SQL语句分组获取记录的第一条数据的方法
SQL语句分组获取记录的第一条数据的方法
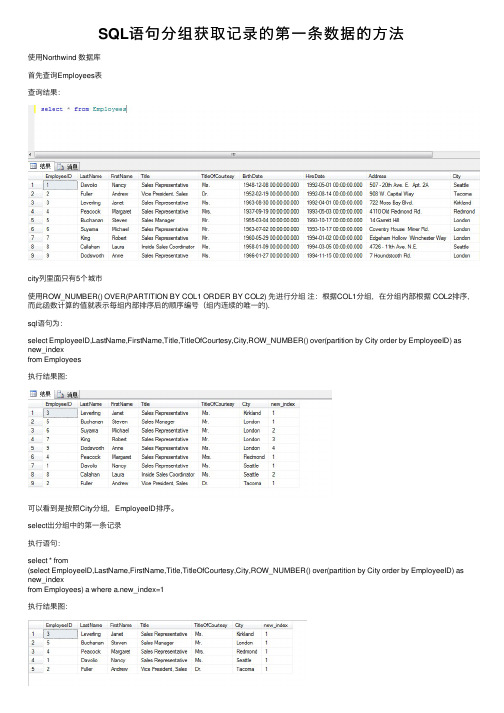
city列里面只有5个城市 使用ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2) 先进行分组 注:根据COL1分组,在分组内部根据 COL2排序, 而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的). sql语句为: select EmployeeID,LastName,FirstName,Title,TitleOfCourtesy,City,ROW_NUMBER() over(partition by City order by EmployeeID) as new_index from Employees 执行结果图:
可以看到是按照City分组,EmployeeID排序。 select出分组中的第一条记录 执行语句: select * from (select EmployeeID,LastName,FirstName,Title,TitleOfCourtesy,City,ROW_NUMBER() over(partition by City order by EmployeeID) as new_index from Employees) a where a.new_index=1 执行结果图:
sqlserver2016ctp22是微软数据平台历史上迈出最大的一步更快的事务处理和查询任何设备更深入的洞察力更先进的分析能力全新安全技术和全新的混合云场景本文给大家介绍sqlserver2016ctp23的关键特性总结需要的朋友可以参考下
SQL语 句 分 组 获 取 记 录 的 第 一 条 数 据 的 方 法
ห้องสมุดไป่ตู้
sqlserver数据分组语句句

sqlserver数据分组语句句1.引言1.1 概述概述在SQL Server数据库中,数据分组语句是一种强大的查询工具,用于对数据进行分组和汇总。
通过使用数据分组语句,我们可以根据指定的列或表达式对数据进行分组,并对每个组内的数据进行汇总计算。
这种功能在处理大量数据时尤为重要,它能够提供对数据的更深入和全面的分析。
数据分组语句的基本思想是将数据按照指定的条件进行分类,然后对每个分类进行汇总计算。
通过这种方式,我们可以获得各个分类的统计信息,如总数、平均值、最大值、最小值等。
这些统计信息对于数据分析和决策制定非常有价值。
在本文中,我们将详细介绍数据分组语句的语法和用法。
我们将讨论如何使用GROUP BY子句对数据进行分组,以及如何使用聚合函数对每个组内的数据进行汇总计算。
我们还将介绍如何使用HAVING子句筛选分组结果,以及一些常见的数据分组场景和应用案例。
通过学习本文,读者将能够更好地理解和应用数据分组语句,从而提高对数据的分析能力和决策支持能力。
无论是在商业领域的市场分析,还是在科学研究中的数据处理,数据分组语句都是必不可少的工具之一。
让我们开始学习吧!1.2 文章结构:本文将按照以下结构进行讨论和说明数据分组语句的相关内容。
1. 引言1.1 概述在数据库中,数据分组是一种常用的数据处理方式,它能够基于某种条件将数据进行分类和统计,使得数据处理更加灵活和高效。
1.2 文章结构(本节)1.3 目的本文旨在介绍和讲解SQL Server中的数据分组语句的基本概念、语法和用法,以及它们在实际应用中的场景、优势和限制。
2. 正文2.1 数据分组语句的基本概念2.1.1 什么是数据分组语句数据分组语句是一种用于将数据按照某个或多个列进行分组、分类和统计的语句。
2.1.2 数据分组的目的和作用数据分组的目的是为了更好地理解和分析数据,通过对数据进行分组和统计,可以得出更有价值的信息和结论。
2.2 数据分组语句的语法和用法2.2.1 基本语法SQL Server中常用的数据分组语句包括GROUP BY、HAVING、COUNT、SUM等,本节将介绍它们的语法和使用方法。
MySql分组后随机获取每组一条数据的操作

MySql分组后随机获取每组⼀条数据的操作思路:先随机排序然后再分组就好了。
1、创建表:CREATE TABLE `xdx_test` (`id` int(11) NOT NULL,`name` varchar(255) DEFAULT NULL,`class` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2、插⼊数据INSERT INTO xdx_test VALUES (1, '张三-1','1');INSERT INTO xdx_test VALUES (2, '李四-1','1');INSERT INTO xdx_test VALUES (3, '王五-1','1');INSERT INTO xdx_test VALUES (4, '张三-2','2');INSERT INTO xdx_test VALUES (5, '李四-2','2');INSERT INTO xdx_test VALUES (6, '王五-2','2');INSERT INTO xdx_test VALUES (7, '张三-3','3');INSERT INTO xdx_test VALUES (8, '李四-3','3');INSERT INTO xdx_test VALUES (9, '王五-3','3');3、查询语句SELECT * FROM(SELECT * FROM xdx_test ORDER BY RAND()) aGROUP BY a.class4、查询结果3 王五-1 15 李四-2 29 王五-3 33 王五-1 14 张三-2 27 张三-3 32 李四-1 15 李四-2 28 李四-3 3补充知识:mysql实现随机获取⼏条数据的⽅法(效率和离散型⽐较)sql语句有⼏种写法、效率、以及离散型⽐较1:SELECT * FROM tablename ORDER BY RAND() LIMIT 想要获取的数据条数;2:SELECT *FROM `table` WHERE id >= (SELECT FLOOR( MAX(id) * RAND()) FROM `table` ) ORDER BY id LIMIT 想要获取的数据条数;3:SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * (SELECT MAX(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.idORDER BY t1.id ASC LIMIT 想要获取的数据条数;4:SELECT * FROM `table`WHERE id >= (SELECT floor(RAND() * (SELECT MAX(id) FROM `table`))) ORDER BY id LIMIT 想要获取的数据条数;5:SELECT * FROM `table` WHERE id >= (SELECT floor( RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`)) + (SELECT MIN(id) FROM `table`))) ORDER BY id LIMIT 想要获取的数据条数;6:SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`))+(SELECT MIN(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id ORDER BY t1.id LIMIT 想要获取的数据条数;1的查询时间>>2的查询时间>>5的查询时间>6的查询时间>4的查询时间>3的查询时间,也就是3的效率最⾼。
mysql分组取最新的一条记录(整条记录)

mysql分组取最新的⼀条记录(整条记录)⽅法:mysql取分组后最新的⼀条记录,下⾯两种⽅法.⼀种是先筛选出最⼤和最新的时间,在连表查询.⼀种是先排序,然后在次分组查询(默认第⼀条),就是最新的⼀条数据了#select*from t_assistant_article as a, (select max(base_id) as base_id, max(create_time) as create_time from t_assistant_article as b group by base_id ) as b where a.base_id=b.base_id and a.create_time = b.create_time #select base_id,max(create_time), max(article_id) as article_id from t_assistant_article as b group by base_idselect*from (select*from t_assistant_article order by create_time desc) as a group by base_id order by create_time desc来源:/swweb/article/details/11059037mysql "group by"与"order by"的研究--分类中最新的内容 /article/23969.htm在使⽤mysql排序的时候会想到按照降序分组来获得⼀组数据,⽽使⽤order by往往得到的不是理想中的结果,那么怎么才能使⽤group by 和order by得到理想中的数据结果呢?例如有⼀个帖⼦的回复表,posts( id , tid , subject , message , dateline ) ,id为⾃动增长字段, tid为该回复的主题帖⼦的id(外键关联), subject 为回复标题, message 为回复内容, dateline 为回复时间,⽤UNIX 时间戳表⽰,现在要求选出前⼗个来⾃不同主题的最新回复SELECT * FROM posts GROUP BY tid LIMIT 10这样⼀个sql语句选出来的并⾮你想要的最新的回复,⽽是最早的回复,实际上是某篇主题的第⼀条回复记录!也就是说 GROUP BY 语句没有排序,那么怎么才能让 GROUP 按照 dateline 倒序排列呢?加上 order by ⼦句?看下⾯:SELECT * FROM posts GROUP BY tid ORDER BY dateline DESC LIMIT 10这条语句选出来的结果和上⾯的完全⼀样,不过把结果倒序排列了,⽽选择出来的每⼀条记录仍然是上⾯的记录,原因是 group by 会⽐ order by 先执⾏,这样也就没有办法将group by 之前,也就是在分组之前进⾏排序了,有⽹友会写出下⾯的sql 语句:SELECT * FROM posts GROUP BY tid DESC ORDER BY dateline DESC LIMIT 10也就是说在 GROUP BY 的字段 tid 后⾯加上递减顺序,这样不就可以取得分组时的最后回复了吗?这个语句执⾏结果会和上⾯的⼀模⼀样,这⾥加上 DESC 和ASC对执⾏结果没有任何影响!其实这是⼀个错误的语句,原因是GROUP BY 之前并没有排序功能,mysql ⼿册上⾯说,GROUP BY 时是按照某种顺序排序的,某种顺序到底是什么顺序?其实根本没有顺序,因为按照tid分组,其实也就是说,把tid相等的归纳到⼀个组,这样想的话,GROUP BY tid DESC 可以认为是在按照 tid 分组的时候,按照tid进⾏倒序排列,这不扯吗,既然是按照tid分组,当然是tid相等的归到⼀组,⽽这时候按照tid倒叙还是升序有个P⽤!于是有⽹友发明下⾯的语句:SELECT * FROM posts GROUP BY tid , dateline DESC ORDER BY dateline DESC LIMIT 10⼼想这样我就可以在分组前按照 dateline 倒序排列了,其实这个语句并没有起到按照tid分组的作⽤,原因还是上⾯的,在group by 字段后加 desc 还是 asc 是错误的写法,⽽这种写法⽹友本意是想按照 tid 分组,并且在分组的时候按照 dateline排倒序!⽽实际这句相当于下⾯的写法:(去掉 GROUP BY 字段后⾯的 DESC)SELECT * FROM posts GROUP BY tid , dateline ORDER BY dateline DESC LIMIT 10也就是说,按照 tid 和 dateline 联合分组,只有在记录tid和dateline 同时相等的时候才归纳到⼀组,这显然不可能,因为 dateline 时间线基本上是唯⼀的!有⼈写出下⾯的语句:SELECT *,max(dateline) as max_line FROM posts GROUP BY tid ORDER BY dateline DESC LIMIT 10这条语句的没错是选出了最⼤发布时间,但是你可以对⽐⼀下 dateline 和 max_dateline 并不相等!(可能有相当的情况,就是分组的⽬标记录只有⼀条的时候!)为什么呢?原因很简单,这条语句相当于是在group by 以后选出本组的最⼤的发布时间!对分组没有起到任何影响!因为SELECT⼦句是最后执⾏的!后来更有⽹友发明了下⾯的写法!SELECT *,max(dateline) as max_line FROM posts GROUP BY tid HAVING dateline=max(dateline) ORDER BY dateline DESC LIMIT 10这条语句的预期结果和想象中的并不相同!因为你会发现,分组的结果中⼤量的记录没有了!为什么?因为 HAVING 是在分组的时候执⾏的,也就说:在分组的时候加上⼀个这样的条件:选择出来的 dateline 要和本组最⼤的dateline 相等,执⾏的结果和下⾯的语句相同:SELECT *,max(dateline) as max_line FROM posts GROUP BY tid HAVING count(*)=1 ORDER BY dateline DESC LIMIT 10看了这条sql语句是不是明⽩了呢?dateline=max(dateline) 只有在分组中的记录只有⼀条的时候才成⽴,原因很明⽩吧!只有⼀条他才会和本组的最⼤发布时间相等阿,(默认dateline为不重复的值)原因还是因为 group by 并没有排序功能,所有的这些排序功能只是错觉,所以你最终选出的 dateline 和max(dateline) 永远不可能相等,除⾮本组的记录只有⼀条!GROUP BY在分组的时候,可能是⼀个⼀个来找的,发现有相等的tid,去掉,保留第⼀个发现的那⼀条记录,所以找出来的记录永远只是按照默认索引顺序排列的!那么说了这么多,到底有没有办法让 group by 执⾏前分组阿?有的,⼦查询阿!最简单的:SELECT * FROM (SELECT * FROM posts ORDER BY dateline DESC) GROUP BY tid ORDER BY dateline DESC LIMIT 10也有⽹友利⽤⾃连接实现的,这样的效率应该⽐上⾯的⼦查询效率⾼,不过,为了简单明了,就只⽤这样⼀种了,GROUP BY没有排序功能,可能是mysql弱智的地⽅,也许是我还没有发现,。
sql分组(orderBy、GroupBy)获取每组前一(几)条数据

6、根据Name分组取最小的两个(N个)Val
--方法一: select a.* from Test_orderByOrGroupBy_tb a where 2 > (select count(*) from Test_orderByOrGroupBy_tb where Name = and val < a.val ) order by ,a.val --方法二: select a.* from Test_orderByOrGroupBy_tb a where val in (select top 2 val from Test_orderByOrGroupBy_tb where name= order by val) order by ,a.val --方法三 SELECT a.* from Test_orderByOrGroupBy_tb a where exists (select count(*) from Test_orderByOrGroupBy_tb where Name = and val < a.val having Count(*) < 2) order by
1、根据Name分组取Val最大的值所在行的数据。
Sql语句代码如下:
--方法1: select a.* from Test_orderByOrGroupBy_tb a where Val = (select max(Val) from Test_orderByOrGroupBy_tb where Name = ) order by --方法2: select a.* from Test_orderByOrGroupBy_tb a,(select Name,max(Val) Val from Test_orderByOrGroupBy_tb group by Name) b where = and a.Val = b.Val order by --方法3: select a.* from Test_orderByOrGroupBy_tb a inner join (select Name,max(Val) Val from Test_orderByOrGroupBy_tb group by Name) b on = and a.Val = b.Val order by --方法4: select a.* from Test_orderByOrGroupBy_tb a where 1 > (select count(*) from Test_orderByOrGroupBy_tb where Name = and Val > a.Val ) order by --其中1表示获取分组中前一条数据 --方法5: select a.* from Test_orderByOrGroupBy_tb a where not exists(select 1 from Test_orderByOrGroupBy_tb where Name = and Val > a.Val)
sql group by方法

一、概述在数据库管理系统中,SQL是一种用于管理和处理数据库的标准化语言。
在实际应用中,Group By方法是SQL中非常重要的一种查询技术,它可以对查询结果进行分组,统计和筛选,为用户提供更加精确和有价值的数据分析结果。
二、Group By方法的基本语法在SQL中,Group By方法通常用于与聚合函数一起使用,以便对查询结果进行分组和统计。
其基本语法如下:SELECT column_name, aggregate_function(column_name) FROM table_nameWHERE conditionGROUP BY column_name;在上面的语法中,column_name是要进行分组的列名,aggregate_function是聚合函数,table_name是要查询的表名,condition是查询条件。
通过Group By方法,可以对指定列的数据进行分组,并对每组数据应用聚合函数进行计算,如计数、求和、平均值等。
三、Group By方法的应用场景1. 数据分组统计在实际应用中,有时需要根据某一列的取值对数据进行分组统计。
统计某个商品的销售量、订单数量或者用户新增数等。
这时候就可以通过Group By方法将数据按照商品ID、订单ID或者用户ID进行分组,并使用聚合函数进行相应的统计。
2. 数据筛选除了对数据进行统计,Group By方法还可以用于数据筛选。
需要找出每个部门中薪水最高的员工,就可以通过Group By方法对部门进行分组,并使用聚合函数找出最高薪水的员工。
3. 多重分组统计在实际应用中,有时候需要根据多个列的取值进行分组统计。
这时候可以通过在Group By方法中指定多个列名,对数据进行多重分组统计。
统计每个部门每年的销售额,就需要同时对部门和年份进行分组统计。
四、Group By方法的注意事项1. Group By列的选择在使用Group By方法时,需要选择合适的列进行分组。
SQL分组排序后取每组最新一条数据的另一种思路

SQL分组排序后取每组最新⼀条数据的另⼀种思路在hibernate框架和mysql、oracle两种数据库兼容的项⽬中实现查询每个id最新更新的⼀条数据。
之前⼯作中⼀直⽤的mybatis+oracle数据库这种,⼀般写这类分组排序取每组最新⼀条数据的sql都是使⽤row_number() over()函数来实现例如:select t1.* from ( select t.*, ROW_NUMBER() over(partition t.id order by t.update_time desc) as rn from table_name t) t1 where t1.rn = 1;但是新公司项⽬是兼容mysql和oracle两种数据库切换的,那么row_number() over()在使⽤mysql的情况下会出现错误,所以我在⽹上查找了⼀下mysql实现分组排序取最新数据的例⼦有两种写法,如下:第⼀种select t1.*from table_name t1, (select t.id, max(t.update_time) as uTime from table_name t group by t.id) t2where 1=1and t1.id = t2.idand t1.update_time = t2.uTime;第⼆种(这⾥limit是为了固定⼦查询中的排序,如果没有这个limit,外层使⽤虚拟表t1进⾏group by的时候就不会根据之前update_time排好的倒序进⾏分组了。
limit具体的数字可以根据要查询数据的总数来决定。
)select t1.* from ( select * from table_name t order by t.update_time desc limit 1000) t1 group by t1.id;这⾥⼜遇到了⼀个问题,虽然第⼀种⽅式使⽤mysql和oracle都可以查询,但是hibernate是不⽀持from (⼦查询) ... 这种结构的sql的,因为hibernate的核⼼是⾯向对象⽽⾮⾯向数据库,⽹上搜到是这种解决⽅案解决hibernate不⽀持from (⼦查询) ... 参考地址:为了⼀个⼦查询再新建⼀个实体类...虽然觉得这样有点⿇烦但是我还是搜索了⼀下整个项⽬看有没有类似的做法,结果⼀个都没有找到!这时候我请教了⼀下部门的⽼⼈想看看他们做这类查询是如何处理的,⼤佬给出的⽅案是换⼀种sql写法如下:select * from table_name t1 where t1.update_time= (select max(t.update_time) from table_name t where t.id= t1.id);⾄此问题解决...。
SQL中遇到多条相同内容只取一条的最简单实现方法

SQL中遇到多条相同内容只取⼀条的最简单实现⽅法SQL中经常遇到如下情况,在⼀张表中有两条记录基本完全⼀样,某个或某⼏个字段有些许差别,这时候可能需要我们踢出这些有差别的数据,即两条或多条记录中只保留⼀项。
如下:表timeand针对time字段相同时有不同total和name的情形,每当遇到相同的则只取其中⼀条数据,最简单的实现⽅法有两种1、select time,max(total) as total,name from timeand group by time;//取记录中total最⼤的值或 select time,min(total) as total,name from timeand group by time;//取记录中total最⼩的值上述两种⽅案都有个缺点,就是⽆法区分name字段的内容,所以⼀般⽤于只有两条字段或其他字段内容完全⼀致的情况2、select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total<total);此中⽅案排除了⽅案1中name字段不准确的问题,取的是total最⼤的值上⾯的例⼦中是只有⼀个字段不相同,假如有两个字段出现相同呢?要求查处第三个字段的最⼤值该如何做呢?其实很简单,在原先的基础上稍微做下修改即可:原先的SQL语句:select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total<total);可修改为:select * from timeand as a where not exists(select 1 from timeand where a.time = time and (a.total<total or (a.total=total and a.outtotal<outtotal)));其中outtotal是另外⼀个字段,为Int类型以上就是SQL中遇到多条相同内容只取⼀条的最简单实现⽅法的全部内容,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
Mysql根据时间取出每组数据中最新的一条

Mysql根据时间取出每组数据中最新的⼀条下策——查询出结果后将时间排序后取第⼀条select * from awhere create_time<="2017-03-29 19:30:36"order by create_time desclimit 1这样做虽然可以取出当前时间最近的⼀条记录,但是⼀次查询需要将表遍历⼀遍,对于百万以上数据查询将⽐较费时;limit是先取出全部结果,然后取第⼀条,相当于查询中占⽤了不必要的时间和空间;还有如果需要批量取出最近⼀条记录,⽐⽅说:“⼀个订单表,有⽤户,订单时间,⾦额,需要⼀次性查询所有⽤户的最近的⼀条订单记录”,那么每个⽤户⼀次查询就要做⼀次整表的遍历,数据⼤的情况下,时间将会以指数形式增长,不能投⼊实际使⽤。
中策——查询排序后group byselect * from (select * from awhere create_time<="2017-03-29 19:30:36"order by create_time desc) group by user_id后来发现使⽤group by 可以根据group by 的参数列分组,但返回的结果只有⼀条,仔细观察发现group by是将分组后的第⼀条记录返回。
时间在查询后默认是顺序排列,因此需要先将时间倒序排列,⽅可取出距离当前最近⼀条。
这样查询实际上还是进⾏了两次查询,虽然时间上相⽐第⼀个⽅法有了质的飞跃,但是还可以进⼀步优化。
上策——将max() ⽅法和group by结合使⽤select *,max(create_time) from awhere create_time<="2017-03-29 19:30:36"group by user_id这句可以理解为将结果集根据user_id分组,每组取time最⼤⼀条记录。
sql 中提取一列数据前几位语句的方法

sql 中提取一列数据前几位语句的方法摘要:1.SQL提取一列数据的前几位语句的常用方法2.方法一:使用ROW_NUMBER()窗口函数3.方法二:使用窗口变量4.示例:使用ROW_NUMBER()方法5.示例:使用窗口变量方法6.总结与建议正文:在SQL中,有时我们需要提取一列数据的前几位,这里介绍两种常用的方法。
方法一:使用ROW_NUMBER()窗口函数ROW_NUMBER()是一个窗口函数,它可以为每一行数据分配一个唯一的数字,这个数字基于指定的排序规则。
以下是一个示例:```sqlWITH ranked_data AS (SELECTcolumn1,ROW_NUMBER() OVER (ORDER BY column1) AS rankFROMyour_table)SELECTcolumn1,rankFROMranked_dataWHERErank <= 3;```这个查询首先对`column1`进行排序,然后为每一行分配一个排名。
最后,我们选择排名小于等于3的行,这些行就是数据的前3位。
方法二:使用窗口变量窗口变量允许我们在查询结果中使用一个虚拟的列,这个虚拟列包含根据特定规则排序的数据。
以下是一个示例:```sqlWITH leading_rows AS (SELECTcolumn1,ROW_NUMBER() OVER (ORDER BY column1) AS row_numFROMyour_table)SELECTcolumn1,row_numFROMleading_rowsWHERErow_num <= 3;```这个查询与上面的示例类似,但使用了窗口变量`leading_rows`来存储排序后的数据。
然后我们筛选出排名小于等于3的行,即数据的前3位。
总结与建议在提取SQL数据表中的一列前几位时,可以使用ROW_NUMBER()窗口函数或窗口变量方法。
根据实际需求和数据量,选择合适的方法。
mysql 提取字符串中第一组数字的方法

mysql 提取字符串中第一组数字的方法摘要:1.介绍MySQL提取字符串中第一组数字的方法2.详解使用MySQL函数提取第一组数字的步骤3.举例说明提取字符串中第一组数字的应用场景4.总结提取字符串中第一组数字的技巧和注意事项正文:在MySQL中,提取字符串中第一组数字的方法主要包括使用字符串函数和正则表达式。
以下将详细介绍如何使用MySQL函数提取字符串中的第一组数字。
一、使用字符串函数提取第一组数字1.使用`SUBSTRING`函数`SUBSTRING`函数用于从字符串中提取子字符串。
以下示例提取字符串中的第一组数字:```sqlSELECT SUBSTRING(column_name, 1, 1) AS first_digitFROM table_name;```2.使用`LEFT`函数`LEFT`函数用于从字符串左侧开始提取子字符串。
以下示例提取字符串中的第一组数字:SELECT LEFT(column_name, 1) AS first_digitFROM table_name;```二、使用正则表达式提取第一组数字1.使用`REGEXP`函数`REGEXP`函数用于在字符串中查找符合正则表达式的内容。
以下示例提取字符串中的第一组数字:```sqlSELECT REGEXP_REPLACE(column_name, "[0-9]+", "") AS first_digit FROM table_name;```2.使用`REPLACE`函数`REPLACE`函数用于替换字符串中的特定内容。
以下示例提取字符串中的第一组数字:```sqlSELECT REPLACE(column_name, "[^0-9]+", "") AS first_digitFROM table_name;```三、应用场景举例在一个用户信息表中,我们需要提取用户手机号的第一组数字,可以使用以下SQL语句:SELECT LEFT(phone_number, 1) AS first_digitFROM user_info;```四、总结与注意事项1.提取字符串中的第一组数字时,要注意字符串的格式和内容,确保提取结果的准确性。
sql语句实现分组聚集操作的过程

sql语句实现分组聚集操作的过程分组聚集操作是在SQL中常用的一种数据处理方式,它可以对数据进行分组,并对每个分组进行聚集计算,如求和、求平均值、计数等。
下面列举10个常见的分组聚集操作的SQL语句。
1. 求和:计算某一列的总和```sqlSELECT SUM(column_name) AS sum_valueFROM table_nameGROUP BY column_name;```这个语句将根据column_name列的值对数据进行分组,并计算每组的column_name列的总和。
2. 求平均值:计算某一列的平均值```sqlSELECT AVG(column_name) AS avg_valueFROM table_nameGROUP BY column_name;```这个语句将根据column_name列的值对数据进行分组,并计算每组的column_name列的平均值。
3. 计数:统计某一列的值的个数```sqlSELECT column_name, COUNT(*) AS count_valueFROM table_nameGROUP BY column_name;```这个语句将根据column_name列的值对数据进行分组,并统计每组的行数,即某一列的值的个数。
4. 求最大值:找出某一列的最大值```sqlSELECT MAX(column_name) AS max_valueFROM table_nameGROUP BY column_name;```这个语句将根据column_name列的值对数据进行分组,并找出每组中column_name列的最大值。
5. 求最小值:找出某一列的最小值```sqlSELECT MIN(column_name) AS min_valueFROM table_nameGROUP BY column_name;```这个语句将根据column_name列的值对数据进行分组,并找出每组中column_name列的最小值。
oracle group by 后取不为空的一条记录

oracle group by 后取不为空的一条记录(实用版)目录1.Oracle 概述2.Group By 的作用3.取不为空的一条记录的方法正文【Oracle 概述】Oracle 是一款广泛应用于企业级数据管理的关系型数据库管理系统。
它以其高效、安全、可扩展性强等特点,在业界享有很高的声誉。
在 Oracle 数据库中,我们可以使用 SQL 语句对数据进行查询、插入、更新和删除等操作。
【Group By 的作用】在 SQL 查询语句中,Group By 子句的作用是将具有相同分组条件的记录分组在一起,然后对每个组进行聚合操作。
它可以帮助我们对数据进行分组统计、筛选等操作。
【取不为空的一条记录的方法】在 Oracle 数据库中,我们可以使用 Group By 子句结合聚合函数(如 MAX、MIN、SUM、AVG 等)来取不为空的一条记录。
以下是一个示例:假设我们有一个名为“employees”的表,包含以下字段:id、name、salary。
现在,我们想要查询每个部门的最高工资。
可以使用以下 SQL 语句:```sqlSELECT department_id, MAX(salary) as max_salaryFROM employeesGROUP BY department_id;```这条 SQL 语句将按照部门对员工记录进行分组,并取每个部门的最高工资。
查询结果将显示每个部门及其对应的最高工资。
需要注意的是,在使用 Group By 子句时,只能对分组字段进行聚合操作。
如果需要对其他字段进行操作,需要使用聚合函数或者 CASE 语句。
例如,如果我们想要查询每个部门的最高工资以及该部门的员工数量,可以使用以下 SQL 语句:```sqlSELECT department_id, MAX(salary) as max_salary, COUNT(*) as employee_countFROM employeesGROUP BY department_id;```以上就是如何在 Oracle 数据库中使用 Group By 子句取不为空的一条记录的方法。
sql limit0,1的用法和搭配 -回复

sql limit0,1的用法和搭配-回复SQL中的LIMIT0,1用法和搭配SQL是用于管理关系数据库的标准查询语言。
其中,LIMIT语句用于限制查询结果的记录数。
在LIMIT语句中,我们可以设置一个偏移量和一个要返回的记录数,通常的语法是LIMIT offset, count。
本文将详细介绍LIMIT0,1的用法和与其他SQL语句的搭配。
一、LIMIT0,1的基本用法LIMIT0,1 是将查询结果限制为只返回第一行,相当于只返回记录集中的第一条记录。
这通常在需要获取某个表中的唯一记录时很有用。
例如,假设我们有一个名为students的表,其中包含学生的姓名、年龄和成绩等列。
如果我们只想获取该表中的第一条记录,可以使用以下查询语句:SELECT * FROM students LIMIT 0,1;这将只返回students表中的第一条记录。
二、LIMIT0,1与ORDER BY的搭配使用LIMIT0,1通常与ORDER BY搭配使用,以获取排在前面的记录。
ORDER BY用于按照某个列或多个列对查询结果进行排序。
我们可以按照升序(ASC)或降序(DESC)的方式对数据进行排序。
例如,我们希望获取students表中成绩最高的学生记录。
可以使用以下查询语句:SELECT * FROM students ORDER BY score DESC LIMIT 0,1;这将根据成绩列的降序排序,然后返回排在最前面的记录,即得到了成绩最高的学生记录。
三、LIMIT0,1和子查询的搭配使用LIMIT0,1还可以与子查询一起使用,以从一个查询结果中获取最前面的记录。
子查询是一个嵌套在主查询内部的查询语句。
它可以作为主查询的一部分,用于过滤、排序和提供其他查询功能。
例如,我们有一个主查询语句,用于获取所有成绩高于80分的学生记录。
然后,我们可以通过在主查询语句外部再加上LIMIT0,1来仅返回第一条记录,即最高分的学生记录:SELECT * FROM (SELECT * FROM students WHERE score > 80) AS subquery LIMIT 0,1;在这个查询中,子查询(SELECT * FROM students WHERE score > 80)用于获取所有成绩高于80分的学生记录。
SQL|分组并选取前N个记录

SQL|分组并选取前N个记录
在SQL中,可以使用窗口函数和子查询来实现分组并选择前N个记录。
下面我们将使用一个示例来说明如何实现这一过程。
首先,我们可以使用窗口函数来为每种语言下的书籍排序,根据字数
降序排列。
然后,我们可以使用子查询来选择每种语言下的前3条记录。
以下是一个具体的实现示例:
```
SELECT language, book_name, author, word_count
FROM
SELECT language, book_name, author, word_count,
ROW_NUMBER( OVER (PARTITION BY language
ORDER BY word_count DESC) as rn
FROM books
sub
WHERE rn <= 3;
```
在上面的示例中,我们使用子查询来对每种语言的书籍进行排序,并
为每条记录分配一个行号。
然后,外部查询中的条件`rn <= 3`筛选了每
种语言下的前3本书。
这样,我们就实现了对每种语言的书籍进行分组,并选取每种语言下字数最多的前3本书。
需要注意的是,具体的语法和用法可能因数据库产品而异。
以上示例基于常见的SQL语法,但不同的数据库可能会有些许差异,请根据自己使用的数据库产品进行相应的调整。