WEKA教程完整版(新)
weka中文教程

WEKA 3-5-5 Explorer 用户指南原文版本 3.5.5翻译王娜校对 C6H5NO2Pentaho 中文讨论组QQ 群:12635055论坛:/bipub/index.asp/目录1 启动WEKA (3)Explorer (5)2 WEKA2.1 标签页 (5)2.2 状态栏 (5)按钮 (5)2.3 Log状态图标 (5)2.4 WEKA3 预处理 (6)3.1 载入数据 (6)3.2 当前关系 (6)3.3 处理属性 (7)3.4 使用筛选器 (7)4 分类 (10)4.1 选择分类器 (10)4.2 测试选项 (10)4.3 Class属性 (11)4.4 训练分类器 (11)4.5 分类器输出文本 (11)4.6 结果列表 (12)5 聚类 (13)5.1 选择聚类器(Clusterer) (13)5.2 聚类模式 (13)5.3 忽略属性 (13)5.4 学习聚类 (14)6 关联规则 (15)6.1 设定 (15)6.2 学习关联规则 (15)7 属性选择 (16)7.1 搜索与评估 (16)7.2 选项 (16)7.3 执行选择 (16)8 可视化 (18)8.1 散点图矩阵 (18)8.2 选择单独的二维散点图 (18)8.3 选择实例 (19)参考文献 (20)启动WEKAWEKA中新的菜单驱动的 GUI 继承了老的 GUI 选择器(类 weka.gui.GUIChooser)的功能。
它的MDI(“多文档界面”)外观,让所有打开的窗口更加明了。
这个菜单包括六个部分。
1.Programz LogWindow打开一个日志窗口,记录输出到stdout或stderr的内容。
在 MS Windows 那样的环境中,WEKA 不是从一个终端启动,这个就比较有用。
z Exit关闭WEKA。
2.Applications 列出 WEKA 中主要的应用程序。
z Explorer 使用 WEKA 探索数据的环境。
weka安装配置

一、WEKA的安装在WEKA的安装文件中有weka-3-5-6.exe和weka-3-5-6jre.exe,这两个软件我们安装一个即可,它们的区别是weka-3-5-6.exe只安装WEKA,而weka-3-5-6jre.exe是将WEKA 和JRE一起安装,所以在安装之前我们应该首先检查一下我们的电脑中是否安装了JRE,如果本机中已经安装了JRE,那么我们就选择weka-3-5-6.exe安装程序,如果没有安装JRE,我们就选择weka-3-5-6jre.exe安装程序,下面我们来分别介绍这两种安装方法。
1、weka-3-5-6.exe若本机中已经安装了JRE,那么我们就选择安装此文件,双击此文件开始进行安装,在出现的窗口中点击Next然后点击I Agree再点击Next此时出现如下窗口,Browse左边的区域是WEKA的默认安装路径,我们可以点击Browse选择我们想要安装WEKA的位置,然后点击窗口下方的NEXT,也可以不点击Browse直接将WEKA安装到默认的目录下,即直接点击窗口下方的NEXT,在新出现的窗口中点击Install开始安装,等待几秒种后点击Next在新窗口中会有一个Start Weka单选框(默认情况下是选中的),如果我们想安装完成后就启动WEKA,那么我们就直接点击新窗口下方的FINISH 完成安装,如果我们不想立即启动WEKA可以单击Start Weka前面的单选框,然后点击FINISH即可完成安装,此时WEKA已经安装到我们的电脑中。
2、weka-3-5-6jre.exe若本机中没有安装JRE,我们选择安装此文件,双击此文件开始进行安装,在出现的窗口中点击Next然后点击I Agree再点击Next此时出现如下窗口Browse左边的区域是默认安装WEKA的地方,我们可以点击Browse选择我们想将WEKA安装的位置,然后点击窗口下方的NEXT,也可以不点击Browse直接将WEKA安装到默认的目录下,即直接点击窗口下方的NEXT,在新出现的窗口中点击Install开始安装,等待几秒种后在新出现的窗口中直接点击下方的接受(此时进行的是典型安装模式),然后等待几分钟,此时正在安装的是J2SE Runtime Environment,待安装完毕我们点击完成,然后在新出现的窗口中点击NEXT,在新窗口中会有一个Start Weka单选框(默认情况下是选中的),如果我们想安装完成后就启动WEKA,那么我们就直接点击新窗口下方的FINISH 完成安装,如果我们不想立即启动WEKA可以单击Start Weka前面的单选框,然后点击FINISH即可完成安装。
数据挖掘实验报告-实验1-Weka基础操作

数据挖掘实验报告-实验1-W e k a基础操作学生实验报告学院:信息管理学院课程名称:数据挖掘教学班级: B01姓名:学号:实验报告课程名称数据挖掘教学班级B01 指导老师学号姓名行政班级实验项目实验一: Weka的基本操作组员名单独立完成实验类型■操作性实验□验证性实验□综合性实验实验地点H535 实验日期2016.09.281. 实验目的和要求:(1)Explorer界面的各项功能;注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。
(2)Weka的两种数据表格编辑文件方式下的功能介绍;①Explorer-Preprocess-edit,弹出Viewer对话框;②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。
(3)ARFF文件组成。
2.实验过程(记录实验步骤、分析实验结果)2.1 Explorer界面的各项功能2.1.1 初始界面示意其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。
Experimenter:实验者选项,提供不同数值的比较,发现其中规律。
KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。
Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。
2.1.2 进入Explorer 界面功能介绍(1)任务面板Preprocess(数据预处理):选择和修改要处理的数据。
Classify(分类):训练和测试分类或回归模型。
Cluster(聚类):从数据中聚类。
聚类分析时用的较多。
Associate(关联分析):从数据中学习关联规则。
Select Attributes(选择属性):选择数据中最相关的属性。
Visualize(可视化):查看数据的二维散布图。
(2)常用按钮Openfile:打开文件Open URL:打开URL格式文件Open DB:打开数据库文件Generate:数据生成Undo:撤销操作Edit:编辑数据Save:保存数据文件,可实现文件格式的转换,比如csv 格式文件向ARFF格式文件转换等等。
2020年整理WEKA汉化教程.pdf
注意在稀疏格式中没有注明的属性值不是缺失值,而是 0 值。若要表示缺失值必须显 式的用问号表示出来。
Relational 型属性 在 WEKA 3.5 版中增加了一种属性类型叫做 Relational,有了这种类型我们可以像关 系型数据库那样处理多个维度了。但是这种类型目前还不见广泛应用,暂不作介绍。 -----整理自 -和
@attribute <attribute-name> <datatype> 其中<attribute-name>是必须以字母开头的字符串。和关系名称一样,如果这个字符 串包含空格,它必须加上引号。 WEKA 支持的<datatype>有四种,分别是 numeric-------------------------数值型 <nominal-specification>-----分类(nominal)型 string----------------------------字符串型
@attribute outlook {sunny, overcast, rainy} 如果类别名称带有空格,仍需要将之放入引号中。 字符串属性 字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘中非常有用。示例:
@ATTRIBUTE LCC string 日期和时间属性 日期和时间属性统一用“date”类型表示,它的格式是
csvwrite('filename',matrixname) 需要注意的是,Matllab 给出的 CSV 文件往往没有属性名(Excel 给出的也有可能没 有)。而 WEKA 必须从 CSV 文件的第一行读取属性名,否则就会把第一行的各属性值读成 变量名。因此我们对于 Matllab 给出的 CSV 文件需要用 UltraEdit 打开,手工添加一行属 性名。注意属性名的个数要跟数据属性的个数一致,仍用逗号隔开。 .csv -> .arff
Weka数据挖掘软件使用指南

Weka数据挖掘软件使用指南Weka 数据挖掘软件使用指南1. Weka简介该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过得到。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。
在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2. Weka启动打开Weka主界面后会出现一个对话框,如图:主要使用右方的四个模块,说明如下:Explorer使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等;(本文主要总结这个部分的使用)Experimenter运行算法试验、管理算法方案之间的统计检验的环境;KnowledgeFlow这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。
它有一个优势,就是支持增量学习;SimpleCLI提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令;(某些情况下使用命令行功能更好一些)3.主要操作说明点击进入Explorer模块开始数据探索环境:3.1主界面进入Explorer模式后的主界面如下:3.1.1标签栏主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是:1. Preprocess. 选择和修改要处理的数据;2. Classify. 训练和测试关于分类或回归的学习方案;3. Cluster. 从数据中学习聚类;4. Associate.从数据中学习关联规则;5. Select attributes. 选择数据中最相关的属性;6. Visualize.查看数据的交互式二维图像。
3.1.2载入、编辑数据标签栏下方是载入数据栏,功能如下:1.Open file.打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat);2.Open URL.请求一个存有数据的URL 地址;3.Open DB.从数据库中读取数据;4.Generate.从一些数据生成器中生成人造数据。
weka数据预处理标准化方法说明

weka数据预处理标准化方法说明Weka(Waikato Environment for Knowledge Analysis)是一套用于数据挖掘和机器学习的开源软件工具集,提供了丰富的功能,包括数据预处理、分类、回归、聚类等。
在Weka中,数据预处理是一个关键的步骤,其中标准化是一个常用的技术,有助于提高机器学习算法的性能。
下面是在Weka中进行数据标准化的一般步骤和方法说明:1. 打开Weka:启动Weka图形用户界面(GUI)或使用命令行界面。
2. 加载数据:选择“Explorer”选项卡,然后点击“Open file”按钮加载您的数据集。
3. 选择过滤器(Filter):在“Preprocess”选项卡中,选择“Filter”子选项卡,然后点击“Choose”按钮选择一个过滤器。
4. 选择标准化过滤器:在弹出的对话框中,找到并选择标准化过滤器。
常见的标准化过滤器包括:- Normalize:这个过滤器将数据标准化为给定的范围,通常是0到1。
- Standardize:使用这个过滤器可以将数据标准化为零均值和单位方差。
- AttributeRange:允许您手动指定每个属性的范围,以进行标准化。
5. 设置标准化选项:选择标准化过滤器后,您可能需要配置一些选项,例如范围、均值和方差等,具体取决于选择的过滤器。
6. 应用过滤器:配置完成后,点击“Apply”按钮,将标准化过滤器应用于数据。
7. 保存处理后的数据:如果需要,您可以将标准化后的数据保存到文件中。
8. 查看结果:在数据预处理完成后,您可以切换到“Classify”选项卡,选择一个分类器,并使用标准化后的数据进行模型训练和测试。
记住,具体的步骤和选项可能会因Weka版本的不同而有所差异,因此建议查阅Weka文档或在线资源以获取更具体的信息。
此外,标准化的适用性取决于您的数据和机器学习任务,因此在应用标准化之前,最好先了解您的数据的分布和特征。
weka使用教程

weka使用教程Weka是一个强大的开源机器学习软件,它提供了各种功能和算法来进行数据挖掘和预测分析。
以下是一个简单的Wea使用教程,帮助您了解如何使用它来进行数据分析和建模。
1. 安装Weka:首先,您需要下载并安装Weka软件。
您可以从官方网站上下载Weka的最新版本,并按照安装说明进行安装。
2. 打开Weka:安装完成后,打开Weka软件。
您将看到一个欢迎界面,上面列出了各种不同的选项和功能。
选择“Explorer”选项卡,这将帮助您导航和执行不同的任务。
3. 导入数据:在Explorer选项卡上,点击“Open file”按钮以导入您的数据集。
选择您要导入的数据文件,并确认数据文件的格式和结构。
4. 数据预处理:在导入数据之后,您可能需要对数据进行预处理,以清除噪声和处理缺失值。
在Weka中,您可以使用各种过滤器和转换器来处理数据。
点击“Preprocess”选项卡,然后选择适当的过滤器和转换器来定义您的预处理流程。
5. 数据探索:在数据预处理之后,您可以使用Weka的可视化工具来探索您的数据。
点击“Classify”选项卡,然后选择“Visualize”选项。
这将显示您的数据集的可视化图表和统计信息。
6. 建立模型:一旦您对数据进行了足够的探索,您可以使用Weka的各种机器学习算法建立模型。
在“Classify”选项卡上选择“Choose”按钮,并从下拉菜单中选择一个适当的分类算法。
然后,使用“Start”按钮训练模型并评估模型的性能。
7. 模型评估:一旦您建立了模型,您可以使用Weka提供的评估指标来评估模型的性能。
在“Classify”选项卡上,选择“Evaluate”选项,Weka将自动计算模型的准确性、精确度、召回率等指标。
8. 导出模型:最后,一旦您满意您的模型性能,您可以将模型导出到其他应用程序或格式中。
在Weka中,点击“Classify”选项卡,选择“Save model”选项,并指定模型的保存位置和格式。
WEKA教程完整版(新)

2、数据格式(续)
数据信息 数据信息中―@data‖标记独占一行,剩下的是各个实例 的数据。 每个实例占一行。实例的各属性值用逗号―,‖隔开。如果 某个属性的值是缺失值(missing value),用问号―?‖ 表示,且这个问号不能省略。例如: @data sunny,85,85,FALSE,no ?,78,90,?,yes
准备数据 选择算法和参数运行 评估实验结果
了解或掌握在WEKA中加入 新算法的方法
1、WEKA简介
WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),其源代码可 从/ml/weka/得到。同时 weka也是新西兰的一种鸟名,而WEKA的主要开发者 来自新西兰。
2、数据格式(续)
字符串属性和标称属性的值是区分大小写的。若值中含 有空格,必须被引号括起来。例如:
@relation LCCvsLCSH @attribute LCC string @attribute LCSH string @data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.' AS262, 'Science -- Soviet Union -- History.'
2、数据格式(续)
数值属性 数值型属性可以是整数或者实数,但WEKA把它们都当作实数看 待。
标称属性 标称属性由<nominal-specification>列出一系列可能的类别名称并 放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。数据集中该属性的值只能是其中一种类 别。 例如如下的属性声明说明―outlook‖属性有三种类别:―sunny‖,― overcast‖和―rainy‖。而数据集中每个实例对应的―outlook‖值必是 这三者之一。 @attribute outlook {sunny, overcast, rainy} 如果类别名称带有空格,仍需要将之放入引号中。
weka操作介绍讲解学习

标变量,直方图中的每个长方形
就会按照该变量的比例分成不同
颜色的段。默认地,分类或回归
任务的默认目标变量是数据集的
最后一个属性。要想换个分段的
依据,即目标变量,在区域7上 方的下拉框中选个不同的分类属
性就可以了。下拉框里选上
“No Class”或者一个数值属性会 变成黑白的直方图。
wekቤተ መጻሕፍቲ ባይዱ操作介绍
在KnowledgeFlow 窗口顶部有八个标签: DataSources--数据载入器 DataSinks--数据保存器 Filters--筛选器 Classifiers--分类器 Clusterers--聚类器 Associations—关联器 Evaluation—评估器 Visualization—可视化
关联运行结果
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好!谢谢
3 4
5 8
1 2
6 7
1.区域1的几个选项卡是用来切换不同的 挖掘任务面板。
Preprocess(数据预处理) Classify(分类) Cluster(聚类) Associate(关联分析) Select Attributes(选择属性) Visualize(可视化)
2. 区域2是一些常用按钮。包括打开数据, 保存及编辑功能。我们可以在这里把 “bank-data.csv”,另存为“bank-data.arff”
Cluster
主要算法包括: SimpleKMeans — 支持分类属性的K均值算法 DBScan — 支持分类属性的基于密度的算法 EM — 基于混合模型的聚类算法 FathestFirst — K中 心点算法 OPTICS — 基于密度的另一个算法 Cobweb — 概念聚类算法 sIB — 基于信息论的聚类算法,不支持分类属性 XMeans — 能自动确定簇个数的扩展K均值算法,不 支持分类属性
Weka使用文档(1)
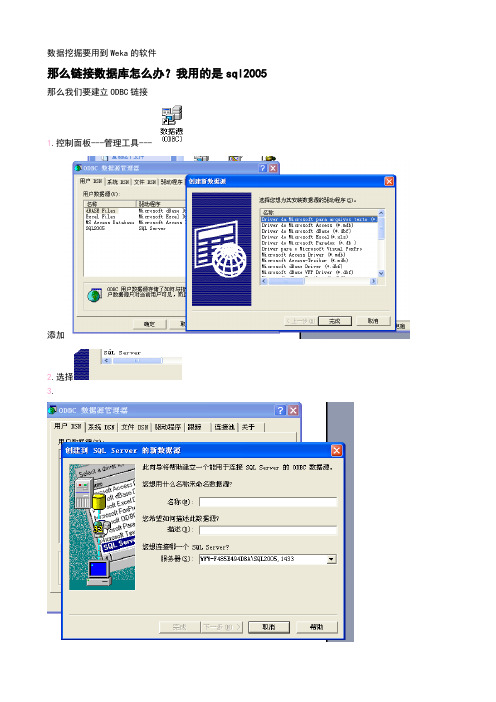
数据挖掘要用到Weka的软件那么链接数据库怎么办?我用的是sql2005 那么我们要建立ODBC链接1.控制面板---管理工具---添加2.选择3.1433是sql服务的端口4.下一步我们来进行安装文件。
在官网上/projects/weka/能够下载到最新版本。
我用的是3.6版本。
安装后请解压weka.jar文件,找到文件名DatabaseUtils.props一下是java数据类型Java type Java method Identifier Weka attribute type VersionString getString() 0 nominalboolean getBoolean() 1 nominaldouble getDouble() 2 numericbyte getByte() 3 numericshort getByte() 4 numericint getInteger() 5 numericlong getLong() 6 numericfloat getFloat() 7 numericdate getDate() 8 datetext getString() 9 string >3.5.5time getTime() 10 string >3.5.8In the props file one lists now the type names that the database returns and what Java type it represents (via the identifier), e.g.:CHAR=0VARCHAR=0CHAR and VARCHAR are both String types, hence they are interpreted as String (identifier 0)Note: in case database types have blanks, one needs to replace those blanks with an underscore, e.g., DOUBLE PRECISION must be listed like this:DOUBLE_PRECISION=2对应你的文件添加修改类型和他的值(注意大小写)修改文件DatabaseUtils.props.odbcjdbcURL=jdbc:odbc:SQL2005(SQL2005是建立连接池的名称)最后把修改后的文件添加到压缩文件中。
WEKA 5

图5. 5 Weka API文档
5.2.2
weka.core包
core(核心)包是Weka系统的核心,几乎所有的其他类 都访问核心包里的类。可以点击页面左上部的 weka.core超链接以了解包内包含什么内容。如图5. 6所 示,页面左下部显示核心包内的对象,按功能将其分为 Interfaces(接口)、Classes(类)、Enums(枚举) 和Exceptions(例外)四个部分。前两个部分比较重要, 其中,Classes部分列出了核心包里的类,Interfaces部 分则列出核心包提供的接口。接口与类相似,唯一的区 别是接口本身基本不做任何工作,它仅仅列出一些方法 而没有真正实现,只有这些接口的实现类才为这些方法 提供实现代码。例如,OptionHandler接口定义了处理命 令行选项的各种方法,实现该接口的类(包括全部的分 类器)必须提供这些方法的实现代码。
图5. 6 核心包内的对象
5.2.3
weka.classifiers包
classifiers包中包含大部分分类算法和数值预测算法的实 现。前文已经叙述过,Weka将分类和回归都归为分类 问题,因此数值预测算法也包含在分类器中,因为数值 预测可以解释为是连续型类别值的预测。在该包中最为 重要的是Classifier接口,它定义了分类或数值预测方案 的总体结构,其他的分类器都要实现该接口。Classifier 接口包含三个重要的方法:buildClassifier()、 classifyInstance()和distributionForInstance()。在面向对 象编程的术语中,学习算法都是Classifier的子类,因此 自动继承了这三种方法,并且每个学习方案重新定义如 何建立一个分类器,以及如何对实例进行分类。这样, 给出一个从其他Java代码来构建和使用分类器的统一接 口。因此,相同的评估模块可以用于对Weka中任意分 类器的性能进行评估。
weka教程_使用方法

“Meta”-classifiers include:
1/28/2014
1/28/2014
University of Waikato
37
1/28/2014
University of Waikato
38
1/28/2014
University of Waikato
University of Waikato 8
1/28/2014
WEKA only deals with “flat” files
@relation heart-disease-simplified @attribute age numeric @attribute sex { female, male} @attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina} @attribute cholesterol numeric @attribute exercise_induced_angina { no, yes} @attribute class { present, not_present} @data 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present ...
作者: Ian H. Witten / Eibe Frank 副标题: Practical Machine Learning Tools and Techniques, Second Edition (Morgan Kaufmann Series in Data Management Systems) 页数: 525 出版社: Morgan Kaufmann 出版年: 2005-06-08
WEKA中文详细教程

Weka可以将分析结果导出为多种格式,如CSV、ARFF、LaTeX等,用户可以通过“文件”菜单 选择“导出数据”来导出数据。
数据清理
缺失值处理
Weka提供了多种方法来处理缺失值, 如删除含有缺失值的实例、填充缺失 值等。
异常值检测
Weka提供了多种异常值检测方法, 如基于距离的异常值检测、基于密度 的异常值检测等。
Weka中文详细教程
目录
• Weka简介 • 数据预处理 • 分类算法 • 关联规则挖掘 • 回归分析 • 聚类分析 • 特征选择与降维 • 模型评估与优化
01
Weka简介
Weka是什么
01 Weka是一款开源的数据挖掘软件,全称是 "Waikato Environment for Knowledge Analysis",由新西兰怀卡托大学开发。
解释性强等优点。
使用Weka进行决策树 分类时,需要设置合 适的参数,如剪枝策 略、停止条件等,以 获得最佳分类效果。
决策树分类结果易于 理解和解释,能够为 决策提供有力支持。
贝叶斯分类器
贝叶斯分类器是一种 基于概率的分类算法, 通过计算不同类别的 概率来进行分类。
Weka中的朴素贝叶斯 分类器是一种基于贝 叶斯定理的简单分类 器,适用于特征之间 相互独立的场景。
08
模型评估与优化
交叉验证
01
交叉验证是一种评估机器学习模型性能的常用方法,通过将数据集分成多个子 集,然后使用其中的一部分子集训练模型,其余子集用于测试模型。
02
常见的交叉验证方法包括k-折交叉验证和留出交叉验证。在k-折交叉验证中, 数据集被分成k个大小相近的子集,每次使用其中的k-1个子集训练模型,剩余 一个子集用于测试。
Weka入门教程

Weka入门教程3. 分类与回归背景知识WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡中,这是有原因的。
在这两个任务中,都有一个目标属性(输出变量)。
我们希望根据一个样本(WEKA 中称作实例)的一组特征(输入变量),对目标进行预测。
为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。
观察训练集中的实例,可以建立起预测的模型。
有了这个模型,我们就可以新的输出未知的实例进行预测了。
衡量模型的好坏就在于预测的准确程度。
在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。
一般的,若Class属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。
选择算法这一节中,我们使用C4.5决策树算法对bank-data建立起分类模型。
我们来看原来的“bank-data.csv”文件。
“ID”属性肯定是不需要的。
由于C4.5算法可以处理数值型的属性,我们不用像前面用关联规则那样把每个变量都离散化成分类型。
尽管如此,我们还是把“Children”属性转换成分类型的两个值“YES”和“NO”。
另外,我们的训练集仅取原来数据集实例的一半;而从另外一半中抽出若干条作为待预测的实例,它们的“pep”属性都设为缺失值。
经过了这些处理的训练集数据在这里下载;待预测集数据在这里下载。
我们用“Explorer”打开训练集“bank.arff”,观察一下它是不是按照前面的要求处理好了。
切换到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。
3.5版的WEKA中,树型框下方有一个“Filter...”按钮,点击可以根据数据集的特性过滤掉不合适的算法。
我们数据集的输入属性中有“Binary”型(即只有两个类的分类型)和数值型的属性,而Class变量是“Binary”的;于是我们勾选“Binary attributes”“Numeric attributes”和“Binary class”。
weka使用教程

大数据导论实验报告
实验一
姓名abc
学号asadsdsa
报告日期
实验一
一.实验目的
1实验开源工具Weka的安装和熟悉;
2.数据理解,数据预处理的实验;
二.实验内容
1.weka介绍
2.数据理解
3.数据预处理
4.保存处理后的数据
三.实验过程
1.导入数据并修改选项
2.用weka.filters.unsupervised.attribute.ReplaceMissingValues处理缺失值
3.用weka.filters.unsupervised.attribute.Discretize离散化第一列数据
4.用weka.filters.unsupervised.instance.RemoveDuplicates删除重复数据
5.用weka.filters.unsupervised.attribute.Discretize离散化第六列数据
6.用weka.filters.unsupervised.attribute.Normalize归一化数据
7.保存数据
四.实验结果与分析
1.数据清理后的对比图,上面的是处理前的图,下图是处理后的图
分析:通过两图对比可发现图一中缺失的数据在图二中已经添加上。
2.离散化第一行后的对比图,图片为离散化之后的效果图
分析:此次处理目标为第一列,可发现处理后‘age’这一列的数据离散化了。
3.删除重复数据之后的效果图
5.离散化第六列后的效果图
分析:此次处理目标为第六列,可清楚看到发生的变化6.归一化后的效果图
此次处理的目标是10,12,13,14列,即将未离散化的数值列进行归一化处理。
Weka如何连接数据库

Weka如何连接数据库以SQL Server2000为例,其他的数据库操作⽅法⼀样,具体细节各异。
1 安装驱动程序,SQL Server2000将三个.jar加到环境变量。
2 修改 weka\experiment下的DatabaseUtils.props⽂件。
我们可以看到有DatabaseUtils.props.odbc DatabaseUtils.props.oracle等我们先将DatabaseUtils.props随便改成⼀个其他的名字,然后将DatabaseUtils.props.mssqlserver改成DatabaseUtils.props,打开现在的DatabaseUtils.props可以看到以下部分:(#表⽰注释)2.1驱动加载# JDBC driver (comma-separated list)jdbcDriver=com.microsoft.jdbc.sqlserver.SQLServerDriver2.2数据库连接,如果在本机上可以将server_name改为127.0.0.1或者localhost# database URLjdbcURL=jdbc:sqlserver://127.0.0.1:14332.3数据类型的转换。
由于weka仅⽀持名词型(nominal)、数值型(numeric)、字符串、⽇期(date)。
所以我们要将现在数据库中的数据类型对应到这四种类型上来。
将以下数据类型对应的句⼦前⾯的注释符合去掉。
由于SQL Server2000有其他的数据类型Weka尚不能识别,所以我们在下⾯再添加上smallint=3datetime=8等等string,getString()= 0; -->nominalboolean,getBoolean() = 1; -->nominaldouble,getDouble() = 2; -->numericbyte,getByte() = 3; -->numericshort,getByte()= 4; -->numericint,getInteger() = 5; -->numericlong,getLong() = 6; -->numericgloat,getFloat() = 7; -->numericdate,getDate() = 8; -->datevarchar=0float=2tinyint=3int=53其他说明,我们暂时⽤不到,不⽤去管了# other optionsCREATE_DOUBLE=DOUBLE PRECISIONCREATE_STRING=VARCHAR(8000)CREATE_INT=INTcheckUpperCaseNames=falsecheckLowerCaseNames=falsecheckForTable=true4 OK,下⾯可以操作了!运⾏weka的Explore界⾯后,通过Open DB..打开SQL Viewer⼯作界⾯(3.5.5版本⽐3.4.10在这⾥精细了许多)。
数据挖掘工具教程

火龙果 整理
1 2 3 4
6
5 7
8
火龙果 整理
3、数据准备(续)
1.
2.
3.
4.
上图显示的是 ―Explorer‖打开―bank-data.csv‖的情况。我 们根据不同的功能把这个界面分成8个区域。 区域1的几个选项卡是用来切换不同的挖掘任务面板。这 一节用到的只有―Preprocess‖,其他面板的功能将在以后 介绍。 区域2是一些常用按钮。包括打开数据,保存及编辑功能。 我们可以在这里把“bank-data.csv‖另存为“bankdata.arff‖。 在区域3中―Choose‖某个―Filter‖,可以实现筛选数据或者 对数据进行某种变换。数据预处理主要就利用它来实现。 区域4展示了数据集的一些基本情况。
火龙果 整理
2、数据格式(续)
日期属性的值必须与属性声明中给定的相一致。例如:
@RELATION Timestamps @ATTRIBUTE timestamp DATE "yyyy-MM-dd HH:mm:ss" @DATA "2001-04-03 12:12:12" "2001-05-03 12:59:55"
火龙果 整理
2、数据格式(续)
字符串属性和标称属性的值是区分大小写的。若值中含 有空格,必须被引号括起来。例如:
@relation LCCvsLCSH @attribute LCC string @attribute LCSH string @data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.' AS262, 'Science -- Soviet Union -- History.'
威尔克姆制版软件简明教程

威尔克姆制版软件简明教程第一节电脑绣花制版基本知识1、花样编辑器和花样浏览器:威尔克姆软件包由花样编辑器和花样浏览器组成;花样编辑器即制版软件,它是电脑绣花制版和设计的主程序,它可以设计、编辑和修改花型,并将已设计好的花型输入到绣花磁盘上,在桌面上的图标为花样浏览器是编辑器的一个辅助程序,在桌面上的图标为它专用于查看和管理已设计好的EMB格式的花形,并可进行一些简单的辅助性操作,如通过双击EMB格式的花型图象可直接打开文件、格式化磁盘、删除、复制花样、将花样文件转换到绣花磁盘上等。
要运行浏览器,必须先打开花样编辑器;读者要注意,花样浏览器不能直接查看 DST或DSB等电脑绣花机可读入的文件,这些类型的文件可由富怡花样管理软件来查看。
2、花样文件格式和绣花磁盘文件格式通常情况下,不论是什么制版软件,它所设计出来的花型都是以一种电脑绣花机不能直接读出的文件格式保存下来的,然后再转换成电脑绣花能读出的格式。
例如:DOS版本的田岛软件所生成的花型设计文件格式为*.ESD,Windows版本的田岛软件所成的花样文件格式为*.EMB,Windows版本的威尔克姆软件所成的花样文件格式为*.EMB ,DOS版本的天木软件所生成的花样文件格式为*.ndp等;这些格式的文件电脑绣花机都不能直接使用,必须转换成*.DST(田岛绣花机三进制格式)或*.DSB(百灵达二进制格式),电脑绣花机才能读进内存进行绣花。
为什么制版软件所生成的花型设计文件(EMB格式)绣花机不能读进呢?这是因花样设计文件实际上是一种特殊的格式的图形文件,它含有图象信息(如图形大小、色彩、相对位置等信息)和制版编辑信息(如选用的针迹类型和密度等信息),而绣花机只能读DST(三进制)或DSB(二进制)格式的针位文件,因为绣花机的步进电机X轴和Y轴的位移尺寸(最低偏移量为0.1mm)以及停止、换色、剪线等控制信息只能用二进制或三进制来编码。
由此可见,DST或DSB格式的文件是由EMB文件经过滤除去制版信息转换而来的。
WEKA 教程 SPSS 教程

实验1:数据挖掘工具研究班级:计算机082姓名:张睿卿指导老师:董一鸿老师目录1Weka1.1Weka简介1.2Weka应用方法1.3Weka操作数据集1.3.1预处理1.3.1.1打开Explore1.3.1.2载入数据1.3.1.3处理属性1.3.1.4使用筛选器1.3.1.5数据离散化1.3.2分类与回归1.3.2.1准备工作1.3.2.2训练分类器1.3.2.3模型应用1.3.3聚类1.3.4关联1.3.5属性选择1.3.6可视化2SPSS2.1SPSS简介2.2SPSS应用方法2.3SPSS操作数据集2.3.1打开数据集2.3.2预处理2.3.2.1数据属性2.3.2.2绘制直方图2.3.2.3按要求统计分析2.3.3聚类2.3.4回归3Weka vs. SPSSWeka简述WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过/ml/weka得到。
同时weka也是新西兰的一种鸟名,而WEKA的主要开发者来自新西兰。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看weka的接口文档。
在weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
Weka是基于java,用于数据挖掘和知识分析一个平台。
来自世界各地的java爱好者们都可以把自己的算法放在这个平台上,然后从海量数据中发掘其背后隐藏的种种关系。
Weka的应用方法Applications:Explorer 使用WEKA 探索数据的环境。
Experimenter 运行算法试验、管理算法方案之间的统计检验的环境。
KnowledgeFlow 这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
广东外语外贸大学 杜剑峰
WEKA教程
1. 2. 3.
4.
5. 6.
7.
8. 9.
WEKA简介 数据格式 数据准备 属性选择 可视化分析 分类预测 关联分析 聚类分析 扩展WEKA
课程的总体目标和要求: 熟悉WEKA的基本操作,了 解WEKA的各项功能 掌握数据挖掘实验的流程
2、数据格式(续)
字符串属性 字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘 中非常有用。 示例: @ATTRIBUTE LCC string 日期和时间属性 日期和时间属性统一用―date‖类型表示,它的格式是 @attribute <name> date [<date-format>] 其中<name>是这个属性的名称,<date-format>是一个字符串, 来规定该怎样解析和显示日期或时间的格式,默认的字符串是 ISO-8601所给的日期时间组合格式―yyyy-MM-ddTHH:mm:ss‖。 数据信息部分表达日期的字符串必须符合声明中规定的格式要求 (下文有例子)。
2、数据格式(续)
WEKA支持的<datatype>有四种
numeric <nominal-specification> string date [<date-format>]
数值型 标称(nominal)型 字符串型 日期和时间型
其中<nominal-specification> 和<date-format> 将在下 面说明。还可以使用两个类型―integer‖和―real‖,但是 WEKA把它们都当作―numeric‖看待。注意―integer‖, ―real‖,―numeric‖,―date‖,―string‖这些关键字是区分 大小写的,而―relation‖、“attribute ‖和―data‖则不区分。
2、数据格式(续)
字符串属性和标称属性的值是区分大小写的。若值中含 有空格,必须被引号括起来。例如:
@relation LCCvsLCSH @attribute LCC string @attribute LCSH string @data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.' AS262, 'Science -- Soviet Union -- History.'
3、数据准备(续)
bank-data数据各属性的含义如下:
id: a unique identification number age: age of customer in years (numeric) sex: MALE / FEMALE region: inner_city/rural/suburban/town income: income of customer (numeric) married: is the customer married (YES/NO) children: number of children (numeric) car: does the customer own a car (YES/NO) save_act: does the customer have a saving account (YES/NO) current_act:does the customer have a current account (YES/NO) mortgage: does the customer have a mortgage (YES/NO) pep: did the customer buy a PEP (Personal Equity Plan, 个人参股计划) after the last mailing (YES/NO)
第一部分给出了头信息(Head information),包括了对关系
的声明和对属性的声明。 第二部分给出了数据信息(Data information),即数据集中 给出的数据。从―@data‖标记开始,后面的就是数据信息了。
Hale Waihona Puke 2、数据格式(续)关系声明 关系名称在ARFF文件的第一个有效行来定义,格式为 @relation <relation-name> <relation-name>是一个字符串。如果这个字符串包含 空格,它必须加上引号(指英文标点的单引号或双引 号)。
3、数据准备(预处理1)
删除无用属性
通常对于数据挖掘任务来说,ID这样的信息是无用的,我们 将之删除。在区域5勾选属性―id‖,并点击―Remove‖。将新 的数据集保存为“bank-data.arff‖,重新打开。 此外,我们 可以通过名为“RemoveType‖的Filter删除某一类型的属性。
2、数据格式(续)
属性声明 属性声明用一列以―@attribute‖开头的语句表示。数据集中的每一 个属性都有它对应的―@attribute‖语句,来定义它的属性名称和数 据类型。 这些声明语句的顺序很重要。首先它表明了该项属性在数据部分 的位置。例如,―humidity‖是第三个被声明的属性,这说明数据部 分那些被逗号分开的列中,第三列数据 85 90 86 96 ... 是相应的 ―humidity‖值。其次,最后一个声明的属性被称作class属性,在分 类或回归任务中,它是默认的目标变量。 属性声明的格式为 @attribute <attribute-name> <datatype> 其中<attribute-name>是必须以字母开头的字符串。和关系名称一 样,如果这个字符串包含空格,它必须加上引号。
3、数据准备
数据文件格式转换 使用WEKA作数据挖掘,面临的第一个问题往往是我们 的数据不是ARFF格式的。幸好,WEKA还提供了对 CSV文件的支持,而这种格式是被很多其他软件,比如 Excel,所支持的。现在我们打开“bank-data.csv‖。 利用WEKA可以将CSV文件格式转化成ARFF文件格式。 ARFF格式是WEKA支持得最好的文件格式。 此外,WEKA还提供了通过JDBC访问数据库的功能。 “Explorer”界面 ―Explorer‖提供了很多功能,是WEKA使用最多的模块。 现在我们先来熟悉它的界面,然后利用它对数据进行预 处理。
2005年8月,在第11届ACM SIGKDD国际会议上,怀卡 托大学的WEKA小组荣获了数据挖掘和知识探索领域的 最高服务奖, WEKA系统得到了广泛的认可,被誉为数 据挖掘和机器学习历史上的里程碑,是现今最完备的数 据挖掘工具之一。 WEKA的每月下载次数已超过万次。
1、WEKA简介(续)
2、数据格式(续)
数据信息 数据信息中―@data‖标记独占一行,剩下的是各个实例 的数据。 每个实例占一行。实例的各属性值用逗号―,‖隔开。如果 某个属性的值是缺失值(missing value),用问号―?‖ 表示,且这个问号不能省略。例如: @data sunny,85,85,FALSE,no ?,78,90,?,yes
1 2 3 4
6
5 7
8
3、数据准备(续)
1.
2.
3.
4. 5.
上图显示的是 ―Explorer‖打开―bank-data.csv‖的情况。我 们根据不同的功能把这个界面分成8个区域。 区域1的几个选项卡是用来切换不同的挖掘任务面板。 区域2是一些常用按钮。包括打开数据,保存及编辑功能。 我们可以在这里把“bank-data.csv‖另存为“bankdata.arff‖。 在区域3中―Choose‖某个―Filter‖,可以实现筛选数据或者 对数据进行某种变换。数据预处理主要就利用它来实现。 区域4展示了数据集的一些基本情况。 区域5中列出了数据集的所有属性。勾选一些属性并 ―Remove‖就可以删除它们,删除后还可以利用区域2的 ―Undo‖按钮找回。区域5上方的一排按钮是用来实现快速 勾选的。在区域5中选中某个属性,则区域6中有关于这个 属性的摘要。注意对于数值属性和标称属性,摘要的方式 是不一样的。图中显示的是对数值属性―income‖的摘要。
3、数据准备(续)
6.
7.
区域7是区域5中选中属性的直方图。若数据集的某个 属性是目标变量,直方图中的每个长方形就会按照该 变量的比例分成不同颜色的段。默认地,分类或回归 任务的默认目标变量是数据集的最后一个属性(这里 的―pep‖正好是)。要想换个分段的依据,即目标变量, 在区域7上方的下拉框中选个不同的分类属性就可以 了。下拉框里选上―No Class‖或者一个数值属性会变 成黑白的直方图。 区域8是状态栏,可以查看Log以判断是否有错。右边 的weka鸟在动的话说明WEKA正在执行挖掘任务。右 键点击状态栏还可以执行JAVA内存的垃圾回收。
2、数据格式(续)
文件内容说明 识别ARFF文件的重要依据是分行,因此不能在这种文 件里随意的断行。空行(或全是空格的行)将被忽略。 以―%‖开始的行是注释,WEKA将忽略这些行。如果你 看到的―weather.arff‖文件多了或少了些―%‖开始的行, 是没有影响的。 除去注释后,整个ARFF文件可以分为两个部分。
2、数据格式(续)
日期属性的值必须与属性声明中给定的相一致。例如:
@RELATION Timestamps @ATTRIBUTE timestamp DATE "yyyy-MM-dd HH:mm:ss" @DATA "2001-04-03 12:12:12" "2001-05-03 12:59:55"
作为一个大众化的数据挖掘工作平台, WEKA集成了大 量能承担数据挖掘任务的机器学习算法,包括对数据进 行预处理、分类、回归、聚类、关联分析以及在新的交 互式界面上的可视化等等。通过其接口,可在其基础上 实现自己的数据挖掘算法。