符号与ASCII码的转换
常用字符与ASCII代码对照表

说明:同一优先级的运算次序由结合方向决定。例如:*号和/号有相同的优先级,其结合方向为自左至右, 因此,3*5/4 的运算次序是先乘后除。单目运算符 - 和 ++ 具有同一优先级,结合方向为自右至左,因此, 表达式 –i++ 相当于 – (i++)。
附录Ⅳ
1、数学函数
常用库函数
调用数学函数时,要求在源文件中包含头文件“math.h” ,即使用以下命令行: #include <math.h> 或 include “math.h”
附录Ⅰ 常用字符与 ASCII 代码对照表
ASCII 值 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 字符 null ☺ ☻ beep backspace tab 换行 ♂ ♀ 回车 ♫ ☼ ► ◄ ↕ ‼ ¶ § ▂ ↨ ↑ ↓ → ← └ ↔ ▲ ▼ 控制字符 NUL SOH STX ETX EOT END ACK BEL BS HT LF VT FF CR SO SI DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US ASCII 值 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 字符 (space) ! " # $ % & ' ( ) * + , . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? ASCII 值 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 字符 @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ ASCII 值 096 097 098 099 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 字符 ’ a b c d e f g h i j k l m n o p q r s t u v w x y z { ¦ } ~ de l
阿斯克码表ascii对照表

阿斯克码表ASCII对照表什么是ASCII码表ASCII(American Standard Code for Information Interchange,简称ASCII码)是计算机中常用的编码系统,包含128个字符,使用7个或8个二进制位表示。
ASCII码从0到127,分别对应了不同的字符,包括数字、字母、标点符号、控制字符等。
通过ASCII码,计算机可以将字符转换为数字,方便在计算机之间传输和存储数据。
ASCII码表的历史ASCII码表最早出现于1960年代,在这之前,不同的计算机厂商使用不同的字符编码方案,互不兼容。
为了解决字符编码的混乱问题,美国信息交换标准委员会(American National Standards Institute,简称ANSI)于1963年发布了ASCII 码表,成为了统一的标准。
ASCII码表的结构ASCII码表共128个字符,使用7个二进制位表示。
其中,前32个字符为控制字符,用来控制打印机、终端等外部设备的运行;后96个字符为可打印字符,对应了数字、字母、标点符号等。
ASCII码表的结构如下:十进制二进制字符描述0 0000000 NUL 空字符/null字符1 0000001 SOH 标题开始2 0000010 STX 正文开始…………32 0100000 空格空格符33 0100001 ! 感叹号…………127 1111111 DEL 删除ASCII码表的应用ASCII码表在计算机科学和信息技术中有着广泛的应用。
1. 字符编码ASCII码表通过将字符与数字的对应关系存储在计算机中,实现了字符的编码和解码。
计算机可以根据ASCII码表将字符转换为二进制形式(编码),也可以根据二进制形式将数字转换为字符(解码)。
这在计算机存储、传输和处理字符时非常重要。
2. 文件传输在计算机的网络通信中,ASCII码表被广泛使用。
例如,当我们在Web上下载一个文本文件时,计算机会根据ASCII码表将二进制数据转换为文本字符,使我们能够正确地读取和理解文件的内容。
常用ASCII码对照表

常用ASCII码对照表1. ASCII码在计算机内部,所有的信息最终都表示为一个二进制的字符串;每一个二进制位bit有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节byte;也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到;上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定;这被称为ASCII码,一直沿用至今;ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32十进制的32,用二进制表示就是00100000,大写的字母A是65二进制01000001;这128个符号包括32个不能打印出来的控制符号,只占用了一个字节的后面7位,最前面的1位统一规定为0;2、非ASCII编码英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的;比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示;于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号;比如,法语中的é的编码为130二进制;这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号;但是,这里又出现了新的问题;不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样;比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel ,在俄语编码中又会代表另一个符号;但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段;至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右;一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号;比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号;正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号;因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码;为什么电子邮件常常出现乱码就是因为发信人和收信人使用的编码方式不一样;解释:同一个文本文件,假设内容是用英语写的,在英语编码的情况下,每个字符会和一个二进制数对应如00101000类似,然后存到计算机中,这时把这个英语文件发给一个俄语国家的用户,计算机传输的是二进制流,即0101之类的数据,到了俄语用户这方,需要有它的俄语编码方式进行解码,把每个二进制流转为字符显示,由于俄语编码表中对每串二进制流数据的解释方式不同,同一个数据如00101000在英语中可能代表A,而在俄语中则代表B,这样就会产生乱码,这是我个人的理解;GB2312编码、日文编码等也是非unicode编码,是要通过转换表codepage转换成unicode 编码的,要不怎么显示出来呢可以想象,如果有一种编码,将世界上所有的符号都纳入其中;每一个符号都给予一个独一无二的编码,那么乱码问题就会消失;这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码;Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号;每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”;具体的符号对应表,可以查询,或者专门的;4. Unicode的问题需要注意的是,Unicode只是一个符号集,只是一种规范、标准,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储在计算机上;比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位01,也就是说这个符号的表示至少需要2个字节;表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多;这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的;它们造成的结果是:1出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode;2unicode在很长一段时间内无法推广,直到互联网的出现;互联网的普及,强烈要求出现一种统一的编码方式;UTF-8就是在互联网上使用最广的一种unicode的实现方式;其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用;重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一,它规定了字符如何在计算机中存储、传输等;UTF-8最大的一个特点,就是它是一种变长的编码方式;它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度;UTF-8的编码规则很简单,只有二条:1对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码;因此对于英语字母,UTF-8编码和ASCII码是相同的;2对于n字节的符号n>1,第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10;剩下的没有提及的二进制位,全部为这个符号的unicode码;下表总结了编码规则,字母x表示可用编码的位;Unicode符号范围 | UTF-8编码方式十六进制 | 二进制--------------------+---------------------------------------------0000 0000-0000 007F | 0xxxxxxx0000 0080-0000 07FF | 110xxxxx 10xxxxxx0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx下面,还是以汉字“严”为例,演示如何实现UTF-8编码;已知“严”的unicode是4E2501,根据上表,可以发现4E25处在第三行的范围内0000 0800-0000 FFFF,因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”;然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0;这样就得到了,“严”的UTF-8编码是“10100101”,这是保存在计算机中的实际数据,转换成十六进制就是E4B8A5,转成十六进制的目的为了便于阅读;6. Unicode与UTF-8之间的转换通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的;它们之间的转换可以通过程序实现;在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序;打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条;里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8;1ANSI是默认的编码方式;对于英文文件是ASCII编码,对于简体中文文件是GB2312编码只针对Windows简体中文版,如果是繁体中文版会采用Big5码;2Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码;这个选项用的little endian格式;3Unicode big endian编码与上一个选项相对应;我在下一节会解释little endian和big endian的涵义;4UTF-8编码,也就是上一节谈到的编码方法;选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了;7. Little endian和Big endian上一节已经提到,Unicode码可以采用UCS-2格式直接存储;以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25;存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式;那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“ZERO WIDTH NO-BREAK SPACE,用FEFF表示;这正好是两个字节,而且FF比FE大1;如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式;8. 实例下面,举一个实例;打开”记事本“程序,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存;然后,用文本编辑软件的”十六进制功能“,观察该文件的内部编码方式;1ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的;2Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25;3Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储;4UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的;推荐这篇文章看一下:解决的问题:一、如何在中文系统中运行非Unicode编码程序有很多意大利文版除英文版学习软件、百科全书等软件在中文系统上会出现乱码,解决方法:WindowsXP内核是Unicode编码,支持多语种,对于Unicode编码的应用程序会正常显示原文因为windows核心是用unicode代码写的,所以不存在问题,但是,很多程序不是用Unicode编码写的,这时WindowsXP系统可以指定以特定的编码运行非Unicode编码程序,中文版WindowsXP默认的是“简体中文GB2312”;你只需在控制面板--〉区域和语言选项--〉高级--〉为非Unicode程序的语言选择“意大利语”,即可正确运行意大利文版的游戏程序;分析:我理解的流程是这样:程序------>意大利语编码转换表codepage------>解释成unicode识别的编码通过指定的转换表将非 Unicode 的字符编码转换为同一字符对应的系统内部使用的 Unicode 编码------>被系统翻译成意大利文因为每个unicode编码对应了相应的意大利文字,便可以正常显示了;二、消除网页乱码网页乱码是浏览器对HTML网页解释时形成的,如果网页制作时编码为繁体big5,浏览器却以编码gb2312显示该网页,就会出现乱码,因此只要你在浏览器中也以繁体big5显示该网页,就会消除乱码;打个比方有些像字典,繁体字得用繁体字典来查看,简体字得用简体字典来查看,不然你看不懂;解决办法:在浏览器中选择“编码”菜单,事先为浏览器安装多语言支持包例如在安装IE时要安装多语言支持包,这样当浏览网页出现乱码时,即可手工更改查看此网页的编码方式,在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文GB2312,如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文BIG5,其他语言依此类推,便可消除网页乱码现象;分析:因为繁体big5编码后的文件,每个文字对应一个二进制流假设是1212对应繁这个字,当我们以编码gb2312显示该网页时,gb2312编码会到表里去找1212二进制流不会变的对应谁,肯定不再是繁这个字了,当然显示的就不再是那个繁字了,也就会出现乱码了;这样理解简单些,其实中间还要转换成同一字符对应的系统内部使用的Unicode 编码,然后通过系统底层unicode编码还原成相应字符显示出来;推荐两个编码查询网站:1. 2.ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备;例如,12 代表换页/新页功能;此命令指示打印机跳到下一页的开头;ASCII 非打印控制字符表十进制十六进制字符十进制十六进制字符000空1610数据链路转意101头标开始1711设备控制 1202正文开始1812设备控制 2303正文结束1913设备控制 3404传输结束2014设备控制 4505查询2115反确认606确认2216同步空闲707震铃2317传输块结束808backspace2418取消909水平制表符2519媒体结束100A换行/新行261A替换110B竖直制表符271B转意120C换页/新页281C文件分隔符130D回车291D组分隔符140E移出301E记录分隔符150F移入311F单元分隔符ASCII 打印字符数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现;数字127 代表 DELETE 命令;ASCII 打印字符表十进制十六进制字符十进制十六进制字符3220space8050P33218151Q3422"8252R35238353S3624$8454T3725%8555U3826&8656V 3927'8757w 40288858X 41298959Y 422A905A Z 432B+915B 442C,925C\ 452D-935D 462E.945E^472F/955F_483009660`493119761a513339963c 5234410064d 5335510165e 5436610266f 5537710367g 5638810468h 5739910569i593B;1076B k 603C<1086C l 613D=1096D m 623E>1106E n 633F1116F o 644011270p 6541A11371q6642B11472r 6743C11573s 6844D11674t 6945E11775u 7046F11876v 7147G11977w 7248H12078x 7349I12179y744A J1227A z754B K1237B{764C L1247C|774D M1257D}784E N1267E~794F O1277F DEL扩展 ASCII 打印字符扩展的 ASCII 字符满足了对更多字符的需求;扩展的 ASCII 包含 ASCII 中已有的 128 个字符数字 0–32 显示在下图中,又增加了 128 个字符,总共是 256 个;即使有了这些更多的字符,许多语言还是包含无法压缩到 256 个字符中的符号;因此,出现了一些 ASCII的变体来囊括地区性字符和符号;例如,许多软件程序把 ASCII 表又称作 ISO 8859-1用于北美、西欧、澳大利亚和非洲的语言;扩展的ASCII 打印字符表十进制十六进制字符十进制十六进制字符12880192C0└12981ü193C1┴13082é194C2┬13284196C4─13385à197C5┼13486198C6╞13587199C7╟13688ê200C8╚13789201C9╔1388Aè202CA╩1408C204CC╠1418Dì205CD═1428E206CE╬1438F207CF╧14490é208D0╨14591209D1╤14692210D2╥14894212D4 14995ò213D5╒15096214D6╓15197ù215D7╫15298216D8╪15399217D9┘1549Aü218DA┌1559B219DB█1569C£220DC▄1579D¥221DD▌1589E222DE 1599F223DF160A0á224E0α161A1í225E1162A2ó226E2Γ164A4228E4Σ165A5229E5σ166A6a230E6μ167A7o231E7τ168A8232E8Φ169A9233E9Θ170AA234EAΩ172AC236EC∞173AD237EDφ174AE238EEε175AF239EF∩176B0240F0≡177B1241F1±178B2▓242F2≥180B4┤244F4 181B5╡245F5 182B6╢246F6÷183B7╖247F7≈184B8╕248F8≈185B9╣249F9 186BA║250FA·187BB╗251FB√188BC╝252FC189BD╜253FD2190BE╛254FE■191BF┐255FFAA 0001100018取消000011000C 换页/新页A6 a CA╩E5σ010******* T 00110001311 010*******U 010011004C L 0010010125% 010*******SC5┼010******* TB10001000111设备控制 1AA AA1818取消0C0C 换页/新页A6A6 a CA CA╩E5E5σ5454 T 31311 5555U4C4C L 2525%1B1B转意0101头标开始。
ascii转文本的转换方法

ASCII(American Standard Code for Information Interchange)是一种字符编码标准,用于将字符和控制字符与数字进行对应。
ASCII 编码使用7 位或8 位二进制数表示一个字符,通常被用于在计算机上表示文本。
将ASCII 转换为文本的方法很简单,因为ASCII 编码中的大部分值都对应于可打印的字符(字母、数字、符号等)。
以下是将ASCII 转换为文本的方法:
1. 查找ASCII 表:
-使用ASCII 表,将每个ASCII 值对应到相应的字符。
ASCII 表可以在许多计算机科学和编程资源中找到。
2. 手动转换:
-手动将ASCII 值转换为相应的字符。
例如,ASCII 值为65 对应大写字母A,ASCII 值为97 对应小写字母a,以此类推。
3. 编程语言中的转换:
-在编程语言中,你可以使用相应的函数或方法将ASCII 值转换为字符。
例如,在Python 中,可以使用内置的`chr()` 函数。
ascii_value = 65
char_value = chr(ascii_value)
print(char_value) # 输出A
4. 在线工具:
-有许多在线工具可以帮助你将ASCII 值转换为字符。
你可以在网上搜索ASCII to text converter或类似的关键词,找到可用的在线工具。
请注意,ASCII 编码范围为0 到127,而扩展的ASCII 编码范围为0 到255。
在将ASCII 转换为文本时,通常使用的是基本的ASCII 编码范围。
ASCII代码转换表

ASCII求助编辑ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是基于拉丁字母的一套电脑编码系统。
它主要用于显示现代英语和其他西欧语言。
它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
目录展开编辑本段名称美国信息交换标准代码( American Standard Code for Information Interchange, ASCII ) 编辑本段产生编辑本段常见ASCII码的大小规则0~9<A~Z<a~z1)数字比字母要小。
如“7”<“F”;2)数字0比数字9要小,并按0到9顺序递增。
如“3”<“8” ;3)字母A比字母Z要小,并按A到Z顺序递增。
如“A”<“Z” ;4)同个字母的大写字母比小写字母要小32。
如“A”<“a” 。
记住几个常见字母的ASCII码大小:换行LF为0x0A;回车CR为0x0D;空格为0x20;“0”为0x30;“A”为0x41;“a”为0x61。
另外还有128-255的ASCII字符编辑本段查询ASCII技巧方便查询ASCII码对应的字符:新建一个文本文档,按住ALT+要查询的码值(注意,这里是十进制)松开即可显示出对应字符。
例如:按住ALT+97,则会显示出‘a’。
编辑本段字符集简史6000年前象形文字3000年前字母表1838年到1854年 Samuel F. B. Morse发明了电报,字母表中的每个字符对应于一系列短的和长的脉冲1821年到1824年 Louis Braille发明盲文,6位代码,它把字符、常用字母组合、常用单字和标点进行编码。
一个特殊的escape代码表示后续的字符代码应解释为大写。
一个特殊的shift代码允许后续代码被解释为数字。
1931年 CCITT标准化Telex代码,包括Baudot #2的代码,都是包括字符和数字的5位代码。
标准ascll码表

标准ascll码表ASCII码表(American Standard Code for Information Interchange)是一种基于拉丁字母的字符编码系统,用于将文本字符转换为数字编码。
它是计算机和通信设备中最常用的字符编码之一,它将每个字符映射到一个唯一的数字值,从0到127不等。
这篇文档将介绍标准ASCII码表的基本知识和使用方法,以帮助大家更好地理解和应用这一编码系统。
ASCII码表共包含128个字符,其中包括控制字符、标点符号、数字、大写字母和小写字母等。
每个字符都有一个唯一的7位二进制编码,用于在计算机中表示和存储。
通过ASCII码表,我们可以将文本信息转换为计算机可以识别和处理的数字编码,实现文本的存储、传输和显示。
在ASCII码表中,数字0到9分别对应的是编码值48到57,大写字母A到Z分别对应的是编码值65到90,小写字母a到z分别对应的是编码值97到122。
此外,一些常见的标点符号和特殊字符也有对应的ASCII编码值。
通过了解这些编码规则,我们可以方便地进行字符和数字之间的转换和识别。
除了基本的ASCII码表外,还有一些扩展的ASCII码表,用于支持更多的字符和符号,如扩展的ASCII码表(Extended ASCII)和Unicode编码等。
这些扩展码表在不同的应用场景中有着不同的作用和优势,可以更好地满足特定领域的需求。
在实际应用中,我们可以通过编程语言或者计算机软件来实现字符和ASCII编码值之间的转换。
例如,在Python编程中,我们可以使用内置的ord()函数来获取一个字符的ASCII编码值,使用chr()函数来将一个ASCII编码值转换为对应的字符。
这些工具和方法可以帮助我们更方便地处理和操作文本信息。
总的来说,标准ASCII码表是计算机和通信设备中最常用的字符编码系统之一,它为我们在计算机中处理文本信息提供了便利和支持。
通过深入了解和熟练掌握ASCII码表的基本知识和使用方法,我们可以更好地应用和理解这一编码系统,为我们的工作和学习带来便利和效率。
ASCII码一览表,ASCII码对照表

ASCII码一览表,ASCII码对照表ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了 128 个字符,用一个字节就可以存储,它等同于国际标准ISO/IEC 646。
ASCII 编码于 1967 年第一次发布,最后一次更新是在 1986 年,迄今为止共收录了 128 个字符,包含了基本的拉丁字母(英文字母)、阿拉伯数字(也就是)、标点符号(,.!等)、特殊符号(@#$%^&等)以及一些具有控制功能的字符(往往不会显示出来)。
ASCII 编码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母,也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视。
计算机也是美国人发明的,起初使用的就是 ASCII 码,只能显示英文字符。
各个国家为了让本国公民也能正常使用计算机,开始效仿 ASCII 开发自己的字符编码,例如 ISO/IEC 8859(欧洲字符集)、shift_Jis(日语字符集)、GBK(中文字符集)等,想深入了解这些字符编码的读者请猛击这里。
ASCII 编码中第 0~31 个字符(开头的 32 个字符)以及第127 个字符(最后一个字符)都是不可见的(无法显示),但是它们都具有一些特殊功能,所以称为NUL (0)NULL,空字符。
空字符起初本意可以看作为 NOP(中文意为空操作,就是啥都不做的意思),此位置可以忽略一个字符。
之所以有这个空字符,主要是用于计算机早期的记录信息的纸带,此处留个 NUL 字符,意思是先占这个位置,以待后用,比如你哪天想起来了,在这个位置在放一个别的啥字符之类的。
后来呢,NUL 被用于C语言中,表示字符串的结束,当一个字符串中间出现 NUL 时,就意味着这个是一个字符串的结尾了。
这样就方便按照自己需求去定义字符串,多长都行,当然只要你内存放得下,然后最后加一个\0,即空字符,意思是当前字符串到此结束。
常用ASCII码对照表

常用ASCII码对照表1. ASCII码在计算机内部,所有的信息最终都表示为一个二进制的字符串。
每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。
也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。
这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(十进制的32,用二进制表示就是00100000),大写的字母A是65(二进制01000001)。
这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。
于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。
比如,法语中的é的编码为130(二进制10000010)。
这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。
不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。
但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。
一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。
比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
ASCII与转义字符

/*************************************************************************************/
ASCII码:
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,
/*************************************************************************************/
带16进制的ASCII:
0 0 NUL 空字符
1 1 SOH 标题起始 (Ctrl/A)
2 2 STX 文本起始 (Ctrl/B)
值 字符 说明 值 字符 值 字符 值 字符
0 NUL 空字符 32 (空格) 64 @ 96 、
1 SOH 标题开始 33 ! 65 A 97 a
2 STX 正文开始 34 ” 66 B 98 b
奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;
偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。
扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
13 CR 回车键 45 - 77 M 109 m
14 SO 不用切换(移位输出) 46 . 78 N 110 n
15 SI 启用切换(移位输入) 47 / 79 O 111 o
16 DLE (空格)数据链路转义 48 0 80 P 112 p
ASCII码和进制转换对照表

ASCII码和进制转换对照表十六进制代码M CS 字符或缩写DEC 多国字符名ASCII 控制字符100 NUL 空字符01 SOH 标题起始(Ctrl/A)02 STX 文本起始(Ctrl/B)03 ETX 文本结束(Ctrl/C)04 EOT 传输结束(Ctrl/D)05 ENQ 询问(Ctrl/E)06 ACK 认可(Ctrl/F)07 BEL 铃(Ctrl/G)08 BS 退格(Ctrl/H)09 HT 水平制表栏(Ctrl/I)0A LF 换行(Ctrl/J)0B VT 垂直制表栏(Ctrl/K)0C FF 换页(Ctrl/L)0D CR 回车(Ctrl/M)0E SO 移出(Ctrl/N)0F SI 移入(Ctrl/O)10 DLE 数据链接丢失(Ctrl/P)11 DC1 设备控制 1 (Ctrl/Q)12 DC2 设备控制 2 (Ctrl/R)13 DC3 设备控制 3 (Ctrl/S)14 DC4 设备控制 4 (Ctrl/T)15 NAK 否定接受(Ctrl/U)16 SYN 同步闲置符(Ctrl/V)17 ETB 传输块结束(Ctrl/W)18 CAN 取消(Ctrl/X)19 EM 媒体结束(Ctrl/Y)1A SUB 替换(Ctrl/Z) 1B ESC 换码符1C FS 文件分隔符1D GS 组分隔符1E RS 记录分隔符1F US 单位分隔符ASCII 特殊和数字字符20 SP 空格21 ! 感叹号22 " 引号(双引号)23 # 数字符号24 $ 美元符25 % 百分号26 & 和号27 " 省略号(单引号)28 ( 左圆括号29 ) 右圆括号2A * 星号2B 加号2C , 逗号2D -- 连字号或减号2E . 句点或小数点2F / 斜杠30 0 零31 1 132 2 233 3 334 4 435 5 536 6 637 7 738 8 839 9 93A : 冒号3B ; 分号3C < 小于3D = 等于3E > 大于3F ? 问号ASCII 字母字符40 @ 商业at 符号41 A 大写字母 A42 B 大写字母 B43 C 大写字母 C44 D 大写字母 D45 E 大写字母 E46 F 大写字母 F47 G 大写字母G48 H 大写字母H49 I 大写字母I 4A J 大写字母J 4B K 大写字母K 4C L 大写字母L 4D M 大写字母M 4E N 大写字母N 4F O 大写字母O50 P 大写字母P51 Q 大写字母Q52 R 大写字母R53 S 大写字母S54 T 大写字母T55 U 大写字母U56 V 大写字母V57 W 大写字母W58 X 大写字母X59 Y 大写字母Y 5A Z 大写字母Z 5B [ 左中括号5C \ 反斜杠5D ] 右中括号5E ^ 音调符号5F _ 下划线60 ` 重音符61 a 小写字母 a62 b 小写字母 b63 c 小写字母 c64 d 小写字母 d65 e 小写字母 e66 f 小写字母 f67 g 小写字母g68 h 小写字母h69 i 小写字母i 6A j 小写字母j 6B k 小写字母k 6C l 小写字母l 6D m 小写字母m 6E n 小写字母n 6F o 小写字母o70 p 小写字母p71 q 小写字母q72 r 小写字母r73 s 小写字母s74 t 小写字母t75 u 小写字母u76 v 小写字母v77 w 小写字母w78 x 小写字母x79 y 小写字母y7A z 小写字母z7B { 左大括号7C | 垂直线7D } 右大括号(ALTMODE) 7E ~ 代字号(ALTMODE)7F DEL 擦掉(DELETE)控制字符80 [保留]81 [保留]82 [保留]83 [保留]84 IND 索引85 NEL 下一行86 SSA 被选区域起始87 ESA 被选区域结束88 HTS 水平制表符集89 HTJ 对齐的水平制表符集8A VTS 垂直制表符集8B PLD 部分行向下8C PLU 部分行向上8D RI 反向索引8E SS2 单移 28F SS3 单移 390 DCS 设备控制字符串91 PU1 专用 192 PU2 专用 293 STS 设置传输状态94 CCH 取消字符95 MW 消息等待96 SPA 保护区起始97 EPA 保护区结束98 [保留]99 [保留]9A [保留]9B CSI 控制序列引导符9C ST 字符串终止符9D OSC 操作系统命令9E PM 秘密消息9F APC 应用程序其他字符A0 [保留] 2A1 ? 反向感叹号A2 ¢分币符A3 £英磅符A4 [保留] 2A5 ¥人民币符A6 [保留] 2A7 §章节符A8 ¤通用货币符号2 A9 ? 版权符号AA a 阴性顺序指示符AB ? 左角引号AC [保留] 2AD [保留] 2AE [保留] 2AF [保留] 2B0 °温度符B1 ±加/减号B2 2 上标 2B3 3 上标 3B4 [保留] 2B5 μ微符B6 ? 段落符,pilcrowB7 ·中点B8 [保留] 2B9 1 上标 1BA o 阳性顺序指示符BB ? 右角引号BC ? 分数四分之一BD ? 分数二分之一BE [保留] 2BF ? 反向问号C0 à带重音符的大写字母 AC1 á带尖锐重音的大写字母 AC2 ? 带音调符号的大写字母 AC3 ? 带代字号的大写字母 AC4 ? 带元音变音(分音符号) 的大写字母 A C5 ? 带铃声的大写字母AC6 ? 大写字母AE 双重元音C7 ? 带变音符号的大写字母 CC8 è带重音符的大写字母 EC9 é带尖锐重音的大写字母 ECA ê带音调符号的大写字母 ECB ? 带元音变音(分音符号) 的大写字母 ECC ì带重音符的大写字母ICD í带尖锐重音的大写字母ICE ? 带音调符号的大写字母ICF ? 带元音变音(分音符号) 的大写字母I D0 [保留] 2D1 ? 带代字号的大写字母ND2 ò带重音符的大写字母OD3 ó带尖锐重音的大写字母OD4 ? 带音调符号的大写字母OD5 ? 带代字号的大写字母OD6 ? 带元音变音(分音符号) 的大写字母O D7 OE 大写字母OE 连字2D8 ? 带斜杠的大写字母OD9 ù带重音符的大写字母UDA ú带尖锐重音的大写字母UDC ü带元音变音(分音符号) 的大写字母U DD Y 带元音变音(分音符号) 的大写字母Y DE [保留] 2DF ? 德语高调小写字母sE0 à带重音符的小写字母 aE1 á带尖锐重音的小写字母 aE2 a 带音调符号的小写字母 aE3 ? 带代字号的小写字母 aE4 ? 带元音变音(分音符号) 的小写字母 a E5 ? 带铃声的小写字母aE6 ? 小写字母ae 双重元音E7 ? 带变音符号的小写字母 cE8 è带重音符的小写字母 eE9 é带尖锐重音的小写字母 eEA ê带音调符号的小写字母 eEB ? 带元音变音(分音符号) 的小写字母e EC ì带重音符的小写字母iED í带尖锐重音的小写字母iEE ? 带音调符号的小写字母iEF ? 带元音变音(分音符号) 的小写字母i F0 [保留] 2F1 ? 带代字号的小写字母nF2 ò带重音符的小写字母oF3 ó带尖锐重音的小写字母oF4 ? 带音调符号的小写字母oF5 ? 带代字号的小写字母oF6 ? 带元音变音(分音符号) 的小写字母o F7 oe 小写字母oe 连字2F8 ? 带斜杠的小写字母oF9 ù带重音符的小写字母uFA ú带尖锐重音的小写字母uFC ü带元音变音(分音符号) 的小写字母u FD ? 带元音变音(分音符号) 的小写字母y 2 FE [保留] 2FF [保留] 2。
python语言ascii码编码方法

一、概述Python语言是一种广泛应用于软件开发、数据分析和人工智能领域的高级编程语言。
在Python中,ASCII码编码方法是一种常见的字符编码方法,它可以将字符转换成对应的ASCII码值。
本文将针对Python 语言中的ASCII码编码方法进行探讨,包括其原理、使用方法以及相关的注意事项。
二、ASCII码编码方法的原理1. ASCII码是一种7位编码方式,共有128个字符编码,包括英文字母、数字、符号和控制字符等。
2. 在Python中,可以通过内置的ord()函数将字符转换为对应的ASCII码值,也可以通过内置的chr()函数将ASCII码值转换为对应的字符。
3. ASCII码编码方法是一种最基本的字符编码方法,它在Python中被广泛应用于字符处理、字符串比较和数据传输等方面。
三、ASCII码编码方法的使用1. 将字符转换为ASCII码值:在Python中,可以使用ord()函数将字符转换为对应的ASCII码值。
使用ord('A')将返回65,即大写字母A 的ASCII码值。
2. 将ASCII码值转换为字符:在Python中,可以使用chr()函数将ASCII码值转换为对应的字符。
使用chr(65)将返回字符'A',即ASCII 码值65对应的字符。
四、ASCII码编码方法的注意事项1. 在使用ASCII码编码方法时,需要注意Python中字符类型和编码类型的兼容性。
使用ASCII码对中文字符进行编码可能会导致编码错误或乱码。
2. 在进行字符处理和字符串比较时,应当注意字符的编码方式,避免因编码不一致导致的错误结果。
3. ASCII码是一种较为简单的字符编码方法,它不支持多语言字符集,因此在处理多语言文本时需要使用其他字符编码方法,如UTF-8。
五、总结本文针对Python语言中ASCII码编码方法进行了探讨,介绍了其原理、使用方法以及注意事项。
了解和掌握ASCII码编码方法对于Python编程和数据处理是至关重要的,同时也有助于提高代码的可读性和可移植性。
ASCII码表
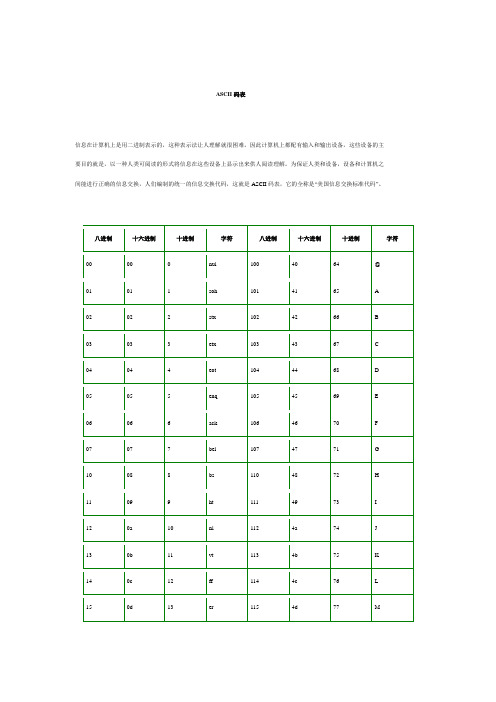
ASCII码表信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。
因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息在这些设备上显示出来供人阅读理解。
为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。
ASCII码对照表在Web开发时,如下的ASCII码只要加上&#和;就可以变成Web可以辨认的字符了在处理特殊字符的时候特别有用,如:' 单引号在数据库查询的时候是杀手,但是如果转换成'(注意:转换后的机构有:&# +字符的ASCII码值+; 三个部分组成)再来存数据库,就没有什么影响了。
其他的字符与ASCII码的对照如下表ASCII表键盘常用ASCII码C键VK_ESCAPE (27)车键:VK_RETURN (13)B键:VK_TAB (9)ps Lock键:VK_CAPITAL (20)ift键:VK_SHIFT ($10)l键:VK_CONTROL (17)键:VK_MENU (18)格键:VK_SPACE ($20/32)格键:VK_BACK (8)徽标键:VK_LWIN (91)徽标键:VK_LWIN (92)标右键快捷键:VK_APPS (93)sert键:VK_INSERT (45)me键:VK_HOME (36)ge Up:VK_PRIOR (33)geDown:VK_NEXT (34)d键:VK_END (35)lete键:VK_DELETE (46)向键(←):VK_LEFT (37)向键(↑):VK_UP (38)向键(→):VK_RIGHT (39)向键(↓):VK_DOWN (40)键:VK_F1 (112)键:VK_F2 (113)键:VK_F3 (114)键:VK_F4 (115)键:VK_F5 (116)F6键:VK_F6 (117)F7键:VK_F7 (118)F8键:VK_F8 (119)F9键:VK_F9 (120)F10键:VK_F10 (121)F11键:VK_F11 (122)F12键:VK_F12 (123)Num Lock键:VK_NUMLOCK (144) 小键盘0:VK_NUMPAD0 (96)小键盘1:VK_NUMPAD0 (97)小键盘2:VK_NUMPAD0 (98)小键盘3:VK_NUMPAD0 (99)小键盘4:VK_NUMPAD0 (100)小键盘5:VK_NUMPAD0 (101)小键盘6:VK_NUMPAD0 (102)小键盘7:VK_NUMPAD0 (103)小键盘8:VK_NUMPAD0 (104)小键盘9:VK_NUMPAD0 (105)小键盘.:VK_DECIMAL (110)小键盘*:VK_MULTIPLY (106)小键盘+:VK_MULTIPLY (107)小键盘-:VK_SUBTRACT (109)小键盘/:VK_DIVIDE (111)Pause Break键:VK_PAUSE (19) Scroll Lock键:VK_SCROLL (145)ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字母的一套电脑编码系统。
字符a对应ascii码中65,转换成二进制 。

字符a对应ascii码中65,转换成二进制。
【字符a对应ASCII码中65的二进制转换】1. ASCII码简介ASCII(American Standard Code for Information Interchange)是一种用于表示文本的字符编码标准,它使用7位或8位二进制数字来表示128个字符。
字符包括字母、数字、符号和控制字符。
在ASCII码中,每个字符都有一个对应的数字值,在计算机中使用二进制来表示这些数字值。
2. 字符a的ASCII码字符a对应的ASCII码是65。
根据ASCII码表,65表示大写字母A。
大写字母A的二进制表示是01000001。
这意味着在计算机内部,字符a被表示为二进制01000001。
3. ASCII码的二进制表示在计算机内部,所有数据都以二进制形式存储和处理。
字符a的ASCII 码65在计算机中实际上是以二进制形式存在的。
这种二进制表示使得计算机能够准确地识别和处理文本字符。
4. 重要性和应用理解字符的ASCII码及其对应的二进制表示对于计算机科学和编程非常重要。
在实际应用中,程序员经常需要处理文本数据,并对其中的字符进行操作和转换。
了解ASCII码的二进制表示能够帮助他们更好地理解和处理字符数据。
5. 结论与展望通过本文对字符a对应ASCII码中65的二进制转换的介绍,我们可以深入了解了ASCII码的基本知识,并对字符在计算机中的表示有了更清晰的认识。
相信在未来的学习和工作中,对ASCII码的二进制表示会起到重要的作用。
个人观点和理解我认为,了解字符的ASCII码及其对应的二进制表示是计算机科学领域的基础知识。
在进行编程和文本处理时,深入理解ASCII码的二进制表示可以帮助程序员更加高效地进行字符操作和转换。
ASCII码的二进制表示也为计算机系统的底层实现提供了重要参考。
对于计算机专业的学生和从事相关工作的人来说,掌握ASCII码的二进制表示是非常必要的。
从二进制角度深入探讨ASCII码在计算机科学领域中,了解字符的ASCII码及其对应的二进制表示是非常重要的基础知识。
1的ascii码是多少

1的ascii码是多少
在计算机中,用于存储的基础单位是字节,即8个Bit。
根据国际标准化组织(International Organization for Standardization, ISO)的定义,1的二进制表示为00110001,换算为十进制为49。
所以,1的ascii码二进制表示为00110001,十进制为49。
下图为常用符号、字母、数字的十进制ascii码表示。
表中的每个字符用行、列号表示,如‘(’为第4行,第0列,十进制值为40,数字“1”为第4行第9列,其值为49。
在计算机中,所有的数据在存储和运算时都要使用二进制数表示,因为二进制数只有0和1 两个数字,而计算机可以用高电平和低电平分别表示1和0。
例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等),都可以用一个二进制数来表示。
美国国家标准学会(American National Standard Institute , ANSI )制定了一套标准,用每个二进制数来表示这些常用的字母、
数字和符号,这就是美国信息交换标准代码(ASCII码)。
它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,后来它被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。
适用于所有拉丁文字字母。
asicll码符号

asicll码符号
ASCII码符号是计算机中用于表示字符的编码方式,它使用7位二进制数来表示128种不同的符号,包括字母、数字、标点符号等等。
在ASCII码中,每个符号都有一个对应的编码值,这些值在0到127之间。
这些符号在计算机中非常重要,因为它们是计算机处理文本的基础。
通过将字符转换成ASCII码,计算机可以准确地表示和传输文本信息。
ASCII码符号也广泛应用于各种应用程序和软件中,例如操作系统、文本编辑器、电子邮件、网页浏览器等等。
除了基本的ASCII码符号外,还有扩展的ASCII码符号,它们使用8位二进制数来表示256种不同的符号。
这些扩展的ASCII码符号包括一些特殊的符号、图形和表情符号等等。
ascii转换方法

ascii转换方法ASCII(American Standard Code for Information Interchange)是一种字符编码标准,用于将字符映射为数字。
ASCII码共包含128个字符,包括英文字母、数字、标点符号和一些特殊字符。
以下是将ASCII码转换为字符和将字符转换为ASCII码的方法:1. 将ASCII码转换为字符:- 使用编程语言提供的内置函数来完成转换。
例如,在Python中,可以使用`chr()`函数来将ASCII码转换为字符。
- 手动计算。
根据ASCII码表,找到对应的字符。
例如,ASCII码为65对应的字符为大写字母"A"。
2. 将字符转换为ASCII码:- 使用编程语言提供的内置函数来完成转换。
例如,在Python中,可以使用`ord()`函数来将字符转换为ASCII码。
- 使用ASCII码表来查找对应的ASCII码。
例如,大写字母"A"对应的ASCII码为65。
下面是一些示例代码,展示如何使用Python将ASCII码转换为字符和将字符转换为ASCII码:```python# ASCII码转换为字符ascii_code = 65character = chr(ascii_code)print(character) # 输出:A# 字符转换为ASCII码character = 'A'ascii_code = ord(character)print(ascii_code) # 输出:65```需要注意的是,ASCII码只能表示128个字符,无法表示其他字符集(如中文字符)。
对于其他字符集的转换,可以使用不同的编码标准,如Unicode。
java字符转换为ascall码的函数

java字符转换为ascall码的函数Java字符转换为ASCII码的函数在Java中,字符是以Unicode编码表示的。
而ASCII码是一种较早期的字符编码方式,它只使用一个字节(8位)来表示一个字符。
在某些情况下,我们可能需要将Java字符转换为ASCII码,以便进行一些特定的操作或者与其他系统进行交互。
本文将介绍如何使用Java编写一个函数,将字符转换为ASCII码。
要将字符转换为ASCII码,我们可以使用Java中的类型转换,将字符转换为整数类型。
Java中的字符类型char是16位的,可以表示一个Unicode字符。
我们可以使用强制类型转换将其转换为整数类型int,从而获得对应的ASCII码。
下面是一个示例函数,将字符转换为ASCII码:```javapublic static int charToAscii(char c) {return (int) c;}```上述函数接受一个字符作为参数,并将其转换为对应的ASCII码。
函数内部使用了类型转换将字符转换为整数,然后返回转换结果。
使用这个函数,我们可以将任意字符转换为ASCII码。
下面是一个示例程序:```javapublic class Main {public static void main(String[] args) {char c = 'A';int ascii = charToAscii(c);System.out.println("字符 " + c + " 的ASCII码为 " + ascii); }public static int charToAscii(char c) {return (int) c;}}```运行上述程序,将输出字符 'A' 的ASCII码为 65。
除了将字符转换为ASCII码,我们还可以将ASCII码转换为字符。
同样地,我们可以使用类型转换来实现这个功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一符号与ASCII码的转换一、实验目的:1、熟悉英文字母和常用符号的基本编码理论。
2、了解数字符号和数字ASCII码值的区别。
3、使用高级语言实现符号与ASCII码的转换。
二、实验要求:1、界面友好、简洁2、变量和函数要有注释3、实验报告中要有程序流程图三、实验环境:1、硬件环境:主流配置计算机2、操作系统:Windows xp(替换成实际应用系统)3、编译平台:Visual C++ 6.0(替换成实际应用平台)(可选语言包括C、C++、Java等等)四、实验内容:1、介绍一下ASCII编码(查找整理资料)–编写ASCII码转换程序(用流程图表示)2、输入符号,打印出对应的ASCII码表(十进制、16进制、二进制)3、输入ASCII码值(十进制、或16进制、或二进制),打印出对应的符号。
4、创建一个文件(内容为一段英文),读入文件并将其中的符号转换为ASCII码,写入另一个文件。
–调试并通过该程序(抓图示例,实验体会)五、实验报告内容:1、实验名称2、实验目的3、实验要求4、实验环境5、实验内容(算法描述、算法流程)6、实验体会六、实验报告正文:1、ASCII编码的介绍ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。
它主要用于显示现代英语,而其扩展版本EASCII则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。
由于万维网使得ASCII广为通用,直到2007年12月,逐渐被Unicode取代。
ASCII码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。
标准ASCII码也叫基础ASCII码,使用7位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。
其中:0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL (响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。
它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。
所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。
奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码,目前许多基于x86的系统都支持使用扩展(或“高”)ASCII。
扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
2、编写ASCII码转换程序(用流程图表示)(1)、功能选择的提示(2)、将符号转换成ASCII码例如:“*”会显示十进制、十六进制、二进制的ASCII码。
ASCII码与进制之间的转换都是通过十进制的,再由十进制转换为二进制、十六进制。
(3)、将符号转换成ASCII码会跳出功能选择:十进制、十六进制、二进制来转换例如:“56”二进制的ASCII码例如:“10”十进制的ASCII码例如:“77”十六进制的ASCII码(4)、创建一个文件(内容为一段英文),读入文件并将其中的符号转换为ASCII码,写入另一个文件。
“summer”写入,先转换为十进制的ASCII码。
3、源代码(借鉴)#include<iostream.h>#include<fstream.h>void trans();void trans_dtob(int y);void trans_dtoh(int y);void convert();void convert_btoA();void convert_dtoA();void convert_htoA();void wjwrite();int main(){int x;while(1){cout<<"请输入您想选择的功能(选择相应代码,选择4结束):"<<endl;cout<<"1.将符号转换成ASCII码"<<endl;cout<<"2.将ASCII码转换成符号"<<endl;cout<<"3.将文件转换成ASCII码存在另外一个文件中"<<endl;cin>>x;switch(x) //进行功能选择的提示{case 1:trans();break;case 2:convert();break;case 3:wjwrite();break;case 4:return 0;}}}void wjwrite() //将文件中的字母转换成ASCII码并存在另一个文件中{ifstream in;ofstream out;out.open("D:\\file1.txt",ios::out); //以写的方式打开文件file1.txtchar a[100],y;int x;cout<<"创建文件(请输入英文字母,以0结束输入):"<<endl;while(1) //通过循环可进行多次的功能选取{cin>>y;if(y=='0')break;out<<y; //将字母写进file1.txt中}out.close();in.open("D:\\file1.txt",ios::in); //以读的方式打开文件file1.txtout.open("D:\\file2.txt",ios::out); //以写的方式打开文件file2.txtcout<<"读取的英文字符转换成十进制的ASCII码为:"<<endl;while(!in.eof()){in.getline(a,sizeof(a));for(int i=0;a[i];i++){x=(int)a[i]; //将读取的字母转换成ASCII码的十进制cout<<x<<" ";out<<x<<" "; //将转换得到的ASCII码存入file2.txt中}}in.close();out.close();cout<<endl;}void trans() //将符号转换成相应的ASCII码{char x;int y;cout<<"请输入需要转换的符号:"<<endl;cin>>x;y=(int)x;cout<<"转换成十进制为:"<<y<<endl;cout<<"转换为二进制:";trans_dtob(y);cout<<endl;cout<<"转换为十六进制:";trans_dtoh(y);cout<<endl;}void trans_dtob(int y) //将十进制转换成二进制{if(y<2)cout<<y;if(y>=2){trans_dtob(y/2); //利用递归的方式cout<<y%2;}}void trans_dtoh(int y) //将十进制转换成十六进制{int x;if(y<10)cout<<y;if(y>=10){trans_dtoh(y/16); //利用递归的方式x=y%16;if(x<10) //对余数小于10的值进行直接输出cout<<x;elseswitch(x) //对余数大于10的值输出值所对应的字母{case 10:cout<<"A";break;case 11:cout<<"B";break;case 12:cout<<"C";break;case 13:cout<<"D";break;case 14:cout<<"E";break;case 15:cout<<"F";break;}}}void convert() //将ASCII码转换成符号{int x;cout<<"请选择您将输入的进制类型:"<<endl;cout<<"1.二进制:"<<endl;cout<<"2.十进制:"<<endl;cout<<"3.十六进制:"<<endl;cin>>x;switch(x) //进行进制选择,确定对应的进制子函数{case 1:convert_btoA();break;case 2:convert_dtoA();break;case 3:convert_htoA();break;}}void convert_btoA() //将二进制的ASCII码转换成符号{char a[10],y;cout<<"请输入ASCII码:"<<endl;cin>>a; //将二进制数当做字符串进行输入int i,t;long sum=0;for(i=0;a[i];i++) //计算出二进制数的每一位上的数的值{t=a[i]-'0'; //与字符'0'进行作减,得到每位上的二进制数值sum=sum*2+t; //将二进制转换成十进制}y=(char)sum; //将ASCII码十进制强制转换成符号cout<<y<<endl;}void convert_dtoA() //将十进制的ASCII码转换成符号{int x;char y;cout<<"请输入ASCII码:"<<endl;cin>>x;y=(char)x;cout<<y<<endl;}void convert_htoA() //将十六进制的ASCII码转换成符号{char a[10],y;cout<<"请输入ASCII码:"<<endl;cin>>a; //将十六进制数当做字符串进行输入int i,t;long sum=0;for(i=0;a[i];i++) //计算出十六进制数的每一位上的数的值{if(a[i]<='9') //对小于'9'的字符,与'0'进行作减,求出该位置上数值的大小t=a[i]-'0';elset=a[i]-'A'+10; //对大于'9'的字符,与'A'进行比较,并求出该位置上数值的大小sum=sum*16+t; //转换成十进制}y=(char)sum;cout<<y<<endl;}4、实验体会这次的实验丰富了我对ASCII码的理解,但着实的知道了自己的编程能力实在是太差了。