实验7 假设检验(一)
假设检验的一般步骤

假设检验的一般步骤各位读友大家好,此文档由网络收集而来,欢迎您下载,谢谢1简述假设检验的一般步骤1 简述假设检验的一般步骤。
(1) 建立假设确定显著性水平计算统计量确定概率值p做出推断结论简述文献检索的基本步骤。
1)明确检索课题,明确检索目的,制定检索策略2)选择检索工具,查找文献线索3)选择检索途径,确定检索标识4)查找文献线索5)获取原始文献3 简述选择研究问题的注意事项。
实用性,创新性,范围不可过大,可行性,结合自己熟悉的专业选题4 简述知情同意书应该包括的基本内容介绍研究目的介绍研究的过程介绍研究的风险和可能带来的不舒适之处介绍研究的益处匿名和保密的保证提供回答受试者问题的途径非强制性的放弃退出研究的选择权5简述减少抽样误差的方法。
1)选取合适的抽样方法,使样本更具有代表性;2)增加样本量到适当水平;3)选择变异程度小的研究指标。
6简述选择研究样本的注意事项。
1、严格规定总体的条件。
2、按随机原则选取样本,并应注意具有代表性。
3、每项研究课题都应规定有足够的样本数,例数太少则无代表性,而样本数太大实验条件不易严格控制。
7按文献的外表特征进行检索的途径。
1、书名途径;2、著者途径;3、序号途径8按文献的内容特征进行检索的途径。
1、分类途径;2、主题途径;3、关键词途径;4、分类主题途径9文献按载体类型划分可分为哪些?印刷型文献、缩微型文献、视听型文献、机读型文献。
10实验性研究的特点有哪些?干预、设对照组、随机取样和随机分组11简述变量的分类。
自变量、依变量、外变量12选择指标时应注意哪些问题?1、客观性2、合理性3、灵敏性4、关联性5、稳定性和准确性13简述概率抽样的类型。
单纯随机抽样、等距抽样、分层抽样、整群抽样14简述非概率抽样的类型。
配额抽样、主观抽样、网络抽样、方便抽样15简述选择性偏倚的种类。
1、诊断性偏倚2、入院率偏倚3、无应答偏倚4、分组偏倚16简述衡量性偏倚的种类。
1、回忆偏倚2、诊断怀疑偏倚3、调查者偏倚4、被调查者偏倚17简述偏倚的控制方法。
第七章假设检验

第七章 假设检验一、单项选择1.关于学生t 分布,下面哪种说法不正确( )。
A 要求随机样本B 适用于任何形式的总体分布C 可用于小样本D 可用样本标准差S 代替总体标准差σ2.二项分布的数学期望为( )。
A n(1-n)pB np(1- p)C npD n(1- p)。
3.处于正态分布概率密度函数与横轴之间、并且大于均值部分的面积为( )。
A 大于0.5B -0.5C 1D 0.5。
4.假设检验的基本思想可用( )来解释。
A 中心极限定理B 置信区间C 小概率事件D 正态分布的性质5.成数与成数方差的关系是( )。
A 成数的数值越接近0,成数的方差越大B 成数的数值越接近0.3,成数的方差越大C 成数的数值越接近1,成数的方差越大D 成数的数值越接近0.5,成数的方差越大6.在统计检验中,那些不大可能的结果称为( )。
如果这类结果真的发生了,我们将否定假设。
A 检验统计量B 显著性水平C 零假设D 否定域7.对于大样本双侧检验,如果根据显著性水平查正态分布表得Z α/2=1.96,则当零假设被否定时,犯第一类错误的概率是( )。
A 20%B 10%C 5%D .1%8.关于二项分布,下面不正确的描述是( )。
A 它为连续型随机变量的分布;B 它的图形当p =0.5时是对称的,当p ≠ 0.5时是非对称的,而当n 愈大时非对称性愈不明显;C 二项分布的数学期望)(X E =μ=np ,变异数)(XD =2σ=npq ;D 二项分布只受成功事件概率p 和试验次数n 两个参数变化的影响。
9.事件A 在一次试验中发生的概率为41,则在3次独立重复试验中,事件A 恰好发生2次的概率为( )。
A21 B 161 C 643 D 649 10.设离散型随机变量X ~),2(p B ,若数学期望4.2)(=X E ,方差44.1)(=X D ,则参数p n ,的值为( ).A 4=n ,p =0.6B 6=n ,p =0.4C 8=n ,p =0.3D 12=n ,p =0.2三、多项选择1.关于正态分布的性质,下面正确的说法是( )。
7.假设检验方法----方差齐性检验、方差分析

单因素完全随机设计方差分析的过程
• 例3 某小学语文教研组为研究学习环境对小 学生学习成绩的影响,从三年级中随机抽取20 名学生,随机分成四组,在四种环境下进行学 习,其效果如表8-5,四种不同的学习环境对 学习成绩的影响是否有显著差异?
方差分析概要表
离差平方和其它求法
• 方差分析中关键步骤:求离差平方和. 为计算方便,往往用原始观测值直接求平 方和,公式如下:
处理 区组 A B C D Xi.
I II III X.j Xi
91 92.5 91.5 275 91.67
64.5 59 54 177.5 59.17
83.5 91.5 83.5 258.5 86.17
75.5 74 71 220.5 73.5
314.5 317 300.0 931.5
单因素随机区组设计方差分析的过程
平均数间的多重比较
单因素随机区组设计方差分析的过程
例 1、 有四种小学语文实验教材,分别代号为A、B、C、D。 为比较其教学效果,按随机区组实验(设计)原则,将小学分 为城镇重点小学、城镇一般小学和乡村小学三个区组,分 别代号为I、II、III,并分别在每个区组中随机地抽取4所 小学,它们分别被随机地指派实验一种教材。经一年教学 后通过统一考试得到各校的平均成绩如下表。问四种教材 的教学效果是否一致?
单因素随机区组设计方差分析的过程
被试的分配分三种情况: (1) 一个被试作为一个区组,不同的被试(区组)均需接受全 部k个实验处理; (2) 每一区组内被试的人数是实验处理数的整数倍; (3) 区组内的基本单元不是个别被试,而是以一个团体为 单元。
随机区组设计由于同一区组接受所有实验处理,试 实验处理之间有相关,所以也称为相关组设计(被试内 设计)。它把区组效应从组内平方和中分离出来。这时, 总平方和=组间平方和+区组平方和+误差项平方和
假设检验与样本数量分析①——单样本Z检验和单样本t检验

X
32.03 + 32.14 + … + 31.87 15
…
1.9 2.0
…
0.029 0.023
…
0.028 0.022
…
0.027 0.022
…
0.0226 0.020
…
0.025 0.020
…
0.024 0.019
…
0.024 0.019
…
0.023 0.018
原假设 (零假设)即上述的可能,符号是H0
备择假设(与原假设对立的假设),符号是H1
如本例:假设外径尺寸 H0:(μ = 32) H1: (μ≠32) 确立检验水准: α——显著水平(通常取α=0.05)
显著水平α是当原假设正确却被拒绝的概率 通常人们取0.05或0.01 这表明,当做出接受原假设的决定时,其正确的可 能性(概率)95% 或99% 概率是0~1之间的一个数,因此小概率就是接近0的 一个数 英国统计家Ronald Fisher 把0.05作为标准,从此0.05 或比0.05小的概率都被认为是小概率
8 作出不拒绝零假设的统计结论,即外径尺寸 均值没有偏离目标Ф 32
<6>
单样本 Z 检验 单样本 t 检验
预备知识
接上页
假设检验的例子(1)
检验 α = 0.05
临界值 临界值
2
=0.025
拒绝范围
1 – α = 95%
不拒绝H0范围
2
=0.025
根据小概率原理,可以先假设总体参数的 某项取值为真,也就是假设其发生的可能 性很大,然后抽取一个样本进行观察,如 果样本信息显示出现了与事先假设相反的 结果(显示出小概率),则说明原来假定 的小概率事件(一次实验中是几乎不可能发 生)在一次实验中居然真的发生了,这是 一个违背小概率原理的不合理现象,因此 有理由怀疑和拒绝原假设;否则不能拒绝 原假设。 在给定了显著水平α 后,根据容量为n的样 本,按照统计量的理论概率分布规律,可 以确定据以判断拒绝和接受原假设的检验 统计量的临界值。 临界值将统计量的所有可能取值区间分为 两个互不相交的部分,即原假设的拒绝域 和接受域。
假设检验

单侧检验的否定域
例如 : H 0为 9 , H A为 9 ,
因为总体、样本和原假设都没有改变, 所以检验统计量不用改变,其值还是 Z 3.1623 只需要在检验统计量抽样分布的左尾确定一 个否定域,其面积等于显著性水平α,在双 侧分位数表中查到临界值 u 2 使P ( Z u 2 ) 当Z的值落在否定域内时认为 9
(二)选择单侧检验 如果根据专业知识可以判断优劣: 例如,根据药理知识判断,某两种药物同时使用, 其疗效一定高于原药单独使用 相反,根据专业知识,作为饲料资源的农副产品 或肉食品中有毒、有害物质的含量不能高于某一
规定值
5)相伴概率:在原假设成立时检验统计 量的观测值以及比它更极端的可能值出 现的概率之和。
单、双侧检验的关系
双侧Zα
>
单侧Zα
双侧检验显著,择单、双侧检验
例:某猪场随机抽测了甲、乙两品种猪血液中白细胞的
密度,测得甲品种13头猪白细胞数的平均值为
10.73×103/mm3,标准差为1.28×103/mm3, 乙品种15头猪白细胞数的平均值为 16.40×103/mm3,标准差为3.44×103/mm3。 两品种猪的白细胞数是否有显著的差异。
( 300 1.96 156.25 275.5,
N(300,156.2)
~N(300,156.2)
300 1.96 156.25 324.5)
1-α
275.5 300
324.5
275. 5
μ0 – 1.96
y
μ0
300
μ1
310
324. 5
μ0 +1.96
接受域H0
y
假定另一个正态总体,μ=310,σ2=625
假设检验例子
例2: 在一项新广告活动的跟踪调查中,在被调查 的400人中有240人会记起广告的标语,试求会 记起广告标语占总体比率的95%置信度的估计区 间。
假设检验: 1:某橡胶厂生产汽车轮胎,根据历史资料统计结 果,平均里程为25000公里,标准差为1900公里。 现采用一种新的工艺制作流程,从新批量的轮胎 中随机抽取400个作实验,求得样本平均里程为 25300公里,试按5%的显著性水平判断新批量 轮胎的平均耐用里程与以前生产的轮胎的耐用里 程有没有显著的差异,或者它们属于同一总体的 假设是否成立。
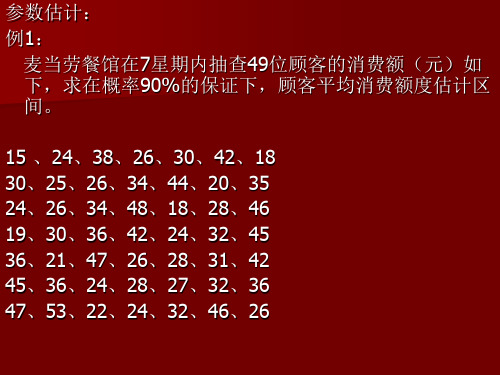
参数估计: 例1: 麦当劳餐馆在7星期内抽查49位顾客的消费额(元)如 下,求在概率90%的保证下,顾客平均消费额度估计区 间。 15 、24、38、26、30、42、18 30、25、26、34、44、20、35 24、26、34、48、18、28、46 19、30、36、42、24、32、45 36、21、47、26、28、31、42 45、36、24、28、27、32、36 47、53、22、24、3者满意其产品 的质量,一家市场调查公司受委托调查该公司此 项声明是否属实,随机抽样调查625位消费者, 表示满意该公司产品质量者有500人,试问在 0.05的显著性水平下,该公司的声明是否属实。
第五章 假设检验(1)

关于平均数差异的显著性检验
一、两个总体都是正态分布,两个总体方差都已知。 (一)两个样本相互独立:(独立样本的Z检验) (二)两个相关样本:(相关样本的Z检验) 二、两个总体都是正态分布,两总体方差都未知。 (一)两个样本相互独立: 1.两个总体方差一致(独立样本的t检验) 2.两个总体方差不等,(柯克兰--柯克斯检验) (二)两个相关样本: 1.相关系数未知(相关样本的t检验) 2.相关系数已知(相关样本的t检验)
总体平均数的假设检验例题2
某心理学家认为一般司机的视反应时平均175毫 秒,有人随机抽取36名汽车司机作为研究样本进 行了测定,结果平均值为180毫秒,标准差25毫秒. 能否根据测试结果否定该心理学家的结论.(假定 人的视反应时符合正态分布)
X
总体平均数的假设检验例题3
某省进行数学竞赛,结果分数的分布不是正态, 总平均分43.5.其中某县参加竞赛的学生 168人,平均分45.1,标准差18.7,该县平均分 与全省平均分有否显著差异?
课堂练习4
医学上测定,正常人的血色素应该是每100毫升13克, 某学校进行抽查,37名学生血色素平均值为12.1克/ 毫升,标准差是1.5克/毫升,试问该校学生的血色素 是否显著低于正常值 ?
课堂练习5
12名被试作为实验组,经过训练后测量深度知觉,结 果误差的平均值为4厘米,标准差为2厘米;另外12名 被试作为控制组不加任何训练,测量结果,误差的平 均值为6.5厘米,标准差为2.5厘米,问训练是否明显 减小了深度知觉的误差?
例
某数学教育家随机抽取49名高一学生进行 ****教学法的教学改革实验研究。已知这些 学生原来所在的总体数学的平均水平为80分, 标准差为10分。经过一学期的教学改革实验 之后,这49名学生在统考中的数学平均成绩 为83分。问:教学改革是否改变了学生的数 学水平。
应用统计学 经管类 第7章 假设检验

• • • • • •
二、假设检验的步骤 (一)提出原假设与备择假设 (二)构造检验统计量 (三)确定拒绝域 (四)计算检验统计量的样本观测值 (五)做出结论
1、提出原假设与备择假设
• 消费者协会实际要进行的是一项统计检验 H0 工作。检验总体平均 =250是否成立。这 就是一个原假设(null hypothesis),通常用 表示,即: H0 : =250
第三节 自由分布检验
一、自由分布检验概述 自由分布检验与限定分布检验不同, 它是指在假设检验时不对总体分布的形状和参数加 以限制的检验。与参数检验相对应,自由分布检验又称为非参数检验,但这里的非参数只是 指未对检验统计量服从的分布及其参数做出限制, 并不意味着在检验中 “不涉及参数” “不 或 对参数进行检验” 。
• 解:通过统计软件进行计算。
(二)配对样本的均值检验 设配对观察值为(x,y),其差值是 d = x-y。设 d 为差值的总体均值,要检验的是:
H 0 : d 0 , H1 : d 0
记d
d ,则其方差是: n
2
2 d d / n Sd n(n 1) n
t
X 1000 S/ n
第三步:确定显著性水平,确定拒绝域。 α=0.05,查 t-分布表(自由度为 8),得临界值是 t / 2, n 1 t0.025,8 =2.306, 拒绝域是(-,-2.306]∪[2.306,+)。在 Excel 中,可以使用函数 TINV(0.05,8) 得到临界值 t0.025,8 。 第四步:计算检验统计量的样本观测值。 将 X 986 ,n=9,S=24,代入 t 统计量得:
H1 • 与原假设对立的是备选假设(alternative hypothesis) ,备选假设是在原假设被否 定时另一种可能成立的结论。备选假设比 原假设还重要,这要由实际问题来确定, 一般把期望出现的结论作为备选假设。
假设检验

1、建立检验假设及确定检验水准 H0: =0 山区成年男子平均脉搏 数与一般人群相等 H1 : >0 山区成年男子平均脉搏 数高于一般人群 单侧 =0.05
23
2 选定检验方法及计算检验统计量
不同分析目的、不同设计类型和不同资料类 型,选用不同检验方法。 样本均数与总体均数比较用单样本t检验 配对设计的两样本均数的比较用配对t 检验 完全随机设计的两样本均数比较时,选用成 组设计的两样本均数比较的t 检验
32
用到假设检验比较的例子:
例1:单样本均数与已知总体均数差异的比较 例2:两个样本均数所代表的总体均数之间差异 的比较 能否列举出其它比较的实例?
不同机器性能是否一致? 不同人群的患病率是否相似? 不同年龄的红细胞数测量值是否不同? 不同厂家产品质量对比?
33
例3 某医生测得18例慢性支气管炎患者及16例 健康人的尿17酮类固醇排出量(mg/dl)分别为 X1 和X2, 试问两组的尿17酮类固醇排出量有无 不同。 成组设计 X 1: 3.14 5.83 7.35 4.62 4.05 5.08 4.98 4.22 4.35 2.35 2.89 2.16 5.55 5.94 4.40 5.35 3.80 4.12 X 2: 4.12 7.89 3.24 6.36 3.48 6.74 4.67 7.38 4.95 4.08 5.34 4.27 6.54 4.62 5.92 5.18
未 知 且 n未知,且体 较小,按t分布 ) % 可 信 区 间 为 : 较 小 的 总 n均 数 的 1 0 0 ( 1 ( X t / 2( ) S X , X t / 2( ) S X ) 或 X t / 2( ) S X
假设检验

假设检验是数理统计学中根据一定假设条件由样本推断总体的一种方法。
具体作法是:根据问题的需要对所研究的总体作某种假设,记作H0;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。
常用的假设检验方法有u—检验法、t—检验法、X2检验法、F—检验法,秩和检验等。
目录简介假设检验亦称“显著性检验(Test of statistical significance)”,是假设检验用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。
其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断。
生物现象的个体差异是客观存在,以致抽样误差不可避免,所以我们不能仅凭个别样本的值来下结论。
当遇到两个或几个样本均数(或率)、样本均数(率)与已知总体均数(率)有大有小时,应当考虑到造成这种差别的原因有两种可能:一是这两个或几个样本均数(或率)来自同一总体,其差别仅仅由于抽样误差即偶然性所造成;二是这两个或几个样本均数(或率)来自不同的总体,即其差别不仅由抽样误差造成,而主要是由实验因素不同所引起的。
假设检验的目的就在于排除抽样误差的影响,区分差别在统计上是否成立,并了解事件发生的概率。
在质量管理工作中经常遇到两者进行比较的情况,如采购原材料的验证,我们抽样所得到的数据在目标值两边波动,有时波动很大,这时你如何进行判定这些原料是否达到了我们规定的要求呢?再例如,你先后做了两批实验,得到两组数据,你想知道在这两试实验中合格率有无显著变化,那怎么做呢?这时你可以使用假设检验这种统计方法,来比较你的数据,它可以告诉你两者是否相等,同时也可以告诉你,在你做出这样的结论时,你所承担的风险。
假设检验的思想是,先假设两者相等,即:µ=µ0,然后用统计的方法来计算验证你的假设是否正确。
统计培训教材1.6-假设检验

(0.5)18k
0.004
k 15
这看来又走到另一个极端了. 如果我们在选择一个方案时,只 敢冒 0.4% 的风险, 未免太胆小, 太怯懦了, 对某先生也未免 太苛刻了.
事实上, 虽然此时我们错误地相信该先生的可能性大大的减 少, 但我们冤枉他的可能性却大大地增加了!
假设检验-7
那么,临界值究竟应取多大合适呢?当然要具体问题具体分 析。事关重大,后果严重的,理应把风险控制的小一点;无 伤大雅,错了可以再来的决策则不妨大胆一点。
80.0 82.5 85.0 87.5 90.0 92.5
假设检验-18
假设检验的前提假设
– 如果数据是连续的,我们假设基本分布是正态。 • 您可能需要转换非正态数据(如周期)。
– 当比较不同总体的子群时,我们假设: • 独立样本。 • 通过随机抽样实现。 • 样本是总体的代表(没有偏差)。
– 当比较不同过程的子群时,我们假设: • 每个过程都是稳定的。 • 没有特殊原因或随时间的变化 (没有与时间相关的差异)。 • 样本是过程的代表(没有偏差)。
假设检验-8
假设检验概要
※工业案例的启示
在工业生产中,我们经常希望能够确定某个分布的参数是否就是某个具体 数值或是否与其有什么关系。也就是说,我们可能希望要检验这样一个假设, 即:某个分布的均值或标准差是否是某些数值,或者两个均值之差是否是零。 这些检验就需要使用假设检验方法。实际工作中的例子有:
假设检验-19
假设(Hypothesis)
一个假设通常是关于总体特性的一个陈述.
待检假设包括两部分:
1) 零假设(null hypothesis) (记为H0)是关于总体参数值的一 个陈述.
2) 备择假设(alternative hypothesis) (记为H1), 也叫对立假 设, 是关于总体参数值的一个与零假设相对立的陈述, 即 若零假设不成立, 则备择假设必定成立.
假设检验原理的应用

假设检验原理的应用引言假设检验是统计学中一种重要的方法,用于判断一个观察到的数据集是否支持某个特定的假设。
在研究中,我们经常需要对某个假设进行验证或者对两个或多个假设进行对比。
本文将介绍假设检验的基本原理,并探讨其在实际应用中的一些例子。
假设检验的基本原理1.假设(null hypothesis):对一个现象或者数据进行描述,我们首先要提出一个假设,即我们认为该现象或数据服从的分布或者具有某种特点。
2.可选择假设(alternative hypothesis):与原假设相对,可供选择的假设。
它通常是与原假设对立的。
3.统计学的检验方法:基于样本数据,通过计算统计量(如t值、z值或卡方值等)来判断是否拒绝原假设。
假设检验的应用场景1. 医学研究•假设:某种新药对治疗某种疾病有效。
•假设检验流程:1.提出原假设:新药对治疗某种疾病无效。
2.收集实验数据,进行统计分析。
3.计算统计量,如p值。
4.根据p值判断是否拒绝原假设。
•结果:如果p值小于事先设定的显著性水平,我们将拒绝原假设,认为新药对治疗某种疾病有效。
2. 工程领域•假设:新设计的产品采用的材料与已有产品相比,寿命更长。
•假设检验流程:1.提出原假设:新设计的产品与已有产品具有相同的寿命。
2.收集产品的寿命数据,进行统计分析。
3.计算统计量,如t值。
4.根据t值判断是否拒绝原假设。
•结果:如果t值大于临界值,我们将拒绝原假设,认为新设计的产品寿命更长。
3. 市场研究•假设:一种新的广告策略能够显著提升产品销量。
•假设检验流程:1.提出原假设:新广告策略对产品销量没有显著影响。
2.随机选取两个样本组,一个使用新广告策略,一个使用旧广告策略。
3.收集两个样本组的销量数据,进行统计分析。
4.计算统计量,如z值。
5.根据z值判断是否拒绝原假设。
•结果:如果z值大于临界值,我们将拒绝原假设,认为新广告策略能够提升产品销量。
假设检验的注意事项1.显著性水平:在进行假设检验时,我们需要设定一个显著性水平(一般取0.05或0.01),用来决定什么样的p值可以被认为是拒绝原假设。
总体均数的估计和假设检验

(一) 单项选择题1. 标准误的英文缩写为:A .SB .SEC .X SD .SD2. 通常可采用以下那种方法来减小抽样误差:A .减小样本标准差B .减小样本含量C .扩大样本含量D .以上都不对 3. 配对设计的目的:A .提高测量精度B .操作方便C .为了可以使用t 检验D .提高组间可比性 4. 以下关于参数估计的说法不正确的是:A . 区间估计优于点估计B . 样本含量越大,参数估计准确的可能性越大C . 样本含量越大,参数估计越精确D .对于一个参数只能有一个估计值5. 关于假设检验,下列那一项说法是正确的A .单侧检验优于双侧检验B .采用配对t 检验还是成组t 检验是由实验设计方法决定的C .检验结果若P 值大于0.05,则接受H 0犯错误的可能性很小D .用u 检验进行两样本总体均数比较时,要求方差齐性6. 两样本比较时,分别取以下检验水准,下列何者所取第二类错误最小A .α=0.05B .α=0.01C .α=0.10D .α=0.20 7. 统计推断的内容是A .用样本指标推断总体指标B .检验统计上的“假设”C .A 、B 均不是D .A 、B 均是8.当两总体方差不齐时,以下哪种方法不适用于两样本总体均数比较 A .t 检验 B .t ’ 检验 C .u 检验(假设是大样本时) D .F 检验9.甲、乙两人分别从随机数字表抽得30个(各取两位数字)随机数字作为两个样本,求得1X ,21S ,2X ,22S ,则理论上A .1X =2X ,21S =22SB .作两样本t 检验,必然得出无差别的结论C .作两方差齐性的F 检验,必然方差齐D .分别由甲、乙两样本求出的总体均数的95%可信区间,很可能有重叠(二) 名词解释1. 统计推断 2. 抽样误差3. 标准误及X σ 4. 可信区间 5. 参数估计6. 假设检验中P 的含义7.I型和II型错误8.检验效能9.检验水准(三)是非题1.若两样本均数比较的假设检验结果P值远远小于0.01,则说明差异非常大。
假设检验的定义和步骤

假设检验的定义和步骤假设检验是一种统计推断方法,用于判断某种假设是否成立。
它可以帮助我们从样本数据中推断总体的特征,并且在决策和判断中起到重要的作用。
下面将介绍假设检验的定义和步骤。
一、定义假设检验是基于样本数据对总体参数进行推断的方法。
它基于一个原假设(H0)和一个备择假设(H1),通过对样本数据进行统计分析,得出关于总体参数的结论。
二、步骤假设检验的步骤一般包括以下几个阶段:1. 建立假设:在进行假设检验之前,需要明确原假设和备择假设。
原假设通常是我们要进行推断的对象是否符合某种特定的条件,备择假设则是原假设的补集。
2. 选择显著性水平:显著性水平是用来判断原假设是否成立的标准。
一般情况下,我们会选择一个显著性水平(通常用α表示),如0.05或0.01,来作为判断的标准。
3. 选择统计检验方法:根据数据类型和假设条件的不同,选择适当的统计检验方法。
常见的统计检验方法包括t检验、F检验、卡方检验等。
4. 计算统计量:根据选定的统计检验方法,计算得到相应的统计量。
统计量的计算方法根据具体的检验方法而定。
5. 确定拒绝域:根据显著性水平和统计量的分布,确定拒绝域。
拒绝域是在原假设成立的条件下,观察到的统计量取值落在其中的区域。
6. 判断结论:将计算得到的统计量与拒绝域进行比较,若统计量的取值落在拒绝域内,则拒绝原假设,接受备择假设;若统计量的取值落在拒绝域外,则接受原假设。
7. 给出推断:根据判断的结论,给出对总体的推断。
若拒绝原假设,则说明总体不符合假设条件;若接受原假设,则说明总体符合假设条件。
假设检验是一种重要的统计分析方法,可以帮助我们从样本数据中推断总体的特征。
通过明确假设、选择显著性水平、选择适当的统计检验方法、计算统计量、确定拒绝域、判断结论和给出推断,我们可以得出对总体的结论。
这种方法在科学研究、医学实验、市场调查等领域都有广泛的应用。
假设检验基本原理

6
(二)确定适当的检验统计量,并计算统计量的具 体数值 • 检验统计量是根据所抽取样本计算的用于检验原 假设是否成立的随机变量。 • 检验统计量中应当含有所要检验的总体参数。 • 检验统计量还应该在“H0成立”的前提下有已知 的分布,从而便于计算出现某种特定的观测结果 的概率。
7
8
(三)规定显著性水平 • 显著性水平是指当原假设为正确时人们却把它拒绝 了的概率或风险。 • 这个概率是人为确定的,通常取α=0.05或0.01。 • 这表明,当作出接受原假设的决定时,其正确的可 能性(概率)为95%或99%。
16
17
六、假设检验中的P值与临界值
(一)P-值规则 • 所谓P-值,实际上是检验统计量超过(大于或小 于)具体样本观测值的概率。 • 如果P-值小于所给定的显著性水平,则认为原 假设不太可能成立;如果P-值大于所给定的标 准,则认为没有充分的证据否定原假设。
18
(二)临界值规则 • 根据所提出的显著性水平标准(它是概率密度曲线 的尾部面积)查表得到相应的检验统计量的数值, 称作临界值。 • 用检验统计量的观测值与临界值作比较,观测值落 在临界值所划定的尾部(称之为拒绝域)内,便拒 绝原假设; • 观测值落在临界值划定的尾部之外(称之为不能拒 绝域)的范围内,则认为拒绝原假设的证据不足。
H1 :θ≠θ0 H1 :θ<θ0 H1 :θ>θ0
15
• 在统计的假设检验中,一般是把“不能轻易否定 的命题”作为原假设,把“需要验证的问题”作 为备择假设。什么是“不能轻易否定的命题”? 一般来说,原有的理论、原有的看法、原有的状 况、或者说是那些保守的、历史的、经验的,在 没有充分论据证明其错误前总是被假定为正确的, 作为原假设,处于被保护的位置,而那些猜测的、 可能的、预期的取为备择假设。假设检验的目的 就是要用事实验证原来的理论、看法、状况等是 否成立,或更明确地说,是希望用事实推翻原假 设。
6.假设检验方法--均值 (1)

• 其中, 为样本平均数; 为两样本来自总体方差. • 例10 在参加了全国统一考试后,已知考生成绩服从正态 分布。甲省抽取153名考生,平均成绩为57.41分,该省标准差 为5.77分;乙省抽取686名考生,平均成绩为55.95分,该省标准 差为5.17分,问两省在该次考试中,平均分是否有显著性差 异?(0.01)
• 2. 小概率事
在随机事件中,概率很小的事件被称 为小概率事件,习惯上约定在0.05以下, 即当P(A)< 5%时,则称A为小概率事件。 在统计推断中认为,小概率事件在一次试 验或观察中是不可能发生的。
3.显著性水平
• 两种水平 (1)α=0.05,显著性水平为0.05,即统计 推断时可能犯错误的概率5%,也就是在95% 的可靠程度上进行检验; (2) α=0.01,显著性水平为0.01,即统计 推断时可能犯错误的概率1%,也就是在99% 的可靠程度上进行检验。
统计假设检验方法
统计假设检验是统计推断的重要方法,根据一定原理,利用样本信息,根 据一定概率,对总体参数或分布的某一假设作出拒绝或保留的决断.基本 思想是假设检验(类似于反正法)在一前提假设下进行推断;基本原则是小 概率事件原理(即,小概率事件在一次试验中实际上是不可能发生的);根 据研究对象分布情况我们所选的统计量不同,相对应的检验方法有Z检验、 t检验、F检验、卡方检验。本章主要介绍: 1、理解统计假设检验的一般原理 2、掌握单\双总体均值\方差假设检验的方法
1.假设 • 虚无假设(零假设):是关于当前样本所属的 总体(指参数)与假设总体(指参数)无区别 的假设,一般H0表示。 • 备择假设(研究假设):是关于当前样本所属 的总体(指参数)与假设总体(指参数)相反 的假设,一般用H1表示。 由于直接检验备择假设的真实性困难,假设检 验一般都是从虚无假设出发,通过虚无假设的 不真实性来证明备假设的真实性。
假设检验的例子及解析

假设检验的例子及解析以下是 9 条关于假设检验的例子及解析:1. 咱就说,你觉得每天喝一杯牛奶能长高,这是不是一个假设呀,就像你觉得学习一门新语言能让你更聪明一样。
那咱们怎么检验呢?那就得观察长期喝牛奶的人是不是真的普遍比不喝的高呀!要是真这样,那这假设可能就有点靠谱呢!2. 比如说你假设经常锻炼的人身体更好,这可不是凭空说的吧!就好像你说经常笑的人运气不会差一样。
那怎么知道对不对呢?那就去看看那些健身达人,他们是不是真的很少生病,身体倍儿棒!3. 你说多吃水果皮肤会变好,这咋检验呀?好比你说早睡早起精神好一样。
那就找一群人,一部分多吃水果,一部分不多吃,过段时间看看他们皮肤状态的差别不就行了嘛!4. 假设下雨天心情会不好,哎呀,这可真太常见了!就像你说考试前会紧张一样。
那咱们去问问周围的人,下雨天的时候是不是大多都有点小情绪低落呀!5. 要是说努力工作就会升职加薪,这是真理吗?这就如同说长得帅就一定有女朋友一样。
那得看看那些努力了很久的同事,是不是真的得到了相应的回报呀!6. 有人假设听音乐能提高工作效率,哇,这有点意思哦!好比说吃巧克力能让人开心一样。
那咱们自己试试呗,边工作边听听音乐,看看效率是高了还是低了!7. 假设玩游戏能锻炼思维能力,这能是真的吗?就像有人说逛街能减肥一样。
那找些爱玩游戏的人,看看他们的思维是不是真的很敏捷呀!8. 你觉得看小说能增长知识,这到底对不对呢?这就好比说发呆能放松身心一样。
拿自己做个实验呗,看看看完一本小说后知识量有没有增加呀!9. 说吃辣能让人性格开朗,这可太神奇了吧!就仿佛说跑步能让人更有毅力一样。
那到底是不是这样呢?去观察那些无辣不欢的人呀!我的观点结论就是:假设检验真是个有意思的事儿,能让我们知道好多事情到底是不是真的像我们想的那样,通过观察和对比来验证,真的很有趣!。
假设检验实验报告

假设检验实验报告摘要:本实验旨在通过假设检验研究新药对患者的治疗效果。
实验组和对照组的患者分别接受新药和安慰剂治疗,记录两组患者的疗效指标,并使用合适的假设检验方法对结果进行分析。
结果表明,新药组的治疗效果明显优于对照组,具有显著统计学意义。
关键词:假设检验,新药,安慰剂,治疗效果,统计学意义引言:假设检验是现代统计学中应用广泛的一种方法,被广泛用于医学、生物学等研究领域。
本实验旨在通过假设检验方法评估新药对患者的治疗效果,为研究提供可靠的统计学依据。
材料与方法:1.参与者招募:从一家医院的患者中随机筛选50名患者作为实验组,选取另外50名患者作为对照组。
2.分组治疗:实验组的患者接受新药治疗,每天服用一次;对照组的患者接受安慰剂治疗,服用方式与实验组相同。
3.记录指标:记录两组患者的疗效指标,包括治疗前后的症状评分和身体指标变化等。
4.数据处理:使用合适的统计学软件进行数据整理和分析,采用适当的假设检验方法对结果进行统计分析。
结果:1.样本特征:实验组和对照组的患者在年龄、性别等方面无显著差异。
2.症状评分:在治疗后的症状评分上,实验组的平均得分为4.5,对照组的平均得分为6.83.变化幅度:实验组患者的症状指标变化平均为-2.1,对照组患者的症状指标变化平均为-0.9讨论:本实验通过假设检验方法对新药治疗和安慰剂治疗的疗效进行了比较。
结果显示,新药组的治疗效果明显优于对照组,并具有显著统计学意义(p<0.05)。
在症状评分和指标变化上,新药组的结果均表现出更好的疗效。
这说明该新药在治疗相关疾病方面具有显著效果,值得进一步开展临床研究。
结论:本实验使用假设检验方法对新药治疗和安慰剂治疗的疗效进行了比较。
结果显示,新药在治疗相关疾病方面表现出显著优势,具有显著统计学意义。
这一结果为该新药的进一步应用提供了可靠的统计学依据,并对相关疾病的治疗提供了新的选择。
致谢:感谢本实验中参与的患者对本研究的支持,感谢实验组和对照组的医护人员的协助和配合,以及导师对本实验的指导和帮助。
第七章假设检验

第三节
u检验
u检验(u test ),亦称z检验(z test) 大样本均数(率)与总体均数(率)比较的u检 验、 两个大样本均数(率)比较的u检验 一、大样本均数比较的u检验 二、大样本率的u检验
一、大样本均数比较的u检验
假定样本数据服从正态分布 ,当总体标准差 未知时,可用样本标准差作为估计值 这里的总体均数一般是指已知的理论值、标准 值或经过大量观察所得到的稳定值,记作µ 0 (或记为 )
两个样本率p1、p2的差值服从正态分布
u p1 p2
1 2
p p
2 2 p p p p 1 (1 1 ) / n1 2 (1 2 ) / n2
1 2 1 2
样本率p介于0.1~0.9之间,每组例数大于60 例
n1 p1 n2 p2 ˆ0 n1 n2
两样本均数比较的u检验
该检验方法适用于完全随机设计中两组 计量资料差别的比较 两样本均数差值服从正态分布
u Leabharlann 1 X 2X1X2
X
1X2
2 2 2 2 X / n 1 1 2 / n2 X2 1
当总体标准差未知,两组例数均超过30
ˆX
1X2
亦称样本率与总体率的比较的u检验,这里的 总体率一般是指已知的理论值、标准值或经大 量观察所获得的稳定值。
例7–3 全国调查的调查结果,学龄前儿童营 养性贫血患病率为23.5%。某医院为了解当
地学龄前儿童能够营养性贫血患病情况,对
当地1396例学龄前儿童进行了抽样调查,查
出营养性贫血患儿363例,患病率为26.0%。
ˆp p
1
2
1 1 ˆ0 (1 ˆ0 )( ) n1 n2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验7 假设检验(一)一、实验目的:1.掌握重要的参数检验方法(单个总体的均值检验,两个总体的均值检验,成对样本的均值的检验,两个总体方差的检验,二项分布总体的检验);2.掌握若干重要的非参数检验方法(Pearson拟合优度 2检验,Kolmogorov-Smirnov单样本和双样本检验)。
二、实验内容:练习:要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“09张立1”,表示学号为09的张立同学的第1次实,法1Alt,即完法2:图标,工具。
)1.2.H0:H1:alternative hypothesis: true mean is not equal to 22595 percent confidence interval:172.3827 211.9173sample estimates:mean of x192.15P=0.002516<0.05,拒绝原假设,认为油漆工人的血小板计数与正常成年男子有差异3.(习题5.2)已知某种灯泡寿命服从正态分布,在某星期所生产的该灯泡中随机抽取10 只,测得其寿命(单位:小时)为1067 919 1196 785 1126 936 918 1156 920 948求这个星期生产出的灯泡能使用1000小时以上的概率。
解:源代码及运行结果:(复制到此处,不需要截图)> x<-c(1067, 919, 1196, 785, 1126, 936, 918, 1156, 920, 948)> p<-pnorm(1000,mean(x),sd(x))> 1-p[1] 0.4912059结论:这个星期生产出的灯泡能使用1000小时以上的概率为0.49120594.(习题5.3)为研究某铁剂治疗和饮食治疗营养性缺铁性贫血的效果,将16名患者按年龄、体重、病程和病情相近的原则配成8对,分别使用饮食疗法和补充铁剂治疗的方法,3个月后测得两种患者血红资白如下表所示,问两种方法治疗后的患者血红蛋白有无差异?H0:H1:5.,分别测试验组与对照组空腹腔血糖下降值(mmol/L)(1)检验试验组和对照组的的数据是否来自正态分布,采用正态性W检验方法(见第3章)、Kolmogorov-Smirnov检验方法和Pearson拟合优度 2检验;解:提出假设:H0:认为国产四类新药阿卡波糖股嚢与拜唐苹股嚢对空腹血糖的降糖效果不同H1:认为国产四类新药阿卡波糖股嚢与拜唐苹股嚢对空腹血糖的降糖效果相同①正态性W检验方法源代码及运行结果:(复制到此处,不需要截图)>x<-c(-0.70,-5.60,2.00,2.80,0.70,3.50,4.00,5.80,7.10,-0.50,2.50,-1.60,1.70,3.00,0.40,4.50,4.6 0,2.50,6.00,-1.4)> shapiro.test(x)Shapiro-Wilk normality testdata: xW = 0.9699, p-value = 0.7527>y<-c(3.70,6.50,5.00,5.20,0.80,0.20,0.60,3.40,6.60,-1.10,6.00,3.80,2.00,1.60,2.00,2.20,1.20,3②结论:试验组p=0.9771>0.05,对照组p=0.9368>0.05,所以检验试验组和对照组的的数据是来自正态分布③Pearson拟合优度 2检验源代码及运行结果:(复制到此处,不需要截图)>x<-c(-0.70,-5.60,2.00,2.80,0.70,3.50,4.00,5.80,7.10,-0.50,2.50,-1.60,1.70,3.00,0.40,4.50,4.6 0,2.50,6.00,-1.4)> A<-table(cut(x,br=c(-6,-3,0,3,6,9)))> p<-pnorm(c(-3,0,3,6,9),mean(x),sd(x))> p> p<-c(p[1],p[2]-p[1],p[3]-p[2],p[4]-p[3],1-p[4])> p> chisq.test(A,p=p)Chi-squared test for given probabilitiesdata: AX-squared = 0.56387, df = 4, p-value = 0.967Warning message:In chisq.test(A, p = p) : Chi-squared近似算法有可能不准>y<-c(3.70,6.50,5.00,5.20,0.80,0.20,0.60,3.40,6.60,-1.10,6.00,3.80,2.00,1.60,2.00,2.20,1.20,3 .10,1.70,-2.00)> B<-table(cut(y,br=c(-2,1,2,4,7)))> p<-pnorm( c(-2,1,2,4,7),mean(y),sd(y))> p> p(2H0:H1:t = -0.64187, df = 38, p-value = 0.5248alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:-2.326179 1.206179sample estimates:mean of x mean of y2.065 2.625结论:p=0.5248>0.05,不拒绝原假设,两组数据均值没有差异②方差不同模型源代码及运行结果:(复制到此处,不需要截图)>x<-c(-0.70,-5.60,2.00,2.80,0.70,3.50,4.00,5.80,7.10,-0.50,2.50,-1.60,1.70,3.00,0.40,4.50,4.6 0,2.50,6.00,-1.4)>y<-c(3.70,6.50,5.00,5.20,0.80,0.20,0.60,3.40,6.60,-1.10,6.00,3.80,2.00,1.60,2.00,2.20,1.20,3 .10,1.70,-2.00)> t.test(x,y)Welch Two Sample t-testdata: x and yt = -0.64187, df = 36.086, p-value = 0.525alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:(3解:提出假设:H0:试验组与对照组的方差相同H1:试验组与对照组的方差不相同源代码及运行结果:(复制到此处,不需要截图)>x<-c(-0.70,-5.60,2.00,2.80,0.70,3.50,4.00,5.80,7.10,-0.50,2.50,-1.60,1.70,3.00,0.40,4.50,4.6 0,2.50,6.00,-1.4)>y<-c(3.70,6.50,5.00,5.20,0.80,0.20,0.60,3.40,6.60,-1.10,6.00,3.80,2.00,1.60,2.00,2.20,1.20,3 .10,1.70,-2.00)> var.test(x,y)F test to compare two variancesdata: x and yF = 1.5984, num df = 19, denom df = 19, p-value = 0.3153alternative hypothesis: true ratio of variances is not equal to 195 percent confidence interval:0.6326505 4.0381795sample estimates:ratio of variances1.598361结论:p= 0.3153>0.05,不拒绝原假设,试验组与对照组的方差相同6.(习题5.5)为研究某种新药对抗凝血酶活力的影响,随机安排新药组病人12例,对照组病人10例,(1(2(3解:(1H0:H1:H0:H1:> y<-c(162, 172 ,177 ,170 ,175, 152 ,157 ,159, 160 ,162)> ks.test(y,"pnorm",mean(y),sd(y))One-sample Kolmogorov-Smirnov testdata: yD = 0.22216, p-value = 0.707alternative hypothesis: two-sidedWarning message:In ks.test(y, "pnorm", mean(y), sd(y)) :Kolmogorov - Smirnov检验里不应该有连结(2)检验两组样本方差是否相同;提出假设:H0:两组样本方差相同H1:两组样本方差不相同源代码及运行结果:(复制到此处,不需要截图)> x<-c(126,125,136,128,123,138,142,116,110,108,115,140)> y<-c(162, 172 ,177 ,170 ,175, 152 ,157 ,159, 160 ,162)> var.test(x,y)F test to compare two variancesdata: x and yF = 1.9646, num df = 11, denom df = 9, p-value = 0.32alternative hypothesis: true ratio of variances is not equal to 1(3H0:H1:7.靠,随机抽选了400名居民,发现其中有57人是老年人。
问调查结果是否支持该市老年人口比重为14.7%的看法( =0.05)。
(提示,此题是二项分布总体的检验)解:提出假设:H0:p=p0=0.147H1:p≠p0源代码及运行结果:(复制到此处,不需要截图)> binom.test(57,400,p=0.147)Exact binomial testdata: 57 and 400number of successes = 57, number of trials = 400, p-value = 0.8876alternative hypothesis: true probability of success is not equal to 0.14795 percent confidence interval:0.1097477 0.1806511sample estimates:probability of success0.1425结论:P值= 0.8876>0.05,不拒绝原假设,调查结果支持该市老年人口比重为14.7%的看法8.(习题5.7)作性别控制试验,经某种处理后,共有雏鸡328只,其中公雏150只,母雏178只,试问这种处理能否增加母雏的比例?(性别比应为1:1)。