Nutch在Windows中安装之细解
Nutch搜索引擎(第1期)_Nutch简介及安装

细细品味Nutch——Nutch搜索引擎(第1期)精华集锦csAxp虾皮工作室/xia520pi/2014年3月18日Nutch搜索引擎(第1期)——Nutch简介及安装1、Nutch简介Nutch是一个由Java实现的,开放源代码(open-source)的web搜索引擎。
主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行查询的一套工具。
其底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做,Solr是一个开源的全文索引框架,从Nutch 1.3开始,其集成了这个索引架构。
Nutch目前最新的版本为version1.4。
1.1 Nutch的目标Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎。
为了完成这一宏伟的目标,Nutch必须能够做到:●每个月取几十亿网页●为这些网页维护一个索引●对索引文件进行每秒上千次的搜索●提供高质量的搜索结果●以最小的成本运作1.2 Nutch的优点●透明度Nutch是开放源代码的,因此任何人都可以查看他的排序算法是如何工作的。
商业的搜索引擎排序算法都是保密的,我们无法知道为什么搜索出来的排序结果是如何算出来的。
更进一步,一些搜索引擎允许竞价排名,比如百度,这样的索引结果并不是和站点内容相关的。
因此Nutch对学术搜索和政府类站点的搜索来说,是个好选择。
因为一个公平的排序结果是非常重要的。
●扩展性你是不是不喜欢其他的搜索引擎展现结果的方式呢?那就用 Nutch 写你自己的搜索引擎吧。
Nutch 是非常灵活的,他可以被很好的客户订制并集成到你的应用程序中。
使用Nutch 的插件机制,Nutch 可以作为一个搜索不同信息载体的搜索平台。
当然,最简单的就是集成Nutch到你的站点,为你的用户提供搜索服务。
●对搜索引擎的理解我们并没有google的源代码,因此学习搜索引擎Nutch是个不错的选择。
Windows 10下应该这样装Ubuntu

Windows 10下应该这样装Ubuntu作者:超载来源:《电脑爱好者》2020年第13期Windows用户想体验Linux有什么方法?双系统还是虚拟机?双系统之间最大的麻烦就是互相访问文件麻烦,虚拟机性能损失较大。
其实,Windows 10提供了一个更好的方式——子系统。
而且,这个子系统的运行效能非常高,访问文件也极为方便。
今天笔者就和大家分享一下Ubuntu子系统的安装使用方法(图1)。
首先点击开始菜单,然后点击齿轮图标进入设置(图2)。
然后再点击进入“更新和安全”页面(图3)。
在“更新和安全”页面的左侧,滚动下拉找到“开发者选项”点击进入(图4)。
在“开发者选项”中,单击选中“开发人员模式”,并依据提示点击“是”开启,此时会提示“正在搜索开发人员模式程序包”,这个过程会比较慢,要耐心等待(图5)。
返回设置界面,点击选择“应用”(图6)。
在应用界面,下拉右侧的“应用和功能”到底部,点击“相关设置”的“程序和功能”(图7)。
在“程序和功能”中,点击左侧的“启用或关闭Windows功能”,在弹出的菜单里下拉滚动条,找到“适用于Linux的Windows子系统”,勾选该项并点击确定。
安装结束后,会提示要求重启系统(图8)。
重启电脑后进入系统,点击开始菜单,输入PowerShell,并右键单击搜索到的程序图标,选择“以管理员身份运行”(图9)。
在PowerShell中输入命令Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux,回车执行,然后关闭窗口(图10)。
然后点击开始菜单,进入Microsoft Store(微軟商店),搜索Ubuntu并下载(图11)。
下载完毕后点击运行Ubuntu,会弹出一个类似命令提示符的窗口,首次安装会提示输入用户名密码,依据自己的喜好并按照提示进行修改即可(图12)。
安装Nutch步骤

header and User-Agent header. A good practice is to mangle this
address (e.g. 'info at example dot com') to avoid spamming.
</description>
在Windows下面配置Nutch有两种方法,一种是使用cygwin模拟Linux环境,另一种是配置到Eclipse中运行。因为linux环境不熟悉,所以还是决定使用eclipse了。
在Eclipse中配置Nutch的步骤:(Eclipse3.4, Nutch0.9)
第一步:下载release版本的nutch-0.9.tar.gz.解压到d盘.保证下载的nutch中没有.classpath和.projsect.即d:/nutch-0.9。注意解压路径中最好不要包含中文,因为将爬行结果在Tomcat中配置时,就可以直接指向保存结果的文件夹。
8. 配置web search服务. 把nutch*.war考到tomcat的webapps下, 运行tomcat, 这时tomcat会自动解压nutch*.war到nutch*目录
9. 进入nutch*目录, 修改web-inf/classes下的nutch-default.xml文件, 找到searcher.dir项, 改为你的index目录, 例如crawl.test
下一步
把conf目录添加到classpath(选择在项目的build选项里面)
把"src/java", "src/test" 还有所有的扩展(plugin)中的 "src/java" 和 "src/test" 添加到源代码目录( source folders)
Nutch搜索引擎安装

</configuration>
有资料这样描述,nutch-1.0版本之后,web项目下的nutch-site.xml的xsl需要更改一下,要不然会有很多问题。修改之后内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href=“nutch-conf.xsl“?>
Nutch的版本是1.1,需要jdk支持,Nutch0.9版本以上的需要jdk1.5以上。安装tomcat,要求tomcat5以上。如果是Windows系统,需安装cygwin或其他shell脚本支持软件。接下来安装步骤如下:
1.Nutch 1.1 解压缩,得到apache-nutch-1.1-bin目录
/
/
这里需要注意,url必须以"/"结束。1.1版本中url地址只有一行的话,会什么都搜不到,更换到1.2版本后没有这个问题。
测试命令:
cd apache-nutch-1.1-bin
./bin/nutch crawl multiurls.txt -dir crawl -depth 3 -threads 4 >& crawl.log
</property>
</configuration>
如果不配置nutch-site.xml文件,也可以配置nutch-default.xml。如果使用nutch-default.xml配置文件,则需保证nutch-site.xml文件未被修改过,也就是空配置。
3.在apache-nutch-1.1-bin目录新增url文件,multiurls.txt,内容如下:
Nutch相关框架安装使用最佳指南

Nutch相关框架安装使用最佳指南一、nutch1.2二、nutch1.5.1三、nutch2.0四、配置SSH五、安装Hadoop Cluster(伪分布式运行模式)并运行Nutch六、安装Hadoop Cluster(分布式运行模式)并运行Nutch七、配置Ganglia监控Hadoop集群和HBase集群八、Hadoop配置Snappy压缩九、Hadoop配置Lzo压缩十、配置zookeeper集群以运行hbase十一、配置Hbase集群以运行nutch-2.1(Region Servers会因为内存的问题宕机)十二、配置Accumulo集群以运行nutch-2.1(gora存在BUG)十三、配置Cassandra 集群以运行nutch-2.1(Cassandra 采用去中心化结构)十四、配置MySQL 单机服务器以运行nutch-2.1十五、nutch2.1 使用DataFileAvroStore作为数据源十六、nutch2.1 使用AvroStore作为数据源十七、配置SOLR十八、Nagios监控十九、配置Splunk二十、配置Pig二十一、配置Hive二十二、配置Hadoop2.x集群一、nutch1.2步骤和二大同小异,在步骤5、配置构建路径中需要多两个操作:在左部Package Explorer 的nutch1.2文件夹上单击右键> Build Path > Configure Build Path... >选中Source选项> Default output folder:修改nutch1.2/bin为nutch1.2/_bin,在左部Package Explorer的nutch1.2文件夹下的bin文件夹上单击右键> Team >还原二中黄色背景部分是版本号的差异,红色部分是1.2版本没有的,绿色部分是不一样的地方,如下:1、Add JARs... > nutch1.2 > lib ,选中所有的.jar文件> OK2、crawl-urlfilter.txt3、将crawl -urlfilter.txt.template改名为crawl -urlfilter.txt4、修改crawl-urlfilter.txt,将# accept hosts in +^http://([a-z0-9]*\.)*/# skip everything else-.5、cd /home/ysc/workspace/nutch1.2nutch1.2是一个完整的搜索引擎,nutch1.5.1只是一个爬虫。
windows下JDK和Tomcat安装配置
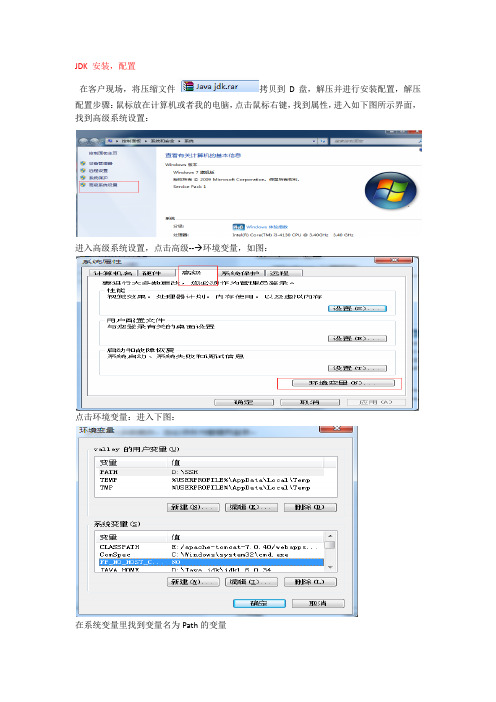
JDK 安装,配置在客户现场,将压缩文件拷贝到D盘,解压并进行安装配置,解压配置步骤:鼠标放在计算机或者我的电脑,点击鼠标右键,找到属性,进入如下图所示界面,找到高级系统设置:进入高级系统设置,点击高级-- 环境变量,如图:点击环境变量:进入下图:在系统变量里找到变量名为Path的变量然后双击该变量,出现下图,在变量值对应的文本框末尾加入:D:\Java jdk\jdk1.6.0_34\bin,注意和前面的变量值用英文状态下的分后隔开,然后点击确定即可。
回到如下界面:点击新建按钮,出现下图界面:在变量名对应的文本框里输入JAVA_HOME,切记要大写,在变量值对应的文本框里输入:D:\Java jdk\jdk1.6.0_34,然后点击确定,知道回到最初界面,到此整个windows下JDK环境变量配置完美结束,然后回到电脑桌面,按下键盘的window(也就是键盘右下角ctrl键右边的按键)+r组合键,出现如下界面,在里面输入cmd,然后回车,出现下面界面,在里面输入javac然后回车:如果出现类似如下提示,那么恭喜你,整个windows下的JDK配置已经完美结束。
Tomcat安装配置本文档主要是讲解关于绿色版的解压安装下载tomcat 文件复制到客户机D盘,如果不想在命令窗口控制tomcat,一般不用配置环境变量。
如果有特殊要求,可参照JDK配置步骤进行。
下面是一些和JDK配置不同的地方,简要说明,主要两个地方:第一步,在上图变量值对应的文本框里输入:D:\Tomcat\bin,注意用英文状态下的分号和前面的变量值进行分隔。
第二部,新建CATALINA_HOME然后一直点击确定回到电脑桌面,到此整个tomcat安装配置结束。
然后进入测试步骤,进入刚才的黑窗口输入:startup 如果出现如下界面,Tomcat配置完美结束:。
在Win10上安装Tomcat服务器及配置环境变量的详细教程(图文)

在Win10上安装Tomcat服务器及配置环境变量的详细教程(图⽂)⽬录下载安装JDK下载Tomcat压缩包解压Tomcat压缩包Tomcat⽬录结构启动Tomcat环境变量配置Tomcat 服务器是⼀个免费的开放源代码的 Web 应⽤服务器,属于轻量级应⽤服务器,在中⼩型系统和并发访问⽤户不是很多的场合下被普遍使⽤,是开发和调试 JSP 程序的⾸选。
本⽂主要讲述Windows环境Tomcat服务器安装与环境变量配置下载安装JDK要想安装Tomcat服务器,⾸先要安装配置好JDK,可以参考Windows + R然后输⼊cmd进⼊命令⾏窗⼝,检查Java是否安装正确,检查的命令为java -version如果输出类似下⾯的内容说明安装成功java version "1.8.0_191"Java(TM) SE Runtime Environment (build 1.8.0_191-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)下载Tomcat压缩包Tomcat有Tomcat7,Tomcat8和Tomcat9,⽬前企业使⽤较多的是Tomcat8,所以这⾥以Tomcat8为列点击左侧Download下的对应版本,这⾥我下载的是64-bit Windows zip,即Windows 64位的zip包Tomcat主要有三个安装版本tar.gz:Linux环境下的压缩包,免安装Windows.zip:Windows压缩包,免安装,解压即⽤,推荐安装,同时注意根据⾃⼰电脑是64位系统还是32位系统下载对应的压缩包Windows Service Installer:Windows安装包,32位和64位版本的Windows系统都适⽤解压Tomcat压缩包将下载好的zip包放到指定的位置,注意:路径不能有中⽂和特殊字符我的zip包放在C:\develop\Tomcat然后解压到当前⽂件夹既可Tomcat⽬录结构解压Tomcat后的⽬录结构如下图具体⽬录⽂件作⽤可参考,说明写的⾮常详细哦启动Tomcat在Tomcat的bin⽬录⾥双击运⾏startup.bat⽂件,如果出现如下的界⾯,说明你的Tomcat服务器已经成功跑起来了,为⾃⼰点赞。
nutch应用-安装与使用

nutch应用-安装与使用Nutch 使用之锋芒初试“工欲善其事,必先利其器。
”经过前文的“细解”,我们已经完成了Nutch在Windows中的安装。
接下来就让我们通过锋芒初试,来亲自体验一下Nutch的强大功能吧!Nutch的爬虫抓取网页有两种方式,一种方式是Intranet Crawling,针对的是企业内部网或少量网站,使用的是crawl命令;另一种方式是Whole-web crawling,针对的是整个互联网,使用inject、generate、fetch和updatedb等更底层的命令。
本文将以使用Nutch为笔者在CSDN处的个人专栏(/zjzcl)文章内容建立搜索功能为例,来讲述Intranet Crawling的基本使用方法(假设用户电脑系统已安装好JDK、Tomcat和Resin,并做过相应的环境配置)。
1、设置Nutch的环境变量在Windows系统的环境变量设置中,增加NUTCH_JAVA_HOME变量,并将其值设为JDK的安装目录。
比如笔者电脑中JDK安装于D:\j2sdk1.4.2_09,因此将NUTCH_JAVA_HOME的值设为D:\j2sdk1.4.2_09。
2、Nutch抓取网站页面前的准备工作(1)在Nutch的安装目录中建立一个名为url.txt的文本文件,文件中写入要抓取网站的顶级网址,即要抓取的起始页。
笔者在此文件中写入如下内容:/zjzcl(2)编辑conf/crawl-urlfilter.txt文件,修改部分:# accept hosts in +^/zjzcl3、运行Crawl命令抓取网站内容双击电脑桌面上的Cygwin图标,在命令行窗口中输入:cd /cygdrive/i/nutch-0.7.1不明白此命令含义的读者请参见前《细解》一文,然后再输入:bin/nutch crawl url.txt -dir crawled -depth 3 -threads 4 >& crawl.log等待大约2分多钟后,程序运行结束。
nutch(windows7环境下的配置)

经过好几天的尝试,终于成功在windows7的环境下将nutch成功运行出来了,下面将经验记下。
1、cygwin的安装:下载地址:/setup.exe(1)因为nutch自身的命令是要在linux环境下才能运行,所以先安装了cygwin,Cygwin 是一个在Windows下的模拟Linux系统程序。
Cygwin的安装:/cfree_ch/doc/help/UsingCF/CompilerSupport/Cygwin/Cygwin1 .htm这个网址对cygwin的安装步骤演示的很详细,对我们这些初步接触cygwin的人有很大的帮助。
(2)下面是我自己安装时的截图1)安装页面,点击下一步2)选择安装目录,可以根据默认,也可以根据自己需要换路径3)建立Downloads文件夹,接收下载包4)选择镜像地址,没有演示中说的:。
.cn代表中国的网站,下载会更快5)选择安装包6)安装完成2、下载安装apache-nutch-1.2-bin.zip并设置。
下载地址:/dist/nutch/(1)下载完成后将其解压到D盘,文件夹名为nutch-1.2(2)输入,打开到d盘目录下nutch-1.2文件夹,输入bin/nutch 进行nutch安装测试:出来一系列nutch的命令,证明nutch安装成功;(3)在Windows系统的环境变量设置中,添加NUTCH_JA V A_HOME环境变量:D:\jdk1.7.0_07。
并将其值设为JDK的安装目录。
(4)Nutch抓取网站页面前的预备工作1)在Nutch-1.2的安装目录下建立一个名为urls的文件夹,并在文件夹下建立url.text 文件,在文件中写入: (即要抓取网站的网址)2))修改网址过滤规则,编辑conf/crawl-urlfilter.txt文件,修改 部分:3)修改conf/nutch-site.xml代理信息,在<configuration>和</configuration>之间添加如下内容4)修改nutch-1.2\conf\nutch-default.xml文件,找<name></name> ,然后随便设置Value值注意:如果为空时,在爬行的时候可能出现空指针异常且在tomcat 中搜索时可能导致0条记录,所以务必加上。
Nutch调试报告

Nutch调试报告一.所需软件:1.Java:Nutch 是Java开发在Java平台上运行的,所以需要下载JDK(调试用的是jdk6)2.Tomcat:用于演示搜索界面3.cygwin:用于在windows下模拟Linux环境4.nutch 1.2二.软件安装1.JA V A安装。
打开安装软件进行安装,我用的是jdk-6u43-windows-i586,直接点击exe文件进行安装,目录选择的是C:/java。
环境变量配置设置好之后,打开命令管理窗口cmd,输入java或者javac、java –version判断是否安装好。
二.Tomcat安装从官网上下载的7.0版本的,直接安装。
安装目录为C:/Tomcat-7.0。
安装好后设置了TOMCAT_HOME环境变量,并且在前面设置的CLASSPATH变量值后面加上了“;%TOMCAT_HOME%\lib”。
安装后可以在浏览器中输入http://localhost:8080/,出现表示安装成功。
三.Cygwin安装安装过程和上面差不多,就不再赘述了。
四.NUTCH的安装从官网上下载的nutch 1.2版本的zip包,解压缩后放在了d 盘,目录为D:/cod/nutch-1.2。
继续配置环境变量。
设置了NUTCH _JA V A_HOME环境变量,变量值为java的安装地址。
安装后进行检验是否安装正确。
打开cygwin,输入cd /cygdrive/d/cod/nutch-1.2(cd是命令符,后面应有空格,自己当时没注意,耽误了好久)转入到当前目录下,然后再输入bin/nutch,出现下面结果,安装成功。
五.配置在nutch-1.2目录下建立了一个urls文件夹,里面建立了url 的文本,输入搜索站点的起始位置。
我输入的是/,我们学校主页。
在nutch目录下找到conf/crawl-urlfilter.txt,进行编辑,设置过滤规则,即要抓取什么样的网站。
Windows操作系统下tomcat安装图文教程WEB服务器-电脑资料

Windows操作系统下tomcat安装图文教程WEB服务器-电
脑资料
1、双击apache-tomcat-7.0.26.exe开始tomcat的安装,见图1,。
图1
2、点击Next,进入第二步,同意它的安装协议条款,见图2,点击I Agree继续安装。
图2
3、选择安装选项,默认是Normal,可以看图3,点开T omcat,选中Service,以后将可以在管理的服务中启动和关闭Tomcat
图-3
4、点击Next开始下一步的安装路径选择,设置成是d:\tomcat7,点击Browse..选择新的安装路径,点击Next继续,见图4。
图4
5、此时会出现管理提示框,要求输入端口和管理密码,保持默认设置就行,
电脑资料
《Windows操作系统下tomcat安装图文教程WEB服务器》(https://www.)。
图5
6、点击Next后会出现下图,它会自动找到JRE位置,如果用户没有安装JRE,可以修改指向JDK目录(很多用户安装后无法编译JSP,
就是这里没找到JRE,请务必先要安装JDK,并把这个目录正确指向JRE或者JDK的目录)。
图6
7、点击Install开始安装。
图7
8、安装结束
图8
9、在计算机管理-服务中可以看到T omcat的服务了,点击启动按钮就可以启动Tomcat了。
开启T omcat后任务栏会出现服务器图标,绿色为运行,红色为停止
图9
图10
下载文档
润稿
写作咨询。
Nutch安装向导

Nutch version 0.8 安装向导Nutch version 0.8 安装向导1、必要的条件1.1 Java 1.4或1.4以上版本。
操作系统推荐用Linux(Sun或IBM的都可以)。
记得在环境变量中设置变量NUTCH_JAVA_HOME=你的虚拟机地址,例如,本人将jdk1.5安装在c:\jdk1.5文件夹下,所以本人的设置为NUTCH_JAVA_HOME=c:\jdk1.5(此为win32 环境下的设置方法)。
1.2 服务器端推荐使用Apache’s Tomcat 4.x或该版本以上的T omcat。
1.3 当要在win32安装Nutch时,请安装cygwin软件,以提供Linux的shell支持。
1.4 安装Nutch需要消耗G字节的磁盘空间,高速的连接并要花费一个小时左右的时间等等。
2、从这开始2.1 首先,你必须获得Nutch源码的一个拷贝。
你可以从网址:/nutch/release/上下载Nutch的发行版,解开下载的文件包即可。
或者通subversion获得最新的源码并且通过Ant工具创建Nutch。
2.2 上述步骤完成以后,你可以通过下面这个命令,试试是否安装成功。
在Nutch所在的目录下,输入 bin/nutch如果显示了一个有关Nutch命令脚本的文档,那么恭喜你,你已经向成功迈出了重要的一步。
2.3 现在,我们可以准备为我们的搜索引挚去“爬行(crawl)”资料。
爬行(crawl)有两种方法:2.3.1 用crwal命令实现内部网的爬行2.3.2 整个web网的爬行,除了上面的crwal命令外,我们需要用得一些更为底层的命令以实现更为强大的功能,如inject, generate, fetch以及updatedb等。
3、内部网爬行(测试未通过)内部网爬行适合用于具有百万级别的web网站。
3.1 内部网:配置要配置内部网爬行,你必需做如下几项工作:3.1.1 在nutch所在的文件夹下建立一个包含纯文本文件的根文件夹urls。
nutch的基本工作流程理解

今天研究了Nutch,差不多已经好几个小时了,到现在还没有搞定,也这么晚了,先记录下来,明天继续吧。
一开始很多时间都浪费在了cygwin的安装上了,bs这个软件的开发者了,一个不伦不类的软件安装程序,安装的时候还要从网上下载东东。
不过最后终于装成功了,先下载到本地后,再安装的(建议下载站点中选 TW 的比较块)。
下面是我安装CYGWIN和NUTCH的过程,都块成功了,但最后卡在了用户查询界面,输入东西什么都查不出来,不知怎么回事。
NUTCH的大致原理如下:安装步骤参考了该文章一、环境:1.操作系统:windowsXp,windows2000+2.javaVM:java1.5.x,设置JAVA_HOME到环境变量3.cygwin,当然这个不是必需的,只是nutch提供的脚本只能在shell环境下使用,所以使用cygwin来虚拟shell命令。
4.nutch版本:0.85.tomcat:5.0二、cygwin的安装:cygwin的安装在Nutch在Windows中安装之细解一文中有较为详细的介绍,此处不再介绍安装步骤,只介绍安装后需要如何判断是否能够使用:在cygwin 的安装目录下,查找x:\cygwin\cygwin\bin\sh.exe,存在此命令即可使用。
cygwin在删除后会发现无法再次成功安装的问题,可以通过注册表内的查找功能,删除所有包含cygwin内容的键值即可。
三、nutch的安装和配置:1。
从/nutch/release/下载0.8或更高的版本,解压缩后,放置到cygwin的根目录下,如图:图中可以看到nutch目录在cygwin的根目录下。
2。
在nutch/bin下,建立urls目录,然后建立一个url.txt文件,在url.txt 文件内写入一个希望爬行的url,例如:,目录结构如图:3。
打开nutch\conf\crawl-urlfilter.txt文件,把字符替换为url.txt内的url的域名,其实更简单点,直接删除 这几个字就可以了,也就是说,只保存+^http://([a-z0-9]*\.)*这几个字就可以了,表示所有http的网站都同意爬行。
windows下nutch的安装

Nutch入门1准备将中文的API文档配置到tomcat,可以通过http://127.0.0.1/api/访问到api的主页即可2下载,安装cygwin官方主页:/2.1 选择install from local directory2.2 安装到的目录2.3 选择已经下载的安装文件所在的目录2.4 选择全部安装(install)……2.5 需要等很长时间……2.6 设置环境变量NUTCH_JA V A_HOME C:\jdk3抓取3.1 配置抓取的起始网站地址3.2 修改nutch-site.xml解释:Nutch中的所有配置文件都放置在总目录下的conf子文件夹中,最基本的配置文件是conf/nutch-default.xml。
这个文件中定义了Nutch的所有必要设置以及一些默认值,它是不可以被修改的。
如果你想进行个性化设置,你需要在conf/nutch-site.xml进行设置,它会对默认设置进行屏蔽。
Nutch考虑了其可扩展性,你可以自定义插件plugins来定制自己的服务,一些plugins 存放于plugins子文件夹。
Nutch的网页解析与索引功能是通过插件形式进行实现的,例如,对HTML文件的解析与索引是通过HTML document parsing plugin, parse-html实现的。
所以你完全可以自定义各种解析插件然后对配置文件进行修改,然后你就可以抓取并索引各种类型的文件了。
3.3 配置crawl-urlfilter.txt解释如下:●Nutch 的爬虫有两种方式⏹爬行企业内部网(Intranet crawling:针对少数网站进行,用crawl 命令。
⏹爬行整个互联网:使用低层的inject, generate, fetch 和updatedb 命令,具有更强的可控制性。
●举例⏹+^http://([a-z0-9]*\.)*/⏹+^http://(\.*)*◆句点符号匹配所有字符,包括空格、Tab字符甚至换行符:◆IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。
windows上搭建自己的搜索引擎nutch

windows上搭建自己的搜索引擎nutchnutch windows install guider--By Liming Liu1 Install Cygwin2 Install JDK3 Install Tomcat4 Pre-Install nutch5 Configure and run nutch6 Begin search7 Referece1 Install CygwinDownload and install the latest version, must select GCC while selecting packages.2 Install JDKDownload jdk-1_5_0_06-windows-i586-p.exe and install(acquiescently, C:/Program Files/Java/jdk1.5.0_06 ).Set environmental variable: NUTCH_JAVA_HOME: C:/ProgramFiles/Java/jdk1.5.0_06JAVA_HOME: C:/Program Files/Java/jdk1.5.0_063 Install TomcatDownload apache-tomcat-6.0.13.exe and install(acquiescently, C:/ProgramFiles/Apache Software Foundation/Tomcat 6.0).Remember the port, account and password.4 Pre-Install nutchDownload nutch-0.9.tar.gz and unzip to nutch-0.9(such asC:/dev/search/netch/nutch-0.9).Start Tomcat service, open http://localhost:8080/manager/htmlMove to “WAR file to deploy”, upload file:C:/dev/search/netch/nutch-0.9/nutch-0.9.war.Close Tomcat service, change directory name “ROOT” in “C:/Program Files/Apache Software Foundation/Tomcat 6.0/webapps” to “ ROOT-backup”, change directory name “nutch-0.9” in “C:/Program Files/Apache Software Foundation/To mcat6.0/webapps” to “ ROOT”.( OR do nothing)5 Configure and run nutchCreate directory “urls” in “C:/dev/search/netch/nutch-0.9”.Create a file “testurlfile” in directory “urls”.Add line: ““ t o file “testurlfile”.Find file “C:/dev/search/netch/nutch-0.9/conf/ crawl-urlfilter.txt”, replace“” with “”Find file “C:/dev/search/netch/nutch-0.9/conf/ nutch-site.xml”, edit it to this:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>nutch</value><description>HTTP 'User-Agent' request header. MUST NOT be empty -please set this to a single word uniquely related to your organization. NOTE: You should also check other related properties:http.robots.agentshttp.agent.descriptionhttp.agent.urlhttp.agent.emailhttp.agent.versionand set their values appropriately.</description></property><property><name>http.agent.description</name><value>liming agent.description</value><description>Further description of our bot- this text is used inthe User-Agent header. It appears in parenthesis after the agent name. </description></property><property><name>http.agent.url</name><value></value><description>A URL to advertise in the User-Agent header. This willappear in parenthesis after the agent name. Custom dictates that this should be a URL of a page explaining the purpose and behavior of thiscrawler.</description></property><property><name>http.agent.email</name><value>agent.email</value><description>An email address to advertise in the HTTP 'From' requestheader and User-Agent header. A good practice is to mangle thisaddress (e.g. 'info at example dot com') to avoid spamming.</description></property></configuration>Find file “C:/Program Files/Apache S oftware Foundation/Tomcat6.0/webapps/ROOT/WEB-INF/classes/”, edit it to this:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>searcher.dir</name><value>C:/dev/search/netch/nutch-0.9/crawl.demo</value></property></configuration>Find file “C:/Program Files/Apache Software Foundation/Tomcat6.0/conf/server.xml”.Edit the item“<Connector port="8080"…/>” to this:<Connector port="8080"maxThreads="150"minSpareThreads="25"maxSpareThrea ds="75"enableLookups="false"redirectPort="8443"acceptCount="100"debug="0" connectionTimeout="20000"disableUploadTimeout="true"URIEncoding="UTF-8"/ >Start tomcat service.Start cygwin, cd to “C:/dev/search/netch/nutch-0.9”,run: bin/nutch crawl urls -dir crawl.demo -depth 2 -topN 506 Begin searchOpen http://localhost:8080 with internet explorer, you will see a real search engine. (Or http://localhost:8080/nutch)7 Referece/topic/81627 Nutch_0.8实践 (1) X.D.Hua/club/simple/index.php?t312.html Nutch 于 winxp Kevin /pwlazy/archive/2006/08/23/1109868.aspx windows下nutch0.8初探pwlazy。
nutch 1.4在windows下安装配置

Nutch1.4在windows下的安装配置0、介绍Apache Nutch是用java语言开发的开源网页爬虫程序。
使用Nutch可以自动获取网页中的超链接,在检查坏链接,创建遍历过的网页副本以便查询等方面,将会减少大量的维护工作。
也由此产生了Apache Solr。
Solr是一个开源的全文搜索框架,通过Solr我们可以搜索Nutch遍历过的网页。
而且Nutch和Solr的集成十分简易。
Apache Nutch框外支持Solr,这极大地简化了两者的集成。
Solr不再依附Apache Tomcat 来运行旧的Nutch Web应用,也不再依靠Apache Lucene来建立索引。
1、提前需要安装的工具和软件1)Jdk1.7下载地址:/javase/downloads/index.jspNutch是Java开发的所以需要下载安装Java JDK。
设置环境变量。
2)Cygwin下载地址:/Nutch的脚本都是用Linux的Shell写的,所以在Windows平台需要一个Shell解释程序。
C ygwin是一个在Windows下的模拟Linux系统程序。
我是下载的setup.exe,选择在线安装。
具体的安装过程网上有很多,可以参照。
3)Nutch1.4下载地址:/后缀名tar.gz为linux系统压缩包,zip为windows系统。
将下载的包,解压到一个盘的根目录下。
可修改名称(便于调试进入)。
4)Solr3.5下载地址:/solr/Solr作用相当于tomcat+webapp。
将下载的包,解压到一个盘的根目录下。
2、验证Nutch的安装打开cygwin,进入nutch-1.4/runtime/local,例如我把文件解压到d盘,文件名为apache-nutch-1.4,于是命令为:c d/cygdrive/d/apache-nutch-1.4/runtime/local,cygwin环境下,进入windows某个盘,加cygdrive,cd/cygdrive/d/就相当于进入d盘。
Nutch部署方法

Nutch部署方法2011-2-24更新朱锴1.如果在windows环境下部署nutch, 则需要先安装cygwinCygwin采用在线下载安装(也可以在网上找到安装包镜像文件)在进行路径、下载网站的配置后需要注意几点选择(注:在实验室ftp服务器,软件开发目录下有cygwin安装镜像文件,因此安装的时候可可不再选择通过网络安装):(1)在“Select Packages”对话框中,必须保证“Net Category”下的“OpenSSL”被安装:(2)如果还打算在eclipse 上编译Hadoop,则还必须安装“Base Category”下的“sed”:需要配置的环境变量包括PATH 和JAVA_HOME:将JDK 的bin 目录、Cygwin 的bin 目录、以及Cygwin 的usr\bin 目录都添加到PATH 环境变量中;JAVA_HOME 指向JRE 安装目录。
注意:设置完环境变量后需要重启计算机,否则可能导致后面的运行不正常!2.将svn上的nutch-1.0代码export到工作目录下(注意是export,而不是checkout,因为checkout后的工程每个目录下会有.svn文件夹,这样会导致nutch运行时读取这些文件,造成错误)。
3.如果使用图片识别模块,需要将svn中“图片识别”文件夹下的dll文件,按照文件夹中的说明拷贝至相应目录4.urls目录下的文件是初始url,ThemeDescription目录下的文件是主题训练集2011年3月21日更新朱锴在windows下启动apache tomcat时需要注意更换tomcat使用的账户名,否则会引起“javax.security.auth.login.LoginException: Login failed: Expect one token as the result of whoami: nt authority\system”的错误。
nuttcp 使用方法

nuttcp 使用方法一、什么是 nuttcp?nuttcp 是一款用于测试网络带宽的工具,它通过在客户端和服务器之间传输数据来测量网络的性能和吞吐量。
nuttcp 支持多种操作系统,包括 Linux、Windows 和 macOS。
它是一个命令行工具,使用简单且功能强大。
二、安装 nuttcp1. 在 Linux 上安装 nuttcp在大多数 Linux 发行版中,nuttcp 可以通过包管理器进行安装。
例如,在Ubuntu 上,可以使用以下命令安装 nuttcp:sudo apt-get install nuttcp2. 在 Windows 上安装 nuttcp在 Windows 上,可以从 nuttcp 的官方网站()下载预编译的二进制文件。
解压缩下载的文件后,将 nuttcp.exe 添加到系统的 PATH 环境变量中,这样就可以在命令提示符中直接运行 nuttcp。
3. 在 macOS 上安装 nuttcp在 macOS 上,可以使用 Homebrew 包管理器来安装 nuttcp。
打开终端,并执行以下命令:brew install nuttcp三、使用 nuttcp 进行带宽测试1. 在服务器端启动 nuttcp在服务器上,打开终端并执行以下命令以启动 nuttcp 服务器:nuttcp -S这将启动一个 nuttcp 服务器,并监听默认端口 5001。
如果你想使用其他端口,可以使用-p参数指定。
2. 在客户端执行带宽测试在客户端上,打开终端并执行以下命令以执行带宽测试:nuttcp <服务器IP地址>替换<服务器IP地址>为实际的服务器 IP 地址。
默认情况下,nuttcp 将使用默认端口 5001 进行测试。
如果服务器使用了其他端口,可以使用-p参数指定。
3. 查看测试结果带宽测试完成后,nuttcp 将显示测试的结果。
其中包括平均传输速度、传输的数据量、传输时间等信息。
蒙克里怎样在win7装

图4
这是权限问题,如果你安装的时候选择了“右击—>兼容性的“以兼容模式运行这个程序”选上就能解决问题。比如在Word上出了这个问题的话具体步骤如下:以管理员身份运行”还出错的话把应用程序的属性
第一பைடு நூலகம்:应用程序的属性
第二步:选择属性里的兼容性
第三步:选择以兼容模式运行这个程序再应用——确定。
1.安装的时候不可以直接打开,要右击选择“以管理员身份运行”。如图1:
图1
2.安装完后打开word或wps输入蒙文,显示空白字(看不到蒙文)。这是Fonts目录里没有蒙科立字体,字体文件在windows目录下写进去了。所以从windows目录下找到字体文件复制到Fonts目录下就能解决这个问题。具体地址:C:\WINDOWS到C:\WINDOWS\Fonts。(如果你的系统安装在别的盘上,那就从别的盘上的windows里找)
评论( 0 )
相关文章
内蒙古蒙科立软件有限责任公司自主研发科技成果项目顺利通过鉴定
“阿拉善蒙古语网”试运行
2011年内蒙古全区西部文化信息资源共享工程技术员培训班在乌审旗举办
我企仅代表自治区参加了“十一五”电子发展基金成果汇报展示会
首府企业知识产权意识不断提高
图2
图3
3.但是标题栏上的蒙文字还是不能显示(如图3标题栏红圈)。
这是C:\WINDOWS\system32目录里没有MenkSoft.tte文件。Win7上安装的时候把这个文件写在C:\WINDOWS\SysWOW64目录下。从C:\WINDOWS\SysWOW64里找到MenkSoft.tte文件复制到C:\WINDOWS\system32里就能解决这个问题。
NUTCH安装和配置

NUTCH安装和配置I.安装和配置jdk下载jdk-6u22-linux-i586.bin执行:chmod a+x jdk-6u22-linux-i586.bin在终端运行:./jdk-6u22-linux-i586.bin,产生文件夹jdk1.6.0_22在/usr/下创建目录java(这个自己随意:-) )将运行bin文件得到文件夹jdk1.6.0_22,全部移到/usr/java目录中编辑添加如下内容到/etc/profile中:export JAVA_HOME=/usr/java/jdk1.6.0_22export PATH=$PATH:$JAVA_HOME/binexportCLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_ HOME/lib/tools.jar(在Centos中,首先要移除默认的java运行环境,即openjava,命令如下:yum remove java-1.4.2-gcj-compatyum remove java.顺便提下:解决yum被锁定的方法为:rm -f/var/run/yum.pid)II.安装和配置tomcat下载tomacat7:download from:/。
解压后得到apache-tomcat-7.0.4文件目录,将该文件目录移到想安装的目录中,例如/usr/local/tomcat/目录下配置tomcat:在/etc/profile中添加如下内容:exportTOMCAT_HOME=/usr/local/tomcat/apache-tomcat-7.0.4export PATH=$PATH:$TOMCAT_HOME/bin #not neccesary 运行TOMCAT:#cd 到tomcat所在的目录#执行:bin/startup.sh关闭TOMCAT:#cd 到tomcat所在的目录#执行:bin/shutdown.shIII.测试java运行环境和tomcat为了使修改后的配置文件生效, 需执行命令:source/etc/profile测试jdk, 在终端输入:#java –version得到:java version "1.6.0_22"Java(TM) SE Runtime Environment (build 1.6.0_22-b04)Java HotSpot(TM) Client VM (build 17.1-b03, mixed mode,sharing)测试tomcat:开启tomcat,然后再浏览器中输入:localhost:8080,又tomcat的网页出现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Nutch在Windows中安装之细解Nutch在Windows中安装之细解近来Nutch一词在网络中时有所见,但囿于平常工作繁忙而未能潜心细读与研究,只知道Nutch是Apache组织的一个开源项目,利用它用户可以建立自己内部网的搜索引擎,也可以建立针对整个网络的搜索引擎。
好在春节假日期间,终于得空可以从容对其进行一番解读与测试了。
在使用Nutch之前,当然是需要先对其进行安装了。
用搜索引擎查找了一下相关内容,发现大部分关于Nutch如何安装的文章都是基于Linux的,而基于Windows安装的文章虽有,但非常简略。
由于运行Nutch自带的脚本命令需要Linux的环境,所以必须首先安装Cygwin来模拟这种环境,而Cygwin本身的安装与使用也不是一件简单的事。
下面,就让笔者对Nutch在Windows系统中的安装进行一番细解吧!1、安装Cygwin首先,我们去/~instcd/iso/下载到Cygwin软件的ISO文件,用Daemon软件将其设为虚拟光驱后,双击其中的Setup文件,出现程序安装的向导界面(如图1所示)。
点击“下一步”后,安装向导要求选择Cygwin的安装方式,如图2所示:图示中共有三种安装方式:(1)Install from Internet:从Internet上下载并安装软件;(2)Download Without Installing:从Internet上下载安装的文件,但暂时不安装;(3)Install from Local Directory:从本地含有安装文件的目录进行安装。
我们选择第三项“Install from Local Directory”后,点击“下一步”,如图3所示:安装向导要求选择Cygwin的安装路径,我们可以在“Root Directory”文本框中更改安装路径,点击“下一步”,如图4所示:安装向导要求选择Cygwin安装文件所在的本地存储路径,可以在“Local Package Directory”中设置,点击“下一步”,如图5所示:安装向导显示出所要安装的内容列表,用户可以根据自己的实际需要来决定安装哪些程序。
点击循环箭头图标后面的文字,可以更改安装的方式,常用的方式有Default(表示只安装缺省的安装项)、Install(表示安装全部程序,空间要求较大)、Reinstall(表示重新安装程序)。
推荐选择“Install”方式,一步到位,以免后扰,不过用户应保证至少有2G以上的空间可供使用。
点击“下一步”后,就开始正式的安装了(如图6所示)。
最后出现如图7所示的窗口,点击“完成”后,Cygwin安装完毕。
至此,笔者还要对Cygwin再多说几句。
Cygwin是一个在Windows平台上模拟运行Unix 的环境,用户可以通过它来熟悉与学习Unix系统的操作。
对于Unix系统还不甚熟悉的读者可以参阅笔者之前写作的《Unix操作系统的入门与基础》、《Unix的轻便“约取而实得”》系列文章,下文中对涉及使用到的Unix命令将不再给予具体解释。
2、安装Nutch去/apache/lUCene/nutch/下载到Nutch的最新版本,将其解压到指定目录中,如笔者是将其解压到I:\nutch-0.7.1中。
3、测试Nutch命令在运行Nutch的脚本命令前,需要设置一些环境变量。
Cygwin提供了一个名为cygwin.bat 的文件,通过它可以自动完成必需环境变量的设置。
该文件可在cygwin所在的根目录下找到,感爱好的读者还可通过UltraEdit等编辑器打开该文件一查究竟。
其实Cygwin安装完成之后,会在Windows系统桌面生成一图标,如图8所示:此图标就是cygwin根目录下cygwin.bat文件的快捷方式,双击此图标将打开一类似DOS窗口。
由于先前笔者将Nutch的压缩包解压至I:\nutch-0.7.1中,故在此命令窗口中输入命令“cd /cygdrive/i/nutch-0.7.1”,读者可根据自己的安装路径进行相应的修改,然后使用命令“ls -l”可查看nutch-0.7.1中的所有子目录及文件信息。
执行命令“bin/nutch”,假如读者能看到如图9所示的提示,那恭喜你,Nutch在Windows系统中的安装已经大功告成了!“工欲善其事,必先利其器。
”经过前文的“细解”,我们已经完成了Nutch在Windows 中的安装。
接下来就让我们通过锋芒初试,来亲自体验一下Nutch的强大功能吧!Nutch的爬虫抓取网页有两种方式,一种方式是Intranet Crawling,针对的是企业内部网或少量网站,使用的是crawl命令;另一种方式是Whole-web crawling,针对的是整个互联网,使用inject、generate、fetch和updatedb等更底层的命令。
本文将以使用Nutch为笔者在CSDN处的个人专栏(/zjzcl)文章内容建立搜索功能为例,来讲述Intranet Crawling的基本使用方法(假设用户电脑系统已安装好JDK、Tomcat和Resin,并做过相应的环境配置)。
1、设置Nutch的环境变量在Windows系统的环境变量设置中,增加NUTCH_Java_HOME变量,并将其值设为JDK的安装目录。
比如笔者电脑中JDK安装于D:\j2sdk1.4.2_09,因此将NUTCH_JAVA_HOME的值设为D:\j2sdk1.4.2_09。
2、Nutch抓取网站页面前的预备工作(1)在Nutch的安装目录中建立一个名为url.txt的文本文件,文件中写入要抓取网站的顶级网址,即要抓取的起始页。
笔者在此文件中写入如下内容:/zjzcl(2)编辑conf/crawl-urlfilter.txt文件,修改部分:# accept hosts in +^/zjzcl3、运行Crawl命令抓取网站内容双击电脑桌面上的Cygwin图标,在命令行窗口中输入:cd /cygdrive/i/nutch-0.7.1不明白此命令含义的读者请参见前《细解》一文,然后再输入:bin/nutch crawl url.txt -dir crawled -depth 3 -threads 4 >& crawl.log等待大约2分多钟后,程序运行结束。
读者会发现在nutch-0.7.1目录下被创建了一个名为crawled的文件夹,同时还生成一个名为crawl.log的日志文件。
利用这一日志文件,我们可以分析可能碰到的任何错误。
另外,在上述命令的参数中,dir指定抓取内容所存放的目录,depth表示以要抓取网站顶级网址为起点的爬行深度,threads指定并发的线程数。
4、使用Tomcat进行搜索测试(1)将tomcat\webapps下的ROOT文件夹名改成ROOT1;(2)将nutch-0.7.1目录的nutch-0.7.1.war复制到tomcat\webapps下,并将其改名为ROOT;(3)打开ROOT\WEB-INF\classes下的nutch-site.XML文件,修改成如下形式:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="nutch-conf.xsl"?><!-- Put site-specific property overrides in this file. --><nutch-conf><property><name>searcher.dir</name><value>I:/nutch-0.7.1/crawled</value></property></nutch-conf>其中的“<value>I:/nutch-0.7.1/crawled</value>”部分,读者应根据自己的设置进行相应修改。
(4)启动Tomcat,打开浏览器在地址栏中输入:http://localhost:8080,如图1所示:点击查看大图在文本框中输入要害字,就可以进行搜索了。
不过用户在使用时会发现,对于英文单词的搜索一切正常,而当要搜索中文词语时会出现乱码。
其实这个问题是Tomcat设置的问题,解决办法是修改tomcat\conf下的server.xml文件,将其中的Connector部分改成如下形式即可:<Connector port="8080" maxThreads="150" minSpareThreads="25"maxSpareThreads="75"enableLookups="false" redirectPort="8443" acceptCount="100"connectionTimeout="20000" disableUploadTimeout="true"URIEncoding="UTF-8" useBodyEncodingForURI="true" />现在我们可以对中文词汇进行搜索了。
如在搜索框中输入“李开复”,点击搜索按钮后,会搜索到笔者之前写的两篇文章《从李开复换门庭开启的缝隙中窥视——试探Google的几招成功“秘诀”》与《从国内首例禽流感假疫苗大案说起——有感于李开复<做最好的自己>中的诚信观》,如图2所示:点击查看大图假如点击show all hits按钮,则会列出更多相关的搜索结果了。
5、使用Resin进行搜索测试由于笔者最近工作中经常使用Resin,因此在Tomcat上测试完毕后也想在Resin上测试一把,未曾想碰到了各种意想不到的情况。
下面就将所碰到的问题以及解决方法列出,以供碰到相同问题的读者参考。
(1)将nutch-0.7.1目录的nutch-0.7.1.war复制到resin-3.0.17\webapps下;(2)打开resin-3.0.17\conf下的resin.conf文件,把<!-- configures the default host, matching any host name -->下面的内容改成:<host id="" root-Directory="."><web-app id="/" document-directory="webapps/nutch-0.7.1"/><stderr-log path='logs/stderr.log' rollover-period='1W'/><stdout-log path='logs/stdout.log' rollover-period='1W'/></host>(3)打开resin-3.0.17\webapps\nutch-0.7.1\WEB-INF\classes下的nutch-site.xml文件,修改成如下形式:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="nutch-conf.xsl"?>。