Matlab工具箱中的BP与RBF函数
MATLAB在RBF神经网络模型中的应用

MATLAB 在RBF 神经网络模型中的应用高宁1,张建中2(1.安徽农业大学信息与计算机学院,安徽合肥230036;2.安徽建筑工业学院电子与信息工程学院,安徽合肥230022)摘要:本文介绍了RBF 神经网络的基本原理及主要特点,并举例说明了基于MATLAB 神经网络工具箱建立RBF 神经网络模型及实现仿真的方法。
关键词:仿真;MATLAB 神经网络工具箱;RBF 神经网络中图分类号:TP399文献标识码:A文章编码:1672-6251(2009)02-0110-02Application of RBF neural network model based on MATLABGAO Ning 1,ZHANG Jan-zhong 2(1.College of Information and computer,Anhui Agriculture University,Hefei 230036,China;2.College of Electronics and Information Enginner,Anhui Architecture University,Hefei 230022,China)Abstract:In this paper,the principle and characteristic of RBF neural network are explained,and the method of building and simulating RBF neural network model is introduced.Key words:Simulation;MATLAB neural network toolbox;RBF neural network人工神经网络具有大规模并行处理能力、分布式存储能力、自适应(学习)能力等特征,神经网络特有的非线性适应性信息处理能力,克服了传统人工智能方法的缺陷,已广泛应用于模式识别、信号处理等各种应用领域。
matlab的BP神经网络讲义

matlab的BP神经网络讲义一、RBF神经网络1985年,Powell提出了多变量插值的径向基函数(Radical Basis Function,RBF)方法,1988年,Moody和Darken提出了一种神经网络结构,即RBF神经网络。
RBF网络是一种三层前向网络,其基本思想是:(1)用RBF作为隐单元的“基”构成隐含层空间,将输入矢量直接(即不需要通过权连接)映射到隐空间(2)当RBF 的中心点确定后,映射关系也就确定(3)隐含层空间到输出空间的映射是线性的。
newrb()函数功能建立一个径向基神经网络格式net = newrb(P,T,GOAL,SPREAD,MN,DF)说明P为输入向量,T为目标向量,GOAL为圴方误差,默认为0,SPREAD为径向基函数的分布密度,默认为1,MN为神经元的最大数目,DF为两次显示之间所添加的神经元神经元数目。
例子:设[P,T]是训练样本,[X,Y]是测试样本;net=newrb(P,T,err_goal,spread); %建立网络q=sim(net,p);e=q-T;plot(p,q); %画训练误差曲线q=sim(net,X);e=q-Y;plot(X,q); %画测试误差曲线二、BP神经网络训练前馈网络的第一步是建立网络对象。
函数newff()建立一个可训练的前馈网络。
这需要4个输入参数。
第一个参数是一个Rx2的矩阵以定义R个输入向量的最小值和最大值。
第二个参数是一个设定每层神经元个数的数组。
第三个参数是包含每层用到的传递函数名称的细胞数组。
最后一个参数是用到的训练函数的名称。
举个例子,下面命令将创建一个二层网络。
它的输入是两个元素的向量,第一层有三个神经元(3),第二层有一个神经元(1)。
第一层的传递函数是tan-sigmoid,输出层的传递函数是linear。
输入向量的第一个元素的范围是-1到2[-1 2],输入向量的第二个元素的范围是0到5[0 5],训练函数是traingd。
matlab神经网络工具箱简介和函数及示例

代码运行结果: 网络训练误差
结论:隐含层节点设为8
BP网络训练步骤
步骤1: 初始化 步骤2:计算网络各层输出矢量 步骤3:计算网络各层反向传播的误差变化,并计算各 层权值的修正值及修正值 步骤4:再次计算权值修正后的误差 平方和 步骤5:检查误差 平方和是否小于 误差期望值,若是, 停止训练,否则继续.
三、BP网络学习函数
learngd 该函数为梯度下降权值/阈值学习函数,通过神经 元的输入和误差,以及权值和阈值的学习速率, 来计算权值或阈值的变化率。
调用格式; [dW,ls]=learngd(W,P,Z,N,A,T,E,gW,gA,D,LP,LS)
问题形式的种类:
数据样本已知; 数据样本之间相互关系不明确; 输入/输出模式为连续的或者离散的; 输入数据按照模式进行分类,模式可能会 具有平移、旋转或者伸缩等变化形式; 数据样本的预处理; 将数据样本分为训练样本和测试样本
② 网络模型的确定 主要是根据问题的实际情况,选择模型的类
例子1: help newff
例子2:设计一个隐含层神经元数目神经元个数
以一个单隐层的BP网络设计为例,介绍利用神经 网络工具箱进行BP网络设计及分析的过程
1. 问题描述
通过对函数进行采样得到了网络的输入变 量P和目标变量T:
P=[-1:0.1:1]; T=[-0.9602 -0.577 -0.0729 0.3771 0.6405 0.6600 0.4609 0.1336 -0.2013 -0.4344 -0.5000 -0.3930 -0.1647 0.0988 0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];
针对给定的输入,得到网络输出 调用其它训练函数,对网络进行训练 对权值和阈值进行训练 自适应函数 网络权值和阈值的学习 对网络进行初始化 对多层网络初始化
matlab工具箱函数汇总

MATLAB工具箱函数汇总Ⅰ.1 统计工具箱函数表Ⅰ-1 概率密度函数表Ⅰ-2 累加分布函数附录I 工具箱函数汇总·521·表Ⅰ-3 累加分布函数的逆函数表Ⅰ-4 随机数生成器函数表Ⅰ-5 分布函数的统计量函数附录I 工具箱函数汇总·523·表Ⅰ-6 参数估计函数表Ⅰ-7 统计量描述函数表Ⅰ-8 统计图形函数表Ⅰ-9 统计过程控制函数附录I 工具箱函数汇总·525·表Ⅰ-10 聚类分析函数表Ⅰ-11 线性模型函数表Ⅰ-12 非线性回归函数表Ⅰ-13 试验设计函数表Ⅰ-14 主成分分析函数附录I 工具箱函数汇总·527·表Ⅰ-15 多元统计函数表Ⅰ-16 假设检验函数表Ⅰ-17 分布检验函数表Ⅰ-18 非参数函数表Ⅰ-19 文件输入输出函数表Ⅰ-20 演示函数Ⅰ.2 优化工具箱函数表Ⅰ-21 最小化函数表表Ⅰ-22 方程求解函数表表Ⅰ-23 最小二乘函数表附录I 工具箱函数汇总·529·表Ⅰ-24 实用函数表表Ⅰ-25 大型方法的演示函数表表Ⅰ-26 中型方法的演示函数表Ⅰ.3 样条工具箱函数表Ⅰ-27 三次样条函数表Ⅰ-28 分段多项式样条函数表Ⅰ-29 B样条函数表Ⅰ-30 有理样条函数表Ⅰ-31 操作样条函数表Ⅰ-32 样条曲线端点和节点处理函数附录I 工具箱函数汇总·531·表Ⅰ-33 样条曲线端点和节点处理函数表Ⅰ-34 解线性方程组的函数表Ⅰ-35 样条GUI函数Ⅰ.4 偏微分方程数值解工具箱函数表Ⅰ-36 偏微分方程求解算法函数表Ⅰ-37 用户界面算法函数表Ⅰ-38 几何算法函数表Ⅰ-39 绘图函数表Ⅰ-40 实用函数附录I 工具箱函数汇总·533·表Ⅰ-41 自定义算法函数表Ⅰ-42 演示函数。
Matlab常用命令和函数-工具箱部分函数

Matlab常用命令和函数-工具箱部分函数Matlab 工具箱部分函数randint 产生均匀分布的随机整数矩阵randsrc 根据给定的数字表产生随机矩阵wgn 产生高斯白噪声信号分析函数biterr 计算比特误差数和比特误差率eyediagram 绘制眼图scatterplot 绘制散点图symerr 计算符号误差数和符号误差率信源编码compand mu律/A律压缩/扩张dpcmdeco DPCM(差分脉冲编码调制)解码dpcmenco DPCM编码dpcmopt 优化DPCM参数lloyds Lloyd法则优化量化器参数quantiz 给出量化后的级和输出值误差控制编码bchpoly 给出二进制BCH码的性能参数和产生多项式convenc 产生卷积码cyclgen 产生循环码的奇偶校验阵和生成矩阵cyclpoly 产生循环码的生成多项式decode 分组码解码器encode 分组码编码器gen2par 将奇偶校验阵和生成矩阵互相转换gfweight 计算线性分组码的最小距离hammgen 产生汉明码的奇偶校验阵和生成矩阵rsdecof 对Reed-Solomon编码的ASCII文件解码rsencof 用Reed-Solomon码对ASCII文件编码rspoly 给出Reed-Solomon码的生成多项式syndtable 产生伴随解码表vitdec 用Viterbi法则解卷积码(误差控制编码的低级函数)bchdeco BCH解码器bchenco BCH编码器rsdeco Reed-Solomon解码器rsdecode 用指数形式进行Reed-Solomon解码rsenco Reed-Solomon编码器rsencode 用指数形式进行Reed-Solomon编码调制与解调ademod 模拟通带解调器ademodce 模拟基带解调器amod 模拟通带调制器amodce 模拟基带调制器apkconst 绘制圆形的复合ASK-PSK星座图ddemod 数字通带解调器ddemodce 数字基带解调器demodmap 解调后的模拟信号星座图反映射到数字信号dmod 数字通带调制器dmodce 数字基带调制器modmap 把数字信号映射到模拟信号星座图(以供调制)qaskdeco 从方形的QASK星座图反映射到数字信号qaskenco 把数字信号映射到方形的QASK星座图专用滤波器hank2sys 把一个Hankel矩阵转换成一个线性系统模型hilbiir 设计一个希尔伯特变换IIR滤波器rcosflt 升余弦滤波器rcosine 设计一个升余弦滤波器(专用滤波器的低级函数)rcosfir 设计一个升余弦FIR滤波器rcosiir 设计一个升余弦IIR滤波器信道函数awgn 添加高斯白噪声gfadd 伽罗域上的多项式加法gfconv 伽罗域上的多项式乘法gfcosets 生成伽罗域的分圆陪集gfdeconv 伽罗域上的多项式除法gfdiv 伽罗域上的元素除法gffilter 在质伽罗域上用多项式过滤数据gflineq 在至伽罗域上求Ax=b的一个特解gfminpol 求伽罗域上元素的最小多项式gfmul 伽罗域上的元素乘法gfplus GF(2^m)上的元素加法gfpretty 以通常方式显示多项式gfprimck 检测多项式是否是基本多项式gfprimdf 给出伽罗域的MATLAB默认的基本多项式gfprimfd 给出伽罗域的基本多项式gfrank 伽罗域上矩阵求秩gfrepcov GF(2)上多项式的表达方式转换gfroots 质伽罗域上的多项式求根gfsub 伽罗域上的多项式减法gftrunc 使多项式的表达最简化gftuple 简化或转换伽罗域上元素的形式工具函数bi2de 把二进制向量转换成十进制数de2bi 把十进制数转换成二进制向量erf 误差函数erfc 余误差函数istrellis 检测输入是否MATLAB的trellis结构(structure)marcumq 通用Marcumoct2dec 八进制数转十进制数poly2trellis 把卷积码多项式转换成MATLAB的trellis描述vec2mat 把向量转换成矩阵。
matlab径向基函数

matlab径向基函数Matlab中的径向基函数(RBF)是一种非常有用的数学工具,它在机器学习、数据挖掘和模式识别等领域中被广泛应用。
本文将详细介绍Matlab中径向基函数的定义、原理、实现以及应用。
一、定义径向基函数是一种基于距离的函数,可以将一个点映射到一个高维空间。
在Matlab中,常见的径向基函数包括高斯函数、多项式函数、细胞函数等等。
高斯函数最常用,定义如下:$$\phi_j(x)=exp(-\frac{\parallel x-x_j\parallel^2}{2\sigma_j^2})$$$x$是数据点,$x_j$是高斯函数的中心点,$\sigma_j$是高斯函数的带宽。
根据高斯函数的定义,带宽越小,函数在中心点处的值就越大,函数在中心点附近的值也会更大,但是随着距离的增加,函数值会急剧下降;带宽越大,函数在中心点处的值就越小,函数在中心点附近的值也会更小,但是随着距离的增加,函数值会缓慢下降。
二、原理径向基函数的原理是基于距离的概念,即同类样本之间的距离相对较小,而不同类样本之间的距离相对较大。
在分类或聚类任务中,将样本点映射到高维空间,利用高斯函数或其他径向基函数完成对样本点的聚类或分类。
三、实现在Matlab中,实现径向基函数可以采用以下步骤:1.读取数据集可以采用读取csv文件、Excel文件等方式获取数据集。
在本文中,我们使用Matlab自带的鸢尾花数据集(Iris)进行演示。
2.选择使用的径向基函数本文采用高斯函数,即:$$\phi_j(x)=exp(-\frac{\parallel x-x_j\parallel^2}{2\sigma_j^2})$$3.计算高斯函数参数可以采用层次聚类(hierarchical clustering)、K-means聚类等方法,计算高斯函数的中心点和带宽。
4.计算径向基函数矩阵根据高斯函数的定义,可以根据数据集、高斯函数中心点和带宽计算径向基函数矩阵,具体方法如下:```matlabfunction Gaussian_RBF_Matrix =Gaussian_RBF(dataPoints,numberOfCenters,Gaussian_RBF_Radii)randomIndexs = randperm(size(dataPoints,1));dataPoints = dataPoints(randomIndexs,:); %shuffle datapointscenters = datasample(dataPoints,numberOfCenters); % selects numberOfCenters number of centers at randomdistances = pdist2(dataPoints,centers);Gaussian_RBF_Matrix = exp(-((distances./Gaussian_RBF_Radii).^2));end````dataPoints`是数据集,`numberOfCenters`是高斯函数中心点的数量,`Gaussian_RBF_Radii`是高斯函数的带宽。
bp和rbf的区别

bp和rbf的区别1、BP网络BP神经元的传输函数为非线性函数,最常用的是logsing和tansig,有的输出层也采用线性函数(purelin)。
BP网络一般为多层神经网络,经验表明一般情况下两层即可满足。
如果多层BP网络的输出层采用S型传输函数,其输出值将会限制在一个较小的范围内(0,1);而采用线性传输函数则可以取任意值。
BP网络的学习过程分为两个阶段:(1)输入已知学习样本,通过设置网络结构和前一次迭代的权值和阈值,从网络的第一层向后计算各神经元的输出。
(2)对权值和阈值进行修改,从最后一层向前计算各权值和阈值对总误差的影响(梯度),据此对各权值和阈值进行修改。
BP网络的学习算法:最速下降BP算法(traingd)、动量BP算法(traingdm)、学习率可变的BP算法(traingdx)、弹性BP算法(trainrp)、变梯度算法(traincgf,traincgp,traincgb,trainscg)、拟牛顿算法(trainoss)、LM算法(trainlm)。
提高BP网络泛化能力的方法:归一化法和提前终止法。
BP网络的局限性:(1)学习率与稳定性的矛盾:梯度算法进行稳定学习的学习率较小,所以通常学习过程得收敛速度很慢。
附加动量法通常比简单的梯度算法快,因为在保证学习时间的同时,可以采用很高的学习率,但对于实际应用仍然很慢。
以上两种个方法只适用于希望增加训练次数的情况。
如果有足够的存储空间,则对于中小规模的神经网络可采用LM算法;如果存储空间有问题,则可采用其他多种快速算法,例如对于大规模的神经网络采用trainrp或trainscg(变梯度算法的一种)。
(2)学习率的选择缺乏有效的方法。
对于线性网络,学习率选择的太大,容易导致学习不稳定;反之,学习率选择的太小,则导致无法忍受的过长的学习时间。
对于非线性网络,还没有找到一种简单易行的方法。
(3)训练过程可能限于局部最小。
在实际应用过程中,BP网络往往在训练过程中,也可能找不到某个问题具体地解,比如在训练过程中陷入局部最小的情况。
RBF网络的matlab实现

RBF⽹络的matlab实现⼀、⽤⼯具箱实现函数拟合参考:(1)newrb()该函数可以⽤来设计⼀个近似径向基⽹络(approximate RBF)。
调⽤格式为:[net,tr]=newrb(P,T,GOAL,SPREAD,MN,DF)其中P为Q组输⼊向量组成的R*Q位矩阵,T为Q组⽬标分类向量组成的S*Q维矩阵。
GOAL为均⽅误差⽬标(Mean Squard Error Goal),默认为0.0;SPREAD为径向基函数的扩展速度,默认为1;MN为神经元的最⼤数⽬,默认为Q;DF维两次显⽰之间所添加的神经元数⽬,默认为25;ner为返回值,⼀个RBF⽹络,tr为返回值,训练记录。
⽤newrb()创建RBF⽹络是⼀个不断尝试的过程(从程序的运⾏可以看出来),在创建过程中,需要不断增加中间层神经元的和个数,知道⽹络的输出误差满⾜预先设定的值为⽌。
(2)newrbe()该函数⽤于设计⼀个精确径向基⽹络(exact RBF),调⽤格式为:net=newrbe(P,T,SPREAD)其中P为Q组输⼊向量组成的R*Q维矩阵,T为Q组⽬标分类向量组成的S*Q维矩阵;SPREAD为径向基函数的扩展速度,默认为1和newrb()不同的是,newrbe()能够基于设计向量快速,⽆误差地设计⼀个径向基⽹络。
(3)radbas()该函数为径向基传递函数,调⽤格式为A=radbas(N)info=radbas(code)其中N为输⼊(列)向量的S*Q维矩阵,A为函数返回矩阵,与N⼀⼀对应,即N的每个元素通过径向基函数得到A;info=radbas(code)表⽰根据code值的不同返回有关函数的不同信息。
包括derive——返回导函数的名称name——返回函数全称output——返回输⼊范围active——返回可⽤输⼊范围使⽤exact径向基⽹络来实现⾮线性的函数回归:%%清空环境变量clcclear%%产⽣输⼊输出数据%设置步长interval=0.01;%产⽣x1,x2x1=-1.5:interval:1.5;x2=-1.5:interval:1.5;%按照函数先求的响应的函数值,作为⽹络的输出F=20+x1.^2-10*cos(2*pi*x1)+x2.^2-10*cos(2*pi*x2);%%⽹络建⽴和训练%⽹络建⽴,输⼊为[x1;x2],输出为F。
Matlab工具箱命令汇总

Ⅰ.1 统计工具箱函数表Ⅰ-1 概率密度函数表Ⅰ-2 累加分布函数表Ⅰ-3 累加分布函数的逆函数表Ⅰ-4 随机数生成器函数表Ⅰ-5 分布函数的统计量函数续表表Ⅰ-6 参数估计函数表Ⅰ-7 统计量描述函数续表表Ⅰ-8 统计图形函数表Ⅰ-9 统计过程控制函数续表表Ⅰ-10 聚类分析函数表Ⅰ-11 线性模型函数续表表Ⅰ-12 非线性回归函数表Ⅰ-13 试验设计函数表Ⅰ表Ⅰ-15 多元统计函数表Ⅰ-16 假设检验函数表Ⅰ-17 分布检验函数表Ⅰ表Ⅰ-19 文件输入输出函数表Ⅰ-20 演示函数Ⅰ.2 优化工具箱函数表Ⅰ-21 最小化函数表表Ⅰ-22 方程求解函数表表Ⅰ-23 最小二乘函数表表Ⅰ-24 实用函数表表Ⅰ-25 大型方法的演示函数表表Ⅰ-26 中型方法的演示函数表Ⅰ.3 样条工具箱函数表Ⅰ-27 三次样条函数表Ⅰ-28 分段多项式样条函数表Ⅰ-29 B样条函数表Ⅰ-30 有理样条函数表Ⅰ-31 操作样条函数表Ⅰ-32 样条曲线端点和节点处理函数表Ⅰ-33 样条曲线端点和节点处理函数表Ⅰ-34 解线性方程组的函数表Ⅰ-35 样条GUI函数Ⅰ.4 偏微分方程数值解工具箱函数表Ⅰ-36 偏微分方程求解算法函数表Ⅰ-37 用户界面算法函数表Ⅰ-38 几何算法函数表Ⅰ-39 绘图函数表Ⅰ-40 实用函数续表表Ⅰ-41 自定义算法函数表Ⅰ-42 演示函数。
Matlab的BP神经网络工具箱及其在函数逼近中的应用

Matlab的BP神经⽹络⼯具箱及其在函数逼近中的应⽤1.神经⽹络⼯具箱概述Matlab神经⽹络⼯具箱⼏乎包含了现有神经⽹络的最新成果,神经⽹络⼯具箱模型包括感知器、线性⽹络、BP⽹络、径向基函数⽹络、竞争型神经⽹络、⾃组织⽹络和学习向量量化⽹络、反馈⽹络。
本⽂只介绍BP神经⽹络⼯具箱。
2.BP神经⽹络⼯具箱介绍BP神经⽹络学习规则是不断地调整神经⽹络的权值和偏值,使得⽹络输出的均⽅误差和最⼩。
下⾯是关于⼀些BP神经⽹络的创建和训练的名称:(1)newff:创建⼀前馈BP⽹络(隐含层只有⼀层)(2)newcf:创建⼀多层前馈BP⽹络(隐含层有多层)(3)train:训练⼀个神经⽹络(4)sim:仿真⼀个神经⽹络以上⼏个是最主要的语句,在后⾯的实例应⽤中会详细说明⽤法。
3.BP神经⽹络⼯具箱在函数逼近中的应⽤BP神经⽹络具有很强的映射能⼒,主要⽤于模式识别分类、函数逼近、函数压缩等。
下⾯通过实例来说明BP⽹络在函数逼近⽅⾯的应⽤。
本⽂需要逼近的函数是f(x)=1+sin(k*pi/2*x),其中,选择k=2进⾏仿真,设置隐藏层神经元数⽬为n,n可以改变,便于后⾯观察隐藏层节点与函数逼近能⼒的关系。
3.1 k=2,n=5时的仿真实验先作出⽬标曲线的图形,以下为matlab代码:clear allclc%%%%%%%%%%设置⽹络输⼊值和⽬标值%%%%%%%%%%k=2;%f(x)中的k值x=[-1:.05:8];f=1+sin(k*pi/2*x);plot(x,f,'-');title('要逼近的⾮线性函数');xlabel('时间');ylabel('⾮线性函数');接着⽤newff函数建⽴BP神经⽹络结构,以下为matlab代码:%%%%%%%%%%建⽴⽹络%%%%%%%%%%n=5;%隐藏层节点数net = newff(minmax(x),[n,1],{'tansig' 'purelin'},'trainlm');%对于初始⽹络,可以应⽤sim()函数观察⽹络输出。
BP与RBF
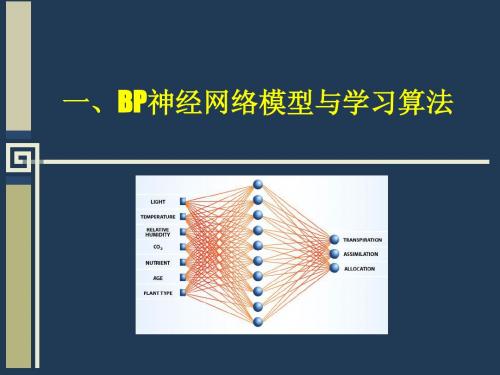
(
1
2
q
)
BP网络的标准学习算法 BP网络的标准学习算法
输入层与中间层的连接权值: wih 隐含层与输出层的连接权值: who 隐含层各神经元的阈值: bh 输出层各神经元的阈值: bo 样本数据个数: k = 1, 2,L m 激活函数: f(⋅) 1 q 误差函数: = ∑ ( d o ( k ) − yoo ( k )) 2 e
2
o =1
BP网络的标准学习算法 BP网络的标准学习算法
第一步, 第一步,网络初始化 给各连接权值分别赋一个区间(-1,1) 内的随机数,设定误差函数e,给定计 算精度值ε 和最大学习次数M。 第二步, 第二步,随机选取第 k个输入样本及对应 期望输出
d o ( k ) = ( d1 ( k ), d 2 ( k ),L , d q ( k ) )
i =1 n
∂wih
= xi ( k )
BP网络的标准学习算法 BP网络的标准学习算法
1 q ∂ ( ∑ (d o ( k ) − yoo (k )) 2 ) ∂e ∂hoh ( k ) 2 o =1 = ∂hih ( k ) ∂hoh ( k ) ∂hih ( k ) 1 q ∂ ( ∑ ( d o ( k ) − f( yio ( k ))) 2 ) ∂hoh ( k ) 2 o =1 = ∂hoh ( k ) ∂hih ( k )
误差的反向传播
BP网络的标准学习算法BP网络的标准学习算法-学习过程 网络的标准学习算法
正向传播: 正向传播:
输入样本---输入层---各隐层---输出层
判断是否转入反向传播阶段: 判断是否转入反向传播阶段:
若输出层的实际输出与期望的输出(教师信号)不 符
RBF神经网络:原理详解和MATLAB实现

RBF神经网络:原理详解和MATLAB实现——2020年2月2日目录RBF神经网络:原理详解和MATLAB实现 (1)一、径向基函数RBF (2)定义(Radial basis function——一种距离) (2)如何理解径向基函数与神经网络? (2)应用 (3)二、RBF神经网络的基本思想(从函数到函数的映射) (3)三、RBF神经网络模型 (3)(一)RBF神经网络神经元结构 (3)(二)高斯核函数 (6)四、基于高斯核的RBF神经网络拓扑结构 (7)五、RBF网络的学习算法 (9)(一)算法需要求解的参数 (9)0.确定输入向量 (9)1.径向基函数的中心(隐含层中心点) (9)2.方差(sigma) (10)3.初始化隐含层至输出层的连接权值 (10)4.初始化宽度向量 (12)(二)计算隐含层第j 个神经元的输出值zj (12)(三)计算输出层神经元的输出 (13)(四)权重参数的迭代计算 (13)六、RBF神经网络算法的MATLAB实现 (14)七、RBF神经网络学习算法的范例 (15)(一)简例 (15)(二)预测汽油辛烷值 (15)八、参考资料 (19)一、径向基函数RBF定义(Radial basis function——一种距离)径向基函数是一个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意一点c的距离,c点称为中心点,也就是Φ(x,c)=Φ(‖x-c‖)。
任意一个满足Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数。
标准的一般使用欧氏距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。
在神经网络结构中,可以作为全连接层和ReLU层的主要函数。
如何理解径向基函数与神经网络?一些径向函数代表性的用到近似给定的函数,这种近似可以被解释成一个简单的神经网络。
径向基函数在支持向量机中也被用做核函数。
常见的径向基函数有:高斯函数,二次函数,逆二次函数等。
神经网络PPT课件-基于MATLAB算法(BP.遗传算法.RBF.小波)

正因为人工神经网络是对生物神经网络的模仿,它具有一些传统 逻辑运算不具有的优点。主要包括: 一、非线性。非线性是自然界的普遍特性。人脑的思考过程就是 非线性的。人工神经网络通过模仿人脑神经元结构的信息传递过 程,可以进行线性或者非线性的运算,这是人工神经网络的最特 出的特性。
二、自适应性。神经网络的结构中设置了权值和阈值参数。网络 能够随着输入输出端的环境变化,自动调节神经节点上的权值和 阈值。因此,神经网络对在一定范围变化的环境有பைடு நூலகம்强的适应能 力。适用于完成信号处理、模式识别、自动控制等任务。系统运 行起来也相当稳定。
③引入陡度因子
误差曲面上存在着平坦区域。权值调整进入平坦区的原因是神经元输出进入了转 移函数的饱和区。如果在调整进入平坦区域后,设法压缩神经元的净输入,使其 输出退出转移函数的饱和区,就可以改变误差函数的形状,从而使调整脱离平坦 区。实现这一思路的具体作法是在原转移函数中引入一个陡度因子。
BP神经网络的MATLAB算法
BP神经网络模型
• BP (Back Propagation)神经网络,即误差反向传播算法的学习过 程,由信息的正向传播和误差的反向传播两个过程组成。输入 层各神经元负责接收来自外界的输入信息,并传递给中间层各 神经元;中间层是内部信息处理层,负责信息变换,根据信息 变化能力的需求,中间层可以设计为单隐含层或者多隐含层结 构;最后一个隐含层传递到输出层各神经元的信息,经进一步 处理后,完成一次学习的正向传播处理过程,由输出层向外界 输出信息处理结果。
l n 1 l
m n a
l log 2 n
步骤2:隐含层输出计算 根据输入变量 X,输入层和隐含层间连接权值 ij 以及隐含层阈值 a, 计算隐含层输出H。
matlab调用高斯核函数 -回复

matlab调用高斯核函数-回复Matlab是一种常用的科学计算和数据分析工具,提供了丰富的函数库和工具箱,可以用于实现各种算法和模型。
其中,高斯核函数是机器学习和模式识别领域常用的一种核函数,用于非线性分类和回归任务。
本文将介绍如何在Matlab中调用高斯核函数,并详细解释其原理和应用。
首先,我们需要知道什么是高斯核函数。
高斯核函数也被称为径向基函数(Radial Basis Function,简称RBF),它是一种基于距离度量的非线性变换。
其定义如下:K(x, y) = exp(- x-y ^2 / (2 * sigma^2))其中,x和y是样本点的特征向量,x-y 表示欧式距离(即样本点之间的直线距离),sigma是高斯核函数的带宽参数,控制了函数的变化速度。
在Matlab中,我们可以使用内置函数pdist2来计算两个样本点之间的欧式距离,使用exp函数来计算指数函数。
以下是一个示例的Matlab代码,实现了高斯核函数的计算:matlabfunction [kernel] = gaussian_kernel(X1, X2, sigma)X1和X2分别是两个样本点的特征向量矩阵,大小分别为N1 x d和N2 x d,sigma是带宽参数返回一个N1 x N2大小的高斯核矩阵使用pdist2函数计算欧式距离矩阵distance_matrix = pdist2(X1, X2);计算高斯核矩阵kernel = exp(-distance_matrix.^2 / (2 * sigma^2));end在这段代码中,我们定义了一个函数`gaussian_kernel`,该函数接受两个特征向量矩阵`X1`和`X2`,以及带宽参数`sigma`作为输入。
函数中首先使用`pdist2`函数计算两个特征向量矩阵之间的欧式距离矩阵`distance_matrix`,然后根据高斯核函数的定义,计算每个距离的高斯核值,并返回一个高斯核矩阵`kernel`。
matlab 的rbf函数编程

matlab 的rbf函数编程在MATLAB中,实现RBF(径向基函数)网络的编程通常需要以下步骤:1. 导入数据,首先,你需要导入你的数据集。
可以使用MATLAB的内置函数如`csvread`或者`xlsread`来导入数据,或者直接创建一个数据矩阵。
2. 数据预处理,对于RBF网络,通常需要对数据进行标准化或归一化处理,以确保网络的训练和预测过程能够顺利进行。
3. 网络训练,使用MATLAB的神经网络工具箱(Neural Network Toolbox)中的函数,比如`newrb`(用于建立RBF网络)和`train`(用于训练网络),来训练RBF网络。
在训练之前,你需要确定RBF网络的结构,比如隐藏层节点的数量和RBF函数的类型。
4. 网络预测,训练完成后,可以使用训练好的RBF网络对新的数据进行预测。
使用`sim`函数来进行预测,传入训练好的网络和待预测的输入数据。
下面是一个简单的示例代码,用于在MATLAB中实现RBF网络的训练和预测:matlab.% 导入数据。
data = load('your_data_file.csv');% 数据预处理。
% 这里假设数据已经进行了合适的预处理。
% 定义RBF网络结构。
hiddenLayerSize = 10; % 设置隐藏层节点数量。
net = newrb(input, target, goal, spread); % 创建RBF网络。
% 网络训练。
net = train(net, input, target); % 训练RBF网络。
% 网络预测。
output = sim(net, input); % 使用训练好的网络进行预测。
在这个示例中,`input`是输入数据,`target`是对应的目标输出,`goal`是训练的目标性能,`spread`是RBF函数的扩展参数。
你需要根据你的数据和需求来调整这些参数。
需要注意的是,RBF网络的性能很大程度上取决于网络结构和参数的选择,因此在实际应用中需要进行一定的调参和验证工作。
MATLAB径向基神经网络函数

众所周知,BP网络用于函数逼近时,权值的调节采用的是负梯度下降法。
这个调节权值的方法有局限性,即收敛慢和局部极小等。
径向基函数网络(RBF)在逼近能力、分类能力和学习速度等方面均优于BP 网络。
Matlab中提供了四个径向基函数相关的函数,它们都是创建两层的神经网络,第一层都是径向基层,第二层是线性层或者竞争层。
主要的区别是它们权值、阀值就算函数不同或者是否有阀值。
注意:径向基函数网络不需要训练,在创建的时候就自动训练好了。
= newrbe(P,T,spread)newrbe()函数可以快速设计一个径向基函数网络,且是的设计误差为0。
第一层(径向基层)神经元数目等于输入向量的个数,加权输入函数为dist,网络输入函数为netprod;第二层(线性层)神经元数模有输出向量T确定,加权输入函数为dotprod,网络输入函数为netsum。
两层都有阀值。
第一层的权值初值为p',阀值初值为0.8326/spread,目的是使加权输入为±spread时径向基层输出为0.5,阀值的设置决定了每一个径向基神经元对输入向量产生响应的区域。
2.[net,tr] = newrb(P,T,goal,spread,MN,DF)该函数和newrbe一样,只是可以自动增加网络的隐层神经元数模直到均方差满足精度或者神经元数模达到最大为止。
P=-1:0.1:1;T=sin(P);spread=1;mse=0.02;net=newrb(P,T,mse,spread);t=sim(net,P);plot(P,T,'r*',P,t) = newgrnn(P,T,spread)泛回归网络(generalized regression neural network)广义回归网络主要用于函数逼近。
它的结构完全与newbre的相同,但是有以下几点区别(没有说明的表示相同):(1)第二网络的权值初值为T(2)第二层没有阀值(3)第二层的权值输入函数为normpod,网络输入函数为netsum>> P=0:1:20;>> T=exp(P).*sin(P);>> net=newgrnn(P,T,0.7);>> p=0:0.1:20;>> t=sim(net,p);>> plot(P,T,'*r',p,t) = newpnn(P,T,spread)概率神经网络(probabilistic neural network)该网络与前面三个最大的区别在于,第二层不再是线性层而是竞争层,并且竞争层没有阀值,其它同newbre,故PNN网络主要用于解决分类问题。
神经网络 作业 -- 使用BP RBF SVM进行函数拟合和分类

神经网络作业作业说明第一题(函数逼近):BP网络和RBF网络均是自己编写的算法实现。
BP网络均采用的三层网络:输入层(1个变量)、隐层神经元、输出层(1个变量)。
转移函数均为sigmoid函数,所以没有做特别说明。
在第1小题中贴出了BP和RBF的Matlab代码,后面的就没有再贴出;而SVM部分由于没有自己编写,所以没有贴出。
而针对其所做的各种优化或测试,都在此代码的基础上进行,相应参数的命名方式也没有再改变。
RBF网络使用了聚类法和梯度法两种来实现。
而对于SVM网络,在后面两题的分类应用中都是自己编写的算法实现,但在本题应用于函数逼近时,发现效果很差,所以后来从网上下载到一个SVM工具包LS-SVMlab1.5aw,调用里面集成化的函数来实现的,在本题函数逼近中均都是采用高斯核函数来测试的。
第二题(分类):BP网络和RBF网络都是使用的Matlab自带的神经网络工具包来实现的,不再贴出代码部分。
而SVM网络则是使用的课上所教的算法来实现的,分别测试了多项式核函数和高斯核函数两种实现方法,给出了相应的Matlab代码实现部分。
第三题:由于问题相对简单,所以就没有再使用Matlab进行编程实现,而是直接进行的计算。
程序中考虑到MATLAB处理程序的特性,尽可能地将所有的循环都转换成了矩阵运算,大大加快了程序的运行速度。
编写时出现了很多错误,常见的如矩阵运算维数不匹配,索引值超出向量大小等;有时候用了很麻烦的运算来实现了后来才知道原来可以直接调用Matlab里面的库函数来实现以及怎么将结果更清晰更完整的展现出来等等。
通过自己编写算法来实现各个网络,一来提升了我对各个网络的理解程度,二来使我熟悉了Matlab环境下的编程。
1.函数拟合(分别使用BP,RBF,SVM),要求比较三个网络。
2π.x ,05x)sin(5x)exp(y(x)4π.x ,0xsinx y(x)100.x x),1exp(y(x)100.x ,1x1y(x)≤≤-=≤≤=≤≤-=≤≤=解:(1).1001,1)(≤≤=x x x ya. BP 网络:Matlab 代码如下:nv=10; %神经元个数:10个err=0.001; %误差阈值J=1; %误差初始值N=1; %迭代次数u=0.2; %学习率wj=rand(1,nv); %输入层到隐层神经元的权值初始化wk=rand(1,nv); %隐层神经元到输出层的权值初始化xtrain=1:4:100; %训练集,25个样本xtest=1:1:100; %测试集,100个dtrain=1./xtrain; %目标输出向量,即教师%训练过程while (J>err)&&(N<100000)uj=wj'*xtrain;h=1./(1+exp(-uj)); %训练集隐层神经元输出uk=wk*h;y=1./(1+exp(-uk)); %训练集输出层实际输出delta_wk = u*(dtrain-y).*y.*(1-y)*h'; %权值调整delta_wj = u*wk.*(((dtrain-y).*y.*(1-y).*xtrain)*(h.*(1-h))'); wk = wk+delta_wk;wj = wj+delta_wj;J=0.5*sum((dtrain-y).^2); %误差计算j(N)=J;N=N+1;end%测试及显示uj=wj'*xtest;h=1./(1+exp(-uj));uk=wk*h;dtest=1./(1+exp(-uk));figuresubplot(1,2,1),plot(xtest,dtest,'ro',xtest,1./xtest);legend('y=1/x', 'network output');subplot(1,2,2),plot(xtest,1./xtest-dtest);x=1:N-1;figureplot(x,j(x));运行条件:10个神经元,误差迭代阈值为0.001.学习率为0.2。
Matlab人工神经网络工具箱中的BP工具函数及其应用

2 Matlab 人工神经网络工具箱中关于 BP 网络的重要工具函数
Matlab 软件包中的人工神经网络工具箱包含了进行 BP 网络设计和分析的大量工具函数 ,由于 Matlab 从 5. 1 、 5. 3 到 6. 0
等的版本不同 ,人工神经网络工具箱中的 BP 工具函数也有一定的差别 ,下面兼顾不同版本 ,给出在 BP 网络设计和分析中 的常用工具函数以及功能说明 . Deltalin Deltalog Deltatan Errsurf Initff Learnbp Learnbpm Logsig Purelin Simuff Tansig Trainbp Trainbpx Learngd Leamgdm Newff Traingd Traingdm Sim Init Train
Δ Δ γ δ γ δ wij (t + 1) = wij (t) +β wij (t) ; j Oi +α j ( t + 1) =γ j ( t ) +β j +α j (t) ; Δvhi (t) ; Δ θ θ θ vhi (t + 1) = vhi (t) +β ej xh +α ei +α i ( t + 1) = i ( t ) +β i (t) 这里 0 <β< 1 为比例系数 α , 为加速收敛的动量因子 .
1 BP 网络模型中的有关计算公式
BP 算法的基本思想是 : 对于一个输入样本 ,经过权值 、 阈值和激励函数运算后 ,得到一个输出 ,然后让它与期望的样本
进行比较 ,若有偏差 ,则从输出开始反向传播该偏差 ,进行权值 、 阈值调整 ,使网络输出逐渐与希望输出一致 .
BP 算法由四个过程组成 : 输入模式由输入层经过中间层向输出层的 “模式顺传播” 过程 , 网络的希望输出与网络的实
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Matlab工具箱中的BP与RBF函数Matlab神经网络工具箱中的函数非常丰富,给网络设置合适的属性,可以加快网络的学习速度,缩短网络的学习进程。
限于篇幅,仅对本章所用到的函数进行介绍,其它的函数及其用法请读者参考联机文档和帮助。
1 BP与RBF网络创建函数在Matlab工具箱中有如表1所示的创建网络的函数,作为示例,这里只介绍函数newff、newcf、newrb和newrbe。
表 1 神经网络创建函数(1) newff函数功能:创建一个前馈BP神经网络。
调用格式:net = newff(PR,[S1 S2...S Nl],{TF1 TF2...TF Nl},BTF,BLF,PF) 参数说明:•PR - R个输入的最小、最大值构成的R×2矩阵;•S i–S NI层网络第i层的神经元个数;•TF i - 第i层的传递函数,可以是任意可导函数,默认为'tansig',可设置为logsig,purelin等;•BTF -反向传播网络训练函数,默认为'trainlm',可设置为trainbfg,trainrp,traingd等;•BLF -反向传播权值、阈值学习函数,默认为'learngdm';•PF -功能函数,默认为'mse';(2) newcf函数功能:创建一个N层的层叠(cascade)BP网络调用格式:net = newcf(Pr,[S1 S2...SNl],{TF1 TF2...TFNl},BTF,BLF,PF) 参数同函数newff。
(3) newrb函数功能:创建一个径向基神经网络。
径向基网络可以用来对一个函数进行逼近。
newrb函数用来创建一个径向基网络,它可以是两参数网络,也可以是四参数网络。
在网络的隐层添加神经元,直到网络满足指定的均方误差要求。
调用格式:net = newrb(P,T,GOAL,SPREAD)参数说明:•P:Q个输入向量构成的R×Q矩阵;•T:Q个期望输出向量构成的S×Q矩阵;•GOAL:均方误差要求,默认为0。
•SPREAD:分散度参数,默认值为1。
SPREAD越大,网络逼近的函数越平滑,但SPREAD取值过大将导致在逼近变化比较剧烈的函数时神经元过多,若SPREAD取值过小,则导致在逼近平滑函数时,导致神经元过多。
(4) newrbe函数功能:创建一个精密径向基网络。
newrbe函数可以很快地根据设计向量创建一个0误差的径向基网络。
调用格式:Net=Newrbe(P,T,SPREAD)参数说明:参数P,T和SPREAD同newrb函数中的参数P,T和SPREAD含义相同。
2 网络训练函数(1) Adapt函数功能:神经网络单步训练函数。
调用格式:[net,Y,E,Pf,Af] = adapt(net,P,T,Pi,Ai)参数说明:Adapt函数调用由net.adaptFcn所指定的函数和net.adaptParam所指定的参数来训练网络。
在执行命令Adapt之前,可以预先指定训练函数net.adaptFcn和训练参数net.adaptParam。
输入参数:•net –所要训练的网络;•P - 网络的输入;•T - 网络的期望输出,可选项,只在有教师训练时需要,一般不用,默认值为0;•Pi –初始输入延迟,可选项,只在有输入延迟时需要,一般不用,默认值为0;•Ai –初始层延迟,可选项,只在有层延迟时需要,默认值为0;•输出参数:NET –训练后的网络;•Y - 网络输出;• E - 网络误差;•Pf -训练后的输入延迟,一般不用.;•Af -训练后的层延迟,一般不用。
ADAPT的参数有两种格式:阵列格式和矩阵格式。
阵列格式易于描述,最适合于多输入多输出网络。
当ADAPT的参数为阵列格式时:P - Ni×TS阵列, 阵列的每个元素P{i,ts}是一个Ri×Q 的矩阵;T - Nt×TS阵列, 阵列的每个元素P{i,ts}是一个V i×Q的矩阵;Pi - Ni×ID阵列, 阵列的每个元素{i,k}是一个Ri×Q 的矩阵;Ai - Nl×LD阵列, 阵列的每个元素{i,k}是一个Si×Q的矩阵;其中:Ni = net.numInputsNl = net.numLayersNt = net.numTargetsID = net.numInputDelaysLD = net.numLayerDelaysTS = Number of time stepsQ = Batch sizeRi = net.inputs{i}.sizeSi = yers{i}.sizeV i = net.targets{i}.size矩阵格式最适合于单输入单输出网络,但也可以用于多输入多输出网络。
每个矩阵元素通过把相应阵列参数元素存储到一个单一的矩阵来寻找。
当ADAPT的参数为矩阵格式时:P-(sum of Ri)×Q matrixT-(sum of V i)×Q matrixPi-(sum of Ri)×(ID*Q) matrixAi-(sum of Si)×LD*Q) matrix其中Pi, Ai, Pf和Af的列为最初的延迟条件到最近的延迟条件。
Pi{i,k}为时刻ts=k-ID的输入i;Pf{i,k}为时刻ts=TS+k-ID 的输入i ;Ai{i,k}为时刻ts=k-LD的层输出i;Af{i,k}为时刻ts=TS+k-LD的层输出i。
(2) adaptwb函数功能:网络权值和偏置单步训练函数调用格式:[net,Ac,El] = adaptwb(net,Pd,T,Ai,Q,TS)info = adaptwb(code)说明:adaptwb函数根据网络的学习函数(net.learnFcn)对网络的权值和偏置进行单步训练。
输入参数:net 所要训练的神经网络;•Pd 延迟输入,是一个No×Ni×TS阵列,元素P{i,j,ts}是一个Zij ×Q矩阵;•Tl 各层的期望输出,Nl×TS阵列,元素P{i,ts}是一个V i×Q矩阵或空矩阵;•Ai 初始输入条件,Nl×LD阵列,元素Ai{i,k}是一个Si×Q矩阵;•Q 输入向量的个数•TS 步长输出参数:•net 更新后的网络•Ac 总的层输出,Nl×(LD+TS)阵列,元素El{i,k}是一个Si×Q 矩阵或空矩阵。
•El 该层的误差其中参数Ni、Nl、LD、Ri、Si和V i同adapt函数中的参数Ni、Nl、LD、Ri、Si和V i相同。
Zij = Ri*length(net.inputW eights{i,j}.delays)adaptwb(code)函数根据code返回有用的信息,code可以取为‘pnames’训练参数的名称‘pdefaults’缺省的训练参数如果要使一个网络使用adaptwb函数进行网络训练,需要作如下设置:•设置net.adaptFcn为adaptwb(net.adaptParam将自动设为adaptwb的缺省值);•设置第i层各偏置的学习函数(net.biases{i}.learnFcn)和各权值的学习函数(net.inputW eights{i,j}.learnFcn 和yerW eights{i,j}.learnFcn)为各自的期望学习函数;(3) train函数功能:神经网络学习函数。
调用格式:[net,tr] = train(net,P,T,Pi,Ai)[net,tr] = train(net,P,T,Pi,Ai,VV,TV)说明:train函数根据net.trainFcn和net.trainParam训练网络net。
输入参数:train函数的输入参数同adapt函数的输入参数相同。
输出参数:•net –返回网络;•tr –网络训练步数和性能;Train函数的信号参数可以有两种格式:阵列或矩阵,输入参数的阵列格式和矩阵格式同adapt函数相同。
Train函数的第二种调用格式[net,tr] =train(NET,P,T,Pi,Ai,VV,TV)与其第一种格式的区别在于:第二种调用格式在训练完网络过程中进行网络测试,确认向量用来尽早终止训练,以免过训练损害网络的普遍性,而第一种调用格式在训练过程中不进行这种测试。
如果VV.Pi、VV.Ai设为空矩阵或空阵列,将使用起默认值。
其中VV.P,TV.P为给定/测试输入,VV.T, TV.T为给定/测试输入的期望输出,默认值为0;VV.Pi,TV.Pi为给定/测试初始输入延迟条件,默认值为0;VV.Ai,TV.Ai为给定/测试层延迟条件,默认值为0;(4) trainwb函数功能:网络权值/偏置训练函数调用格式:[net,tr]=trainwb(net,Pd,Tl,Ai,Q,TS,VV)info = trainwb(code)说明:输入参数:•Pd 延迟输入,No×Ni×TS阵列,元素P{i,j,ts}是一个Dij×Q矩阵,其中◆Dij=Ri*length(net.inputW eights{i,j}.delays)•VV 变量向量结构体或空矩阵其它参数同adaptwb函数中相应的参数相同。
•输出参数:•net 训练后的网络•tr 每一步中各个值的训练记录,它有四个参量,tr.epoch为训练次数,tr.perf为训练性能,tr.vperf为验证性能,tr.tperf为测试性能。
同adaptwb函数一样,若要设计一个用trainwb函数进行训练的网络,需要对网络作一些设置,设置的参数与设置方法同adaptwb相同。
3 网络初始化函数(1) init函数功能:网络初始化函数。
调用格式:init(net)说明:根据由net.initFcn说明的网络初始化函数和net.initParam说明的参数值重新初始化网络的权值和阈值。
示例:net = newp([0 1;-2 2],1); %创建一个感知器神经网络;net.iw{1,1} %显示网络的输入权值,其结果为ans =00P = [0 1 0 1; 0 0 1 1]; %网络的输入矩阵T = [0 0 0 1]; %网络的输出矩阵net = train(net,P,T); %对网络进行训练net.iw{1,1} %显示训练后网络的输入权值,其结果为ans =1 1net = init(net); %重新初始化网络net.iw{1,1} %显示重新初始化后网络的输入权值,其结果为ans =00(2) initlay函数功能:网络层初始化函数。