Linux内核分析-网络[五]:网桥
网桥的工作原理简述

网桥的工作原理简述
网桥是一种网络设备,用于将两个或多个局域网(LAN)连接在
一起,以便它们可以共享资源和通信。
它的工作原理是通过监视和分析网络上的数据帧,确定其目标地址所属的局域网,然后仅将数据帧转发到目标局域网。
网桥工作在OSI模型的数据链路层,具有两个主要功能:学
习和转发。
学习功能是指网桥通过检查每个数据帧的源MAC地址,将该
地址与所接收到的接口关联起来,并将其存储在一个地址表中。
通过不断接收和分析网络上的数据帧,网桥可以学习到连接的各个局域网上的设备的MAC地址和其所连接的接口。
转发功能是指网桥根据地址表中存储的信息,将数据帧转发到目标设备所在的局域网上的正确接口。
当网桥接收到一个数据帧时,它会检查数据帧中的目标MAC地址,并通过查找地址
表来确定应该将数据帧转发到哪个接口。
如果目标地址在同一局域网上,网桥会丢弃该数据帧;如果目标地址在不同的局域网上,网桥将该数据帧转发到正确的接口,并将其传送到目标设备。
通过学习和转发功能,网桥可以提供局域网之间的通信,并且可以避免网络中的冲突和数据包的冗余传输。
它还可以提高网络的性能和可靠性,使各个局域网之间的通信更加高效。
网桥

网桥网桥(Bridge)像一个聪明的中继器。
中继器从一个网络电缆里接收信号,放大它们,将其送入下一个电缆。
它们毫无目的的这么做,对它们所转发消息的内容毫不在意。
相比较而言,网桥对从关卡上传下来的信息更敏锐一些。
网桥将两个相似的网络连接起来,并对网络数据的流通进行管理。
它工作于数据链路层,不但能扩展网络的距离或范围,而且可提高网络的性能、可靠性和安全性。
网络1 和网络2 通过网桥连接后,网桥接收网络1 发送的数据包,检查数据包中的地址,如果地址属于网络1 ,它就将其放弃,相反,如果是网络2 的地址,它就继续发送给网络2.这样可利用网桥隔离信息,将网络划分成多个网段,隔离出安全网段,防止其他网段内的用户非法访问。
由于网络的分段,各网段相对独立,一个网段的故障不会影响到另一个网段的运行。
网桥可以是专门硬件设备,也可以由计算机加装的网桥软件来实现,这时计算机上会安装多个网络适配器(网卡)。
网桥的功能网桥的功能在延长网络跨度上类似于中继器,然而它能提供智能化连接服务,即根据帧的终点地址处于哪一网段来进行转发和滤除。
网桥对站点所处网段的了解是靠“自学习”实现的。
当使用网桥连接两段LAN 时,网桥对来自网段1 的MAC 帧,首先要检查其终点地址。
如果该帧是发往网段1 上某一站的,网桥则不将帧转发到网段2 ,而将其滤除;如果该帧是发往网段2 上某一站的,网桥则将它转发到网段2.这表明,如果LAN1和LAN2上各有一对用户在本网段上同时进行通信,显然是可以实现的。
因为网桥起到了隔离作用。
可以看出,网桥在一定条件下具有增加网络带宽的作用。
网桥的存储和转发功能与中继器相比有优点也有缺点,其优点是:使用网桥进行互连克服了物理限制,这意味着构成LAN 的数据站总数和网段数很容易扩充。
网桥纳入存储和转发功能可使其适应于连接使用不同MAC 协议的两个LAN.因而构成一个不同LAN 混连在一起的混合网络环境。
网桥的中继功能仅仅依赖于MAC 帧的地址,因而对高层协议完全透明。
Linux路由表详解及route命令详解

Linux路由表详解及route命令详解Linux 内核的路由表通过route命令查看 Linux 内核的路由表:[root@VM_139_74_centos ~]# routeKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Ifacedefault gateway 0.0.0.0 UG 0 0 0 eth010.0.0.10 10.139.128.1 255.255.255.255 UGH 0 0 0 eth010.139.128.0 0.0.0.0 255.255.224.0 U 0 0 0 eth0link-local 0.0.0.0 255.255.0.0 U 1002 0 0 eth0172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-0ab63c131848172.19.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-bccbfb788da0172.20.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-7485db25f958[root@VM_139_74_centos ~]# route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 10.139.128.1 0.0.0.0 UG 0 0 0 eth010.0.0.10 10.139.128.1 255.255.255.255 UGH 0 0 0 eth010.139.128.0 0.0.0.0 255.255.224.0 U 0 0 0 eth0169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-0ab63c131848172.19.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-bccbfb788da0172.20.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-7485db25f958各列字段说明:列含义Destination⽬标⽹络或⽬标主机。
linux网络基础知识

Linux网络基础知识TCP/IP通讯协议采用了4层的层级结构,每一层都呼叫它的下一层所提供的网络来完成自己的需求。
这4层分别为:应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间的数据传送服务,如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
网络接口层(网络接口层例如以太网设备驱动程序):对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
网络接口层在发送端将上层的IP数据报封装成帧后发送到网络上;数据帧通过网络到达接收端时,该结点的网络接口层对数据帧拆封,并检查帧中包含的MAC地址。
如果该地址就是本机的MAC地址或者是广播地址,则上传到网络层,否则丢弃该帧。
网络接口层可细分为数据链路层和物理层,数据链路层实际上就是网卡的驱动程序,物理层实际上就是布线、光纤、网卡和其它用来把两台网络通信设备连接在一起的东西。
链路层,有时也称作数据链路层或网络接口层,通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。
它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。
网卡驱动程序主要实现发送数据帧与接受数据帧的功能,发送数据帧采用内核函数hard_start_xmit();接收数据帧采用内核函数netif_rx();网卡驱动程序主要是分配设置及注册net_dev结构体;数据帧的载体采用sk-buff结构体。
用浏览网页为例:发送方:1.输入网址:,按了回车键,电脑使用应用层用IE浏览器将数据从80端口发出,给了下一层协议——传输层。
网桥的工作原理和特点是什么

网桥的工作原理和特点是什么网桥是一种用于连接同一网络的多个局域网(LAN)的设备。
它的工作原理和特点如下:1. 工作原理:网桥基于物理层和数据链路层的MAC地址进行工作。
当数据包从一个端口进入网桥时,网桥会检查数据包的目的MAC地址,并通过查找自己的MAC地址表,确定数据包是向哪个端口转发。
如果目的地址在同一网桥的另一个端口上,则数据包不会被转发到其他网桥端口;如果目的地址在另一个网桥上,则数据包会被转发到相应的网桥。
2. 学习和转发:网桥通过学习数据包的源MAC地址和对应端口,建立起一个MAC地址表。
这样,当它接收到特定MAC地址的数据包时,就可以根据表中的信息决定是否转发该数据包。
网桥只会将数据包转发到目标设备所在的网段,从而限制了冲突域的范围。
3. 分割冲突域:网桥能够将局域网划分为多个冲突域。
冲突域是指共享同一物理介质的设备之间发生冲突的范围。
网桥通过将不同的冲突域连接起来,可以减少各个冲突域之间的干扰,提高网络性能和可靠性。
4. 过滤和隔离:网桥可以过滤网络中的广播和多播数据包,只将其转发到其他网络。
这样可以避免网络中出现广播风暴和浪费带宽的问题。
此外,网桥可以隔离网络中的通信,提高网络的安全性。
5. 自我维护和纠错:网桥可以自动检测和纠正网络中的错误和故障。
当发现一个端口或链路出现问题时,网桥会将该端口或链路隔离起来,确保问题不会影响整个网络的正常运行。
总结来说,网桥的工作原理是基于MAC地址进行数据转发,具有学习和转发、分割冲突域、过滤和隔离、自我维护和纠错等特点。
通过使用网桥,可以提高局域网的性能、可靠性和安全性。
Linux-网桥原理分析(三)
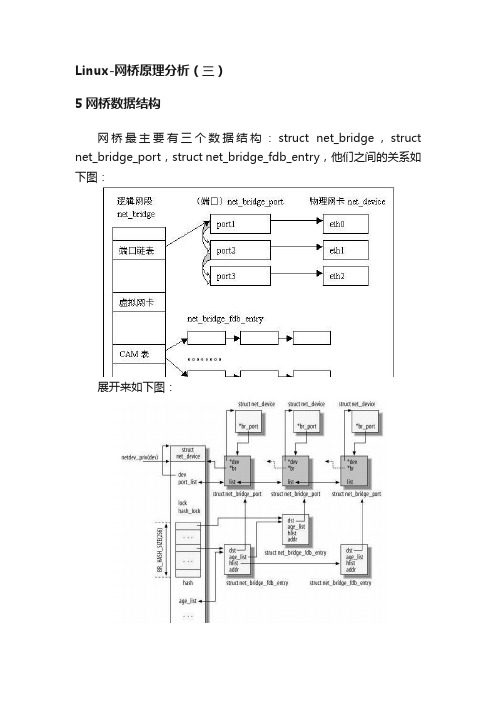
Linux-网桥原理分析(三)5网桥数据结构网桥最主要有三个数据结构:struct net_bridge,struct net_bridge_port,struct net_bridge_fdb_entry,他们之间的关系如下图:展开来如下图:说明:1. 其中最左边的net_device是一个代表网桥的虚拟设备结构,它关联了一个net_bridge结构,这是网桥设备所特有的数据结构。
2. 在net_bridge结构中,port_list成员下挂一个链表,链表中的每一个节点(net_bridge_port结构)关联到一个真实的网口设备的net_device。
网口设备也通过其br_port指针做反向的关联(那么显然,一个网口最多只能同时被绑定到一个网桥)。
3. net_bridge结构中还维护了一个hash表,是用来处理地址学习的。
当网桥准备转发一个报文时,以报文的目的Mac地址为key,如果可以在hash表中索引到一个net_bridge_fdb_entry结构,通过这个结构能找到一个网口设备的net_device,于是报文就应该从这个网口转发出去;否则,报文将从所有网口转发。
各个结构体具体内容如下:struct net_bridgespinlock_t hash_lock;//hash表的锁/*--CAM: 保存forwarding database的一个hash链表(这个也就是地址学习的东东,所以通过hash能快速定位),这里每个元素都是一个net_bridge_fsb_entry结构--*/struct hlist_head hash[BR_HASH_SIZE];struct list_head age_list;/* STP *///与stp 协议对应的数据bridge_id designated_root;bridge_id bridge_id;u32 root_path_cost;unsigned long max_age;unsigned long hello_time;unsigned long forward_delay;unsigned long bridge_max_age;unsigned long ageing_time;unsigned long bridge_hello_time;unsignedlong bridge_forward_delay;u16 root_port;2. struct net_bridge_portu8 priority;u8 state;u16 port_no;//本端口在网桥中的编号unsignedchar topology_change_ack;unsigned char config_pending;port_id port_id;port_id designated_port;bridge_id designated_root;bridge_id designated_bridge;u32 path_cost;u32 designated_cost;//端口定时器,也就是stp控制超时的一些定时器列表struct timer_list forward_delay_timer;struct timer_list hold_timer;struct timer_list message_age_timer;struct kobject kobj;struct rcu_head rcu;}3. struct net_bridge_fdb_entrystruct hlist_node hlist;//桥的端口(最主要的两个域就是这个域和下面的mac地址域)struct net_bridge_port *dst;struct rcu_head rcu;//当使用RCU 策略,才用到atomic_t use_count;//引用计数unsigned long ageing_timer;//MAC 超时时间mac_addr addr;//mac地址。
Linux网桥的分析

Linux网桥的分析——计算机0707 石龙 20073093一、综述网桥,类似于中继器,连接局域网中两个或者多个网段。
它与中继器的不同之处就在于它能够解析它收发的数据,读取目标地址信息(MAC),并决定是否向所连接网络的其他网段转发数据包。
为了能够决策向那个网段发送数据包,网桥学习接收到数据包的源MAC地址,在本地建立一个以 MAC和端口为记录项的信息数据库。
Linux 内核分别在2.2 和 2.4内核中实现了网桥。
但是2.2 内核和 2.4内核的实现有很大的区别,2.4中的实现几乎是全部重写了所有的实现代码。
本文以2.4.0内核版本为例进行分析。
在分析具体的实现之前,先描述几个概念,有助于对网桥的功能及实现有更深的理解。
冲突域一个冲突域由所有能够看到同一个冲突或者被该冲突涉及到的设备组成。
以太网使用C S M A / C D(Carrier Sense Multiple Access withCollision Detection,带有冲突监测的载波侦听多址访问)技术来保证同一时刻,只有一个节点能够在冲突域内传送数据。
网桥或者交换机,构成了一个冲突域的边界。
缺省情况下,网桥中的每个端口实际上就是一个冲突域的结束点。
广播域一个广播域由所有能够看到一个广播数据包的设备组成。
一个路由器,构成一个广播域的边界。
网桥能够延伸到的最大范围就是一个广播域。
缺省的情况下,一个网桥或交换机的所有端口在同一个广播域中。
VLAN技术可以把交换机或者网桥的不同端口分割成不同的广播域。
一般情况下,一个广播域代表一个逻辑网段。
网桥中的CAM表网桥和交换机一样,为了能够实现对数据包的转发,网桥保存着许多(MAC,端口)项。
所有的这些项组成一个表,叫做CAM表。
每个项有超时机制,如果一定时间内未接收到以这个MAC为源MAC地址的数据包,这个项就会被删除。
在Linux内核网桥的实现中,一个逻辑网段用net_bridge结构体表示。
linux的bridge分析

linux的bridge分析Linux网桥模型:Linux内核通过一个虚拟的网桥设备来实现桥接的,这个设备可以绑定若干个以太网接口设备,从而将它们桥接起来。
如下图所示:网桥设备br0绑定了eth0和eth1。
对于网络协议栈的上层来说,只看得到br0,因为桥接是在数据链路层实现的,上层不需要关心桥接的细节。
于是协议栈上层需要发送的报文被送到br0,网桥设备的处理代码再来判断报文该被转发到eth0或是eth1,或者两者皆是;反过来,从eth0或从eth1接收到的报文被提交给网桥的处理代码,在这里会判断报文该转发、丢弃、或提交到协议栈上层。
而有时候eth0、eth1也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收(从而绕过网桥)。
相关数据结构:其中最左边的net_device是一个代表网桥的虚拟设备结构,它关联了一个net_bridge结构,这是网桥设备所特有的数据结构。
在net_bridge结构中,port_list成员下挂一个链表,链表中的每一个节点(net_bridge_port结构)关联到一个真实的网口设备的net_device。
网口设备也通过其br_port指针做反向的关联(那么显然,一个网口最多只能同时被绑定到一个网桥)。
net_bridge结构中还维护了一个hash表,是用来处理地址学习的。
当网桥准备转发一个报文时,以报文的目的Mac地址为key,如果可以在hash表中索引到一个net_bridge_fdb_entry结构,通过这个结构能找到一个网口设备的net_device,于是报文就应该从这个网口转发出去;否则,报文将从所有网口转发。
网桥数据包的处理流程:接收过程:对于数据包的处理流程并没有明显的主线,主要就是根据内核代码中网桥部分的源码进行分析。
网口设备接收到的报文最终通过net_receive_skb函数被网络协议栈所接收。
这个函数主要做三件事情:1、如果有抓包程序需要skb,将skb复制给它们;2、处理桥接;3、将skb提交给网络层。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
看完了路由表,重新回到netif_receive_skb ()函数,在提交给上层协议处理前,会执行下面一句,这就是网桥的相关操作,也是这篇要讲解的容。
view plaincopy to clipboardprint?1. s kb = handle_bridge(skb, &pt_prev, &ret, orig_dev);网桥可以简单理解为交换机,以下图为例,一台linux机器可以看作网桥和路由的结合,网桥将物理上的两个局域网LAN1、LAN2当作一个局域网处理,路由连接了两个子网1.0和2.0。
从eth0和eth1网卡收到的报文在Bridge模块中会被处理成是由Bridge收到的,因此Bridge也相当于一个虚拟网卡。
STP五种状态DISABLEDBLOCKINGLISTENINGLEARNINGFORWARDING创建新的网桥br_add_bridge [net\bridge\br_if.c]当使用SIOCBRADDBR调用ioctl时,会创建新的网桥br_add_bridge。
首先是创建新的网桥:view plaincopy to clipboardprint?1. d ev = new_bridge_dev(net, name);然后设置dev->dev.type为br_type,而br_type是个全局变量,只初始化了一个名字变量view plaincopy to clipboardprint?1. S ET_NETDEV_DEVTYPE(dev, &br_type);2. s tatic struct device_type br_type = {3. .name = "bridge",4. };然后注册新创建的设备dev,网桥就相当一个虚拟网卡设备,注册过的设备用ifconfig 就可查看到:view plaincopy to clipboardprint?1. r et = register_netdevice(dev);最后在sysfs文件系统中也创建相应项,便于查看和管理:view plaincopy to clipboardprint?1. r et = br_sysfs_addbr(dev);将端口加入网桥br_add_if() [net\bridge\br_if.c]当使用SIOCBRADDIF调用ioctl时,会向网卡加入新的端口br_add_if。
创建新的net_bridge_port p,会从br->port_list中分配一个未用的port_no,p->br会指向br,p->state设为BR_STATE_DISABLED。
这里的p实际代表的就是网卡设备。
view plaincopy to clipboardprint?1. p = new_nbp(br, dev);将新创建的p加入CAM表中,CAM表是用来记录mac地址与物理端口的对应关系;而刚刚创建了p,因此也要加入CAM表中,并且该表项应是local的[关系如下图],可以看到,CAM表在实现中作为net_bridge的hash表,以addr作为hash值,链入net_bridge_fdb_entry,再由它的dst指向net_bridge_port。
view plaincopy to clipboardprint?1. e rr = br_fdb_insert(br, p, dev->dev_addr);设备的br_port指向p。
这里要明白的是,net_bridge可以看作全局量,是网桥,而net_bridge_port则是与网卡相对应的端口,因此每个设备dev有个指针br_port指向该端口。
view plaincopy to clipboardprint?1. r cu_assign_pointer(dev->br_port, p);将新创建的net_bridge_port加入br的链表port_list中,在创建新的net_bridge_port 时,会分配一个未用的port_no,而这个port_no就是根据br->port_list中的已经添加的net_bridge_port来找到未用的port_no的[具体如下图]。
view plaincopy to clipboardprint?1. l ist_add_rcu(&p->list, &br->port_list);重新计算网桥的ID,这里根据br->port_list链表中的net_bridge_port的最小的addr 来作为网桥的ID。
view plaincopy to clipboardprint?1. b r_stp_recalculate_bridge_id(br);网卡设备的删除br_del_bridge()与端口的移除add_del_if()与添加差不多,不再详述。
熟悉了网桥的创建与添加,再来看下网桥是如何工作的。
当收到数据包,通过netif_receive_skb()->handle_bridge()处理网桥:view plaincopy to clipboardprint?1. s tatic inline struct sk_buff *handle_bridge(struct sk_buff *skb,2. struct packet_type **pt_prev, int *ret,3. struct net_device *orig_dev)4. {5. struct net_bridge_port *port;6.7. if (skb->pkt_type == PACKET_LOOPBACK ||8. (port = rcu_dereference(skb->dev->br_port)) == NULL)9. return skb;10.11. if (*pt_prev) {12. *ret = deliver_skb(skb, *pt_prev, orig_dev);13. *pt_prev = NULL;14. }15.16. return br_handle_frame_hook(port, skb);17. }1. 如果报文来自lo设备,或者dev->br_port为空(skb->dev是收到报文的网卡设备,而在向网桥添加端口时,dev->br_port被赋予了创建的与网卡相对应的端口p),此时不需要网桥处理,直接返回报文;2. 如果报文匹配了之前的ptype_all中的协议,则pt_prev不为空,此时要先进行ptype_all中协议的处理,再进行网桥的处理;3. br_handle_frame_hook是网桥处理钩子函数,在br_init() [net\bridge\br.c]中br_handle_frame_hook = br_handle_frame;br_handle_frame() [net\bridge\br_input.c]是真正的网桥处理函数,下面进入br_handle_frame()开始网桥部分的处理:与前面802.1q讲的一样,首先检查users来决定是否复制报文:view plaincopy to clipboardprint?1. s kb = skb_share_check(skb, GFP_ATOMIC);如果报文的目的地址是01:80:c2:00:00:0X,则是发往STP的多播地址,此时调用br_handle_local_finish()来完成报文的进一步处理:view plaincopy to clipboardprint?1. i f (unlikely(is_link_local(dest))){2. ……3. i f (NF_HOOK(PF_BRIDGE, NF_BR_LOCAL_IN, skb, skb->dev,4. NULL, br_handle_local_finish))5. return NULL; /* frame consumed by filter */6. else7. return skb;8. }而br_handle_local_finish()所做的容很简单,因为是多播报文,主机要做的仅仅是更新报文的源mac与接收端口的关系(在CAM表中)。
1. s tatic int br_handle_local_finish(struct sk_buff *skb)2. {3. struct net_bridge_port *p = rcu_dereference(skb->dev->br_port);4.5. if (p)6. br_fdb_update(p->br, p, eth_hdr(skb)->h_source);7. return 0; /* process further */8. }接着br_handle_frame()继续往下看,然后根据端口的状态来处理报文,如果端口state= BR_STATE_FORWARDING且设置了br_should_route_hook,则转发后返回skb;否则继续往下执行state=BR_STATE_LEARNING段的代码:view plaincopy to clipboardprint?1. r hook = rcu_dereference(br_should_route_hook);2. i f (rhook != NULL) {3. if (rhook(skb))4. return skb;5. dest = eth_hdr(skb)->h_dest;6. }如果端口state= BR_STATE_LEARNING,如果是发往本机的报文,则设置pkt_type 为PACKET_HOST,然后执行br_handle_frame_finish来完成报文的进一步处理。
要注意的是,这里将报文发往本机的报文设为PACKET_HOST,实现了经过网桥处理后,再次进入netif_receive_skb()时,不会再被网桥处理(结果进入网桥的条件理解):view plaincopy to clipboardprint?1. i f (!compare_ether_addr(p->br->dev->dev_addr, dest))2. skb->pkt_type = PACKET_HOST;3. N F_HOOK(PF_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,4. br_handle_frame_finish);除此之外,端口处于不可用状态,此时丢弃掉报文:1. k free_skb(skb);下面来详细看下br_handle_frame_finish()函数。