python threading 参数
Python3入门之线程threading常用方法

Python3⼊门之线程threading常⽤⽅法Python3 线程中常⽤的两个模块为:_threadthreading(推荐使⽤)thread 模块已被废弃。
⽤户可以使⽤ threading 模块代替。
所以,在 Python3 中不能再使⽤"thread" 模块。
为了兼容性,Python3 将 thread 重命名为"_thread"。
下⾯将介绍threading模块常⽤⽅法:1. threading.Lock()如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进⾏同步。
使⽤ Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire ⽅法和 release ⽅法,对于那些需要每次只允许⼀个线程操作的数据,可以将其操作放到 acquire 和 release ⽅法之间。
来看看多个线程同时操作⼀个变量怎么把内容给改乱了(在windows下不会出现内容混乱情况,可能python在Windows下⾃动加上锁了;不过在Linux 下可以测试出内容会被改乱):#!/usr/bin/env python3import time, threading# 假定这是你的银⾏存款:balance = 0def change_it(n):# 先存后取,结果应该为0:global balancebalance = balance + nbalance = balance - ndef run_thread(n):for i in range(100000):change_it(n)t1 = threading.Thread(target=run_thread, args=(5,))t2 = threading.Thread(target=run_thread, args=(8,))t1.start()t2.start()t1.join()t2.join()print(balance)执⾏结果:[root@localhost ~]# python3 thread_lock.py5[root@localhost ~]# python3 thread_lock.py5[root@localhost ~]# python3 thread_lock.py[root@localhost ~]# python3 thread_lock.py8[root@localhost ~]# python3 thread_lock.py-8[root@localhost ~]# python3 thread_lock.py5[root@localhost ~]# python3 thread_lock.py-8[root@localhost ~]# python3 thread_lock.py3[root@localhost ~]# python3 thread_lock.py5我们定义了⼀个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执⾏时,只要循环次数⾜够多,balance的结果就不⼀定是0了。
Python中threading模块的join函数

Python中threading模块的join函数Join的作⽤是阻塞进程直到线程执⾏完毕。
通⽤的做法是我们启动⼀批线程,最后join这些线程结束,例如:1for i in range(10):23 t = ThreadTest(i)45 thread_arr.append(t)67for i in range(10):89 thread_arr[i].start()1011for i in range(10):1213 thread_arr[i].join()此处join的原理就是依次检验线程池中的线程是否结束,没有结束就阻塞直到线程结束,如果结束则跳转执⾏下⼀个线程的join函数。
⽽py的join函数还有⼀个特殊的功能就是可以设置超时,如下:Thread.join([timeout])Wait until the thread terminates. This blocks the calling thread until the thread whose method is called terminates –either normally or through an unhandled exception – or until the optional timeout occurs.也就是通过传给join⼀个参数来设置超时,也就是超过指定时间join就不在阻塞进程。
⽽在实际应⽤测试的时候发现并不是所有的线程在超时时间内都结束的,⽽是顺序执⾏检验是否在time_out时间内超时,例如,超时时间设置成2s,前⾯⼀个线程在没有完成的情况下,后⾯线程执⾏join会从上⼀个线程结束时间起再设置2s的超时。
threading的用法

Threading是Python标准库中的一个模块,用于多线程编程。
它提供了创建和管理线程的方法,使得程序可以同时执行多个任务。
使用Threading模块的基本步骤如下:
1. 导入Threading模块
```python
import threading
```
2. 定义一个函数,这个函数将作为线程的执行体
```python
def my_function():
# do something
```
3. 创建一个Thread对象,并将上一步定义的函数作为参数传递给Thread类的构造函数中
```python
my_thread = threading.Thread(target=my_function)
```
4. 启动线程,调用Thread对象的start方法
```python
my_thread.start()
```
5. 如果需要等待线程执行完毕,可以使用join方法阻塞主线程,直到子线程执行完毕
```python
my_thread.join()
```
除了基本的用法之外,Threading模块还提供了一些其他的功能,如设置线程优先级、获取线程ID等。
Python中Threading用法详解

Python中Threading⽤法详解Python的threading模块松散地基于Java的threading模块。
但现在线程没有优先级,没有线程组,不能被销毁、停⽌、暂停、开始和打断。
Java Thread类的静态⽅法,被移植成了模块⽅法。
main thread: 运⾏python程序的线程daemon thread 守护线程,如果守护线程之外的线程都结束了。
守护线程也会结束,并强⾏终⽌整个程序。
不要在守护进程中进⾏资源相关操作。
会导致资源不能正确的释放。
在⾮守护进程中使⽤Event。
Thread 类(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)group: 为以后的ThreadGroup类预留target: 被执⾏的对象,由run()⽅法执⾏args: target对象使⽤的参数daemon: 是否为守护进程start()每个thread 对象都只能被调⽤1次start()run()如果创建Thread的⼦类,重写该⽅法。
负责执⾏target参数传来的可执⾏对象。
join()阻塞线程直到结束。
GIL在CPython中,由于GIL的存在,Python每次只能执⾏⼀个线程。
如果要充分利⽤多核机器的计算资源需要使⽤multiprocessing或者是concurrent.futures.ProcessPollExecutor。
但,但如果你想要很多I/O相关的并发操作,threding仍然是⼀个很好的选择。
?因为系统⾃动实现了线程的上下⽂切换。
from threading import Threadimport requestsurl = ''urls = [url]*20threads = []for url in urls:t = Thread(target=requests.get, args=(url, ))t.start()threads.append(t)for t in threads:t.join()锁(Lock)对象原始锁(primitive lock),当它锁住的时候,它是⼀种不属于任何⼀个线程的同步原语(synchronization primitive)。
python笔记9-多线程Threading之阻塞(join)和守护线程(setDaemon)

python笔记9-多线程Threading之阻塞(join)和守护线程(setDaemon)前⾔今天⼩王请xiaoming和xiaowang吃⽕锅,吃完⽕锅的时候会有以下三种场景:场景⼀:⼩王(主)先吃完了,海海(客)和⽼王(客)还没吃完,这种场景会导致结账的⼈先⾛了,剩下两个⼩伙伴傻眼了。
场景⼆:⼩王(主)先吃完了,海海和⽼王还没吃饱,⼀起结账⾛⼈。
场景三:⼩王(主)先等海海和⽼王吃饱了,⼩编最后结账⼀起⾛⼈。
主线程与⼦线程场景⼀:主线程已经结束了,⼦线程还在跑1.我们把thread1.start()和thread2.start()称为两个⼦线程,写在外⾯的代码就是主线程了。
# -*- coding:utf-8 -*-import timeimport threadingdef chiHuoGuo(people):print("%s 吃⽕锅的⼩伙伴-⽺⾁:%s" % (time.ctime(),people))time.sleep(1)print("%s 吃⽕锅的⼩伙伴-鱼丸:%s" % (time.ctime(),people))class myThread(threading.Thread):def __init__(self, people, name):'''重写threading.Thread初始化内容'''threading.Thread.__init__(self)self.threadNmae = nameself.people = peopledef run(self):print("开始线程:" + self.threadNmae)chiHuoGuo(self.people)print("结束线程:" + self.threadNmae)if __name__ == "__main__":# 启动线程thread1 = myThread("xiaoming", "Thread-1")thread2 = myThread("xiaowang", "Thread-2")thread1.start()thread2.start()time.sleep(0.1)print("退出主线程:吃⽕锅,结账⾛⼈")守护线程setDaemon()场景⼆:主线程结束了,⼦线程必须也跟着结束1.主线程中,创建了⼦线程线程A和线程B,并且在主线程中调⽤了thread.setDaemon(),这个的意思是,把主线程设置为守护线程,这时候,要是主线程执⾏结束了,就不管⼦线程是否完成,⼀并和主线程退出.(敲⿊板:必须在start()⽅法调⽤之前设置,如果不设置为守护线程,程序会被⽆限挂起。
python threading 参数

python threading 参数摘要:1.Python 线程简介2.Python 线程的创建方式3.Python 线程的主要参数4.Python 线程的同步与通信5.Python 线程的优缺点正文:1.Python 线程简介Python 是一种解释型的高级编程语言,具有简洁、易读和可扩展的特点。
在Python 中,线程是一种实现多任务并发执行的方式。
通过使用线程,可以在一个程序中同时执行多个任务,从而提高程序的执行效率。
2.Python 线程的创建方式Python 中可以使用`threading`模块来创建和管理线程。
`threading`模块提供了多种线程创建方式,主要包括以下几种:- 通过继承`threading.Thread`类创建线程- 使用`threading.Thread`类的`start()`方法创建线程- 使用`threading.Thread`类的`join()`方法启动线程3.Python 线程的主要参数Python 线程的主要参数包括以下几个:- `threading.Thread`类:`threading.Thread`类是Python 线程的基本类,用于创建和管理线程。
- `args`参数:`args`参数是一个元组,用于传递给线程的初始化参数。
- `kwargs`参数:`kwargs`参数是一个字典,用于传递给线程的额外参数。
- `lock`参数:`lock`参数是一个`threading.Lock`对象,用于实现线程的同步。
- `signal`参数:`signal`参数是一个整数,表示线程在接收到中断信号时应该执行的操作。
4.Python 线程的同步与通信在多线程环境下,为了防止多个线程同时访问共享资源导致数据不一致问题,需要使用线程同步机制。
Python 提供了`threading.Lock`和`threading.RLock`两种线程同步对象。
此外,还可以使用`threading.Semaphore`实现线程的同步。
python多线程的高级用法,以及线程同步和互斥机制

python多线程的高级用法,以及线程同步和互斥机制Python 的多线程模块 `threading` 提供了一种方法来创建和管理线程。
下面是一些 Python 多线程的高级用法,以及线程同步和互斥机制的介绍。
高级用法1. 线程局部存储:使用 `()` 可以为每个线程提供独立的存储空间。
这对于在线程之间存储和检索数据非常有用。
```pythonimport threading创建一个线程局部存储对象thread_local = ()def worker():设置线程局部变量的值thread_ = "thread-{}".format(_thread().name)print(thread_)threads = []for i in range(5):t = (target=worker)(t)()```2. 线程池:使用 `` 可以更方便地管理线程池。
这个类提供了一个 `map()` 方法,可以并行地对可迭代对象中的每个元素执行函数。
```pythonfrom import ThreadPoolExecutordef square(n):return n nwith ThreadPoolExecutor(max_workers=5) as executor:results = (square, range(10))```3. 线程锁:使用 `` 可以实现线程之间的互斥。
当一个线程拥有锁时,其他线程必须等待锁被释放后才能继续执行。
```pythonlock = ()with lock:临界区,只有一个线程可以执行这部分代码pass```4. 信号量:使用 `` 可以实现线程之间的同步。
信号量是一个计数器,用于控制同时访问共享资源的线程数量。
```pythonfrom import Semaphoresem = Semaphore(3) 最多允许3个线程同时访问共享资源with sem:临界区,只有当信号量计数大于0时,线程才能执行这部分代码pass```5. 事件循环:使用 `asyncio` 模块可以实现异步 I/O 和协程的并发执行。
threading 穿参数

threading 穿参数在Python中,threading 模块允许你创建和管理线程。
当你想在多个线程之间传递参数时,可以使用多种方式。
这里是一些方法来穿参数(传递参数)给线程:1. 通过target函数最常见的方式是在定义线程时要执行的函数时,将其作为target参数传递给Thread 类,并在该函数中定义所需的参数。
pythonimport threadingdef worker_function(arg1, arg2):# 处理参数print(f"Working with {arg1} and {arg2}")# 创建线程实例,并传递参数thread = threading.Thread(target=worker_function, args=("Hello", 123)) thread.start()thread.join()2. 使用类你也可以定义一个线程类,并在__init__方法中接收参数。
pythonimport threadingclass WorkerThread(threading.Thread):def __init__(self, arg1, arg2):threading.Thread.__init__(self)self.arg1 = arg1self.arg2 = arg2def run(self):# 使用self.arg1和self.arg2print(f"Working with {self.arg1} and {self.arg2}")# 创建线程实例,并传递参数thread = WorkerThread("Hello", 123)thread.start()thread.join()注意事项当在线程间传递参数时,确保这些参数是线程安全的,或者它们在使用时不会被多个线程同时修改。
Python的多线程(threading)与多进程(multiprocessing)

Python的多线程(threading)与多进程(multiprocessing)进程:程序的⼀次执⾏(程序载⼊内存,系统分配资源运⾏)。
每个进程有⾃⼰的内存空间,数据栈等,进程之间可以进⾏通讯,但是不能共享信息。
线程:所有的线程运⾏在同⼀个进程中,共享相同的运⾏环境。
每个独⽴的线程有⼀个程序⼊⼝,顺序执⾏序列和程序的出⼝。
线程的运⾏可以被强占,中断或者暂时被挂起(睡眠),让其他的线程运⾏。
⼀个进程中的各个线程共享同⼀⽚数据空间。
多线程import threadingdef thread_job():print "this is added thread,number is {}".format(threading.current_thread())def main():added_thread = threading.Thread(target = thread_job) #添加线程added_thread.start() #执⾏添加的线程print threading.active_count() #当前已被激活的线程的数⽬print threading.enumerate() #激活的是哪些线程print threading.current_thread() #正在运⾏的是哪些线程if __name__ == "__main__":main()this is added thread,number is <Thread(Thread-6, started 6244)>6[<HistorySavingThread(IPythonHistorySavingThread, started 7588)>, <ParentPollerWindows(Thread-3, started daemon 3364)>, <Heartbeat(Thread-5, started daemon 3056)>, <_MainThread(MainThread, started 1528)>, <Thread(Thread-6, started <_MainThread(MainThread, started 1528)>#join 功能等到线程执⾏完之后再回到主线程中去import threadingimport timedef T1_job():print "T1 start\n"for i in range(10):time.sleep(0.1)print "T1 finish"def T2_job():print 'T2 start'print 'T2 finish'def main():thread1 = threading.Thread(target = T1_job) #添加线程thread2 = threading.Thread(target = T2_job)thread1.start() #执⾏添加的线程thread2.start()thread1.join()thread2.join()print 'all done\n'if __name__ == "__main__":main()T1 startT2 startT2 finishT1 finishall done#queue 多线程各个线程的运算的值放到⼀个队列中,到主线程的时候再拿出来,以此来代替#return的功能,因为在线程是不能返回⼀个值的import timeimport threadingfrom Queue import Queuedef job(l,q):q.put([i**2 for i in l])def multithreading(data):q = Queue()threads = []for i in xrange(4):t = threading.Thread(target = job,args = (data[i],q))t.start()threads.append(t)for thread in threads:thread.join()results = []for _ in range(4):results.append(q.get())print resultsif __name__ == "__main__":data = [[1,2,3],[4,5,6],[3,4,3],[5,5,5]]multithreading(data)[[1, 4, 9], [16, 25, 36], [9, 16, 9], [25, 25, 25]]#多线程的锁import threadingimport timedef T1_job():global A,locklock.acquire()for i in xrange(10):A += 1print 'T1_job',Alock.release()def T2_job():global A,locklock.acquire()for i in xrange(10):A += 10print 'T2_job',Aif __name__ == "__main__":lock = threading.Lock()A = 0 #全局变量thread1 = threading.Thread(target = T1_job) #添加线程thread2 = threading.Thread(target = T2_job)thread1.start() #执⾏添加的线程thread2.start()thread1.join()thread2.join() 全局解释器锁GIL(Global Interpreter Lock)GIL并不是Python的特性,他是CPython引⼊的概念,是⼀个全局排他锁。
Python线程threading模块用法详解

Python线程threading模块⽤法详解本⽂实例讲述了Python线程threading模块⽤法。
分享给⼤家供⼤家参考,具体如下:threading-更⾼级别的线程接⼝源代码:该模块在较低级别thread模块之上构建更⾼级别的线程接⼝。
另请参见mutex和Queue模块。
该dummy_threading模块适⽤于threading因thread缺失⽽⽆法使⽤的情况。
注意:从Python 2.6开始,该模块提供符合 PEP 8的别名和属性,以替换camelCase受Java的线程API启发的名称。
此更新的API与multiprocessing模块的API兼容。
但是,没有为camelCase名称的弃⽤设置计划,它们在Python 2.x和3.x中仍然完全受⽀持。
注意:从Python 2.5开始,⼏个Thread⽅法引发RuntimeError ⽽不是AssertionError错误地调⽤。
该模块定义了以下功能和对象:threading.active_count()threading.activeCount()返回Thread当前活动的对象数。
返回的计数等于返回的列表的长度enumerate()。
在2.6版中更改:添加了active_count()拼写。
threading.Condition()返回新条件变量对象的⼯⼚函数。
条件变量允许⼀个或多个线程等待,直到另⼀个线程通知它们。
请参阅条件对象。
threading.current_thread()threading.currentThread()返回当前Thread对象,对应于调⽤者的控制线程。
如果未通过threading模块创建调⽤者的控制线程,则返回具有有限功能的虚拟线程对象。
在2.6版中更改:添加了current_thread()拼写。
threading.enumerate()返回Thread当前活动的所有对象的列表。
该列表包括守护线程,由其创建的虚拟线程对象 current_thread()和主线程。
python 线程详细用法

python 线程详细用法
def producer(): # 生产者线程代码 my_queue.put(item)
希望这些详细的用法可以帮助您理解和使用Python中的线程功能。
# 线程要执行的代码 my_thread = threading.Thread(target=my_function) 3. 启动线程:使用`start()`方法来启动线程,使其开始执行。例如: my_thread.start()
python 线程详细法
4. 线程同步:可以使用锁(Lock)或条件(Condition)来实现线程之间的同步。例如: lock = threading.Lock() def my_function():
while is_running: # 线程要执行的代码
# 在需要退出线程时,设置is_running为False is_running = False
python 线程详细用法
需要注意的是,Python中的线程是基于操作系统的线程实现的,而不是真正的并行执行 。这是因为Python的全局解释器锁(GIL)限制了同一时刻只能有一个线程执行Python字节 码。因此,在需要并行执行的情况下,可以考虑使用多进程(multiprocessing)来实现。
def consumer(): # 消费者线程代码 item = my_queue.get()
python 线程详细用法
6. 线程等待:可以使用`join()`方法来等待线程执行完毕。例如: my_thread.join() 7. 线程退出:线程可以通过设置一个标志来退出执行。例如: is_running = True def my_function():
python中的线程threading.Thread()使用详解

python中的线程threading.Thread()使⽤详解1. 线程的概念:线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执⾏流的最⼩单元。
⼀个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。
另外,线程是进程中的⼀个实体,是被系统独⽴调度和分派的基本单位,线程⾃⼰不拥有系统资源,只拥有⼀点⼉在运⾏中必不可少的资源,但它可与同属⼀个进程的其它线程共享进程所拥有的全部资源。
2. threading.thread()的简单使⽤2.1 python的thread模块是⽐较底层的模块,python的threading模块是对thread做了⼀些包装的,可以更加⽅便的被使⽤import threadingimport timedef saySorry():print("亲爱的,我错了,我能吃饭了吗?")time.sleep(1)if __name__ == "__main__":for i in range(5):t = threading.Thread(target=saySorry)t.start() #启动线程,即让线程开始执⾏运⾏结果:使⽤说明:可以明显看出使⽤了多线程并发的操作,花费时间要短很多当调⽤start()时,才会真正的创建线程,并且开始执⾏每个线程都有⼀个唯⼀标⽰符,来区分线程中的主次关系主线程:mainThread,Main函数或者程序主⼊⼝,都可以称为主线程⼦线程:Thread-x 使⽤ threading.Thread() 创建出来的都是⼦线程线程数量:主线程数 + ⼦线程数2.2 主线程会等待所有的⼦线程结束后才结束import threadingfrom time import sleep,ctimedef sing():for i in range(3):print("正在唱歌...%d"%i)sleep(1)def dance():for i in range(3):print("正在跳舞...%d"%i)sleep(1)if __name__ == '__main__':print('---开始---:%s'%ctime())t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)t1.start()t2.start()#sleep(5) # 屏蔽此⾏代码,试试看,程序是否会⽴马结束?print('---结束---:%s'%ctime())3.查看线程数量import threadingfrom time import sleep,ctimedef sing():for i in range(3):print("正在唱歌...%d"%i)sleep(1)def dance():for i in range(3):print("正在跳舞...%d"%i)sleep(1)if __name__ == '__main__':print('---开始---:%s'%ctime())t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)t1.start()t2.start()while True:length = len(threading.enumerate())print('当前运⾏的线程数为:%d'%length)if length<=1:breaksleep(0.5)4.线程参数及顺序4.1 传递参数的⽅法:使⽤args 传递参数 threading.Thread(target=sing, args=(10, 100, 100))使⽤kwargs传递参数 threading.Thread(target=sing, kwargs={“a”: 10, “b”:100, “c”: 100})同时使⽤ args 和 kwargs 传递参数 threading.Thread(target=sing, args=(10, ), kwargs={“b”: 100,“c”: 100})4.2 线程的执⾏顺序import socketimport threadingimport timedef sing():for i in range(10):print("------------------------------")time.sleep(0.5)def dance():for i in range(10):print("-----")time.sleep(0.5)if __name__ == '__main__':# 创建两个⼦线程t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)# 启动⼦线程t1.start()t2.start()说明:从代码和执⾏结果我们可以看出,多线程程序的执⾏顺序是不确定的。
python中thread的用法

python中thread的用法Python中的thread用于实现多线程编程。
多线程可以提高程序的执行效率,同时也可以方便地进行并发编程。
Python中的thread模块提供了Thread类,可以通过继承该类来创建线程。
使用thread模块创建线程的基本步骤如下:1. 导入thread模块。
2. 创建一个Thread对象,同时传入一个可调用对象(比如函数或方法)作为参数。
3. 调用Thread对象的start()方法,启动线程。
例如:import threadimport time# 定义一个函数作为线程的执行体def print_time(threadName, delay):count = 0while count < 5:time.sleep(delay)count += 1print('%s: %s' % (threadName, time.ctime(time.time()))) # 创建两个线程try:thread.start_new_thread(print_time, ('Thread-1', 2,)) thread.start_new_thread(print_time, ('Thread-2', 4,)) except:print('Error: unable to start thread')# 等待所有线程执行完毕while 1:pass上述代码中,我们定义了一个print_time()函数作为线程的执行体,该函数会打印出当前时间并等待一段时间。
然后我们通过thread.start_new_thread()函数创建了两个线程,并启动它们。
最后我们使用一个无限循环等待所有线程执行完毕。
除了使用thread模块创建线程之外,Python中还可以使用threading模块来实现多线程编程。
threading模块提供了更高级别的线程操作接口,使用起来更加方便。
python中threading模块详解及常用方法
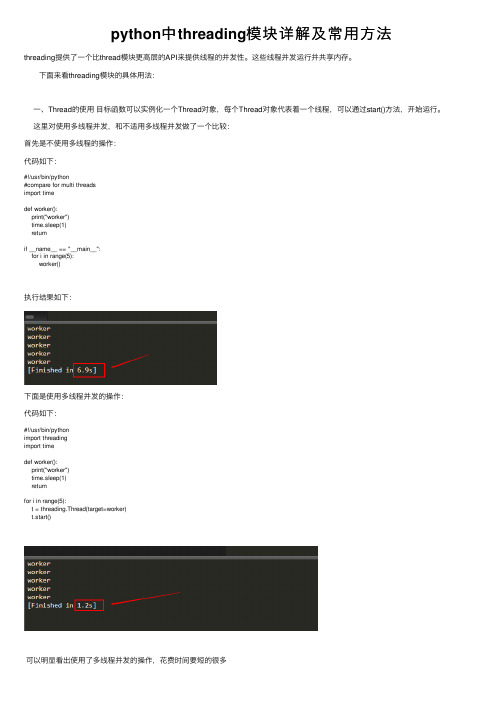
python中threading模块详解及常⽤⽅法
threading提供了⼀个⽐thread模块更⾼层的API来提供线程的并发性。
这些线程并发运⾏并共享内存。
下⾯来看threading模块的具体⽤法:
⼀、Thread的使⽤⽬标函数可以实例化⼀个Thread对象,每个Thread对象代表着⼀个线程,可以通过start()⽅法,开始运⾏。
这⾥对使⽤多线程并发,和不适⽤多线程并发做了⼀个⽐较:
⾸先是不使⽤多线程的操作:
代码如下:
#!/usr/bin/python
#compare for multi threads
import time
def worker():
print("worker")
time.sleep(1)
return
if __name__ == "__main__":
for i in range(5):
worker()
执⾏结果如下:
下⾯是使⽤多线程并发的操作:
代码如下:
#!/usr/bin/python
import threading
import time
def worker():
print("worker")
time.sleep(1)
return
for i in range(5):
t = threading.Thread(target=worker)
t.start()
可以明显看出使⽤了多线程并发的操作,花费时间要短的很多。
pythonthreading获取线程函数返回值

pythonthreading获取线程函数返回值最近需要⽤python写⼀个环境搭建⼯具,多线程并⾏对环境各个部分执⾏⼀些操作,并最终知道这些并⾏执⾏的操作是否都执⾏成功了,也就是判断这些操作函数的返回值是否为0。
但是threading并没有显式的提供获取各个线程函数返回值的⽅法,只好⾃⼰动⼿,下⾯就介绍⼀下⾃⼰的实现⽅式。
⼀开始考虑到执⾏的操作可能有很多,⽽且后续会不断补充,因此先写了⼀个通⽤的多线程执⾏类,封装线程操作的基本⽅法,如下:import threadingclass MyThread(object):def __init__(self, func_list=None):#所有线程函数的返回值汇总,如果最后为0,说明全部成功self.ret_flag = 0self.func_list = func_listself.threads = []def set_thread_func_list(self, func_list):"""@note: func_list是⼀个list,每个元素是⼀个dict,有func和args两个参数"""self.func_list = func_listdef start(self):"""@note: 启动多线程执⾏,并阻塞到结束"""self.threads = []self.ret_flag = 0for func_dict in self.func_list:if func_dict["args"]:t = threading.Thread(target=func_dict["func"], args=func_dict["args"])else:t = threading.Thread(target=func_dict["func"])self.threads.append(t)for thread_obj in self.threads:thread_obj.start()for thread_obj in self.threads:thread_obj.join()def ret_value(self):"""@note: 所有线程函数的返回值之和,如果为0那么表⽰所有函数执⾏成功"""return self.ret_flagMyThread类会接受⼀个func_list参数,每个元素是⼀个dict,有func和args两个key,func是真正要执⾏的函数引⽤,args是函数的参数。
对python:threading.Thread类的使用方法详解

对python:threading.Thread类的使⽤⽅法详解Python Thread类表⽰在单独的控制线程中运⾏的活动。
有两种⽅法可以指定这种活动:1、给构造函数传递回调对象mthread=threading.Thread(target=xxxx,args=(xxxx))mthread.start()2、在⼦类中重写run() ⽅法这⾥举个⼩例⼦:import threading, timeclass MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global n, locktime.sleep(1)if lock.acquire():print n , n += 1lock.release()if "__main__" == __name__:n = 1ThreadList = []lock = threading.Lock()for i in range(1, 200):t = MyThread()ThreadList.append(t)for t in ThreadList:t.start()for t in ThreadList:t.join()派⽣类中重写了⽗类threading.Thread的run()⽅法,其他⽅法(除了构造函数)都不应在⼦类中被重写,换句话说,在⼦类中只有_init_()和run()⽅法被重写。
使⽤线程的时候先⽣成⼀个⼦线程类的对象,然后对象调⽤start()⽅法就可以运⾏线程啦(start 调⽤run)下⾯我们进⼊本⽂的正题threading.Thread类的常⽤函数与⽅法:1、⼀旦线程对象被创建,它的活动需要通过调⽤线程的start()⽅法来启动。
这⽅法再调⽤控制线程中的run⽅法。
2、⼀旦线程被激活,则这线程被认为是'alive'(活动)。
PythonThreadjoin()用法详解

PythonThreadjoin()⽤法详解1import threading2#定义线程要调⽤的⽅法,*add可接收多个以⾮关键字⽅式传⼊的参数3def action(*add):4for arc in add:5#调⽤ getName() ⽅法获取当前执⾏该程序的线程名6print(threading.current_thread().getName() +""+ arc)7#定义为线程⽅法传⼊的参数8 my_tuple = ("/python/",\9"/shell/",\10"/java/")11#创建线程12 thread = threading.Thread(target = action,args =my_tuple)13#启动线程14 thread.start()15#主线程执⾏如下语句16for i in range(5):17print(threading.current_thread().getName())程序执⾏结果为(不唯⼀):可以看到,我们⽤ Thread 类创建了⼀个线程(线程名为 Thread-1),其任务是执⾏ action() 函数。
同时,我们也给主线程 MainThread 安排了循环任务(第 16、17 ⾏)。
通过前⾯的学习我们知道,主线程 MainThread 和⼦线程 Thread-1 会轮流获得 CPU 资源,因此该程序的输出结果才会向上⾯显⽰的这样。
但是,如果我们想让 Thread-1 ⼦线程先执⾏,然后再让 MainThread 执⾏第 16、17 ⾏代码,该如何实现呢?很简单,通过调⽤线程对象的join() ⽅法即可。
join() ⽅法的功能是在程序指定位置,优先让该⽅法的调⽤者使⽤ CPU 资源。
该⽅法的语法格式如下:thread.join( [timeout] )其中,thread 为 Thread 类或其⼦类的实例化对象;timeout 参数作为可选参数,其功能是指定 thread 线程最多可以霸占 CPU 资源的时间(以秒为单位),如果省略,则默认直到 thread 执⾏结束(进⼊死亡状态)才释放 CPU 资源。
Python中高级知识threadingTimer

Python中⾼级知识threadingTimerTimerTimer 是threading模块⾥⾯的⼀个类,主要是做简单的定时任务。
适⽤于设置⼀段时间后执⾏某⼀种逻辑的场景。
更加专业的计划任务其实Timer不能胜任,应该是sched,不过⼀般场景我们使⽤Timer也够⽤源码class Timer(Thread):"""Call a function after a specified number of seconds:t = Timer(30.0, f, args=None, kwargs=None)t.start()t.cancel() # stop the timer's action if it's still waiting"""def __init__(self, interval, function, args=None, kwargs=None):Thread.__init__(self)self.interval = intervalself.function = functionself.args = args if args is not None else[]self.kwargs = kwargs if kwargs is not None else{}self.finished = Event()def cancel(self):"""Stop the timer if it hasn't finished yet."""self.finished.set()def run(self):self.finished.wait(self.interval)if not self.finished.is_set():self.function(*self.args, **self.kwargs)self.finished.set()python给了说明: 传⼊function作为将要执⾏的逻辑体,并传⼊可变和关键字参数,设置多少时间后执⾏。
python中threading方式创建的线程的终止

python中threading⽅式创建的线程的终⽌对于采⽤threading⽅式创建的线程,没有提供推出的⽅法,只能是等线程函数结束。
但是有些情况需要强制结束,这就⽐较⿇烦了。
有如下实现⽅式:import threadingimport inspectimport ctypesdef _async_raise(tid, exctype):"""raises the exception, performs cleanup if needed"""if not inspect.isclass(exctype):exctype = type(exctype)res = ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, ctypes.py_object(exctype))if res == 0:raise ValueError("invalid thread id")elif res != 1:# """if it returns a number greater than one, you're in trouble,# and you should call it again with exc=NULL to revert the effect"""ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, None)raise SystemError("PyThreadState_SetAsyncExc failed")def stop_thread(thread):_async_raise(thread.ident, SystemExit)import threadingimport inspectimport ctypesdef _async_raise(tid, exctype):"""raises the exception, performs cleanup if needed"""if not inspect.isclass(exctype):raise TypeError("Only types can be raised (not instances)")res = ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, ctypes.py_object(exctype))if res == 0:raise ValueError("invalid thread id")elif res != 1:# """if it returns a number greater than one, you're in trouble,# and you should call it again with exc=NULL to revert the effect"""ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, 0)raise SystemError("PyThreadState_SetAsyncExc failed")class Thread(threading.Thread):def _get_my_tid(self):"""determines this (self's) thread id"""if not self.isAlive():raise threading.ThreadError("the thread is not active")# do we have it cached?if hasattr(self, "_thread_id"):return self._thread_id# no, look for it in the _active dictfor tid, tobj in threading._active.items():if tobj is self:self._thread_id = tidreturn tidraise AssertionError("could not determine the thread's id")def raise_exc(self, exctype):"""raises the given exception type in the context of this thread"""_async_raise(self._get_my_tid(), exctype)def terminate(self):"""raises SystemExit in the context of the given thread, which shouldcause the thread to exit silently (unless caught)"""self.raise_exc(SystemExit)其实两者是⼀样的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python threading 参数
摘要:
1.引言
2.Python 线程简介
3.线程参数介绍
3.1.线程数量
3.2.线程守护模式
3.3.线程优先级
3.4.线程同步与锁
4.参数应用实例
4.1.线程数量设置
4.2.线程守护模式应用
4.3.线程优先级调整
4.4.线程同步与锁的使用
5.总结
正文:
Python 作为一门广泛应用于多线程编程的语言,提供了强大的线程支持。
在使用Python 线程时,合理地设置线程参数能够提高程序的性能和效率。
本文将详细介绍Python 线程的几个重要参数。
首先,让我们了解一下Python 线程的基本概念。
Python 线程是操作系统线程的封装,通过Python 的threading 模块,我们可以轻松地创建、同
步和管理线程。
线程在执行过程中,可以共享进程的内存资源,这使得多线程程序能够实现高效的数据交换和协同工作。
接下来,我们将详细介绍Python 线程的几个重要参数:
1.线程数量:在创建线程时,可以通过设置线程数量来控制并发的线程数量。
过多或过少的线程数量都可能影响程序的性能。
线程数量应该根据计算机硬件性能、程序任务需求以及程序运行环境来合理设置。
2.线程守护模式:Python 线程有两种运行模式,一种是守护模式(daemon),另一种是用户模式(user)。
默认情况下,线程处于用户模式,当主线程结束时,所有子线程也会被强制退出。
在守护模式下,当主线程结束时,子线程会继续执行,直到所有线程都完成任务。
设置线程守护模式的参数为threading.Thread 的daemon 参数,将其设置为True 即可。
3.线程优先级:线程优先级用于控制线程执行的顺序。
优先级较高的线程会比优先级较低的线程更早执行。
Python 线程优先级范围从-1 到1,优先级越低,线程执行越晚。
可以通过设置threading.Thread 的priority 参数来调整线程优先级。
4.线程同步与锁:在多线程程序中,为了避免数据竞争和资源争用,我们需要对共享资源进行同步。
Python 线程提供了多种同步方法,如Lock、Semaphore、Condition 等。
这些同步方法可以保证在某一时刻只有一个线程能够访问共享资源,从而避免数据不一致和程序错误。
下面通过一个简单的实例来展示如何应用这些参数:
```python
import threading
import time
# 设置线程数量
um_threads = 5
# 设置线程守护模式
daemon_mode = True
# 设置线程优先级
priority = 1
# 共享资源
shared_resource = 0
# 锁对象
lock = threading.Lock()
# 线程函数
def worker(arg):
global shared_resource
with lock:
shared_resource += arg
print(f"Shared resource: {shared_resource}") # 创建线程
threads = []
for i in range(num_threads):
t = threading.Thread(target=worker, args=(i,)) t.daemon = daemon_mode
t.priority = priority
threads.append(t)
t.start()
# 等待线程执行完毕
for t in threads:
t.join()
print("All threads finished.")
```
通过合理地设置线程参数,我们能够更好地利用多线程技术提高程序的性能。