WebScarab小教程
webscarab使用方法

webscarab使用方法摘要:1.WebScarab简介2.WebScarab的安装与配置3.WebScarab的主要功能3.1 网络数据包捕获3.2 数据包解析3.3 数据包过滤与筛选3.4 数据包修改与重放4.WebScarab的使用场景4.1 网络故障排查4.2 网络安全测试4.3 网络协议研究与开发5.WebScarab的高级应用5.1 定制数据包过滤规则5.2 数据包的深入分析5.3 与其他工具的集成使用6.WebScarab的使用技巧与注意事项7.总结正文:WebScarab是一款功能强大的网络数据包处理工具,广泛应用于网络故障排查、网络安全测试以及网络协议研究与开发等领域。
本文将详细介绍WebScarab的使用方法,包括安装与配置、主要功能、使用场景、高级应用以及使用技巧与注意事项。
1.WebScarab简介WebScarab是一款基于Java的网络数据包处理工具,支持多种网络协议,如TCP、UDP、HTTP等。
它能够捕获、解析、过滤、修改和重放网络数据包,为网络工程师和安全分析师提供了强大的工具支持。
2.WebScarab的安装与配置WebScarab的安装过程相对简单,只需下载对应版本的Java JRE(Java Runtime Environment),然后将WebScarab的JAR文件放入JRE的“lib”目录下即可。
配置方面,用户可以根据实际需求调整过滤规则、网络接口等参数。
3.WebScarab的主要功能WebScarab主要包括以下四个方面的功能:3.1 网络数据包捕获WebScarab可以捕获指定网络接口的实时数据包,用户可以通过配置过滤规则来筛选感兴趣的数据包。
3.2 数据包解析WebScarab能够解析多种网络协议,如TCP、UDP、HTTP等,并以树状结构展示数据包的详细信息。
3.3 数据包过滤与筛选WebScarab支持灵活的过滤规则配置,用户可以根据需求自定义过滤条件,快速定位感兴趣的数据包。
burpsuite基本用法

burpsuite基本用法
Burp Suite是一款用于web渗透应用程序的集成平台,包含了许多工具,如Proxy、Spider、Scanner(专业版特供)、Intruder、Repeater、Sequencer、Decoder、Comparer。
以下是Burp Suite的基本使用方法:
1. 打开Burp Suite,点击Proxy -> Options,在“Proxy Listeners”中添加一个代理端口,比如说8888。
2. 在浏览器中设置代理服务器,地址为127.0.0.1,端口为8888。
这样就完成了基本的设置。
3. 抓取HTTP请求:在Burp Suite中,点击Proxy -> Intercept,勾选Intercept is on,这样就可以开始抓取HTTP请求。
当浏览器发起HTTP请求时,这个请求会被Burp Suite捕捉到,并停止,显示在Intercept窗口中。
可以对请求进行修改,比如说改变请求头等。
当完成修改后,点击Forward按钮,请求就会继续发送。
4. 漏洞扫描:Burp Suite也可以进行漏洞扫描,首先需要在Proxy -> Options中将“Request handling”中的“Intercept Client Requests”选项勾选上。
接着,当浏览器发送请求时,Burp Suite会自动拦截,此时点击左侧菜单中的“Scanner”选项卡,点击“Start Scanner”即可开始扫描。
不过需要说明的是,只有pro版本才具有更强大的扫描功能。
以上信息仅供参考,如需了解更多信息,建议查阅Burp Suite官方网站或咨询专业人士。
50行代码实现贪吃蛇

50行代码实现贪吃蛇之阿布丰王创作最近一直在准备用来面试的几个小demo,为了能展现自己,所以都是亲自设计并实现的,其中一个就是在50行代码内来实现一个贪吃蛇,为了说明不才自己练习编程的一种方式--把代码写短,为了理解语言细节...[python] view plaincopy<span style="font-size:14px;">import sys, pygamefrom pygame.locals import *from random import randrangeup =lambda x:(x[0]-1,x[1])down = lambda x :(x[0]+1,x[1])left = lambda x : (x[0],x[1]-1)right = lambda x : (x[0],x[1]+1)tl = lambda x :x<3 and x+1 or 0tr = lambda x :x==0 and 3 or x-1dire = [up,left,down,right]move = lambda x,y:[y(x[0])]+x[:-1]grow = lambda x,y:[y(x[0])]+xs = [(5,5),(5,6),(5,7)]d = upfood = randrange(0,30),randrange(0,40)FPSCLOCK=pygame.time.Clock()pygame.init()pygame.display.set_mode((800,600))pygame.mouse.set_visible(0)screen = pygame.display.get_surface()screen.fill((0,0,0))times=0.0while True:time_passed = FPSCLOCK.tick(30)if times>=150:times =0.0s = move(s,d)else:times +=time_passedfor event in pygame.event.get():if event.type == QUIT:sys.exit()if event.type == KEYDOWN and event.key == K_UP:s = move(s,d)if event.type == KEYDOWN and event.key == K_LEFT: d=dire[tl(dire.index(d))]if event.type == KEYDOWN and event.key == K_RIGHT:d=dire[tr(dire.index(d))]if s[0]==food:s = grow(s,d)food =randrange(0,30),randrange(0,40)if s[0] in s[1:] or s[0][0]<0 or s[0][0] >= 30 or s[0][1]<0 or s[0][1]>=40:breakscreen.fill((0,0,0))for r,c in s:pygame.draw.rect(screen,(255,0,0),(c*20,r*20,20,20))pygame.draw.rect(screen,(0,255,0),(food[1]*20,food[0]*20, 20,20))pygame.display.update()</span>游戏截图:说明:1.其实不用pygame,在把一些条件判断改改,估计可以再短一半..等以后自己python水平高了再回来试试..2.可是50行的贪吃蛇代码,还是有可读性的,写的太短就真没有了..3.关键是把旋转,移动,等等这些算法用lamda表达式实现,还有函数对象..4.哪位“行者”能写的更短,小弟愿意赐教....。
webscraper 使用方法

webscraper 使用方法网页爬取器的使用方法网页爬取器(webscraper)是一种用于从互联网上收集数据的工具。
它可以自动访问网页,并从网页的HTML代码中提取所需要的数据。
这种工具在信息收集、市场调研和数据分析等领域非常有用。
首先,为了使用网页爬取器,您需要选择一个合适的编程语言和库来编写爬取代码。
常用的语言包括Python、JavaScript和Ruby。
其中,Python语言的Beautiful Soup和Scrapy库是非常受欢迎的选择,它们提供了简洁而强大的功能。
在编写爬取代码之前,您需要明确您希望从哪些网页上收集数据。
这可以包括特定的网站、特定的页面或者整个网站。
了解所要爬取的网页的结构和格式是非常重要的,因为您需要根据这些信息来定制您的爬取代码。
接下来,您需要设置爬取器的参数。
这包括指定爬取的起始页面、设置爬取的深度(即爬取多少层的链接)、设定每个页面的爬取间隔时间等。
合理地设置这些参数可以有效控制爬取的效率和效果。
编写爬取代码时,您需要指定如何定位和提取所需的数据。
通常,您可以使用HTML标签、CSS选择器或XPath来定位数据所在的位置。
然后,使用合适的方法来从网页中提取所需的数据,并进行适当的处理和存储。
在编写完爬取代码之后,您可以运行爬取器并观察其工作情况。
您可以查看它是否按照您的预期进行爬取,并检查爬取到的数据是否准确无误。
如果爬取过程中出现问题,您可以根据报错信息和日志进行调试和改进。
最后,当您满意爬取结果后,您可以对获得的数据进行进一步的处理和分析。
这可能包括数据清洗、数据转换、数据可视化等操作,以使数据更具有实用价值。
总的来说,网页爬取器是一种功能强大的工具,可以帮助您从互联网上收集所需的数据。
通过选择合适的编程语言和库,并合理设置参数,您可以编写出高效而准确的爬取代码,并获得可靠的爬取结果。
请记住,在使用网页爬取器进行数据收集时,要遵守相关法律法规和网络道德规范,同时避免对网站造成不必要的负荷和影响。
木马制作

1.冰狐浪子网页木马生成器
2.一个网页编辑器(frontpage或dreamweaver都可以,我习惯用的是dreamweaver);
3.图片一张(主要用来起迷惑作用,至于放什么样的图片大家可以自由发挥)
4.木马一个,至于是QQ盗号器?灰鸽子?还是黑洞?都可以,我建议大家准备一个50KB以下的小马,否则木马还没
下面我们打开网页编辑器,新建一个网页,"插入"---"图片"打开插入图片的对话框,选择刚才准备好的图
片按确定.
然后转到代码编辑窗口,插入一个嵌入式框架,把框架长度和宽度都改为0,框架连接到刚才icyfox.htm文件的
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional// EN"
把<A href="/Article/UploadFiles/200510/20051011015656342.gif)里修改下就可以用了.冰狐浪子的使用方法:用你的木马程序替换" icyfox?目录下的?#.exe?<BR><U><FONT color=#0000ff>然后运行"生成.bat",你会在"muma"目录下得到文件"icyfox.js"修 改"icyfox.htm"文件中的两处<BR><A href="/muma">/muma</A><BR>为你上传到主页空间的"icyfox.js"文件的URL路径</P>
s t a c k 的 常 见 用 法

[Python爬虫] 在Windows下安装PhantomJS和CasperJS及入门介绍(上)最近在使用Python爬取网页内容时,总是遇到JS临时加载、动态获取网页信息的困难。
例如爬取CSDN下载资-源评论、搜狐图片中的“原图”等,此时尝试学习Phantomjs和CasperJS来解决这个问题。
这第一篇文章当然就是安装过程及入门介绍。
一. 安装Phantomjsweb standards: DOM handling, CSS selector, JSON, Canvas, and SVG. ?Full web stack?No browser required. PhantomJS是一个服务器端的 JavaScript API 的WebKit(开源的浏览器引擎)。
其支持各种Web标准:DOM 处理, CSS 选择器, JSON, Canvas 和 SVG。
PhantomJS可以用于页面自动化,网络监测,网页截屏,以及无界面测试等。
下载PhantomJS解压后如下图所示:在该文件夹下创建test.js文件,代码如下:console.log('Hello world!');同时其自带的examples文件夹中有很多模板代码,其中获取脚本参数代码如下:var system = require('system');if (system.args.length === 1) {console.log('Try to pass some args when invoking this script!');system.args.forEach(function (arg, i) {console.log(i + ': ' + arg);phantom.exit(); 运行程序及输出结果如下图所示:phantomjs examples-arguments.js arg0 agr1 arg2 arg32、网页截图在根目录新建文件loadpic.js,其代码如下:var page = require('webpage').create();page.render('example.png');phantom.exit();}); 运行程序结果如下图所示: phantomjs?loadpic.js短短5行代码让我第一次体会到了PhantomJS和调用脚本函数的强大,它加载baidu页面并存储为一张PNG图片,这个特性可以广泛适用于网页快拍、获取网页在线知识等功能。
webscarab使用方法

webscarab使用方法WebScarab是一个用于分析HTTP和HTTPS协议的应用程序框架,可以记录和检测会话内容(请求和应答),使用者可以通过多种形式来查看记录。
WebScarab的使用步骤如下:1. 确保已安装Java环境,因为WebScarab运行需要Java环境支持。
2. 打开WebScarab应用程序,默认运行模式为Lite模式。
如需切换至全功能模式,可点击菜单栏“Tools”,然后选择“use full-featured interface”。
注意,切换后必须重启WebScarab才可以生效。
3. WebScarab默认使用localhost的8008端口作为其代理。
需要对IE进行配置,让IE把各种请求转发给WebScarab,而不是让IE读取这些请求。
具体来说,需确保除“为LAN使用代理服务器”之外的所有复选框都处于未选中状态。
为IE配置好这个代理后,在其它对话框中单击确定按钮,并重新回到浏览器。
4. 浏览一个非SSL的网站,浏览器会自动转向WebScarab。
5. 至于如何使用WebScarab分析HTTP和HTTPS协议,可以在具体的HTTP请求中使用请求数据。
例如,可以在POST方法中使用请求数据。
此外,与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
请注意,使用WebScarab时要遵守法律法规和道德规范,不能用于非法用途,如网络攻击或侵犯他人隐私等。
同时,WebScarab只是一个工具,具体使用方式和效果因个人需求和实际情况而异。
如果需要深入了解和使用WebScarab,建议查阅相关资料或寻求专业人士的帮助。
webscarab工具使用介绍

Webscarab工具使用介绍
【功能及原理】
webscarab工具的主要功能:利用代理机制,它可以截获客户端提交至服务器的所有http请求消息,还原http请求消息并以图形化界面显示其内容,并支持对http请求信息进行编辑修改。
原理:webscarab工具采用web代理原理,客户端与web服务器之间的http请求与响应都需要经过webscarab进行转发,webscarab将收到的http请求消息进行分析,并将分析结果图形化显示如下:
【工具使用】
1、运行WebScarab,我们选择了get与post,我们只需要get与post请求的http消息进行篡改。
2、打开IE浏览器的属性---连接--局域网设置,在代理地址中配置host为127.0.0.1或localhost,
port为8008(此为软件件固定监听端口)
3、以上配置便完成了,没可以进行测试了,注意:RTX里的OA最好退掉,或者再在上步设置代理的
旁边,点击[高级]设置如下
4、下面开始测试,打开测试网页,webscarab就会拦截到请求,点击“Accept changes”进行提交,
操作完成。
5、下面选择一个功能测试一下,以修改验证手机号为例,输入正确信息,点击修改,此时WebScarab
会弹出提示框,显示http传递参数信息,可以http请求进行新增、删除和修改参数.
1).输入号码
2). WebScarab会弹出提示框,显示http传递参数信息,修改号码为你想要的号码,然后点击点击“Accept changes”进行提交,完成操作。
6、测试操作步骤大致如此,请自已举一反三,深入发掘.
(注:可编辑下载,若有不当之处,请指正,谢谢!)。
HTTP协议分析工具-WebScrarb的使用[9页]
![HTTP协议分析工具-WebScrarb的使用[9页]](https://img.taocdn.com/s3/m/2a62d589172ded630a1cb60d.png)
一、WebScarab界面介绍-Summary
标签栏:完成各自特定功能
URL树:用来表示站点布局,以 及经过WebScarab的各个会话
会话列表:可以双击打开特定会 话的详细信息进行查看或编辑
一、WebScarab界面介绍-Proxy
➢ 设定代理监听地址和 端口号
➢ 配置代理拦截方法和 开关
二、IE代理服务器的设置
1. 打开IE的“Internet选 项”菜单
2. 选择“连接”标签后, 点击局域网设置按钮
3. 勾选“为LAN使用代 理服务器”复选框,
a) 地址填入127.0.0.1 b) 端口填入8008
三、启用代理拦截
1. 勾选“Intercept requests”复选框, 方法选择GET和 POST(默认)
2. 在“Include Paths matching”中输入 匹配域名
四、捕Scarab会自动 弹出“Edit Reauest” 窗口,此时可观察相 关会话信息,若无修 改项,点击“Cancle changes”按钮
四、捕获HTTP请求-POST
3. 浏览器页面会正常显 示,输入测试的账户 名和密码并点击Login 按钮
4. 在弹出窗口中可见捕 获的用户名和密码, 为测试此处先单击 “Cancel Changes” 按钮,以便让浏览器 发送原始数据
五、编辑拦截请求
1. 因为是不存在的用户名, 系统提示不能登录
2. 再次输入任意密码让 WebScarab进行拦截
3. 将用户名和密码修改为 admin/admin后点击 “Accept Changes” 按钮
4. 此时可见已正常登录进 系统
webscarab使用方法

webscarab使用方法(原创实用版1篇)篇1 目录1.WebP 格式概述2.WebP 极限压缩方法的原理3.WebP 极限压缩方法的实现4.WebP 极限压缩方法的优缺点5.WebP 极限压缩方法的应用前景篇1正文1.WebP 格式概述WebP 是一种由 Google 开发的图像格式,主要用于网络图像的传输和显示。
相较于传统的 JPEG 格式,WebP 具有更高的压缩率和更快的加载速度,因此在网络应用中具有广泛的应用前景。
2.WebP 极限压缩方法的原理WebP 极限压缩方法是一种基于 WebP 图像格式的高效图像压缩技术。
其主要原理是将图像中的颜色信息进行量化和编码,以减少图像的数据量。
同时,WebP 极限压缩方法还可以根据图像的特征,对图像进行有损压缩,从而在保证图像质量的前提下,进一步提高压缩率。
3.WebP 极限压缩方法的实现WebP 极限压缩方法的实现主要包括以下几个步骤:(1)颜色量化:通过对图像中的颜色进行量化,将原本连续的颜色值映射到离散的颜色值,从而减少图像的数据量。
(2)编码:将量化后的颜色值进行编码,以便在存储和传输过程中能够被有效还原。
(3)有损压缩:通过对图像的特征进行分析,采用有损压缩算法对图像进行压缩,以进一步提高压缩率。
4.WebP 极限压缩方法的优缺点WebP 极限压缩方法具有以下优缺点:优点:(1)压缩率高:相较于传统的 JPEG 格式,WebP 极限压缩方法具有更高的压缩率,能够有效减少图像的数据量。
(2)加载速度快:由于 WebP 极限压缩方法的压缩率较高,因此图像的加载速度较快,能够提高用户的浏览体验。
缺点:(1)兼容性问题:由于 WebP 格式相较于 JPEG 格式较新,因此在一些较老的设备或浏览器上,可能存在兼容性问题。
(2)存储空间需求:由于 WebP 极限压缩方法需要存储量化和编码后的颜色值,因此相对于 JPEG 格式,WebP 格式的存储空间需求较大。
Scrape-Box从入门到精通完全中文教程要点

ScrapeBox作为外贸SEO领域中最为常见的外链工具,几乎人手一份,虽然性能较xRumer要弱很多,但是这并没有阻挡黑帽seoer们对它的喜爱。
蓝月这次带来一份超级详细的ScrapeBox中文教程,希望能帮助到跟我一样迷茫的英文SEO新人。
本文主要借鉴了腿哥的《SEO中文宝典》,整理成了能被搜索引擎理解的纯文字信息,版权归腿哥所有,苏州SEO只做整理。
Scrapebox主要功能区使用简介ScrapeBox作者将工作界面分为4个区域——harvester;SelectEngines&P roxies;URL’s harvested;commentposter,如果用中文解释,搜索区;代理区;URL整理区;操作区比较合适。
对于其主要操作流程,可以看下面这张图:下面一个一个区域进行功能介绍:先说搜索区:搜索区功能主要有:关键词拼合;清理footprint;关键词、footprint输入区;关键词抓取按钮;关键词导入功能代理区:这个区很重要,会直接影响到Scrapebox搜刮资源以及发布资源的效率和成功率。
代理区主要由搜索结果来源(搜索引擎);代理IP存放区;代理IP管理区URL整理区:这个区是Scrapebox的主要操作区,涉及到了URL列表存放区;去重过滤按钮;整理URL到根目录;PR 查询;收录查询;邮箱抓取;导入URL;导出URL;导出URL&PR;开始收割资源等10个项目。
操作区:当填写完footprint、整理了代理列表、搜刮到你想要的资源之后,你就可以在这个区里面操作了,这个区主要由4部分组成,分别是操作模式选择区;群发网站信息;状态区;开始操作区当你选择不同的操作模式,工具会显示对应的操作区,也只有对应的操作区可以操作,其他的不可操作去都是灰色的。
Scrapebox菜单栏设置介绍菜单区:Settings菜单Adjust MaximumConnection调整最大连接数,在批量检查PR、批量群发的时候,最大链接数越多,能够增加群发的效率,降低群发的时间,但是我个人建议保持默认比较好。
web scraper使用方法

web scraper使用方法
Web Scraper是一种技术,可以自动从网站上抓取数据。
以下
是使用Web Scraper的简略步骤:
1. 安装Web Scraper浏览器扩展程序:Web Scraper可以在Firefox和Chrome浏览器中安装。
2. 选择一个网站:Web Scraper可以从任何一个网站抓取数据,但是网站的结构和内容会影响Web Scraper的配置。
3. 指定目标数据:Web Scraper需要知道要抓取的数据的位置
和类型。
用户可以通过选择HTML元素或CSS选择器来指定
目标数据。
4. 配置抓取规则:Web Scraper需要配置抓取规则来指定如何
抓取数据。
例如,用户可以指定一个抓取规则,以便在网站的所有页面上自动抓取类似的数据。
5. 运行Web Scraper:配置好Web Scraper后,用户可以运行Web Scraper,以便它可以从网站上抓取目标数据。
6. 处理抓取数据:Web Scraper可以将所有抓取的数据存储在
一个CSV文件中。
用户可以对该文件进行分析,或将其用于
其他目的。
总而言之,Web Scraper是一种非常有用和强大的技术,可以
在网站上节省大量的时间和精力,以及捕捉到有价值的信息。
WebGoat中文手册

WebGoat中文手册版本:5.4webgoat团队2013年1月Revision record 修订记录 项目任务 参与人员 完成时间项目人员协调 Rip,袁明坤,Ivy 2012年7月翻译及整核以往版本袁明坤,傅奎,beer,南国利剑,lion 2012年8月 Webgoat5.4 版本测试袁明坤,傅奎,beer,南国利剑,lion 2012年8月 Webgoat5.4 中文手册傅奎 2012年9月 审核发布阿保,王颉, 王侯宝 2013年1月 前期参与人员 蒋根伟,宋飞,蒋增,贺新朋,吴明,akast ,杨天识,Snake ,孟祥坤,tony ,范俊,胡晓斌,袁明坤[感谢所有关注并参与过OWASP 项目的成员,感谢你们的分享和付出,webgoat 和大家一起成长!如有修改建议,请发送至webgoat@ 我们一起改进,谢谢!目录1 WebGoat简介 (6)1.1 什么是WebGoat (6)1.2 什么是OWASP (6)1.3 WebGoat部署 (6)1.4 用到的工具 (7)1.4.1 WebScarab (7)1.4.2 Firebug和IEwatch (8)1.5 其他说明 (8)2 WebGoat教程 (9)2.1 综合(General) (9)2.1.1 HTTP基础知识(Http Basics) (9)2.1.2 HTTP拆分(HTTP Splitting) (11)2.2 访问控制缺陷(Access Control Flaws) (19)2.2.1 使用访问控制模型(Using an Access Control Matrix) (19)2.2.2 绕过基于路径的访问控制方案(Bypass a Path Based Access Control Scheme) (22)2.2.3 基于角色的访问控制(LAB: Role Based Access Control) (25)2.2.4 远程管理访问(Remote Admin Access) (36)2.3 Ajax安全(Ajax Security) (38)2.3.1 同源策略保护(Same Origin Policy Protection) (38)2.3.2 基于DOM的跨站点访问(LAB: DOM‐Based cross‐site scripting) (39)2.3.3 小实验:客户端过滤(LAB: Client Side Filtering) (43)2.3.4 DOM注入(DOM Injection) (46)2.3.5 XML注入(XML Injection) (49)2.3.6 JSON注入(JSON Injection) (52)2.3.7 静默交易攻击(Silent Transactions Attacks) (54)2.3.8 危险指令使用(Dangerous Use of Eval) (57)2.3.9 不安全的客户端存储(Insecure Client Storage) (59)2.4 认证缺陷(Authentication Flaws) (62)2.4.1 密码强度(Password Strength) (62)2.4.2 忘记密码(Forgot Password) (64)2.4.3 基本认证(Basic Authentication) (66)2.4.4 多级登录1(Multi Level Login 1) (71)2.4.5 多级登录2(Multi Level Login 2) (73)2.5 缓冲区溢出(Buffer Overflows) (74)2.5.1 Off‐by‐One 缓冲区溢出(Off‐by‐One Overflows) (74)2.6 代码质量(Code Quality) (78)2.6.1 在HTML中找线索(Discover Clues in the HTML) (78)2.7 并发(Concurrency) (79)2.7.1 线程安全问题(Thread Safety Problems) (79)2.7.2 购物车并发缺陷(Shopping Cart Concurrency Flaw) (80)2.8 跨站脚本攻击(Cross‐Site Scripting (XSS)) (82)2.8.1 使用XSS钓鱼(Phishing with XSS) (82)2.8.2 小实验:跨站脚本攻击(LAB: Cross Site Scripting) (84)2.8.3 存储型XSS攻击(Stored XSS Attacks) (90)2.8.4 跨站请求伪造(Cross Site Request Forgery (CSRF)) (91)2.8.5 绕过CSRF确认( CSRF Prompt By‐Pass) (93)2.8.6 绕过CSRF Token(CSRF Token By‐Pass) (98)2.8.7 HTTPOnly测试(HTTPOnly Test) (102)2.8.8 跨站跟踪攻击(Cross Site Tracing (XST) Attacks) (103)2.9 不当的错误处理(Improper Error Handling) (105)2.9.1 打开认证失败方案(Fail Open Authentication Scheme) (105)2.10 注入缺陷(Injection Flaws) (107)2.10.1 命令注入(Command Injection) (107)2.10.2 数字型SQL注入(Numeric SQL Injection) (109)2.10.3 日志欺骗(Log Spoofing) (110)2.10.4 XPATH型注入(XPATH Injection) (112)2.10.5 字符串型注入(String SQL Injection) (113)2.10.6 小实验:SQL注入(LAB: SQL Injection) (115)2.10.7 通过SQL注入修改数据(Modify Data with SQL Injection) (119)2.10.8 通过SQL注入添加数据(Add Data with SQL Injection) (120)2.10.9 数据库后门(Database Backdoors) (121)2.10.10 数字型盲注入(Blind Numeric SQL Injection) (123)2.10.11 字符串型盲注入(Blind String SQL Injection) (124)2.11 拒绝服务(Denial of Service) (126)2.11.1 多个登录引起的拒绝服务(Denial of Service from Multiple Logins) (126)2.12 不安全的通信(Insecure Communication) (127)2.12.1 不安全的登录(Insecure Login) (127)2.13 不安全的配置(Insecure Configuration) (130)2.13.1 强制浏览(How to Exploit Forced Browsing) (130)2.14 不安全的存储(Insecure Storage) (131)2.14.1 强制浏览(How to Exploit Forced Browsing) (131)2.15 恶意执行(Malicious Execution) (132)2.15.1 恶意文件执行(Malicious File Execution) (132)2.16 参数篡改(Parameter Tampering) (134)2.16.1 绕过HTML字段限制(Bypass HTML Field Restrictions) (134)2.16.2 利用隐藏字段(Exploit Hidden Fields) (136)2.16.3 利用未检查的E‐mail(Exploit Unchecked Email) (138)2.16.4 绕过客户端JavaScript校验(Bypass Client Side JavaScript Validation) (142)2.17 会话管理缺陷(Session Management Flaws) (148)2.17.1 会话劫持(Hijack a Session) (148)2.17.2 认证Cookie欺骗(Spoof an Authentication Cookie) (154)2.17.3 会话固定(Session Fixation) (158)2.18 Web服务(Web Services) (162)2.18.1 创建SOAP请求(Create a SOAP Request) (162)2.18.2 WSDL扫描(WSDL Scanning) (168)2.18.3 Web Service SAX注入(Web Service SAX Injection) (170)2.18.4 Web Service SQL注入(Web Service SQL Injection) (172)2.19 管理功能(Admin Functions) (175)2.19.1 报告卡(Report Card) (175)2.20 挑战(Challenge) (176)2.20.1 挑战(The CHALLENGE!) (176)1WebGoat简介1.1什么是WebGoatWebGoat是OWASP组织研制出的用于进行web漏洞实验的应用平台,用来说明web 应用中存在的安全漏洞。
web scraperb步骤

一、确定目标全球信息站需要确定要爬取数据的目标全球信息站。
在选择目标全球信息站时,需要确保该全球信息站允许爬取数据,并且没有明确的禁止条款。
需要分析目标全球信息站的结构和页面布局,以便更好地编写爬取程序。
二、获取网页内容通过网络请求,可以获取目标全球信息站的网页内容。
可以使用Python中的requests库或者其他网络请求库来发送HTTP请求,并获取网页的HTML内容。
在进行网络请求时,需要注意设置适当的headers,以模拟浏览器的行为,避免被全球信息站识别为爬虫程序而被拒绝访问。
三、解析网页内容获取网页内容后,需要解析HTML内容,提取出目标数据。
可以使用Python中的BeautifulSoup库或者lxml库来解析HTML内容,通过选择器或者XPath来定位和提取需要的数据。
在解析网页内容时,需要注意处理异常情况,如网页加载失败、或者目标数据未找到的情况。
四、保存数据在提取出目标数据后,需要将数据保存到合适的数据存储介质中,如CSV文件、数据库等。
可以使用Python中的pandas库或者其他数据处理库来保存数据到CSV文件,或者使用SQLAlchemy等ORM库将数据保存到数据库中。
在保存数据时,需要注意数据的格式转换和去重等处理。
五、定时任务如果需要定期爬取数据,可以使用Python中的schedule库或者其他定时任务库来实现定时运行爬取程序。
通过设置定时任务,可以自动化地爬取数据,并将数据保存到合适的存储介质中,实现数据定期更新和持久化。
六、反爬处理在爬取数据的过程中,可能会遇到目标全球信息站对爬虫程序的反爬措施,如验证码、IP封锁等。
针对这种情况,可以使用代理IP池、请求头随机化、使用浏览器渲染引擎等方式来规避反爬策略,确保爬取数据的顺利进行。
总结通过以上步骤,可以实现一个简单的Web Scraper程序,用于爬取目标全球信息站的数据。
在实际开发中,需要结合具体的目标全球信息站和数据需求,设计合理的爬取策略和程序架构,以确保数据的高效、稳定地爬取和保存。
webscarab使用方法

webscarab使用方法WebScarab是一个用于漏洞评估的Web应用程序代理。
它可以充当代理服务器,截取应用程序和Web服务器之间的所有HTTP和HTTPS请求和响应,以便对其进行分析。
设置:配置:启动WebScarab后,可以选择手动配置代理服务器。
打开WebScarab 界面后,选择“Proxy”选项卡,然后选择“Settings”(设置)。
在这里,您可以指定代理服务器的端口号以及其他选项,如代理的范围(包括哪些主机和端口号),以及是否对HTTPS进行中间人攻击。
拦截:在“Proxy”选项卡下,单击“Intercept”(拦截)选项。
启用拦截后,WebScarab将拦截通过代理服务器的所有请求和响应。
您可以在这里查看和修改请求和响应的内容。
分析:WebScarab具有多种功能和插件,可用于分析和评估Web应用程序的安全性。
1. 参数处理:在Web应用程序中,用户输入通常作为参数发送到服务器。
在“Parameters”选项卡下,您可以查看和修改每个请求的参数。
通过修改和测试参数,您可以检查应用程序对恶意输入的处理方式。
2. 跨站点脚本(XSS):在“Scripts”选项卡下,您可以使用XSS检查器来测试Web应用程序是否容易受到XSS攻击。
输入潜在的恶意脚本,并查看应用程序对其的处理方式。
3. SQL注入:在“Scripts”选项卡下,您可以使用SQL注入检查器测试Web应用程序是否容易受到SQL注入攻击。
输入潜在的恶意SQL查询,并查看应用程序对其的处理方式。
4. Fuzzing:在“Fuzz”选项卡下,您可以使用Fuzzer插件来模糊测试Web应用程序的输入。
Fuzzing是一种测试方法,通过提供大量无效、随机或异常的输入来发现应用程序中的错误和漏洞。
5. 身份验证和会话管理:WebScarab还提供了用于测试身份验证和会话管理的插件。
您可以测试应用程序在用户登录、注销和更改密码时的行为。
SpringBoot实现STOMP协议的WebSocket的方法步骤

SpringBoot实现STOMP协议的WebSocket的⽅法步骤1.概述我们之前讨论过Java Generics的基础知识。
在本⽂中,我们将了解Java中的通⽤构造函数。
泛型构造函数是⾄少需要有⼀个泛型类型参数的构造函数。
我们将看到泛型构造函数并不都是在泛型类中出现的,⽽且并⾮所有泛型类中的构造函数都必须是泛型。
2.⾮泛型类⾸先,先写⼀个简单的类:Entry,它不是泛型类:public class Entry {private String data;private int rank;}在这个类中,我们将添加两个构造函数:⼀个带有两个参数的基本构造函数和⼀个通⽤构造函数。
2.1 基本构造器Entry第⼀个构造函数:带有两个参数的简单构造函数:public Entry(String data, int rank) {this.data = data;this.rank = rank;}现在,让我们使⽤这个基本构造函数来创建⼀个Entry对象@Testpublic void givenNonGenericConstructor_whenCreateNonGenericEntry_thenOK() {Entry entry = new Entry("sample", 1);assertEquals("sample", entry.getData());assertEquals(1, entry.getRank());}2.2 泛型构造器接下来,第⼆个构造器是泛型构造器:public <E extends Rankable & Serializable> Entry(E element) {this.data = element.toString();this.rank = element.getRank();}虽然Entry类不是通⽤的,但它有⼀个参数为E的泛型构造函数。
WebScarab操作说明-推荐下载

5.6.2 WebScarabWebScarab 可以分析使用HTTP 和HTTPS 协议进行通信的应用程序,可以用最简单的形式记录它观察的会话,并提供多种方式来观察会话。
WebScarab 功能较多,初学者可以先使用拦截、修改浏览器和HTTP/S 服务器的请求和响应等功能。
这里以Firefox 浏览器为例来介绍WebScarab 的使用,并要求能够自由访问因特网,即并非位于一个代理之后。
WebScarab 是一个可执行的jar 文件,下载后,双击打开,初始页面如图5-11所示。
图5-11 首次打开WebScarab图5-11是WebScarab 启动后的截图,其中有几个主要的区域需要介绍一下。
首先要介绍的是工具栏,从这里可以访问各个插件、摘要窗口(主视图)和消息窗口。
摘要窗口分成两个部分,图5-11上面部分标记为“窗口1”的是一个树表,显示访问的站点的布局,以及各个URL 的属性。
下面部分标记为“窗口2”的是一个表格,显示通过WebScarab 可以看到的所有会话,正常情况下以ID 逆序排列,所以靠近表顶部的是最近的会话。
当然,会话的排列顺序是可以更改的,如果需要的话,只需通过单击列的标题即可。
为了将WebScarab 作为代理使用,需要配置浏览器的设置。
单击Firefox 的“选项”菜单,打开如图5-12所示窗口,在“网络”页框中单击“设置”按钮,打开如图5-13所示的代理配置对话框。
若使用IE 浏览器,依次选择【工具】|【Internet 选项】|【连接】|【局域网设置】,同样打开如图5-13所示的对话框。
、管路敷设技术且可保障各类管路习题到位。
在管路敷设过程中,要加强看护关于管路高中资料试卷连接管口处理高中资料试卷弯扁度固定盒位置保护层防腐跨接地线弯曲半径标高等,要求技术交底。
管线敷设技术中包含线槽、管架等多项方式,为解决高中语文电气课件中管壁薄、接口不严等问题,合理利用管线敷设技术。
线缆敷设原则:在分线盒处,当不同电压回路交叉时,应采用金属隔板进行隔开处理;同一线槽内,强电回路须同时切断习题电源,线缆敷设完毕,要进行检查和检测处理、电气课件中调试资料试卷调控试验;对设备进行调整使其在正常工况下与过度工作下都可以正常工作;对于继电保护进行整核对定值,审核与校对图纸,编写复杂设备与装置高中资料试卷调试方案,编写重要设备高中资料试卷试验方案以及系统启动方案;对整套启动过程中高中资料试卷电气设备进行调试工作并且进行过关运行高中资料试卷技术指导。
web实验一-PIKACHU平台搭建与暴力破解
web实验⼀-PIKACHU平台搭建与暴⼒破解平台搭建开始。
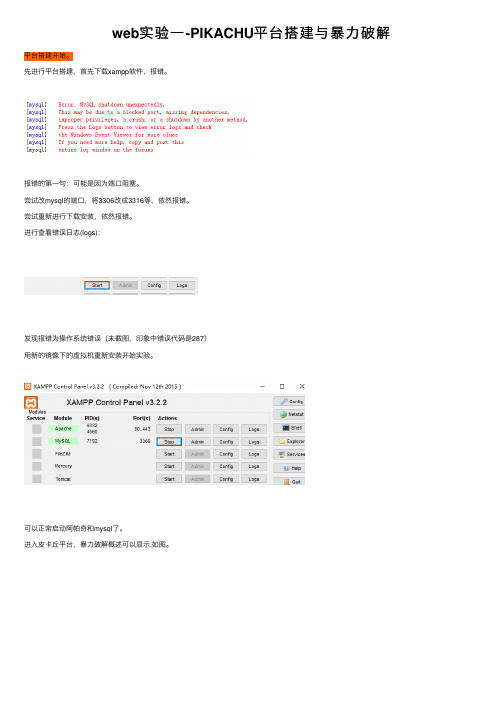
先进⾏平台搭建,⾸先下载xampp软件,报错。
报错的第⼀句:可能是因为端⼝阻塞。
尝试改mysql的端⼝,将3306改成3316等,依然报错。
尝试重新进⾏下载安装,依然报错。
进⾏查看错误⽇志(logs):发现报错为操作系统错误(未截图,印象中错误代码是287)⽤新的镜像下的虚拟机重新安装开始实验。
可以正常启动阿帕奇和mysql了。
进⼊⽪卡丘平台,暴⼒破解概述可以显⽰,如图。
点击「基于表单的暴⼒破解」,显⽰数据库未连接。
将xampp的第三个和第五个也打开,(中间也按照百度进⾏了⼀些其他操作),然后平台可以正常使⽤。
平台可以正常使⽤。
平台搭建结束。
暴⼒破解实验开始。
⼀、基于表单的暴⼒破解接下来安装burpsuite。
改好浏览器代理等(我是⽕狐)。
但是,burpsuite依然抓不到包,如图。
将⽹页中的localhost改成本机的ip地址。
cmd中输⼊ipconfig进⾏本机ip地址查询:进⾏修改:结果⼀直显⽰正在加载。
曾以为是证书认证问题,尝试修改。
未果。
问题原因:因为burpsuite⼀直开着,所以才⼀直加载,与证书认证⽆关。
(待续)(续上)上⾯的问题解决,如图。
继续进⾏。
输⼊账号密码。
抓到了。
但是target⾥没有post的包。
等了⼀会⼉,有了。
继续实验。
右键将其发送到intruder。
在攻击种类中选择常⽤的Cluster bomb。
设置好动态变量.设置Payload以及字典这个当时搞错了,应该是在2中⽽不是1,改正后的图没有截。
⼤概这样(补)将字符串username or password is not exists复制到burpsuite的Grep-Match.1.6的burpsuite没有找到开始攻击的按钮。
重新安装成1.7的。
重复之前所有过程。
开始攻击。
得到结果。
完成。
login success.⼆、On client随便输⼊⼀个⽤户名和密码并且输⼊正确的验证码.抓到的数据包通过查看源代码可以发现验证码的逻辑是在js中完成的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
来自:/thanks4sec/blog/item/6350e83d758f380290ef39c5.html
这个东东和burpsuite差不多,很有用
SQL注入是目前Web应用中最常见的漏洞,只要网页上有提交框并且该提交框的内容影响后台的查询的SQL语句,就可能存在该漏洞。
一般程序员在编写Web应用程序时都是直接从request中取出提交的参数的值放入到SQL语句中进行查询,这就造成了一个又一个的SQL注入风险。
熟悉SQL语句的攻击者会在网页输入框中输入设计好的内容,将SQL的查询逻辑改变,从而得到自己想要的东西。
举几个例子:
案例1:绕过登录界面:
常见的登录页面有两个输入框,一个用户名,一个密码,后台的SQL语句为
select*from Users where username=’[用户名]’and password=’[密码]’
其中[用户名]和[密码]分别为在两个输入框中输入的内容,一般来说没有什么问题,程序员只要判断返回的recordset的记录数大于0就可以使用户登录进去,但是如果恶意用户在用户名中输入x’or‘1’=’1,密码随便输,那么后台的SQL查询语句就会变为
select*from Users where username=’x’or‘1’=’1’and password=’[密码]’
其中where语句的逻辑值始终为真,如果能猜中用户名,即可以使用该用户登录
案例2:执行危险的SQL语句;
现在不少数据库支持批处理,使用分号隔开多个SQL语句,如一个查询界面,可以查询客户号(客户号为数字类型),后台的SQL语句为:
select*from customers where ID=[客户号]
其中[客户号]为用户输入内容,假如用户输入的为1;drop table customers。
则整个SQL语句变为select*from customers where ID=[客户号]1;drop table customers,这样的查询一过,Customers表就没了。
使用同样的手法,恶意用户还可以植入触发器,修改数据,总之,可以执行后台的SQL执行时使用的数据用户权限内的所有操作。
当然SQL注入攻击也不见得都是这么简单,有的时候需要认真分析网页,猜测其SQL的结构,并且需要利用一些工具进行辅助。
本文对WebGoat教程中的一段有关SQL注入测试进行解释,WebGoat我在另一篇文章【学习Web应用漏洞最好的教程----WebGoat】中有过介绍。
因为在测试中用到了WebScarab,这里简单介绍一下。
WebScarab说白了就是一个代理工具,他可以截获web浏览器的通信过程,将其中的内容分析出来,使你很容易修改,比如我发一个submit请求,WebScarab首先截获到,不急着给真正的服务器,而是弹出一个窗口让你可以修改其中的内容,修改结束了再提交给服务器,如果网页的输入框进行了一些限制,如长度限制、数字格式限制等,只能使用这种方式进行修改了;它也可以修改服务器返回的response,这就可以过滤掉一些对客户端进行限制的js 等。
这是OWASP的另一利器。
下面开始注入过程:
首先明确目标,webgoat的教程:
界面上只有一个输入框,该教程的要求是要我们使用SQL注入方法登入界面,兴冲冲的在password中输入x’or‘1’=’1,不行,原来这个password框只能输入8个字符,刚才的那个有12个字符之多!这时看样子要祭出WebScarab了。
WebScarab的默认运行模式为Lite模式,如下图:
重新启动WebScarab,界面如下,多了很多功能选项:
因为我们要截获发出的请求,将【Proxy】-【Manual Edit】-【Intercept request】勾选上。
在IE中将代理服务器指向本机的8008端口(webscarab的),在webgoat的密码框中输入111提
交,马上弹出了如下界面:
其中password可以修改为:x’or‘1’=’1,点击Accept Changes,成功,界面如下:。