监督分类与非监督分类汇总教材
实习监督分类与非监督分类
1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigated land 水库reservoir裸地barren land 工业区industrial area滩地shoaly land 林地forest草地grassland 河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色5. 分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进行解释。
实习8、监督分类与非监督分类
1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigated land 水库reservoir裸地barren land 工业区industrial area滩地shoaly land 林地forest草地grassland 河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色5. 分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进行解释。
监督分类和非监督分类
影像的分类可分为监督与非监督分类。
监督分类器根据其原理有基于传统统计分析的、基于神经网络的、基于模式识别的等。
本专题以ENVI的监督与非监督分类的实际操作为例,介绍这两种分类方法。
有以下内容组成:∙ ∙ ●非监督分类∙ ∙ ●监督分类∙ ∙ ●分类后处理非监督分类非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
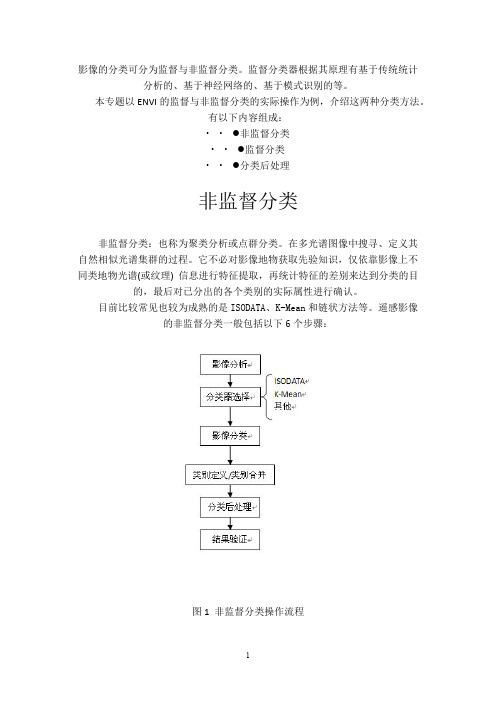
遥感影像的非监督分类一般包括以下6个步骤:图1 非监督分类操作流程1、影像分析大体上判断主要地物的类别数量。
一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
确定在非监督分类中的类别数为15。
2、分类器选择目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。
ENVI包括了ISODATA和K-Mean方法。
ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类打开ENVI,选择主菜单->Classification->Unsupervised->IsoData或者K-Means。
实习8、监督分类与非监督分类

操作方法及过程1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigat ed land 水库reservoi r裸地barrenl and 工业区industri al area滩地shoalyland 林地forest草地grassla nd河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择poin t、polylin e、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选O p tions的统计训练区可分性Com pute ROI Separab ility,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classifi catio n|Supervi sed| Maximum Likelih ood,在Set Input File对话框中导入影像。
在打开的对话框中选Sele ct All Items,其中Set Probabi lity Threshol d设为NO,Output R ule Image设为N o,选择保存路径。
ENVI监督分类与非监督分类

选择classification/unsupervised/Isodata,选择子区为输入文件,,点击OK,设置参数如下图所示。
对照原影像将30种类型进行编号并改名字,改变颜色;进行相同类别的合并:选择Classification中的分类后处理post classification,选择合并同类别Combine Classes,选择之前的非监督分类影像,在输入的文件中依次选择要合并的类,在输出的文件中选择相同的类别,点击Add Combination,所有的类别合并完后点击确定即可。
原影像最大似然法进行监督分类结果监督分类的最大似然法分类结果中,主要的地物都可以被区分出来,地物分布也很清楚的展现出来,只是生成的结果又很严重的椒盐现象,分析可能是选取训练区时认为造成了误差。
缺点就是没有将结果中的颜色按照真实地物的颜色进行修改,下次在聚类统计的结果上很容易看出原本监督分类的生成结果中严重的椒盐现象消失但有些细节已经被消除看不清楚,3*3窗口与5*5窗口生成的5*5窗口的更加清楚具体, 5*5窗口将周边的面积较对影像的过滤分析生成的结果显得椒盐现象更加严重Number of Neighbors的值设置的越小,小黑点越密集象都已经消失.主要成分分析得到的结果较好,椒盐现象得到避免邻地物之间的合并,分析窗口越小,地物信息更加具体次要分析(kernal size为3*3):利用次要成分分析的影像不但没有减轻椒盐现象,反而椒盐现象更加严重,未定义的黑点更密集,并且变得更大,效果很不好.7、非监督分类结果:在进行非监督分类的时候首先将地物分成了30类,然后人工进行识别分类后最终与监督分类结果一样合并成了8类,但是最后的效果并不是很好,在非监督分类一开始就将水稻田与林地分类到一起,最后生成的结果只能区分大致的地物分布,与监督分类结果相比,非监督分类结果更粗糙.。
envi遥感图像监督分类与非监督分类

envi遥感图像监督分类监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。
它就是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
使每个像元和训练样本作比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。
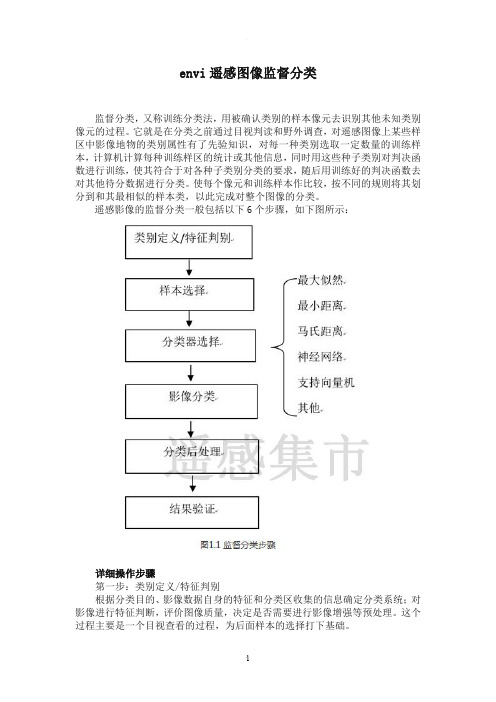
遥感影像的监督分类一般包括以下6个步骤,如下图所示:详细操作步骤第一步:类别定义/特征判别根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。
这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
启动ENVI5.1,打开待分类数据:can_tmr.img。
以R:TM Band 5,G: TM Band 4,B:TM Band 3波段组合显示。
通过目视可分辨六类地物:林地、草地/灌木、耕地、裸地、沙地、其他六类。
第二步:样本选择(1)在图层管理器Layer Manager中,can_tmr.img图层上右键,选择"New Region Of Interest",打开Region of Interest (ROI) Tool面板,下面学习利用选择样本。
1)在Region of Interest (ROI) Tool面板上,设置以下参数:ROI Name:林地ROI Color:2)默认ROIs绘制类型为多边形,在影像上辨别林地区域并单击鼠标左键开始绘制多边形样本,一个多边形绘制结束后,双击鼠标左键或者点击鼠标右键,选择Complete and Accept Polygon,完成一个多边形样本的选择;3)同样方法,在图像别的区域绘制其他样本,样本尽量均匀分布在整个图像上;4)这样就为林地选好了训练样本。
实习三 遥感图像的监督分类与非监督分类

实验三遥感图像的监督分类与非监督分类[实验目的]1.理解遥感图像的监督分的含义;2.会使用ENVI软件对遥感图像进行监督分类。
[实验原理]在遥感图像分类中,按照是否有已知训练样本的分类依据,分类方法又分为两大类:监督分类与非监督分类。
遥感图像的监督分类是在已知类别的训练场地上提取各类别训练样本,通过选择特征变量、确定判别函数或判别式(判别规则),进而把图像中的各个像元点划归到各个给定类的分类。
遥感图像的非监督分类是在没有先验知识(训练场地)的情况下,根据图像本身的统计特征及自然点群的分布情况来划分地物类别的分类处理,事后再对已分出的各类的地物属性进行确认,也称作“边学习边分类法”。
两者的最大区别在于,监督分类首先给定类别,而非监督分类则由图像数据本身的统计特征来决定。
[实验步骤]一监督分类(数据采用njtmcorrected)监督分类技术需要在执行以前事先定义训练分类器(training classes), 训练分类器也可以用ENVI 感兴趣区(ROI)函数限定。
ENVI的监督分类技术包括平行六面体(平行管道)、最小距离、马氏距离、最大似然、波谱角度制图仪以及二进制编码方法1. “开始”->“程序”->RSI ENVI4.0->ENVI,打开ENVI4.0界面;2. 选择File > Open Image File.3. 当出现Enter Data Filename 对话框,选择要打开的文件名,再点击“OK”,在Available Bands List框里点击Load Band ,图像显示在图像显示窗口。
4. 选择“基本工具”->感兴趣区->ROI工具,弹出ROI Tool对话框。
5. 在ROI_Type菜单里选择建立感兴趣区的类型,可以选择Polygon、Polyline、point、Rectangle、Ellipse等类型。
6. 在Window栏里选择要建立感兴趣区的窗口,可以选择Image、Scroll、Zoom窗口。
监督分类与非监督分类

缺点
• 主观性; • 由于图象中间类别的光谱差异,使得训练样
本没有很好的代表性; • 训练样本的获取和评估花费较多人力时间; • 只能识别训练中定义的类别。
第 8 章 遥感图像自动识别分类
§8-4 非监督分类
§8-4非监督分类
二 非监督分类 仅凭遥感影像地物的光谱特征的分布规
律,即自然聚类的特性,进行“盲目”的 分类;
否 是
迭代次数=I或相邻两次迭代类别中心变动小于限值
否 否
σ > TS 是
确定分裂后的中心
输出
否
DIK< TC
是
确定并类后的中心
ISODATA算法过程框图
(三) 平行管道法聚类分析
它以地物的光谱特性曲线为基础,同 类地物在特征空间上表现为以特征曲线 为中心,以相似阈值为半径的管子,此 即为所谓的“平行管道”。
(二) ISODATA算法聚类分析
可以自动地进行类别的“合并”和“分 裂”,从而得到类数比较合理的聚类结 果。
迭代次数 每类集群允许
选定初始类别中心
的最大标准差
输入迭代限值参数:I,Tn, TS ,TC
集群允许的最 短距离
对样本像素进行聚类并统计ni,m,σ
每类集群至少 的点数
ni<Tn
是 取消第i类
第 8 章 遥感图像自动识别分类
§8-3 监督分类(续)
原始影像数据的准备
(二) 分类过程
图像变换及特征选择 分类器的设计
初始类别参数的确定 逐个像素的分类判别
形成分类编码图像 输出专题图
▪ 选择样本区域 植被 老城区 耕地 水 新城区
将样本数据在特征空间进行聚类
遥感实习遥感图像监督分类

实验五:监督分类与非监督分类一、实验目的采用监督分类对多光谱遥感图像进行分类,并对分类后的数据进行处理,处理方法包括:聚合(clump)处理、筛选(sieve)处理、并类(combine)处理,以及精度评估。
监督法分类需要用户选择作为分类基础的训练样区。
分析下面处理的分类结果,或者采用每个分类法默认的分类参数,生成自己的类,然后对分类结果进行比较。
我们将使用各种监督分类法,并对它们进行比较,确定单个具体像素是否有资格作为某类的一部分。
二、实验数据与原理美国科罗拉多州(Colorado)Canon市的Landsat TM 影像数据,其中包括can_tmr.img、can_tmr.hdr、can_km.img、can_km.hdr、can_iso.img、can_iso.hdr、classes.roi、can_pcls.img、can_pcls.hdr 、can_bin.img、can_bin.hdr 、can_sam.img、can_sam.hdr 、can_rul.img 、can_rul.hdr、can_sv.img、can_sv.hdr、can_clmp.img、can_clmp.hdr。
ENVI 提供了多种不同的监督分类法,其中包括了平行六面体(Parallelepiped)、最小距离法(Minimum Distance)、马氏距离法(Mahalanobis Distance)、最大似然法(Maximum Likelihood)、波谱角法(Spectral Angle Mapper)、二值编码法(Binary Encoding)以及神经网络法(Neural Net)。
三、实验过程:1、打开TM图像,File →Open Image File,选择ljs-can_tmr.img文件,在可用波段列表中,选择RGB Color 单选按钮,然后使用鼠标左键,顺次点击波段4、波段3 和波段2。
点击Load RGB 按钮,把该影像加载到一个新的显示窗口中。
envi遥感图像监督分类与非监督分类
envi遥感图像监督分类监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。
它就是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
使每个像元和训练样本作比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。
遥感影像的监督分类一般包括以下6个步骤,如下图所示:详细操作步骤第一步:类别定义/特征判别根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。
这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
启动ENVI5.1,打开待分类数据:can_tmr.img。
以R:TM Band 5,G: TM Band 4,B:TM Band 3波段组合显示。
通过目视可分辨六类地物:林地、草地/灌木、耕地、裸地、沙地、其他六类。
第二步:样本选择(1)在图层管理器Layer Manager中,can_tmr.img图层上右键,选择"New Region Of Interest",打开Region of Interest (ROI) Tool面板,下面学习利用选择样本。
1)在Region of Interest (ROI) Tool面板上,设置以下参数:ROI Name:林地ROI Color:2)默认ROIs绘制类型为多边形,在影像上辨别林地区域并单击鼠标左键开始绘制多边形样本,一个多边形绘制结束后,双击鼠标左键或者点击鼠标右键,选择Complete and Accept Polygon,完成一个多边形样本的选择;3)同样方法,在图像别的区域绘制其他样本,样本尽量均匀分布在整个图像上;4)这样就为林地选好了训练样本。
监督分类、非监督分类操作手册

ERDAS IMAGINE Professional 操作手册—监督分类和非监督分类图像分类简介:图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。
常规图像分类主要有两种方法:非监督分类与监督分类,专家分类方法是近年来发展起来的新兴遥感图像分类方法,下面介绍这三种分类方法。
非监督分类运用1SODATA(Iterative Self-Organizing Data Analysis Technique )算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。
使用该方法时。
原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。
由于人为干预较少,非监督分类过程的自动化程度较高。
非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。
监督分类比非监督分类更多地要求用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类图、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
专家分类首先需要建立知识库,根据分类目标提出假设,井依据所拥有的数据资料定义支持假设的规则、条件和变量,然后应用知识库自动进行分类,ERDAS IMAG1NE图像处理系统率先推出专家分类器模块,包括知识工程师和知识分类器两部分,分别应用于不同的情况。
由于基本的非监督分类属于IMAGINE Essentia1s级产品功能、但在1MAGINE Professional级产品中有一定的功能扩展,而监督分类和专家分类只属于IMAGINE ProfeSsiona1级产品,所以,非监督分类命令分别出现在Data Preparation菜单和classification 菜单中,而监督分类和专家分类命令仅出现在Classification菜单中。
监督分类与非监督分类
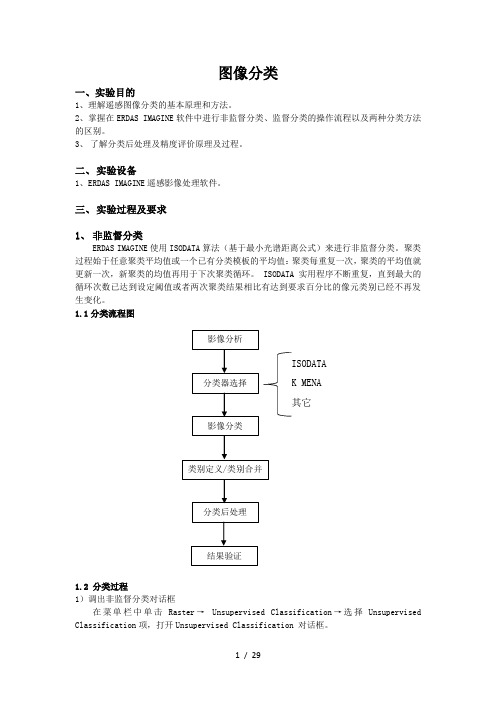
图像分类一、实验目的1、理解遥感图像分类的基本原理和方法。
2、掌握在ERDAS IMAGINE 软件中进行非监督分类、监督分类的操作流程以及两种分类方法的区别。
3、 了解分类后处理及精度评价原理及过程。
二、 实验设备1、ERDAS IMAGINE 遥感影像处理软件。
三、 实验过程及要求1、 非监督分类ERDAS IMAGINE 使用ISODATA 算法(基于最小光谱距离公式)来进行非监督分类。
聚类过程始于任意聚类平均值或一个已有分类模板的平均值:聚类每重复一次,聚类的平均值就更新一次,新聚类的均值再用于下次聚类循环。
ISODATA 实用程序不断重复,直到最大的循环次数已达到设定阈值或者两次聚类结果相比有达到要求百分比的像元类别已经不再发生变化。
1.1 分类流程图1.2 分类过程1)调出非监督分类对话框在菜单栏中单击Raster → Unsupervised Classification →选择Unsupervised Classification 项,打开Unsupervised Classification 对话框。
影像分析结果验证分类后处理类别定义/类别合并影像分类分类器选择ISODATAK MENA 其它2)进行非监督分类在 Unsupervised Classification 对话框中→Input Raster File (确定输入文件):待分类的图像(此处为经过主成分分析后的图像)。
→Output Cluster Layer (确定输出文件)。
→勾选Output signature Set (选择生成分类模板文件)→ (确定分类模板文件) 。
→Cluster Options:选择 Initiate from Statistics.→分类方法:选择isodata.→Number of Classes(确定初始分类数):7→对于 Initializing Options 和 Color Scheme Options 两项均取缺省值。
[转载]监督分类和非监督分类
![[转载]监督分类和非监督分类](https://img.taocdn.com/s3/m/b84adcd49fc3d5bbfd0a79563c1ec5da50e2d630.png)
[转载]监督分类和⾮监督分类原⽂地址:监督分类和⾮监督分类作者:维度空间实习序号及题⽬实习⼋、监督分类和⾮监督分类实习⼈姓名xuanfengling专业班级及编号地信0834任课教师姓名实习指导教师姓名实习地点榆中校区实验楼A209实习⽇期时间2010年12⽉16⽇实习⽬的理解影像监督分类和⾮监督分类的原理、⽅法和步骤,初步掌握⼟地覆盖的计算机⾃动分类⽅法实习内容1、通过遥感影像解译确定的⼟地覆盖分类类型、⾊调和编码:编码地物名称编码地物名称11⽔稻⽥ paddy land51河流 stream12⽔浇地 irrigated land52⽔库、坑塘 reservoir or pond20园地 garden61城镇及农村居民地 town or village30草地 grassland62⼯业区 industrial31林地 forest71沙漠 sandy desert32防护林 prevention desert72砾漠 gravel desert33幼林地 young forest73裸地及盐碱地 barren land4公路/铁路 road or railway53设施农⽤地 facility agricultural land 2、按照监督分类的步骤,在影像上找出对应各个⼟地利⽤/覆盖类型的图斑,建⽴训练区,给出各个类别的特征统计表3、采⽤4种可分性度量⽅法(欧⽒距离、分散度、变换散度、J-M距离)给出可分性矩阵,判断类型之间的可分性,要求将可分性矩阵转换为⽂本⽂件格式并以表格形式插⼊实习报告中,注意在输出时选取CellArray。
4、监督分类:利⽤最⼤似然法完成分类;5、分类精度评价,从随机采集100~200个样本点,进⾏分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进⾏解释。
6、⽣成特征空间影像和监督分类的结果专题特征空间影像,7、⾮监督分类:预先假定地表覆盖类型为30类,叠代次数选为20,由系统完成⾮监督分类;参照监督分类的结果对分类结果进⾏分析,修改类别属性值,进⽽确定新的⼟地利⽤/覆盖分类⽅案。
非监督分类

2. 影响分类结果的因素是什么? 为什么利用同样的方法分类,两幅影像的分类结果会存在很大的差别?
a.影像分类结果的因素包括 (1)计算机的分辨率、识别和计算方法 (2)判读者的经验 (3)图像分辨率 (4)同物异谱和异物同谱 (5)分类的计算方法 (6)云和大气等干扰 (7)分类数量的定义 b.分类结果产生差异的原因 (1)计算机的分辨率、识别和计算方法 (2)判读者的子类定义不同 (3)图像分辨率 (4)云和大气等干扰
1.监督分类 对南宁市2006年影像进行监督分类,并保存ROI文件和分类结果图像。 步骤: (1)定义样本 (2)选择训练样区 (3)分离性评价 (4)监督分类 (5)去噪 (6)精度评价
根据南宁市土地利用情况及国际撒分类要求, 将南宁市土地类别分为林地、水体、建筑用 地、灌草地、裸地和耕地六类
3. 非监督分类与监督分类有什么区别? 你认为非监督分类适合什么情景下采用?
a.监督分类与非监督分类的根本区别点在于是否利用训练场地来获取先验的类别知识。 (1)训练场地的选择是监督分类的关键, 监督分类根据训练场提供的样本选择特征参数, 建立判别函数,对待分类地区进行分类。 (2)非监督分类方法简单,且分类具有一定精度, 非监督分类不需要更多的先验知识,它根据地物的光谱统计特 性进行分类,分类结果的好坏需要经过实际调查来检验。
最大释然法分类分类结果
去噪
(3)监督分类ROI作为真实ROI对监督分类结果进行验证
(4)非监督分类结果图像作为真实地表影像对监督分类结果惊醒验证
2. 非监督分类 对南宁市2006年影像进行非监督分类,并保存分类结果。
步骤:
(1)选择分类方法及分类数 (2)识别和定义子类 (3)合并子类 (4)精度评价
监督分类ROI 和分类结果作 为检验样本
模式识别第七章 非监督分类

8
样本在整个特征空间中呈现两个分布高峰。 如果从分布的谷点将此特征空间划分为两个区, 则对应每个区域,样本分布就只有一个峰值, 这些区域被称为单峰区域。 每个单峰区域看作一个不同的决策域。落在同 一单峰区域的待分类样本就被划分成同一类, 称为单峰子类。
9
(1)多维空间投影方法
多维空间y中直接划分成单峰区域比较困 难,把它投影到一维空间x中简化问题。
16
(2)单峰子集分离的迭代算法
迭代算法步骤
对数据集进行初始划分:K1, K2, …,Kc 用Parzen方法估计各聚类的概率密度函数 按照最大似然概率逐个对样本xk进行分类:
j argmax f (x k | K i ), x k K j
i
若没有数据点发生类别迁移变化,则停止。 否则转2
17
7.3 类别分离的间接方法
两个要点:相似性度量,准则函数 相似性度量
样本间相似性度量: 特征空间的某种距离度量
(xi , x j ) (xi x j ) (xi x j )
T
样本与样本聚类间相似性度量������
(xi , K j )
18
准则函数
准则函数:聚类质量的判别标准,常用 的最小误差平方和准则������
第七章 非监督学习方法
1
主要内容
引言 单峰子集分离方法 类别分离的间接方法 分级聚类方法 聚类中的问题
2
7.1 引言
有监督学习(supervised learning):用已知 类别的样本训练分类器,以求对训练集的 数据达到某种最优,并能推广到对新数据 的分类������ 非监督学习(unsupervised learning) :样本 数据类别未知,需要根据样本间的相似性 对样本集进行分类(聚类,clustering)������
4.分类(监督与非监督分类)与裁剪

实验四分类(监督与非监督分类)与裁剪一、实验目的:理解计算机图像分类的基本原理以及监督分类的过程,达到能熟练地对遥感图像进行监督分类的目的。
进一步理解计算机图像分类的基本原理以及监督分类的过程,达到能熟练地对遥感图像进行监督分类的目的,同时深刻理解监督分类与非监督分类的区别。
学习通过ERDAS进行遥感图像规则分幅裁剪,不规则分幅裁剪的实验过程,能够对一幅大的遥感图像按照要求裁剪图像;二、实验内容:ERDAS遥感图像监督分类。
ERDAS遥感图像非监督分类。
遥感图像规则分幅裁剪,不规则分幅裁剪。
三、实验步骤1、定义分类模板第一步:显示要进行分类的图像第二步:打开摸板编辑器并调整显示字段图5-1 分类模板编辑器第三步:获取分类模板信息指导学生掌握四中获取分类模板信息方法中的两种。
第四步:保存分类模板2、评价分类模板介绍报警评价、可能性矩阵、直方图三种分类模板评价方法。
要求学生重点掌握利用可能性矩阵方法评价分类模板。
3、执行监督分类在监督分类中,用于分类决策的规则是多层次的,如对非参数模板有特征空间、平行六面体等方法。
对参数模板有最大似然法、最小距离法等。
但要注意对应用范围,如非参数模板只能应用于非参数型模板;对于参数型模板,要使用参数型规则。
另外,使用非参数型模板,还要确定叠加规则和未分类规则。
监督分类对话框2、分类过程(Classification Procedure)第一步:调出非监督分类对话框方法一:DATA PRETATION→UNSUPERVISED CLASSIFICATION.方法二:Classifier图标→classification→unsupervised classification第二步:进行监督分类调出:unsupervised classification对话框,逐项填写。
实际工作中常将分类数目取为最终分类数目的两倍;收敛域值是指两次分类结果相比保持不变的像原所占最大百分比。
人工智能与信息社会课件:601监督学习和非监督学习

基于神经网络的智能系统II:监督学习和非监督学习陈斌北京大学gischen@〉利用标注好信息的样本,经过训练得到一个模型,可以用来预测新的样本〉利用标注好信息的样本,经过训练得到一个模型,可以用来预测新的样本标记数预测结果据样本训练模型〉当新来一个数据时,可以自动预测所属类型x 1x 2=〉对于一幅遥感影像,对其中的部分水体、农田、建筑做好标记,通过监督分类方法就能得到其余的水体、农田、建筑。
〉支持向量机:寻找最大化样本间隔的边界〉分类决策树颜色尺寸葡萄青柠苹果形状柠檬香蕉〉神经网络方法〉直线拟合(最小二乘法)我们希望通过已有的训练数据学习一个模型,当新来一个面积数据时,可以自动预测出销售价格750面积价格〉人脸好看程度评分。
通过标记分数的图片得出回归模型,输入新的图片就能得出分数。
〉线性回归在平面上拟合线性函数〉最邻近方法使用最相似的训练样本来预测新样本值〉神经网络方法〉所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。
x2x1〉把这些没有标签的数据分成一个一个组合,就是聚类(Clustering)。
x2x1〉Google新闻每天会搜集大量的新闻,然后把它们全部聚类,就会自动分成几十个不同的组(比如商业,科技,体育......),每个组内新闻都具有相似的内容结构〉景区提取对大量游客的微博定位点进行聚类,能够自动提取出不同的景点的位置分布〉鸡尾酒会问题在一个满是人的房间中,人们都在互相对话。
我们记录下房间中的声音,利用非监督学习算法就能够识别房间中某一个人所说的话。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
操作步骤
一、监督分类:
1、选取研究区数据(512×512或者1024×1024),结合GoogleEarth影像通过目视解译建立分类系统及其编码体系;
编码体系如下:
编码地物名称色调
12 水浇地irrigated land R225 G225 B150
30 草地grassland R170 G190 B030
51 河流stream R150 G240 B255
52 水库、坑塘reservoir or pond R160 G205 B240
71 沙漠sandy desert R200 G190 B170
72 砾漠 gravel desert R215 G200 B185
73 裸地及盐碱地barren land R200 G205 B200
2、按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区:
训练样本如下:
对训练样本进行统计,结果如下:
ban d7 241388.
72
320377.
44
538052.
43
808207.
37
1071346
.47
1460959
.07
1327725
.27
相关系数矩阵
ban
d1
1.00 0.99 0.97 0.93 0.83 0.69 0.76
ban
d2
0.99 1.00 0.98 0.95 0.86 0.72 0.79
ban
d3
0.97 0.98 1.00 0.99 0.92 0.79 0.86
ban
d4
0.93 0.95 0.99 1.00 0.97 0.85 0.90
ban
d5
0.83 0.86 0.92 0.97 1.00 0.93 0.95
ban
d6
0.69 0.72 0.79 0.85 0.93 1.00 0.99
ban
d7
0.76 0.79 0.86 0.90 0.95 0.99 1.00 3、对所选ROI样本进行可分离性评价,结果如下:
JM值统计表:
Jeffries-Matusita
30 12 51 52 71 72 73
30草地 1.999 1.999 2.000 1.999 1.998 1.998
12水浇
地
1.999 1.999
2.000 2.000 2.000 2.000
51河流 1.999 1.999 1.995 2.000 2.000 2.000 52水库 2.000 2.000 1.995 1.993 2.000 2.000
71沙漠 1.999 2.000 2.000 2.000 1.999 1.999
72砾漠 1.998 2.000 2.000 2.000 1.999 1.896
73裸地 1.999 2.000 2.000 2.000 1.999 1.896
分离散度统计表:
Transformed Divergence
30 12 51 52 71 72 73
30草地 1.941 2.000 1.785 2.000 2.000 2.000
12水浇
2.000 2.000 2.000 2.000 2.000 2.000
地
51河流 2.000 2.000 1.980 2.000 2.000 2.000
52水库 2.000 2.000 2.000 2.000 2.000 2.000
71沙漠 2.000 2.000 2.000 2.000 2.000 1.999
72砾漠 2.000 2.000 2.000 2.000 2.000 2.000
73裸地 2.000 2.000 2.000 2.000 2.000 2.000
分析上述可分性度量矩阵可知,各地物间JM值均在1.8以上,因此可以有效的对各地物进行区分,因此所选ROI样本很适合与此监督分类。
4、利用最大似然法对影像数据完成监督分类。
最大似然法分类后结果如下:
汇总结果,可知:
对以上分类混淆矩阵及Kappa系数结果进行分析可知,分类混淆矩阵中错分误差与漏分误差均较小且分类后Kappa系数为0.9190,总体而言,分类结果较好。
5、分类后处理(clump—sieve—majority):对分类后影像分别依次进行clump、sieve、majority处理,结果如下:
Clump后:
Sieve后:
Majority后:
对非监督分类后结果进行精度评价,结果如下:
由此精度评价结果可知,非监督分类后,影像分类总体精度为74.6265%,Kappa系数为0.6060,总体而言,影像分类效果略差,不能满足影像分析及制图需要。