dbmd数据库更新工具使用手册
DB 查询分析器使用手册1

DB 查询分析器使用手册第一章系统简介 (3)1.1 前言 (3)1.2 产品特点 (4)第二章安装过程 (5)2.1 下载 (5)2.2 进行程序的安装 (5)2.2 卸载 (9)第三章操作基础 (11)第三章操作基础 (11)3.1 建立DB ODBC数据源 (11)3.2 使用《DB 查询分析器》来登录后台数据库 (12)3.3 《DB 查询分析器》的开发环境 (13)3.4 对象浏览器的使用 (16)3.4.1 查看数据对象(如用户表) (16)3.4.2 生成常用的SQL语句(如TOP N) (18)3.4.3 查看存贮过程 (19)第四章高级操作 (20)4.1 《DB 查询分析器》中的系统参数设置 (20)4.2 手工管理事务 (21)4.3 手工管理事务示例 (21)4.3.1 启动手工管理事务模式 (21)4.3.2 删除部分记录 (22)4.3.3 取消事务 (23)4.3.3 提交事务 (23)4.4 中断查询的执行 (24)4.5 多条SQL语句的执行 (26)4.6 对SQL语句的执行结果按某一字段排序 (27)4.7 导出查询结果 (28)4.8 在查询结果中查找字符串 (28)4.9 如何设计效率高的SQL语句 (29)4.10 创建存贮过程 (30)4.11 执行存贮过程 (31)第五章运行环境 (32)第六章进行注册 ............................................................................... 错误!未定义书签。
第七章结束语................................................................................... 错误!未定义书签。
第一章系统简介1.1 前言从关系数据库产生至今,有许多种数据库产品问世,大型数据库系统如Oracle、Sybase、DB2、Informix,企业级数据库系统如MS SQL SERVER、MySql,还有桌面数据库系统如MS ACCESS、FoxPro和Paradox。
Kvdbgrd控件命令语言使用方法6.5

Kvdbgrd控件命令语言使用范例本文档实际使用例程请见KVDBGRD控件使用例程(适用6.5版本)――请在公司网站技术主页下的功能解决方案中下载KvDBGrid控件有许多控件属性和事件等,这里介绍一些常用的属性和方法一.方法说明:1.Where属性:字符串型属性,设置查询条件,如果不需要任何条件,则字符串为空。
如按时间查询:数据库控件.Where="AlarmDate='2003/1/1'";2.FetchData()方法:执行数据查询,并将查询到的数据填充到表格中。
在使用FetchData ()方法后,必须调用FetchEnd()方法,结束本次查询。
否则回造成系统资源上的不必要的丢失。
如下图所示,为简单的数据查询使用方法。
3.Print()方法:执行表格打印。
4.RefreshData()方法:按照上次查询的条件,重新刷新一遍表格中的数据。
5.RemoveAllData()方法:删除KvDBGrid表中的所有数据。
6.SaveToCSV(STRING bstrCSV)方法:将当前KvDBGrid表中的所有数据保存成指定的CSV 格式的文件。
需要指定参数:保存路径和文件名。
7.ScrollToBottom()方法:鼠标焦点定位到KvDBGrid表的最底部。
8.UpdateCellTextToDB(LONG lRow,LONG lCol)方法:将指定KvDBGrid表中修改的单元格的数据更新到数据库中。
如修改了KvDBGrid中某个单元格的数据,可以按照下图中的方法将数据更新到数据库中。
注:Access数据库不支持这种方法,所以如果用户使用的是Access数据库,执行该方法将不起作用。
二.使用实例:数据库中字段:日期时间品名数量控件名:grid1.查看所有数据grid.FetchData() ;grid.FetchEnd() ;2.对数据进行排序查看(1)。
按照品名字段进行升序排列grid.Where=" order by 品名asc";grid.FetchData() ;grid.FetchEnd() ;(2)按照品名、重量进行排序(desc为降序)grid.Where=" order by 品名asc,重量desc";grid.FetchData() ;grid.FetchEnd() ;3.静态条件查询(1)符串查询――查询所有品名为玉米的记录grid.Where="品名='玉米'";// 如果需要排序可写为grid.Where="品名='玉米' Order by 日期ASC”grid.FetchData() ;grid.FetchEnd() ;(2)数值查询:查询重量数值为73的记录grid.Where="重量=73"; // 查询条件grid.FetchData() ;grid.FetchEnd() ;(3)类似查询-查询2002年的记录grid.Where="日期like '2002%'"; // 查询条件grid.FetchData() ;grid.FetchEnd() ;4.动态查询(1)字符串查询string chaxun; // 自定义一个字符串变量chaxun="品名='"+\\本站点\品名查询+"'";//将查询条件赋值给自定义变量grid.Where=chaxun+" Order by 日期ASC"; // 查询条件,Order by 时间ASC-按时间排序grid.FetchData() ;grid.FetchEnd() ;(2)数据查询string chaxun;chaxun="重量="+StrFromInt( \\本站点\查询重量, 10 );//将数值自动转换为字符//注:如果查询变量为字符串变量则chaxun="重量="+\\本站点\查询重量;grid.Where=chaxun+" Order by 日期ASC,时间ASC ";grid.FetchData() ;grid.FetchEnd() ;(3)多条件查询string chaxun;chaxun="日期='"+\\本站点\查询日期+"' and 重量="+StrFromInt( \\本站点\查询重量,10 );grid.Where=chaxun+" Order by 时间ASC"; // 查询条件grid.FetchData() ;grid.FetchEnd() ;KvDBGrid控件可以用做大批量数据的查询工具使用。
Oracle Database 19c 升级服务说明书

Oracle Database Upgrade ServicesOracle Database Platform is the cornerstone for maintaining and protecting yourorganization’s data. Take advantage of the latest features by upgrading to OracleDatabase 19c. Upgrading to 19c will reduce support cost and extend support lifetime while accelerating your environment towards cloud ready. The new features in the latestDatabase Platform release of 19c ensures your databases runs at optimal performance.Oracle Consulting Database experts can help achieve this with our extensive product experience, leading practices, proven methodology and tools. The Oracle ConsultingDatabase Upgrade Service is designed to ensure your current Production Databaseconfiguration and workloads are validated during the process up the upgrade.ORACLE DATABASE AT THE CORE OF YOUR ENTERPRISE The Oracle Consulting (OCS) Database Upgrade Service assesses your database(s) and application(s) to ensure you that the upgrade process is smooth and transparent. OCS will work with your team to perform upgrade pre/post-analysis to determine the appropriate upgrade method and strategies to limit downtime.The Database Platform Upgrade addresses the following:-Database upgrade pre-analysis validation and recommendations-Database validation to ensure production workloads are not impacted by the upgrade.-Database upgrade for Non-Production Development/Testing environments-Database upgrade for Production environments with limited downtime-Database post-analysis validation and recommendationsThe pre/post-analysis will identify existing concerns and deliver a plan of action for those areas identified. Some of these areas can be addressed with attention and focus of existing resources; others will require expert consultation.OCS will conduct a collaborative discovery and analysis workshop to review Oracle Database Platform Upgrade requirements. Oracle Consulting experts will deliver a holistic, actionable project plan for your Database Upgrades.KEY DELIVERABLES-Workshop covering database upgrade requirements and upgrade methods-Project Management Plan and Baseline Project Plan-Production upgrade and validation results-Database Upgrade Reports Key New Features•Automated Installation,Configuration and Patching •SQL Quarantine•Zero-Downtime Oracle GridInfrastructure Patching•Active Data Guard DML redirect •Automated Optimizer features •Hybrid partitioning•Terminal “Final” long term release of 12c/18c database series•Full Support through 2023 •Extended Support 2026Key Business Benefits•Oracle Consulting Databaseexperts that understand yourupgrade requirements •Increase agility with focus ondatabase upgrades and leadingpractices•Accelerate your business practices with proven methodology andtools•Advise and guide your IT team •Database validated workload post upgrade.HOW WE ARE DIFFERENTThe Oracle Consulting team is focused exclusively on Oracle Technologies, and we have the experts that others turn to for leading practices in Oracle hardware and software implementations. We know how critical it is for any business to best optimize your investment in Oracle products and can provide your business with tightly integrated, comprehensive, superior services throughout your Oracle Technology experience.GETTING STARTEDLeverage Oracle’s methods, tools, and extensive experience with customer implementations across diverse industries and geographies. Tight integration across Consulting, Development, Support, Education, and Global Delivery puts the entire Oracle team behind your success. To learn more, contact your local Oracle Consulting representative, or visit /consulting. Related Services from OCS•Data Replication with OracleGolden Gate•Disaster Recovery with OracleData-guard•Database Assessments •Database Migrations •Application Architecture •Cloud Transformations •Database Performance TuningWhy Oracle Consulting•Leading expertise: Oracle's own experts providing thoughtleadership for every Oraclesolution.•Broad Coverage: “End-to-end”lifecycle services across the entireOracle product footprint •Global Scale: 13,000 Oracleexperts in 145 countries, servingover 20 million users. •Upgrade Methods: Based onindustry standards, high qualityresults across complex projectsCONNECT WITH USCall +1.800.ORACLE1 or visit .Outside North America, find your local office at /contact. /oracle /oracleCopyright © 2020, Oracle and/or its affiliates. All rights reserved. This document is provided for information purposes only, and the contents hereof are subject to change without notice. This document is not warranted to be error-free, nor subject to any other warranties or conditions, whether expressed orally or implied in law, including implied warranties and conditions of merchantability or fitness for a particular purpose. We specifically disclaim any liability with respect to this document, and no contractual obligations are formed either directly or indirectly by this document. This document may not be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without our prior written permission.This device has not been authorized as required by the rules of the Federal Communications Commission. This device is not, and may not be, offered for sale or lease, or sold or leased, until authorization is obtained.Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Opteron, the AMD logo, and the AMD Opteron logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registered trademark of The Open Group. 0120Disclaimer: This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, timing, and pricing of any features or functionality described in this document may change and remains at the sole discretion of Oracle Corporation.。
goldendb手册指南

goldendb手册指南Goldendb 手册指南Goldendb 是一款功能强大的数据库管理工具,它为用户提供了简单、高效的方式来管理和操作数据库。
本手册将帮助您全面了解Goldendb 的各项功能和使用方法,以便您能够充分发挥其潜力。
一、什么是 Goldendb?1. Goldendb 是一款开源的数据库管理工具,它被设计用于简化数据库的创建、维护和操作过程。
2. Goldendb 支持多种数据库系统,包括 MySQL、PostgreSQL、MongoDB 等,并提供了一致的用户界面,使得用户能够更轻松地切换和管理不同类型的数据库。
3. Goldendb 提供了丰富的功能,包括数据库连接管理、数据导入导出、查询和分析、性能优化、安全管理等,并且支持扩展插件的方式来满足用户的个性化需求。
二、Goldendb 的安装和配置1. 安装 Goldendb:您可以从官方网站下载最新版本的 Goldendb,并按照官方文档的指引进行安装。
在安装过程中,您需要选择所需的数据库系统,并进行相应的配置。
2. 配置数据库连接:一旦安装完成,您需要配置数据库连接信息,包括数据库服务器位置区域、端口号、用户名和密码等。
这些信息将通过 Goldendb 进行数据库的管理和操作。
三、Goldendb 的基本功能1. 数据库连接管理:Goldendb 提供了一个集中管理数据库连接的界面,您可以在其中添加、编辑和删除数据库连接。
每个连接都可以进行测试,以确保连接信息的准确性。
2. 数据导入导出:通过 Goldendb,您可以将数据从一个数据库导出到另一个数据库,或者将数据导入到现有数据库中。
这一功能能够节省您的时间和精力,并且保证数据的一致性和完整性。
3. 查询和分析:Goldendb 具有强大的查询和分析功能,您可以通过SQL 查询语言来访问数据库,并对查询结果进行进一步的统计和分析。
Goldendb 还支持可视化图表展示,以便更直观地理解和分析数据。
数据库管理器DBMGR参数设置手册

数据库管理器DBMGR参数设置手册脚本执行完成后,开启“电能量系统平台”,就要开始DBMGR的参数设置。
1.如下图,点击“置库界面”。
2.进入数据库管理器的主界面:点击“登录”,先登录系统。
登录界面如下:(密码为201203)图中红框部分,“系统类”和“基础类”在脚本执行以后就已经生成了。
不需要重新设置参数。
需要手动设置的有“网络类”、“权限类”“设备类”“采集类”。
(最后的“SCADA”用一个程序生成,后面再述。
)3.“网络类”的设置,如下图:(1)关于“节点参数表”的说明:“节点”即电脑,节点参数表是设置要连接终端采集设备的电脑的信息。
双击“节点参数表”,点击“添加”右边显示如图:必须填写的有“代码”“描述”“A网地址”“远程节点标志”。
“代码”:本机名,在我的电脑——右键——属性里查看。
“描述”:可随意填写,只是便于识别,可以与“代码”一样。
“A网地址”:本机的IP地址,在网络属性里查看。
“远程节点标志”:一般选“否”。
可添加多个节点,添加完注意保存。
添加完如图:(2)关于“节点服务器对照表”的说明:即添加的节点主要用于做什么事情,比如做数据采集服务器。
如设置刚才添加的节点用作数据采集服务器,双击“数据采集服务器”,点击“添加”,第一个“代码”,下拉菜单中选择添加的节点,如“test”。
第二个“代码”,下拉菜单中选择服务器类型,如“数据采集服务器”。
“优先级”,主要是用来判断主备机的,比如,有2个节点作数据采集服务器,有一个优先级要选0,作为主机,另一个优先级选1,作为备机。
添加完注意保存,如图:综上所述:我们设置了一个节点叫“test”,这个节点用作“数据采集服务器”和“数据处理服务器”。
4.“权限类”设置,如下图:(1)“角色表”:设置系统总共有哪些角色可以操作,一般系统已经设置好,可以根据客户需要修改即可。
如下图:(2)“角色功能表”:设置每一个角色能操作什么样的功能,一般系统已经设置好,可以根据客户需要修改即可。
数据库监控软件MyDBMon使用说明
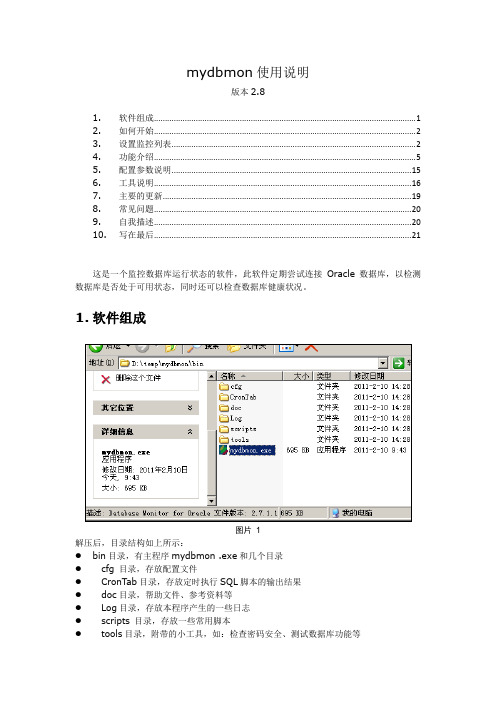
mydbmon使用说明版本2.81.软件组成 (1)2.如何开始 (2)3.设置监控列表 (2)4.功能介绍 (5)5.配置参数说明 (15)6.工具说明 (16)7.主要的更新 (19)8.常见问题 (20)9.自我描述 (20)10.写在最后 (21)这是一个监控数据库运行状态的软件,此软件定期尝试连接Oracle 数据库,以检测数据库是否处于可用状态,同时还可以检查数据库健康状况。
1.软件组成图片 1解压后,目录结构如上所示:●bin目录,有主程序mydbmon .exe和几个目录●cfg 目录,存放配置文件●CronTab目录,存放定时执行SQL脚本的输出结果●doc目录,帮助文件、参考资料等●Log目录,存放本程序产生的一些日志●scripts 目录,存放一些常用脚本●tools目录,附带的小工具,如:检查密码安全、测试数据库功能等●db目录,有个Access 数据库文件,存放数据库列表、SQL语句等设置信息2.如何开始到.\bin 目录下直接双击mydbmon .exe 来运行主程序,界面如下:图片2点击菜单“扫描-开始”,就开始定期检查数据库了(这些都是演示数据)。
顺便介绍一下此界面:●界面左边是数据库分类列表,选中一类,就可以在右边显示此类中的数据库●界面右边上半部分是数据库列表,如果检测过一次后,数据库的其它信息也会显示出来,如当前会话数、将满的表空间、字符集等;可以点击列头进行排序●检查的结果会显示在“明细”页框中,如果检查到异常信息显示在“警告”页框中,如果是严重的异常,会置于“警告”页框的顶部3.设置监控列表要想真正使用此程序,需先设置被监控数据库的信息,两种方法:(1)点击菜单“文件-初始化监控列表”图片3打开对话框,如下图所示:图片4点击“打开”按钮,可以选择一个比较全的tnsnames.ora,将里面的实例信息一次全部导入到本程序中,省去了逐个设置的麻烦。
此方法适用于第一次运行本程序时。
mongodb curd 手册

很高兴接到您的文章写手任务,让我们开始撰写关于 MongoDB CURD 手册的高质量文章。
1. MongoDB CURD 是指什么?MongoDB CURD 是对 MongoDB 数据库常用操作的缩写,其中包括Create(创建)、Update(更新)、Read(读取)和Delete(删除)四个操作。
这些操作是在 MongoDB 数据库中对数据进行管理和操作时常用的基本操作。
2. Create(创建)在 MongoDB 中,创建数据是非常常见的操作。
您可以通过指定集合和字段来创建新的文档。
在进行创建操作时,可以指定字段的值,并且还可以在创建文档时指定文档的唯一标识符。
3. Update(更新)更新操作是在 MongoDB 中对已存在的文档进行更新。
您可以通过指定条件来定位需要更新的文档,并且可以根据需要更新文档中的字段值。
更新操作也可以用来更新多个文档,以及根据不同的条件来进行更新操作。
4. Read(读取)读取操作是指从 MongoDB 数据库中检索数据的操作。
您可以通过指定条件来获取符合条件的文档,并且可以根据需要对结果进行排序、分页、投影等操作。
读取操作还可以进行聚合操作,以及对数据进行统计分析。
5. Delete(删除)删除操作是在 MongoDB 中对不再需要的文档进行删除。
您可以通过指定条件来定位需要删除的文档,并且可以根据需要删除单个或多个文档。
删除操作还可以对集合进行删除,以及删除整个数据库。
总结回顾:通过本文我们对 MongoDB CURD 进行了深入的探讨,包括了Create、Update、Read 和 Delete 四个操作,并且针对每个操作进行了详细的介绍。
在实际使用 MongoDB 数据库时,这些 CURD 操作是非常重要的,能帮助我们对数据进行管理和操作。
MongoDB CURD 手册是每个开发者在使用 MongoDB 时不可或缺的工具。
个人观点和理解:作为一名资深的 MongoDB 开发者,我对 MongoDB CURD 操作有着丰富的实践经验。
DBMaster 快速使用手册说明书

如何使用此手册本手册主要介绍如何安装及运行DBMaster。
如果您是Microsoft Windows用户,DBMaster提供了可自动执行的安装程序,您可以利用它来安装DBMaster。
在UNIX和LINUX系统上,DBMaster也提供了简易的安装程序,您只需按照画面提示,就能顺利安装。
有关在线文件请直接使用Adobe Acrobat© Reader TM来浏览。
DBMaster简介DBMaster数据库管理系统是唯一由国人自行研发且行销世界的大型关系数据库。
安装轻松、操作简便、管理容易,可以让您在最短的时间内掌握数据的处理流程和变化。
DBMaster拥有新一代的引擎核心,符合时代潮流。
完整的多媒体数据管理模式,内建中英日全文检索功能及分布式的运算环境,是企业追求信息自动化的最佳利器。
此外,DBMaster支持常见的操作系统。
快捷的技术支持、完善的售后服务、最佳性能价格比,是企业扩展商机与成功开拓市场的最大保障。
您所使用的 DBMaster 光盘主要包含 DBMaster 在下列各个平台上的安装程序,您可以根据具体需求选择正确的安装程序。
•Windows 32bit和x86_64bit(Windows 2008/7/8/2012/10)•Linux 32bit (glibc 2.3) 和 x86_64bit (glibc 2.7)DBMaster也会依需求提供下列平台的支持程序:•Windows 32bit和x86_64bit (Windows 2000/XP/2003/Vista)系统需求•Intel Pentium Pro或以上•建议200 MB的硬盘空间•支持TCP/IP网络协议•彩色VGA或以上的显示卡•光驱安装DBMasterDBMaster 自动安装程序可让您自由选择想要安装的组件,例如:database server, database client, ODBC driver, samples, documentation 等。
DB数据库加新东西说明

(17)delay 技能延迟时间
(18)descr 备注
-----------------------------------------------------------------
MonsterDb: 是关于怪物的攻击,经验,还有等级方面的东西
Npc.wil &??nbsp;游戏里NPC的图片
Object.wil~Object7.wil(No 1) 建筑物、陆地上物体的图片
Prguse1~2.wil 游戏界面所看到的图片
SmTiles.wil 地图的小图片
Tiles.wil 地图的大图片
Weapon.wil 手里的武器各个方向的图片。StateItem.wil 装备在身上的样子 二、数据库说明MagicDb:是你所修炼的法术和各种技能.(1)magsid 物品代号
项链类
项链可带的属性可真不少,什么魔法恢复啊,生命恢复啊 幸运,行动速度
都能带
Mode是0的:绿色,蓝翡翠之类的是加准确和敏捷
而狂风,记忆,之类的是加幸运和生命魔法恢复
手镯类
一个是加敏捷和准确
一个是加防
加准确和敏捷的手镯改DC 是加敏和准
而加防和攻的改则是加防特殊的:
白色虎齿项链:道术1-0 魔法躲避20%
降魔:准确+1(其他属性略)
数据库体现:
AC2 1
PK刀:幸运+7,准确+7(其他属性略)
数据库体现:
AC2 7
Source -7(注意这个属性)
超级无极棍:幸运+10 准确+10 神圣+10
Ollydbg2.0x简明帮助手册

OllyDbg 2.01 简明帮助手册Translated by Antiy Cert免责声明本译文译者为安天实验室工程师,本文系出自个人兴趣在业余时间所译,本文原文来自互联网的公共方式,译者力图忠于所获得之电子版本进行翻译,但受翻译水平和技术水平所限,不能完全保证译文完全与原文含义一致,同时对所获得原文是否存在臆造、或者是否与其原始版本一致未进行可靠性验证和评价。
本译文对应原文所有观点亦不受本译文中任何打字、排版、印刷或翻译错误的影响。
译者与安天实验室不对译文及原文中包含或引用的信息的真实性、准确性、可靠性、或完整性提供任何明示或暗示的保证。
译者与安天实验室亦对原文和译文的任何内容不承担任何责任。
翻译本文的行为不代表译者和安天实验室对原文立场持有任何立场和态度。
译者与安天实验室均与原作者与原始发布者积极联系未果,亦未获得相关的版权授权,鉴于译者及安天实验室出于学习参考之目的翻译本文,而无出版、发售译文等任何商业利益意图,因此亦不对任何可能因此导致的版权问题承担责任。
本文为安天内部参考文献,主要用于安天实验室内部进行外语和技术学习使用,亦向中国大陆境内的网络安全领域的研究人士进行有限分享。
望尊重译者的劳动和意愿,不得以任何方式修改本译文。
译者和安天实验室并未授权任何人士和第三方二次分享本译文,因此第三方对本译文的全部或者部分所做的分享、传播、报道、张贴行为,及所带来的后果与译者和安天实验室无关。
本译文亦不得用于任何商业目的,基于上述问题产生的法律责任,译者与安天实验室一律不予承担。
注:如有原作者联系方式或信息请与我们联系。
前言Ollydbg是一款结合IDA和SoftICE功能的调试工具,因其简易的操作和强大的功能,目前已成为安全研究领域使用最广泛的调试解密工具。
目前Ollydbg软件已发布2.0x版本,但内附的帮助手册尚无中文翻译版发布。
基于合作分享,互惠互利的理念,同时为更多新版Ollydbg的使用者提供便利的条件,安天CERT对帮助手册展开翻译工作,并形成当前的译文版本。
DM大梦数据库数据库使用手册

DM大梦数据库数据库使用手册华中科技大学计算机学院数据库课程实验操作指导数据库系统课程教学组二0 一四年三月目录1.DM数据库的安装 (1)2.DDL使用方法 (1)2.1.数据库创建 (1)2.2.基本表的创建 (1)2.3.视图的创建/删除 (3)3.DML使用方法 (6)3.1.INSERT命令 (6)3.2.DELETE命令 (8)3.3.UPDATE命令 (9)4.SELECT命令 (10)4.1.简单查询 (11)4.2.使用谓词的查询 (12)4.3.连接查询 (12)4.4.复杂查询 (14)5.DCL的使用方法 (15)5.1.SQL Server 登录管理 (15)5.2.用户管理 (15)5.3.授权用户(GRANT、REVOKE) (17) 6.游标的使用 (20)6.1.游标的定义 (20)6.2.游标的操作 (20)7.数据库的备份和恢复 (22)8.实验练习 (23)实验1:基本表的创建、数据插入 (23)实验2:数据查询 (24)实验3:数据修改、删除 (24)实验4:视图的操作 (24)实验5:库函数,授权的控制 (24)实验6:数据库的备份、恢复 (24)9.数据库课程设计基本要求 (25)9.1.设计目标 (25)9.2.基本要求 (25)9.3.实验系统参考题目 (26)9.4.文档内容 (26)1.DM数据库的安装此部分见安装文件自带的DM_Install_zh.pdf文件,十分详细。
2.DDL使用方法2.1.数据库创建创建一个模式实际上定义了一个命名空间,在这个空间中可以进一步定义该模式包含的数据库对象,例如基本表、视图、索引等。
定义模式:CREATE SCHEMA <模式名> AUTHORIZATION <用户名>例1:创建名为ems的模式:create schema ems authorization SYSDBA;2.2.基本表的创建创建基本表的命令为:CREATE TABLE table_name,在该命令中定义主码和外码时,可以使用列约束(Column Constraint)或表约束(Table Constraint)子句。
Oracle数据库工具包用户指南说明书

Package‘ora’October14,2022Version2.0-1Date2014-04-10Title Convenient Tools for Working with Oracle DatabasesAuthor Arni MagnussonMaintainer Arni Magnusson<***************>Depends DBI,ROracleSystemRequirements Oracle clientDescription Easy-to-use functions to explore Oracle databases and import datainto er interface for the ROracle package.License GPL(>=2)NeedsCompilation noRepository CRANDate/Publication2014-04-1015:27:20R topics documented:ora-package (1)desc (2)sql (4)tables (5)views (7)Index10 ora-package Convenient Tools for Working with Oracle DatabasesDescriptionEasy-to-use functions to explore Oracle databases and import data into er interface for the ROracle package.12descDetailsExplore database:tables list tablesviews list viewsExamine table:desc describe table or viewImport data:sql import dataAuthor(s)Arni Magnusson.ReferencesThe official Oracle manuals are available at /technetwork/indexes/ documentation/.See AlsoThe functions that do the actual work are described in the DBI and ROracle packages.desc Describe Oracle TableDescriptionShow the column names of an Oracle table(or view)and various column properties,not unlike the Oracle SQL*Plus DESC command.Also show the number of rows when the table was last analyzed. Usagedesc(table,tolower=TRUE,dots=FALSE,...)Argumentstable Oracle table name,often in the‘owner.table’format.tolower whether output table strings should be lowercased.dots whether underscores in column names should be replaced with dots,converting ‘col_name’to‘’....passed to dbConnect.desc3DetailsThe...argument can be used to set username,password,and/or dbname(see dbConnect).Abbre-vations like user and‘pass’are allowed.The default database name is determined by the environ-ment variable ORACLE_SID,which can be redefined within an R session using Sys.setenv(ORACLE_SID="foo").ValueA data frame with named rows and the following columns:name Oracle column name.Sclass storage mode in R.type Oracle type.len Oracle length.precision Oracle precision.scale Oracle scale.isVarLength whether the variable has varying length in Oracle.nullOK whether the variable can be null.Furthermore,the data frame contains two attributes:rows(the number of rows when the table waslast analyzed)and analyzed(when the table was last analyzed).These attributes are not availablefor all Oracle tables,but are more likely to be available when the main argument table has the fullowner.table format.NoteSee the Oracle manuals for details about type,length,precision,scale,and nulls.See Alsodesc is to Oracle tables as ll(in package gdata)is to R data frames.ora gives an overview of the package.Examples##Not run:desc("dual",tolower=FALSE)desc("all_users")##End(Not run)4sql sql Import Data from OracleDescriptionRun SQL query returning an R data frame.Usagesql(query,tolower=TRUE,dots=TRUE,encoding="unknown",useBytes=TRUE,stringsAsFactors=FALSE,warn=-1,debug=FALSE,...)Argumentsquery string containing SQL query or the name of afile containing a query.tolower whether column names should be lowercased.dots whether underscores in column names should be replaced with dots,converting‘col_name’to‘’.encoding passed to readLines.useBytes passed to gsub.stringsAsFactorswhether to convert string columns to factors.warn sets the handling of warning messages,e.g.when Oracle columns are of type‘LONG’.debug whether to return thefinalized SQL query string,instead of submitting it toOracle....passed to dbConnect.DetailsThe query is not required to end with a semicolon.In fact,semicolons are removed internallybefore submitting the query to Oracle.The arguments encoding and useBytes enable the user to solve character encoding problemswithin the SQL query.If the query contains non-ASCII characters,readLines and gsub(calledby sql)may convert the query to a different encoding than the Oracle database expects.The arguments stringsAsFactors and warn correspond to options with the same names,but thesession options are not used as default values.Therefore,it is necessary to pass stringsAsFactors=TRUEdirectly to sql in order to import string columns as factor.This option-overriding is designed tomake results more predictable and facilitate collaboration between database users.debug=TRUE is helpful for solving problems,and also to save complex queries(possibly to afile)for later use.The...argument can be used to set username,password,and/or dbname(see dbConnect).Abbre-vations like user and‘pass’are allowed.The default database name is determined by the environ-ment variable ORACLE_SID,which can be redefined within an R session using Sys.setenv(ORACLE_SID="foo").ValueData frame containing the imported data,or a simple string if debug=TRUE.See Alsosql is to Oracle tables as read.table is to textfiles.ora gives an overview of the package.Examples##Not run:##1Basic queries#Pass query as a simple stringsql("SELECT username,created FROM all_users WHERE rownum<=10")#Pass query as a multiline stringsql("SELECT extract(year from created)AS year,count(username)AS usersFROM all_usersGROUP BY extract(year from created)")#Pass query as a filewrite(c("SELECT username,created","FROM all_users","WHERE rownum<=10;"),"query.sql")sql("query.sql")##2Review query string,before sending it to Oraclesql(paste0("SELECT username,created FROM all_users WHERE rownum<=",5+5), debug=TRUE)##End(Not run)tables List Oracle TablesDescriptionList all tables in the database belonging to a specific owner or table space. Usagetables(owner="%",table="%",space="%",tolower=TRUE,...)Argumentsowner owner name.table table name.space table space name.tolower whether owner,table,and space output entries should be lowercased....passed to dbConnect.DetailsThe arguments owner,table,and space are passed as patterns that are matched by‘LIKE’,where%means any number of characters and_means exactly one character.Literal%and_are escapedusing two backslashes:"\\%"and"\\_".In other words,the default value"%"matches all strings.The...argument can be used to set username,password,and/or dbname(see dbConnect).Abbre-vations like user and‘pass’are allowed.The default database name is determined by the environ-ment variable ORACLE_SID,which can be redefined within an R session using Sys.setenv(ORACLE_SID="foo"). ValueData frame containingfive columns:owner owner name.table table name.space table space name.rows number of rows when the table was last analyzed.analyzed when the table was last analyzed.NoteThe output is a subset of‘ALL_TABLES’in Oracle,with simplified column names:‘OWNER’‘->owner’‘TABLE_NAME’‘->table’‘TABLESPACE_NAME’‘->space’‘NUM_ROWS’‘->rows’‘LAST_ANALYZED’‘->analyzed’See Alsotables is to Oracle as ll(in package gdata)is to R environments.ora gives an overview of the package.Examples##Not run:#Tables belonging to owner"sys":tables("sys")#Tables whose name contains"map",preceded by at least one character:tables(,"%_map%")#Tables whose name ends with"_map":tables(,"%\\_map")##End(Not run)views List Oracle ViewsDescriptionList all views in the database belonging to a specific owner.Usageviews(owner="%",view="%",tolower=TRUE,...)Argumentsowner owner name.view view name.tolower whether owner and view output entries should be lowercased....passed to dbConnect.DetailsThe arguments owner and view,are passed as patterns that are matched by‘LIKE’,where%meansany number of characters and_means exactly one character.Literal%and_are escaped using twobackslashes:"\\%"and"\\_".In other words,the default value"%"matches all strings.The...argument can be used to set username,password,and/or dbname(see dbConnect).Abbre-vations like user and‘pass’are allowed.The default database name is determined by the environ-ment variable ORACLE_SID,which can be redefined within an R session using Sys.setenv(ORACLE_SID="foo").ValueData frame containing two columns:owner owner name.view view name.NoteThe output is a subset of‘ALL_VIEWS’in Oracle,with simplified column names:‘OWNER’‘->owner’‘VIEW_NAME’‘->view’See Alsoviews is to Oracle as ll(in package gdata)is to R environments.ora gives an overview of the package.Examples##Not run:#Views belonging to owner"sys":views("sys")#Views whose name contains"all",followed by at least one character: views(,"%all_%")#Views whose name begins with"all_":views(,"all\\_%")##End(Not run)Index∗classesdesc,2∗databasedesc,2ora-package,1sql,4tables,5views,7∗utilitiesdesc,2ora-package,1sql,4tables,5views,7dbConnect,3,4,6,7desc,2,2gsub,4options,4ora,3,5,6,9ora(ora-package),1ora-package,1read.table,5readLines,4sql,2,4tables,2,5views,2,710。
DM7_Disql使用手册

行完后不保存在内存区域中。
表 1.1 SQL 语句和 DIsql 命令的区别
SQL 语句 ANSI 标准 语言 关健字不可缩写 部分语句以分号结束,部分语句以/结束 可以更新表中的数据
DIsql 命令 DM 内部标准 命令 关健字可缩写 分号可有可无,/完全用不到 不能更新表中的数据
接收服务器的执行结果,并按用户的要求将执行结果展示给用户。为了更好地与用户交互和
展示执行结果,用户也可以在 DIsql 中执行 DIsql 命令,这些命令由 DIsql 工具自身进
行处理,不被发送给数据库服务器。
SQL 语句在 DIsql 中执行完后都被保存在一个特定的内存区域中,用户可以通过上下
键查找到这些保存在内存中的 SQL 语句,并可以进行修改,然后再次执行。DIsql 命令执
表示正文。
Courier new 表示代码或者屏幕显示内容。
粗体 <>
表示命令行中的关键字(命令中保持不变、必须照输的部分)或者正文中强调的内容。 标题、警告、注意、小窍门、说明等内容均采用粗体。 语法符号中,表示一个语法对象。
语法符号中,表示定义符,用来定义一个语法对象。定义符左边为语法对象,右边为相 ::=
IV
DIsql 使用手册
1 功能简介
DIsql 是 DM 数据库的一个命令行客户端工具,用来与 DM 数据库服务器进行交互。
DIsql 是 DM 数据库自带的工具,只要安装了 DM 数据库,就可以在应用菜单和安装目录中
找到。
DIsql 识别用户输入,将用户输入的 SQL 语句打包发送给 DM 数据库服务器执行,并
2.1 启动 DISQL....................................................................................................................................2 2.2 切换登录 ......................................................................................................................................8 2.3 使用 DISQL..................................................................................................................................10 2.4 退出 DISQL..................................................................................................................................11 3 DISQL 环境变量设置 ..................................................................................................................12 3.1DISQL 环境变量 ..........................................................................................................................12 3.2 SET 命令用法 ...........................................................................................................................13 3.3 用 SET 命令设置环境变量详解 ...............................................................................................13 3.4 SHOW 命令查看环境变量 .........................................................................................................22 4DISQL 常用命令 ...........................................................................................................................23 4.1 帮助 HELP..................................................................................................................................23 4.2 输出文件 SPOOL........................................................................................................................23 4.3 切换到操作系统命令 HOST ......................................................................................................24 4.4 获取对象结构信息 DESCRIBE.................................................................................................24 4.5 定义本地变量 DEFINE 和 COLUMN.........................................................................................30 4.6 查看执行计划 EXPLAIN............................................................................................................36 4.7 设置异常处理方式 WHENEVER .................................................................................................36 4.8 查看下一个结果集 MORE ..........................................................................................................37 4.9 显示 SQL 语句或块信息 LIST .................................................................................................37 5 如何在 DISQL 中使用脚本 .........................................................................................................38 5.1 编写脚本 ....................................................................................................................................38 5.2 使用 START 命令运行脚本 ......................................................................................................38 5.3 使用 EDIT 命令编辑脚本 .........................................................................................................40 5.4 如何在脚本中使用变量 ............................................................................................................40 5.5 使用 PROMPT 命令传递信息 .......................................................................................................44
Oracle数据库补丁和升级指南说明书

Pankaj Chandiramani Consulting Product Manager Oracle
Copyright © 2019 Oracle and/or its affiliates.
Push Image as Shadow
Home
Software “End State” Image – Versioning
Centralized Operations Schedule, fix, retry Flexible and extensible Self Service Maintenance
Production
Copyright © 2019 Oracle and/or its affiliates.
OH – 18.6
OH – 18.3 *OH = Database Oracle Home
Database Fleet Maintenance – Process
Patching Cycle 1 Goal: Patch Production 18.3 DBs to 18.6
Enterprise Manager 13c
Gold Image Environment
Production
OH – 18.6
MAINTENANCE WINDOW
Update
Rollback
Copyright © 2019 Oracle and/or its affiliates.
OH – 18.6
Subscribing Databases
UCMDB 10.33 升级助手用户指南说明书

Universal CMDBSoftware Version: 10.33User Guide: UCMDB 10.33 upgrade helperDocument Release Date: February 2018Software Release Date: February 2018Legal NoticesDisclaimerCertain versions of software and/or documents (“Material”) accessible here may contain branding from Hewlett-Packard Company (now HP Inc.) and Hewlett Packard Enterprise Company. As of September 1, 2017, the Material is now offered by Micro Focus, a separately owned and operated company. Any reference to the HP and Hewlett Packard Enterprise/HPE marks is historical in nature, and the HP and Hewlett Packard Enterprise/HPE marks are the property of their respective owners.WarrantyThe only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice.Restricted Rights LegendConfidential computer software. Except as specifically indicated otherwise, a valid license from Micro Focus is required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license.Copyright Notice© 2011 - 2018 Micro Focus or one of its affiliates.Trademark NoticesMICRO FOCUS and the Micro Focus logo, among others, are trademarks or registered trademarks of Micro Focus (IP) Limited or its subsidiaries in the United Kingdom, United States and other countries. All other marks are the property of their respective owners.Adobe™ is a trademark of Adobe Systems Incorporated.Microsoft® and Windows® are U.S. registered trademarks of Microsoft Corporation.UNIX® is a registered trademark of The Open Group.Documentation UpdatesTo check for recent updates or to verify that you are using the most recent edition of a document, go to: h ttps://.This site requires that you register for a Software Passport and to sign in. To register for a Software Passport ID, click Register for Software Passport on the Micro Focus Support website at https://.You will also receive updated or new editions if you subscribe to the appropriate product support service. Contact your Micro Focus sales representative for details.SupportVisit the Micro Focus Support site at: https://.This website provides contact information and details about the products, services, and support that Micro Focus offers.Micro Focus online support provides customer self-solve capabilities. It provides a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued support customer, you can benefit by using the support website to:Search for knowledge documents of interestSubmit and track support cases and enhancement requestsDownload software patchesManage support contractsLook up Micro Focus support contactsReview information about available servicesEnter into discussions with other software customersResearch and register for software trainingMost of the support areas require that you register as a Software Passport user and to sign in. Many also require a support contract. To register for a Software Passport ID, click Register for Software Passport on the Micro Focus Support website at https://.To find more information about access levels, go to: https:///web/softwaresupport/access-levels.Integration Catalog accesses the Micro Focus Integration Catalog website. This site enables you to explore Micro Focus Product Solutions to meet your business needs, includes a full list of Integrations between Micro Focus Products, as well as a listing of ITIL Processes. The URL for this website ishttps:///km/KM01702731.ContentsUser Guide: UCMDB 10.33 Upgrade Helper4 Prerequisites4 Run the upgrade helper on a standalone server or on the writer machine in an HA environment4 Run the upgrade helper on the reader machines in an HA environment5 Send documentation feedback7User Guide: UCMDB 10.33 Upgrade HelperThe UCMDB 10.33 upgrade helper i s a script-based tool designed to simplify the process of upgrading to UCMDB 10.33. In addition to upgrading servers to UCMDB 10.33, the upgrade helper backs up and re-applies existing custom settings (files related to DB security hardening, including jdbc.properties, local_policy.jar, US_export_policy.jar, and cacerts), creates a backup of configuration files (cmdb.conf, server.keystore, and server.truststore) that can be re-used if you upgrade another server, and ensures compliance with the stricter password policies of UCMDB 10.33.Prerequisitesl You must be running UCMDB 10.20 or a later version.l Port 5005 must be open.Run the upgrade helper on a standalone server or on the writer machine in an HA environmentTo run the upgrade helper, follow these steps.1. On Windows-based machines, open <path to upgrade helper> > UCMDB 10.33 UpgradeHelper > windows-platform, and then double-click upgrade-helper-for-1033.bat.On Linux-based machines, open <path to upgrade helper> > UCMDB 10.33 Upgrade Helper > linux-platform, and then run upgrade-helper-for-1033.sh.2. Enter the path to your existing UCMDB installation, and then press Enter. The upgrade helper willnow back up your custom settings.o If you are prompted to set a Master key, use the JMX console to set a Master key, and then restart the UCMDB server.o If the Keystore or Truststore password is still the default password, you are prompted to set a new password. Enter a password that meets the criteria described by the upgrade helper, and then press Enter.o If port 5005 is in use, you are prompted to open it. Open the port, and then type Y to continue.3. Enter the path to the UCMDB 10.33 installer file, and then press Enter. The upgrade helper willnow launch the installer and upgrade the UCMDB server to version 10.33.4. When the upgrade is finished, you are prompted to check that the server is now version 10.33.Check the server version is correct, and then type Y to continue. The upgrade helper will nowrestore your custom settings, and then create a backup of configuration settings.o The upgrade helper will also deploy a hotfix to resolve a server startup issue. If the hotfix fails to deploy correctly, you will be prompted to apply it manually.5. When prompted, exit the upgrade helper.Run the upgrade helper on the reader machines in an HA environmentOnce you have run the upgrade helper on the writer machine, you can use it to upgrade the reader machines. To do this, follow these steps:1. Copy the upgrade helper directory from the writer machine to the reader machine that you want toupgrade.o Do not save the upgrade helper in the UCMDB folder.o Do not use any special characters (for example, brackets) in the folder name.2. On Windows-based machines, open <path to upgrade helper> > UCMDB 10.33 UpgradeHelper > windows-platform, and then double-click upgrade-helper-for-1033.bat.On Linux-based machines, open <path to upgrade helper> > UCMDB 10.33 Upgrade Helper > linux-platform, and then run upgrade-helper-for-1033.sh3. Enter the path to your existing UCMDB installation, and then press Enter. The upgrade helper willnow back up your custom settings.o If port 5005 is in use, you are prompted to open it. Open the port, and then type Y to continue.4. Type Y to continue the upgrade process by using the configuration settings that were backed upwhen you upgraded the writer machine.5. Enter the path to the UCMDB 10.33 installer file, and then press Enter. The upgrade helper willnow launch the installer and upgrade the UCMDB server to version 10.33.6. When the upgrade is finished, you are prompted to check that the server is now version 10.33.Check the server version is correct, and then type Y to continue. The upgrade helper will now restore your custom settings.o The upgrade helper will also deploy a hotfix to resolve a server startup issue. If the hotfix fails to deploy correctly, you will be prompted to apply it manually.7. When prompted, exit the upgrade helper.Send documentation feedbackIf you have comments about this document, you can contact the documentation team by email. If an email client is configured on this system, click the link above and an email window opens with the following information in the subject line:Feedback on User Guide: UCMDB 10.33 upgrade helper (Universal CMDB 10.33)Just add your feedback to the email and click send.If no email client is available, copy the information above to a new message in a web mail client, and send your feedback to **********************.We appreciate your feedback!。
巨杉数据库版本在线升级介绍说明

2.3 数据集群部署部署架构
3 版本升级兼容性说明
SequoiaDB 版本 1.*
是否支持升级
是否支持降级
说明
1.*版本支持向 1.*更 1.* 版 本 之 间 支 持 无 由于 1.*版本和 2.*版
高版本升级
缝降级
本在数据存储结构上
1.*版本支持向 2.*版 1.*版本升级到 2.*版 有比较大的调整,所
升级步骤必须逐台服务器执行,不能够同时在所有服务器上执行升级数据库版本步骤。 作者以升级 01 服务器为例,详细记录一台服务器上升级 SequoiaDB 版本的步骤。 切换 sdbadmin 用户 su - sdbadmin 停止当前服务器的 sdbcm 服务 /opt/sequoiadb/bin/sdbcmtop 停止当前服务器所有的 SequoiaDB 服务 /opt/sequoiadb/bin/sdbstop /opt/sequoiadb/bin/sdbstop -p 11780 检查当前服务器是否所有 SequoiaDB 服务器停止 /opt/sequoiadb/bin/sdblist -t all -m run 如果还有 SequoiaDB 服务在运行,执行 sdblist 命令会在屏幕上打印 SequoiaDB 正在运行 的服务信息,例如
5.2 数据库版本升级
/opt/sequoiadb/database/catalog/11800 NO /opt/sequoiadb/database/data/11910 NO /opt/sequoiadb/database/data/11910 NO /opt/sequoiadb/database/data/11910 YES /opt/sequoiadb/database/data/11920 NO /opt/sequoiadb/database/data/11920 NO /opt/sequoiadb/database/data/11920 YES /opt/sequoiadb/database/data/11930 NO /opt/sequoiadb/database/data/11930 NO /opt/sequoiadb/database/data/11930 YES /opt/sequoiadb/database/coord/11810 NO /opt/sequoiadb/database/ coord /11810 NO /opt/sequoiadb/database/ coord /11810 NO /opt/sequoiadb/database/om/11780
Weed EMDAT数据库处理工具版本1.1.2用户指南说明书

Package‘weed’October17,2023Title Wrangler for Emergency Events DatabaseVersion1.1.2Maintainer Ram Kripa<************************>Description Makes research involving EMDAT and related datasets easier.These Datasets are manu-allyfilled and have several formatting and compatibility issues.Weed aims to re-solve these with its functions.License MIT+file LICENSEEncoding UTF-8RoxygenNote7.1.1Imports readxl,dplyr,magrittr,tidytext,stringr,tibble,geonames,countrycode,purrr,tidyr,forcats,ggplot2,sf,hereURL https:///rammkripa/weedBugReports https:///rammkripa/weed/issuesNeedsCompilation noAuthor Ram Kripa[aut,cre]Repository CRANDate/Publication2023-10-1622:20:02UTCR topics documented:geocode (2)geocode_batches (3)located_in_box (4)located_in_shapefile (5)nest_locations (6)percent_located_disasters (7)percent_located_locations (8)read_emdat (9)split_locations (9)Index1112geocode geocode GeoCodes text locations using the GeoNames APIDescriptionUses the location_word and Country columns of the data frame to make queries to the geonames API and geocode the locations in the dataset.Note:1.The Geonames API(for free accounts)limits you to1000queries an hour2.You need a geonames username to make queries.You can learn more about that hereUsagegeocode(.,n_results=1,unwrap=FALSE,geonames_username)Arguments.a data frame which has been locationized(see weed::split_locations)n_results number of lat/longs to getunwrap if true,returns lat1,lat2,lng1,lng2etc.as different columns,otherwise one lat column and1lng columngeonames_usernameUsername for geonames API.More about getting one is in the note above. Valuethe same data frame with a lat column/columns and lng column/columnsExamplesdf<-tibble::tribble(~value,~location_word,~Country,"mumbai region,district of seattle,sichuan province","mumbai","India","mumbai region,district of seattle,sichuan province","seattle","USA")geocode(df,n_results=1,unwrap=TRUE,geonames_username="rammkripa")geocode_batches3 geocode_batches Geocode in batchesDescriptionGeocode in batchesUsagegeocode_batches(.,batch_size=990,wait_time=4800,n_results=1,unwrap=FALSE,geonames_username)Arguments.data framebatch_size size of each batch to geocodewait_time in seconds between batches Note:default batch_size and wait_time were setto accomplish the geocoding task optimally within the constraints of geonamesfree accessn_results same as geocodeunwrap as in geocodegeonames_usernameas in geocodeValuedf geocodedExamplesdf<-tibble::tribble(~value,~location_word,~Country,"mumbai region,district of seattle,sichuan province","mumbai","India","mumbai region,district of seattle,sichuan province","seattle","USA","mumbai region,district of seattle,sichuan province","sichuan","China,People s Republic")geocode_batches(df,batch_size=2,wait_time=0.4,geonames_username="rammkripa")4located_in_box located_in_box Locations In the BoxDescriptionCreates a new column(in_box)that tells whether the lat/long is in a certain box or not.Usagelocated_in_box(.,lat_column="lat",lng_column="lng",top_left_lat,top_left_lng,bottom_right_lat,bottom_right_lng)Arguments.Data Frame that has been locationized.see weed::split_locationslat_column Name of column containing Latitude datalng_column Name of column containing Longitude datatop_left_lat Latitude at top left corner of boxtop_left_lng Longitude at top left corner of boxbottom_right_latLatitude at bottom right corner of boxbottom_right_lngLongitude at bottom right corner of boxValueA dataframe that contains the latlong box dataExamplesd<-tibble::tribble(~value,~location_word,~Country,~lat,~lng,"city of new york","new york","USA",40.71427,-74.00597, "kerala,chennai municipality,and san francisco","kerala","India",10.41667,76.5, "kerala,chennai municipality,and san francisco","chennai","India",13.08784,80.27847) located_in_box(d,lat_column="lat",lng_column="lng",top_left_lat=45,bottom_right_lat=12,top_left_lng=-80,bottom_right_lng=90)located_in_shapefile5 located_in_shapefile Locations In the ShapefileDescriptionCreates a new column(in_shape)that tells whether the lat/long is in a certain shapefile.Usagelocated_in_shapefile(.,lat_column="lat",lng_column="lng",shapefile=NA,shapefile_name=NA)Arguments.Data Frame that has been locationized.see weed::split_locationslat_column Name of column containing Latitude datalng_column Name of column containing Longitude datashapefile The shapefile itself(either shapefile or shapefile_name must be provided)shapefile_name FileName/Path to shapefile(either shapefile or shapefile_name must be pro-vided)ValueData Frame with the shapefile data as well as the previous dataExamples##Not run:d<-tibble::tribble(~value,~location_word,~Country,~lat,~lng,"city of new york","new york","USA",40.71427,-74.00597, "kerala,chennai municipality,and san francisco","kerala","India",10.41667,76.5, "kerala,chennai municipality,and san francisco","chennai","India",13.08784,80.2847) located_in_shapefile(d,lat_column="lat",lng_column="lng",shapefile_name="~/dummy_name")##End(Not run)6nest_locations nest_locations Nest Location Data into a column of TibblesDescriptionNest Location Data into a column of TibblesUsagenest_locations(.,key_column="Dis No",columns_to_nest=c("location_word","lat","lng"),keep_nested_cols=FALSE)Arguments.Locationized data frame(see weed::split_locations)key_column Column name for Column that uniquely IDs each observationcolumns_to_nestColumn names for Columns to nest inside the mini-dataframes keep_nested_colsBoolean to Keep the nested columns externally or not.ValueData Frame with A column of data framesExamplesd<-tibble::tribble(~value,~location_word,~Country,~lat,~lng,"city of new york","new york","USA",c(40.71427,40.6501),c(-74.00597,-73.94958), "kerala","kerala","India",c(10.41667,8.4855),c(76.5,76.94924),"chennai municipality","chennai","India",c(13.08784,12.98833),c(80.27847,80.16578), "san francisco","san francisco","USA",c(37.77493,37.33939),c(-122.41942,-121.89496)) nest_locations(d,key_column="value")percent_located_disasters7 percent_located_disastersPercent of Disasters Successfully GeocodedDescriptionTells us how successful the geocoding is.How many of the disasters in this data frame have non NA coordinates?Usagepercent_located_disasters(.,how="any",lat_column="lat",lng_column="lng",plot_result=TRUE)Arguments.Data Frame that has been locationized.see weed::split_locationshow takes in a function,"any",or"all"to determine how to count the disaster asbeing geocoded if any,at least one location must be coded,if all,all locationsmust have lat/lng if a function,it must take in a logical vector and return a singlelogicallat_column Name of column containing Latitude datalng_column Name of column containing Longitude dataplot_result Determines output type(Plot or Summarized Data Frame)ValueThe percent and number of Locations that have been geocoded(see plot_result for type of output) Examplesd<-tibble::tribble(~ Dis No ,~value,~location_word,~Country,~lat,~lng,1,"city of new york","new york","USA",40.71427,-74.00597, 2,"kerala,chennai municipality,and san francisco","kerala","India",10.41667,76.5, 2,"kerala,chennai municipality,and san francisco","chennai","India",13.08784,80.27847) percent_located_disasters(d,how="any",lat_column="lat",lng_column="lng",plot_result=FALSE)8percent_located_locations percent_located_locationsPercent of Locations Successfully GeocodedDescriptionTells us how successful the geocoding is.How many of the locations in this data frame have non NA coordinates?Usagepercent_located_locations(.,lat_column="lat",lng_column="lng",plot_result=TRUE)Arguments.Data Frame that has been locationized.see weed::split_locationslat_column Name of column containing Latitude datalng_column Name of column containing Longitude dataplot_result Determines output type(Plot or Summarized Data Frame)ValueThe percent and number of Locations that have been geocoded(see plot_result for type of output) Examplesd<-tibble::tribble(~value,~location_word,~Country,~lat,~lng,"city of new york","new york","USA",40.71427,-74.00597, "kerala,chennai municipality,and san francisco","kerala","India",10.41667,76.5, "kerala,chennai municipality,and san francisco","chennai","India",13.08784,80.27847) percent_located_locations(d,lat_column="lat",lng_column="lng",plot_result=FALSE)read_emdat9 read_emdat Reads Excel Files obtained from EM-DAT DatabaseDescriptionReads Excelfiles downloaded from the EMDAT Database linked hereUsageread_emdat(path_to_file,file_data=TRUE)Argumentspath_to_file A String,the Path to thefile downloaded.file_data A Boolean,Do you want information about thefile and how it was created? ValueReturns a list containing one or two tibbles,one for the Disaster Data,and one for File Metadata.Examples##Not run:read_emdat(path_to_file="~/dummy",file_data=TRUE)##End(Not run)split_locations Splits string of manually entered locations into one row for each loca-tionDescriptionChanges the unit of analysis from a disaster,to a disaster-location.This is useful as preprocessing before geocoding each disaster-location pair.Can be used in piped operations,making it tidy!Usagesplit_locations(.,column_name="locations",dummy_words=c("cities","states","provinces","districts","municipalities", "regions","villages","city","state","province","district","municipality", "region","township","village","near","department"),joiner_regex=",|\\(|\\)|;|\\+|(and)|(of)")10split_locationsArguments.data frame of disaster datacolumn_name name of the column containing the locationsdummy_words a vector of words that we don’t want in ourfinal output.joiner_regex a regex that tells us how to split the locationsValuesame data frame with the location_word column added as well as a column called uncertain_location_specificity where the same location could be referred to in varying levels of specificityExampleslocs<-c("city of new york","kerala,chennai municipality,and san francisco","mumbai region,district of seattle,sichuan province")d<-tibble::as_tibble(locs)split_locations(d,column_name="value")Indexgeocode,2geocode_batches,3located_in_box,4located_in_shapefile,5nest_locations,6percent_located_disasters,7percent_located_locations,8read_emdat,9split_locations,911。
DB DBM CFG

Database Configuration for Database macrodb--Macrodb库的数据库配置Database configuration release level = 0x0d00--数据库配置版本Database release level = 0x0d00--数据库版本Database territory = CN--数据库区域Database code page = 1386--数据库编码页Database code set = gbk‘--数据库编码组Database country/region code = 86--数据库国家代码Database collating sequence = UNIQUE--数据库排序方式Alternate collating sequence (ALT_COLLA TE) =--预备排序Number compatibility = OFF--数字兼容性V archar2 compatibility = OFF--字符兼容Date compatibility = OFF--时间兼容Database page size = 8192--数据库页面大小Dynamic SQL Query management (DYN_QUERY_MGMT) = DISABLE --动态SQL查询管理残疾Statement concentrator (STMT_CONC) = OFF--集中器声明Discovery support for this database (DISCOVER_DB) = ENABLE--数据库支持Restrict access = NO--限制访问Default query optimization class (DFT_QUERYOPT) = 5--缺省查询优化等级Degree of parallelism (DFT_DEGREE) = 1--Continue upon arithmetic exceptions (DFT_SQLMA THWARN) = NO--Default refresh age (DFT_REFRESH_AGE) = 0--缺省更新时间Default maintained table types for opt (DFT_MTTB_TYPES) = SYSTEM--缺省维护的表类型Number of frequent values retained (NUM_FREQV ALUES) = 10--Number of quantiles retained (NUM_QUANTILES) = 20Decimal floating point rounding mode (DECFLT_ROUNDING) = ROUND_HALF_EVEN Backup pending = NOAll committed transactions have been written to disk = NORollforward pending = NORestore pending = NOMulti-page file allocation enabled = YESLog retain for recovery status = RECOVERYUser exit for logging status = NOSelf tuning memory (SELF_TUNING_MEM) = ONSize of database shared memory (4KB) (DA TABASE_MEMORY) = AUTOMA TIC(238360) Database memory threshold (DB_MEM_THRESH) = 10Max storage for lock list (4KB) (LOCKLIST) = AUTOMA TIC(4096) Percent. of lock lists per application (MAXLOCKS) = AUTOMA TIC(98)Package cache size (4KB) (PCKCACHESZ) = AUTOMA TIC(8033) Sort heap thres for shared sorts (4KB) (SHEAPTHRES_SHR) = AUTOMA TIC(4402)Sort list heap (4KB) (SORTHEAP) = AUTOMA TIC(880)Database heap (4KB) (DBHEAP) = AUTOMA TIC(2495) Catalog cache size (4KB) (CA TALOGCACHE_SZ) = 300Log buffer size (4KB) (LOGBUFSZ) = 256Utilities heap size (4KB) (UTIL_HEAP_SZ) = 61163Buffer pool size (pages) (BUFFPAGE) = 10000SQL statement heap (4KB) (STMTHEAP) = AUTOMA TIC(4096) Default application heap (4KB) (APPLHEAPSZ) = AUTOMA TIC(256) Application Memory Size (4KB) (APPL_MEMORY) = AUTOMA TIC(40000) Statistics heap size (4KB) (STA T_HEAP_SZ) = AUTOMA TIC(4384)Interval for checking deadlock (ms) (DLCHKTIME) = 10000Lock timeout (sec) (LOCKTIMEOUT) = -1Changed pages threshold (CHNGPGS_THRESH) = 80Number of asynchronous page cleaners (NUM_IOCLEANERS) = AUTOMA TIC(7) Number of I/O servers (NUM_IOSERVERS) = AUTOMA TIC(6)Index sort flag (INDEXSORT) = YESSequential detect flag (SEQDETECT) = YESDefault prefetch size (pages) (DFT_PREFETCH_SZ) = AUTOMA TICTrack modified pages (TRACKMOD) = OFFDefault number of containers = 1Default tablespace extentsize (pages) (DFT_EXTENT_SZ) = 32Max number of active applications (MAXAPPLS) = 1000A verage number of active applications (A VG_APPLS) = AUTOMA TIC(1)Max DB files open per application (MAXFILOP) = 200Log file size (4KB) (LOGFILSIZ) = 2000Number of primary log files (LOGPRIMARY) = 6Number of secondary log files (LOGSECOND) = 4Changed path to log files (NEWLOGPA TH) =Path to log files = /home/db2inst1/db2inst1/NODE0000/SQL00002/SQLOGDIR/Overflow log path (OVERFLOWLOGPA TH) =Mirror log path (MIRRORLOGPA TH) =First active log file = S0000054.LOGBlock log on disk full (BLK_LOG_DSK_FUL) = NOBlock non logged operations (BLOCKNONLOGGED) = NOPercent max primary log space by transaction (MAX_LOG) = 0Num. of active log files for 1 active UOW(NUM_LOG_SPAN) = 0Group commit count (MINCOMMIT) = 1Percent log file reclaimed before soft chckpt (SOFTMAX) = 520Log retain for recovery enabled (LOGRETAIN) = RECOVERYUser exit for logging enabled (USEREXIT) = OFFHADR database role = STANDARDHADR local host name (HADR_LOCAL_HOST) =HADR local service name (HADR_LOCAL_SVC) =HADR remote host name (HADR_REMOTE_HOST) =HADR remote service name (HADR_REMOTE_SVC) =HADR instance name of remote server (HADR_REMOTE_INST) =HADR timeout value (HADR_TIMEOUT) = 120HADR log write synchronization mode (HADR_SYNCMODE) = NEARSYNCHADR peer window duration (seconds) (HADR_PEER_WINDOW) = 0First log archive method (LOGARCHMETH1) = LOGRETAIN Options for logarchmeth1 (LOGARCHOPT1) =Second log archive method (LOGARCHMETH2) = OFFOptions for logarchmeth2 (LOGARCHOPT2) =Failover log archive path (FAILARCHPA TH) =Number of log archive retries on error (NUMARCHRETRY) = 5Log archive retry Delay (secs) (ARCHRETRYDELAY) = 20V endor options (VENDOROPT) =Auto restart enabled (AUTORESTART) = ONIndex re-creation time and redo index build (INDEXREC) = SYSTEM (RESTART)Log pages during index build (LOGINDEXBUILD) = OFFDefault number of loadrec sessions (DFT_LOADREC_SES) = 1Number of database backups to retain (NUM_DB_BACKUPS) = 12Recovery history retention (days) (REC_HIS_RETENTN) = 366Auto deletion of recovery objects (AUTO_DEL_REC_OBJ) = OFFTSM management class (TSM_MGMTCLASS) =TSM node name (TSM_NODENAME) =TSM owner (TSM_OWNER) =TSM password (TSM_PASSWORD) =Automatic maintenance (AUTO_MAINT) = ONAutomatic database backup (AUTO_DB_BACKUP) = OFFAutomatic table maintenance (AUTO_TBL_MAINT) = ONAutomatic runstats (AUTO_RUNSTA TS) = ONAutomatic statement statistics (AUTO_STMT_STA TS) = ONAutomatic statistics profiling (AUTO_STA TS_PROF) = OFFAutomatic profile updates (AUTO_PROF_UPD) = OFFAutomatic reorganization (AUTO_REORG) = OFFAuto-Revalidation (AUTO_REV AL) = DEFERRED Currently Committed (CUR_COMMIT) = ONCHAR output with DECIMAL input (DEC_TO_CHAR_FMT) = NEWEnable XML Character operations (ENABLE_XMLCHAR) = YESWLM Collection Interval (minutes) (WLM_COLLECT_INT) = 0Monitor Collect SettingsRequest metrics (MON_REQ_METRICS) = BASEActivity metrics (MON_ACT_METRICS) = BASEObject metrics (MON_OBJ_METRICS) = BASEUnit of work events (MON_UOW_DA TA) = NONELock timeout events (MON_LOCKTIMEOUT) = NONE Deadlock events (MON_DEADLOCK) = WITHOUT_HISTLock wait events (MON_LOCKWAIT) = NONE Lock wait event threshold (MON_LW_THRESH) = 5000000SMTP Server (SMTP_SERVER) =。
数据升级工具使用手册 for softup

数据升级工具使用手册for SoftUp拟制:王宇日期:2002-08-26修订:王宇日期:2004-03-22审核:日期:批准:日期:© 港湾网络有限公司版权所有,并保留对本手册及本声明的最终解释权和修改权。
目录1. 准备 (3)2. 备份 (3)3. 启动数据升级工具 (3)4. 原数据库改名 (4)5. 安装新系统 (5)6. 连接数据库 (6)7. 分析数据库 (6)8. 不需要修改的表 (7)9. 需要修改的表 (8)10. 升级数据 (10)11. 升级工具执行完成 (10)12. 重新生成可供主机加载的数据 (11)13. 为主机加载数据 (11)数据升级工具使用手册for SoftUp1.准备在数据升级之前,您必须完成下面的准备:≅为了防止出现意想不到的结果请先备份旧数据库,可使用下面方法中的一种:i.在命令行客户端执行命令:data backup本例子中采用此种方式ii.在SQL Server查询分析器(query analyzer)中运行:backup database oam to disk = 'd:\oam_d05.dat'≅为旧数据库改名,可以使用下面3种方法中的任何一种:i.在SQL Server查询分析器(query analyzer)中运行:sp_renamedb oam, oam_d5;ii.使用数据升级工具为您提供的改名功能(稍后介绍);iii.使用其他您认为可行的办法≅最新版本的安装盘2.备份为了防止升级失败,需要备份原数据库和原格式化的数据文件。
打开OAM IP网络管理系统的安装目录,如:C:\Program Files\OAM Chinese\,进入server\目录,拷贝DatFiles\目录至其它位置。
启动OAM IP网络管理系统服务器端和命令行客户端,并登陆客户端,登陆成功后执行命令:data backup。
退出命令行客户端和服务器端3.启动数据升级工具启动数据升级工具DBUpdate.exe,您会看到下面的窗口。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
1、使用环境要求
(1)安装JDK/JRE 1.7以上版本
(2)支持oralce、 mysql、 sqlserver三种数据库
2、启动
windows系统,运行dbmt\run.bat,打开浏览器,在地址栏输入localhost:9999,打开界面。
第一次运行使用可能会出现如下情况:
解决方法:刷新界面,显示正常界面:
2、配置的保存与加载
对于固定的数据库,为了避免每次对比时都需要输入数据库配置信息,该工具提供了配置信息的保存和加载功能。
第一次使用时,填好配置信息,点击保存配置,以后使用时直接加载配置,选择相应的配置信息,就会自动加载到页面。
数据库连接信息更改时,需要重新输入配置信息并保存配置。
3、数据库比对
该功能用于在线比对两个同种类型的数据库之间的元数据(数据库结构)。
基准数据库为标准数据库,目标数据库为待同步的数据库。
切记比对时不要弄反了。
选择相应的数据库类型、输入地址(包含IP地址和端口号:mysql 为3306,oracle为1521)、数据库名称、用户名、密码。
上述步骤,如果之前配置已保存,可直接加载配置。
配置好数据库之后,点击比对数据源,弹出同步脚本预览。
升级语句为目标库需要升级的sql语句,点击同步数据库,完成目标库的元数据升级。
多余的表和多余的列为目标库比基准库多出来的语句,用户可根据需要选择保留不处理或者自行线下执行,删除多余的表或列。
4、元数据比对
该功能适用于基准数据库离线的场景。
实施人员使用该功能升级项目上的目标数据库。
输入配置信息后(或直接加载配置),点击元数据比对,选择相应的元数据文件(.dbmd),弹出元数据比对结果,执行即可。
5、导出元数据
该功能用于导出某个数据库的元数据,下载到相应目录下,保存目录可以在浏览器设置中修改。