nutch-1.0配置过程中文版
RouterOS中文手册

RouterOS中文手册RouterOS中文手册RouterOS命令行操作/sy reset 恢复路由原始状态/sy reboot 重启路由/sy showdown 关机/sy ide set name=机器名设置机器名/export 查看配置export file= 备份配置/import 恢复配置/ip export 查看IP配置/sy backup 回车save name=你要设置文件名备份路由LOAD NAME=你要设置文件名恢复备份/ip fir con print 查看当前所有网络边接/ip service set www port=88 改变www服务端口为88 /ip hotspot user add name=ytmxkj password=431054 增加用户复原:systemresety第一步---开启网卡接口/interfaceprintenable 0enable 1第二步---设置接口名称/interfaceprintset 0 name=Localset 1 name=Public第三步---设置网卡地址/ip addressadd addr=58.60.105.250/24 int=Publicadd addr=172.16.0.1/16 int=Local第四步---添加默认路由/ip routeadd gateway=58.60.187.46第五步---设置DNS服务器/ip dnsset primary-dns=202.96.134.133set allow-remote-requests=yes/ip dns staticadd name /doc/6917744338.html, addr=172.16.0.6add name /doc/6917744338.html, addr=172.16.0.6add name /doc/6917744338.html, addr=172.16.0.6add name /doc/6917744338.html, addr=172.16.0.6最后一步---地址伪装/ip firewall src-natadd action=masquerade一、RouterOS安装:先把盘格式化:再分好区:以下就是安装开始:RouterOS安装配置菜单,按A全选我一般选择这几项: system. ppp advanced-tools security web-proxy为了方便学习.你可以全部都装上..呵按I开始再按两次y选择完安装组件后按“I”,就进入安装界面,这里系统会问你两个(Y/N),关于是否清理硬盘之类的,全“Y”就可以了。
Nutch相关框架视频教程

Nutch相关框架视频教程第一讲1、通过nutch,诞生了hadoop、tika、gora。
2、nutch通过ivy来进行依赖管理(1.2之后)。
3、nutch是使用svn进行源代码管理的。
4、lucene、nutch、hadoop,在搜索界相当有名。
5、ant构建之后,生成runtime文件夹,该文件夹下面有deploy和local文件夹,分别代表了nutch的两种运行方式。
6、nutch和hadoop是通过什么连接起来的?通过nutch脚本。
通过hadoop命令把apache-nutch-1.6.job提交给hadoop的JobTracker。
7、nutch入门重点在于分析nutch脚本文件。
第二讲1、git来作为分布式版本控制工具,github作为server。
提供免费的私有库。
2、nutch的提高在于研读nutch-default.xml文件中的每一个配置项的实际含义(需要结合源代码理解)。
3、定制开发nutch的入门方法是研读build.xml文件。
4、命令:apt-get install subversionsvn co https:///repos/asf/nutch/tags/release-1.6/cd release-1.6apt-get install antantcd runtime/localmkdir urlsvi urls/url.txt 并输入nohup bin/nutch crawl urls -dir data -depth 3 -threads 100 &vi release-1.6/conf/nutch-site.xml 增加配置cd ../../release-1.6antcd runtime/localnohup bin/nutch crawl urls -dir data -depth 3 -threads 100 & 删除报错的文件夹nohup bin/nutch crawl urls -dir data -depth 1 -threads 100 &第三讲1、nutch的存储文件夹data下面各个文件夹和文件里面的内容究竟是什么?2、命令:crawldbbin/nutch | grep readbin/nutch readdb data/crawldb -statsbin/nutchreaddb data/crawldb -dump data/crawldb/crawldb_dumpbin/nutch readdb data/crawldb -url/bin/nutch readdb data/crawldb -topN 10 data/crawldb/crawldb_topNbin/nutchreaddbdata/crawldb -topN 10data/crawldb/crawldb_topN_m 1 segmentscrawl_generate:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nocontent -nofetch -noparse -noparsedata –noparsetextcrawl_fetch:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nocontent -nogenerate -noparse -noparsedata –noparsetextcontent:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nofetch -nogenerate -noparse -noparsedata –noparsetextcrawl_parse:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nofetch -nogenerate -nocontent –noparsedata –noparsetextparse_data:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nofetch -nogenerate -nocontent -noparse –noparsetextparse_text:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dump -nofetch -nogenerate -nocontent -noparse -noparsedata全部:bin/nutch readseg -dump data/segments/20130325042858 data/segments/20130325042858_dumpsegmentsbin/nutch readseg -list -dir data/segmentsbin/nutch readseg -list data/segments/20130325043023bin/nutch readseg -get data/segments/20130325042858 / linkdbbin/nutch readlinkdb data/linkdb -url /bin/nutch readlinkdb data/linkdb -dump data/linkdb_dump第四讲1、深入分析nutch的抓取周期injectgenerate -> fetch -> parse ->updatedb2、3大merge和3大read命令阐释bin/nutch | grep mergebin/nutch | grep readbin/nutch mergesegsdata/segments_all -dir data/segments 3、反转链接bin/nutch invertlinks data/linkdb -dir data/segments4、解析页面bin/nutch parsechecker 第五讲1、域统计bin/nutch domainstats data2/crawldb/currenthost hostbin/nutch domainstats data2/crawldb/current domain domainbin/nutch domainstats data2/crawldb/current suffix suffixbin/nutch domainstats data2/crawldb/current tld tld2、webgraphbin/nutch webgraph -segmentDir data2/segments -webgraphdb data2/webgraphdb有相同inlinks的URL,只输出topn条bin/nutch nodedumper-inlinks -output inlinks-topn 1-webgraphdb data2/webgraphdb有相同outlinks的URL,只输出topn条bin/nutch nodedumper -outlinks -output outlinks-topn 1-webgraphdb data2/webgraphdb有相同scores的URL,只输出topn条(初始分值全为0)bin/nutch nodedumper -scores -output scores-topn 1-webgraphdb data2/webgraphdb计算URL分值bin/nutch linkrank-webgraphdb data2/webgraphdb再次查看分值bin/nutch nodedumper -scores -output scores–topn 1-webgraphdb data2/webgraphdb对结果进行分组,取最大值或是连加和(topn参数不参与)bin/nutch nodedumper -group domain sum -inlinks -output inlinks_group_sum -webgraphdb data2/webgraphdbbin/nutch nodedumper -group domain max -inlinks -output inlinks_group_max -webgraphdb data2/webgraphdb对url进行分组,分组方式可选择为host或是domain,对同一组的url执行topn限制,对执行了topn限制的url集合执行max或是sum操作,max和sum 所针对的排序值是3种方式之一inlinks、outlinks以及scores。
Nutch搜索引擎(第1期)_Nutch简介及安装

细细品味Nutch——Nutch搜索引擎(第1期)精华集锦csAxp虾皮工作室/xia520pi/2014年3月18日Nutch搜索引擎(第1期)——Nutch简介及安装1、Nutch简介Nutch是一个由Java实现的,开放源代码(open-source)的web搜索引擎。
主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行查询的一套工具。
其底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做,Solr是一个开源的全文索引框架,从Nutch 1.3开始,其集成了这个索引架构。
Nutch目前最新的版本为version1.4。
1.1 Nutch的目标Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎。
为了完成这一宏伟的目标,Nutch必须能够做到:●每个月取几十亿网页●为这些网页维护一个索引●对索引文件进行每秒上千次的搜索●提供高质量的搜索结果●以最小的成本运作1.2 Nutch的优点●透明度Nutch是开放源代码的,因此任何人都可以查看他的排序算法是如何工作的。
商业的搜索引擎排序算法都是保密的,我们无法知道为什么搜索出来的排序结果是如何算出来的。
更进一步,一些搜索引擎允许竞价排名,比如百度,这样的索引结果并不是和站点内容相关的。
因此Nutch对学术搜索和政府类站点的搜索来说,是个好选择。
因为一个公平的排序结果是非常重要的。
●扩展性你是不是不喜欢其他的搜索引擎展现结果的方式呢?那就用 Nutch 写你自己的搜索引擎吧。
Nutch 是非常灵活的,他可以被很好的客户订制并集成到你的应用程序中。
使用Nutch 的插件机制,Nutch 可以作为一个搜索不同信息载体的搜索平台。
当然,最简单的就是集成Nutch到你的站点,为你的用户提供搜索服务。
●对搜索引擎的理解我们并没有google的源代码,因此学习搜索引擎Nutch是个不错的选择。
Nutch-1.2+Hadoop-0.20.2集群的分布式爬取

Hadoop-0.20.2+ Nutch-1.2+Tomcat-7——分布式搜索配置随着nutch的发展,各模块逐渐独立性增强,我从2.1到1.6装过来,也没有实现整个完整的功能。
今天装一下nutch1.2,这应该是最后一个有war文件的稳定版本。
1. 准备工作下载apache-nutch-1.2-bin.zip、apache-tomcat-7.0.39.tar.gz、hadoop-0.20.2.tar.gz。
将下载的hadoop-0.20.2.tar.gz解压到/opt文件夹下。
将下载的apache-nutch-1.2-bin.zip解压到/opt文件夹下。
将下载的apache-tomcat-7.0.39.tar.gz解压到/opt文件夹下。
2. 配置hadoop-0.20.2(1) 编辑conf/hadoop-env.sh,最后添加export JAVA_HOME=/opt/java-7-sunexport HADOOP_HEAPSIZE=1000exportHADOOP_CLASSPATH=.:/opt/nutch-1.2/lib:/opt/hadoop-0.20.2export NUTCH_HOME=/opt/nutch-1.2/lib(2) 编辑/etc/profile,添加#Hadoopexport HADOOP_HOME=/opt/hadoop-0.20.2export PATH=$PATH:$HADOOP_HOME/bin(3) 编辑conf/core-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://m2:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-0.20.2/tempdata/var</value></property><property><name>hadoop.native.lib</name><value>true</value><description>Should native hadoop libraries, if present, beused.</description></property></configuration>(4) 编辑conf/hdfs-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>.dir</name><value>/opt/hadoop-0.20.2/tempdata/name1,/opt/hadoop-1.0.4/tempdata /name2</value> #hadoop的name目录路径<description> </description><property><name>dfs.data.dir</name><value>/opt/hadoop-0.20.2/tempdata/data1,/opt/hadoop-1.0.4/tempdata/ data2</value><description> </description></property><property><name>dfs.replication</name><value>2</value></property></configuration>(5) 编辑conf/mapred-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapred.job.tracker</name><value>m2:9001</value></property><property><name>mapred.local.dir</name><value>/opt/hadoop-0.20.2/tempdata/var</value></property><name>pression.type</name><value>BLOCK</value><description>If the job outputs are to compressed as SequenceFiles,how shouldthey be compressed? Should be one of NONE, RECORD or BLOCK.</description></property><property><name>press</name><value>true</value><description>Should the job outputs be compressed?</description></property><property><name>press.map.output</name><value>true</value></property>(6) 将conf/master和conf/slave文件写好。
Nutch 的配置文件

Nutch 的配置Nutch的配置文件主要有三类:1.Hadoop的配置文件,Hadoop-default.xml和Hadoop-site.xml。
2.Nutch的配置文件,Nutch-default.xml和Nutch-site.xml。
3.Nutch的插件的配置文件,这些插件的配置文件在加载插件的时候由插件自行加载,如filter的配置文件。
配置文件的加载顺序决定了配置文件的优先级,先加载的配置文件优先级低,后加载的配置文件优先级高,优先级低的配置会被优先级高的配置覆盖。
因此,了解Nutch配置文件加载的顺序对学习使用Nutch是非常必要的。
下面我们通过对Nutch源代码的分析来看看Nutch加载配置文件的过程。
Nutch1.0使用入门(一)介绍了Nutch主要命令--crawl的使用,下面我们就从crawl的main类(org.apache.nutch.crawl.Crawl)的main方法开始分析:Crawl类main方法中加载配置文件的源码如下:Configuration conf = NutchConfiguration.create();conf.addResource("crawl-tool.xml");JobConf job = new NutchJob(conf);上面代码中,生成了一个NutchConfiguration类的对象,NutchConfiguration 是Nutch管理自己配置文件的类,Configuration是Hadoop管理自己配置文件的类。
下面我们进入NutchConfiguration类的create()方法。
/** Create a {@link Configuration} for Nutch. */public static Configuration create() {Configuration conf = new Configuration();addNutchResources(conf);return conf;}create()方法中,先生成了一个Configuration类的对象。
nuttcp 使用方法

nuttcp 使用方法一、什么是 nuttcp?nuttcp 是一款用于测试网络带宽的工具,它通过在客户端和服务器之间传输数据来测量网络的性能和吞吐量。
nuttcp 支持多种操作系统,包括 Linux、Windows 和 macOS。
它是一个命令行工具,使用简单且功能强大。
二、安装 nuttcp1. 在 Linux 上安装 nuttcp在大多数 Linux 发行版中,nuttcp 可以通过包管理器进行安装。
例如,在Ubuntu 上,可以使用以下命令安装 nuttcp:sudo apt-get install nuttcp2. 在 Windows 上安装 nuttcp在 Windows 上,可以从 nuttcp 的官方网站()下载预编译的二进制文件。
解压缩下载的文件后,将 nuttcp.exe 添加到系统的 PATH 环境变量中,这样就可以在命令提示符中直接运行 nuttcp。
3. 在 macOS 上安装 nuttcp在 macOS 上,可以使用 Homebrew 包管理器来安装 nuttcp。
打开终端,并执行以下命令:brew install nuttcp三、使用 nuttcp 进行带宽测试1. 在服务器端启动 nuttcp在服务器上,打开终端并执行以下命令以启动 nuttcp 服务器:nuttcp -S这将启动一个 nuttcp 服务器,并监听默认端口 5001。
如果你想使用其他端口,可以使用-p参数指定。
2. 在客户端执行带宽测试在客户端上,打开终端并执行以下命令以执行带宽测试:nuttcp <服务器IP地址>替换<服务器IP地址>为实际的服务器 IP 地址。
默认情况下,nuttcp 将使用默认端口 5001 进行测试。
如果服务器使用了其他端口,可以使用-p参数指定。
3. 查看测试结果带宽测试完成后,nuttcp 将显示测试的结果。
其中包括平均传输速度、传输的数据量、传输时间等信息。
Lucene in Action(中文版)

Lucene in Action(中文版)--------------------------------------------------------------------------------Lucene in Action中文版第一部分 Lucene核心1. 接触Lucene2. 索引3. 为程序添加搜索4. 分析5. 高极搜索技术6. 扩展搜索第二部分 Lucene应用7. 分析常用文档格式8. 工具和扩充9. Lucene其它版本10. 案例学习序Lucene开始是做为私有项目。
在1997年末,因为工作不稳定,我寻找自己的一些东西来卖。
Java是比较热门的编程语言,我需要一个理由来学习它。
我已经了解如何来编写搜索软件,所以我想我可以通过用Java写搜索软件来维持生计。
所以我写了Lucene。
几年以后,在2000年,我意识到我没有销售天赋。
我对谈判许可和合同没有任何兴趣,并且我也不想雇人开一家公司。
我喜欢做软件,而不是出售它。
所以我把Lucene放在SourceForge上,看看是不是开源能让我继续我想做的。
有些人马上开始使用Lucene。
大约一年后,在2001年,Apache提出要采纳Lucene。
Lucene 邮件列表中的消息每天都稳定地增长。
也有人开始贡献代码,大多是围绕Lucene的边缘补充:我依然是仅有的理解它的核心的开发者。
尽管如些,Lucene开始成为真正的合作项目。
现在,2004年,Lucene有一群积极的深刻理解其核心的开发者。
我早已不再每天作开发,这个强有力的工作组在进行实质性的增加与改进。
这些年来,Lucene已经翻译成很多其它的语言包括C++、C#、Perl和Python。
在最开始的Java和其它这些语言中,Lucene的应用比我预想的要广泛地多。
它为不同的应用(如财富100公司讨论组、商业Bug跟踪、Microsoft提供的邮件搜索和100页面范围的Web搜索引擎)提供搜索动力。
瘦客户机设置、连接操作指南.

瘦客户机设置、连接操作指南
一、开机界面
终端开机后会出现短暂的花屏现象,然后会出现连接信息,最后固定在登录的界面上,用户可以选择你所要进入的系统进行登录(如图1)。
图1
终端包含的参数:
Connection to 主计算机名:这是 NStation L110 在本地局域网中找到装有 NCT-2000-XP 服务的主计算机名
Connection:中文意思“ 连接” ,登陆到列表框选定的主计算机。
Sleep:中文意思“ 睡眠”
Setup:中文意思“设置”,包括本机IP设置、TS Options设置、CMOS密码设置等。
Info:中文“ 信息”,包括产品系列号,IP 地址等
二、简单设置
打开登录的界面后,如果Connection to选项中没有可供选择的系统名称列表,则需要进行一些简单的设置:
1、点击登录界面上的setup进入设置界面(如图2)。
图2
2、在设置面板选择Autodetdction(自动选择局域网内装有NTC-2000-XP系统的计算机)选
项,然后点击Eable-Diseable按钮添加选项(如图3),Autodetdction后有“√”为已选择。
(TS Options:TS 全称 Terminal Server,是指装有 NCT-2000-XP 软件的服务。
)
图3
3、有时候选择项需要进行编辑设置,这时,需要在选择并点击Autodetdction(或TS2、TS3)
后,再点击Edit按钮进行编辑。
下面是终端设置的其他几个相关界面的简单介绍,在一般应用中基本不用用户自己更改设置。
nutch应用-安装与使用

nutch应用-安装与使用Nutch 使用之锋芒初试“工欲善其事,必先利其器。
”经过前文的“细解”,我们已经完成了Nutch在Windows中的安装。
接下来就让我们通过锋芒初试,来亲自体验一下Nutch的强大功能吧!Nutch的爬虫抓取网页有两种方式,一种方式是Intranet Crawling,针对的是企业内部网或少量网站,使用的是crawl命令;另一种方式是Whole-web crawling,针对的是整个互联网,使用inject、generate、fetch和updatedb等更底层的命令。
本文将以使用Nutch为笔者在CSDN处的个人专栏(/zjzcl)文章内容建立搜索功能为例,来讲述Intranet Crawling的基本使用方法(假设用户电脑系统已安装好JDK、Tomcat和Resin,并做过相应的环境配置)。
1、设置Nutch的环境变量在Windows系统的环境变量设置中,增加NUTCH_JAVA_HOME变量,并将其值设为JDK的安装目录。
比如笔者电脑中JDK安装于D:\j2sdk1.4.2_09,因此将NUTCH_JAVA_HOME的值设为D:\j2sdk1.4.2_09。
2、Nutch抓取网站页面前的准备工作(1)在Nutch的安装目录中建立一个名为url.txt的文本文件,文件中写入要抓取网站的顶级网址,即要抓取的起始页。
笔者在此文件中写入如下内容:/zjzcl(2)编辑conf/crawl-urlfilter.txt文件,修改部分:# accept hosts in +^/zjzcl3、运行Crawl命令抓取网站内容双击电脑桌面上的Cygwin图标,在命令行窗口中输入:cd /cygdrive/i/nutch-0.7.1不明白此命令含义的读者请参见前《细解》一文,然后再输入:bin/nutch crawl url.txt -dir crawled -depth 3 -threads 4 >& crawl.log等待大约2分多钟后,程序运行结束。
Nutch 使用总结

Nutch 是一个开源Java 实现的搜索引擎。
它提供了我们运行自己的搜索引擎所需的全部工具。
包括全文搜索和Web爬虫。
Nutch使用方法简介:/pengpengfly/archive/2008/09/29/2994664.aspx nutch1.2 eclipse tomcat6.0 配置:/oliverwinner/blog/item/4be3f1370284b32f5ab5f565.htmlNutch 实战:介绍了开源搜索引擎Nutch 的基本信息,详细说明了在Eclispe 下运行Nutch 的步骤和需要注意的问题,还分析了部分源代码。
很好的文章Nutch 目录结构bin:用于命令行运行的文件;conf:Nutch的配置文件lib:一些运行所需要的jar文件;plugins:存放相应的插件;src:Nutch的所有源文件;webapps:web运行相关文件;nutch-0.9.war是Nutch所提供的基于Tomcat的应用程序包。
Nutch工作流程1. 将起始URL 集合注入到Nutch 系统之中。
2. 生成片段文件,其中包含了将要抓取的URL 地址。
3. 根据URL地址在互联网上抓取相应的内容。
4. 解析所抓取到的网页,并分析其中的文本和数据。
5. 根据新抓取的网页中的URL集合来更新起始URL集合,并再次进行抓取。
6. 同时,对抓取到的网页内容建立索引,生成索引文件存放在系统之中。
(1)准备需要的软件列表Cygwin (下载地址:/setup.exe)Jdk(1.4.2以上版本,下载地址/technetwork/java/javase/downloads/jdk-6u29-download-513648.html)Nutch(推荐使用0.9版本,下载地址/dyn/closer.cgi/lucene/nutch/)Tomcat(下载地址/)(2)安装软件1) Cygwin 打开安装程序Cygwin.exe后,在"Choose Installation Type"页选择"Install from Internet"(如果你已经把全部安装包下载到本地,就可以选择"Install from local directory"选项)。
nutek操作手册

nutek操作手册第一章:简介Nutek是一款功能强大的操作软件,旨在提高用户的工作效率和操作体验。
本手册将详细介绍Nutek的安装、基本操作和常用功能。
第二章:安装与设置1. 下载Nutek软件包:从Nutek官方网站或授权渠道下载安装包。
2. 运行安装程序:双击安装包并按照提示完成安装过程。
3. 设置个人信息:打开Nutek,填写个人信息,包括姓名、邮箱、联系电话等,以便于日后的数据管理和协作。
第三章:基本操作1. 登录Nutek:输入用户名和密码登录Nutek系统,以获得更多的功能和权限。
2. 导航面板:在Nutek的主界面上,您将看到导航面板,包括Dashboard、项目管理、任务管理、通知中心等模块,方便您快速切换和浏览。
3. 创建项目:点击项目管理,选择新建项目,并填写项目名称、描述和其他相关信息。
4. 创建任务:在项目中创建任务,设置任务的名称、负责人、截止日期等要素,并进行任务分配和优先级设定。
第四章:高级功能1. 任务管理:在任务列表中可对任务进行增删改查等操作,还可设置任务间的依赖关系和任务的属性。
2. 文档管理:Nutek 提供丰富的文档管理功能,用户可以上传、下载、编辑、共享等。
3. 通知中心:Nutek将各种重要通知集中在一个地方,确保您不会错过任何消息。
4. 数据分析:Nutek内置了数据分析工具,可以根据用户的需求生成各种图表和报告,帮助用户了解项目进展和效果。
第五章:实用技巧1. 快捷键:Nutek提供了一系列的快捷键,可以极大地提高操作速度和效率。
请参考Nutek的快捷键指南。
2. 个性化设置:根据个人需求,您可以自定义Nutek的界面外观、语言、时区等设置,以适应不同的工作环境。
3. 协同合作:Nutek支持多人在线协作,您可以邀请团队成员加入项目,并设定权限,方便项目管理和任务分配。
第六章:常见问题解答1. 如何导出任务清单:在任务列表中,选择要导出的任务,点击导出按钮,选择导出格式和路径即可。
nutch_1.2

Nutch实验报告1.1安装Nutch1.1.1实验环境Linux操作系统,采用的是VMWare虚拟机下的Ubuntu 10.10系统。
1.1.2安装的必要软件1.JDK,采用的是JDK1.6版本,此次实验的版本是jdk-6u24-linux-i586.bin。
/technetwork/java/javase/downloads/index.html2.Tomcat,采用的是apache-tomcat-7.0版本,此次实验的版本是apache-tomcat-7.0.11.tar.gz。
/3.Nutch, 采用的是apache-nutch-1.2版本,此次实验的版本是apache-nutch-1.2-bin.tar.gz。
/1.1.3软件的安装方法和安装过程1.安装JDK1)将下载好的jdk的bin文件放到虚拟机环境下,例如,可以放在/home/root2)到jdk的bin文件目录下,执行命令,安装jdk。
安装命令:[root@ubuntu:/home/root]#sh jdk-6u24-linux-i586.bin3)修改环境变量编辑~/.bashrc文件[root@ubuntu:~]# vi ~/.bashrc在最后加入如下配置export JA V A_HOME=/home/root/jdk1.6.0_24export JA V A_BIN=/home/root/jdk1.6.0_24/binexport PATH=$PATH:$JA V A_HOME/binexport CLASSPATH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jar 注意:在网上看其他资料是配置:/etc/environment但在配置后重启,出现无法进入系统的状况。
4)查看jdk是否安装成功命令如下:[root@ubuntu:~]# java –version如果出现下列结果,jdk安装成功。
Hadoop权威指南---中文版

目录目录 I初识Hadoop 11.1 数据!数据 11.2 数据的存储和分析 31.3 相较于其他系统 41.4 Hadoop发展简史 91.5 Apache Hadoop项目 12 MapReduce简介 152.1 一个气象数据集 152.2 使用Unix Tools来分析数据 17 2.3 使用Hadoop进行数据分析 19 2.4 分布化 302.5 Hadoop流 352.6 Hadoop管道 40Hadoop分布式文件系统 443.1 HDFS的设计 443.2 HDFS的概念 453.3 命令行接口 483.4 Hadoop文件系统 503.5 Java接口 543.6 数据流 683.7 通过distcp进行并行复制 75 3.8 Hadoop归档文件 77Hadoop的I/O 804.1 数据完整性 804.2 压缩 834.3 序列化 924.4 基于文件的数据结构 111 MapReduce应用开发 1255.1 API的配置 1265.2 配置开发环境 1285.3 编写单元测试 1345.4 本地运行测试数据 1385.5 在集群上运行 1445.6 作业调优 1595.7 MapReduce的工作流 162 MapReduce的工作原理 1666.1 运行MapReduce作业 166 6.2 失败 1726.3 作业的调度 1746.4 shuffle和排序 1756.6 任务的执行 181 MapReduce的类型与格式 1887.1 MapReduce类型 1887.3 输出格式 217 MapReduce 特性 2278.1 计数器 2278.2 排序 2358.3 联接 2528.4 次要数据的分布 2588.5 MapReduce的类库 263 Hadoop集群的安装 2649.1 集群说明 2649.2 集群的建立和安装 268 9.3 SSH配置 2709.4 Hadoop配置 2719.5 安装之后 2869.6 Hadoop集群基准测试 286 9.7 云计算中的Hadoop 290 Hadoop的管理 29310.1 HDFS 29310.2 监控 30610.3 维护 313Pig简介 32111.1 安装和运行Pig 322 11.2 实例 32511.3 与数据库比较 32911.4 Pig Latin 33011.5 用户定义函数 34311.6 数据处理操作符 35311.7 Pig实践提示与技巧 363Hbase简介 36612.1 HBase基础 36612.2 概念 36712.3 安装 37112.4 客户端 37412.5 示例 37712.6 HBase与RDBMS的比较 38512.7 实践 390ZooKeeper简介 39413.1 ZooKeeper的安装和运行 39513.2 范例 39613.3 ZooKeeper服务 40513.4 使用ZooKeeper建立应用程序 417 13.5 工业界中的ZooKeeper 428案例研究 43114.1 Hadoop在Last.fm的应用 43114.2 Hadoop和Hive在Facebook的应用 441 14.3 Hadoop在Nutch搜索引擎 45114.4 Hadoop用于Rackspace的日志处理 466 14.5 Cascading项目 47414.6 Apache Hadoop的1 TB排序 488 Apache Hadoop的安装 491Cloudera的Hadoop分发包 497预备NCDC气象资料 502第1章初识Hadoop古时候,人们用牛来拉重物,当一头牛拉不动一根圆木的时候,他们不曾想过培育个头更大的牛。
Hadoop添加节点的方法

Hadoop添加节点的方法自己实际添加节点过程:1. 先在slave上配置好环境,包括ssh,jdk,相关config,lib,bin等的拷贝;2. 将新的datanode的host加到集群namenode及其他datanode中去;3. 将新的datanode的ip加到master的conf/slaves中;4. 重启cluster,在cluster中看到新的datanode节点;5. 运行bin/start-balancer.sh,这个会很耗时间备注:1. 如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低mr的工作效率;2. 也可调用bin/start-balancer.sh 命令执行,也可加参数-threshold 5threshold 是平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长。
3. balancer也可以在有mr job的cluster上运行,默认dfs.balance.bandwidthPerSec很低,为1M/s。
在没有mr job时,可以提高该设置加快负载均衡时间。
其他备注:1. 必须确保slave的firewall已关闭;2. 确保新的slave的ip已经添加到master及其他slaves的/etc/hosts中,反之也要将master 及其他slave的ip添加到新的slave的/etc/hosts中mapper及reducer个数url地址:/hadoop/HowManyMapsAndReduces HowManyMapsAndReducesPartitioning your job into maps and reducesPicking the appropriate size for the tasks for your job can radically change the performance of Hadoop. Increasing the number of tasks increases the framework overhead, but increases load balancing and lowers the cost of failures. At one extreme is the 1 map/1 reduce case where nothing is distributed. The other extreme is to have 1,000,000 maps/ 1,000,000 reduces where the framework runs out of resources for the overhead.Number of MapsThe number of maps is usually driven by the number of DFS blocks in the input files. Although that causes people to adjust their DFS block size to adjust the number of maps. The right level of parallelism for maps seems to be around 10-100 maps/node, although we have taken it up to 300 or so for very cpu-light map tasks. Task setup takes awhile, so it is best if the maps take at least a minute to execute.Actually controlling the number of maps is subtle. The mapred.map.tasks parameter is just a hint to the InputFormat for the number of maps. The default InputFormat behavior is to split the total number of bytes into the right number of fragments. However, in the default case the DFS block size of the input files is treated as an upper bound for input splits. A lower bound on the split size can be set via mapred.min.split.size. Thus, if you expect 10TB of input data and have 128MB DFS blocks, you'll end up with 82k maps, unless your mapred.map.tasks is even larger. Ultimately the [WWW] InputFormat determines the number of maps.The number of map tasks can also be increased manually using the JobConf's conf.setNumMapTasks(int num). This can be used to increase the number of map tasks, but will not set the number below that which Hadoop determines via splitting the input data.Number of ReducesThe right number of reduces seems to be 0.95 or 1.75 * (nodes * mapred.tasktracker.tasks.maximum). At 0.95 all of the reduces can launch immediately and start transfering map outputs as the maps finish. At 1.75 the faster nodes will finish their first round of reduces and launch a second round of reduces doing a much better job of load balancing. Currently the number of reduces is limited to roughly 1000 by the buffer size for the output files (io.buffer.size * 2 * numReduces << heapSize). This will be fixed at some point, but until it is it provides a pretty firm upper bound.The number of reduces also controls the number of output files in the output directory, but usually that is not important because the next map/reduce step will split them into even smaller splits for the maps.The number of reduce tasks can also be increased in the same way as the map tasks, via JobConf's conf.setNumReduceTasks(int num).自己的理解:mapper个数的设置:跟input file 有关系,也跟filesplits有关系,filesplits的上线为dfs.block.size,下线可以通过mapred.min.split.size设置,最后还是由InputFormat决定。
Nutch中文分词的研究和改进

Nutch中文分词的研究和改进摘要:介绍了在Nutch1.0中加入Paoding's Knives中文分词的原因及实现方法。
通过实例测试,对结果进行分析和比较,说明了Paoding's Knives中文分词能够较好地满足实际的中文搜索需求。
关键词:Nutch;搜索引擎;中文分词;Paoding's Knives1 中文分词和Nutch中文分词的缺点中文分词是构建检索类系统需要重点考虑的一个因素,它直接影响着搜索结果的相关度排序和搜索的效率及准确程度。
分词的准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。
因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。
Nutch的分词对英文的切分比较完善,在中文分词上使用的是默认的单字切分,即每个字被认为是一个词。
这种以单个汉字索引方式来分词的方法效果不是很理想,不能满足中文搜索的实际需求。
因此我们需要新的分词器,来实现对中文搜索的良好支持。
目前的中文分词组件有Paoding's Knives、CJKAnalyzer、JE、ICTCLAS等,其中Paoding's Knives是一个开源的,使用Java开发的分词组件。
它具有高效和高扩展性等特点,采用基于不限制个数的词典文件对文章进行有效切分,能够对词汇分类定义,能够对未知的词汇进行合理解析,成为首选的中文分词开源组件。
2 Nutch中文分词的实现2.1 Nutch分词架构Nutch分词的最底层使用的是lucene的Analyzer抽象类,它位于org.apache.lucene.analysis包。
NutchAnalyzer继承了Analyzer类,是Nutch中扩展分析文本的扩展点,所有用于解析文本的插件都得实现这个扩展点。
NUT操作手册
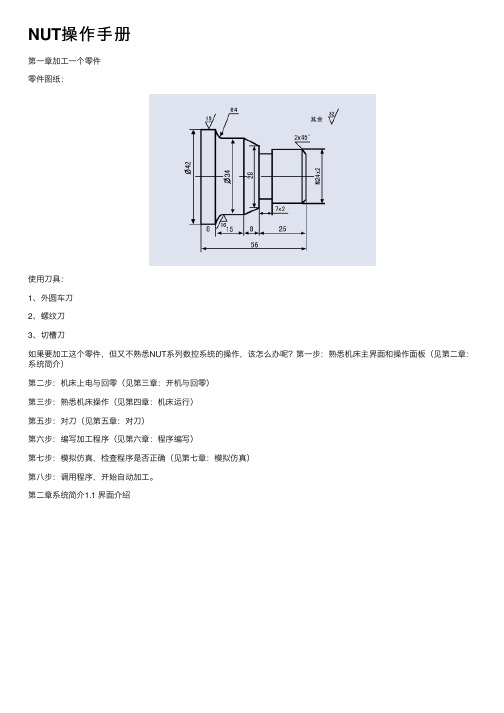
NUT操作⼿册第⼀章加⼯⼀个零件零件图纸:使⽤⼑具:1、外圆车⼑2、螺纹⼑3、切槽⼑如果要加⼯这个零件,但⼜不熟悉NUT系列数控系统的操作,该怎么办呢?第⼀步:熟悉机床主界⾯和操作⾯板(见第⼆章:系统简介)第⼆步:机床上电与回零(见第三章:开机与回零)第三步:熟悉机床操作(见第四章:机床运⾏)第五步:对⼑(见第五章:对⼑)第六步:编写加⼯程序(见第六章:程序编写)第七步:模拟仿真,检查程序是否正确(见第七章:模拟仿真)第⼋步:调⽤程序,开始⾃动加⼯。
第⼆章系统简介1.1 界⾯介绍图1 系统主界⾯1区:左上⾓LOGO显⽰区2区:右上⾓系统时间和系统状态显⽰区3区:坐标显⽰区4区:速度显⽰区5区:G代码状态显⽰区6区:⼑具和⼯件测量区7区:程序⾃动运⾏显⽰区8区:⼑具运⾏路径的图形显⽰区9区:⽣产管理显⽰区10区:MDA操作区11区:功能按钮显⽰区12区:信息和报警信息显⽰区1.2 操作⾯板介绍图1.3 操作⾯板表1.2 ⾯板按钮列表1.3 系统状态介绍飞阳NUT系统的操作状态分为:空闲和运⾏两个状态。
第三章开机与回零2.1 开机1、机床上电,系统⾃动启动;2、系统启动结束后,释放急停按钮;3、按操作⾯板上的(上电按钮),系统上电;4、按操作⾯板上的(复位按钮),系统报“复位完成”信息,则系统进⼊⼯作状态。
2.2 回零机床正常启动后,需要回零后才能执⾏程序的⾃动加⼯。
当系统处于空闲状态下,回零操作可以通过以下两种⽅式实现:1、单轴回零2、全部回零2.2.1 单轴回零1、开机后系统处于空闲状态;2、点击主界⾯上的回零按钮,则操作⾯板上的(循环启动)按钮灯长亮;3、按下(循环启动)按钮后,相应的轴开始回零;4、回零完成后,主界⾯对应轴的回零按钮消失。
2.2.2 全部回零1、开机后系统处于空闲状态;2、按下操作⾯板上的(回零)按钮,该按钮灯长亮,同时(循环启动)按钮灯长亮;3、按下(循环启动)按钮后,所有轴开始回零;4、回零完成后,主界⾯上的回零按钮消失。
linux下建立nuttx开发环境

linux下建立nuttx开发环境1.安装ARM Toolchain。
(也可以选择使用buildroot自己搭建开发环境,不过我在linux下使用ARM Toolchain觉得挺好用,官方的开发环境也能够比较好支持ARM T oolchain)1.1sudo apt‐get install gcc‐arm‐none‐eabi2.安装Kconfig-frontends package(这个包是Nuttx用来配置建立一个nuttx系统的,可以方便的使用界面进行配置board)/doc/af1955072.html,/download/kcon fig-frontends/将下载下来的包解压到:"local path"/nx/misc下载依赖项:2.1sudo apt‐get install flex bison libncurses5-devlibgmp3-dev libmpc-dev libmpfr-dev binutils-dev编译安装kconfig-frontends:2.2cd"local path"/nx/misc/kconfig‐frontends/2.3sudo./configure--enable-mconf2.4sudo make2.5sudo make install3.下载Nuttx源代码下载地址:/doc/af1955072.html,/projects/nuttx/files/ nuttx/将文件解压到文件夹nx下去掉版本号,即文件夹重新命名为:nuttx和apps4.现在可以尝试在menuconfig里边对板子进行配置,下边以stm32_tiny为例。
4.1cd"local path"/nx/nuttx/tools4.2./configure.sh stm32_tiny/nsh上边两行代码会把config/stm32_tiny/nsh里边的链接配置文件复制到nuttx根目录下。
nutek操作手册

Nutek操作手册简要指南Nutek是一款高效、稳定的操作软件,为用户提供友好的操作界面和丰富的功能。
以下是Nutek操作手册的简要概述,以帮助您快速了解和使用该软件:一、软件安装与启动1.下载Nutek安装包,并双击运行安装程序。
2.按照安装向导提示,完成软件的安装过程。
3.安装完成后,双击桌面上的Nutek图标启动软件。
二、软件界面与功能1.Nutek的主界面分为菜单栏、工具栏、项目栏和状态栏四个部分。
2.通过菜单栏,您可以访问软件的所有功能,如文件操作、编辑、视图等。
3.工具栏提供了常用功能的快捷按钮,方便用户快速执行操作。
4.项目栏显示了当前打开的项目和文件列表,方便用户管理和切换。
5.状态栏显示了当前软件的状态和相关信息。
三、基本操作1.创建新项目:点击菜单栏中的“文件”选项,选择“新建项目”,输入项目名称和保存路径。
2.打开项目:在项目栏中选择要打开的项目,双击打开。
3.保存项目:点击菜单栏中的“文件”选项,选择“保存项目”。
4.导入文件:在项目栏中选择要导入的文件类型,点击“导入”按钮,选择文件并导入。
5.导出文件:在项目栏中选择要导出的文件,点击“导出”按钮,选择导出格式并保存。
四、高级功能Nutek还提供了许多高级功能,如自动化脚本编写、数据可视化等,用户可以通过查看软件的详细操作手册或在线教程进一步了解和使用这些功能。
五、注意事项1.在使用Nutek时,请确保您的计算机满足最低系统要求。
2.在执行关键操作前,建议备份重要数据以防万一。
3.如遇任何问题或困难,可查看软件的帮助文档或联系技术支持寻求帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7.搜索页面上的部分中文出现乱码。该问题主要由jsp:include引起。
将被包含文件nutch\zh\include\header.html的乱码修改为简介和常见问题
8.搜索中文出现乱码。修改tomcat配置文件tomcat6\conf\server.xml。增加URIEncoding/useBodyEncodingForURI两项。
-dir dir names the directory to put the crawl in.
-threads threads determines the number of threads that will fetch in parallel.
-depth depth indicates the link depth from the root page that should be crawled.
每次重新修改nutch配置文件的时候,需要把crawl文件夹删掉
/nutch/tutorial8.html
/blog/382726
/category/41935
3.下载nutch-1.0
3.1在解压后的目录里面建urls文件夹
urls目录下面建url.txt
内容为: / 来自3.2修改解压目录下 conf/crawl-urlfilter.txt
# accept hosts in
#+^http://([a-z0-9]*\.)*/
内容为
<configuration>
<property>
<name></name>
<value>my nutch agent</value>
</property>
/s/blog_60edc5890100e0x0.html~type=v5_one&label=rela_nextarticle
/nutch/RunNutchInEclipse1.0
/nutch/NutchTutorial
4.本地运行
运行cygwin,cd到nutch-1.0的解压目录 cd /cygdrive/..
输入 bin/nutch crawl urls -dir crawl -depth 3 -threads 4 -topN 500
dir指定抓取内容所存放的目录,depth表示以要抓取网站顶级网址为起点的爬行深度,threads指定并发的线程数。
5.1nutch部署到tomcat
将nutch-1.0.war复制到tomcat6\webapps目录下面
运行tomcat6\bin\startup.bat启动tomcat,tomcat将自动对war文件进行解压。
5.2修改文件tomcat6\webapps\nutch\WEB-INF\classes\nutch-site.xml,设置nutch的索引文件位置。
<configuration>
<property>
<name>searcher.dir</name>
<value>D:\nutch-1.0\crawl\</value>
</property>
</configuration>
6.重启tomcat,访问http://localhost:8080/nutch-1.0/进行搜索
1.下载jdk1.6
1.1将bin目录加入环境变量path里面
1.2新建环境变量JAVA_HOME=java安装的目录(tomcat启动的时候需要)
2.安装cygwin
路径/
安装镜像选择kernel比较快一点
运行nutch自带的脚本命令需要linux的环境,cygwin是用来模拟linux的bash环境
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
URIEncoding="UTF-8"
useBodyEncodingForURI="true"
/>
<property>
<name>http.agent.version</name>
<value>1.0</value>
</property>
</configuration>
如果没有配置此agent,爬取时会出现 Agent name not configured! 的错误。
+^/discuz/viewthread.php\?tid=\d+&extra=page%3D\d+$
+^/discuz/viewthread.php\?tid=\d+&extra=page%3D\d+&page=\d+$
3.3修改 conf/nutch-site.xml
-topN N determines the maximum number of pages that will be retrieved at each level up to the depth.
5.下载tomcat6.0.24
下载地址/download-60.cgi
把这里改成需要爬的域名
如:
+^/
+^/discuz/index.php$
+^/discuz/forumdisplay.php\?fid=\d+$
+^/discuz/forumdisplay.php\?fid=\d+&page=\d+$
9.网页快照乱码问题修正。
修改页面tomcat6\webapps\nutch\cached.jsp,将encoding改为UTF-8
2.下载myeclipse7.0
下载地址/downloads/products/eworkbench/7.0M1/MyEclipse_7.0M1_E3.4.0_Installer.exe