基于MGR的数据高可用架构
数据库技术中的高可用解决方案

数据库技术中的高可用解决方案随着互联网的发展,数据已经成为了企业经营的重要资源。
为了保障数据的安全性和稳定性,高可用性成为了数据库技术中的重要解决方案之一。
本文将从高可用性的概念入手,探讨数据库技术中的高可用性解决方案。
一、高可用性的概念高可用性是指系统在发生故障或者部分故障时,仍然能够维持其功能性,并且在故障切换后进行自动恢复的能力。
尤其是对于企业级别的数据库系统,高可用性显得尤为关键。
二、高可用性的实现方法1. 数据库镜像数据库镜像是指一种利用两个或多个数据库之间的同步机制来保证数据库高可用性的技术。
主要是通过将主库数据同步到从库,从而保证从库在主库故障或者出现负载高峰时,能够直接对外提供服务。
2. 数据库复制数据库复制是另外一种常见的高可用性方案,它是指在多个服务器中设置一个主数据库,并将主数据库中的数据实时备份到从数据库中。
复制可以实现高可用性,因为数据维护在多个服务器上,数据库系统在主服务器出现故障时,从服务器将会自动接管,从而保证数据可用性。
3. 数据库分布式数据库分布式则是一种将数据分散到多个服务器中去的高可用性解决方案。
通常情况下,数据库分布式能够保证企业数据库的高可用性以及容灾能力。
通过将数据分布到不同的服务器中去,可以避免单点故障,并且在某个服务器发生故障时,也不会影响到所有服务的正常运转。
三、如何选择合适的高可用性解决方案在实际场景中,选择合适的高可用性解决方案是十分重要的。
首先,需要根据自己企业的实际情况进行判断选择数据库解决方案。
具体可从如下几个方面进行探讨:1. 对于企业来说,数据库的服务时间很重要,所以需要选择一种能够实现全天候服务的数据库解决方案。
2. 对于企业来讲,数据安全很重要,因此高可用解决方案的备份和恢复功能都需要很强的数据安全性能。
3. 数据库解决方案需要考虑多节点架构,非常有可能包含元数据节点和存储节点,而元数据节点故障将会导致存储节点整个离线。
4. 数据库解决方案需要兼容开源数据库和SQL Server。
MySQLMGR架构原理简介

MySQLMGR架构原理简介⼀、MGR架构原理简介状态机复制MGR本质上⼀个状态机复制的集群。
在状态机复制的架构中,数据库被当做⼀个状态机。
每⼀次写操作都会导致数据库的状态变化。
为了创建⼀个⾼可⽤的数据库集群,有⼀个组件,即事务分发器,将这些操作按照同样的顺序发送到多个初始状态⼀致的数据库上,让这些数据库执⾏同样的操作。
因为初始状态相同,每次执⾏的操作也相同,所以每次状态变化后各个数据库上的数据保持⼀致。
分布式的状态机复制事务分发器是⼀个单点,为了避免单点故障,可以采⽤分布式的状态机复制。
在分布式的状态机复制中,有多个事务分发器,它们彼此互相通信。
事务分发器可以同时接收事务请求,就像单个事务分发器同时接收事务请求⼀样。
从应⽤层来说,并发的事务发到同⼀个事务分发器和发到不同的事务分发器上效果是⼀样的。
事务分发器之间会互相通信,把所有的事务汇总、排序。
最终,每个事务分发器上都有⼀份完整的排好序的事务请求。
每个事务分发器只连接到⼀个数据库上,并负责把事务请求依次发送到相连的数据库上去执⾏,其就是⼀个分布式状态机复制的模型了。
分布式的⾼可⽤数据库将分布式的事务分发模块集成到数据库系统中,就变成了⼀个分布式的⾼可⽤数据库系统。
⽤户通过数据库的⽤户接⼝执⾏事务。
数据库收到事务请求后,⾸先交由事务分发模块处理。
事务分发模块将事务汇总排序,然后依次交由数据处理模块去执⾏这些事务。
如果去掉内部的细节,就会发现这是⼀个⾮常简洁的数据库集群⽅案。
MGR就是这样⼀个分布式的⾼可⽤MySQL系统。
⼆、MYSQL⾼可⽤的背景为了创建⾼可⽤数据库系统,传统的实现⽅式是创建⼀个或多个备⽤的数据库实例,原有的数据库实例通常称为主库master,其它备⽤的数据库实例称为备库或从库slave。
当master故障⽆法正常⼯作后,slave就会接替其⼯作,保证整个数据库系统不会对外中断服务。
master 与slaver的切换不管是主动的还是被动的都需要外部⼲预才能进⾏,这与数据库内核本⾝是按照单机来设计的理念悉悉相关,并且数据库系统本⾝也没有提供管理多个实例的能⼒,当slave数⽬不断增多时,这对数据库管理员来说就是⼀个巨⼤的负担。
构建高可用性的服务器架构

构建高可用性的服务器架构在当今数字化时代,各个行业都对服务器的高可用性有着极高的要求。
服务器作为信息处理和存储的核心,一旦出现故障或中断将带来巨大的损失。
因此,构建高可用性的服务器架构成为了迫切的需求。
一、高可用性的概念和意义高可用性是指系统或服务在面临各种故障或中断时仍能坚持提供服务,不会停止或降低性能。
这种系统可以通过多种手段来实现,如硬件冗余、软件容错和自动故障转移等。
构建高可用性的服务器架构不仅可以有效地保障用户的需求,同时也能提高企业的竞争力和口碑。
二、冗余备份技术构建高可用性的服务器架构的第一步,是通过冗余备份技术来保障服务器的稳定性。
主要有硬件冗余和软件冗余两种方式。
硬件冗余方面,可以通过实现双电源、双网卡、双机架等手段来保证服务器的可用性。
当一个硬件出现故障时,备用硬件会自动接管工作。
此外,还可以采用硬盘阵列技术,将多块硬盘组合在一起,提高数据的读写速度和容错能力。
软件冗余方面,可以通过使用主备机制来确保服务器的可用性。
主备机制是指将两台服务器绑定在一起,其中一台为主服务器,另一台为备份服务器。
主服务器负责正常的服务处理,而备份服务器则随时监控主服务器的状态。
一旦主服务器出现故障,备份服务器会立即接管工作,保证服务的连续性。
三、负载均衡技术负载均衡技术在构建高可用性的服务器架构中起到了至关重要的作用。
通过将用户请求分发到不同的服务器上,可以平衡每个服务器的负载,提高整个系统的性能和稳定性。
负载均衡可以分为硬件负载均衡和软件负载均衡两种方式。
硬件负载均衡是通过使用专门的硬件设备,如负载均衡器来实现的。
负载均衡器可以根据服务器的负载情况,智能地将请求分配到不同的服务器上,提高响应速度和并发处理能力。
而软件负载均衡则是通过在集群中的各个服务器上运行特殊的软件来实现的。
这些软件可以根据服务器的负载情况和性能指标,智能地分发请求。
常见的软件负载均衡方案有Nginx和HAProxy等。
四、容灾备份技术容灾备份技术是构建高可用性的服务器架构中另一个重要的方面。
数据库的高可用性架构与故障恢复

数据库的高可用性架构与故障恢复随着计算机技术的不断进步,数据库已经成为现代社会中重要的数据存储和处理工具之一。
在大型企业和组织中,数据库的高可用性架构和故障恢复是确保业务连续性和数据完整性的重要组成部分。
本文将探讨数据库的高可用性架构和故障恢复的一些关键概念和方法。
首先,我们需要理解高可用性架构的概念。
高可用性是指在面对硬件、软件或网络故障时,系统仍然能够继续运行并提供服务。
数据库的高可用性架构旨在确保数据库系统在故障发生时能够快速恢复并保持数据的连续性。
为达到这一目标,常见的架构模式包括备份和恢复、主从复制和集群。
备份和恢复是数据库高可用性架构中最常见的一种方式。
它通过定期备份数据库,并在发生故障时恢复备份文件以恢复数据完整性。
备份可以以全量备份或增量备份的方式进行,全量备份是指备份整个数据库,而增量备份则是只备份发生变更的部分。
通过组合使用不同类型的备份,可以保证不同程度的数据丢失。
另一种常见的高可用性架构是主从复制。
主从复制是通过建立一个主数据库和一个或多个从数据库的关系。
主数据库负责处理读写操作,而从数据库则复制主数据库的数据,只处理读操作。
当主数据库发生故障时,从数据库可以接管并提供服务,实现快速故障恢复。
主从复制还可以用于水平扩展,通过增加从数据库来提高处理能力。
除备份和恢复和主从复制外,还有一种被广泛采用的高可用性架构是集群。
集群是指通过多个服务器(节点)组成的系统,这些节点共享相同的硬件和软件配置,并提供相同的数据库服务。
集群通过分布数据和计算负载来提供高可用性和扩展性。
常见的集群技术包括主备集群和主主集群。
主备集群是指在多个节点中,只有一个节点处于活动状态,其他节点处于待命状态,一旦活动节点失败,待命节点可以快速接管。
主主集群则是所有节点都处于活动状态,数据进行双向同步,提供更好的性能和数据一致性。
当数据库发生故障时,快速恢复数据是至关重要的。
数据库的故障恢复可以通过以下步骤来实现。
如何构建高可用架构

如何构建高可用架构随着互联网的飞速发展,各种业务系统走向线上,高可用架构已成为了企业建设基础设施不可或缺的一部分。
如何构建高可用架构,成为了每一位技术人员必备的技能之一。
一、什么是高可用架构高可用架构是指一个系统在经历部分组件或者硬件故障之后,仍然能够保持系统的可用性和稳定性。
高可用架构的目标是保证系统随时随地都能24小时全天候地运行。
二、高可用架构的实现1. 集群化架构应用服务器和数据库服务器都采用集群的方式来构建,通过负载均衡技术,将请求均衡分配到不同的节点上,实现了系统高效的响应和负载的分流,提升了系统的可用性。
2. 数据库主从复制通过主数据库和备份数据库采用异步复制以及数据同步机制,高可用架构可以在主数据库出现故障时,灵活切换到备份数据库,保证业务不会中断。
并且在数据同步时,备份数据库始终与主数据库保持同步状态,保证了数据的一致性和可靠性。
3. 负载均衡负载均衡技术在高可用架构中扮演着至关重要的角色。
它可以在多个节点之间平衡流量,防止某个节点负载过高造成的性能损失,提升系统的整体性能。
4. 健康检查系统运行时需要不断地检查各个组件,例如数据库、服务等组件是否运行正常。
一旦检查到某个组件出现问题,立即采取相应的措施,以保证系统的高可用性。
5. 故障容错故障容错技术可以在系统出现故障时,自动恢复。
这项技术的目的是保障系统在遇到故障时能够自动重启或自动切换,让系统在最短的时间内重新获得稳定性。
三、如何保障高可用架构的可靠性1. 设计合理的架构方案高可用架构的设计方案必须综合考虑业务需求、硬件设备、数据存储和负载等方面的因素,制定出一套合适的架构方案。
同时还需要考虑扩展性和灵活性,让整套系统具备更高的可靠性。
2. 运维保障系统建设对于运维人员来说,非常关键。
运维人员要具备一定的技术实力和相关知识,保障系统的日常运行和维护。
在常规备份、灾备恢复和系统升级等维护工作中,以快速响应、及时处理为原则,以保障系统运行状态。
构建高可用系统架构的几个关键要素

构建高可用系统架构的几个关键要素在如今的数字时代,高可用性已经成为了一个系统或服务设计中至关重要的要素。
无论是互联网企业、金融机构还是其他行业,都需要依赖可靠的系统架构来确保服务的连续性和稳定性。
本文将讨论构建高可用系统架构的几个关键要素。
一、负载均衡负载均衡是构建高可用性系统架构的首要要素之一。
它通过将流量分布到多个服务器或处理单元上,从而实现对请求的分流和负载的平衡。
通过负载均衡,可以提高系统的整体性能和可用性。
常见的负载均衡技术包括硬件负载均衡器和软件负载均衡器。
硬件负载均衡器通常在网络层面上进行分发,而软件负载均衡器则在应用层面上进行请求的分发。
二、冗余备份冗余备份是保证系统高可用性的重要手段。
通过在关键部件或服务上多配置一份冗余备份,可以在主要组件宕机或故障时快速切换到备份,从而避免单点故障对系统造成的影响。
冗余备份可以是硬件冗余,比如多个服务器或存储设备的冗余配置;也可以是软件冗余,比如搭建多个相同功能的服务节点,实现对数据和请求的备份和冗余。
三、容灾备份容灾备份是构建高可用系统架构必不可少的要素之一。
容灾备份的主要目标是在灾难性情况下保护系统的可用性,并在灾难发生后快速恢复系统的功能。
容灾备份通常包括远程数据备份和灾难恢复计划。
远程数据备份可以通过定期将数据备份到远程位置,确保数据在灾难发生时不丢失。
灾难恢复计划则是在系统遭受灾难性故障时,能够快速切换到备份系统或数据中心,恢复服务。
四、监控和告警监控和告警是保障高可用系统运行的重要环节。
通过实时监控系统的性能指标、服务状态和关键组件的健康状况,可以及时发现潜在问题并采取相应的措施。
监控系统应覆盖各个环节,包括网络、服务器、数据库等,同时提供预警和告警机制,及时通知相关人员并采取行动。
五、弹性伸缩弹性伸缩是构建高可用系统架构的一项重要策略。
通过弹性伸缩,系统可以根据当前负载情况自动增加或减少资源,以应对不同的业务需求和流量峰值。
弹性伸缩可以利用自动化工具和云计算平台来实现,提高系统的灵活性和可用性。
Oracle三种高可用方案原理介绍--解决方案

Oracle三种高可用方案原理介绍--解决方案Oracle 三种高可用方案原理介绍一、概述Oracle因为是商用版本,所以高可用方案都已经非常成熟,主要有三种高可用方案,下边分别介绍一下。
1 RAC(Real Application Clusters)多个Oracle服务器组成一个共享的Cache,而这些oracle服务器共享一个基于网络的存储。
这个系统可以容忍单机/或是多机失败。
不过系统内部的多个节点需要高速网络互连,基本上也就是要全部东西放在在一个机房内,或者说一个数据中心内。
如果机房出故障,比如网络不通,那就坏了。
所以仅仅用RAC还是满足不了一般互联网公司的重要业务的需要,重要业务需要多机房来容忍单个机房的事故。
2 Data Guard.(最主要的功能是冗灾)Data Guard这个方案就适合多机房的。
某机房一个production 的数据库,另外其他机房部署standby的数据库。
Standby数据库分物理的和逻辑的。
物理的standby数据库主要用于production失败后做切换。
而逻辑的standby数据库则在平时可以分担production数据库的读负载。
3 MAAMAA(Maximum Availability Architecture)其实不是独立的第三种,而是前面两种的结合,来提供最高的可用性。
每个机房内部署RAC集群,多个机房间用Data Guard同步。
二、三种高可用方式工作原理1、Oracle 11G RACRAC环境与单实例最主要的区别是:.RAC的每个实例都有属于自己的SGA、后台进程。
由于数据文件、控制文件共享于所有实例,所以必须放在共享存储中。
..联机重做日志文件:只有一个实例可以写入,但是其他实例可以再回复和存档期间读取。
..归档日志:属于该实例,但在介质恢复期间,其他实例需要访问所需的归档日志。
..alter和trace日志:属于每个实例自己,其他实例不可读写。
如何构建高可用架构

如何构建高可用架构随着互联网的快速发展和更新换代,越来越多的企业意识到构建高可用架构的重要性。
在星际时代,任何一点故障都将造成无限的影响,因此,企业必须有足够的技术能力来应对。
构建一个高可用架构的最高目标是确保100%的应用程序可用性,来应对所有的计算需求。
然而,构建高可用架构并不容易,需要使用一系列技术和方法才能确保其成功。
本文旨在通过分析高可用架构要素和相关技术进行探讨,帮助企业构建出稳定的高可用架构。
一、高可用架构要素高可用架构确保系统的可用性并最小化停机时间,同时保证了系统的高性能。
因此,高可用架构包括以下要素:1.数据可用性数据是企业最重要的资产之一,因此,确保其可用性至关重要。
高可用架构要求在数据库中部署数据备份和恢复策略,同时在部署过程中考虑数据的复制和同步方式,以确保数据的可用性。
此外,定期测试数据配合策略也是非常重要的。
2.服务可用性服务可用性是高可用架构的另一重要要素。
构建稳定和高效的服务器和网络设施是最为基础的。
企业必须考虑如何平衡服务器负载,避免出现瓶颈问题,保证服务的可用性。
3.应用程序可用性应用程序是企业的关键业务流程,必须保证其可用性。
高可用架构需要考虑多台服务器和分布式架构的应用程序效率和负载均衡,确保其可靠度和时效性。
4.自动化构建高可用架构的关键之一是实现自动化,包括软件部署、配置管理和变更管理等。
为了提高可用性和灵活性,企业必须自动化部署和管理重要应用程序和系统配置,以降低人为错误的发生率和实现更及时的响应。
二、高可用架构相关技术1.负载均衡对于每个运行中的应用程序来说,如何平衡不同的服务器负载是最重要的。
负载均衡可用于分散服务器上的负载,实现动态路由,确保服务可用性。
企业可以采用不同的负载均衡技术,比如DNS、软件或硬件负载均衡,来维持高可用架构,确保应用程序的稳定性和可用性。
2.故障转移故障转移技术可以确保应用程序在服务器出现故障时自动重定向到健康的服务器上。
数据库的容灾与高可用性架构设计

数据库的容灾与高可用性架构设计在现代企业中,数据库作为存储和管理重要数据的关键组件,在保障数据安全和可用性方面起着至关重要的作用。
为了在遇到灾难性故障时能够实现数据的恢复和系统的快速恢复,数据库的容灾与高可用性架构设计成为不可忽视的问题。
本文将从容灾和高可用性两个方面来探讨数据库架构的设计。
一、容灾架构设计容灾是指在遭受灾害或故障时,能够保证系统和数据的连续性、完整性和可用性的能力。
常见的容灾架构设计方案有备份和恢复、冷备份、热备份、以及异地多活等。
以下将介绍这些方案的特点和适用场景。
1. 备份和恢复备份和恢复是最基本也是最常用的容灾方案。
通过定期对数据库进行备份,并将备份文件保存在不同地点,以便在数据库故障时能够快速恢复。
备份可以是完整备份或增量备份,具体根据数据量和恢复的时间要求来决定。
备份和恢复需要有明确的策略和计划,包括备份频率、备份存储位置、备份验证等。
2. 冷备份冷备份是指在数据库故障时,将备份数据拷贝到目标服务器上,并启动该数据库实例的过程。
由于数据库备份是离线状态进行的,所以恢复数据库的时间较长。
冷备份适用于数据量较大、恢复时间要求相对宽松的情况。
3. 热备份热备份是指在数据库故障时,将备份数据拷贝到目标服务器上,并将该数据文件应用到实时数据库中。
这种方式下数据库恢复的时间较短,可以保证业务的连续性。
热备份适用于恢复时间要求比较短的情况。
4. 异地多活异地多活是指在两个或多个地理位置上构建相同的数据库环境,并通过数据同步来保持数据一致性。
当一个地点的数据库出现故障时,可以切换到另一个地点的数据库继续提供服务。
异地多活适用于对系统可用性要求较高的场景,但需要考虑数据同步和网络延迟等问题。
二、高可用性架构设计高可用性是指系统能够在故障发生时保持功能正常和高效运行的能力。
在数据库高可用性架构设计中,常见的方案有主从复制、主从复制+读写分离、集群等。
1. 主从复制主从复制是指将主数据库的数据实时复制到一个或多个从数据库上,从数据库作为备份和故障切换的目标。
数据库高可用性方案汇总
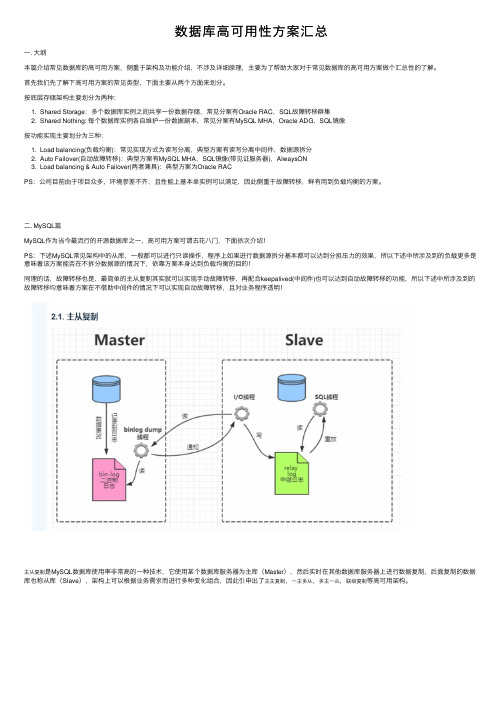
数据库⾼可⽤性⽅案汇总⼀. ⼤纲本篇介绍常见数据库的⾼可⽤⽅案,侧重于架构及功能介绍,不涉及详细原理,主要为了帮助⼤家对于常见数据库的⾼可⽤⽅案做个汇总性的了解。
⾸先我们先了解下⾼可⽤⽅案的常见类型,下⾯主要从两个⽅⾯来划分。
按底层存储架构主要划分为两种:1. Shared Storage:多个数据库实例之间共享⼀份数据存储,常见分案有Oracle RAC,SQL故障转移群集2. Shared Nothing: 每个数据库实例各⾃维护⼀份数据副本,常见分案有MySQL MHA,Oracle ADG,SQL镜像按功能实现主要划分为三种:1. Load balancing(负载均衡):常见实现⽅式为读写分离,典型⽅案有读写分离中间件,数据源拆分2. Auto Failover(⾃动故障转移):典型⽅案有MySQL MHA,SQL镜像(带见证服务器),AlwaysON3. Load balancing & Auto Failover(两者兼具):典型⽅案为Oracle RACPS:公司⽬前由于项⽬众多,环境参差不齐,且性能上基本单实例可以满⾜,因此侧重于故障转移,鲜有⽤到负载均衡的⽅案。
⼆. MySQL篇MySQL作为当今最流⾏的开源数据库之⼀,⾼可⽤⽅案可谓五花⼋门,下⾯依次介绍!PS:下述MySQL常见架构中的从库,⼀般都可以进⾏只读操作,程序上如果进⾏数据源拆分基本都可以达到分担压⼒的效果,所以下述中所涉及到的负载更多是意味着该⽅案能否在不拆分数据源的情况下,依靠⽅案本⾝达到负载均衡的⽬的!同理的话,故障转移也是,最简单的主从复制其实就可以实现⼿动故障转移,再配合keepalived(中间件)也可以达到⾃动故障转移的功能,所以下述中所涉及到的故障转移均意味着⽅案在不借助中间件的情况下可以实现⾃动故障转移,且对业务程序透明!主从复制是MySQL数据库使⽤率⾮常⾼的⼀种技术,它使⽤某个数据库服务器为主库(Master),然后实时在其他数据库服务器上进⾏数据复制,后⾯复制的数据库也称从库(Slave),架构上可以根据业务需求⽽进⾏多种变化组合,因此引申出了主主复制,⼀主多从,多主⼀从,联级复制等⾼可⽤架构。
数据库管理中的高可用机制是什么

数据库管理中的高可用机制是什么在当今数字化的时代,数据已经成为了企业和组织的重要资产。
数据库作为存储和管理数据的核心系统,其可用性至关重要。
一旦数据库出现故障或不可用,可能会导致业务中断、数据丢失、客户满意度下降等严重后果。
为了确保数据库能够持续稳定地运行,高可用机制应运而生。
那么,究竟什么是数据库管理中的高可用机制呢?简单来说,高可用机制就是一系列技术和策略的组合,旨在最大程度地减少数据库的停机时间,提高数据库系统的可靠性和稳定性,以保障业务的正常运行。
要理解高可用机制,我们首先需要明白数据库可能面临的故障类型。
这些故障可以大致分为硬件故障、软件故障、网络故障以及人为错误等。
硬件故障包括服务器宕机、硬盘损坏、电源故障等;软件故障可能是数据库系统本身的漏洞、错误配置或者应用程序的错误导致;网络故障如网络延迟、丢包甚至网络中断;而人为错误可能是误操作、数据误删除等。
为了应对这些可能的故障,高可用机制采用了多种技术手段。
其中,最常见的一种是冗余技术。
冗余可以在多个层面实现,比如硬件冗余,通过使用多台服务器、多个硬盘等来避免单点故障。
如果一台服务器出现问题,其他服务器可以立即接管工作,确保业务不受影响。
还有数据冗余,通过数据备份和复制技术,将数据存储在多个位置,这样即使某个存储设备损坏,数据也不会丢失。
数据库复制是实现高可用的重要技术之一。
它可以将数据从一个数据库实例同步到另一个或多个数据库实例。
常见的复制方式有主从复制、主主复制等。
在主从复制中,主数据库负责处理写操作,并将数据变更同步到从数据库,从数据库主要用于读操作。
这种方式既能提高系统的读性能,又能在主数据库出现故障时,快速将从数据库提升为主数据库,继续提供服务。
除了复制,集群技术也是高可用机制的重要组成部分。
数据库集群是由多个数据库节点组成的一个整体,它们协同工作,共同处理数据库请求。
当一个节点出现故障时,其他节点可以自动接管其工作,从而保证系统的持续运行。
mysql mgr原理

mysql mgr原理MySQL MGR (MySQL Group Replication)是MySQL官方推出的一种高可用性和可扩展性的解决方案。
它基于新一代MySQL复制技术,使用了多主复制和Paxos协议来实现自动故障转移和数据一致性。
MGR的工作原理如下:1. 节点选举:当一个节点加入到集群中时,它将成为一个备选节点。
MGR使用Paxos协议来选举主节点。
选举算法保证了选出的主节点具有唯一性和最高优先级,这个主节点会负责处理所有写操作。
2.数据同步:一旦选出主节点,所有的写操作都会被发送到主节点。
主节点将写操作记录在自己的二进制日志文件中,并异步地将这些写操作发送给所有备选节点。
备选节点则通过异步复制和应用来同步数据。
3. 自动故障转移:如果主节点失效,备选节点之间将通过Paxos协议重新选举一个新的主节点。
选举完成后,新主节点将继续负责处理所有的写操作,并将写操作发送给所有备选节点进行同步。
4.数据一致性:MGR使用多主复制技术,因此集群中的所有节点都可以接收写请求。
为了保证数据一致性,MGR引入了一个“一致性协议”,用于确保所有节点在某个时刻数据的一致性状态。
当节点加入集群时会在一致性协议中进行标记,主节点会将所有的写请求发送到所有节点,当集群中的大多数节点都已确认该写操作时,在主节点上记录该操作为已提交,然后将确认消息发送到所有节点。
从节点再通过异步复制和应用的方式更新数据。
通过以上步骤,MGR可以提供高可用性和可扩展性的解决方案。
由于它是MySQL官方推出的一种解决方案,因此它具有完整的技术支持和文档资料,可以方便快捷地进行集群部署和管理。
mgr 应用场景

mgr 应用场景
MGR是MySQL Group Replication的缩写,是MySQL官方推出的基于Paxos分布式一致性协议的状态机复制,实现了分布式下数据的最终一致性。
MGR提供了高可用、高扩展、高可靠的MySQL集群解决方案,适用于以下场景:
- 金融场景:MGR是为金融场景设计的,例如支付、证券交易、保险和银行等。
这些场景要求数据必须做到零丢失,数据库可用性达到4个9甚至5个9(即年度停机时间不超过5分钟)。
- 容错系统:组复制是一种可以用来部署容错系统的技术,复制组中的服务器通过massage passing来进行交互,通信层通过atomic message 和 total order message delivery来保证组内成员数据的一致性。
总之,MGR在金融、容错系统等领域具有广泛的应用前景,可以帮助企业实现高可用、高扩展和高可靠的数据库解决方案。
【mysql】Mgr实现数据库高可用架构
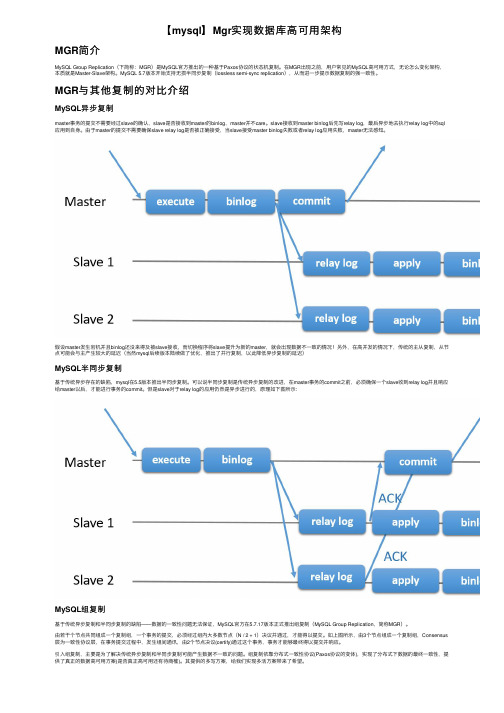
【mysql】Mgr实现数据库⾼可⽤架构MGR简介MySQL Group Replication(下简称:MGR)是MySQL官⽅推出的⼀种基于Paxos协议的状态机复制。
在MGR出现之前,⽤户常见的MySQL⾼可⽤⽅式,⽆论怎么变化架构,本质就是Master-Slave架构。
MySQL 5.7版本开始⽀持⽆损半同步复制(lossless semi-sync replication),从⽽进⼀步提⽰数据复制的强⼀致性。
MGR与其他复制的对⽐介绍MySQL异步复制master事务的提交不需要经过slave的确认,slave是否接收到master的binlog,master并不care。
slave接收到master binlog后先写relay log,最后异步地去执⾏relay log中的sql 应⽤到⾃⾝。
由于master的提交不需要确保slave relay log是否被正确接受,当slave接受master binlog失败或者relay log应⽤失败,master⽆法感知。
假设master发⽣宕机并且binlog还没来得及被slave接收,⽽切换程序将slave提升为新的master,就会出现数据不⼀致的情况!另外,在⾼并发的情况下,传统的主从复制,从节点可能会与主产⽣较⼤的延迟(当然mysql后续版本陆续做了优化,推出了并⾏复制,以此降低异步复制的延迟)MySQL半同步复制基于传统异步存在的缺陷,mysql在5.5版本推出半同步复制。
可以说半同步复制是传统异步复制的改进,在master事务的commit之前,必须确保⼀个slave收到relay log并且响应给master以后,才能进⾏事务的commit。
但是slave对于relay log的应⽤仍然是异步进⾏的,原理如下图所⽰:MySQL组复制基于传统异步复制和半同步复制的缺陷——数据的⼀致性问题⽆法保证,MySQL官⽅在5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR)。
美团点评基于MGR的CMDB高可用架构搭建之路

美团点评基于MGR的CMDB高可用架构搭建之路本文根据王志朋老师在dbaplus社群〖2018年8月4日北京数据架构与数据优化技术沙龙〗现场演讲内容整理而成。
MySQL Group Replication(以下简称MGR),于5.7.17版本正式GA,由Oracle官方出品,为MySQL的高可用方案注入了新血液。
其一致性,以及不依赖外部组件实现的自动切换、多点写入,给DBA带来了不少期待。
一、背景以MHA作为切换工具,CMDB管理元数据,结合中间件的高可用方案在MySQL生态中是比较常见的架构。
在这个体系中,CMDB 作为基础组件之一,不能再依赖这个架构实现自身的高可用,而需要一套自成体系的高可用架构保障。
2017年下半年开始,美团点评数据库计划全面升级上线5.7版本,也正是这个契机,基于MGR的CMDB高可用想法应运而生。
二、关于MGRMGR是以Plugin的形式嵌入在MySQL实例中,插件内部实现了冲突检测、Paxos协议通信等。
可能有同学了解它与PXC很像,社区中关于二者的口水战也非常的热闹,具体二者的优劣与争端此处不表,但有一点值得说明,MGR 集群当中,仍然是通过binlog实现节点同步的。
这一点对DBA很友好,意味着我们可以很轻易的找回熟悉的主从的感觉(Still A MySQL)。
三、解决方案MGR包括多主与单主两个模式,出于多主模式的一些已知问题以及实际业务场景的考虑,我们决定选择单主模式作为主要方案,即当主节点故障后,集群自动选举新的主节点,应用将写访问指向新的主节点。
那么具体的解决方案还有哪些需要考虑呢?•MGR的限制;•相关测试;•合理的参数。
1.MGR的限制•只支持InnoDB存储引擎;•必须有主键;•binlog_format只支持ROW格式;•不支持save point(后修复);•……官方给出了一些明确的要求及限制。
针对这些限制我们要对线上要接入的数据库进行排查,调研可行性,规范其满足MGR的要求。
MGR集群搭建及配置过程

MGR集群搭建及配置过程 MGR全称MySQL Group Replication(Mysql组复制),是MySQL官⽅于2016年12⽉推出的⼀个全新的⾼可⽤与⾼扩展的解决⽅案。
MGR提供了⾼可⽤、⾼扩展、⾼可靠的MySQL集群服务。
在MGR出现之前,⽤户常见的MySQL⾼可⽤⽅式,⽆论怎么变化架构,本质就是Master-Slave架构。
MySQL 5.7版本开始⽀持⽆损半同步复制(lossless semi-sync replication),从⽽进⼀步提⽰数据复制的强⼀致性。
MGR是MySQL数据库未来发展的⼀个重要⽅向。
注意:根据本⼈测试group_replication.so插件是mysql-community-server安装包中携带,如果是rpm安装或yum安装存放地址为/usr/lib64/mysql/plugin/⽬录下,看下图。
另外在安装5.7.16版本时是没有这个插件,⽽在安装5.7.20版本有这个插件,推测这是⼀个5.7.16到5.7.20之间新加的插件,个⼈建议安装5.7.20以上的版本。
另外⼤家请在安装好mysql后查看⼀下是否存在这个插件。
如果提⽰group_replication.so不存在,或提⽰有问题并且查看时发现group_replication.so不存在,请重点看⼀下mysql的版本。
(我搜了⼀⼤圈,没有⼀个⼈说这个问题。
表⽰怀疑⾃⼰,如果我错了,请留⾔。
)(1).MGR的特性 ⾼⼀致性。
基于原⽣复制及paxos协议的组复制技术,并以插件的⽅式提供,提供⼀致数据安全保证; ⾼容错性。
只要不是⼤多数节点坏掉就可以继续⼯作,有⾃动检测机制,当不同节点产⽣资源争⽤冲突时,不会出现错误,按照先到者优先原则进⾏处理,并且内置了⾃动化脑裂防护机制; ⾼扩展性。
节点的新增和移除都是⾃动的,新节点加⼊后,会⾃动从其他节点上同步状态,直到新节点和其他节点保持⼀致,如果某节点被移除了,其他节点⾃动更新组信息,⾃动维护新的组信息; ⾼灵活性。
mysql的mgr原理

mysql的mgr原理
MySQL的MGR原理是指MySQLGroupReplication,它是MySQL 5.7版本中一个新的高可用性解决方案。
MGR实现了多主复制架构,可以实现自动容错和故障转移,从而提高了系统的可用性。
MGR的实现基于Paxos协议,通过在组成员之间共享信息,达成一致的决策。
在MGR中,每个节点都可以作为主节点接收客户端的请求,并将数据同步到其他节点。
当主节点发生故障时,其他节点会自动选出新的主节点,确保系统的可用性。
MGR还支持读取操作的负载均衡,通过将读取请求分配到不同的节点上,提高了系统的性能。
此外,MGR还支持异步复制和半同步复制模式,可以根据具体应用场景选择合适的模式。
不过,MGR也存在一些限制和注意事项,例如需要保证网络延迟较低,节点配置需要一致等。
在使用MGR时需要谨慎评估自身的需求和实际情况,选择合适的方案。
- 1 -。
mgr集群原理

mgr集群原理
Mgr集群是一种高可用性和容错性的集群管理架构。
它由一个主节点和多个从节点组成,主节点负责处理客户端请求和管理集群状态,从节点主要用于备份主节点的数据和提供故障转移。
Mgr集群的工作原理如下:
1. 客户端通过访问主节点发起请求,主节点将请求分发给从节点处理。
客户端可以直接连接到主节点或者通过代理连接。
2. 主节点接收到请求后,将请求复制到所有从节点。
从节点根据复制的数据进行相同的操作。
3. 当主节点发生故障或者网络中断时,从节点会检测到主节点的状态变化。
如果主节点无法响应,从节点会选举出新的主节点来继续处理客户端请求。
4. 一旦主节点恢复正常,它会重新加入集群,并与之前选举出的主节点进行数据同步。
这样可以确保数据的一致性和完整性。
5. Mgr集群还支持自动故障转移和数据恢复。
当一个从节点发生故障时,主节点会将该从节点的工作转移到其他正常的从节点上。
同时,它也会监测故障节点的状态,一旦故障节点恢复正常,它会重新加入集群并进行数据同步。
6. Mgr集群使用心跳机制来检测节点的存活状态,当节点长时间未发送心跳信号时会被认为是失效的。
7. Mgr集群还提供了监控和日志记录功能,可以帮助管理员及时发现和解决问题。
总之,Mgr集群通过主节点和从节点的协作来实现高可用性和容错性,保证系统的稳定性和可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
全事务的排序
存在问题:
• 用户请求不均衡,集群处理速 度受限于集群中处理最慢的节 点
• 成员节点宕机或者出现网络分 区,无法发送Skip,导致其他 节点日志无法提交
解决方案:
• 基于逻辑时钟,慢的节点收到 快节点的suggest请求,Skip 当 前序号到请求序号之间的请求 序列
• 流控 • Group_replication_flow_control_applier_threshold/certifier_threshold
基于MGR的高可用架构设计
客户端切换: • Replication_group_members 识别主从切换 • 通过group_replication_weight 影响选主 • 等待所有远端同步的日志回放
Count_transactions_in_queue + Count_transactions_remote_in_applier_queu e
网易考拉基于MGR的高可用架构
技术创新 变革未来
01 深入MySQL Group Replication
02 基于MGR 多副本高可用集群架构设计 03 基于MGR Muti-Primary水平扩展方案 04 基于MGR的跨机房高可用实践
MySQL 数据库的高可用发展历程
Share Nothing
MGR 提供了什么? • 基于Paxos协议实现的数据同步 • 宕机自动选主 • 多节点写入的冲突检测 • Failover后集群内数据修复 • 基于write set 的并行复制
MGR 没有提供什么? • 客户端的切换方案 • 新成员节点加入,Donar节点随机 • 复制延迟 • 大事务支持不足,容易OOM • 新节点加入,SST 不支持
分别进行冲突检测 • 每个成员节点都维护了一个“冲突检测数据库”,
所有待检测的事务对应的数据库版本必须大于冲 突检测数据库中已经通过检测的记录的版本 • 所有节点都已经执行的事务对应的记录会从冲突 检测数据库中异步purge
节点流控
为什么要引入流控机制: • 确保集群内各个节点的延迟
尽可能的小 • 避免Fail over时relay log 回放
A
Basic Paxos
全局事务的排序
accept
A
0,3,6… 3*n P1
accept
A
accept
A
accept
A
1,4,7… 3*n+1
P2
P
A accept
accept
A
accept
A
2,5,8… 3*n+2 P3
accept
A
Raft/Multi Paxos
Mencious
Paxos Instance Paxos Instance No.
• Flow Control • Paxos Instance • Certification • Write Relay Log • Parallel Replay
MGR 事务提交处理流程
Client
Server UPDATE
OK Native Process ng i
COMMIT
Paxos
Certification
10.172.15.3
Avaliable Zone
192.168.8.16
Secondary
10.172.15.4
Avaliable Zone
基于MGR的Single-Primary 方案
• Secondary 读到过旧的数据,最终数据一致性 • 大事务导致OOM
• Single-Primary 冲突检测不需要,但是并行复制需要,可以限制冲突检测数 据库大小
OK
Not OK
Commit
rollback
Other Server
Other Server
Certification
Certification
OK
Not OK OK
Not OK
Commit
Commit
rollback
rollback
prepare A
P prepare A
accept
A
P
accept
全局事务的排序 成员节点的管理 冲突检测机制 节点处理能力协同
Mencious Group View
Write Set Flow Control
• Client Execute DML • Native Processing • Before Commit Hook • GTID Allocated • Create WriteSet
• 由被选举的新的节点接管提案 权力,将新节点未被宕机节点 learned到宕机节点序号之间的 提案需要重新提议
成员节点的管理
冲突检测机制
Write set: • 每个事务新增加一个Log Event
(Transaction_context_log_event) • 包含信息 • 事务更新的主键 • 数据库快照版本(gtid_executed) • 只在内存中维护,不写入binlog 文件,保证兼容性 冲突检测: • 每个成员节点按照相同的次序(Paxox协议保障),
时间过长
流控机制: • 检测对象:事务个数 • 作用对象:本节点写事务 • 调控周期:默认1秒
01 深入MySQL Group Replication
02 基于MGR 多副本高可用集群架构设计
03 基于MGR Muti-Primary水平扩展 04 基于MGR的跨机房高可用实践
基于MGR的高可用架构设计
• 管控服务通过调用弹性网关服务切换客户 端的状态
故障切换的修复
• 重启实例,加入集群 • 在Secondary 全量备份,重新加入集群
Customer VPC
Application
R/W
R
RDS VPC
192.168.5.12
Primary
10.172.15.2
Avaliable Zone
Secondary
Share Storage
Master-Slave Rpl
MMM
MHA
Loss-Less Rpl Binlog DW
Galera
MGR
DRBD
SAN
Aurora
PolarDB
MySQL Group Replication
多副本数据库集群面临的挑战
• MySQL 5.7.17 Release • A new MySQL Plugin • Muti-Duplicate Cluster • Data Consistency • Single/Muti-Primary mode