【盛唐】JAVA版数据清洗工具操作手册v1.0
大数据分析中数据清洗的使用教程

大数据分析中数据清洗的使用教程在大数据分析中,数据清洗是一个非常重要的步骤。
它的作用是从原始数据集中去除不完整、不准确、重复或无用的数据,并将其转化为更适合进行分析的格式。
本文将为大家提供一份详细的数据清洗使用教程,帮助您更好地理解和应用数据清洗技术。
一、什么是数据清洗?数据清洗是指对原始数据进行处理、筛选和转换的过程,目的是将数据转化为更高质量、更完整、更规范的数据集。
数据清洗的目标是消除数据中的噪声、错误和冗余,并提高数据的一致性和可用性。
二、为什么需要数据清洗?在数据分析过程中,原始数据中常常包含许多问题,如缺失值、异常值、重复数据和错误数据。
这些问题数据对于分析的准确性和可靠性会产生不良影响。
因此,进行数据清洗是必要的。
除此之外,数据清洗还可以提高数据的质量,为后续的数据分析提供更可靠的基础。
三、数据清洗的常用步骤1. 数据收集和整理:在进行数据清洗之前,需要首先收集原始数据并对其进行整理。
这包括将数据从不同来源整合到一个数据集中,并进行必要的数据格式转换。
2. 处理缺失值:缺失值是指数据集中的某些值未被记录或者未能获取。
在数据清洗过程中,需要先检测并处理缺失值。
常用的处理方法包括删除包含缺失值的数据行、进行插补(如均值插补、回归插补等)或根据实际情况进行适当的处理。
3. 处理异常值:异常值是指与其他观测值明显不同的数据。
异常值可能是由于数据输入错误、测量误差、系统错误或其他原因引起的。
在数据清洗过程中,需要识别并处理异常值。
一种常见的方法是使用统计学方法,如均值加减3倍标准差等来判断异常值,并将其进行修正或删除。
4. 去重:数据集中可能存在重复数据,这会对后续的分析造成偏差。
因此,在进行数据清洗时,需要去除重复数据。
可以使用数据处理软件或编程语言中的去重函数或算法进行去重操作。
5. 数据格式转换:在数据清洗过程中,还需要将数据转化为适合进行后续分析的格式。
数据格式转换可能涉及到数值类型、日期类型、文本类型等的转换。
数据库的数据清洗与整理说明书

数据库的数据清洗与整理说明书一、背景介绍在现代社会中,数据的重要性得到了广泛认可和应用。
数据库作为存储、管理和处理数据的重要工具,充当着数据驱动决策的基础。
然而,数据的质量问题一直是困扰数据库应用的重要挑战之一。
数据清洗和整理是保证数据库数据质量的关键步骤。
本说明书旨在介绍数据库数据清洗与整理的具体步骤和方法,以指导用户进行数据清洗和整理工作。
二、数据清洗1. 数据清洗的定义数据清洗是指通过识别、更正或删除数据库中的错误、不一致或不完整的数据,以提高数据的准确性和一致性。
2. 数据清洗步骤(1)数据审查:对数据库中的数据进行全面审查,包括数据格式、数据完整性和数据一致性等方面。
(2)数据验证:通过验证规则和逻辑,对数据的准确性进行验证,识别出可能存在的错误或异常数据。
(3)数据修复:对识别出的错误数据进行修复,可以通过手动修复、自动修复或者数据替换等方式进行。
(4)数据删除:对无效的、冗余的或重复的数据进行删除,以提高数据库的运行效率和数据的整洁性。
三、数据整理1. 数据整理的定义数据整理是指对数据库中的原始数据进行分类、排序和组织,以提高数据的可读性和可用性。
2. 数据整理步骤(1)数据分类:将数据库中的数据按照一定的规则和标准进行分类,可以根据数据的类型、属性或者业务需求进行分类。
(2)数据排序:对分类后的数据进行排序,可以按照字母、数字、时间或其他用户定义的排序规则进行排序。
(3)数据组织:将排序后的数据按照一定的结构和格式进行组织,以便用户进行查阅和利用。
(4)数据标准化:对数据库中的数据进行统一的格式和标准化处理,以提高数据的一致性和可比性。
四、附加说明1. 数据备份:在进行数据清洗和整理之前,务必进行数据库的备份,以避免数据丢失和不可逆的操作错误。
2. 数据安全:在数据清洗和整理过程中,要注意数据的安全性,避免数据泄露或被非法利用。
3. 数据更新:数据库中的数据是动态变化的,需要定期进行数据清洗和整理的更新,以保证数据的准确性和完整性。
数据清洗与整理的流程与步骤详解(六)

数据清洗与整理的流程与步骤详解数据在如今的社会中扮演着越来越重要的角色,它们是我们从各种资源中提取知识和洞见的基础。
然而,真实世界中的数据并非总是干净、整洁的。
数据清洗和整理是为了确保数据的准确性、一致性和完整性,从而为后续数据分析和建模提供可靠的基础。
本文将详细介绍数据清洗和整理的流程与步骤。
1. 数据获取数据清洗和整理的第一步是获取原始数据。
原始数据可以来自各种渠道,如数据库、日志文件、传感器等。
在获取数据之前,需要先确定所需数据的类型和格式,以便在后续的清洗和整理过程中使用相应的工具和技术。
2. 数据评估在进行数据清洗和整理之前,需要对原始数据进行评估。
评估包括对数据的质量、完整性和一致性进行检查。
例如,检查是否存在缺失值、重复值、错误值、异常值等。
评估可以帮助我们了解数据的整体状况,并决定采取哪些措施来清洗和整理数据。
3. 数据清洗数据清洗是指对原始数据进行处理,以修复其错误、缺失或不一致的部分。
在清洗数据时,可以采用以下几种常见的技术:- 缺失值处理:当数据中存在缺失值时,可以选择删除缺失值所在的行,或者根据其他数据进行插值填充。
- 异常值处理:对于异常值,可以选择删除或修正。
删除异常值可能会导致数据的缺失,而修正异常值可能需要依赖领域知识和统计方法。
- 重复值处理:重复值是指数据集中存在多个相同的观测值。
对于重复值,可以直接删除或合并为一个唯一的值。
- 数据格式化:数据格式化是指将数据转换为特定的格式,以满足后续分析和建模的需求。
例如,将日期和时间格式标准化为统一的格式。
4. 数据整理数据整理是指对清洗后的数据进行组织,以便后续分析使用。
数据整理可以包括以下步骤:- 数据变量选择:根据分析目标,选择需要的数据变量。
- 数据变量命名规范化:为了保持数据集的一致性和易读性,可以对数据变量进行命名规范化。
- 数据变量转换:根据分析的需要,可以对数据进行转换,如对数变换、归一化等。
- 数据集合并:如果有多个数据源,可以将它们合并为一个数据集,以便进行综合分析。
数据清洗:第4章 常用数据清洗工具及基本操作
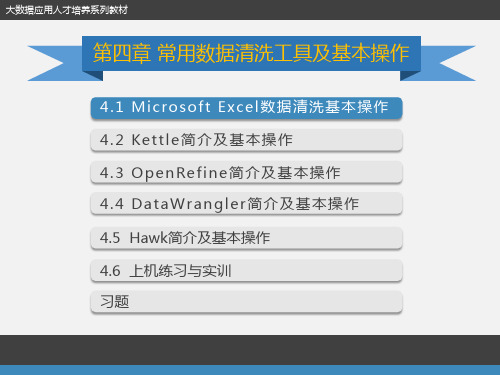
4.1 Microsoft Excel数据清洗基本操作 4.1.1Excel数据清洗概述
第四章 常用数据清洗工具及基 本操作
Microsoft Excel是微软公司Microsoft Office系列办公软件的重要组件之一,是一 个功能强大的电子表格程序,能将整齐而美观的表格呈现给用户,还可以将表格中的数 据通过多种形式的图形、图表表现出来,增强表格的表达力和感染力。Microsoft Excel 也是一个复杂的数据管理和分析软件,能完成许多复杂的数据运算,帮助使用者做出最 优的决策。利用Excel内嵌的各种函数可以方便地实现数据清洗的功能,并且可以借助过 滤、排序、作图等工具看出数据的规律。另外,Excel还支持VBA编程,可以实现各种更 加复杂的数据运算和清理。
图4118显示爬取的前20条数据图4119经过删除操作后的数据集图4120提取数字操作第四章常用数据清洗工具及基本操作kettle简介及基本操作microsofexcel数据清洗基本操作ne简介及基本操作45hawk简介及基本操作datawrangler简介及基本操作46上机练习与实训习题大数据应用人才培养系列教材7046上机练习与实训第四章常用数据清洗工具及基本操作7070实训题目使用工具进行数据清洗练习实训原理数据清洗就是利用有关技术如数理统计数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据
第四章 常用数据清洗工具及基本 操作
存储 存储成本下降
图4-7 完成数据分列
4.1 Microsoft Excel数据清洗基本操作
第四章 常用数据清洗工具及基本 操作
2 快速定位和快速填充
在日常的工作中经常会看到一些重复项合并的Excel表格,如月份、地区等,主要 是为了方便查看,如图4-8所示A列的销售区。但这样的工作表,没有办法使用数据 透视表功能进行统计、汇总和分析等。
数据清洗方法

数据清洗方法
数据清洗是数据处理过程中的一项重要任务,通过去除冗余、不一致、重复或错误的数据,提高数据质量和准确性。
以下是一些常用的数据清洗方法:
1. 去除重复数据:查找数据集中重复的记录,并将其删除。
可以使用工具或编程语言的函数来实现。
2. 处理缺失值:检查数据中的缺失值,并决定如何处理。
可以选择删除包含缺失值的记录,或使用合适的插值方法填充缺失值。
3. 格式转换:对数据中的不同格式进行统一,以便后续分析。
例如,将日期格式转换为统一的日期时间格式,将字符串转换为数字等。
4. 异常值处理:检测和处理异常值,这些值可能是由于数据收集或输入错误导致的。
可以根据业务知识或统计方法来处理异常值。
5. 数据类型转换:将数据字段的类型更改为正确的类型。
例如,将字符串转换为日期、将数字转换为分类变量等。
6. 解决不一致性:检查数据中的不一致或不准确的值,并进行修正或删除。
例如,对于性别字段,将不一致的“男”和“M”转
换为统一的“男性”。
7. 删除无关数据:删除对于分析任务无关的列或行,以减少数据集的复杂度和冗余程度。
8. 标准化和归一化:将数据转换为相同的标准或范围,以消除单位或大小的差异,以便进行比较和分析。
9. 数据合并:将多个数据源中的相关数据合并到一个数据集中,以便进行综合分析。
10. 数据采样:从大型数据集中抽取代表性的样本,以减少计
算和分析的复杂度。
以上是一些常用的数据清洗方法,根据具体的数据和分析任务,可以选择合适的方法来清洗数据,提高数据的质量和可用性。
数据清洗与整理软件的基本操作

数据清洗与整理软件的基本操作第一章:数据清洗的概念与意义数据清洗是指对原始数据进行处理,去除错误、重复、不完整和冗余等无效信息,保证数据的准确性和完整性,为后续的数据分析和建模提供可靠的基础。
数据清洗是数据科学中不可或缺的一部分,其重要性不言而喻。
第二章:数据清洗的流程与方法2.1 数据预处理:数据预处理是数据清洗的首要步骤,包括数据采集、数据清洗、数据集成和数据转换等。
在这一阶段,需要对数据进行正确的格式化和标准化,对缺失值进行处理,处理异常值等。
2.2 数据质量评估:数据质量评估是对清洗后的数据进行质量的评估和监控,以确保数据的准确性和一致性。
常见的数据质量评估方法包括数据可视化、数据统计和数据挖掘等。
2.3 数据清洗方法:数据清洗方法主要包括数据去重、数据变换、数据标准化和数据规范化等。
其中,数据去重是指去除数据集中的重复记录;数据变换是指对数据进行转换,以满足分析模型的需求;数据标准化是将数据按照一定的标准进行处理,以保证数据的一致性;数据规范化是对数据进行统一的格式标准化处理,以方便后续的数据分析和处理。
第三章:3.1 Excel:Excel是最常用的办公软件之一,也是数据清洗与整理的重要工具之一。
通过Excel可以进行数据筛选、排序、去重、替换、拆分、合并等操作,大大提高数据清洗与整理的效率和准确性。
3.2 OpenRefine:OpenRefine是一款免费的数据清洗工具,可以处理各种格式的数据,如CSV、Excel、JSON等。
OpenRefine提供了丰富的数据清洗函数,包括拆分列、合并列、转化数据类型、去除空格等,方便用户进行定制化的数据清洗操作。
3.3 Python:Python是一种通用的编程语言,在数据科学领域被广泛应用于数据清洗与整理。
通过Python中的pandas库和numpy 库,可以进行数据的读取、处理、清洗和整理等操作。
此外,Python还提供了丰富的数据可视化工具,如matplotlib和seaborn 等,方便用户对清洗后的数据进行可视化分析。
(完整版)数据清洗规则

(完整版)数据清洗规则数据清洗是数据分析中非常重要的一步,它可以匡助我们提高数据的质量和准确性,从而为后续的数据分析工作打下坚实的基础。
本文将介绍数据清洗的完整版规则,包括数据清洗的概述以及五个部份的详细内容。
一、数据清洗的概述数据清洗是指对原始数据进行筛选、处理和转换,以消除数据中的错误、不一致和冗余,从而使数据变得更加可靠和准确。
数据清洗的目标是提高数据的质量,使其适合于后续的数据分析和挖掘工作。
二、数据清洗规则的制定1.1 数据格式的规范化在数据清洗过程中,首先需要对数据的格式进行规范化处理。
这包括统一日期、时间、货币和单位的表示方式,统一缺失值和异常值的表示方式等。
通过规范化数据格式,可以减少后续数据处理的复杂性,提高数据的可靠性和一致性。
1.2 数据缺失值的处理数据中往往存在缺失值,这会影响后续的数据分析和挖掘工作。
对于缺失值的处理,可以采取删除、插值和填充等方法。
删除缺失值可以简化数据分析的过程,但可能会导致数据的丢失。
插值方法可以根据已有数据的特征来猜测缺失值,但可能会引入不确定性。
填充方法可以使用统计指标(如均值、中位数等)来填充缺失值,但需要注意不要引入过多的偏差。
1.3 数据异常值的处理数据中的异常值可能是由于测量误差、数据录入错误或者数据采集问题等原因引起的。
对于异常值的处理,可以采取删除、替换和标记等方法。
删除异常值可以提高数据的准确性,但可能会导致数据的丢失。
替换异常值可以使用统计指标(如均值、中位数等)来替换异常值,但需要注意不要引入过多的偏差。
标记异常值可以将其标记为特殊值,以便后续的数据分析和挖掘工作。
三、数据清洗的具体步骤2.1 数据质量的评估在进行数据清洗之前,需要对原始数据的质量进行评估。
这包括检查数据的完整性、一致性、准确性和可用性等方面。
通过评估数据的质量,可以确定数据清洗的重点和方法。
2.2 数据清洗的处理方法根据数据质量评估的结果,可以选择合适的数据清洗方法。
使用编程技术进行数据清洗和预处理的方法和工具

使用编程技术进行数据清洗和预处理的方法和工具数据清洗和预处理是数据分析和机器学习中不可或缺的重要步骤。
通过使用编程技术,我们可以有效地处理和准备数据,以便后续的分析和建模工作。
在本文中,我们将介绍一些常用的方法和工具,帮助您更好地进行数据清洗和预处理。
一、数据清洗数据清洗是指对原始数据进行处理,以去除错误、缺失或异常值。
以下是一些常用的数据清洗方法和技术:1. 缺失值处理:在实际数据中,经常会出现一些缺失值。
处理缺失值的常用方法包括删除包含缺失值的行或列、用平均值或中位数填充缺失值、使用插值方法进行填充等。
2. 异常值处理:异常值可能会对数据分析和建模产生不良影响。
常见的异常值处理方法包括删除异常值、用平均值或中位数替代异常值、使用统计方法检测和处理异常值等。
3. 数据格式转换:有时,数据可能以不正确的格式存储,例如日期时间格式不一致、字符串格式错误等。
通过使用编程技术,可以轻松地将数据转换为正确的格式。
4. 数据去重:在某些情况下,数据集中可能存在重复的记录。
通过去重操作,可以去除重复的数据,确保数据的唯一性。
二、数据预处理数据预处理是指对清洗后的数据进行进一步的处理和转换,以便于后续的分析和建模。
以下是一些常用的数据预处理方法和技术:1. 特征选择:在数据分析和建模过程中,选择合适的特征对结果的准确性至关重要。
通过使用特征选择方法,可以从原始数据中选择出最具有代表性和相关性的特征。
2. 特征缩放:不同特征的取值范围可能不同,这可能会导致某些特征对结果的影响更大。
通过特征缩放,可以将特征的取值范围映射到相同的区间,以便更好地进行比较和分析。
3. 数据变换:有时,数据可能不满足模型的假设,例如非正态分布、异方差等。
通过使用数据变换方法,可以将数据转换为满足模型假设的形式。
4. 数据标准化:在某些情况下,数据的单位和量纲可能不同,这可能会对结果产生不良影响。
通过数据标准化,可以将数据转换为无量纲的形式,以便更好地进行比较和分析。
工具使用手册

工具使用手册1. 引言此工具使用手册旨在为用户提供关于特定工具的详细使用说明和操作指南。
2. 工具概述工具是为解决特定问题或完成特定任务而设计和开发的软件程序。
该工具提供了一系列功能和功能,使用户能够更高效地完成工作。
3. 安装和配置在开始使用该工具之前,用户需要按照以下步骤进行安装和配置:3. 在安装完成后,根据需要配置工具的设置和选项。
4. 工具界面该工具的界面是用户与工具进行交互的主要方式。
以下是工具界面的主要组成部分:1. 菜单栏:包含各种功能和选项的菜单。
2. 工具栏:提供常用功能的快速访问按钮。
3. 主窗口:显示工具的当前状态和操作结果。
4. 侧边栏:显示相关信息和其他辅助功能。
5. 基本操作下面是使用该工具的基本操作步骤:1. 打开工具并登录。
2. 导航到所需的功能或选项。
3. 根据需要输入相关信息和参数。
4. 点击相应的按钮或执行相应的命令以完成操作。
6. 高级功能除了基本操作外,该工具还提供了一些高级功能和选项,以满足用户更复杂的需求。
以下是一些高级功能的示例:- 数据分析和报告生成- 自定义设置和配置- 批量处理和自动化操作- 与其他工具的集成7. 常见问题解答在使用该工具的过程中,用户可能会遇到一些常见问题。
以下是一些常见问题的解答:1. 如何解决登录问题?答:请确保用户名和密码正确,并检查网络连接是否正常。
2. 如何导出数据?答:在相关功能或选项中选择导出操作,并选择目标格式和文件位置。
8. 技术支持和联系方式如果用户在使用该工具的过程中遇到问题或需要进一步帮助,可以通过以下方式联系技术支持团队:- 123-456-78909. 结论本工具使用手册提供了用户所需的详细使用说明和操作指南,以帮助用户更好地使用该工具完成工作。
如果用户有任何进一步的问题或建议,请与技术支持团队联系。
数据清洗实战指南

数据清洗实战指南数据清洗是数据分析过程中不可或缺的一部分。
通过清洗数据,可以去除数据集中的噪声、错误值和冗余信息,提高数据质量,从而得到更准确、可靠的分析结果。
本文将为你详细介绍数据清洗的步骤和技巧。
一、数据清洗的步骤1. 数据获取与导入首先需要获取原始数据,可以通过现有系统、数据库、文件或网络等途径获得。
将数据导入到数据分析工具(如Excel、Python等)中进行后续的清洗操作。
2. 数据评估与理解在清洗之前,我们需要对数据进行评估和理解。
观察数据的整体结构、格式、类型、缺失值、异常值等情况,掌握数据的基本特征,并确保数据集与分析目标一致。
3. 缺失值处理缺失值是数据清洗中常见的问题。
处理缺失值的方法有多种,常见的方法包括删除含有缺失值的样本、用均值、中位数或众数填充缺失值等。
4. 异常值处理异常值指的是与样本总体相差较大的值,可能由于人为错误或测量误差引起。
异常值的存在可能对数据分析造成较大的影响。
处理异常值时,可以根据实际情况选择删除异常值或用合理的值进行替换。
5. 重复值处理重复值是指数据集中某些观测值在特定字段上具有相同的取值。
重复值的存在可能影响数据分析的准确性。
处理重复值时,可以使用去重操作,保留一份唯一的观测值。
6. 数据类型转换在数据清洗过程中,可能需要对数据类型进行转换。
例如,将字符串类型转换为数值类型,或将日期类型进行格式化等。
数据类型转换是为了方便后续的计算和分析操作。
7. 冗余信息处理冗余信息是指在数据集中存在完全相同或高度相似的字段。
冗余信息会增加数据分析的复杂性,并可能导致分析结果的不准确。
在清洗过程中,需要剔除冗余信息,保留唯一的、有意义的字段。
二、数据清洗的技巧1. 使用可视化工具辅助清洗可视化工具如图表、散点矩阵、箱线图等可以帮助我们更直观地观察数据的分布和特征,发现隐藏的问题和异常值。
通过可视化分析,可以更加准确地判断数据是否存在异常和错误。
2. 制定清洗规则和标准在数据清洗过程中,可以预先定义清洗规则和标准,以保证清洗操作的一致性和准确性。
简述数据清洗流程 -回复

简述数据清洗流程-回复数据清洗是指在数据分析之前对原始数据进行处理和整理,以去除噪音、填补缺失值、纠正错误和规范数据格式等操作,从而提高数据的质量和准确性。
数据清洗流程是一个迭代的过程,包括数据导入、数据探索、数据预处理和数据输出等步骤。
下面将详细介绍数据清洗的流程。
一、数据导入(Data Import)数据导入是指将原始数据导入到数据分析软件中进行处理和分析。
常见的数据源包括Excel表格、CSV文件、数据库、API接口等。
在导入数据之前,需要对数据的格式进行了解,包括数据的结构、类型、缺失值的表示形式等。
常见的数据导入工具有Python的pandas库、R语言的readr 库等。
二、数据探索(Data Exploration)数据探索是对数据进行初步观察和分析,以了解数据的特征和分布情况。
主要包括以下几个方面的内容。
1. 变量类型检查:检查变量的数据类型,是否与预期一致,例如数值型、字符型、日期型等。
2. 缺失值检查:检查数据中是否存在缺失值,缺失值常用NaN、NULL 或者空格表示。
对于存在缺失值的变量,需要进一步判断缺失原因。
3. 异常值检查:检查数据中是否存在异常值,即与其他值相比较明显不合理的数据点。
异常值可能是数据录入错误、设备故障等引起的。
4. 重复值检查:检查数据中是否存在重复值,即完全相同的数据记录。
重复值的存在可能会导致样本不均衡,影响数据分析的结果。
5. 数据分布分析:分析数据的分布情况,包括均值、中位数、方差、偏度、峰度等统计指标,以及绘制直方图、箱线图等图形分析数据的分布情况。
三、数据预处理(Data Preprocessing)数据预处理是对原始数据进行处理和转换,以满足数据分析的要求。
主要包括以下几个步骤。
1. 缺失值处理:根据缺失值的原因选择合适的方法进行填补,常见的方法有删除、插值、均值填补、中位数填补等。
2. 异常值处理:根据异常值的原因选择合适的方法进行处理,常见的方法有删除、替换为均值、中位数或者截断等。
数据清洗与处理软件操作指南

数据清洗与处理软件操作指南第一章软件介绍1.1 软件概述数据清洗与处理软件是一种用于清洗、转换和处理数据的工具,能够帮助用户有效管理和分析大量数据,提高数据质量和可信度。
1.2 软件特点- 强大的数据清洗功能:可以去除重复值、空值、异常值等,并进行数据规范化和格式转换。
- 数据预处理:能够进行数据清洗、缺失值填充、异常值处理等操作,提高数据的准确性和可靠性。
- 数据整合和合并:可以将多个数据源中的数据进行整合和合并,减少数据冗余。
- 可视化分析:提供丰富的图表和可视化工具,帮助用户更好地理解和分析数据。
- 批处理功能:支持大规模数据的批量处理,提高数据处理效率。
第二章安装与配置2.1 软件下载与安装- 在官方网站上下载数据清洗与处理软件的安装包。
- 双击安装包,按照提示完成软件的安装过程。
2.2 配置软件环境- 打开软件,在设置中选择数据源、连接和格式等配置选项。
- 根据需要进行必要的配置,点击保存以应用配置更改。
- 确保软件与所需数据源的连接正常。
第三章数据清洗与处理3.1 数据导入- 在软件主界面选择“导入数据”选项,并选择需要导入的数据文件或数据源。
- 选择正确的数据源和文件格式,并进行必要的设置。
- 点击“确定”按钮,等待数据导入完成。
3.2 数据质量检查- 选择“数据质量检查”选项,在弹出的窗口中选择需要进行检查的数据字段。
- 设定检查规则和条件,并设置异常值处理策略。
- 点击“开始检查”按钮,等待检查结果输出。
3.3 数据清洗- 选择“数据清洗”选项,在弹出的窗口中选择需要清洗的数据字段。
- 设定清洗规则和条件,如去除重复值、空值、异常值等。
- 点击“开始清洗”按钮,等待清洗结果输出。
3.4 数据转换与整合- 选择“数据转换”选项,在窗口中选择需要进行转换和整合的数据字段。
- 设定转换和整合规则,如计算新字段、合并数据等。
- 点击“开始转换”按钮,等待转换结果输出。
3.5 数据导出- 选择“数据导出”选项,在窗口中选择需要导出的数据字段和格式。
数据清洗的步骤和技巧

汇报人:
评估数据清洗的效果
清洗前数据的评估
清洗后数据的评估
比较清洗前后的数 据差异
评估清洗效果是否 达到预期目的
使用适当的数据结构
表格结构:将数据 整理成表格形式, 方便查看和操作
数据库结构:使用 数据库管理系统, 如MySQL、Oracle 等,对数据进行存 储和管理
数据仓库结构:将 数据按照星型模型 或雪花模型进行组 织,提高查询性能 和数据质量
a click to unlimited possibilities
汇报人:
目录
确定数据清洗的目标
确定数据清洗的目标和范围 制定数据清洗的计划和标准 数据预处理和转换 数据清洗和修正
制定数据清洗的计划
确定数据清洗的目标和范围
评估数据的质量和完整性
制定数据清洗的策略和步骤
实施数据清洗并检查结果
迭代和反馈:根 据清洗效果,不 断调整和优化清 洗策略
保护原始数据
不改变原始数据
备份原始数据
不要过度清洗
验证清洗后的数据准确性
确定合适的数据清洗策略
根据数据类型和 问题,选择合适 的数据清洗方法
确定数据清洗的 优先级,根据业 务需求和数据质 量评估结果进行 排序
制定数据清洗计 划,包括清洗目 标、清洗范围、 清洗规则、清洗 流程等
培训员工提高数据清洗技能
确定数据清洗 标准和流程
提供培训课程 和资料
实践操作和指 导
定期评估和改 进
数据清洗过程中遇到的问题及解决方法
问题:数据不完整或 缺失
解决方法:补充或估 算缺失值
问题:数据重复或冗 余
解决方法:去重或合 并重复数据
问题:数据格式不一 致
如何正确使用数据清洗与整理工具进行数据处理(五)

数据处理在当今的信息时代中扮演着至关重要的角色。
然而,原始数据的质量往往难以保证。
因此,正确使用数据清洗与整理工具变得至关重要。
本文将讨论如何正确使用这些工具进行数据处理。
一、数据清洗的重要性数据清洗是数据处理的第一步,它包括去除重复项、填充空缺、修复格式错误等。
数据清洗的目的是确保数据的准确性和一致性。
如果原始数据存在问题,后续的数据分析工作将无法进行,可能导致错误结果和做出错误的决策。
二、选择合适的工具市场上有许多数据清洗与整理工具可供选择。
要根据自身需求和技能水平选择合适的工具。
其中一些工具具有用户友好的图形界面,适合初学者;而其他工具则需要一定的编程知识,适合有技术背景的用户。
三、了解数据在进行数据清洗与整理之前,了解数据的结构和内容至关重要。
这包括数据的字段、数据类型以及数据之间的关系。
只有了解数据,才能更好地选择适合的清洗和整理方法。
四、去除重复项重复数据是常见的问题。
它可能是由于人工录入错误、软件问题或其他原因导致的。
要去除重复项,可以使用工具提供的去重功能。
这些功能可以根据指定的字段,快速识别和删除重复的数据行。
五、填充空缺空缺数据是数据处理中的另一个常见问题。
要填充空缺,可以使用工具的填充功能。
填充功能提供了根据相邻数据、均值、中位数等填充缺失值的选项。
根据数据的特点,选择合适的填充方法。
六、修复格式错误格式错误可能影响数据的可读性和处理能力。
例如,日期字段可以以不同的格式存在,需要统一格式。
又如,数字字段可能包含字母或其他非数字字符,需要进行清理。
数据清洗与整理工具通常提供了格式修复功能,可以自动或手动修复格式错误。
七、筛选数据在数据分析中,经常需要根据特定的条件筛选出感兴趣的数据。
数据清洗与整理工具提供了筛选功能,可以根据条件进行数据筛选。
例如,根据时间范围、数据范围、关键词等进行筛选,以获取符合要求的数据集。
八、归并数据集如果需要合并多个数据集,可以使用工具提供的合并功能。
如何正确使用数据清洗与整理工具进行数据处理(八)

如何正确使用数据清洗与整理工具进行数据处理在当今信息爆炸的时代,数据已经成为企业和个人决策的重要依据。
然而,在海量的数据中找出真正有价值的信息并不容易,这就需要使用数据清洗与整理工具进行数据处理。
本文将探讨如何正确地使用这些工具,以提高数据的质量和价值。
一、数据清洗的意义与方法数据清洗是指根据特定的标准和要求,对数据进行筛选、过滤、纠错等操作,以确保数据的准确性和完整性。
数据清洗的目的是消除数据中的噪声、错误和冗余信息,从而得到更加可靠和可用的数据。
在进行数据清洗时,需要注意以下几点:1. 删除冗余数据:冗余数据是指在数据集中存在重复或多余的信息。
这些信息可能会造成数据分析的偏差,因此应该将其删除或合并。
2. 过滤异常值:异常值是指与大部分数据存在较大差异的数据点,可能是由于测量误差或录入错误所导致。
在数据清洗过程中,应该对异常值进行识别并进行处理,以避免对后续分析的影响。
3. 校正错误数据:数据中可能存在错误、缺失或不一致的情况。
正确的处理方法是通过合适的算法或规则,对这些数据进行校正或补充。
二、数据整理的意义与方法数据整理是指将原始数据进行结构化、格式化和规范化的过程。
通过数据整理,可以提高数据的可读性、可理解性和可用性,方便后续的数据分析和挖掘工作。
在进行数据整理时,应注意以下几点:1. 数据格式化:将数据按照特定的格式进行整理,如日期、时间、数值等。
这样做可以确保不同数据具有一致的格式,便于后续的计算和处理。
2. 命名规范化:在数据整理过程中,应保持统一的命名规范。
命名规范可以提高数据的可读性和可管理性,并方便后续的数据查询和使用。
3. 数据归类:将数据按照一定的分类标准进行分组和归类。
这样做可以方便对数据进行汇总和比较,以得出更准确的结论。
三、正确使用数据清洗与整理工具在进行数据清洗与整理时,可以借助各种专业的数据处理软件和工具来提高效率和准确性。
以下是一些常用的工具:1. Microsoft Excel:Excel是一款功能强大的电子表格软件,可以进行数据清洗、整理和分析。
【盛唐】JAVA版数据清洗工具操作手册v1.0

【盛唐】JAVA版数据清洗工具操作手册v1.0文档密级:普通文档状态:[√ ] 草案 [ ]正式发布 [ ]正在修订目录1 系统初始化 (3)1.1 创建MySQL中间库etl-mid (3)1.2 修改中间库配置文件conf/mysql.xml (5)1.2.1 中间库配置文件 (5)1.3 导入建表脚本conf/etl-mid.sql (5)2 系统启动 (7)2.1 启动ETL工具 (7)3 主界面 (8)3.1 系统主界面 (8)3.1.1 主界面介绍 (8)4 模块功能 (9)4.1 任务 (9)4.1.1 任务 (9)4.1.2 打开配置文件 (9)4.1.3 配置文件编写指导 (10)4.1.4 测试数据源(是否可以连接数据库) (11)4.1.5 执行任务或停止任务 (12)4.1.6 定时设置 (14)4.1.7 详细错误日志 (15)4.2 字典管理 (16)4.2.1 字典管理主界面 (16)4.2.2 机构类别管理 (17)4.2.3 字典管理 (23)4.2.4 字典子项管理 (25)4.3 参数配置 (27)4.4 系统帮助 (28)4.4.1 系统帮助 (28)5 常见或重点关注的问题 (29)5.1 导入字典文本 (29)5.1.1 格式及编码 (29)5.2 数据库 (30)5.2.1 密码 (30)【盛唐】JAVA版数据清洗工具操作手册v1.0 1系统初始化1.1创建MySQL中间库etl-mid1.安装MySQL数据库。
2.安装Navicat Premium数据库管理工具。
图1- 1:安装Navicat Premium3.创建新连接,操作如图1-2所示。
图1- 2:创建新连接4.添加数据库连接信息,操作如图1-3所示。
图1- 3:连接数据库5.右键点击连接,新建数据库。
操作如图1-4所示。
图1- 4:新建数据库6.新建数据库,操作如图1-5所示。
数据库名称为:“etl-mid”。
Data Cleaning 1.0 数据清洗包说明书

Package‘DataClean’October12,2022Type PackageTitle Data CleaningVersion1.0Date2016-03-20Author Xiaorui(Jeremy)ZhuMaintainer Xiaorui(Jeremy)Zhu<************************>Depends R(>=3.1.0)Imports xlsx,XMLDescription Includes functions that researchers or practitioners may use to cleanraw data,transferring html,xlsx,txt datafile into other formats.And italso can be used to manipulate text variables,extract numeric variables fromtext variables and other variable cleaning processes.It is originated from aauthor's project which focuses on creative performance in online educationenvironment.The resulting paper of that study will be published soon.License GPL-3RoxygenNote5.0.1NeedsCompilation noRepository CRANDate/Publication2016-03-2509:10:37R topics documented:consolida (2)getSfilesPath (2)htmltodata (3)MergerXLSX (4)Index512getSfilesPath consolida An internal function for data merging.DescriptionThis is a function that use to match original data and addin data with identified variable.Usageconsolida(row,data,mergeVar)Argumentsrow One sample that is already divided from the originalfile.data The"addin"file.mergeVar The variable that use to merge.DetailsThis function is for internal use only,so no need to export it.Itfigures out the ID in the"addin"file then merge variables in addinfile to the originalfile.This function is used for further"lapply"porcess.Valueis single line contains original variables and addin variables.Author(s)Xiaorui.ZhugetSfilesPath Collecting paths of some specifiedfiles that you want to import or read.DescriptionIf you want to collect allfiles under certain folder,this function should be the perfect one.It will collect allfiles with certain name.Then this function will return a list will all paths of thosefiles so that further import or read is feasible.UsagegetSfilesPath(root.path,filename)htmltodata3 Argumentsroot.path is the root path including all folders andfiles that you would like to search.filename is the name offiles that you want to collect.ValueThe whole paths of allfiles that meet the criteria were saved as a list.ExamplesgetSfilesPath(root.path=R.home(),filename="?.exe")htmltodata htmltodataDescription"htmltodata"function is used to transfer information from htmlfiles to R or xlsxfilesUsagehtmltodata(path)Argumentspath is the path of thefile that you want to import into R and then export.ValueThe return data are a list include all text results of submitters’answers.Author(s)Xiaorui(Jeremy)Zhu4MergerXLSX MergerXLSX A function to merger xlsxfiles by a same variable.DescriptionThis is a function that can be used to merger xlsxfile using identified variables.UsageMergerXLSX(original_file,addin_file,mergeID)Argumentsoriginal_file The name of originalfile.Thisfile contains all original data.It should be a "xlsx"file and saved in the same working folder.This input must be a characterstring offile name if it is saved in working directory,or it should include savingpath offile.addin_file Thefile that need to be merged.It should be"xlsx"file and saved in the same working folder.mergeID The merger variable name in bothfiles.The variable name should be same in twofiles.DetailsThis function need three parameters.First is name of the originalfile that contains original data.Second is name offile that need to be merged.Third is the identifiable variable name that in both files.ValueReturn data are all original data with addin variables.Author(s)Xiaorui(Jeremy)ZhuReferencesAuthor’s Github https:///XiaoruiZhu.If you have trouble with rJava or xlsx,please check http://stackoverfl/questions/7019912/using-the-rjava-package-on-win7-64-bit-with-r for fur-ther information tofix it.Examples#file1<-"C:/data.xlsx"#file2<-"C:/data2.xlsx"#merged<-MergerXLSX(file1,file2,mergeID)Indexconsolida,2getSfilesPath,2htmltodata,3MergerXLSX,45。
数据清洗--操作说明

对象监管及清洗功能操作说明
一、登录甘肃精准扶贫大数据平台,点击扶贫对象模块→之后点击导航菜单
→“对象监管”模块,进入功能页面。
二、对象监管功能分为:对象监管、对象清洗管理和规则库三个模块。
1.对象监管:对象监管功能展示2014年以及2015年贫困户信息核查的
统计信息。
其中包括辍学、住房、饮水、大病、收入、致贫原因、身份
校验、贫困户属性八个大类的统计,如下图所示:
2.点击每个分类根据用户行政区划进入用户所属行政区划内该类统计列表页面,点击行政区划可以查看下级该类的统计信息,最后可以定位至户列表,在户列表,点击修改按钮在新页面根据系统提示修改有误数据,如下图所示:
2.1在户详情页面展示该户的对象核查结果,可根据提示进行信息清洗,
核查结果更新请查看更新时间(如果该户没有显示任何问题,则不显示核查结果),如下图:
2.2对象清洗管理:用户可以根据行政区划及分类信息查询用户所在区域内需要清洗对象,点击修改按钮根据页面提示修改信息,如下图所示:
三、规则库:规则库指所有的对象核查筛选数据的规则,如下图所示:
特别说明:对象核查结果统一由系统定时更新,具体更新时间系统在各个功能里面都有显示,对象信息清洗后,结果不会立即更新,最新的结果需要系统数据更新完后才会显示。
数据清洗规程

数据清洗规程数据清洗在数据分析和数据挖掘中扮演着至关重要的角色。
它是将原始数据进行加工处理,通过清理、整合、转换等操作,使得数据可以更好地用于后续的分析和挖掘工作。
数据清洗规程是一个规范化的过程,旨在确保数据的质量和准确性。
本文将介绍一个通用的数据清洗规程,以帮助读者更好地进行数据清洗工作。
一、确定数据清洗目标和需求在进行数据清洗之前,我们需要明确数据清洗的目标和需求。
首先,我们需要确定需要清洗的数据集,并对数据集的性质、结构和特点进行分析。
其次,我们需要明确清洗的目标,例如修正错误数据、填充缺失值、剔除异常值等。
最后,我们需要定义清洗的需求,包括对字段的重命名、增加计算字段、转换数据类型等。
二、处理缺失值缺失值是指在数据集中某些字段中出现的空值或缺失的数据。
处理缺失值是数据清洗中一个重要的步骤。
常见的处理缺失值的方法有删除法、插值法和替换法。
删除法是直接将包含缺失值的样本或字段删除;插值法是通过已知数据来推测缺失值;替换法是根据一定的规则将缺失值替换为特定的值,如均值、中位数等。
三、清除异常值异常值是指与大部分数据不一致的极端值,它们可能是输入错误、记录错误或者表示特殊情况。
异常值对于数据分析和挖掘会产生不利影响,因此需要对其进行清除。
常见的清除异常值的方法有基于统计学的方法和基于规则的方法。
统计学方法是通过计算数据的统计指标,如均值、标准差等,标识和清除异常值;规则方法是根据领域知识和经验设置一些规则,对满足规则的数据进行清除。
四、处理重复值重复值是指数据集中存在完全相同或者相似度非常高的记录。
处理重复值的目的是确保数据的唯一性和准确性。
常见的处理重复值的方法有去重和合并。
去重是通过对数据集中的记录进行比较,并删除重复的记录;合并是将具有相同或者相似特征的记录合并为一条记录。
五、处理错误值错误值是指在数据集中存在的与实际情况不符的数据,通常是由于输入错误或者记录错误引起的。
处理错误值的目的是修正这些错误,使得数据更加准确可靠。
数据清洗与整理的自动化处理方法与工具推荐(六)

数据清洗与整理的自动化处理方法与工具推荐近年来,数据的重要性在各个领域得到了广泛认可。
然而,原始数据往往包含着各种问题和错误,这使得数据清洗和整理成为数据分析中不可或缺的环节。
本文将介绍一些数据清洗和整理的自动化处理方法,并推荐几款工具供大家选择使用。
一、数据清洗的自动化处理方法1. 异常值处理异常值是原始数据中超出正常范围的值,可能是由于输入错误、测量误差或其他原因引起的。
为了保证数据的准确性,我们需要将异常值进行处理。
常用的异常值处理方法包括删除异常值、替换异常值和离散化处理。
2. 缺失值处理缺失值在真实数据中很常见,可能是由于记录错误、非响应或其他原因导致的。
处理缺失值的方法有多种,如删除缺失值、用均值或中位数填充缺失值、根据样本特征进行预测填充等。
3. 数据重复和冗余处理数据重复和冗余会导致数据分析结果不准确,并增加计算的复杂性。
处理数据重复和冗余可以通过去重和合并重复数据等方法实现。
4. 格式规范化原始数据可能存在格式不一致或不规范的情况,如日期格式、单位转换等。
为了方便后续分析和计算,我们需要对数据进行格式规范化处理。
二、数据整理的自动化处理方法1. 数据连接与合并在实际的数据分析工作中,常常需要将多个数据源进行连接或合并。
这时,我们可以利用数据库的连接操作或使用数据处理软件进行数据合并。
2. 数据透视表数据透视表是一种强大的数据整理工具,可以对数据进行分类、汇总和计算。
通过数据透视表,我们可以快速有效地进行数据整理和分析工作。
3. 数据转换与逆转换有时候,我们需要对数据进行转换,如数据的标准化、归一化等。
而在某些情况下,可能需要将数据进行逆转换,以便进行原始数据的分析。
三、数据清洗与整理的工具推荐1. OpenRefineOpenRefine是一款开源的数据清洗工具,它提供了丰富的数据清洗和整理功能,可以灵活处理各种数据格式。
2. Python PandasPython Pandas库是一种功能强大的数据处理工具,它提供了丰富的数据清洗和整理函数,支持灵活的数据操作和转换。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【盛唐】JAVA版数据清洗工具操作手册v1.0文档密级:普通文档状态:[√ ] 草案 [ ]正式发布 [ ]正在修订目录1 系统初始化 (3)1.1 创建MySQL中间库etl-mid (3)1.2 修改中间库配置文件conf/mysql.xml (5)1.2.1 中间库配置文件 (5)1.3 导入建表脚本conf/etl-mid.sql (5)2 系统启动 (7)2.1 启动ETL工具 (7)3 主界面 (8)3.1 系统主界面 (8)3.1.1 主界面介绍 (8)4 模块功能 (9)4.1 任务 (9)4.1.1 任务 (9)4.1.2 打开配置文件 (9)4.1.3 配置文件编写指导 (10)4.1.4 测试数据源(是否可以连接数据库) (11)4.1.5 执行任务或停止任务 (12)4.1.6 定时设置 (14)4.1.7 详细错误日志 (15)4.2 字典管理 (16)4.2.1 字典管理主界面 (16)4.2.2 机构类别管理 (17)4.2.3 字典管理 (23)4.2.4 字典子项管理 (25)4.3 参数配置 (27)4.4 系统帮助 (28)4.4.1 系统帮助 (28)5 常见或重点关注的问题 (29)5.1 导入字典文本 (29)5.1.1 格式及编码 (29)5.2 数据库 (30)5.2.1 密码 (30)【盛唐】JAVA版数据清洗工具操作手册v1.0 1系统初始化1.1创建MySQL中间库etl-mid1.安装MySQL数据库。
2.安装Navicat Premium数据库管理工具。
图1- 1:安装Navicat Premium3.创建新连接,操作如图1-2所示。
图1- 2:创建新连接4.添加数据库连接信息,操作如图1-3所示。
图1- 3:连接数据库5.右键点击连接,新建数据库。
操作如图1-4所示。
图1- 4:新建数据库6.新建数据库,操作如图1-5所示。
数据库名称为:“etl-mid”。
字符集需选择“utf-8—UTF-8 Unicode”;排序规则设置为“utf8_general_ci”。
图1- 5:新建数据库1.2修改中间库配置文件conf/mysql.xml1.2.1中间库配置文件1.中间库配置文件为文件夹config下的mysql.xml。
图1- 6:中间库配置文件2.中间库配置文件中,可以配置服务器名称、数据库名称、登录名、密码和数据源最大连接数,如图1-7所示。
图1- 7:中间库配置1.3导入建表脚本conf/etl-mid.sql1.打开管理工具Navicat Premium,右键点击数据库,运行SQL文件。
图1- 8:运行SQL文件2.选择运行的sql文件(如图1-9所示),操作如图1-10所示。
图1- 9:中间库图1- 10:运行SQL文件3.也可以导入建表脚本,输入命令行:sourse <文件目录>/conf/etl-mid.sql。
2系统启动2.1启动ETL工具1.将名为ETLTools.rar的压缩包解压,得到如图2-1所示的文件夹appTool。
图2- 1:解压压缩包2.进入文件夹,双击etltools.jar,启动工具,如图2-3所示。
图2- 2:双击启动工具图2- 3:工具主界面3主界面3.1系统主界面3.1.1主界面介绍1.通过顶端导航选择操作;其它三个区域可进行相关信息的查看。
图3- 1:主界面介绍2.可以通过点击如图3-2所示的箭头,伸缩区域,方便查看相应信息。
也可以通过鼠标,拖动边框,调整区域适合的大小。
图3- 2:区域伸缩4模块功能4.1任务4.1.1任务1.点击“任务”,可以看到如图4-1所示菜单。
图4- 1:点击任务4.1.2打开配置文件1.点击“打开配置文件”,位置如图4-2所示。
弹出如图4-4所示窗口。
图4- 2:打开配置文件2.选择配置文件,并打开,任务列表中将添加一条任务(当任务taskId没有重复,且配置文件编码为UTF-8时)。
配置文件写法,可参考template.xml。
操作如图4-4所示。
图4- 3:配置文件模板图4- 4:选择配置文件图4- 5:添加新的任务4.1.3配置文件编写指导1.mysql.xml配置文件为该工具的数据库配置文件,即中间库配置文件。
根据实际情况修改服务器地址,数据库名称等信息。
图4- 6:清洗工具数据库配置2.添加任务时需打开配置文件,配置文件编写请参考template.xml。
mysql、sqlserver、oracle数据库配置示例如图4-7所示。
图4- 7:数据库配置3.每个任务有唯一的taskId;具体参数请查看template.xml文件。
上传至服务器的数据转换规则和校验条件可以使用系统提供的,当系统提供的不能满足要求时可以在TransformSupport.js(转换)、ValidateSupport.js(校验)文件中添加方法。
如图4-8为例,“TransformRule”的值为“dict”,代表调用数据字典规则转换数据,“dictCode”后面对应字典码;如为“custom”,即自定义模式,“dictCode”后面通过“$JS”调用对应TransformSupport.js文件里的方法。
“validateMethod”后面“$SYS”为使用系统方法,$JS为调用ValidateSupport.js里的校验方法。
提示:系统内置校验方法在CommonUtil.java中。
“autoUpload”值为“true”时,清洗数后直接上传至目标服务器;“false”时不会上传。
图4- 8:任务配置4.1.4测试数据源(是否可以连接数据库)1.选择“测试数据源”,位置如图4-9所示。
弹出如图4-10所示窗口。
图4- 9:测试数据源2.选择数据库信息前的复选框,点击“测试”按钮,对数据源进行连接测试。
操作如图4-10所示。
图4- 10:测试数据源4.1.5执行任务或停止任务1.选择任务前的复选框,如图4-11所示。
选中任务,任务信息变蓝色,可通过右键点击任务,取消选定。
执行任务前,请测试数据源连接是否正常。
图4- 11:选中任务2.点击“任务”,如要将未启动的任务执行,选择“执行任务”;如要将启动中的任务停止,选择“停止任务”。
操作如图4-12所示。
图4- 12:执行或停止任务3.如果任务已经执行过,想要重新执行任务,第二次打开该任务对应的配置文件,之前执行的结果将会清空。
注意:如停止任务时,已经上传数据至中心服务器,中心服务器上的数据需手动删除。
4.执行任务中,可以查看执行任务的具体信息,如图4-13所示。
图4- 13:执行任务详情5.执行中产生的错误信息会在右侧区域显示。
图4- 14:执行中产生的错误信息6.当执行多个任务时,未选中任何一个任务,右侧区域显示任务错误信息为所有执行任务的错误信息。
当任务列表选中一个任务时,右侧区域显示对应任务的错误信息。
如图4-15所示,左侧任务列表选中taskId为“task_LISRESULT_TEST”的任务,右侧区域显示错误信息都是taskId为“task_LISRESULT_TEST”的任务错误信息。
选中任务后需要查看全部信息时,鼠标右键点击选中的任务,所点击的选中任务将取消选中。
错误信息列表将显示所有未选中任务的错误信息。
图4- 15:选中任务的执行错误信息4.1.6定时设置4.1.6.1设置定时设置功能的配置信息1.点击“定时设置”,位置如图4-16所示。
图4- 16:定制设置2.配置文件中,可以对“定时设置”功能进行配置。
配置信息如图4-17所示。
“autoStartTime”表示自动化作业的开始时间,“cyclePeriod”表示循环周期(小时),“durationTime”表示任务每次运行多久(小时)。
具体信息请参考配置模板template.xml。
图4- 17:“定时设置”配置3.点击“定时设置”弹出如图4-18所示窗口,在配置文件中设置的autoStartTime、cyclePeriod、durationTime值对应“自动执行时间”、“循环周期”、“每次时长”。
4.1.6.2修改定时设置配置信息1.选择需修改信息前的复选框(每次只能选择一个复选框),点击“修改”按钮。
或通过双击信息的方式,进行修改。
图4- 19:修改配置信息4.1.6.3打开或关闭定时1.选择需要执行的任务前的复选框,点击“开启定时”或“关闭定时”即可改变任务的定时状态。
当“状态”为打开时,对应的数据清洗任务将在指定时间(即自动执行时间)开始执行,不需要手动点击“执行任务”。
已知一任务已经设置定时,并“状态”为打开,在非该任务执行时间段内,手动执行该任务,任务将被执行,但系统检测出当前时间非该任务运行时间时,任务停止执行。
图4- 20:开启定时或关闭定时4.1.7详细错误日志1.点击“详细错误日志”,位置如图4-21所示。
弹出如图4-22所示窗口。
图4- 21:详细错误日志2.在错误日志窗口中,用户可以选择每页条数,选择任务,进行查询。
点击“清空错误信息”按钮,系统将清空数据库中对应的错误记录。
如图4-22所示。
图4- 22:错误日志3.执行任务时,或执行任务后,可以在任务右侧查看错误信息。
错误列表区域如图4-23所示。
图4- 23:错误信息4.2字典管理4.2.1字典管理主界面1.点击“字典管理”,弹出如图4-24所示窗口。
图4- 24:字典管理2.双击左侧机构类别,查看如图4-25所示信息。
3.选择字典信息,即可在下边表格中查看对应字典的子项信息。
如图4-26所示。
图4- 26:查看字典子项4.2.2机构类别管理1.右键点击类别,可出现如图4-27所示菜单。
图4- 27:机构类别管理2.点击“添加子节点”,添加节点名称后,点击“确定”按钮,可完成子节点添加操作。
图4- 28:添加子节点3.点击“修改本节点”,即可进入如图4-29所示的操作窗口。
图4- 29:修改本节点4.点击“删除本节点”,会出现如图4-30所示的提示框,点击确定后即可完成删除节点操作。
注意:删除节点(即机构),将同时删除其下属机构和字典。
图4- 30:删除节点警示框5.点击“导入字典”,可以选择字典信息文件,进行导入操作。
此步骤只是完成了源库字典的导入,导入字典前的准备工作请参考4.2.2.1。
4.2.2.1导入字典前的准备工作1.找出数据库中字典表(以表YY_YYDMK为例),如图4-31所示。
当字典数据很多,录入工作量很大时,可使用字典的导入功能,批量导入字典数据。
图4- 31:字典表示例2.选中表格,右键点击表格,选择“导出向导”。
提示:建议使用Navicat支持mysql数据库的界面管理工具。
图4- 32:导出表3.选择文本文件,点击下一步。