数据分析与挖掘习题
大数据分析与挖掘复习 题集附答案

大数据分析与挖掘复习题集附答案大数据分析与挖掘复习题集附答案一、选择题1. 数据挖掘的主要任务是:A. 模式发现和模型评估B. 数据收集和整理C. 数据分析和可视化D. 数据传输和存储答案:A2. 在数据挖掘过程中,数据预处理的目的是:A. 提取有价值的信息B. 去除异常值和噪声C. 构建合适的模型D. 优化数据存储结构答案:B3. 关联规则挖掘是指:A. 发现不同属性之间的关联关系B. 预测未来事件的发生C. 分析数据的变化趋势D. 构建数据的分类模型答案:A4. 在数据挖掘中,分类和聚类的主要区别在于:A. 数据来源的不同B. 目标的不同C. 算法的不同D. 结果的不同答案:B5. 大数据分析的核心挑战是:A. 数据存储和处理速度B. 数据质量和准确性C. 数据安全和隐私保护D. 数据可视化和展示答案:A二、填空题1. __________是指通过对海量数据进行深入分析和挖掘,从中发现有价值的信息。
答案:大数据分析与挖掘2. 在数据挖掘过程中,将数据按照一定的规则进行重新排列,以便更方便地进行分析和挖掘,这个过程称为__________。
答案:数据预处理3. 数据挖掘中的分类算法主要是通过对已有的样本进行学习和训练,从而预测新的样本所属的__________。
答案:类别4. 聚类算法是将相似的数据样本归为一类,不需要事先知道数据的__________。
答案:类别5. 在大数据分析中,数据的__________对于结果的准确性和可靠性至关重要。
答案:质量三、简答题1. 请简要说明大数据分析与挖掘的步骤和流程。
答:大数据分析与挖掘的步骤主要包括数据收集与清洗、数据预处理、模式发现、模型评估和应用。
首先,需要从各个数据源收集所需数据,并对数据进行清洗,去除异常值和噪声。
然后,通过数据预处理,对数据进行规范化、离散化等处理,以便于后续的分析和挖掘。
接着,利用合适的算法和技术,进行模式发现,例如关联规则挖掘、分类和聚类等。
SAS数据挖掘与分析 习题答案

附录A 习题答案习题1答案1.什么是观测值OBS?答:一份问卷、一个单一的整体、一个人、一个被测对象就是一个观测值,或称一个“个案”。
每个个案是由若干变量组成。
2. 什么是变量Variable?一份问卷一般有几个甚至几十个问答题,一个问答题就是一个变量。
如id、sex、age、location、income等。
3.下面的变量名哪些有效?哪些无效?sex、age、v1、location、_ab_、1age、1v、location1、@1、#1、%1、&2答:(1)有效的变量名是由1-8个有效字符组成且字母领头,后跟数字或有效的字母。
但字母@、#、$、%、^、&、*等是无效的字符。
比如:sex、age、v1、location、_ab_等变量名是正确的;(2)无效的变量名:1age、1v、location1、@1、#1、%1、&2等。
4.变量有哪些类型?答:变量有2种类型。
数字型:如INPUT id sex age;字符型:如“INPUT id sex $ age;”中的“sex $”表示性别是以m=男性,f=女性表示的。
5.给下面程序A.1a改错。
程序A.1a:DATA sj5; INPUT a b c @@; IF 4=<a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/ OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;解答:错在第3条语句上。
改错后的程序见程序A.1b。
程序A.1b:DATA sj5; INPUT a b c @@; IF a>=4 & a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;习题2答案1.指出下列命令的作用。
第6章 大数据分析与挖掘习题答案

(1)请阐述什么是大数据分析。
大数据分析的主要任务主要有:第一类是预测任务,目标是根据某些属性的值,预测另外一些特定属性的值。
被预测的属性一般称为目标变量或因变量,被用来做预测的属性称为解释变量和自变量;第二类是描述任务,目标是导出概括数据中潜在联系的模式,包括相关、趋势、聚类、轨迹和异常等。
描述性任务通常是探查性的,常常需要后处理技术来验证和解释结果。
具体可分为分类、回归、关联分析、聚类分析、推荐系统、异常检测、链接分析等几种。
(2)大数据分析的类型有哪些?大数据分析主要有描述性统计分析、探索性数据分析以及验证性数据分析等。
(3)举例两种数据挖掘的应用场景?(1)电子邮件系统中垃圾邮件的判断电子邮件系统判断一封Email是否属于垃圾邮件。
这应该属于文本挖掘的范畴,通常会采用朴素贝叶斯的方法进行判别。
它的主要原理就是,根据电子邮件中的词汇,是否经常出现在垃圾邮件中进行判断。
例如,如果一份电子邮件的正文中包含“推广”、“广告”、“促销”等词汇时,该邮件被判定为垃圾邮件的概率将会比较大。
(2)金融领域中金融产品的推广营销针对商业银行中的零售客户进行细分,基于零售客户的特征变量(人口特征、资产特征、负债特征、结算特征),计算客户之间的距离。
然后,按照距离的远近,把相似的客户聚集为一类,从而有效地细分客户。
将全体客户划分为诸如:理财偏好者、基金偏好者、活期偏好者、国债偏好者等。
其目的在于识别不同的客户群体,然后针对不同的客户群体,精准地进行产品设计和推送,从而节约营销成本,提高营销效率。
(4)简述数据挖掘的分类算法及应用。
K-Means算法也叫作k均值聚类算法,它是最著名的划分聚类算法,由于简洁和效率使得它成为所有聚类算法中最广泛使用的。
决策树算法是一种能解决分类或回归问题的机器学习算法,它是一种典型的分类方法,最早产生于上世纪60年代。
决策树算法首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析,因此在本质上决策树是通过一系列规则对数据进行分类的过程。
数据挖掘考试习题

数据挖掘考试习题 work Information Technology Company.2020YEAR数据挖掘考试题一.选择题1. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离()A.分类B.聚类C.关联分析D.主成分分析2. ( )将两个簇的邻近度定义为不同簇的所有点对邻近度的平均值,它是一种凝聚层次聚类技术。
A.MIN(单链)B.MAX(全链)C.组平均D.Ward方法3.数据挖掘的经典案例“啤酒与尿布试验”最主要是应用了( )数据挖掘方法。
A 分类B 预测 C关联规则分析 D聚类4.关于K均值和DBSCAN的比较,以下说法不正确的是( )A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。
B.K均值使用簇的基于原型的概念,DBSCAN使用基于密度的概念。
C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇5.下列关于Ward’s Method说法错误的是:( )A.对噪声点和离群点敏感度比较小B.擅长处理球状的簇C.对于Ward方法,两个簇的邻近度定义为两个簇合并时导致的平方误差D.当两个点之间的邻近度取它们之间距离的平方时,Ward方法与组平均非常相似6.下列关于层次聚类存在的问题说法正确的是:( )A.具有全局优化目标函数B.Group Average擅长处理球状的簇C.可以处理不同大小簇的能力D.Max对噪声点和离群点很敏感7.下列关于凝聚层次聚类的说法中,说法错误的事:( )A.一旦两个簇合并,该操作就不能撤销B.算法的终止条件是仅剩下一个簇OC.空间复杂度为()2mD.具有全局优化目标函数8.规则{牛奶,尿布}→{啤酒}的支持度和置信度分别为:( )9.下列( )是属于分裂层次聚类的方法。
A.MinB.MaxC.Group AverageD.MST10.对下图数据进行凝聚聚类操作,簇间相似度使用MAX计算,第二步是哪两个簇合并:( )A.在{3}和{l,2}合并B.{3}和{4,5}合并C.{2,3}和{4,5}合并D. {2,3}和{4,5}形成簇和{3}合并二.填空题:1.属性包括的四种类型:、、、。
数据挖掘习题及解答-完美版

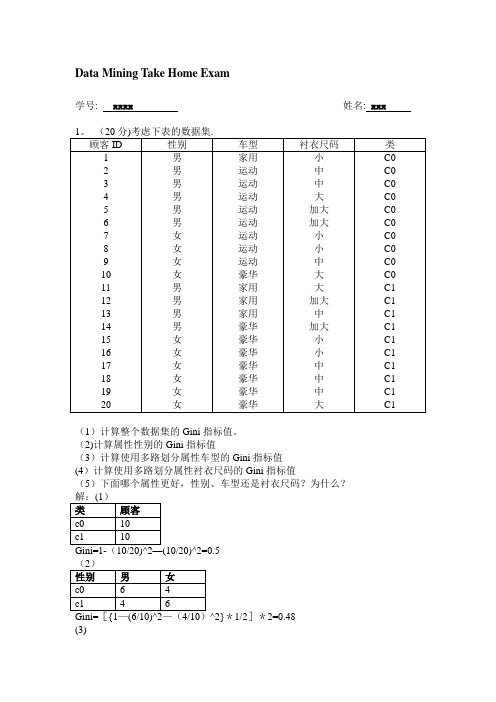
Data Mining Take Home Exam学号: xxxx 姓名: xxx 1. (20分)考虑下表的数据集。
(1)计算整个数据集的Gini 指标值。
(2)计算属性性别的Gini 指标值(3)计算使用多路划分属性车型的Gini 指标值 (4)计算使用多路划分属性衬衣尺码的Gini 指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么? 解:(1) Gini=1-(10/20)^2-(10/20)^2=0.5 (2)Gini=[{1-(6/10)^2-(4/10)^2}*1/2]*2=0.48 (3)Gini={1-(1/4)^2-(3/4)^2}*4/20+{1-(8/8)^2-(0/8)^2}*8/20+{1-(1/8)^2-(7/8)^2}*8/2 0=26/160=0.1625(4)Gini={1-(3/5)^2-(2/5)^2}*5/20+{1-(3/7)^2-(4/7)^2}*7/20+[{1-(2/4)^2-(2/4)^2}*4/ 20]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. (20分)考虑下表中的购物篮事务数据集。
(1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
数据分析与挖掘习题

数据分析与挖掘习题第一章作业1.1什么是数据挖掘?在你的回答中,强调以下问题:(a) 它是又一个骗局吗?数据挖掘,在人工智能领域,习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD),也有人把数据挖掘视为数据库中知识发现过程的一个基本步骤。
数据挖掘可以与用户或知识库交互。
并非所有的信息发现任务都被视为数据挖掘。
例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索(information retrieval)领域的任务。
虽然这些任务是重要的,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。
尽管如此,数据挖掘技术也已用来增强信息检索系统的能力。
(b) 它是一种从数据库,统计学和机器学习发展的技术的简单转换吗?硬要去区分Data Mining和Statistics的差异其实是没有太大意义的。
一般将之定义为Data Mining技术的CART、CHAID或模糊计算等等理论方法,也都是由统计学者根据统计理论所发展衍生,换另一个角度看,Data Mining有相当大的比重是由高等统计学中的多变量分析所支撑。
但是为什么Data Mining的出现会引发各领域的广泛注意呢?主要原因在相较于传统统计分析而言,Data Mining有下列几项特性:1.处理大量实际数据更强势,且无须太专业的统计背景去使用Data Mining的工具2.数据分析趋势为从大型数据库抓取所需数据并使用专属计算机分析软件,Data Mining 的工具更符合企业需求;3. 纯就理论的基础点来看,Data Mining和统计分析有应用上的差别,毕竟Data Mining 目的是方便企业终端用户使用而非给统计学家检测用的。
(c) 解释数据库技术发展如何导致数据挖掘近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
数据挖掘习题

数据挖掘习题二

数据挖掘习题二简答:1.何谓数据挖掘?它有哪些方面的功能?2.何谓数据仓库?为什么要建立数据仓库?3.常见的分箱方法有哪些?数据平滑处理的方法有哪些?4.何谓数据规范化?规范化的方法有哪些?写出对应的变换公式。
数据挖掘讨论题1、(20分)讨论::下列每项活动是否是数据挖掘任务?简单陈述你的理由。
(a)根据性别划分公司的顾客。
(b)根据可赢利性划分公司的顾客。
(c)预测投一对骰子的结果。
(d)使用历史记录预测某公司未来的股票价格。
简答:5. 何谓数据挖掘?它有哪些方面的功能?从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程称为数据挖掘。
相关的名称有知识发现、数据分析、数据融合、决策支持等。
数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚类分析、趋势分析、孤立点分析以及偏差分析等。
6. 何谓数据仓库?为什么要建立数据仓库?数据仓库是一种新的数据处理体系结构,是面向主题的、集成的、不可更新的(稳定性)、随时间不断变化(不同时间)的数据集合,为企业决策支持系统提供所需的集成信息。
建立数据仓库的目的有3个:一是为了解决企业决策分析中的系统响应问题,数据仓库能提供比传统事务数据库更快的大规模决策分析的响应速度。
二是解决决策分析对数据的特殊需求问题。
决策分析需要全面的、正确的集成数据,这是传统事务数据库不能直接提供的。
三是解决决策分析对数据的特殊操作要求。
决策分析是面向专业用户而非一般业务员,需要使用专业的分析工具,对分析结果还要以商业智能的方式进行表现,这是事务数据库不能提供的。
7. 常见的分箱方法有哪些?数据平滑处理的方法有哪些?分箱的方法主要有:① 统一权重法(又称等深分箱法)② 统一区间法(又称等宽分箱法)③ 最小熵法④ 自定义区间法数据平滑的方法主要有:平均值法、边界值法和中值法。
8. 何谓数据规范化?规范化的方法有哪些?写出对应的变换公式。
大数据挖掘技术练习(习题卷6)

大数据挖掘技术练习(习题卷6)第1部分:单项选择题,共51题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]基于输入的用户信息,通过模型的训练学习,找出数据中的规律和趋势,以确定未来目标数据的预测值()A)聚类B)分类C)预测D)关联答案:C解析:2.[单选题]使用pip工具升级科学计算扩展库numpy的完整命令是()A)pip install --upgrade numpyB)pip list --upgrade numpyC)upgrade numpyD)upg numpy--pip install答案:A解析:3.[单选题]在一个表中有字段“专业”,要查找包含“信息”两个字的记录,正确的表达式是______。
A)LEFT(专业, 2)="信息"B)LIKE "%信息%"C)LIKE "_信息_"D)RIGHT(专业, 2)="信息"答案:B解析:4.[单选题]两台路由器成为OSPF邻居关系的必要条件不包括A)两台路由器的Hello时间一致B)两台路由器的Dead时间一致C)两台路由器的Router ID一致D)两台路由器所属区域一致答案:C解析:5.[单选题]自动化高级分析实验室,实现与统一数据资源库互联,实现数据的自助组表、自助分析功能,满足不同层级、不同水平的用户需求的是( )A)初级分析;B)综合分析C)典型分析D)高级分析答案:D解析:6.[单选题]关于 K 均值和 DBSCAN 的比较,以下说法不正确的是( )。
A)KB)KC)KD)K答案:A解析:7.[单选题]属于定量的属性类型是A)标称B)序数C)区间D)相异答案:C解析:8.[单选题]终端支持的频段,在下列哪个流程中会得以体现A)ATTACHB)DETACHC)切换流程D)呼叫流程答案:A解析:9.[单选题]概念分层图是____图。
A)无向无环B)有向无环C)有向有环D)无向有环答案:B解析:10.[单选题]关于OLAP和OLTP的区别描述,不正确的是:A)OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同.B)与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务.C)OLAP的特点在于事务量大,但事务内容比较简单且重复率高.D)OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的.答案:C解析:11.[单选题]在FP-GROWTH算法中,已构造FP-Tree如图则项 I3 的条件模式基为A)<(I1,I2:2)>、I2:2、 I1:2B)<(I2,I1:2)>、I2:1、 I1:1C)<(I2,I1:2)>、I2:2、 I1:2D)<(I2,I1:1)>、I2:2、 I1:2答案:C解析:12.[单选题]下面的代码其功能为()>>> x = [range(3*i, 3*i+5) for i in range(2)]>>> x = list(map(list, x))>>> x = list(map(list, zip(*x)))A)首先生成一个随机的列表,然后生成矩阵B)首先生成一个包含列表的列表,然后生成矩阵C)首先生成一个包含列表的列表,然后模拟矩阵转置D)首先排序列表,然后模拟矩阵转置答案:C解析:13.[单选题]下述方法不属于聚类方法的是( )A)K-均值B)K-中心性C)DBSCAN算法D)神经网络答案:D解析:14.[单选题]设有一个回归方程为y=2-2.5x,则变量x增加一个单位时()A)y平均增加2.5个单位B)y平均增加2个单位C)y平均减少2.5个单位D)y平均减少2个单位答案:C解析:15.[单选题]JSON 中的中括号一般来表示( )。
计算机思维导论课程 第8章-数据分析与数据挖掘练习题-带答案

第 8 章数据分析与数据挖掘
一、单选题
1. 某超市研究销售记录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的【 】问题。 A:关联规则 B:聚类 C:分类 D:自然语言处理 答案:A
2. 将原始数据进行集成、变换、维度规约、数值规约是【 】步骤的任务。 A:频繁模式挖掘 B:分类和预测 C:数据预处理 D:数据流挖掘 答案:C
Y(千) 30 57 64 72 36 43 59 90 20 83
【提示】:设线性回归方程公式为������=ax+������,计算回归系数 a、b 公式为:
������ = ∑(���∑���−(������������−̅)(���������̅���)−2 ���̅���),������ = ���̅��� − ������������̅。
频繁三项集的频繁子集有:EK、EO、OK、E、K、O,得以下关联规则及置信度: 1)EKO 3/4 = 75% 2)EOK 3/3 = 100% 3)OKE 3/3 = 100% 4)EKO 3/4 = 75% 5)KEO 3/5 = 60% 6)OEK 3/3 = 100%
(4)求有效规则:满足最小置信度min_conf=80%的有效规则有: 1)EOK 2)OKE 3)OEK
������
甲的均值为:(9.7+8.6+9.6+8.6+7.9+9.6+9.3+8.9+9.6+9.2)/10 = 9.1 乙的均值为:(9.4+9.5+8.5+9.5+9.1+9.2+9+8.6+8.8+9.6)/10 = 9.12
R语言数据分析与挖掘(谢佳标微课版) 习题及答案chapter08

一、多选题1.常用聚类分析技术有(ABCDE)A.K-均值聚类(K-MeanS)B.K•中心点聚类(K-MedOidS)C.密度聚类(DenSit-basedSpatia1C1usteringofApp1icationwithNoise z DBSCAN)D.层次聚类(系谱聚类Hierarchica1C1ustering,HC)E.期望最大化聚类(EXPeCtationMaximization z EM)2.常用划分(分类)方法的聚类算法有(AB)A.K-均值聚类(K-MeanS)B.K•中心点聚类(K-MedoidS)C.密度聚类(DenSit-basedSpatia1C1usteringofApp1icationwithNoise z DBSCAN)D.聚类高维空间算法(OJOUE)3.层次聚类分析常用的函数有(ABC)A.hc1ust()B.cutree()C.rect.hc1ust()D.ctree()4. K.均值聚类方法效率高,结果易于理解,但也有(ABCD)缺点A.需要事先指定簇个数kB.只能对数值数据进行处理C.只能保证是局部最优,而不一定是全局最优D.对噪声和孤立点数据敏感二、上机题1.数据集(1A.Neighborhoodsisv)是美国普查局2000年的洛杉矶街区数据,一共有I1O个参考答案:>u<-w[,c(1,2,5,6,11,16)]>rownames(u)<-u[,1]>#标准化数据,聚类方法="comp1ete">hh<-hc1ust(dist(sca1e(u[z-1])1"comp1ete") >#画树状图(分成五类)>Iibraryffactoextra)>fviz-dend(hh,k=5,rect=TRUE)OuΛ∙rD∙oαogr∙fr。
大数据分析与挖掘课后习题参考答案

题;
数据集成:负责解决不同数据源的数据匹配问题、数值冲突问题和冗余问
题;
数据变换:将原始数据转换为适合数据挖掘的形式。包括数据的汇总、聚
集、概化、规范化,同时可能需要对属性进行重构;
数据归约:负责搜小数据的取值范围,使其更适合数据挖掘算法的需要。
bucketedData = bucketizer.transform(dataFrame)
bucketedData.show()
7
(1)简单随机抽样:从总体 N 个单位里抽出 n 个单位作为样本(可以重
复抽样,也可以不重复抽样),最常用的抽样方式,参数估计和假设检
验主要依据的就是简单随机样本;
(2)系统抽样:将总体中的所有单位(抽样单位)按一定顺序排列,在规
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import MaxAbsScaler
from pyspark.ml.feature import MinMaxScaler
sc=SparkContext('local')
spark=SQLContext(sc)
每次扫描题表 3-1 中的数据库后得到的所有频繁项集。在频繁项集的基础上,
产生所有的强关联规则。
题表 3-1
TID
商品
A,B,C,
1
D,E
2
A,B,D,E
3
B,C,D
4
C,D,E
5
A,C,E
6
A,B,D
某商店统计了上个季度 10000 笔交易记录,给出如题表 3-2 所示的统计信息:
数据挖掘习题及解答-完美版
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?^2}*1/2]*2=0.48(3)—(8/8)^2-(0/8)^2}*8/20+{1—(1/8)^2—(7/8)^2}*8/20=26/160=0。
16254/7)^2}*7/20+[{1—(2/4)^2—(2/4)^2}*4/20]*2=8/25+6/35=0。
4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0。
1625最小,即使用车型属性更好。
2。
((1)将每个事务ID视为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度.(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0). (4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0。
8;{b,d}的支持度为2/10=0。
2;{b,d,e}的支持度为2/10=0。
2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0。
8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)〉anova(ls1)Df Sum Sq Mean Sq F value Pr(〉F)x1 1 10021.2 10021.2 62。
数据挖掘练习题.doc

一、填空题1、 数据预处理对于数据挖掘是一个重要问题,主要包括 _______________ 、数 据集成、 ____________ 和数据归约。
2、 多维数据模型的星形模式中,主要依靠事实表中 __________ 的与维表联系在一起。
3、 __________ 允许从多个维对数据建模和观察,它由维和事实定义。
}的中位数为 _______ , 4、 数据集{5, 10, 11, 13, 15, 15, 35, 50, 55, 72, 92, 204, 215众数为 _________ o5、 在多个抽象层上挖掘数据产生的关联规则称为 _____________ o6、 将物理或抽象对象的集合分成相似的对象类(或簇)的过程称为 ___________O7、 分类和预测是两种数据分析形式,可以用来建立模型,预测数据未来的趋势,其中 _____________ 用来预测类别标号, ___________ 用来建立连续函数 模型。
),两个对象8、 给定两个对象,分别表示为(22, 1, 42, 10), (20, 0, 36, 8之间的曼哈顿距离为 _______________o9、 通常数据仓库与0LAP工具是基于 ___________ 模型进行设计的。
10、 涉及两个或多个维的关联规则称为 ______________o二、单项选择题1、 S PSS作为通用的统计软件包不仅被广泛地用于经济、管理、工业等领域的数据统计处理,而且在()中得到了应用。
A、数据挖掘领域B、数据仓库领域C、信息管理领域D、系统管理领域2、 下列度量中,哪一个度量不属于集中趋势度量:()。
A、中位数B、中列数C、众数D、极差3、 OLAP技术的核心是:( )。
A、在线性B、对用户的快速响应C、互操作性D、多维分析4、 关于OLAP和OLTP的说法,下列不正确的是:()A、 OLTP事务量大,但事务内容比较简单且重复率高B、 OLAP的数据来源与OLTP不完全一样C、 OLTP面对的是决策人员和高层管理人员D、 OLTP以应用为核心,是应用驱动的5、 下列哪种操作可以使用户更加直观地从不同角度观察数据立方体中不同维之间的关系:()0A、上卷B、下钻C、切片D、旋转6、数据挖掘的经典案例“啤酒与尿布试验”最主要是应用了哪种数据挖掘方法: ()0A、分类B、预测C、关联分析D、聚类7、 利用信息增益方法作为属性选择度量建立决策树时,已知某训练样本集的四个属性的信息增益分别为:Gain(收入戶0.940位,Gain(职业)=0.151位,Gain(年龄)=0.780位,Gain(信誉)=0.048位,则应该选择哪个属性作为决策树的测试属 性:()。
数据挖掘考试习题汇总

第一章1、数据仓库就是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合;2、元数据是描述数据仓库内数据的结构和建立方法的数据,它为访问数据仓库提供了一个信息目录,根据数据用途的不同可将数据仓库的元数据分为技术元数据和业务元数据两类;3、数据处理通常分成两大类:联机事务处理和联机分析处理;4、多维分析是指以“维”形式组织起来的数据多维数据集采取切片、切块、钻取和旋转等各种分析动作,以求剖析数据,使拥护能从不同角度、不同侧面观察数据仓库中的数据,从而深入理解多维数据集中的信息;5、ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP实现;6、数据仓库按照其开发过程,其关键环节包括数据抽取、数据存储与管理和数据表现等;7、数据仓库系统的体系结构根据应用需求的不同,可以分为以下4种类型:两层架构、独立型数据集合、以来型数据结合和操作型数据存储和逻辑型数据集中和实时数据仓库;8、操作型数据存储实际上是一个集成的、面向主题的、可更新的、当前值的但是可“挥发”的、企业级的、详细的数据库,也叫运营数据存储;9、“实时数据仓库”以为着源数据系统、决策支持服务和仓库仓库之间以一个接近实时的速度交换数据和业务规则;10、从应用的角度看,数据仓库的发展演变可以归纳为5个阶段:以报表为主、以分析为主、以预测模型为主、以运营导向为主和以实时数据仓库和自动决策为主;第二章1、调和数据是存储在企业级数据仓库和操作型数据存储中的数据;2、抽取、转换、加载过程的目的是为决策支持应用提供一个单一的、权威数据源;因此,我们要求ETL过程产生的数据即调和数据层是详细的、历史的、规范的、可理解的、即时的和质量可控制的;3、数据抽取的两个常见类型是静态抽取和增量抽取;静态抽取用于最初填充数据仓库,增量抽取用于进行数据仓库的维护;4、粒度是对数据仓库中数据的综合程度高低的一个衡量;粒度越小,细节程度越高,综合程度越低,回答查询的种类越多;5、使用星型模式可以从一定程度上提高查询效率;因为星型模式中数据的组织已经经过预处理,主要数据都在庞大的事实表中;6、维度表一般又主键、分类层次和描述属性组成;对于主键可以选择两种方式:一种是采用自然键,另一种是采用代理键;7、雪花型模式是对星型模式维表的进一步层次化和规范化来消除冗余的数据;8、数据仓库中存在不同综合级别的数据;一般把数据分成4个级别:早期细节级、当前细节级、轻度综合级和高度综合级;第三章1、SQL Server SSAS提供了所有业务数据的同意整合试图,可以作为传统报表、在线分析处理、关键性能指示器记分卡和数据挖掘的基础;2、数据仓库的概念模型通常采用信息包图法来进行设计,要求将其5个组成部分包括名称、维度、类别、层次和度量全面地描述出来;3、数据仓库的逻辑模型通常采用星型图法来进行设计,要求将星型的各类逻辑实体完整地描述出来;4、按照事实表中度量的可加性情况,可以把事实表对应的事实分为4种类型:事务事实、快照事实、线性项目事实和事件事实;5、确定了数据仓库的粒度模型以后,为提高数据仓库的使用性能,还需要根据拥护需求设计聚合模型;6、在项目实施时,根据事实表的特点和拥护的查询需求,可以选用时间、业务类型、区域和下属组织等多种数据分割类型;7、当维表中的主键在事实表中没有与外键关联时,这样的维称为退化维;它于事实表并无关系,但有时在查询限制条件如订单号码、出货单编号等中需要用到;8、维度可以根据其变化快慢分为元变化维度、缓慢变化维度和剧烈变化维度三类;9、数据仓库的数据量通常较大,且数据一般很少更新,可以通过设计和优化索引结构来提高数据存取性能;10、数据仓库数据库常见的存储优化方法包括表的归并与簇文件、反向规范化引入冗余、表的物理分割分区;第四章1、关联规则的经典算法包括Apriori算法和FP-growth算法,其中FP-grownth算法的效率更高;2、如果L2={{a,b},{a,c},{a,d},{b,c},{b,d}},则连接产生的C3={{a,b,c},{a,b,d},{a,c,d},{b,c,d}}再经过修剪,C3={{a,b,c},{a,b,d}}3、设定supmin=50%,交易集如则L1={A},{B},{C} L2={A,C}T1 A B CT2 A CT3 A DT4 B E F第五章1、分类的过程包括获取数据、预处理、分类器设计和分类决策;2、分类器设计阶段包含三个过程:划分数据集、分类器构造和分类器测试;3、分类问题中常用的评价准则有精确度、查全率和查准率和集合均值;4、支持向量机中常用的核函数有多项式核函数、径向基核函数和S型核函数;第六章1、聚类分析包括连续型、二值离散型、多值离散型和混合类型4种类型描述属性的相似度计算方法;2、连续型属性的数据样本之间的距离有欧氏距离、曼哈顿距离和明考斯基距离;3、划分聚类方法对数据集进行聚类时包含三个要点:选种某种距离作为数据样本减的相似性度量、选择评价聚类性能的准则函数和选择某个初始分类,之后用迭代的方法得到聚类结果,使得评价聚类的准则函数取得最优值;4、层次聚类方法包括凝聚型和分解型两中层次聚类方法;填空题20分,简答题25分,计算题2个25分,综合题30分1、数据仓库的组成P2数据仓库数据库,数据抽取工具,元数据,访问工具,数据集市,数据仓库管理,信息发布系统2、数据挖掘技术对聚类分析的要求有哪几个方面P131可伸缩性;处理不同类型属性的能力;发现任意形状聚类的能力;减小对先验知识和用户自定义参数的依赖性;处理噪声数据的能力;可解释性和实用性3、数据仓库在存储和管理方面的特点与关键技术P7数据仓库面对的是大量数据的存储与管理并行处理针对决策支持查询的优化支持多维分析的查询模式4、常见的聚类算法可以分为几类P132基于划分的聚类算法,基于层次的聚类算法,基于密度的聚类算法,基于网格的聚类算法,基于模型的聚类算法等;5、一个典型的数据仓库系统的组成P12数据源、数据存储与管理、OLAP 服务器、前端工具与应用6、 数据仓库常见的存储优化方法P717、 表的归并与簇文件;反向规范化,引入冗余;表的物理分割;8、 数据仓库发展演变的5个阶段P209、 以报表为主10、以分析为主11、以预测模型为主12、 以运行向导为主以实时数据仓库、自动决策应用为主13、 ID3算法主要存在的缺点P11614、1ID3算法在选择根结点和各内部结点中的分枝属性时,使用信息增益作为评价标准;信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息;15、 2ID3算法只能对描述属性为离散型属性的数据集构造决策树;16、 简述数据仓库ETL 软件的主要功能和对产生数据的目标要求;P3017、ETL 软件的主要功能:18、数据的抽取,数据的转换,数据的加载19、对产生数据的目标要求:20、 详细的、历史的、规范化的、可理解的、即时的、质量可控制的21、 简述分类器设计阶段包含的3个过程;★22、 划分数据集,分类器构造,分类器测试23、 什么是数据清洗P33★24、 数据清洗是一种使用模式识别和其他技术,在将原始数据转换和移到数据仓库之前来升级原始数据质量的技术;25、 支持度和置信度的计算公式及数据计算P9026、找出所有的规则X Y , 使支持度和置信度分别大于门限支持度: 事务中X 和Y 同时发生的比例,PX Y置信度:项集X 发生时,Y 同时发生的条件概率PY|X27、 Example:28、29、13、利用信息包图设计数据仓库概念模型需要确定的三方面内容;P57 确定指标,确定维度,确定类别14、K-近邻分类方法的操作步骤包括算法的输入和输出;P128 ()()()Support X Y c X Y Support X →=0.67) Beer(0.4,}Diaper ,Milk {⇒15、什么是技术元数据,主要包含的内容P29技术元数据是描述关于数据仓库技术细节的数据,应用于开发、管理和维护DW,包含:●DW结构的描述,如DW的模式、视图、维、层次结构和导出数据的定义,数据集市的位置和内容等●业务系统、DW和数据集市的体系结构和模式●汇总算法;包括度量和维定义算法,数据粒度、主题领域、聚合、汇总和预定义的查询和报告;●由操作型业务环境到数据仓库业务环境的映射;包括源数据和他们的内容、数据分割、数据提取、清洗、转换规则和数据刷新规则及安全用户授权和存取控制16、业务元数据主要包含的内容P29业务元数据:从业务角度描述了DW中的数据,提供了介于使用者和实际系统之间的语义层,主要包括:●使用者的业务属于所表达的数据模型、对象名和属性名●访问数据的原则和数据的来源●系统提供的分析方法及公式和报表的信息;17、K-means算法的基本操作步骤包括算法的输入和输出;P138★18、数据从集结区加载到数据仓库中的主要方法P36●SQL命令如Insert或Update●由DW供应商或第三方提供专门的加载工具●由DW管理员编写自定义程序19、多维数据模型中的基本概念:维,维类别,维属性,粒度P37●维:人们观察数据的特定角度,是考虑问题的一类属性,如时间维或产品维●维类别:也称维分层;即同一维度还可以存在细节程度不同的各个类别属性如时间维包括年、季度、月等●维属性:是维的一个取值,是数据线在某维中位置的描述;●粒度:DW中数据综合程度高低的一个衡量;粒度低,细节程度高,回答查询的种类多20、Apriori算法的基本操作步骤P93★Apriori使用一种称作逐层搜索的迭代方法,K项集用于探索K+1项集;该方法是基于候选的策略,降低候选数Apriori 剪枝原则:若任何项集是非频繁的,则其超集必然是非频繁的不用产生和测试超集该原则基于以下支持度的特性: ☜ 项集的支持度不会超过其子集☜ 支持度的反单调特性anti-monotone :如果一个集合不能通过测试,则它的所有超集也都不能通过相同的测试;令 k=1产生长度为1的频繁项集 循环,直到无新的频繁项集产生☜ 从长度为k 的频繁项集产生长度为k+1的候选频繁项集☟连接步:项集的各项排序,前k-1个项相同 ☜ 若候选频繁子集包含长度为k 的非频繁子集,则剪枝☟ 剪枝步:利用支持度属性原则 ☜ 扫描数据库,计算每个候选频繁集的支持度☜ 删除非频繁项, 保留频繁项 )()()(:,Y s X s Y X Y X ≥⇒⊆∀。
大数据挖掘技术练习(习题卷4)

大数据挖掘技术练习(习题卷4)说明:答案和解析在试卷最后第1部分:单项选择题,共51题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]关于性能度量不正确的是()A)性能度量是衡量模型泛化能力的评价标准,反映了任务需求B)在对比不同模型的能力时,使用不同的性能度量会导致不同的评判结果,这就意味着模型的“好坏”是相对的C)回归任务最常用的性能度量是“均方误差”D)性能度量实用意义不大2.[单选题]MySQL中,删除视图su_view的命令是 ______ 。
A)delete su_viewB)drop table su_viewC)drop view su_viewD)drop su_view3.[单选题]通常,我们可通过实验测试来对学习器的泛化误差进行评估并进而做出选择。
为此,需使用一个()来测试学习期对新样本的判别能力A)数据集B)测试集C)模型集D)训练集4.[单选题]根据《居民区4G&宽带网络能力全景分析》中的建议,优先考虑4G深度覆盖建设居民区标签为A)4G弱覆盖居民区&用户感知差居民区&高价值居民区&常驻用户多居民区B)4G弱覆盖居民区&高价值居民区&常驻用户多居民区C)4G弱覆盖居民区&用户感知差居民区&高价值居民区D)用户感知差居民区&高价值居民区&常驻用户多居民区5.[单选题]BIRCH 是一种( )。
A)分类器B)聚类算法C)关联分析算法D)特征选择算法6.[单选题]因子分析的主要作用有()A)对变量进行降维B)对变量进行判别C)对变量进行聚类D)以上都不对B)基金经理人针对个股做出未来价格预测C)电信公司将人户区分为数个群体D)以上均不是8.[单选题]下列关于DPI规则识别中业务大类的说法错误的是?A)业务大类为1的是即时通信类业务B)数据流量业务大类分类除了其他业务外一共有15类C)视频大类不包括传统意义上基于P2P技术的视频业务D)彩信单独属于一类业务大类9.[单选题]一个对象的离群点得分是该对象周围密度的逆。
数据分析练习题统计学数据挖掘等

数据分析练习题统计学数据挖掘等数据分析练习题-统计学与数据挖掘数据分析在当今信息化社会中扮演着重要的角色,而统计学和数据挖掘则是数据分析过程中不可或缺的工具和方法。
本文旨在通过一系列的数据分析练习题,帮助读者巩固和应用统计学和数据挖掘的相关知识,拓展数据分析的能力和技巧。
一、题目一:问题定义与数据准备在进行数据分析之前,首先需要明确问题定义并准备好相应的数据。
以某电商平台为例,假设我们想了解用户对于不同品牌手机的购买偏好。
为了解决这一问题,我们需要收集和整理包括用户购买记录、品牌信息以及用户个人特征等数据。
二、题目二:探索性数据分析在进行正式的统计学分析之前,我们可以通过探索性数据分析(Exploratory Data Analysis,简称EDA)来对数据进行初步的观察和分析。
例如,我们可以计算不同品牌手机的销售数量、销售额等统计指标,绘制饼图或者柱状图等图表展示不同品牌手机的市场份额。
三、题目三:统计假设检验为了验证不同品牌手机销售数量是否存在显著差异,我们可以使用统计假设检验的方法。
通过计算样本均值、标准差等统计量,应用t检验或者方差分析等方法,得出关于不同品牌手机销售数量差异的统计结论。
此外,还可以进行配对样本的相关性分析,探究用户购买手机前后的满意度变化等。
四、题目四:数据挖掘算法应用在统计学分析的基础上,我们可以进一步应用数据挖掘算法,从数据中挖掘出隐藏的模式和规律。
例如,可以使用关联规则挖掘发现用户购买手机时的搭配购买规律,或者通过聚类算法将用户分群,探索不同群体的购买偏好和特征。
五、题目五:模型评估与优化在应用数据挖掘算法之后,我们需要对构建的模型进行评估和优化。
可以使用交叉验证、ROC曲线等方法评估模型的性能,同时对模型进行调参,提高模型的准确性和稳定性。
六、题目六:结果解释与可视化呈现最后,对于得到的数据分析结果,我们需要进行解释和呈现。
可以撰写报告或者制作演示文稿,用清晰简洁的语言描述数据分析的结果和结论,并结合图表和可视化工具展示相关的统计图、地理图等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据分析与挖掘习题第一章作业1.1什么是数据挖掘?在你的回答中,强调以下问题:(a) 它是又一个骗局吗?数据挖掘,在人工智能领域,习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD),也有人把数据挖掘视为数据库中知识发现过程的一个基本步骤。
数据挖掘可以与用户或知识库交互。
并非所有的信息发现任务都被视为数据挖掘。
例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索(information retrieval)领域的任务。
虽然这些任务是重要的,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。
尽管如此,数据挖掘技术也已用来增强信息检索系统的能力。
(b) 它是一种从数据库,统计学和机器学习发展的技术的简单转换吗?硬要去区分Data Mining和Statistics的差异其实是没有太大意义的。
一般将之定义为Data Mining技术的CART、CHAID或模糊计算等等理论方法,也都是由统计学者根据统计理论所发展衍生,换另一个角度看,Data Mining有相当大的比重是由高等统计学中的多变量分析所支撑。
但是为什么Data Mining的出现会引发各领域的广泛注意呢?主要原因在相较于传统统计分析而言,Data Mining有下列几项特性:1.处理大量实际数据更强势,且无须太专业的统计背景去使用Data Mining的工具2.数据分析趋势为从大型数据库抓取所需数据并使用专属计算机分析软件,Data Mining 的工具更符合企业需求;3. 纯就理论的基础点来看,Data Mining和统计分析有应用上的差别,毕竟Data Mining 目的是方便企业终端用户使用而非给统计学家检测用的。
(c) 解释数据库技术发展如何导致数据挖掘近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等。
数据挖掘利用了来自如下一些领域的思想:(1) 来自统计学的抽样、估计和假设检验,(2) 人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论。
数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化计算、信息论、信号处理、可视化和信息检索。
一些其他领域也起到重要的支撑作用。
特别地,需要数据库系统提供有效的存储、索引和查询处理支持。
源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。
分布式技术也能帮助处理海量数据,并且当数据不能集中到一起处理时更是至关重要。
(d) 当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。
知识发现过程以下三个阶段组成:(1)数据准备,(2)数据挖掘,(3)结果表达和解释。
1.2 给出一个例子,其中数据挖掘对于一种商务的成功至关重要的。
这种商务需要什么数据挖掘功能?他们能够由数据查询处理或简单的统计分析来实现吗?由于统计学基础的建立在计算机的发明和发展之前,所以常用的统计学工具包含很多可以手工实现的方法。
因此,对于很多统计学家来说,1000个数据就已经是很大的了。
但这个“大”对于英国大的信用卡公司每年350,000,000笔业务或A T&T每天200,000,000个长途呼叫来说相差太远了。
很明显,面对这么多的数据,则需要设计不同于那些“原则上可以用手工实现”的方法。
这意味这计算机(正是计算机使得大数据可能实现)对于数据的分析和处理是关键的。
分析者直接处理数据将变得不可行。
相反,计算机在分析者和数据之间起到了必要的过滤的作用。
这也是数据挖掘特别注重准则的另一原因。
尽管有必要,把分析者和数据分离开很明显导致了一些关联任务。
这里就有一个真正的危险:非预期的模式可能会误导分析者。
在现代统计中计算机是一个重要的工具,并不是因为数据的规模。
而是对数据的精确分析方法如bootstrap方法、随机测试,迭代估计方法以及比较适合的复杂的模型正是有了计算机才是可能的。
计算机已经使得传统统计模型的视野大大的扩展了,还促进了新工具的飞速发展。
下面来关注一下歪曲数据的非预期的模式出现的可能性。
这和数据质量相关。
所有数据分析的结论依赖于数据质量。
GIGO的意思是垃圾进,垃圾出,它的引用到处可见。
一个数据分析者,无论他多聪明,也不可能从垃圾中发现宝石。
对于大的数据集,尤其是要发现精细的小型或偏离常规的模型的时候,这个问题尤其突出。
当一个人在寻找百万分之一的模型的时候,第二个小数位的偏离就会起作用。
一个经验丰富的人对于此类最常见的问题会比较警觉,但出错的可能性太多了。
1.3 数据仓库和数据库有何不同?它们有那些相似之处?数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。
维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID。
单从概念上讲,有些晦涩。
任何技术都是为应用服务的,结合应用可以很容易地理解。
以银行业务为例。
数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记帐。
数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。
比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。
如果存款又多,消费交易又多,那么该地区就有必要设立A TM了。
显然,银行的交易量是巨大的,通常以百万甚至千万次来计算。
事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。
而分析系统是事后的,它要提供关注时间段内所有的有效数据。
这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的了。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。
那么,数据仓库与传统数据库比较,有哪些不同呢?让我们先看看W.H.Inmon关于数据仓库的定义:面向主题的、集成的、与时间相关且不可修改的数据集合。
“面向主题的”:传统数据库主要是为应用程序进行数据处理,未必按照同一主题存储数据;数据仓库侧重于数据分析工作,是按照主题存储的“与时间相关”:数据库保存信息的时候,并不强调一定有时间信息。
数据仓库则不同,出于决策的需要,数据仓库中的数据都要标明时间属性。
决策中,时间属性很重要。
同样都是累计购买过九车产品的顾客,一位是最近三个月购买九车,一位是最近一年从未买过,这对于决策者意义是不同的。
“不可修改”:数据仓库中的数据并不是最新的,而是来源于其它数据源。
数据仓库反映的是历史信息,并不是很多数据库处理的那种日常事务数据(有的数据库例如电信计费数据库甚至处理实时信息)。
因此,数据仓库中的数据是极少或根本不修改的;当然,向数据仓库添加数据是允许的。
数据仓库的出现,并不是要取代数据库。
目前,大部分数据仓库还是用关系数据库管理系统来管理的。
可以说,数据库、数据仓库相辅相成、各有千秋。
为了更好地为前端应用服务,数据仓库必须有如下几点优点,否则是失败的数据仓库方案。
1.效率足够高。
客户要求的分析数据一般分为日、周、月、季、年等,可以看出,日为周期的数据要求的效率最高,要求24小时甚至12小时内,客户能看到昨天的数据分析。
由于有的企业每日的数据量很大,设计不好的数据仓库经常会出问题,延迟1-3日才能给出数据,显然不行的。
2.数据质量。
客户要看各种信息,肯定要准确的数据,但由于数据仓库流程至少分为3步,2次ETL,复杂的架构会更多层次,那么由于数据源有脏数据或者代码不严谨,都可以导致数据失真,客户看到错误的信息就可能导致分析出错误的决策,造成损失,而不是效益。
3.扩展性。
之所以有的大型数据仓库系统架构设计复杂,是因为考虑到了未来3-5年的扩展性,这样的话,客户不用太快花钱去重建数据仓库系统,就能很稳定运行。
主要体现在数据建模的合理性,数据仓库方案中多出一些中间层,使海量数据流有足够的缓冲,不至于数据量大很多,就运行不起来了。
第二章作业1. 简述以下高级数据库系统和应用:面向对象数据库、空间数据库、文本数据库、多媒体数据库和W W W。
面向对象是一种认识方法学,也是一种新的程序设计方法学。
把面向对象的方法和数据库技术结合起来可以使数据库系统的分析、设计最大程度地与人们对客观世界的认识相一致。
面向对象数据库系统是为了满足新的数据库应用需要而产生的新一代数据库系统。
在数据库中提供面向对象的技术是为了满足特定应用的需要。
随着许多基本设计应用(如MACD和ECAD)中的数据库向面向对象数据库的过渡,面向对象思想也逐渐延伸到其它涉及复杂数据的应用中,其中包括辅助软件工程(CASE)、计算机辅助印刷(CAP)和材料需求计划(MRP)。
这些应用如同设计应用一样在程序设计方面和数据类型方面都是数据密集型的,它们需要识别于类型关系的存储技术,并能对相近数据备份进行调整.空间数据库指的是地理信息系统在计算机物理存储介质上存储的与应用相关的地理空间数据的总和,一般是以一系列特定结构的文件的形式组织在存储介质之上的。
空间数据库的研究始于20 世纪70年代的地图制图与遥感图像处理领域,其目的是为了有效地利用卫星遥感资源迅速绘制出各种经济专题地图。
由于传统的关系数据库在空间数据的表示、存储、管理、检索上存在许多缺陷,从而形成了空间数据库这一数据库研究领域。
而传统数据库系统只针对简单对象,无法有效的支持复杂对象(如图形、图像)。
空间数据库引擎技术是目前系统集成中广泛使用的中间件技术在空间数据库应用解决方案中的一种实现,虽然付出了附加中间层的额外代价,但它较好地解决了GIS 应用与空间数据库集成中数据提供与访问模式方面的制约瓶颈问题,是一种比较可行的方案.而面向对象的Geodatabase 是第三代数据模型,它克服了拓扑关系数据模型的缺点,由于它是面向对象的,因此能够方便地构造用户需要的任何复杂地理实体,而且这种模式符合人们看待客观世界的思维习惯,便于用户理解。
文本数据库(TXTDB)是一种常用的数据库,也是最简单的数据库。
任何文件都可以成为文本数据库。