数据库设计编码规范
数据库编码规范

数据库编码规范在当今数字化的时代,数据库作为存储和管理数据的核心组件,其重要性不言而喻。
为了确保数据库的高效运行、数据的准确性和一致性,以及便于维护和扩展,制定一套完善的数据库编码规范是至关重要的。
首先,让我们来谈谈数据库命名规范。
数据库中的对象,如表、视图、存储过程等,都应该有清晰、有意义且易于理解的名称。
表名应该准确反映其所存储的数据内容,例如,如果是存储用户信息的表,可以命名为“users”。
避免使用模糊、无意义的名称,如“table1”、“temp_table”等。
同样,视图的名称应该能够表明其提供的数据视图的性质,存储过程的名称应该能够清晰地表达其功能。
对于字段命名,也要遵循相似的原则。
字段名应该具有描述性,使用完整的单词而不是缩写,除非缩写是行业内普遍认可且不会产生歧义的。
例如,“user_name”比“uname”更清晰易懂。
此外,要保持命名的一致性,比如,如果采用了驼峰命名法,就应在整个数据库中都保持这种命名风格。
接下来是数据类型的选择。
正确选择数据类型不仅可以节省存储空间,还能提高数据处理的效率。
对于整数类型,如果值的范围较小,可以选择 tinyint 或 smallint;如果范围较大,则选择 int 或 bigint。
对于字符串类型,如果长度固定且较短,使用 char 类型;如果长度不固定且长度可能较大,使用 varchar 类型。
对于日期和时间类型,根据具体的需求选择 date、datetime 或 timestamp 等。
在设计表结构时,要遵循数据库的范式原则。
通常,达到第三范式是一个比较理想的状态。
这意味着每个表中的非主键字段都完全依赖于主键,且不存在传递依赖。
例如,如果有一个订单表,订单号是主键,而客户信息应该存储在单独的客户表中,通过客户 ID 与订单表关联,而不是直接将客户信息存储在订单表中。
索引的使用也是数据库优化的重要方面。
索引可以大大提高数据查询的效率,但过多或不当的索引也会影响数据的插入、更新和删除操作。
掌握数据库设计与编码的基本原则

掌握数据库设计与编码的基本原则数据库设计与编码是软件开发中非常重要的一环,它直接影响着系统的性能、稳定性以及可维护性。
在进行数据库设计与编码时,需要遵循一些基本原则,以确保系统的高效运行和可靠性。
下面我将介绍一些数据库设计与编码的基本原则。
1.数据库设计原则:1.1.数据库范式化:在设计数据库时,应该尽量遵循范式化设计原则,将数据分解成逻辑上相关的表,避免数据冗余和数据不一致的情况。
1.2.数据库表的规范命名:数据库表和字段的命名应该具有描述性,能够准确表达其所存储的数据内容,避免使用含糊不清的命名或者无意义的缩写。
1.3.设计合适的主键和外键:每个表应该有一个唯一的主键来标识记录,同时需要使用外键来建立表之间的关联关系,确保数据的完整性和一致性。
1.4.优化查询性能:在设计数据库时,需要考虑到系统的查询需求,合理设计索引和查询语句,以提高系统的查询性能。
1.5.考虑数据存储和访问的效率:在设计数据存储结构时,应该考虑到数据的访问频率和存储位置,尽量减少数据的冗余和无效存储。
2.数据库编码原则:2.1.避免硬编码:在编写数据库查询语句时,应该避免硬编码数据,尽量使用参数化查询,以防止SQL注入攻击和提高系统的安全性。
2.2.合理使用事务:在进行数据库操作时,需要使用事务来保证数据的完整性,将多个数据库操作视为一个原子操作,保证数据的一致性。
2.3.避免过度使用存储过程和触发器:存储过程和触发器能够提高数据库的处理效率,但过度使用会使数据库结构复杂难以维护,应该谨慎使用。
2.4.数据库连接池的管理:在编写数据库连接代码时,需要合理管理数据库连接池,避免频繁的连接和断开操作,提高系统的性能和稳定性。
2.5.合理使用缓存:在对数据库进行读取操作时,可以通过缓存技术来提高读取效率,但需要注意缓存的更新和失效,避免数据不一致的情况发生。
综上所述,数据库设计与编码是软件开发中至关重要的一环,设计和编码时需要遵循一些基本原则,如范式化设计、规范命名、优化查询性能、避免硬编码、合理使用事务等,以确保系统的高效运行和可靠性。
SQL数据库设计,编码开发规范(转)

SQL数据库设计,编码开发规范(转)SQL Server Database Design, Code and DevelopmentStandards1.更改Change Name Date命名原则:表意性原则(增加) DavidDong Jan/05数据库命名DavidDong Jan/05表命名DavidDong Jan/05Server/Instance命名DavidDong Jan/05JOB,复制命名DavidDong Jan/052.简介数据库设计是指对于⼀个给定的应⽤环境,构造最优的数据库模式,建⽴数据库及其应⽤系统,有效存储数据,满⾜⽤户信息要求和处理要求数据库设计和开发标准是使Newegg Support Center的数据库系统的设计和开发正式化的标准。
通过此标准,来规范数据库设计。
通过⼀致的系统解决⽅案,能给我们的系统带来以下优点:¨开发出⾼可管理性的⾼质量系统¨能够快速的进⾏开发¨减少维护代码的时间Ø ⾮常容易的把代码从⼀个项⽬拷贝⾄另⼀个项⽬Ø 节省把游标,错误处理信息从⼀个项⽬中拷贝到另⼀个项⽬中的时间Ø 使程序逻辑简单化Ø 不⽤花费时间在常规的事情上,⽐如对象名称转换等,并可允许多次设计,编程和对复杂事件的测试⼯作¨在代码出错时⼤⼤节省时间¨只要在第⼀次是有个良好的设计3.开发环境3.1数据库模型CA公司的ERwin/SQL是数据建模的⼀个⾸选⼯具.在开发经常改变的项⽬时,使⽤ERwin来⽣成表(创建/删除),索引,规则,数据类型等数据库对象的脚本,在对项⽬⽂件进⾏修改之前,请确认已经对这些脚本进⾏过备份.任何数据库的改变,不管是在开发中还是在产品服务器中,都要⽤ERwinDiagram中进⾏相应的修改.如果产品服务器上做出了更改,则⼀定要对主脚本和ERwin diagram进⾏相应更新.3.2 Diagrams使⽤Visio进⾏数据diagram,流程图,服务器拓朴和其它diagrams进⾏设计.⽂档化系统或者处理流程可以⼤⼤有利于团队间的协作.3.3版本控制推荐使⽤Visual SourceSafe(VSS)对NESE数据库对象进⾏管理.在任何项⽬中,都应该有很好的代码更改控制,初始版本⽂件应该放到VSS中并被注释.所有对这些⽂件的后继更改都应该放到VSS中管理.3.4 源码⽬录结构在项⽬刚开始时,找到⼀个所有Team成员都能够访问的共享.按照以下结构初始化VSS⽬录和数据库⼦⽬录:\CMD 包括全系统脚本的脚本⽂件,如果是⼀个多数据库的系统,应该有⼀个可能创建所有数据库的命令⽂件.\DBName 在系统中的每个数据库应该有⾃⼰的⽬录结构,如下:\CMD:⽤来创建此数据库的脚本⽂件,并且来更改数据库构架.\DAT:⽤来刷新此数据库的数据⽂件.\SP:⽤来存储存储过程的脚本\TBL:除了下⾯⼦⽬录,这个⽬录应该包括表的定义脚本,每个表应该有它⾃⼰的脚本,此脚本应该包括经表的删除,创建语句,索引,触发器,完整性参照,Check约束,默认值约束等,每个表创建语句应该包括在不同的脚本中,并被把归类到类似于下⾯的相应的⼦⽬录中.注意:本⽬录中的脚本和以下⼦⽬录的脚本应该命名为它所影响的表名,⽐如:表名.sql:\Check:为每个表创建独⽴的Check约束定义脚本,Check约束应该使⽤alter table add constraint 来创建,并且每个altertable 语句只能包括⼀个contraint。
数据库编码规范

数据库编码规范技术研发中心2020年12月12日文档修订目录1. 概述 (4)1.1 编写目的 (4)1.2 使用范围 (4)1.3 参考文献 (4)2. 数据库开发 (5)2.1 概述 (5)2.2 注释编写规范 (5)2.3 SQL在JAVA代码中的编写规范 (5)2.4 SQL编写原则 (6)3.附录 (10)3.1 建议 (10)3.2 SQL优化 (13)3.2.1 利用Navicat Premium工具分析SQL执行效率 (13)1.概述1.1编写目的本文描述了使用SQL技术进行编程的一些规范。
为保证在开发过程中产出高效、格式统一、易阅读、易维护的SQL代码,利于不同开发人员维护,所有的数据库代码和相关文档都应遵循本文档描述的规则和约定。
1.2使用范围开发人员、工程实施人员、系统维护人员1.3参考文献《数据库开发规范》2.数据库开发2.1概述1、数据库开发工具使用Navicat Premium,便于应用统一的美化器对所有数据库程序代码实现统一的格式化;便于使用数据库程序模版创建统一格式的数据程序对象。
2、数据库中存储的程序代码不可具备事务提交功能,所有事务的提交在应用层完成。
3、数据库中的程序代码统一使用存储包的形式,不再出现单独的存储过程或者函数。
4、存储包超过6000行需另建存储包。
5、动态SQL执行必须使用BIND变量。
6、程序代码内中不可出现DDL语句。
2.2注释编写规范每个数据库程序对象(包、包内过程函数、触发器、自定义类等)、变量及常量必须使用注释。
注释方式:/**/2.3SQL在JAVA代码中的编写规范SQL语句在程序中应尽量少的出现(写在数据库存储过程中,后台执行效率较高),必须出现则一般以字符串的形式出现,现对程序中的SQL书写做以下约定。
●java代码中出现的SQL语句包括(字段名,表名,SQL关键字、保留字)均应采用大写形式;●避免在java代码中,使用循环语句多次执行数据库查询;●用于查询/更新/删除的SQL,WHERE条件固定的,必须使用预编译方式;●对SQL语句加上适当的注释,特别是对语句上出现的枚举值要标明其含义;●合理使用空格和缩进,保证SQL语句结构清晰;➢在SQL内置运算符前后加上空格;➢在SQL关键字、保留字前后都要有空格;➢拼接SQL时,新一行加上空格;●SQL语句较长时,应把SQL语句放在一个方法内;➢在每一个子句及逻辑判断占一行;➢对子查询使用缩进,一般为4个字符;➢SQL语句应该保持在80行以内;●代码中严禁使用SELECT * 代替具体的字段名。
数据库设计规范_编码规范

数据库设计规范_编码规范数据库设计规范包括数据库表结构的设计原则和数据库编码规范。
数据库表结构的设计原则包括表的命名规范、字段的命名规范、主键和外键的设计、索引的使用、约束的定义等。
数据库编码规范包括SQL语句的书写规范、存储过程和函数的命名规范、变量和参数的命名规范、注释的使用等。
1.表的命名规范-表名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:user_info。
- 表名使用单数形式,如:user、order。
2.字段的命名规范-字段名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 字段名使用小写字母,使用下划线(_)作为单词之间的分隔符,如:user_name。
- 字段名要具有描述性,可以清楚地表示其含义,如:user_name、user_age。
3.主键和外键的设计-每张表应该有一个主键,用于唯一标识表中的记录。
- 主键字段的命名为表名加上“_id”,如:user_id。
- 外键字段的命名为关联的表名加上“_id”,如:user_info_id,指向user_info表的主键。
4.索引的使用-对于经常用于查询条件或连接条件的字段,可以创建索引,提高查询性能。
-索引的选择要权衡查询性能和写入性能之间的平衡。
-不宜为每个字段都创建索引,避免索引过多导致性能下降。
5.约束的定义-定义必要的约束,保证数据的完整性和一致性。
-主键约束用于保证唯一性和数据完整性。
-外键约束用于保证数据的一致性和关联完整性。
6.SQL语句的书写规范-SQL关键字使用大写字母,表名和字段名使用小写字母。
-SQL语句按照功能和逻辑进行分行和缩进,提高可读性。
-使用注释清晰地描述SQL语句的功能和用途。
7.存储过程和函数的命名规范-存储过程和函数的命名要具有描述性,可以清楚地表示其功能和用途。
-使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:get_user_info。
数据库编码规范

命名和注释规范1.数据库涉及字符规范采用26个英文字母(区分大小写)和0-9这十个自然数,加上下划线_组成,共63个字符。
不能出现其他字符(注释除外)。
2.数据库对象命名规范数据库对象包括表、视图(查询)、存储过程(参数查询)、函数、约束。
对象名字由前缀和实际名字组成,长度不超过30。
在SYBASE ASE下,对象名区分大小写,统一使用大写,其他数据库按照本规范。
前缀:使用小写字母字典表d_视图view存储过程proc函数func实际名字:实际名字尽量描述实体的内容,由单词或单词组合,每个单词的首字母大写,其他字母小写,不以数字和_开头。
如视图User_List存储过程User_Delete因此,合法的对象名字类似如下。
视图view_Message_List存储过程proc_Message_Add3.视图命名规范我们约定,字段由前缀和实际名字组成,中间用下划线连接。
前缀:使用小写字母view,表示视图。
因此,合法的视图名类似如下。
view_Userview_UserInfo4.存储过程命名规范我们约定,过程由前缀和实际名字加操作名字组成,中间用下划线连接。
前缀:使用小写字母proc,表示存储过程。
操作名字:Insert|Delelte|Update|Caculate|Confirm|Init例如:proc_User_Insert5.存储过程设计注释规范注释大致格式如下:CREATE OR REPLACE PROCEDURE proc_xxxx_xxxx ()IS(或AS)/*************************************************** 存储过程名:proc_xxxx_xxxx* 作者:Yezi(叶子)* 日期:2004-12-17* 版本: 1.0* 描述:保存用户资料* 入口参数:* 出口参数:* 具体流程:* 变更过程及变更内容描述:*************************************************/6.sql语句规范所有sql关键词全部大写,比如SELECT,UPDATE,FROM,ORDER,BY等。
数据库设计规范_编码规范

数据库设计规范_编码规范1.命名规范:表名、字段名和约束名应该具有描述性,遵循一致的命名规则。
避免使用保留字作为名称,使用下划线或驼峰命名法。
2.数据类型选择:选择合适的数据类型来存储数据,避免过大或过小的数据类型。
这有助于减小数据库的存储空间,提高查询性能。
3.主键和外键:每个表都应该有一个主键来唯一标识每条记录。
外键用于建立表之间的关系,确保数据的一致性和完整性。
4.表的范式:根据具体需求,遵循规范化设计原则。
将数据分解为多个表,减少数据冗余和更新异常。
5.索引设计:根据查询需求和数据量,设计适当的索引。
避免过多或不必要的索引,以减小索引维护的开销。
6.分区设计:对大型表进行分区,将数据分散存储在不同的物理磁盘上,提高查询性能。
7.安全性设计:为数据库设置适当的权限和访问控制,限制不必要的用户访问和操作。
数据库编码规范:1.编码一致性:统一使用同一种编码方式,如UTF-8,避免不同编码之间的转换问题。
2.参数化查询:使用参数化查询语句,预编译SQL语句。
这样可以防止SQL注入攻击,提高查询性能。
3.事务管理:使用事务控制语句(如BEGIN、COMMIT和ROLLBACK)来管理数据库事务,确保数据的一致性和完整性。
4.错误处理:在代码中捕获和处理数据库错误和异常,提高系统的容错性。
5.SQL语句编写:编写简洁且优化的SQL语句,避免使用多个嵌套的子查询,使用JOIN操作符进行表之间的关联。
6.数据库连接管理:优化数据库连接,避免频繁地打开和关闭数据库连接。
7.缓存机制:对于频繁查询的数据,使用缓存机制来减少数据库的压力。
8.日志记录:记录数据库操作日志,包括增删改查的操作,以便后续的问题跟踪和审计。
综上所述,数据库设计规范和编码规范对于确保数据库系统的性能、安全性和可维护性至关重要。
遵循这些规范能够提高数据库系统的效率和可靠性,减少潜在的问题和风险。
因此,在进行数据库设计和编码时,应该遵循这些规范。
Oracle数据库编码规范

Oracle数据库编码规范1目的使用统一的命名和编码规范,使数据库命名及编码风格标准化,以便于阅读、理解和继承。
2适用范围本规范适用于公司范围内所有以ORACLE作为后台数据库的应用系统和项目开发工作。
3规范3.1书写规范丑陋的书写规范不仅可读性较差,而且给人以敬而远之的感觉;而良好的书写规范则给人以享受和艺术的体验。
3.1.1大小写风格规则3.1.1.1所有数据库关键字和保留字命名使用大小写不做要求。
3.1.2缩进风格规则3.1.2.1程序块严格采用缩进风格书写,保证代码清晰易读,风格一致,缩进格数统一为2/4个。
必须使用空格,不允许使用【Tab】键。
以免在用不同的编辑器阅读程序时,因【Tab】键所设置的空格数目不同而造成程序布局不整齐。
规则3.1.2.2当同一条语句需要占用多于一行时,每行的其他关键字与第一行的关键字进行右对齐。
IF flag = True THENSelect usernameInto vUserInfoFrom userInfoWhere userId = ‘id’END IF;3.1.3空格及换行规则3.1.3.1不允许把多个语句写在一行中,即一行只写一条语句且一行最长不能超过80字符;规则3.1.3.2避免将复杂的SQL语句写到同一行,建议要在关键字和谓词间换行。
WHERE子句书写时,每个条件占一行。
规则3.1.3.3相对独立的程序块之间必须加空行。
BEGIN、END独立成行。
3.1.4其它规则3.1.4.1确保变量和参数在类型和长度上与表数据列相匹配。
如果与表数据列宽度不匹配,则当较宽或较大的数据传进来时会产生运行异常。
3.2命名规范对于命名规范来说,想要做到完全统一的确是不可能的任务。
命名规范更多的是个人层面的爱好,既使无法完全做到一致,但是我们仍然要尽量去遵守。
3.2.1字段命名规范在此仅提供几种常见的命名方法,如表3-2-1所示。
表3-2-1 命名规范表规则3.2.1.1不建议使用数据库关键字和保留字,原因是为了避免不必要的冲突和麻烦。
数据库设计规范_编码规范标准[详]
![数据库设计规范_编码规范标准[详]](https://img.taocdn.com/s3/m/c18fd279336c1eb91b375d32.png)
数据库编码规范1 目的为了统一公司软件开发的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。
2 范围本规范适用于全体开发人员,作用于软件项目开发的数据库设计、维护阶段。
3 术语Ø数据库对象:在数据库软件开发中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
Ø物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。
一般对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
Ø逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。
4 设计概要4.1 设计环境a) ORACLE 11G R2数据库ORACLE 11G R2操作系统LINUX 6以上版本,显示图形操作界面b) MS SQL SERVER 2005数据库SQL SERVER 2005 企业版打sp3以上补丁和安全补丁操作系统WINDOWS 2008 SERVER4.2 设计使用工具a) 使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说明。
对于SQL Server 尽量使用企业管理器对数据库进行设计,并且要求对表,字段编写详细的说明(这些将作为扩展属性存入SQL Server中)b) 通过PowerDesigner 定制word格式报表,并导出word文档,作为数据字典保存,格式。
(PowerDesigner v10 才具有定制导出word格式报表的功能)。
对于SQL Server 一旦在企业管理器进行数据库设计时加入扩展属性,就可以通过编写简单的工具将数据字典导出。
c) 编写数据库建数据库、建数据库对象、初始化数据脚本文件4.3 设计原则a) 采用多数据文件b) 禁止使用过大的数据文件,unix系统不大于2GB,window系统不超过500MBc) oracle数据库中必须将索引建立在索引表空间里。
数据库设计编码规范

SQL Serve数据库设计规范一、数据库命名规范:对象前缀命名:前缀命名一般用小写表的前缀:业务模块组名前缀数据列的前缀:一般采用列的数据类型做前缀存储过程前缀:udp ,系统存储过程(sp)自定义函数前缀:udf(User define function)视图前缀:udv(User Define View)表示用户自定义视图自定义规则前缀:udr(User Define rule)用户自定义规则自定义约束前缀:uck(User Checker)用户自定义约束索引前缀:idx(Index)表示索引主键前缀:pk(primary keys)表示主键数据列的前缀示例:编号 1 2 3 4 5 6 7数据类型char varchar int smallint datetime money numeric 前缀 c vc i si dt m n 编号8 9 10 11 12 13数据类型decimal float bit binary image text前缀 d f b b img tx二、数据库设计规范:1、每个表中都可以考虑添加的的几个有用的字段RecoredID,记录唯一编号,不建议采用业务数据作为记录的唯一编号CreationDate,在SQL Server 下默认为GETDATE()RecordCreator,在SQL Server下默认为NOT NULL DEFAULT USERRecordVersion,记录的版本标记;有助于准确说明记录中出现null 数据或者丢失数据的原因2、数据类型:字符类型一般不建议采用char而采用varchar数据类型,除非当这列数据的长度特别固定时可以考虑用char。
数值类型如果表示金额货币建议用money型数据,如果表示科学记数建议用numeric数据类型记录标识一般采用int类型标识唯一一行记录。
自增or 非自增3、索引:所有的表都应该有一个主键索引,这对提高数据库的性能很有帮助根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
数据库设计、命名、编码规范

4.4 视图名
Pascal 命名规范 视图的名称 如 = "vw_" + 视图内容标识
vw_UserPerm
4.5 触发器名
触发类型 触发标识
----------------------------------Insert Delete Update I D U
触发名=
"tr_"
+模块名称 +
相应的表名 +
查询或其它 存储过程名称 识 如 UP_Sale_Client_I =
S UP_模块名 + 下划线 + 表名 + 存储过程功能标
4.7 变量名
Pascal 命名规范
4.8 游标命名
游标应该以下面的标准来命名: 表名或者对象名字{使用此游标的对象名字}+CURSOR 例如: FiscalMonthCURSOR EmployeeListCURSOR
Sales_FK_Customer
4.12 索引命名
索引的命名应该在表空间内唯一,当查看执行计划时可以有效的对索引进行识 别.. [IX][类型(U 标识 Unique,C 标识 Clustered)][列名(s)] Ø Ø Ø Ø Ø 例如: IXUC_SalesId (clustered unique) 当对单列进行索引时,你可能需要使用列的全名. 当对多列进行索引时,要使用你所能想到的最优的缩写. 当对一个表的所有列进行索引时,使用 ALL 单词. 在多列名中使用下划线以增加可读性. 不要为索引加上序列号
6.
注释
注释可以包含在批处理中。在触发器、存储过程中包含描述性注释将大大增加文本 的可读性和可维护性。 1. 注释语法包含两种情况:单行注释、多行注释 单行注释:注释前有两个连字符(--),一般,对变量、条件子句可以采用该 类注释,在注释代码上一行。 多行注释:符号/*和*/之间的内容为注释内容。对某项完整的操作建议使用该类 注释。 2. 注释以中文为主。 实际应用中,发现以中文注释的 SQL 语句版本在英文环境中不可用。为避免后 续版本执行过程中发生某些异常错误,中文环境下用中文,外包项目一律用英 文。 3、 注释尽可能详细、全面。 创建每一数据对象前,应具体描述该对象的功能和用途。 传入参数的含义应该有所说明。如果取值范围确定,也应该一并说明。取值有 特定含义的变量(如 boolean 类型变量),应给出每个值的含义。 4、 注释简洁,同时应描述清晰。
数据库设计编码规范
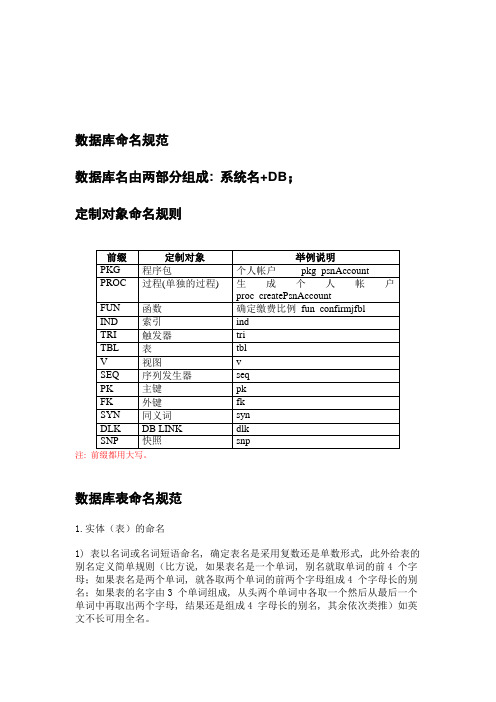
数据库命名规范数据库名由两部分组成: 系统名+DB;定制对象命名规则注:数据库表命名规范1.实体(表)的命名1) 表以名词或名词短语命名, 确定表名是采用复数还是单数形式, 此外给表的别名定义简单规则(比方说, 如果表名是一个单词, 别名就取单词的前4 个字母;如果表名是两个单词, 就各取两个单词的前两个字母组成4 个字母长的别名;如果表的名字由3 个单词组成, 从头两个单词中各取一个然后从最后一个单词中再取出两个字母, 结果还是组成4 字母长的别名, 其余依次类推)如英文不长可用全名。
对工作用表来说, 表名可以加上前缀WORK_ 后面附上采用该表的应用程序的名字。
在命名过程当中, 根据语义拼凑缩写即可。
注意, 由于ORCLE会将字段名称统一成大写或者小写中的一种, 所以要求加上下划线。
举例:定义的缩写 Sales: SAL 销售;Order: ORD 订单;Detail: DTL 明细;则销售订单明细表命名为: TBL_SAL_ORD_DTL;2) 如果表或者是字段的名称仅有一个单词, 那么建议不使用缩写, 而是用完整的单词。
举例:定义的缩写 Material MA 物品;物品表名为: TBL_Material, 而不是 MA.但是字段物品编码则是: MATERIAL_ID3) 关联类通过用下划线连接两个基本类之后, 再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母, 必须将原来的表名的进行缩写。
如果没有其他原因, 建议都使用缩写。
举例: 表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_OBJECT;表 Depart和Employee;存在多对多的关系;则关联表命名为TBL_R_DEPT_EMP 属性命名规范1.属性(列)的命名1) 采用有意义的列名, 表内的列要针对键采用一整套设计规则。
每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码, 统一命名为: ID;如果是自定义的逻辑上的编码则用缩写加“ID”的方法命名。
数据库编码的标准和准则

数据库编码的标准和准则本章文档提供一种规范,通过定义一种合理,一致,有效的编码样式来帮助用户使用为应用程序开发的Microsoft SQL Server 2005框架,脚本和存储过程。
决定编码可用性有以下4点。
<1>对其他数据人员的可读性<2>实现的难易程度<3>可维护性<4>一致性此框架可用来改善应用程序,不会给开发带来不必要的影响,也不会限制个人的编码习惯。
因此,此框架主要针对所有开发人员都使用的通用标识符命名约定,所以说明SQL语言组建的首选格式和常用样式准则,以及数据库开发方法论的定义。
此标准的“标识符”部分将对命名约定进行规范化。
所有框架,脚本和存储过程应符合本文当中这一部分中所有原则。
常用准则包括SQL语句的格式化以及处理脚本和存储过程中更复杂的组建和格式要点。
必要时,可以修改准则以满足应用程序中的特殊格式要求。
尽管该准则不是强制性的,遵循它有助于应用程序的最终成功,使用应用程序更易于维护。
所有人员在合理的范围内避免出现与该准则的不一致。
遵循标准并根据本文档中的准则进行开发,在“方法论”部分将对这种行为进行评测。
有必要定义一个大家都遵循的,通用的,强制性的编码标准。
如果没有这样的标准,存储过程和脚本的开发可能会变的很随便,并且可读性差,从而降低了可用性。
这是开发人员或开发方法存在的缺点,而不是框架的缺点。
在准则的范围内,定义大多数的样式和布局,但同时不做刻板的要求,可以是开发人员轻松的编写可靠的,有创意的代码。
框架中的这种自由度,用来协议编码工作的常规性与创造性。
明确的定义管理措施,并执行可以确保实现该标准或任何编码标准的目的。
下面对各部分进行说明1 大小写(1)表明和视图名都使用大写形式。
(2)列名和变量名使用大小写混合形式。
(3)存储过程名使用大小写混合形式。
(4)其他名称使用小写形式,但如果表名或列名用于其他对象名中,则使用上述大小写形式。
数据仓库设计编码规范3.0

分级存储(四)
近线存储 近线存储是指将数据存放在低速的磁盘系统上,一般 是一些存取速度和价格介于高速磁盘与磁带之间的低端磁盘设 备。 近线存储外延相对比较广泛,主要定位于客户在线存储和 离线存储之间的应用。就是指将那些并不是经常用到(例如一 些长期保存的不常用的文件归档),或者说访问量并不大的数 据存放在性能较低的存储设备上。但对这些设备的要求是寻址 迅速、传输率高。 因此,近线存储对性能要求相对来说并不高,但又要 求相对较好的访问性能。同时多数情况下由于不常用的数据要 占总数据量的较大比重,这也就要求近线存储设备在需要容量 上相对较大。近线设备主要有SATA磁盘阵列、DVD-RAM光盘塔 和光盘库等设备。
26数据库对象命名前后缀一前后缀说明dmsifdwdwmfctlogbufhisusrexpdm维表接口表明细数据表轻量汇总数据汇总中间层事实事实表日志表中间计算缓冲表历史数据表用户信息及权限相关信息表数据导出挖掘相关结果表27数据库对象命名前后缀二pk主键fk外键ixu唯一索引ck检查约束28ix索引ixbmp位图索引seq序列vw视图mv物化视图fun函数数据库帐户管理类别帐户用途描述管理perfdb管理数据库管理和监控取代sys用户应用backgrounduser后台处理etl处理fforegroundusergdu前台
6
数据仓库基本概念(三)
ODS: : ODS是企业数据架构中最为复杂的一种形态,既要满足数据事务操作要求, 又要满足数据分析要求,从技术构建角度考察,难度相当之大。其主要功能是 给数据仓库提供数据,作为EDW的数据源。 ODS与数据仓库的重要区别如下: (一)、ODS只存储明细数据。 (二)、ODS中存储的数据一般不超过一个月。 (三)、ODS支持事务更新操作。 (四)、ODS是应用系统数据库的一个延迟快照。 根据延迟时间的长度,分为: I类ODS,实时或近似实时,与应用系统的数据延迟为1~2秒。 II类ODS,与应用系统的数据延迟为2~4小时。 III类ODS,与应用系统的数据延迟为12~24小时。
数据库编码规则

fs表名如果表名超过一个单词第一个单词头字母小写外其它单词的头字母都大写如
数据库编码规则
数据库编码规则
1、 数据库名称:FDAYS + “库名”,如:FDAYSTour 2、 数据表名称:FS + “_” +“表名”,如果表名超过一个单词,第一个单词头字母小写外,其它单词的头字母都大写,如:FS_adminUser 3、 数据表字段命名:“字段名”,如:UserName,注ID字段名为:UserId 4、 视图名称:VI + “_” + “视图名”,如:VI_adminUser 5、 存储过程名称:PR + “_” + “存储过程名”,如:PR_addAdminUser 6、 函数名称:FN + “_”+ “函数名称”,如:FN_getUser 7、 规则名称:RU + “_” + “规则名称”,如:RU_userCode 8、 游标名称:CU + “_” + “游标名称”,如:CU_getUser 9、 触发器名称:TG + “_” + “触发器名称”,如:TG_delUserByDate 10、SQL语句用大写字母书写,如:SELECT * FROM FS_adminUser
Oracle数据库编码规范

Oracle数据库编码规范数据库命名规范1、编写目的使用统一的命名和编码规范,使数据库命名及编码风格标准化,以便于阅读、理解和继承。
2、适用范围本规范适用于公司范围内所有以ORACLE作为后台数据库的应用系统和项目开发工作。
3、对象命名规范3.1数据库和SID数据库名定义为系统名+模块名★全局数据库名和例程SID 名要求一致★因SID 名只能包含字符和数字,所以全局数据库名和SID 名中不能含有“_”等字符3.2表相关3.2.1 表空间★面向用户的专用数据表空间以用户名+_+data命名,如Aud 用户专用数据表空间可命名为Aud_data★面向应用的表空间:应用名+_+模块名+_data (数据空间)应用名+_+模块名+_idx (索引空间)应用名+_+模块名+_tmp (临时空间)3.2.2 表空间文件表空间文件命名以表空间名+两位数序号(序号从01开始)组成,如dms_vorder_data01 等3.2.3 表表命名要遵循以下原则:★一般表采用“系统名+t_+模块名+_+表义名”格式构成(模块名一般不超过10位) ★若数据库中只含有单个模块,命名可采用“系统名+t_+表义名”格式构成★模块名或表义名均以其英文命名,命名过程中适当截取,最多不超过50个字符;★表别名命名规则:取表义名的前3 个字符加最后一个字符。
如果存在冲突,适当增加字符(如取表义名的前4 个字符加最后一个字符等)★临时表采用“系统名+t_tmp_+表义名”格式构成★表的命名如dmst_vorder_declare:系统名(经销商管理系统 dms)+t_+模块名(整车订单 vorder)+_+表义名(申报 declare)★关联表命名为Re_表A_表B,Re 是Relative的缩写,表A 和表B均采用其表义名或缩写形式。
3.2.4 属性(列或字段)属性命名遵循以下原则:★采用有意义的列名,为实际含义的英文截取,且字符间可有下划线★属性名前不要加表名等作为前缀★属性后不加任何类型标识作为后缀★关联字段命名以“cd+_+关联表的表义名(或缩写)+_+字段名”进行所有表必须有以下字段:字段名中文字段类型备注Id Id号Number 表主键,对应sequence 为seq_+表名factorycode 工厂编码Varchar2(50)createtime 创建时间Date 默认系统时间createby 创建人Varchar2(100)updatedtime 修改时间Dateupdatedby 修改人Varchar2(100)Lockedflag 锁定标记Varchar2(2) 默认为0,1为锁定,0为解锁Lockedtime 锁定时间DateLockedby 锁定人Varchar2(100)Deleteflag 删除标记Varchar2(2) 默认为0,1为删除,0为正常可用注意:在用POWER DESIGNER进行设计时,注意将每个字段的备注都填上(内容可为其中文含义及特殊说明,以便数据库文档的生成及后续开发的人员的理解)3.2.5 主键★任何表都必须定义主键★表主键命名为:“pk+_+表名(或缩写)+_+主键标识3.2.6 外键表外键命名为:“fk+_+表名(或缩写)+_主表名(或缩写)+_+主键标识3.2.7 CHECK约束CHECK 约束命名为:“chk+_+CHECK约束的列名(或缩写)”3.2.8 UNIQUE约束UNIQUE 约束命名为:“unq+_+UNIQUE约束的列名(或缩写)”3.2.9 索引索引的命名为:“idx_+表名(或缩写)+_+列名”。
数据库编码标准

数据库编码标准MIS系统课程设计规范(草案)1.开发环境规范使用windows 操作系统使用SQL Server 或ACCESS数据库2.开发语言规范使用团队熟悉的一种开发语言,如:VB,Delphi,ASP,JSP,Java……3.开发文档的规范需求文档规范设计文档规范程序编码标准附录:数据库编码标准9.1大小写规则1.关键字采用大写。
2.系统定义的对象及数据类型采用小写。
3.引用变量、参数、列名,以及表、过程和视图之类的对象名时,使用混合的大小写9.2缩进与空白1.选择a.一般缩进为两个英文字符的宽度,但SELECT语句的折行显示应字段对齐,例如:SELECT CustomerID,Companyname,ContactName,ContactTitle,Address, City,Region,PostalCode,Country,Phone,Fax,FROM Northwind.dbo.customersb.没有理由将一个短的SELECT语句拆为多行。
例如:IF EXISTS(SELEC * FROM Northwind.dbo.Customers)c.对于比较长的SELECT语句,通常将每个主要子句放置在单独的一行中,并且让它们左对齐。
通常将列紧挨SELECT保留字之右放置。
如果存在许多列而无法放置在同一行中,则只要在下一行中继续给出此列表,通常对位于第二行和后续行中的列缩进排列,以便它们与第一行中的列对齐。
例如:SELECTCustomerID,Companyname,ContactName,ContactTitle,Address, City,Region,PostalCode,Country,Phone,Fax,FROM Northwind.dbo.customersWHERE City IN('London','Madred')2.字句与谓词a.构成主要子句的较小子句让它们相互对齐, 如果将一个复合句的组成部分放置在同一行中,则通常用圆括号分隔它们。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SQL Serve数据库设计规范一、数据库命名规范:对象前缀命名:前缀命名一般用小写表的前缀:业务模块组名前缀数据列的前缀:一般采用列的数据类型做前缀存储过程前缀:udp ,系统存储过程(sp)自定义函数前缀:udf(User define function)视图前缀:udv(User Define View)表示用户自定义视图自定义规则前缀:udr(User Define rule)用户自定义规则自定义约束前缀:uck(User Checker)用户自定义约束索引前缀:idx(Index)表示索引主键前缀:pk(primary keys)表示主键数据列的前缀示例:编号 1 2 3 4 5 6 7数据类型char varchar int smallint datetime money numeric 前缀 c vc i si dt m n 编号8 9 10 11 12 13数据类型decimal float bit binary image text前缀 d f b b img tx二、数据库设计规范:1、每个表中都可以考虑添加的的几个有用的字段RecoredID,记录唯一编号,不建议采用业务数据作为记录的唯一编号CreationDate,在SQL Server 下默认为GETDATE()RecordCreator,在SQL Server下默认为NOT NULL DEFAULT USERRecordVersion,记录的版本标记;有助于准确说明记录中出现null 数据或者丢失数据的原因2、数据类型:字符类型一般不建议采用char而采用varchar数据类型,除非当这列数据的长度特别固定时可以考虑用char。
数值类型如果表示金额货币建议用money型数据,如果表示科学记数建议用numeric数据类型记录标识一般采用int类型标识唯一一行记录。
自增or 非自增3、索引:所有的表都应该有一个主键索引,这对提高数据库的性能很有帮助根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
把经常一起出现的字段组合在一起,组成组合索引,组合索引的字段顺序与主键一样,也需要把最常用的字段放在前面,把重复率低的字段放在前面。
一个表不要加太多索引,因为索引影响插入和更新的速度。
4、保证数据的一致性和完整性:主外键关联SQL SERVER的主键同时是一个唯一索引外键是最高效的一致性维护方法,数据库的一致性要求,依次可以用外键CHECK 约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。
谨慎使用级联删除和级联更新5、建立约束实现数据有效性检测A、可以为某一列特别重要的值建立好约束。
例如:需要凭数据库里面的SaleKind列数据判定销售类别,0值为门店销售,1为网上销售。
系统只有这两种销售渠道,就应该为它建立约束,它的值只能在0和1之间。
即SaleKind>0 and SaleKind<3B、设置默认值适当的设置默认值。
4、视图数据的安全性还可以用视图来控制。
视图可以把用户关心的那部分数据显示给用户,而把无关的数据隐藏起来。
5、安全性:操作数据库不建议用SA用户,因为SA用户权限过大。
具体的应用应该创建相应的数据库操作用户,并只赋给它指定数据库操作的权限!6、编码所有程序员要有性能意识,也就是在实现功能同时有考虑性能的思想,数据库是能进行集合运算的工具,我们应该尽量的利用这个工具,所谓集合运算实际是批量运算,就是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。
A、只返回需要的数据。
横向来看,不要写SELECT *的语句,而是选择你需要的字段。
纵向来看,合理写WHERE子句,不要写没有WHERE的SQL语句。
注意SELECT INTO后的WHERE子句,因为SELECT INTO把数据插入到临时表,这个过程会锁定一些系统表,如果这个WHERE子句返回的数据过多或者速度太慢,会造成系统表长期锁定,诸塞其他进程。
对于聚合查询,可以用HA VING子句进一步限定返回的行。
B、注意临时表和表变量的用法在复杂系统中,临时表和表变量很难避免,关于临时表和表变量的用法,需要注意:如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成;如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据;如果需要综合多个表的数据,形成一个结果,可以考虑用临时表和表变量分步汇总这多个表的数据;其他情况下,应该控制临时表和表变量的使用;关于临时表和表变量的选择,很多说法是表变量在内存,速度快,应该首选表变量,但是在实际使用中发现,这个选择主要考虑需要放在临时表的数据量,在数据量较多的情况下,临时表的速度反而更快。
关于临时表产生使用SELECT INTO和CREATE TABLE + INSERT INTO的选择,我们做过测试,一般情况下,SELECT INTO会比CREATE TABLE + INSERT INTO的方法快很多,但是SELECT INTO会锁定TEMPDB的系统表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,在多用户并发环境下,容易阻塞其他进程,所以我的建议是,在并发系统中,尽量使用CREATE TABLE + INSERT INTO,而大数据量的单个语句使用中,使用SELECT INTO。
注意排序规则,用CREA TE TABLE建立的临时表,如果不指定字段的排序规则,会选择TEMPDB的默认排序规则,而不是当前数据库的排序规则。
如果当前数据库的排序规则和TEMPDB的排序规则不同,连接的时候就会出现排序规则的冲突错误。
一般可以在CREATE TABLE建立临时表时指定字段的排序规则为DATABASE_DEFAULT来避免上述问题。
三、SQL编码优化:设计阶段设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能调优的过程—数据库设计。
在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效率的代码,为整个系统的性能打下良好的基础。
以下是性能要求设计阶段需要注意的:1、数据库逻辑设计的规范化数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式:第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。
第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组成部分。
消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。
第3规范: 一个非关键字段不能依赖于另一个非关键字段。
消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。
更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三范式,系统会产生较少的列和较多的表,因而减少了数据冗余,也利于性能的提高。
2、合理的冗余完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。
冗余可以是冗余数据库、冗余表或者冗余字段,不同粒度的冗余可以起到不同的作用。
冗余可以是为了编程方便而增加,也可以是为了性能的提高而增加。
从性能角度来说,冗余数据库可以分散数据库压力,冗余表可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
3、主键的设计主键是必要的,SQL SERVER的主键同时是一个唯一索引,而且在实际应用中,我们往往选择最小的键组合作为主键,所以主键往往适合作为表的聚集索引。
聚集索引对查询的影响是比较大的,这个在下面索引的叙述。
在有多个键的表,主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。
主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。
4、外键的设计外键作为数据库对象,很多人认为麻烦而不用,实际上,外键在大部分情况下是很有用的,理由是:外键是最高效的一致性维护方法,数据库的一致性要求,依次可以用外键、CHECK约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。
谨慎使用级联删除和级联更新,级联删除和级联更新作为SQL SERVER 2000当年的新功能,在2005作了保留,应该有其可用之处。
我这里说的谨慎,是因为级联删除和级联更新有些突破了传统的关于外键的定义,功能有点太过强大,使用前必须确定自己已经把握好其功能范围,否则,级联删除和级联更新可能让你的数据莫名其妙的被修改或者丢失。
从性能看级联删除和级联更新是比其他方法更高效的方法。
5、字段的设计字段是数据库最基本的单位,其设计对性能的影响是很大的。
需要注意如下:A、数据类型尽量用数字型,数字型的比较比字符型的快很多。
B、数据类型尽量小,这里的尽量小是指在满足可以预见的未来需求的前提下的。
C、尽量不要允许NUL L,除非必要,可以用NOT NULL+DEFAULT代替。
D、少用TEXT和IMAGE,二进制字段的读写是比较慢的,而且,读取的方法也不多,大部分情况下最好不用。
E、自增字段要慎用,不利于数据迁移。
6、数据库物理存储和环境的设计在设计阶段,可以对数据库的物理存储、操作系统环境、网络环境进行必要的设计,使得我们的系统在将来能适应比较多的用户并发和比较大的数据量。
这里需要注意文件组的作用,适用文件组可以有效把I/O操作分散到不同的物理硬盘,提高并发能力。
7、系统设计整个系统的设计特别是系统结构设计对性能是有很大影响的,对于一般的OLTP系统,可以选择C/S结构、三层的C/S结构等,不同的系统结构其性能的关键也有所不同。
系统设计阶段应该归纳一些业务逻辑放在数据库编程实现,数据库编程包括数据库存储过程、触发器和函数。
用数据库编程实现业务逻辑的好处是减少网络流量并可更充分利用数据库的预编译和缓存功能。
8、索引的设计在设计阶段,可以根据功能和性能的需求进行初步的索引设计,这里需要根据预计的数据量和查询来设计索引,可能与将来实际使用的时候会有所区别。
关于索引的选择,应改主意:A、根据数据量决定哪些表需要增加索引,数据量小的可以只有主键。
B、根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
C、把经常一起出现的字段组合在一起,组成组合索引,组合索引的字段顺序与主键一样,也需要把最常用的字段放在前面,把重复率低的字段放在前面。
D、一个表不要加太多索引,因为索引影响插入和更新的速度。