广工数据挖掘2015
数据挖掘名老中医治疗慢性肾功能衰竭的经验

30
13 丹参,黄罠,大黄 28
14 土茯苓,黄英
27
15 川茸,丹参
27
16 茯苓,泽泻
25
17 土茯苓,丹参
25
18 丹参,黄英,白术 25
19 生地黄,黄罠
25
2.7药物间关联度分析 基于改进的互信息法的药物间关联度分析,得关联系数
0.04以上的药对16对,见表5。
表5治疗慢性肾功能衰竭处方中药物间关联度分析(关联系数>0.04)
川茸,五灵脂, 蒲公英,
7
17 弄菜花
三棱,蒲黄炭,弄菜
川茸,土茯苓, 蒲黄炭,
8
18 弄菜花
茵陈, 蒲公英,蒲黄炭,弄
水蛭,般牡蛎, 肉桂,干
9 菜花
19
大黄炭,五味子,蒲公英, 10 蒲黄炭
表7治疗慢性肾功能衰竭处方中演化的5味药核心组合
序号
核心组合
— 川茸,大黄炭,三棱,蒲黄炭,弄菜花
2 川茸,大黄炭,蒲公英,蒲黄炭,莽菜花
9
茯苓皮,玉米须,茯苓,僵蚕,蝉蜕
10
猪苓,椒目,清半夏,熟大黄
11
猪苓,鳖甲,芦荟,骨碎补
13
山茱萸,肉桂,红花,熟地黄,山药,葛根
14
山茱萸,红花,炮姜,熟地黄,牡丹皮
15
车前草,大黄炭,三棱,五味子,蒲公英,蒲黄炭
16
荆芥,炒麦芽,槟榔,地榆,独活
3讨论
CRF属中医学“水肿”“癮闭”“关格”等范畴,病机复 杂,但多属本虚标实。名老中医多以活血化瘀、祛湿化浊、解 毒泄浊等为立法,临床疗效良好。数据挖掘结果表明本虚有脾 肾气虚、脾肾阳虚、气阴两虚等,主要涉及脾肾二脏。脾为 制水之脏,肾为主水之脏,脾肾既为先后天之本,治宜脾肾 双补,如《医宗必读》言:''夫人之虚,不属于气,即属于血, 五脏六腑,莫能外焉。而独举脾肾者,水为万物之元,土为万 物之母,二脏安和,一身皆治,百疾不生”。邪实多责之于瘀 血、湿浊、浊毒、湿热、风湿等,湿浊内蕴,浊毒瘀血互结, 气血雍滞,三焦气化失利,久之脾肾衰败、阴阳失调、变症丛 生。林韦翰等旳总结慢性肾衰竭名医经验文献,发现活血化 瘀的治法频次最高,为456次,与本研究结果一致。
6、数据挖掘随堂案例答案
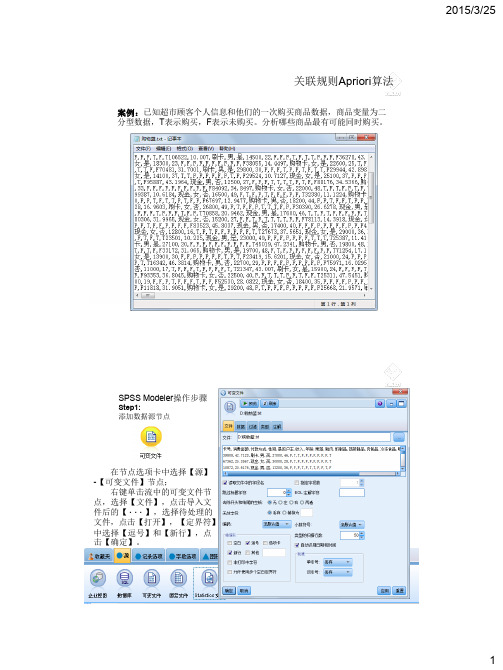
案例:已知超市顾客个人信息和他们的一次购买商品数据,商品变量为二分型数据,T 表示购买,F 表示未购买。
分析哪些商品最有可能同时购买。
关联规则Apriori 算法SPSS Modeler 操作步骤Step1:添加数据源节点在节点选项卡中选择【源】-【可变文件】节点;右键单击流中的可变文件节点,选择【文件】,点击导入文件后的【 · · · 】,选择待处理的文件,点击【打开】,【定界符】中选择【逗号】和【新行】,点击【确定】。
Step2:添加类型节点SPSS Modeler 操作步骤在节点选项卡中选择【字段选项】-【类型】节点;右键单击流中的类型节点,选择【编辑】,在【类型】选项卡下设置卡号、消费金额、付款方式、性别、是否户主、收入、年龄的【角色】为“无”果蔬、鲜肉、奶制品、蔬菜制品、肉制品、冷冻食品、啤酒、红酒、软饮料、鱼类、糖果的【角色】为“两者”,其他保持默认,点击【确定】。
Step3:添加Apriori 节点SPSS Modeler 操作步骤在节点选项卡中选择【建模】-【关联】-【 Apriori 】节点;右键单击流中的Apriori 节点,选择【编辑】,保持默认设置,点击【运行】。
Step4:运行Apriori 节点得到结果SPSS Modeler 操作步骤Apriori 结果节点会自动添加到工作流中。
右键点击(或双击) Apriori 结果节点会弹出聚类的具体信息。
点击显示\隐藏标准菜单(图中红色圈内的图标),可以根据需要自主选择显示规则、实例等内容。
本例产生了三条关联规则:啤酒和蔬菜制品→冷冻食品(前项支持度=16.7%,置信度=87.427%); 啤酒和冷冻食品→蔬菜制品(前项支持度=17.0%,置信度=85.882%); 冷冻食品和蔬菜制品→啤酒(前项支持度=17.3%,置信度=84.393%)。
同时,三条关联规则的提升度都可以接受。
因此,啤酒、冷冻食品和蔬菜制品是最可能连带销售的商品。
数据挖掘中的数据分类算法综述

分析Technology AnalysisI G I T C W 技术136DIGITCW2021.021 决策树分类算法1.1 C 4.5分类算法的简介及分析C4.5分类算法在我国是应用相对较早的分类算法之一,并且应用非常广泛,所以为了确保其能够满足在对规模相对较大的数据集进行处理的过程中有更好的实用性能,对C4.5分类算法也进行了相应的改进。
C4.5分类算法是假如设一个训练集为T ,在对这个训练集建造相应的决策树的过程中,则可以根据In-formation Gain 值选择合理的分裂节点,并且根据分裂节点的具体属性和标准,可以将训练集分为多个子级,然后分别用不同的字母代替,每一个字母中所含有的元组的类别一致。
而分裂节点就成为了整个决策树的叶子节点,因而将会停止再进行分裂过程,对于不满足训练集中要求条件的其他子集来说,仍然需要按照以上方法继续进行分裂,直到子集所有的元组都属于一个类别,停止分裂流程。
决策树分类算法与统计方法和神经网络分类算法相比较具备以下优点:首先,通过决策树分类算法进行分类,出现的分类规则相对较容易理解,并且在决策树中由于每一个分支都对应不同的分类规则,所以在最终进行分类的过程中,能够说出一个更加便于了解的规则集。
其次,在使用决策树分类算法对数据挖掘中的数据进行相应的分类过程中,与其他分类方法相比,速率更快,效率更高。
最后,决策树分类算法还具有较高的准确度,从而确保在分类的过程中能够提高工作效率和工作质量。
决策树分类算法与其他分类算法相比,虽然具备很多优点,但是也存在一定的缺点,其缺点主要体现在以下几个方面:首先,在进行决策树的构造过程中,由于需要对数据集进行多次的排序和扫描,因此导致在实际工作过程中工作量相对较大,从而可能会使分类算法出现较低能效的问题。
其次,在使用C4.5进行数据集分类的过程中,由于只是用于驻留于内存的数据集进行使用,所以当出现规模相对较大或者不在内存的程序及数据即时无法进行运行和使用,因此,C4.5决策树分类算法具备一定的局限性。
大数据分析与挖掘 实训1 基于时间序列的分仓商品预测

开篇讨论——农夫山泉如何大卖矿泉水?
城市 1 城市 5 城市 2
总仓
城市 4
需求 预测
城市 3
开篇讨论——农夫山泉如何大卖矿泉水?
天气
配送中 心辐射 半径
需求 变化
季节性 变化
甚至突 发性的 需求
开篇讨论——农夫山泉如何大卖矿泉水?
大幅度降低物流成本
地区供销平衡
开始实验
数据导入
是否 满足要求
否 是 数据预处理
大数据挖掘与分析流程
参数设置
大数据挖掘与分析工具——PMT(北京络捷斯特 开发)
时间序列
调整 参数
实验结束
问题解决——时间序列挖掘流程图
问题解决—数据探索分析
问题解决—数据探索分析
问题解决——预测结果
问题解决——预测结果
问题学习——知识点1-数据挖掘
直通车引 淘宝客引 聚划算引 直通车引 搜索引导 成交件数 成交人次 导浏览次 导浏览次 导浏览次 导浏览人 浏览次数 数 数 数 次 淘宝客引 聚划算引 搜索引导 非聚划算 非聚划算 非聚划算 非聚划算 导浏览人 导浏览人 浏览人次 支付笔数 支付金额 支付件数 支付人次 次 次
成交笔 数
问题解决——数据探索与数据挖掘
统计 学
数据 库
数据 挖掘
模式 识别
机器 学习
问题学习——知识点1-预测方法
统计理论模型
人工智能模型
时 间 序 列
卡 尔 曼 滤 波
线 性 回 归
非 参 数 回 归
历 史 平 均
神 经 网 络
支 持 向 量 机
模 糊 神 经 网 络
关联规则
2015上半年软考数据库系统工程师考试真题及答案解析

n n-1 2015 年上半年数据库系统工程师考试真题单项选择题(每题的四个选项中只有一个答案是正确的,请将正确的选项选择出来。
)1机器字长为n 位的二进制数可以用补码来表示()个不同的有符号定点小数。
A.2B.2C.2n-1D.2n-1 +12计算机中CPU对其访问速度最快的是()。
A.内存B.CacheC.通用寄存器D.硬盘3Cache的地址映像方式中,发生块冲突次数最小的是()。
A.全相联映像B.组相联映像C.直接映像D.无法确定的4计算机中CPU的中断响应时间指的是()的时间。
A.从发出中断请求到中断处理结束B.从中断处理开始到中断处理结束C.CPU分析判断中断请求D.从发出中断请求到开始进入中断处理程序总线宽度为32bit ,时钟频率为200MH,z 的带宽为()MB/S。
A.40B.80C.160D.2005若总线上每 5 个时钟周期传送一个32bit 的字,则该总线6以下关于指令流水线性能度量的描述中,错误的是()。
A.最大吞吐率取决于流水线中最慢一段所需的时间B.如果流水线出现断流,加速比会明显下降C.要使加速比和效率最大化应该对流水线各级采用相同的运行时间D.流水线采用异步控制会明显提高其性能7()协议在终端设备与远程站点之间建立安全连接。
A.ARPB.TelnetC.SSHD.WEP8安全需求可划分为物理线路安全、网络安全、系统安全和应用安全。
下面的安全需求中属于系统安全的是(),属于应用安全的是()。
A.机房安全B.入侵检测C.漏洞补丁管理D.数据库安全A.机房安全B.入侵检测C.漏洞补丁管理D.数据库安全9王某是某公司的软件设计师,每当软件开发完成后均按公司规定编写软件文档,并提交公司存档。
那么该软件文档的著作权()享有。
A.应由公司B.应由公司和王某共同C.应由王某D.除署名权以外,著作权的其他权利由王某10甲、乙两公司的软件设计师分别完成了相同的计算机程序发明,甲公司先于乙公司完成,乙公司先于甲公司使用。
2015秋浙江大学网络学院《数据挖掘》在线作业及答案

2015秋浙江大学网络学院《数据挖掘》在线作业及答案单选题1.置信度(confidence)是衡量兴趣度度量()的指标。
A 简洁性B 确定性C 实用性D 新颖性正确答案:B 单选题2.哪种OLAP操作可以让用户在更高的抽象层,更概化的审视数据?A 上卷B 下钻C 切块D 转轴正确答案:A 单选题3.下列几种数据挖掘功能中,()被广泛的用于购物篮分析。
A 关联分析B 分类和预测C 聚类分析D 演变分析正确答案:A 单选题4.下列哪个描述是正确的?A 分类和聚类都是有指导的学习B 分类和聚类都是无指导的学习C 分类是有指导的学习,聚类是无指导的学习D 分类是无指导的学习,聚类是有指导的学习正确答案:C单选题5.计算一个单位的平均工资,使用哪个中心趋势度量将得到最合理的结果?A 算术平均值B 截尾均值C 中位数D 众数正确答案:B 单选题6.规则:age(X,”19-25”) ∧buys(X, “popcorn”) => buys(X, “coke”)是一个()。
A 单维关联规则B 多维关联规则C 混合维关联规则D 不是一个关联规则正确答案:B 单选题7.假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是()。
A 关联分析B 分类和预测C 孤立点分析D 演变分析 E概念描述正确答案:E 单选题8.下面哪种数据预处理技术可以用来平滑数据,消除数据噪声?A 数据清理B 数据集成C 数据变换D 数据归约正确答案:A 单选题9.进行数据规范化的目的是()。
A 去掉数据中的噪声B 对数据进行汇总和聚集C 使用概念分层,用高层次概念替换低层次“原始”数据D 将属性按比例缩放,使之落入一个小的特定区间正确答案:D 单选题10.平均值函数avg()属于哪种类型的度量?A 分布的B 代数的C 整体的D 混合的正确答案:B 单选题11.下面哪种分类方法是属于统计学的分类方法?A 判定树归纳B 贝叶斯分类C 后向传播分类D 基于案例的推理正确答案:B 单选题12.下列几种数据挖掘功能中,()被广泛的用于购物篮分析。
数据挖掘期末考试题

11.将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( A. 频繁模式挖掘 B. 分类和预测 ) C. 数据预处理 D. 数据流挖掘
)
12. 决策树中不包含一下哪种结点(
A,根结点(root node) B,内部结点(internal node) C,外部结点(external node) D,叶结点(leaf node)
10.DBSCAN 是相对抗噪声的,并且能够处理任意形状和大小的簇。 ( )
课程代码: C0204413
题目 得分 阅卷教师
一 二 三 四 五 六
课程: 数据挖掘 A 卷
七 八 九 十 总成绩 复核
二、选择题(每题 2 分,30 分)
1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?( A. 关联规则发现 B. 聚类 ) B. 领域知识发现 C. 文档知识发现 D. 动态知识发现 C. 分类 D. 自然语言处理 )
分成四个箱。等频(等深)划分时,15 在第几个箱子内? ( A 第一个 B 第二个 )
) D 第四个
姓名:
C 第三个
班
4. 关于 OLAP 和 OLTP 的区别描述,不正确的是: (
2. 数据仓库中间层 OLAP 服务器只能采用关系型 OLAP
A. OLAP 主要是关于如何理解聚集的大量不同的数据.它与 OTAP 应用程序不同. B. 与 OLAP 应用程序不同,OLTP 应用程序包含大量相对简单的事务. C. OLAP 的特点在于事务量大,但事务内容比较简单且重复率高. D. OLAP 是以数据仓库为基础的,但其最终数据来源与 OLTP 一样均来自底层的数据库系统,两者面对的用户是相同的.
泰迪杯全国大学生数据挖掘竞赛试题

第三届泰迪杯全国大学生数据挖掘竞赛试题说明:1、参赛选手可从下述试题中任选一题作答,并在论文报告中标明2、论文等级会综合考虑论文质量和难度系数试题一基于电商平台家电设备的消费者需求及产品数据挖掘分析(难度系数:1.0)试题来源:背景:随着互联网与移动互联网的快速发展,截止2014年6月,我国的网民规模达6.32亿,互联网普及率为46.9%,2015年中国网民的渗透率将接近50%。
2014年天猫双十一的交易额达571亿,网上购物将成为人民生活的一部分。
网民在电商平台上浏览和购物,产生了海量的数据,如何利用好这些碎片化、非结构化的数据,将直接影响到企业产品在电商平台上的发展,也是大数据在实际企业经营中的应用。
对于用户在电商平台上留下的评论数据,运用文本分析方法,了解用户的需求、抱怨,购买原因以及产品的优点、缺点,对于改善家电设备产品及用户体验有着重要的意义。
据观研天下行业分析:近年来我国家电设备销量增长迅速,以电热水器为例,2011年电热水器市场销量比2010年增长2.29%,销售额增长5.23%;2013年热水器零售量达到2842万台,零售额达到459亿元,2014年热水器整体规模向上,但增速较2013年有所回落,零售量达到2985万台,零售额达到504亿元。
需求:1、分析用户对于热水器/净水器产品的个性化需求;2、分析现有电商热水器/净水器的产品劣势(用户抱怨点)及产品优势(用户赞点);3、分析各品牌的产品间的差异,进行差异化卖点提炼;4、分析用户购买的原因;5、对用户的购买行为进行分析挖掘(搜索关键字、购买时关注点、购买步骤、使用、评价)(此部分可选择来做)。
提示:1、在电商平台进行评论数据抓取(可用火车头采集器进行评论爬虫);2、对评论数据进行预处理(处理掉水军及随意发表的评论数据);3、可分品类进行细化分析(热水器:电热热水器、燃气热水器;净水器:净水机、纯水机);4、对评论数据进行文本分析(好评、差评、中文分词、词频统计、情感分析、语义网络);5、可利用百度指数、淘宝指数等互联网工具对热水器和净水器的消费人群及搜索关注点进行分析;6、建议在国内外相关文献的基础上尽量选择新技术手段进行挖掘,比如基于深度学习理论模型完成情感分析,参见文献:《基于深度学习的微博情感分析》、《基于深度学习的文本情感分类研究》等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程名称:数据挖掘试卷满分100分
考试时间: 2015年6月19日(第周星期)
题号
一
二
三
四
五
六
七
八
九
十
总分
评卷得分
评卷签名
复核得分
复核签名
1。(10分)计算{2,9,7,6,20,100,35,21,11}的均值,中位数和p=40%的截断均值,并且简单说明三种不同的均值在反映数据中心方面有什么特点?
4。(10分)某学校对入学的新生进行性格问卷调查,没有心理学家的参与,根据学生对问题的回答,把学生的性格分成了8个类别。请说明该数据挖掘任务是属于分类任务还是聚类任务?为什么?并利用该例说明聚类分析和分类分析的异同点。
5.(12分)假设描述学生的信息包含属性:性别,籍贯,年龄。有两条记录p,q和C1,C2的信息如下,分别求出记录和簇彼此之间的距离。
p={男,广州,18},q={女,韶关,20}
C1={男:25,女:5;广州:20,深圳:6,韶关:4;20}
C2={男:3,女:12;汕头:12,深圳:1,韶关:2;24}
,ቤተ መጻሕፍቲ ባይዱ
6.(12分)请举例说明什么是关联数据挖掘任务?
7.(12分)新闻报道说,有科学家根据当前通行的血液检查的指标,来预测一个人五年后得老年痴呆病的情况。假设需要你重复该实验,并且可以通过血液检查的指标来做出预测,请你说明从采集数据到建立模型的大概步骤,以及可能使用的算法。
2。(10分)有如下的数据:{2,4,5,6,11,13,21,22,24,26,28,40},使用深度为4的分箱方法进行数据平滑,分别使用箱平均值,中值和边界值进行平滑,请写出平滑后的结果。并说明分箱方法的用途是什么?
3.(10分)请说明在数据预处理的时候,可以发现并清除噪音数据吗?对噪音数据一般有哪些处理方法?
2
D,O,N,K,E,Y
3
M,A,K,E
4
M,U,C,K,Y
5
C,O,K,I,E
6
Y,M,K,O
8.(12分)如下表所示:
A
B
C
类
0
0
0
+
0
0
1
-
0
1
1
-
0
1
1
-
0
0
1
+
1
0
1
+
1
0
1
-
1
0
1
-
1
1
1
+
1
0
1
+
用K-最近邻算法(使用曼哈顿距离),预测样本(A=0,B=1,C=1)的类标号是什么?
9.(12分)画出如下数据的FP树,并按支持度阈值是2找到频繁项集。
序号
事务
1
M,O,N,K,E,Y