R命令参考卡片中文版
R语言 命令

基本一、数据管理vector:向量 numeric:数值型向量 logical:逻辑型向量character;字符型向量 list:列表data.frame:数据框c:连接为向量或列表 length:求长度 subset:求子集seq,from:to,sequence:等差序列rep:重复 NA:缺失值 NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性 mode,typeof:对象存储模式与类型names:对象的名属性二、字符串处理character:字符型向量nchar:字符数substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子 codes:因子的编码 levels:因子的各水平的名字nlevels:因子的水平个数 cut:把数值型对象分区间转换为因子table:交叉频数表 split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值 range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组 matrix:生成矩阵data.matrix:把数据框转换为数值型矩阵lower.tri:矩阵的下三角部分mat.or.vec:生成矩阵或向量t:矩阵转置cbind:把列合并为矩阵rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置nrow, ncol:计算数组的行数和列数dim:对象的维向量dimnames:对象的维名row/colnames:行名或列名 %*%:矩阵乘法crossprod:矩阵交叉乘积(内积) outer:数组外积kronecker:数组的Kronecker 积 apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数 sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量 scale:矩阵标准化matplot:对矩阵各列绘图cor:相关阵或协差阵Contrast:对照矩阵 row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算,=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量 all,any:逻辑向量都为真或存在真ifelse():二者择一 match,%in%:查找unique:找出互不相同的元素 which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
R命令

length(x)针对向量返回长度,针对列表或者数据框返回维数dim(x)//显示x的维度str(x)//显示x的结构class(x)//x的对象类型mode(x)//对象模式names(x)//对象中各成分的名称head(x)//显示x的开始部分tail(x)//显示x的最后部分edit(x)/fix(x)//编辑xoptions()//全局选项设定,如options(digits=3)将小数位数设为3q() //退出mean,sum中的na.rm=T参数表示移除缺失值,mean参数trim取值在0.1~0.5表示去除距离均值较大的异常值的比例Sys.getenv(“HADOOP_CMD”)//获取环境Sys.setenv(“HADOOP_CMD”=”/usr/local/hadoop/bin/hadoop”)//设置环境安装Rhadoop时R或者Rstudio最好在sudosu后执行,不然总是很多问题,不要sudoR 这样来做,要么R要么sudosu后Rlevels(x)//查看x的水平mean(x)//求平均数dimnames(x,list(c('a','b','c'))list是列表,列与列之间类型可以不同,选中i列采用x=[[i]],这样就可以把那一列选中向量中追加元素:a=c(a,10),a[length(a)+1]=10weighted.mean(x,w...)加权平均,权值是与x长度相同的w向量sort(x)后各数据按有序排列,order向量的元素表示排序后该下标处的元素对应原向量的哪个位置,rank向量的元素表示相应下标处原向量的元素排序后的位置。
例:a=c(55,66,57,60,62,780)sort(a) 5557 60 62 66 780order(a) 13 4 5 2 6 7 8 该处3表示排序后处于下标2处的元素是57rank(a) 15 2 3 4 6 7 8该处5表示66排序后在下标5处sort()参数partial是指定排序的部分下标向量,methods指定排序方式…shell‟(默认)…quick‟,index.return=T返回一个列表第一个变量是排序顺序,第二个变量是排序的值(该下标处元素在原向量中的位置,等同于order(x)),decreasing指定顺序例:找到值在50和90之间元素在原向量的下标号order(x)[sort(x)>50&sort(x)<90] sort(x)>50返回一个逻辑向量match(subset(x,x>50&x<90),x) which(x>50&x<90)x[order(x[,2],decreasing=T),]针对矩阵x的第二列降序排序并得到排序后的矩阵median(x)缺省不能处理带缺失值的数据(na.rm=F),注:很多函数默认不能处理缺失值quantile(x,c(.25,.6),na.rm=T)偏度系数刻画数据对称性指标,若数据关于均值对称则该系数为0,右侧更分散则为正,否则为负中心矩u峰度系数:正态分布为0,较整体分布时尾部分散数据较多为正(两侧极端数据更多),否则为负在给定数据均值和方差的情形下(这里仅针对正态分布),它们均返回数值向量:dnorm(x,mean,sd)密度函数,参数指定一个数值型向量,返回拟合数据的密度函数(数值向量)pnorm分布函数,参数指定一个数值型向量,返回拟合数据的分布函数qnorm分位函数,参数指定概率向量,返回各个概率对应的分位数rnorm随机函数,指定一个生成数目,返回随机数向量有参数lower.tail=F时分布函数的计算方式和正常的反向与此组函数相似的有:dunif,punif,qunif,runif它们指定在某个区间的正态数据直方图:给定组距的情况下,考察数据落入各区间的频数或频率hist(x,breaks,col)参数x是样本数据,breaks是组数(具体形式有:向量(起点,终点,组距),数值(组距),函数(组距)),col填充颜色问:只画出样本数据中指定范围内的条形统计图?hist(x[x>2&x<10])density(x)核密度函数,用样本数据估计密度函数 eg.plot(density(x))问:参数bw?eg. hist(xwfreq=F)#禁用频数,否则纵坐标不在0-1之间lines(density(w),col='red')x=x1:x2#这里值得注意下lines(x,dnorm(x,mean(w),sd(w)),col='blue')注:实践中反复出现的一个问题是画密度分布函数时纵坐标要在0-1之间ecdf(x)估计总体分布函数eg. plot(ecdf(x),verticals=T,do.p=F);lines(x,pnorm(x,mean(x),sd(x))参数verticals表示画竖线,do.p画点与否plot(data.frame$a~data.frame$b)==plot(~data.frame$b+data.frame$a)plot(data.frame)==pairs(data.frame)coplot(a~b|c)在给定因子或变量c下,作a关于b的散点图(处理多变量)dotchart(x...)画x的点图,y轴x的标记,x轴为x的数值image()绘出三维图像的影响contour(x,y,z)绘出三维图像的等值线persp(x,y,z)绘出三维图形的表面曲线注:z不是简单的冠以xy的运算,而是需要在函数f下作外积运算outer(x,y,f)形成网格才能绘出三维图形高级绘图命令:add=T表示在原图增加新元素,默认是替换原图F(增加低级绘图指令)axes=F表示不加坐标轴,默认为Tlog=‟xy‟表示对xy轴均取对数type=‟b‟绘图类型p散点图,l实线,b所有点被实线连接,o实线通过所有点,h绘出点到x轴的实线,s阶梯形曲线,n不绘(可以先采用n绘出一个图形边界,然后在上面绘图)低水平作图函数:points(x,y)加点lines(x,y)==plot(x,y,type=‟l‟)加直线text(x,y,labels)对数据集xy加文本labels(字符串,默认是1:length(x))abline()增加直线,四种格式:ablie(a,b)/y=a+bx,abline(h=y/0)过所有点的水平直线ablien(v=0)画竖线,abline(线性拟合结果对象)ploygon(x,y)以xy为点画出多边形在图上加文字标题或其它内容title(main=‟‟,sub=‟‟)图上增加标题axis(side=1/2/3/4)将坐标值置于图形的下左上右正态性检验:QQ图帮助我们鉴别样本的分布是否近似于某种分布,若正态QQ图上的点近似在一条直线附近(该直线斜率是标准差,截距是均值),则可认为样本来自一个正态分布总体。
R语言 mgcv包 gam()函数中文帮助文档(中英文对照)

Generalized additive models with integrated smoothness estimation广义加性模型与集成的平滑估计描述----------Description----------Fits a generalized additive model (GAM) to data, the term "GAM" being taken to include any quadratically penalized GLM. The degree of smoothness of model terms is estimated as part of fitting. gam can also fit any GLM subject to multiple quadratic penalties (including estimation of degree of penalization). Isotropic or scale invariant smooths of any number of variables are available as model terms, as are linear functionals of such smooths; confidence/credible intervals are readily available for any quantity predicted using a fitted model; gam is extendable: users can add smooths.适合一个广义相加模型(GAM)的数据,“GAM”被视为包括任何二次处罚GLM。
模型计算的平滑度估计作为拟合的一部分。
gam也可以适用于任何GLM多个二次处罚(包括估计程度的处罚)。
各向同性或规模不变平滑的任意数量的变量的模型计算,这样的线性泛函平滑的信心/可信区间都是现成的使用拟合模型预测任何数量,“gam是可扩展的:用户可以添加平滑。
r语言可视化手册第二版

r语言可视化手册第二版R语言作为一种强大的统计分析工具和编程语言,其具备灵活性和可扩展性,使得它成为数据分析领域的热门选择。
在R语言中,可视化是一种重要的手段,能够帮助用户更好地理解数据,发现规律,并有效地传达分析结果。
本文为您介绍R语言可视化手册第二版,通过详细的案例和示范,帮助您快速掌握R语言可视化的技巧和方法。
第一章:R语言可视化概述在本章中,我们将简要介绍R语言可视化的重要性和作用,以及本手册的内容安排。
同时,我们还将讨论R语言可视化的基本原理和常用的图形类型。
第二章:基础图形绘制本章将详细介绍R语言中基础图形的绘制方法,包括散点图、折线图、柱状图等。
我们将通过实际的案例演示如何使用R语言命令进行图形绘制,并介绍各种图形的参数调整方法,以及图形风格的设定。
第三章:高级图形绘制在本章中,我们将深入探讨R语言中一些高级图形的绘制方法,如箱线图、热力图、雷达图等。
我们将详细介绍每种图形的特点和用途,并通过实际例子演示如何使用R语言命令进行绘制。
第四章:数据可视化与交互式图形本章将介绍R语言中数据可视化和交互式图形的方法和应用。
我们将讨论如何使用R语言的DataFrame对象进行数据可视化,并介绍一些常用的交互式图形库,如ggplot2和Plotly。
第五章:地理数据可视化在这一章中,我们将介绍如何利用R语言进行地理数据的可视化分析。
我们将讨论如何在地图上绘制各种地理图形,并介绍一些R语言中常用的地理信息处理包,如ggmap和leaflet。
第六章:动态可视化本章将重点介绍如何使用R语言进行动态可视化的方法。
我们将详细讨论如何创建动态图形和动画,并介绍一些常用的动态可视化包,如gganimate和plotly。
第七章:报告和演示文档在这一章中,我们将介绍如何使用R语言生成报告和演示文档。
我们将讨论如何使用R Markdown和knitr包来创建可交互的报告和演示文档,并介绍一些常用的演示文档生成工具,如Shiny。
R命令

AutoCAD 2011命令速查手册
RENDERCROP
渲染视口内指定的矩形区域(称为修剪窗口)。 访问方法
按钮 功能区:“渲染”选项卡 “渲染”面板 “渲染面域”
概要 渲染视口中指定矩形区域内的内容,而保留渲染窗口的其他部分不变。 在需要渲染模型的某一部分以测试设置和效果时使用此命令。 命令行提示 将显示以下提示:
命令行提示 将显示以下提示:
选择参照:在当前图形中选择一个外部参照或块 如果在功能区处于激活状态时编辑外部参照,则将显示“编辑参照”功能区上下文选项卡。 如果在命令提示下输入-refedit,则将显示选项。
REFSET
在位编辑参照(外部参照或块定义)时从工作集添加或删除对象。
访问方法 464
R命令
REDRAW
刷新当前视口中的显示。 访问方法
命令条目:'redraw 用于透明使用 概要 当 BLIPMODE 打开时,将从当前视口中删除编辑命令留下的点标记。
REDRAWALL
刷新所有视口中的显示。 访问方法
菜单:“视图” “重画” 命令条目:'redrawall 用于透明使用 概要 当 BLIPMODE 打开时,将从所有视口中删除编辑命令留下的点标记。
菜单:“工具” “外部参照和块在位编辑” “添加到工作集或外部参照和块在位编辑” “从工 作集删除”
概要 作为工作集组成部分的对象与当前图形中的其他对象明显不同。在当前图形中,工作集以外的 所有对象都将呈淡入显示。
命令行提示 将显示以下提示:
在参照编辑工作集和宿主图形之间传输对象... 输入选项[添加(A)/删除(R)]<添加>:输入选项或按 Enter 键
另一个角点 使用指定的点作为对角点创建矩形。
R语言基本命令

R语言基本命令1.> mean(X1) 均值2.>sd(X1) 标准差var(x)方差median(x)中位数3.>plot() 体重和数据的散点图lines()用线连接,get_dist()热量图4.在读取R文件时,文件路径出错,使用getwd()和setwd()两种命令来查询和修改R语言的工作空间5.载入工作空间> load("MyWorkSpace.RData")6.保存工作空间> save.image("MyWorkSpace.RData")7.列出全部变量名>ls()8. %/%表示整数除法,%%表示求余数9. range(x)表示范围10. which.min(x)在第几个位置取到最大值11. seq()等间隔函数12. rep() 重复函数13. is.na()检测缺失数据的函数14. is.nan()检测数据是否不确定15. is.finite()检测数据是否有限), is.infinite()检测数据是否无穷16. paste()可以把字符向量变成字符串17.x[v]取出所有v为真值的数18.读文件表rd <- read.delim("C:/R语言工作空间/文件名”)19.table()可以看出良性和阴性的个数20. M = matrix(0,c(m,n))#生成m行n列的0矩阵。
21. M = rbind(X,Y)#按行合并矩阵X和Y形成新矩阵M。
(X和Y列数需相同)22. M = cbind(X,Y)#按列合并矩阵X和Y形成新矩阵M。
(X和Y行数需相同)23. colnames(M)#矩阵M的列名。
24. rownames(M)#矩阵M的行名。
25. nrow(M)#矩阵M的行数。
26. ncol(M)#矩阵M的列数。
27.diag(M)#矩阵M的对角线元素形成的向量28.M = diag(x)#生成以向量x为对角线元素,其他位置元素为0的矩阵M。
Scratch参考指南简体中文版

Scratch参考指南简体中文版译者言在一个偶然的机会下,我发现了Scratch,一个由MIT(麻省理工学院)开发的一套开源的,为儿童准备的编程环境。
它不需要你写任何编码,只要使用鼠标拖拽事先为你准备好的部件就可以组成游戏,卡通和动画。
就象小孩玩积木一样简单而有趣。
我使用过KPL(Kids Program Language)和微软的SmallBasic,也是为儿童准备的,跟专业的编程语言相比他们的确很简单。
但由于还是需要手动编码,也许并不适合8-16岁的孩子,特别的,他们不适合作为入门语言。
而Scratch则没有问题。
和其它一些儿童编程语言相比Scratch更加直观,简单,不需要孩子记住那些难记的单词和代码。
以我多年的编程经验来看,Scratch作为儿童的入门语言最好不过了。
儿童的最爱的就是玩。
玩游戏,卡通,动画等。
而Scratch紧紧围绕这个中心,让孩子设计自己的游戏,卡通,动画。
虽然Scratch编程同专业的编程语言还有一些区别,但其基本概念如坐标,方向,逻辑运算,条件,循环,事件等等都是一样的。
学好Scratch对于孩子以后学习专业级(企业级)的语言(如C,C++,java,C#.net等)是非常有帮助的。
本文版权归译者所有,你可以出于个人目的自由的使用,传播它。
但不允许用在商业用途上(如出版,印刷等)。
由于本人英文实现很抱歉。
在根据以往经验并借助词典的情况下,才勉强将该文件翻译完成。
其中错误一定不少。
如果你发现其中的错误或有什么建议,请发email告诉我(******************)。
如果你想了解作者或者Scratch的最新状态,请访问:http: ///Scratch下载地址:/ScratchInstaller1.4.exeScratch官网地址: 1.概述Scratch是一种新的编程语言,它使得制作动画,游戏,卡通变得更加容易,并且你可以在网络上共享你的作品。
本参考指南会介绍Scratch的方方面面。
R基本命令

因为是考R命令,建议大家敲一下这些命令,理解的更容易一些,而且也方便以后使用。
R基本命令:R赋值:=和<-和->查看当前环境变量ls() 删除变量rm() 查看和导入R中的预存数据data()eg.删除所有对象rm(list=ls()),删除变量x和y:rm(x,y)测试运行时间:system.time()获取帮助:(eg.solve函数):①?solve②help(solve)③example(solve)加载R文件:source(“one.r”)sink函数:sink(“a.r”) 输出流定向到a.r里,sink()重新将输出流定向到控制台常用函数:log2(),log10(),幂exp(),平方sqrt()…R基本数据结构R的基本数据结构:向量(最重要的对象)、矩阵、数组、数据框、因子、列表构建向量:x<-c(1,2,3,4,5)等价于c(1:5)->x等价于assign("x", c(1,2,3,4,5))等价于x<-seq(1,5,length=5)表示构建从1到5 的长度为5的等差数列z<-c(8,6,4,2)等价于z<-c(2*4:1)等价于z<-seq(8,2,length=4)y<-c(x,0,x) 创建11个元素的y向量。
向量的运算:每一个元素都可以进行相应的运算,且长度可以不同。
v <- 2*x + y + 1产生长度为11的向量v,它由2*x重复2.2次,y重复一次,1重复11次得到的向量相加而成。
常用函数(针对向量):均值mean()、方差var()、最大值max()、最小值min()长度length(), 累积乘积prod(),升序排序sort()、最大最小值range()。
unique()可去重复其他函数:s5 <- rep(x, times=5)将x拷贝5次放到s5中is.na(x)返回一个逻辑向量,表示x中是否是NA(not available),若是NA则返回TRUE类似的有is.nan(x)判断是否为NaN(NaN表示数据不可利用,如0/0)is.null(x)判断对象x是否为空,is.infinite判断x的元素是否为Inf(无穷)构建字符向量:x<-c(“Hello”,”World”)等价于x=c(‘Hello’,’World’)等价于x<-paste(c(‘Hello’,’World’)) paste()函数将参数一个接一个按照分隔符连接:如paste(c("chr"),c(1:22,’X’,’Y’),sep="")返回chr1,chr2直到chrY.索引向量:在向量x的方括号中加入索引变量可获得x的子集eg. x[is.infinite(x)]<- -1将x中为无穷的数全部替换成-1x[c(3,1,5,1,2,3)] 取x的第3,1,5,1,2,3个元素,x[1:5]取x前5个元素。
R语言常见命令

R语⾔常见命令1. 获取帮助> help.start() 开启帮助⽂档>help(solve) 显⽰某命令的帮助信息,或者>?solve对于由特殊字符指定的功能,这些参数必须⽤单引号或双引号括起来,使之成为⼀个“字符串”,如> help("[[")与某个主题相关的例⼦通常可以⽤下⾯的命令得到> example(topic)2. 命令简介R对⼤⼩写是敏感的;名称不能以数字开始;基本的命令由表达式或者赋值语句组成。
如果⼀个表达式被作为⼀条命令给出,它将被求值、打印⽽表达式的值并不被保存。
⼀个赋值语句同样对表达式求值之后把表达式的值传给⼀个变量,不过并不会⾃动的被打印出来;命令由分号(;)来分隔,或者另起新⾏;基本命令可以由花括号(f和g)合并为⼀组复合表达式;注释⼏乎可以被放在任何地⽅,只要是以井号( # )开始,到⾏末结束;如果⼀个命令在⾏莫仍没有结束,R将会给出⼀个不同的提⽰符,默认的是‘+’。
3. 命令⽂件的执⾏和输出转向到⽂件如果命令存储于⼀个外部⽂件xx,⽐如⼯作⽬录workxx的commands.R,他们可以随时在R的任务xx被执⾏> source("commands.R")在WindowsxxSource也可以由File菜单执⾏。
函数sink,> sink("record.lis")将把所有后续的输出由终端转向⼀个外部⽂件,record.lis。
命令> sink() 将把信息重新恢复到终端上。
4. 数据的保持与对象的清除R所创建、操作的实体是对象。
对象可以是变量、数组、字符串、函数以及由这些元素组成的其它结构;> objects()⽤来显⽰⽬前存储在R中的对象的名字。
⽽当前存储的所有对象的组合被称为workspace;清除对象可以使⽤rm命令:> rm(x, y, z, ink, junk, temp, foo, bar)所有在⼀个R任务中被创建的对象都可以在⽂件中被永久保存,并在其它的R任务中被使⽤。
R语言入门基础教程

向量(vector)1、seq():产生有规律的数列,间距省略时默认值为1。
例1:seq(10, 20, 0.5)例2:seq(0, by = 0.03, length = 15)2、rep():产生有规律的数列,重复第一个变量若干次。
例1:rep(1:3, 1:3)例2:rep(1:3, rep(2, 3))例3:rep(1:3, length = 10)3、向量运算:一般是对应元素之间的运算,所以两个或多个向量运算时,要求它们包含的元素个素相同(或一个是另一个的整数倍)。
例1:a <- 1:3; b <- 4:6; a * b; b^a例2:a <- 1:3; b <- 4:9; a * b; b^a4、获取向量某一个或多个子集,向量前的负号"-"表示去除相应内容。
例1:x <- c(3, 4, 5, 2, 6); x[1:2]; x[-(1:2)]例2:x <- c(3, 4, 5, 2, 6); x[c(1, 2, 4, 1)]; x[-c(1, 2, 4, 1)]例3:xx <- seq(1, by = 3, length = 10); xx[xx > 13]例4:x <- 1:20; y <--9:11; x[y > (1)] #注意最后一个是"NA"5、主要向量运算函数。
例1:xx <- c(2, 6, 10, 8, 4)sum(xx) #和max(xx) #最大值min(xx) #最小值range(xx) #取值范围mean(xx) #平均值var(xx) #方差sort(xx) #从小到大排序rev(xx) #反排列,所以从大到小排序应该是rev(sort(xx))rank(xx) #单元值大小顺序prod(xx) #乘积,所以阶乘是prod(1:n)例2:x <- seq(1, 15, 2)append(x, 20:30, after = 5) #插入数据append(x, 20:30) #参数after缺省默认从向量的最后插入值replace(x, c(2, 4, 6), -1) #替换函数例3:match(c('Ohio', 'Wyoming'), ) #完全匹配函数pmatch(c('Oh', 'Wy'), ) #部分匹配函数[pmatch(c('Oh', 'Wy'), )]例4:yy <--9:10all(yy > 0) #判断所有all(yy > -10)any(yy == 0) #判断部分any(yy > 0)any(yy < -10)矩阵(matrix)矩阵生成函数matrix():matrix(data, nrow = , ncol = , byrow = F),其中,数据data 是必须的,其他都是选择参数,可以不选。
R 绘图中文(谢益辉)

文库帮手网 免费帮下载百度文库积分资料本文由for_si贡献pdf文档可能在WAP端浏览体验不佳。
建议您优先选择TXT,或下载源文件到本机查看。
现代统计图形谢益辉 2010 年 8 月 13 日版权声明本书电子版采用Creative Commons(简称CC)许可证“署名—非商业性使用—相同方式共享 2.5 中国大陆”,该许可证的全文可以从http:// /licenses/by-nc-sa/2.5/cn/获得;一份普通人可以理解的法律文本概要可以从/licenses/ by-nc-sa/2.5/cn/legalcode获得。
责任权利本CC许可证赋予读者复制、发行、展览、表演、放映、广播或通过信息网络传播本作品以及创作演绎作品的自由,而无需向原作者征求许可或支付任何费用;本许可证与出版社版权独立,因此复制、传播或演绎本作品也无须征求出版社许可。
您需要遵循的条件是: ? 声明原作者的署名(Attribution):不得将本作品归为自己的劳动 ? 不得将本作品用于商业目的(Noncommercial) ? 基于本作品的演绎作品须遵守同样许可证发布(Share Alike)作者采用CC许可证的考虑主要有三点: ? 让读者能免费、自由获得本书,节省经济支出;在有网络和电子文档的时代,我们应该充分利用这些工具的优势,如传播快捷、读者交流反馈方便(以便提高书籍质量)等 ? 版权的本来意义不在于控制所有权,它只不过是为了对原创者的一种署名激励;如果版权的存在妨碍了知识的传播,那么本人认为版权就没有太大的意义;CC许可证中的“非商业”和“同样许可证”限制条款在书籍出版14年后会自动取消,即读者可以用于商业目的或更改至其它许可证;CC许可证规定的14年似乎是很长的时间,但读者须知:通常的版权只有在原作者去世后50年才会被取消!换句话说,版权告诉我们一个很深刻的哲理:长寿是很重要的自由软件用户往往有某种痴狂的特征,而这种痴狂往往来源于自由软件的分享精神;R 语言让本人受益颇多,这本书可视作是对它的一种回馈;既然R语言是自由的,那么本书也将尽量“自由”特别声明尽管CC许可证没有限制作品的传播方式,但本作者不愿看到本书被任何人以论坛附件的方式发布在任何论坛,原因是本书稿尚未成熟,或许有诸多不完善之处甚至严重错误,作者在不断更新中,若要传播本书稿给他人,请仅仅给出本书的原始链接/cn/publication/,否则作者对传播过程中的错误概不负责。
R命令参考卡片中文版

), ;
,
sample(x, size) replace = TRUE prop.table(x,margin=) margin ,
x margin 1
size
, ,
pmin(x,y,...) x[i], y[i] , pmax(x,y,...) . cumsum(x) x , x[i]=sum{ x[1]: x[i]} cumprod(x) . cummin(x) . cummax(x) . union(x,y) x ∪ y − x ∩ y intersect(x,y) x ∩ y setdiff(x,y) x − x ∩ y setequal(x,y) x, y ( x, y is.element(el,set) x %in% y Re(x) Im(x) Mod(x) ( ); abs(x) Arg(x) (in radians) Conj(x) x convolve(x,y) fft(x) (array) mvfft(x) filter(x,filter) na.rm=FALSE t(x) diag(x) %*% solve(a,b) a %*% x = b x solve(a) eigen(x) rowsum(x) ; rowSums(x) colsum(x), colSums(x) . rowMeans(x) colMeans(x) dist(x) x apply(X,INDEX,FUN=) , lapply(X,FUN) FUN tapply(X,INDEX,FUN=) FUN sapply lapply, by(data,INDEX,FUN) merge(a,b) xtabs(a b,data=x) aggregate(x,by,FUN) , stack(x, ...) unstack(x, ...) stack() reshape(x, ...) ‘wide’ ‘wide’ (direction=“long”) (INDEX) X x (INDEX) FUN
R语言入门经典中文版

R for BeginnersChinese Edition2.0Emmanuel ParadisInstitut des Sciences de l’´EvolutionUniversit´e Montpellier IIF-34095Montpellier c´e dex05FranceE-mail:paradis@isem.univ-montp2.frCo-translated by:XF Wang,YH Xie,JT Li and GH Ding中文版说明“R for beginners”是一本公认的经典手册,非常适合R的初学者。
英文原版初著于2002年,而此稿是基于作者在2005年重新修订的第二版。
Emmanuel Paradis博士为本稿提供了原版所有L A T E X源文件。
翻译工作由四名志愿者共同完成(Chap1–2:王学枫;Chap3:谢益辉;Chap4:李军焘;Chap5–7:丁国徽)。
由华东师范大学汤银才老师负责本文档的编辑校订。
北京大学李东风老师审阅了全稿并提出了大量宝贵意见。
在此一并表示衷心感谢!编译仓促,差错难免,亟盼诸R友襄正。
任何意见请通过pwxf@ 联系我们。
译者2006年4月版权c 2002,2005,Emmanuel ParadisPermission is granted to make and distribute copies,either in part or in full and in any language,of this document on any support provided the above copyright notice is included in all copies.Permission is granted to translate this document,either in part or in full,in any language provided the above copyright notice is included.目录1导言12基本原理与概念32.1基本原理 (3) (5)2.3在线帮助 (7)3R的数据操作93.1对象 (9) (11)3.3存储数据 (14)3.4生成数据 (15)3.4.1规则序列 (15)3.4.2随机序列 (18) (19)3.5.1创建对象 (19)3.5.2对象的类型转换 (24) (26)3.5.4访问一个对象的数值:下标系统 (27)3.5.5访问对象的名称 (30) (32)3.5.7数学运算和一些简单的函数 (32) (34)4R绘图374.1管理绘图 (37)4.1.1打开多个绘图设备 (37)4.1.2图形的分割 (38)4.2绘图函数 (41)4.3低级绘图命令 (42) (44)4.5一个实例 (45)4.6grid和lattice包 (49)5R的统计分析565.1关于方差分析的一个简单例子 (56)5.2公式 (58)5.3泛型函数 (59) (62)6R编程实践656.1循环和向量化 (65)6.2用R写程序 (67) (68)7R相关的文献721导言该手册是关于R的一个入门教材.由于主要针对初学者,我将重点放在了对R的工作原理的解释上。
R语言_第一章

形参实参作用域就不多说了。
R语言默认参数这样定义:
>g<-function(x,y=2,z=T){...} #有歧义时 TURE和FALSE不能在缩写为首字母
调用时,可以使用默认值,也可以用新值覆 盖。
>g(12,z=FALSE) #x=12,y=2,z=FALSE
1.4 R语言中的数据结构
向量:可以是字符模式(用mode函数调 用可显示向量模式),也可以是数值模式, 但不可以混合。 字符串:字符模式的单元素向量。有些函 数可以把字符串连接或拆开(如paste和 strsplit)
> u=paste("abc","de") >u [1] "abc de" > v=strsplit(u,"") >v [[1]] [1] "a" "b" "c" " " "d" "e" > v=strsplit(u) 错误于as.character(split) : 缺少'split' > v=strsplit(u,",") >v [[1]] [1] "abc de" > v=strsplit(u," ") >v [[1]] [1] "abc" "de"
1.6 获取帮助
在线帮助的语法为
> help(seq) starting httpd help server ... Done 或者 > ?seq 特殊字符要用引号 同事,R还提供了example()函数来提供例子代码。 > example(seq) seq> seq(0, 1, length.out=11) [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ……
★RStudio学习手册(中文翻译)
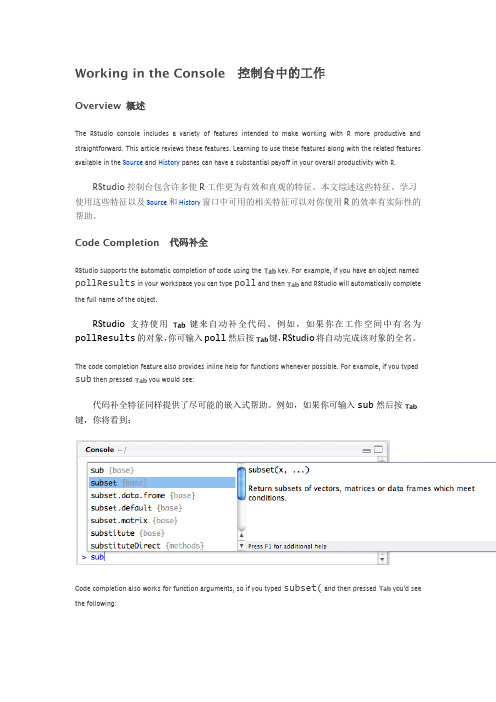
控制台中的工作概述The RStudio console includes a variety of features intended to make working with R more productive and straightforward. This article reviews these features. Learning to use these features along with the related features available in the Source and History panes can have a substantial payoff in your overall productivity with R.RStudio控制台包含许多使R工作更为有效和直观的特征。
本文综述这些特征。
学习使用这些特征以及Source和History窗口中可用的相关特征可以对你使用R的效率有实际性的帮助。
代码补全RStudio supports the automatic completion of code using the key. For example, if you have an object named pollResults in your workspace you can type poll and then and RStudio will automatically completethe full name of the object.RStudio支持使用键来自动补全代码。
例如,如果你在工作空间中有名为pollResults的对象,你可输入poll然后按键,RStudio将自动完成该对象的全名。
The code completion feature also provides inline help for functions whenever possible. For example, if you typed sub then pressed you would see:代码补全特征同样提供了尽可能的嵌入式帮助。
R参考卡片(1)

目录一、 获得帮助二、 输入与输出三、 数据创建四、 数据切割和分离五、 变量变换六、 变量信息七、 数据选取和操作八、 数学函数九、 矩阵十、 高级数据处理十一、 字符十二、 日期和时间十三、 绘图十四、 低水平绘图命令十五、 绘图参数十六、 网格(Lattice)绘图十七、 模型拟和十八、 统计十九、 分布二十、 编程获得帮助一、获得帮助一、1.大部分R函数都有在线文档。
help(topic)关于topic的文档.2.?topic同上3.help.search(ntopicn) 搜索帮助系统4.apropos("topic") 返回所有在搜索路径下满足正则表达式"topic"的所有对象名称。
5.help.start() HTML形式的帮助6.str(a) 显示R对象的内在属性(structure)或简要说明对象7.summary(a) 给出a的概要,通常是一个一般性统计概要;且它有不同的机理和a的属性8.ls() 显示搜索路径下的对象;指定pat="pat"时,按式样条件搜索9.ls.str() str()搜索路径下的每个变量10.dir() 在当前的目录下显示文件11.methods(a) 显示a的“S3methods”12.methods(class=class(a)) 列表所有可以解决属于对象类的方法输入与输出二、输入与输出二、1.load() 加载由save命令得到的数组2.data(x) 加载指定的数组3.library(x) 加载包4.read.table(file) 读取表格式的文件并将其创建成数据框;默认分割符sep=""为任意whitespace;使用header=TRUE读取第一行作为列标题;使用as.is=TRUE防止字符向量变为factors;使用comment.char=""防止被解释为注释;使用skip=n在读数据前跳过n行;详细见帮助关于行命名,NA处理,和其他5.read.csv("filename",header=TRUE) 同上,但默认设置为读取逗点分割文件6.read.delim("filename",header=TRUE) 同上,默认设置为读取tab分割文件7.read.fwf(file,widths,header=FALSE,sep="",as.is=FALSE) 以fixed width formatted形式读取数据金数据框;widths是整数向量,用于设置调整宽度字段8.save(file,...) 以不分平台的二进制保存指定的对象9.save.image(file) 保存所有的对象10.cat(..., file="", sep="")强制转化为字符后打印arguments;sep为arguments间的分割字符11.print(a, ...) 显示arguments;—般性的,且它有不同的机理和a的属性12.format(x,...) 格式化,更好的显示R对象13.write.table(x,file="",s=TRUE,s=TRUE,sep="") 在把x转化为数据框后,写到文件;如果quote为TRUE,字符和因子列就会被(")所包围;sep是字段分隔符;eol为尾行分割符;na为缺失值字符串;使用s=NA增加列标题以便于和表格输入一致14.sink(file) 输出到文件file,直到输入命令sink()15.大部分I /O函数都有file参数。
R语言丨diRblo:中文文本分析方便工具包chinese.misc简介(附文本样例)

R语言丨diRblo:中文文本分析方便工具包chinese.misc简介(附文本样例)展开全文现在NLP技术那么发达了,各种工具那么NB了,可是用R做文本分析的人居然还得为如何读文件不乱码、如何分词、如何统计词频这样的事犯难,也是醉了。
如果老停留在这个水平上,那各位亲你们离自己整天挂在嘴边儿的大数据机器学习之类的基本上就无缘了。
所以希望大家能把更多精力放到算法上,而不是用在一些琐碎、浪费时间又极其恼人的事情上。
其实像文本清理这种活儿,基本上就应该是用鼠标点吧点吧就能自动完成的,若要还费半天劲的话纯属扯淡。
所以,chinese.misc这个R包就要来完成这个任务。
chinese.misc(目前为0.1.3版本)的功能极其简单,主要用于对中文文本进行数据清理工作,此外还包含另外一些实用的处理和分析功能。
在生成文档-词语矩阵的功能上,可以代替对中文不是太支持的tm包,特别是在减少乱码方面。
如果你现在还忙于看如何分词、如何删去停用词、如何计算词频之类的工作,那么这些都用不着看了,让我们把工作变得更无脑些!这个包的中文手册见https:///githubwwwjjj/chinese.misc。
不过,英文pdf 比中文说明详细多了。
chinese.misc的核心函数是corp_or_dtm,可直接从文件夹名/文件名/文本向量中生成文档-词语矩阵,并且自动或按使用者要求进行一些文本清理工作。
此外,软件包中dir_or_file、scancn、make_stoplist、slim_text 等函数都是在中文文本分析中比较实用的函数,可以帮助使用者减少很多麻烦。
在这里,我只展示一下这个包的少数功能,其它功能还请大家去看中文手册。
文本样例请到/s/1nuXLBg1下载,里边是30篇中纪委巡视报告。
如果你解压后文件数不对或是乱码,那几乎只可能是因为你正在使用MAC。
请尽量在WINDOWS上搞。
我们假设你解压后的文件路径是'f:/sample'。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
,
, .
R ‘x’
; ; as.is=TRUE header=TRUE factors;
sort(x) x ; :rev(sort(x)) cut(x,breaks) x ( ); breaks . match(x, y) x y , NA which(x == a) TRUE , x choose(n, k) =n!/[(n − k)!k!] sign(x) 0, 1 , -1 , 0 na.omit(x) NA , x , na.fail(x) x NA unique(x) x , duplicated(x) x table(x) x ( subset(x, ...) x ... select x , : x$V1 < 10
expand.grid() rbind(...) cbind(...) .
,
,
x[n] x[-n] x[1:n] x[-(1:n)] x[c(1,4,2)] x["name"] x[x > 3] x[x > 3 & x < 5] x[x %in% c("a","and","the")] x[n] x[[n]] x[["name"]] x$name x[i,j] x[i,] x[,j] x[,c(1,3)] x["name",] ( x[["name"]] x$name n n "name" . (i,j) i j 1
;
I /O file . . file="" . (Connections) (file), (pipes), (zipped files) R windows clipboard . Excel Excel , x <- read.delim("clipboard") Excel , write.table(x,"clipboard",sep="\t",s=NA) clipboard , Excel , RODBC, DBI,RMySQL, RPgSQL, and ROracle . XML, hdf5, netCDF . c(...) ; recቤተ መጻሕፍቲ ባይዱrsive=TRUE
3 "name" ) "name" .
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), plex(x), as.character(x), , ; : methods(as) is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), plex(x), is.character(x), ... ; , methods(is) length(x) x dim(x) ; dim(x) <- c(3,2) dimnames(x) nrow(x) NROW(x) dim(x)[1] ncol(x) NCOL(x) dim(x)[2] class(x) x ;class(x) <- "myclass" unclass(x) x names(x) (names) unname(x) R (names) (dimnames) unlist(x) x attr(x,which) x which attributes(obj) obj which.max(x) which.min(x) rev(x) x rle(x) x x Runs
n n n n+1 "name" 3 (3,5) x
(
)
”topic”
help.start() HTML demo() R example(f) str(a) R (*str*ucture) summary(a) a , a . ls() “ ” ; ls.str() str() dir() list.files() getwd() setwd() methods(a) a “S3 methods” methods(class=class(a)) options(...) ; error install.packages(pkg) pkg update.packages() library(pkg) pkg require(x) library(help=pkg) pkg attach(x) x R ;x save R data file. search() detach(x) attach . assign(x,value) value x, ”< −” quit() R (q() Ctrl z) data(x) edit() fix(x) ‘fix’ ‘edit’ data.entry(x) scan(x) read.table(file) sep="" ;
: width, digits, . from:to ; “:” ; 1:4 + 1 “2,3,4,5” seq(from,to) by= ; length= seq(along=x) 1, 2, ..., length(along); rep(x,times) x times ; each= x ;rep(c(1,2,3),2) 1 2 3 1 2 3; rep(c(1,2,3),each=2) 112233 data.frame(...) , ; data.frame(v=1:4,ch=c("a","B","c","d"),n=10); list(...) , list(a=c(1,2),b="hi",c=3i); array(x,dim=) x ; ; x , x matrix(x,nrow=,ncol=) ; factor(x,levels=) x gl(n,k,length=n*k,labels=1:n) ( ); k ;n ; dim=c(3,4,2)
expression(expr) ‘ ’(expression) is.expression(x), as.expression(x, ...) parse(file = "", n = NULL) , (expression) eval(expr) R (expression)
.
).
(NA).
paste(...) ; sep= ( ); collapse= “collapsed” substr(x,start,stop) ; , substr(x, start, stop) <- value strsplit(x,split) split x grep(pattern,x) pattern ; ?regex gsub(pattern,replacement,x) , sub() , tolower(x) toupper(x) casefold(x, upper = TRUE) x (TRUE) (FALSE) chartr(old, new, x) x old new match(x,table) table x . x %in% table . pmatch(x,table) table x nchar(x) . POSIXct . ( .>), seq() difftime() . Date + ?DateTimeClasses . chron . as.Date(s) as.POSIXct(s) ; format(dt) . “2006-07-24”. . : Date %a, %A “ ”(weekday) %b, %B %d (01–31). %H (00–23). %I (01–12). %j (001–366). %m (01–12). %M (00–59). %p AM/PM . %S (00–61). %U (00–53); %w (0–6, 0). %W (00–53); %y (00–99). . %Y . %z ( .) ; -0800 %Z ( .) ( ). weekdays(x) months(x) quarters(x) . x x x (Q1 - Q4) , “ ”
.
comment.char="" "#" ; skip=n n ; ,NA , read.csv("filename",header=TRUE) , csv (Comma Separated values) read.delim("filename",header=TRUE) , tab read.fwf(file,widths,header=F,sep="\t",as.is=FALSE) f ixed width f ormatted ; widths , save(file,...) save.image(file) load() save dump("x","...") x “...” cat(..., file="", sep=" ") ; sep print(a, ...) a format(x,...) , R write.table(x,file="",s= T ,s= T , sep="") x , ; quote TRUE, (") ; sep ; eol ; na ; s=NA sink(file) file, sink()
R
( com , , sunbjt@. 1.3 2008-8-3 ) Tom Short tshort@eprisolutions. . ( Tom Short ) . ,
R help(topic) topic ?topic help.search("topic") apropos("topic")