BP神经网络实验——【机器学习与算法分析 精品资源池】
BP神经网络算法步骤

BP神经网络算法步骤
<br>一、概述
BP神经网络(Back Propagation Neural Network,BPNN)是一种经
典的人工神经网络,其发展始于上世纪80年代。
BP神经网络的原理是按
照误差反向传播算法,以及前馈神经网络的模型,利用反向传播方法来调
整网络各层的权值。
由于其具有自动学习和非线性特性,BP神经网络被
广泛应用在很多和人工智能、计算智能紧密相关的诸如计算机视觉、自然
语言处理、语音识别等领域。
<br>二、BP神经网络的结构
BP神经网络经常使用的是一种多层前馈结构,它可以由输入层,若
干隐藏层,以及输出层三部分组成。
其中,输入层是输入信号的正向传输
路径,将输入信号正向传送至隐藏层,在隐藏层中神经元以其中一种复杂
模式对输入信号进行处理,并将其正向传送至输出层,在输出层中将获得
的输出信号和设定的模式进行比较,以获得预期的输出结果。
<br>三、BP神经网络的学习过程
BP神经网络的学习过程包括正向传播和反向传播两个阶段。
其中,
正向传播是指从输入层到隐藏层和输出层,利用现有的训练数据,根据神
经网络结构,计算出网络每一层上各结点的的激活值,从而得到输出结果。
正向传播的过程是完全可以确定的。
BP神经网络算法

BP神经网络算法一、算法原理在BP神经网络中,每个神经元都与上一层的所有神经元以及下一层的所有神经元相连。
每个连接都有一个权重,表示信息传递的强度或权重。
算法流程:1.初始化权重和阈值:通过随机初始化权重和阈值,为网络赋予初值。
2.前向传播:从输入层开始,通过激活函数计算每个神经元的输出值,并将输出传递到下一层。
重复该过程,直到达到输出层。
3.计算误差:将输出层的输出值与期望输出进行比较,计算输出误差。
4.反向传播:根据误差反向传播,调整网络参数。
通过链式求导法则,计算每层的误差并更新对应的权重和阈值。
5.重复训练:不断重复前向传播和反向传播的过程,直到达到预设的训练次数或误差限度。
优缺点:1.优点:(1)非线性建模能力强:BP神经网络能够很好地处理非线性问题,具有较强的拟合能力。
(2)自适应性:网络参数可以在训练过程中自动调整,逐渐逼近期望输出。
(3)灵活性:可以通过调整网络结构和参数来适应不同的问题和任务。
(4)并行计算:网络中的神经元之间存在并行计算的特点,能够提高训练速度。
2.缺点:(1)容易陷入局部最优点:由于BP神经网络使用梯度下降算法进行权重调整,容易陷入局部最优点,导致模型精度不高。
(2)训练耗时:BP神经网络的训练过程需要大量的计算资源和耗时,特别是对于较大规模的网络和复杂的输入数据。
(3)需要大量样本:BP神经网络对于训练样本的要求较高,需要足够多的训练样本以避免过拟合或欠拟合的情况。
三、应用领域1.模式识别:BP神经网络可以用于图像识别、手写字符识别、语音识别等方面,具有优秀的分类能力。
2.预测与回归:BP神经网络可以应用于股票预测、销量预测、房价预测等问题,进行趋势预测和数据拟合。
3.控制系统:BP神经网络可以用于自适应控制、智能控制、机器人运动控制等方面,提高系统的稳定性和精度。
4.数据挖掘:BP神经网络可以应用于聚类分析、异常检测、关联规则挖掘等方面,发现数据中的隐藏信息和规律。
BP神经网络学习及算法

BP神经网络学习及算法1.前向传播:在BP神经网络中,前向传播用于将输入数据从输入层传递到输出层,其中包括两个主要步骤:输入层到隐藏层的传播和隐藏层到输出层的传播。
(1)输入层到隐藏层的传播:首先,输入数据通过输入层的神经元进行传递。
每个输入层神经元都与隐藏层神经元连接,并且每个连接都有一个对应的权值。
输入数据乘以对应的权值,并通过激活函数进行处理,得到隐藏层神经元的输出。
(2)隐藏层到输出层的传播:隐藏层的输出被传递到输出层的神经元。
同样,每个隐藏层神经元与输出层神经元连接,并有对应的权值。
隐藏层输出乘以对应的权值,并通过激活函数处理,得到输出层神经元的输出。
2.反向传播:在前向传播后,可以计算出网络的输出值。
接下来,需要计算输出和期望输出之间的误差,并将误差通过反向传播的方式传递回隐藏层和输入层,以更新权值。
(1)计算误差:使用误差函数(通常为均方差函数)计算网络输出与期望输出之间的误差。
误差函数的具体形式根据问题的特点而定。
(2)反向传播误差:从输出层开始,将误差通过反向传播的方式传递回隐藏层和输入层。
首先,计算输出层神经元的误差,然后将误差按照权值比例分配给连接到该神经元的隐藏层神经元,并计算隐藏层神经元的误差。
依此类推,直到计算出输入层神经元的误差。
(3)更新权值:利用误差和学习率来更新网络中的权值。
通过梯度下降法,沿着误差最速下降的方向对权值和阈值进行更新。
权值的更新公式为:Δwij = ηδjxi,其中η为学习率,δj为神经元的误差,xi为连接该神经元的输入。
以上就是BP神经网络的学习算法。
在实际应用中,还需要考虑一些其他的优化方法和技巧,比如动量法、自适应学习率和正则化等,以提高网络的性能和稳定性。
此外,BP神经网络也存在一些问题,比如容易陷入局部极小值、收敛速度慢等,这些问题需要根据实际情况进行调优和改进。
BP神经网络实验报告

BP神经网络实验报告一、引言BP神经网络是一种常见的人工神经网络模型,其基本原理是通过将输入数据通过多层神经元进行加权计算并经过非线性激活函数的作用,输出结果达到预测或分类的目标。
本实验旨在探究BP神经网络的基本原理和应用,以及对其进行实验验证。
二、实验方法1.数据集准备本次实验选取了一个包含1000个样本的分类数据集,每个样本有12个特征。
将数据集进行标准化处理,以提高神经网络的收敛速度和精度。
2.神经网络的搭建3.参数的初始化对神经网络的权重和偏置进行初始化,常用的初始化方法有随机初始化和Xavier初始化。
本实验采用Xavier初始化方法。
4.前向传播将标准化后的数据输入到神经网络中,在神经网络的每一层进行加权计算和激活函数的作用,传递给下一层进行计算。
5.反向传播根据预测结果与实际结果的差异,通过计算损失函数对神经网络的权重和偏置进行调整。
使用梯度下降算法对参数进行优化,减小损失函数的值。
6.模型评估与验证将训练好的模型应用于测试集,计算准确率、精确率、召回率和F1-score等指标进行模型评估。
三、实验结果与分析将数据集按照7:3的比例划分为训练集和测试集,分别进行模型训练和验证。
经过10次训练迭代后,模型在测试集上的准确率稳定在90%以上,证明了BP神经网络在本实验中的有效性和鲁棒性。
通过调整隐藏层结点个数和迭代次数进行模型性能优化实验,可以发现隐藏层结点个数对模型性能的影响较大。
随着隐藏层结点个数的增加,模型在训练集上的拟合效果逐渐提升,但过多的结点数会导致模型的复杂度过高,容易出现过拟合现象。
因此,选择合适的隐藏层结点个数是模型性能优化的关键。
此外,迭代次数对模型性能也有影响。
随着迭代次数的增加,模型在训练集上的拟合效果逐渐提高,但过多的迭代次数也会导致模型过度拟合。
因此,需要选择合适的迭代次数,使模型在训练集上有好的拟合效果的同时,避免过度拟合。
四、实验总结本实验通过搭建BP神经网络模型,对分类数据集进行预测和分类。
实训神经网络实验报告

一、实验背景随着人工智能技术的飞速发展,神经网络作为一种强大的机器学习模型,在各个领域得到了广泛应用。
为了更好地理解神经网络的原理和应用,我们进行了一系列的实训实验。
本报告将详细记录实验过程、结果和分析。
二、实验目的1. 理解神经网络的原理和结构。
2. 掌握神经网络的训练和测试方法。
3. 分析不同神经网络模型在特定任务上的性能差异。
三、实验内容1. 实验一:BP神经网络(1)实验目的:掌握BP神经网络的原理和实现方法,并在手写数字识别任务上应用。
(2)实验内容:- 使用Python编程实现BP神经网络。
- 使用MNIST数据集进行手写数字识别。
- 分析不同学习率、隐层神经元个数对网络性能的影响。
(3)实验结果:- 在MNIST数据集上,网络在训练集上的准确率达到98%以上。
- 通过调整学习率和隐层神经元个数,可以进一步提高网络性能。
2. 实验二:卷积神经网络(CNN)(1)实验目的:掌握CNN的原理和实现方法,并在图像分类任务上应用。
(2)实验内容:- 使用Python编程实现CNN。
- 使用CIFAR-10数据集进行图像分类。
- 分析不同卷积核大小、池化层大小对网络性能的影响。
(3)实验结果:- 在CIFAR-10数据集上,网络在训练集上的准确率达到80%以上。
- 通过调整卷积核大小和池化层大小,可以进一步提高网络性能。
3. 实验三:循环神经网络(RNN)(1)实验目的:掌握RNN的原理和实现方法,并在时间序列预测任务上应用。
(2)实验内容:- 使用Python编程实现RNN。
- 使用Stock数据集进行时间序列预测。
- 分析不同隐层神经元个数、学习率对网络性能的影响。
(3)实验结果:- 在Stock数据集上,网络在训练集上的预测准确率达到80%以上。
- 通过调整隐层神经元个数和学习率,可以进一步提高网络性能。
四、实验分析1. BP神经网络:BP神经网络是一种前向传播和反向传播相结合的神经网络,适用于回归和分类问题。
神经网络的BP算法实验报告

计算智能基础实验报告实验名称:BP神经网络算法实验班级名称:341521班专业:探测制导与控制技术姓名:***学号:********一、 实验目的1)编程实现BP 神经网络算法;2)探究BP 算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、 实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差ε5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果 。
三、 实验原理1BP 神经网络算法的基本思想误差逆传播(back propagation, BP)算法是一种计算单个权值变化引起网络性能变化的较为简单的方法。
由于BP 算法过程包含从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正,所以称为“反向传播”。
BP 神经网络是有教师指导训练方式的多层前馈网络,其基本思想是:从网络输入节点输入的样本信号向前传播,经隐含层节点和输出层节点处的非线性函数作用后,从输出节点获得输出。
若在输出节点得不到样本的期望输出,则建立样本的网络输出与其期望输出的误差信号,并将此误差信号沿原连接路径逆向传播,去逐层修改网络的权值和节点处阈值,这种信号正向传播与误差信号逆向传播修改权值和阈值的过程反复进行,直训练样本集的网络输出误差满足一定精度要求为止。
2 BP 神经网络算法步骤和流程BP 神经网络步骤和流程如下:1) 初始化,给各连接权{},{}ij jt W V 及阈值{},{}j t θγ赋予(-1,1)间的随机值;2) 随机选取一学习模式对1212(,),(,,)k k k k k k k n k n A a a a Y y y y ==提供给网络;3) 计算隐含层各单元的输入、输出;1n j ij i j i s w a θ==⋅-∑,()1,2,,j j b f s j p ==4) 计算输出层各单元的输入、输出;1t t jt j t j l V b γ==⋅-∑,()1,2,,t t c f l t q ==5) 计算输出层各单元的一般化误差;()(1)1,2,,k k t t tt t t d y c c c t q =-⋅-=6) 计算中间层各单元的一般化误差;1[](1)1,2,,q kk jt jt j j t e d V b b j p ==⋅⋅-=∑7) 修正中间层至输出层连接权值和输出层各单元阈值;(1)()k jt jt t j V iter V iter d b α+=+⋅⋅(1)()k t t t iter iter d γγα+=+⋅8) 修正输入层至中间层连接权值和中间层各单元阈值;(1)()kk ij ij j i W iter W iter e a β+=+⋅⋅(1)()kj j j iter iter e θθβ+=+⋅9) 随机选取下一个学习模式对提供给网络,返回步骤3),直至全部m 个模式训练完毕;10) 重新从m 个学习模式对中随机选取一个模式对,返回步骤3),直至网络全局误差函数E 小于预先设定的一个极小值,即网络收敛;或者,当训练次数大于预先设定值,强制网络停止学习(网络可能无法收敛)。
BP神经网络实验详解(MATLAB实现)

BP神经网络实验详解(MATLAB实现)BP(Back Propagation)神经网络是一种常用的人工神经网络结构,用于解决分类和回归问题。
在本文中,将详细介绍如何使用MATLAB实现BP神经网络的实验。
首先,需要准备一个数据集来训练和测试BP神经网络。
数据集可以是一个CSV文件,每一行代表一个样本,每一列代表一个特征。
一般来说,数据集应该被分成训练集和测试集,用于训练和测试模型的性能。
在MATLAB中,可以使用`csvread`函数来读取CSV文件,并将数据集划分为输入和输出。
假设数据集的前几列是输入特征,最后一列是输出。
可以使用以下代码来实现:```matlabdata = csvread('dataset.csv');input = data(:, 1:end-1);output = data(:, end);```然后,需要创建一个BP神经网络模型。
可以使用MATLAB的`patternnet`函数来创建一个全连接的神经网络模型。
该函数的输入参数为每个隐藏层的神经元数量。
下面的代码创建了一个具有10个隐藏神经元的单隐藏层BP神经网络:```matlabhidden_neurons = 10;net = patternnet(hidden_neurons);```接下来,需要对BP神经网络进行训练。
可以使用`train`函数来训练模型。
该函数的输入参数包括训练集的输入和输出,以及其他可选参数,如最大训练次数和停止条件。
下面的代码展示了如何使用`train`函数来训练模型:```matlabnet = train(net, input_train, output_train);```训练完成后,可以使用训练好的BP神经网络进行预测。
可以使用`net`模型的`sim`函数来进行预测。
下面的代码展示了如何使用`sim`函数预测测试集的输出:```matlaboutput_pred = sim(net, input_test);```最后,可以使用各种性能指标来评估预测的准确性。
BP神经网络原理与应用实习论文

学年论文(本科)学院数学与信息科学学院专业信息与计算科学专业年级10级4班姓名徐玉琳于正平马孝慧李运凤郭双双任培培论文题目BP神经网络原理与应用指导教师冯志敏成绩2013年 9月 24日BP神经网络的原理与应用1.BP神经网络的原理1.1 BP神经网络的结构BP神经网络模型是一个三层网络,它的拓扑结构可被划分为:输入层(InputLayer )、输出层(Outp ut Layer ) ,隐含层(Hide Layer ).其中,输入层与输出层具有更重要的意义,因此也可以为两层网络结构(把隐含层划入输入层,或者把隐含层去掉)每层都有许多简单的能够执行并行运算的神经元组成,这些神经元与生物系统中的那些神经元非常类似,但其并行性并没有生物神经元的并行性高.BP神经网络的特点:1)网络由多层构成,层与层之间全连接,同一层之间的神经元无连接.2)BP网络的传递函数必须可微.因此,感知器的传递函数-——二值函数在这里没有用武之地.BP网络一般使用Sigmoid函数或线性函数作为传递函数.3)采用误差反向传播算法(Back-Propagation Algorithm)进行学习.在BP 网络中,数据从输入层隐含层逐层向后传播,训练网络权值时,则沿着减少误差的方向,从输出层经过中间各层逐层向前修正网络的连接权值.随着学习的不断进行,最终的误差越来越来小.BP神经网络的学习过程BP神经网络的学习算法实际上就是对误差函数求极小值的算法,它采用的算法是最速下降法,使它对多个样本进行反复的学习训练并通过误差的反向传播来修改连接权系数,它是沿着输出误差函数的负梯度方向对其进行改变的,并且到最后使误差函数收敛于该函数的最小点.1.3 BP网络的学习算法BP网络的学习属于有监督学习,需要一组已知目标输出的学习样本集.训练时先使用随机值作为权值,修改权值有不同的规则.标准的BP神经网络沿着误差性能函数梯度的反向修改权值,原理与LMS算法比较类似,属于最速下降法.拟牛顿算法牛顿法是一种基于二阶泰勒级数的快速优化算法.其基本方法是1(1)()()()x k x k A k g k -+=-式中 ()A k ----误差性能函数在当前权值和阀值下的Hessian 矩阵(二阶导数),即2()()()x x k A k F x ==∇牛顿法通常比较梯度法的收敛速度快,但对于前向型神经网络计算Hessian 矩阵是很复杂的,付出的代价也很大.有一类基于牛顿法的算法不需要二阶导数,此类方法称为拟牛顿法(或正切法),在算法中的Hessian 矩阵用其近似值进行修正,修正值被看成梯度的函数. 1)BFGS 算法在公开发表的研究成果中,你牛顿法应用最为成功得有Boryden,Fletcher,Goldfard 和Shanno 修正算法,合称为BFG 算法. 该算法虽然收敛所需的步长通常较少,但在每次迭代过程所需要的计算量和存储空间比变梯度算法都要大,对近似Hessian 矩阵必须进行存储,其大小为n n ⨯,这里n 网络的链接权和阀值的数量.所以对于规模很大的网络用RPROP 算法或任何一种梯度算法可能好些;而对于规模较小的网络则用BFGS 算法可能更有效. 2)OSS 算法 由于BFGS 算法在每次迭代时比变梯度算法需要更多的存储空间和计算量,所以对于正切近似法减少其存储量和计算量是必要的.OSS 算法试图解决变梯度法和拟牛顿(正切)法之间的矛盾,该算法不必存储全部Hessian 矩阵,它假设每一次迭代时与前一次迭代的Hessian 矩阵具有一致性,这样做的一个有点是,在新的搜索方向进行计算时不必计算矩阵的逆.该算法每次迭代所需要的存储量和计算量介于梯度算法和完全拟牛顿算法之间. 最速下降BP 法最速下降BP 算法的BP 神经网络,设k 为迭代次数,则每一层权值和阀值的修正按下式进行(1)()()x k x k g k α+=-式中()x k —第k 次迭代各层之间的连接权向量或阀值向量;()g k =()()E k x k ∂∂—第k 次迭代的神经网络输出误差对各权值或阀值的梯度向量.负号表示梯度的反方向,即梯度的最速下降方向;α—学习效率,在训练时是一常数.在MATLAB 神经网络工具箱中,,可以通过改变训练参数进行设置;()E K —第k 次迭代的网络输出的总误差性能函数,在MATLAB 神经网络工具箱中BP 网络误差性能函数默认值为均方误差MSE,以二层BP 网络为例,只有一个输入样本时,有2()()E K E e k ⎡⎤=⎣⎦21S≈22221()S i i i t a k =⎡⎤-⎣⎦∑ 222212,1()()()()s ii j i i j a k f w k a k b k =⎧⎫⎪⎪⎡⎤=-⎨⎬⎣⎦⎪⎪⎩⎭∑21221112,,11()(()())()s s i j i j i i i j j f w k f iw k p ib k b k ==⎧⎫⎡⎤⎛⎫⎪⎪=++⎢⎥ ⎪⎨⎬⎢⎥⎝⎭⎪⎪⎣⎦⎩⎭∑∑若有n 个输入样本2()()E K E e k ⎡⎤=⎣⎦21nS ≈22221()S ii i ta k =⎡⎤-⎣⎦∑根据公式和各层的传输函数,可以求出第k 次迭代总误差曲面的梯度()g k =()()E k x k ∂∂,分别代入式子便可以逐次修正其权值和阀值,并是总的误差向减小的方向变化,直到达到所需要的误差性能为止. 1.4 BP 算法的改进BP 算法理论具有依据可靠、推导过程严谨、精度较高、通用性较好等优点,但标准BP 算法存在以下缺点:收敛速度缓慢;容易陷入局部极小值;难以确定隐层数和隐层节点个数.在实际应用中,BP 算法很难胜任,因此出现了很多改进算.利用动量法改进BP 算法标准BP 算法实质上是一种简单的最速下降静态寻优方法,在修正W(K)时,只按照第K 步的负梯度方向进行修正,而没有考虑到以前积累的经验,即以前时刻的梯度方向,从而常常使学习过程发生振荡,收敛缓慢.动量法权值调整算法的具体做法是:将上一次权值调整量的一部分迭加到按本次误差计算所得的权值调整量上,作为本次的实际权值调整量,即:其中:α为动量系数,通常0<α<0.9;η—学习率,范围在0.001~10之间.这种方法所加的动量因子实际上相当于阻尼项,它减小了学习过程中的振荡趋势,从而改善了收敛性.动量法降低了网络对于误差曲面局部细节的敏感性,有效的抑制了网络陷入局部极小.自适应调整学习速率标准BP算法收敛速度缓慢的一个重要原因是学习率选择不当,学习率选得太小,收敛太慢;学习率选得太大,则有可能修正过头,导致振荡甚至发散.可采用图所示的自适应方法调整学习率.调整的基本指导思想是:在学习收敛的情况下,增大η,以缩短学习时间;当η偏大致使不能收敛时,要及时减小η,直到收敛为止.动量-自适应学习速率调整算法采用动量法时,BP算法可以找到更优的解;采用自适应学习速率法时,BP算法可以缩短训练时间.将以上两种方法结合起来,就得到动量-自适应学习速率调整算法.1. L-M学习规则L-M(Levenberg-Marquardt)算法比前述几种使用梯度下降法的BP算法要快得多,但对于复杂问题,这种方法需要相当大的存储空间L-M(Levenberg-Marquardt)优化方法的权值调整率选为:其中:e —误差向量;J —网络误差对权值导数的雅可比(Jacobian )矩阵;μ—标量,当μ很大时上式接近于梯度法,当μ很小时上式变成了Gauss-Newton 法,在这种方法中,μ也是自适应调整的. 1.5 BP 神经网络的设计 网络的层数输入层节点数取决于输入向量的维数.应用神经网络解决实际问题时,首先应从问题中提炼出一个抽象模型,形成输入空间和输出空间.因此,数据的表达方式会影响输入向量的维数大小.例如,如果输入的是64*64的图像,则输入的向量应为图像中所有的像素形成的4096维向量.如果待解决的问题是二元函数拟合,则输入向量应为二维向量.理论上已证明:具有偏差和至少一个S 型隐含层加上一个线性输出层的网络,能够逼近任何有理数.增加层数可以更进一步的降低误差,提高精度,但同时也使网络复杂化,从而增加了网络权值的训练时间.而误差精度的提高实际上也可以通过增加神经元数目来获得,其训练效果也比增加层数更容易观察和调整.所以一般情况下,应优先考虑增加隐含层中的神经元数. 隐含层的神经元数网络训练精度的提高,可以通过采用一个隐含层,而增加神经元数了的方法来获得.这在结构实现上,要比增加隐含层数要简单得多.那么究竟选取多少隐含层节点才合适?这在理论上并没有一个明确的规定.在具体设计时,比较实际的做法是通过对不同神经元数进行训练对比,然后适当地加上一点余量.1)0niMi C k =>∑,k 为样本数,M 为隐含层神经元个数,n 为输入层神经元个数.如i>M,规定C i M =0.2)和n 分别是输出层和输入层的神经元数,a 是[0.10]之间的常量.3)M=2log n ,n 为输入层神经元个数.初始权值的选取由于系统是非线性的,初始值对于学习是否达到局部最小、是否能够收敛及训练时间的长短关系很大.如果初始值太大,使得加权后的输入和n落在了S型激活函数的饱和区,从而导致其导数f (n)非常小,从而使得调节过程几乎停顿下来.所以一般总是希望经过初始加权后的每个神经元的输出值都接近于零,这样可以保证每个神经元的权值都能够在它们的S型激活函数变化最大之处进行调节.所以,一般取初始权值在(-1,1)之间的随机数.学习速率学习速率决定每一次循环训练中所产生的权值变化量.大的学习速率可能导致系统的不稳定;但小的学习速率导致较长的训练时间,可能收敛很慢,不过能保证网络的误差值不跳出误差表面的低谷而最终趋于最小误差值.所以在一般情况下,倾向于选取较小的学习速率以保证系统的稳定性.学习速率的选取范围在0.01-0.8之间.1.6BP神经网络局限性需要参数多且参数选择没有有效的方法对于一些复杂问题 ,BP 算法可能要进行几小时甚至更长的时间训练,这主要是由于学习速率太小所造成的.标准BP 网络学习过程缓慢,易出现平台,这与学习参数率l r的选取有很大关系.当l r较时,权值修改量大,学习速率也快,但可能产生振荡;当l r较小时,虽然学习比较平稳,但速度十分缓慢.容易陷入局部最优BP网络易陷入局部最小, 使 BP网络不能以高精度逼近实际系统.目前对于这一问题的解决有加入动量项以及其它一些方法.BP 算法本质上是以误差平方和为目标函数 , 用梯度法求其最小值的算法.于是除非误差平方和函数是正定的, 否则必然产生局部极小点, 当局部极小点产生时 , BP算法所求的就不是解.1.6.3 样本依赖性这主要表现在网络出现的麻痹现象上.在网络的训练过程中,如其权值调的过大,可能使得所有的或大部分神经元的加权值偏大,这使得激活函数的输入工作在S型转移函数的饱和区,从而导致其导函数非常小,使得对网络权值的调节过程几乎停顿下来.通常为避免这种现象的发生,一是选取较小的初始权值,二是采用较小的学习速率,但又要增加时间训练.初始权敏感对于一些复杂的问题,BP算法可能要进行几个小时甚至更长时间的训练.这主要是由于学习速率太小造成的.可采用变化的学习速率或自适应的学习速率来加以改进.2.BP神经网络应用2.1 手算实现二值逻辑—异或这个例子中,采用手算实现基于BP网络的异或逻辑.训练时采用批量训练的方法,训练算法使用带动量因子的最速下降法.在MATLAB中新建脚本文件main_xor.m,输入代码如下:%脚本%批量训练方式.BP网络实现异或逻辑%%清理clear allclcrand('seed',2)eb = 0.01; %误差容限eta = 0.6; %学习率mc = 0.8; %动量因子maxiter = 1000; %最大迭代次数%% 初始化网络nSampNum = 4;nSampDim = 2;nHidden = 3;nOut = 1;w = 2*(rand(nHidden,nSampDim)-1/2);b = 2*(rand(nHidden,1)-1/2);wex = [w,b];W = 2*(rand(nOut,nHidden)-1/2);B = 2*(rand(nOut,1)-1/2);WEX = [W,B];%%数据SampIn=[0,0,1,1;...0,1,0,1;…1,1,1,1];expected = [0,1,1,0];%%训练iteration = 0;errRec = [];outRec =[];for i = 1:maxiter% 工作信号正向传播hp = wex*SampIn;tau = logsig(hp);tauex = [tau',1*ones(nSampNum,1)]';HM = WEX*tauex;out = logsig(HM);outRec = [outRec,out'];err = expected - out;sse = sumsqr(err);errRec = [errRec,sse];fprintf('第%d 次迭代,误差:%f \n',i,sse);% 判断是否收敛iteration = iteration + 1;if sse <= ebbreak;end% 误差信号反向传播% DELTA 和delta 为局部梯度DELTA = err.*dlogsig(HM,out);delta = W' * DELTA.*dlogsig(hp,tau);dWEX = DELTA*tauex';dwex = delta*SampIn';% 更新权值if i == 1WEX = WEX + eta*dWEX;wex = wex + eta*dwex;elseWEX = WEX + (1-mc)*eta*dWEX + mc*dWEXold;wex = wex + (1-mc)*eta*dwex+mc*dwexold;enddWEXold = dWEX;dwexold = dwex;W = WEX(:,1:nHidden);end%%显示figure(1)grid[nRow,nCol]=size(errRec);semilogy(1:nCol,errRec,'LineWidth',1.5);title('误差曲线');xlabel('迭代次数');x=-0.2:.05:1.2;[xx,yy] = meshgrid(x);for i=1:length(xx)for j=1:length(yy)xi=[xx(i,j),yy(i,j),1];hp = wex*xi';tau = logsig(hp);tauex = [tau',1]';HM = WEX*tauex;out = logsig(HM);z (i,j) =out;endendfigure(2)mesh(x,x,z);figure(3)plot([0,1],[0,1],'*','LineWidth',2);hold onplot([0,1],[1,0],'O','LineWidth',2);[c,h]=contour(x,x,z,0.5,'b');clabel(c,h);legend('0','1','分类面');title('分类面')2.2 误差下降曲线如下图所示:Finger 1010*******400500600700800900100010-210-110误差曲线迭代次数网格上的点在BP 网络映射下的输出如下图:Finger 2异或本质上是一个分类问题,,分类面如图:Finger 3分类面-0.200.20.40.60.81 1.2本文介绍了神经网络的研究背景和现状,分析了目前神经网络研究中存在的问题.然后描述了BP神经网络算法的实现以及BP神经网络的工作原理,给出了BP网络的局限性.本文虽然总结分析了BP神经网络算法的实现,给出了实例分析,但是还有很多的不足.所总结的BP神经网络和目前研究的现状都还不够全面,经过程序调试的图形有可能都还存在很多细节上的问题,而图形曲线所实现效果都还不够好,以及结果分析不够全面、正确、缺乏科学性等,这些都还是需加强提高的.近几年的不断发展,神经网络更是取得了非常广泛的应用,和令人瞩目的发展.在很多方面都发挥了其独特的作用,特别是在人工智能、自动控制、计算机科学、信息处理、机器人、模式识别等众多方面的应用实例,给人们带来了很多应用上到思考,和解决方法的研究.但是神经网络的研究最近几年还没有达到非常热门的阶段,这还需有很多热爱神经网络和研究神经网络人员的不断研究和创新,在科技高度发达的现在,我们有理由期待,也有理由相信.我想在不久的将来神经网络会应用到更多更广的方面,人们的生活会更加便捷.学年论文成绩评定表。
BP神经网络算法

1
目
录
一、BP神经网络算法概述
二、BP神经网络算法原理
三、BP神经网络算法特点及改进
2
一.BP神经网络算法概述
BP神经网络(Back-Propagation Neural Network),即误差
后向传播神经网络,是一种按误差逆向传播算法训练的多层前馈网
络,是目前应用最广泛的网络模型之一。
11
二.BP神经网络算法原理
图5 Tan-Sigmoid函数在(-4,4)范围内的函数曲线
12
二.BP神经网络算法原理
激活函数性质:
① 非线性
② 可导性:神经网络的优化是基于梯度的,求解梯度需要确保函
数可导。
③ 单调性:激活函数是单调的,否则不能保证神经网络抽象的优
化问题转化为凸优化问题。
④ 输出范围有限:激活函数的输出值范围有限时,基于梯度的方
= 1
=1
7
,
= 1,2,3 … , q
二.BP神经网络算法原理
输出层节点的输出为:
j = 2 ,
= 1,2,3. . . ,
=1
至此,BP网络完成了n维空间向量对m维空间的近似映射。
图2 三层神经网络的拓扑结构
8
二.BP神经网络算法原理
BP神经网络是多层前馈型神经网络中的一种,属于人工神经网
络的一类,理论可以对任何一种非线性输入输出关系进行模仿,因
此 被 广 泛 应 用 在 分 类 识 别 ( classification ) 、 回 归
(regression)、压缩(compression)、逼近(fitting)等领域。
在工程应用中,大约80%的神经网络模型都选择采用BP神经网
BP人工神经网络试验报告一

BP⼈⼯神经⽹络试验报告⼀学号:北京⼯商⼤学⼈⼯神经⽹络实验报告实验⼀基于BP算法的XX及Matlab实现院(系)专业学⽣姓名成绩指导教师2011年10⽉⼀、实验⽬的:1、熟悉MATLAB 中神经⽹络⼯具箱的使⽤⽅法;2、了解BP 神经⽹络各种优化算法的原理;3、掌握BP 神经⽹络各种优化算法的特点;4、掌握使⽤BP 神经⽹络各种优化算法解决实际问题的⽅法。
⼆、实验内容:1 案例背景1.1 BP 神经⽹络概述BP 神经⽹络是⼀种多层前馈神经⽹络,该⽹络的主要特点是信号前向传递,误差反向传播。
在前向传递中,输⼊信号从输⼊层经隐含层逐层处理,直⾄输出层。
每⼀层的神经元状态只影响下⼀层神经元状态。
如果输出层得不到期望输出,则转⼊反向传播,根据预测误差调整⽹络权值和阈值,从⽽使BP 神经⽹络预测输出不断逼近期望输出。
BP 神经⽹络的拓扑结构如图1.1所⽰。
图1.1 BP 神经⽹络拓扑结构图图1.1中1x ,2x , ……n x 是BP 神经⽹络的输⼊值1y ,2y , ……n y 是BP 神经的预测值,ij ω和jk ω为BP 神经⽹络权值。
从图1.1可以看出,BP 神经⽹络可以看成⼀个⾮线性函数,⽹络输⼊值和预测值分别为该函数的⾃变量和因变量。
当输⼊节点数为n ,输出节点数为m 时,BP 神经⽹络就表达了从n 个⾃变量到m 个因变量的函数映射关系。
BP 神经⽹络预测前⾸先要训练⽹络,通过训练使⽹络具有联想记忆和预测能⼒。
BP 神经⽹络的训练过程包括以下⼏个步骤。
步骤1:⽹络初始化。
根据系统输⼊输出序列()y x ,确定⽹络输⼊层节点数n 、隐含层节点数l ,输出层节点数m ,初始化输⼊层、隐含层和输出层神经元之间的连接权值ij ω和式中, l 为隐含层节点数; f 为隐含层激励函数,该函数有多种表达形式,本章所选函数为:步骤3:输出层输出计算。
根据隐含层输出H ,连接权值jk ω和阈值b ,计算BP 神经⽹络预测输出O 。
BP神经网络算法

BP神经网络算法BP神经网络算法(BackPropagation Neural Network)是一种基于梯度下降法训练的人工神经网络模型,广泛应用于分类、回归和模式识别等领域。
它通过多个神经元之间的连接和权重来模拟真实神经系统中的信息传递过程,从而实现复杂的非线性函数拟合和预测。
BP神经网络由输入层、隐含层和输出层组成,其中输入层接受外部输入的特征向量,隐含层负责进行特征的抽取和转换,输出层产生最终的预测结果。
每个神经元都与上一层的所有神经元相连,且每个连接都有一个权重,通过不断调整权重来优化神经网络的性能。
BP神经网络的训练过程主要包括前向传播和反向传播两个阶段。
在前向传播中,通过输入层将特征向量引入网络,逐层计算每个神经元的输出值,直至得到输出层的预测结果。
在反向传播中,通过计算输出层的误差,逐层地反向传播误差信号,并根据误差信号调整每个连接的权重值。
具体来说,在前向传播过程中,每个神经元的输出可以通过激活函数来计算。
常见的激活函数包括Sigmoid函数、ReLU函数等,用于引入非线性因素,增加模型的表达能力。
然后,根据权重和输入信号的乘积来计算每个神经元的加权和,并通过激活函数将其转化为输出。
在反向传播过程中,首先需要计算输出层的误差。
一般采用均方差损失函数,通过计算预测值与真实值之间的差异来衡量模型的性能。
然后,根据误差信号逐层传播,通过链式法则来计算每个神经元的局部梯度。
最后,根据梯度下降法则,更新每个连接的权重值,以减小误差并提高模型的拟合能力。
总结来说,BP神经网络算法是一种通过多层神经元之间的连接和权重来模拟信息传递的人工神经网络模型。
通过前向传播和反向传播两个阶段,通过不断调整权重来训练模型,并通过激活函数引入非线性因素。
BP 神经网络算法在分类、回归和模式识别等领域具有广泛的应用前景。
机器学习-BP(back propagation)神经网络介绍
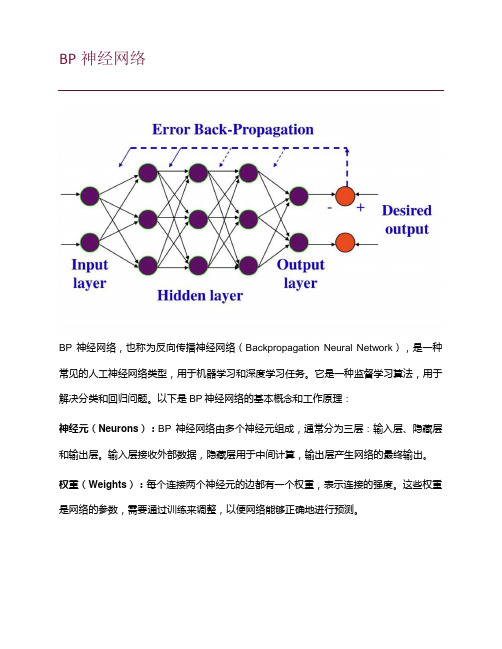
BP神经网络BP神经网络,也称为反向传播神经网络(Backpropagation Neural Network),是一种常见的人工神经网络类型,用于机器学习和深度学习任务。
它是一种监督学习算法,用于解决分类和回归问题。
以下是BP神经网络的基本概念和工作原理:神经元(Neurons):BP神经网络由多个神经元组成,通常分为三层:输入层、隐藏层和输出层。
输入层接收外部数据,隐藏层用于中间计算,输出层产生网络的最终输出。
权重(Weights):每个连接两个神经元的边都有一个权重,表示连接的强度。
这些权重是网络的参数,需要通过训练来调整,以便网络能够正确地进行预测。
激活函数(Activation Function):每个神经元都有一个激活函数,用于计算神经元的输出。
常见的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和tanh(双曲正切)等。
前向传播(Forward Propagation):在训练过程中,输入数据从输入层传递到输出层的过程称为前向传播。
数据经过一系列线性和非线性变换,最终产生网络的预测输出。
反向传播(Backpropagation):反向传播是BP神经网络的核心。
它用于计算网络预测的误差,并根据误差调整网络中的权重。
这个过程分为以下几个步骤:1.计算预测输出与实际标签之间的误差。
2.将误差反向传播回隐藏层和输入层,计算它们的误差贡献。
3.根据误差贡献来更新权重,通常使用梯度下降法或其变种来进行权重更新。
训练(Training):训练是通过多次迭代前向传播和反向传播来完成的过程。
目标是通过调整权重来减小网络的误差,使其能够正确地进行预测。
超参数(Hyperparameters):BP神经网络中有一些需要人工设置的参数,如学习率、隐藏层的数量和神经元数量等。
这些参数的选择对网络的性能和训练速度具有重要影响。
BP神经网络在各种应用中都得到了广泛的使用,包括图像分类、语音识别、自然语言处理等领域。
BP神经网络算法步骤

BP神经网络算法步骤
1.初始化神经网络参数
-设置网络的输入层、隐藏层和输出层的神经元数目。
-初始化权重和偏置参数,通常使用随机小值进行初始化。
2.前向传播计算输出
-将输入样本数据传入输入层神经元。
-根据权重和偏置参数,计算隐藏层和输出层神经元的输出。
- 使用激活函数(如Sigmoid函数)将输出映射到0到1之间。
3.计算误差
4.反向传播更新权重和偏置
-根据误差函数的值,逆向计算梯度,并将梯度传播回网络中。
-使用链式法则计算隐藏层和输出层的梯度。
-根据梯度和学习率参数,更新权重和偏置值。
5.重复迭代训练
-重复执行2-4步,直到网络输出误差满足预定的停止条件。
-在每次迭代中,使用不同的训练样本对网络进行训练,以提高泛化性能。
-可以设置训练轮数和学习率等参数来控制训练过程。
6.测试和应用网络
-使用测试集或新样本对训练好的网络进行测试。
-将测试样本输入网络,获取网络的输出结果。
-根据输出结果进行分类、回归等任务,评估网络的性能。
7.对网络进行优化
-根据网络在训练和测试中的性能,调整网络的结构和参数。
-可以增加隐藏层的数目,改变激活函数,调整学习率等参数,以提高网络的性能。
以上是BP神经网络算法的基本步骤。
在实际应用中,还可以对算法进行改进和扩展,如引入正则化技术、批量更新权重等。
同时,数据的预处理和特征选择也对网络的性能有着重要的影响。
在使用BP神经网络算法时,需要根据实际问题对网络参数和训练策略进行适当调整,以获得更好的结果。
BP神经网络算法实验报告

计算各层的输入和输出
es
计算输出层误差 E(q)
E(q)<ε
修正权值和阈值
结
束
图 2-2 BP 算法程序流程图
3、实验结果
任课教师: 何勇强
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 班号:131081 学号:13108117 姓名:韩垚 成绩:
任课教师: 何勇强
(2-7)
wki
输出层阈值调整公式:
(2-8)
ak
任课教师: 何勇强
E E netk E ok netk ak netk ak ok netk ak
(2-9)
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 隐含层权值调整公式: 班号:131081 学号:13108117 姓名:韩垚 成绩:
Ep
系统对 P 个训练样本的总误差准则函数为:
1 L (Tk ok ) 2 2 k 1
(2-5)
E
1 P L (Tkp okp )2 2 p 1 k 1
(2-6)
根据误差梯度下降法依次修正输出层权值的修正量 Δwki,输出层阈值的修正量 Δak,隐含层权 值的修正量 Δwij,隐含层阈值的修正量
日期: 2010 年 12 月 24 日
隐含层第 i 个节点的输出 yi:
M
yi (neti ) ( wij x j i )
j 1
(2-2)
输出层第 k 个节点的输入 netk:
q q M j 1
netk wki yi ak wki ( wij x j i ) ak
(完整版)bp神经网络算法
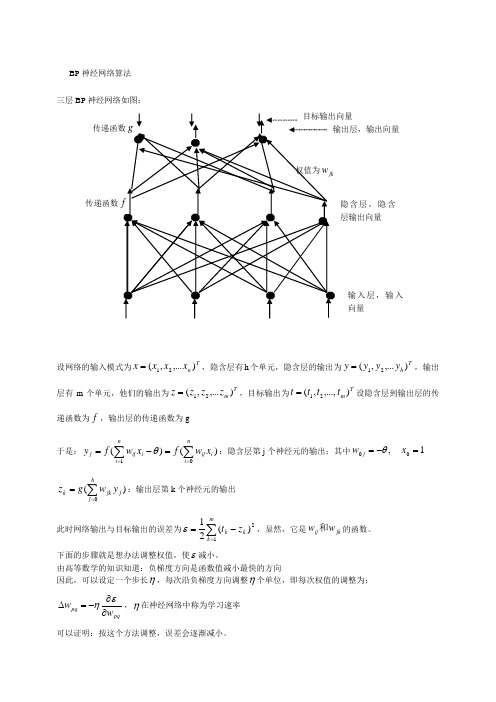
BP 神经网络算法 三层BP 神经网络如图:设网络的输入模式为Tn x x x x ),...,(21=,隐含层有h 个单元,隐含层的输出为Th y y y y ),...,(21=,输出层有m 个单元,他们的输出为Tm z z z z ),...,(21=,目标输出为Tm t t t t ),...,,(21=设隐含层到输出层的传递函数为f ,输出层的传递函数为g于是:)()(1∑∑===-=ni i ij ni iij j x w f xw f y θ:隐含层第j 个神经元的输出;其中1,00=-=x w j θ)(0∑==hj j jk k y w g z :输出层第k 个神经元的输出此时网络输出与目标输出的误差为∑=-=m k k k z t 12)(21ε,显然,它是jk ij w w 和的函数。
下面的步骤就是想办法调整权值,使ε减小。
由高等数学的知识知道:负梯度方向是函数值减小最快的方向因此,可以设定一个步长η,每次沿负梯度方向调整η个单位,即每次权值的调整为:pqpq w w ∂∂-=∆εη,η在神经网络中称为学习速率 可以证明:按这个方法调整,误差会逐渐减小。
隐含层,隐含层输出向量传递函数输入层,输入向量BP 神经网络(反向传播)的调整顺序为: 1)先调整隐含层到输出层的权值 设k v 为输出层第k 个神经元的输入∑==hj j jkk y wv 0-------复合函数偏导公式若取x e x f x g -+==11)()(,则)1()111(11)1()('2k k v v v v k z z ee e e u g kk k k -=+-+=+=---- 于是隐含层到输出层的权值调整迭代公式为: 2)从输入层到隐含层的权值调整迭代公式为: 其中j u 为隐含层第j 个神经元的输入:∑==ni i ijj x wu 0注意:隐含层第j 个神经元与输出层的各个神经元都有连接,即jy ∂∂ε涉及所有的权值ij w ,因此∑∑==--=∂∂∂∂∂-∂=∂∂m k jk k k k j k k k m k k k k j w u f z t y u u z z z t y 002)(')()(ε于是:因此从输入层到隐含层的权值调整迭代为公式为: 例:下表给出了某地区公路运力的历史统计数据,请建立相应的预测模型,并对给出的2010和2011年的数据,预测相应的公路客运量和货运量。
BP神经网络算法步骤

BP神经网络算法步骤1.初始化网络参数:首先,需要确定网络的架构,包括输入层、输出层和隐藏层的数量和节点数。
然后,通过随机选取初始权重和阈值来初始化网络参数,这些参数将用于每个节点的计算。
2.前向传播计算:对于每个输入样本,将其输入到网络中,通过计算每个节点的输出来实现前向传播。
每个节点的输入是上一层节点的输出,通过加权求和并使用激活函数得到节点的输出。
3.计算误差:对于每个输出节点,将其输出与实际的目标值进行比较,得到误差。
通常使用均方误差函数来计算误差。
4.反向传播调整权重:根据误差大小来调整网络的权重和阈值。
先从输出层开始计算误差梯度,并根据梯度下降算法调整输出层的权重和阈值。
然后,逐层向前计算误差梯度并调整隐藏层的权重和阈值,直到达到输入层。
5.更新参数:根据反向传播计算得到的梯度更新网络的参数。
通常使用梯度下降法来更新权重和阈值。
梯度下降法根据每个参数的梯度进行参数更新,以使误差最小化。
6.重复迭代:通过多次重复迭代步骤2到步骤5,持续调整网络参数,使得网络能够逐渐学习和逼近目标函数。
每次迭代都会计算新的误差和梯度,并根据梯度下降法更新参数。
7.终止条件:迭代过程应设置一个终止条件,通常是达到一定的最大迭代次数或者误差的变化小到一定程度时停止。
8.测试网络性能:使用测试数据集对训练好的网络进行性能评估。
将测试数据输入网络中,通过前向传播计算输出结果,并与实际结果进行比较,计算准确率或其他性能指标。
以上就是BP神经网络算法的基本步骤。
这个算法能够通过不断的反向传播和参数更新,使得网络能够学习和逼近非线性函数,是一种非常常用的神经网络算法。
BP神经网络训练分类器——【机器学习与算法分析 精品资源池】

# 提前结束训练的阈值,下面参数,观察误差,连续5次无改善.则结束训练 early_stopping = keras.callbacks.EarlyStopping(monitor='loss', patience=5, verbose=0, mode='auto')
# 模型训练,写入数据,目标,迭代次数,批数,训练详情(0不显示),训练提早结束条件 model.fit(train_data_x, train_data_y, epochs=1000, batch_size=32, verbose=1, callbacks=[early_stopping])
# 构建神经网络需要的数据结构 df_train_net = np.array(df_train_norm) train_data_x = df_train_net[:, 0:13] train_data_y = df_train_net[:, 13:]
实例:构建神经网络结构
人工智能实验报告-BP神经网络算法的简单实现

⼈⼯智能实验报告-BP神经⽹络算法的简单实现⼈⼯神经⽹络是⼀种模仿⼈脑结构及其功能的信息处理系统,能提⾼⼈们对信息处理的智能化⽔平。
它是⼀门新兴的边缘和交叉学科,它在理论、模型、算法等⽅⾯⽐起以前有了较⼤的发展,但⾄今⽆根本性的突破,还有很多空⽩点需要努⼒探索和研究。
1⼈⼯神经⽹络研究背景神经⽹络的研究包括神经⽹络基本理论、⽹络学习算法、⽹络模型以及⽹络应⽤等⽅⾯。
其中⽐较热门的⼀个课题就是神经⽹络学习算法的研究。
近年来⼰研究出许多与神经⽹络模型相对应的神经⽹络学习算法,这些算法⼤致可以分为三类:有监督学习、⽆监督学习和增强学习。
在理论上和实际应⽤中都⽐较成熟的算法有以下三种:(1) 误差反向传播算法(Back Propagation,简称BP 算法);(2) 模拟退⽕算法;(3) 竞争学习算法。
⽬前为⽌,在训练多层前向神经⽹络的算法中,BP 算法是最有影响的算法之⼀。
但这种算法存在不少缺点,诸如收敛速度⽐较慢,或者只求得了局部极⼩点等等。
因此,近年来,国外许多专家对⽹络算法进⾏深⼊研究,提出了许多改进的⽅法。
主要有:(1) 增加动量法:在⽹络权值的调整公式中增加⼀动量项,该动量项对某⼀时刻的调整起阻尼作⽤。
它可以在误差曲⾯出现骤然起伏时,减⼩振荡的趋势,提⾼⽹络训练速度;(2) ⾃适应调节学习率:在训练中⾃适应地改变学习率,使其该⼤时增⼤,该⼩时减⼩。
使⽤动态学习率,从⽽加快算法的收敛速度;(3) 引⼊陡度因⼦:为了提⾼BP 算法的收敛速度,在权值调整进⼊误差曲⾯的平坦区时,引⼊陡度因⼦,设法压缩神经元的净输⼊,使权值调整脱离平坦区。
此外,很多国内的学者也做了不少有关⽹络算法改进⽅⾯的研究,并把改进的算法运⽤到实际中,取得了⼀定的成果:(1) 王晓敏等提出了⼀种基于改进的差分进化算法,利⽤差分进化算法的全局寻优能⼒,能够快速地得到BP 神经⽹络的权值,提⾼算法的速度;(2) 董国君等提出了⼀种基于随机退⽕机制的竞争层神经⽹络学习算法,该算法将竞争层神经⽹络的串⾏迭代模式改为随机优化模式,通过采⽤退⽕技术避免⽹络收敛到能量函数的局部极⼩点,从⽽得到全局最优值;(3) 赵青提出⼀种分层遗传算法与BP 算法相结合的前馈神经⽹络学习算法。
实验五BP神经网络的构建与使用(一)

人工神经网络实验五BP神经网络的构建与使用(一)一、实验目的1、熟悉MATLAB中神经网络工具箱的使用方法;2、掌握BP神经网络的特性和应用范围;3、掌握使用BP神经网络解决实际问题的方法;二、实验内容:在第四次实验中,试图用线性神经网络求解函数逼近问题,从实验的结果可以看到未能达到预期的效果,下面使用BP 神经网络来求解函数逼近问题:1、有21组单输入矢量和相对应的目标矢量,参考书《神经网络实验教程》P36的示例程序,试设计一个BP神经网络来实现这对数组的函数关系。
BP神经网络的部分参数输入与目标数据如下:BP神经网络参数:隐含层神经元个数为5个,设置BP神经网络的最大训练次数为1000。
提示:正确选择输入层到隐含层、隐含层到输出层的激活函数,tansig的定义域为负无穷到正无穷,值域为-1到1,logsig的定义域为负无穷到正无穷,值域为0到1;为观察训练后神经网络的效果,可以利用sim()函数(参见书P22)和plot()函数(参见书P15)在同坐标中画出输入数据和期望目标数据、测试数据和测试数据输出的图形输入数据:P=-1:0.1:1期望目标数据:T=[-0.96、0.577、-0.0729、0.377、0.641、0.66、0.461、0.1336、0.201、-0.434、-0.5、-0.393、-0.1647、0.0988、0.3072、0.396、0.3449、0.1816、-0.0312、-0.2183、-0.3201](注意:为了清楚的表示数据,我在数据间加了逗号,同学们在MATLAB中使用进请将逗号改为空格)截图:代码:P=-1:0.1:1;T=[-0.960.577-0.07290.3770.6410.660.4610.13360.201-0.434-0.5-0.393-0.16470.09880.30720.3960.34490.1816-0.0312-0.2183-0.3201];%创建一个BP神经网络,每一个输入向量的取值范围为[-1,1],隐含层有5个神经元,输出层%有一个神经元,隐含层的激活函数为tansig,输出层的激活函数为logsig,训练函数为梯度下%降函数,即2.3.2节中所描述的标准学习算法net=newff([-11],[5,1],{'tansig','tansig'},'traingd');%可以改变训练步数为3000、5000、10000来查看网络的训练结果net.trainParam.epochs=5000;%目标误差设为0.01net.trainParam.goal=0.01;%设置学习速率为0.1LP.lr=0.1;net=train(net,P,T);y=sim(net,P);figurehndl1=plot(P,y);%设置线宽为2set(hndl1,'linewidth',2);%设置线的颜色为红色set(hndl1,'color','red');hold onhndl2=plot(P,T);set(hndl2,'linewidth',2);%设置图形标题title('BP神经网络逼近非线性函数的MATLAB实现'); %设置图例legend('BP神经网络逼近非线性函数','原数据')2、对1中建立的BP神经网络进行测试,测试数据为:P2=-1:0.025:1并对测试结果进行分析,3、当最大训练次数设置为3000、5000、10000时,分析网络的输出效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验算法BP神经网络实验
【实验名称】
BP神经网络实验
【实验要求】
掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用;
【背景描述】
神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
其基本组成单元是感知器神经元。
【知识准备】
了解BP神经网络模型的使用场景,数据标准。
掌握Python/TensorFlow数据处理一般方法。
了解keras神经网络模型搭建,训练以及应用方法
【实验设备】
Windows或Linux操作系统的计算机。
部署TensorFlow,Python。
本实验提供centos6.8环境。
【实验说明】
采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。
【实验环境】
Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。
【实验步骤】
第一步:启动python:
1
命令行中键入python。
第二步:导入用到的包,并读取数据:
(1).导入所需第三方包
import pandas as pd
import numpy as np
from keras.models import Sequential
from yers import Dense
import keras
(2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txt
df_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据
df_wine.head()
1
第三步:数据预处理
(1).划分60%数据
p = 0.6
cut = int(np.ceil(len(df_wine) * p))
(2).划分数据集
df_wine_train = df_wine.iloc[:cut]
df_wine_test = df_wine.iloc[cut:]
(3).类别标识编码(深度学习常用手段,类别1 = (1,0),类别2 = (0,1),类别3 = (0,0))
label_train = pd.DataFrame(df_wine_train[0])
label_train["one-hot_1"] = label_train[0].map(lambda x: 1 if (x == 1) else 0)
label_train["one-hot_2"] = label_train[0].map(lambda x: 1 if (x == 2) else 0)
label_train["one-hot_3"] = [1]*len(label_train)
(4).数据标准化,获取每列均值,标准差
avg_col = df_wine_train.mean()
td_col = df_wine_train.std()
(5).标准化结果
df_train_norm = (df_wine_train - avg_col) / td_col
(6).整理数据
df_train_norm=df_train_norm.drop([0], axis=1).join(label_train[["one-hot_1", "one-hot_2"]]) (7).构建神经网络需要的数据结构
df_train_net = np.array(df_train_norm)
train_data_x = df_train_net[:, 0:13]
train_data_y = df_train_net[:, 13:]
1。