Flickr网站架构研究
yui

5
ya ho o ev en t do m
YUI 2.6.0
se le ct or yu ilo ad er co nn ec ti o n an im at io n dr ag &d ro p js on
el em en t
开始使用YUI进行开发
YUI Grids Builder快速创建页面布局
/yui/theater/
/
• /yuilibrary
YUI In The Wild
/blog/category/in-the-wild/
YUI 3: popup.set('innerHTML', desc.get('innerHTML')) .setStyles({ opacity: 0.9, top: (ev.clientY + 10) + "px", left: (ev.clientX + 10) + "px" });
jQuery: popup.html(desc.html()) .show() .css("opacity", 0.9) .css("top", (ev.clientY + 10) + "px") .css("left", (ev.clientX + 10) + "px");
/cheilmann/the-role-of-java-script
伴随前端技术的演变 开发中的问题也在随之改变
"The page is an application with a data connection to a server."
复杂网络研究简介

∑d
i> j
ij
d12 = 1
d13 = 1 d 23 = 1
d14 = 2 d 24 = 1 d 34 = 2
d15 = 1 d 25 = 2 d 35 = 2 d 45 = 3
Total = 16 Average:
L = 16 / 10 = 1.6
聚类系数
• 一个网络的聚类系数 C满足:
0<C<1
规则网络
(a) 完全连接;
(b) 最近邻居连接;
(c) 星形连接
规则网络
... ...
(d) Lattice
(z) Layers
随机图理论
• 随机图论 - Erdös and Rényi (1960) • ER 随机图模型统治四十余年…… 直到今天 …… • 当今大量可获取的数据+高级计算工具,促使人们 重新考虑随机图模型及其方法
“图论之父”
看作4个节点,7条边的 图
路必须有起点和终点。 一次走完所有的桥,不重复,除起点与终点外,其余点必须有偶数 条边,所以七桥问题无解。 1875年, B 与 C 之间新建了一条桥解决了该问题!☺
Euler 对复杂网络的贡献
Euler 开启了数学图论,抽象为顶点与边的集 合 图论是网络研究的基础 网络结构是理解复杂世界的关键
电信网络
(Stephen G. Eick)
美国航空网
世界性的新闻组网络
(Naveen Jamal)
生物网络
人际关系网络
复杂网络概念
• • • • • • 结构复杂:节点数目巨大,网络结构呈现多种不同特征。 节点多样性:同一网络中可能有多种不同的节点。 连接多样性:节点之间的连接权重存在差异,且有可能存在方向性。 网络进化:表现在节点或连接的产生与消失。例如WWW,网页或链 接随时可能出现或断开,导致网络结构不断发生变化。 动力学复杂性:节点集可能属于非线性动力学系统,例如节点状态随 时间发生复杂变化。 多重复杂性融合:即以上多重复杂性相互影响,导致更为难以预料的 结果。例如,设计一个电力供应网络需要考虑此网络的进化过程,其 进化过程决定网络的拓扑结构。当两个节点之间频繁进行能量传输时, 他们之间的连接权重会随之增加,通过不断的学习与记忆逐步改善网 络性能。 复杂网络简而言之即呈现高度复杂性的网络。
1.1女性类网站分析
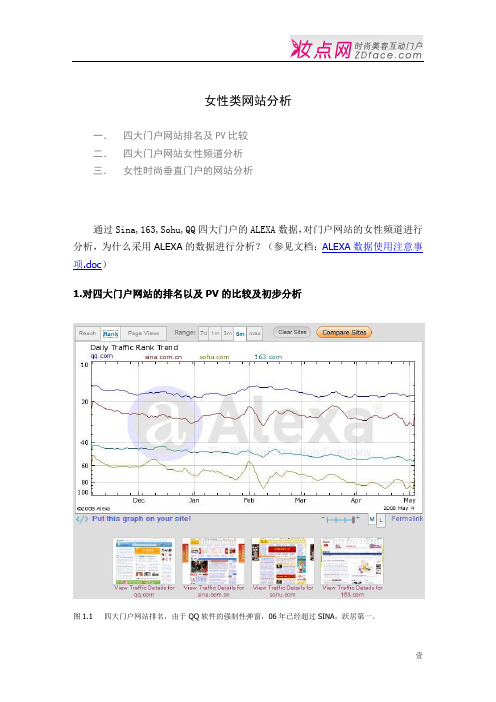
女性类网站分析一.四大门户网站排名及PV比较二.四大门户网站女性频道分析三.女性时尚垂直门户的网站分析通过Sina,163,Sohu,QQ四大门户的ALEXA数据,对门户网站的女性频道进行分析,为什么采用ALEXA的数据进行分析?(参见文档:ALEXA数据使用注意事项.doc)1.对四大门户网站的排名以及PV的比较及初步分析图1.1 四大门户网站排名,由于QQ软件的强制性弹窗,06年已经超过SINA,跃居第一。
图1.2 四大门户站PV图,在2月前后人群相对闲置的时期,PV有明显的相应上升。
结合图1.1还可以看到,SOHU排名比163低了近20名,但PV基本重合,可见SOHU的页面用户体验做的很不错提升了PV,也不排除SOHU被传言作弊的可能。
2.女性频道所占门户站整体流量的比例,整站PV,女性频道的PV,具体频道分类和首页第一版的初步分析。
2.1 腾讯图2.1 前三的频道分别是QQ空间,QQ娱乐,QQ新闻。
QQ空间是腾讯推出的一种博客形式,也是腾讯用户主要的活动场所。
QQ的虚拟币是腾讯主要的盈利手段,而女性是Q币的主要消费群体。
QQ的女性频道,做的很成功。
PV也是最高的11.3。
图2.2 QQ整站PV三个月平均值7.62图2.3 QQ女性频道主打栏目特色---秀发沙龙,选美模特,二级栏目特色---专家答疑,新娘,星工场,IN图2.4 头版位置头条三栏分层显示,对应右边热门排行呼应头条,中部各时尚栏目精选四条。
缺点:颜色单一2.2 新浪图2.5 前三的频道分别是SINA首页,SINA体育,SINA博客。
SINA主要以新闻资讯为主打,首页所占流量比例远远超过其他频道。
SINA女性频道只占1%访问比例,PV6.9。
图2.6 SINA整站PV三个月平均值8.13图2.7 SINA女性频道主打栏目特色---两性,八卦,二级栏目特色---杨澜天下女人,搭配手册图2.8头版位置头条三栏分段显示,右边广告+视频精选,中部各时尚栏目精选六条。
基于深度学习的图像描述算法研究

2023-10-31•研究背景和意义•相关工作•研究方法目录•实验结果与分析•结论与展望01研究背景和意义研究背景图像描述算法旨在将图像转化为自然语言描述,为视觉信息提供了文字表达方式。
深度学习技术的兴起为图像描述算法提供了新的解决方案,使其在多个领域具有广泛的应用前景。
图像作为信息的重要载体,在多媒体时代中扮演着不可或缺的角色。
研究意义推动多模态信息处理技术的发展图像描述算法是跨模态信息处理的一个重要方向,其研究有助于推动多模态信息处理技术的发展。
为相关领域提供技术支持例如,新闻媒体、广告、医疗影像等领域均可受益于图像描述算法的应用,从而为其提供技术支持。
提升图像理解与表达的准确性通过研究深度学习在图像描述算法中的应用,能够提高图像理解的准确性,进而提高图像的表达质量。
02相关工作图像描述算法相关工作•基于区域的方法:这类方法首先识别图像中的各种区域,然后使用逻辑规则或机器学习算法从这些区域中生成描述。
包括早期的工作如SIFT(Scale-Invariant Feature Transform)和SURF(Speeded Up Robust Features)。
•基于模板的方法:这种方法使用预先定义的模板或模式来描述图像中的对象和场景。
例如,简单模板匹配方法、基于机器学习的方法如使用SVM(Support Vector Machines)和神经网络等。
•基于关系的方法:这种方法通过分析对象之间的关系来生成描述。
例如,ObjectBank方法、SceneGraph 方法等。
•基于上下文的方法:这种方法利用图像中的上下文信息来生成描述。
例如,Context-based Object Detection(COCO)方法等。
深度学习在图像描述中的应用相关工作使用卷积神经网络(CNN)的方法例如,Faster R-CNN(Region-based Convolutional Networks)、YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等,这些方法在目标检测方面取得了显著的成功。
Web1.0、 Web2.0、Web3.0、Web4.0、Web5.0及Web6.0的涵义

Web1.0、Web2.0、Web3.0、Web4.0、Web5.0及Web6.0的涵义一、Web1.0web1.0时代是一个群雄并起,逐鹿网络的时代,虽然各个网站采用的手段和方法不同,但第一代互联网有诸多共同的特征,表现在:1、web1.0基本采用的是技术创新主导模式,信息技术的变革和使用对于网站的新生与发展起到了关键性的作用。
新浪的最初就是以技术平台起家,搜狐以搜索技术起家,腾讯以即时通讯技术起家,盛大以网络游戏起家,在这些网站的创始阶段,技术性的痕迹相当之重。
2、web1.0的盈利都基于一个共通点,即巨大的点击流量。
无论是早期融资还是后期获利,依托的都是为数众多的用户和点击率,以点击率为基础上市或开展增值服务,受众群众的基础,决定了盈利的水平和速度,充分地体现了互联网的眼球经济色彩。
3、web1.0的发展出现了向综合门户合流现象,早期的新浪与搜狐、网易等,继续坚持了门户网站的道路,而腾讯、MSN、GOOGLE等网络新贵,都纷纷走向了门户网络,尤其是对于新闻信息,有着极大的、共同的兴趣。
这一情况的出现,在于门户网站本身的盈利空间更加广阔,盈利方式更加多元化,占据网站平台,可以更加有效地实现增值意图,并延伸由主营业务之外的各类服务。
4、web1.0的合流同时,还形成了主营与兼营结合的明晰产业结构。
新浪以新闻+广告为主,网易拓展游戏,搜狐延伸门户矩阵,各家以主营作为突破口,以兼营作为补充点,形成拳头加肉掌的发展方式。
5、web1.0不以html 为言,在1.0时代,动态网站已经广泛应用,比如论坛等。
二、Web2.0Web2.0,是相对Web1.0(2003年以前的互联网模式)的新的一类互联网应用的统称,是一次从核心内容到外部应用的革命。
由Web1.0单纯通过网络浏览器浏览html网页模式向内容更丰富、联系性更强、工具性更强的Web2.0互联网模式的发展已经成为互联网新的发展趋势。
“Web 2.0”的概念开始于一个会议中,展开于O’Reilly公司和MediaLive国际公司之间的头脑风暴部分。
web1.0于web2.0的区别

Web2.0是以Flickr、等网站为代表,以Blog、TAG、SNS、RSS、wiki等社会软件的应用为核心,依据六度分隔、xml、ajax等新理论和技术实现的互联网新一代模式。
”Blog——博客/网志:Blog的全名应该是Web log,后来缩写为Blog。
Blog是一个易于使用的网站,您可以在其中迅速发布想法、与他人交流以及从事其他活动。
所有这一切都是免费的。
RSS——站点摘要:RSS是站点用来和其他站点之间共享内容的一种简易方式(也叫聚合内容)的技术。
最初源自浏览器“新闻频道”的技术,现在通常被用于新闻和其他按顺序排列的网站,例如Blog。
WIKI——百科全书:Wiki--一种多人协作的写作工具。
Wiki站点可以有多人(甚至任何访问者)维护,每个人都可以发表自己的意见,或者对共同的主题进行扩展或者探讨。
Wiki指一种超文本系统。
这种超文本系统支持面向社群的协作式写作,同时也包括一组支持这种写作的辅助工具。
网摘:“网摘”又名“网页书签”,起源于一家叫做的美国网站自2003年开始提供的一项叫做“社会化书签”(Social Bookmarks)的网络服务,网友们称之为“美味书签”(Delicious在英文中的意思就是“美味的;有趣的”)。
SNS——社会网络:Social Network Sofwaret,社会性网络软件,依据六度理论,以认识朋友的朋友为基础,扩展自己的人脉。
P2P——对等联网:P2P是peer-to-peer的缩写,peer在英语里有“(地位、能力等)同等者”、“同事”和“伙伴”等意义。
这样一来,P2P也就可以理解为“伙伴对伙伴”、“点对点”的意思,或称为对等联网。
目前人们认为其在加强网络上人的交流、文件交换、分布计算等方面大有前途。
IM——即时通讯:即时通讯(Instant Messenger,简称IM)软件可以说是目前我国上网用户使用率最高的软件。
聊天一直是网民们上网的主要活动之一,网上聊天的主要工具已经从初期的聊天室、论坛变为以MSN、QQ为代表的即时通讯软件。
困难会激发我们的创造力——Flickr创始人之一卡泰丽娜·费克访谈

其实早 在1 9 年 的时候 ,杰 森和斯 图尔特就 合伙创 办 了~ 家公 司,但大约6 99 到9
个 月 后 ,公 司就 被 波 士 顿 的一 家 风 险 资 本 财 团收 购 。 后 来 杰 森 到 波 士顿 工 作 了一
创 始 人 , 并 在 2 0 年 将 网 站 卖 05
Y C mbn trU 人 之 一 。著 有 优 秀 图 o i o ̄ 始 a 书 《 业 者 》 ( 书 名 《 o n esa 创 原 F u d r t wo k)) , 包 括 有 3 家 著 名 的数 字 公 r) 2 司 创业 者 的精 彩 故事 。
[ 编者 按 ]0 2 夏 天 ,卡 泰 丽娜 ・ 20年 费克 ( t r a a e) Ca e i F k 、斯 图 尔特 ・ n 巴特菲 尔德 ( e r St wa t B t e f l) u t ri d 和杰 森 ・ e 克拉森 ( a o a s n 创 办 了网络软件公 司L dc r 。L dc r 公司的 J s n Cls o ) u io p u io p 第一款产品是 “ 永不 结束 的游 戏 ” ( me N v r n ig ,这是 一种大型 的多人在 线角色扮 演游 Ga e e e dn ) 戏 。在2 0 年 ,他们 为原来 的游 戏增加 了一个新功 能 ,就是 即时交换照 片功能 的多人 聊天室 ,正是 04 这项新 的功能 ,使 得这款游 戏迅速火 爆起来 ,新加功能 的受欢迎 程度甚至 超过 了游戏本 身 。此 时 , 整个开发 团队意识 到 了其 问的价值 ,于是他们 决定抓住 “ 永不结束 的游戏 ”这个机会 ,在 其基础上 开发一款新的照 片交换 社区网站 ,网站 的名 字就叫做Fik 。果然 ,Fik 迅速崛起 ,成 为最 著名 的 l r c l r c We 2 O b .公司之 一 。尽管 它在2 0 年3 0 5 月被雅虎 公司所 收购 ,但卡泰 丽娜 ・ 费克 的创 业激情永远不 会 停止 。
网站架构的设计方案

网站架构的设计方案网站架构,一般认为是根据客户需求分析的结果,准确定位网站目标群体,设定网站整体架构,规划、设计网站栏目及其内容,制定网站开发流程及顺序,以最大限度地进行高效资源分配与管理的设计。
其内容有程序架构,呈现架构,和信息架构三种表现。
而步骤主要分为硬架构和软架构两步程序。
网络架构是现代网络学习和发展的一个必须的基础技术。
在选择机房的时候,根据网站用户的地域分布,可以选择网通或电信机房,但更多时候,可能双线机房才是合适的。
越大的城市,机房价格越贵,从成本的角度看可以在一些中小城市托管服务器,比如说北京的公司可以考虑把服务器托管在天津,廊坊等地,不是特别远,但是价格会便宜很多。
现在的PHP框架有很多选择,比如:CakePHP,Symfony,Zend Framework等等,至于应该使用哪一个并没有唯一的答案,要根据Team里团队成员对各个框架的了解程度而定。
很多时候,即使没有使用框架,一样能写出好的程序来,比如Flickr据说就是用Pear+Smarty这样的类库写出来的,所以,是否用框架,用什么框架,一般不是最重要的,重要的是我们的编程思想里要有框架的意识。
网站规模到了一定的程度之后,代码里各种逻辑纠缠在一起,会给维护和扩展带来巨大的障碍,这时我们的解决方式其实很简单,那就是重构,将逻辑进行分层。
通常,自上而下可以分为表现层,应用层,领域层,持久层。
所谓表现层,并不仅仅就指模板,它的范围要更广一些,所有和表现相关的逻辑都应该被纳入表现层的范畴。
比如说某处的字体要显示为红色,某处的开头要空两格,这些都属于表现层。
很多时候,我们容易犯的错误就是把本属于表现层的逻辑放到了其他层面去完成,这里说一个很常见的例子:我们在列表页显示文章标题的时候,都会设定一个最大字数,一旦标题长度超过了这个限制,就截断,并在后面显示“..”,这就是最典型的表现层逻辑,但是实际情况,有很多程序员都是在非表现层代码里完成数据的获取和截断,然后赋值给表现层模板,这样的代码最直接的缺点就是同样一段数据,在这个页面我可能想显示前10个字,再另一个页面我可能想显示前15个字,而一旦我们在程序里固化了这个字数,也就丧失了可移植性。
基于双层路由注意力及特征融合的细粒度图像分类

基于双层路由注意力及特征融合的细粒度图像分类沈宇麒;崔衍【期刊名称】《计算机技术与发展》【年(卷),期】2024(34)6【摘要】近年来,视觉Transformer(Vision Transformer,ViT)在图像识别领域取得了突破性进展,其自注意力机制能够从图像中提取出不同像素块的判别性标记信息,进而提升图像分类的精度。
在图像分类领域中,细粒度图像分类具有类与类之间的特征差距小、类内的特征差距大的特点,从而导致了分类困难。
针对细粒度图像分类中数据分布具有小型、非均匀和难以发现类与类之间的差异等特征,提出一种基于双层路由注意力(Bi-level Routing Attention,BRA)的细粒度图像分类模型。
基准骨干网络采用多阶段层级架构设计的新型视觉Transformer模型作为视觉特征提取器,从中获得局部信息和全局信息以及多尺度的特征。
同时引入特征增强、融合模块,以此提高网络对关键特征的学习能力。
实验结果表明,该模型在CUB-200-2011和Stanford Dogs这两个细粒度图像数据集上的分类精度分别达到了91.7%和92.2%,相较于多个主流细粒度图像分类模型,该模型具有更好的分类结果。
【总页数】6页(P23-28)【作者】沈宇麒;崔衍【作者单位】南京邮电大学物联网学院【正文语种】中文【中图分类】TP391.41【相关文献】1.基于多尺度特征融合与反复注意力机制的细粒度图像分类算法2.基于注意力自身线性融合的弱监督细粒度图像分类算法3.基于注意力特征融合的SqueezeNet细粒度图像分类模型4.基于自适应特征融合的小样本细粒度图像分类5.一种新的基于通道-空间融合注意力及SwinT的细粒度图像分类算法因版权原因,仅展示原文概要,查看原文内容请购买。
全开源数据集训练vision language model

全开源数据集训练视觉语言模型(Vision-Language Models)是一个研究领域,旨在开发能够理解和生成图像和文本的混合模型的算法。
这些模型通常被训练来执行各种任务,如图像描述、视觉问答、图像字幕生成、跨模态检索等。
要训练一个视觉语言模型,通常需要以下几个步骤:
1. 数据收集:首先需要收集一个大规模的全开源数据集,这些数据集应该包含图像和对应的文本描述。
一些流行的数据集包括COCO(Common Objects in Context)、Flickr30k、ImageNet等。
2. 数据预处理:对收集的数据进行清洗和预处理,以确保模型的质量和效率。
这可能包括去除噪声数据、标准化图像尺寸、标记化文本等。
3. 模型选择:选择一个合适的模型架构,如Transformer、ResNet、VGG等,这些模型可以处理图像和文本数据。
4. 训练:使用预处理的数据集来训练模型。
这通常涉及到前向传播和反向传播过程,以及使用优化算法(如Adam、SGD等)来更新模型的权重。
5. 评估和调优:在验证集上评估模型的性能,并根据需要调整模型的参数和架构以提高其准确性和泛化能力。
6. 测试和部署:在测试集上测试模型的最终性能,并在实际应用中部署模型。
这个领域的挑战之一是如何处理图像和文本之间的复杂关系,以及如何让模型能够理解这两种模态之间的语义对应关系。
此外,数据集的多样性和规模也是影响模型性能的关键因素。
在中国,研究人员和开发者也在积极参与视觉语言模型的研究和应用,他们通常会遵循国家的法律法规和道德准则,确保数据集的合规性和模型的安全性。
领导者失败案例分析三:雅虎的失败之路

谷歌、亚马逊等公司的品牌影响力 日益扩大,成为全球最具价值的品 牌之一,吸引了大量用户和广告商 。
广告市场变化挑战
广告主需求变化
随着数字广告市场的快速发展, 广告主对广告投放效果和数据透 明度的要求越来越高,雅虎等传 统广告平台难以满足这些需求。
广告技术革新
实时竞价、程序化购买等广告技 术的革新,使得广告投放更加精 准、高效,对雅虎等公司的广告
创新驱动发展
鼓励创新思维,加大研发 投入,推动技术和产品升 级,以抢占市场先机。
强化组织管理与创新能力
优化组织结构
建立高效、灵活的组织结 构,明确职责划分,提升 团队协作效率。
培养创新人才
注重人才选拔和培养,打 造具备创新精神和实践能 力的专业团队。
营造创新氛围
鼓励员工提出创新性想法 和建议,为员工提供充足 的资源和支持,实现企业 内部创新。
02
战略决策失误
错过搜索引擎发展机遇
忽视搜索引擎技术重要性
在搜索引擎技术迅速发展的时期,雅虎未能及时把握机遇,导致 在搜索引擎市场上的份额逐渐被谷歌等竞争对手蚕食。
缺乏创新
雅虎在搜索引擎技术方面缺乏足够的创新,无法满足用户对高效 、准确搜索的需求,使得用户逐渐流失。
社交媒体战略滞后
未能预见社交媒体发展趋势
பைடு நூலகம்
培养健康企业文化氛围
树立企业价值观
明确企业使命和愿景,树立积极向上的企业价值 观,引导员工共同追求企业目标。
倡导团队精神
加强团队建设和员工沟通,培养员工之间的信任 和协作精神,形成团队合力。
关注员工福利
关注员工成长和生活质量,提供完善的福利待遇 和职业发展机会,增强员工归属感和忠诚度。
CNN典型网络结构与常用框架

CNN典型网络结构与常用框架CNN,即卷积神经网络(Convolutional Neural Network),是一种常用的深度学习网络结构,特别适用于图像和视频处理任务。
本文将介绍CNN的典型网络结构和常用框架,并进行详细讨论。
一、典型网络结构:1. LeNet-5:LeNet是最早出现的CNN结构,由Yann Lecun等人提出。
它主要用于手写数字识别任务,包含两个卷积层和三个全连接层。
LeNet-5提出了卷积,池化和全连接等重要概念,并定义了后续CNN的基本框架。
2. AlexNet:AlexNet是由Alex Krizhevsky等人提出的一个重要CNN结构。
它在2024年的ImageNet图像分类大赛上大放异彩,引起了广泛关注。
AlexNet包含8层神经网络,其中有5个卷积层和3个全连接层。
AlexNet增加了模型的深度和宽度,采用了更大的卷积核和更多的参数,使得模型能够更好地提取图像的特征。
3. VGG:VGG是由Karen Simonyan和Andrew Zisserman提出的一种深层CNN结构。
它使用了非常小的卷积核(3x3)和更深的网络结构,共有16-19层卷积层。
VGG网络结构非常简洁清晰,具有良好的可扩展性,并且在图像分类和物体检测等任务上取得了很好的效果。
4. GoogLeNet:GoogLeNet是由Google公司的研究员提出的CNN结构。
它在2024年的ImageNet图像分类比赛上获得了冠军,并引起了广泛关注。
GoogLeNet采用了一个称为Inception Module的模块化结构,可以有效地减少参数数量,提高模型的效率和准确性。
5. ResNet:ResNet是由Kaiming He等人提出的一个深度残差网络结构。
它采用了残差学习的思想,允许网络层直接学习输入残差的映射,解决了深度CNN难以训练的问题。
ResNet在多个图像处理任务上取得了最好的效果,并引发了更深层次的CNN模型的研究热潮。
基于Python的关于Flickr图片网站的爬虫

1引言随着大数据时代的到来,大数据具有数据体量巨大(Volume)、数据类型繁多(Variety)、价值密度低(Value)、处理速度快(Velocity)的特点[1]。
面对人们越来越多样的需求[2],可以根据自己的实际需求,继续修改程序来达到自己的要求[3]。
程序按照一个检索词列表进行批量爬取,并把图片信息存入数据库中。
本文提供了一个通过Python调用Flickr API实现通过关键字检索获取图片信息并批量下载的程序。
2相关技术2.1PythonPython是一种计算机程序设计语言,是一种动态的、面向对象的脚本语言。
Python语言的一大优势就是其语法简洁清晰,并具有丰富和强大的类库[5],这为程序的编写提供了极大的便利使得数据抓取工作变得生动有趣[6],从而简化了程序。
2.2Flickr APIFlickr是雅虎旗下的图片分享网站,上面有全世界网友分享的大量精彩图片,被认为是专业的图片网站。
3爬虫系统工作系统分为两部分:第一部分即调用Flickr API获取图片等数据,第二部分即根据数据库中的图片Url下载图。
获取图片信息的流程图如图1所示,下载的流程图如图2所示。
3.1调用API获取信息Flickr网站上的每张图片都有一个唯一标识的ID,如果想要知道图片的信息首先就是要获取图片在Flickr上的ID,再通过调用Flickr的多种方法来获取图片的不同信息。
Flickr API库有很多方法可以调用,可以获取不同的图片数据[4]。
但是使用前提都是需要有Flickr API的密钥,参考代码如下:Flickr=flickrapi.FlickrAPI(API_KEY,API_SECRET,cache= True)程序主要通过关键词来进行检索相应的图片,tags和text 就是对应输入相应的关键词参数,extras为要求返回不同大小图片的Url。
参考代码如下:photos=flickr.photos.search(extras='url_c',per_page=5,text=keyword, tag_mode='all',content_type=7,tags=keyword,sort='relevance')通过photos.search方法就可以获得检索图片的Json列基于Python的关于Flickr图片网站的爬虫The Web Crawler of Flickr Photo Website Based on Python王金峰1,李世良1,王明2,罗星宇1,张雪玉1(1.防灾科技学院信息工程学院,河北三河065201,2.河北女子职业技术学院,石家庄050091)WANG Jin-feng1,LI Shi-liang1,WANG Ming2,LUO Xing-yu1,ZHANG Xue-yu1(1.School ofInformation Engineering,InstituteofDisasterPrevention,Sanhe065201,China;2.HebeiWomen's Vocational College,Shijiazhuang050091,China)【摘要】如今的互联网已然进入大数据时代,网络上有数以百计的图片,图片网络爬虫可以通过既定的规则自动地抓取互联网上的图片并下载至本地存储,通过对国内外各大图片网站的调查研究,决定以国外网站Flickr为对象通过Python程序设计语言来实现获取高质量的,准确的,完整的图片和信息。
复杂网络结构与动态演化机理研究

复杂网络结构与动态演化机理研究1. 引言复杂网络结构与动态演化机理是近年来在网络科学领域引起广泛关注的研究领域。
随着信息技术的飞速发展和互联网的蓬勃发展,人们对网络结构的认识越来越深入,网络的形态也越来越复杂。
在这样的背景下,研究复杂网络结构与动态演化机理就成为了一个重要的课题。
2. 复杂网络结构的特征复杂网络的结构具有许多特征,其中最重要的包括:小世界效应、无标度性和聚集性。
小世界效应指的是网络中的节点之间的平均路径长度相对较短,即任意两个节点之间通过少数几个中间节点就可以相互到达。
无标度性则表示网络中存在少数节点的度数远大于其他节点,这些节点被称为“关键节点”,具有极其重要的功能。
聚集性则代表着网络中节点的连接有一定的倾向性,即同一领域的节点更容易相互连通。
3. 复杂网络的生成模型为了解释复杂网络结构的形成机制,研究者提出了多种生成模型。
其中最著名的是小世界模型和无标度模型。
小世界模型通过添加少量的随机边来实现节点之间的短路径连接,从而模拟了现实世界中的小世界效应。
无标度模型则通过优先连接高度连接的节点,生成具有无标度性的网络结构。
4. 复杂网络的动态演化过程除了研究网络的静态结构外,人们还对网络的动态演化过程进行了广泛研究。
网络的动态演化过程通常包括节点的添加、删除和连接方式的变化等。
这些变化往往受到外部环境和节点本身的因素的影响。
例如,在社交网络中,人们的交友行为会影响到网络的结构演化。
而在互联网中,节点的添加和删除则与网站的上线和下线相关。
5. 复杂网络在现实生活中的应用复杂网络结构与动态演化机理的研究不仅仅是学术上的追求,还有许多实际应用。
比如在社交网络中,研究网络结构可以帮助我们了解人际关系的形成和演化规律,为社交媒体的发展提供支持。
在物流和交通领域,复杂网络的动态演化研究可以帮助我们优化路网设计和物流调度,提高交通效率。
此外,在生物学和医学领域,研究复杂网络结构可以帮助我们理解生物网络的形成和功能,为疾病的诊断和治疗提供帮助。
Flickr

如果要列举那些被大公司收购之后走向没落的热门产品,Flickr一定排名靠前。
这个当年具有划时代财力来满足雅虎方面的各种苛刻要求,而没有更多的资源来进一步创新。
更为残酷的是,由于Flickr团队所能贡献的收入远远少于当时雅虎的其他主要服务项目(雅虎邮箱、雅虎体育等等),因此Flickr团队所能得到的资源也就十分稀少,资源的不足导致Flickr团队在完成整合进程之外无力开发新特性吸引用户扩大社区,而用户社区无法增长又意味着无法贡献更多的收入,无法贡献更多收入就无法获得更多资源。
于是出现了死循环,Flickr团队无法有效地发展和壮大自己的产品。
在这样资源不足的窘境中,Flickr团队不得不取消了大部分增加新特性适应新潮流的计划。
Flickr错过了一波又一波浪潮,没有办法从图像领域扩展到视频领域,于是Youtube壮大了起来;也没有办法进一步强化构建在照片分享之上的社交关系,眼看着Facebook一步步取得了成功;Flickr只能继续停留在照片存储和分享的旧领域里原地踏步,不久以后Instagram等一批新兴服务出现,更是将Flickr从自己的传统地盘上给踢了出去。
错失社交良机事实上,Flickr真正的价值并不在于照片分享这样的行为,而是构筑在照片分享行为之上的社交关系。
在一个大部分人还不知道社交网络是什么的年代里,Flickr 就已经依托照片分享构建出了一个用户之间的社交网络。
Flickr还是最早实践用户圈子概念的产品,用户与用户之间的关系并不只有传统的好友/非好友,比如一名用户可以将另一名用户放到“家庭”的分组里而并不需要互加好友。
用户可以将照片设为“私密”仅限自己查看,也可以分享给指定的一两位用户,还可以按照不同的分组进行分享,这样的灵活设定很大程度上鼓励了用户之间的分享、评论和交互,取得了很好的效果。
然而当时的雅虎根本就没有任何这方面的打算,当时雅虎收购这些服务,实际上是出于另外一个可笑的理由——那个时候,雅虎刚刚被谷歌从搜索引擎服务老大的位置上挤下来,雅虎公司的高层试图整合更多的资源来重新夺回这一位置。
Underlay网络架构设计指南

互联网接入区
园区网接入区 核心
Spine
POD1
Spine
POD2
Leaf 服务器
生产环境区
Leaf 服务器
非生产环境区
DC
广域网接入区
Spine
PODn
Leaf 服务器
测试环境区
数据中心网络架构演进的三个版本
DCN 1.0 STP+VRRP
核心 VRRP
汇聚
STP 接入
核心 汇聚 接入
VRRP+STP
FI数据平面(带内)
FI物理图
Leaf
Leaf
Spine FabricInsight-Leaf
物理服务器
虚拟化服务器
FabricInsight 采集器集群
FabricInsight 分析器集群
FI逻辑图
VXLAN的报文格式
VXLAN封装 50(54)Bytes Overhead
外层 以太帧头部
出口设计 – 两个L3接口
PE独立部署
1
2
Border Leaf Border Leaf侧L3接口 逃生链路
出口设计 – PE VRRP方案
物理视角
PE VRRP
PE VRRP
VRRP Border Leaf
VRRP Border Leaf
逻辑视角
PE VRRP
VRRP Border Leaf
控制器部署
POD2
EBGP
LEAF
EBGP
LEAF
AS 65501
AS 65502
AS 65521
AS 65522
服务器接入设计
1 :服务器双活接入M-LAG
基于位置信息的用户行为轨迹分析与应用综述

基于位置信息的用户行为轨迹分析与应用综述陈康;黄晓宇;王爱宝;陶彩霞;关迎晖;李磊【摘要】近年来,随着空间数据采集技术的发展,基于位置信息的用户行为轨迹分析及其应用的研究引起了广泛关注,并已展现了良好的商业前景.根据应用的领域,对这一问题的研究主要可以分为智能交通应用和用户行为分析应用两种类型.本文分别对这两类应用的研究现状进行了较为全面的总结,对每类应用,都概括了在相关领域中研究的典型问题和代表性结果.最后,讨论了在用户行为轨迹分析研究中的主要技术特点,并对未来的研究工作进行了展望.【期刊名称】《电信科学》【年(卷),期】2013(029)004【总页数】7页(P118-124)【关键词】位置服务;行为轨迹分析;智能交通;社交网络;大数据【作者】陈康;黄晓宇;王爱宝;陶彩霞;关迎晖;李磊【作者单位】中国电信股份有限公司广东研究院广州510630;华南理工大学经济与贸易学院广州510006;中山大学软件研究所广州510275;中国电信集团公司北京 100032;中国电信股份有限公司广东研究院广州510630;中国电信股份有限公司广东研究院广州510630;中山大学软件研究所广州510275【正文语种】中文1 前言近年来,随着以GPS导航仪和智能手机为代表的智能终端的普及与应用,人们已经能够以相对低廉的代价获得大量的用户实时位置数据,如在GPS导航系统的支持下,可以实时获得汽车驾驶员当前所在的经、纬度位置信息和行驶方向信息;对于随身携带移动电话的用户,能以基站定位的方式,估计出该用户所在的大概区域。
特别地,对于给定的用户,将其在一组连续时间点上的位置“串联”起来后,就形成了他在这个时间段内的行为轨迹数据。
在大量用户位置和行为轨迹数据的背后,隐含了丰富的空间结构信息和用户行为规律信息,通过对这些信息进行深入的挖掘和利用,不仅有可能发现个体用户的日常行为规律和群体用户的共性行为特征,甚至还有可能掌握其社交关系信息,这对智能交通、广告推荐等应用具有非常重要的意义。
异构信息网络中基于元路径的搜索和挖掘(上)

异构信息网络中基于元路径的搜索和挖掘Meta-Path-Based Search and Mining in Heterogeneous InformationNetworks学院(系):专业:学生姓名:学号:指导教师:完成日期:异构信息网络中基于元路径的搜索和挖掘摘要:最近,从各个领域提取出来的信息网络被广泛的研究,提出和发展了不同的功能挖掘这些网络,如排名,社区检测和链路预测。
大多数现有的网络研究是同构网络,其中的节点和链接假设为一个单一类型。
然而在现实中,异构信息网络可以更好地模拟真实世界的系统,这是典型的半结构化和类型化,承接网络架构。
为了直接开采这些异构信息网络,我们提出探索信息网络的元结构,即网络架构。
提出的元路径的概念,系统地捕获在多个类型的对象,通过网络架构的图形的众多语义关系,它们被定义为一个路径。
元路径可以为搜索和挖掘网络提供指导,帮助分析和了解网络中的对象和关系的语义。
在此框架下,相似性搜索和其他挖掘任务,如关系的预测和集群可以通过网络的元结构的系统的探索加以解决。
此外,随着用户的指导和反馈,我们可以为一个特定的挖掘任务选择最好的元路径或它们的加权组合。
关键词:异构信息网络;元路径;相似性搜索;关系预测;用户指导引言真实世界的物理和抽象的数据对象是相互关联的,形成一个庞大互连网络。
通过这些结构化数据对象和这些对象之间的交互成多种类型,如网络成为半结构化的异构信息网络。
用于处理大数据的现实世界的应用,包括相互连接的社交媒体和社交网络,科学,工程或医疗信息系统,在线电子商务系统,和大多数数据库系统,可以被结构化为异构信息网络。
不同于对象和链接被看做相同类型或无类型的节点或链路的同构信息网络,在我们的模型中,异构信息网络是半结构化和类型,即节点和链接被构造一组类型,形成了网络架构。
例如在像书目数据库DBLP 和PubMed,论文通过作者,期刊和条件连在一起。
Flickr,一个社交网络,照片是通过用户,组,标签和评论连接在一起。
alexnet原理的介绍,形式化描述

AlexNet原理的介绍如下:
AlexNet是由多伦多大学SuperVision组设计的8层卷积神经网络,由Alex Krizhevsky、Geoffrey Hinton和Ilya Sutskever组成。
该网络证明了深度学习的能力,也是第一个使用并行计算和GPU进行加速的网络。
AlexNet共有8层结构,其中前5层为卷积层,后面3层为全连接层。
该网络采用两路GTX 580 3G并行训练,并在第2、4、5层进行GPU内连接,第3层与前面两层全连接。
AlexNet使用ReLU激活函数,解决了sigmoid函数在训练过程中梯度消失的问题,并采用局部响应归一化(LRN)提高性能。
以上内容仅供参考,如需更多信息,建议查阅相关文献或咨询相关研究人员。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Flickr网站架构研究引言 是网上最受欢迎的照片共享网站之一,还记得那位给Windows Vista拍摄壁纸的Hamad Darwish吗?他就是将照片上传到Flickr,后而被微软看中成为Vista壁纸御用摄影师。
是最初由位于温哥华的Ludicorp公司开发设计并于2004年2月正式发布的,由于大量应用了WEB 2.0技术,注重用户体验,使得其迅速获得了大量的用户,2007年11月,Flickr迎来了第20亿张照片,一年后,这个数字就达到了30亿,并且还在以加速度增长。
2005年3月,雅虎公司以3千500万美元收购了Ludicorp公司和。
虽然Flickr并不是最大的照片共享网站(Facebook以超过100亿张照片排名第一),但这笔收购仍然被认为是WEB 2.0浪潮中最精明的收购,因为仅仅一年后,Google就以16亿美元的高价收购了YouTube,而2007年10月,微软斥资2.4亿美元收购Facebook 1.6%股份,此举使Facebook估值高达150亿美元。
估计Ludicorp公司的创始人Stewart Butterfield和Caterina Fake夫妇现在还在后悔吧。
在2005年温哥华PHP协会的简报以及随后的一系列会议上,Flickr的架构师Cal Henderson公开了大部分Flickr所使用的后台技术,使得我们能有机会来分享和研究其在构建可扩展Web站点的经验。
本文大部分资料来自互联网和自己的一点点心得,欢迎大家参与讨论,要是能够起到抛砖引玉的作用,本人将不胜荣幸。
Flickr 网站架构综述在讨论Flickr 网站架构之前,让我们先来看一组统计数据(数据来源:April 2007 MySQL Conf and Expo和Flickr网站)。
每天多达40亿次的查询请求。
squid总计约有3500万张照片(硬盘+内存)。
squid内存中约有200万张照片。
总计有大约4亿7000万张照片,每张图片又生成不同尺寸大小的4-5份图片。
每秒38,000次Memcached请求(Memcached总共存储了1200万对象) 。
超过2 PB 存储,其中数据库12TB。
每天新增图片超过40万(周日峰值超过200万,约1.5TB)。
超过8百50万注册用户。
超过1千万的唯一标签(tags)你如果觉得这些过时的数据都已经很惊人了,那么让我们来看看Cal Henderson在2008年9月的一次会议上公布的另一组数据,在短短的一秒钟内:。
响应4万个照片访问请求。
处理10万个缓存操作。
运行13万个数据库查询这张是Flickr的网站架构图,我们这里只作一些简要的描述,具体的分析请静待后续文章。
Pair of ServerIron's-Load Balancer。
Squid Caches-反向代理,用于缓存静态的HTML和照片。
Net App'-NetApp 公司的Filer, NAS存储设备,用于存储照片。
PHP App Servers-运行REDHAT LINUX,Apache上的PHP应用,Flickr网站的主体是大约6万行PHP代码-没有使用PHP session, 应用是stateless,便于扩展,并避免PHP Server 故障所带来的Session失效。
-每个页面有大约27~35个查询(不知道为什么这么设计,个人觉得没有必要)-另有专门的Apache Web Farm 服务于静态文件(HTML和照片)的访问。
Storage Manager-运行私有的,适用于海量文件存储的Flickr File System。
Dual Tree Central Database-MySQL 数据库,存放用户表,记录的信息是用户主键以及此用户对以的数据库Shard区,从中心用户表中查出用户数据所在位置,然后直接从目标Shard中取出数据。
-“Dual Tree"架构是”Master-Master"和“Master-Slave"的有效结合,双Master 避免了“单点故障”,Master-Slave又提高了读取速度,因为用户表的操作90%以上是读。
Master-master shards-MySQL 数据库,存储实际的用户数据和照片的元数据(Meta Data),每个Shard 大约40万个用户,120GB 数据。
每个用户的所有数据存放在同一个shard中。
-Shard中的每一个server的负载只是其可最大负载的50%,这样在需要的时候可以Online停掉一半的server进行升级或维护而不影响系统性能。
-为了避免跨Shard查询所带来的性能影响,一些数据有在不同的Shard 有两份拷贝,比如用户对照片的评论,通过事务来保证其同步。
Memcached Cluster-中间层缓存服务器,用于缓存数据库的SQL查询结果等。
Big Search Engine- 复制部分Shard数据(Owner’s single tag)到Search Engine Farm以响应实时的全文检索。
- 其他全文检索请求利用Yahoo的搜索引擎处理(Flickr是Yahoo旗下的公司)服务器的硬件配置:- Intel或AMD 64位CPU,16GB RAM- 6-disk 15K RPM RAID-10.- 2U boxes.服务器数量:(数据来源:April 2008 MySQL Conference & Expo)166 DB servers, 244 web servers(不知道是否包括squid server?), 14 Memcached servers数据库最初的扩展-Replication也许有人不相信,不过Flickr确实是从一台服务器起步的,即Apache/PHP 和MySQL是运行在同一台服务器上的,很快MySQL服务器就独立了出来,成了双服务器架构。
随着用户和访问量的快速增长,MySQL数据库开始承受越来越大的压力,成为应用瓶颈,导致网站应用响应速度变慢,MySQL 的扩展问题就摆在了Flickr的技术团队面前。
不幸的是,在当时,他们的选择并不多。
一般来说,数据库的扩展无外是两条路,Scale-Up和Scale-Out,所谓Scale-Up,简单的说就是在同一台机器内增加CPU,内存等硬件来增加数据库系统的处理能力,一般不需要修改应用程序;而Scale-Out,就是我们通常所说的数据库集群方式,即通过增加运行数据库服务器的数量来提高系统整体的能力,而应用程序则一般需要进行相应的修改。
在常见的商业数据库中,Oracle具有很强的Scale-Up的能力,很早就能够支持几十个甚至数百个CPU,运行大型关键业务应用;而微软的SQL SERVER,早期受Wintel架构所限,以Scale-Out著称,但自从几年前突破了Wintel体系架构8路CPU的的限制,Scale-Up的能力一路突飞猛进,最近更是发布了SQL 2008在Windows 2008 R2版运行256个CPU核心(core)的测试结果,开始挑战Oracle的高端市场。
而MySQL,直到今年4月,在最终采纳了GOOGLE公司贡献的SMP性能增强的代码后,发布了MySQL5.4后,才开始支持16路CPU 的X86系统和64路CPU的CMT系统(基于Sun UltraSPARC 的系统)。
从另一方面来说,Scale-Up受软硬件体系的限制,不可能无限增加CPU和内存,相反Scale-Out却是可以"几乎"无限的扩展,以Google 为例,2006年Google一共有超过45万台服务器(谁能告诉我现在他们有多少?!);而且大型SMP服务器的价格远远超过普通的双路服务器,对于很多刚刚起步或是业务增长很难预测的网站来说,不可能也没必要一次性投资购买大型的硬件设备,因而虽然Scale-Out会随着服务器数量的增多而带来管理,部署和维护的成本急剧上升,但确是大多数大型网站当然也包括Flickr的唯一选择。
经过统计,Flickr的技术人员发现,查询即SELECT语句的数量要远远大于添加,更新和删除的数量,比例达到了大约13:1甚至更多,所以他们采用了“Master-Slave”的复制模式,即所有的“写”操作都在发生在“Master",然后”异步“复制到一台或多台“Slave"上,而所有的”读“操作都转到”Slave"上运行,这样随着“读”交易量的增加,只需增加Slave服务器就可以了。
让我们来看一下应用系统应该如何修改来适应这样的架构,除了”读/写“分离外,对于”读“操作最基本的要求是:1)应用程序能够在多个”Slave“上进行负载均分;2)当一个或多个”slave"出现故障时,应用程序能自动尝试下一个“slave”,如果全部“Slave"失效,则返回错误。
Flickr曾经考虑过的方案是在Web应用和”Slave“群之间加入一个硬件或软件的”Load Balancer“,如下图这样的好处是应用所需的改动最小,因为对于应用来说,所有的读操作都是通过一个虚拟的Slave来进行,添加和删除“Slave"服务器对应用透明,Load Balancer 实现对各个Slave服务器状态的监控并将出现故障的Slave从可用节点列表里删除,并可以实现一些复杂的负载分担策略,比如新买的服务器处理能力要高过Slave群中其他的老机器,那么我们可以给这个机器多分配一些负载以最有效的利用资源。
一个简单的利用Apache proxy_balancer_module的例子如下:。
LoadModule proxy_module modules/mod_proxy.soLoadModule proxy_balancer_module modules/mod_proxy_balancer.so LoadModule proxy_http_module modules/mod_proxy_http.so 。
<Proxy balancer://mycluster>BalancerMember "http://slave1:8008/App" loadfactor=4 BalancerMember "http://slave2:8008/App" loadfactor=3 BalancerMember "http://slave3:8008/App" loadfactor=3 ....................///slave load ratio 4:3:3.最终,Flickr采用了一种非常“轻量”但有效的“简易”PHP实现,基本的代码只有10几行,Ffunction db_connect($hosts, $user, $pass){shuffle($hosts); //shuffle()是PHP函数,作用是将数组中每个元素的顺序随机打乱。