的类,Interfaces部 分则列出核心包提供的接口。接口与类相似,唯一的区 别是接口本身基本不做任何工作,它仅仅列出一些方法 而没有真正实现,只有这些接口的实现类才为这些方法 提供实现代码。例如,OptionHandler接口定义了处理命 令行选项的各种方法,实现该接口的类(包括全部的分 类器)必须提供这些方法的实现代码。
图5. 6 核心包内的对象
5.2.3
weka.classifiers包
classifiers包中包含大部分分类算法和数值预测算法的实 现。前文已经叙述过,Weka将分类和回归都归为分类 问题,因此数值预测算法也包含在分类器中,因为数值 预测可以解释为是连续型类别值的预测。在该包中最为 重要的是Classifier接口,它定义了分类或数值预测方案 的总体结构,其他的分类器都要实现该接口。Classifier 接口包含三个重要的方法:buildClassifier()、 classifyInstance()和distributionForInstance()。在面向对 象编程的术语中,学习算法都是Classifier的子类,因此 自动继承了这三种方法,并且每个学习方案重新定义如 何建立一个分类器,以及如何对实例进行分类。这样, 给出一个从其他Java代码来构建和使用分类器的统一接 口。因此,相同的评估模块可以用于对Weka中任意分 类器的性能进行评估。
WEKA中文详细教程

Weka可以将分析结果导出为多种格式,如CSV、ARFF、LaTeX等,用户可以通过“文件”菜单 选择“导出数据”来导出数据。
数据清理
缺失值处理
Weka提供了多种方法来处理缺失值, 如删除含有缺失值的实例、填充缺失 值等。
异常值检测
Weka提供了多种异常值检测方法, 如基于距离的异常值检测、基于密度 的异常值检测等。
Weka中文详细教程
目录
• Weka简介 • 数据预处理 • 分类算法 • 关联规则挖掘 • 回归分析 • 聚类分析 • 特征选择与降维 • 模型评估与优化
01
Weka简介
Weka是什么
01 Weka是一款开源的数据挖掘软件,全称是 "Waikato Environment for Knowledge Analysis",由新西兰怀卡托大学开发。
解释性强等优点。
使用Weka进行决策树 分类时,需要设置合 适的参数,如剪枝策 略、停止条件等,以 获得最佳分类效果。
决策树分类结果易于 理解和解释,能够为 决策提供有力支持。
贝叶斯分类器
贝叶斯分类器是一种 基于概率的分类算法, 通过计算不同类别的 概率来进行分类。
Weka中的朴素贝叶斯 分类器是一种基于贝 叶斯定理的简单分类 器,适用于特征之间 相互独立的场景。
08
模型评估与优化
交叉验证
01
交叉验证是一种评估机器学习模型性能的常用方法,通过将数据集分成多个子 集,然后使用其中的一部分子集训练模型,其余子集用于测试模型。
02
常见的交叉验证方法包括k-折交叉验证和留出交叉验证。在k-折交叉验证中, 数据集被分成k个大小相近的子集,每次使用其中的k-1个子集训练模型,剩余 一个子集用于测试。
Weka入门教程

Weka入门教程3. 分类与回归背景知识WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡中,这是有原因的。
在这两个任务中,都有一个目标属性(输出变量)。
我们希望根据一个样本(WEKA 中称作实例)的一组特征(输入变量),对目标进行预测。
为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。
观察训练集中的实例,可以建立起预测的模型。
有了这个模型,我们就可以新的输出未知的实例进行预测了。
衡量模型的好坏就在于预测的准确程度。
在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。
一般的,若Class属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。
选择算法这一节中,我们使用C4.5决策树算法对bank-data建立起分类模型。
我们来看原来的“bank-data.csv”文件。
“ID”属性肯定是不需要的。
由于C4.5算法可以处理数值型的属性,我们不用像前面用关联规则那样把每个变量都离散化成分类型。
尽管如此,我们还是把“Children”属性转换成分类型的两个值“YES”和“NO”。
另外,我们的训练集仅取原来数据集实例的一半;而从另外一半中抽出若干条作为待预测的实例,它们的“pep”属性都设为缺失值。
经过了这些处理的训练集数据在这里下载;待预测集数据在这里下载。
我们用“Explorer”打开训练集“bank.arff”,观察一下它是不是按照前面的要求处理好了。
切换到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。
3.5版的WEKA中,树型框下方有一个“Filter...”按钮,点击可以根据数据集的特性过滤掉不合适的算法。
我们数据集的输入属性中有“Binary”型(即只有两个类的分类型)和数值型的属性,而Class变量是“Binary”的;于是我们勾选“Binary attributes”“Numeric attributes”和“Binary class”。
weka使用教程

大数据导论实验报告
实验一
姓名abc
学号asadsdsa
报告日期
实验一
一.实验目的
1实验开源工具Weka的安装和熟悉;
2.数据理解,数据预处理的实验;
二.实验内容
1.weka介绍
2.数据理解
3.数据预处理
4.保存处理后的数据
三.实验过程
1.导入数据并修改选项
2.用weka.filters.unsupervised.attribute.ReplaceMissingValues处理缺失值
3.用weka.filters.unsupervised.attribute.Discretize离散化第一列数据
4.用weka.filters.unsupervised.instance.RemoveDuplicates删除重复数据
5.用weka.filters.unsupervised.attribute.Discretize离散化第六列数据
6.用weka.filters.unsupervised.attribute.Normalize归一化数据
7.保存数据
四.实验结果与分析
1.数据清理后的对比图,上面的是处理前的图,下图是处理后的图
分析:通过两图对比可发现图一中缺失的数据在图二中已经添加上。
2.离散化第一行后的对比图,图片为离散化之后的效果图
分析:此次处理目标为第一列,可发现处理后‘age’这一列的数据离散化了。
3.删除重复数据之后的效果图
5.离散化第六列后的效果图
分析:此次处理目标为第六列,可清楚看到发生的变化6.归一化后的效果图
此次处理的目标是10,12,13,14列,即将未离散化的数值列进行归一化处理。
weka使用教程

WEKA使用教程目录1. 简介2. 数据格式3.数据准备4. 关联规则(购物篮分析)5. 分类与回归6. 聚类分析1. 简介WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过/ml/weka得到。
同时weka也是新西兰的一种鸟名,而WEK A的主要开发者来自新西兰。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看weka的接口文档。
在weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的Weka小组荣获了数据挖掘和知识探索领域的最高服务奖,Weka系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一(已有11年的发展历史)。
Weka的每月下载次数已超过万次。
--整理自/computers/common/info.asp?id=293042. 数据格式巧妇难为无米之炊。
首先我们来看看WEKA所用的数据应是什么样的格式。
跟很多电子表格或数据分析软件一样,WEKA所处理的数据集是图1那样的一个二维的表格。
图1 新窗口打开这里我们要介绍一下WEKA中的术语。
表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。
竖行称作一个属性(Attrbute),相当于统计学中的一个变量,或者数据库中的一个字段。
这样一个表格,或者叫数据集,在WEKA看来,呈现了属性之间的一种关系(Rela tion)。
图1中一共有14个实例,5个属性,关系名称为“weather”。
WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。
Weka如何连接数据库

Weka如何连接数据库以SQL Server2000为例,其他的数据库操作⽅法⼀样,具体细节各异。
1 安装驱动程序,SQL Server2000将三个.jar加到环境变量。
2 修改 weka\experiment下的DatabaseUtils.props⽂件。
我们可以看到有DatabaseUtils.props.odbc DatabaseUtils.props.oracle等我们先将DatabaseUtils.props随便改成⼀个其他的名字,然后将DatabaseUtils.props.mssqlserver改成DatabaseUtils.props,打开现在的DatabaseUtils.props可以看到以下部分:(#表⽰注释)2.1驱动加载# JDBC driver (comma-separated list)jdbcDriver=com.microsoft.jdbc.sqlserver.SQLServerDriver2.2数据库连接,如果在本机上可以将server_name改为127.0.0.1或者localhost# database URLjdbcURL=jdbc:sqlserver://127.0.0.1:14332.3数据类型的转换。
由于weka仅⽀持名词型(nominal)、数值型(numeric)、字符串、⽇期(date)。
所以我们要将现在数据库中的数据类型对应到这四种类型上来。
将以下数据类型对应的句⼦前⾯的注释符合去掉。
由于SQL Server2000有其他的数据类型Weka尚不能识别,所以我们在下⾯再添加上smallint=3datetime=8等等string,getString()= 0; -->nominalboolean,getBoolean() = 1; -->nominaldouble,getDouble() = 2; -->numericbyte,getByte() = 3; -->numericshort,getByte()= 4; -->numericint,getInteger() = 5; -->numericlong,getLong() = 6; -->numericgloat,getFloat() = 7; -->numericdate,getDate() = 8; -->datevarchar=0float=2tinyint=3int=53其他说明,我们暂时⽤不到,不⽤去管了# other optionsCREATE_DOUBLE=DOUBLE PRECISIONCREATE_STRING=VARCHAR(8000)CREATE_INT=INTcheckUpperCaseNames=falsecheckLowerCaseNames=falsecheckForTable=true4 OK,下⾯可以操作了!运⾏weka的Explore界⾯后,通过Open DB..打开SQL Viewer⼯作界⾯(3.5.5版本⽐3.4.10在这⾥精细了许多)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
WEKA使用教程目录1. 简介2. 数据格式3.数据准备4. 关联规则(购物篮分析)5. 分类与回归6. 聚类分析1. 简介WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过/ml/weka得到。
同时weka也是新西兰的一种鸟名,而WEK A的主要开发者来自新西兰。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看weka的接口文档。
在weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的Weka小组荣获了数据挖掘和知识探索领域的最高服务奖,Weka系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一(已有11年的发展历史)。
Weka的每月下载次数已超过万次。
--整理自/computers/common/info.asp?id=293042. 数据格式巧妇难为无米之炊。
首先我们来看看WEKA所用的数据应是什么样的格式。
跟很多电子表格或数据分析软件一样,WEKA所处理的数据集是图1那样的一个二维的表格。
图1 新窗口打开这里我们要介绍一下WEKA中的术语。
表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。
竖行称作一个属性(Attrbute),相当于统计学中的一个变量,或者数据库中的一个字段。
这样一个表格,或者叫数据集,在WEKA看来,呈现了属性之间的一种关系(Rela tion)。
图1中一共有14个实例,5个属性,关系名称为“weather”。
WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。
图1所示的二维表格存储在如下的ARFF文件中。
这也就是WEKA自带的“weather.arff”文件,在WEK A安装目录的“data”子目录下可以找到。
Code:% ARFF file for the weather data with some numric features%@relation weather@attribute outlook {sunny, overcast, rainy}@attribute temperature real@attribute humidity real@attribute windy {TRUE, FALSE}@attribute play {yes, no}@data%% 14 instances%sunny,85,85,FALSE,nosunny,80,90,TRUE,noovercast,83,86,FALSE,yesrainy,70,96,FALSE,yesrainy,68,80,FALSE,yesrainy,65,70,TRUE,noovercast,64,65,TRUE,yessunny,72,95,FALSE,nosunny,69,70,FALSE,yesrainy,75,80,FALSE,yessunny,75,70,TRUE,yesovercast,72,90,TRUE,yesovercast,81,75,FALSE,yesrainy,71,91,TRUE,no需要注意的是,在Windows记事本打开这个文件时,可能会因为回车符定义不一致而导致分行不正常。
推荐使用UltraEdit这样的字符编辑软件察看ARFF文件的内容。
下面我们来对这个文件的内容进行说明。
识别ARFF文件的重要依据是分行,因此不能在这种文件里随意的断行。
空行(或全是空格的行)将被忽略。
以“%”开始的行是注释,WEKA将忽略这些行。
如果你看到的“weather.arff”文件多了或少了些“%”开始的行,是没有影响的。
除去注释后,整个ARFF文件可以分为两个部分。
第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。
第二部分给出了数据信息(Data information),即数据集中给出的数据。
从“@data”标记开始,后面的就是数据信息了。
关系声明关系名称在ARFF文件的第一个有效行来定义,格式为@relation <relation-name><relation-name>是一个字符串。
如果这个字符串包含空格,它必须加上引号(指英文标点的单引号或双引号)。
属性声明属性声明用一列以“@attribute”开头的语句表示。
数据集中的每一个属性都有它对应的“@attribute”语句,来定义它的属性名称和数据类型。
这些声明语句的顺序很重要。
首先它表明了该项属性在数据部分的位置。
例如,“humidity”是第三个被声明的属性,这说明数据部分那些被逗号分开的列中,第三列数据85 90 86 96 ... 是相应的“humidity”值。
其次,最后一个声明的属性被称作class属性,在分类或回归任务中,它是默认的目标变量。
属性声明的格式为@attribute <attribute-name> <datatype>其中<attribute-name>是必须以字母开头的字符串。
和关系名称一样,如果这个字符串包含空格,它必须加上引号。
WEKA支持的<datatype>有四种,分别是numeric-------------------------数值型<nominal-specification>-----分类(nominal)型string----------------------------字符串型date [<date-format>]--------日期和时间型其中<nominal-specification> 和<date-format> 将在下面说明。
还可以使用两个类型“integer”和“real”,但是WEKA把它们都当作“numeric”看待。
注意“integer”,“real”,“numeric”,“date”,“string”这些关键字是区分大小写的,而“relation”“attribute ”和“date”则不区分。
数值属性数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。
分类属性分类属性由<nominal-specification>列出一系列可能的类别名称并放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。
数据集中该属性的值只能是其中一种类别。
例如如下的属性声明说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”。
而数据集中每个实例对应的“outlook”值必是这三者之一。
@attribute outlook {sunny, overcast, rainy}如果类别名称带有空格,仍需要将之放入引号中。
字符串属性字符串属性中可以包含任意的文本。
这种类型的属性在文本挖掘中非常有用。
示例:@ATTRIBUTE LCC string日期和时间属性日期和时间属性统一用“date”类型表示,它的格式是@attribute <name> date [<date-format>]其中<name>是这个属性的名称,<date-format>是一个字符串,来规定该怎样解析和显示日期或时间的格式,默认的字符串是ISO-8601所给的日期时间组合格式“yyyy-MM-dd T HH:mm:ss”。
数据信息部分表达日期的字符串必须符合声明中规定的格式要求(下文有例子)。
数据信息数据信息中“@data”标记独占一行,剩下的是各个实例的数据。
每个实例占一行。
实例的各属性值用逗号“,”隔开。
如果某个属性的值是缺失值(missing value),用问号“?”表示,且这个问号不能省略。
例如:@datasunny,85,85,FALSE,no?,78,90,?,yes字符串属性和分类属性的值是区分大小写的。
若值中含有空格,必须被引号括起来。
例如:@relation LCCvsLCSH@attribute LCC string@attribute LCSH string@dataAG5, 'Encyclopedias and dictionaries.;Twentieth century.'AS262, 'Science -- Soviet Union -- History.'日期属性的值必须与属性声明中给定的相一致。
例如:@RELATION Timestamps@ATTRIBUTE timestamp DATE "yyyy-MM-dd HH:mm:ss"@DATA"2001-04-03 12:12:12""2001-05-03 12:59:55"稀疏数据有的时候数据集中含有大量的0值(比如购物篮分析),这个时候用稀疏格式的数据存贮更加省空间。
稀疏格式是针对数据信息中某个实例的表示而言,不需要修改ARFF文件的其它部分。
看如下的数据:@data0, X, 0, Y, "class A"0, 0, W, 0, "class B"用稀疏格式表达的话就是@data{1 X, 3 Y, 4 "class A"}{2 W, 4 "class B"}每个实例用花括号括起来。
实例中每一个非0的属性值用<index> <空格> <value>表示。
<index>是属性的序号,从0开始计;<value>是属性值。
属性值之间仍用逗号隔开。
这里每个实例的数值必须按属性的顺序来写,如{1 X, 3 Y, 4 "class A"},不能写成{3 Y, 1 X, 4 "class A"}。
注意在稀疏格式中没有注明的属性值不是缺失值,而是0值。
若要表示缺失值必须显式的用问号表示出来。
Relational型属性在WEKA 3.5版中增加了一种属性类型叫做Relational,有了这种类型我们可以像关系型数据库那样处理多个维度了。