oracle列转行sql详细讲解
Oracle列转行和行转列的几种用法

Oracle列转行和行转列的几种用法栏到栏主要讨论sys_connect_by_path的用法1,具有分层关系SQL > createtabledept(deptnononumber,deptname varchar2 (20),mgrnononumber);table created .SQL >插入deptvalues (1,“总部”,空);1 row created .SQL >插入deptvalues (2,’浙江分公司’,1);1 row created .SQL > insert into dept values(3,’杭州分公司’,2);已创建1行。
SQL >提交;提交完成。
SQL >从部门连接中选择最大值(子串(sys_connect_by_path(deptname,’,’),2))由先前部门连接= mgrno 最大值(SUBSTER(SYS _ CONNECT _ BY _ PATH(DEPTNAME),’),2)-总部,浙江分行,杭州分行2,行-列转换如果一个表的所有列都连接到一行,用逗号分隔:SQL >选择最大值(SUBSTER(SYS _ CONNECT _ BY _ PATH(column _ name,’,’),2))MAX(SUBSTRA(SYS _ CONNECT _ BY _ PATH(COLUMN _ NAME,’,’),2))- DEPTNO,DEPTNAME,MGRNO3,ListAgg(Oracle 11g)SQL >选择DEPTNO,2 ListAgg(NAME,’;’)3在组4内(由搪瓷订购)搪瓷5来自emp6组由deptno7由deptno 8 /DEPTNO搪瓷- -10 CLARK。
国王;米勒20亚当斯;福特。
琼斯;SCOTT。
史密斯30艾伦;布莱克;JAMES;马丁;TURNER;下面的W ARD是使用tempas的列转换1的两种用法(从t_cc_l2_employee 256中选择account_no,user_party_id,data_hierarchy_id+ where account_no不为空)从temp union中选择account _ no,user _ party _ id全部选择account _ no,data _ hierarchy _ id从temp 2 256中选择来自t_cc_l2_employee的data_hierarchy_id,其中account_no不为空,user_party_id不为空,data_hierarchy_id不为空)MODELRETURE UPDATED ROWSPARTITION BY(account _ no)DIMENSION BY(0 AS n) MEASURES(‘ xx ‘ AS cn,’ yyyyyy’ AS cv,user_party_id,data _ hierarchy _ id)RULES UPSERT ALL(cn[1-注意:模型语法SQL经常遇到两个问题1 ora-32638:模型维度中的非唯一寻址(问题是模型结果集中对应于分区依据的列具有重复值)2 ora-25137数据值超出范围(将“yyyyyyyy”中的“yyyyyyy”扩展几个位置可以解决您的问题)255。
sql语句中行转列,以及列转行

sql语句中⾏转列,以及列转⾏⾏转列:图1: --------------------------------------------》》》》 图2:sql执⾏原理:根据id分组,然后select后⾯创建多次查询,⽣成列信息(利⽤case语句给分group by后的语句分类)-- ⾏转列select t.id,sum(case name when'仓库1'then t.num else NULL end) 仓库1,sum(case name when'仓库2'then t.num else NULL end) 仓库2,sum(case name when'仓库3'then t.num else NULL end) 仓库3from tGROUP BY t.id;列转⾏:图1: --------------------------------------------》》》》 图2:第⼀步:sql执⾏原理:每个select语句只查某⼀个字段的值,创建多个查询,然后将多个select语句通过union链接,实现⼀条多列数据变成多⾏⼀列;⽐如⼀⾏仓库1,仓库2,仓库3 最后变成多⾏select p.id, '仓库1' name, p.`仓库1` numfrom pr punionselect p.id, '仓库2' name, p.`仓库2` numfrom pr punionselect p.id, '仓库3' name, p.`仓库3` numfrom pr p执⾏结果:第⼆步:去掉为null的,即不存在⾏select*from (select p.id, '仓库1' name, p.`仓库1` num from pr punionselect p.id, '仓库2' name, p.`仓库2` num from pr punionselect p.id, '仓库3' name, p.`仓库3` num from pr p ) T where T.num is not null order by id, name。
oracle 列转行sql详解

3 start with dept ='人事'
4 connect by prior emp = mgr;
ERROR:
ORA-01436:用户数据中的CONNECT BY循环
未选定行
说明:张强和李飞互为管理者,因此,要用nocycle,如下所示:
SQL> select rpad( ' ', 2*(level-1), ' ' ) || emp "emp"
SQL>
SQL> select rpad( ' ', 2*(level-1), ' ' ) || area_name "AreaName",
2 connect_by_root area_name "Root",
3 connect_by_isleaf "IsLeaf",
4 level ,
5 SYS_CONNECT_BY_PATH(area_name, '/') "Path"
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr;
得到结果为:>KING
>KING>JONES
>KING>JONES>SCOTT
>KING>JONES>SCOTT>ADAMS
>KING>JONES>FORD
>KING>JONES>FORD>SMITH
connect_by_root t.area_name as root, --是单一操作符,返回当前层的最顶层节点
oraclesql一列转多行最简单的方法

oraclesql一列转多行最简单的方法在Oracle SQL中,一列转换为多行的最简单方法是使用UNION ALL 操作符结合SELECT语句。
下面给出一个例子来说明该方法。
假设我们有一个包含员工姓名和城市的表格,我们想将这些信息分开显示在不同的行上。
首先,我们创建一个示例表格并插入一些数据。
CREATE TABLE employeesemployee_id NUMBER,employee_name VARCHAR2(100),city VARCHAR2(100)INSERT INTO employees VALUES (1, 'John Doe', 'New York');INSERT INTO employees VALUES (2, 'Jane Smith', 'Los Angeles');INSERT INTO employees VALUES (3, 'Mike Johnson', 'Chicago');现在,我们可以使用UNIONALL操作符来将姓名和城市分开显示在不同的行上。
SELECT employee_name AS data FROM employeesUNIONALLSELECT city AS data FROM employees;在这个例子中,我们先选择员工姓名并将其命名为"data",然后使用UNION ALL操作符将结果与选择城市结果进行合并。
最终的结果是将一列数据转换为多行数据。
结果如下:DATA---------John DoeJane SmithMike JohnsonNew YorkLos AngelesChicago这种方法非常简单直观,但需要注意的是,UNIONALL操作符合并结果时会保留重复的行。
如果你希望去除重复的值,可以使用UNION操作符代替UNIONALL。
Oracle:Oracle行转列、列转行的Sql语句总结

Oracle:Oracle⾏转列、列转⾏的Sql语句总结例⼦原型:select bkg_num,shpr_cde from CD_XLS_UPLOAD_DETAIL where cd_xls_upload_uuid='392' ;运⾏结果如下:⼀、多字段的拼接将两个或者多个字段拼接成⼀个字段:select bkg_num||shpr_cde from CD_XLS_UPLOAD_DETAIL where cd_xls_upload_uuid='392' ;运⾏结果:⼆、⾏转列将某个字段的多⾏结果,拼接成⼀个字段,获取拼接的字符串【默认逗号隔开】select wm_concat(bkg_num) from CD_XLS_UPLOAD_DETAIL where cd_xls_upload_uuid='392' ;运⾏结果:6098621760,6098621760开拓:如果不想⽤逗号隔开,可以进⾏替换:select replace(wm_concat(bkg_num),',','|') from test; 也可以进⾏分组的拼接:select id,wm_concat(bkg_num) name from test group by id;三、列转⾏原图如下:转成⾏的形式:实现的sql:create table demo(id int,name varchar(20),nums int); ---- 创建表insert into demo values(1, 'apple', 1000);insert into demo values(2, 'apple', 2000);insert into demo values(3, 'apple', 4000);insert into demo values(4, 'orange', 5000);insert into demo values(5, 'orange', 3000);insert into demo values(6, 'grape', 3500);insert into demo values(7, 'mango', 4200);insert into demo values(8, 'mango', 5500);commit;select name, sum(nums) from demo group by name;select * from (select name, nums from demo) pivot(sum(nums) for name in ('apple','orange','grape','mango')); --实现sql注意: pivot(聚合函数 for 列名 in(类型)),其中 in('') 中可以指定别名,in中还可以指定⼦查询,⽐如 select distinct code from customers指定别名如:select * from (select name, nums from demo) pivot(sum(nums) for name in ('apple' 苹果,'orange' 橘⼦,'grape' 葡萄,'mango' 芒果));。
oracle行列转换关系

最近论坛很多人提的问题都与行列转换有关系,所以我对行列转换的相关知识做了一个总结,希望对大家有所帮助,同时有何错疏,恳请大家指出,我也是在写作过程中学习,算是一起和大家学习吧。
行列转换包括以下六种情况:*列转行*行转列*多列转换成字符串*多行转换成字符串*字符串转换成多列*字符串转换成多行下面分别进行举例介绍。
首先声明一点,有些例子需要如下10g及以后才有的知识:a。
掌握model子句,b。
正则表达式c。
加强的层次查询讨论的适用范围只包括8i,9i,10g及以后版本。
begin:1、列转行CREATE TABLE t_col_row(ID INT,c1 VARCHAR2(10),c2 VARCHAR2(10),c3 VARCHAR2(10));INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);COMMIT;SELECT * FROM t_col_row;1)UNION ALL适用范围:8i,9i,10g及以后版本SELECT id, 'c1' cn, c1 cvFROM t_col_rowUNION ALLFROM t_col_rowUNION ALLSELECT id, 'c3' cn, c3 cv FROM t_col_row;若空行不需要转换,只需加一个where条件,WHERE COLUMN IS NOT NULL 即可。
Oracle行转列、列转行的Sql语句总结

Oracle⾏转列、列转⾏的Sql语句总结多⾏转字符串这个⽐较简单,⽤||或concat函数可以实现SQL Code1 2select concat(id,username) str from app_user select id||username str from app_user字符串转多列实际上就是拆分字符串的问题,可以使⽤ substr、instr、regexp_substr函数⽅式字符串转多⾏使⽤union all函数等⽅式wm_concat函数⾸先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显⽰成⼀⾏,接下来上例⼦,看看这个神奇的函数如何应⽤准备测试数据 SQL Code1 2 3 4 5 6create table test(id number,name varchar2(20)); insert into test values(1,'a');insert into test values(1,'b');insert into test values(1,'c');insert into test values(2,'d');insert into test values(2,'e');效果1 : ⾏转列,默认逗号隔开SQL Code1select wm_concat(name) name from test;效果2: 把结果⾥的逗号替换成"|"SQL Code1select replace(wm_concat(name),',','|') from test;效果3: 按ID分组合并nameSQL Code1select id,wm_concat(name) name from test group by id;sql语句等同于下⾯的sql语句:SQL Code1 2 3 4 5 6-------- 适⽤范围:8i,9i,10g及以后版本( MAX + DECODE )select id,max(decode(rn, 1, name, null)) ||max(decode(rn, 2, ',' || name, null)) ||max(decode(rn, 3, ',' || name, null)) strfrom (select id,789101112131415161718192021222324252627282930313233343536 name,row_number () over(partition by id order by name) as rnfrom test) tgroup by idorder by 1;-------- 适⽤范围:8i,9i,10g 及以后版本 ( ROW_NUMBER + LEAD )select id, strfrom (select id,row_number () over(partition by id order by name) as rn,name || lead (',' || name, 1) over(partition by id order by name) ||lead (',' || name, 2) over(partition by id order by name) ||lead (',' || name, 3) over(partition by id order by name) as str from test)where rn = 1order by 1;-------- 适⽤范围:10g 及以后版本 ( MODEL )select id, substr (str, 2) strfrom test model return updated rows partition by (id) dimension by (row_number ()over(partition by id order by name) as rn) measures(cast (name as varchar2(20)) as str)rules upsert iterate (3) until(presentv(str [ iteration_number + 2 ], 1, 0) = 0)(str [ 0 ] = str [ 0 ] || ',' || str [ iteration_number + 1 ])order by 1;-------- 适⽤范围:8i,9i,10g 及以后版本 ( MAX + DECODE )select t.id id, max (substr (sys_connect_by_path(, ','), 2)) strfrom (select id, name, row_number () over(partition by id order by name) rnfrom test) tstart with rn = 1connect by rn = prior rn + 1and id = prior idgroup by t.id;懒⼈扩展⽤法:案例: 我要写⼀个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠⼿⼯写太⿇烦了,有没有什么简便的⽅法? 当然有了,看我如果应⽤wm_concat 来让这个需求变简单,假设我的APP_USER 表中有(id,username,password,age )4个字段。
sql查询结果列转行方法

sql查询结果列转行方法要将SQL查询结果的列转为行,我们一般可以使用UNIONALL操作符来实现。
下面是详细步骤:1.首先,我们需要确保查询结果的列类型和取值范围是一致的。
如果有需要,可以使用CAST(或CONVERT(函数进行类型转换。
2.使用UNIONALL操作符将所有列合并成一列。
每个SELECT语句表示一个原始列,其中的列名称可以通过别名进行重命名。
例如:SELECT column1 AS column FROM tableUNIONALLSELECT column2 AS column FROM tableUNIONALLSELECT column3 AS column FROM table这样我们就将table表中的column1、column2和column3列合并成一列,并使用别名column进行表示。
3.如果查询结果中有多个表,我们需要使用JOIN操作符将这些表连接起来,然后再进行列转行的操作。
例如:SELECT column1 AS column FROM table1JOIN table2 ON table1.id = table2.idUNIONALLSELECT column2 AS column FROM table1JOIN table2 ON table1.id = table2.id这里我们将table1和table2两个表连接起来,并将table1中的column1和table2中的column2列合并成一列。
4.如果查询结果中有多个条件或是函数,我们可以使用子查询来实现列转行。
例如:SELECT columnFROMSELECT col1 + col2 AS column FROM tableWHERE conditionUNIONALLSELECT col3 - col4 AS column FROM tableWHERE conditionAS subquer这里我们将table表中col1和col2两列相加,并将结果作为column列,然后与table表中col3和col4两列相减的结果进行合并。
Oracle专题-11G列转行
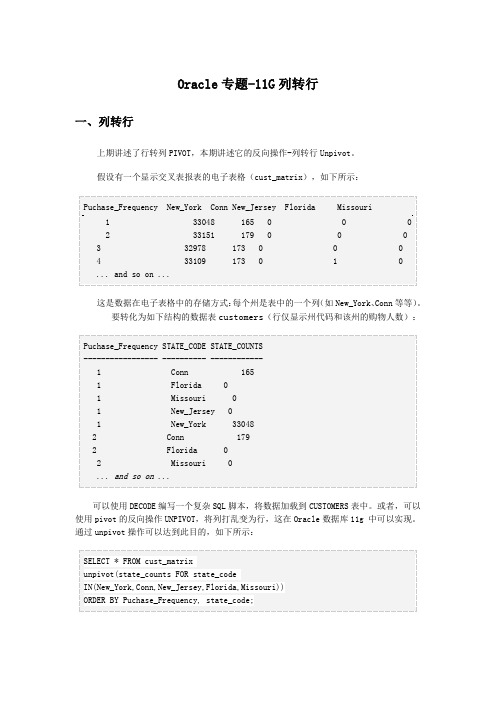
Oracle 专题-11G 列转行一、列转行上期讲述了行转列 PIVOT,本期讲述它的反向操作-列转行 Unpivot。
假设有一个显示交叉表报表的电子表格(cust_matrix),如下所示: Puchase_Frequency New_York Conn New_Jersey Florida 1 2 3 4 ... and so on 33048 33151 32978 33109 ... 165 0 179 0 173 0 173 0 0 0 0 1 Missouri 0 0 0 0这是数据在电子表格中的存储方式: 每个州是表中的一个列 (如 New_York、 Conn 等等) 。
要转化为如下结构的数据表 customers(行仅显示州代码和该州的购物人数): Puchase_Frequency STATE_CODE STATE_COUNTS ----------------- ---------- -----------1 Conn 165 1 Florida 0 1 Missouri 0 1 New_Jersey 0 1 New_York 33048 2 Conn 179 2 Florida 0 2 Missouri 0 ... and so on ... 可以使用 DECODE 编写一个复杂 SQL 脚本,将数据加载到 CUSTOMERS 表中。
或者,可以 使用 pivot 的反向操作 UNPIVOT,将列打乱变为行,这在 Oracle 数据库 11g 中可以实现。
通过 unpivot 操作可以达到此目的,如下所示: SELECT * FROM cust_matrix unpivot(state_counts FOR state_code IN(New_York,Conn,New_Jersey,Florida,Missouri)) ORDER BY Puchase_Frequency, state_code;注意每个列名如何变为 STATE_CODE 列中的一个值。
Oracle中的列转行例子详解

此外,列转行还可以使用union all和unpivot(oracle 11g新特性)等,待后续补充
--写法4: select name, substr(','||id||',',instr(','||id||',', ',', 1, level) + 1, instr(','||id||',', ',', 1, level + 1) -( instr(','||id||',', ',', 1, level) + 1)) from tmp connect by level <= regexp_count(id,',')+1 order by level
--写法2: select name,trim(regexp_substr(id,'[^,]+',1,level)) as id from tmp connect by name = prior name and prior dbms_random.value is not null and level <= length(regexp_replace(id, '[^,]'))+1;
oracle行转列,列转行函数的使用(listagg,xmlagg)

oracle⾏转列,列转⾏函数的使⽤(listagg,xmlagg)⼀、⾏转列listagg函数:场景:这⾥的表数据使⽤的是oracle默认的scott账户下的emp(员⼯)表。
规范写法 : LISTAGG(字段, 连接符) WITHIN GROUP (ORDER BY 字段)通常情况下,LISTAGG是满⾜需要的,LISTAGG 返回的是⼀个varchar2类型的数据,最⼤字节长度为4000。
所以,在实际开发中,我们可能会遇到⼀个问题,连接长度过长。
在这个时候,我们需要将LISTAGG函数改成XMLAGG函数。
XMLAGG返回的类型为CLOB,最⼤字节长度为32767。
LISTAGG例⼦:1、使⽤条件查询部门号为20号的员⼯:-- 查询部门为20的员⼯列表SELECT t.DEPTNO,t.ENAME FROM SCOTT.EMP t where t.DEPTNO = '20' ;2、使⽤listagg() WITH GROUP()将多⾏合并成⼀⾏(⽐较常⽤)复制代码SELECTT.DEPTNO,listagg (T.ENAME, ',') WITHIN GROUP (ORDER BY T.ENAME) namesFROMSCOTT.EMP TWHERET.DEPTNO = '20'GROUP BYT.DEPTNO3、使⽤listagg() width group() over将多⾏记录在⼀⾏显⽰(不常⽤)SELECTT .DEPTNO,listagg (T .ENAME, ',') WITHIN GROUP (ORDER BY T .ENAME) over(PARTITION BY T .DEPTNO)FROMSCOTT.EMP TWHERET .DEPTNO = '20'⼆、XMLAGG函数的例⼦:XMLAGG(XMLPARSE(CONTENT BSO.ID || ',' WELLFORMED) ORDER BY BSO.ID).GETCLOBVAL()规划写法: XMLAGG(XMLPARSE(CONTENT 字段 || 字符串 WELLFORMED) ORDER BY 字段).GETCLOBVAL()三、对于mysql相同的效果实现,可以使⽤group_concat() 函数,详情可参考:。
Oracle四种列转行的方法

Oracle四种列转⾏的⽅法1. Oracle⾃带列转⾏函数listagg:实例:with temp as(select 'China' nation ,'Guangzhou' city from dual union allselect 'China' nation ,'Shanghai' city from dual union allselect 'China' nation ,'Beijing' city from dual union allselect 'USA' nation ,'New York' city from dual union allselect 'USA' nation ,'Bostom' city from dual union allselect 'Japan' nation ,'Tokyo' city from dual)--1select nation, listagg(city, ',') within GROUP(order by city) all_citysfrom tempgroup by nation;Result:NATIONALL_CITYSChina Beijing,Guangzhou,ShanghaiJapan TokyoUSA Bostom,New York2. ⾃定义函数实现:1) 定义函数string_agg:CREATE OR REPLACE FUNCTION string_agg (p_input VARCHAR2)RETURN VARCHAR2PARALLEL_ENABLE AGGREGATE USING t_string_agg;2) 定义Type t_string_agg:CREATE OR REPLACE TYPE "T_STRING_AGG" AS OBJECT(g_string VARCHAR2(32767),STATIC FUNCTION ODCIAggregateInitialize(sctx IN OUT t_string_agg)RETURN NUMBER,MEMBER FUNCTION ODCIAggregateIterate(self IN OUT t_string_agg,value IN VARCHAR2 )RETURN NUMBER,MEMBER FUNCTION ODCIAggregateTerminate(self IN t_string_agg,returnValue OUT VARCHAR2,flags IN NUMBER)RETURN NUMBER,MEMBER FUNCTION ODCIAggregateMerge(self IN OUT t_string_agg,ctx2 IN t_string_agg)RETURN NUMBER);3) 定义Type body:CREATE OR REPLACE TYPE BODY "T_STRING_AGG" ISSTATIC FUNCTION ODCIAggregateInitialize(sctx IN OUT t_string_agg)RETURN NUMBER ISBEGINsctx := t_string_agg(NULL);RETURN ODCIConst.Success;END;MEMBER FUNCTION ODCIAggregateIterate(self IN OUT t_string_agg,value IN VARCHAR2 )RETURN NUMBER ISBEGINSELF.g_string := self.g_string || ',' || value;RETURN ODCIConst.Success;END;MEMBER FUNCTION ODCIAggregateTerminate(self IN t_string_agg,returnValue OUT VARCHAR2,flags IN NUMBER)RETURN NUMBER ISBEGINreturnValue := RTRIM(LTRIM(SELF.g_string, ','), ',');RETURN ODCIConst.Success;END;MEMBER FUNCTION ODCIAggregateMerge(self IN OUT t_string_agg,ctx2 IN t_string_agg)RETURN NUMBER ISBEGINSELF.g_string := SELF.g_string || ',' || ctx2.g_string;RETURN ODCIConst.Success;END;END;4)实例:--2with temp as(select 'China' nation ,'Guangzhou' city from dual union allselect 'China' nation ,'Shanghai' city from dual union allselect 'China' nation ,'Beijing' city from dual union allselect 'USA' nation ,'New York' city from dual union allselect 'USA' nation ,'Bostom' city from dual union allselect 'Japan' nation ,'Tokyo' city from dual)select nation, string_agg(city) all_citys from temp group by nation;Result:NATIONALL_CITYSChina Beijing,Guangzhou,ShanghaiJapan TokyoUSA Bostom,New York以下两种是针对⼤数据的⾏转列:3. 针对⼤数据的⾏转列1:暂存⼊本地XML。
Oracle中行转列,列转行pivot的用法

Oracle中⾏转列,列转⾏pivot的⽤法测试数据准备--建表--drop table SalesList;create table SalesList(keHu varchar2(20), --客户shangPin varchar2(20), --商品名称salesNum number(8) --销售数量);--插⼊数据declare--谈⼏个客户cursor lr_kh isselect regexp_substr('张三、李四、王五、赵六','[^、]+',1, level) keHu from dualconnect by level<=4;--进点货cursor lr_sp isselect regexp_substr('上⾐、裤⼦、袜⼦、帽⼦','[^、]+',1, level) shangPin from dualconnect by level<=4;begin--循环插⼊for v_kh in lr_kh loopfor v_sp in lr_sp loopinsert into SalesListselect v_kh.keHu, v_sp.shangPin, floor(dbms_random.value(10,50)) from dual;end loop;end loop;commit;end;pivot进⾏转换的sql如下:--⾏转列select*from SalesList pivot(max(salesNum) for shangPin in ( --shangPin 即要转成列的字段'上⾐'as上⾐, --max(salesNum) 此处必须为聚合函数,'裤⼦'as裤⼦, --in () 对要转成列的每⼀个值指定⼀个列名'袜⼦'as袜⼦,'帽⼦'as帽⼦))where1=1; --这⾥可以写查询条件,没有可以直接不要where查询结果如下图:希望这个简单的例⼦能够对⼤家有帮助~~~~~~~~。
Oracle 动态 列转行 or 行转列 SQL 行列互转

BUSI_TYPE,
TRADE_MKT_CODE,
TRADE_SEC_KIND_CODE,
TRUST_TYPE,
TRADE_DIRECT,
CHARGE_TYPE,
AV_I_FUNC_CODE IN VARCHAR2) AS
/******************************************************************
CLEAR_TYPE,
IS_UNITE,
CAL_TYPE,
FEE_MODE,
FEE_RATIO_ID,
ASSIST_FEE_ITEM_ID,
EXECUTE IMMEDIATE 'TRUNCATE TABLE CL_TEMP_CLEAR_JOUR_TOTAL_FEE';
EXECUTE IMMEDIATE 'TRUNCATE TABLE CL_TEMP_FEE_RATIO';
--准备资费信息
INSERT INTO CL_TEMP_FEE_RATIO
V_SYSTEM_FLAG VARCHAR2(1) := '1';
BEGIN
AV_O_RET_MSG := '操作成功';
AN_O_RET_CODE := 0;
EXECUTE IMMEDIATE 'TRUNCATE TABLE CL_TEMP_BUSI_JOUR_EXCH_FEE';
TRUST_TYPE,
TRADE_DIRECT,
CHARGE_TYPE,
SETTLE_TYPE,
oracle行列转换方法汇总

oracle行列转换方法汇总Oracle是一种关系型数据库管理系统,提供了丰富的行列转换方法,用于对数据进行灵活的处理和分析。
本文将总结和介绍几种常用的Oracle行列转换方法。
一、行列转换概述行列转换是指将数据从行的形式转换为列的形式,或者从列的形式转换为行的形式。
在数据分析和报表生成过程中,行列转换可以方便地对数据进行透视和展示,使数据更加直观和易于理解。
二、使用PIVOT进行行列转换PIVOT是Oracle提供的一种行列转换函数,可以将行数据转换为列。
其基本语法如下:```SELECT *FROM (SELECT 列1, 列2FROM 表名)PIVOT(聚合函数(列2)FOR 列1 IN (值1, 值2, ...))```其中,列1表示要进行行列转换的列,列2表示要进行聚合的列,聚合函数可以是SUM、AVG、COUNT等。
三、使用UNPIVOT进行行列转换UNPIVOT是PIVOT的逆操作,可以将列数据转换为行。
其基本语法如下:```SELECT *FROM (SELECT 列1, 列2FROM 表名)UNPIVOT(列值FOR 列名 IN (列1, 列2, ...))```其中,列1、列2表示要进行行列转换的列,列值表示转换后的值,列名表示转换后的列。
四、使用CASE语句进行行列转换除了使用PIVOT和UNPIVOT函数外,还可以使用CASE语句进行行列转换。
CASE语句可以根据条件对数据进行分类和分组,从而实现行列转换的效果。
其基本语法如下:```SELECT列1,MAX(CASE WHEN 条件1 THEN 列2 END) AS 列名1,MAX(CASE WHEN 条件2 THEN 列2 END) AS 列名2,...FROM 表名GROUP BY 列1```其中,列1表示要进行行列转换的列,条件1、条件2表示根据哪些条件进行分类和分组,列2表示要进行转换的列,列名1、列名2表示转换后的列。
Oracle行转列(不固定行数的行转列,动态)(转)

Oracle⾏转列(不固定⾏数的⾏转列,动态)(转)1. Oracle 11g之后新增了⾏列转换的函数 pivot 和 unpivot⼤⼤简化了⾏列转换处理。
2. 在Oracle 10g及以前版本,⼀般是通过各种SQL进⾏⾏列转换,列⼊下⾯例⼦:create or replace procedure P_row_to_col(tabname in varchar2,group_col in varchar2,column_col in varchar2,value_col in varchar2,Aggregate_func in varchar2default'max',colorder in varchar2default null,roworder in varchar2default null,when_value_null in varchar2default null,viewname in varchar2default'v_tmp')Authid Current_User as sqlstr varchar2(2000) :='create or replace view '|| viewname ||' as select '|| group_col ||'';c1 sys_refcursor;v1 varchar2(100);beginopen c1 for'select distinct '|| column_col ||' from '|| tabname ||case when colorder isnot null then' order by '|| colorderend;loop fetch c1 into v1;exit when c1%notfound;sqlstr := sqlstr || chr(10) ||','||case when when_value_null isnot null then'nvl('end|| Aggregate_func ||'(decode(to_char('|| column_col ||'),'''|| v1 ||''','|| value_col ||'))'||case when when_value_null isnot null then chr(44) || when_value_null || chr(41)end||'"'|| v1 ||'"';end loop;close c1;sqlstr := sqlstr ||' from '|| tabname ||' group by '|| group_col ||case when roworder isnot null then' order by '|| roworderend;execute immediate sqlstr;end P_row_to_col;--测试数据create table rowtocol_test asselect2009year,1month,'AAA1' dept,50000 expenditure from dualunion all select2009,2,'AAA1',20000from dualunion all select2009,2,'AAA1',30000from dualunion all select2010,1,'AAA1',35000from dualunion all select2009,2,'BBB2',40000from dualunion all select2009,3,'BBB2',25000from dualunion all select2010,2,'DDD3',60000from dualunion all select2009,2,'DDD3',15000from dualunion all select2009,2,'DDD3',10000from dual;select*from rowtocol_test;--执⾏测试beginp_row_to_col('rowtocol_test','year,month','dept','expenditure',Aggregate_func =>'sum',colorder =>'dept',roworder =>'1,2',when_value_null =>'0');end;select*from v_tmp;================================================================================================================例⼦⼆三:--测试数据create table t (XH varchar2(10), DDATE date, SXF int);insert into t select1,sysdate,10from dualunion all select1,sysdate+1,14from dualunion allselect 1,sysdate+2,23from dualunion allselect 2,sysdate,21from dualunion allselect 2,sysdate+1,24from dualunion allselect 3,sysdate,13from dualunion allselect 3,sysdate+1,22from dual;--create or replace package sp_test istype ResultData is ref cursor;procedure getRstData( rst out ResultData); end sp_test;/create or replace package body sp_test isprocedure getRstData( rst out ResultData)is begindeclare cursor cur is select distinct (DDATE) from t;tmp_ddate date;str varchar2(4000);beginstr:='select xh';open cur;loop fetch cur into tmp_ddate;exit when cur%notfound;str:=str||',sum(decode(to_char(ddate,''yyyymmdd''),'||chr(39)||to_char(tmp_ddate,'yyyymmdd')||chr(39)||',sxf,0)) "'||to_char(tmp_ddate,'yyyymmdd')||'"'; end loop;str:=str||' from t group by xh';--dbms_output.put_line(str);close cur;open rst for str; end;end;end sp_test;/--输出结果1101423221240313220========================例⼦三:------------建表CREATE TABLE TEST(WL VARCHAR2(10),XYSL INTEGER,XYCK VARCHAR2(10),XCLCK VARCHAR2(10),XCLCKSL INTEGER,PC INTEGER); ------------ 第⼀部分测试数据INSERT INTO TEST VALUES('A1', 2, 'C1', 'C1' , 20, 123);INSERT INTO TEST VALUES('A1', 2, 'C1', 'C2' , 30, 111);INSERT INTO TEST VALUES('A1', 2, 'C1', 'C2' , 20, 222);INSERT INTO TEST VALUES('A1', 2, 'C1', 'C3' , 10, 211);INSERT INTO TEST VALUES('A2', 3, 'C4', 'C1' , 40, 321);INSERT INTO TEST VALUES('A2', 3, 'C4', 'C4' , 50, 222);INSERT INTO TEST VALUES('A2', 3, 'C4', 'C4' , 60, 333);INSERT INTO TEST VALUES('A2', 3, 'C4', 'C5' , 70, 223);COMMIT;-------------------- 动态⽣成结果表DECLARE V_SQL VARCHAR2(2000);CURSOR CURSOR_1 IS SELECT DISTINCT T.XCLCK FROM TEST T ORDER BY XCLCK;BEGIN V_SQL :='SELECT WL,XYSL,XYCK';FOR V_XCLCK IN CURSOR_1LOOP V_SQL := V_SQL ||','||'SUM(DECODE(XCLCK,'''|| V_XCLCK.XCLCK ||''',XCLCKSL,0)) AS '|| V_XCLCK.XCLCK;END LOOP;V_SQL := V_SQL ||' FROM TEST GROUP BY WL,XYSL,XYCK ORDER BY WL,XYSL,XYCK';--DBMS_OUTPUT.PUT_LINE(V_SQL);V_SQL :='CREATE TABLE RESULT AS '|| V_SQL;--DBMS_OUTPUT.PUT_LINE(V_SQL);EXECUTE IMMEDIATE V_SQL;END;--------------- 结果SELECT*FROM RESULT T;。
oracle sql一列转多行最简单的方法

oracle sql一列转多行最简单的方法在Oracle SQL中,要将一列数据转换为多行,最简单的方法是使用UNION ALL运算符。
以下是具体步骤:
假设有以下表格`table1`,包含一列`column1`:
```
column1
-------
value1
value2
value3
```
要将上述数据转换为多行,你可以使用以下查询:
```
SELECT 'value1' AS column1 FROM dual
UNIONALL
SELECT 'value2' AS column1 FROM dual
UNIONALL
SELECT 'value3' AS column1 FROM dual;
```
这会返回以下结果:
```
column1
-------
value1
value2
value3
```
查询中的`dual`是Oracle SQL中的一个虚拟表,用于在没有实际表格可用时生成和返回一个行。
UNIONALL运算符用于将多个SELECT语句的结果合并为一个结果集。
在每个SELECT语句中,你可以使用`AS`关键字来为列指定别名,以匹配原始列名。
通过多个UNIONALL运算符将所有值合并后,最终结果将包含多行。
以上就是将一列数据转换为多行的最简单方法。
注意,如果你有大量的数据,使用UNIONALL可能会影响查询性能。
在那种情况下,你可能需要考虑其他更高效的方法,如使用PL/SQL的循环或使用递归查询。
oracle列转行sql详解

-- 当期时间贷款时间SELECTDK_ID,max(substr(activeDate,2))activeDateFROM(SELECTDK_ID,sys_connect_by_path(activeDate,',')activeDate FROM(SELECTDK_ID,activeDate,DK_ID||rnrchild,DK_ID||(rn-1)rfather FROM(SELECTTEMP .DK_ID, -- 查询项目所在地树形结构全名SELECTt.area_id,substr(sys_connect_by_path(t.area_name,'-'),2)asallname, connect_by_roott.area_nameasroot,-- 是单一操作符,返回当前层的最顶层节点connect_by_isleafasIsLeaf,-- 是伪列,判断当前层是否为叶子节点,1 代表是,0 代表否levelaslel-- 是伪列,显示当前节点层所处的层数FROMdk_project_area_infotSTARTWITHt.area_name=' 项目所在地'CONNECTBYPRIORt.area_id=t.area_pidSYS_CONNECT_BY_PATH 学习2008-09-0810:59SELECTename FROMscott.empSTARTWITHename='KING'CONNECTBYPRIORempno=mgr;得到结果为:KINGJONESSCOTTADAMSFORDSMITHBLAKEALLENWARDMARTINTURNERJAMES而:SELECTSYS_CONNECT_BY_PATH(ename,'>')"Path"FROMscott.empSTARTWITHename='KING'CONNECTBYPRIORempno=mgr; 得到结果为:>KING >KING>JONES >KING>JONES>SCOTT >KING>JONES>SCOTT>ADAMS >KING>JONES>FOR D >KING>JONES>FORD>SMITH >KING>BLAKE >KING>BLAKE>ALLEN >KING>BLAKE>WARD >KING>BLAKE>MARTIN >KING>BLAKE>TURNER >KING>BLAKE>JAMES >KING>CLARK>KING>CLARK>MILLER其实SYS_CONNECT_BY_PATH 这个函数是oracle9i 才新提出来的!它一定要和connectby 子句合用!第一个参数是形成树形式的字段,第二个参数是父级和其子级分隔显示用的分隔符!STARTWITH 代表你要开始遍历的的节点,CONNECTBYPRIOR 是标示父子关系的对应!如下例子:selectmax(substr(sys_connect_by_path(column_name,','),2)) from(selectcolumn_name,rownumrnfromuser_tab_columnswheretable_name='AA_T EST')startwithrn=1connectbyrn=rownum;是将列用,进行分割成为一行,然后将首个,去掉,只取取最大的那个数据。
Oracle SQL精妙SQL语句讲解

--行列转换行转列DROP TABLE t_change_lc;CREA TE TABLE t_change_lc (card_code V ARCHAR2(3), q NUMBER, bal NUMBER); INSERT INTO t_change_lcSELECT '001' card_code, ROWNUM q, trunc(dbms_random.V ALUE * 100) bal from dual CONNECT BY ROWNUM <= 4UNIONSELECT '002' card_code, ROWNUM q, trunc(dbms_random.V ALUE * 100) bal from dual CONNECT BY ROWNUM <= 4;SELECT * from t_change_lc;SELECT a.card_code,SUM(decode(a.q, 1, a.bal, 0)) q1,SUM(decode(a.q, 2, a.bal, 0)) q2,SUM(decode(a.q, 3, a.bal, 0)) q3,SUM(decode(a.q, 4, a.bal, 0)) q4from t_change_lc aGROUP BY a.card_codeORDER BY 1;--行列转换列转行DROP TABLE t_change_cl;CREA TE TABLE t_change_cl ASSELECT a.card_code,SUM(decode(a.q, 1, a.bal, 0)) q1,SUM(decode(a.q, 2, a.bal, 0)) q2,SUM(decode(a.q, 3, a.bal, 0)) q3,SUM(decode(a.q, 4, a.bal, 0)) q4from t_change_lc aGROUP BY a.card_codeORDER BY 1;SELECT * from t_change_cl;SELECT t.card_code,t.rn q,decode(t.rn, 1, t.q1, 2, t.q2, 3, t.q3, 4, t.q4) balfrom (SELECT a.*, b.rnfrom t_change_cl a,(SELECT ROWNUM rn from dual CONNECT BY ROWNUM <= 4) b) tORDER BY 1, 2;--行列转换行转列合并DROP TABLE t_change_lc_comma;CREA TE TABLE t_change_lc_comma AS SELECT card_code,'quarter_'||q AS q from t_change_lc;SELECT * from t_change_lc_comma;SELECT t1.card_code, substr(MAX(sys_connect_by_path(t1.q, ';')), 2) qfrom (SELECT a.card_code,a.q,row_number() over(PARTITION BY a.card_code ORDER BY a.q) rnfrom t_change_lc_comma a) t1START WITH t1.rn = 1CONNECT BY t1.card_code = PRIOR t1.card_codeAND t1.rn - 1 = PRIOR t1.rnGROUP BY t1.card_code;--行列转换列转行分割DROP TABLE t_change_cl_comma;CREA TE TABLE t_change_cl_comma ASSELECT t1.card_code, substr(MAX(sys_connect_by_path(t1.q, ';')), 2) qfrom (SELECT a.card_code,a.q,row_number() over(PARTITION BY a.card_code ORDER BY a.q) rnfrom t_change_lc_comma a) t1START WITH t1.rn = 1CONNECT BY t1.card_code = PRIOR t1.card_codeAND t1.rn - 1 = PRIOR t1.rnGROUP BY t1.card_code;SELECT * from t_change_cl_comma;SELECT t.card_code,substr(t.q,instr(';' || t.q, ';', 1, rn),instr(t.q || ';', ';', 1, rn) - instr(';' || t.q, ';', 1, rn)) qfrom (SELECT a.card_code, a.q, b.rnfrom t_change_cl_comma a,(SELECT ROWNUM rn from dual CONNECT BY ROWNUM <= 100) bWHERE instr(';' || a.q, ';', 1, rn) > 0) tORDER BY 1, 2;-- 实现一条记录根据条件多表插入DROP TABLE t_ia_src;CREA TE TABLE t_ia_src AS SELECT 'a'||ROWNUM c1, 'b'||ROWNUM c2 from dual CONNECT BY ROWNUM<=5;DROP TABLE t_ia_dest_1;CREA TE TABLE t_ia_dest_1(flag V ARCHAR2(10) , c V ARCHAR2(10));DROP TABLE t_ia_dest_2;CREA TE TABLE t_ia_dest_2(flag V ARCHAR2(10) , c V ARCHAR2(10));DROP TABLE t_ia_dest_3;CREA TE TABLE t_ia_dest_3(flag V ARCHAR2(10) , c V ARCHAR2(10));SELECT * from t_ia_src;SELECT * from t_ia_dest_1;SELECT * from t_ia_dest_2;SELECT * from t_ia_dest_3;INSERT ALLWHEN (c1 IN ('a1','a3')) THENINTO t_ia_dest_1(flag,c) V ALUES(flag1,c2)WHEN (c1 IN ('a2','a4')) THENINTO t_ia_dest_2(flag,c) V ALUES(flag2,c2)ELSEINTO t_ia_dest_3(flag,c) V ALUES(flag1||flag2,c1||c2)SELECT c1,c2, 'f1' flag1, 'f2' flag2 from t_ia_src;-- 如果存在就更新,不存在就插入用一个语句实现DROP TABLE t_mg;CREA TE TABLE t_mg(code V ARCHAR2(10), NAME V ARCHAR2(10));SELECT * from t_mg;MERGE INTO t_mg aUSING (SELECT 'the code' code, 'the name' NAME from dual) bON (a.code = b.code)WHEN MA TCHED THENUPDA TE SET = WHEN NOT MA TCHED THENINSERT (code, NAME) V ALUES (b.code, );-- 抽取/删除重复记录DROP TABLE t_dup;CREA TE TABLE t_dup AS SELECT 'code_'||ROWNUM code, dbms_random.string('z',5) NAME from dual CONNECT BY ROWNUM<=10;INSERT INTO t_dup SELECT 'code_'||ROWNUM code, dbms_random.string('z',5) NAME from dual CONNECT BY ROWNUM<=2;SELECT * from t_dup;SELECT * from t_dup a WHERE a.ROWID <> (SELECT MIN(b.ROWID) from t_dup b WHERE a.code=b.code);SELECT b.code, from (SELECT a.code,,row_number() over(PARTITION BY a.code ORDER BY a.ROWID) rnfrom t_dup a) bWHERE b.rn > 1;-- IN/EXISTS的不同适用环境-- t_orders.customer_id有索引SELECT a.*from t_employees aWHERE a.employee_id IN(SELECT b.sales_rep_id from t_orders b WHERE b.customer_id = 12);SELECT a.*from t_employees aWHERE EXISTS (SELECT 1from t_orders bWHERE b.customer_id = 12AND a.employee_id = b.sales_rep_id);-- t_employees.department_id有索引SELECT a.*from t_employees aWHERE a.department_id = 10AND EXISTS(SELECT 1 from t_orders b WHERE a.employee_id = b.sales_rep_id);SELECT a.*from t_employees aWHERE a.department_id = 10AND a.employee_id IN (SELECT b.sales_rep_id from t_orders b);-- FBIDROP TABLE t_fbi;CREA TE TABLE t_fbi ASSELECT ROWNUM rn, dbms_random.STRING('z',10) NAME , SYSDA TE + dbms_random.V ALUE * 10 dt from dualCONNECT BY ROWNUM <=10;CREA TE INDEX idx_nonfbi ON t_fbi(dt);DROP INDEX idx_fbi_1;CREA TE INDEX idx_fbi_1 ON t_fbi(trunc(dt));SELECT * from t_fbi WHERE trunc(dt) = to_date('2006-09-21','yyyy-mm-dd') ;-- 不建议使用SELECT * from t_fbi WHERE to_char(dt, 'yyyy-mm-dd') = '2006-09-21';-- LOOP中的COMMIT/ROLLBACKDROP TABLE t_loop PURGE;create TABLE t_loop AS SELECT * from user_objects WHERE 1=2;SELECT * from t_loop;-- 逐行提交DECLAREBEGINFOR cur IN (SELECT * from user_objects) LOOPINSERT INTO t_loop V ALUES cur;COMMIT;END LOOP;END;-- 模拟批量提交/DECLAREv_count NUMBER;BEGINFOR cur IN (SELECT * from user_objects) LOOPINSERT INTO t_loop V ALUES cur;v_count := v_count + 1;IF v_count >= 100 THENCOMMIT;END IF;END LOOP;COMMIT;END;-- 真正的批量提交DECLARECURSOR cur ISSELECT * from user_objects;TYPE rec IS TABLE OF user_objects%ROWTYPE;recs rec;BEGINOPEN cur;WHILE (TRUE) LOOPFETCH cur BULK COLLECTINTO recs LIMIT 100;-- forall 实现批量FORALL i IN 1 .. recs.COUNTINSERT INTO t_loop V ALUES recs (i);COMMIT;EXIT WHEN cur%NOTFOUND;END LOOP;CLOSE cur;END;-- 悲观锁定/乐观锁定DROP TABLE t_lock PURGE;CREA TE TABLE t_lock AS SELECT 1 ID from dual;SELECT * from t_lock;-- 常见的实现逻辑,隐含bugDECLAREv_cnt NUMBER;BEGIN-- 这里有并发性的bugSELECT MAX(ID) INTO v_cnt from t_lock;-- here for other operationv_cnt := v_cnt + 1;INSERT INTO t_lock (ID) V ALUES (v_cnt);COMMIT;END;-- 高并发环境下,安全的实现逻辑DECLAREv_cnt NUMBER;BEGIN-- 对指定的行取得lockSELECT ID INTO v_cnt from t_lock WHERE ID=1 FOR UPDA TE;-- 在有lock的情况下继续下面的操作SELECT MAX(ID) INTO v_cnt from t_lock;-- here for other operationv_cnt := v_cnt + 1;INSERT INTO t_lock (ID) V ALUES (v_cnt);COMMIT; --提交并且释放lockEND;-- 硬解析/软解析DROP TABLE t_hard PURGE;CREA TE TABLE t_hard (ID INT);SELECT * from t_hard;DECLAREsql_1 V ARCHAR2(200);BEGIN-- hard parse-- java中的同等语句是Statement.execute()FOR i IN 1 .. 1000 LOOPsql_1 := 'insert into t_hard(id) values(' || i || ')';EXECUTE IMMEDIA TE sql_1;END LOOP;COMMIT;-- soft parse--java中的同等语句是PreparedStatement.execute()sql_1 := 'insert into t_hard(id) values(:id)';FOR i IN 1 .. 1000 LOOPEXECUTE IMMEDIA TE sql_1USING i;END LOOP;COMMIT;END;-- 正确的分页算法SELECT *from (SELECT a.*, ROWNUM rnfrom (SELECT * from t_employees ORDER BY first_name) a WHERE ROWNUM <= 500)WHERE rn > 480 ;-- 分页算法(why not this one)SELECT a.*, ROWNUM rnfrom (SELECT * from t_employees ORDER BY first_name) a WHERE ROWNUM <= 500 AND ROWNUM > 480;-- 分页算法(why not this one)SELECT b.*from (SELECT a.*, ROWNUM rnfrom t_employees aWHERE ROWNUM < = 500ORDER BY first_name) bWHERE b.rn > 480;-- OLAP-- 小计合计SELECT CASEWHEN a.deptno IS NULL THEN'合计'WHEN a.deptno IS NOT NULL AND a.empno IS NULL THEN'小计'ELSE'' || a.deptnoEND deptno,a.empno,a.ename,SUM(a.sal) total_salfrom scott.emp aGROUP BY GROUPING SETS((a.deptno),(a.deptno, a.empno, a.ename),()); -- 分组排序SELECT a.deptno,a.empno,a.ename,a.sal,-- 可跳跃的rankrank() over(PARTITION BY a.deptno ORDER BY a.sal DESC) r1,-- 密集型rankdense_rank() over(PARTITION BY a.deptno ORDER BY a.sal DESC) r2, -- 不分组排序rank() over(ORDER BY sal DESC) r3from scott.emp aORDER BY a.deptno,a.sal DESC;-- 当前行数据和前/后n行的数据比较SELECT a.empno,a.ename,a.sal,-- 上面一行lag(a.sal) over(ORDER BY a.sal DESC) lag_1,-- 下面三行lead(a.sal, 3) over(ORDER BY a.sal DESC) lead_3from scott.emp aORDER BY a.sal DESC;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
--当期时间贷款时间SELECT DK_ID, max(substr(activeDate, 2)) activeDateFROM (SELECT DK_ID, sys_connect_by_path(activeDate, ',') activeDateFROM (SELECT DK_ID,activeDate,DK_ID || rn rchild,DK_ID || (rn - 1) rfatherFROM (SELECT TEMP.DK_ID,--查询项目所在地树形结构全名SELECT t.area_id,substr(sys_connect_by_path(t.area_name, '-'), 2) as allname ,connect_by_root t.area_name as root, --是单一操作符,返回当前层的最顶层节点connect_by_isleaf as IsLeaf, --是伪列,判断当前层是否为叶子节点,1代表是,0代表否level as lel --是伪列,显示当前节点层所处的层数FROM dk_project_area_info tSTART WITH t.area_name = '项目所在地'CONNECT BY PRIOR t.area_id = t.area_pidSYS_CONNECT_BY_PATH 学习2008-09-08 10:59SELECT enameFROM scott.empSTART WITH ename = 'KING'CONNECT BY PRIOR empno = mgr;得到结果为:KINGJONESSCOTTADAMSFORDSMITHBLAKEALLENWARDMARTINTURNERJAMES而:SELECT SYS_CONNECT_BY_PATH(ename, '>') "Path"FROM scott.empSTART WITH ename = 'KING'CONNECT BY PRIOR empno = mgr;得到结果为:>KING>KING>JONES>KING>JONES>SCOTT>KING>JONES>SCOTT>ADAMS>KING>JONES>FORD>KING>JONES>FORD>SMITH>KING>BLAKE>KING>BLAKE>ALLEN>KING>BLAKE>WARD>KING>BLAKE>MARTIN>KING>BLAKE>TURNER>KING>BLAKE>JAMES>KING>CLARK>KING>CLARK>MILLER其实SYS_CONNECT_BY_PATH这个函数是oracle9i才新提出来的!它一定要和connect by子句合用!第一个参数是形成树形式的字段,第二个参数是父级和其子级分隔显示用的分隔符!START WITH 代表你要开始遍历的的节点,CONNECT BY PRIOR 是标示父子关系的对应!如下例子:select max(substr(sys_connect_by_path(column_name,','),2))from (select column_name,rownum rn from user_tab_columns where table_name ='AA_TEST')start with rn=1 connect by rn=rownum ;是将列用,进行分割成为一行,然后将首个,去掉,只取取最大的那个数据。
---------下面是别人的例子:1、带层次关系SQL> create table dept(deptno number,deptname varchar2(20),mgrno number);Table created.SQL> insert into dept values(1,'总公司',null);1 row created.SQL> insert into dept values(2,'分公司',1);1 row created.SQL> insert into dept values(3,'分公司',2);1 row created.SQL> commit;Commit complete.SQL> select max(substr(sys_connect_by_path(deptname,','),2)) from dept connect by prior deptno=mgrno;MAX(SUBSTR(SYS_CONNECT_BY_PATH(DEPTNAME,','),2))-------------------------------------------------------------------------------- 总公司,分公司,分公司2、行列转换如把一个表的所有列连成一行,用逗号分隔:SQL> select max(substr(sys_connect_by_path(column_name,','),2))from (select column_name,rownum rn from user_tab_columns where table_name ='DEPT') start with rn=1 connect by rn=rownum ;MAX(SUBSTR(SYS_CONNECT_BY_PATH(COLUMN_NAME,','),2))-------------------------------------------------------------------------------- DEPTNO,DEPTNAME,MGRNOconnect by 例子2009-04-21 09:18层次查询子句connect by,用于构造层次结果集的查询。
语法:[ START WITH condition ]CONNECT BY [ NOCYCLE ] condition说明:a、START WITH:告诉系统以哪个节点作为根结点开始查找并构造结果集,该节点即为返回记录中的最高节点。
b、当分层查询中存在上下层互为父子节点的情况时,会返回ORA-01436错误。
此时,需要在connect by后面加上NOCYCLE关键字。
同时,可用connect_by_iscycle伪列定位出存在互为父子循环的具体节点。
connect_by_iscycle必须要跟关键字NOCYCLE结合起来使用,用法见示例2。
用法举例:示例1:显示所有地名关系结构。
SQL> select * from t;AREA_ID AREA_NAME MGR_ID-------- ---------- ------86 中国01 8602 860101 海淀区 010102 区 010103 东城区 010104 西城区 010201 020202 02020101 湖里 0201020102 思明 0201010401 复兴门 0104010402 西单 0104已选择13行。
SQL>SQL> set pagesize 50SQL> col AreaName for a12SQL> col Root for a10SQL> col Path for a24SQL>SQL> select rpad( ' ', 2*(level-1), ' ' ) || area_name "AreaName",2 connect_by_root area_name "Root",3 connect_by_isleaf "IsLeaf",4 level ,5 SYS_CONNECT_BY_PATH(area_name, '/') "Path"6 from t7 start with mgr_id is null8 connect by prior area_id = mgr_id;AreaName Root IsLeaf LEVEL Path------------ ---------- ------ ---------- ------------------------中国中国 0 1 /中国中国 0 2 /中国/海淀区中国 1 3 /中国//海淀区区中国 1 3 /中国//区东城区中国 1 3 /中国//东城区西城区中国 0 3 /中国//西城区复兴门中国 1 4 /中国//西城区/复兴门西单中国 1 4 /中国//西城区/西单中国 0 2 /中国/中国 0 3 /中国//湖里中国 1 4 /中国///湖里思明中国 1 4 /中国///思明中国 1 3 /中国//已选择13行。
说明:a、prior:是单一操作符,放在列名的前面,等号左右均可;放在父 ID 就是寻找祖先节点,放到本身 ID就是寻找子节点;b、connect_by_root:是单一操作符,返回当前层的最顶层节点;c、connect_by_isleaf:是伪列,判断当前层是否为叶子节点,1代表是,0代表否;d、level:是伪列,显示当前节点层所处的层数;e、SYS_CONNECT_BY_PATH:是函数,显示当前层的详细路径。
示例2:找出人事部门中存在跟其他部门互为管理者的人员。
SQL> select * from t2;EMP DEPT MGR------------ ------ ----------涛总裁办飞总裁办涛强总裁办涛王鹏人事飞华人事飞强人事飞飞行政强吴华行政强已选择8行。
SQL>SQL> col emp for a12SQL> select rpad( ' ', 2*(level-1), ' ' ) || emp "emp"2 from t23 start with dept ='人事'4 connect by prior emp = mgr;ERROR:ORA-01436: 用户数据中的 CONNECT BY 循环未选定行说明:强和飞互为管理者,因此,要用nocycle,如下所示:SQL> select rpad( ' ', 2*(level-1), ' ' ) || emp "emp"2 from t23 start with dept ='人事'4 connect by nocycle prior emp = mgr;emp------------王鹏华强飞王鹏华吴华已选择7行。