Mentor MP简易样本
MentorCES使用介绍

Mentor CES使用介绍本介绍从我们使用Expeditionpcb的流程角度介绍如何利用CES快速设置物理规则和电气规则。
对于Allegro转换的Expedition数据,原先CES是不支持的。
从2005SP1起,CES已支持Allegro转换过来的数据。
因此现在我们可以在协同设计流程中,直接采用Mentor的CES对进行转换过来的规则进行检查、纠正和输入复杂的高速电气规则。
关于200SP1和CES使用的基本情况,可参见《Expedition2005SP1和AllExp2WayAssit使用说明》,本介绍重点在于电气规则的设置。
希望能够通过该介绍使得能够理解CES设置规则机理,输入正确的合适并能够为工具所支持的规则,既简单能够使得布线工具支持,同时也能很好地符合电气要求。
本介绍分为三个部分:1 CES界面和基本设置 2 物理规则设置 3 电气规则设置。
1.CES 界面和基本设置将数据从Allegro转换到Expedition后,启动Expeditionpcb后,点击Setup -Project Intergration,按下图所示,勾选使用CES。
然后点击Setup-Constraints启动CES,我们可以看到Setup菜单条的发生了变化,Net Class和Net Properties菜单条项现场变成了一个Constraints。
点击Constraints,就启动了CES。
现在我们可以通过CES来方便地设置所有物理规则和电气规则。
如果Allegro 已经设置了一些物理规则和差分对定义,这时,使用者可以在CES看到原来在Allegro设置的线宽和间距规则,也可以看到在Specctraquest中定义的差分线定义、匹配对。
由于目前版本的转换器并不能完全100%地将Specctraquest中定义的所有约束一一传递到CES中,使用者需要在CES中重新检查、补充相应的约束。
为此,建议不要在SQ设置过多的高速约束,一切移到CES设置,这样可以节约时间。
使用Mentor公司PCB设计工具经验

Mentor公司PCB设计工具(DxDesigner及Expedition PCB)的设计体会Expedition的设计思想大部分硬件工程师,PCB设计使用最多的恐怕就是protel,因此在使用Expedition做PCB设计时不自觉的就会把两者设计思想进行比较,从本质上来讲,两者并无什么不同,都是符号,封装,互连关系,但是在具体形式上,Expedition比起Protel要更为细致。
Protel在设计时只需要两个库:符号库及封装库,原理图设计时在元件的属性中进行两者的对应,然后生成网表文件,就可以带入到PCB中进行布局布线,如图1所示。
与此不同,Expedition中引入了中心库(Central library)的概念,符号(Symbol)与封装(Cell)的对应是在中心库中完成,形成器件(Part)。
可以说,中心库是整个设计的基础,从焊盘定义,封装制作、符号与封装的对应,都在中心库中完成。
在进行原理图设计时,可以从中心库中调符号,当然也可以自己建立本地符号库,但是在进行编译之前,要用中心库中的符号代替自己建立的符号,并在符号的属性中指定与中心库中Part的对应关系,同时指定中心库路径,这样才可以完成编译,进入下一步PCB的流程(图2)。
前端输入工具DxDesigner我购置的Mentor软件的前端管理工具是DxDesigner。
由于我们手中没有现成的中心库可用,时间又比较紧张,在设计之初,我们采用的是两个人分头进行的设计方法:一个人负责建立符号库及原理图设计,另一个人则负责作封装库,到基本完成后再整合在一起。
原理图设计工具是viewdraw,在viewdraw的环境中也可以编辑制作符号,符号(symbol)创建有导航,在编辑时比较方便,也可以用VHDL或Verilog语言作为输入源,由于现在器件公司网站上一般都会提供语言的描述,所以有时候会比较快,但是用这种方式做出来的符号往往管脚排列不规则,需要改动,有时并不比手动输入时方便多少;元器件的属性种类比较丰富,但常用的基本属性就几个,只要填写正确一般也不会出大问题;他的路径设定比较麻烦,若想把在别的机器上的设计拷过来,必须先进行归档(Archive)操作,把库、设计数据进行打包,这样的工程才能在新的机器上打开;原理图编辑功能也都大同小异,总的感觉,它的原理图输入工具没什么优势可言,输入的方便性及直观性都比较一般。
Mentor库管理工具(Symbol的制作)

利用Mentor实现Symbol的制作康讯EDA设计部孟有权 2008年4月【摘要】在制作原理图前,先要制作原理图所要用到的器件的图形符号,Symbol 也就是电路元器件所对应的图形,Symbol是带有PIN的图形符号,Symbol不但有相应的属性,而且不同的Symbol有不同的属性,本文仅仅介绍如何利用Mentor里面的Symbol Editor、Symbol Wizard和DxDesigner这三个工具来制作Symbol,以及在制作Symbol的过程中应该注意的问题。
另外,在运用过程中可能还会有些问题出现,不足之处还需要自己的摸索和探讨。
【关键字】Symbol、Expedition、Wizard、DxDesigner、Partation、Parts、Cells 【正文】在制作原理图前,先要制作原理图所要用到的器件的图形符号,Symbol 也就是电路元器件所对应的图形,用图形来描述一个器件的结构,在画原理图的时候用Symbol表示的是一个器件,但是Symbol并不是简简单单的图形,而是带有PIN的图形符号,Symbol不但有相应的属性,而且不同的Symbol有不同的属性,而且Symbol 所带的PIN根据功能和用途的不同也有不同的属性。
下图就是一些简单的Symbol。
在此仅仅介绍如何利用Library Manager里面的工具来制作Symbol。
图 1注:在这里要说明一点的是,在建库时如果选择的是DX Designer/Expedition,那么在这里所建的Symbol就是上面的那些类型的Symbol,但是如果选择的是Design Capture/Expedition,那么在这里制作的就不是上面类型的Symbol了,但是两者都是可以用来制作原理图的,前者就是下面要制作的原理图,而后者目前只是知道能够用来实现电路的仿真、测试。
下面主要介绍在DX Designer/Expedition类型的库下来制作Symbol。
Mentor工具

Mentor Graphics各大系列系统单芯片验证系列硬件描述语言的仿真、硬件与软件的协同验证、多核心内嵌式系统的除错以及「可测试设计」(Design-for-Test)等。
●Seamless:可提供早期而精确的硬件/软件协同验证;●Nucleus:嵌入式实时操作系统;●XRAY:芯片制造前与制造后的软件除错工具;●FastScan:芯片测试资料的自动产生工具;●VStation和Celaro:硬件仿真工具/虚拟原型建构系统。
硬件描述语言与FPGA设计VHDL及混合硬件描述语言的仿真、FPGA组件的合成、以及设计的捕捉与管理等;在百万逻辑闸等级的FPGA设计领域里,能够提供整合式设计解决方案。
●ModelSim:提供数字仿真的功能;●HDL Designer Series:设计的输入、分析与管理工具;●Precision Synthesis:强大的FPGA合成解决方案。
实体设计与分析设计人员必须克服深次微米制程技术带来的许多复杂实体效应所产生的影响,才能把设计转换为实际的芯片。
●Calibre:速度最快且结果最精确的深次微米设计实体验证工具;●Calibre OPC与PSM:次波长光学制程修正及相偏移光罩的发展工具;●ADvance MS:混合模拟讯号设计解决方案;●Eldo:晶体管阶层的仿真工具;●EldoRF:射频分析工具;●IC Station:全订制型集成电路设计与察看的整合式工具流程。
电路板与系统设计●Board Station系列:不受限制的企业设计环境;●Expedition系列:最适合个别设计人员或小型工程团队的设计环境;●AutoActive RE:最佳的绕线作业环境,不但能立刻增加工程师的生产力,还能与Expedition及Board Station整合在一起;●DMS:数据管理系统。
工具简介设计技术平台Mentor Graphics公司面向“IP/ASIC/SoC设计环境平台”提供定制IC芯片设计技术、混合信号混合语言SoC的仿真验证技术、FPGA与PCB设计技术、系统设计技术等。
Mentor公司MBIST说明文档

/silicon-yieldCopyright Mentor Graphics Corporation 2010 All rights reservedThis document contains information that is proprietary to Mentor Graphics Corporation. The original recipient of this document may duplicate this document in whole or in part for internal business purposes only, provided that this entire notice appears in all copies. In duplicating any part of this document, the recipient agrees to make every reasonable effort to prevent the unauthorized use and distribution of the proprietary information.Silicon Test & Yield Analysis WhitepaperA G UIDE TO P OWER -A WARE M EMORY R EPAIRM AY 2010AbstractThe number of embedded memories contained within an SoC continues to grow rapidly. This growth has driven the need for rethinking manufacturing test strategies as embedded memories represent in most cases a die’s largest contributor to yield loss due to the very large area and density of these regular circuits. A successful memory strategy must incorporate some form of repair methodology in order to achieve profitable yield levels. This paper explores how to formulate an effective repair methodology by leveraging available memory redundancy schemes and advanced on-chip memory repair capabilities. The adaptation of memory repair techniques to the increasing use of power management schemes such as voltage and power islands is also examined.Table of ContentsINTRODUCTION (3)EFFECTIVE TEST FOR EFFECTIVE REPAIR (4)MEMORY REPAIR APPROACHES (5)POWER-AWARE SELF-REPAIR (8)CHOOSING A REDUNDANCY SCHEME (9)MANUFACTURING REPAIR FLOW (11)CONCLUSION (12)REFERENCES (13)APPENDIX A: GUIDE TO CHOOSING REDUNDANCY LEVELS (14)APPENDIX B: GUIDE TO CHOOSING NUMBER OF FUSES (17)IntroductionOne of the most notable consequences of the semiconductor industry moving to deeper nanoscale technology nodes is the significant growth in both the number and densities of embedded memories. Designs have migrated from containing a handful of memories to containing hundreds and in some cases thousands of memories of all types. This explosion in embedded memories is driving the need for rethinking the manufacturing test strategy for these designs [1].Embedded memories often represent a die’s largest contributor to yield loss because of the very large area and density of these regular circuits. A successful memory test strategy must now incorporate some form of repair methodology to achieve profitable yield levels.Another important and growing design consideration is power management. Low power requirements affect test in two separate ways. First, any functional power constraints must be met (or at least adequately managed) during test execution. Second, a test solution needs to be compatible with whatever low-power design techniques are used. This compatibility requirement is particularly important with regard to memory repair because the repair process must generally operate in conjunction with the normal operational mode of the device.Formulating a power-aware repair methodology often requires combining IP from memory providers, automation from DFT providers, as well as IP and data from foundries. This often represents a significant challenge, as not only are there several combinations and choices to consider, but more importantly, there is generally very little information on how to best make these choices. This document attempts to address this challenge by explaining the power-aware memory repair process along with all of its components and trade-offs.Effective Test for Effective RepairThe memory repair process has three basic components: test, repair analysis, and repair delivery. A comprehensive test capability is fundamental as the repair process is only effective if it addresses all existing defects. In the great majority of cases, embedded memories today are tested with Built-In Self-Test (BIST). In its simplest form, memory BIST consists of an on-chip engine placed next to each embedded memory that writes algorithmically generated patterns to the memory and then reads these patterns back to discover and possibly log any defects. The memory BIST engine is typically designed to generate patterns based on a pre-determined memory test algorithm encoded in a finite state machine (figure 1a). Decreases in process geometries and associated increases in memory densities are resulting in a growing number of memory defect types. Many of these new defect mechanisms are difficult to predict and hence properly test for. These defects are therefore being discovered during the production testing of a device or worse during the analysis of field returns. This can result in significant quality and cost issues if the predetermined test algorithm does not detect a newly discovered defect type. The cost issues are worse when repair is used as the added repair cost is wasted on a part that will remain defective.To address this growing problem, some commercial memory BIST solutions now provide programmable BIST engines (figure 1b). With these engines it is possible to download (on the tester or in-system) program code that implements an arbitrary memory test algorithm, allowing new or enhanced algorithms to be applied as needed to specific memories as new defect mechanisms need to be addressed. To maintain a simplified manufacturing test flow, these programmable BIST engines will typically support predetermined default algorithms as well. This removes the need to program the BIST engine if the default algorithm is sufficient. Only when new defect mechanisms are discovered does it become necessary to program each BIST engine before having it execute the memory test. The programmable BIST engines are larger than the more traditional hard-coded ones and therefore should only be used when the need is justified. This tends to be when a new memory design and/or a new foundry process are to be used.Figure 1: Memory BIST ArchitecturesT O / F R O M M E M O R YT O / F R O M M E M O R Y(a)(b)Memory Repair ApproachesIn addition to an effective test capability, a memory repair solution consists of two additional basic components: repair analysis and repair delivery. These are described in detail in this section.R EPAIR A NALYSISThis component of the repair process consists of determining which of a memory’s defective sections (typically rows or columns) must be replaced with available spares. Repair analysis can be performed on or off chip. In the off-chip approach, all memory failures are logged on the tester and the resulting fail data is post-processed offline. A significant drawback of the off-chip approach is that logging all of the fail data off-chip results in a large increase in test time. Because of this, the majority of today’s repair approaches use an on-chip repair analysis capability, often referred to as BIRA for Built-In Repair Analysis. With BIRA, absolutely no fail data needs to be logged externally as the BIRA circuitry or engine analyzes the fail data coming out of an associated BIST controller on the fly. By the end of the memory test, the BIRA engine has determined the spare element allocation necessary to repair the chip. A key requirement for a BIRA engine is to maximize its success at finding spare allocation solutions. If only spare rows or spare columns are used then the repair analysis is straightforward as any defective row or column is simply replaced. The analysis becomes much more complex however when both spare rows and columns are available. Take for example the memory represented in figure 2a which contains 2 spare rows and one spare column and contains the six defects shown. If a simple linear algorithmic approach is taken to allocate spares, then the allocation shown in figure 2b would be the outcome and the repair would not be successful. A successful allocation is possible in this case however as shown in figure 2c. In general, determining the optimum allocation when both spare rows and columns are used is in mathematical terms an NP -Complete problem, or more simply put, a problem that grows exponentially in difficulty with growing number of spare elements. Fortunately though, when theFigure 2: Optimal spare allocationSpare RowsS p a r e C o l u m n(a)(b)(c)number of rows and columns is relatively small (which is generally the case) an optimal solution can typically always be computed.R EPAIR D ELIVERYThere are two general forms of repair delivery: hard repair and soft repair.Hard RepairIn this approach, repair instructions are stored permanently within the die through the programming of fuses. The two common fuse types are laser and electrical. Laser fuses are programmed by cutting a metal link, while electrical fuses (eFuses) are typically one-time programmable or flash memory elements and are programmed using an elevated voltage level. eFuse usage is growing rapidly as they are generally smaller than laser fuses—typically by a factor of 2 to 3 (e.g. 0.02 mm2 vs. 0.05 mm2), and they do not require special equipment or a different test insertion to be programmed. For this last reason, eFuses are also associated with Self-Repair approaches which are described later in this section. Soft RepairIn this approach, repair instructions are stored in volatile memory, typically in scan registers, at each power up of the device. Soft repair has the advantage of being able to address defects that may arise over time as new repair instructions can be created and stored throughout the life of the device. This provides higher long term availability and reliability. Because the repair instructions are not permanently stored within the device, they have to be either stored somewhere external to the device (somewhere in the system) or they have to be generated on-the-fly at power-up. Storing the repair instructions in the system can be daunting from a logistics point of view as the repair instructions for typically many different memories within many different devices have to be properly managed. For this reason, soft repair is almost exclusively associated with a BIRA mechanism to calculate repair instructions on-chip at power up.Self-Repair:A self-repair solution, typically referred to as BISR (Built-In Self-Repair), is one where both the repair analysis and repair delivery are performed on-chip. In its simplest form, a BISR solution consists of the combined BIRA and soft repair capabilities described above. One important disadvantage of this approach however is that since the repair instructions are calculated once at power-up, they may not take into account defects that only manifest themselves under specific operating conditions such as high temperature. For this reason, more advanced BISR solutions now incorporate a combination of both soft and hard repair capabilities. Hard repair is used to store repair instructions determined during manufacturing test and soft repair is then used at each power up to address any new defects. These advanced solutions provide several advantages including: a simplified manufacturing test and repair process, support for long term reliability using soft-repair as explained above, and significant silicon area savings through pooling of fuse data as explained below. A potential drawback of this incremental soft repair approach is that the power up cycle time for a device becomes longer as the BIST must be executed twice. For some applications this extended time may be problematic.The on-chip architecture for the Tessent MemoryBIST BISR solution is shown in figure 3. A key component of this architecture is the concept of a centralized fuse pool (eFuse array). Because most memories with redundancy will typically need little to no repair on any given die, sharing a pool of fuses for all memories allows for much better fuse utilization. Memories needing little to no repair will require little to no fuse information to be stored, freeing that fuse storage for other memories. In order to simplify the fuse data allotment, standard data compression techniques are used to implicitly allocate the necessary amount of fuse storage per memory. On-chip management of a centralized programmable fuse pool is performed by a fuse controller . This controller together with one or more BIST controllers performs all necessary activities for testing and repairing memories. In this architecture, the BIST interfaces to memories containing redundancy are equipped with a BIRA engine to analyze failures and generate any necessary repair instructions in the form of fuse data. A dedicated chip-wide (BISR) scan chain is used by the fuse controller to transfer fuse data to and from the eFuse array and the various memories. This scan chain contains a BISR register for each memory with redundancy. The operation of this BISR architecture is described in detail in the next section.Figure 3: BISR ArchitectureRegistersPower-Aware Self-RepairThe self-repair architecture described above breaks down when voltage islands or power domains are used. This increasing popular power management approach involves using a separate supply voltage for each core (or, possibly, group of cores) within a design. Each resulting power domain can then be shut down when not required and re-activated when needed. This powering up and down activity has a direct effect on repairable memories. When a sleeping power domain is re-activated, the repair information for the repairable memories in that domain will have been lost and will need to be reloaded. The challenge here is that the reloading has to occur without disrupting the already active domains, and the reloading can’t be affected by the fact that some domains may still be inactive.To handle these constraints, the self-repair architecture described above has to be augmented to provide at least one repair shift register for each power domain as illustrated in figure 4. Each shift register can be of arbitrary length. A functional power management unit indicates to the fuse controller which shift register(s) need to be loaded. The other shift registers are kept in a stable state as they might contain repair information of active power domains. When multiple domains are re-activated, the controller will generally need to load them sequentially according to a default priority defined at design time. The operation is sequential because all repair information is typically stored in the same eFuse array. If the loading order needs to be changed, the power management unit simply needs to re-activate each island one at a time in the desired order.The functional power management unit and the fuse controller must both be in an always on power domain while the various memory BIST controllers are placed within the same power domains as the memories they test. Power domains can span multiple physical regions (shown as blocks in figure 4) and a physical region can also contain multiple power domains. In the current Tessent BISR solution, the association of memories to power domains is specified manually through a configuration file. A future enhancement will make use of available UPF or CPF files to automatically derive the associations.Always OnFigure 4: Power-Aware BISR ArchitectureChoosing a Redundancy SchemeThere are three general forms of redundancy to choose from. Each is described here along with some associated advantages and disadvantages. The reader is encouraged to work with the memory vendor and/or foundry to ultimately determine the best choice for his or her design.Row Only RedundancyOne or more spare rows are added per memory. In the case of several spare rows, some redundancy schemes force all rows to be allocated as a contiguous block while others allow each row to be allocated separately. For memories that support bank addressing, it is also possible to have an entire spare bank added to the memory.Advantages: This is the cheapest repair method from a BIST and BIRA overhead point of view. The BIST overhead is cheapest as a serial test interface between the BIST controller and memory can be used. A serial interface only requires one comparator per word rather than one per bit (I/O). The amount of BIRA logic is also low and varies only slightly with the memory size as only the most significant bits(MSBs) of the row address bits are logged.Disadvantages: Has a slight impact on performance as the setup time on the address inputs is slightly increased. Bit level diagnostics are not possible if the serial interface is used.Column Only RedundancyThere are two forms of column redundancy. In the IO replacement scheme, one or more entire memory sub-arrays are added. Each redundant element can repair any failing column associated with a memory IO. Figure 5a illustrates the structure of an 8-bit repairable memory with 4-to-1 column multiplexing and 1 redundant IO. The redundancy logic for the IO replacement mechanism is highlighted in grey. In the column replacement scheme, one or more single columns are added. Each redundant element can repair one failing column withinany memory IO. Figure 5b illustrates(a)(b)Figure 5: Column Redundancy Schemesthe structure of an 8-bit repairable memory with 4-to-1 column multiplexing and 1 redundant column. The logic for the column replacement mechanism is highlighted in grey.Advantages: This has the least effect on memory performance as there is no impact on address decoding.Disadvantages: It precludes the use of a serial interface between the BIST controller and the memory as a comparator per bit (I/O) is needed. The area cost is a function of the number of I/Os so that even a small memory can require a large amount of repair circuitry. The BIRA circuitry required to encode the failing I/O number is relatively big and slow. This may reduce the maximum frequency at which the BIST and BIRA can operate.Row and Column RedundancyIn row and column redundancy schemes, one or more spare rows as well as one or more spare columns are added per memory. The number of spares rows or spare columns rarely exceeds two.Advantages: Provides the highest repair success rate for a given number of spares. Having spares in both dimensions not only improves the ability to cover a random distribution of defects, but also improves the ability to cover defect mechanisms that affect an entire word (e.g. word line fault) or entire column (e.g. bit line fault).Disadvantages: Very expensive from both a memory overhead as well as from a BIRA overhead point of view. Can only be justified for very large memories and generally for less mature processes.Manufacturing Repair FlowThe manufacturing repair flow is typically performed at wafer sort and depends of course on the repair capabilities used. The following steps define the flow when the on-chip self-repair solution described in the previous section is used. Each of the steps is also represented graphically in figure 6.◆ Action : Power up/Reset the chip. Result : The fuse controller is automaticallyenabled and loads the chip-wide BISR chain with all 0s. This ensures that only the non-redundant portion of each memory is tested in the next step.Action : Run the memory BIST/BIRA controllers(at typically different test corners) Result : Each memory is fully tested and anynecessary repair info is automatically calculated and accumulated across different test corners. The repair info is stored in the local BIRA registers.♦ Action : Run “transfer BIRA to BISR” instruction Result : Transfers local repair info into chip-wide BISR chain for subsequent fuseprocessing.⌧ Action : Scan out BIRA registers from each BISTcontroller. Result : The BIRA registers contain the repairstatus. If any memory is not reparable then exit as chip is bad. If no repair info is generated for all memories then exit as chip is good.⍓ Action : Run fuse controller in programming mode. Result : The repair info contained in the BISRchip-wide chain is scanned out, compressed and programmed on-the-fly into the eFuse array. High voltage is applied to the eFuse array during this step from on-chip generator or off-chip supply.Figure 6: Manufacturing repair flowRegistersRegistersAction: Power up/Reset the chipResult: The fuse controller is automatically enabled and loads the chip wide BISR chain with all of the stored repair info. This results in all the memories with redundancy being repaired as the BISR registers directly drive the memory repair ports. Note that some memory types contain an internal scannable repair register rather than a repair port. For these memories, the internal repair register is scan loaded in parallel with the BISR register.Action: Run the memory BIST controllers.Result: The (repaired) memories are fully re-tested to ensure that the repair was successful.In the field, all memories are repaired automatically at power up by the fuse controller as described in step 6. For long term reliability, the Tessent BISR solution will soon support the ability to perform additional incremental soft repair at power up to address any defects that may have developed over time. To accomplish this, once the fuse controller has loaded the BISR registers to repair the memories, the BIRA registers are then loaded with the BISR register contents to create a baseline. The BIST controllers (with BIRA) are then executed and the BIRA registers are then updated to contain the baseline repair info combined with any new repair info. This combined repair info is then transferred back into the BISR registers to repair the memories. This is a soft repair as the new repair info cannot be programmed into the eFuse array and is therefore only available while the device is powered up. ConclusionPower-aware memory repair is a rapidly growing requirement for today’s leading edge designs. Maximizing yield and thus profitability requires proper planning and selection of an effective on-chip solution and related resources. Although it is recommended to work with your memory provider and foundry when making repair architecture and resource decisions, understanding the basic principles and some simple rules of thumb can help ensure the implementation of a successful solution.References[1] S. Pateras, “Best Practices for Cost Effective Test and Yield Optimization of Embedded Memories”,FSA Forum, vol. 13, no. 4, December 2006[2] J.A. Cunningham, “The Use and Evaluation of Yield Models in Integrated Circuit Manufacturing”,IEEE Transactions on Semiconductor Manufacturing, vol. 3, no. 2, May 1990, pp. 60-71.Appendix A: Guide to choosing redundancy levelsThe most basic question regarding memory repair is: how much redundancy, if any, should be added to each embedded memory? The answer to that question depends on several factors which are explored in this appendix. Although some guidelines are presented here, the reader is encouraged to work with his or her memory IP provider and/or foundry to determine the optimum redundancy strategy for a particular design.Redundancy is added to improve memory yield and thus die yield. A method to calculate yield is therefore required in order to analyze redundancy requirements. There is a long history of work on determining accurate yield models [2]. A common model for memory yield used by several companies is one based on the Negative Binomial model: Y MEM = ( 1 + D MEM A MEM )-C(1) where:D MEM = memory defect density(defects/mm 2) A MEM = memory core size (mm 2) C = complexity factor. This parameterrelates to the complexity of the underlying process and is derived from the number of critical steps in the manufacturing flow. Values between 5 and 15 have been used successfully with processes of varying complexity.Figure A1 plots yields for memories ranging in size from 1 mm 2 to 10 mm 2, for complexity factor values ranging from 8 to 14. A relatively high defect density of 0.002 defects/mm 2 (1.3 defects/in 2) is assumed. It is clear that redundancy will be needed if even a few of the larger memories are placed together on a die as the die’s yield will be the product of the already low memory yields.To calculate the effect of redundancy on a memory’s yield, consider first the case when one spare element (row or column) is added to a memory. In this case the memory can be viewed as being divided into N equal parts of the size of the spare element. For example, if a spare row is added to a memory then N is equal to the number of rows. With the spare element, the memory has N +1 parts each with the same yield value, Y MEM/N , which can be calculated using equation (1) with an area value N times smaller than the full memory. The yield of the memory can be closely approximated by the probability of no more than one of the N+1 parts being bad. The memory yield with one spare element can therefore be calculated by:Memory core size (mm 0.80.850.90.95112345678910Y MEM2)Figure A1: Memory YieldY 1SP = (Y MEM/N )N+1 + (N+1) (Y MEM/N )N (1- Y MEM/N ) (2)As additional independent spare elements are added, the yield calculation becomes increasingly complex as all combinations of allowable bad part combinations must be taken into account. With 2 spare elements, the yield calculation grows to:Y 2SP = (Y MEM/N )N+2 + (N+2) (Y MEM/N )N+1 (1- Y MEM/N ) + ½ (N+2)(N+1) (Y MEM/N )N (1- Y MEM/N )2 (3)Figure A2 shows the improved yield values for both the single and double spare element cases for the same memory sizes and defect density used in figure A1. It is interesting to note that even at the relatively high defect density, a single spare element seems sufficient for all but the largest memories. It also appears from this data that it will be rare to need more than 2 spare elements within an individual memory.Determining the optimum number of spares to use within any given memory requires more than just analyzing the memory yield improvement. Redundancy of course increases the memory’sarea and thus the die’s area. The increase in area results in an increase in cost. Another way to view this is that the increase in the die’s area reduces the number of die that can be manufactured per wafer. The end goal is to maximize the number of good die per wafer DPW GOOD . DPW GOOD is the product of the die yield times the number of die that can be manufactured per wafer, or:Adding redundancy to a given memory will therefore increase the DPW GOOD value if the resulting percentage increase in the die yield, Y DIE (which is equal to the percentage increase in the given memory yield as yields are multiplied together) is greater than the resulting percentage increase in the die area A DIE . The ratio Y DIE / A DIE must increase to justify the added redundancy. For example, if one spare element is added to a memory, then the ratio Y 1SP / A 1SP must be greater than the ratio Y 0SP / A 0SP orDPW GOOD = Y DIE DPW =Y DIE A WAFER =A DIEA WAFER A DIEY DIEMemory core size (mm 0.800.820.840.860.880.900.920.940.960.981.0012345678910Y MEM2)Figure A2: Improved Yield from added redundancywhere:Y 1SP = die yield with one spare element added to the memory Y 0SP = die yield with no spare element added to the memory A 1SP = die area with one spare element added to the memory A 0SP = die area with no spare element added to the memoryThe graph in figure A3a displays the above ratio for the memory sizes and yield data used in figure A1. The ratio is greater than one for all memory sizes and therefore indicates that one spare element should be added in all cases. The graph also displays the ratiowhich measures whether a second spare element should be added. In this case, the values indicate that a second spare element should only be added for memory sizes 4 mm 2 or greater.Figure A3b shows the same two ratios for the same memory sizes but with the defect density decreased from 0.002 defects/mm 2 (1.3 defects/in 2) to 0.0002 defects/mm 2(0.13 defects/in 2). At this reduced defect density, two spare elements are never justified, and one spare element helps for only memory sizes 3 mm 2 or greater.Note that if the design starts off pad-limited then there is some unused silicon area in the core that can be used for redundancy without any cost. The above ratios are still useful in this case as they serve to rank the relative benefits of adding redundancy to the various memories.The above analysis also assumes that the die area can grow to an arbitrary size. This is often not the case as specific die sizes may only be available due to packaging and other issues. In this case adding redundancy may force a change to the next die size resulting in a more significant area increase.Y 0SP A 0SPY 1SP A 1SP> 111.11.212345678910Memory core size (mm2)0.990.99511.0051.011.0151.0212345678910Memory core size (mm 2)。
MENTOR ROUTING 命令简介

MENTOR ROUTING 命令简介1、打开Expedition PCB,进入做图界面在OPEN 调出所要的图(*.pcb文件)。
~ MENTOR的图面它的目录下会包含着很多文件我们只是打开PCB文件。
~2、打开图后我们会在工具栏快捷键按钮界面上看到几种模式::ROUTE模式:PLACE模式:画图模式下面主要介绍ROUTE模式下的快捷键按钮功能:1):ROUTE模式:点击ROUTE模式将出现上那排快捷键按钮,那些都是我们在ROUTE过程所需用到,:fanout :拉线:自动完成拉线:改变优化原有的拉线:绕线:可以从一根线中COPY出一段相同信号的线(可以做为平移一段线也可用于绕等长):可以从一根线中COPY出多段相同信号的线:自动布线:平滑走线::COPY线:三种不同的线锁定状态:固定:解固定:线弧度:change线宽MENTOR在做图时可以像ALLEGRO一样先点命令再点对象,也可以像POWERPCB一样先点中对象再点命令。
以下将详细介绍在做图过程所需要的命令和功能:a.快捷键按钮:我们可以在按钮处点击右键选择所需模式的按钮,(如下图)1-a-1我们也可以在工具栏命令View---Toolbars下选择所需的模式按钮。
b.MENTOR给我们提供了鼠标笔画命令,例如按住鼠标右键从下往上画正斜杆是放大图,面,相反从上往下画正斜杆是缩小。
我们可以画出一个问号,如:“”将出现具体的笔画规则1-b-1,里面有详细介绍各种命令的鼠标笔画。
(以下也会介绍一些常用的鼠标笔画命令)。
c.Display Control 也可以用笔画命令“L”画出,.Display Control可以设置一些在做图时所需修改的各类型的参数、颜色。
可以修改走线的颜色和走线的开关可以修改PADS的颜色和PADS的开关老鼠线开关格点开关设定自己做图时习惯用的风格后输入一个名字进行存盘,下回做图时只需调出这个文件就切换到自己所需的风格。
MENTOR软件讲稿

MENTOR软件讲稿Dxdesiger-Expedition Flow 版图设计1.准备⼯作1.1⼏个概念:1.1.1中⼼库、本地库:中⼼库(Central Library)即电路设计中常⽤到的所有器件库,为了让不同设计者、同⼀设计者的不同设计电路的设计规范统⼀,⼤家采⽤相同的中⼼库。
中⼼库包含相关联的器件、符号、封装、焊盘(焊盘堆叠)、焊盘(图形)、孔。
中⼼库可以有多个,但每个PCB设计只能与⼀个中⼼库关联。
本地库(Local Library)即每个设计专⽤的元器件库,每个原理图和PCB版图设计均有对应本地库。
PCB版图本地库仅包含设计中⽤到的器件、封装、焊盘、孔等。
本地库可以从其他库包含中⼼库中导⼊需要的器件、封装、焊盘等。
1.1.2器件、符号、封装、焊盘(焊盘堆叠)、焊盘(图形)、孔:器件Part:是器件数据库(Part Database)中联结原理图符号和封装单元的逻辑结构。
符号Symbol:具有某种功能的电⼦元件在原理图中的图⽰。
封装cell:组成物理元件的焊盘⼏何形状与分布。
封装由引出端焊盘、引出端号、元件外框、器件标识号及其他辅助信息(如丝印、装配框、特殊装配信息)。
焊盘(焊盘堆叠padstack):物理意义上的焊盘(未被绿油覆盖,覆有焊锡,可能有孔的铜布线区),由多个pad(可能含hole)叠加在⼀起构成。
焊盘(pad):可构成引出端焊盘、安装孔、过孔等的图形。
孔hole:钻头在板材上形成的机械孔或模具在板材上冲压出的机械孔,包含⾦属化和⾮⾦属化孔两种。
上述⼏个概念关系图⽰如下:1.1.3 PDB(Part Datadase):器件数据库,原理图设计中放置器件(device)将调⽤该数据库。
1.1.4 CDB(Common Datadase):共⽤数据库,最开始由原理图创建,记录该原理图中的连接、标号、元件号等信息,还可能包含各种组件属性和⽹络属性。
CDB作为原理图设计⼯具Dxdesigner和版图设计⼯具Expedition PCB之间的数据通信桥梁。
PI 样本

Tel: Fax:WebPROFORMA INVOICETO THE BUYER: PI NO. Date: Place:SHIPMENT QUANTITY AND AMOUNT 5% MORE OR LESS ALLOWED1.PAYMENT TERM: 100% T/T ADV ANCE2.LOADING PORT:TIANJIN XINGANG:3.TRANSSHIPMENT: ALLOWED.4.PARTIAL SHIPMENT: NOT ALLOWED.5.INSURANCE:TO BE COVERED BY THE BUYER6. SHIPPING MARK: AS PER BUYER’S REQUE ST.7.PACKING: 25KG PAPER BAG,,12.5MT IN 20FCL8.ORIGINBENEFICIARY:XXXXXXXOUR BANK:Tel: Fax:WebCOMPANY NAME: xxxxxxxxxBANK NAME: xxxxxxxxxxxxxxxxxxADDRESS: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxACCOUNT NO: xxxxxxxxxxxSWIFT CODE: xxxxxxxxxxxxxxFORCE MAJEURE:EITHER PARTY SHALL NOT BE HELD RESPONSIBLE FOR FAILURE OR DELAY TO PERFORM ALL OR ANY PART OF THIS AGREEMENT DUE TO FLOOD, FIRE, EARTHQUAKE, DRAUGHT, WAR OR ANY OTHER EVENTS WHICH COULD NOT BE PREDICTED, CONTROLLED, A VOIDED OR OVERCOME BY THE RELATIVE PARTY. HOWEVER, THE PARTY AFFECTED BY THE EVENT OF FORCE MAJEURE SHALL INFORM THE OTHER PARTY OF ITS OCCURRENCE IN WRITING AS SOON AS POSSIBLE AND THEREAFTER SEND A CERTIFICATE OF THE EVENT ISSUED BY THE RELEV ANT AUTHORITIES TO THE OTHER PARTY WITHIN 15 DAYS AFTER ITS OCCURRENCECLAIMS:WITHIN 7 DAYS AFTER THE ARRIV AL OF THE GOODS AT THE DESTINATION, SHOULD THE QUALITY OR QUANTITY BE FOUND NOT IN CONFORMITY WITH THE CONTRACT EXCEPT THOSE CLAIMS FOR WHICH THE INSURANCE COMPANY OR THE OWNERS OF THE VESSEL ARE LIABLE, THE BUYERS SHALL, HAS THE RIGHT ON THE STRENGTH OF THE INSPECTION CERTIFICATE ISSUED BY THE FORMAL INSPECTION ORGANIZATION AND THE RELATIVE DOCUMENTS TO CLAIM FOR COMPENSATION TO THE SELLERSARBITRATION:ALL DISPUTES IN CONNECTION WITH THE EXECUTION OF THIS CONTRACT SHALL BE SETTLED FRIENDL Y THROUGH NEGOTIATION. IN CASE NO SETTLEMENT CAN BE REACHED, THE CASE THEN MAY BE SUBMITTED FOR ARBITRA TION TO THE ARBITRA TION COMMISSION OF THE CHINA COUNCIL FOR THE PROMOTION OF INTERNA TIONAL TRADE HEBEI BRANCH IN ACCORDANCE WITH THE PROVISIONAL RULES OF PROCEDURE PROMULGATED BY THE SAID ARBITRATION COMMISSION. THE ARBITRATION COMMITTEE SHALL BE FINAL AND BINDING UPON BOTH PARTIES. AND THE ARBITRATION FEE SHALL BE BORNE BY THE LOSING PARTIES.THE BUYER SIGNATURE THE SELLE SIGNATURE。
mentor_intro
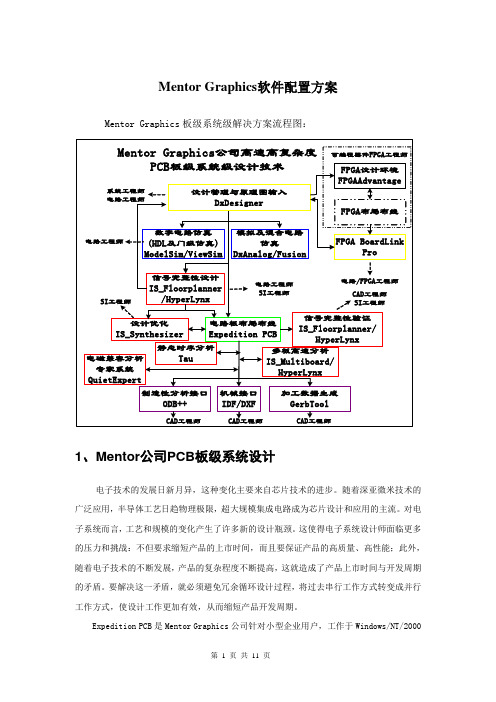
Mentor Graphics软件配置方案Mentor Graphics板级系统级解决方案流程图:1、Mentor公司PCB板级系统设计电子技术的发展日新月异,这种变化主要来自芯片技术的进步。
随着深亚微米技术的广泛应用,半导体工艺日趋物理极限,超大规模集成电路成为芯片设计和应用的主流。
对电子系统而言,工艺和规模的变化产生了许多新的设计瓶颈。
这使得电子系统设计师面临更多的压力和挑战:不但要求缩短产品的上市时间,而且要保证产品的高质量、高性能;此外,随着电子技术的不断发展,产品的复杂程度不断提高,这就造成了产品上市时间与开发周期的矛盾。
要解决这一矛盾,就必须避免冗余循环设计过程,将过去串行工作方式转变成并行工作方式,使设计工作更加有效,从而缩短产品开发周期。
Expedition PCB是Mentor Graphics公司针对小型企业用户,工作于Windows/NT/2000平台的EDA设计工具,其PCB设计功能强大,又非常易于使用。
它涵盖了从设计创建、版图布局到产品加工的设计过程,同时使设计者可以进行简单的高速电路分析,板级热分析、库开发与管理等。
充分满足了项目组的需求。
Expedition提供了优秀的无网格布线器及最新的先进技术,如扩展的设计复用工具、改进的微孔检查以及功能管理的参数化设计能力等,以增强设计的可制造性并大幅度缩短设计时间。
该系列工具中采用业界领先的AutoActive 布局布线技术,可将基于形状的自动布线与交互布线功能结合到单一、易用的设计环境之中。
可将一个复杂的交互和自动布线时间从几周缩短到几小时。
实践证明,AutoActive的特性可有效提高布通率、缩短布线时间、提高设计质量与可制造性。
Expedition统一的设计环境将FPGA设计与PCB设计完整地结合在一起,将FPGA设计结果自动生成PCB 设计中的原理图符号和几何封装,大大提高设计师的设计效率。
为达到平台选择的最大灵活性,Expedition可应用Windows98/NT/2000多种操作系统。
mentorkg参数

mentorkg参数
Mentorkg是一个基于知识图谱的智能问答系统,其参数主要包括以下几个方面:
1.知识图谱:Mentorkg使用知识图谱来构建问答系统,
因此需要一个高质量的知识图谱作为基础。
知识图谱中的实
体、关系和属性等都是Mentorkg参数的重要组成部分。
2.问答模型:Mentorkg使用深度学习技术构建问答模
型,该模型能够根据用户的问题生成相应的答案。
问答模型的参数包括模型架构、训练数据、优化器、学习率等。
3.自然语言处理技术:Mentorkg使用自然语言处理技术
对用户输入的问题进行语义理解和分析,从而生成相应的答
案。
自然语言处理技术的参数包括分词、词性标注、命名实体识别、依存句法分析等。
4.搜索技术:Mentorkg使用搜索技术来查找与用户问题
相关的知识图谱实体和属性,从而生成相应的答案。
搜索技术的参数包括搜索算法、搜索范围、搜索精度等。
5.推理技术:Mentorkg使用推理技术来对知识图谱中的
实体和属性进行推理,从而生成更加准确和全面的答案。
推理技术的参数包括推理规则、推理算法等。
总之,Mentorkg的参数主要包括知识图谱、问答模型、自然语言处理技术、搜索技术和推理技术等方面。
这些参数的选择和调整都会对Mentorkg的性能和效果产生影响。
mentor部分操作方法

线加粗方法:先选中要加粗的线,在Keyin 命令栏中输入CW (线加宽的数值)或者在菜单栏中点击按钮,在弹出的对话框中输入要加宽的数值。
布局选择布局模式点击图标进入布局模式:1、器件的调入a)快速调入所有器件,其方法是在Keyin 命令栏中输入:“pr –dist * ”b)器件单个调入1)在从菜单栏中点击Place—Place Parts and Cells或者点击图标进入如图界面。
2)选中Unplace选项3)在搜索栏中输入要调入的器件如C14)在下面的列表中选中期间点击按钮把器件添加到下面的列表中。
5)选中添加的器件点击Apply按钮应用。
2、器件的移动选中要移动的器件按F2,器件会随着鼠标移动,或者双击鼠标左键移动单个器件。
旋转器件时选中器件并按F33、原理图和pcb映射点击Setup‐‐‐Cross Probe—Setup弹出对话框,选中所有的选项,点击Apply应用。
然后进入Setup ‐‐‐ Design Entry 打开原理图,选择器件,pcb中对应的器件将会高亮并伴随鼠标移动。
4、器件对其齐(a) (b)1)选中要对其的器件,选择菜单栏中器件对齐命令,从左到右依次是左对齐、右对齐、上对齐、下对齐。
如图(a)所示。
2)选择右对齐命令,器件就会右对齐如图(b)所示。
其它的对齐方式一样,这里就不在叙述。
5、器件Group1)选择要添加成一组的器件2)点击Group图标,将器件变为一组3)取消Group 选择要取消的器件,点击UnGroup取消。
6、查看PIN数1)Output‐‐‐Design Statu 弹出文本框,查看pcb的PIN数2)或者点击菜单栏中的按钮弹出文本框,查看pcb的PIN数。
7、铺铜设置1)选择绘图模式2)在Properties Type 下拉列表中选择Plane Shape3)选择要铺铜的层数和铜的属性4)选择铺铜时的倒角方式5)选择铺铜的形状6)对需要铺铜区域进行铺铜。
Mentor PCB软件入门级操作教程

MENTOR软件操作教程目录一、Mentor设计界面和环境 (2)1、打开MEMTOR及界面介绍: (2)2、常用菜单介绍: (3)3、 Expedition PCB项目设置: (5)二、PCB的前处理。
(12)1、软件的打开 (12)2、导入DXF。
(12)3、点击菜单栏File---Import进入下面的菜单; (12)4、工程文件(原理图)、库文件、网表的导入。
(12)5、板框的制作和层数的定义。
(13)6、过孔的制作。
(15)7、定位孔的制作 (17)8、Mark点的制作。
(19)一、Mentor设计界面和环境1、打开MEMTOR及界面介绍:打开图标,进入下面的界面;单机操作时,选第一个操作,其余全不选,多人协作勾选选项,其余全不选。
点击OK进入软件。
2、常用菜单介绍:①File②Edit③View ●Undo---撤销上一步操作。
●Redo---重复上步操作。
●Copy Bitmap to Clipboard---将选中对象复制到剪切板。
或者用笔画命令●Select All---全选(Ctrl+A).●Add to Select Set---对选中的对象执行其子选项中的操作,如锁定等。
●Find---查找。
如查找器件、网络等。
●Review---检查设计状态、冲突、最小距离、焊盘等。
●Place---摆放如图中子选项中的对象。
●Fix/Semi Fix/Unfix---固定选中的对象/半固定选中的对象/解除固定。
●Lock/Unlock---锁定选中的对象/解除锁定。
●Highlight/Unhighlight/Unhighlight All---高亮选中的对象/解除选中对象的高亮/去除全部高亮。
●Delete/Delete all Traces and Vias---删除选定对象/删除所有连线和过孔。
④Setup⑤Place⑥Planes●Display Contral---显示控制。
PPAP主要提交资料样本格式

(设计FMEA)系统 FMEA编号:子系统页码:第页共页零组件:设计责任:编制者:车型年度/车辆类型:关键日期: FMEA日期:(编制):(修订):希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
(过程FMEA)FMEA编号:项目名称:过程责任部门:编制者:车型年度/车辆:关键日期: FMEA日期:(编制)(修订)核心小组:希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
控制计划希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
外观件批准报告(AAR)希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
零件提交的保证书(PSW)希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
希望是本无所谓有,无所谓无的。
这正如地上的路;其实地上本没有路,走的人多了,也便成了路。
生命赐给我们,我们必须奉献生命,才能获得生命。
附录A:零件提交保证书(PSW)的填写零件信息1.零件名称2.顾客零件编号:工程签发的最终零件名称和编号。
3.安全/法规项:若零件图上注明为安全/法规项,则选择“是”,否则为“否”。
4.工程图样更改等级和批准日期:说明更改的等级和提交日期。
5.附加的工程更改:列出所有在图样上没有纳入的,但已在该零件上体现的,并已批准的工程更改。
6.图纸编号:规定提交的顾客零件编号的设计记录。
7.采购订单代号:依据采购订单填入本代号。
8.零件重量:填入用千克表示的零件实际重量,精确到小数点后四位。
9.检查辅具代码:如果辅助工具用于尺寸检验,应填入其代号。
10.工程更改等级和批准日期。
供方制造厂信息11.供方名称和供方代码:填入在采购订单上指定的制造厂址代码。
12.供方制造厂地址:填入零件生产地的完整的地址。
提交信息13.提交类型:选择提交类型,并在相应的方框上划“√”。
mentor使用说明(中文)
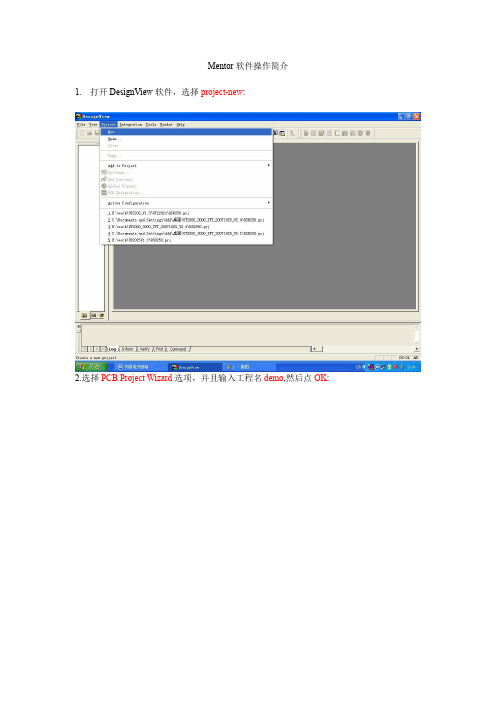
Mentor软件操作简介1.打开DesignView软件,选择project-new:2.选择PCB Project Wizard选项,并且输入工程名demo,然后点OK:然后点下一步:4.鼠标点击Add,添加已有的设计文件,然后点下一步:5. 用鼠标勾掉Use CES for constrain前面的√,然后点完成:6. 以上设置完成后,新工程就建好了,如下图所示:7. 接着要新建原理图,选择File->new,然后点击鼠标左键:8. 在弹出的菜单选择Schematic,然后点OK:9. 出现如下新建的原理图:10. 接着开始画原理图,先放元器件,将鼠标移动到下图所示的图标:11. 这时会弹出一个选择框,根据你设计的要求选择,如果你要布的是4层板就选4Layer Template,然后点OK:12. 如下图,将Partition下拉菜单改为[ALL]:13. 在Parts found表格中用鼠标左键选择需要的元件,同时会在右边显示该元件的symbol(符号)和cell(封装),比如选择Part Number为1206的元件,然后Place如下图:14. 在合适的地方点击鼠标左键来放置此元件:15. 然后出现如下的画面,表示如果再按一下鼠标左键会继续放置此元件,本例不需要,故按键盘上的Esc:16.按了Esc后又出现之前的画面,接着你可以继续放置需要的元件,操作过程与上同,不再赘述:17. 鼠标左键选择如下图中的四个图标可以对元件旋转:18. 若要放置一些没有CELL的特殊元件,如GND符号,可以用鼠标左键点击下图中的图标,弹出Symbol Menu窗口,在里面找到GND这个符号放到原理图上,如下图:19. 接着用同样的方法放置VCC符号,全部元件放好如下图所示:20. 元件放好后开始连线,用鼠标点击可以开始连线,在元件的一端点鼠标左键开始连线,在目标处再点鼠标左键结束本次连线,连好后如下图所示:21. 这样本次原理图就画完了,然后鼠标左键点如下图中的图标保存此原理图:22.弹出如下图的窗口,输入文件名保存:23. 输入完成后,如下图所示,鼠标单击保存(S):24. 鼠标单击Yes:25. 此时软件窗口如下图显示:26. 鼠标选中demo_schematic,右键选择Open in Pcb:27. 在弹出的窗口中选中,然后点:28. 在接下来的窗口中设置最初我们建立的demo.prj工程文件的路径,鼠标单击下图的按钮来设置:29.选中如下图所示的demo.prj文件,点打开(O):30. 在接下来弹出的窗口中直接选择:31. 在接下来弹出的窗口中直接选择:32. 在接下来弹出的窗口中直接选择:33. 接着将出现如下图所示的窗口,直接点OK:34.在接下来弹出的窗口中直接选择:这样才能将原理图里的元件放到PCB中来,所以这步是必须的:36. 上一步完了后,原先,现在变成了,表示原理图和PCB同步起来了:形),选中下图中图标(画图模式):38. 然后点击下图中(属性图标),弹出窗口:39. 在Type下拉菜单中选择:40.然后在PCB中用鼠标左键画出一个封闭的:41. 画完后,如下图所示:42. 接下来就可以放元件了,点击图标,如下图所示:43. 在弹出的窗口中勾选前面的,如下图所示:44. 选中位号为L1和U1的元件,如下图:45. 然后点击旁边的图标,就把刚选中的LI和U1元件导入到active框中了,接着点击按钮开始放置LI和U1元件,如下图:46. 然后出现下图的情景,我们在合适的位置单击鼠标左键就放好L1元件了,接着在其他地方再单击鼠标左键就放好U1元件了:47. 放好元件后如下图所示:48. 为了在PCB上看的比较直观,我们把一些用处不大的东西隐藏起来,单击鼠标右键,选择Display Control选项,如下图:49. 在弹出的窗口中选择Part选项,勾掉和和这三行上的√,如下图:50. 上面的设置以后,PCB上的元件就看起来比较直观了,如下图所示:51. 我们看到PCB上L1(其实就是元件L1的位号)字符有两个一模一样的,就删掉其中任意一个,然后在剩下的L1字符上双击鼠标左键,如下图:52. 在弹出的Properties窗口中设置和,表示将此位号L1的字高设为30mil,线宽设为5mil,如下图:53. 同理设置位号U1,完成后如下图:54. 接着点击图标,切换到布线模式,接下来开始布线了,如下图:55.点击图标,开始一次布线,如下图:56. 在L1元件的1脚(1:S)单击鼠标左键,开始拉线,如下图:57. 然后在元件U1的1脚(1:L)上单击鼠标左键,完成拉线,如下图:58. 完成以上操作后,如下图所示:59. 接下来开始敷铜,鼠标单击菜单,在弹出的子菜单中选择选项,如下图:60. 然后点击图标,如下图:61. 在弹出的Properties窗口中选择Layer 为1,Net为GND,如下图:62.然后使用鼠标左键在元件U1的周围画出一个封闭的敷铜外形,如下图:63. 完成后的敷铜外形如下图中的虚线框:64. 同理,画出Net为VCC的另一个敷铜外形,鼠标单击菜单,在弹出的子菜单中选择选项,如下图:65. 在弹出的Properties窗口中选择Layer 为1,Net为VCC,然后使用鼠标左键在元件L1的周围画出一个封闭的敷铜外形,如下图:66. 完成后的敷铜外形如下图中的虚线框:67. 两个敷铜外形都已画完,现在开始生成敷铜,鼠标单击菜单,在弹出的子菜单中选择选项,如下图:68. 在弹出的窗口中勾选和以及之前的√,如下图:69. 然后点击按钮,开始敷铜,如下图:70. 敷铜完成后弹出如下提示信息,点确定,如下图:71. 敷铜完成后如下图所示:72. 接下来生成丝印层,鼠标单击菜单,在弹出的子菜单中选择选项,如下图所示:73. 在弹出的菜单中按下图设置,然后点击OK按钮:74. 弹出生成成功的提示信息,如下图,点击确定:75. 接下来生成NC Drill文件(转孔文件),鼠标单击菜单,在弹出的子菜单中选择选项,如下图:76. 在弹出的窗口中选择的路径,点击图标,如下图:77. 我们选用公制格式的,所以在下图窗口中选择DrillMetric.dff文件,然后点击打开:78. 然后选择选项,如下图设置:79. 设置好后,点击OK按钮,弹出成功提示信息,点击确定,如下图:80. 生成转孔文件后如下图所示:。
mentor简单入门
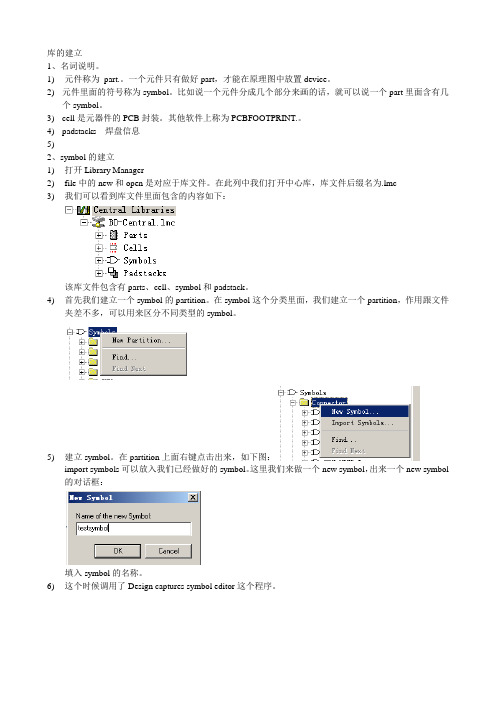
库的建立1、名词说明。
1) 元件称为part.。
一个元件只有做好part,才能在原理图中放置device。
2)元件里面的符号称为symbol。
比如说一个元件分成几个部分来画的话,就可以说一个part里面含有几个symbol。
3)cell是元器件的PCB封装。
其他软件上称为PCBFOOTPRINT.。
4)padstacks 焊盘信息5)2、symbol的建立1)打开Library Manager2)file中的new和open是对应于库文件。
在此列中我们打开中心库,库文件后缀名为.lmc3)我们可以看到库文件里面包含的内容如下:该库文件包含有parts、cell、symbol和padstack。
4)首先我们建立一个symbol的partition。
在symbol这个分类里面,我们建立一个partition,作用跟文件夹差不多,可以用来区分不同类型的symbol。
5)建立symbol。
在partition上面右键点击出来,如下图:import symbols可以放入我们已经做好的symbol。
这里我们来做一个new symbol,出来一个new symbol 的对话框:填入symbol的名称。
6)这个时候调用了Design captures symbol editor这个程序。
7)先用rectangle和line画出symbol的框和引脚的引线,如下图:引脚的引线最低得隔开2个格子,以备后面的pin name和pin number的显示8)由于line不具备电气特性,因此我们加pin的时候得把pin加在line的外侧,双击pin,输入pin Number和pin name。
9)调整pin name和pin number的位置,如下图10)增加文字U,其属性为ref designator11)我们建立这样的两个symbol12)建立一个part ,在part里面的一个partition上面右键点击new part13)出现part editor14)选中需要编辑的part,如testpart,点击右下角的pin mapping15)出现pin mapping 对话框16)因为这个part分成2个框图,我们需要加入2个symbol17)点击左上角的import symbol,选择相应的symbol,把两个include勾选框勾选上,输入框里面填入1,这个slot就是说这个part里面含有几个这样的symbol18)插入第二个symbol,这个时候要把create勾选框勾上,其他的设置同上。
13.欧盟GMP取样、留样

谢谢
2、留样原则 :
生产商、进口商、特殊情况下的产品 放行地点,都应保存每批成品对照样品 或留样。 原辅料生产企业应保存每批发货的对 照样品。 每个包装点应保留每批内包装材料和 印刷包装材料的对照样品。
对照样品或留样可作为批成品或 原辅料的记录论处,在遇到质量投 诉、对怀疑是否符合质量标准、质 疑贴签、包装、出现药品不良反应 或怀疑产品稳定性时,可供评估之 用。
一、原辅包装材 料的取样
1、概要
取样是一项重要操作,每次取 样只能是批的一小部分。 正确取样是质量保证体系的基 本要素。
2、人员培训:
取样人员应接受正确取样的培训,内容包括以下各个 方面 : - 取样计划, - 书面取样规程, - 取样技术和取样器具/设备, - 交叉污染的风险, - 不稳定和/或无菌原辅材料取样应采 取的保护措施, - 对物料、容器、标签等进行外观检查的重要性, - 对意外情况和异常情况作好记录的重要性。
对照样品 指一个批的起始原料、包装材料或成 品的样品,用于相关批有效期内可能需 要进行测试而保存的样品。如果稳定性 允许,可以从重要的中间体生产阶段抽 取对照样品,如包衣工艺的不同阶段的 片芯。
留样 从一批成品中抽取的完整包装的样品, 供各种鉴别对照用。如有效期内因故需 要时,可用于产品的演示,鉴别包装、 贴签、产品性状特征、供病人用的说明 书、批号、有效期等。
3、存贮时间
每批成品的对照样品和留样应至少 保留到有效期后一年。 对照样品的包装材料和上市成品的 包装材料应一致。
起始原料的样品(生产过程中使用 的溶剂,气体或水除外)一般应保留 至少产品放行的后两年,如果质量 标准中该物料的稳定时间较短,则 留样时间可以缩短。 包装材料的留样时间与成品相同。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ENVIROMENTAL MANAGEMENT
003
Certificate No. Q 05176
QUALITY MANAGEMENT
003
E171230
2
Mentor MP 直流驱动器特性
交流输入端子,配有可拆卸 的保护盖
驱动器工程标牌 驱动器铭牌
直流输出端子, 配有可拆卸的保 护盖
电枢电压反馈端 子,用于带直流 接触器和逆频器 公共直流母线系 统应用
7 个数字 I/O 5 个模拟 I/O 2 个固态继电器
BECKHOFF BK7200
REMOTE I/O
CTNet HEALTHY BUS ERR COMRUN 24V 0V INIT ERR I/O RUN I/O ERR
PE PE
集中式 PLC/运动控制
运动控制器
24V DC Class 2
MC206 Motion
简单的再生发电解 决方案
Mentor MP 可将机械能轻松地 再生转换为电能
4
可回收性
所有 Mentor MP 部件都可回收 4
6
艾默生电动机与驱动器解决方案
艾默生 CT Mentor MP 直流驱动器和 Leroy Somer 直流电 动机提供整体艾默生解决方案。这两家在质量与技术方面 均处于领先地位的公司可提供最佳电动机与驱动器组合方 案。高效直流电动机结合变速控制可成就完美匹配的能源 优化解决方案。
标准
MP-键盘 LCD,配置 MP 固件
标准 SM-键盘 LED
CTSoft CTScope
选项
?
输入/输出
智能卡
Data Storage
SM–I/O 32 SM–I/O Plus SM–I/O Lite SM–I/O Timer SM–I/O 120V SM–PELV
5
精通各种行业应用
我们精通众多行业,这使我们成为直流解决方案的理想合 作伙伴。 Mentor MP的典型应用领域包括: • 港机和起重机 • 测试台和测功机 • 电磁抓斗 • 电梯 • 轮胎和橡胶 • 冶金 • 线缆 • 造纸 • 海事 • 卷绕 • 挤出机 • 玻璃 • 物流 • 舞台设备 • 主轴驱动器 • 粉碎机 • 提供交流驱动系统公共直流母线
请从 下载完整版本的 CTSoft 和 CTScope 软件并试用
10
CTOPCServer
CTOPCServer 是一种符合 OPC 规定的服务器,可实现 PC 机与艾默生 CT 驱动器之间的通信。这种服务器支持以太 网、CTNet、RS485 和 USB 通信。OPC 是 SCADA 产品 上的标准接口,在 Microsoft® 产品中已得到充分支持。该 服务器软件免费供应,可从 下载。
用于磁场保护的熔断器 (可拆卸的保险丝盒)
励磁接线端子
3
选配键盘,可提供 高亮度 LED 或多语 种 LCD(显示普通 文本)
用于储存参 数、PLC 与运动 控制的智能卡
用于 PC 机编程 和设备连接的 Modbus 通信端口
端子保护盖
护手板
外部励磁控制器或并联驱 动器的通信端口
接地支架,用于电缆连接 及公共屏蔽
使用寿命更长
由于散热器冷却风扇全部采用速度控制,只在需要时运 行,因此驱动器实际上没有“易损件”,这有助于最长久 的使用寿命。
根据您的需要可定制其他功能
卡扣式选配模块可帮助您根据自己的需要定制驱动器提ห้องสมุดไป่ตู้ 18 种不同选项,包括 Fieldbus、以太网、I/O、反馈附件和 自动化控制器。
智能驱动
Mentor MP 可帮助驱动器系统设计人员将自动化与运动控 制嵌入驱动器,由此可提高通讯速度,同时 CTNet(一种高 性能点对点网络)可连接系统的不同部分。
简单升级
Mentor MP 可作为Mentor II 的简易替代产品。它们具有 相同的物理尺寸和连接布局。软件工具的设计使之可轻 松迁移到新的平台。
我们的主要目标是提高可靠性和性能。升级直 流驱动器系统可在不更换原电机的前提下实现 系统升级,快速处置将生产降到最低点。
Certificate No. EMS 54446
11
Mentor MP — 无与伦比的集成灵活性
控制模式
估计速度 反馈
测速机 反馈
编码器 反馈
励磁控制
选项
标准
操作界面 标准
Mentor MP 用于励磁模式 FXMP25 励磁控制器
电流高于 25A
电流最高可达 25A
驱动器编程和操作界面
选项
内置励磁控制器的 Mentor MP Size 1:8A Size 2:20A
高性能直流驱动器
25A 至 7400A 400V / 575V / 690V 单或 4 象限运行
Mentor MP 顶级直流驱动器
25A 至 7400A,400V/575V/690V
Mentor MP 是艾默生 CT 第五代直流驱动器产品,集成 了来自全球顶级智能交流驱动型 Unidrive SP 的控制平 台。这使 Mentor MP 成为目前最先进的直流驱动器, 具有最佳性能和灵活的系统连接功能。
Coordinator
P135
TRIO
PLC
CPU314C-2 DP
PC
12
标准 板载 PLC
选项
使用 PLC 或者运动功能的应用场合
SM–Applications Lite V2
• 首页可帮助新用户缩短学习周期,并为具有丰富经验的 用户提供功能强大的快捷方式
• 迁移向导可以系统化地引导新手/高级用户为现有的 Mentor II 应用项目完成 Mentor MP 的配置。现有参数集 合可从存储文件导入或者直接从现有驱动器读取。
CTScope 是一种功能全面的软件示波器,用于查看和分析 驱动器内部的变化数据。用户可设置基准时间实现高速捕 捉功能,以便进行调节或者显示更长期的趋势。用户界面 采用的是一种传统的示波器,因此对全世界的工程师而言 都非常熟悉且方便使用。
可靠的性能和创新的理念
Mentor MP 采用了久经考验的设计开发流程,非常注重创 新和可靠性。这一流程为艾默生 CT 在产品性能和质量方面 赢得了至高无上的市场领先地位。
8
Mentor MP 设置、配置和监控
Mentor MP 的设置快速而且简单。用户可使用可拆卸键盘、 智能卡或者提供的 PC 机调试软件(引导用户完成配置过程) 设置驱动器。CTSoft 具有迁移向导工具,可将原 MentorⅡ 设备直接升级到 Mentor MP。
更高功率直流电动机
Mentor MP 还可使用多种其他系列的直流电动机,因此我 们能够涵盖 Mentor MP 直流驱动器的整个功率范围。
Leroy Somer LSK 方形架直流电动机:
• 额定功率 4.7kW 至 517 kW • 机座号 112 至 280 • IP23S,防水滴 • S1 工作制 • PTC 热敏电阻 • IC06 强制通风冷却,配置标准聚酯过滤网 • H 级绝缘 • 3 相全控整流输入 • 右侧接线盒 • 顶部强制风机 • REO444 型测速发电机 • 增量式编码器和绝对编码器
艾默生 CT 正在申请一个专利以保护一项独特的 Mentor MP 设计。电源与控制之间的绝缘隔离是交流驱动器的 一个标准特性,一旦出现故障,它可避免控制电路和 连接的设备受到电源电路中的高电压的损害。Mentor MP 使用了一种创新技术,既可实现强弱电隔离功能, 又不会降低性能或者可靠性。
与真正了解并正在投资开发直流技术的供应 商合作使我们受益匪浅。
请从 下载完整版本的 CTOPCServer 并 试用
智能卡
简单的参数自整定
通过 CTSoft 或者键盘可执行参数自整定,帮助您测量电动 机和机器属性并自动优化控制参数,使设备达到最佳性能。
智能卡是每一套 Mentor MP 都配置的存储设备,它可用于备 份参数组和 PLC 程序,还可在驱动器之间复制这些数据。 • 参数和程序存储 • 简化了驱动器的维护和调试 • 可快速设置类似负载程序 • 机器升级程序可保存在智能卡中并发送给客户进行安装
• 所有电动机数据在输入时都采用实际单位,电流限幅窗 口可根据环境温度和要求过载额定值来计算参数设置。
CTScope
CTSoft
CTSoft 是一种用于调试、优化和监控艾默生 CT 驱动器的 驱动器配置工具。它可帮助您: • 使用配置向导调试驱动器 • 读取、保存和上传下载调试参数 • 管理驱动器的智能卡数据 • 使用在线动态图表显示并修改配置
全球服务
作为直流技术的市场领先者,我们理解您的需求。艾默生 CT 的 89 个下属驱动器产品中心和经销商遍布 65 个国家, 确保在全球范围为客户提供最方便的服务、支持和专业技 术。
环保
重新利用原有的直
流电动机
无需配置新电动机
4
高效解决方案
直流驱动器和电动机可达到与
许多交流解决方案同样高的效 4
率
符合 RoHS 规定 Mentor MP 采用无铅工艺制造 4
4
3 个通用选配模块插槽可用 于通信、I/O、反馈附件和 自动化/运动控制器
I/O、继电器、测速机反 馈、编码器的可插拔端子, 电枢电流反馈端子
直流技术领导者
过去的 35 年来,艾默生 CT 在许多如今已广泛应用的直流 驱动器技术方面处于绝对领先地位。其中包括首款数字直流 驱动器和首款配置板载可编程自动控制器的直流驱动器。
用户界面选项
Mentor MP 可借助各种键盘选项满足您的应用需求。
订单代码 SM–键盘
MP-键盘
详细信息
可热插拔的高亮度 LED 显示屏。
多语种、可热插拔的背光 LCD 显示 屏。该显示屏可自定义,以根据具 体应用设置文本。