数据库如何支持分布式事务设置手册
分布式事务的实现方法

分布式事务的实现方法
分布式事务的实现方法有多种,以下是其中几种常见的方案:
1. 两阶段提交(XA 方案):事务管理器先询问各个数据库是否准备好了,每个要操作的数据库都回复事务管理器ok,那么就正式提交事务。
2. TCC方案:TCC的全称是:Try、Confirm、Cancel。
Try阶段是对各个服务的资源做检测以及对资源进行锁定或者预留;Confirm阶段是在各个服务中执行实际的操作;Cancel阶段是如果任何一个服务的业务方法执行出错,那么就需要进行补偿,即执行已经执行成功的业务逻辑的回滚操作。
一般来说,支付、交易等需要严格保证资金正确性的场景会使用TCC方案。
3. 可靠消息最终一致性方案:通过消息队列将分布式事务中的操作进行异步解耦,从而实现最终的一致性。
这种方式能够处理大量并发操作,但是可能会存在数据不一致的风险。
4. 最大努力通知方案:通过最大努力的方式将通知发送给其他服务,以实现分布式事务的一致性。
这种方式简单易行,但是可能会因为网络问题或者服务不可用等原因导致通知失败。
5. SAGA方案:SAGA是一种基于事务的分布式事务处理模型,它将一个分布式事务视为一系列本地事务的组合。
每个本地事务在一个单独的节点上执行,并且通过消息传递进行通信。
SAGA能够保证全局事务的最终一致性,同时具有较好的容错性和可恢复性。
以上是分布式事务的几种常见实现方案,每种方案都有其优缺点,需要根据具体的业务场景和需求来选择适合的方案。
SpringCloud分布式事务的解决方案

SpringCloud分布式事务的解决⽅案常见的分布式解决⽅案1、两阶段提交协议(2PC) 解决分布式系统的数据⼀致性问题出现了两阶段提交协议(2 Phase Commitment Protocol),两阶段提交由协调者和参与者组成,共经过两个阶段和三个操作,部分关系数据库如Oracle、MySQL⽀持两阶段提交协议。
说到2pc就不得不聊聊数据库分布式事务中的XA transactions在XA协议中分为两阶段:第⼀阶段:事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.第⼆阶段:事务协调器要求每个数据库提交数据,或者回滚数据。
举⼀个例⼦:1、应⽤程序通过事务协调器向两个库发起prepare,两个数据库收到消息分别执⾏本地事务(记录⽇志), 但不提交,如果执⾏成功则回复yes,否则回复no。
2、事务协调器收到回复,只要有⼀⽅回复no则分别向参与者发起回滚事务,参与者开始回滚事务。
3、事务协调器收到回复,全部回复yes,此时向参与者发起提交事务。
如果参与者有⼀⽅提交事务失败则由事务协调器发起回滚事务。
优点: 尽量保证了数据的强⼀致,实现成本较低,在各⼤主流数据库都有⾃⼰实现,对于MySQL是从5.5开始⽀持。
缺点:单点问题:事务管理器在整个流程中扮演的⾓⾊很关键,如果其宕机,⽐如在第⼀阶段已经完成, 在第⼆阶段正准备提交的时候事务管理器宕机,资源管理器就会⼀直阻塞,导致数据库⽆法使⽤。
同步阻塞:在准备就绪之后,资源管理器中的资源⼀直处于阻塞,直到提交完成,释放资源。
数据不⼀致:两阶段提交协议虽然为分布式数据强⼀致性所设计,但仍然存在数据不⼀致性的可能,⽐如在第⼆阶段中,假设协调者发出了事务commit的通知,但是因为⽹络问题该通知仅被⼀部分参与者所收到并执⾏了commit操作,其余的参与者则因为没有收到通知⼀直处于阻塞状态,这时候就产⽣了数据的不⼀致性。
分布式事务型关系数据库管理系统技术要求

分布式事务型关系数据库管理系统技术要求分布式事务型关系数据库管理系统(DT-RDBMS)是用于处理大规模分布式数据的关键技术。
为了确保数据一致性和可靠性,这类系统需要满足以下技术要求:1. 分布式事务处理能力:DT-RDBMS需要支持分布式事务处理,确保多个数据库节点之间的事务操作可以协调一致完成。
这包括事务的并发控制、锁定机制、事务的隔离能力等。
2. 数据分布与复制管理:DT-RDBMS需要能够有效地管理数据在分布式环境下的分布和复制。
这包括数据的划分、分片策略的设计、数据冗余和副本的管理,以提高系统的可用性和容错能力。
3. 节点的容错与恢复:DT-RDBMS需要具备故障检测、故障转移、容错恢复的能力。
当节点出现故障时,系统应能够及时检测到,将受影响的事务进行适当的转移或恢复,确保系统的连续性。
4. 性能优化与负载均衡:DT-RDBMS需要具备性能优化和负载均衡的策略。
通过合理的查询优化、索引和缓存机制,提高系统的处理能力和响应速度,并确保各个数据库节点的负载均衡,避免出现瓶颈和性能下降。
5. 数据一致性和同步机制:DT-RDBMS需要确保分布式环境下数据的一致性和同步。
这包括数据的原子性、一致性、隔离性和持久性(ACID特性),以及正确处理多个节点之间的数据同步、更新和冲突解决。
6. 安全性与权限控制:DT-RDBMS需要具备强大的安全性和权限控制机制,保护数据不受非法访问和篡改。
这包括用户认证、访问控制、数据加密和审计跟踪等功能,以保证数据的安全性和机密性。
综上所述,分布式事务型关系数据库管理系统需要具备分布式事务处理能力、数据分布与复制管理、节点容错与恢复、性能优化与负载均衡、数据一致性和同步机制,以及安全性与权限控制等关键技术要求。
这些技术要求确保了系统的可靠性、性能和安全性,适用于处理大规模分布式数据的应用场景。
ODP-Net操作Oracle分布式事务
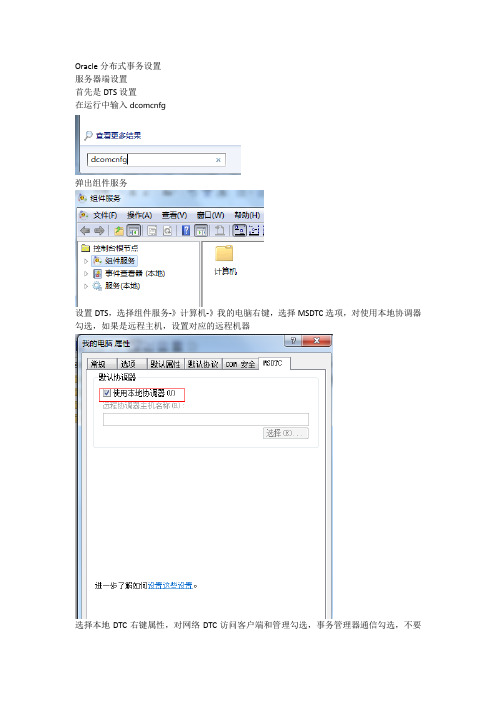
Oracle分布式事务设置服务器端设置首先是DTS设置在运行中输入dcomcnfg弹出组件服务设置DTS,选择组件服务-》计算机-》我的电脑右键,选择MSDTC选项,对使用本地协调器勾选,如果是远程主机,设置对应的远程机器选择本地DTC右键属性,对网络DTC访问客户端和管理勾选,事务管理器通信勾选,不要求进行验证,启用XA事务,启用SNA LU6.2事务,DTC账号:NT AUTHORITY\NetworkService关闭防火墙,如果不关闭防火墙,开启对应进出站规则,点击高级设置开启入站规则中,红色框中分布式处理协调器全部启用开启出站规则中,红色框中的分布式事务处理协调器,并保持端口畅通查看OracleMTSRecoveryService服务是否存在,如果不存在,安装Oracle对应的项目已经安装过Oracle的,进入卸载安装点击下一步选择原有的安装目录对应的Product.xml(PS该文件一般都在安装目录中的Stage目录中),点击下一步选择定制安装,继续下一步选择对应的Oracle安装目录检查安装条件,继续下一步选择Oracle Services For Microsoft Transaction Server勾选下一步安装完成!运行输入services.msc,查看服务中对应的Oracle服务是否启动.以上服务器端设置完成。
客户端设置根据Oracle数据库版本,安装对应的Oralce的ODAC版本。
本文根据对应的数据库,安装ODAC的11g32版本进入安装界面选择客户端安装选择需要安装的位置选择对应需要安装的项目,如果没有安装过客户端,请必须勾选客户端选项,红色框的是必选。
安装完成!客户端设置完成。
项目添加引用,选择Oracle.DataAcess.dll的4.0版本,不要选择2.0版本。
分布式代码如下Console.WriteLine("Oracle.DataAccess.Client操作方式:");using (TransactionScope scope = newTransactionScope(TransactionScopeOption.Required)){using (Odp.OracleConnection connection1 = newOdp.OracleConnection(ConfigurationManager.ConnectionStrings["OdpOdpConn"].ToString())) {connection1.Open();Console.WriteLine("连接OdpConn成功!");Odp.OracleCommand command1 = newOdp.OracleCommand(ConfigurationManager.AppSettings["OdpConnSql"].ToString(),connection1);command1.ExecuteNonQuery();Console.WriteLine("执行OdpConnSql成功!");}using (Odp.OracleConnection connection2 = newOdp.OracleConnection(ConfigurationManager.ConnectionStrings["OdpEtmConn"].ToString())) {connection2.Open();Console.WriteLine("连接EtmConn成功!");// Execute the second command in the second database.Odp.OracleCommand command2 = newOdp.OracleCommand(ConfigurationManager.AppSettings["EtmConnSql"].ToString(),connection2);command2.ExecuteNonQuery();Console.WriteLine("执行EtmConnSql成功!");//writer.WriteLine("Rows to be affected by command2: {0}", returnValue);}plete();Console.WriteLine("事务提交完成!");如果Connection.Open()报TNS超时错误,请把tnsnames.ora文件更新到对应的Client目录中,如:D:\app\ \product\11.2.0\client_1\Network\Admin下。
sqlserver分布式数据库msdtc分布式事务错误和解决方法

SQL Server 分布式数据库MSDTC 分布式事务错误和解决方法一、问题现象假如分布式事务的客户端和服务器端(可能N个)不在同一台服务器上,如分别为应用程序服务器和数据库服务器,经常会出现一下错误:①在建立与服务器的连接时出错。
在连接到SQL Server 2005 时,在默认的设置下SQL Server 不允许进行远程连接可能会导致此失败。
(provider: 命名管道提供程序, error: 40 - 无法打开到SQL Server 的连接)。
②事务已被隐式或显式提交,或已终止。
③该伙伴事务管理器已经禁止了它对远程/网络事务的支持。
(异常来自HRESULT:0x8004D025)。
(TransactionScope异常)④[COMException (0x8004d00e):此事务已明地或暗地被确认或终止(异常来自HRESULT:0x8004D00E)]。
(MSDTC 分布式事务错误)⑤Import of MSDTC transaction failed: Result Code = 0x8004d023. (MSDTC安全性配置问题)二、解决方法遇到以上的问题或SQL Server分布式的问题,请按照以下步骤设置,问题应该可以得到解决。
可能有些步骤对您来说是多余的,但求全不求漏。
1. 启动MSDTC服务。
MSDTC简介:MSDTC是Microsoft Distributed Transaction Coordinator的简称,即微软分布式事务协调器,描述:协调跨多个数据库、消息队列、文件系统等资源管理器的事务。
如果停止次服务,则不会发生这些事务。
如果禁用此服务,显式依赖此服务的其他服务将无法启动。
MSDTC启动方法:①“开始”|“运行”,输入“services.msc”,或者“控制面板”|“管理工具”|“服务”,打开“服务”窗口,在名称中找到“Distributed Transaction Coordinator”,将其启动。
如何进行分布式事务处理和一致性保证

如何进行分布式事务处理和一致性保证分布式事务是指在分布式系统中多个节点之间进行的一组操作,为了确保这些操作的一致性和原子性,需要采用一致性保证的机制。
本文将主要介绍分布式事务处理和一致性保证的一些常见方法和技术。
1.事务概述分布式事务是指跨多个节点的一组操作,这些操作要么全部成功,要么全部失败。
分布式事务处理主要面临两个挑战:一是数据的一致性问题,即保证不同节点的数据在事务执行前后保持一致;二是并发冲突问题,即多个节点同时访问共享资源时的并发控制。
2. ACID原则ACID(原子性、一致性、隔离性和持久性)是一组保证事务的关键特性。
原子性指事务在执行过程中要么全部成功,要么全部失败;一致性指事务前后数据库的状态必须保持一致;隔离性指并发事务之间要相互隔离,互不干扰;持久性指事务一旦提交,其结果就应该永久保存。
3.两阶段提交(2PC)两阶段提交是最常见的实现分布式事务的协议。
它基本上是一个分布式的锁定协议,包括协调者和参与者两种角色。
第一阶段,协调者询问所有参与者是否可以提交事务;第二阶段,根据所有参与者的回复,协调者决定是提交还是中止事务。
4.补偿事务(TCC)补偿事务是另一种常见的实现分布式事务的方法。
它将事务分为三个阶段:Try、Confirm和Cancel。
Try阶段进行预处理,如果所有的Try操作都成功,事务进入Confirm阶段,执行真正的业务操作;如果任何一个Try操作失败,事务进入Cancel阶段,进行回滚操作。
5.最大努力通知(BCC)最大努力通知也是一种常用的分布式事务处理的机制,它基于消息传递。
在这种模式下,事务的参与者不会被直接调用来执行事务,而是通过消息发送来通知参与者执行事务。
这种模式下无法保证所有参与者的一致性,需要通过额外的机制来解决。
6.分布式共识算法分布式共识算法是一种用于解决分布式系统中一致性问题的算法。
最著名的分布式共识算法是Paxos和Raft。
这些算法通过选出一个领导者来确保系统的一致性,领导者负责接受和处理客户端的请求,并传播给其他参与者。
在SQL SERVER中使用分布式事务全攻略(图解)

在SQL SERVER中使用分布式事务全攻略(图解)[原创文章] 作者:cyw操作系统:Win2003 Enterprise Edition。
版本:5.2.3790 Service Pack 2 内部版本号 3790。
数据库:SQL Server 2000 企业版 + SP4 + SP4后的补丁。
版本:8.00.2187 (Intel X86) Mar 9 2006。
网络环境:两台服务器仅安装TCP/IP协议,处于相同网段,工作组可以不同,相互间Ping主机名成功,Ping IP地址也能成功。
如果不能Ping成功,请在两台服务器上安装NETBIOS协议后再重试。
如果还不行,请在“C:\WINDOWS\system32\drivers\etc\hosts”文件中增加一条记录:xxx.xxx.xxx.xxx 服务器主机名作用同样是把服务器名对应到链接服务器的IP地址。
一、建立链接服务器假设服务器A的IP是172.16.10.6,SQLServer登录用户sa,密码8888;服务器B的IP是172.16.10.16,SQLServer登录用户sa,密码9999。
现在先在服务器A上建立与B通信的远程链接服务器,假设链接的别名是BServer,如图:点击“确定”,完成。
同理,在B服务器上也建立对A服务器的远程链接,链接别名为AServer,数据源地址改为172.16.10.6,密码输入8888,其他相同。
当然,也可以使用SQL语句完成以上操作,如下:-- 建立远程链接服务器BServerEXEC sp_addlinkedserve r @server = 'BServer', @srvproduct = '', @provider = 'SQLOLEDB',@datasrc = '172.16.10.16', @catalog = 'HYCommon'-- 建立远程登录到BServerEXEC sp_addlinkedsrvlogin@rmtsrvname = 'BServer', @useself = 'false', @rmtuser = 'sa',@rmtpassword = '9999'-- 设置远程服务器选项:允许RPC和RPC输出(该步可选)Exec sp_serveroption'BServer', 'RPC', 'true'Exec sp_serveroption'BServer', 'RPC Out', 'true'现在测试一下链接是否成功,打开查询分析器,登录到A服务器,输入以下SQL运行:Select * From BServer.pubs.dbo.titles正常的话就可以看到B服务器上pubs数据库的titles表数据,如果不行,请检查网络连接是否满足文章开头所述的网络环境。
解析分布式事务的四种解决方案

解析分布式事务的四种解决方案分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性。
例如在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
在分布式系统中,要实现分布式事务,无外乎那几种解决方案。
一、两阶段提交(2PC)两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,最终决定这些参与者是否要真正执行事务。
1、运行过程①准备阶段:协调者询问参与者事务是否执行成功,参与者发回事务执行结果。
②提交阶段:如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。
只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
2、存在的问题①同步阻塞:所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
②单点问题:协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。
特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作。
③数据不一致:在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
④太过保守:任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
二、补偿事务(TCC)TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
它分为三个阶段:①Try 阶段主要是对业务系统做检测及资源预留。
②Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认 Confirm阶段是不会出错的。
即:只要Try成功,Confirm一定成功。
③Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
itc分布式系统操作手册

itc分布式系统操作手册分布式系统操作手册1. 什么是分布式系统?分布式系统是指由多个计算机或服务器组成的网络系统,这些计算机或服务器相互协作,共同处理数据和运行应用程序。
分布式系统允许将计算任务分配到不同的节点上,并通过消息传递或共享存储等方式实现节点间的通信和数据共享。
2. 如何搭建分布式系统?搭建一个分布式系统需要以下几个步骤:- 首先,确定系统的规模和需求,选择合适的硬件设备和操作系统。
- 其次,设计系统架构,确定节点间的通信方式和数据共享方式。
常见的通信方式有RPC(远程过程调用)和消息队列等,数据共享方式有共享存储和分布式文件系统等。
- 第三,部署和配置各个节点,并确保节点之间可以相互通信。
此步骤包括安装操作系统、安装相关软件、设置网络和配置节点间的安全认证等。
- 最后,测试和优化系统性能,确保分布式系统能够高效稳定地运行。
3. 如何管理分布式系统?管理一个分布式系统需要注意以下几点:- 监控系统状态:使用监控工具实时监测各个节点的运行状态和性能指标,及时发现并解决问题。
- 异常处理:对于系统故障或错误,及时采取相应的措施进行修复和恢复,保证系统的可靠性和稳定性。
- 扩展系统规模:根据业务需求和系统负载情况,适时扩展分布式系统的规模,增加节点数量或者调整节点配置。
- 日志和错误追踪:记录系统日志和错误信息,方便排查问题和进行系统的优化和改进。
4. 如何保证分布式系统的安全性?保证分布式系统的安全性是一个重要的任务。
以下是一些常见的保护措施:- 访问控制:限制对系统资源的访问权限,只允许有权限的用户或节点进行访问。
- 数据加密:对敏感数据进行加密处理,确保数据在传输和存储过程中的安全性。
- 身份认证:对用户或节点进行身份验证,防止未经授权的访问。
- 安全审计:定期检查和审计系统安全配置和日志,发现和排除潜在的安全隐患。
总结:分布式系统是现代计算环境中常见的系统架构,具有高可靠性、高性能和可扩展性的优势。
多数据源事务控制解决方案(分布式事务控制)

多数据源事务控制解决方案(分布式事务控制)在分布式系统中,多数据源事务控制是一个常见的挑战。
分布式系统中的数据通常存储在不同的数据库中,每个数据库都有自己的事务管理机制。
在跨多个数据源执行事务时,确保数据的一致性和正确性变得非常重要。
为了解决这个问题,可以采用以下几种多数据源事务控制解决方案。
两阶段提交是一种经典的分布式事务控制协议。
它通过协调者(coordinator)和参与者(participant)之间的通信来实现多数据源事务的一致性。
协议的执行过程分为两个阶段:准备阶段和提交阶段。
在准备阶段,协调者向所有参与者发送准备请求,询问它们是否可以执行事务。
如果所有参与者都同意,则进入提交阶段,并向所有参与者发送提交请求。
否则,协调者会向所有参与者发送回滚请求,取消事务的执行。
尽管两阶段提交能够确保事务的一致性,但它的缺点是协调者的单点故障和阻塞问题。
三阶段提交是对两阶段提交的改进。
它引入了超时机制来应对协调者的单点故障和阻塞问题。
三阶段提交的执行过程分为准备阶段、提交前准备阶段和提交阶段。
在准备阶段,协调者向所有参与者发送准备请求,询问它们是否可以执行事务。
如果所有参与者都同意,则进入提交前准备阶段,并向所有参与者发送预提交请求。
在预提交阶段,参与者将事务写入日志,并等待协调者的最终决策。
如果参与者在预提交阶段发生故障,则会进入回滚状态。
最后,在提交阶段,协调者向所有参与者发送提交请求,参与者根据日志的状态来确定是否提交或回滚事务。
三阶段提交相对于两阶段提交,能够减少长时间的阻塞情况,但仍然存在协调者故障时的一致性问题。
3. 可靠消息服务(Reliable message service)可靠消息服务是一种解耦发送方和接收方的通信机制。
在多数据源事务控制中,可靠消息服务可以用来确保不同数据源之间的事务操作的一致性。
发送方将事务消息发送到消息队列中,并等待确认。
接收方从消息队列中接收消息进行处理,并给发送方发送一个确认消息。
分布式事务解决方案3--本地消息表(事务最终一致方案)

分布式事务解决⽅案3--本地消息表(事务最终⼀致⽅案)⼀、本地消息表原理1、本地消息表⽅案介绍本地消息表的最终⼀致⽅案采⽤BASE原理,保证事务最终⼀致在⼀致性⽅⾯,允许⼀段时间内的不⼀致,但最终会⼀致。
在实际系统中,要根据具体情况,判断是否采⽤。
(有些场景对⼀致性要求较⾼,谨慎使⽤)2、本地消息表的使⽤场景基于本地消息表的⽅案中,将本事务外操作,记录在消息表中其他事务,提供操作接⼝定时任务轮询本地消息表,将未执⾏的消息发送给操作接⼝。
操作接⼝处理成功,返回成功标识,处理失败,返回失败标识。
定时任务接到标识,更新消息的状态定时任务按照⼀定的周期反复执⾏对于屡次失败的消息,可以设置最⼤失败次数超过最⼤失败次数的消息,不进⾏接⼝调⽤等待⼈⼯处理例如使⽤⽀付宝的⽀付场景,系统⽣成订单,⽀付宝系统⽀付成功后,调⽤我们系统提供的回调接⼝,回调接⼝更新订单状态为已⽀付。
回调通知执⾏失败,⽀付宝会过⼀段时间再次调⽤。
3、本地消息表架构图4、优缺点优点:避免了分布式事务,实现了最终⼀致性缺点:注意重试时的幂等性操作⼆、本地消息表数据库设计整体⼯程复⽤前⾯的my-tcc-demo1、两台数据库 134和129。
user_134 创建⽀付消息表payment_msg, user_129数据库创建订单表t_order2、使⽤MyBatis-generator ⽣成数据库映射⽂件,⽣成后的结构如下图所⽰三、⽀付接⼝1、创建⽀付服务PaymentService@Servicepublic class PaymentService {@Resourceprivate AccountAMapper accountAMapper;@Resourceprivate PaymentMsgMapper paymentMsgMapper;/*** ⽀付接⼝* @param userId ⽤户Id* @param orderId 订单Id* @param amount ⽀付⾦额* @return 0: 成功; 1:⽤户不存在 2:余额不⾜*/public int payment(int userId, int orderId, BigDecimal amount){//⽀付操作AccountA accountA = accountAMapper.selectByPrimaryKey(userId);if(accountA == null){return 1;}if(accountA.getBalance().compareTo(amount) < 0){return 2;}accountA.setBalance(accountA.getBalance().subtract(amount));accountAMapper.updateByPrimaryKey(accountA);PaymentMsg paymentMsg = new PaymentMsg();paymentMsg.setOrderId(orderId);paymentMsg.setStatus(0); //未发送paymentMsg.setFailCnt(0); //失败次数paymentMsg.setCreateTime(new Date());paymentMsg.setCreateUser(userId);paymentMsg.setUpdateTime(new Date());paymentMsg.setUpdateUser(userId);paymentMsgMapper.insertSelective(paymentMsg);return 0;}}2、创建Controller层@RestControllerpublic class PaymentController {@Autowiredprivate PaymentService paymentService;//localhost:8080/payment?userId=1&orderId=10010&amount=200@RequestMapping("payment")public String payment(int userId, int orderId, BigDecimal amount){int result = paymentService.payment(userId, orderId,amount);return "⽀付结果:" + result;}}3、调⽤接⼝localhost:8080/payment?userId=1&orderId=10010&amount=200查看表。
数据库分布式系统的说明书

数据库分布式系统的说明书一、引言数据库分布式系统是一种基于分布式计算和存储的数据库系统,可以将数据和计算任务分散到多个节点上进行并行处理,从而提高系统的性能与可扩展性。
本文将详细介绍数据库分布式系统的原理、架构以及应用场景。
二、原理与架构1. 分布式数据存储数据库分布式系统中的数据通常被分散存储在多个节点上,每个节点负责管理一部分数据。
这样的分布方式可以提高数据的可用性和容错性,同时也增加了系统的并行处理能力。
2. 分布式数据访问为了实现对分布式存储的数据的高效访问,数据库分布式系统采用了一些常用的技术手段,如数据划分、数据复制、数据分片等。
这些技术可以提高数据的可靠性、查询效率和负载均衡能力。
3. 分布式事务处理在分布式环境下,事务处理变得更加复杂。
数据库分布式系统通过引入分布式事务协调器来协调多个节点上的事务执行,保证数据的一致性和可靠性。
4. 分布式查询与计算数据库分布式系统支持将查询和计算任务分发到多个节点上进行并行处理,从而提高系统的查询性能和计算能力。
常用的分布式查询与计算技术包括MapReduce、Spark等。
三、应用场景数据库分布式系统在许多领域都有广泛的应用,以下是几个典型的应用场景。
1. 大规模数据分析对于大规模的数据分析任务,传统的单机数据库往往无法满足性能要求。
通过将数据分散存储在多个节点上,并使用分布式查询和计算技术,可以大幅提高数据分析的效率和速度。
2. 云计算平台云计算平台需要支持大规模用户的数据存储和查询需求,因此数据库分布式系统是其基础设施之一。
通过将数据库分布在多个物理节点上,可以提供高可用性和扩展性的数据服务。
3. 实时数据处理对于实时数据处理场景,数据库分布式系统可以通过数据的并行处理和分布式计算来实现对实时数据的快速处理和分析。
这在金融、物联网等领域有着重要的应用价值。
四、总结数据库分布式系统是一个基于分布式计算和存储的数据库架构,可以提高系统的性能、可靠性和可扩展性。
seata分布式事务的环境搭建与使用

seata分布式事务的环境搭建与使⽤⽬录⼀、seata介绍1. 什么是 seata2. seata 的基本原理⾸先我们先看⼀张分布式环境下,服务与服务之间的调⽤关系图:其实分布式事务是由⼀批分⽀事务组成的全局事务,通常分⽀事务只是本地事务。
seata的核⼼主要有三部分组成:事务协调器(TC):维护全局事务和分⽀事务的状态,驱动全局事务提交或者回滚。
事务管理器(TM):定义全局事务的范围:开启全局事务,提交或回滚全局事务(在分布式环境中相当于事务的发起⽅)。
资源管理器(RM):管理分⽀事务正在处理的资源,与TC进⾏对话以注册分⽀事务并报告分⽀事务的状态。
并驱动分⽀事务的提交或者回滚(在分布式环境中相当于事务的参与者)。
seata管理的分布式事务的⽣命周期:⾸先,需要构建⼀个全局事务的协调者TC。
发起⽅与参与⽅与全局事务协调者TC建⽴长连接。
发起⽅向全局事务协调者申请⼀个全局事务XID,缓存在本地线程中。
当发起⽅调⽤参与⽅的服务接⼝时,会将申请到的全局事务XID放⼊请求头中。
参与⽅从请求头中获取XID,如果获取成功,则会向全局事务协调者注册(为参与⽅),缓存XID到本地线程。
执⾏完成之后提交本地事务,插⼊undo_log⽇志(后期⽤于回滚使⽤)。
调⽤完成参与⽅服务接⼝,如果整个业务流程没有异常,则会通知全局事务协调者,全局事务协调者通知所有的参与⽅提交事务。
事务提交成功后,删除undo_log⽇志。
调⽤完成参与⽅服务接⼝,如果整个业务流程存在异常,则会通知全局事务协调者,全局事务协调者通知所有的参与⽅回滚事务。
事务回滚时候,删除undo_log⽇志。
⼆、seata 环境搭建seata环境搭建会使⽤到mysql及nacos环境。
具体搭建步骤可参照之前发布的⽂章,如有不详细的地⽅,请指正。
1. 服务器端环境搭建[client] 主要是客户端配置,undo_log⽇志等。
[server] 服务端部署脚本,⽐如使⽤db存储模式的时候,会从这⾥获取建表语句。
分布式事务详解

分布式事务详解1. 什么是分布式事务1.1 事务严格意义上的事务实现应该是具备原⼦性、⼀致性、隔离性和持久性,简称 ACID。
通俗意义上来说,事务就是为了使得⼀些更新等操作要么都成功,要么都失败。
原⼦性(Atomicity):可以理解为⼀个事务内的所有操作要么都执⾏,要么都不执⾏。
⼀致性(Consistency):可以理解为数据是满⾜完整性约束的,也就是不会存在中间状态的数据,⽐如你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态。
隔离性(Isolation):指的是多个事务并发执⾏的时候不会互相⼲扰,即⼀个事务内部的数据对于其他事务来说是隔离的。
持久性(Durability):指的是⼀个事务完成了之后数据就被永远保存下来,之后的其他操作或故障都不会对事务的结果产⽣影响。
其中,原⼦性和持久性就是靠undo和redo⽇志来实现的。
在Mysql中,有许多⽇志⽂件,这2个⽂件就是与事务有关的。
1.2 undo⽇志undo⽇志:⽤于保证事务的原⼦性。
原理:1. 在操作任何数据之前,先将数据备份到Undo Log。
2. 然后进⾏数据的修改。
3. 若出现了错误或⽤户执⾏了ROLLBACK语句,系统就可以利⽤Undo Log中的备份数据恢复到事务开始之前的状态。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录B=2到undo log5. 修改B=46. 将undo log写到磁盘7. 将数据写到磁盘8. 事务提交1.3 redo⽇志redo⽇志:⽤于保证事务的持久性原理:1. redo log与undo log 相反,redo log记录的是新数据的备份,undo log记录的是旧数据的备份2. 在事务提交前只需要将redo log持久化即可。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录A=3到redo log5. 记录B=2到undo log6. 修改B=47. 记录B=4到redo log8. 将undo log写到磁盘9. 将redo log写⼊磁盘10. 事务提交1.4 分布式事务分布式事务:顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合⽽成。
stata分布式事务注解

stata分布式事务注解Stata是一种统计分析软件,它并不直接支持分布式事务。
分布式事务是指涉及多个独立的数据源或数据库的事务操作,它们可以在不同的计算机或服务器上执行。
然而,Stata是一种本地软件,主要用于单机数据分析和统计建模,没有内置的分布式事务处理功能。
要在Stata中处理分布式事务,你可能需要借助其他工具或技术。
以下是一些可能的方法:1. 数据预处理,如果你的数据分布在不同的数据源中,你可以使用Stata中的数据导入功能将数据从各个数据源导入到Stata中进行预处理。
你可以使用Stata的数据合并命令(如merge)将来自不同数据源的数据合并到一个数据集中。
2. 数据库连接,如果你的数据存储在不同的数据库中,你可以使用Stata中的数据库连接功能来连接这些数据库。
Stata支持连接多种数据库,如MySQL、PostgreSQL等。
通过连接数据库,你可以在Stata中执行SQL查询,将查询结果导入到Stata中进行进一步的分析。
3. 外部工具,如果你需要在分布式环境中执行复杂的事务操作,你可能需要借助其他工具或编程语言。
例如,你可以使用Python或R等编程语言来编写分布式事务处理的代码,并与Stata进行集成。
你可以使用Stata的外部命令(如shell)来调用外部工具,并将结果导入到Stata中进行分析。
需要注意的是,以上方法都需要你具备一定的编程和数据处理技能。
此外,具体的分布式事务处理方法还取决于你的数据源和具体的需求。
因此,在实际操作中,你可能需要进一步研究和探索适合你情况的解决方案。
总结起来,虽然Stata本身不直接支持分布式事务,但你可以通过数据预处理、数据库连接和外部工具等方法来处理分布式事务,并将结果导入到Stata中进行进一步的分析。
希望这些信息对你有帮助。
Mysql数据库分布式事务XA详解

Mysql数据库分布式事务XA详解XA事务简介XA 事务的基础是两阶段提交协议。
需要有⼀个事务协调者来保证所有的事务参与者都完成了准备⼯作(第⼀阶段)。
如果协调者收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第⼆阶段)。
在这个XA事务中扮演的是参与者的⾓⾊,⽽不是协调者(事务管理器)。
的XA事务分为内部XA和外部XA。
外部XA可以参与到外部的分布式事务中,需要应⽤层介⼊作为协调者;内部XA事务⽤于同⼀实例下跨多引擎事务,由Binlog作为协调者,⽐如在⼀个存储引擎提交时,需要将提交信息写⼊⼆进制⽇志,这就是⼀个分布式内部XA事务,只不过⼆进制⽇志的参与者是MySQL本⾝。
Mysql 在XA事务中扮演的是⼀个参与者的⾓⾊,⽽不是协调者。
MySQL XA 事务基本语法XA {START|BEGIN} xid [JOIN|RESUME] 启动⼀个XA事务 (xid 必须是⼀个唯⼀值; [JOIN|RESUME] 字句不被⽀持)XA END xid [SUSPEND [FOR MIGRATE]] 结束⼀个XA事务 ( [SUSPEND [FOR MIGRATE]] 字句不被⽀持)XA PREPARE xid 准备XA COMMIT xid [ONE PHASE] 提交XA事务XA ROLLBACK xid 回滚XA事务XA RECOVER 查看处于PREPARE 阶段的所有XA事务事务标识符xidxid 是⼀个事务标识符,它由客户端提供或者有mysql服务器⽣成。
xid的格式⼀般为 xid : gtrid [, bqual [, formatID]] ;gtrid是⼀个全局事务标识符,bqual是⼀个分⽀限定符,formatID是⼀个数字,⽤于标识由gtrid和bqual值使⽤的格式。
根据语法的表⽰,bqual和formatID是⾃选的。
如果没有给定,默认的bqual值是''。
MySQL的分布式事务处理和跨库事务的解决方案

MySQL的分布式事务处理和跨库事务的解决方案随着互联网的快速发展和大数据的兴起,对于数据库系统的性能和可扩展性提出了更高的要求。
在很多应用场景中,单一的数据库已经无法满足需求,需要将数据分布在多个数据库上进行处理和存储。
而在这种分布式环境下,如何保证事务的一致性和数据的可靠性成为了一个重要的挑战。
本文将介绍MySQL的分布式事务处理和跨库事务的解决方案。
一、MySQL的事务机制MySQL是一个开源的关系型数据库管理系统,它的事务机制是基于ACID原则的。
ACID是指原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
MySQL通过实现多版本并发控制(MVCC)和锁机制来实现事务的隔离性,对于单个数据库的事务处理是非常可靠的。
然而,在分布式环境下,由于存在多个数据库节点,每个节点之间可能存在网络延迟和故障等问题,导致事务的一致性无法得到保证。
二、分布式事务处理的问题在分布式架构中,事务跨越多个数据库节点是很常见的需求。
然而,由于每个节点拥有自己的独立事务,没有统一的事务控制机制,导致跨库事务会面临以下问题:1. 事务的一致性:由于网络延迟和节点故障等原因,导致事务在某个节点上失败,可能会引起数据不一致的问题。
例如,一个转账操作同时操作了两个数据库节点,如果其中一个节点操作成功,而另一个节点操作失败,那么账户的余额就会不一致。
2. 事务的隔离性:在分布式环境下,每个节点都有自己的事务隔离级别,可能导致事务的隔离性无法保证。
例如,一个事务读取了一个节点的数据后,如果读取到了另一个节点正在修改的数据,就可能导致读取到脏数据。
3. 事务的并发性:在分布式环境下,并发访问多个数据库节点的事务会导致性能问题。
由于每个节点都有自己的事务处理机制,无法有效地并发执行事务。
三、跨库事务的解决方案为了解决分布式事务的问题,MySQL提供了多种跨库事务的解决方案。
cirrodata 分布式数据库 安装及使用手册说明书

CirroData分布式数据库安装及使用手册产品版本:V2.13.0文档版本:V0.3北京东方国信科技股份有限公司版权声明本文档是北京东方国信科技股份有限公司的技术资料,版权等知识产权归北京东方国信科技股份有限公司所有,受法律保护。
未经版权所有人书面许可,任何单位和个人不得使用、复制、摘编、传播,或以其他方式非法使用本文档的部分或全部内容。
对于侵犯版权的,版权所有人将追究其法律责任。
目录前言 (1)1安装前的准备 (3)1.1创建cirrodata用户 (3)1.2用户权限 (3)1.3Zookeeper (3)1.4所有节点时钟同步 (4)1.5在所有CirroData节点中更改系统参数 (4)1.6修改或追加HDFS设置 (5)1.7在所有CirroData节点中追加重启后自动初始化cgroup的命令 (6)2部署行云管理服务端 (7)2.1部署CirroData Enterprise Administrator(CEA) (7)2.2初始化CEA服务 (8)3行云数据库服务的安装与配置 (12)3.1License认证管理 (12)3.2上传安装源 (13)3.3增加集群 (14)3.4部署Zookeeper服务 (14)3.5部署HDFS元数据代理 (19)3.6部署行云计算引擎 (25)3.7行云计算引擎部分参数说明 (31)3.8部署存储过程执行引擎 (34)3.9存储过程执行引擎部分参数说明 (41)4Kerberos环境下的部署 (43)4.1部署HDFSMetaQueryProxy (43)4.2部署行云计算引擎 (43)5部署进程组(多租户)集群 (45)5.1安装相关库和工具 (45)5.2节点初始化 (45)5.3集群信息及资源规划 (46)5.4部署进程组集群 (47)5.5创建数据库实例与用户 (52)5.6规划进程组与数据库实例&用户的关系 (52)5.7为数据库实例分配空闲的CirroData进程 (52)5.8创建逻辑进程组并分配进程 (55)5.9为用户授权进程组访问权限 (58)5.10查看进程组相关信息 (61)6安装行云数据管理客户端 (62)6.1网络需求 (62)6.2安装SQLDeveloper客户端 (63)7创建数据库实例与用户 (64)7.1配置代理地址 (64)7.2创建数据库实例 (64)7.3创建数据库用户 (66)7.4用户赋权 (69)7.5创建连接并访问行云 (71)8创建DBLINK (74)8.1创建ORACLE DBLINK (74)8.2创建MySQL DBLINK (75)8.3创建CirroData DBLINK (77)8.4创建DB2DBLINK (78)8.5创建Infomix DBLINK (80)8.6创建HIVE DBLINK (82)8.7创建GBase DBLINK (84)8.8创建Sybase IQ DBLINK (85)9数据库服务的升级 (88)9.1停止行云服务 (88)9.2删除行云节点 (88)9.3停止并卸载HDFSMetaQueryProxy服务 (89)9.4停止并卸载taskmanager (90)9.5更新CEA服务 (91)9.6更新HDFS元数据代理 (91)9.7升级行云计算引擎 (92)9.8升级存储过程执行引擎服务 (92)10行云节点的扩容 (93)11行云数据库服务的卸载 (94)11.1卸载存储过程执行引擎 (94)11.2卸载行云计算引擎 (96)11.3卸载HDFS元数据代理 (97)11.4卸载Zookeeper服务 (99)11.5卸载CEA服务 (101)附录CirroData的其他用法说明 (103)前言运行环境1.软件环境:⏹CEA节点操作系统:CentOS/Redhat-7.2+(64bit)JAVA:JDK1.8.0-251+或OpenJDK1.8.0-312+Linux系统命令:ifconfig⏹CirroData节点操作系统:推荐CentOS/Redhat-7.6+(64bit)或内核kernel-3.10.0-693.el7.x86_64以上的CentOS/Redhat版本JAVA:推荐JDK1.8.0-251+或OpenJDK1.8.0-312+Hadoop:推荐hadoop-2.7.8/2.8.5/2.9.2/3.1.3或CDH5.13.4/5.16.2Linux系统命令:nc、stat⏹SQLDeveloper客户机操作系统:Windows XP/7/10(32/64bit)注:●CirroData支持CentOS/Redhat-7.2+(64bit)以上操作系统,但使用低于推荐的操作系统版本可能会触发内核底层bug●CirroData支持JDK1.8+以上JAVA环境,但使用低于推荐的JAVA版本有可能触发JAVA底层bug●CirroData支持hadoop2.3.0~hadoop3.1.x/CDH5.0.1~CDH5.16.x的Hadoop版本,但使用低于推荐的Hadoop版本有可能触发HDFS底层bug●无nc、stat命令不影响CirroData的使用,但会导致CirroData无法获取Zookeeper服务的版本。
如何使用事务处理解决跨数据库操作问题(一)

如何使用事务处理解决跨数据库操作问题引言在日常软件开发中,经常会遇到需要同时操作多个数据库的情况,而这些数据库可能来自不同的厂商或者不同的部署环境。
由于数据库之间的隔离性,对于跨数据库操作的要求会增加开发的复杂度。
为了解决这个问题,我们可以使用事务处理来确保数据的一致性和完整性。
本文将介绍如何使用事务处理解决跨数据库操作问题。
1. 事务处理的基本概念事务是指一系列操作被视为一个整体进行处理的机制。
事务处理的四个基本特性是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
原子性要求事务中的所有操作要么全部执行成功,要么全部失败回滚;一致性要求事务执行前后数据库的状态保持一致;隔离性要求不同事务之间的操作相互隔离,一个事务的操作不会对其他事务产生影响;持久性要求事务一旦提交,其结果将永久保存。
事务能够确保多个数据库操作的一致性,即使其中一个操作失败也可以回滚其他操作。
2. 使用分布式事务管理器在跨数据库操作中,我们可以使用分布式事务管理器来确保事务的一致性。
分布式事务管理器(如Atomikos、Bitronix等)是一种中间件软件,它可以跨多个数据库系统进行事务管理。
通过分布式事务管理器,我们可以定义一个事务,将多个数据库操作包装在其中,然后通过提交或回滚来控制这些操作的执行。
分布式事务管理器会自动处理分布式事务的协调和失败恢复,从而简化了开发工作。
3. 使用两阶段提交协议在使用分布式事务管理器时,常用的事务提交协议是两阶段提交协议(Two Phase Commit,2PC)。
2PC是一种保证分布式事务的原子性和一致性的协议。
在2PC中,事务的提交过程分为两个阶段。
第一阶段,事务协调器向所有参与者发送事务准备请求,要求参与者告知是否可以提交。
参与者接收到请求后,会执行事务操作,然后将回答告知协调器,表示是否可以提交。
第二阶段,协调器根据所有参与者的回答来决定事务是否可以提交。
Windows中MSDTC(分布式事务处理)系统配置方法

Windows中MSDTC(分布式事务处理)系统配置方法DTC帮助我们实现分布式数据库服务器之间集合事务处理,即远程异地事务处理功能;例如:有多个SQL SERVER服务器,我们要让它互相执行更新操作,但又要保证事务的完整性,就可以开启DTC功能进行实现;SQL SERVER分布式事务脚本举例:{SET XACT_ABORT ONBEGIN TRANINSERT INTO [192.168.88.61].ccerp_test.dbo.spkfk ( spid , spbh )SELECT'远程','远程'INSERT INTO spkfk ( spid , spbh )SELECT'本地','本地'COMMIT}DTC配置方法如下:1、检查系统开启了DTC服务;打开【管理工具】->【服务】,检查Distributed Transaction Coordinator、Remote Procedure Call (RPC)两个组件是否已启动;如果没有启动就将它们启动;如图1:(一般正常启动了Distributed Transaction Coordinator组件,Remote Procedure Call (RPC)也会自动启动)(图1)2、设置DTC服务;打开【管理工具】->【组件服务】,找到【分布式事务处理协调器】,点属性对它进行设置;2003、2008 SERVER设置它时,操作位置界面会若有区别;但其需要设置的内容:(1)、【默认协调器】:使用本地协调器;(2)、设置内容:如图2:(图2)3、设置参加DTC的各机防火墙;打开【控制面板】->【防火墙】,添加例外的应用程序:将分布式协调器MSDTC.exe添加到例外中;C:\Windows\System32\MSDTC.exe设置完后防火墙设置如图3:分布式事务协调器(如图3)4、MSDTC配置完后的测试;(注:把防火墙关了进行测)微软提供的:DTCPing工具绿色的,直接点击:Dtcping.exe进行运行;如图4-1,点击【Start Server】(图4-1)如图4-2,点击【PING】,如果上面的英文反馈是RPC拼通无问题就Ok,反之报错就需要继续检查;(图4-2)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
步骤一:下载支持数据库SQL Server 2005分布式事务包sqljdbc_4.2.6420.100_chs.exe
步骤二:在sqljdbc_4.2包中打开chs→xa→x64/x86(根据系统选择)→sqljdbc_xa.dll拷贝到SQL Server 2005 数据库目录D:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Binn下。
步骤三:sqljdbc_4.2包中打开chs→xa→xa_install.sql语句在数据中执行默认用户选择master 中执行
步骤四:开始→管理软件→组件服务,打开组件服务,组件服务→计算机→我的电脑(右键属性)选择MSDTC→安全配置→启用XA事务。
步骤五:重新启动数据库MS DTC服务
步骤六:创建一个新的登录名,强制实施密码策略取消,默认数据库TianKong
步骤七:服务器角色选择sysadmin
步骤八:用户映射选择TianKong,数据库角色成员身份勾选db_owner,之后在用户映射中选择master,数据库角色成员身份勾选SQLJDBCXAUser
步骤九:重新启动数据库服务,服务器程序配置文件使用新建的登录名和密码。