【IT专家】yolo模型移植到android手机端
yolo v5原理

yolo v5原理YOLO V5是一种用于目标检测的神经网络模型,它的全称是You Only Look Once Version 5。
目标检测是计算机视觉领域中的一项重要任务,它的目标是在图像或视频中准确地定位和识别出不同类别的物体。
YOLO V5的原理基于深度学习技术,特别是卷积神经网络(Convolutional Neural Network,CNN)。
它采用了一种单阶段的检测方式,即将目标检测任务直接作为回归问题来解决,而不需要使用传统方法中的两阶段流程。
YOLO V5的网络结构主要由两个部分组成:主干网络和检测头。
主干网络负责提取图像的特征,而检测头则负责预测目标的位置和类别。
主干网络通常采用预训练的卷积神经网络模型,如Darknet、CSPDarknet、EfficientNet等。
这些模型在大规模图像数据集上进行了训练,能够提取出丰富的图像特征。
检测头是YOLO V5的核心部分,它由一系列的卷积层和全连接层组成。
检测头的输入是主干网络提取的特征图,经过一系列的卷积操作后,会输出一个固定大小的特征图。
这个特征图可以看作是一个网格,每个网格单元都负责预测一个目标的位置和类别。
具体来说,每个网格单元会预测出一组边界框(Bounding Box),每个边界框由四个坐标值(x、y、w、h)表示,分别表示边界框的中心坐标和宽高。
此外,每个边界框还会预测出一个置信度(Confidence),用于表示该边界框包含目标的可信程度。
最后,每个网格单元还会预测出目标的类别概率,用于判断目标属于哪一类。
在训练阶段,YOLO V5会使用标注的数据集进行监督学习。
通过比较预测的边界框和真实边界框之间的差异,可以计算出损失函数。
然后,通过反向传播算法,调整网络的权重和偏置,使得预测的结果更加准确。
在推理阶段,YOLO V5会将输入图像通过主干网络提取特征,并将特征图输入到检测头进行预测。
通过对每个网格单元的预测结果进行解码和筛选,可以得到最终的目标检测结果。
如何将pytorch模型部署到安卓上的方法示例

如何将pytorch模型部署到安卓上的⽅法⽰例⽬录模型转化安卓部署新建项⽬导⼊包页⾯⽂件模型推理这篇⽂章演⽰如何将训练好的pytorch模型部署到安卓设备上。
我也是刚开始学安卓,代码写的简单。
环境:pytorch版本:1.10.0模型转化pytorch_android⽀持的模型是.pt模型,我们训练出来的模型是.pth。
所以需要转化才可以⽤。
先看官⽹上给的转化⽅式:import torchimport torchvisionfrom torch.utils.mobile_optimizer import optimize_for_mobilemodel = torchvision.models.mobilenet_v3_small(pretrained=True)model.eval()example = torch.rand(1, 3, 224, 224)traced_script_module = torch.jit.trace(model, example)optimized_traced_model = optimize_for_mobile(traced_script_module)optimized_traced_model._save_for_lite_interpreter("app/src/main/assets/model.ptl")这个模型在安卓对应的包:repositories {jcenter()}dependencies {implementation 'org.pytorch:pytorch_android_lite:1.9.0'implementation 'org.pytorch:pytorch_android_torchvision:1.9.0'}注:pytorch_android_lite版本和转化模型⽤的版本要⼀致,不⼀致就会报各种错误。
深度学习——YOLO模型的原理与实战

深度学习——YOLO模型的原理与实战YOLO(You Only Look Once)是一种基于深度学习的目标检测算法。
它通过将目标检测问题转化为回归问题,实现了实时高效的目标检测。
本文将介绍YOLO模型的原理,并讲述如何在实战中使用YOLO进行目标检测。
YOLO模型的原理:YOLO模型的核心思想是将目标检测问题转化为一个回归问题。
传统的目标检测算法通常由两个关键步骤组成:候选区域生成和对象分类。
这些算法需要先生成候选区域,然后对每个候选区域进行分类和定位。
这种两步法的方式效率较低,无法满足实时场景的需求。
相比之下,YOLO模型是一个单阶段的目标检测器,它将目标检测问题转化为一个回归问题。
YOLO模型直接在整个图像上进行预测,而不需要先生成候选区域。
具体来说,YOLO模型将图像分为SxS个网格(grid),每个网格预测C个类别的目标,同时预测每个目标的边界框信息。
这样,整个目标检测问题就可以转化为一个SxSxC个类别的多类别预测问题。
YOLO模型由多个卷积层和全连接层组成,其中最后一个全连接层负责预测每个网格中所有目标的类别概率、边界框位置以及置信度。
具体来说,每个目标的预测结果包括5个值:目标所属类别的概率、边界框中心坐标的相对值(相对于整个图像的宽度和高度)、边界框的相对宽度和高度。
YOLO模型的训练过程包括两个阶段:预训练和微调。
预训练阶段使用ImageNet数据集进行训练,得到一个基础模型。
然后,微调阶段使用自定义数据集对模型进行进一步训练,以适应目标检测任务。
YOLO模型的实战应用:在实战中使用YOLO进行目标检测通常需要以下步骤:2.构建YOLO模型:根据自己的需求和数据特点,选择YOLO的不同版本(如YOLOv1、YOLOv2等),并根据数据集和目标特点调整模型的参数和架构。
4.训练模型:使用预处理后的数据集对YOLO模型进行训练。
训练过程中需要注意选择适当的损失函数(如交叉熵函数)和优化算法(如梯度下降算法)。
yolo 数据处理的流程

yolo 数据处理的流程YOLO(You Only Look Once)是一种快速高效的目标检测算法,它的数据处理流程如下:1. 数据收集:首先需要收集包含目标物体的图像数据集。
这可以通过人工标注、网络爬虫等方式获得。
2. 数据预处理:对收集的图像数据进行预处理,包括图像尺寸调整、图像增强、数据增强等操作。
常见的预处理操作有图像缩放、归一化、旋转、平移、翻转等。
3. 数据划分:将收集的数据集划分为训练集、验证集和测试集。
训练集用于模型的训练,验证集用于选择超参数和模型调优,测试集用于评估模型的性能。
4. 标签生成:对训练集中的图像进行标签生成。
YOLO算法以边界框的形式定位和识别目标物体,因此需要将目标物体的边界框标注在图像中。
5. 特征提取:使用卷积神经网络(CNN)等方法对图像进行特征提取。
YOLO算法使用Darknet网络作为其主干网络,将图像输入网络中,经过卷积和池化等操作,最终生成特征图。
6. 目标检测:在特征图上进行目标检测,即通过预测每个特征框的类别和位置来确定图像中的目标物体。
YOLO算法通过在特征图上滑动固定大小的窗口进行预测,并使用置信度指标来判断窗口中是否包含目标。
7. 非极大值抑制:由于YOLO算法在特征图上滑动窗口进行预测,同一个目标可能会被多个窗口检测到,因此需要进行非极大值抑制(NMS)来去除冗余的检测框。
8. 输出结果:最后将检测到的目标框的位置和类别输出为最终的检测结果。
可以将结果可视化在图像上,或者以其他格式输出,如标注文件、XML文件等。
这是YOLO算法数据处理的一般流程,具体的实现细节和算法参数设置会因各种情况而异。
在移动设备上部署神经网络模型的技巧与指南

在移动设备上部署神经网络模型的技巧与指南移动设备的普及和性能的提升使得人们可以在手机和平板等移动设备上运行复杂的应用程序,其中包括了神经网络模型。
神经网络模型在计算机视觉、自然语言处理等领域有着广泛的应用,因此在移动设备上部署神经网络模型的技巧和指南变得尤为重要。
一、模型压缩与优化在移动设备上部署神经网络模型时,首先需要考虑的是模型的大小和计算量。
大型的神经网络模型往往需要较长的推理时间和较大的内存消耗,这对于移动设备来说是不可接受的。
因此,模型压缩与优化是必不可少的一步。
1.1 参数剪枝参数剪枝是一种常用的模型压缩方法,通过去除冗余的参数来减小模型的大小。
剪枝可以根据参数的重要性进行,将不重要的参数置零或删除,从而达到减小模型大小的目的。
同时,剪枝还可以提高模型的推理速度,减少内存消耗。
1.2 量化量化是另一种常用的模型压缩方法,它通过减少模型中参数的比特数来减小模型的大小。
通常情况下,将浮点数参数转换为更低精度的定点数或整数可以显著减小模型的大小。
虽然量化会带来一定的精度损失,但对于移动设备上的应用来说,这种损失是可以接受的。
1.3 网络结构优化除了对模型参数进行压缩和优化外,还可以对网络结构进行优化。
例如,可以通过减少网络层数、减少卷积核的数量等方式来降低模型的计算量和内存消耗。
此外,还可以采用轻量级的网络结构,如MobileNet、ShuffleNet等,来满足移动设备上的资源限制。
二、硬件加速与部署在移动设备上部署神经网络模型时,还需要考虑硬件加速和部署的问题。
移动设备的硬件资源有限,因此需要采用一些技巧来提高模型的推理速度和性能。
2.1 GPU加速大多数移动设备都配备了GPU,可以利用GPU的并行计算能力来加速神经网络的推理过程。
通过使用GPU加速库,如CUDA、OpenCL等,可以将模型的计算任务分配给GPU来并行处理,从而提高推理速度。
2.2 硬件优化除了利用GPU加速外,还可以通过硬件优化来提高神经网络模型的性能。
yolo参数转定点onnx

yolo参数转定点onnx
将YOLO参数转换为定点ONNX格式需要经历以下步骤:
1.导出YOLO模型:将训练好的YOLO模型导出为ONNX格式。
可以使用YOLO 框架提供的导出工具或使用第三方库(如pytorch或tensorflow)来导出模型。
具体的导出方法会根据使用的YOLO版本和框架而有所不同。
2.量化模型:将浮点模型转换为定点模型。
定点表示使用整数表示权重和激活值,以降低模型的存储和计算成本。
可以使用量化工具,如TensorRT或ONNX Runtime等,将浮点模型转换为定点模型。
3.设置定点参数:在转换为定点模型后,需要设置模型的定点参数,包括比例因子、位宽和偏移量等。
这些参数用于将浮点值映射到定点表示,并在推理过程中保持正确的精度。
4.重新编译和优化:对定点模型进行重新编译和优化,以确保模型在定点硬件上的有效性和性能。
这可能涉及到模型的量化、量化感知训练、动态固定点缩放等技术。
5.测试和调优:在转换为定点ONNX模型后,需要对模型进行测试和调优,以确保模型在定点推理过程中的准确性和性能。
可以使用测试集进行性能评估和验证。
需要注意的是,YOLO模型的参数转换为定点ONNX格式是一个复杂的过程,需要深入了解YOLO模型和定点推理技术。
具体的实现方法和工具选择会根据的需求和环境而有所不同。
建议参考YOLO和ONNX的官方文档,以获取更详细的指导和资料。
目标检测yolo原理

目标检测yolo原理你知道有种技术,能让电脑像人一样“看”世界吗?它就叫目标检测,嗯,听起来挺高大上的。
现在说到目标检测,大家脑袋里最先浮现的可能就是YOLO。
别急,咱们先来聊聊这个YOLO是什么,它是怎么让计算机“眼观六路,耳听八方”的。
它背后的原理,说简单也不简单,说复杂也不复杂,咱们就一起来拆解拆解,看能不能让你一听就懂。
YOLO这个名字呢,很多人都知道,但大多数人对它的理解就停留在“它是个很牛的技术”这儿。
说实话,YOLO的全称是“you only look once”,意思就是“你只看一次”。
什么意思呢?简单说,就是计算机通过一次扫描,就能在图像里找出所有它能认出来的物体,像个超厉害的侦探,几乎不需要做任何多余的动作。
想象一下,如果你走进一个拥挤的市场,普通人可能得转好几圈才能看清楚各个摊位的商品,但YOLO呢,直接一眼扫过去,所有的东西都能被抓进眼里。
不过,YOLO这么强大,可是它可不是凭空就能做到的。
想要让机器“一眼看穿”,得有点“过人之处”。
它的原理,简单来说就是把图像切成网格,然后每个小网格负责找到图像里的东西,并且告诉你这个东西在哪,长什么样子。
如果网格里面有物体,YOLO就能画出框框,框出物体的位置,还能告诉你是什么东西。
比如,看到一只狗,YOLO会给你一个框框,框着那只狗的身影,还会在框上写上“dog”这俩字,告诉你:“嘿,兄弟,这是只狗!”那这技术到底是怎么做到的呢?想象一下,YOLO就像是一个精明的侦探,他观察世界的方法就是一次性看清所有细节,而不是东看看西看看再做判断。
这样一来,处理速度比起其他方法简直快得多。
不像以前那些技术,要分好几步,先找物体、再判断种类、再定位,慢得你想拍手。
YOLO一条龙服务,快速又高效。
再来一个有趣的地方,YOLO不光是“看”得快,它“看”得还准。
通过一个聪明的设计,它能够把图像中各个物体的边界框画得很精准,几乎不会错。
举个例子,咱们平时看到一个盒子,脑袋里自动就会浮现出它的形状。
yolo转化onnx格式

yolo转化onnx格式如何将YOLO模型转化为ONNX格式。
一、介绍YOLO和ONNXYOLO(You Only Look Once)是一种目标检测的算法,它在一张图像上一次性预测多个边界框和分类概率。
YOLO算法具有高效性能和准确率,因此被广泛应用于计算机视觉领域。
ONNX(Open Neural Network Exchange)是一种跨平台的深度学习模型表示和转换格式。
它允许不同深度学习框架之间的模型可互操作性,使得可以在不同框架上使用训练好的模型,无需重新训练。
本文将介绍如何将YOLO模型转化为ONNX格式,以实现跨框架的模型应用。
二、安装必要的工具和库在开始转化之前,需要安装一些必要的工具和库:1. 安装YOLO框架:根据YOLO框架的官方文档,安装YOLO框架并成功运行它。
2. 安装ONNX框架:根据ONNX框架的官方文档,安装ONNX框架并成功运行它。
3. 下载YOLO预训练权重:确保已经下载了YOLO的预训练权重文件,它通常是一个`.weights`文件。
三、使用YOLO转化脚本将模型转化为Darknet格式YOLO模型通常以Darknet格式(`.cfg`和`.weights`)存储。
为了转化为ONNX格式,首先需要将模型转化为Darknet格式,然后再进行进一步转化。
1. 准备YOLO的配置文件:首先打开YOLO的配置文件,修改其中的一些配置参数,比如输入图像的维度、类别数等。
2. 下载YOLO的权重文件:确保已下载YOLO的预训练权重文件(通常是一个`.weights`文件)。
3. 运行YOLO转化脚本:使用YOLO的转化脚本将模型从YOLO格式转化为Darknet格式。
命令可能如下所示:yolo_to_darknet.py config yolov3.cfg weights yolov3.weights output yolov3_darknet.weights此命令将使用YOLO的配置文件和权重文件作为输入,并将其转化为Darknet格式的权重文件。
yolov7 transfer learning 用法

yolov7 transfer learning 用法
Yolov7是一种基于深度学习的目标检测算法,它可以在图像中识别出不同的物体,并给出它们的位置和类别。
然而,在使用yolov7进行目标检测时,需要大量的训练数据和计算资源。
因此,对于大多数实际应用场景而言,使用迁移学习可以大大减少训练时间和计算成本。
迁移学习是将已经训练好的模型在新的数据集上继续学习的过程。
对于yolov7,我们可以使用已经训练好的模型,在新的数据集上进行微调,以达到更好的检测效果。
具体的操作步骤如下:
1. 下载预先训练好的yolov7权重文件,例如在COCO数据集上训练的权重文件,可以从官方网站或GitHub上下载。
2. 准备新的数据集,并将其按照yolov7的数据格式进行标注。
可以使用一些开源的工具,如labelImg等,进行标注。
3. 将使用迁移学习的相关参数添加到yolov7的配置文件中。
例如,设置新的数据集、调整训练批次大小和迭代次数等。
4. 开始训练。
在训练的过程中,可以使用一些技巧,如学习率衰减、数据增强等,来加速训练和提高检测效果。
5. 在训练完成后,可以使用新的模型进行目标检测,并评估模型的性能。
总之,使用迁移学习可以使yolov7的训练更加高效和准确,是实际应用中的重要技巧之一。
yolopose框架讲解

yolopose框架讲解
Yolopose框架是一种用于实现实时人体姿态估计的开源框架。
它可以在各种计算机平台上运行,包括移动设备和桌面电脑。
Yolopose框架的基本原理是利用深度神经网络实现人体姿态估计。
它使用了一种特殊的神经网络结构,称为YOLOv3-tiny。
这种结构可以快速计算出图像中所有人体关键点的位置,从而实现姿态估计。
Yolopose框架与其他人体姿态估计框架相比具有以下优点:
1. 高精度:Yolopose框架可以实现高精度的人体姿态估计,对于不同种类的人体姿势都有很好的识别能力。
2. 实时性:由于采用了特殊的神经网络结构,Yolopose框架可以在实时性要求很高的场景下使用,例如体育比赛、现场表演等。
3. 跨平台支持:Yolopose框架可以在各种计算机平台上使用,包括移动设备、桌面电脑等。
4. 开源:Yolopose框架是一种开源框架,任何人都可以免费使用和修改。
Yolopose框架的应用领域非常广泛,包括体育竞技、人体姿态分析、智能医疗等等。
例如,在体育竞技中,Yolopose框架可以用于识别运动员的动作姿态,帮助教练和运动员进行训练改进;在人体姿态分析中,Yolopose框架可以用于研究人体生理结构和人体健康状况等;在智能医疗中,Yolopose框架可以用于帮助医生进行患者姿态分析和康复治疗等。
总之,Yolopose框架是一种非常有用的开源框架,可以广泛地应用于各种领域。
随着技术的不断进步,相信Yolopose框架将会越来越普及和应用,为人们带来更多的便利和价值。
ChatGPT 集成到智能智能手机中的方法

ChatGPT 集成到智能智能手机中的方法ChatGPT 集成到智能手机中的方法智能手机已经成为我们生活中不可或缺的一部分,它们不仅仅是通信工具,更是我们获取信息、娱乐和交流的重要工具。
近年来,人工智能技术的快速发展,为智能手机带来了更多的可能性。
ChatGPT,作为一种强大的自然语言处理模型,可以为智能手机的用户体验带来革命性的变化。
本文将探讨如何将ChatGPT集成到智能手机中,并为用户带来更加智能、便捷的交流体验。
首先,要将ChatGPT集成到智能手机中,我们需要考虑到模型的运行环境和资源消耗。
由于ChatGPT是一个庞大的模型,运行它需要大量的计算资源和存储空间。
因此,我们可以选择将ChatGPT模型部署到云服务器上,并通过智能手机上的应用程序进行访问。
这种方式可以有效地节省智能手机的资源,并保证模型的高效运行。
其次,为了提供更好的用户体验,我们可以将ChatGPT与智能手机上的语音识别技术相结合。
用户可以通过语音输入与ChatGPT进行交流,而无需手动输入文字。
这种语音交互的方式更加自然和便捷,使用户能够更加轻松地与智能手机进行沟通。
同时,为了提高语音交互的准确性,我们可以引入自然语言理解技术,将用户的语音指令转化为机器可理解的格式,以便更好地与ChatGPT进行交互。
此外,为了提供更加个性化的服务,我们可以通过智能手机上的传感器数据来优化ChatGPT的回答。
智能手机上的传感器可以获取到用户的地理位置、环境噪声、光线等信息,这些信息可以帮助ChatGPT更好地理解用户的需求和上下文。
例如,当用户询问附近的餐厅时,ChatGPT可以根据用户的地理位置提供相关的推荐,从而提供更加个性化的服务。
另外,为了提高ChatGPT的交互能力,我们可以将其与智能手机上的其他应用程序进行整合。
例如,我们可以将ChatGPT与智能手机上的日历应用程序相结合,使ChatGPT能够帮助用户管理日程安排和提醒。
部署应用程序到Android手机
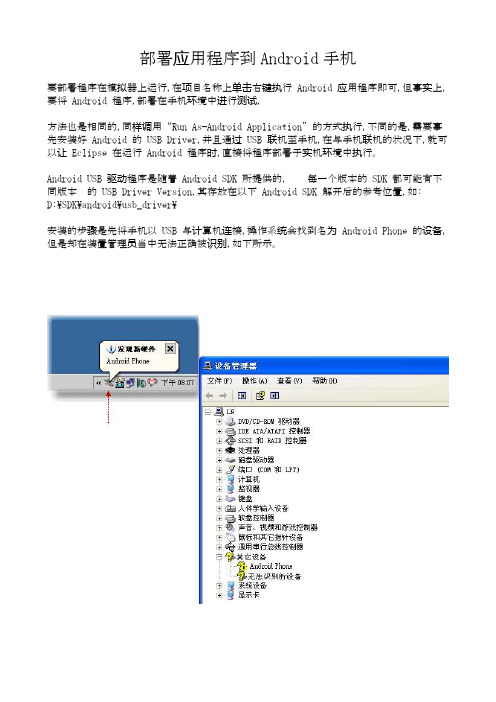
部署应用程序到Android手机要部署程序在模拟器上运行,在项目名称上单击右键执行 Android 应用程序即可,但事实上,要将 Android 程序,部署在手机环境中进行测试,方法也是相同的,同样调用“Run As—Android Application”的方式执行,不同的是,需要事先安装好 Android 的 USB Driver,并且通过 USB 联机至手机,在与手机联机的状况下,就可以让 Eclipse 在运行 Android 程序时,直接将程序部署于实机环境中执行。
Android USB 驱动程序是随着 Android SDK 所提供的, 每一个版本的 SDK 都可能有不同版本的 USB Driver Version,其存放在以下 Android SDK 解开后的参考位置,如: D:\SDK\android\usb_driver\安装的步骤是先将手机以 USB 与计算机连接,操作系统会找到名为 Android Phone 的设备,但是却在装置管理员当中无法正确被识别,如下所示。
▲ 图 1 操作系统找到名为 Android Phone 的装置,但无法正确被识别接着画面会跳出添加硬件向导,选择“从列表或指定位置安装(高级)”来自行挑选驱动程序位置。
▲ 图 2选择“从列表或指定位置安装”自己安装驱动程序在“搜索和安装选项”的画面中,选择“不要搜索,我要自己选择要安装的驱动程序”选项, 选择“显示所有设备”后,按下“下一步”。
▲ 图 3 选择不要搜索系统数据,改以自行挑选硬件的方式利用浏览按钮选择复制源为 Android USB Driver 程序路径:▲ 图 4 选择 Android SDK 里所附的 USB Driver选择驱动程序后,于显示兼容硬件列表中选择“HTC Dream Composite ADB Interface”,程序将 Android 手机的 USB ADB Interface 安装完成。
基于TensorFlowLite的深度学习模型在移动端的部署与应用

基于TensorFlowLite的深度学习模型在移动端的部署与应用深度学习技术在近年来取得了巨大的发展,已经在各个领域展现出强大的应用潜力。
随着移动设备性能的不断提升,将深度学习模型部署到移动端已经成为一个热门话题。
TensorFlowLite作为Google推出的针对移动和嵌入式设备优化的轻量级解决方案,为在移动端部署深度学习模型提供了便利。
本文将探讨基于TensorFlowLite的深度学习模型在移动端的部署与应用。
TensorFlowLite简介TensorFlowLite是TensorFlow针对移动设备和嵌入式设备推出的一种轻量级解决方案。
它可以帮助开发者在移动端部署机器学习模型,实现在移动设备上进行实时推理。
TensorFlowLite通过对模型进行量化、剪枝等优化技术,使得模型在移动端能够高效地运行,同时减小模型体积,降低内存占用,提高推理速度。
深度学习模型部署流程在将深度学习模型部署到移动端之前,首先需要完成模型训练和优化。
接着,我们可以按照以下步骤进行部署:选择合适的模型:在移动端部署深度学习模型时,需要考虑模型大小、推理速度和准确率之间的平衡。
通常会选择一些轻量级的网络结构,如MobileNet、EfficientNet等。
转换为TensorFlowLite格式:使用TensorFlow框架将训练好的深度学习模型转换为TensorFlowLite格式。
这一步通常包括量化、剪枝等操作,以便在移动设备上高效运行。
集成到移动应用:将转换后的TensorFlowLite模型集成到移动应用中,并编写相应的代码进行调用。
可以使用Java、Kotlin等语言进行开发,并通过TensorFlowLite官方提供的API进行推理操作。
性能优化:针对具体的移动设备进行性能优化,包括线程管理、内存管理、推理加速等方面的优化,以提高模型在移动端的运行效率。
TensorFlowLite在移动端的应用案例图像分类基于TensorFlowLite的深度学习模型在移动端广泛应用于图像分类任务。
基于YOLOv5s和Android部署的电气设备识别

基于YOLOv5s和Android部署的电气设备识别廖晓辉;谢子晨;路铭硕【期刊名称】《郑州大学学报(工学版)》【年(卷),期】2024(45)1【摘要】针对变电站多种电气设备实时检测的需求,提出了一种基于改进YOLOv5s的电气设备识别方法,并设计基于Android部署的电气设备识别APP,以便对电气设备进行识别与学习。
以电力变压器、绝缘子串等6种常见变电站电气设备为例构建图像数据集。
数据集进行图像预处理后对YOLOv5s算法进行改进。
通过引入C2f模块提高小目标检测精度,采用Soft-NMS提高检测框筛选能力,减少漏检和误检的情况,使用改进后的算法对数据集进行模型训练。
将训练好的识别网络模型通过TensorFlow Lite框架进行模型部署,设计电气设备识别APP。
经验证,改进后的变电站电气设备识别网络模型mAP稳定在91.6%,与原模型相比提高了3.3百分点。
部署后的APP具有设备识别和设备介绍等界面,使用移动端进行识别时每张图片识别时间都小于1 s,具有较快的识别速度和较高的识别精度,可以高效地实现变电站电气设备的实时检测与设备学习。
【总页数】7页(P122-128)【作者】廖晓辉;谢子晨;路铭硕【作者单位】郑州大学电气与信息工程学院【正文语种】中文【中图分类】TP391.4【相关文献】1.基于YOLOv5s和Android的苹果树皮病害识别系统设计2.一种基于树莓派部署的改进YOLOv5植物生长状态检测算法3.基于改进YOLOv5s和TensorRT部署的鱼道过鱼监测4.基于改进YOLOv5s网络模型的火灾图像识别方法5.基于改进YOLOv5的飞机舱门识别与定位方法研究因版权原因,仅展示原文概要,查看原文内容请购买。
yolo模型识别原理

yolo模型识别原理YOLO(You Only Look Once)是一种用于实时目标检测的深度学习模型。
相比于传统的目标检测算法,YOLO具有更快的速度和更高的准确率。
YOLO模型的识别原理可以分为两个阶段:网络的训练和目标检测的过程。
首先,我们来看看YOLO网络的训练过程。
YOLO网络是一个深度卷积神经网络,结构上采用了Darknet架构。
训练YOLO模型的输入是一张固定大小的图像,输出是将图像分成了一个SxS的网格(每个格子负责检测一个目标)和每个格子中的N个候选框。
网络的输出可以用一个(S,S,(B*5+C))的张量表示,其中B是每个网格负责预测的候选框的数量,C是类别的数量。
YOLO模型的损失函数由三个部分组成:分类损失、位置损失和有物体置信度损失。
分类损失是对对象类别的预测错误的损失,位置损失是描述边界框预测位置的损失,有物体置信度损失是预测的目标与实际目标之间的损失。
在目标检测过程中,YOLO模型将输入图像分成SxS的网格,并在每个格子中预测N个候选框。
每个候选框包含一个边界框和目标的类别概率。
YOLO模型通过将每个候选框中的边界框位置校正为原始图像中的坐标来预测目标的位置,并通过非极大值抑制(NMS)来消除重叠的候选框。
YOLO模型能够实现实时目标检测的原因在于它的并行计算策略。
传统的目标检测算法在图像上运行检测子多次,而YOLO只需一次前向传播来预测所有的候选框。
这使得YOLO比传统算法更快,并且可以在实时应用中运行。
此外,YOLO模型还具有更好的准确率。
由于检测子的计算只需一次,YOLO能够捕捉到整张图像中的全局上下文信息,从而更好地理解图像中的目标。
与此同时,YOLO使用多尺度特征图来检测不同大小的目标,使得模型对于尺度变换具有很好的鲁棒性。
总的来说,YOLO模型是一种快速而准确的目标检测算法。
通过将目标检测问题转化为一个回归问题,并利用深度学习模型进行端到端的训练,YOLO能够在实时应用中以惊人的速度检测出图像中的目标。
yolo工作原理

yolo工作原理YOLO是一种基于深度学习的目标检测算法,全称是"You Only Look Once",即一次看到整个图像,它在运行时可以同时完成目标检测和分类的任务。
相对于之前的目标检测算法,YOLO在速度上更快、精度更高,因此被广泛应用于实时物体识别、自动驾驶、人脸识别等领域。
YOLO的工作原理可以概括为下面的几个步骤:1. 图像预处理首先,针对输入图像进行一系列预处理,将其归一化、缩放、平移或者旋转等操作,以保证输入数据的规范化和统一性。
2. 建立神经网络在图像预处理的基础上,可以通过深度学习的方法来构建一个卷积神经网络(Convolutional Neural Network, CNN)。
这个网络通常由多个卷积层、池化层、全连接层等组成,其中不同层的输出被用作后续计算的输入。
3. 特征提取卷积神经网络可以对原始图像进行特征提取,比如提取出图像中物体的轮廓、纹理、颜色等信息。
这些特征可以被用来辅助目标检测和分类的任务。
4. 特征映射在特征提取的基础上,可以使用一种叫做锚框(Anchor Boxes)的方法来对图像中的物体进行定位。
锚框是一些预先定义好的矩形框,可以理解为是模型对不同尺寸和比例物体的预先假设。
YOLO可以通过计算图像中物体和锚框的IoU (交并比)等信息来判断一个锚框是否匹配上了图像中的一个真实物体。
5. 目标回归和分类一旦一个锚框匹配上了图像中的一个真实物体,可以通过回归方法和分类方法来确定该物体的位置和类别。
回归方法通常是预测物体的中心点坐标、宽度和高度等属性,而分类方法则是将物体分到事先定义好的一些类别中去,比如人脸、车辆、交通标识等。
6. 反向传播和训练经过几轮迭代训练后,神经网络可以不断地优化自身的权重和偏置,以最小化损失函数并提升模型的检测精度。
综上所述,YOLO算法的工作原理是通过预处理、卷积神经网络、特征提取、特征映射、目标回归分类等步骤完成目标检测和分类的任务。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本文由我司收集整编,推荐下载,如有疑问,请与我司联系
yolo模型移植到android手机端
2017/08/18 665 之前写了android demo在手机上的运用,但是模型都是官方给的,想要替换成自己的模型,因此尝试了下将自己训练的yolo模型来替换demo给的模型。
首先,darknet的训练和.weight文件到.pb文件的转化,以及android demo 的实现见之前的博客。
在此不再叙述sdk,nkd等配置问题,且直接使用.pb文件。
其次,默认已安装android studio。
(1)终端进入(android安装目录)/bin,输入./stuodio.sh开启android studio
(2)点击new,import project导入(tensorflow所在路径)/tensorflow/examples/android文件夹(可连接手机先run,保证demo能够正常运行后再行修改)
(3)将build.gradle中68行的bazelLocation改为自己bazel的路径:def bazelLocation = ‘/home/seven/bin/bazel’185行apply from: “download-models.gradle”注释掉,并在第112行,增加//*/(不然后面的内容都被当做注释了):
if (nativeBuildSystem == ‘bazel’ || nativeBuildSystem == ‘makefile’) { // TensorFlow Java API sources. java { srcDir ‘../../java/src/main/java’ exclude ‘**/examples/**’//*/ } // Android TensorFlow wrappers, etc. java { 最后,将第76行开始的内容改为自己需要的版本号:
android { compileSdkVersion 25 buildToolsVersion “26.0.1” if (nativeBuildSystem == ‘cmake’) { defaultConfig { applicationId = ‘org.tensorflow.demo’ minSdkVersion 21 targetSdkVersion 25 ndk { abiFilters “${cpuType}” } (4)将转化得到的.pb文件放在(tensorflow所在路径)/tensorflow/examples/android/assets文件夹内,为方便起见,可将此.pb重命名为graph-tiny-yolo-voc.pb。
若文件夹中已存在此文件名的文件,删除之。
(5)该项目将一次性生成三个app,因为我只需要detect一个,在AndroidManifest.xml中删除关于另外的两个activity,修改后的文件如图。