实验1
实验报告1

实验1:学生自身知识系统结构设计实验基本要求实验(实训)学时(学分):3学时实验(实训)目的与要求:训练学生结合自身实际和系统分析原理设计自身知识结构实验(实训)主要仪器、设备:微机实验教室,网络及相关软件实验(实训)主要内容:能够结合自身实际和外部环境对人才的要求(即自身SWOT分析),确立适当的人生梦想与目标,根据人生目标确立自己的可实现的职业规划和行动计划,进而建立层次清晰、相互关联、逻辑严密、操作性强知识结构系统。
实验内容所涉及本课程或相关课程的知识点:涉及管理学计划、组织等概念,涉及管理信息系统信息论、系统论和控制论等概念。
特别是要把握——目标明确是评价系统性能的第一指标;设置目标是系统计划的第一步;而职业规划即系统计划有不同的层次。
同时要深刻理解——系统是一些部件为了某种目的而有机地结合的一个整体,就其本质而言是一定环境中一类为达到某种目的而相互联系、相互作用的事物有机集合体;系统的特点包括整体性、目的性、关联性、层次性等;系统性能的评价指标包括目标明确、结构合理、接口清楚、能观能控等。
实验(实训)步骤:1、上网查询“SWOT分析“的含义;2、根据自身的SWOT,进行分析;3、根据自身实际情况,制定近两年计划;4、根据实习情况,寻找工作。
实验(实训)结果:1、了解到“SWOT分析”含义如下:s代表strength(优势),w代表weakness(弱势),o代表opportunity(机会),t代表threat(威胁),其中,s、w是内部因素,o、t是外部因素。
2、(一)内部因素:优势:性格上:做事认真,待人真诚,赋有责任感,热衷于自己的专业,喜欢思考问题。
能力上:有一定的分析能力,并有寻根问底的兴趣,一定要把问题弄清楚的决心。
生活上:态度乐观向上,自控能力强学习上:努力勤奋,上课专心。
弱势:做事不够果断,在大众面前显得不够热情大方。
有时不够积极参加学校的各项活动。
创新能力有待提高,英文表达与听说能力差。
实验一、网络认识实验

EIA/TIA-232 EIA/TIA-449 X.121 V.24 V.35 HSSI
RJ-45 注意: 插脚引线不同于 典型网中用到的RJ-45
区分不同的WAN串行连接器
端接用户 设备 DTE 连接到路由器
CSU/ DSU
服务商
DCE
EIA/TIA-232
EIA/TIA-449
V.35
X.21
移动用户
分部
公司总部
因特网
LAN的物理层实现
• 物理层实现多种多样
• 有些物理层实现方式支持多种物理介质
数据链路层 (MAC子层) 10Base2 10Base5 10BaseT
802.3
10BaseF 802.3u 说明了100mb (快速) 以太网规范
物理层
DIX 标准
802.3 说明了10mb 以太网规范
位, 1个停止位, 不设流量控制
这是通过控制口的一种管外管理方式
AUX端口用于调制解调器的远程连接访问
当主机与router的console口用反转线连好后,启动 Window系统里的HyperTerminal程序即可对router 进行连接,其配置如下: 1.Bps:9600 2.Data bits:8 3.Parity:None (奇偶校验) 4.Stop bits:1 5.Flow control:none (流量控制)
以太网介质比较
10BaseT
双工型介质接口 连接器 (MIC) ST
区分不同的连接类型
ISO 8877 (RJ-45) 连接器和插孔比电话连接 器RJ-11和插孔略大 AUI 连接器是DB15
光纤连接器接口
实验一(开放大学试题)

实验一实验目的熟悉MySQL环境的使用,掌握在MySQL中创建数据库和表的方法,理解MySQL 支持的数据类型、数据完整性在MySQL下的表现形式,练习MySQL数据库服务器的使用,练习CREATE TABLE,SHOW TABLES,DESCRIBE TABLE,ALTER TABLE,DROP TABLE语句的操作方法。
实验内容:【实验1-1】MySQL的安装与配置。
参见4.1节内容,完成MySQL数据库的安装与配置。
【实验1-2】创建“汽车用品网上商城系统”数据库。
用CREATE DATABASE语句创建Shopping数据库,或者通过MySQL Workbench图形化工具创建Shopping数据库。
【实验1-3】在Shopping数据库下,参见3.5节,创建表3-4~表3-11的八个表。
可以使用CREATE TABLE语句,也可以用MySQL Workbench创建表。
【实验1-4】使用SHOW、DESCRIBE语句查看表。
【实验1-5】使用ALTER TABLE、RENAME TABLE语句管理表。
【实验1-6】使用DROP TABLE语句删除表,也可以使用MySQL Workbench删除表。
(注意:删除前最好对已经创建的表进行复制。
)【实验1-7】连接、断开MySQL服务器,启动、停止MySQL服务器。
【实验1-8】使用SHOW DATABASE、USE DATABASE、DROP DATABASE语句管理“网上商城系统” Shopping数据库。
实验要求:1.配合第1章第3章的理论讲解,理解数据库系统。
2.掌握MySQL工具的使用,通过MySQL Workbench图形化工具完成。
3.每执行一种创建、删除或修改语句后,均要求通过MySQL Workbench查看执行结果。
4.将操作过程以屏幕抓图的方式复制,形成实验文档。
实验二请到电脑端查看实验目的熟悉MySQL环境的使用,掌握在MySQL中创建数据库和表的方法,理解MySQL 支持的数据类型、数据完整性在MySQL下的表现形式,练习MySQL数据库服务器的使用,练习CREATE TABLE,SHOW TABLES,DESCRIBE TABLE,ALTER TABLE,DROP TABLE语句的操作方法。
实验一减数分裂实验

实验一减数分裂实验
一、实验目的
1、掌握花粉母细胞染色体制片技术;
2、了解减数分裂各时期染色体的变化特征。
3、了解动植物生殖细胞的形成过程。
二、实验原理
1、减数分裂是性母细胞(2n)在形成配子时发生的一种特殊的细胞分裂方
式,细胞连续进行两次分裂,而染色体只进行一次复制。
结果产生的4
个子细胞中染色体数目只含有原来的一半(n),所以称作减数分裂。
2、当雌雄配子产生合子时染色体数目又恢复为2n,这样保证了物种世代间
染色体数目的稳定。
3、两次分裂均包括前期、中期、后期和末期,其中前期Ⅰ染色体变化十分
复杂,又细分为细线期、偶线期、粗线期、双线期和终变期等5个时期。
三、实验材料、器具及试剂
1、大葱花穗
2、镊子、解剖针、载玻片、盖玻片、吸水纸、大培养皿、立式染缸、酒精
灯、量筒、显微镜。
无水乙醇、冰醋酸、洋红、甘油、松香石蜡。
四、实验步骤
1、固定:12-24h。
经95%、80%乙醇中各停留约30min后,于70%的乙醇中保
存备用;
2、取材:取已固定好的花序,剥开花蕾,取出花药,放在载玻片上;
3、制片:在花药上滴一滴1%醋酸洋红,染色2min-3min;
4、压片:以45度斜角盖上盖玻片,上面放吸水纸,用拇指适当用力垂直压
下,把周围染色液吸干;
5、烤片:细胞质颜色减退,使染色体得到充分鲜明的着色;
6、显微镜观察,先低倍镜后高倍镜。
五、作业
1、记录观察到的时期,绘制简图。
2、简单描述该时期染色体的形态特征。
实验一.称量实验

实验一称量实验1.实验目的1.1学会正确使用分析天平。
1.2掌握减重称量的方法,了解直接称量法。
2.实验仪器及方法2.1仪器:分析天平,砝码,软毛刷,称量瓶,称量用样品等。
2.2实验仪器装置图:1.横梁。
2平衡螺丝。
4指针,微分标牌5支点刀和承重刀6框罩7圈码8指数盘9支力销10托梁架11阻尼器12投影屏13称盘14盘托15螺旋脚17开关旋钮18调零杆2.3方法:a.使用单盘电光天平,1g以上用砝码盒中的砝码,100~900mg由加砝码(或称指数盘)外圈转加,10~90mg有加码器内圈转加,10mg以下有光幕标尺读取,读准至0.1mg。
b.使用单盘电光自动天平,100mg以上由加码器加放,100mg以下由光幕标尺读取,读准至0.1mgc..使用电子分析天平,直接由读数屏幕读数,读准至0.1mg3.实验步骤3.1检查天平:观察天平各部件是否处于正常状态,检查天平的水平与清洁情况,砝码盒中的砝码有无短缺,调节天平零点。
3.2直接称量练习3.21称量称量瓶的质量从干燥器中取一称量瓶,放在天平盘上,称其重量并进行记录。
重复称量2~3次,求出平均值。
3.22称量瓶盖的质量将瓶盖放在天平盘上(瓶体放回干燥器内),称其质量并进行记录。
重复称量2~3次,求出平均值。
3.23称量瓶体的质量将瓶体放在天平盘上(瓶体放回干燥器内),称其质量并进行记录。
重复称量2~3次,求出平均值。
3.3减重称量练习3.31取一空称量瓶A(空),在托盘天平粗称并记录。
3.32将样品粉末(用小药匙)小心地装入空瓶内约2.0~2.3g(勿洒落瓶外),粗称A并记录。
3.33将A精称(分析天平上)并记录。
3.34将A中平行倒出三样样品(每份0.45~0.55g)于另一容器,每倒出一份需精称A并记录。
此次实验是最基本的称量实验,以前总是觉得非常简单,做得不够精确,所以没有做得很好,这次经过老师的提醒,更加注重数据的准确性,对实验的态度也更端正点了。
实验一-种子活力测定

高级植物生理实验报告种子生理农学院农药学东保柱20132020542013年12月27日种子活力种子活力即种子的健壮度,是种子发芽和出苗率、幼苗生长的潜势、植株抗逆能力和生产潜力的总和,是种子品质的重要指标。
长期以来都用发芽试验检验种子的质量,生产实践表明,实验室的发芽率与田间的出苗率之间往往存在很大差距。
由于种子活力是一项综合性指标,因此靠单一活力测定指标判定其总活力水平或健壮度是不科学的。
实验 1 种子活力的测定种子发芽率、发芽势和发芽指数的测定(垂直板发芽法)一 原理种子在适宜的水分、氧气、温度条件下经一段时间可以萌发。
在最适宜条件和规定天数内,发芽的种子数与供试的种子的百分比,叫发芽率。
为了表示萌发速度与整齐度,反映种子活力程度,规定在短时间内能正常萌发的种子数叫发芽率(测定发芽与发芽天数可参看下述的《种子发芽试验的技术规定》)。
发芽数与发芽相应天数之比的和叫发芽指数。
二 材料与设备1 材料 :小麦种子。
2 设备:玻璃板 滤纸或湿沙 恒温箱 镊子3 药品: 1%次氯酸钠(NaClO ) 三 实验步骤1 选取完整健壮的种子10-15粒,三个重复,用1%次氯酸钠消毒0.5—1min,将种子均匀地排列在有滤纸的培养皿中,种子之间留有一定距离,加入适量蒸馏水,放于所需温度条件下萌发。
2 每天定时记录发芽粒数。
根据附表《种子发芽试验的技术规定》计算种子的发芽势、发芽率和发芽指数。
3 计算正常发芽的种子数 1、发芽率(%)= ×100供试种子数 2、发芽指数(∑=Dt GtGi )式中:Gi —发芽指数Gt ——在时间t 日发芽日数 Dt ——相应的发芽日数四 注意事项1 对于1—2天内全部萌发的迅速发芽类型种子,不适用上述公式计算,宜采用简化活力指数(见实验21)。
2 种子发芽试验的技术规定(附表)实验2 种子活力指数的测定一 原理萌发种子幼根的生长势是反映活力的一个较好生理指标,如将发芽指数与幼苗生长量联系起来(二者的乘机),以活力指数(Vl )来表示,可以作为种子的活力指标。
experiment1
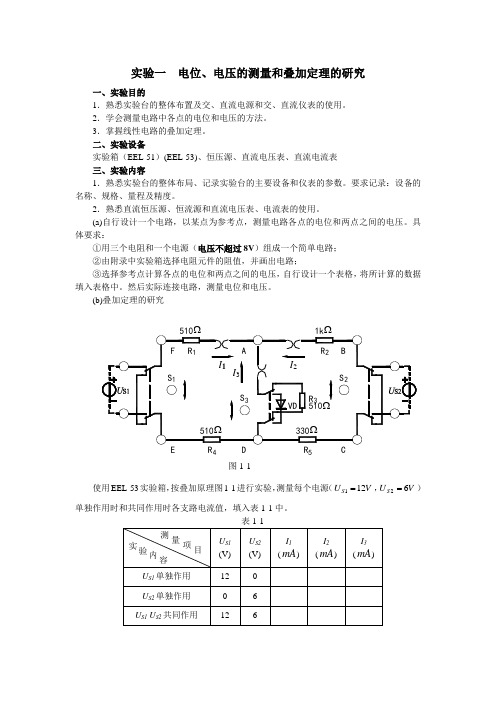
实验一 电位、电压的测量和叠加定理的研究一、实验目的1.熟悉实验台的整体布置及交、直流电源和交、直流仪表的使用。
2.学会测量电路中各点的电位和电压的方法。
3.掌握线性电路的叠加定理。
二、实验设备实验箱(EEL-51)(EEL-53)、恒压源、直流电压表、直流电流表 三、实验内容1.熟悉实验台的整体布局、记录实验台的主要设备和仪表的参数。
要求记录:设备的名称、规格、量程及精度。
2.熟悉直流恒压源、恒流源和直流电压表、电流表的使用。
(a)自行设计一个电路,以某点为参考点,测量电路各点的电位和两点之间的电压。
具体要求:①用三个电阻和一个电源(电压不超过8V )组成一个简单电路; ②由附录中实验箱选择电阻元件的阻值,并画出电路; ③选择参考点计算各点的电位和两点之间的电压,自行设计一个表格,将所计算的数据填入表格中。
然后实际连接电路,测量电位和电压。
(b)叠加定理的研究使用EEL-53实验箱,按叠加原理图1-1进行实验,测量每个电源(VU S 121=,VUS 62=)单独作用时和共同作用时各支路电流值,填入表1-1中。
表1-1图1-1 4 5四、实验注意事项1.测量直流电压应并联在被测元件上,注意正负极性。
测量直流电流时应串联在被测支路中,要注意电流的方向。
2.选择测量仪表的量程,根据估算选择稍大的量程,如电流偏小,再降低量程,以保证测量的精度。
注意测量仪表报警铃响时,应关闭仪表的电源,检查原因,改正后重新合上仪表的电源。
3.正确使用可调直流恒压源和恒流源,正确读数(读数以电压表测量为准,而不以电源表盘指示值为准)。
4.使用电流插头测量时应注意仪表的极性的正确连接,以及读数时"",""-+号的记录。
5.叠加定理实验中,每个电源单独作用时,去掉另一个电源,是由开关S 1 ,S 2 操作完成,而不能将直流电源短路。
五、预习思考题1.叠加定理实验中1S U,2S U分别单独作用时实验中应如何操作?2.如将叠加定理中电阻R 3改为二极管D 时,叠加定理是否成立?3.电路中各点电位与选择的参考点有什么关系?任意两点之间的电压与参考点的选择有关系吗?六、实验报告要求1.预习报告内容的要求:实验目的、实验设备(写出具体实验箱的型号和测量仪表的型号)、实验内容及步骤、根据实验内容,具体画出线路及实验参数,计算结果,以及设计出测量用的记录表格。
实验一-减数分裂

玉米大喇叭口期
玉米雄花序
玉米小穗
玉米的雄花序及花药
三、实验用品
1. 试剂:卡宝品红染色剂 2. 仪器及器具:显微镜、镊子、解剖针、载
玻片、盖玻片等
四、实验方法与步骤
1. 取幼小花蕾置载玻片上,用解剖针剥取长大约12mm的花药2-3枚。
2. 加1滴卡宝品红染色剂后,用镊子充分挤压花药, 使其内的花粉母细胞释放出来。
3. 将大片的残渣去掉后。 4. 染色约5-10分钟,加盖玻片。 5. 用吸水纸包住载玻片,用大拇指垂直向下压片。 6. 显微镜下观察,先在10×物镜下观察概况,找到
合适的目标后再换40×物镜观察并绘图。(注意区 分体细胞、花粉母细胞、幼小花粉粒及成熟花粉粒 个时期的细胞学特征。 实验报告要求绘(至少6个)不同减数分裂
普通遗传学实验一
玉米花粉母细胞减数分裂制片与观察
一、实验目的
1. 了解植物花粉母细胞减数分裂全过程及各个 时期染色体的行为变化特征。
2. 从遗传学角度,熟悉减数分裂各个时期的细 胞学特点,加深对减数分裂的认识。
3. 掌握植物花粉母细胞减数分裂的取材、固定 染色及制片方法
二、实验材料
1. 实验材料:玉米的雄花序(玉米2n=20)
的盖玻片丢弃。 使用过的纱布、滤纸、盖玻片放到废品杯或垃圾
桶,不得直接冲入水池。
值日生打扫卫生、检查仪器及门窗。
附:显微镜操作和使用
开关显微镜,移动显微镜。 调节目镜间距和目镜微调,使两个眼睛视野相同和
清晰,防止眼睛疲劳。 先低倍镜,后高倍镜观察,高倍镜下不准用粗调。 高倍镜下不得取放载玻片。 使用结束:电压或光亮度调至最小,关闭并拔下
电源,降低载物台,最低倍物镜或无目镜的镜筒居 中,防尘罩,填写使用记录,请老师验收方可离开。
实验1

实验表明,在一定温度范围内,半导体材料的电阻率 和绝对温度T的关系可表示为:
,其中 为常数,仅与材料的物理性质有关。由欧姆定律得热敏电阻的阻值
-----------------(1) 其中 , S、L分别为热敏电阻的横截面积和电极间的距离。
三、实验原理
1、热敏电阻的分类
热敏电阻是对温度变化非常敏感的一种半导体电阻元件,它能测量出温度的微小变化,并且体积小,工作稳定,结构简单。因此,它在测温技术、无线电技术、自动化和遥控等方面都有广泛的应用。热敏电阻按其电阻随温度变化的典型特性可分为三类:负温度系数(NTC)热敏电阻,正温度系数(PTC)热敏电阻和临界温度电阻器(CTR)。PTC和CTR型热敏电阻在某些温度范围内,其电阻值会产生急剧变化,适用于某些狭窄温度范围内的一些特殊应用,而NTC热敏电阻可用于较宽温度范围的测量。
3. 调零点:将游码移至“0”刻度,空载时旋转升降旋钮,支起横梁(起动),若不平衡,制动,调节平衡螺母。重复操作直到平衡。
二、 密度的计算
4. 用螺旋测微计测量钢球的直径并记录,计算出其体积。
5. 用游标卡尺测量圆柱体的高及底面圆的直径并记录,计算出其体积。
6. 用物理天平测量钢球及圆柱体的质量,并记录。
4 根据等位线和电力线互相垂直的关系画出各组电极的电力线。
五 实验数据记录与处理
将处理好的坐标纸粘贴于此!
六 注意事项
1 水槽由有机玻璃构成,注意小心轻放,如有破裂,及时处理。
2 实验过程中探针移动要缓慢,不要将水溅到桌面上。
3 记录电位相同的各点坐标位置时,要垂直观测,不要斜视。
对上式取对数有: -------- (2)
实验一 实验报告

实验报告一、实验名称:实验1 Linux文件与目录管理二、实验目的及要求掌握文件与目录管理命令掌握文件内容查阅命令三、实验环境硬件环境:计算机软件环境:linux操作系统四、实验内容及方法1. 文件与目录管理(1) 查看根目录下有哪些内容?(2) 进入/tmp目录,以自己的学号建一个目录,并进入该目录。
(3) 显示目前所在的目录。
(4) 在当前目录下,建立权限为741的目录test1,查看是否创建成功。
(5) 在目录test1下建立目录test2/teat3/test4。
(6) 进入test2,删除目录test3/test4。
(7) 将root用户家目录下的.bashrc复制到/tmp下,并更名为bashrc(8) 重复步骤6,要求在覆盖前询问是否覆盖。
(9) 复制目录/etc/下的内容到/tmp下。
(10) 在当前目录下建立文件aaa。
(11)查看该文件的权限、大小及时间(12) 强制删除该文件。
(13) 将/tmp下的bashrc移到/tmp/test1/test2中。
(14) 将/test1目录及其下面包含的所有文件删除。
2. 文件内容查阅、权限与文件查找(1) 使用cat命令加行号显示文件/etc/issue的内容。
(2) 反向显示/etc/issue中的内容。
(3) 用nl列出/etc/issue中的内容。
(4) 使用more命令查看文件/etc/man.config(5) 使用less命令前后翻看文件/etc/man.config中的内容(6) 使用head命令查看文件/etc/man.config前20行(7) 使用less命令查看文件/etc/man.config后5行(8) 查看文件/etc/man.config前20行中后5行的内容(9) 将/usr/bin/passwd中的内容使用ASCII方式输出(10) 进入/tmp目录,将/root/.bashrc复制成bashrc,复制完全的属性,检查其日期(11) 修改文件bashrc的时间为当前时间五、实验原理及实验步骤1. 文件与目录管理(1) 查看根目录下有哪些内容?ls /(2) 进入/tmp目录,以自己的学号建一个目录,并进入该目录。
实验一实验报告表

实验一实验报告表一、实验目的本次实验的主要目的是探究_____在_____条件下的_____变化规律,并通过实验数据的分析和处理,验证相关理论和假设,为进一步的研究和应用提供基础数据和理论支持。
二、实验原理本实验基于_____原理,该原理指出_____。
在实验中,我们通过控制_____变量,观察_____因变量的变化情况,从而揭示其内在的规律和机制。
三、实验设备与材料1、实验设备主要设备:_____,其型号为_____,精度为_____,用于_____。
辅助设备:_____,用于_____。
2、实验材料材料名称:_____,其规格为_____,纯度为_____。
材料用量:_____。
四、实验步骤1、实验准备检查实验设备是否正常运行,确保仪器的精度和准确性。
准备实验所需的材料,按照规定的用量和规格进行称量和配制。
2、实验操作步骤一:_____。
步骤二:_____。
步骤三:_____。
(详细描述每个步骤的具体操作方法和注意事项)3、数据记录在实验过程中,按照规定的时间间隔和测量指标,准确记录实验数据。
数据记录表格如下:|时间|测量指标 1 |测量指标 2 |测量指标 3 |||||||||||||||||||||五、实验数据处理与分析1、数据处理对实验数据进行整理和筛选,去除异常值和错误数据。
采用合适的数学方法对数据进行处理,如平均值、标准差等,以提高数据的可靠性和准确性。
2、数据分析绘制实验数据的图表,如折线图、柱状图等,直观地展示数据的变化趋势和规律。
通过对图表的分析,找出数据之间的关系和趋势,并与实验预期结果进行比较。
(结合具体数据和图表进行详细的分析和讨论)六、实验结果与讨论1、实验结果本次实验得到的主要结果如下:结果一:_____。
结果二:_____。
结果三:_____。
2、结果讨论对实验结果进行分析和讨论,解释结果产生的原因和机制。
与相关理论和前人的研究成果进行比较,讨论实验结果的一致性和差异性。
实验一 实验室环境和人体表面的微生物检查

实验2 实验室环境和人体表面的微生物检查13生物基地刘洋201300140059一、实验目的1.证实实验室环境与人体表面存在微生物2.体会无菌操作的重要性3.观察不同类群微生物的菌落形态特征4.掌握生理生化反应培养基的配置原理和一般方法步骤5.巩固无菌操作技术二、实验器材1.肉膏蛋白胨琼脂平板牛肉膏1.05g、蛋白胨3.5g、NaCl 1.75g、琼脂7g、水350ml、pH 7.0~7.2、121 ℃灭菌20min。
2.溶液和试剂无菌水3.仪器和其他用品灭菌棉签(装在试管内)、试管架、煤气灯或酒精灯、记号笔和废物缸等。
三、实验原理通过培养的方法使肉眼看不见的单个菌体在固体培养基上,经过生长繁殖形成几百万个菌聚集在一起的肉眼可见的菌落。
四、实验内容及步骤1.在标签纸上做好标记并贴在培养皿侧面。
2.牛肉膏蛋白胨培养基的制备:(1)称量:准确称取牛肉膏1.05g、蛋白胨3.5g、NaCl 1.75g放入烧杯中。
(2)熔化:在上述烧杯中加入少于所需的水量(所需水量为350ml),用玻璃棒搅匀,补充水到所需的总体积350ml。
(3)调pH:用1mol/L NaOH和1mol/L HCl进行调节,直至溶液pH达到7.0~7.2。
(4)分装:将其中200ml溶液装入500ml三角瓶中,向三角瓶中加入4.0克琼脂,向烧杯剩余液体中加入3.0克琼脂,在石棉网上加热烧杯,使琼脂溶解,将烧杯中溶液分装到10支试管中,每支试管中加入体积为试管总体积的1/5左右。
(5)加塞:在三角瓶口上塞上棉塞,防止外界微生物进入造成污染。
(6)包扎:加塞后,在棉塞外包一层牛皮纸,将全部试管用麻绳捆好(还有一支装有无菌水的试管),同样的方法把三角瓶包好,扎好。
用记号笔注明培养及名称、组别、配制日期。
(7)灭菌:将上述培养基以0.1MPa,121℃,90min高压蒸汽灭菌。
(8)搁置斜面:将灭菌的试管培养基冷却至50℃左右,将试管口端搁在玻璃棒或其他合适高度的器具上,搁置的斜面长度以不超过试管的总长的一般为宜。
实验一(基尔霍夫定律)

实验一 基尔霍夫定律的验证一、实验目的1. 验证基尔霍夫定律的正确性,加深对基尔霍夫定律的理解。
2. 掌握使用直流电工仪表测量电流、电压的方法。
3. 学会应用电路的基本定律,分析、查找电路故障的一般方法。
二、实验原理1. 基尔霍夫定律是电路的基本定律。
测量某电路的各支路电流及多个元件两端的电压,应能分别满足基尔霍夫电流定律和电压定律。
即: 对电路中任何一个节点而言,应满足ΣI =0; 对电路中任何一个闭合回路而言,应满足ΣU =0。
运用上述定律时,必须注意电流、电压的实际方向和参考方向的关系。
2. 依据基尔霍夫定律和欧姆定律可对电路的故障现象进行分析,准确定位故障点。
若在一个接有电源的闭合回路中,电路的电流为零,则可能存在开路故障;若某元件上有电压而无电流,则说明该元件开路;若某元件上有电流而无电压,说明该元件出现了短路故障。
三、实验内容1. 先任意设定三条支路的电流参考方向,如图1-2所示。
三个回路的正方向可设为ADEFA 、BADCB 、FBCEF 。
图1-1 实验电路2. 分别将两路直流稳压源接入电路,令E 1=6V ,E 2=12V 。
3. 将电流插头的两端接至数字毫安表的“+、-”两端, 将电流插头分别插入三条支路的三个电流插座中,读出并记录各电流值。
图1-2是电流插头插座的U U 2F1N40071用法示意。
4. 用直流数字电压表分别测量、并记录两路电源及电阻元件上的电压值。
5. 分别按下故障开关A 、B 、C ,借助电压表、电流表,找出电路的故障性质和故障点。
图1-2 使用插头插座测量电流表1-1 测量数据及计算值电流单位: mA 电压单位:V表1-2 故障分析记录四、实验设备电流插座五、注意事项1. 测量验证基尔霍夫定律的数据时,三个故障开关均不按下,即不设人为故障。
2. 实验电路中的开关K3应向上,拨向330Ω侧。
3. 测量电压时应注意表棒的使用。
测U AB,应该用数字直流电压表的正表棒(红色)接A点,负表棒(黑色)接B点,否则记录测出的数值时,必须添加一负号。
微型计算机实验一实验报告

微型计算机实验一实验报告实验一:微型计算机的基本操作及应用探究一、实验目的1.了解微型计算机的基本组成和工作原理;2.学习使用微型计算机进行基本操作;3.探究微型计算机在实际应用中的作用。
二、实验器材和仪器1.微型计算机实验箱;2.微型计算机主机;3.显示器;4.键盘。
三、实验内容1.将微型计算机主机与显示器、键盘连接;2.打开微型计算机并进行基本操作;3.使用微型计算机进行基本应用。
四、实验步骤1.将微型计算机主机与显示器、键盘连接,确保连接稳固;2.打开微型计算机主机,等待系统启动完毕;3.使用键盘进行基本操作,包括输入字符、回车等;4.运行预装的基本应用软件,并进行相应操作。
五、实验结果和分析在本次实验中,通过连接主机与显示器、键盘,我们成功打开了微型计算机并进行了基本操作。
使用键盘输入字符并通过回车键确认后,我们可以在显示器上看到相应的结果。
这表明微型计算机能够正确地接收和处理我们输入的指令,并将结果显示出来。
通过运行预装的基本应用软件,我们还可以进行更加复杂的操作,如文字处理、图形绘制等。
本次实验中,我们还了解到微型计算机的基本组成和工作原理。
微型计算机由主机、显示器、键盘组成。
在主机中,CPU是主要的控制中心,负责接收和处理指令;内存存储了计算机运行时所需的数据和程序;硬盘则保存了大容量的数据。
显示器负责将计算机处理的结果显示出来,键盘则用于输入指令和数据。
微型计算机的应用领域十分广泛。
它可以用于文字处理、数据处理、图形绘制等多个方面。
在今天的社会中,无论是企事业单位还是个人用户,几乎都需要使用微型计算机进行日常工作和生活。
微型计算机的快速计算和大容量存储能力,使得数据处理和信息管理变得更加便捷和高效。
六、实验总结通过本次实验,我们学习了微型计算机的基本操作和应用,并了解了微型计算机的基本组成和工作原理。
微型计算机在今天的社会中扮演着重要的角色,其广泛的应用范围使得人们的工作和生活更加便捷和高效。
实验一基本测量

第三章 基础性实验Chapter 3 Fundamental physics experiment实验一 基本测量Experiment 1 Fundamental technology of measuring实验目的Experimental purpose1. 掌握游标卡尺、外径千分尺米、天平的测量原理和使用方法;2. 掌握用流体静力称衡法测量形状不规则物体密度的测量原理和方法;3. 学会实验数据的处理方法,正确写出测量结果表达式;实验原理Experimental principle1.测不规则物体的密度d etermining density of irregular objects 设物体在空气中的重量为W 1=m 1gm 1为物体的质量,若它全部浸入水中的视重为W 2= m 2gm 2为物体在水中的表观质量,则物体所受浮力为实重与视重之差:()gV g m m F 021ρ=-= 1 式中,ρ0为水的密度,不同温度下水的密度可查表得知;由此可得物体的体积:021ρm m V -=2将2式代入V m =ρ,得物体密度ρ: 0211ρρm m m -= 3 若待测物体的密度小于液体的密度,则可采用在待测物体下拴挂重物的方法进行测量;所拴挂重物的大小,以拴挂后待测物体能浸没于液体中为准;如图1a 所示,先使待测物、重物分别处于液面的上、下,即只将重物浸没液体中,此时称衡,相应的砝码质量为m 4;再将待测物连同重物全部浸入液体中进行称衡,如图1b 所示,相应的砝码质量为m 5,则物体在液体中所受的浮力为()gV g m m F 054ρ=-=物体的密度为0543ρρm m m -=' 4 其中,m 3为待测物在空气中的质量;避开不易直接测量的体积V ,将其转换为只需测量较易测准的质量称衡问题,是流体静力称衡法的优点;一般在实验时,液体常用水,ρ0即水的密度;不同温度下水的密度值详见本书的附录;为减小或消除可能存在的天平不等臂系统误差,宜采用交换法也称复称法测量;2.测液体的密度d etermining density of liquid用静力称衡法测液体的密度,要借助于不溶于水并且和被测液体不发生化学被测物体重物图1小密度值的测定 ab反应的物体一般用玻璃块等;设物体的质量为m a ,将其悬吊在被测液体中的称衡值为m b ;悬吊在水中称衡值为m c ;则依阿基米德定律有液体中 ()g m m gV b a x -=ρ水中 ()g m m gV c a -=0ρ式中,V 为物体的体积;ρx 为待测液体的密度;ρ0为水的密度;由此二式消去V ,得0ρρca b a x m m m m --= 5 若以式3中m 1,m 2分别代替式5中m a 和m c ,则式5变为0211ρρm m m m b x --= 实验仪器Experimental device1.游标卡尺vernier caliper我们通常用量程和分度值表示长度测量仪器的规格;量程是测量范围,分度值是仪器所标示的最小分度单位;分度值的大小反映仪器的精密程度;游标卡尺的精度分度值有0.02mm,0.05mm,0.10mm 三种.常见的游标卡尺如图2所示;游标卡尺一般由尺身主尺、尺框附游标、量爪和深度尺等组成;尺身上刻有间距为1mm 的刻度,尺框可沿尺身滑动,游标固定在尺框上;外量爪用来测量物体的长度和外径,内量爪用来测量内径,深度尺用来测量深度;1) 游标原理游标卡尺的设计,一般有以下两类:① 若主尺上n -1个分格的长度等于游标上n 个分格的长度,如图3a 所示;设主尺每格长度为a ,游标每格长度为b ,则有a n nb )1(-=6 游标卡尺的精度为na b a =-=∆ 7 ② 主尺上2n -1个分格的长度等于游标上n 个分格的长度,如图2b 所示,即()a n nb 12-=8 游标卡尺的精度为n a b a =-=∆2 92) 读数方法图3所示游标卡尺主尺一分格的长度为a =1mm,游标上一分格的长度为b =0.98mm,分度值为501==n a i mm=0.02mm;游标上第1根刻线与主尺上第1根刻线对齐时,游标“0”刻线与主尺“0”刻线之间距离为1×0.02mm ;两尺第2根刻线对齐时,两“0”刻线之间距离为2×0.02mm;依此类推,两尺第m 根刻线对齐时,两“0”刻线之间距离为m ×0.02mm;因此,游标可用来测量毫米以下的长度;图2 三用游标卡尺图3游标卡尺的读数使用游标卡尺进行测量时,首先要弄清楚分度值是多少,然后看清楚游标第几根刻线与主尺的某刻线对齐,具体步骤如下:①由游标“0”线在主尺上的位置读出整毫米数k;②若游标第m根刻线与主尺上某刻线对齐,则从游标上读出毫米以下小数部分为m×i,则有待测尺寸=k+ m×i例如图3所示的游标卡尺的分度值i=0.02mm,游标上第22根刻线与主尺上的刻线对齐,则有待测尺寸=k+ m×i =100mm+37×0.02mm=100.74mm直接读数法:游标尺的分度值为0.02mm,游标尺上的数字表示为0.1mm、0.2mm、……,则上图对齐线的读数为0.74mm,待测尺寸=100mm+0.74mm=100.74mm3注意事项①测量前检查游标卡尺;应将量爪间的脏物、灰尘和油污等擦干净;②工件的被测量表面也应该擦干净,并检查表面有无毛刺、损伤等缺陷,以免刮伤游标卡尺量爪的测量面或测量刀口,影响测量的结果;③测量小零件时,可用左手拿零件、右手拿卡尺进行测量,如图4a,对比较长的零件,要多测几个位置,如图4b;2.外径千分尺螺旋测微计micrometer screw外径千分尺见图5是比游标卡尺更精密的长度测量仪器,又称为螺旋测微计,主要用来测量工件的外部尺寸,精度一般可达0.01mm;图5外径千分尺结构如图5所示,A为测砧,F为测微螺杆,它的螺距为0.5mm的螺纹,当它在固定套管B的螺套中转动时,将前进或后退,可动套管刻度E和测杆F连成一体,其周边等分为50个分格;D为粗调旋钮,D'为细调旋钮,也称为棘轮装置,拧动D'可使测杆移动,当测杆与被测物或砧台E相接后的压力达到某一数值时,棘轮将滑动并有咔、咔的响声,活动套管不再转动,测杆也停止前进,锁住制动旋钮,这时就可读数;设置棘轮可保证每次的测量条件对被测物的压力一定,并能保护螺纹和测杆,测杆和砧台相接时,活动套管上的零线应当刚好和固定套管上的横线对齐;原理是精密螺纹的螺距为0.5mm;即D 每旋转一周,F 前进或后退0.5mm,可动刻度E 上的刻度为50等分,即把0.5mm 分为50等份,则可动刻度E 上的每个刻度为0.01mm,即精度为0.01mm;读数方法,被测物的长度的整毫米数和半毫米部分由固定刻度读出,小于半毫米的部分由可动刻度E 读出,但是要注意固定刻度上表示半毫米的刻度线是否已经露出;螺杆转动的整圈数由固定刻度上间隔0.5mm 的刻线去测量,不足一圈的部分由可动刻度去测量,二者相加就是测量值;使用外径千分尺测量时,要注意防止错读整圈数,图6所示的三例, a 的读数为0.002mm b 的读数为+=6.635mm,c 的读数是5+=5.135mm;图6千分尺的读数 千分尺的零误差,测杆和砧台相接时,活动套管上的零线应当刚好和固定套管上的横线对齐;实际使用的外径千分尺,由于调整得不充分或使用得不当,其零点读数不为零,图7表示两个零点读数的例子;要注意它们的符号不同,顺刻度序列的记为正值,反之为负值; 每次测量之后,要从测量值中减去零点读数,以便对测量值进行修正;3.天平 balancea bc 图7千分尺的零点读数天平是称衡物体质量的精密仪器,天平具有稳定性、灵敏性、正确性和示值不变性四种性能;稳定性是指天平在其平衡状态被扰动后,经过若干次摆动仍能回复到原来的平衡位置;天平指针第i 次摆动幅值A i 与下一次摆幅值A i +1之比称为衰减比;灵敏性是指天平察觉两称盘所放物体质量之差的能力,通常用灵敏度S =m n ∆∆表示,Δn 是指针偏转分格数,Δm 是称盘上所加的微小质量;灵敏度的倒数是感量E =n m ∆∆;正确性是指天平的等臂性;示值不变性是指在不改变天平工作状态的情况下,多次开启天平时其平衡位置的重复性;对比上述四项性能指标,物理天平不及工业天平;物理天平如图8所示;天平的操作程序是:1) 调水平 调天平的底脚螺丝,观察铅锤或圆气泡水准器,将天平立柱调成铅直;2调零点 空载时支起天平,通过横梁两端的调节螺母,进行零点调节;但是对比较灵敏的天平,很难使指针停在标尺中点处,所以一般要求观察指针的停点图8物理天平和标尺中点相差不超过格;3称衡;一般将物体放在左盘,砝码放在右盘;升起横梁观察平衡;若不平衡按操作程序反复增减砝码直至平衡为止;平衡时,砝码与游码读数之和即为物体的质量;4)复原天平复原、砝码放回盒中常用的称量方法:一般称量方法有直接称量法单称法和交换称量法复称法;1直接称量法的公式为Sa a m m 01--= 式中,m 1是砝码的质量;S 是荷载灵敏度;a 是停点;a 0是空载时的停点; 2交换称量法的公式为S a a m m m 22右左右左---=式中,m 左,a 左分别是物体放在左盘时砝码的质量和停点;m 右,a 右分别是物体放在右盘时砝码的质量和停点;实验任务Experimental assignment1.用游标卡尺测量圆柱体的直径D 1和高度H 1,各测6次,记入数据表格中;进而由圆柱体的体积V 柱=1214H D π,写出V 柱的测量结果表达式,用天平测量圆柱体的质量m 0,进而计算圆柱体的密度;2.用外径千分尺测量钢珠的直径D 2,各测6次;进而由钢球的体积326D V π=珠,写出珠V 的测量结果表达式;3.测量不规则物体的密度ρ1) 测量物体在空气中的表观质量m 1;2)称出物体浸没于水中的表观质量m2采用交换法亦可;3)测读水温,查表记录该温度下水的密度ρ0;计算ρ;4.测定蜡块的密度ρ′1)测出蜡块在空气中的表观质量m3;2)按图.a,将蜡块吊在空气中,使重物浸没水中,测出m4;3)按图.b,将蜡块和重物都浸没在水中,测出m5;4)测出水温,由表中查出ρ0,计算ρ′;注意事项cautions1.天平称衡时,每次用镊子加减砝码或取放物体时必须使天平止动,只有在判断天平是否平衡时才启动天平;天平启、止动时动作要轻;2.浸没物体时,托板和烧杯的位置、细线的长度及液体的数量均适宜;3.称衡后,检查、调整天平的横梁、吊耳、砝码等,以使天平始终保持正常状态;4.天平的各部分以及砝码都要防锈、防蚀,高温物体及带腐蚀性的化学药品不得直接放在秤盘内称衡;5.操作完毕,天平复原,砝码放回盒中;数据记录及数据处理data recording and processing例用游标卡尺测量圆柱体举例:1)数据记录表格table of data recording量具:,量程:mm,Δins=0.02mm,零点读数:表1空气中待测规则物体质量的砝码示值m 0=2) 测量结果表达式expression of measuring result ① 111D U D D ±==±mm=±cm 111H U H H ±==±mm=±cm② ∵ 12114H D V π= ∴()11.3069.344421211⨯⨯==ππH D V ≈mm 32221212111.3002.069.3402.042111⎪⎭⎫ ⎝⎛+⎪⎭⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛+⎪⎪⎭⎫ ⎝⎛=H U D U V U H D V ≈×10-3=% 104995816.36%13.011⨯≈=⨯=V U V mm 3因为1v U 只取1位有效数字这样1V 末位与1v U 取齐,1V =2846×10mm 3;圆柱体体积的结果表达式为V1=2846±4×10mm3=±0.04cm3用天平测质量数据表格:天平型号:,称量:,分度值:水温:, 查表知水的密度ρ0=表2 空气中待测不规则物体质量的砝码示值单位g思考题Exercises1.游标卡尺的设计一般有两类,对照实验提供的游标卡尺确定它属于哪一类精度是多少怎样正确使用游标卡尺2.外径千分尺活动套管每转一格,测杆移动多少毫米3.棘轮有什么用处怎样正确使用外径千分尺4.5.你用的外径千分尺的零点读数是多少是正还是负怎样确定的几次测量的零点读数一样吗待测长度如何确定6.建议你用具有统计功能的计算器,以教材中圆柱体的测量数据为例,亲自计算一下,看是否与教材中的结果一样如不一样,一定找出产生错误的原因,直到算对为止,这样你处理实验数据时才会心中有数;7.8.流体静力称衡法测固体密度有什么优点此法对待测物试件有什么要求9.10.天平的主要技术参数是什么简要说明其意义;11.有人把天平的使用要点总结为四句话:“称量、分度值先看清,柱直、梁平、‘游码’零,物左、码右、制动勤,仪器用毕收拾净”;请给出解释;12.在使用物理天平测量前,应进行哪些调节,如何消除天平不等臂误差13.14.若待测物体的密度比水的密度小,则测其密度时应测哪些物理量15.测m2时,待测物体置于水中的位置如何选择16.17.只有在时,才能将天平启动,否则必须将天平止动;关键词key words游标卡尺Caliper gauge with vernier 外径千分尺螺旋测微计Micrometer screw,天平balance,物体密度density of the object,液体的密度density of the fluid,阿基米德定律archimedes’s principle,浮力buoyant f orce,物体的质量mass of the object,物体重量the weight of the object,物体的体积volume of the object,部浸入水中的物体totally submerged object.。
实验一

} else { if(p[3]>=cigama) { p[3]=p[3]-cigama;
for(int dd=0;dd<3;dd++) p[dd]=p[dd]+cigama/3.0; } else { for(int dd1=0;dd1<3;dd1++) p[dd1]=p[dd1]+p[3]/3.0; p[3]=0; } } } }
randd2=(333332+rand()%3001)/1000000000.0; if(randd2<seita[1]) {Y[1]++; for(int jj1=0;jj1<4;jj1++) { if(p[jj1]>=cigama/3.0&&jj1!=1) p[jj1]=p[jj1]-cigama/3.0; else p[jj1]=0;
//随机生成运行剖面如下: switch(j){ case 0: p[0]=(rand()%100)/100.0;
case 1: temp=1-p[0]; a=temp*100; p[1]=float(rand()%(a+1)/100.0); case 2: temp=temp-p[1]; a=temp*100; p[2]=float(rand()%(a+1)/100.0); case 3: p[3]=temp-p[2]; default: break; } for(int m=0;m<3000;m++) { float randd1=0,randd2=0,randd3=0,randd4=0; float randnum=(rand()%100)/100.0; if(randnum<=p[0]) { n[0]++;
实验一 实验报告

云南大学软件学院实验报告课程:数据库原理与实用技术实验任课教师:包崇明专业:软件工程学号:201311….姓名:。
成绩:实验1 熟悉实验环境1.安装SQL Server 2008系统(请同学实验课后自己练习)。
2.找到“SQL Server配置管理器”,查看已经启动了哪些SQL Server服务。
已经启动的服务有:其中服务类型为“SQL Server”服务对Microsoft SQL Server 数据库引擎提供支持,必须启动它。
你所启动的SQL Server服务名称是数据库引擎如何启动后停止SQL Server服务器:SQL配置管理器,找到SQLServer服务,单击后在右侧找到SQL Server Browser 服务,右键启动,如果无法启动,可能是服务器给禁用了,双击这个服务,从窗口中选择服务,找到启动模式,选择自动,单击应用,就可以启动了,点击停止,则可以停止SQL Server服务器3.使用“SQL Server Management Studio”(1)了解SQL Server Management Studio的界面、菜单结构以及各项功能;SQL Server提供两种身份认证方式,分别是__window_身份验证__________和_______Sql server身份验证___________,配置中采用的身份验证是什么方式:windows身份验证(2)了解“数据库服务器”的属性配置;你所使用的SQL Server服务器数据库的默认数据存储位置是:D:\ProgramFiles\MicrosoftSQLServer\MSSQL10_50.MSSQLSERVER\MSSQL \DATA 默认日志存储位置是:D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DA TA___________________________ (3)进入master数据库。
实验1-白盒测试实验报告

第一章白盒测试实验1 语句覆盖【实验目的】1、掌握测试用例的设计要素和关键组成部分。
2、掌握语句覆盖标准,应用语句覆盖设计测试用例。
3、掌握语句覆盖测试的优点和缺点。
【实验原理】设计足够多的测试用例,使得程序中的每个语句至少执行一次。
【实验内容】根据下面提供的程序,设计满足语句覆盖的测试用例。
1、程序1源代码如下所示:#include <iostream.h>void main(){int b;int c;int a;if(a*b*c!=0&&(a+b>c&&b+c>a&&a+c>b)){if(a==b&&b==c){cout<<"您输入的是等边三角形!";}else if((a+b>c&&a==b)||(b+c>a&&b==c)||(a+c>b&&a==c)){cout<<"您输入的是等腰三角形!";}else if((a*a+b*b==c*c)||(b*b+c*c==a*a)||(a*a+c*c==b*b)){cout<<您输入的是直角三角形";}else{cout <<”普通三角形”;}输入数据预期输出A=6,b=7,c=8普通三角形A=3,b=4,c=5直角三角形A=4,b=2,c=4等腰三角形A=1,b=1,c=1等边三角形A=20,b=10,c=1非三角形2、程序2源代码如下所示:输入数据预期输出x=6 z=3 x=4 y=6k=35 j=34x=6 z=3 x=3 y=5k=29 j=25x=6 z=11 x=4 y=8k=0 j=42x=6 z=3 x=2 y=4k=23 j=03、程序3源代码如下所示:预期输出x y magic4418400040100-585-1-104、程序4源代码如下所示:printf("请输入借书证号:");scanf("%d",&borrowerid);for(int i=0;i<10;i++){if(borrowers[i].id==borrowerid){ a=i; flag=false; break; }}if(a==0)printf("\n您的借书证号出错.\n");if(borrowers[a].books==4) {printf("\n您已达最大借书量.\n");flag=true;}}printf("请输入图书编号:");scanf("%d",&bookid);printf("借书成功!!\n");printf("借书证号图书编号剩余借书量\n");printf("%d %d %d\n",borrowers[a].id,bookid,borrowers[a].books-1); }缺陷:1.当输入借书证号为非数值型时程序会陷入死循环2.当输入图书编号为非数值型时程序会异常退出5、程序5源代码如下所示:#include<stdio.h>int Search(int somearray[],int size,int value){for(int i=1;i<=size;i++){if(sonearray[i]==value)return i;}return -1;}void main(){int size=6;int value;int array[size]={5,8,-56,235,-65,449};do{printf(“请输入一个整数:”);scanf(“%d”,&value);}while(int(value)!=value);if(int(value)==value)Search(array,size+1,value);}程序存在错误:修改错误后程序依然无法输出,定义value直接退出程序【实验要求】1、实验前认真听讲,服从安排,独立思考并与小组成员合作完成实验。
01实验一--小信号调谐(单、双调谐)放大器实验

01实验一--小信号调谐(单、双调谐)放大器实验0实验一高频小信号调谐放大器实验、实验目的1.掌握小信号调谐放大器的基本工作原理;2.掌握谐振放大器电压增益、通频带、选择性的定义、测试及计算;3.了解高频小信号放大器动态范围的测试方法;、实验原理(一)单调谐放大器小信号谐振放大器是通信机接收端的前端电路,主要用于高频小信号或微弱信号的线性放大。
其实验单元电路如图1-1(a)所示。
该电路由晶体管Qi、选频回路Ti二部分组成。
它不仅对高频小信号进行放大,而且还有一定的选频作用。
本实验中输入信号的频率fs=12MHz。
基极偏置电阻W3、R22、R4和射极电阻R5决定晶体管的静态工作点。
可变电阻W3改变基极偏置电阻将改变晶体管的静态工作点,从而可以改变放大器的增益。
表征高频小信号调谐放大器的主要性能指标有谐振频率fo,谐振电压放大倍数Avo,放大器的通频带BW及选择性(通常用矩形系数Kro.1来表示)等。
放大器各项性能指标及测量方法如下:1.谐振频率放大器的调谐回路谐振时所对应的频率fo称为放大器的谐振频率,对1于图1-1(a)所示电路(也是以下各项指标所对应电路),fo的表达式为fo式中,L为调谐回路电感线圈的电感量;C为调谐回路的总电容,C的表达式为2电压放大倍数的电压放大倍数。
Avo的表达式为数,所以谐振时输出电压Vo与输入电压Vi相位差不是fe。
AV0的测量方法是:在谐振回路已处于谐振状态时,用高频电压表测量图1-1(a)中输出信号Vo及输入信号Vi的大小,则电压放大倍数AV0由下式计算:Avo=Vo/Vi或Avo=2Olg(Vo/Vi)dB3.通频带由于谐振回路的选频作用,当工作频率偏离谐振频率时,放大器的电压放大倍数下降,习惯上称电压放大倍数AV下降到谐振电压放大倍数AV0的0.707倍时所对应的频率偏移称为放大器的通频带BW,其表达式为CPjCoeP/Cie式中,Coe为晶体管的输出电容;Cie为晶体管的输入电容;线圈抽头系数;P2为次级线圈抽头系数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一词法分析
一、实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、词法分析器的功能
完成对源程序字符串的词法分析,输出形式是源程序的五类单词符号的二元式代码,并保存在文件中。
三、设计内容
选择以下三个任务之一,编写其词法分析程序。
1.初级任务
已知某语言标识符由小写字母、数字和下划线3种符号组成,起始字符为字母,结束符为字母或数字,且下划线字符两两不相连,对该标识符集,试写出描述它的正规式及DFA,编写识别它的程序。
分析:L=(a|b|c|......) D=(0|1|2 (9)
则描述带下划线的标识符集正规式为:L(L|D)*(_(L|D)+)*
DFA如下图(参考):
注:可用状态转换矩阵代替状态图,方便计算机处理。
标识符的识别程序设计如下:
Identifier()
{ char ch;
L0:getch(ch); //读单词的第一个字符
if(ch>=‟a‟&& ch<=‟z‟)
{L1:getch(ch);
If(ch>=‟a‟&& ch<=‟z‟|| ch>=‟0‟&& ch<=‟9‟)
Goto L1;
Elseif(ch==‟_‟)
Goto L2;
Else
Goto L3;
L2:getch(ch);
If(ch>=‟a‟&& ch<=‟z‟|| ch>=‟0‟&& ch<=‟9‟)
Goto L1;
Else return error;
}
Else return error;
L3:return Ok;
}
以上程序仅供参考,读者可自行设计。
2.中级任务
∑={d,. ,e,+,-},则∑上的正规式d*( . dd *∣ε )(e(+∣- ε∣)dd*ε∣) 表示的是无符号数的集合。
其中d为0~9的数字。
(详见课本P.53)
借鉴正规式到FA的转换规则(三条),试构造其自动机,然后确定化,需要时化简之,最后编写无符号数的识别程序。
实验预习提示
DFA的行为很容易用程序来模拟。
DFA M=(K,Σ,f,S,Z)的行为的模拟程序流程如下:
K:=S;
c:=getchar;
while c<>eof do
{K:=f(K,c);
c:=getchar;
};
if K is in Z then return (…yes‟)
else return (…no‟)
根据该流程提示以及得出的无符号数的状态转换矩阵,编写程序代码。
3. 高级任务
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)
实验预习提示
1)词法分析器的功能和输出格式
词法分析器的功能是输入源程序,输出单词符号。
词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
本实验中,采用的是一类符号一种别码的方式。
2)单词的BNF表示
<标识符>→<字母><字母数字串>
<字母数字串>→<字母><字母数字串>|<数字><字母数字串>|
<下划线><字母数字串>|ε
<无符号整数>→<数字><数字串>|ε
<数字串>→-<数字><数字串> |ε
<加法运算符>→+
<减法运算符>→-
<大于关系运算符>→>
<大于等于关系运算符>→>=
3)“超前搜索”方法
词法分析时,常常会用到超前搜索方法。
如当前待分析字符串为“a> -5”,当前字符为‟>‟,此时,分析器倒底是将其分析为大于关系运算符还是大于等于关系运算符呢?显然,只有知道下一个字符是什么才能下结论。
于是分析器读入下一个字符‟-‟,这时可知应将‟‟解释为大于运算符。
但此时,超前读了一个字符‟-‟,所以要回退一个字符,词法分析器才能正常运行。
在分析标识符,无符号整数等时也有类似情况。
4)模块结构
实验过程和指导:
1)准备
阅读课本有关章节,明确语言的语法,写出基本保留字、标识符、常数、运算符、分隔符和程序例。
初步编制好程序。
准备好多组测试数据。
将源代码拷贝到机上调试,发现错误,再修改完善。
2)程序要求
程序输入/输出示例:
如源程序为C语言。
输入如下一段:
main()
{
int a,b;
a = 10;
b = a + 20;
}
要求输出如右图。
(2,”main”)(5,”(“)(5,”)“)(5,”{“)(1,”int”)(2,”a”)(5,”,”)(2,”b”)(5,”;”)(2,”a”)(4,”=”)(3,”10”)(5,”;”)(2,”b”)(4,”=”)(2,”a”)(4,”+”)(3,”20”)(5,”;”)(5,”}“)
要求:
识别保留字:if、int、for、while、do、return、break、continue;
单词种别码为1。
其他的都识别为标识符;单词种别码为2。
常数为无符号整形数;单词种别码为3。
运算符包括:+、-、*、/、=、、<、=、<=、!= ;
单词种别码为4。
分隔符包括:,、;、{、}、(、);单词种别码为5。
•程序思路(仅供参考):
这里以开始定义的C语言子集的源程序作为词法分析程序的输入数据。
在词法分析中,自文件头开始扫描源程序字符,一旦发现符合“单词”定义的源程序字符串时,将它翻译成固定长度的单词内部表示,并查填适当的信息表。
经过词法分析后,源程序字符串(源程序的外部表示)被翻译成具有等长信息的单词串(源程序的内部表示),并产生两个表格:常数表和标识符表,它们分别包含了源程序中的所有常数和所有标识符。
∙定义部分:定义常量、变量、数据结构。
∙初始化:从文件将源程序全部输入到字符缓冲区中。
∙取单词前:去掉多余空白。
∙取单词后:去掉多余空白(可选)。
∙取单词:利用实验一的成果读出单词的每一个字符,组成单词,分析类型。
(关键是如何判断取单词结束?取到的单词是什么类型的单
词?)
∙显示结果。
•注意以下事情:
1.模块设计:将程序分成合理的多个模块(函数),每个模块做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
四、实验报告
编制并调试程序程序,运行通过后,书写实验报告,报告包括以下内容。
1.实验题目与要求
2.总的设计思想,及环境语言、工具等
3.数据结构与模块说明(功能与框图)
4.源程序(核心代码)
5.运行结果与运行情况
6.总结。