如何使用统计软件SPSS进行回归分析_罗凤明
如何使用统计软件SPSS进行回归分析

软件设计开发本栏目责任编辑:谢媛媛1引言回归分析用来研究多个预报因子对预报量的影响程度,然后建立它们的统计关系的方程式,对未来时刻的预报量做出预报估计,是目前气象业务与研究中最为常用的一种统计分析与预报方法[1-8]。
逐步回归可从影响预报量的许多因子中,挑选出一批相关较好的作为预报因子,在气象业务中应用甚广[9-11]。
回归分析在气象业务和研究中应用非常广,但该过程目前基本上都是编程来实现,编程复杂、易出错,基层气象工作者较难掌握不利于推广应用。
SPSS(StatisticalProductandServiceSolutions)意为统计产品与服务解决方案,统计和数据分析功能强大,界面友好,易学易用,目前是非统计专业人员应用最多的统计软件[12-13]。
SPSS提供了多种回归分析过程,如Linear(线性回归)、Nonlinear(非线性回归)、CurveEstimation(曲线拟合)、BinaryLogistic(二分类,即事件概率回归)等。
本文简要介绍如何使用统计软件SPSS进行线性回归分析,为便于与传统编程方式对比,分析实例采用目前气象常用统计教科书中介绍“逐步回归分析”一节中的经典案例,逐步回归分析的原理和编程实现过程可参考文献[1-2]。
2线性逐步回归分析过程首先根据表1建立数据文件,其中y为预报量,x1、x2、x3和x4为预报因子。
表1预报因子与预报量资料表在SPSS菜单栏上选择Analyze→Regression→Linear(图1左),则出现LinearRegression(线性回归分析)主对话框(图1右)。
将“y”选入Dependent(因变量)框中,“x1”、“x2”、“x3”和“x4”选入Independent(自变量)框中,Method框选择Stepwise(逐步回归);Save子对话框中选择PredictedValues下的Unstandardized(将预报量的估计值另存为新变量),Options子对话框选择UseFValue;其余默认,点OK,则得线性逐步回归分析结果。
SPSS回归分析过程详解

线性回归的假设检验
01
线性回归的假设检验主要包括拟合优度检验和参数显著性 检验。
02
拟合优度检验用于检验模型是否能够很好地拟合数据,常 用的方法有R方、调整R方等。
1 2
完整性
确保数据集中的所有变量都有值,避免缺失数据 对分析结果的影响。
准确性
核实数据是否准确无误,避免误差和异常值对回 归分析的干扰。
3
异常值处理
识别并处理异常值,可以使用标准化得分等方法。
模型选择与适用性
明确研究目的
根据研究目的选择合适的回归模型,如线性回 归、逻辑回归等。
考虑自变量和因变量的关系
数据来源
某地区不同年龄段人群的身高 和体重数据
模型选择
多项式回归模型,考虑X和Y之 间的非线性关系
结果解释
根据分析结果,得出年龄与体 重之间的非线性关系,并给出 相应的预测和建议。
05 多元回归分析
多元回归模型
线性回归模型
多元回归分析中最常用的模型,其中因变量与多个自变量之间存 在线性关系。
非线性回归模型
常见的非线性回归模型
对数回归、幂回归、多项式回归、逻辑回归等
非线性回归的假设检验
线性回归的假设检验
H0:b1=0,H1:b1≠0
非线性回归的假设检验
H0:f(X)=Y,H1:f(X)≠Y
检验方法
残差图、残差的正态性检验、异方差性检验等
非线性回归的评估指标
判定系数R²
SPSS回归分析

SPSS回归分析SPSS(统计包统计软件,Statistical Package for the Social Sciences)是一种强大的统计分析软件,广泛应用于各个领域的数据分析。
在SPSS中,回归分析是最常用的方法之一,用于研究和预测变量之间的关系。
接下来,我将详细介绍SPSS回归分析的步骤和意义。
一、回归分析的定义和意义回归分析是一种对于因变量和自变量之间关系的统计方法,通过建立一个回归方程,可以对未来的数据进行预测和预估。
在实际应用中,回归分析广泛应用于经济学、社会科学、医学、市场营销等领域,帮助研究人员发现变量之间的关联、预测和解释未来的趋势。
二、SPSS回归分析的步骤1. 导入数据:首先,需要将需要进行回归分析的数据导入SPSS软件中。
数据可以以Excel、CSV等格式准备好,然后使用SPSS的数据导入功能将数据导入软件。
2. 变量选择:选择需要作为自变量和因变量的变量。
自变量是被用来预测或解释因变量的变量,而因变量是我们希望研究或预测的变量。
可以通过点击"Variable View"选项卡来定义变量的属性。
3. 回归分析:选择菜单栏中的"Analyze" -> "Regression" -> "Linear"。
然后将因变量和自变量添加到正确的框中。
4.回归模型选择:选择回归方法和模型。
SPSS提供了多种回归方法,通常使用最小二乘法进行回归分析。
然后,选择要放入回归模型的自变量。
可以进行逐步回归或者全模型回归。
6.残差分析:通过检查残差(因变量和回归方程预测值之间的差异)来评估回归模型的拟合程度。
可以使用SPSS的统计模块来生成残差,并进行残差分析。
7.结果解释:最后,对回归结果进行解释,并提出对于研究问题的结论。
要注意的是,回归分析只能描述变量之间的关系,不能说明因果关系。
因此,在解释回归结果时要慎重。
SPSS如何进行线性回归分析操作 精品

SPSS如何进行线性回归分析操作本节内容主要介绍如何确定并建立线性回归方程。
包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。
为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。
也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。
另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。
一、一元线性回归分析用SPSS进行回归分析,实例操作如下:1.单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。
从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。
在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。
所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。
具体如下图所示:2.请单击Statistics…按钮,可以选择需要输出的一些统计量。
如RegressionCoefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。
Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。
上述两项为默认选项,请注意保持选中。
设置如图7-10所示。
设置完成后点击Continue返回主对话框。
回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。
由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。
3.用户在进行回归分析时,还可以选择是否输出方程常数。
如何使用统计软件SPSS进行回归分析

如何使用统计软件SPSS进行回归分析如何使用统计软件SPSS进行回归分析引言:回归分析是一种广泛应用于统计学和数据分析领域的方法,用于研究变量之间的关系和预测未来的趋势。
SPSS作为一款功能强大的统计软件,在进行回归分析方面提供了很多便捷的工具和功能。
本文将介绍如何使用SPSS进行回归分析,包括数据准备、模型建立和结果解释等方面的内容。
一、数据准备在进行回归分析前,首先需要准备好需要分析的数据。
将数据保存为SPSS支持的格式(.sav),然后打开SPSS软件。
1. 导入数据:在SPSS软件中选择“文件”-“导入”-“数据”命令,找到数据文件并选择打开。
此时数据文件将被导入到SPSS的数据编辑器中。
2. 数据清洗:在进行回归分析之前,需要对数据进行清洗,包括处理缺失值、异常值和离群值等。
可以使用SPSS中的“转换”-“计算变量”功能来对数据进行处理。
3. 变量选择:根据回归分析的目的,选择合适的自变量和因变量。
可以使用SPSS的“变量视图”或“数据视图”来查看和选择变量。
二、模型建立在进行回归分析时,需要建立合适的模型来描述变量之间的关系。
1. 确定回归模型类型:根据研究目的和数据类型,选择适合的回归模型,如线性回归、多项式回归、对数回归等。
2. 自变量的选择:根据自变量与因变量的相关性和理论基础,选择合适的自变量。
可以使用SPSS的“逐步回归”功能来进行自动选择变量。
3. 建立回归模型:在SPSS软件中选择“回归”-“线性”命令,然后将因变量和自变量添加到相应的框中。
点击“确定”即可建立回归模型。
三、结果解释在进行回归分析后,需要对结果进行解释和验证。
1. 检验模型拟合度:可以使用SPSS的“模型拟合度”命令来检验模型的拟合度,包括R方值、调整R方值和显著性水平等指标。
2. 检验回归系数:回归系数表示自变量对因变量的影响程度。
通过检验回归系数的显著性,可以判断自变量是否对因变量有统计上显著的影响。
数据统计分析软件SPSS的应用(五)——相关分析与回归分析

数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS是目前应用广泛且非常强大的数据分析工具之一。
在前几篇文章中,我们介绍了SPSS的基本操作和一些常用的统计方法。
本篇文章将继续介绍SPSS中的相关分析与回归分析,这些方法是数据分析中非常重要且常用的。
一、相关分析相关分析是一种用于确定变量之间关系的统计方法。
SPSS提供了多种相关分析方法,如皮尔逊相关、斯皮尔曼相关等。
在进行相关分析之前,我们首先需要收集相应的数据,并确保数据符合正态分布的假设。
下面以皮尔逊相关为例,介绍SPSS 中的相关分析的步骤。
1. 打开SPSS软件并导入数据。
可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备相关分析的变量。
选择菜单栏中的“Analyze”选项,然后选择“Correlate”子菜单中的“Bivariate”。
在弹出的对话框中,选择要进行相关分析的变量,并将它们添加到相应的框中。
3. 进行相关分析。
点击“OK”按钮后,SPSS会自动计算所选变量之间的相关系数,并将结果输出到分析结果窗口。
4. 解读相关分析结果。
SPSS会给出相关系数的值以及显著性水平。
相关系数的取值范围为-1到1,其中-1表示完全负相关,1表示完全正相关,0表示没有相关关系。
显著性水平一般取0.05,如果相关系数的显著性水平低于设定的显著性水平,则可以认为两个变量之间存在相关关系。
二、回归分析回归分析是一种用于探索因果关系的统计方法,广泛应用于预测和解释变量之间的关系。
SPSS提供了多种回归分析方法,如简单线性回归、多元线性回归等。
下面以简单线性回归为例,介绍SPSS中的回归分析的步骤。
1. 打开SPSS软件并导入数据。
同样可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备回归分析的变量。
相关分析和回归分析SPSS实现

相关分析和回归分析SPSS实现SPSS(统计包统计分析软件)是一种广泛使用的数据分析工具,在相关分析和回归分析方面具有强大的功能。
本文将介绍如何使用SPSS进行相关分析和回归分析。
相关分析(Correlation Analysis)用于探索两个或多个变量之间的关系。
在SPSS中,可以通过如下步骤进行相关分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“相关”子菜单。
3.在“相关”对话框中,选择将要分析的变量,然后单击“箭头”将其添加到“变量”框中。
4.选择相关系数的计算方法(如皮尔逊相关系数、斯皮尔曼等级相关系数)。
5.单击“确定”按钮,SPSS将计算相关系数并将结果显示在输出窗口中。
回归分析(Regression Analysis)用于建立一个预测模型,来预测因变量在自变量影响下的变化。
在SPSS中,可以通过如下步骤进行回归分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“回归”子菜单。
3.在“回归”对话框中,选择要分析的因变量和自变量,然后单击“箭头”将其添加到“因变量”和“自变量”框中。
4.选择回归模型的方法(如线性回归、多项式回归等)。
5.单击“统计”按钮,选择要计算的统计量(如参数估计、拟合优度等)。
6.单击“确定”按钮,SPSS将计算回归模型并将结果显示在输出窗口中。
在分析结果中,相关分析会显示相关系数的数值和统计显著性水平,以评估变量之间的关系强度和统计显著性。
回归分析会显示回归系数的数值和显著性水平,以评估自变量对因变量的影响。
值得注意的是,相关分析和回归分析在使用前需要考虑数据的要求和前提条件。
例如,相关分析要求变量间的关系是线性的,回归分析要求自变量与因变量之间存在一定的关联关系。
总结起来,SPSS提供了强大的功能和工具,便于进行相关分析和回归分析。
通过上述步骤,用户可以轻松地完成数据分析和结果呈现。
然而,分析结果的解释和应用需要结合具体的研究背景和目的进行综合考虑。
如何使用统计软件SPSS进行回归分析

如何使用统计软件SPSS进行回归分析一、本文概述在当今的数据分析领域,回归分析已成为了一种重要的统计方法,广泛应用于社会科学、商业、医学等多个领域。
SPSS作为一款功能强大的统计软件,为用户提供了进行回归分析的便捷工具。
本文将详细介绍如何使用SPSS进行回归分析,包括回归分析的基本原理、SPSS 中回归分析的操作步骤、结果解读以及常见问题的解决方法。
通过本文的学习,读者将能够熟练掌握SPSS进行回归分析的方法和技巧,提高数据分析的能力,更好地应用回归分析解决实际问题。
二、SPSS软件基础SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)是一款广泛应用于社会科学领域的数据分析软件,具有强大的数据处理、统计分析、图表制作等功能。
对于回归分析,SPSS 提供了多种方法,如线性回归、曲线估计、逻辑回归等,可以满足用户的不同需求。
在使用SPSS进行回归分析之前,用户需要对其基本操作有一定的了解。
打开SPSS软件后,用户需要熟悉其界面布局,包括菜单栏、工具栏、数据视图和变量视图等。
在数据视图中,用户可以输入或导入需要分析的数据,而在变量视图中,用户可以定义和编辑变量的属性,如变量名、变量类型、测量级别等。
在SPSS中进行回归分析的基本步骤如下:用户需要选择“分析”菜单中的“回归”选项,然后选择适当的回归类型,如线性回归。
接下来,用户需要指定自变量和因变量,可以选择一个或多个自变量,并将它们添加到回归模型中。
在指定变量后,用户还可以设置其他选项,如选择回归模型的类型、设置显著性水平等。
完成这些设置后,用户可以点击“确定”按钮开始回归分析。
SPSS将自动计算回归模型的系数、标准误、显著性水平等统计量,并生成相应的输出表格和图表。
用户可以根据这些结果来评估回归模型的拟合优度、预测能力以及各自变量的贡献程度。
除了基本的回归分析功能外,SPSS还提供了许多高级选项和工具,如模型诊断、变量筛选、多重共线性检测等,以帮助用户更深入地理解和分析回归模型。
用SPSS做回归分析

用SPSS做回归分析回归分析是一种统计方法,用于研究两个或多个变量之间的关系,并预测一个或多个因变量如何随着一个或多个自变量的变化而变化。
SPSS(统计软件包的统计产品与服务)是一种流行的统计分析软件,广泛应用于研究、教育和业务领域。
要进行回归分析,首先需要确定研究中的因变量和自变量。
因变量是被研究者感兴趣的目标变量,而自变量是可能影响因变量的变量。
例如,在研究投资回报率时,投资回报率可能是因变量,而投资额、行业类型和利率可能是自变量。
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,并导入数据:首先打开SPSS软件,然后点击“打开文件”按钮导入数据文件。
确保数据文件包含因变量和自变量的值。
2.选择回归分析方法:在SPSS中,有多种类型的回归分析可供选择。
最常见的是简单线性回归和多元回归。
简单线性回归适用于只有一个自变量的情况,而多元回归适用于有多个自变量的情况。
3.设置因变量和自变量:SPSS中的回归分析工具要求用户指定因变量和自变量。
选择适当的变量,并将其移动到正确的框中。
4.运行回归分析:点击“运行”按钮开始进行回归分析。
SPSS将计算适当的统计结果,包括回归方程、相关系数、误差项等。
这些结果可以帮助解释自变量如何影响因变量。
5.解释结果:在完成回归分析后,需要解释得到的统计结果。
回归方程表示因变量与自变量之间的关系。
相关系数表示自变量和因变量之间的相关性。
误差项表示回归方程无法解释的变异。
6.进行模型诊断:完成回归分析后,还应进行模型诊断。
模型诊断包括检查模型的假设、残差的正态性、残差的方差齐性等。
SPSS提供了多种图形和统计工具,可用于评估回归模型的质量。
回归分析是一种强大的统计分析方法,可用于解释变量之间的关系,并预测因变量的值。
SPSS作为一种广泛使用的统计软件,可用于执行回归分析,并提供了丰富的功能和工具,可帮助研究者更好地理解和解释数据。
通过了解回归分析的步骤和SPSS的基本操作,可以更好地利用这种方法来分析数据。
回归分析SPSS操作

2)校正的决定系数Adj R2
Adj R2
1
MSE MST
0<AdjR2≤1, 越接近于1, 说明回归方程效果越好。
即使自变量对Y无显著意义,R2也随方程中的变量 个数增加而增加。Adj R2可以惩罚复杂模型。
结果显示:回归方程显著,即合成纤维的强度受拉伸倍数的显著影响
截距 回归系数
F=t2
b1
r
sY sX
标准化回归系数
zˆY rzx
zˆY zx
(2)第二部分 异常值分析
resid standardized
yˆi yi s
where s std dev of residuals
n
yi yˆi 2
s i1 n2
如果标准化残差超过2/-2,称为异常值outliers。 当样本量比较小,异常值又会影响回归系数的估计时, 应该关注异常值的影响。
1.00
25.00
60.00 53.00 47.00 1.31
1.14
27.00
52.00 51.00 55.00 1.23
1.14
20.00
56.00 57.00 59.00 1.00
1.14
26.00
68.00 58.00 53.00 1.00
1.00
30.00
60.00 53.00 56.00 1.00
1.00
27.00
64.00 56.00 59.00 1.85
1.14
18.00
67.00 53.00 53.00 1.00
1.00
24.00
56.00 56.00 56.00 1.00
1.00
《2024年数据统计分析软件SPSS的应用(五)——相关分析与回归分析》范文

《数据统计分析软件SPSS的应用(五)——相关分析与回归分析》篇一数据统计分析软件SPSS的应用(五)——相关分析与回归分析一、引言在当今的大数据时代,数据统计分析成为了科学研究、商业决策以及社会分析等领域中不可或缺的环节。
其中,相关分析与回归分析是数据统计分析中的两种重要方法。
本文将重点介绍这两种分析方法在数据统计分析软件SPSS中的应用,以及它们在现实研究中的应用实例。
二、相关分析1. 概念解释相关分析是研究两个或多个变量之间关系密切程度的一种统计方法。
通过计算相关系数,可以了解变量之间的线性关系强度和方向。
2. SPSS操作步骤(1)数据导入:将需要分析的数据导入到SPSS软件中。
(2)选择相关分析:在SPSS的菜单栏中选择“分析”->“相关”->“双变量”。
(3)选择变量:在弹出的对话框中选择需要进行相关分析的变量。
(4)设置选项:设置相关系数的计算方法、显著性水平等选项。
(5)运行分析:点击“运行”按钮,SPSS将自动计算相关系数并生成结果报告。
3. 实例应用以某市居民的年收入与消费支出为例,通过SPSS进行相关分析,可以了解年收入与消费支出之间的线性关系强度和方向,为政策制定提供参考依据。
三、回归分析1. 概念解释回归分析是研究一个或多个自变量与因变量之间关系的统计方法。
通过建立回归模型,可以预测因变量的值,并了解自变量对因变量的影响程度。
2. SPSS操作步骤(1)数据导入:将需要分析的数据导入到SPSS软件中。
(2)选择回归分析:在SPSS的菜单栏中选择“分析”->“回归”->“线性”。
(3)选择因变量和自变量:在弹出的对话框中设置因变量和自变量。
(4)设置模型:设置回归模型的类型、方法等选项。
(5)运行分析:点击“运行”按钮,SPSS将自动建立回归模型并生成结果报告。
3. 实例应用以某企业的销售额与广告投入为例,通过SPSS进行回归分析,可以了解广告投入对销售额的影响程度,为企业制定营销策略提供参考依据。
SPSS回归分析操作流程
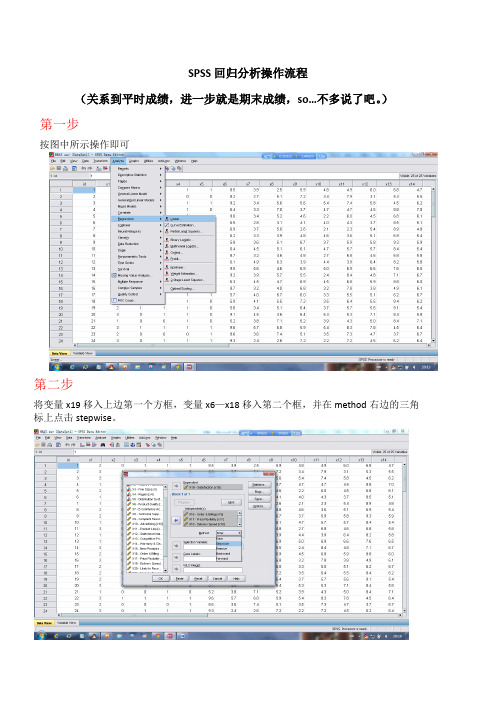
SPSS回归分析操作流程(关系到平时成绩,进一步就是期末成绩,so…不多说了吧。
)第一步按图中所示操作即可第二步将变量x19移入上边第一个方框,变量x6—x18移入第二个框,并在method右边的三角标上点击stepwise。
第三步点击右边第一个选项,把该画勾的画上,然后点continue第四步把该勾的勾上,把移近XY的两个选项拖进去,然后continue数据分析(这两个图就是个简单的描述,不用怎么解释)(这个图的官方名称是“变量移入/移出的方式”,通过这个图我们可以看到有5个变量进入了回归方程,依次是x9,x6……)(中间这个小图,是一个模型概述的表,由表可知,model5的R值为0.889,这个数值说明这5个自变量对于回归方程的贡献为88.9%,所以有继续研究的必要。
)(这是个方差分析表,很重要,以第一个为例解释。
F分布的显著性概率为o.ooo,显著,即拒绝原假设“回归系数B=0”,所以回归系数不为零,即变量x9的回归效果很好。
)(这是又一个重要的表,叫做“回归系数表”)(以第一个为例,constant(截距)对应的t值的显著性水平为0.000,显著,因此拒绝“截距=0”的原假设,即总体中回归方程的截距不为零,斜率对应的T值的显著性水平为0.000,显著,拒绝“斜率=0”的原假设,综上所述,x9对x19具有线性相关关系。
)(从第二个模型开始用到VIF值,VIF不大于10,说明没有多重共线性,可以继续分析。
)(这个叫做“被剔除的变量信息表”,看第一个发现已经没有X9变量了,第二个没有X6变量,说明他们依次被剔除了。
)(这个直译叫做“共线性诊断”,我不知道怎么分析,问杜建军,他说这个表多余…然后他百度了:第二列是特征根,特征根(Eigenvalue):该方法实际上就是对自变量进行主成分分析,如果相当多维度的特征根等于0,则可能有比较严重的共线性。
条件指数(Condition Idex):由Stewart等提出,当某些维度的该指标数值大于30时,则能存在共线性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
软件设计开发本栏目责任编辑:谢媛媛1引言回归分析用来研究多个预报因子对预报量的影响程度,然后建立它们的统计关系的方程式,对未来时刻的预报量做出预报估计,是目前气象业务与研究中最为常用的一种统计分析与预报方法[1-8]。
逐步回归可从影响预报量的许多因子中,挑选出一批相关较好的作为预报因子,在气象业务中应用甚广[9-11]。
回归分析在气象业务和研究中应用非常广,但该过程目前基本上都是编程来实现,编程复杂、易出错,基层气象工作者较难掌握不利于推广应用。
SPSS(StatisticalProductandServiceSolutions)意为统计产品与服务解决方案,统计和数据分析功能强大,界面友好,易学易用,目前是非统计专业人员应用最多的统计软件[12-13]。
SPSS提供了多种回归分析过程,如Linear(线性回归)、Nonlinear(非线性回归)、CurveEstimation(曲线拟合)、BinaryLogistic(二分类,即事件概率回归)等。
本文简要介绍如何使用统计软件SPSS进行线性回归分析,为便于与传统编程方式对比,分析实例采用目前气象常用统计教科书中介绍“逐步回归分析”一节中的经典案例,逐步回归分析的原理和编程实现过程可参考文献[1-2]。
2线性逐步回归分析过程首先根据表1建立数据文件,其中y为预报量,x1、x2、x3和x4为预报因子。
表1预报因子与预报量资料表在SPSS菜单栏上选择Analyze→Regression→Linear(图1左),则出现LinearRegression(线性回归分析)主对话框(图1右)。
将“y”选入Dependent(因变量)框中,“x1”、“x2”、“x3”和“x4”选入Independent(自变量)框中,Method框选择Stepwise(逐步回归);Save子对话框中选择PredictedValues下的Unstandardized(将预报量的估计值另存为新变量),Options子对话框选择UseFValue;其余默认,点OK,则得线性逐步回归分析结果。
图1线性回归分析过程(左为Regression菜单;右为LinearRegression主对话框)收稿日期:2007-12-17作者简介:罗凤明,男,工程师,主要从事网络维护,业务开发及服务工作。
如何使用统计软件SPSS进行回归分析罗凤明,邱劲飚,李明华,肖炳坤(惠州市气象局,广东惠州516001)摘要:简要介绍如何使用统计软件SPSS进行线性回归分析,并给出了逐步回归分析实例。
使用SPSS进行回归分析操作简单且全面,与编程相比大大减小了难度、节约了时间。
关键词:计算机应用;SPSS;回归分析;逐步回归中图分类号:TP312文献标识码:A文章编号:1009-3044(2008)02-10293-02HowtodoRegressionAnalysisbyStatisticalSoftwareSPSSLUOFeng-ming,QIUJin-biao,LIMing-hua,XIAOBin-kun(HuizhouMeteorologicalStation,Huizhou516001,China)Abstract:IntroducedinbriefhowtodolinearregressionanalysisbystatisticalsoftwareSPSS,andgaveanex-ampleofstepwiseregressionanalysis.ItissimplyandroundlytodoregressionanalysisbySPSS,andiseasierandtimesavingcomparedwithprogramme.Keywords:computerapllication;SPSS;regressionanalysis;stepwiseregressionLinearRegression过程Method单选框中提供了Enter(强制引进法)、Stepwise、Remove(强制剔除法)、Backward(逐步剔除法)和Forward(逐步引进法)5种方法,Method单选框与Block按钮组的组合使用,可对引入的不同变量组进入回归方程的方法进行单独设置。
Statistics子对话框可供用户选择更多的输出统计量。
Plots子对话框中提供了散点图、标准化残差图等,主要用于残差序列的分析。
Save子对话框中提供了将预测值、残差等分析结果存为数据编辑窗口中新变量的功能,以便进一步分析。
Options子对话框可供用户设置多元线性回归分析中纳入和排除的标准以及缺失值的处理方式。
3线性逐步回归分析结果表2、表3和表4给出了线性逐步回归分析的部分结果。
表2给出了回归模型(方程)的拟合优度,表3给出了回归系数,表4给出了回归模型方差分析结果。
由表2、表3和表4可知:回归方程1:y!=117.568-0.738x4,R为0.821,校正的决定系数Ra2为0.645,残差均方差σ!2为80.352,回归方程和回归系数都通过了0.01的显著性检验。
回归方程2:y!=103.097+1.440x1-0.614x4,R为0.986,校正的决定系数Ra2为0.967,残差均方差σ!2为7.476,回归方程和回归系数都通过了0.01的显著性检验。
回归方程3:y!=71.648+1.452x1+0.416x2-0.237x4,R为0.991,校正的决定系数Ra2为0.976,残差均方差σ!2为5.330,回归方程通过了0.01的显著性检验,但预报因子x2和x4的回归系数未通过0.05的显著性检验。
回归方程4:y!=52.577+1.468x1+0.662x2,R为0.989,校正的决定系数Ra2为0.974,残差均方差σ!2为5.790,回归方程和回归系数都通过了0.01的显著性检验,该方程为“最优”回归方程,分析结果与参考文献一致。
应用统计学中逐步回归筛选自变量的准则,一般有残差平方准则和统计量显著性检验准则2种。
前者是将自变量个数与残差平方和的值结合起来(σ!2)考虑选取哪些自变量构造模型,但SPSS目前尚未提供该项功能;后者是通过对回归系数进行显著性检验,选择有统计学意义的自变量构成模型,SPSS目前支持该项功能。
而气象统计分析中常根据因子既显著、方程的残差均方差σ!2又最小的原则来挑选“最优”回归方程,此时可以对多个回归模型通过人工判断找出“最优”回归方程。
由上面的分析可知,回归方程2和方程4较好,其中方程4为“最优”回归方程,与参考文献的分析结果一致。
图2给出了预报量和预报方程2和方程4估计量的变化图。
由图2可知,预报量与预报方程2和方程4的估计量的变化趋势基本一致,2个回归方程拟合都较好。
表2ModelSummary(回归模型拟合优度)表3Coefficients(回归系数)表4ANOVA(回归模型方差分析结果)图2预报量与预报方程的估计量变化图由上面的回归分析过程可知,统计软件SPSS集数据处理、多种回归分析方法、回归检验、回归预测、残差分析和绘制图表等功能于一身,回归分析功能强大且易学易用。
使用统计软件SPSS进行回归分析非常简单,靠鼠标点击即可完成操作,同时利用Paste键可将操作过程存为程序,方便下次直接调用,与教科书中提供的编程方法相比提供了更多回归分析功能、提高了方程的精度、且大大减小了操作难度、节约了时间。
参考文献:[1]黄嘉佑.气象统计分析与预报方法[M].第3版.北京:气象出版社,2004:58-72.(下转第304页)(上接第294页)[2]施能.气象科研与预报中的多元分析方法[M].第2版.北京:气象出版社,2002:46-55.[3]林良勋.广东省天气预报技术手册[M].北京:气象出版社,2006.[4]徐海量,陈亚宁.塔里木河下游荒漠化多元回归模型分析[J].干旱区资源与环境,2003,17(4):78-82.[5]李丽.用深层地温资料建立多元非线性回归方程预报韶关站前汛期降水量[J].广东气象,2003,25(2):8-9.[6]彭武坚.主分量逐步回归法在桂东南低温阴雨预报的应用[J].广西气象,2005,26(S1):41-44.[7]孔宁谦,陈润珍.用统计动力方法作盛夏南海中北部热带气旋强度预报[J].广西气象,2006,27(1):4-5.[8]唐毓勇,蒋国兴.均生函数残差预报模型在降水预报中的试验研究[J].广西气象,2006,27(3):5-8.[9]曾琮,陈创买.主分量逐步回归在气温预测中的应用[J].中山大学学报:自然科学版,2006,45(4):107-110.[10]陈慧娴,黄露菁,陈创买.用逐步回归方法预报番禺年降水量[J].广东气象,2004,26(4):7-9.[11]彭端,黄天文,郭媚媚,等.用逐步回归模型预测肇庆市汛期降水[J].广东气象,2005,27(2):16-17.[12]张文彤.SPSS11统计分析教程(高级篇)[M].北京:希望电子出版社,2002.[13]张文彤.SPSS统计分析高级教程[M].北京:高等教育出版社,2004.(1)计算信息系统S的区分矩阵M(S);(2)根据区分矩阵M(S)计算相关的区分函数fm(s);(3)计算区分函数fm(s)的最小析取范式,求出所有的约简。
下面给出基于区分矩阵的算法:输入:一个目标决策系统S=(U,A,V,f),其中U是论域,A=CUD,C是条件属性集合,D是决策属性集合。
输出:S的属性约简及核属性。
(1)计算“U/IND(C),令Core=0,Reduct=0,n={U/IND(C)},定义一个nxn的矩阵结构M(n,n),并令其所有元素为O;(2)生成区分矩阵:fori=1ton{forj=i+lton{fork=1to|C|{ifCk(Xi)≠Ck(Xj)andD(Xi)≠D(Xj)thenM(i,j)=M(i,j)∪Ck}}}(3)求约简及核值:fori=lton{forj=i+1ton{if|M(i,j)|=1thenCore=Core∪M(i,j)Reduct=Reduct∩M(i,j)}}Core为核值,Reduct为约简。
该算法的优点是能够直接提取出规则,缺点是计算的复杂度高。
因此,只能处理非常小的数据。
考虑到区分矩阵算法复杂度的问题,从而提出了区分矩阵的简化方法。
所谓简化方法就是一边从信息系统中提取关于属性值是区分的属性并构成区分合取范式,一边做这种逻辑公式的等价变化,直接得到最小析取范式,从而避免生成区分矩阵的中间环节,最终达到节省空间和时间,降低约简算法复杂度。
当然建立在区分矩阵的基础上,还有很多改进算法,而且在一定程度上,都对算法复杂度有一定的降低。