java利用word模版导出word文档详细说明
java导出之导出word文档

java导出之导出word⽂档Springboot之word导出1.简介导出word实现⽤的⼯具是poi-tl,主要是通过预先设置word模板格式,通过数据填充来实现数据动态录⼊。
⽀持动态表格以及图。
使⽤步骤主要分为准备冰箱,准备象,把象装进冰箱。
2.准备环境(冰箱)包括两种,导包和模板预设置com.deepoove poi-tl 1.9.1 注意:poi-tl版本对阿帕奇的poi版本依赖有条件,低版本会报错,Tomcat会默认依赖低版本的jar包。
准备模板,模板可以设置⾏⾼,位置,固定宽度和最⼩⾼度,可以保证内容显⽰完全3.准备数据(⼤象)######Controller 层,返回值和两个⼊参public ResponseEntity<byte[]> exportJbZwJlxx(HttpServletRequest request, HttpServletResponse response) {//任免表⾥,需要基本信息,职务信息,部门⼈员信息,简历信息以及个⼈经历信息if(jbZwJlxxScCxDto.getDxbz()==null || "".equals(jbZwJlxxScCxDto.getDxbz()) ){log.error("档案薪酬判断标志不能为空");throw new RuntimeException("dxbz不能为空,或者为空字符串");}try {return jbZwJlxxService.getParams(jbZwJlxxScCxDto);} catch (Exception e) {log.error("导出失败",e);}return null;}######Service层获取数据,格式如下,和模板上对应即可Map<String, Object> params = new HashMap<>(100);params.put("jljj",!jlxxBean.getJljj().equals(CmGbglConstants.SPACE)? jlxxBean.getJljj() : "⽆");######动态表格的数据封装,通过**对象的属性赋值**int length = 7;// 返回数据超过七条if (res.size() > length) {length = res.size();// 封装查询回来的⼤于7的对象for (int i = 0; i < length; i++) {QtxxDto qtxxDto = new QtxxDto();qtxxDto = res.get(i);Map<String,Object> detailMap = new HashMap<String, Object>(7);detailMap.put("cw", qtxxDto.getCw());detailMap.put("name", qtxxDto.getName());qtxxDto.setCsny(getAge(qtxxDto.getCsny())+"");detailMap.put("csny", qtxxDto.getCsny());detailMap.put("zzmmmc",qtxxDto.getZzmmmc());detailMap.put("gzdwjzw",qtxxDto.getGzdwjzw());detailList.add(detailMap);qtxxDtos.add(qtxxDto);}} else {// 数据集长度⼩于七条for (int i = 0; i < res.size(); i++) {QtxxDto qtxxDto = new QtxxDto();qtxxDto = res.get(i);qtxxDto.setCsny(getAge(qtxxDto.getCsny())+"");qtxxDtos.add(qtxxDto);}for (int j = 0; j < (length - res.size()); j++) {QtxxDto qtxxDto = new QtxxDto();qtxxDtos.add(qtxxDto);}}}params.put("detailList", qtxxDtos);4.和模板建⽴关系try{//获得模板⽂件的输⼊流,这个是放在启动器的那个项⽬的resource下InputStream in = this.getClass().getResourceAsStream("/word/rmb.docx");//表格⾏循环插件HackLoopTableRenderPolicy policy = new HackLoopTableRenderPolicy();//绑定detailListConfigure config = Configure.builder().bind("detailList", policy).build();XWPFTemplate template = pile(in , config).render(params);String fileName = new String("rmb.docx".getBytes("UTF-8"), "iso-8859-1");ByteArrayOutputStream outputStream = new ByteArrayOutputStream();template.write(outputStream);template.close();HttpHeaders httpHeaders = new HttpHeaders();httpHeaders.add("content-disposition", "attachment;filename=" + fileName);httpHeaders.setContentType(MediaType.APPLICATION_OCTET_STREAM);ResponseEntity<byte[]> filebyte = new ResponseEntity<byte[]>(outputStream.toByteArray(), httpHeaders,HttpStatus.CREATED);outputStream.close();return filebyte;} catch (Exception e) {log.error("导出失败", e);throw e;}注意:模板放置的位置可以放在resource下,在本地编译的时候可以使⽤类加载器获取,但是打包到正式环境后就会找不到模板。
Java使用Poi-tlword模板导出word

Java使⽤Poi-tlword模板导出word 1.导⼊依赖<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version></dependency><dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.7.3</version></dependency>2.新建⼀个word,制作导出模板模板放⼊ resource/static/word/template⽂件夹下3.编写⼯具类⼯具类--WordExportServer.javapublic class WordExportServer {/*** 导出word**/public static void export(WordExportData wordExportData) throws IOException {HttpServletResponse response=wordExportData.getResponse();OutputStream out = response.getOutputStream();;XWPFTemplate template =null;try{ClassPathResource classPathResource = new ClassPathResource(wordExportData.getTemplateDocPath());String resource = classPathResource.getURL().getPath();resource= PdfUtil1.handleFontPath(resource);//渲染表格HackLoopTableRenderPolicy policy = new HackLoopTableRenderPolicy();Configure config = Configure.newBuilder().bind(wordExportData.getTableDataField(), policy).build();template = pile(resource, config).render(wordExportData.getWordData());String fileName=getFileName(wordExportData);/** ===============⽣成word到设置浏览默认下载地址=============== **/// 设置强制下载不打开response.setContentType("application/force-download");// 设置⽂件名response.addHeader("Content-Disposition", "attachment;fileName=" + fileName);template.write(out);}catch (Exception e){e.printStackTrace();}finally {out.flush();out.close();template.close();}}/*** 获取导出下载的word名称* @param wordExportData* @return ng.String**/public static String getFileName(WordExportData wordExportData){if(null !=wordExportData.getFileName()){return wordExportData.getFileName()+".docx";}return System.currentTimeMillis()+".docx";}}word数据包装类--WordExportData .java@Datapublic class WordExportData {/*** word模板路径(static/wordTemplate/dealerListDocTemplate.docx)**/private String templateDocPath;/*** word填充数据(key值与模板中的key值要保持⼀致)**/private Map<String,Object> wordData;/*** word表格数据key值**/private String tableDataField;/*** word导出后的⽂件名(不填则⽤当前时间代替)**/private String fileName;private HttpServletResponse response;}4.controller层调⽤@RequestMapping("/printWord")public void printWord(HttpServletRequest request, HttpServletResponse response) throws IOException{String[] ids=request.getParameter("ids").split(";");List<DealerDto> goodsDataList=goodsService.getDealerListByIds(ids);Map<String,Object> docData=new HashMap<>(3);docData.put("detailList",goodsDataList);docData.put("title",标题);docData.put("subTitle",副标题);WordExportData wordExportData=new WordExportData();wordExportData.setResponse(response);wordExportData.setTableDataField("detailList");wordExportData.setTemplateDocPath(DEALER_DOC_TEMPLATE_PATH);//副本存放路径wordExportData.setWordData(docData);WordExportServer.export(wordExportData);}5.前端调⽤var ids = [];for (var index in checkData) {ids.push(checkData[index].id);}var batchIds = ids.join(";");layer.confirm('确定下载选中的数据吗?', function (index) {layer.close(index);window.location.href ='/goods/printWord?ids=' + batchIds;});6.总结优点:使⽤⽅法很简单,使⽤⼯具类的⽅法,⽅便复⽤于其他模块。
java根据模板生成pdf文件并导出

java根据模板生成pdf文件并导出首先你的制作一个pdf模板:1.先用word做出模板界面2.文件另存为pdf格式文件3.通过Adobe Acrobat pro软件打开刚刚用word转换成的pdf文件(注:如果没有这个软件可以通过我的百度云下载,链接:/s/1pL2klzt)如果无法下载可以联系博主。
4.点击右边的"准备表单"按钮,选择"测试.pdf"选择开始进去到编辑页面,打开后它会自动侦测并命名表单域,右键表单域,点击属性,出现文本域属性对话框(其实无需任何操作,一般情况下不需要修改什么东西,至少我没有修改哦。
如果你想修改fill1等信息,可以进行修改)5.做完上面的工作后,直接"另存为"将pdf存储就可以****************************************************************** ***********以上部分是制作pdf模板操作,上述完成后,就开始通过程序来根据pdf模板生成pdf文件了,上java程序:1.首先需要依赖包:itext的jar包,我是maven项目,所以附上maven依赖[html] view plain copy print?<!--https:///artifact/com.itextpdf/itextpdf--> <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.10</version></dependency> [html] view plain copy print?<!-- https:///artifact/com.itextpdf/itext-asian --> <span style="white-space:pre;"></span><dependency> <spanstyle="white-space:pre;"> </span><groupId>com.itextpdf</groupId> <span style="white-space:pre;"> </span><artifactId>itext-asian</artifactId> <span style="white-space:pre;"> </span><version>5.2.0</version> <spanstyle="white-space:pre;"></span></dependency> 2.下面就是生成pdf代码了[java] view plain copy print?importjava.io.ByteArrayOutputStream; importjava.io.FileOutputStream; import java.io.IOException; import com.itextpdf.text.Document; importcom.itextpdf.text.DocumentException; importcom.itextpdf.text.pdf.AcroFields; importcom.itextpdf.text.pdf.PdfCopy; importcom.itextpdf.text.pdf.PdfImportedPage; importcom.itextpdf.text.pdf.PdfReader; importcom.itextpdf.text.pdf.PdfStamper; public class Snippet { // 利用模板生成pdf public static void fillTemplate() { // 模板路径String templatePath = "E:/测试3.pdf"; // 生成的新文件路径String newPDFPath = "E:/ceshi.pdf"; PdfReader reader; FileOutputStream out; ByteArrayOutputStream bos; PdfStamper stamper; try { out = new FileOutputStream(newPDFPath);// 输出流reader = new PdfReader(templatePath);// 读取pdf模板bos = new ByteArrayOutputStream();stamper = new PdfStamper(reader, bos);AcroFields form = stamper.getAcroFields();String[] str = { "123456789", "TOP__ONE", "男","1991-01-01", "130222111133338888", "河北省保定市" };int i = 0; java.util.Iterator<String> it = form.getFields().keySet().iterator(); while (it.hasNext()) { String name =it.next().toString();System.out.println(name);form.setField(name, str[i++]); }stamper.setFormFlattening(true);// 如果为false那么生成的PDF文件还能编辑,一定要设为truestamper.close(); Document doc = new Document(); PdfCopy copy = new PdfCopy(doc, out); doc.open(); PdfImportedPage importPage =copy.getImportedPage(new PdfReader(bos.toByteArray()), 1); copy.addPage(importPage);doc.close(); } catch (IOException e){ System.out.println(1); } catch (DocumentException e){ System.out.println(2); }} public static void main(String[] args){ fillTemplate(); } } 3.运行结果如下****************************************************************** ***如果没有模板,就行自己生成pdf文件保存到磁盘:下面的方法可以实现:[java] view plain copy print?public static void test1(){//生成pdf Document document = new Document();try { PdfWriter.getInstance(document, new FileOutputStream("E:/1.pdf"));document.open(); document.add(new Paragraph("hello word"));document.close(); } catch (Exception e){ System.out.println("file create exception"); } } 但是上述方法中包含中文时就会出现问题,所以可以使用下面这行代码实现,所使用的jar包,上面的两个依赖都包含了:[java] view plain copy print?public static voidtest1_1(){ BaseFont bf; Font font = null; try { bf =BaseFont.createFont( "STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);//创建字体font = new Font(bf,12);//使用字体} catch (Exception e){ e.printStackTrace(); }Document document = new Document(); try{ PdfWriter.getInstance(document, new FileOutputStream("E:/2.pdf"));document.open(); document.add(new Paragraph("hello word 你好世界",font));//引用字体document.close(); } catch (Exception e){ System.out.println("file create exception"); } }****************************************************************** ********************当然,如果你想弄的炫一点,想实现其他字体,可以去网上搜字体文件然后下载下来,放到项目里,我这里是在项目里新建了一个font文件夹,将字体文件放到了里面。
java根据模板生成word文档,兼容富文本、图片

java根据模板⽣成word⽂档,兼容富⽂本、图⽚Java⾃动⽣成带图⽚、富⽂本、表格等的word⽂档使⽤技术 freemark+jsoup ⽣成mht格式的伪word⽂档,已经应⽤项⽬中,确实是可⾏的,⽆论是富⽂本中是图⽚还是表格,都能在word中展现出来使⽤jsoup解析富⽂本框,将其中的图⽚进⾏Base64位转码,使⽤freemark替换模板的占位符,将变量以及图⽚资源放⼊模板中在输出⽂件maven地址<!--freemarker--><!--<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.23</version></dependency><!--JavaHTMLParser--><!--<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version></dependency>制作word的freemark模板1. 先将wrod的格式内容定义好,如果需要插⼊参数的地⽅以${xxx}为表⽰,例:${product}模板例⼦: 2. 将模板另存为mht格式的⽂件,打开该⽂件检查每个变量(${product})是否完整,有可能在${}中出现其他代码,需要删除。
3. 将mht⽂件变更⽂件类型,改成ftl为结尾的⽂件,引⼊到项⽬中 4. 修改ftl模板⽂件,在⽂件中加上图⽚资源占位符${imagesBase64String},${imagesXmlHrefString}具体位置如下图所⽰: 5. ftl⽂件中由⼏个关键配置需要引⼊到代码中:docSrcParent = word.filesdocSrcLocationPrex =nextPartId = 01D2C8DD.BC13AF60上⾯三个参数,在模板⽂件中可以找到,需要进⾏配置,如果配置错误,图⽚⽂件将不会显⽰下⾯这三个参数固定,切换模板也不会改变shapeidPrex = _x56fe__x7247__x0020typeid = #_x0000_t75spidPrex = _x0000_i 6. 模板引⼊之后进⾏代码编辑源码地址为:下载源码后需要进⾏调整下内容:1. 录⼊步骤5中的6个参数2. 修改freemark获取模板⽅式下⾯这种⽅式能获取模板,但是在项⽬打包之后⽆法获取jar包内的⽂件Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));Template template=configuration.getTemplate("xxx.ftl");通过流的形式直接创建模板对象Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));InputStream inputStream=newFileInputStream(newFile(templatePath+"/"+templateName)); InputStreamReader inputStreamReader=newInputStreamReader(inputStream,StandardCharsets.UTF_8); Template template=newTemplate(templateName,inputStreamReader,configuration);。
Java使用模板导出word文档

Java使⽤模板导出word⽂档Java使⽤模板导出word⽂档需要导⼊freemark的jar包1. 使⽤word模板,在需要填值的地⽅使⽤字符串代替,是因为word转换为xml⽂件时查找不到要填⼊内容的位置。
尽量不要在写字符串的时候就加上${},xml⽂件会让它和字符串分离。
⽐如:姓名| name2. 填充完之后,把word⽂件另存为xml⽂件,然后使⽤notepad 等编辑软件打开,打开之后代码很多,也很乱,根本看不懂,其实也不⽤看懂哈,搜索找到你要替换的位置的字符串,⽐如name,然后加上${},变成${name}这样,然后就可以保存了,之后把保存的⽂件名后缀替换为.ftl。
模板就ok了。
3. 有个注意事项,这⾥的值⼀定不可以为空,否则会报错,freemark有判断为空的语句,这⾥⽰例⼀个,根据个⼈需求,意思是判断name是否为空,trim之后的lenth是否⼤于0:<#if name?default("")?trim?length gt 0><w:t>${name}</w:t></#if>4. 如果在本地的话可以直接下载下来,但是想要在通过前端下载的话那就需要先将⽂件下载到本地,当作临时⽂件,然后在下载⽂件。
接下来上代码,⽰例:public void downloadCharge(String name, HttpServletRequest request, HttpServletResponse response) {Map<String, Object> map = new HashMap<>();map.put("name", name);Configuration configuration = new Configuration();configuration.setDefaultEncoding("utf-8");try { //模板存放位置InputStream inputStream = this.getClass().getResourceAsStream("/template/report/XXX.ftl");Template t = new Template(null, new InputStreamReader(inputStream));String filePath = "tempFile/";//导出⽂件名String fileName = "XXX.doc";//⽂件名和路径不分开写的话createNewFile()会报错File outFile = new File(filePath + fileName);if (!outFile.getParentFile().exists()) {outFile.getParentFile().mkdirs();}if (!outFile.exists()) {outFile.createNewFile();}Writer out = null;FileOutputStream fos = null;fos = new FileOutputStream(outFile);OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");//这个地⽅对流的编码不可或缺,使⽤main()单独调⽤时,应该可以,但是如果是web请求导出时导出后word⽂档就会打不开,并且包XML⽂件错误。
java的xwpftemplate api说明

一、介绍Java是一种跨评台的面向对象编程语言,广泛应用于企业级应用开发、手机应用程序开发等领域。
XWPTemplate是Java中一款强大的模板引擎,用于生成Word文档。
本文将对XWPTemplate API进行详细说明,帮助开发者更好地了解和使用该工具。
二、XWPTemplate API的基本概念1. XWPTemplate是一个开源的Java模板引擎,可以用于生成Word 文档。
2. XWPTemplate基于Apache POI,支持Office Open XML格式的Word文档(.docx)。
3. XWPTemplate采用模板+数据的方式生成文档,使用简单灵活。
三、XWPTemplate API的核心功能1. 模板的加载和解析:XWPTemplate提供了丰富的API用于加载和解析模板文件,开发者可以轻松地将模板文件加载到内存中,并对模板进行解析。
2. 数据的填充和替换:XWPTemplate支持数据的填充和替换,开发者可以将数据动态地填充到模板中,实现自定义的文档生成需求。
3. 表格和图片的处理:XWPTemplate提供了对表格和图片的处理功能,可以对文档中的表格和图片进行动态添加、删除和修改操作。
4. 样式和格式的设置:XWPTemplate支持对文档的样式和格式进行定制,包括字体、颜色、对齐方式等各种样式属性的设置。
四、XWPTemplate API的使用方法1. 引入依赖:在Maven项目中,可以通过在pom.xml中引入以下依赖来使用XWPTemplate:```<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.xmlbeans</groupId><artifactId>xmlbeans</artifactId><version>3.1.0</version></dependency><dependency><groupId>org.apachemons</groupId><artifactIdmons-collections4</artifactId><version>4.4</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.openxmlformats</groupId><artifactId>ooxml-schemas</artifactId><version>1.4</version></dependency><dependency><groupId.deepoove</groupId><artifactId>xwpf-template</artifactId><version>3.7.4</version></dependency>```2. 创建模板:开发者可以使用Microsoft Word等工具创建模板,通过${}标记需要填充的动态数据。
JAVA不使用POI,用PageOffice动态导出Word文档

JAVA不使用POI,用PageOffice动态导出Word文档很多情况下,软件开发者需要从数据库读取数据,然后将数据动态填充到手工预先准备好的Word模板文档里,这对于大批量生成拥有相同格式排版的正式文件非常有用,这个功能应用PageOffice的基本动态填充功能即可实现。
但若是用户想动态生成一个没有固定模版的公文时,换句话说,没有办法事先准备一个固定格式的模板时,就需要开发人员在后台用代码实现Word文档的从零到图文并茂的动态生成功能了。
这里的“零”指的是Word空白文档。
那如何实现Word文档的从无到有呢,下面我就把自己实现这一功能的过程介绍一下。
例如,我想打开一个Word文档,里面的内容为:标题(粗体、黑体、字体大小为20、居中显示)、第一段内容(内容(略)、字体倾斜、字体大小为10、中文“楷体”、英文“Times New Roman”、红色、最小行间距、左对齐、首行缩进)、第二段内容(内容(略)、字体大小为12、黑体、1.5倍行间距、左对齐、首行缩进、插入图片)、第三段内容(内容(略)、字体大小为14、华文彩云、2倍行间距、左对齐、首行缩进)第一步:请先安装PageOffice的服务器端的安装程序,之后在WEB项目下的“WebRoot/WEB-INF/lib”路径中添加pageoffice.cab和pageoffice.jar(在网站的“下载中心”中可下载相应的压缩包,解压之后直接将pageoffice.cab和pageoffice.jar文件拷贝到该目录下就可以了)文件。
第二步:修改WEB项目的配置文件,将如下代码添加到配置文件中:<!-- PageOffice Begin --><servlet><servlet-name>poserver</servlet-name><servlet-class>com.zhuozhengsoft .pageoffice.poserver.Server</servlet-class></servlet><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/poserver.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/pageoffice.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/popdf.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/sealsetup.exe</url-pattern></servlet-mapping><servlet><servlet-name>adminseal</servlet-name><servlet-class>com.zhuozhengsoft.pageoffice.poserver.AdminSeal </servlet-class></servlet><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/adminseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/loginseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/sealimage.do</url-pattern></servlet-mapping><mime-mapping><extension>mht</extension><mime-type>message/rfc822</mime-type></mime-mapping><context-param><param-name>adminseal-password</param-name><param-value>123456</param-value></context-param><!-- PageOffice End -->第三步:在WEB项目的WebRoot目录下添加文件夹存放word模板文件,在此命名为“doc”,将要打开的空白Word文件拷贝到该文件夹下,我要打开的Word文件为“test.doc”。
JAVA生成word文档代码加说明

import java.io.ByteArrayOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.util.Iterator;import java.util.Map;import javax.servlet.http.HttpServletResponse;import org.apache.poi.hwpf.HWPFDocument;import org.apache.poi.hwpf.model.FieldsDocumentPart;import ermodel.Field;import ermodel.Fields;import ermodel.Range;import ermodel.Table;import ermodel.TableIterator;import ermodel.TableRow;publicclass WordUtil {publicstaticvoid readwriteWord(String filePath, String downPath, Map<String, String> map, int[] num, String downFileName) { //读取word模板FileInputStream in = null;try {in = new FileInputStream(new File(filePath));} catch (FileNotFoundException e1) {e1.printStackTrace();}HWPFDocument hdt = null;try {hdt = new HWPFDocument(in);} catch (IOException e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//读取word表格内容try {Range range = hdt.getRange();//得到文档的读取范围TableIterator it2 = new TableIterator(range);//迭代文档中的表格int tabCount = 0;while (it2.hasNext()) {//System.out.println(" 第几个表格 "+tabCount);//System.out.println(num[tabCount] +" 行");Table tb2 = (Table) it2.next();//迭代行,默认从0开始for (int i = 0; i < tb2.numRows(); i++) {TableRow tr = tb2.getRow(i);// System.out.println(" fu "+num[tabCount] +" 行");if (num[tabCount] < i && i < 7) {tr.delete();}} //end fortabCount++;} //end while//替换word表格内容for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$"+ entry.getKey().trim() + "$", entry.getValue());}// System.out.println("替换后------------:"+range.text().trim());} catch (Exception e) {e.printStackTrace();}//System.out.println("--------------------------------------------------------------------------------------");ByteArrayOutputStream ostream = new ByteArrayOutputStream();String fileName = downFileName;fileName += ".doc";String pathAndName = downPath + fileName;File file = new File(pathAndName);if (file.canRead()) {file.delete();}FileOutputStream out = null;out = new FileOutputStream(pathAndName, true);} catch (FileNotFoundException e) {e.printStackTrace();}try {hdt.write(ostream);} catch (IOException e) {e.printStackTrace();}//输出字节流try {out.write(ostream.toByteArray());} catch (IOException e) {e.printStackTrace();}try {out.close();} catch (IOException e) {e.printStackTrace();}try {ostream.close();} catch (IOException e) {e.printStackTrace();}}/***实现对word读取和修改操作(输出文件流下载方式)*@param response响应,设置生成的文件类型,文件头编码方式和文件名,以及输出*@param filePathword模板路径和名称*@param map待填充的数据,从数据库读取*/publicstaticvoid readwriteWord(HttpServletResponse response, String filePath, Map<String, String> map) {//读取word模板文件//String fileDir = newFile(base.getFile(),"//.. /doc/").getCanonicalPath();//FileInputStream in = new FileInputStream(newFile(fileDir+"/laokboke.doc"));FileInputStream in;HWPFDocument hdt = null;in = new FileInputStream(new File(filePath));hdt = new HWPFDocument(in);} catch (Exception e1) {e1.printStackTrace();}Fields fields = hdt.getFields();Iterator<Field> it = fields.getFields(FieldsDocumentPart.MAIN) .iterator();while (it.hasNext()) {System.out.println(it.next().getType());}//替换读取到的word模板内容的指定字段Range range = hdt.getRange();for (Map.Entry<String, String> entry : map.entrySet()) { range.replaceText("$" + entry.getKey() + "$",entry.getValue());}//输出word内容文件流,提供下载response.reset();response.setContentType("application/x-msdownload");String fileName = "" + System.currentTimeMillis() + ".doc";response.addHeader("Content-Disposition", "attachment;filename="+ fileName);ByteArrayOutputStream ostream = new ByteArrayOutputStream();OutputStream servletOS = null;try {servletOS = response.getOutputStream();hdt.write(ostream);servletOS.write(ostream.toByteArray());servletOS.flush();servletOS.close();} catch (Exception e) {e.printStackTrace();}}}注:以上代码需要poi包, 可以下载。
javafreemarker导出word时添加或勾选复选框

javafreemarker导出word时添加或勾选复选框最近项⽬导出word碰到⼀个需求,要求根据数据动态的决定word⾥的复选框是否勾选,公司导出word⽤的是freemarker,相⽐较其他技术,freemarker可以很容易的控制输出样式,在word⾥编辑好模板,将要输出的数据⽤${变量名}代替,然后java代码⾥给变量塞了值就可以输出了.⾸先我们要知道在word⾥打钩和不打勾的复选框究竟是什么,新建⼀个word⽂档,在⾥⾯分别输⼊打钩和不打勾的复选框,然后右键另存为.xml ⽂件,因为freemarker导出就是在这样的xml⽂件的基础上的之所以在后⾯加了两个字,是为了之后能在n多的xml节点中找到两种框的表现是什么这个时候我们查看xml⽂件只有⼏⾏,有⼀⾏还特别长,是很⾮⼈类的,我们可以把它拷贝到eclipse等第三⽅⼯具中,然后格式化⼀下,看到的就是格式化都的xml,我们搜索⼀下清算两个字,然后可以清晰的看到在xml中两种框的表现如下:这个时候要实现功能就要⽤到freemarker中的if else标签了,⾸先我们在java代码中添加变量值,⽐如map.put("check","true");然后修改模板,使⽤标签判断,模板修改成类似这样:其实输出的勾选复选框主要的核⼼就是<w:sym w:font="Wingdings 2" w:char="F052" />这句话,把之前的<w:r>标签去掉也⾏,最简单的写法可以直接这样:<#if check=="true"><w:sym w:font="Wingdings 2" w:char="F052" /><#else><w:t>□</w:t></#if>但是这样的输出时有问题,会发现⼤⼩不是你想要的,很容易理解,因为没有了那么多节点的样式控制,输出的⾃然按word默认表现来了所以实际使⽤还是在⾃⼰模板中设置两个框,然后存成xml⽂件看两个框的表现,这样最后输出的框⼤⼩表现和你的word⽂档字体⼤⼩等是⼀样的.最后将xml⽂件后缀名修改成.ftl,就可以导出了,随着代码中check变量的值不同,会导出不同的选择框,效果如下:其实freemarker⾥除了if标签,还有很多其他的标签,灵活使⽤这些标签可以很⽅便的完成我们的需求,感觉有点类似jsp,可以让我们灵活输出结果。
Java模板动态生成word文件的方法步骤

Java模板动态⽣成word⽂件的⽅法步骤最近项⽬中需要根据模板⽣成word⽂档,模板⽂件也是word⽂档。
当时思考⼀下想⽤POI API来做,但是觉得⽤起来相对复杂。
后来⼜找了⼀种⽅式,使⽤freemarker模板⽣成word⽂件,经过尝试觉得还是相对简单易⾏的。
使⽤freemarker模板⽣成word⽂档主要有这么⼏个步骤1、创建word模板:因为我项⽬中⽤到的模板本⾝是word,所以我就直接编辑word⽂档转成freemarker(.ftl)格式的。
2、将改word⽂件另存为xml格式,注意使⽤另存为,不是直接修改扩展名。
3、将xml⽂件的扩展名改为ftl4、编写java代码完成导出使⽤到的jar:freemarker.jar (2.3.28) ,其中Configuration对象不推荐直接new Configuration(),仔细看Configuration.class⽂件会发现,推荐的是 Configuration(Version incompatibleImprovements) 这个构造⽅法,具体这个构造⽅法⾥⾯传的就是Version版本类,⽽且版本号不能低于2.3.0闲⾔碎语不再讲,直接上代码public static void exportDoc() {String picturePath = "D:/image.png";Map<String, Object> dataMap = new HashMap<String, Object>();dataMap.put("brand", "海尔");dataMap.put("store_name", "海尔天津");dataMap.put("user_name", "⼩明");//经过编码后的图⽚路径String image = getWatermarkImage(picturePath);dataMap.put("image", image);//Configuration⽤于读取ftl⽂件Configuration configuration = new Configuration(new Version("2.3.0"));configuration.setDefaultEncoding("utf-8");Writer out = null;try {//输出⽂档路径及名称File outFile = new File("D:/导出优惠证明.doc");out = new BufferedWriter(new OutputStreamWriter(newFileOutputStream(new File("outFile")), "utf-8"), 10240);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (FileNotFoundException e) {e.printStackTrace();}// 加载⽂档模板Template template = null;try {//指定路径,例如C:/a.ftl 注意:此处指定ftl⽂件所在⽬录的路径,⽽不是ftl⽂件的路径configuration.setDirectoryForTemplateLoading(new File("C:/"));//以utf-8的编码格式读取⽂件template = configuration.getTemplate("导出优惠证明.ftl", "utf-8");} catch (IOException e) {e.printStackTrace();throw new RuntimeException("⽂件模板加载失败!", e);}// 填充数据try {template.process(dataMap, out);} catch (TemplateException e) {e.printStackTrace();throw new RuntimeException("模板数据填充异常!", e);} catch (IOException e) {e.printStackTrace();throw new RuntimeException("模板数据填充异常!", e);} finally {if (null != out) {try {out.close();} catch (IOException e) {e.printStackTrace();throw new RuntimeException("⽂件输出流关闭异常!", e);}}}}因为很多时候我们根据模板⽣成⽂件需要添加⽔印,也就是插⼊图⽚/**** 处理图⽚* @param watermarkPath 图⽚路径 D:/image.png* @return*/private String getWatermarkImage(String watermarkPath) {InputStream in = null;byte[] data = null;try {in = new FileInputStream(watermarkPath);data = new byte[in.available()];in.read(data);in.close();} catch (Exception e) {e.printStackTrace();}BASE64Encoder encoder = new BASE64Encoder();return encoder.encode(data);}注意点:插⼊图⽚后的word转化为ftl模板⽂件(ps:⽔印图⽚可以在word上调整到⾃⼰想要的⼤⼩,然后在执⾏下⾯的步骤)1、先另存为xml2、将xml扩展名改为ftl3、打开ftl⽂件, 搜索w:binData 或者 png可以快速定位图⽚的位置,图⽚已经编码成0-Z的字符串了, 如下:5、将上述0-Z的字符串全部删掉,写上${image}(变量名随便写,跟dataMap⾥的key保持⼀致)后保存6、也是创建⼀个Map, 将数据存到map中,只不过我们要把图⽚⽤代码进⾏编码,将其也编成0-Z的字符串,代码请看上边⾄此⼀个简单的按照模板⽣成word并插⼊图⽚(⽔印)功能基本完成。
Aspose.wordsJava基于模板生成word之纯文本内容
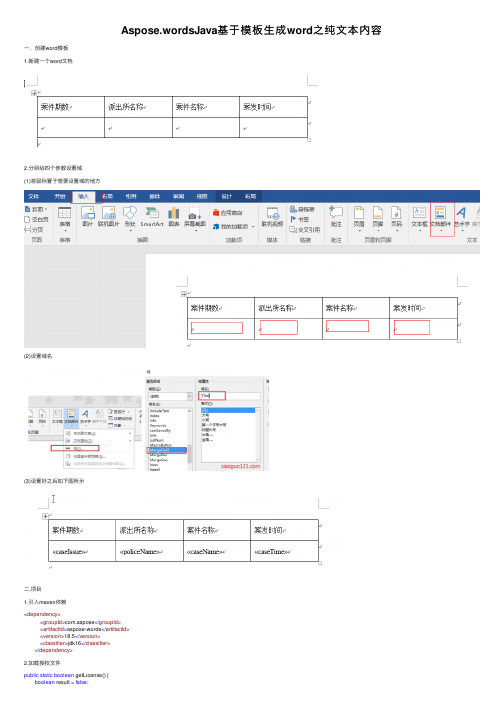
Aspose.wordsJava基于模板⽣成word之纯⽂本内容⼀,创建word模板1.新建⼀个word⽂档2.分别给四个参数设置域(1)将⿏标置于想要设置域的地⽅(2)设置域名(3)设置好之后如下图所⽰⼆,项⽬1,引⼊maven依赖<dependency><groupId>com.aspose</groupId><artifactId>aspose-words</artifactId><version>18.5</version><classifier>jdk16</classifier></dependency>2,加载授权⽂件public static boolean getLicense() {boolean result = false;try {InputStream is = AsposeToWordTest.class.getClassLoader().getResourceAsStream("license-word.xml"); License aposeLic = new License();aposeLic.setLicense(is);result = true;} catch (Exception e) {e.printStackTrace();}return result;}3,获取值以及插⼊到模板中并⽣成新的⽂档public static void main(String[] args) throws Exception {// 验证Licenseif (!getLicense()) {return;}//模板wordString template = "E:\\test\\temp.docx";//⽬标wordString destdoc = "E:\\test\\edit.docx";//定义⽂档接⼝Document doc = new Document(template);//⽂本域String[] Flds = new String[]{"caseIssue","policeName", "caseName", "caseTime"};String caseIssue = "001";String policeName = "XX派出所";String caseName = "0727电动车盗窃案";String caseTime = "2018-07-26 12:20:22";//值Object[] Vals = new Object[]{caseIssue,policeName, caseName, caseTime};//调⽤接⼝doc.getMailMerge().execute(Flds, Vals);doc.save(destdoc);System.out.println("完成");}4,结果。
java 根据word模板生成word文件

java 根据word模板生成word文件Java可以使用Apache POI库来生成Word文件,并且也可以使用freemarker等模板引擎来实现根据Word模板生成Word 文件的功能。
下面是一个简单的示例代码,可以帮助您快速入门。
模板制作:offer,wps都行,我使用wps进行操作第一步制作模板CTRL+f9生成域------》鼠标右键编辑域------》选择邮件合并-----》在域代码后面加上英文${跟代码内的一致}。
这样模板就创建好了。
首先需要引入POI和freemarker的依赖:<!-- Apache POI --><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.core</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template< /artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.document.docx</artifactId><version>2.0.2</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>fr.opensagres.xdocreport.template.freemarker</artifactId><version>2.0.2</version></dependency>接下来是一个简单的示例代码:public class WordGenerator {public static void main(String[] args) throws IOException, TemplateException {// 读取Word模板try {= null;//wordInputStream in = new (new File("模板文件.docx"));//注册xdocreport实例并加载FreeMarker模板引擎IXDocReport r = XDocReportRegistry.getRegistry().loadReport(in, TemplateEngineKind.Freemarker);// 生成Word文件//创建xdocreport上下文对象IContext context =r.createContext();//将需要替换的数据数据添加到上下文中//其中key为word模板中的域名,value是需要替换的值User user = new User("zhangsan", 18, "福建泉州");context.put("uesrname",user.getUsername());context.put("age", user.getAge()); context.put("address",user.getAddress());out = new (newFile("D://xxx.docx"));//处理word文档并输出r.process(context, out);} catch (IOException e) {e.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}}在这个示例代码中,我们读取了名为模板文件.docx的Word 模板,然后准备了一些数据,利用Freemarker模板引擎将数据填充到模板中,最后生成了一个名为xxx.docx的Word文件。
java利用word模版导出word文档详细说明

t = configuration.getTemplate(fileName);
//configuration.setDirectoryForTemplateLoading(new File("E:/"));
public class DocumentHandler {
private Configuration configuration = null;
public DocumentHandler() {
configuration = new Configuration();
configuration.setDefaultEncoding("UTF-8");
我用的jar包为freemarker-2.3.15.jar
首先把代码贴了,这是主程序
package com.tiger.document;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
java.io.Writer;
import java.util.HashMap;
import java.util.Map;
import freemarker.template.Configuration;
}
public void createDoc(String dir,String fileName, String savePath,String[][] sDate) {
Java使用IText(VM模版)导出PDF,IText导出word(二)

Java使⽤IText(VM模版)导出PDF,IText导出word(⼆)===============action===========================//退款导出wordpublic void exportWordTk() throws IOException{Long userId=(Long)ServletActionContext.getContext().getSession().get(Constant.SESSION_USER_ID);//获取⽣成Pdf需要的⼀些路径String tmPath=ServletActionContext.getServletContext().getRealPath("download/template");//vm 模板路径String wordPath=ServletActionContext.getServletContext().getRealPath("download/file");//⽣成word路径//wordPath+"/"+userId+"_"+fk+".doc"//数据Map map=new HashMap();//velocity模板中的变量map.put("date1",this.fk);map.put("date",new SimpleDateFormat("yyyy-MM-dd HH:mm").format(new Date()));String newFile=wordPath+"/tk_word_"+userId+".doc";File file=new File(newFile);if(!file.exists()){//设置字体,⽀持中⽂显⽰new PdfUtil().addFontAbsolutePath(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun.ttf"));//这个字体需要⾃⼰去下载PdfUtil.createByVelocityPdf(tmPath,"tk_word.vm", wordPath+"/tk_word_"+userId+".pdf", map);//导出PDFPdfUtil.createByVelocityDoc(tmPath,"tk_word.vm",newFile, map);//导出word}sendMsgAjax("dzz/download/file/tk_word_"+userId+".doc");}=================vm ⽂件模板(tk_word.vm)=====================<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><title></title><style type="text/css">body, button, input, select, textarea {color: color:rgb(0,0,0);font: 14px/1.5 tahoma,arial,宋体,sans-serif;}p{margin:0;padding:0;}.title{border-bottom:1px solid rgb(0,0,0);margin:0;padding:0;width:85%;height:25px;}li{list-style:none;}.li_left li{text-align:left;line-height:47px;font-size:14pt;}.li_left{width:610px;}.fnt-21{font-size:16pt;}table{width:90%;/*argin-left:25px;*/}div_cls{width:100%;text-align:center;}</style></head><body style="font-family: songti;width:100%;text-align:center;"><div style="text-align:center;"><b class="fnt-21"> 本组评审结果清单</b> </div> <table border="1" cellpadding="0" cellspacing="0" style="width:90%;margin-left:25px;"> <tr><td style="width:20%" align="center">申报单位</td><td style="width:10%" align="center">申报经费(万元)</td></tr></table><br/><div><ul style="float:right;margin-right:40px;"><li>$date</li><!--获取后天封装的数据--></ul></div></body></html>====================⼯具类======================package com.qgc.dzz.util;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.io.PrintWriter;import .URL;import java.util.ArrayList;import java.util.List;import java.util.Map;import java.util.UUID;import org.apache.struts2.ServletActionContext;import org.apache.velocity.Template;import org.apache.velocity.VelocityContext;import org.apache.velocity.app.VelocityEngine;import org.xhtmlrenderer.pdf.ITextFontResolver;import org.xhtmlrenderer.pdf.ITextRenderer;import com.lowagie.text.Document;import com.lowagie.text.DocumentException;import com.lowagie.text.Font;import com.lowagie.text.Image;import com.lowagie.text.Rectangle;import com.lowagie.text.pdf.BaseFont;import com.lowagie.text.pdf.PdfImportedPage;import com.lowagie.text.pdf.PdfReader;import com.lowagie.text.pdf.PdfWriter;public class PdfUtil {private static List<String> fonts = new ArrayList();//字体路径/*** 使⽤vm导出word* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param docPath ⽣成⽂件的路径,包含⽂件如:d://temp.doc* @param map 参数,传递到vm* @return*/public static boolean createByVelocityDoc(String localPath, String templateFileName, String docPath, Map<String, Object> map) {try{createFile(localPath,templateFileName,docPath, map);return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 导出pdf* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param pdfPath ⽣成⽂件的路径,包含⽂件如:d://temp.pdf* @param map 参数,传递到vm* @return*/public static boolean createByVelocityPdf(String localPath, String templateFileName, String pdfPath, Map<String, Object> map) {try{String htmlPath = pdfPath + UUID.randomUUID().toString() + ".html";createFile(localPath, templateFileName, htmlPath, map);//⽣成html 临时⽂件HTML2OPDF(htmlPath, pdfPath, fonts);//html转成pdfFile file = new File(htmlPath);file.delete();return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 合并PDF* @param writer* @param document* @param reader* @throws DocumentException*/public void addToPdfUtil(PdfWriter writer, Document document,PdfReader reader) throws DocumentException {int n = reader.getNumberOfPages();Rectangle pageSize = document.getPageSize();float docHeight = pageSize.getHeight();float docWidth = pageSize.getWidth();for (int i = 1; i <= n; i++) {document.newPage();PdfImportedPage page = writer.getImportedPage(reader, i);Image image = Image.getInstance(page);float imgHeight = image.getPlainHeight();float imgWidth = image.getPlainWidth();if (imgHeight < imgWidth) {float temp = imgHeight;imgHeight = imgWidth;imgWidth = temp;image.setRotationDegrees(90.0F);}if ((imgHeight > docHeight) || (imgWidth > docWidth)) {float hc = imgHeight / docHeight;float wc = imgWidth / docHeight;float suoScale = 0.0F;if (hc > wc)suoScale = 1.0F / hc * 100.0F;else {suoScale = 1.0F / wc * 100.0F;}image.scalePercent(suoScale);}image.setAbsolutePosition(0.0F, 0.0F);document.add(image);}}/*** html 转成 pdf ⽅法* @param htmlPath html路径* @param pdfPath pdf路径* @param fontPaths 字体路径* @throws Exception*/public static void HTML2OPDF(String htmlPath, String pdfPath,List<String> fontPaths)throws Exception{String url = new File(htmlPath).toURI().toURL().toString();//获取⽣成html的路径OutputStream os = new FileOutputStream(pdfPath);//创建输出流ITextRenderer renderer = new ITextRenderer();//itext 对象ITextFontResolver fontResolver = renderer.getFontResolver();//字体// //⽀持中⽂显⽰字体// fontResolver.addFont(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun_0.ttf"), // BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);if ((fontPaths != null) && (!fontPaths.isEmpty())) {URL classPath = PdfUtil.class.getResource("/");for (String font : fontPaths) {if (font.contains(":"))fontResolver.addFont(font, "Identity-H", false);else {fontResolver.addFont(classPath + "/" + font, "Identity-H",false);}}}renderer.setDocument(url);//设置html路径yout();renderer.createPDF(os);//html转换成pdfSystem.gc();os.close();System.gc();}public static boolean createFile(String localPath, String templateFileName,String newFilePath, Map<String, Object> map){try{VelocityEngine engine = new VelocityEngine();engine.setProperty("file.resource.loader.path", localPath);//指定vm路径Template template = engine.getTemplate(templateFileName, "UTF-8");//指定vm模板VelocityContext context = new VelocityContext();//创建上下⽂对象if (map != null){Object[] keys = map.keySet().toArray();for (Object key : keys) {String keyStr = key.toString();context.put(keyStr, map.get(keyStr));//传递参数到上下⽂对象}}PrintWriter writer = new PrintWriter(newFilePath, "UTF-8");//写⼊参数到vm template.merge(context, writer);writer.flush();writer.close();return true;} catch (Exception e) {e.printStackTrace();}return false;}public static Font FONT = getChineseFont();public static BaseFont BSAE_FONT = getBaseFont();/*** ⽀持显⽰中⽂* @return*/public static Font getChineseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}Font fontChinese = new Font(bfChinese);return fontChinese;}public static BaseFont getBaseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return bfChinese;}public void addFontAbsolutePath(String path) {this.fonts.add(path);}public void addFontClassPath(String path) {this.fonts.add(path);}public List<String> getFonts() {return this.fonts;}public void setFonts(List<String> fonts) {this.fonts = fonts;}}。
java生成word

java⽣成word当我们使⽤Java⽣成word⽂档时,通常⾸先会想到iText和POI,这是因为我们习惯了使⽤这两种⽅法操作Excel,⾃然⽽然的也想使⽤这种⽣成word⽂档。
但是当我们需要动态⽣成word时,通常不仅要能够显⽰word中的内容,还要能够很好的保持word中的复杂样式。
这时如果再使⽤IText和POI去操作,就好⽐程序员去搬砖⼀样痛苦。
这时候,我们应该考虑使⽤FreeMarker的模板技术快速实现这个复杂的功能,让程序员在喝咖啡的过程中就把问题解决。
实现思路是这样的:先创建⼀个word⽂档,按照需求在word中填好⼀个模板,然后把对应的数据换成变量${},然后将⽂档保存为xml⽂档格式,使⽤⽂档编辑器打开这个xml格式的⽂档,去掉多余的xml符号,使⽤Freemarker读取这个⽂档然后替换掉变量,输出word⽂档即可。
具体过程如下:1.创建带有格式的word⽂档,将该需要动态展⽰的数据使⽤变量符替换。
2. 将刚刚创建的word⽂档另存为xml格式。
3.编辑这个XMl⽂档去掉多余的xml标记,如图中蓝⾊部分 4.从官⽹最新的开发包,将freemarker.jar拷贝到⾃⼰的开发项⽬中。
5.新建DocUtil类,实现根据Doc模板⽣成word⽂件的⽅法1234 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36package com.favccxx.secret.util;import java.io.BufferedWriter;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import java.util.Map;import freemarker.template.Configuration;import freemarker.template.DefaultObjectWrapper;import freemarker.template.Template;import freemarker.template.TemplateExceptionHandler;public class DocUtil {privateConfiguration configure = null;publicDocUtil(){configure= new Configuration();configure.setDefaultEncoding("utf-8");}/*** 根据Doc模板⽣成word⽂件* @param dataMap Map 需要填⼊模板的数据* @param fileName ⽂件名称* @param savePath 保存路径*/publicvoid createDoc(Map<String, Object> dataMap, String downloadType, StringsavePath){try{//加载需要装填的模板Templatetemplate = null;//加载模板⽂件configure.setClassForTemplateLoading(this.getClass(),"/com/favccxx/secret/templates"); //设置对象包装器configure.setObjectWrapper(newDefaultObjectWrapper());//设置异常处理器configure.setTemplateExceptionHandler(TemplateExceptionHandler.IGNORE_HANDLER); //定义Template对象,注意模板类型名字与downloadType要⼀致template= configure.getTemplate(downloadType + ".xml");//输出⽂档FileoutFile = new File(savePath);Writerout = null;3637 38 39 40 41 42 43 44 45 46 out= new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"utf-8")); template.process(dataMap,out);outFile.delete();}catch(Exception e) {e.printStackTrace();}}} 6.⽤户根据⾃⼰的需要,调⽤使⽤getDataMap获取需要传递的变量,然后调⽤createDoc⽅法⽣成所需要的⽂档。
Java使用word文档模板下载文件(内容为表格)

Java使⽤word⽂档模板下载⽂件(内容为表格)注意:1、此Demo操作的是word的表格2、本次使⽤的word后缀为docx1、pom引⽤jar<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency>2、代码import org.apache.poi.openxml4j.exceptions.InvalidFormatException;import org.apache.poi.util.Units;import ermodel.*;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.core.io.ClassPathResource;import java.io.*;import java.util.HashMap;import java.util.List;import java.util.Map;/*** word模板赋值下载** @author a*/@SpringBootApplicationpublic class ReadResourceApplication {/*** 主⽅法** @param args*/public static void main(String[] args) {SpringApplication.run(ReadResourceApplication.class, args);Map map = new HashMap(3);map.put("${name}", "测试");map.put("${sexName}", "男");map.put("${mzName}", "汉");getBuild("wordXML/领导⼲部基本情况信息表.docx", map, "D:/aaa.doc");}/*** 赋值并下载⽂件** @param tmpFile* @param contentMap* @param exportFile*/public static void getBuild(String tmpFile, Map<String, String> contentMap, String exportFile) {InputStream inputStream = null;try {// 加载Word⽂件inputStream = new ClassPathResource(tmpFile).getInputStream();} catch (IOException e) {e.printStackTrace();}XWPFDocument document = null;try {// 加载流到documentdocument = new XWPFDocument(inputStream);} catch (IOException e) {e.printStackTrace();}// 获取⽂档中的表格List<XWPFTable> tables = document.getTables();for (int j = 0; j < tables.size(); j++) {XWPFTable table = tables.get(j);// 获取表格⾏List<XWPFTableRow> rows = table.getRows();for (int i = 0; i < rows.size(); i++) {// 得到每⼀⾏XWPFTableRow newRow = table.getRow(i);// 得到所有的单元格List<XWPFTableCell> cells = newRow.getTableCells();for (int k = 0; k < cells.size(); k++) {// 得到每⼀列XWPFTableCell cell = cells.get(k);// 以下为更新替换值逻辑List<XWPFParagraph> paragraphs = cell.getParagraphs();for (XWPFParagraph paragraph : paragraphs) {List<XWPFRun> runs = paragraph.getRuns();String cellText = cell.getText();if (contentMap.keySet().contains(cellText)) {for (int m = 0; m < runs.size(); m++) {if (m == runs.size() - 1) {runs.get(m).setText(contentMap.get(cellText), 0);} else {runs.get(m).setText("", 0);}}} else if (cellText.equals("${picture}")) {for (int m = 0; m < runs.size(); m++) {if (m == runs.size() - 1) {try {runs.get(m).setText("", 0);runs.get(m).addPicture(new ClassPathResource("wordXML/培训⼆维码.png").getInputStream(), XWPFDocument.PICTURE_TYPE_PNG, "培训⼆维码.png,", Units.toEMU(200), Units.toEMU(200)); } catch (InvalidFormatException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}} else {runs.get(m).setText("", 0);}}}}}}}//导出⽂件到磁盘try {ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();document.write(byteArrayOutputStream);OutputStream outputStream = new FileOutputStream(exportFile);outputStream.write(byteArrayOutputStream.toByteArray());outputStream.close();} catch (IOException e) {e.printStackTrace();}}}需要更改的地⽅:1、word⽂档路径2、图⽚路径(不需要图⽚的可直接删除相关代码)。
JAVA+根据WORD模板生成WORD+文档

/** * 把选定内容替换为设定文本 * @param selection Dispatch 选定内容 * @param newText String 替换为文本 */ public void replace(Dispatch selection,String newText) {
//设置替换文本 Dispatch.put(selection,"Text",newText); }
/* * 传入数据为 HashMap 对象,对象中的 Key 代表 word 模板中要替换的字段,Value 代表用来替换的值。 * word 模板中所有要替换的字段(即 HashMap 中的 Key)以特殊字符开头和结尾,如:$code$、$date$……, 以免执行错误的替换。 * 所有要替换为图片的字段,Key 中需包含 image 或者 Value 为图片的全路径(目前只判断文件后缀名 为:.bmp、 .jpg、.gif)。 * 要替换表格中的数据时,HashMap 中的 Key 格式为“table$R@N”,其中:R 代表从表格的第 R 行开始 替换,N 代表 word 模板中的第 N 张表格;Value 为 ArrayList 对象,ArrayList 中包含的对象统一为 String[],一条 String[] 代 表一行数据,ArrayList 中第一条记录为特殊记录,记录的是表格中要替换的列号,如:要替换第一列、第 三列、 第五列的数据,则第一条记录为 String[3] {“1”,”3”,”5”}。 */
for(int i = 0;i < count;i ++) {
Dispatch.call(selection,"MoveLeft"); } }
/** * 把选定内容或插入点向右移动 * @param selection Dispatch 要移动的内容 * @param count int 移动的距离 */ public void moveRight(Dispatch selection,int count) {
javaweb页面导出word

javaweb页⾯导出word①我做了⼀个word模板,定义好了书签为listyd,书签是在⼀个表格中,在书签位置动态的⽣成表格,例⼦代码如下:var ole = new ActiveXObject("Word.Application");var url=c:\nsqktzs_fm.doc"var doc =ole.documents.open(url,false,false);ole.V isible = true;ole.selection.find.forward =true;var rg=ole.selection.goto(true,0,0,"listyd");var tab=doc.Tables.Add(rg, 2,2) ;for(var i=1;i<=2;i++){for(var j=1;j<=2;j++){var rgcell=tab.Cell(i,j).Range;rgcell.InsertAfter(i+j);}}⽣成的表格嵌套在以前的表格中,很难看,如何能让⽣成的表格和外边的表格看上去是⼀个整体。
rgcell.InsertAfter(i+j);可以⽤insertBefore么。
也可以考虑⽤java语⾔做word模板。
③.⼩弟最近在做JSP页⾯内容导出到Word,但遇到了很多困难,望各位⼤侠急救需求:1.将JSP页⾯中的内容导出到Word⽂件中。
2.JSP页⾯中包含图⽚,图⽚的数据是从数据库中加载出来,实时⽣成的。
⼩弟在⽹上看过N个例⼦,也测试了,就是⽆法解决,问题如下:1.通过window.document.location.href='test.action'的链接⽅式,访问加⼀个JSP页⾯,⽂件头为:<%@ page contentType="application/msword;charset=gbk"%>当点击“导出”按钮时,可以⽣成Word⽂件,但是图⽚⽆法在Word中⽣成.2.直接在页⾯中加JS脚本:var oWD = new ActiveXObject("Word.Application");oWD.WindowState = 2;var oDC = oWD.Documents.Add("",0,1);var oRange =oDC.Range(0,1);var sel = document.body.createTextRange();sel.moveToElementText(PrintA);sel.select();sel.execCommand("Copy");oRange.Paste();oWD.Application.Visible = true;在我的电脑上可以导出Word(我的office版本是2007)⽂件,并且可以显⽰图⽚。
java实现的导出word文档

java实现的导出word⽂档之前没有做过类似的功能,所以第⼀次接触的时候费了我⼀天的时间来完成这个功能。
先说⼀下原理,其实就是通过修改后缀来完成的。
需要先⽤office2013做⼀个word模板,就是你想要⽣成的word的模板,保存为xml格式。
然后在线格式化⼀下,这样⽣成的代码⽐较规范,然后将后缀修改为ftl,内容为⼀下格式:、我使⽤的⽅法是通过Action跳转的⽅法来进⾏调⽤的,Action⽅法如下,[java] view plain copy print?1. public String exportProWorkOrder(){2.3. /** 取出参数**/4.5. /** 输出审批 **/6. Template t=null;7. PrintWriter wt = null;8.9. try {10. /** 查询数据 **/11. ProjectWorkOrder pwo = consultingProjectBo.findPWOMessage(18);12.13. Map<String,Object> dataMap=new HashMap<String,Object>();14.15. //getData(dataMap);16. /** 放置数据 **/17. consultingProjectBo.makeExportProWorkOrderData(pwo,dataMap);18. String fn = makeFileName(pwo);19.20. //FTL⽂件所存在的位置21. t = freeMarkerConfiguration.getTemplate("export_proworkorder.ftl"); //⽂件名22.23.24. //配置 Response 参数25. getResponse().setContentType(26. "application/msword; charset=UTF-8");27. getResponse().setHeader(28. "Content-Disposition",29. "Attachment;filename= "30. + new String(fn.toString().getBytes(31. //"UTF-8"),"UTF-8"));32. "gb2312"), "ISO8859_1"));//20151030 改为UTF-8 需要兼容性测试33. wt = getResponse().getWriter();34. t.process(dataMap, wt);34. t.process(dataMap, wt);35.36. } catch (IOException e) {37. e.printStackTrace();38. } catch (Exception e) {39. e.printStackTrace();40. } finally {41. if(wt!=null){42. wt.flush();43. wt.close();44. }45. }46. return null;47. }48.49. protected String makeFileName(ProjectWorkOrder pwo) {50. if(pwo==null){51. return "⽂件不存在";52. }53.54. String filename = "";55. if(pwo.getProjectTitle()!=null){56. filename = pwo.getProjectTitle() + "⼯程造价咨询项⽬⼯作交办单" + ".doc";57. }else{58. filename = "⼯程造价咨询项⽬⼯作交办单"+".doc";59. }60.61. return filename;62. }跳转进⼊⽅法中,期中放置数据的⽅法如下,[java] view plain copy print?1. public ProjectWorkOrder findPWOMessage(Integer projectId){2. SimpleDateFormat sdf = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss" );3. Project project = null;4. List<ProjectDepartment> list = null;5. ProjectEngineering pe = null;6. project = projectBo.findFull(projectId);7. list = projectDepartmentBo.findPDByProjectId(projectId);8. pe = projectEngineeringBo.findPEByProjectId(projectId);9. ProjectWorkOrder pwo = new ProjectWorkOrder();10. if(projectId != null){11. pwo.setProjectId(projectId);12. }13. if(project.getProject_title() != null){14. pwo.setProjectTitle(project.getProject_title());15. }16. if(project.getBegin_date() != null){17. pwo.setBeginDate(sdf.format(project.getBegin_date()));18. }19. if(project.getEnd_date() != null){20. pwo.setEndDate(sdf.format(project.getEnd_date()));21. }22. if(project.getProject_target() != null){23. pwo.setProjecTarget(project.getProject_target());24. }24. }25. if(project.getMember_id() != null){26. Member member = memberBo.getCacheMember(project.getMember_id());27. pwo.setMemberId(member.getMember_name());28. }29. if(pe.getPlan_no() != null){30. pwo.setPlanNu(pe.getPlan_no());31. }32. if(pe.getIncrement() != null){33. pwo.setInvestment(pe.getIncrement());34. }35. if(pe.getDo_item() != null){36. pwo.setDoItem(pe.getDo_item());37. }38. if(pe.getKey_point() != null){39. pwo.setKeyPoint(pe.getKey_point());40. }41. if(list != null){42. pwo.setChild(addtypePlus(list));43. }44. return pwo;45. }46. /**47. *将⼯程造价咨询项⽬⼯作交办单导出为word48. */49. @Override50. public void makeExportProWorkOrderData(ProjectWorkOrder pwo, Map<String, Object> dataMap) {51. if(pwo==null){52. return;53. }54. if(pwo.getProjectTitle() != null){55. dataMap.put("ptitle",pwo.getProjectTitle());//项⽬名称56. }else{57. dataMap.put("ptitle","⽆");58. }59. if(pwo.getProjectId() != null){60. dataMap.put("pid", pwo.getProjectId());//⼯程id61. }else{62. dataMap.put("pid", "0");63. }64. if(pwo.getBeginDate() != null){65. dataMap.put("begindate", pwo.getBeginDate());//项⽬开始时间66. }else{67. dataMap.put("begindate", "⽆");68. }69. if(pwo.getEndDate() != null){70. dataMap.put("endate", pwo.getEndDate());//结束⽇期71. }else{72. dataMap.put("endate", "⽆");73. }74. if(pwo.getProjecTarget() != null){75. dataMap.put("ptarget", pwo.getProjecTarget());//⽬标76. }else{77. dataMap.put("ptarget", "⽆");78. }79. if(pwo.getMemberId() != null){80. dataMap.put("pmemberid", pwo.getMemberId());//负责⼈81. }else{81. }else{82. dataMap.put("pmemberid", "⽆");83. }84. if(pwo.getPlanNu() != null){85. dataMap.put("plano", pwo.getPlanNu());//计划编号86. }else{87. dataMap.put("plano", "⽆");88. }if(pwo.getInvestment() != null){89. dataMap.put("investment", pwo.getInvestment());//总投资90. }else{91. dataMap.put("investment", "⽆");92. }93. if(pwo.getDoItem() != null){94. dataMap.put("doitem", pwo.getDoItem());//事项95. }else{96. dataMap.put("doitem", "⽆");97. }98. if(pwo.getKeyPoint() != null){99. dataMap.put("keypoint", pwo.getKeyPoint());//重点100. }else{101. dataMap.put("keypoint", "⽆");102. }103. if(pwo.getChild() != null){104. dataMap.put("list", pwo.getChild());//联系⼈列表105. }else{106. dataMap.put("list", "⽆");107. }108. SimpleDateFormat tempDate = new SimpleDateFormat("yyyy年MM⽉dd⽇"); 109. String datetime = tempDate.format(DateTimeUtil.getCurrDate());110. dataMap.put("datetime", datetime);111. }112. /**113. * 将单位类型数字转换为对应的字符114. */115. private List<ProjectDepartment> addtypePlus(List<ProjectDepartment> list){116. for (ProjectDepartment projectDepartment : list) {117. if(projectDepartment.getType() == 1){projectDepartment.setTypePlus("委托单位");} 118. if(projectDepartment.getType() == 2){projectDepartment.setTypePlus("建设单位");} 119. if(projectDepartment.getType() == 3){projectDepartment.setTypePlus("施⼯单位");} 120. if(projectDepartment.getType() == 4){projectDepartment.setTypePlus("监理单位");} 121. if(projectDepartment.getType() == 5){projectDepartment.setTypePlus("设计单位");} 122. if(projectDepartment.getType() == 6){projectDepartment.setTypePlus("编制单位");} 123. }124. return list;125. }配置⽂件的信息这⾥就不在多说了,同时需要修改ftl中的参数,修改⽅法如下,[html] view plain copy print?1. <w:r wsp:rsidRPr="002C3578">2. <w:rPr>3. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>4. <wx:font wx:val="宋体"/>5. <w:sz-cs w:val="21"/>6. </w:rPr>7. <w:t><![CDATA[${doitem}]]></w:t>7. <w:t><![CDATA[${doitem}]]></w:t>8. </w:r>与jsp中的⽅法基本⼀致,处理list,如果遇到循环的话,使⽤如下的⽅法,[html] view plain copy print?1. <#list list as bean><!-- Start 循环体 -->2. <w:tr wsp:rsidR="002C3578" wsp:rsidRPr="002C3578" wsp:rsidTr="002C3578">3. <w:trPr>4. <w:trHeight w:val="427"/>5. </w:trPr>6. <w:tc>7. <w:tcPr>8. <w:tcW w:w="534" w:type="dxa"/>9. <w:vmerge/>10. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>11. </w:tcPr>12. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">13. <w:pPr>14. <w:jc w:val="center"/>15. <w:rPr>16. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>17. <wx:font wx:val="宋体"/>18. <w:sz-cs w:val="21"/>19. </w:rPr>20. </w:pPr>21. </w:p>22. </w:tc>23. <w:tc>24. <w:tcPr>25. <w:tcW w:w="1596" w:type="dxa"/>26. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>27. </w:tcPr>28. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">29. <w:pPr>30. <w:spacing w:line="360" w:line-rule="auto"/>31. <w:jc w:val="center"/>32. <w:rPr>33. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>34. <wx:font wx:val="宋体"/>35. <w:sz-cs w:val="21"/>36. </w:rPr>37. </w:pPr>38. <w:r wsp:rsidRPr="002C3578">39. <w:rPr>40. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>41. <wx:font wx:val="宋体"/>42. <w:sz-cs w:val="21"/>43. </w:rPr>44. <w:t><![CDATA[${bean.typePlus}]]></w:t>45. </w:r>46. </w:p>47. </w:tc>48. <w:tc>48. <w:tc>49. <w:tcPr>50. <w:tcW w:w="2130" w:type="dxa"/>51. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>52. </w:tcPr>53. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">54. <w:pPr>55. <w:spacing w:line="360" w:line-rule="auto"/>56. <w:jc w:val="center"/>57. <w:rPr>58. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>59. <wx:font wx:val="宋体"/>60. <w:sz-cs w:val="21"/>61. </w:rPr>62. </w:pPr>63. <w:r wsp:rsidRPr="002C3578">64. <w:rPr>65. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>66. <wx:font wx:val="宋体"/>67. <w:sz-cs w:val="21"/>68. </w:rPr>69. <w:t><![CDATA[${bean.department_name}]]></w:t>70. </w:r>71. </w:p>72. </w:tc>73. <w:tc>74. <w:tcPr>75. <w:tcW w:w="2131" w:type="dxa"/>76. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>77. </w:tcPr>78. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578">79. <w:pPr>80. <w:spacing w:line="360" w:line-rule="auto"/>81. <w:jc w:val="center"/>82. <w:rPr>83. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>84. <wx:font wx:val="宋体"/>85. <w:sz-cs w:val="21"/>86. </w:rPr>87. </w:pPr>88. <w:r wsp:rsidRPr="002C3578">89. <w:rPr>90. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>91. <wx:font wx:val="宋体"/>92. <w:sz-cs w:val="21"/>93. </w:rPr>94. <w:t><![CDATA[${bean.linkman}]]></w:t>95. </w:r>96. </w:p>97. </w:tc>98. <w:tc>99. <w:tcPr>100. <w:tcW w:w="2131" w:type="dxa"/>101. <w:shd w:val="clear" w:color="auto" w:fill="auto"/>102. </w:tcPr>103. <w:p wsp:rsidR="0068277C" wsp:rsidRPr="002C3578" wsp:rsidRDefault="0068277C" wsp:rsidP="002C3578"> 104. <w:pPr>104. <w:pPr>105. <w:spacing w:line="360" w:line-rule="auto"/>106. <w:jc w:val="center"/>107. <w:rPr>108. <w:rFonts w:ascii="宋体" w:h-ansi="宋体" w:hint="fareast"/>109. <wx:font wx:val="宋体"/>110. <w:sz-cs w:val="21"/>111. </w:rPr>112. </w:pPr>113. <w:r wsp:rsidRPr="002C3578">114. <w:rPr>115. <w:rFonts w:ascii="宋体" w:h-ansi="宋体"/>116. <wx:font wx:val="宋体"/>117. <w:sz-cs w:val="21"/>118. </w:rPr>119. <w:t><![CDATA[${bean.phone}]]></w:t>120. </w:r>121. </w:p>122. </w:tc>123. </w:tr>124. </#list><!-- End 循环体 -->这样就能导出想要的word⽂档,⼀定要记住,使⽤office2013,我试着⽤WPS,但是⽣成内容让我很懵逼,全是xml代码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
import freemarker.template.Configuration;
import freemarker.template.DefaultObjectWrapper;
import freemarker.template.Template;
dataMap.put(sDate[i][0],sDate[i][1]);
}
}
}
这是测试类
package com.tiger.document;
public class Main {
public static void main(String[] args) {
long start=System.currentTimeMillis();
<w:wordDocument xmlns:aml="/aml/2001/core" xmlns:wpc="/office/word/2010/wordprocessingCanvas" xmlns:dt="uuid:C2F41010-65B3-11d1-A29F-00AA00C14882" xmlns:mc="/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="/office/word/2003/wordml" xmlns:wx="/office/word/2003/auxHint" xmlns:wne="/office/word/2006/wordml" xmlns:wsp="/office/word/2003/wordml/sp2" xmlns:sl="/schemaLibrary/2003/core" w:macrosPresent="no" w:embeddedObjPresent="no" w:ocxPresent="no" xml:space="preserve"><w:ignoreSubtree w:val="/office/word/2003/wordml/sp2"/><o:DocumentProperties><o:Author>eBPM</o:Author><o:LastAuthor>eBPM</o:LastAuthor><o:Revision>2</o:Revision><o:TotalTime>0</o:TotalTime><o:Created>2012-11-27T01:57:00Z</o:Created><o:LastSaved>2012-11-27T01:57:00Z</o:LastSaved><o:Pages>1</o:Pages><o:Words>18</o:Words><o:Characters>105</o:Characters><o:Lines>1</o:Lines><o:Paragraphs>1</o:Paragraphs><o:CharactersWithSpaces>122</o:CharactersWithSpaces><o:Version>14</o:Version></o:DocumentProperties><w:fonts><w:defaultFonts w:ascii="Calibri" w:fareast="宋体" w:h-ansi="Calibri" w:cs="Times New Roman"/><w:font w:name="Times New Roman"><w:panose-1 w:val="02020603050405020304"/><w:charset w:val="00"/><w:family w:val="Roman"/><w:pitch w:val="variable"/><w:sig w:usb-0="E0002AFF" w:usb-1="C0007841" w:usb-2="00000009" w:usb-3="00000000" w:csb-0="000001FF" w:csb-1="00000000"/></w:font><w:font w:name="宋体"><w:altNa
long end=System.currentTimeMillis();
System.out.println(end-start);
} Biblioteka } 这个是需要的模版文件,当然因为不能上传附件所以只能贴出来了,这些文件的存放位置就是测试类中的第一个参数了
word模版源文件test.doc这个文档你可以另存为xml文件格式,当然你还要看一下里面的内容是否发生变化比如${abcd1}有没有被拆开,这些变量如果被拆开那就会出现解析失败的问题
//定义Template对象
t = configuration.getTemplate(fileName);
//configuration.setDirectoryForTemplateLoading(new File("E:/"));
// test.ftl为要装载的模板
//设置对象包装器
configuration.setObjectWrapper(new DefaultObjectWrapper());
//设置异常处理器
configuration.setTemplateExceptionHandler(TemplateExceptionHandler.IGNORE_HANDLER);
// 这里我们的模板是放在com.havenliu.document.template包下面
Template t = null;
try {
//从什么地方加载freemarker模板文件
configuration.setDirectoryForTemplateLoading(new File(dir));
sDate[11][0]="abcd12";
sDate[11][1]="abcd12";
dh.createDoc("E:\\doc1","test.xml","E:/outFile.doc",sDate);
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<?mso-application progid="Word.Document"?>
} catch (IOException e) {
e.printStackTrace();
}
// 输出文档路径及名称
File outFile = new File(savePath);
Writer out = null;