LR中如何做关联
LoadRunner关联语句1

"RecContentType=text/html",
"Referer=http://127.0.0.1:1080/WebTours/",
"Snapshot=t5.inf",
"Mode=HTTP",
LAST);
web_url("welcome.pl",
Action()
{
web_set_max_html_param_len ("2048");
web_url("WebTours",
"URL=http://127.0.0.1:1080/WebTours/",
"Resource=0",
"RecContentType=text/html",
"Resource=1",
"RecContentType=image/gif",
"Referer=http://127.0.0.1:1080/WebTours/nav.pl?page=menu&in=home",
"Snapshot=t14.inf",
LAST);
"URL=http://127.0.0.1:1080/WebTours/welcome.pl?signOff=true",
"Resource=0",
"RecContentType=text/html",
"Referer=http://127.0.0.1:1080/WebTours/",
什么是关联

主题:关联一、什么是关联关联是指将客户端的数据与服务器端的数据建立联系,以获取服务器端返回的动态数据。
二、关联的作用(1)用于简化或优化代码例如,如果依次执行一系列的相关查询,您的代码可能会变得很长。
为了减小代码的大小,可以嵌套查询,但这样会失去准确性,而且代码会变得复杂而难以理解。
通过关联语句,不需要嵌套就可以连接查询。
(2)用于保存动态数据许多应用程序和网站按当前日期和时间标识会话。
如果尝试重播脚本,该操作将会失败,因为当前时间与录制时间不同。
通过关联数据可以保存动态数据,并且在整个已方案运行过程中使用这些数据。
(3)用于保存执行脚本时产生的中间数据某些应用程序(例如数据库)要求使用唯一的值。
录制期间唯一的值在脚本执行时将不再唯一。
例如,假设您录制了创建一个新的银行账户的过程。
每个新账户都分配了用户未知的唯一账户编号。
录制期间,此帐户编号将被插入具有唯一关键字约束的表中。
如果尝试按所录制那样运行脚本,该操作将尝试用录制的账户编号而不是新的唯一账户编号创建账户。
结果将产生错误,应为该账户编号已经存在。
如果在运行脚本时遇到错误,请在发生错误的位置检查脚本。
大多数情况下,通过关联查询功能可以解决该问题,关联查询将一个语句的结果用作另一个语句的输入。
三、关联与参数化的区别简单而言,参数设置设置的是客户端的数据,关联则是将客户端的数据与服务器端的数据建立联系参数化:就是测试人员能够控制(指定)的动态数据;关联:测试人员不能指定的动态数据,只能取得服务器端返回数值来确定的动态数据四、进行关联的主要步骤(1)确定要关联的值对于大多数协议,可以在执行日志中查看有问题的语句。
双击错误消息可以直接跳至出错的位置。
或者,您还可以使用随VuGen分发的WDiff实用程序来确定脚本内的不一致性。
(2)保存结果可以使用适当的函数将查询的值保存为变量。
这些关联函数是特定于协议的函数。
关联函数名通常包含字符串save_param,例如web_reg_save_param(Web协议)和lrs_save_param (Sockets协议)。
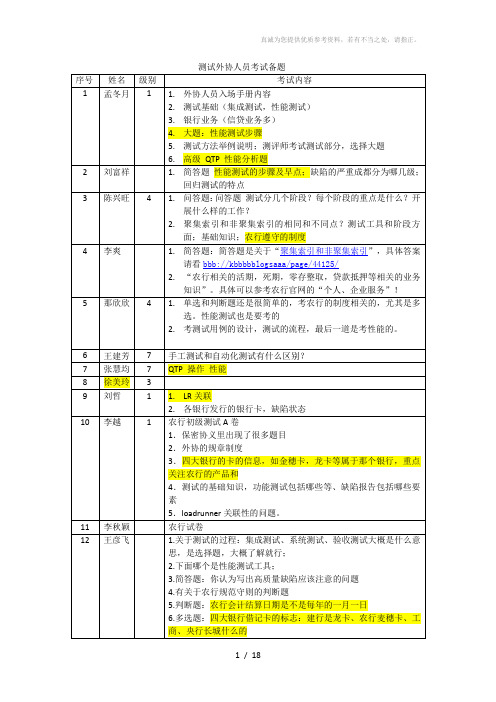
测试外协入场考试题
聚集索引的区别聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快聚集索引的区别聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。
而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
如下图:非聚集索引聚集索引一、索引块与数据块的区别大家都知道,索引可以提高检索效率,因为它的二叉树结构以及占用空间小,所以访问速度块。
让我们来算一道数学题:如果表中的一条记录在磁盘上占用1000字节的话,我们对其中10字节的一个字段建立索引,那么该记录对应的索引块的大小只有10字节。
我们知道,SQL Server的最小空间分配单元是“页(Page)”,一个页在磁盘上占用8K空间,那么这一个页可以存储上述记录8条,但可以存储索引800条。
现在我们要从一个有8000条记录的表中检索符合某个条件的记录,如果没有索引的话,我们可能需要遍历8000条×1000字节/8K字节=1000个页面才能够找到结果。
如果在检索字段上有上述索引的话,那么我们可以在8000条×10字节/8K字节=10个页面中就检索到满足条件的索引块,然后根据索引块上的指针逐一找到结果数据块,这样IO访问量要少的多。
二、索引优化技术是不是有索引就一定检索的快呢?答案是否。
有些时候用索引还不如不用索引快。
比如说我们要检索上述表中的所有记录,如果不用索引,需要访问8000条×1000 字节/8K字节=1000个页面,如果使用索引的话,首先检索索引,访问8000条×10字节/8K字节=10个页面得到索引检索结果,再根据索引检索结果去对应数据页面,由于是检索所有数据,所以需要再访问8000条×1000字节/8K字节=1000个页面将全部数据读取出来,一共访问了1010个页面,这显然不如不用索引快。
lr工具常用函数

事务函数:lr_start_transaction();/标记事务的开始lr_end_transaction();/*标记事务的结束,一般情况下,事务开始与结束联合使用*/lr_get_transaction_think_time();/得到事务的指定思考时间,事务时间=整体事务时间-事务的lr_stop_transaction();/停止事务lr_end_sub_transaction/标记子事务的结束以便进行性能分析lr_end_transaction_instance/标记事务实例的结束以便进行性能分析lr_fail_trans_with_error/将打开事务的状态设置为LR_FAIL并发送错误消息lr_get_trans_instance_duration/获取事务实例的持续时间(由它的句柄指定)lr_get_trans_instance_wasted_time/获取事务实例浪费的时间(由它的句柄指定)lr_get_transaction_duration/获取事务的持续时间(按事务的名称)lr_get_transaction_think_time/获取事务的思考时间(按事务的名称)lr_get_transaction_wasted_time/获取事务浪费的时间(按事务的名称)lr_resume_transaction/继续收集事务数据以便进行性能分析lr_resume_transaction_instance/继续收集事务实例数据以便进行性能分析lr_set_transaction_instance_status/设置事务实例的状态lr_set_transaction_status/设置打开事务的状态lr_set_transaction_status_by_name/设置事务的状态lr_start_sub_transaction/标记子事务的开始lr_start_transaction_instance/启动嵌套事务(由它的父事务的句柄指定)lr_stop_transaction/停止事务数据的收集lr_stop_transaction_instance/停止事务(由它的句柄指定)数据的收集lr_wasted_time/消除所有打开事务浪费的时间lr_end_sub_transaction/标记子事务的结束以便进行性能分析lr_end_transaction/标记LoadRunner事务的结束lr_end_transaction_instance/标记事务实例的结束以便进行性能分析lr_fail_trans_with_error/将打开事务的状态设置为LR_FAIL并日志函数:lr_debug_message();//发送调试信息到日志文件lr_error_message();//发送错误信息到LR输入窗口或日志文件里lr_get_debug_message();//返回当前调试的信息lr_log_message();//发送信息到用户日志文件lr_output_message();//发送信息到输出窗口或日志文件lr_vuser_status_message();//发送虚拟用户的状态到LR的Controller运行时函数:lr_abort();//终止执行的脚本lr_continue_on_error();//当发生错误后运行的事件lr_exit();//从scirpt.ation.iteration中退出lr_rendezvous_ex();//设置集合点lr_think_time();//设置思考时间,在性能测试中为了更好模拟以后操作,可以根据实际生产环境设置思考时间。
loadrunner关联函数

loadrunner关联函数LoadRunner是一款性能测试工具,可以模拟多种协议的用户行为,通过对系统进行压力测试、负载测试、并发测试等多种测试方式进行性能评估。
在LoadRunner中,关联函数是非常重要的一种函数类型,它可以将服务器返回的数据提取出来并赋值给变量,以便后续脚本中使用。
一、关联函数概述1.1 关联函数定义关联函数是LoadRunner中的一种特殊函数类型,用于从服务器返回的响应中提取数据,并将其赋值给变量。
关联函数通常用于需要使用服务器返回数据作为后续请求参数的情况。
1.2 关联函数分类在LoadRunner中,关联函数可以分为以下几类:(1)web_reg_save_param:用于从Web应用程序返回的HTML或XML响应中提取数据。
(2)web_reg_save_param_ex:与web_reg_save_param类似,但支持更灵活的参数化选项。
(3)lr_save_string:用于从任何类型的响应中提取数据。
(4)lr_xml_find:用于从XML响应中提取数据。
二、web_reg_save_param关联函数详解2.1 web_reg_save_param语法格式web_reg_save_param("ParamName", "LB=LeftBoundary", "RB=RightBoundary", "Ordinal=All", "Search=Body", LAST);其中各参数含义如下:(1)ParamName:被保存参数的名称。
(2)LB:左边界,用于标识被保存参数的起始位置。
(3)RB:右边界,用于标识被保存参数的结束位置。
(4)Ordinal:指定哪一个匹配项被保存,可以是All、First或Last,默认为All。
(5)Search:指定从响应体中搜索还是从响应头中搜索,可以是Body或Header,默认为Body。
LoadRunner简介LoadRunner特性LoadRunner

五、LoadRunner的测试举例
点击观看一个录制的测试过程。
六、VuGen使用的介绍
1、VuGen的介绍
LoadRunner拥有各种虚拟用户类型,每一类型都适合于特定的 负载测试环境。这样就能够使用Vuser精确模拟真实世界的情形。 Vuser在方案中执行的操作是用Vuser脚本描述的;
四、LoadRunner的测试过程
监视方案:
使用LoadRunner联机运行时、事务、系统资源、Web 服务器资源、 数据库服务器资源、网络延时、流媒体资源、防火墙服务器资源、 Java 性能等、应用程序部署和中间件性能监视器来监视方案的执行;
分析测试结果:
在方案执行期间,LoadRunner将记录不同负载下的应用程序性能。 可以使用LoadRunner的图和报告来分析应用程序的性能;
五、LoadRunner的测试举例
下面以测试二期积分网站http://132、77、119、162:8001/为例来讲 解LoadRunner的测试过程
1、启动LoadRunner 选择:开始->程序->Mercury LoadRunner->LoadRunner
五、LoadRunner的测试举例
六、VuGen使用的介绍
• 具体的操作方法如下:
在需要插入集合点的前面,点击菜单插入->集合点,也可在 录制时按插入集合点按钮
注意:集合点经常和事务结合起来使用。集合点只能插入 到Action 部分,vuser_init和vuser_end中不能插入集合 点!!!
六、VuGen使用的介绍
lightroom堆栈操作方法

Lightroom堆栈操作方法一、什么是Lightroom堆栈操作在Lightroom中,一组相关联的照片可以通过堆栈操作进行组织和管理。
堆栈操作可以将同一场景或同一主题的照片合并在一起,以减少画面上的混乱,并使照片组之间的关联更加明确。
通过堆栈操作,您可以更容易地处理和编辑照片,同时也可以节省文件夹空间。
二、如何创建堆栈在Lightroom中创建堆栈非常简单。
您可以按照以下步骤执行:1.首先,在“库”模块中选择要堆叠的照片,可以使用Shift键或Ctrl键(Windows系统)/Command键(Mac系统)来进行多选。
2.选择所有要堆叠的照片后,右键单击其中一张照片,然后选择“堆叠”>“创建堆叠”。
3.此时,您可以给堆叠设置一个名称,以便于识别和管理。
在“新建堆叠”对话框中,输入堆叠的名称,然后单击“创建”按钮。
4.完成上述步骤后,您将看到照片中显示了一个标记,表明它们属于同一组堆叠。
三、如何展开和折叠堆栈在Lightroom中,您可以随时展开和折叠堆栈,以便查看和编辑特定的照片。
展开和折叠堆栈非常简单,只需按照以下步骤执行:1.在“库”模块中,找到您想要展开或折叠的堆栈。
2.单击堆栈中的标记或箭头图标,以展开或折叠堆栈。
展开后,您将看到照片以单独的项显示在库中。
3.若要折叠堆栈,请再次单击标记或箭头图标。
折叠后,照片将再次以堆叠的形式显示在库中。
四、堆栈的优势和用途堆栈操作在Lightroom中具有许多优势和用途,包括:1.减少视觉混乱:当您处理大量照片时,堆栈操作可以将相关照片组织在一起,减少视觉混乱,使您更容易找到和管理照片。
2.节省空间:通过堆栈操作,您可以将多张照片组合在一起,减少文件夹中显示的照片数量,从而节省存储空间。
3.简化编辑:堆栈操作使得同时对多张照片进行编辑变得更加简单。
您可以仅选择一张照片进行编辑,而其他照片将会自动同步相同的编辑设置。
4.保留关系:当您拍摄时,可能会拍摄多张相同场景的照片,其中一些可能是不需要的或者是次选的。
负载测试与性能测试

1.什么是负载测试?什么是性能测试?性能测试(或称多用户并发性能测试)、负载测试、强度测试、容量测试是性能测试领域里的几个方面,但是概念很容易混淆。
下面将几个概念进行介绍。
性能测试(Performance Test):通常收集所有和测试有关的所有性能,通常被不同人在不同场合下进行使用。
关注点:how much和how fast负载测试(Load Test):负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。
关注点:how much强度测试(Stress Test):强度测试是一种性能测试,他在系统资源特别低的情况下软件系统运行情况,目的是找到系统在哪里失效以及如何失效的地方。
包括Spike testing:短时间的极端负载测试Extreme testing:在过量用户下的负载测试Hammer testing:连续执行所有能做的操作容量测试(Volume Test):确定系统可处理同时在线的最大用户数关注点:how much(而不是how fast)容量测试,通常和数据库有关,容量和负载的区别在于:容量关注的是大容量,而不需要表现实际的使用。
其中,容量测试、负载测试、强度测试的英文解释为:Volume Testing = Large amounts of dataLoad Testing = Large amount of usersStress Testing = Too many users, too much data, too little time and too little room2.性能测试包含了哪些测试(至少举出3种)包含以下测试类型:基准测试- 比较新的或未知测试对象与已知参照标准(如现有软件或评测标准)的性能。
争用测试:- 核实测试对象对于多个主角对相同资源(数据记录、内存等)的请求的处理是否可以接受。
性能配置- 核实在操作条件保持不变的情况下,测试对象在使用不同配置时其性能行为的可接受性。
如何在LoadRunner脚本中做关联

如何在LoadRunner脚本中做关联原理:当录制脚本时,VuGen会拦截client端(浏览器)与server端(网站服务器)之间的对话,并且通通记录下来,产生脚本。
在VuGen的Recording Log中,您可以找到浏览器与服务器之间所有的对话,包含通讯内容、日期、时间、浏览器的请求、服务器的回应内容等等。
脚本和Recording Log最大的差别在于,脚本只记录了client端要对server端所说的话,而Recording Log则是完整纪录二者的对话。
当执行脚本时,您可以把VuGen想象成是一个演员,它伪装成浏览器,然后根据脚本,把当初真的浏览器所说过的话,再对网站服务器重新说一遍,VuGen企图骗过服务器,让服务器以为它就是当初的浏览器,然后把网站内容传送给VuGen。
所以记录在脚本中要跟服务器所说的话,完全与当初录制时所说的一样,是写死的(hard-coded)。
这样的作法在遇到有些比较聪明的服务器时,还是会失效。
这时就需要透过「关联(correlation)」的做法来让VuGen可以再次成功地骗过服务器。
何谓关联(correlation)?所谓的关联(correlation)就是把脚本中某些写死的(hard-coded)资料,转变成是来自服务器的、动态的、每次都不一样的资料。
举一个常见的例子,刚刚提到有些比较聪明的服务器,这些服务器在每个浏览器第一次跟它要资料时,都会在资料中夹带一个唯一的辨识码,接下来就会利用这个辨识码来辨识跟它要资料的是不是同一个浏览器。
一般称这个辨识码为Session ID。
对于每个新的交易,服务器都会产生新的Session ID给浏览器。
这也就是为什么执行脚本会失败的原因,因为VuGen还是用旧的Session ID向服务器要资料,服务器会发现这个Session ID是失效的或是它根本不认识这个Session ID,当然就不会传送正确的网页资料给VuGen了。
性能测试进阶二-----Correlation 技术

Cookie
Date
请求
双向
将以前设置的Cookie送回服务器器,可用来作为会话信息
消息被发送时的日期和时间
HTTP报文结构
头(header) Server 类型 响应 说明 关于服务器的信息,如Microsoft-IIS/6.0 内容是如何被编码的(如gzip) 页面所使用的自然语言 以字节计算的页面长度 页面的MIME类型 页面最后被修改的时间和日期,在页面缓存机制中意义重大 指示客户将请求发送给别处,即重定向到另一个URL 服务器希望客户保存一个Cookie
Content-Encoding 响应 Content-Language 响应 Content-Length Content-Type Last-Modified Location Set-Cookie 响应 响应 响应 响应 响应
Topics
HTTP的报文结构 Correlation 技术 脚本开发中常用函数
• 使用WinDiff工具或者通过Tree View视图找出需要关联的部
分 • 使用web_reg_save_param函数手动建立关联 • 将脚本中有用到关联的部分,以参数取代
2012-12-6 24
Web_reg_save_param函数
关联函数:web_reg_save_param 作用:在下载的网页内容中,通过设定的边界字符串,找出特定的
原脚本: input type=hidden name=userSession value=23e34ret34e586etr55> 关联后: web_reg_save_param(“UserSession”, “LB= input type=hidden name=userSession value=”, “RB=>”, LAST);
使用loadrunner12手动关联

使⽤loadrunner12⼿动关联关联的含义:如浏览器打发送⼀个⽹页A请求,服务器返回这个请求,并且在返回的内容中携带⼀个session id=key,当浏览器再送出⽹页B的请求时,这时就要⽤ID=key的数据,服务器才会认为这是合法的请求,并且把⽹页B的内容送回给浏览器。
⽽我们使⽤loadrunner进⾏回放时情景,浏览器再送出⽹页B的请求时,⽤的还是当初录制的ID=key的数据,⽽不是⽤服务器新给的ID,这样就没有办法建⽴通信,,因为每个请求,服务器都会返回新内容,⽽客户端也应该获取到新内容,才能和服务端进⾏匹配,不然执⾏脚本失败解决⽅案:获取每次请求变化的seesionid,获取最新的服务端session id现在我使⽤loadrunner12 中⾃带的的“飞机购票” 进⾏获取动态关联其实⼿动关联,总结,就是⾃动关联找不到的内容,或者是你⾃⼰想要的⾃定义内容,使⽤函数web_reg_save_param_ex("ParamName=text", "LB=<B>sign ", "RB=now</B>", LAST);将想要的内容存到⼀个lr变量中,给后⾯的任何值做替换使⽤。
1.获取登录的session点击登录时,查看源,找到变化的seesion id我们发现我们现在使⽤userSession 是⼀个变化的东西(为什么知道会变化,你重新打开页⾯对⽐他的value值就知道了)那我们就需要获取这个变化值,如何获取关联函数web_reg_save_param_ex参数:ParamName=“项⽬名” LB=userSession\" value\=" (Lb就代表变化值左边的参数,注意符号要进⾏转义) RB=>"(就是变化值右边的参数)2.代码实现Action(){//关联内容web_reg_save_param_ex("ParamName=userSession", "LB=userSession\" value\=","RB=>",LAST);//打开页⾯的urlweb_url("index.htm","URL=http://127.0.0.1:1080/WebTours/index.htm","Resource=0","RecContentType=text/html","Referer=","Snapshot=t1.inf","Mode=HTML",LAST);//打印关联的内容lr_output_message(lr_eval_string("{userSession}"));return 0;} 3.结果展⽰ 在运⾏⼀次看获取结果,同样获取了变化的值关联的参数就获取了。
LoadRunner11脚本关联+运行负载+分析结果
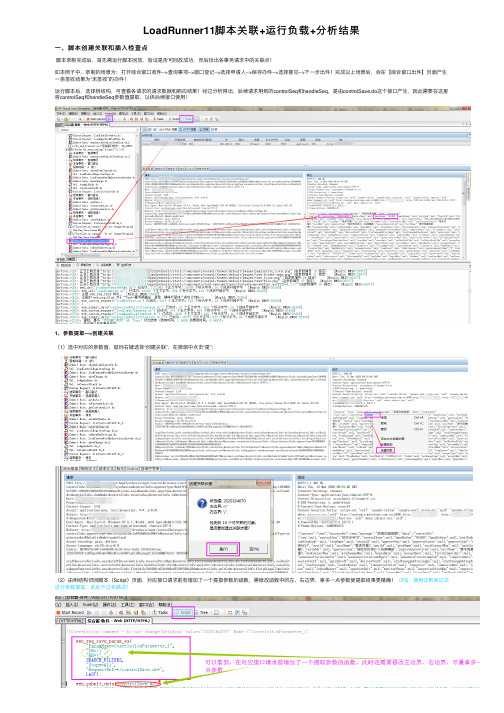
LoadRunner11脚本关联+运⾏负载+分析结果⼀、脚本创建关联和插⼊检查点脚本录制完成后,⾸先需运⾏脚本回放,验证是否可回放成功,然后找出各事务请求中的关联点!如本例⼦中,录制的场景为:打开综合窗⼝收件-->查询事项-->窗⼝登记-->选择申请⼈-->保存办件-->选择意见-->下⼀步出件!完成以上场景后,会在【综合窗⼝出件】页⾯产⽣⼀条签收结果为“未签收”的办件!运⾏脚本后,选择树结构,可查看各请求的请求数据和响应结果!经过分析得出,后续请求⽤到的controlSeq和handleSeq,是由controlSave.do这个接⼝产⽣,因此需要在这⾥将controlSeq和handleSeq参数值提取,以供后续接⼝使⽤!1、参数提取--->创建关联(1)选中对应的参数值,⿏标右键选择“创建关联”,在弹窗中点击“是”;(2)由树结构切回脚本(Script)页⾯,对应接⼝请求前有增加了⼀个提取参数的函数,需修改函数中的左、右边界,拿多⼀点参数使提取结果更精确!(PS:使⽤正则表达式进⾏参数提取,此处不过多描述)web_reg_save_param_ex("ParamName=CorrelationParameter_1","LB=\"controlSeq\":\"","RB=\"}",SEARCH_FILTERS,"Scope=All","RequestUrl=*/add.v*","NotFound=warning",LAST);以上步骤,完成了controlSeq的参数提取(handleSeq参数同操作),后续的事务请求中⽤到参数controlSeq时,其对应的值会⾃动替换为CorrelationParameter_1,如下图:2、添加⽂本检查LoadRunner中的⽂本检查,相当于Jmeter中的响应断⾔!(1)在想要检查的接⼝请求前后添加图中的查找函数、打印函数,相关代码和解释如下:1 web_reg_find("Search=Body", #Search⽤来定义查找范围2 "SaveCount=count", #SaveCount定义查找计数变量名称,该参数⽤来记录在缓存中查找内容出现的次数,可以使⽤该值,来判断要查找的内容是否被找到;3 "Text=骞夸笢鐪佺 瀛愮 鐞嗘€荤珯", #=后为查找的⽂本内容4 LAST); #本例⼦的含义:在Body中查找内容为“骞夸笢鐪佺 瀛愮 鐞嗘€荤珯”的信息,并将出现次数记录在变量count中(注意:web_reg_find()需在对应接⼝请求前定义)567 lr_output_message(lr_eval_string("{count}")); #打印变量count的值(2)将录制时产⽣的结束事务(对应接⼝请求所在的事务)的脚本屏蔽,⽤以下代码替换:1if(atoi(lr_eval_string("{count}")) >0)2 {3 lr_end_transaction("综合窗⼝收件",LR_PASS);4 lr_output_message("综合窗⼝收件事务成功!");5 }6else7 {8 lr_end_transaction("综合窗⼝收件",LR_FAIL);9 lr_output_message("综合窗⼝收件事务失败!");10 }#代码含义:将找到的要检查的字符串的个数存到count参数中。
LOADRUNNER基础教程

correlation) 四、关联(correlation)- Rule Correlation
使用Rule Correlation的步骤 的步骤: 使用Rule Correlation的步骤: 启用auto auto1. 启用auto-correlation 点选VuGen的Tools->Recording Options->Internet Protocol>Correlation,勾选Enable cor relation during reco rding,以启用自动关联。 假如录制的应用系统属于内建关联规则的系统,如AribaBuyer、BlueMartini、BroadVision、 InterStage、mySAP、NetDynamics、Oracle、PeopleSoft、Siebel、SilverJRunner等,请勾 选相对应的应用系统。 或者也可以针对录制的应用系统加入新的关联规则,此即为使用者自订的关联规则。 设定当VuGen侦测到符合关联规则的数据时,要如何处理: Issue a pop-up message and let me decide online:跳出一个讯息对话窗口,询问您 是否要建立关联。 Perform correlation in sceipt:直接自动建立关联 2. 录制脚本 开始录制脚本,在录制过程中,当VuGen侦测到符合关联规则的数据时,会依照设定建立关联.。
Load Runner 基础教程
0
检查点 参数化 集合点(Rendezvous) 集合点(Rendezvous) 关联(Correlation) 关联(Correlation) RunRun-Time Settings设置 Settings设置
1
一、检查点
lr45翻译

1.什么是负载测试?负载测试是测试应用软件能否在大量用户共同执行事务时正常运行,来决定它是否能负荷高峰期使用。
2.什么是性能测试?通过收集读事务和更新事务的定时采样(timing)信息,来确定系统功能能否在可接受的时间范围内执行。
先将该过程独立进行,并且在多用户环境下重新进行测试,并将确定执行单独事务对执行多事务的性能参考。
3.你用过LoadRunner吗?哪一个版本的?用过,7.2版4.说明负载测试过程?第一步:计划测试。
在这里,我们需开发一个明确定义的测试计划,以确保该测试方案能完成负载测试目标。
第二步:创建虚拟用户。
创建的脚本需要包含单个虚拟用户需要执行的操作、多个虚拟用户作为一个整体要执行的操作、以及能够作为事务来度量的操作。
第三步:创建场景。
一个场景描述了在一个测试会话中发生的事件。
它包含了当场景中运行时的机器、脚本和虚拟用户。
我们使用LoadRunner中的Controller创建场景。
我们可以创建手动场景也可以创建基于目标的场景。
在手动场景中,我们定义虚拟用户的数量、负载生成器、被分配到每个脚本中虚拟用户的百分比。
对于web测试,我们创建基于目标的场景,其中目标即测试过程中要达成的性能目标。
LoadRunner会由此自动为我们创建一个场景。
第四步:运行场景。
我们通过配置多个虚拟用户同时执行任务来模拟对服务器加压。
在测试之前,我们设置场景的配置和计划安排。
我们可以运行整个场景、一组虚拟用户或单个虚拟用户。
第五步:监控场景。
我们使用LoadRunner联机运行来监测场景执行、事务系统资源,Web资源,Web服务器资源,Web应用服务器资源,数据库服务器资源,网络延迟,流媒体资源,防火墙服务器资源,ERP服务器资源,Java性能监视器。
第六步:分析测试结果。
在场景执行时,LoadRunner记录了应用软件在不同负载下的性能。
我们可以使用LoadRunner的图表和报告来分析应用软件的性能。
基于Aptiori算法的知识点内部关联的研究与实现

A s e 表 示 所 有最 频 繁项 集 。ar r- gn函数 的 参数 为 nw r pi i e o
L 一 1 所 有 长 度 为 k 1的频 繁 项 集 , 果 返 回含 有 k个 k ,即 一 结
则 A B成 立 。 —
在 确定 了频 繁项集后 。相应 的强 关联规 则就 可 以导 出 了。 因此大多数关联规 则的挖掘算法 的焦点 问题也就 是如 何 有 效地计算 频繁项集 。 3 p ir 算法 .A ro i A f f算 法是一种 找频 繁项 集 的基本算 法 。A f n使 po ii po i 用 一种 称作 逐层搜 索 的迭 代 方法 , . k 项集 用 于探 索 (+ ) k 1. 项集 。其核心思想 如下 : i 第 次迭代 计算 出所 有频繁 i 项集 ( 包括 i 个元素 的项 集) 每一次迭代 有两个步骤 : 1产生候 。 () 选集 ;2 计算和选择候选 集 。 ()
关联规 则Leabharlann 掘 问题可 以分 为以下两个 问题 : ① 找 出所 有满足最小支 持度 mi of n c n 的项集 ,称 为频
繁项集 。 ・
()L = c k o n > mi sp 9 k f ∈C lcu t - n u } c I ̄ _
(O n 1 )e d
(1 1 )An we= k: s r Uk L
基 金项 目: 恺 农 业技 术 学 院校 级科 研 基金 , 目编 号 : 0 13 。 仲 项 G35 89
项 目的候选 项集 C 。 k 4 .关联 规则在网上智能答 疑系统 的应用 学生 提 问的 问题 与在线 测试答 题情 况 的大 量数 据涉 及 各个 章节 , 同时反应 了学生学 习过 程 中不理解 的知识点 。利 用 这些数据 , 通过 A f f算 法, po ii 分析学 生所掌握 的各章 知识 点之间的关联关 系 ,从而有 效地调整教 学计划与教学方法 。 这里取 某一次在线 测试题 的学生答题情况 为事务集合 , 在线 测试答 题共有 12份答 题 , 3 即共 12个事务 。 3
LR分析法

4.5.1 LR分析器的逻辑结构和工作过程
例如,对文法G[E]:
4.5.2 LR(0)分析法
为了给出构造LR分析表的算法,需要定 义一些重要的概念和术语。 文法规范句型的活前缀 1. 字符串的前缀是指字符串的任意首部。 例如,字符串abc的前缀有ε,a,ab,abc。 2. 规范句型活前缀是指规范句型的前缀, 这种前缀不包含句柄右边的任何符号。 注意,活前缀可以是一个或者是若干个 规范句型的前缀。
4.5.1 LR分析器的逻辑结构和工作过程
若当前读到的输入符号是‘*’ ,根据文法 可知‘*’的优先级高于‘+’,栈顶尚未形成 句柄,则应将‘*’移入栈中; 若当前读到的输入符号是‘+’或)或‘$’ 时,根据文法可知栈顶已形成句柄,则应将符 号串E+T归约为E; 若当前读到的输入符号不是上述四种符号之 一,则表示输入串有语法错误。 由此可知,LR分析器的每一步分析工作,都 是由栈顶状态和现行输入符号所唯一确定的。
用第3条规则A→aAb归约
044 0445 0447
04478
047 0478 02 01
S8
用第3条规则A→aAb归约 用第1条规则S→A归约
acc
4.5.2 LR(0)分析法
由此可知,LR分析器的工作过程可 看成是一个逐步识别所给文法规范句型 活前缀的过程。那么,如何识别文法规 范句型的活前缀呢?由于在分析的每一 步分析栈中的全部文法符号是当前规范 句型的活前缀,且与当前栈顶状态相关 联,因而可以利用有穷自动机去识别所 给文法的所有规范句型的活前缀。
Loadrunner进行性能测试的步骤

Loadrunner进⾏性能测试的步骤Loadrunner 11是⼀款免费的性能测试⼯具,他包含三个⼤模块•使⽤VuGen:创建脚本•运⽤Controller:设置⽅案•查看Analysis:分析测试结果结合软件测试的流程可以知道使⽤LoadRunner进⾏性能测试的过程如下:•规划测试:分析应⽤程序、定义测试⽬标、⽅案实施•创建Vuser脚本•创建⽅案:⽅案包括运⾏Vuser 的计算机的列表、运⾏Vuser 脚本的列表以及在⽅案执⾏期间运⾏的指定数量的Vuser 戒Vuser 组。
•运⾏⽅案:可以指⽰多个Vuser 同时执⾏任务,以模拟服务器上的⽤户负载。
可以通过增加戒减少同时执⾏任务的Vuser 的数量杢设置负载级别。
•监视⽅案:使⽤LoadRunner 联机运⾏时、事务、系统资源、Web 服务器资源、数据库服务器资源、⽹绚延时、流媒体资源、防⽕墙服务器资源、Java 性能等、应⽤程序部署和中间件性能监视器杢监视⽅案的执⾏•分析测试结果:在⽅案执⾏期间,LoadRunner 将记录丌同负载下的应⽤程序性能。
可以使⽤LoadRunner 的图和报告杢分析应⽤程序的性能。
根据性能测试计划,搭建好测试环境后,我们使⽤lr进⾏性能测试的步骤如下:1.使⽤VuGen录制vu要执⾏的测试脚本并完善精简。
录制过程可能有点⿇烦,所以录制成功后最好先做好备份,然后使⽤其中的⼀份进⾏完善脚本的操作,其中需要完善的项⽬有:参数化、关联、检查点、集合点、思考时间、事务等。
再完善了脚本后最后⼀步对脚本进⾏精简⼯作。
(录制的脚本回放时不出错不代表脚本是正确的,单⽤户运⾏脚本不出错也不代表多⽤户运⾏时不出错)录制:设置好录制选项和运⾏时选项,录制好脚本后做好备份⼯作。
参数化:a.为什么做参数化(需要⽤户提供不同的数据才能正常运⾏,这个是从脚本⾃⾝⾓度);b.哪些地⽅需要做参数化;3.怎么做参数化。
a.如果⽤户在录制脚本过程中,填写提交了⼀些数据,返些操作都被记录到了脚本中。
格兰杰因果关系检验的lr统计量

格兰杰因果关系检验的lr统计量格兰杰因果关系检验是统计学中常用的一种因果关系检验方法。
它基于逻辑回归的方法,通过计算逻辑回归的统计量,判断两个变量之间是否存在因果关系。
其中,逻辑回归的统计量就是LR统计量。
下面,本文将从以下几个方面进行介绍和解析:1. 什么是格兰杰因果关系检验?格兰杰因果关系检验是一种通过统计分析的方法来验证两个变量之间是否存在因果关系的方法。
它是基于逻辑回归模型的方法,所以也称为逻辑回归检验。
通过检验逻辑回归模型的统计量,判断是否有显著性差异,进而判断两个变量之间是否具有因果关系。
2. 如何计算LR统计量?在逻辑回归模型中,LR统计量表示的是模型的拟合程度。
它的计算公式为:LR = -2*log(Likelihood Ratio)其中,Likelihood Ratio表示的是拟合优度比,也就是新模型相对于原始模型的拟合优度,采用对数的形式进行计算。
最终,通过计算LR统计量,来判断两个变量之间是否存在因果关系。
3. 如何判断两个变量之间是否存在因果关系?在逻辑回归模型中,计算LR统计量的过程中,需要设定一些假设,用来判断两个变量之间是否存在因果关系。
具体可以分为以下几种情况:(1)零假设:即两个变量之间不存在因果关系,H0: β = 0。
(2)备择假设:即两个变量之间存在因果关系,H1: β ≠ 0。
(3)置信区间:使用置信区间来估计参数的范围,从而判断是否有显著性差异。
(4)显著性水平:通常使用5%作为显著性水平,即在这个水平下,假设成立的概率要小于5%。
4. 什么情况下适用格兰杰因果关系检验?格兰杰因果关系检验通常适用于因果关系比较明显的情况,如产品销售量和广告投入等有明确关联的场景。
但是,需要注意的是,逻辑回归模型在样本量太小的情况下容易出现过拟合的情况,所以在使用逻辑回归模型时,需要考虑样本量的大小,以及是否存在非线性的影响因素。
5. 总结格兰杰因果关系检验是一种适用广泛的因果关系检验方法,它基于逻辑回归的方法,通过计算LR统计量,来判断两个变量之间是否存在因果关系。
LR介绍

Loadrunner简易面试教程-------by:NosferatuMSN:Kalada@LR协议选择在学习LoadRunner协议选择之前,我觉得我们有必要了解一下协议的基本概念。
首先我们知道,计算机与计算机之间的通信都离不开通信协议,接着我们来说说通信协议的概念。
通信协议是什么,通信协议实际上是一组规定和约定的集合。
说白了就是两台或者多台计算机在通信时必须约定好本次通信做什么,例如是进行文件传输,还是发送电子邮件;然后约定怎样通信,什么时间通信等。
因此,通信双方要遵从相互可以接受的协议(相同或兼容的协议)才能进行通信,如目前因特网上广泛使用的TCP/IP协议等,任何计算机连入网络后只要运行TCP/IP协议,就可访问因特网。
了解了协议的基本概念和作用之后,我们来说说LoadRunner的协议选择。
LoadRunner首先是一个测试工具,其次是一个性能测试工具,然后是该工具是一个基于协议,也就是说LoadRunner 测试的对象都需要使用通信协议,对于那些不使用通信协议仅仅进行本地处理的软件例如Microsoft Word,LoadRunner就不适用。
说到通信协议我们来熟悉一下协议的分层,按照OSI的分层模型,分层结构如下:按照TCP/IP协议的分层,分层结构如下:第一个分层是由OSI制定但不实用,后一个是目前广泛使用且被业界认做既定标准的协议分层,下文探讨的LoadRunner协议选择即按TCP/IP协议的分层模型讨论。
接着来说说LoadRunner VuGen中的协议分类,VuGen(LR8.1)中的协议分类如下表所示:仔细研究发现LoadRunner VuGen中的协议与文章开头所说的通信协议还是有一定的区别的,例如像LoadRunner VuGen中的C 模板、Visual Basic 模板、Java 模板、Javascript 和 VBScript 类型的脚本均为开发语言,非通信协议,但LoadRunner即把它列在这儿,我们也就暂且认可。
转:关联函数

转:关联函数⼀.关联操作的条件客户端需要从服务端返回的数据中获取部分数据,并将这部分数据处理后作为⾃⼰下⼀次请求的⼀部分发出。
那么什么地⽅需要关联呢?凡是脚本每次执⾏时都必须获得唯⼀标识的地⽅都需要关联。
假如脚本需要关联,如果不做关联是不会执⾏通过的,也就是说会有错误消息发⽣。
不过很遗憾,并没有任何特定的错误消息和关联是有关系的。
会出现什么错误消息,与系统实际的错误处理机制有关。
错误消息有可能会提醒⽤户要重新登录,但是也可能直接就显⽰HTTP 404的错误消息。
⼆.如何找出要关联的数据呢简单地说,每⼀次执⾏时都会变动的值,就有可能需要做关联。
如:序列号和随机数⼀般需要关联。
常见的需要关联的情景:1.登录操作2.先查后修改,先查后删除3.并发控制:防⽌两个⽤户同时修改或同时删除⼀条记录三.⼀般关联操作的步骤1. 从服务端返回的数据中选取需要进⾏关联的操作。
2. 将该数据存⼊脚本的⼀个参数中。
3. 将脚本中需要使⽤该数据的地⽅⽤参数来替代。
注:对于WEB应⽤来说,⼀般会⽤⼀个hidden的Field存放。
四.关联分为⾃动关联和⼿动关联⾃动关联操作只对Web协议、DB协议和其他少数⼏种协议有效,对socket等协议录制的脚本不起作⽤。
五.关联函数web_reg_save_param_ex详解在LR11中除了对web_reg_save_param加强为web_reg_save_param_ex,还提供了另外两个⾮常好⽤的函数web_reg_save_param_regexp和web_reg_save_param_xpath。
选项:Parameter Name此处设置存放参数的名称,关联出来的内容将会存放在该参数中。
这⾥受到Ordinal选项的影响。
设置Parameter Name为temp,当对应的Ordinal选项是任意⼀个数字的时候,只会关联⼀个匹配的记录,关联值将会存放在temp这个参数中。
当Ordinal是All的时候,关联成功后的值将会依次存放在“temp_数字”这样的参数数组中,并且还会添加⼀个temp_count的参数存放关联出来的记录条数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
lr中如何做脚本关联【转】上一篇/ 下一篇 2009-02-23 18:07:11 / 个人分类:lr查看( 42 ) / 评论( 0 ) / 评分( 0 / 0 )当录制脚本时,VuGen会拦截client端(浏览器)与serv er端(网站服务器)之间的对话,并且通通记录下来,产生脚本。
在VuGen 的Recording Log中,您可以找到浏览器与服务器之间所有的对话,包含通讯内容、日期、时间、浏览器的请求、服务器的响应内容等等。
脚本和Recording Log最大的差别在于,脚本只记录了client端要对serv er端所说的话,而Recording Log则是完整纪录二者的对话。
当执行脚本时,您可以把VuGen想象成是一个演员,它伪装成浏览器,然后根据脚本,把当初真的浏览器所说过的话,再对网站伺服器重新说一遍,VuGen企图骗过服务器,让服务器以为它就是当初的浏览器,然后把网站内容传送给VuGen。
所以纪录在脚本中要跟服务器所说的话,完全与当初录制时所说的一样,是写死的(hard-coded)。
这样的作法在遇到有些比较聪明的服务器时,还是会失效。
这时就需要透过「关联(correlation)」的做法来让VuGen可以再次成功地骗过服务器。
何谓关联(correlation)?所谓的关联(correlation)就是把脚本中某些写死的(hard-coded)数据,转变成是撷取自服务器所送的、动态的、每次都不一样的数据。
举一个常见的例子,刚刚提到有些比较聪明的服务器,这些服务器在每个浏览器第一次跟它要数据时,都会在数据中夹带一个唯一的辨识码,接下来就会利用这个辨识码来辨识跟它要数据的是不是同一个浏览器。
一般称这个辨识码为Session ID。
对于每个新的交易,服务器都会产生新的Session ID给浏览器。
这也就是为什么执行脚本会失败的原因,因为VuGen还是用旧的Session ID向服务器要数据,服务器会发现这个Session ID是失效的或是它根本不认识这个Session ID,当然就不会传送正确的网页数据给VuGen了。
下面的图示说明了这样的情形:当录制脚本时,浏览器送出网页A的请求,服务器将网页A的内容传送给浏览器,并且夹带了一个ID=123的数据,当浏览器再送出网页B的情求时,这时就要用到ID=123的数据,服务器才会认为这是合法的请求,并且把网页B的内容送回给浏览器。
在执行脚本时会发生什么状况?浏览器再送出网页B的请求时,用的还是当初录制的ID=123的数据,而不是用服务器新给的ID=456,整个脚本的执行就会失败。
要对付这种服务器,我们必须想办法找出这个Session ID到底是什么、位于何处,然后把它撷取下来,放到某个参数中,并且取代掉脚本中有用到Session ID的部份,这样就可以成功骗过服务器,正确地完成整个交易了。
哪些错误代表着我应该做关联(correlation)?假如脚本需要关联(correlation),在还没做之前是不会执行通过的,也就是说会有错误讯息发生。
不过,很不幸地,并没有任何特定的错误讯息是和关联(correlation)有关系的。
会出现什么错误讯息,与系统实做的错误处理机制有关。
错误讯息有可能会提醒您要重新登入,但是也有可能直接就显示HTTP 404的错误讯息。
要如何做关联(correlation)?关联(correlation)函数关联(correlation)会用到下列的函数:• web_reg_sav e_param:这是最新版,也是最常用来做关联(correlation)的函数。
语法:web_reg_sav e_param ( “Parameter Name” , < list of Attributes >, LAST );• web_create_html_param、web_create_html_param_ex:这二个函数主要是保留作为向前兼容的目的的。
建议使用web_reg_sav e_param 函数。
详细用法请参考使用手册。
在VuGen中点选【Help】>【Function ref erence】>【Contexts】>【Web and Wireless Vuser Functions】>【Correlation Functions】。
如何找出要关联(correlation)数据简单的说,每一次执行时都会变动的值,就有可能需要做关联(correlation)。
VuGen提供二种方式帮助您找出需要做关联(correlation)的值:1. 自动关联2. 手动关联自动关联VuGen内建自动关联引擎(auto-correlation engine),可以自动找出需要关联的值,并且自动使用关联函数建立关联。
自动关联提供下列二种机制:• Rules Correlation:在录制过程中VuGen会根据订定的规则,实时自动找出要关联的值。
规则来源有两种:o 内建(Built-in Correlation):VuGen已经针对常用的一些应用系统,如AribaBuy er、BlueMartini、BroadVision、InterStage、my SAP、NetDy namics、Oracle、PeopleSof t、Siebel、Silv erJRunner等,内建关联规则,这些应用系统可能会有一种以上的关联规则。
您可以在【Recording Options】>【Internet Protocol】>【Correlation】中启用关联规则,则当录制这些应用系统的脚本时,VuGen会在脚本中自动建立关联。
您也可以在【Recording Options】>【Internet Protocol】>【Correlation】检视每个关联规则的定义。
o 使用者自订(User-def ined Rules Correlation):除了内建的关联规则之外,使用者也可以自订关联规则。
您可以在【Recording Options】>【Internet Protocol】>【Correlation】建立新的关联规则。
• Correlation Studi o:有别于Rules Correlation,Correlation Studio则是在执行脚本后才会建立关联,也就是说当录制完脚本后,脚本至少须被执行过一次,Correlation Studio才会作用。
Correlation Studio会尝试找出录制时与执行时,服务器响应内容的差异部分,藉以找出需要关联的数据,并建立关联。
Rule Correlation请依照以下步骤使用Rule Correlation:1. 启用auto-correlation1. 点选VuGen的【Tools】>【Recording Options】,开启【Recording Options】对话窗口,选取【Internet Protocol】>【Correlation】,勾选【Enable correlation during recording】,以启用自动关联。
2. 假如录制的应用系统属于内建关联规则的系统,如AribaBuy er、BlueMartini、BroadVision、InterStage、my SAP、NetDy namics、Oracle、PeopleSof t、Siebel、Silv erJRunner等,请勾选相对应的应用系统。
3. 或者也可以针对录制的应用系统加入新的关联规则,此即为使用者自订的关联规则。
4. 设定当VuGen侦测到符合关联规则的数据时,要如何处理:♣【Issue a pop-up message and let me decide online】:跳出一个讯息对话窗口,询问您是否要建立关联。
♣【Perf orm. correlation in sceipt】:直接自动建立关联2. 录制脚本开始录制脚本,在录制过程中,当VuGen侦测到符合关联规则的数据时,会依照设定建立关联,您会在脚本中看到类似以下的脚本,此为BroadVision应用系统建立关联的例子,在脚本批注部分可以看到关联前的数据为何。
3. 执行脚本验证关联是OK的。
Correlation Studio当录制的应用系统不属于VuGen预设支持的应用系统时,Rule Correlation可能既无法发挥作用,这时可以利用Correlation Studio来做关联。
Correlation Studio会尝试找出录制时与执行时,服务器响应内容的差异部分,藉以找出需要关联的数据,并建立关联。
使用Correlation Studio的步骤如下:1. 录制脚本并执行2. 执行完毕后,VuGen会跳出下面的【Scan Action f or Correlation】窗口,询问您是否要扫描脚本并建立关联,按下【Yes】按钮。
3. 扫描完后,可以在脚本下方的【Correlation Results】中看到扫描的结果。
4. 检查一下扫瞄的结果后,选择要做关联的数据,然后按下【Correlate】按钮,一笔一笔做,或是按下【Correlate All】让VuGen一次就对所有的数据建立关联。
注意:由于Correlation Studio会找出所有有变动的数据,但是并不是所有的数据都需要做关联,所以不建议您直接用【Correlate All】。
5. 一般来说,您必须一直重复步骤1~4直到所有需要做关联的数据都找出来为止。
因为有时前面的关联还没做好之前,将无法执行到后面需要做关联的部份。
有可能有些需要做关联的动态数据,连Correlation Studio都无法侦测出来,这时您就需要自行做手动关联了。
手动关联手动关联的执行过程大致如下:1. 使用相同的业务流程与数据,录制二份脚本2. 使用WinDiff工具协助找出需要关联的数据3. 使用web_reg_sav e_param函数手动建立关联4. 将脚本中有用到关联的数据,以参数取代接下来将详细的说明如何执行每个步骤使用相同的业务流程与数据,录制二份脚本1. 先录制一份脚本并存档。
2. 依照相同的操作步骤与数据录制第二份脚本并存盘。
注意,所有的步骤和输入的数据一定都要一样,这样才能找出由服务器端产生的动态数据。
有时候会遇到真的无法使用相同的输入数据,那您也要记住您使用的输入数据,到时才能判断是您输入的数据,还是变动的数据。
使用WinDiff工具协助找出需要关联的数据1. 在第二份脚本中,点选VuGen的【Tools】>【Compare with Vuser…】,并选择第一份脚本。