CubeSuite+解决中文编码问题引起的编译错误
代码调试中的常见错误与解决方法

代码调试中的常见错误与解决方法代码调试是软件开发过程中不可或缺的一环。
通过调试,开发人员能够找出程序中存在的错误并进行修复,确保程序的正常运行。
然而,调试过程中常常会遇到一些常见的错误。
本文将介绍一些常见的调试错误,并提供相应的解决方法,帮助开发人员快速解决问题。
1. 语法错误语法错误是最常见的错误之一,通常是由于代码中的拼写错误、缺少分号或者括号不匹配等导致的。
在调试过程中,编译器会给出相应的错误提示。
解决方法:- 仔细检查代码,在有错误提示的行进行排查,查看是否有拼写错误、缺少分号等。
- 使用编译器或者集成开发环境(IDE)的语法检查工具,帮助找出语法错误并进行修复。
2. 逻辑错误逻辑错误是指代码的执行结果与预期结果不符合。
这类错误通常由于对程序逻辑的理解不准确或者数据处理错误导致的。
解决方法:- 使用调试工具,在关键的代码处设置断点,并逐步执行代码,观察变量的值是否符合预期。
- 使用日志输出,将关键变量的值输出到日志文件中,以便查看程序执行过程中的数据变化。
- 使用单元测试,编写测试用例来验证程序的逻辑,以便及早发现错误并进行修复。
3. 内存错误内存错误是指程序在使用内存时出现的问题,比如内存泄漏、访问越界等。
这类错误通常会导致程序崩溃或者产生意料之外的结果。
解决方法:- 使用内存调试工具,如Valgrind等,检查程序的内存使用情况,找出内存泄漏或者越界访问的问题。
- 仔细检查代码,查看是否有未释放的内存或者越界访问的情况,并进行修复。
4. 硬件相关错误在某些情况下,代码调试中出现的错误可能与硬件相关。
比如网络连接错误、设备驱动问题等。
解决方法:- 检查硬件设备的连接情况,确保硬件正常工作。
- 检查硬件驱动是否正确安装,更新驱动程序以解决兼容性问题。
- 使用网络调试工具,如Wireshark等,来检查网络连接和数据传输情况。
5. 并发错误并发错误是多线程或多进程程序中常见的问题。
这类错误通常是由于竞争条件、死锁或者资源争夺等引起的。
php如何解决中文乱码问题

php如何解决中文乱码问题php如何解决中文乱码问题很多新手朋友学习PHP的时候,发现程序中的中文在输出的时候会出现乱码的问题,那么为什么会出现这种乱码的情况呢?下面是店铺为大家带来的php如何解决中文乱码问题的知识,欢迎阅读。
I. 为什么会出现中文乱码?很多新手朋友学习PHP的时候,发现程序中的中文在输出的时候会出现乱码的.问题,那么为什么会出现这种乱码的情况呢?一般来说,乱码的出现有2种原因,一种是由于编码 (charset) 设置错误,导致浏览器以错误的编码来解析,从而出现了满屏乱七八糟的“天书”,第二种就是文件被以错误的编码打开,然后保存,比如一个文本文件原先是 GB2312 编码的,却以 UTF-8 编码打开再保存,就会出现乱码的问题。
本篇文章,就带大家了解一下,怎么解决php中乱码的问题。
我们将乱码情况分为以下几种,有需要的可以对照下面的几种情况有针对性的解决乱码问题第一种:解决HTML中中文乱码问题方法如果你的HTML 文件文件出现了乱码问题,那么你可以在head 标签里面加入UTF8编码(国际化编码):UTF-8 是没有国家的编码,也就是独立于任何一种语言,任何语言都可以使用的。
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>示例我们现在的 HTML5 文件,设置编码更为简单,像下面这样第二种、HTML和PHP混合的页面解决方案如何是HTML 和PHP 混编,除了按照第一个方法所说的操作之外,还需要在 PHP 文件的最上面加入这句代码:<?phpheader("content-type:text/html;charset=utf-8"); //设置编码>第三种、纯PHP页面的中文乱码问题(数据是静态的)如果你的 PHP 页面出现了乱码,只需要在页面的开始处加入下面代码就可以了。
史上最全的PHP+MySql中文乱码解决方案word版

我相信PHPmyadmin里查看是乱码,调用出来的话肯定100%也是乱码。
乱码问题其实也就是编码不一致导致的。
要解决这个问题需要回顾乱码问题出现以前的操作是否使用的是同一种编码。
总之一句话,要解决PHP中文乱码最好最快的解决办法就是:页面申明的编码与数据库内部编码一致,如果页面申请的页码与数据库内部编码不一致时,就设定连接编码mysql_query(”SET NAMES XXX”); XXX为连接编码。
一定可以解决乱码的问题。
在mysql+php程序开发中,总结了产生乱码原因:mysql数据库默认的编码是utf8,如果这种编码与你的PHP网页不一致,可能就会造成MYSQL乱码.MYSQL中创建表时会让你选择一种编码,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码.MYSQL创建表时添加字段是可以选择编码的,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码.用户提交页面的编码与显示数据的页面编码不一致,就肯定会造成PHP页面乱码.如用户输入资料的页面是big5码, 显示用户输入的页面却是gb2312,这种100%会造成PHP页面乱码.PHP页面字符集不正确.PHP连接MYSQL数据库语句指定的编码不正确.一.首先是PHP网页的编码1. php文件本身的编码与网页的编码应匹配a. 如果欲使用gb2312编码,那么php要输出头:header(“Content-Type: text/html; charset=gb2312″),静态页面添加<metahttp-equiv=”Content-Type” content=”text/html; charset=gb2312″>,所有文件的编码格式为ANSI,可用记事本打开,另存为选择编码为ANSI,覆盖源文件。
b. 如果欲使用utf-8编码,那么php要输出头:header(“Content-Type: text/html; charset=utf-8″),静态页面添加<metahttp-equiv=”Content-Type” content=”text/html; charset=utf-8″>,所有文件的编码格式为utf-8。
web解决中文乱码问题的代码

web解决中文乱码问题的代码- 什么是中文乱码问题?中文乱码问题是指在网页或者其他文本编辑器中,中文字符无法正确显示,而出现乱码的情况。
这种情况通常是由于编码格式不一致或者不正确导致的。
- 为什么会出现中文乱码问题?中文乱码问题通常是由于以下原因导致的:1. 编码格式不一致或者不正确;2. 网页或者文本编辑器的编码设置不正确;3. 中文字符集不支持当前的编码格式。
- 如何解决中文乱码问题?解决中文乱码问题可以采用以下方法:1. 修改网页或者文本编辑器的编码设置,将编码格式设置为UTF-8或者GBK;2. 在网页的<head>标签内添加<meta charset="UTF-8">;3. 在文本编辑器中选择正确的编码格式,如UTF-8或者GBK;4. 将中文字符转换为Unicode编码,再进行显示;5. 使用专门的中文乱码解决工具进行解决。
- 代码示例以下是一段解决中文乱码问题的代码示例:```html<!DOCTYPE html><html><head><meta charset="UTF-8"><title>中文乱码问题解决示例</title></head><body><h1>中文乱码问题解决示例</h1><p>以下是一段中文文本:</p><p>这是一段中文文本,如果编码格式设置不正确,就会出现乱码的情况。
</p></body></html>```在上面的代码中,我们在<head>标签内添加了<metacharset="UTF-8">,这样就可以将编码格式设置为UTF-8,从而解决中文乱码问题。
preparestatement 预编译 中文乱码

主题:探究preparestatement预编译及其在遇到中文乱码时的解决方法一、预编译preparestatement的基本概念1.1 preparestatement是什么?在Java中,preparestatement是一种预编译的SQL语句,通过在执行之前进行编译和封装可以提高数据库操作的性能和安全性。
1.2 preparestatement与statement的区别preparestatement是预编译的SQL语句,而statement是直接执行的SQL语句。
由于preparestatement已经进行了编译,因此执行时效率更高,可以防止SQL注入等安全问题。
二、preparestatement在遇到中文乱码时的原因分析2.1 数据库编码设置不正确当数据库的编码与数据传输的编码不一致时,就会导致中文乱码的问题。
比如数据库使用UTF-8编码,而传输的连接使用了GBK编码,就容易出现乱码。
2.2 数据库驱动版本与数据库版本不匹配在使用preparestatement时,可能会遇到数据库驱动的版本与数据库的版本不匹配的情况,这也会导致中文乱码的问题。
三、解决preparestatement中文乱码的方法3.1 设置数据库连接的编码在创建数据库连接时,可以通过设置连接的编码来保证数据传输的一致性。
比如在使用JDBC连接数据库时,可以在URL中指定编码类型。
3.2 设置preparestatement的编码在创建preparestatement时,可以通过设置编码方式来保证正确的数据传输和存储。
可以使用setCharacterStream等方法设置编码类型。
3.3 更新数据库驱动如果使用的数据库驱动与数据库版本不匹配,可以尝试更新数据库驱动到适配的版本,以解决中文乱码的问题。
四、实例分析:使用preparestatement解决中文乱码问题4.1 编写preparestatement的示例代码假设我们需要向数据库插入中文数据,可以通过preparestatement 来解决可能出现的中文乱码问题。
中文转码乱码规律-概述说明以及解释

中文转码乱码规律-概述说明以及解释1.引言1.1 概述概述部分:中文乱码是指在文本处理过程中因编码格式不统一导致中文字符显示不正确的现象。
在数字化时代,人们越来越频繁地在互联网上进行文字交流,而中文乱码问题也随之变得更加普遍。
中文乱码的产生源于多方面原因,例如使用不同的编码格式、系统之间的不兼容性、网页编码错误等。
为了有效解决中文乱码问题,我们需要深入了解其产生原因和解决方法,以便更好地处理和显示中文文本。
本文将探讨中文乱码的原因、现象及解决方法,希望能帮助读者更好地理解和处理中文乱码问题。
1.2文章结构文章结构部分的内容:本文共分为引言、正文和结论三部分。
在引言部分,将介绍本文的概述、文章结构和目的;在正文部分,将详细讨论中文乱码产生原因、中文乱码现象和中文乱码解决方法;最后在结论部分,对本文进行总结、归纳并展望未来研究方向。
整个文章结构清晰,逻辑严谨,旨在全面而系统地讨论中文转码乱码规律相关问题。
1.3 目的本文旨在探讨中文转码乱码现象的规律和机制,通过对中文乱码产生原因、现象以及解决方法的分析,希望能够帮助读者更好地理解和解决在日常使用电脑、网络等场景中遇到的中文乱码问题。
同时,也旨在引起更多人对中文乱码问题的关注,促进相关技术的改进和提升,提升中文信息传输的效率和准确性。
通过深入研究和讨论,希望能够为解决中文乱码问题提供一些新的思路和方法。
2.正文2.1 中文乱码产生原因中文乱码产生的主要原因可以归纳为以下几点:1.字符编码不一致:在传输过程中,如果发送端和接收端使用的字符编码不一致,就会导致中文乱码。
例如,发送端使用UTF-8编码发送数据,而接收端使用GBK编码接收数据,就会出现乱码现象。
2.文本信息传输过程中被篡改:在信息传输过程中,可能会经过多个中间节点,如果有中间节点对文本信息进行了篡改,可能会导致中文乱码。
3.文件格式不匹配:如果在打开文件时使用的解码器与文件本身的编码格式不匹配,也会导致中文乱码。
如何处理代码中的编译器错误

如何处理代码中的编译器错误编写代码时,经常会遇到编译器错误。
这些错误可能是语法错误、类型错误、逻辑错误等。
对于初学者来说,正确处理这些错误是一项重要的技能。
本文将介绍一些处理编译器错误的方法,帮助您更好地解决问题。
处理编译器错误的步骤如下:1.仔细阅读错误信息:当编译器发现错误时,它会生成错误信息,通常包括错误的类型、错误的位置和相关的详细信息。
首先,要仔细阅读错误信息,理解错误的类型和位置。
2.检查错误的代码行:根据错误信息,找到代码中与错误相关的行。
检查这些行,看看是否有明显的错误,比如拼写错误、缺少分号等。
3.阅读文档或向导:如果您遇到不熟悉的错误,可以阅读编程语言的官方文档、教程或向导,寻找错误的解决方案。
这些资源通常提供了常见错误的解释和解决方法。
4.使用搜索引擎:如果您无法找到编程语言的文档或解决方案,可以使用搜索引擎搜索错误信息或相关关键字。
通常会有其他开发者遇到类似的问题,并提供了解决方法。
5.检查变量和函数:编译器错误可能与变量或函数的类型不匹配有关。
检查相关的变量和函数声明,并确保它们的类型正确。
如果类型不匹配,可能需要修改它们的声明或进行类型转换。
6.注释或删除问题代码:如果错误是由于特定代码行引起的,可以尝试注释掉该行或删除它,然后重新编译程序。
如果编译成功,可以逐步恢复修改,找出引起错误的具体原因。
7.检查依赖库或模块:如果错误涉及到使用第三方库或模块,可能是由于缺少依赖项或版本不兼容引起的。
确保已正确安装和配置所需的依赖库,并检查版本是否匹配。
8.请求帮助:如果您尝试了以上方法仍然无法解决错误,可以寻求他人的帮助。
您可以向同事、论坛、开发者社区或在线编程问答网站(如Stack Overflow)提问,并提供尽可能详细的错误信息和相关代码。
9.实验和调试:处理编译器错误通常需要进行反复尝试和实验。
您可以尝试修改代码、引入调试语句、使用调试工具等,来定位和解决问题。
如果可能,尝试在更简化的环境中复现错误,以便更容易找到问题。
Linux下Ncurses显示中文乱码怎么办?
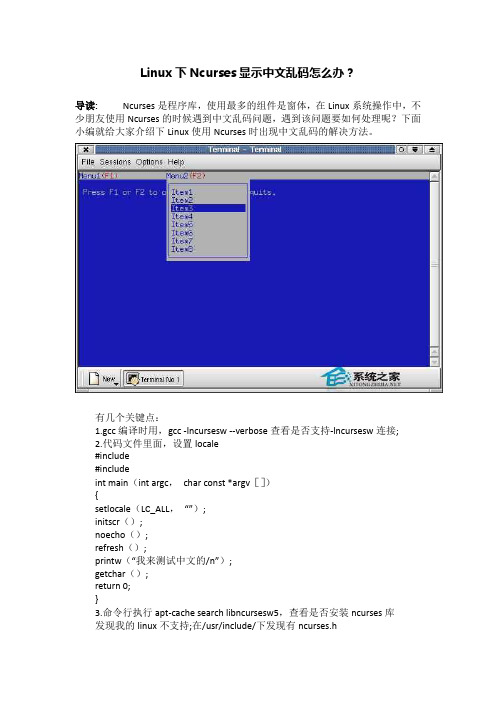
Linux下Ncurses显示中文乱码怎么办?导读:Ncurses是程序库,使用最多的组件是窗体,在Linux系统操作中,不少朋友使用Ncurses的时候遇到中文乱码问题,遇到该问题要如何处理呢?下面小编就给大家介绍下Linux使用Ncurses时出现中文乱码的解决方法。
有几个关键点:1.gcc编译时用,gcc -lncursesw --verbose查看是否支持-lncursesw连接;2.代码文件里面,设置locale#include#includeint main(int argc,char const *argv[]){setlocale(LC_ALL,“”);initscr();noecho();refresh();printw(“我来测试中文的/n”);getchar();return 0;}3.命令行执行apt-cache search libncursesw5,查看是否安装ncurses库发现我的linux不支持;在/usr/include/下发现有ncurses.h但是,没有别人说的ncursesw目录;后来发现,我装了libncurses5,也装了libncursesw5,导致-lncursesw选项不能用,我就把libncurses5卸载了,然后再重新装libncursesw5;具体命令是1. apt-cache search libncurses52. apt-get purge libncurses53. sudo apt-get purge libncurses5-dbg4. sudo apt-get purge libncurses5-dev5. sudo apt-get autoremove6. sudo apt-get clean7. dpkg -l |grep ^rc|awk ‘{print $2}’ |xargs dpkg -P接着再安装libncursesw5,命令如下1. sudo apt-get install libncursesw52. sudo apt-get install libncursesw5-dbg3. sudo apt-get install libncursesw5-dev然后gcc -c test.o test.cgcc -o test test.o -lncursesw接着运行。
c语言,中文注释出现乱码

c语言,中文注释出现乱码
在C语言中,注释是用于解释代码的文字。
如果中文注释出现乱码,可能是因为编译器或文本编辑器的字符编码设置不正确。
解决这个问题,你可以尝试以下方法:
1. 确保你的文本编辑器的字符编码设置为UTF-8。
大多数现代的文本编辑器默认使用UTF-8编码,但你仍然需要确认一下。
2. 如果你使用的是Windows系统,可以尝试将源文件的编码格式设置为UTF-8。
在一些编辑器中,你可以通过"文件" -> "另存为" -> "编码"选项来设置文件的编码格式。
3. 如果你在源代码中使用了特殊字符或非ASCII字符,可以尝试将这些字符转换为Unicode转义序列。
例如,中文字符"你好"可以写成"\u4f60\u597d"。
4. 如果你使用的是老版本的编译器,可能不支持UTF-8编码。
在这种情况下,你可以尝试使用其他编码格式,如GBK或GB2312。
如果以上方法仍然无效,你可能需要考虑更换文本编辑器或编译器,以确保正确显示中文注释。
关于cubesuite+的安装与配置

开发工具软件CubeSuite+的安装与配置注意1:CubeSuite+软件不能安装在中文路径中,单片机程序也不用使用中文文件名或在中文路径下进行编译和调试。
注意2:CubeSuite+软件可以在32/64位操作系统XP、Win7下安装,但是同时也要求计算机中装有.net库。
一般Win7系统都自带.net库,而XP系统则可能需要另行安装.net 库。
如系统没有安装.net库,可在微软官网下载.net Framework安装包进行安装。
下载地址:/zh-cn/download/details.aspx?id=17718一、CubeSuite+软件安装安装路径可以按照个人选择进行设置(注意选择英文路径),其余设置依照默认选项,点击“下一步“即可。
二、在开发环境中建立工程及参数设置以下针对uPD78F0485单片机的开发为例进行说明。
1、运行CubeSuiteW+软件从开始菜单的程序中找到CubeSuiteW+运行,或者根据CubeSuiteW+软件安装路径找到CubeSuiteW+软件运行,是CubeSuiteW+软件的图标。
运行程序后进入图1界面。
图12. 进入Project New Project功能(图1中第2项),弹出图2界面,按图 2所示先选择单片机系列78K0,然后根据实验盒上单片机型号(uPD78F0485(80pin)或uPD78F0495(80pin))在78K0/LF3下选择对应的芯片,再输入工程名、选择工程路径(不能是中文路径),最后点击“Create”按钮完成新建工程操作。
图23.选择仿真器型号在开发环境的左侧一栏中,选择78K0 Simulator (Dubug),右击,选择Using Debug Tool 下的78K0 EZ Emulator。
如图3所示。
图34. 选择时钟源仿真器型号选定后会出现如图4所示界面,在Clock选项中将Main clock source选为Genarate by emulator,接着设置主时钟频率为8。
由一次诡异的codeblocks中文乱码想到的汉字编码知识

由一次诡异的codeblocks中文乱码想到的汉字编码知识一、问题复现1.用codeblocks新建一个1.c,里面写入:#include "stdio.h"main(){printf("中文");}保存,编译,可以正常显示。
关闭codeblocks,复制了一份1.c,改叫“1-对照.c”,再打开1.c,发现“中文”两个字变成了乱码(是四个字母,好像是俄文)2.用codeblocks新建一个2.c,里面写入:#include "stdio.h"main(){printf("为啥这样的中文可以");}保存,编译,可以正常显示。
关闭codeblocks,再打开2.c,发现一切正常。
二、思考百思不得其解,遂查阅了大量关于汉字编码的文章。
用winhex查看“1.c”(用codeblocks再次打开过)和“1-对照.c”(没有用codeblocks再次打开过),发现两个文件内码都一样,而且中文两个字的内码没有错,就是GBK对应的编码“D6D0 CEC4“。
于是我吐了。
”吐定思痛“,我怀疑是codeblocks的自动检测编码机制工作失误,查看了codeblocks的状态栏,果然是将编码错认成了KOI8-R。
为什么2.c没有错认呢?可能是因为那几个字的机内码已经不在KOI8-R的范围内了,所以codeblocks正确的认成了GBK。
实际上,因为默认是Windows-936,所以刚新建文件时,editor界面显示正常,保存时,也是用的ANSI编码(在简体中文win7上就是Windows-936就是GBK)个人认为,源码是什么编码,gcc就认为是什么编码,生成的exe也就是什么编码,而不是像网上说的“如果源文件的字符集是GBk,那么就必须指定-finput-charset=GBK,如果不指定,一律当做UTF-8处理。
除非你源文件真的是UTF-8,否则就会出现转换错误。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策一、中文乱码问题的原因中文乱码问题在Java Web项目开发中往往是由于编码格式不统一所导致的。
在Java 中,常见的编码格式包括GBK、UTF-8等,而在Web项目中,前端页面、数据库、Java代码等部分可能使用不同的编码格式,当它们之间出现不一致时就会导致中文乱码问题的发生。
具体来说,中文乱码问题可能出现在以下几个方面:1. 前端页面的编码格式与后端编码格式不一致;2. 请求数据的编码格式与后端处理编码格式不一致;3. 数据库表字段的编码格式与Java代码读取编码格式不一致;4. 文本文件或配置文件的编码格式与Java代码读取编码格式不一致。
中文乱码问题的存在会严重影响用户体验和数据准确性,给Web项目带来一系列不良后果。
具体表现为:1. 用户提交的中文数据在系统中出现乱码,降低了系统的可读性和友好性;2. 保存到数据库中的中文数据乱码,影响了数据的准确性和可用性;3. 在后台系统中处理中文数据时出现乱码,可能导致错误的逻辑判断和处理结果;4. 在导出文本文件或配置文件时出现乱码,影响了文件的可用性和可读性。
针对中文乱码问题,我们可以采取一些对策来预防和解决这一问题,从而提升Web项目的质量和稳定性。
1. 统一编码格式在Web项目中,应尽量统一使用UTF-8编码格式,包括前端页面、请求数据、后端处理和数据库存储等部分。
这样可以避免不同编码格式之间的兼容性问题,减少中文乱码问题的发生。
2. 前端页面设置编码在前端页面的<head>标签中添加<meta charset="UTF-8">,以确保前端页面以UTF-8编码格式进行显示和提交数据。
3. 请求数据编码设置在后端处理请求数据时,需要明确指定请求数据的编码格式,可以通过设置HttpServletRequest.setCharacterEncoding("UTF-8")来确保请求数据按照UTF-8格式进行处理。
Unity3D脚本中文字符乱码的解决方案

点评:用Unity这么久,一直就听别人说遇到在脚本里面用中文字符会乱码的问题。
这些问题在Visual Studio比较少,通常都是在MonoDevelop上会出现,甚至在Monodevelop编辑器,写了中文注释,会出现程序报错等问题。
用Unity这么久,一直就听别人说遇到在脚本里面用中文字符会乱码的问题。
这些问题在Visual Studio比较少,通常都是在MonoDevelop上会出现,甚至在Monodevelop 编辑器,写了中文注释,会出现程序报错等问题。
其实这些问题都是由于脚本的编码有问题,修改一下脚本编码为UTF8,这些问题都可以解决。
首先,你可以修改Unity提供的脚本模板,让你以后生成的脚本都不出现编码问题:找到Unity3D的安装目录:文章来自【狗刨学习网】注意看路径,找到这个脚本模板的文件夹,上面两个就是javaScript和c#的脚本模板,我们可以修改他们,鼠标右键,使用记事本打开它们。
选择另存为,然后把编码改成UTF8,保存,可以了。
以后你生成的脚本就全部都是UTF8的了。
既然都改了脚本模板了,我们可以做更多的修改,让我们的脚本生成的时候符合自己的要求,比如我的是这样的,加上了必要的类注释。
对于之前就已经写好的脚本,你也可以这样用记事本打开,然后另存为UTF8,同样可以解决编码的问题。
不过如果你之前已经写了很多脚本,现在要一个个改,估计会把你改傻。
我自己写了一个工具,可以把脚本改成自己想要的编码:选择脚本的目录,将会把目录下的所有js或者c#脚本全部打开然后我可以选择想要的编码类型最后点击一下转换的按钮,ok!全部都转换成功了。
这时候就觉得程序员还是挺不错的,是吧?。
解决SQLite数据库中文乱码问题

解决SQLite数据库中⽂乱码问题关于SQLite中出现中⽂乱码的分析以及解决⽅案我们在使⽤SQLite数据库时候,可能会发现,向数据库插⼊数据时候显⽰的是汉字,但通过SQLite读出来时却显⽰的乱码,这是因为SQLite数据库所⽀持的编码⽅式和我们程序中的编码⽅式不⼀样,SQLite数据库采⽤的是UTF-8编码⽅式,⽽我们在程序中常常使⽤的是宽字节uncoid编码⽅式,所以使⽤SQLite数据库读出来以后会显⽰乱码,就是因为编码⽅式不⼀样,举个例⼦,基于对话框的程序,我们要在listctrl控件上显⽰我们数据库中读⼊的数据,当我们编写程序让读出来时,列表控件上显⽰的却是不可读的乱码,这就是原因所在。
例如在VC++中通过sqlite3.dll接⼝对sqlite数据库进⾏操作,包括打开数据库,插⼊,查询数据库等,如果操作接⼝输⼊参数包含中⽂字符,会导致操作异常。
例如调⽤sqlite3_open打开数据库⽂件,如果⽂件路径出现中⽂,就会导致打开失败。
sqlite3_exec执⾏sql语句,如果包含中⽂对应字符就会变成乱码。
有问题肯定是要解决滴,本⼈初学SQLite,通过查找资料,这是由于sqlite数据库使⽤的是UTF-8编码⽅式,⽽传⼊的字符串是ASCII编码或Unicode编码,导致字符串格式错误。
解决⽅案是在调⽤sqlite接⼝之前,先将字符串转换成UTF-8编码,以下提供各种字符串编码转换函数。
函数如下:⼀般我们使⽤vc++编程时最多使⽤的函数是UTF-8转Unicode ,⼀下函数仅供参考//UTF-8转Unicodestd::wstring Utf82Unicode(const std::string& utf8string){int widesize = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//unicode 转为 asciistring WideByte2Acsi(wstring& wstrcode){int asciisize = ::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, NULL, 0, NULL, NULL);if (asciisize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (asciisize == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(asciisize);int convresult =::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, &resultstring[0], asciisize, NULL, NULL);if (convresult != asciisize){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//utf-8 转 asciistring UTF_82ASCII(string& strUtf8Code){string strRet("");//先把 utf8 转为 unicodewstring wstr = Utf82Unicode(strUtf8Code);//最后把 unicode 转为 asciistrRet = WideByte2Acsi(wstr);return strRet;}/////////////////////////////////////////////////////////////////////////ascii 转 Unicodewstring Acsi2WideByte(string& strascii){int widesize = MultiByteToWideChar (CP_ACP, 0, (char*)strascii.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = MultiByteToWideChar (CP_ACP, 0, (char*)strascii.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//Unicode 转 Utf8std::string Unicode2Utf8(const std::wstring& widestring){int utf8size = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, NULL, 0, NULL, NULL);if (utf8size == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(utf8size);int convresult = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, &resultstring[0], utf8size, NULL, NULL); if (convresult != utf8size){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//ascii 转 Utf8string ASCII2UTF_8(string& strAsciiCode){string strRet("");//先把 ascii 转为 unicodewstring wstr = Acsi2WideByte(strAsciiCode);//最后把 unicode 转为 utf8strRet = Unicode2Utf8(wstr);return strRet;}。
CubeSuite+解决中文编码问题引起的编译错误
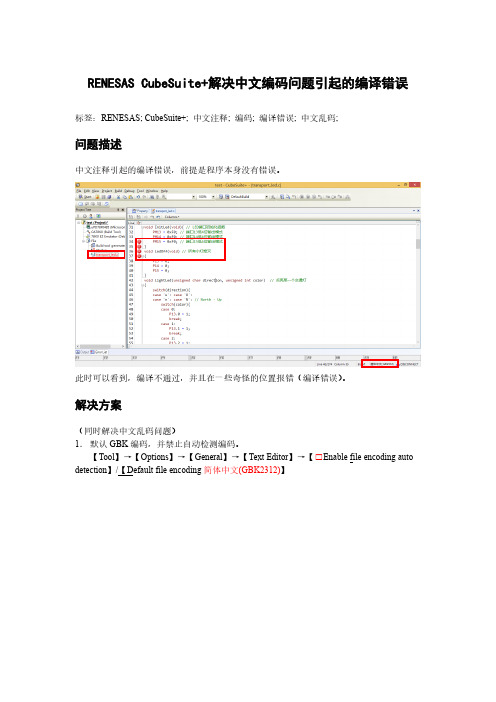
RENESAS CubeSuite+解决中文编码问题引起的编译错误标签:RENESAS; CubeSuite+; 中文注释; 编码; 编译错误; 中文乱码;
问题描述
中文注释引起的编译错误,前提是程序本身没有错误。
此时可以看到,编译不通过,并且在一些奇怪的位置报错(编译错误)。
解决方案
(同时解决中文乱码问题)
1.默认GBK编码,并禁止自动检测编码。
【Tool】→【Options】→【General】→【Text Editor】→【□Enable file encoding auto detection】/【Default file encoding简体中文(GBK2312)】
2.设置【汉字代码源】为【EUC-JP(-ze)】
【Build Tool】→【Compile Options】→【Extension】→【Kanji character code of source】→【EUC-JP(-ze)】
结果呈现
问题顺利解决,没有出现任何编译错误,可以成功编译并下载调试。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
解决SublimeText3中文显示乱码(tab中文方块)问题

解决SublimeText3中文显示乱码(tab中文方块)问题一、文本出现中文乱码问题1、打开Sublime T ext 3,按Ctrl+~打开控制行,复制粘贴以下python代码,然后回车运行。
2. 复制并粘贴如下代码:Python代码1.import urllib.request,os,sys; exec("if sys.version_info < (3,) or != 'nt': raise OSError('This code is for Windows ST3 only!')"); pr='Preferences.sublime-settings'; ip='ignored_packages'; n='Package Control'; s=sublim e.load_settings(pr); ig=s.get(ip); ig.append(n); s.set(ip,ig); sublim e.save_settings('Preferences.sublime-settings'); pf=n+'.sublime-package'; urllib.request.install_opener(urllib.request.build_opene r(urllib.request.ProxyHandler())); by=urllib.request.urlopen('https ://packagecontrol.io/'+pf.replace(' ','%20')).read(); open(os.path.j oin(sublime.installed_packages_path(),pf),'wb').write(by); ig.rem ove(n); s.set(ip,ig); sublime.save_settings(pr); print('Package Con trol: 3.0.0 upgrade successful!')2、重启Sublime Text 3。
Qt中文乱码解决方案

Qt中⽂乱码解决⽅案⼀、问题是什么?在学习Qt编程的过程中,⼤多数⼈都遇到过中⽂乱码的问题。
总结起来有三类:1. Qt Creator中显⽰的汉字变为乱码,编辑器上⽅有“Could not decode "..." with "UTF-8"-encoding. Editing not possible.”的错误提⽰。
此时,出现乱码的⽂档是不可编辑的。
2. Qt Creator中显⽰的汉字正常,但编译的时候会出现“常量中有换⾏符”等⼀系列错误报警。
其实,这也是⽂字编码的问题。
3. 编译时未报错,但⽣成的程序中⽂乱码。
原因. Qt Creator的编辑器默认使⽤UTF-8(代码页65001)编码来读取⽂本⽂件。
⽽Visual Studio保存⽂件时默认采⽤的是本地编码,对于简体中⽂的Windows操作系统,这个编码就是GB2312(代码页936)。
如果使⽤Qt Creator读取由Visual Studio创建的⽂件,那么编辑器就会以UTF-8编码格式读取GB2312编码格式的⽂件,出现中⽂乱码,因为这两套编码系统对汉字编码是不同的。
⾄于英⽂部分不会乱码,是因为UTF-8和GB2312在单字节字符部分是兼容的。
解决办法:⾸先,要把项⽬中所有的头⽂件和源⽂件全都转换成UTF-8+BOM编码保存,全选⽂本,然后右键选择Add UTF-8 BOM on save。
1. 第1个问题不存在了。
2. 第2个问题也不存在了。
3. 第3个问题,你也可以⽤上个⽅案中的⽅法来解决,但有更好的⽅法。
那就是要⽤到中⽂字符的头⽂件和源⽂件开头加上MSVC的⼀个宏:1#if _MSC_VER >= 16002#pragma execution_character_set("utf-8")3#endif。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
RENESAS CubeSuite+解决中文编码问题引起的编译错误标签:RENESAS; CubeSuite+; 中文注释; 编码; 编译错误; 中文乱码;
问题描述
中文注释引起的编译错误,前提是程序本身没有错误。
此时可以看到,编译不通过,并且在一些奇怪的位置报错(编译错误)。
解决方案
(同时解决中文乱码问题)
1.默认GBK编码,并禁止自动检测编码。
【Tool】→【Options】→【General】→【Text Editor】→【□Enable file encoding auto detection】/【Default file encoding简体中文(GBK2312)】
2.设置【汉字代码源】为【EUC-JP(-ze)】
【Build Tool】→【Compile Options】→【Extension】→【Kanji character code of source】→【EUC-JP(-ze)】
结果呈现
问题顺利解决,没有出现任何编译错误,可以成功编译并下载调试。