recurrent_neural_network_regularization
了解递归神经网络在自然语言处理中的应用

了解递归神经网络在自然语言处理中的应用递归神经网络(Recurrent Neural Networks)是一种具有很强表达能力和建模能力的深度学习模型,广泛应用于自然语言处理任务中。
本文将详细介绍递归神经网络在自然语言处理中的应用,包括语言模型、机器翻译、情感分析等方面。
一、什么是递归神经网络递归神经网络是一种特殊结构的神经网络,能够充分考虑时间序列上的信息,对序列中的上下文关系进行建模。
递归神经网络不同于传统的前馈神经网络,它在处理序列数据时能够将当前时间步输出作为下一个时间步的输入,因此能够适应变长序列的处理需求。
递归神经网络具有记忆性,能够记录下历史信息,比如循环神经网络RNN就是一种递归神经网络的典型表现形式。
二、递归神经网络在自然语言处理中的应用(一)语言模型语言模型是NLP领域中的一个关键问题,它的任务是预测一个给定的句子是否符合语法规则和语境环境。
语言模型中的一个重要问题是如何确定上下文依赖。
递归神经网络可以天然地处理这种上下文依赖关系,因此在语言模型任务中取得了很好的效果。
对于传统的n-gram语言模型而言,它的假设是当前单词只与之前的n-1个单词有关,对于长距离的上下文表示能力很弱。
而递归神经网络没有这个限制,可以考虑整个序列信息,通过对序列信息的处理,使模型能够更好地学习到上下文依赖。
(二)机器翻译机器翻译是自然语言处理中的一个重要应用领域,其任务是将一种语言自动地翻译成另一种语言。
传统的机器翻译模型采用统计机器学习方法,输出翻译结果的质量不稳定,而且需要大量的人工特性提取。
递归神经网络被广泛用于机器翻译中,通过对源语言和目标语言语句的建模,进行序列到序列的学习,可以实现端到端的翻译。
著名的神经机器翻译模型有seq2seq模型,其使用了编码器和解码器的结构,分别将源语言和目标语言序列编码为定长的向量,然后通过解码器生成目标语言的序列。
递归神经网络结合Attention机制,可以有效提高翻译质量。
理解卷积神经网络中的自注意力机制

理解卷积神经网络中的自注意力机制展开全文作者:Shuchen Du编译:ronghuaiyang导读计算机视觉中的编解码结构的局限性以及提升方法。
卷积神经网络(CNN)广泛应用于深度学习和计算机视觉算法中。
虽然很多基于CNN的算法符合行业标准,可以嵌入到商业产品中,但是标准的CNN算法仍然有局限性,在很多方面还可以改进。
这篇文章讨论了语义分割和编码器-解码器架构作为例子,阐明了其局限性,以及为什么自注意机制可以帮助缓解问题。
标准编解码结构的局限性图1:标准编解码结构解码器架构(图1)是许多计算机视觉任务中的标准方法,特别是像素级预测任务,如语义分割、深度预测和一些与GAN相关的图像生成器。
在编码器-解码器网络中,输入图像进行卷积、激活以及池化得到一个潜向量,然后恢复到与输入图像大小相同的输出图像。
该架构是对称的,由精心设计的卷积块组成。
由于其简单和准确,该体系结构被广泛使用。
图2:卷积的计算但是,如果我们深入研究卷积的计算(图2),编码器-解码器架构的局限性就会浮出表面。
例如,在3x3卷积中,卷积滤波器有9个像素,目标像素的值仅参照自身和周围的8个像素计算。
这意味着卷积只能利用局部信息来计算目标像素,这可能会带来一些偏差,因为看不到全局信息。
也有一些朴素的方法来缓解这个问题:使用更大的卷积滤波器或有更多卷积层的更深的网络。
然而,计算开销越来越大,结果并没有得到显著的改善。
理解方差和协方差方差和协方差都是统计学和机器学习中的重要概念。
它们是为随机变量定义的。
顾名思义,方差描述的是单个随机变量与其均值之间的偏差,而协方差描述的是两个随机变量之间的相似性。
如果两个随机变量的分布相似,它们的协方差很大。
否则,它们的协方差很小。
如果我们将feature map中的每个像素作为一个随机变量,计算所有像素之间的配对协方差,我们可以根据每个预测像素在图像中与其他像素之间的相似性来增强或减弱每个预测像素的值。
在训练和预测时使用相似的像素,忽略不相似的像素。
吴恩达深度学习第二课第一周编程作业_regularization(正则化)
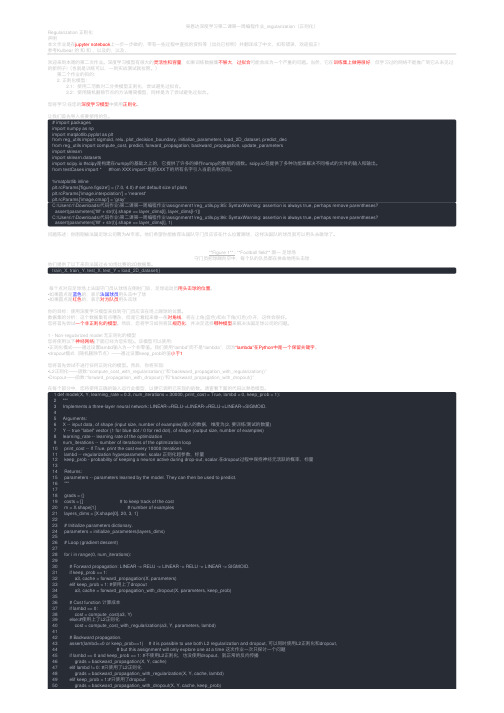
吴恩达深度学习第⼆课第⼀周编程作业_regularization(正则化)Regularization 正则化声明本⽂作业是在jupyter notebook上⼀步⼀步做的,带有⼀些过程中查找的资料等(出处已标明)并翻译成了中⽂,如有错误,欢迎指正!参考Kulbear 的和和,以及的,以及,欢迎来到本周的第⼆次作业。
深度学习模型有很⼤的灵活性和容量,如果训练数据集不够⼤,过拟合可能会成为⼀个严重的问题。
当然,它在训练集上做得很好,但学习过的⽹络不能推⼴到它从未见过的新例⼦!(也就是训练可以,⼀到实战测试就拉胯。
) 第⼆个作业的⽬的: 2. 正则化模型: 2.1:使⽤⼆范数对⼆分类模型正则化,尝试避免过拟合。
2.2:使⽤随机删除节点的⽅法精简模型,同样是为了尝试避免过拟合。
您将学习:在您的深度学习模型中使⽤正则化。
让我们⾸先导⼊将要使⽤的包。
# import packagesimport numpy as npimport matplotlib.pyplot as pltfrom reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_decfrom reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parametersimport sklearnimport sklearn.datasetsimport scipy.io #scipy是构建在numpy的基础之上的,它提供了许多的操作numpy的数组的函数。
scipy.io包提供了多种功能来解决不同格式的⽂件的输⼊和输出。
from testCases import * #from XXX import*是把XXX下的所有名字引⼊当前名称空间。
递归神经网络在深度学习中的应用(八)

递归神经网络(Recurrent Neural Networks, RNN)作为深度学习领域的一种重要模型,具有广泛的应用。
本文将从几个角度探讨递归神经网络在深度学习中的应用,包括自然语言处理、图像识别和时间序列分析。
一、递归神经网络在自然语言处理中的应用递归神经网络在自然语言处理中有着广泛的应用。
以机器翻译为例,递归神经网络可以有效处理语言句子中的长距离依赖关系,从而提高翻译的准确性和流畅度。
此外,递归神经网络还可以用于情感分析、文本生成等任务。
通过学习语句的上下文信息,递归神经网络能够更好地理解语义和语法结构,从而提高文本处理的效果。
二、递归神经网络在图像识别中的应用虽然递归神经网络主要用于处理序列数据,但是在图像识别领域也发挥了重要作用。
递归神经网络可以将图像划分为一系列的局部区域,并通过递归循环将这些局部区域进行组合和处理,最终得到整个图像的特征表示。
这种方法使得递归神经网络能够更好地捕捉图像中的局部特征和全局结构,并且在图像分类、目标检测等任务中取得了很好的效果。
三、递归神经网络在时间序列分析中的应用时间序列数据广泛存在于金融、气象、交通等领域,递归神经网络可以很好地处理这类数据。
递归神经网络通过对时间序列数据进行递归计算,可以捕捉前后时间点的相关性,并且具有记忆能力,可以有效地预测未来的趋势。
因此,递归神经网络在时间序列预测、异常检测等任务中得到了广泛应用,并取得了不错的结果。
综上所述,递归神经网络作为深度学习的一种重要模型,具有广泛的应用前景。
无论是在自然语言处理、图像识别还是时间序列分析中,递归神经网络都可以发挥重要作用。
递归神经网络通过建立递归连接,能够更好地处理序列数据,捕捉数据的长距离依赖关系,并且具有一定的记忆能力。
随着深度学习的不断发展,递归神经网络的应用前景必将更加广阔。
注意力机制的自然语言处理

注意力机制的自然语言处理一、前言自然语言处理(Natural Language Processing,NLP)是人工智能领域的重要分支之一,它涉及到计算机对自然语言进行理解、生成和应用的技术。
在NLP中,注意力机制(Attention Mechanism)是一种重要的技术手段。
本文将从什么是注意力机制、注意力机制的应用场景、注意力机制在NLP中的应用以及未来发展方向等方面进行详细阐述。
二、什么是注意力机制1.定义注意力机制(Attention Mechanism)是指计算机模拟人类视觉或听觉系统,在处理信息时能够有选择地关注某些部分,而忽略其他部分的能力。
它可以将输入序列中与当前输出有关联的部分加权相加,以提高模型预测准确度。
2.原理在传统的神经网络中,每个输入都会被平等地对待,而在使用注意力机制时,计算机会根据当前任务需要选择性地关注输入序列中某些部分。
具体来说,在使用注意力机制时,计算机会通过一定方式计算出每个输入与当前任务之间的相关性,并将这些相关性转化为权重进行加权求和。
这样可以使得模型更加注重与当前任务相关的信息。
3.分类根据注意力机制的不同应用场景和实现方式,可以将其分为以下几种类型:(1)Self-Attention:自注意力机制,又称为内部注意力机制。
在该机制中,输入序列中的每个元素都会与其他元素进行交互,并计算出它们之间的相似度,再将相似度转化为权重进行加权求和。
(2)Global Attention:全局注意力机制。
在该机制中,模型会将输入序列中所有元素的信息进行加权求和,并得到一个加权向量作为模型输出。
(3)Local Attention:局部注意力机制。
在该机制中,模型只关注输入序列中某些部分,并对这些部分进行加权求和。
三、注意力机制的应用场景1.图像处理在图像处理领域中,注意力机制被广泛应用于目标检测、图像分类、图像生成等任务。
例如,在目标检测任务中,可以使用自注意力机制对图像中不同区域的特征进行加权融合,以提高目标检测准确率。
注意力机制提取极化特征

注意力机制提取极化特征首先,我们需要明确什么是极化特征。
在情感分析、意见挖掘等任务中,我们通常需要判断一段文本或一张图像中所表达的情感极性,即正面、负面或中性。
极化特征表示的是文本或图像中包含的与情感相关的信息。
为了提取极化特征,我们可以使用注意力机制来自适应地选择输入数据中与情感极性有关的部分。
注意力机制可以根据输入数据的不同部分给予不同的权重,使得模型能够更加关注最重要的部分。
在自然语言处理任务中,我们常常使用循环神经网络(RNN)和注意力机制来提取极化特征。
以情感分类任务为例,我们可以使用双向长短时记忆网络(BiLSTM)作为编码器,将文本序列转化为向量序列。
然后,我们可以使用一个注意力机制来对这些向量序列进行加权求和,得到一个固定长度的向量表示,即极化特征。
具体地,我们可以使用一个全连接层来计算每个时间步上的注意力权重。
这个全连接层的输入是BiLSTM的输出,输出是一个权重向量。
然后,我们可以使用这个权重向量对BiLSTM的输出进行加权求和,得到一个加权后的表示。
最后,我们可以将这个加权后的表示作为极化特征输入给后续的分类器。
在计算机视觉任务中,我们也可以使用注意力机制来提取极化特征。
以图像情感分析为例,我们可以使用卷积神经网络(CNN)来提取图像的特征。
然后,我们可以使用一个注意力机制来对这些特征进行加权求和,得到一个固定长度的向量表示,即极化特征。
具体地,我们可以使用一个全连接层来计算每个图像区域的注意力权重。
这个全连接层的输入是CNN的输出,输出是一个权重向量。
然后,我们可以使用这个权重向量对CNN的输出进行加权求和,得到一个加权后的表示。
最后,我们可以将这个加权后的表示作为极化特征输入给后续的分类器。
总之,注意力机制在提取极化特征方面有着重要的应用。
通过使用注意力机制,我们可以自适应地选择输入数据中与情感极性有关的部分,从而提高模型对关键信息的关注度。
注意力机制已经在许多任务中取得了良好的效果,并成为深度学习中不可或缺的一环。
《基于特征融合和注意力机制的直肠癌的检测与分割》范文

《基于特征融合和注意力机制的直肠癌的检测与分割》篇一一、引言直肠癌是结肠直肠部位的常见癌症类型,早发现早治疗对患者的预后有着极其重要的意义。
在医学图像处理中,针对直肠癌的检测与分割是一个关键环节,可以辅助医生进行精确诊断和有效治疗。
本文旨在探讨基于特征融合和注意力机制的直肠癌的检测与分割方法,以提高诊断的准确性和效率。
二、特征融合技术特征融合是计算机视觉领域的一种重要技术,其核心思想是将多个不同来源的特征图进行融合,以提高模型的性能。
在直肠癌的检测与分割中,我们采用了多模态特征融合的方法。
多模态特征融合可以充分利用不同模态图像的信息,如CT、MRI等医学影像。
这些不同模态的图像提供了不同的信息,如形态、纹理和密度等,将这些信息进行融合可以更全面地描述病灶特征。
在本文中,我们采用卷积神经网络(CNN)对不同模态的图像进行特征提取,并将提取的特征图进行融合。
这样可以在一定程度上提高直肠癌检测与分割的准确性。
三、注意力机制注意力机制是深度学习领域的一个研究热点,其核心思想是根据任务需求对不同区域进行不同程度的关注。
在直肠癌的检测与分割中,我们采用了自注意力机制和空间注意力机制。
自注意力机制可以自动学习图像中不同区域之间的依赖关系,从而对重要区域进行加强。
在本文中,我们利用自注意力机制对多模态特征图进行加权,使得模型能够更好地关注病灶区域。
空间注意力机制则是对图像中的空间信息进行加权,以突出重要区域。
我们将空间注意力机制应用于卷积神经网络的各个层级,以进一步提高直肠癌的检测与分割效果。
四、实验与分析为了验证本文所提方法的有效性,我们在公开的医学影像数据集上进行了实验。
实验结果表明,基于特征融合和注意力机制的直肠癌检测与分割方法在准确率、召回率和F1分数等指标上均取得了较好的结果。
与传统的医学图像处理方法相比,本文所提方法具有以下优点:首先,多模态特征融合可以充分利用不同模态图像的信息,提高诊断的准确性;其次,自注意力机制和空间注意力机制可以自动学习图像中的重要区域,提高模型的关注度;最后,该方法可以在一定程度上提高诊断的效率,为医生提供更准确的诊断依据。
卷积神经网络中的自注意力机制详解

卷积神经网络中的自注意力机制详解卷积神经网络(Convolutional Neural Network,简称CNN)是一种广泛应用于图像识别、语音识别等领域的深度学习模型。
近年来,随着自然语言处理领域的发展,CNN也开始应用于文本分类、机器翻译等任务。
而在卷积神经网络中,自注意力机制(Self-Attention)被广泛应用,成为提升模型性能的重要技术。
自注意力机制是一种允许模型在处理序列数据时能够关注不同位置之间的依赖关系的方法。
在传统的卷积神经网络中,卷积操作只能捕捉局部的特征,无法有效地处理长距离的依赖关系。
而自注意力机制通过引入注意力机制,使模型能够根据不同位置之间的关系,动态地调整特征的权重,从而更好地捕捉序列中的长距离依赖。
在自注意力机制中,首先需要计算一个注意力权重矩阵。
该矩阵的大小与输入序列的长度相同,每个位置上的权重表示该位置与其他位置之间的关联程度。
为了计算注意力权重,需要引入三个线性变换,分别是查询(Query)、键(Key)和值(Value)。
查询向量用于衡量每个位置与其他位置的关联程度,键向量用于表示每个位置的特征,值向量则是输入序列的特征表示。
通过计算查询向量与键向量的点积,再进行归一化处理,可以得到注意力权重。
这些权重可以乘以值向量,得到加权后的值向量,从而实现对不同位置的特征进行加权求和。
这样,模型就能够根据不同位置之间的依赖关系,动态地调整特征的权重,更好地捕捉序列中的长距离依赖。
自注意力机制的一个重要应用是在Transformer模型中。
Transformer是一种基于自注意力机制的编码器-解码器结构,被广泛应用于机器翻译、文本生成等任务。
在Transformer模型中,自注意力机制被用于编码器和解码器中,分别用于捕捉输入序列和输出序列中的依赖关系。
在编码器中,自注意力机制能够帮助模型捕捉输入序列中的长距离依赖。
通过多层自注意力机制的堆叠,模型能够逐渐聚焦于不同层次的特征,从而更好地理解输入序列。
基于深度学习的特征提取方法(五)

深度学习是一种模仿人类大脑神经网络结构的人工智能技术。
在过去的几年里,深度学习已经在计算机视觉、语音识别、自然语言处理等领域取得了巨大的进展。
特征提取是深度学习中的一个重要环节,它是将原始数据转换成可供机器学习算法使用的形式,从而提高算法的性能和效果。
本文将介绍基于深度学习的特征提取方法,并讨论其在不同领域的应用。
深度学习的特征提取方法主要包括卷积神经网络(CNN)和循环神经网络(RNN)。
CNN是一种前馈神经网络,它通过多层卷积和池化层来提取图像和视频数据的特征。
RNN则适用于序列数据的特征提取,它能够捕捉数据中的时间依赖关系。
这两种方法都能够有效地提取数据的高级特征,为后续的机器学习任务提供更加丰富的信息。
在计算机视觉领域,深度学习的特征提取方法已经取得了许多重要的成果。
例如,在图像分类任务中,CNN能够提取出图像中的边缘、纹理和形状等特征,从而实现对图像的自动分类。
在目标检测任务中,CNN也能够通过多层卷积和池化层来提取出目标的位置和大小等信息,从而实现对目标的自动识别和定位。
此外,在图像生成任务中,RNN则能够捕捉图像中的时间依赖关系,从而实现对图像的自动生成。
在语音识别和自然语言处理领域,深度学习的特征提取方法也取得了重要的进展。
在语音识别任务中,RNN能够提取出语音数据的时间依赖关系,从而实现对语音的自动识别和转录。
在自然语言处理任务中,CNN和RNN则能够提取出文本数据中的词语、句法和语义等特征,从而实现对文本的自动理解和分析。
除了传统的深度学习方法,还有一些新的特征提取方法也值得关注。
例如,生成对抗网络(GAN)能够通过两个神经网络的对抗训练来提取数据的高级特征,从而实现对数据的自动生成和增强。
另外,自动编码器(Autoencoder)也能够通过无监督学习来提取数据的高级特征,从而实现对数据的自动降维和重构。
总之,基于深度学习的特征提取方法在计算机视觉、语音识别、自然语言处理等领域都取得了重要的进展。
recet原理

Recurrent Neural Networks (RNNs) and the BasicPrinciples of RecencyRecurrent Neural Networks (RNNs) are a type of artificial neural network that are designed to process sequential data, such as time series or natural language. They are particularly effective in capturing and modeling temporal dependencies in data. One key property of RNNs istheir ability to remember and utilize information from previous steps or time points in the sequence, which is crucial for tasks that require an understanding of context and recency. In this article, we will delveinto the basic principles of RNNs and how they enable the modeling of recency.1. Introduction to Recurrent Neural Networks (RNNs)An RNN is a type of neural network that introduces the concept of “recurrent connections” to capture the temporal nature of sequential data. Unlike feedforward neural networks, which process data in astrictly one-directional manner, RNNs have connections that allow information to flow not only from the input layer to the output layer but also across different time steps or iterations.At each time step, an RNN takes an input vector and produces an output vector. Additionally, it maintains a hidden state vector that serves as the memory of the network. This hidden state is updated at each time step based on the current input and the previous hidden state, allowing the network to retain information from previous steps.2. The Recurrent Connection and the Hidden StateThe recurrent connection in an RNN is what enables it to capture and utilize information from previous time steps. It connects the hidden state of the current step with the hidden state of the previous step. This connection forms a loop, allowing the network to maintain a form of memory.Mathematically, the hidden state at time step t, denoted by h(t), is calculated using the following equation:h(t) = f(W * x(t) + U * h(t-1))where x(t) is the input vector at time step t, W is the weight matrix connecting the input to the hidden state, U is the weight matrix connecting the hidden state to itself, and f is a non-linear activation function.The hidden state serves as a summary of the information processed by the network up to the current time step. It contains information not only from the current input but also from all previous inputs, allowing the network to have a notion of context and recency.3. Backpropagation Through Time (BPTT)Training an RNN involves updating the weights of the network to minimize the difference between the predicted output and the target output. This is typically done using the backpropagation algorithm, which calculates the gradients of the loss function with respect to the weights.In the case of RNNs, training involves a variant of backpropagation called “Backpropagation Through Time” (BPTT). BPTT unfolds the recurrent connections over time, treating the RNN as a deep neural network with shared weights. This allows the gradients to flow through the recurrent connections and update the weights accordingly.BPTT works by calculating the gradients at each time step and accumulating them over the entire sequence. The gradients are then used to update the weights using an optimization algorithm such as gradient descent. By iteratively adjusting the weights based on the accumulated gradients, the network learns to better model the temporal dependencies in the data.4. Modeling Recency with RNNsThe ability of RNNs to capture and utilize information from previous time steps makes them well-suited for tasks that require an understanding of recency. By maintaining a hidden state that retains information from past inputs, RNNs can effectively model the context and dependencies in sequential data.For example, in natural language processing tasks such as language modeling or machine translation, the meaning of a word or phrase often depends on the words that came before it. RNNs can capture these dependencies by using the hidden state to remember the context of previous words and incorporate it into the prediction of the current word.Similarly, in time series analysis, the value of a variable at a given time point is often influenced by its previous values. RNNs can learn to model these dependencies by considering the hidden state, which contains information about the past values of the variable.Overall, the ability of RNNs to model recency allows them to capture the dynamics and temporal dependencies in sequential data, making them a powerful tool in various domains.5. Variants and Extensions of RNNsWhile basic RNNs are capable of modeling recency, they suffer from certain limitations. One major issue is the vanishing gradient problem, where the gradients diminish exponentially as they propagate through time. This makes it difficult for the network to learn long-term dependencies.To overcome this problem, several variants and extensions of RNNs have been proposed. One popular variant is the Long Short-Term Memory (LSTM) network, which introduces additional gating mechanisms to control the flow of information in and out of the hidden state. LSTMs are better able to capture long-term dependencies and have been widely used in tasks such as speech recognition and sentiment analysis.Another extension is the Gated Recurrent Unit (GRU), which simplifies the LSTM architecture by combining the forget and input gates into a single update gate. GRUs have similar capabilities to LSTMs but with fewer parameters, making them computationally more efficient.These variants and extensions of RNNs have further improved theirability to model recency and capture complex dependencies in sequential data.6. ConclusionRecurrent Neural Networks (RNNs) are a class of neural networks that excel at modeling sequential data by utilizing recurrent connections and hidden states. The recurrent connection allows the network to retain information from previous time steps, enabling it to capture context and recency. Through the Backpropagation Through Time (BPTT) algorithm, RNNs can be trained to learn the temporal dependencies in the data.The ability of RNNs to model recency makes them well-suited for tasks that involve sequential data, such as natural language processing andtime series analysis. Various variants and extensions of RNNs, such as LSTMs and GRUs, have been developed to address the limitations of basic RNNs and further enhance their modeling capabilities.Overall, RNNs and their principles provide a powerful framework for understanding and modeling recency in sequential data, opening up possibilities for advancements in a wide range of fields.。
50道高频人工智能面试题汇总

50道高频人工智能面试题汇总随着人工智能技术的不断发展和应用,越来越多的企业开始寻求具备相关技能的人才。
作为应聘者,如果能够回答下面这些高频人工智能面试题,无疑将增加自己在竞争中的优势。
1. 简述一下人工智能的发展历程及未来发展趋势。
2. 什么是机器学习?其主要的分类有哪些?3. 请解释一下监督学习与无监督学习的区别。
4. 什么是深度学习?它有哪些主要的应用场景?5. 请简述一下卷积神经网络(CNN)的工作原理。
6. 请简述一下循环神经网络(RNN)的工作原理。
7. 什么是自然语言处理(NLP)?请举例说明NLP的应用场景。
8. 请介绍一下聚类算法,以及如何评估聚类结果。
9. 什么是回归问题?请简述一下回归问题的求解方法。
10. 模型的泛化能力是指什么?如何提高模型的泛化能力?11. 请解释一下过拟合与欠拟合的概念,并提出应对方法。
12. 模型的预测准确率是怎么定义的?如何评估一个模型的预测准确率?13. 什么是决策树?请简述决策树的构建方法。
14. 请简述一下支持向量机(SVM)的原理以及应用场景。
15. 什么是随机森林?请简述随机森林的工作原理。
16. 集成学习是怎么工作的?有哪些常见的方法?17. 什么是强化学习?请举例说明强化学习的应用场景。
18. 请介绍一下半监督学习以及其使用场景。
19. 什么是迁移学习?请简述一下迁移学习的原理。
20. 请介绍一下人工神经元的结构及其在神经网络中的作用。
21. 什么是梯度下降?请介绍一下梯度下降的主要优化算法。
22. 请介绍一下反向传播算法,以及如何应用于神经网络中。
23. 什么是批处理和在线学习?它们有哪些区别?24. 请介绍一下卷积神经网络中的反卷积\/转置卷积。
25. 什么是卷积漏斗(convolutional funnel)?26. 简述神经网络中的丢弃(dropout)算法。
27. 请介绍一下卷积神经网络中的池化(pooling)操作。
28. 请介绍一下循环神经网络中的门控循环单元(GRU)。
recurrent models of visual attention

recurrent models of visualattentionRecurrent models of visual attention are a type of deep neural networks that are used to simulate the human visual system and its ability to focus on different areas of an image for a certain period of time. This is done by using recurrent neural networks (RNNs) combined with convolutional neural networks (CNNs). The recurrent model of visual attention is designed to mimic the way humans shift their focus from one area to another in order to identify objects and features in images.In general, recurrent models of visualattention use a combination of CNNs and RNNs to detect which elements or features of an image are most important. This is done in two stages. First, the CNN extracts the features of the image, such as edges and shapes. Then, the RNN takes thesefeatures and uses them to determine which elements of the image should be focused on, and for howlong. This is done through a process called “attention”, where the RNN assigns more importance to certain elements of the image over others based on their relevance to the task at hand.For example, if an image contains both a cat and a dog, the RNN might assign more attention to the cat than the dog. This is because cats tend to be more relevant to the task of identifying animals in images than dogs. Similarly, if an image contains both a car and a tree, the RNN might assign more attention to the car than the tree. This is because cars tend to be more relevant to the task of identifying vehicles in images than trees.The advantage of using recurrent models of visual attention is that they can learn to focus on the most relevant elements in an image, instead of just relying on the fixed filters used in regular CNNs. This makes them more suitable for tasks such as object detection, where it is important to identify the specific objects in an image.Furthermore, since they are able to focus on different elements of an image for different lengths of time, they can also be used for tasks such as scene recognition, where it is important to recognize not only individual objects but also the overall structure of the scene.Overall, recurrent models of visual attention are a powerful tool for simulating the human visual system and its ability to focus on different elements of an image for various lengths of time. By combining CNNs and RNNs, these models can learn to focus on the most relevant elements in an image, making them well suited for tasks such as object detection and scene recognition.。
ChatGPT技术对多轮对话的连贯性建模

ChatGPT技术对多轮对话的连贯性建模在人工智能技术的不断发展中,自然语言处理成为了研究的重点之一。
当今社交媒体和聊天应用的广泛普及,促使人们对多轮对话的连贯性建模提出了更高的要求。
ChatGPT技术应运而生,它通过深度学习的方式实现了对多轮对话的更加准确的理解和生成。
本文将对ChatGPT技术对多轮对话连贯性建模的重要性以及其原理进行探讨。
ChatGPT技术利用了深度学习中的循环神经网络(Recurrent Neural Networks,RNN)和注意力机制(Attention Mechanism)的优点,使得模型能够更好地捕捉到上下文信息,并在生成回复时保持一定的连贯性。
它通过对历史对话进行大规模的预训练,使得模型具备了对各种语义和语法结构的理解能力。
在实际使用中,ChatGPT技术不仅可以应用于智能客服、聊天机器人等场景,还有助于提升实时翻译、语音识别等自然语言处理领域的应用效果。
对于多轮对话连贯性建模的重要性不言而喻。
在传统的基于规则的对话系统中,每次回复都是独立生成的,很难保持和前几轮对话的一致性,使得对话显得生硬和不自然。
而ChatGPT技术通过模型的预训练和微调,使得模型能够更好地理解上下文信息,并生成具备连贯性的回复。
这种连贯性建模使得对话更加流畅,不再是一句一句的单独回答问题,而是能够在多轮对话中进行有效的信息交流和理解。
ChatGPT技术中的循环神经网络和注意力机制是实现多轮对话连贯性的关键。
循环神经网络通过将前一轮对话的隐藏状态传递到下一轮对话,使得模型能够记忆之前的上下文信息。
同时,注意力机制使得模型在生成回复时能够更加关注和考虑到前面几轮的对话内容,有选择性地对不同部分进行加权。
这使得生成的回复更加有针对性和连贯性。
然而,ChatGPT技术在处理多轮对话中的挑战仍然存在。
首先是上下文理解的挑战。
多轮对话中,上下文信息可能会非常复杂,涉及到多个话题和语义关系。
模型需要具备较强的语义理解能力,才能够准确地抓住对话的主线和重点。
自然语言处理互注意力机制

自然语言处理互注意力机制自然语言处理(Natural Language Processing,简称NLP)是计算机科学与人工智能领域中一个重要的研究方向。
它的主要目标是使计算机能够理解、处理和生成自然语言文本。
互注意力机制(Self-Attention Mechanism)是NLP中一种重要的技术,它能够帮助模型捕捉文本中不同单词之间的关系,从而提高模型在各种自然语言处理任务上的表现。
互注意力机制是基于Transformer模型的关键组成部分之一。
它通过对输入文本中的各个单词进行注意力计算,从而获取每个单词与其他单词之间的相关性权重。
这种注意力机制允许模型在理解文本时关注重要信息,并将其引入到后续的处理过程中。
在互注意力机制中,每个单词都会与其他单词进行相似度计算,并根据相似度计算结果调整权重。
这种相似度计算通常使用点积或双线性函数来实现。
通过这种方式,模型可以根据文本中的上下文信息对每个单词进行加权,从而更好地理解整个文本的语义。
互注意力机制的一个重要特点是它可以捕捉到文本中的长距离依赖关系。
传统的循环神经网络(Recurrent Neural Network,简称RNN)在处理长文本时往往会出现梯度消失或爆炸的问题,而互注意力机制则可以通过直接关注不同位置的单词来解决这个问题。
除了在语义理解任务中的应用,互注意力机制还可以用于生成式任务,如机器翻译和文本摘要。
在这些任务中,模型需要根据输入文本生成相应的输出文本。
互注意力机制可以帮助模型在生成过程中更好地关注输入文本中的重要信息,从而提高生成文本的质量和流畅度。
总的来说,互注意力机制是自然语言处理中一种重要的技术,它通过计算不同单词之间的相关性权重,帮助模型更好地理解和生成自然语言文本。
它在各种自然语言处理任务中都有广泛的应用,并且具有很好的效果。
随着深度学习技术的不断发展,互注意力机制有望在未来的研究和应用中发挥更重要的作用。
详解循环神经网络(RecurrentNeuralNetwork)

详解循环神经⽹络(RecurrentNeuralNetwork)本⽂结构:1. 模型2. 训练算法3. 基于 RNN 的语⾔模型例⼦4. 代码实现1. 模型和全连接⽹络的区别更细致到向量级的连接图为什么循环神经⽹络可以往前看任意多个输⼊值循环神经⽹络种类繁多,今天只看最基本的循环神经⽹络,这个基础攻克下来,理解拓展形式也不是问题。
⾸先看它和全连接⽹络的区别:下图是⼀个全连接⽹络:它的隐藏层的值只取决于输⼊的 x⽽ RNN 的隐藏层的值 s 不仅仅取决于当前这次的输⼊ x,还取决于上⼀次隐藏层的值 s:这个过程画成简图是这个样⼦:其中,t 是时刻, x 是输⼊层, s 是隐藏层, o 是输出层,矩阵 W 就是隐藏层上⼀次的值作为这⼀次的输⼊的权重。
上⾯的简图还不能够说明细节,来看⼀下更细致到向量级的连接图:Elman networkElman and Jordan networks are also known as "simple recurrent networks" (SRN).其中各变量含义:输出层是⼀个全连接层,它的每个节点都和隐藏层的每个节点相连,隐藏层是循环层。
图来⾃wiki:为什么循环神经⽹络可以往前看任意多个输⼊值呢?来看下⾯的公式,即 RNN 的输出层 o 和隐藏层 s 的计算⽅法:如果反复把式 2 带⼊到式 1,将得到:这就是原因。
2. 训练算法RNN 的训练算法为:BPTTBPTT 的基本原理和 BP 算法是⼀样的,同样是三步:1. 前向计算每个神经元的输出值;2. 反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输⼊的偏导数;3. 计算每个权重的梯度。
最后再⽤随机梯度下降算法更新权重。
BP 算法的详细推导可以看这篇:下⾯详细解析各步骤:1. 前向计算计算隐藏层 S 以及它的矩阵形式:注意下图中,各变量的维度,标在右下⾓了,s 的上标代表时刻,下标代表这个向量的第⼏个元素。
如何在神经网络中处理具有时间突变的数据

如何在神经网络中处理具有时间突变的数据近年来,神经网络在各个领域的应用越来越广泛。
然而,对于具有时间突变的数据的处理仍然是一个挑战。
在这篇文章中,我们将探讨如何在神经网络中处理这种类型的数据。
在许多实际应用中,数据的特征会随着时间的推移而发生变化。
例如,股票价格、天气预测和心电图等数据都具有时间突变的特征。
传统的神经网络模型在处理这种数据时会遇到困难,因为它们无法捕捉到时间的动态变化。
为了解决这个问题,研究人员提出了一种新的神经网络模型,称为时序神经网络(Temporal Neural Network)。
时序神经网络通过引入时间维度来处理具有时间突变的数据。
它可以捕捉到数据在不同时间点上的变化,并根据这些变化做出预测。
时序神经网络的核心是循环神经网络(Recurrent Neural Network,RNN)。
RNN是一种具有反馈连接的神经网络,它可以将之前的状态信息传递给当前的状态。
这使得RNN可以对时间序列数据进行建模,并在每个时间步骤上更新其隐藏状态。
然而,传统的RNN模型也存在一些问题。
例如,当时间序列数据非常长时,RNN往往会出现梯度消失或梯度爆炸的问题。
为了解决这个问题,研究人员提出了一种改进的RNN模型,称为长短期记忆网络(Long Short-Term Memory,LSTM)。
LSTM模型通过引入门控机制来解决梯度消失和梯度爆炸的问题。
它包含了一个输入门、遗忘门和输出门,可以选择性地更新和遗忘信息。
这使得LSTM能够更好地处理具有时间突变的数据。
除了LSTM,还有其他一些改进的RNN模型,如门控循环单元(Gated Recurrent Unit,GRU)。
GRU模型通过合并输入门和遗忘门,减少了LSTM的参数数量,提高了计算效率。
它在一些场景下表现出与LSTM相当的性能。
除了RNN模型之外,还有一些其他的神经网络模型可以用于处理具有时间突变的数据。
例如,卷积神经网络(Convolutional Neural Network,CNN)可以通过卷积操作捕捉到时间序列数据的局部特征。
segmented_recurrent_transformer_概述及解释说明

segmented recurrent transformer 概述及解释说明1. 引言1.1 概述Segmented Recurrent Transformer(分段循环变压器)是一种结合了RNN 和Transformer模型的混合架构,旨在解决文本分割和语音识别等任务中的问题。
该模型采用了长短期记忆网络(Long Short-Term Memory, LSTM)和自注意力机制(Self-Attention)相结合的方式,具有较强的对上下文信息建模能力。
1.2 文章结构本文将首先介绍RNN和Transformer模型的基本原理,以帮助读者更好地理解Segmented Recurrent Transformer。
随后,我们将详细阐述Segmented Recurrent Transformer的工作原理,并探讨其在文本分割任务和语音识别任务中的优势和应用场景。
此外,我们还将提供实验结果并进行性能评估,以展示该模型在不同任务上的表现。
1.3 目的本文旨在全面介绍Segmented Recurrent Transformer这一新兴的混合模型,并为读者提供对其功能、原理及应用领域有清晰的认识。
通过阐述基于Segmented Recurrent Transformer的文本分割和语音识别方法,我们将揭示该模型在处理这些重要任务时所取得的显著成果。
最后,我们还会对该模型的研究总结进行讨论,并展望未来在这一领域的研究方向。
2. Segmented Recurrent Transformer 模型概述2.1 RNN 和Transformer 模型简介在介绍Segmented Recurrent Transformer之前,我们需要先了解一些相关的模型,包括循环神经网络(Recurrent Neural Network,RNN)和Transformer 模型。
循环神经网络是一种经典的序列建模方法,它通过逐步处理输入序列中的每个元素,并通过隐藏状态来捕捉序列中的上下文信息。
特征抽取中的卷积自编码器方法介绍

特征抽取中的卷积自编码器方法介绍特征抽取是机器学习和深度学习领域中一个重要的任务,它可以帮助我们从原始数据中提取出最具有代表性和有用的特征,从而提高模型的性能和泛化能力。
在特征抽取的过程中,卷积自编码器是一种常用的方法,它通过学习数据的稀疏表示来实现特征的抽取。
卷积自编码器是一种基于卷积神经网络的自编码器模型。
自编码器是一种无监督学习的模型,它可以通过学习数据的低维表示来实现数据的压缩和重构。
在卷积自编码器中,卷积层和池化层被用来学习数据的局部特征,并且通过反卷积层来实现数据的重构。
卷积自编码器的特点是能够捕捉到数据的空间结构和局部相关性。
卷积自编码器的训练过程分为两个阶段:编码阶段和解码阶段。
在编码阶段,输入数据经过一系列的卷积和池化操作,得到数据的低维表示。
在解码阶段,低维表示经过一系列的反卷积和上采样操作,最终重构出输入数据。
在整个训练过程中,卷积自编码器通过最小化输入数据与重构数据之间的差异来学习数据的稀疏表示。
卷积自编码器在特征抽取中的应用非常广泛。
例如,在图像处理领域,卷积自编码器可以用来学习图像的纹理和形状特征。
通过将卷积自编码器与分类器结合起来,可以实现图像的分类和识别任务。
在自然语言处理领域,卷积自编码器可以用来学习文本的语义和句法特征。
通过将卷积自编码器与循环神经网络结合起来,可以实现文本的情感分析和语义理解任务。
除了在特征抽取中的应用,卷积自编码器还可以用于数据的降维和可视化。
通过将高维数据映射到低维空间,可以更好地理解和可视化数据的结构和分布。
卷积自编码器在这方面的应用非常广泛,例如在图像生成和图像重建任务中,可以通过学习数据的低维表示来实现更好的图像合成和重建效果。
总结起来,卷积自编码器是一种在特征抽取中非常有效的方法。
它通过学习数据的稀疏表示来实现特征的抽取,并且可以捕捉到数据的空间结构和局部相关性。
卷积自编码器在图像处理、自然语言处理和数据可视化等领域有广泛的应用。
RecurrentNeuralNetwork系列3--理解RNN的BPTT算法和梯度消失

RecurrentNeuralNetwork 系列3--理解RNN 的BPTT 算法和梯度消失作者:zhbzz2007 出处: 欢迎转载,也请保留这段声明。
谢谢!这是的第三部分。
在前⾯的教程中,我们从头实现了⼀个循环神经⽹络,但是并没有涉及随时间反向传播(BPTT )算法如何计算梯度的细节。
在这部分,我们将会简要介绍BPTT 并解释它和传统的反向传播有何区别。
我们也会尝试着理解梯度消失问题,这也是LSTM 和GRU (⽬前NLP 及其它领域中最为流⾏和有⽤的模型)得以发展的原因。
梯度消失问题最早是由 在1991年发现,最近由于深度框架的⼴泛应⽤再次获得很多关注。
为了能够完全理解这部分,我建议你熟悉偏微分和基本的反向传播⼯作原理。
如果你不熟悉这些内容,你需要看这些教程 、 、 ,这些教程的难度依次增加 。
1 BPTT让我们快速回忆⼀下循环神经⽹络中的⼀些基本公式。
定义中略微有些变化,我们将 o 修改为 ˆy。
这是为了与⼀些参考⽂献保持⼀致。
s t =tanh (Ux t +Ws t −1)^y t =softmax (Vs t)我们定义损失或者误差为互熵损失,如下所⽰,E t (y t ,^y t)=−y t log (^y t )E t (y ,ˆy )=∑t E t (y t ,^y t )=−∑t y tlog (^y t )在这⾥, y t 是时刻 t 上正确的词, ^y t 是预测出来的词。
我们通常将⼀整个序列(⼀个句⼦)作为⼀个训练实例,所以总的误差就是各个时刻(词)的误差之和。
请牢记,我们的⽬标是计算误差关于参数U 、V 和W 的梯度,然后使⽤梯度下降法学习出好的参数。
正如我们将误差相加,我们也将⼀个训练实例在每时刻的梯度相加: ∂E ∂W =∑t ∂E t∂W 。
为了计算这些梯度,我们需要使⽤微分的链式法则。
当从误差开始向后时,这就是 。
在本⽂后续的部分,我们将会以 E 3 为例,仅仅是为了使⽤具体的数字。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
R ELATED
WORK
Dropout Srivastava (2013) is a recently introduced regularization method that has been very successful with feed-forward neural networks. While much work has extended dropout in various ways Wang & Manning (2013); Wan et al. (2013), there has been relatively little research in applying it to RNNs. The only paper on this topic is by Bayer et al. (2013), who focuses on “marginalized dropout” Wang & Manning (2013), a noiseless deterministic approximation to standard dropout. Bayer et al. (2013) claim that conventional dropout does not work well with RNNs because the recurrence amplifies noise, which in turn hurts learning. In this work, we show that this problem can be fixed by applying dropout to a certain subset of the RNNs’ connections. As a result, RNNs can now also benefit from dropout. Independently of our work, Pham et al. (2013) developed the very same RNN regularization method and applied it to handwriting recognition. We rediscovered this method and demonstrated strong empirical results over a wide range of problems. Other work that applied dropout to LSTMs is Pachitariu & Sahani (2013).
l− 1 l RNN : ht , hl t−1 → ht
For classical RNNs, this function is given by
l− 1 hl + Tn,n hl t = f (Tn,n ht t−1 ), where f ∈ {sigm, tanh}
The LSTM has complicated dynamics that allow it to easily “memorize” information for an extended n number of timesteps. The “long term” memory is stored in a vector of memory cells cl t ∈ R . Although many LSTM architectures that differ in their connectivity structure and activation functions, all LSTM architectures have explicit memory cells for storing information for long periods of time. The LSTM can decide to overwrite the memory cell, retrieve it, or keep it for the next time step. The LSTM architecture used in our experiments is given by the following equations Graves et al. (2013):
3
R EGULARIZING RNN S
WITH
LSTM
CELLS
In this section we describe the deep LSTM (Section 3.1). Next, we show how to regularize them (Section 3.2), and explain why our regularization scheme works. We let subscripts denote timesteps and superscripts denote layers. All our states are n-dimensional. n n m Let hl t ∈ R be a hidden state in layer l in timestep t. Moreover, let Tn,m : R → R be an affine transform (W x + b for some W and b). Let ⊙ be element-wise multiplication and let h0 t be an input word vector at timestep k . We use the activations hL t to predict yt , since L is the number of layers in our deep LSTM. 3.1 L ONG - SHORT
TERM MEMORY UNITS
The RNN dynamics can be described using deterministic transitions from previous to current hidden states. The deterministic state transition is a function
∗
1
I NTRODUCTION
The Recurrent Neural Network (RNN) is neural sequence model that achieves state of the art performance on important tasks that include language modeling Mikolov (2012), speech recognition Graves et al. (2013), and machine translation Kalchbrenner & Blunsom (2013). It is known that successful applications of neural networks require good regularization. Unfortunately, dropout Srivastava (2013), the most powerful regularization method for feedforward neural networks, does not work well with RNNs. As a result, practical applications of RNNs often use models that are too small because large RNNs tend to overfit. Existing regularization methods give relatively small improvements for RNNs Graves (2013). In this work, we show that dropout, when correctly used, greatly reduces overfitting in LSTMs, and evaluate it on three different problems. The code for this work can be found in https:///wojzaremba/lstm.
Under review as a conference paper at ICLR 2015
R ECURRENT N EURAL N ETWORK R EGULARIZATION
Wojciech Zaremba∗ New York University woj.zaremba@ Ilya Sutskever, Oriol Vinyals Google Brain {ilyasu,vinyals}@
arXiv:1409.2329v5 [cs.NE] 19 Feb 2015
A BSTRACT
We present a simple regularization technique for Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) units. Dropout, the most successful technique for regularizing neural networks, does not work well with RNNs and LSTMs. In this paper, we show how to correctly apply dropout to LSTMs, and show that it substantially reduces overfitting on a variety of tasks. These tasks include language modeling, speech recognition, image caption generation, and machine translation.