CssSelector定位分享
8大元素定位方法

掌握 8 大元素定位方法,轻松定位网页元素一、By.IdBy.Id 是最常用的元素定位方法之一。
它通过元素的 ID 属性来定位元素,只返回找到的第一个元素。
例如:```WebElement element = driver.findElementById("abc");System.out.println(element.getText());```二、 也是常用的元素定位方法之一。
它通过元素的 name 属性来定位元素,只返回找到的第一个元素。
例如:```WebElement element = driver.findElementByName("abd"); System.out.println(element.getText());```三、By.LinkTextBy.LinkText 是根据链接文本来定位元素,只返回找到的第一个元素。
例如:```WebElement element = driver.findElementByLinkText("点击进入百度");element.click();```四、By.ClassNameBy.ClassName 是根据元素的类名来定位元素,返回匹配的第一个元素。
例如:```WebElement element =driver.findElementByClassName("helloniceworld");System.out.println(element.getText());```五、By.CssSelectorBy.CssSelector 是根据元素的 CSS 选择器来定位元素,返回匹配的第一个元素。
例如:```WebElement element = driver.findElementByCssSelector("ul li:first-child");System.out.println(element.getText());```六、By.XPathBy.XPath 是根据 XPATH 路径来定位元素,返回匹配的第一个元素。
css_selector定位法

css_selector定位法
CSS选择器定位法是一种在网页上定位元素的方法,它使用CSS 选择器语法来选择HTML元素。
通过CSS选择器,我们可以精确地定位页面上的元素,从而对其进行操作或者提取信息。
CSS选择器可以根据元素的标签名、类名、ID、属性等特征来定位元素。
首先,我们可以使用元素的标签名来选择元素,例如使用"div" 来选择所有的div元素。
另外,我们还可以通过类名来选择元素,使用 ".classname" 的形式来选择具有特定类名的元素。
此外,我们还可以通过ID来选择元素,使用 "#id" 的形式来选择具有特定ID的元素。
除此之外,CSS选择器还支持使用属性来选择元素,比如选择具有特定属性的元素,或者选择属性值匹配特定模式的元素。
我们还可以使用组合选择器来选择元素,比如选择父元素下的子元素,或者选择兄弟元素等。
总的来说,CSS选择器提供了丰富的选择元素的方法,可以根据元素的不同特征进行精确的定位。
在实际应用中,我们可以结合使用不同的选择器来定位页面上的元素,从而实现自动化测试、网
页数据抓取等功能。
CSS选择器定位法是前端开发和自动化测试中常用的技术,能够帮助我们准确地定位和操作页面上的元素。
使用CSS选择器提取特定网页元素的技巧和实践建议

使用CSS选择器提取特定网页元素的技巧和实践建议在网页设计和开发中,使用CSS选择器是非常常见的需求。
通过选择器,我们可以直接定位到特定网页元素,并对其进行样式的修改或者操作。
然而,有时候我们可能会遇到一些困难,难以精确地选择到目标元素。
本文将介绍一些技巧和实践建议,帮助我们更好地使用CSS选择器。
1. 使用基础的选择器CSS提供了一系列基础的选择器,如元素选择器、类选择器、ID选择器等。
在处理简单的网页结构时,这些选择器已经足够使用。
元素选择器可通过元素的标签名选择对应的元素,类选择器可通过元素的class属性选择对应的元素,ID选择器则可通过元素的id属性选择对应的元素。
使用这些基础选择器时,要注意避免使用选择器的嵌套,因为嵌套过多会增加选择器的复杂性,降低性能。
2. 使用属性选择器除了基础的选择器,CSS还提供了属性选择器,可以根据元素的属性来选择对应的元素。
比如,我们可以使用[attr]选择所有具有指定属性的元素,使用[attr=value]选择具有指定属性值的元素等。
属性选择器在处理多个具有共同属性的元素时非常有用,避免了针对每个元素都编写独立的选择器。
3. 使用伪类和伪元素CSS还提供了一系列伪类和伪元素,用于选择特定状态下的元素或者元素的特定部分。
比如,:hover伪类可选择鼠标悬停的元素,:nth-child(n)伪类可选择父元素下的第n个子元素等。
另外,::before和::after伪元素可在元素的内容前后插入特定的内容。
使用伪类和伪元素可以更精确地选择到目标元素的某些状态或者特定部分。
4. 结合其他选择器在实际应用中,我们可能会遇到一些复杂的选择需求,需要使用多个选择器结合起来使用。
CSS提供了多种方式来结合选择器,如选择器的组合、选择器的并集、选择器的交集等。
通过结合不同的选择器,我们可以更灵活地选择到目标元素。
5. 使用父元素、子元素和同级元素除了通过选择器直接选择目标元素,我们还可以通过元素之间的关系来进行选择。
xpath——父子、兄弟、相邻节点定位方式详解

xpath——⽗⼦、兄弟、相邻节点定位⽅式详解转载最后发布于2019-06-15 20:47:17 阅读数 1215 收藏1. 由⽗节点定位⼦节点最简单的肯定就是由⽗节点定位⼦节点了,我们有很多⽅法可以定位,下⾯上个例⼦:对以下代码:1.<html>2.<body>3.<div id="A">4.<!--⽗节点定位⼦节点-->5.<div id="B">6.<div>parent to child</div>7.</div>8.</div>9.</body>10.</html>1想要根据 B节点定位⽆id的⼦节点,代码⽰例如下:1.# -*- coding: utf-8 -*-2.from selenium import webdriver3.4.driver = webdriver.Firefox()5.driver.get('D:\\py\\AutoTestFramework\\src\\others\\test.html')6.7.# 1.串联寻找8.print driver.find_element_by_id('B').find_element_by_tag_name('div').text9.10.# 2.xpath⽗⼦关系寻找11.print driver.find_element_by_xpath("//div[@id='B']/div").text12.13.# 3.css selector⽗⼦关系寻找14.print driver.find_element_by_css_selector('div#B>div').text15.16.# 4.css selector nth-child17.print driver.find_element_by_css_selector('div#B div:nth-child(1)').text18.19.# 5.css selector nth-of-type20.print driver.find_element_by_css_selector('div#B div:nth-of-type(1)').text21.22.# 6.xpath轴 child23.print driver.find_element_by_xpath("//div[@id='B']/child::div").text24.25.driver.quit()1结果:1.parent to child2.parent to child3.parent to child4.parent to child5.parent to child6.parent to child1第1到第3都是我们熟悉的⽅法,便不再多⾔。
python定位元素的技巧

python定位元素的技巧在Python中,我们可以使用多种方法来定位元素。
在这篇文章中,我将分享一些常见的定位元素的技巧,帮助您更方便地使用Python进行元素定位。
1. 使用ID定位:元素的ID属性通常是唯一的,使用find_element_by_id方法可以快速定位到元素。
例如:element = driver.find_element_by_id("element_id")2. 使用Name定位:元素的Name属性也可以是唯一的,使用find_element_by_name方法可以定位到元素。
例如:element = driver.find_element_by_name("element_name")4. 使用CSS选择器定位:CSS选择器是一种用于选择HTML元素的模式,CSS选择器非常常见且简洁。
使用find_element_by_css_selector 方法可以通过CSS选择器定位元素。
例如:element =driver.find_element_by_css_selector("tag_name[attribute='attribu te_value']")5. 使用类名定位:如果元素有一个唯一的类名,可以使用find_element_by_class_name方法定位元素。
例如:element = driver.find_element_by_class_name("class_name")6. 使用链接文本定位:如果需要定位链接元素,可以使用find_element_by_link_text方法。
例如:element =driver.find_element_by_link_text("link_text")7. 使用部分链接文本定位:如果链接文本太长或包含动态生成的部分,可以使用find_element_by_partial_link_text方法定位链接元素。
元素定位之cssselector(选择器定位)

元素定位之cssselector(选择器定位)CSS选择器是一种用来选择HTML元素的方法,它通过指定元素的一些特征、属性和层次关系来定位元素。
其中,CSS选择器中最强大的定位方法之一是CSS选择器定位(CSS Selector Locators),也称为CSS选择器定位。
CSS选择器定位有以下几种常用的方法:2. 类选择器(Class Selector):通过选择元素的class属性值来定位元素。
在HTML中,可以通过在元素的class属性值前添加`.`(英文句点)来指定类选择器。
例如,通过`.header`选择所有class属性值为`header`的元素。
3. ID选择器(ID Selector):通过选择元素的id属性值来定位元素。
在HTML中,可以通过在元素的id属性值前添加`#`(井号)来指定ID选择器。
例如,通过`#logo`选择id属性值为`logo`的元素。
5. 子元素选择器(Child Selector):通过选择元素的直接子元素来定位元素。
子元素选择器使用`>`符号来表示。
例如,通过`div > p`选择所有直接子元素为`<p>`的`<div>`元素。
6. 后代元素选择器(Descendant Selector):通过选择元素的后代元素来定位元素。
后代元素选择器使用空格来表示。
例如,通过`div p`选择所有后代元素为`<p>`的`<div>`元素。
7. 兄弟元素选择器(Adjacent Sibling Selector):通过选择元素的相邻兄弟元素来定位元素。
兄弟元素选择器使用`+`符号来表示。
例如,通过`p + ul`选择所有与`<p>`元素相邻的`<ul>`元素。
以上只是CSS选择器定位的一些常见例子,实际应用中还有更多复杂的选择器定位方法。
通过灵活运用CSS选择器定位,我们可以精确地在HTML页面中定位到想要的元素,从而进行元素操作和页面交互。
元素定位之cssselector(选择器定位)

加油站可行性分析加油站作为一个重要的基础设施,为车辆提供加油服务并满足车辆日常运行需求。
对于一个地区来说,是否建设加油站很大程度上影响着该地区的经济和交通运输发展。
因此,进行对加油站的可行性分析具有重要意义。
一、市场需求分析加油站的建设与否首先要根据市场需求进行评估。
我们需要对该地区的车辆数量、车辆类型、车辆使用情况等因素进行综合考察。
通过调查和统计数据,我们可以获得市场对于加油站的需求量和潜在增长趋势。
同时,还要考虑周边地区的加油站分布情况以及交通运输枢纽的位置,确定是否存在市场空缺。
二、投资成本分析建设加油站需要投入大量的资金,包括土地购买、设备安装、职工薪资等各项费用。
首先要评估土地的价格和合适的地点,考虑交通便利性和土地价值增长潜力。
其次,根据预估的市场需求,确定加油站的规模,并评估所需设备的购买和安装费用。
同时,还要考虑运营成本,包括人力资源和运输成本等。
通过对投资成本的分析,可以判断是否值得建设加油站。
三、收益分析建设加油站的目的是为了盈利。
除了加油业务本身的收益外,还可以通过提供其他服务或销售商品来增加额外收入。
例如,提供洗车服务、便利店销售等。
同时,还要考虑地域经济发展的趋势,以及车辆保有量的预测,从而分析加油站未来的收入能力。
通过综合分析收入和支出,可以评估加油站的盈利潜力。
四、竞争对手分析在加油站行业中,竞争对手的存在是不可避免的。
为了评估建设加油站的可行性,要进行竞争对手的分析。
了解周边已有加油站的规模、服务质量和价格,以及其它竞争因素。
通过比较和评估,确定自己的竞争优势和定位。
同时,要考虑未来可能出现的新竞争对手,进行充分的市场预测和预估。
五、风险评估在进行可行性分析时也要考虑到投资风险。
加油站的成功与否不仅取决于市场需求和盈利能力,还受到政策法规、环境保护等方面的影响。
同时,加油站也存在一些因素风险,如油价波动、交通状况和恶劣天气等不可控因素。
要对这些风险进行评估和预案制定,降低风险可能对加油站运营造成的不利影响。
css_selector用法

css_selector用法什么是CSS选择器?CSS选择器是一种用于选择HTML元素以进行样式化的模式。
它们基于特定的规则和语法,允许开发者根据元素的属性、层级关系以及其他条件来选择并应用样式。
使用CSS选择器可以有效地控制页面中的元素,改善用户界面的外观和体验。
为什么我们需要使用CSS选择器?在网页开发中,元素选择是一项重要的任务。
通过选择器,我们可以为特定的HTML元素或一组元素应用样式。
这样,我们可以确保页面的各个部分具有一致的外观和风格,使页面更加易读、易用和美观。
使用CSS选择器还可以减少重复代码的使用,提高代码的可维护性。
下面我们来逐步学习CSS选择器的用法:1. 元素选择器(Element Selector):这是最基本的选择器,通过选择HTML元素的标签名称来应用样式。
例如,如果要为所有段落(<p>标签)设置样式,可以使用选择器"p"。
2. ID选择器(ID Selector):通过HTML标签上的唯一ID属性来选择元素。
使用选择器"#"后跟ID 值来选择元素。
例如,要选择一个具有ID为"header"的元素,可以使用选择器"#header"。
3. 类选择器(Class Selector):通过HTML标签上的class属性来选择元素。
使用选择器"."后跟class 名称来选择元素。
例如,要选择class为"button"的元素,可以使用选择器".button"。
4. 属性选择器(Attribute Selector):通过HTML元素的属性来选择元素。
使用属性名或属性名加属性值的组合来选择元素。
例如,要选择所有具有属性"title"的链接元素,可以使用选择器"a[title]"。
5. 后代选择器(Descendant Selector):通过元素的层级关系来选择元素。
CSS选择器的用法知识点

CSS选择器的用法知识点CSS(层叠样式表)是一种用于描述网页中元素样式的语言。
它通过选择器来定位和选择要应用样式的HTML元素,从而实现页面的排版和装饰效果。
在本文中,将介绍一些CSS选择器的常用用法知识点。
1. 元素选择器元素选择器是最基本的CSS选择器,它通过指定元素的标签名来选择对应的HTML元素。
例如,使用“p”选择器将选中所有的段落元素<p>。
</p>2. 类选择器类选择器是通过指定元素的class属性值来选择对应的HTML元素。
在HTML元素的class属性值前面添加“.”来定义类选择器。
例如,使用“.red”选择器将选中所有class属性值为“red”的元素。
3. ID选择器ID选择器是通过指定元素的id属性值来选择对应的HTML元素。
在HTML元素的id属性值前面添加“#”来定义ID选择器。
例如,使用“#header”选择器将选中id属性值为“header”的元素。
4. 属性选择器属性选择器是通过选择元素的属性来选择对应的HTML元素。
例如,使用“[type='text']”选择器将选中所有type属性值为“text”的元素。
5. 后代选择器后代选择器是通过选择元素的后代元素来选择对应的HTML元素。
它使用空格分隔多个选择器。
例如,使用“div p”选择器将选中所有位于<div>元素内的<p>元素。
6. 子元素选择器子元素选择器是通过选择元素的直接子元素来选择对应的HTML元素。
它使用“>”符号分隔父元素和子元素的选择器。
例如,使用“ul > li”选择器将选中所有作为<ul>直接子元素的<li>元素。
7. 相邻兄弟选择器相邻兄弟选择器是通过选择元素的相邻兄弟元素来选择对应的HTML元素。
它使用“+”符号分隔前一个选择器和后一个选择器。
例如,使用“h1 + p”选择器将选中紧接在<h1>元素后的第一个<p>元素。
【最新2018】选择器selector笔记总结word版本 (5页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==选择器selector笔记总结导读:小编在此分享关于选择器(selector)的笔记。
这对其他朋友应该也是有用的,毕竟选择器是制作网页效果的第一步。
笔记分为两个部分,今天是CSS的选择器,以后还有一部分xPath的选择器。
今天的笔记中包括44个选择器,基本涵盖了CSS 2和CSS 3的所有规定。
一、序号选择器含义* 通用元素选择器,匹配任何元素2.E标签选择器,匹配所有使用E标签的元素class选择器,匹配所有class属性中包含info的元素4. #footer id选择器,匹配所有id属性等于footer的元素实例:复制代码代码如下:* { margin:0; padding:0; }p { font-size:2em; }.info { background:#ff0; } { background:#ff0; }.error { color:#900; font-weight:bold; }#info { background:#ff0; }p#info { background:#ff0; }二、多元素的组合选择器序号选择器含义5. E,F多元素选择器,同时匹配所有E元素或F元素,E和F之间用逗号分隔6. E F后代元素选择器,匹配所有属于E元素后代的F元素,E和F之间用空格分隔7.E > F子元素选择器,匹配所有E元素的子元素F8.E + F毗邻元素选择器,匹配所有紧随E元素之后的同级元素F实例:复制代码代码如下:div p { color:#f00; }#nav li { display:inline; }#nav a { font-weight:bold; }div > strong { color:#f00; }p + p { color:#f00; }三、CSS 2.1 属性选择器序号选择器含义9. E[att]匹配所有具有att属性的E元素,不考虑它的值。
css selector 元素定位语法

CSS Selector:元素定位语法的强大与灵活CSS (Cascading Style Sheets) 是用于描述HTML 或XML (包括如SVG, MathML 等派生语言) 文档样式的样式表语言。
它提供了丰富的选择器,使我们能够精确地定位和样式化HTML 元素。
在CSS 中,选择器是用于选择你想要样式化的HTML 元素的模式。
CSS 选择器可以分为几种类型,包括元素选择器、类选择器、ID 选择器、属性选择器等。
这些选择器可以单独使用,也可以组合使用,以实现更复杂的元素定位。
1.元素选择器:这是最基础的选择器,它根据HTML 元素的名称来选择元素。
例如,p 选择器会选择页面上的所有 <p> 元素。
2.类选择器:类选择器使用 . 符号,后面跟着类名。
例如,.intro 选择器会选择所有带有 intro 类的元素。
3.ID 选择器:ID 选择器使用 # 符号,后面跟着ID 名。
例如,#firstname 选择器会选择带有 id="firstname" 的元素。
4.属性选择器:属性选择器用于选择具有指定属性的元素。
例如,[target] 选择器会选择所有带有 target 属性的元素。
5.伪类和伪元素选择器:这些选择器用于选择处于特定状态的元素(例如被鼠标悬停的元素)或者元素的特定部分(例如元素的第一个字)。
例如,:hover 选择器会选择鼠标指针下的元素。
1.组合选择器:组合选择器允许你组合多个选择器来定位元素。
例如,divp 选择器会选择所有在 <div> 元素内的 <p> 元素。
2.子代和后代选择器:除了组合选择器,还有子代选择器和后代选择器。
div >p 选择器会选择所有 <div> 的直接子代 <p> 元素,而 div p 会选择所有在 <div> 内的 <p> 元素,不论它们是直接子代还是后代。
前端面试 css中知识点 selector 整理

面试官:css选择器有哪些?优先级?哪些属性可以继承?一、选择器CSS选择器是CSS规则的第一部分它是元素和其他部分组合起来告诉浏览器哪个HTML元素应当是被选为应用规则中的CSS属性值的方式选择器所选择的元素,叫做“选择器的对象”我们从一个Html结构开始<div id="box"><div class="one"><p class="one_1"></p><p class="one_1"></p></div><div class="two"></div><div class="two"></div><div class="two"></div></div>关于css属性选择器常用的有:•id选择器(#box),选择id为box的元素•类选择器(.one),选择类名为one的所有元素•标签选择器(div),选择标签为div的所有元素•后代选择器(#box div),选择id为box元素内部所有的div元素•子选择器(.one>one_1),选择父元素为.one的所有.one_1的元素•相邻同胞选择器(.one+.two),选择紧接在.one之后的所有.two元素•群组选择器(div,p),选择div、p的所有元素还有一些使用频率相对没那么多的选择器:•伪类选择器:link:选择未被访问的链接:visited:选取已被访问的链接:active:选择活动链接:hover:鼠标指针浮动在上面的元素:focus:选择具有焦点的:first-child:父元素的首个子元素•伪元素选择器:first-letter:用于选取指定选择器的首字母:first-line:选取指定选择器的首行:before: 选择器在被选元素的内容前面插入内容:after: 选择器在被选元素的内容后面插入内容•属性选择器[attribute] 选择带有attribute属性的元素[attribute=value] 选择所有使用attribute=value的元素[attribute~=value] 选择attribute属性包含value的元素[attribute|=value]:选择attribute属性以value开头的元素在CSS3中新增的选择器有如下:•层次选择器(p~ul),选择前面有p元素的每个ul元素•伪类选择器:first-of-type父元素的首个元素:last-of-type父元素的最后一个元素:only-of-type父元素的特定类型的唯一子元素:only-child父元素中唯一子元素:nth-child(n)选择父元素中第N个子元素:nth-last-of-type(n)选择父元素中第N个子元素,从后往前:last-child父元素的最后一个元素:root设置HTML文档:empty指定空的元素:enabled选择被禁用元素:disabled选择被禁用元素:checked选择选中的元素:not(selector)选择非 <selector>元素的所有元素•属性选择器[attribute*=value]:选择attribute属性值包含value的所有元素[attribute^=value]:选择attribute属性开头为value的所有元素[attribute$=value]:选择attribute属性结尾为value的所有元素二、优先级相信大家对CSS选择器的优先级都不陌生:内联 > ID选择器 > 类选择器 > 标签选择器到具体的计算层⾯,优先级是由 A 、B、C、D 的值来决定的,其中它们的值计算规则如下:•如果存在内联样式,那么 A = 1, 否则 A = 0•B的值等于 ID选择器出现的次数•C的值等于类选择器和属性选择器和伪类出现的总次数• D 的值等于标签选择器和伪元素出现的总次数这里举个例子:#nav-global> ul > li > a.nav-link套用上面的算法,依次求出A B C D的值:•因为没有内联样式,所以 A = 0•ID选择器总共出现了1次, B = 1•类选择器出现了1次,属性选择器出现了0次,伪类选择器出现0次,所以 C = (1 + 0 + 0) = 1•标签选择器出现了3次,伪元素出现了0次,所以 D = (3 + 0) = 3上面算出的A、B、C、D可以简记作:(0, 1, 1, 3)知道了优先级是如何计算之后,就来看看比较规则:•从左往右依次进行比较,较大者优先级更高•如果相等,则继续往右移动一位进行比较•如果4位全部相等,则后面的会覆盖前面的经过上面的优先级计算规则,我们知道内联样式的优先级最高,如果外部样式需要覆盖内联样式,就需要使用!important三、继承属性在css中,继承是指的是给父元素设置一些属性,后代元素会自动拥有这些属性关于继承属性,可以分成:•字体系列属性font:组合字体font-family:规定元素的字体系列font-weight:设置字体的粗细font-size:设置字体的尺寸font-style:定义字体的风格font-variant:偏大或偏小的字体•文本系列属性text-indent:文本缩进text-align:文本水平对刘line-height:行高word-spacing:增加或减少单词间的空白letter-spacing:增加或减少字符间的空白text-transform:控制文本大小写direction:规定文本的书写方向color:文本颜色•元素可见性visibility•表格布局属性caption-side:定位表格标题位置border-collapse:合并表格边框border-spacing:设置相邻单元格的边框间的距离empty-cells:单元格的边框的出现与消失table-layout:表格的宽度由什么决定•列表属性list-style-type:文字前面的小点点样式list-style-position:小点点位置list-style:以上的属性可通过这属性集合•引用quotes:设置嵌套引用的引号类型•光标属性cursor:箭头可以变成需要的形状继承中比较特殊的几点:• a 标签的字体颜色不能被继承•h1-h6标签字体的大下也是不能被继承的无继承的属性•display•文本属性:vertical-align、text-decoration•盒子模型的属性:宽度、高度、内外边距、边框等•背景属性:背景图片、颜色、位置等•定位属性:浮动、清除浮动、定位position等•生成内容属性:content、counter-reset、counter-increment•轮廓样式属性:outline-style、outline-width、outline-color、outline •页面样式属性:size、page-break-before、page-break-after。
新版slenium中定位元素的方法

新版slenium中定位元素的方法在自动化测试领域,Selenium是一个广泛使用的工具,它支持各种编程语言来进行网页元素的定位和操作。
随着版本的更新,Selenium提供了一系列更加高效和灵活的元素定位方法。
本文将详细介绍在新版Selenium中定位元素的各种方法。
### 新版Selenium中定位元素的方法在新版的Selenium中,元素定位是进行自动化测试的基础。
以下是一些常用的定位元素的方法:#### 1.ID定位使用元素的ID进行定位是最快的方法,因为ID在页面中通常是唯一的。
```javaWebElement element = driver.findElement(By.id("elementID"));```#### 定位如果元素具有name属性,可以使用这个属性值来定位。
```javaWebElement element =driver.findElement(("elementName"));```#### 3.Class Name定位通过元素的class属性值来定位,适用于有特定样式类的元素。
```javaWebElement element =driver.findElement(By.className("className"));```#### 4.Tag Name定位根据元素的标签名定位,如果页面中只有一个这样的标签,这是一个简单的方法。
```javaWebElement element =driver.findElement(By.tagName("tagName"));```#### 5.Link Text定位对于超链接(a标签),可以通过链接的完整文本来定位。
```javaWebElement element = driver.findElement(By.linkText("linkText"));```#### 6.Partial Link T ext定位当链接文本过长时,可以使用部分链接文本来定位。
selenium css 元素定位写法

selenium css 元素定位写法Selenium可以使用CSS选择器来定位元素,以下是一些常见的CSS选择器定位写法:1. 使用元素标签名定位:```pythondriver.find_element_by_css_selector("tag_name")```2. 使用元素的class属性定位:```pythondriver.find_element_by_css_selector(".class_name")```3. 使用元素的id属性定位:```pythondriver.find_element_by_css_selector("#id_name")```4. 使用元素的属性或属性值定位:```pythondriver.find_element_by_css_selector("[attribute_name='attribute_v alue']")```5. 使用多个属性定位:```pythondriver.find_element_by_css_selector("[attribute1_name='attribute1 _value'][attribute2_name='attribute2_value']")```6. 使用选择器组合定位:```pythondriver.find_element_by_css_selector("selector1, selector2")```7. 使用层级关系定位:- 子元素:```parent > child```- 后代元素:```ancestor descendant```- 相邻兄弟元素:```prev + next```- 后续兄弟元素:```prev ~ siblings```例如,定位一个class属性为"example"的div元素可以使用以下写法:```pythondriver.find_element_by_css_selector("div.example")```注意:CSS选择器定位是大小写敏感的,确保选择器的大小写与页面元素的属性匹配。
CSS中的CSSSelector优化技巧有哪些

CSS中的CSSSelector优化技巧有哪些在网页开发中,CSS(层叠样式表)是用于定义网页样式的重要工具。
而CSS Selector(选择器)则是用来指定我们想要应用样式的元素。
有效的选择器能够准确地选取目标元素,从而提高样式表的效率和可维护性。
下面就让我们来探讨一下 CSS 中的 CSS Selector 优化技巧。
一、理解选择器的性能开销不同类型的选择器在性能上是有差异的。
一般来说,简单的选择器(如元素选择器、类选择器和 ID 选择器)性能较好,而复杂的选择器(如后代选择器、通配符选择器等)性能相对较差。
元素选择器(如`div`、`p` 等)直接指定元素类型,性能较为高效。
类选择器(如`classname`)通过指定类名来选取元素,也是常见且性能不错的选择方式。
ID 选择器(如`idname`)由于在文档中必须是唯一的,所以性能也较好。
而后代选择器(如`div p`)需要遍历多个层次的元素来匹配,通配符选择器(如``)则会匹配文档中的所有元素,这两种选择器的性能开销较大,应谨慎使用。
二、避免过度使用通配符选择器通配符选择器虽然可以快速选择所有元素,但它会带来不必要的性能开销。
因为它会遍历整个文档中的每一个元素,无论是否需要应用样式。
例如,如果我们只想设置所有段落的字体颜色,使用`p { color: red; }`要比`{ color: red; }`高效得多。
三、减少后代选择器的层级当使用后代选择器时,层级越多,浏览器查找和匹配元素所需的时间就越长。
假设我们有以下的 HTML 结构:```html<div class="container"><ul><li><span>Some Text</span></li></ul></div>```如果我们要为内部的`span` 元素设置样式,`divcontainer ul li span { fontsize: 14px; }`这样的选择器就包含了过多的层级。
cssSelector常用定位方法
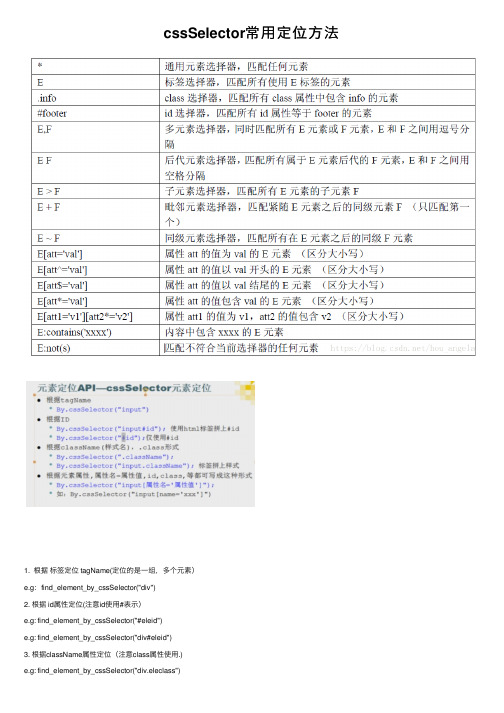
cssSelector常⽤定位⽅法1. 根据标签定位 tagName(定位的是⼀组,多个元素)e.g:find_element_by_cssSelector("div")2. 根据 id属性定位(注意id使⽤#表⽰)e.g: find_element_by_cssSelector("#eleid")e.g: find_element_by_cssSelector("div#eleid")3. 根据className属性定位(注意class属性使⽤.)e.g: find_element_by_cssSelector("div.eleclass")4. 根据元素属性定位4.1 精确匹配:e.g: find_element_by_cssSelector("div[name=elename]") #属性名=属性值,精确值匹配e.g: find_element_by_cssSelector("a[href]") #是否存在该属性,判断a元素是否存在href属性注意:如果 class属性值⾥带空格,⽤.来代替空格4.2 模糊匹配e.g: find_element_by_cssSelector("div[name^=elename]") #从起始位置开始匹配e.g: find_element_by_cssSelector("div[name$=name2]") #从结尾匹配e.g: find_element_by_cssSelector("div[name*=name1]") #从中间匹配,包含4.3 多属性匹配e.g: find_element_by_cssSelector("div[type='eletype][value='elevalue']") #同时有多属性e.g: find_element_by_cssSelector("div.eleclsss[name='namevalue'] #选择class属性为eleclass并且name为namevalue的div节点e.g: find_element_by_cssSelector("div[name='elename'][type='eletype']:nth-of-type(1) #选择name为elename并且type为eletype的第1个div节点5. 定位⼦元素 (A>B)e.g: find_element_by_cssSelector("div#eleid>input") #选择id为eleid的div下的所有input节点e.g: find_element_by_cssSelector("div#eleid>input:nth-of-type(4) #选择id为eleid的div下的第4个input节点e.g: find_element_by_cssSelector("div#eleid>nth-child(1)") #选择id为eleid的div下的第⼀个⼦节点6. 定位后代元素 (A空格B)e.g: find_element_by_cssSelector("div#eleid input") #选择id为eleid的div下的所有的⼦孙后代的 input 节点e.g: find_element_by_cssSelector("div#eleid>input:nth-of-type(4)+label #选择id为eleid的div下的第4个input节点的相邻的label节点e.g: find_element_by_cssSelector("div#eleid>input:nth-of-type(4)~label #选择id为eleid的div下的第4个input节点之后中的所有label节点7. 不为e.g: find_element_by_cssSelector("div#eleid>*.not(input)") #选择id为eleid的div下的⼦节点中不为input 的所有⼦节点e.g: find_element_by_cssSelector("div:not([type='eletype'])") #选择div节点中type不为eletype的所有节点8. 包含Bycontente.g: find_element_by_cssSelector("li:contains('Goa')") # <li>Goat</li>e.g: find_element_by_cssSelector("li:not(contains('Goa'))) # <li>Cat</li>9. by indexe.g: find_element_by_cssSelector("li:nth(5)")。
css选择器元素定位方法

css选择器元素定位⽅法选择器例⼦例⼦描述CSS .intro选择 class="intro" 的所有元素。
1#firstname选择 id="firstname" 的所有元素。
1*选择所有元素。
2p选择所有 <p> 元素。
1div,p选择所有 <div> 元素和所有 <p> 元素。
1div p选择 <div> 元素内部的所有 <p> 元素。
1div>p选择⽗元素为 <div> 元素的所有 <p> 元素。
2div+p选择紧接在 <div> 元素之后的所有 <p> 元素。
2[target]选择带有 target 属性所有元素。
2[target=_blank]选择 target="_blank" 的所有元素。
2[title~=flower]选择 title 属性包含单词 "flower" 的所有元素。
2[lang|=en]选择 lang 属性值以 "en" 开头的所有元素。
2a:link选择所有未被访问的链接。
1a:visited选择所有已被访问的链接。
1a:active选择活动链接。
1a:hover选择⿏标指针位于其上的链接。
1input:focus选择获得焦点的 input 元素。
2p:first-letter选择每个 <p> 元素的⾸字母。
1p:first-line选择每个 <p> 元素的⾸⾏。
1p:first-child选择属于⽗元素的第⼀个⼦元素的每个 <p> 元素。
2p:before在每个 <p> 元素的内容之前插⼊内容。
2p:after在每个 <p> 元素的内容之后插⼊内容。
2p:lang(it)选择带有以 "it" 开头的 lang 属性值的每个 <p> 元素。
css selector 语法

css selector 语法CSS(层叠样式表)选择器是一种用于确定HTML元素及其样式的语法。
它允许你使用文本规则来定义元素的样式,而不是使用更复杂的编程语言。
CSS Selector法允许开发人员使用文本规则来定义哪些HTML元素和哪些样式可以用来渲染网页。
CSS Selector法可以被用来精确地定位HTML元素的细节,也可以定义更基本的、更简单的规则来定义大量的HTML元素。
CSS Selector法主要有三种类型:类选择器,ID选择器以及属性选择器。
三种选择器可以用来将页面上的某个元素与某种样式或功能相关联。
类选择器是CSS Selector法中最常用的类型。
类选择器使用CSS 中的类属性来定义样式表,且可以用于多个元素。
通过使用类选择器,开发人员可以将相同样式应用于同一类元素,例如把相同的文字大小或颜色应用于页面上所有标题元素。
ID选择器是CSS Selector法中最强大的选择器类型,它可以用来将一个唯一元素与某种样式或功能相关联。
当在HTML代码中指定某元素的ID属性时,你就可以在CSS文件中使用ID选择器来定义该元素的特定样式或功能,而不会影响到其它元素的样式。
属性选择器是CSS Selector法中最灵活的类型,它允许开发人员定义特定元素的某种特定属性的样式或功能。
例如,属性选择器可以用来把特定的链接格式应用于页面中指定的链接,也可以用来把某种特定的字体大小应用于文本框中的文字。
另外,CSS Selector法还有一种类型叫做层叠式选择器。
层叠式选择器允许开发人员为特定元素定义继承样式,以便将同一种样式应用于多个元素。
例如,通过使用层叠式选择器,开发人员可以针对页面中所有标题元素指定一种相同的文字大小。
总而言之,CSS Selector法是一种方便的工具,可以使开发人员用简单的文本规则定义特定元素的样式和功能,因此可以极大地提高开发人员创建和编辑网页的效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cssSelector定位
一.为什么使用cssSelector定位元素?
目前针对一些常规定位方式有:By.id、、By.LinkTest(针对<a>标签)、By.ClassName 针对不太好定位的,比如:没有id、name、class的定位方式,或者说id、name、class的value值显示重复,不太方便一下写出定位方式,这样可以考虑下其它定位方式。
以下主要介绍cssSelector如何解决id、name、class的value值显示重复的定位方式。
二.基础语法
三.css常用的定位方式介绍
1.E代表的是标签;
2.E>F:F也是代表的标签,称为子代元素,F是E的子代元素,说通俗一点F是E的儿子
关系,F紧跟着E后面的第一个元素,直接的下一级;
3. E F:隔着多层标签,称为后代元素。
通俗点说祖宗辈关系,例如爷爷和孙子关系;
4.E+F:匹配紧随E元素之后的同级元素F(只匹配第一个),称为毗邻元素选择器。
通俗
点解释E是大哥,后面有多个弟弟,只取它最近一个弟弟F;
5. E ~ F:同级标签,称为同级元素选择器。
通俗称为兄弟关系,例如哥哥和弟弟关系;
6.E[att='val']:E代表标签,att代表属性,val指属性的值;
7.E[att1='v1'][att2*='v2']:多属性选择器,针对一个标签有多个属性,做并且的关系同时满
足条件;
class:点代表class;
9.#footer id:#号代表id;
10.ele:nth-of-type(n)是指其父元素下第n个ele元素。
例如:同一级下有10个div标签,那
么只需要定位其中6个div,这时代码可以这样写:div:nth-of-type(6),括号中的数据代表索引查找第n个元素;
四.cssSelector常用定位方式的案例
1.例如这样一段html代码的网页
<div class="formdiv">
<form name="fnfn">
<input name="username" type="text"></input>
<input name="password" type="text"></input>
<input name="continue" type="button"></input>
<input name="cancel" type="button"></input>
<input value="SYS123456" name="vid" type="text">
<input value="ks10cf6d6" name="cid" type="text"> </form>
<div class="subdiv">
<ul id="recordlist">
<p>Heading</p>
<li>Cat</li>
<li>Dog</li>
<li>Car</li>
<li>Goat</li>
</ul>
</div>
</div>
2.匹配示例:
3.针对特殊标签定位方式:
a).如果class里带的空格,用.来代替空格如:
<button class="x-btn-text module_picker_icon">...
可以这样写:
css=button.x-btn-text.module_picker_icon
b).如果你想定位一个显示OK的Button,但页面上有几个Button,id是自动生成的,class是一样的,我又想用一个简单点的CSS locator的时候,
<button id="ext-eng-1026" class="x-right-button">OK</button>
<button id="ext-eng-1027" class="x-right-button">Cancel</button>
可以这样写:
css=button.x-right-button:contains("OK")
:contains是个Pseudo-class,用冒号开头,括号里是内容。
Pseudo-classes是CSS提供的伪类,用来访问页面上DOM tree之外的信息,还有Pseudo-elements 用来最精准的定位页面上的某一行文字,甚至某一行文字的第一个字母。
这个得具体研究一下css3 selector文档的Chapter 6.6 Pseudo-classes 和 Chapter 7 Pseudo-elements
4.综上所述,就是:
有固定id的用id selector,
没有固定id的用css selector。
Pseudo-selements :contains()很好用。
会了这几下子,基本上定位就不成问题了。