Linux oracle命令大全
实用linux命令大全(详细)

linux命令(重新整理)Linux基本操作命令首先介绍一个名词“控制台(console)”,它就是我们通常见到的使用字符操作界面的人机接口,例如dos。
我们说控制台命令,就是指通过字符界面输入的可以操作系统的命令,例如dos命令就是控制台命令。
我们现在要了解的是基于Linux操作系统的基本控制台命令。
有一点一定要注意,和dos命令不同的是,Linux的命令(也包括文件名等等)对大小写是敏感的,也就是说,如果你输入的命令大小写不对的话,系统是不会做出你期望的响应的。
模式切换1、由字符到图型#startx或#init 52、由图形到字符#logout或init 33、注销#logout或exit或ctrl+d4、关机#poweroff或init 0或shutdown now或halt -p5、重启#reboot或init 6或shutdown -r now获得帮助#help提供内部命令的帮助#man或info提供外部命令的帮助。
如果你的英文足够好,那完全可以不靠任何人就精通linux,只要你会用man。
Man实际上就是察看指令用法的help,学习任何一种UNIX类的操作系统最重要的就是学会使用man这个辅助命令。
man是manual(手册)的缩写字,它的说明非常的详细,但是因为它都是英文,看起来非常的头痛。
建议大家需要的时候再去看man,平常吗,记得一些基本用法就可以了。
ls这个命令就相当于dos下的dir命令一样,这也是Linux控制台命令中最为重要几个命令之一。
ls最常用的参数有三个:-a -l -F。
ls -aLinux上的文件以“.”开头的文件被系统视为隐藏文件,仅用ls命令是看不到他们的,而用ls -a除了显示一般文件名外,连隐藏文件也会显示出来。
ls -l(这个参数是字母L的小写,不是数字1)这个命令可以使用长格式显示文件内容,如果需要察看更详细的文件资料,就要用到ls -l这个指令。
oracle查询实例命令

oracle查询实例命令以下是一些Oracle数据库中常用的查询实例命令示例:1.查询表的所有数据:SELECT * FROM table_name;2.查询指定列的数据:SELECT column1, column2, ... FROM table_name;3.查询满足特定条件的数据:SELECT * FROM table_name WHERE condition;4.对结果进行排序:SELECT * FROM table_name ORDER BY column_name [ASC|DESC];5.使用聚合函数进行数据统计:SELECT COUNT(*) FROM table_name; -- 统计行数SELECT SUM(column_name) FROM table_name; -- 求和SELECT AVG(column_name) FROM table_name; -- 平均值SELECT MAX(column_name) FROM table_name; -- 最大值SELECT MIN(column_name) FROM table_name; -- 最小值6.连接多个表进行查询:SELECT t1.column1, t2.column2 FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id;7.使用条件进行分组:SELECT column1, COUNT(*) FROM table_name GROUP BY column1;8.使用LIKE进行模糊查询:SELECT * FROM table_name WHERE column_name LIKE 'keyword%';以上只是一些常见的查询示例,实际查询命令会根据具体的表结构和查询需求而有所不同。
在使用Oracle数据库时,请根据具体情况和需求构建和调整查询语句。
oracle数据库语句汇总

oracle数据库语句汇总在Oracle数据库中,有许多常用的SQL语句可以用于查询、插入、更新和删除数据。
下面列举了一些常见的Oracle数据库语句,以供参考。
1. 查询表中的所有数据:```SELECT * FROM 表名;```2. 查询表中的特定字段数据:```SELECT 字段1, 字段2, ... FROM 表名;```3. 查询表中满足特定条件的数据:```SELECT * FROM 表名 WHERE 条件;```4. 对查询结果进行排序:```SELECT * FROM 表名 ORDER BY 字段 ASC/DESC;```5. 对查询结果进行分组:```SELECT 字段1, 字段2, ... FROM 表名 GROUP BY 字段;```6. 对查询结果进行统计:```SELECT COUNT(*) FROM 表名;```7. 插入数据到表中:```INSERT INTO 表名(字段1, 字段2, ...) VALUES (值1, 值2, ...);```8. 更新表中的数据:```UPDATE 表名 SET 字段1 = 值1, 字段2 = 值2 WHERE 条件;9. 删除表中的数据:```DELETE FROM 表名 WHERE 条件;```10. 创建新表:```CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型,...);```11. 修改表结构:```ALTER TABLE 表名 ADD (字段数据类型); ```12. 删除表:DROP TABLE 表名;```13. 创建索引:```CREATE INDEX 索引名 ON 表名 (字段);```14. 删除索引:```DROP INDEX 索引名;```15. 创建视图:```CREATE VIEW 视图名 AS SELECT * FROM 表名 WHERE 条件; ```16. 删除视图:```DROP VIEW 视图名;17. 创建存储过程:```CREATE PROCEDURE 存储过程名ISBEGIN-- 存储过程的具体逻辑END;```18. 调用存储过程:```EXEC 存储过程名;```以上是一些常见的Oracle数据库语句,可以满足大部分基本的数据操作需求。
Oracle常用命令大全(很有用,做笔记)

Oracle常⽤命令⼤全(很有⽤,做笔记)⼀、ORACLE的启动和关闭1、在单机环境下要想启动或关闭ORACLE系统必须⾸先切换到ORACLE⽤户,如下su - oraclea、启动ORACLE系统oracle>svrmgrlSVRMGR>connect internalSVRMGR>startupSVRMGR>quitb、关闭ORACLE系统oracle>svrmgrlSVRMGR>connect internalSVRMGR>shutdownSVRMGR>quit启动oracle9i数据库命令:$ sqlplus /nologSQL*Plus: Release 9.2.0.1.0 - Production on Fri Oct 31 13:53:53 2003Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.SQL> connect / as sysdbaConnected to an idle instance.SQL> startup^CSQL> startupORACLE instance started.2、在双机环境下要想启动或关闭ORACLE系统必须⾸先切换到root⽤户,如下su - roota、启动ORACLE系统hareg -y oracleb、关闭ORACLE系统hareg -n oracleOracle数据库有哪⼏种启动⽅式说明:有以下⼏种启动⽅式:1、startup nomount⾮安装启动,这种⽅式启动下可执⾏:重建控制⽂件、重建数据库读取init.ora⽂件,启动instance,即启动SGA和后台进程,这种启动只需要init.ora⽂件。
2、startup mount dbname安装启动,这种⽅式启动下可执⾏:数据库⽇志归档、数据库介质恢复、使数据⽂件联机或脱机,重新定位数据⽂件、重做⽇志⽂件。
Linux下安装oracle12C数据库,附带问题解决方法
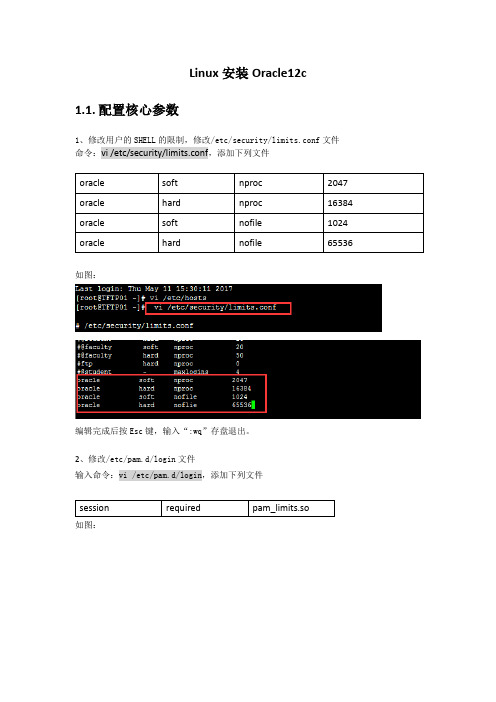
Linux安装Oracle12c1.1.配置核心参数1、修改用户的SHELL的限制,修改/etc/security/limits.conf文件命令:vi/etc/security/limits.conf,添加下列文件如图:编辑完成后按Esc键,输入“:wq”存盘退出。
2、修改/etc/pam.d/login文件输入命令:vi/etc/pam.d/login,添加下列文件如图:编辑完成后按Esc键,输入“:wq”存盘退出。
3、通过修改/etc/sysctl.conf文件,修改linux内核命令:vi /etc/sysctl.conf,添加下列内容如图:编辑完成后按Esc键,输入“:wq”存盘退出。
将更改的内容生效激活:sysctl-p,显示结果如下图4、编辑文件/etc/profile,命令:vi /etc/profile,添加下列内容编辑完成后按Esc键,输入“:wq”存盘退出。
5、创建相关用户和组,作为软件安装和支持组的拥有者。
(1)、创建用户组,命令如下:groupadd oinstallgroupadd dbagroupadd oper如图:(2)创建Oracle用户和密码,命令如下:useradd -g oinstall -G dba,oper -m oraclepasswd oracle然后会让你输入密码,密码任意输入2次,但必须保持一致,回车确认。
如图:6、创建数据库软件目录和数据文件存放目录,目录的位置,根据自己的情况来定,注意磁盘空间即可,示例命令如下:mkdir /datamkdir /data/oraclemkdir /data/oracle/appmkdir /data/oracle/app/oraclemkdir /data/oracle/app/oradatamkdir /data/oracle/app/oracle/productmkdir /data/oracle/app/oracle/oralnventory7、更改目录属主为Oracle用户所有,输入命令:chown -R oracle:oinstall /data/oracle/app8、配置oracle用户的环境变量(1)切换oracle用户命令:su– oracle编辑文件.bash_profile,命令:vi .bash_profile添加内容如下:编辑完成后按Esc键,输入“:wq”存盘退出。
Linux_oracle数据库的备份与恢复

Linux_oracle数据库的备份与恢复1 数据库备份和恢复(备份和恢复均已做成脚本自动运行,下列操作供参考,请不要在生产机上做测试) 1)数据库备份:◆将dbexp.parm,dbexp.sh 拷贝至/home/oracle/backup/.以oracle用户登录系统$ cd /home/oracle/backup$ dos2unix *$ chmod 755 dbexp.sh◆手工执行备份,用oracle用户登录:$ cd /home/oracle/backup$ ./dbexp.sh◆自动执行备份,用root用户登录:#crontab -e 00 01 * * * su - oracle -c "/home/oracle/backup/dbexp.sh"2)数据库恢复:以oracle用户登录系统◆删除用户:sqlplus /nolog>connect / as sysdba;>drop user center cascade;>create user center identified by center;>grant connect,resource,dba to center◆恢复数据库$imp center/center full=y grants=y INDEXES=y constraints=y LOG=/tmp/backup.log rows=y ignore=y file=xxx(xxx--为以前备份的数据文件,如checkid_20041123.dat)oracle数据库的备份与恢复原理及方法:导出(备份)exp 用户名/密码@服务名file=d:daochu.dmp (rows=no(导出空结构)) 导入(恢复)imp 用户名/密码@服务名file=d:daochu.dmp fromuser=原用户名touser=新用户名---- 当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(包括机器故障、介质故障、误操作等),数据库有时也可能遭到破坏,这时如何尽快恢复数据就成为当务之急。
ORACLECMD命令(最全的)

启动Orac le,在c md模式下依次启动:netstart orac leser vice服务名l snrct l sta rt 启动监听程序关闭服务为:ls nrctl stopnetstoporacl eserv iceDa ta1. Or acle安装完成后的初始口令?inte rnal/oracl esys/chan ge_on_inst alls ystem/mana gers cott/tigersysm an/oe m_tem p2. ORAC LE9IA S WEB CACH E的初始默认用户和密码?ad minis trato r/adm inist rator3.oracl e 8.0.5怎么创建数据库?用ora inst。
如果有mo tif界面,可以用o rains t /m4. o racle 8.1.7怎么创建数据库?dbass ist5. or acle9i 怎么创建数据库?dbc a6. orac le中的裸设备指的是什么?裸设备就是绕过文件系统直接访问的储存空间7. o racle如何区分64-bi t/32b it 版本$ sqlp lus '/ ASSYSDB A'S QL*Pl us: R eleas e 9.0.1.0.0 - P roduc tionon Mo n Jul 14 17:01:09 2003 (c) Co pyrig ht 2001 Or acleCorpo ratio n. Al l rig hts r eserv ed. Conne ctedto: Oracl e9i E nterp riseEditi on Re lease 9.0.1.0.0 - Pr oduct ion Withthe P artit ionin g opt ion JServ er Re lease 9.0.1.0.0 - Pr oduct ion SQL>selec t * f rom v$vers ion;BANN ER---------------------------------------------------------------- Oracl e9i E nterp riseEditi on Re lease 9.0.1.0.0 - Pr oduct ion PL/SQ L Rel ease9.0.1.0.0- Pro ducti onC ORE 9.0.1.0.0 P roduc tionTNSfor S olari s: Ve rsion 9.0.1.0.0 - Pr oduct ion NLSRT L Ver sion9.0.1.0.0- Pro ducti onS QL>8. SV RMGR什么意思?svrmg rl,Se rverManag er. 9i下没有,已经改为用SQLP LUS了sqlp lus /nolog变为归档日志型的9.请问如何分辨某个用户是从哪台机器登陆OR ACLE的?SEL ECT m achin e , t ermin al FR OM V$SESSI ON;10. 用什么语句查询字段呢?desc tabl e_nam e 可以查询表的结构sel ect f ield_name,... f rom ... 可以查询字段的值sel ect * from all_table s whe re ta ble_n ame l ike '%'s elect * fr om al l_tab_colu mns w heretable_name='??'11.怎样得到触发器、过程、函数的创建脚本?desc user_sour ceus er_tr igger s12. 怎样计算一个表占用的空间的大小?selec t own er,ta ble_n ame,NUM_ROWS,BLO CKS*A AA/1024/1024 "S ize M",E MPTY_BLOCK S,L AST_A NALYZ EDf rom d ba_ta bleswher e tab le_na me='X XX';Her e: AA A isthe v alueof db_bloc k_siz e ; XXX i s the tabl e nam e you want to c heck13.如何查看最大会话数?SELE CT *FROMV$PAR AMETE R WHE RE NA ME LI KE 'p roc%'; SQL>SQ L> sh ow pa ramet er pr ocess esNAMETYPEVALUE------------------------------------ ------- ------------------------------a q_tm_proce ssesinteg er 1db_w riter_proc esses inte ger 1job_queu e_pro cesse s int eger4lo g_arc hive_max_p roces ses i ntege r 1 proce ssesinteg er 200这里为200个用户。
linux oracle expdp语句

linux oracle expdp语句Linux Oracle expdp语句是用于导出Oracle数据库中的数据的命令。
expdp即“export data pump”,是Oracle数据库提供的一个快速且高效的备份工具。
通过expdp命令,我们可以将数据库的数据导出为可用于备份、迁移或还原的文件。
本文将一步一步回答关于Linux Oracle expdp语句的相关问题。
第一步:了解expdp语句的基本语法和选项expdp命令的基本语法如下:expdp username/password@connection_stringDIRECTORY=directory_name DUMPFILE=dump_file_name其中,username是数据库用户的用户名,password是用户的密码,connection_string表示数据库的连接字符串,directory_name指定导出文件的目录,dump_file_name是导出文件的名称。
expdp命令还可以使用多个选项来指定导出的内容和行为。
常用的选项包括:- TABLES:指定要导出的表。
- SCHEMAS:指定要导出的模式。
- INCLUDE/EXCLUDE:指定要导出的对象类型或特定对象。
- CONTENT:指定导出的类型,如只导出数据、导出数据和元数据等。
- LOGFILE:指定导出操作的日志文件。
第二步:使用expdp导出整个数据库或指定的表1. 导出整个数据库:expdp username/password@connection_stringDIRECTORY=directory_name DUMPFILE=database_dump_file2. 导出指定的表:expdp username/password@connection_stringDIRECTORY=directory_name DUMPFILE=table_dump_file TABLES=table_name第三步:导出过程中的高级选项1. 并行导出:增加导出速度的一个方法是使用并行处理。
Linux服务器下oracle数据库启动服务操作步骤

Linux服务器下oracle数据库启动服务操作步骤⼀、在Linux下启动Oracle1.登录到Linux服务器,切换到oracle⽤户权限(命令是:# su –l oracle)2.进⼊sqlplus界⾯(命令是:$ sqlplus /nolog 或 sqlplus / as sysdba)原本的画⾯会变为SQL>接着请输⼊SQL>conn / as sysdba ;输⼊SQL> startup (作⽤:启动数据库实例)另外停⽌数据库的指令如下:SQL> shutdown immediate1 [oracle@localhost ~]$ sqlplus / as sysdba --进⼊sqlplus界⾯23 SQL*Plus: Release 11.2.0.1.0 Production on Thu Mar 1710:48:08202245 Copyright (c) 1982, 2009, Oracle. All rights reserved.67 Connected to an idle instance.89 SQL> quit10 Disconnected11 [oracle@localhost ~]$ sqlplus /nolog --进⼊sqlplus界⾯1213 SQL*Plus: Release 11.2.0.1.0 Production on Thu Mar 1710:48:4220221415 Copyright (c) 1982, 2009, Oracle. All rights reserved.1617 SQL> conn / as sysdba --sysdba登录18 Connected to an idle instance.19 SQL> startup --启动数据库实例20 ORACLE instance started.2122 Total System Global Area 1068937216 bytes23 Fixed Size 2220200 bytes24 Variable Size 281022296 bytes25 Database Buffers 780140544 bytes26 Redo Buffers 5554176 bytes27 Database mounted.28 Database opened.29 SQL> shutdown immediate --关闭数据库实例3031 Database closed.32 Database dismounted.333435 ORACLE instance shut down.36 SQL>quit --退出⼆、检查Oracle 数据库是否启动回到终端机模式,输⼊:ps -ef|grep ora_ (作⽤是:查看是否有Oracle的进程,如果有,⼤多数情况说明启动了。
SUSELINUX配置ORACLE命令

suse linu x 命令收藏1.修改vf tpd配置文件vi /e tc/vs ftpd.conf #l isten=YESvi/etc/xinet d.d/v sftpd将“disa ble=y es” 改为“di sable=no”使xinet d服务启动后接收到f tp连接请求时,能够自动启动v sftpd服务进程2. m kdir-p /srv/ftp/l inux-10 创建文件夹 -p 如果文件夹不存在自动创建3. cho wn -R ftp:ftp /srv/f tp/li nux-10 指定linux-10目录及其子目录的拥有者为ftp 用户和ftp组4. ch mod -R 755 /srv/ftp/linux-10 指定linu x-10目录及其子目录的访问权限5. moun t /de v/hdc /srv/ftp/linux-10/d isk1将设备中的内容挂载到dis k1中um ount/srv/ftp/l inux-10/di sk1 卸载掉dis k1中挂载的文件6. /e tc/in it.d/xinet d sta rt 启动FTP服务7. df命令功能:检查文件系统的磁盘空间占用情况。
可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:df [选项]说明:df命令可显示所有文件系统对i节点和磁盘块的使用情况。
该命令各个选项的含义如下: -a 显示所有文件系统的磁盘使用情况,包括0块(block)的文件系统,如/p roc 文件系统。
oracle数据库命令大全

更改用户密码
sql>alter user 管理员 identified by 密码;
创建表空间的数据文件
sql>create tablespace test datafile 'd:\oracle\binbo.dbf' size 10m;
创建用户
sql>create user 用户名 identified by 密码;
操作表结构数据库定义语言命令
(不记录在日志文件中)
create table建表
sql>create table test(name varchar2(20),age date,sex char(2));
sql>insert into test(name,age,sex) values('aa',sysdate,'男');
删除隐藏的列 SQL>alter table studen drop unused columns;
向表中加入约束 SQL>alter table studen add constraint pk primary key(stuno);
删除约束 SQL>alter table studen drop constraint pk;
打开监听器
lsnrctl start
关闭服务器
net stop OracleServiceORCL
关闭监听器 ຫໍສະໝຸດ lsnrctl stop 清屏
clear screen
数据字典 ===========desc user_views(关键词)
查看当前用户的角色
SQL>select * from user_role_privs;
oracle常用命令

--关闭数据库Oracle自动搜集功能alter system set "_optimizer_autostats_job"=false scope=spfile--修改表的默认表空间alter table 表名 move tablespace 表空间名;--修改索引表空间ALTER INDEX 索引名 REBUILD tablespace 表空间名;--修改LOB类型默认表空间ALTER TABLE SIGNATUREWORD MOVE LOB(IMAGE) STORE AS (TABLESPACE CZDJ);--创建数据表空间(表空间名称CZDJ,表空间文件大小1024M,数据文件满后自动扩展增量100MB,文件大小无限制)create tablespace CZDJ(表空间名)datafile 'd:\oracle\product\10.2.0\oradata\orcl\ CZDJ.dbf'(存放路径)size 1024m AUTOEXTEND ONNEXT 100m maxsize unlimited;--创建临时表空间create temporary tablespace dzdj31cz_temp (表空间名)tempfile 'd:\oracle\product\10.2.0\oradata\orcl\dzdj31cz_temp01.dbf'size 32Mautoextend onnext 32M maxsize 2048Mextent management local;本地管理表空间:extent management local字典管理表空间:extent management dictionary--修改表空间alter database datafile 'D:\oracle\product\10.2.0\oradata\orclzhaowei\test.dbf' resize 10m; alter database datafile 'D:\oracle\product\10.2.0\oradata\orclzhaowei\test.dbf' autoextend on next 50m maxsize unlimited;--创建用户并指定表空间create user 用户名 identified by 密码default tablespace 默认表空间temporary tablespace 临时表空间;--修改用户密码alter user 用户名 identified by 密码;--给表空间增加数据文件ALTER TABLESPACE sdeADD DATAFILE 'D:\oracle\product\10.2.0\oradata\orcl\sde01.dbf' size 20480M autoextend on next 50M maxsize unlimited;--给用户授予权限grant connect,dba,resource to 用户名--给用户解锁alter user username account unlock;--OraOLEDB.Oracle.1没有注册解决方法:regsvr32 D:\oracle\product\10.2.0\db_1\BIN\OraOLEDB10.dll--查询表空间状态select tablespace_name,status from dba_tablespaces;--表空间离线在线:离线的表空间无法访问,用于数据维护。
Linux_oracle命令大全

Linux_oracle命令大全一,启动1.#su - oracle 切换到oracle用户且切换到它的环境2.$lsnrctl status 查看监听及数据库状态3.$lsnrctl start 启动监听4.$sqlplus / as sysdba 以DBA身份进入sqlplus5.SQL>startup 启动db二,停止1.#su - oracle 切换到oracle用户且切换到它的环境2.$lsnrctl stop 停止监听3.$sqlplus / as sysdba 以DBA身份进入sqlplus4.SQL>SHUTDOWN IMMEDIATE 关闭db其中startup和shutdowm还有其他一些可选参数,有兴趣可以另行查阅三,查看初始化参数及修改1.#su - oracle 切换到oracle用户且切换到它的环境2.$sqlplus / as sysdba 以DBA身份进入sqlplus3.SQL>show parameter session; 查看所接受的session数量###################################################### Oracle process与session2008年12月29日星期一15:47Connected to Oracle Database 10g Release 10.1.0.5.0Connected as ifsappSQL> show parameter sessionNAME TYPE V ALUE------------------------------------ ----------- ------------------------------java_max_sessionspace_size integer 0java_soft_sessionspace_limit integer 0license_max_sessions integer 0license_sessions_warning integer 0logmnr_max_persistent_sessions integer 1session_cached_cursors integer 0session_max_open_files integer 10sessions integer 225shared_server_sessions integerSQL> show parameters processes;NAME TYPE V ALUE------------------------------------ ----------- ------------------------------aq_tm_processes integer 0db_writer_processes integer 1gcs_server_processes integer 0job_queue_processes integer 3log_archive_max_processes integer 2processes integer 200SQL> alter system set processes=600 scope=both;SQL>SQL> alter system set processes=600 scope=both;alter system set processes=600 scope=bothORA-02095: specified initialization parameter cannot be modified SQL> alter system set sessions=600 scope=both;alter system set sessions=600 scope=bothORA-02095: specified initialization parameter cannot be modified SQL>SQL> alter system set processes=600 scope=spfile;System alteredSQL> show parameters processes;NAME TYPE V ALUE ------------------------------------ ----------- ------------------------------ aq_tm_processes integer 0db_writer_processes integer 1gcs_server_processes integer 0job_queue_processes integer 3log_archive_max_processes integer 2processes integer 200SQL> alter system set processes=600 scope=memory;alter system set processes=600 scope=memoryORA-02095: specified initialization parameter cannot be modified重启数据库之后生效:SQL> show parameters processes;NAME TYPE V ALUE ------------------------------------ ----------- ------------------------------ aq_tm_processes integer 0db_writer_processes integer 1gcs_server_processes integer 0job_queue_processes integer 3log_archive_max_processes integer 2processes integer 600SQL> show parameter sessionNAME TYPE V ALUE------------------------------------ ----------- ------------------------------java_max_sessionspace_size integer 0java_soft_sessionspace_limit integer 0license_max_sessions integer 0license_sessions_warning integer 0logmnr_max_persistent_sessions integer 1session_cached_cursors integer 0session_max_open_files integer 10sessions integer 665shared_server_sessions integer修改Oracle process 和session 的方法先备份spfile1.通过SQLPlus修改Oracle的sessions和processes的关系是sessions=1.1*processes + 5使用sys,以sysdba权限登录:SQL> show parameter processes;NAME TYPE V ALUE------------------------------------ ----------- --------------------------------------- aq_tm_processes integer 1db_writer_processes integer 1job_queue_processes integer 10log_archive_max_processes integer 1processes integer 150SQL> alter system set processes=400 scope = spfile;系统已更改。
ORACLECMD命令(最全的)

ORACLECMD命令(最全的)启动Oracle,在cmd模式下依次启动:net start oracleservice服务名lsnrctl start 启动监听程序关闭服务为:lsnrctl stopnet stop oracleserviceData1. Oracle安装完成后的初始口令?internal/oraclesys/change_on_installsystem/managerscott/tigersysman/oem_temp2. ORACLE9IAS WEB CACHE的初始默认用户和密码?administrator/administrator3. oracle 8.0.5怎么创建数据库?用orainst。
如果有motif界面,可以用orainst /m4. oracle 8.1.7怎么创建数据库?dbassist5. oracle 9i 怎么创建数据库?dbca6. oracle中的裸设备指的是什么?裸设备就是绕过文件系统直接访问的储存空间7. oracle如何区分 64-bit/32bit 版本$ sqlplus '/ AS SYSDBA'SQL*Plus: Release 9.0.1.0.0 - Production on Mon Jul 14 17:01:09 2003(c) Copyright 2001 Oracle Corporation. All rights reserved.Connected to:Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionWith the Partitioning optionJServer Release 9.0.1.0.0 - ProductionSQL> select * from v$version;BANNER---------------------------------------------------------------- Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionPL/SQL Release 9.0.1.0.0 - ProductionCORE 9.0.1.0.0 ProductionTNS for Solaris: Version 9.0.1.0.0 - ProductionNLSRTL Version 9.0.1.0.0 - ProductionSQL>8. SVRMGR什么意思?svrmgrl,Server Manager.9i下没有,已经改为用SQLPLUS了sqlplus /nolog变为归档日志型的9. 请问如何分辨某个用户是从哪台机器登陆ORACLE的?SELECT machine , terminal FROM V$SESSION;10. 用什么语句查询字段呢?desc table_name 可以查询表的结构select field_name,... from ... 可以查询字段的值select * from all_tables where table_name like '%'select * from all_tab_columns where table_name='??'11. 怎样得到触发器、过程、函数的创建脚本?desc user_sourceuser_triggers12. 怎样计算一个表占用的空间的大小?select owner,table_name,NUM_ROWS,BLOCKS*AAA/1024/1024 "Size M",EMPTY_BLOCKS,LAST_ANALYZEDfrom dba_tableswhere table_name='XXX';Here: AAA is the value of db_block_size ;XXX is the table name you want to check13. 如何查看最大会话数?SELECT * FROM V$PARAMETER WHERE NAME LIKE 'proc%';SQL>SQL> show parameter processesNAME TYPE VALUE------------------------------------ ------- ------------------------------aq_tm_processes integer 1db_writer_processes integer 1job_queue_processes integer 4log_archive_max_processes integer 1processes integer 200这里为200个用户。
(完整版)ORACLE命令大全

ORACLE命令大全1. 执行一个SQL脚本文件SQL>start file_nameSQL>@ file_name我们可以将多条sql语句保存在一个文本文件中,这样当要执行这个文件中的所有的sql语句时,上面的任一命令即可,这类似于dos中的批处理。
2. 对当前的输入进行编辑SQL>edit3. 重新运行上一次运行的sql语句SQL>/4. 将显示的内容输出到指定文件SQL> SPOOL file_name在屏幕上的所有内容都包含在该文件中,包括你输入的sql语句。
5. 关闭spool输出SQL> SPOOL OFF只有关闭spool输出,才会在输出文件中看到输出的内容。
6.显示一个表的结构SQL> desc table_name7. COL命令:主要格式化列的显示形式。
该命令有许多选项,具体如下:COL[UMN] [{ column|expr} [ option ...]]Option选项可以是如下的子句:ALI[AS] aliasCLE[AR]FOLD_A[FTER]FOLD_B[EFORE]FOR[MAT] formatHEA[DING] textJUS[TIFY] {L[EFT]|C[ENTER]|C[ENTRE]|R[IGHT]}LIKE { expr|alias}NEWL[INE]NEW_V[ALUE] variableNOPRI[NT]|PRI[NT]NUL[L] textOLD_V[ALUE] variableON|OFFWRA[PPED]|WOR[D_WRAPPED]|TRU[NCATED]1). 改变缺省的列标题COLUMN column_name HEADING column_headingFor example:Sql>select * from dept;DEPTNO DNAME LOC---------- ---------------------------- ---------10 ACCOUNTING NEW YORK sql>col LOC heading locationsql>select * from dept;DEPTNO DNAME location--------- ---------------------------- -----------10 ACCOUNTING NEW YORK2). 将列名ENAME改为新列名EMPLOYEE NAME并将新列名放在两行上:Sql>select * from empDepartment name Salary---------- ---------- ----------10 aaa 11SQL> COLUMN ENAME HEADING ’Employee|Name’Sql>select * from empEmployeeDepartment name Salary---------- ---------- ----------10 aaa 11note: the col heading turn into two lines from one line.3). 改变列的显示长度:FOR[MAT] formatSql>select empno,ename,job from emp;EMPNO ENAME JOB---------- ---------- ---------7369 SMITH CLERK7499 ALLEN SALESMAN7521 WARD SALESMANSql> col ename format a40EMPNOENAME JOB ---------- ---------------------------------------- --------- 7369SMITH CLERK 7499ALLEN SALESMA 7521WARD SALESMAN4). 设置列标题的对齐方式JUS[TIFY] {L[EFT]|C[ENTER]|C[ENTRE]|R[IGHT]}SQL> col ename justify centerSQL> /EMPNO ENAME---------- ---------------------------------------- --------- 7369SMITH CLERK 7499ALLEN SALESMA 7521WARD SALESM 对于NUMBER型的列,列标题缺省在右边,其它类型的列标题缺省在左边5). 不让一个列显示在屏幕上NOPRI[NT]|PRI[NT]SQL> col job noprintSQL> /EMPNO ENAME---------- ----------------------------------------7369 SMITH7499 ALLEN7521 WARD6). 格式化NUMBER类型列的显示:SQL> COLUMN SAL FORMAT $99,990SQL> /EmployeeDepartment Name Salary Commission---------- ---------- --------- ----------30 ALLEN $1,600 3007). 显示列值时,如果列值为NULL值,用text值代替NULL值COMM NUL[L] textSQL>COL COMM NUL[L] text8). 设置一个列的回绕方式WRA[PPED]|WOR[D_WRAPPED]|TRU[NCATED]COL1--------------------HOW ARE YOU?SQL>COL COL1 FORMAT A5SQL>COL COL1 WRAPPEDCOL1-----HOW ARE YOU?SQL> COL COL1 WORD_WRAPPEDCOL1-----HOWAREYOU?SQL> COL COL1 WORD_WRAPPEDCOL1-----HOW A9). 显示列的当前的显示属性值SQL> COLUMN column_name10). 将所有列的显示属性设为缺省值SQL> CLEAR COLUMNS8. 屏蔽掉一个列中显示的相同的值BREAK ON break_columnSQL> BREAK ON DEPTNOSQL> SELECT DEPTNO, ENAME, SALFROM EMPWHERE SAL < 2500ORDER BY DEPTNO;DEPTNO ENAME SAL---------- ----------- ---------10 CLARK 2450MILLER 130020 SMITH 800ADAMS 11009. 在上面屏蔽掉一个列中显示的相同的值的显示中,每当列值变化时在值变化之前插入n个空行BREAK ON break_column SKIP nSQL> BREAK ON DEPTNO SKIP 1SQL> /DEPTNO ENAME SAL---------- ----------- ---------10 CLARK 2450MILLER 130020 SMITH 800ADAMS 110010. 显示对BREAK的设置SQL> BREAK11. 删除6、7的设置SQL> CLEAR BREAKS12. Set 命令:该命令包含许多子命令:SET system_variable valuesystem_variable value 可以是如下的子句之一:APPI[NFO]{ON|OFF|text}ARRAY[SIZE] {15|n}AUTO[COMMIT]{ON|OFF|IMM[EDIATE]|n}AUTOP[RINT] {ON|OFF}AUTORECOVERY [ON|OFF]AUTOT[RACE] {ON|OFF|TRACE[ONLY]} [EXP[LAIN]] [STAT[ISTICS]] BLO[CKTERMINATOR] {.|c}CMDS[EP] {;|c|ON|OFF}COLSEP {_|text}COM[PATIBILITY]{V7|V8|NATIVE}CON[CAT] {.|c|ON|OFF}COPYC[OMMIT] {0|n}COPYTYPECHECK {ON|OFF}DEF[INE] {&|c|ON|OFF}DESCRIBE [DEPTH {1|n|ALL}][LINENUM {ON|OFF}][INDENT {ON|OFF}] ECHO {ON|OFF}EDITF[ILE] file_name[.ext]EMB[EDDED] {ON|OFF}ESC[APE] {\|c|ON|OFF}FEED[BACK] {6|n|ON|OFF}FLAGGER {OFF|ENTRY |INTERMED[IATE]|FULL}FLU[SH] {ON|OFF}HEA[DING] {ON|OFF}HEADS[EP] {||c|ON|OFF}INSTANCE [instance_path|LOCAL]LIN[ESIZE] {80|n}LOBOF[FSET] {n|1}LOGSOURCE [pathname]LONG {80|n}LONGC[HUNKSIZE] {80|n}MARK[UP] HTML [ON|OFF] [HEAD text] [BODY text] [ENTMAP {ON|OFF}] [SPOOL {ON|OFF}] [PRE[FORMAT] {ON|OFF}]NEWP[AGE] {1|n|NONE}NULL textNUMF[ORMAT] formatNUM[WIDTH] {10|n}PAGES[IZE] {24|n}PAU[SE] {ON|OFF|text}RECSEP {WR[APPED]|EA[CH]|OFF}RECSEPCHAR {_|c}SERVEROUT[PUT] {ON|OFF} [SIZE n] [FOR[MAT] {WRA[PPED]|WOR[D_ WRAPPED]|TRU[NCATED]}]SHIFT[INOUT] {VIS[IBLE]|INV[ISIBLE]}SHOW[MODE] {ON|OFF}SQLBL[ANKLINES] {ON|OFF}SQLC[ASE] {MIX[ED]|LO[WER]|UP[PER]}SQLCO[NTINUE] {> |text}SQLN[UMBER] {ON|OFF}SQLPRE[FIX] {#|c}SQLP[ROMPT] {SQL>|text}SQLT[ERMINATOR] {;|c|ON|OFF}SUF[FIX] {SQL|text}TAB {ON|OFF}TERM[OUT] {ON|OFF}TI[ME] {ON|OFF}TIMI[NG] {ON|OFF}TRIM[OUT] {ON|OFF}TRIMS[POOL] {ON|OFF}UND[ERLINE] {-|c|ON|OFF}VER[IFY] {ON|OFF}WRA[P] {ON|OFF}1). 设置当前session是否对修改的数据进行自动提交SQL>SET AUTO[COMMIT] {ON|OFF|IMM[EDIATE]| n}2).在用start命令执行一个sql脚本时,是否显示脚本中正在执行的SQL语句SQL> SET ECHO {ON|OFF}3).是否显示当前sql语句查询或修改的行数SQL> SET FEED[BACK] {6|n|ON|OFF}默认只有结果大于6行时才显示结果的行数。
linux删除数据库命令

linux删除数据库命令在Linux系统中想要删除数据库可以通过命令来执行,下面由店铺为大家整理了linux删除数据库命令的相关知识,希望对大家有帮助!linux删除数据库命令linux删除oracle数据库命令和方法1.关闭所有oracle进程因为准备要删除数据库,所以不用正常完成数据的保存shutdown abort11如果没有设置开机自动启动,服务器也没有运行其它系统,可以考虑重启服务器2.删除实例数据文件和dump文件find $ORACLE_BASE/ -name $ORACLE_SID11在我系统里面显示如下,将这些目录直接删除/u01/app/oracle/admin/testdb/u01/app/oracle/oradata/testdb/u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/emca/tes tdb/u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/dbca/tes tdb123412343.删除其他配置文件find $ORACLE_BASE/* -name '*[Bb][Tt][Ss][Dd][Bb]2*' | grep -v admin| grep -v oradata11将查找结果出现的文件也一一删除,当然你可以用xarg结合rm 删除。
我find结果如下:/u01/app/oracle/flash_recovery_area/testdb/u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/emca/tes tdb/u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/dbca/testdb/u01/app/oracle/product/10.2.0/db_1/oc4j/j2ee/OC4J_DBC onsole_host_testdb/u01/app/oracle/product/10.2.0/db_1/rdbms/log/alert_test db.log/u01/app/oracle/product/10.2.0/db_1/host_testdb/u01/app/oracle/product/10.2.0/db_1/host_testdb/sysman/ emd/state/A190EE260BF6B09EB580580728916A3B.alert_testdb.l og/u01/app/oracle/product/10.2.0/db_1/host_testdb/sysman/l og/nmctestdb1521/u01/app/oracle/product/10.2.0/db_1/dbs/alert_testdb.log /u01/app/oracle/product/10.2.0/db_1/dbs/lktestdb/u01/app/oracle/product/10.2.0/db_1/dbs/hc_testdb.dat/u01/app/oracle/product/10.2.0/db_1/dbs/orapwtestdb/u01/app/oracle/product/10.2.0/db_1/dbs/spfiletestdb.ora1 234567891011121312345678910111213最重要的一步,如果你要重建的实例和刚删除实例的实例名一样的话,删除 /etc/oratab 文件最后一段。
Oracle11g常用基本操作命令
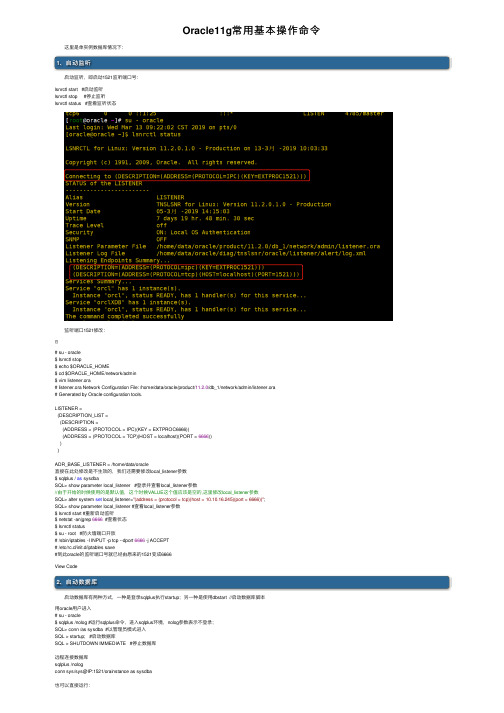
Oracle11g常⽤基本操作命令 这⾥是单实例数据库情况下:1、启动监听 启动监听,即启动1521监听端⼝号:lsnrctl start #启动监听lsnrctl stop #停⽌监听lsnrctl status #查看监听状态 监听端⼝1521修改:# su - oracle$ lsnrctl stop$ echo $ORACLE_HOME$ cd $ORACLE_HOME/network/admin$ vim listener.ora# listener.ora Network Configuration File: /home/data/oracle/product/11.2.0/db_1/network/admin/listener.ora# Generated by Oracle configuration tools.LISTENER =(DESCRIPTION_LIST =(DESCRIPTION =(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC6666))(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 6666))))ADR_BASE_LISTENER = /home/data/oracle直接在此处修改是不⽣效的,我们还需要修改local_listener参数$ sqlplus / as sysdbaSQL> show parameter local_listener #登录并查看local_listener参数//由于开始的时候使⽤的是默认值,这个时候VALUE这个值应该是空的,这⾥修改local_listener参数SQL> alter system set local_listener="(address = (protocol = tcp)(host = 10.10.16.245)(port = 6666))";SQL> show parameter local_listener #查看local_listener参数$ lsnrctl start #重新启动监听$ netstat -an|grep 6666 #查看状态$ lsnrctl status$ su - root #防⽕墙端⼝开放# /sbin/iptables -I INPUT -p tcp --dport 6666 -j ACCEPT# /etc/rc.d/init.d/iptables save#到此oracle的监听端⼝号就已经由原来的1521变成6666View Code2、启动数据库 启动数据库有两种⽅式,⼀种是登录sqlplus执⾏startup;另⼀种是使⽤dbstart //启动数据库脚本⽤oracle⽤户进⼊# su - oracle$ sqlplus /nolog #运⾏sqlplus命令,进⼊sqlplus环境,nolog参数表⽰不登录;SQL> conn /as sysdba #以管理员模式进⼊SQL > startup; #启动数据库SQL > SHUTDOWN IMMEDIATE #停⽌数据库远程连接数据库sqlplus /nologconn sys/sys@IP:1521/orainstance as sysdba也可以直接运⾏:dbstart //启动数据库脚本dbshut //停⽌数据库脚本3、⽤户管理 创建普通⽤户,权限相关:创建⽤户:SQL> create user "username" identified by "userpasswd" ; #注:后⾯可带表空间删除⽤户:SQL> drop user “username” cascade; #注:cascade 参数是级联删除该⽤户所有对象,经常遇到如⽤户有对象⽽未加此参数则⽤户删不了的问题,所以习惯性的加此参数授权⽤户:SQL> grant connect,resource,dba to "username" ;查看当前⽤户的⾓⾊SQL> select * from user_role_privs;SQL> select * from session_privs;查看当前⽤户的系统权限和表级权限SQL> select * from user_sys_privs;SQL> select * from user_tab_privs;查询⽤户表SQL> select username from dba_users;修改⽤户⼝令SQL> alter user "username" identified by "password";显⽰当前⽤户SQL> show user;4、表和表空间创建表空间SQL> CREATE TABLESPACE data01 DATAFILE '/oracle/oradata/db/DATA01.dbf' SIZE 500M;删除表空间SQL> DROP TABLESPACE data01 INCLUDING CONTENTS AND DATAFILES;修改表空间⼤⼩SQL> alter database datafile '/path/NADDate05.dbf' resize 100M;增加表空间SQL> ALTER TABLESPACE NEWCCS ADD DATAFILE '/u03/oradata/newccs/newccs04.dbf' SIZE 4896M;查询数据库⽂件SQL> select * from dba_data_files;查询当前存在的表空间SQL> select * from v$tablespace;表空间情况SQL> select tablespace_name,sum(bytes)/1024/1024 from dba_data_files group by tablespace_name;查询表空间剩余空间SQL> select tablespace_name,sum(bytes)/1024/1024 from dba_free_space group by tablespace_name;查看表结构SQL> desc table;修改连接数:要重启数据库SQL> alter system set processes=1000 scope=spfile;SQL> shutdown immediate;SQL> startup;查看⽤户当前连接数SQL> select count(*) from sys.v_$session;5、修改字符集相关 将数据库启动到RESTRICTED模式下做字符集更改:$ sqlplus / as sysdbaSQL> select * from v$nls_parameters; #查看当前系统使⽤的各种字符集SQL> select * from nls_database_parameters where parameter ='NLS_CHARACTERSET'; #精确查询NLS_CHARACTERSET值SQL> shutdown immediate; #关闭数据库SQL> startup mount #启动实例,可以加载数据库,不运⾏数据库DBA在做⼀些操作的时候不希望有⼈登⼊数据库可以使⽤restrict模式:SQL> ALTER SYSTEM ENABLE RESTRICTED SESSION; #开启限制会话模式Oracle job进程,包含协调进程(主进程)以及奴⾪进程(⼦进程),job_queue_processes取值范围为0到1000,总共可创建多少个job进程由job_queue_processes参数来决定。
查看linux中oracle版本号有哪些方法

查看linux中oracle版本号有哪些方法在Linux系统下,当我们需要查看Oracle的版本号时候,有多种方法,具体怎么操作呢。
下面由店铺整理了查看linux中oracle版本号的方法总结,希望对你有帮助。
查看linux中oracle版本号的方法总结查看oracle版本方法一:v$versionSQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64bit ProductionPL/SQL Release 11.1.0.7.0 - ProductionCORE 11.1.0.7.0 ProductionTNS for Linux: Version 11.1.0.7.0 - ProductionNLSRTL Version 11.1.0.7.0 - Production查看oracle版本方法二:product_component_versionSQL> select * from product_component_version;PRODUCT VERSION STATUS---------------------------------------------------------------------------------------------NLSRTL 11.1.0.7.0 ProductionOracle Database 11g Enterprise Edition 11.1.0.7.0 64bit ProductionPL/SQL 11.1.0.7.0 ProductionTNS for Linux: 11.1.0.7.0 ProductionSQL>查看oracle版本方法三:dbms_output.put_line( dbms_db_version.version )SQL> SET SERVEROUTPUT ONSQL> EXEC dbms_output.put_line( dbms_db_version.version );11PL/SQL procedure successfully completed.SQL>查看Linux中的oracle版本号命令实例select * from v$version;结果如下:BANNER1 Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod2 PL/SQL Release 10.2.0.1.0 - Production3 CORE 10.2.0.1.0 Production4 TNS for 32-bit Windows: Version 10.2.0.1.0 - Production5 NLSRTL Version 10.2.0.1.0 - Production例如:Oracle 9.0.1.1.29:版本号0:新特性版本号1(第一个):维护版本号1(第二个):普通的补丁设置号码2:非凡的平台补丁设置号码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ORA-02095: specified initialization parameter cannot be modified
重启数据库之后生效:
SQL> show parameters processes;
NAME TYPE VALUE
3.$sqlplus / as sysdba 以DBA身份进入sqlplus
4.SQL>SHUTDOWN IMMEDIATE 关闭db
其中startup和shutdowm还有其他一些可选参数,有兴趣可以另行查阅
三,查看初始化参数及修改
1.#su - oracle 切换到oracle用户且切换到它的环境
db_writer_processes integer r 0
job_queue_processes integer 3
log_archive_max_processes integer 2
alter system set sessions=600 scope=both
ORA-02095: specified initialization parameter cannot be modified
SQL>
SQL> alter system set processes=600 scope=spfile;
一,启动
1.#su - oracle 切换到oracle用户且切换到它的环境
2.$lsnrctl status 查看监听及数据库状态
3.$lsnrctl start 启动监听
4.$sqlplus / as sysdba 以DBA身份进入sqlplus
------------------------------------ ----------- ------------------------------
aq_tm_processes integer 0
db_writer_processes integer 1
alter system set processes=600 scope=both
ORA-02095: specified initialization parameter cannot be modified
SQL> alter system set sessions=600 scope=both;
session_max_open_files integer 10
sessions integer 225
shared_server_sessions integer
SQL> show parameters processes;
Oracle process与session2008年12月29日 星期一 15:47
Connected to Oracle Database 10g Release 10.1.0.5.0
Connected as ifsapp
SQL> show parameter session
NAME TYPE VALUE
license_max_sessions integer 0
license_sessions_warning integer 0
logmnr_max_persistent_sessions integer 1
session_cached_cursors integer 0
2.$sqlplus / as sysdba 以DBA身份进入sqlplus
3.SQL>show parameter session; 查看所接受的session数量
######################################################
aq_tm_processes integer 0
db_writer_processes integer 1
gcs_server_processes integer 0
job_queue_processes integer 3
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
aq_tm_processes integer 0
系统已更改。
SQL> show parameter processes;
NAME TYPE VALUE
------------------------------------ ----------- -----------------------------------------
aq_tm_processes integer 1
否则会报错误ORA-27101 Shared memory realm does not exist。使用UltraEdit或者EditPlus之类的可以编辑二进制文件的编辑器打开此文件(直接编辑二进制文件),然后在Windows服务中重新启动Oracle服务器即可。
java_max_sessionspace_size integer 0
java_soft_sessionspace_limit integer 0
license_max_sessions integer 0
license_sessions_warning integer 0
db_writer_processes integer 1
job_queue_processes integer 10
log_archive_max_processes integer 1
processes integer 150
SQL> create pfile from spfile;
文件已创建。
重启数据库,OK!
【注:sessions是个派生值,由processes的值决定,公式sessions=1.1*process + 5】
2.通过修改oracle配置文件进行修改
修改SPFILEORCL.ORA文件中的processes的值。8.1.5中是init.ora文件,在9i中修改init.ora文件是无效的,这个文件由于是一个二进制的文件,不能直接使用notepad此类的编辑器打开。
aq_tm_processes integer 1
db_writer_processes integer 1
job_queue_processes integer 10
log_archive_max_processes integer 1
processes integer 150
SQL> alter system set processes=400 scope = spfile;
System altered
SQL> show parameters processes;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
SQL> show parameter session
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
gcs_server_processes integer 0
job_queue_processes integer 3
log_archive_max_processes integer 2
processes integer 600
logmnr_max_persistent_sessions integer 1
session_cached_cursors integer 0
session_max_open_files integer 10
sessions integer 665
shared_server_sessions integer
修改Oracle process 和 session 的方法
先备份spfile
1.通过SQLPlus修改
Oracle的sessions和processes的关系是
sessions=1.1*processes + 5
使用sys,以sysdba权限登录:
SQL> show parameter processes;
NAME TYPE VALUE
------------------------------------ ----------- ---------------------------------------
------------------------------------ ----------- ------------------------------
java_max_sessionspace_size integer 0
java_soft_sessionspace_limit integer 0
processes integer 200
SQL> alter system set processes=600 scope=both;
SQL>
SQL> alter system set processes=600 scope=both;
log_archive_max_processes integer 2