CODE编码方式中文
常用code码 -回复

常用code码-回复[常用code码]在软件开发和计算机科学领域,常常会使用各种编码来表示和处理数据。
编码是用来将字符、数字和其他信息转换成计算机可以理解和处理的二进制形式的一种方式。
本文将介绍一些常用的编码格式,以及它们在实际应用中的用途和特点。
一、ASCII码ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是计算机中最常用的字符编码之一。
它使用7位二进制数来表示128个字符,包括大小写字母、数字、标点符号和一些特殊的控制字符。
ASCII码常用于英文和其他拉丁字母的文本处理。
二、UnicodeUnicode是一种字符编码标准,它包含了世界上大部分字符的编码,不仅包括各种文字,还有符号、表情等。
Unicode编码是由国际标准化组织(ISO)维护和发布的。
与ASCII码不同,Unicode使用16位二进制数表示一个字符,因此可以表示更多的字符。
Unicode编码有多种实现方式,其中比较常见的是UTF-8、UTF-16和UTF-32。
三、UTF-8UTF-8(Unicode Transformation Format-8)是一种可变长度的Unicode编码方案,其中英文字符使用一个字节表示,而中文和其他非英文字符使用两个或多个字节表示。
UTF-8广泛应用于互联网上的文本处理,因为它既能够兼容ASCII字符,又能够表示世界上的任意字符。
UTF-8也是现代编程语言和数据库的默认编码方式。
四、URL编码URL编码通常用于将URL中的特殊字符转义成可安全传输的形式。
URL 中常见的特殊字符包括空格、井号、问号、斜杠等。
URL编码使用百分号()后跟两位十六进制数来表示一个字符的编码。
例如,空格在URL编码中表示为"20",而井号表示为"23"。
URL编码保证了URL的完整性和可靠性。
code blocks中文输出乱码的解决方法

code blocks中文输出乱码的解决方法code blocks是一款常用的集成开发环境(IDE),广泛应用于编程开发和调试。
然而,有时在code blocks中输出的中文字符会出现乱码的情况,这给中文程序员带来了不小的困扰。
本文将介绍code blocks中文输出乱码的原因以及如何解决这个问题。
首先,我们需要了解code blocks中文输出乱码的原因。
主要有以下几个方面:1.字符编码问题:在code blocks中,中文字符的编码方式通常是UTF-8,而某些操作系统默认采用的编码方式可能不同,例如GBK。
所以在输出中文字符时,如果code blocks的配置与操作系统的编码方式不匹配,就会导致乱码问题的出现。
2.字体设置问题:code blocks中的默认字体对于中文字符的支持可能不完善,特别是一些特殊的中文字符(如繁体字)。
这可能导致这些字符在输出时显示为乱码。
解决code blocks中文输出乱码问题的方法有多种,下面逐一介绍。
1.修改默认编码方式:打开code blocks,选择"Settings" -> "Editor" -> "Default Encoding",将编码方式修改为UTF-8。
这样可以保证code blocks与大多数操作系统的编码方式一致,避免乱码问题。
2.修改代码文件的编码方式:如果在code blocks中创建的代码文件已经出现乱码,可以右键点击文件,选择"Properties" -> "Advanced" -> "Encoding",将编码方式修改为UTF-8。
重新保存文件后,乱码问题应该得到解决。
3.修改代码文件的字符集:可以在代码文件的开头添加如下注释,指定代码文件的字符集为UTF-8:```c// -*- coding: utf-8 -*-```或者使用以下注释:```c// coding=utf-8```这样可以确保code blocks在处理代码文件时按照UTF-8编码方式进行操作,从而避免乱码问题。
中文编码系统中国际码定义

中文编码系统中国际码定义
中国际码(China Interim Code,简称CIC)是中文编码系统的一种标准,用于
统一表示汉字和中文字符。
中国际码是在GB 1988中文编码基础上发展而来,由
中国国家标准化管理委员会(SAC)负责管理和发布。
中国际码的编码方式是采用一个24位的二进制数来表示每个汉字和中文字符。
这个24位的二进制数可以分为三个8位的子段,分别表示区位码、位码和位码延
伸码。
区位码是由区号和位号组成,用于确定一个字符在字符集中的位置。
它可以表
示6763个区位,其中前509个区位用于表示常用汉字,后面的173个区位用于表
示罕见汉字和外文字符。
位码是用来表示一个区位字内的字符在字符集中的位置。
每个区位字最多可以
有94个位码,用于表示94个不同的字符。
位码延伸码是为了容纳更多的汉字和字符而设计的。
当一个区位字的位码已经
用满时,可以通过添加位码延伸码来扩展字符集。
位码延伸码有自己的编码规则,用于表示额外的字符。
中国际码的设计考虑了汉字的使用频率和字形结构,以及国内外的使用需求。
它具有较高的兼容性,能够较好地满足大部分中文应用的需求。
总结起来,中国际码是一种用于表示汉字和中文字符的编码系统。
它采用24
位的二进制数来表示每个字符,通过区位码、位码和位码延伸码来确定字符在字符集中的位置。
中国际码具有较高的兼容性和广泛的应用性,是中文编码系统中的重要标准之一。
中国地区Zip Code

中国Zip Code (China Zip) 什么是Zip(Zip Code)其实Zip(Zip Code)就是国际通用的一种邮政编码方式,因为中国的邮政编码是6位的,而国外的邮政编码也一般不是5位的,但是国际上大多会使用Zip编码方式,Zip编码方式是类似的,像美国的是由州的编码作为前2位字母,城市有一个3位数字的编码,这样两者组成了5位的Zip编码。
中国的也是如此。
如“Changchun, JL, 431”表示“长春的Zip是JL431”。
其中JL表示长春所在省份吉林,431是长春在吉林省的编码(可能是和电话号码有关,我只看了这一条,长春的电话区号是0431)。
以上是我自己看了编码后总结的,有不对之处望网友们指出改正。
看到有的朋友没有找到自己的城市,我又查了一下(原来好难查呀,我找了很久),又补充了一些,希望能帮助更多的朋友。
以下是China Zip编码表:China city codes:Akesu, XJ 997Alashanzuoqi, NM 483Aletai, XJ 906Ankang, SN 915Anqing, AH 556Anshan, LN 412Anshun, GZ 853Anyang, HEN 372Atushi, XJ 908Baicheng, JL 436Baise, GX 776Baishan, JL 439Baiyin, GS 943Baoding, HEB 312Baoji, SN 917Baoshan, YN 875Baotou, NM 472Bazhong, SC 827Beihai, GX 779Beijing, BJ 10Bengbu, AH 552Benxi, LN 414Bijie, GZ 857Binzhou, SD 543Bole, XJ 909Cangzhou, HEB 317Changchun, JL 431Changde, HN 736Changdu, XZ 895 Changji, XJ 994 Changsha, HN 731 Changzhi, SX 355 Changzhou, JS 519 Chaohu, AH 565 Chaoyang, GD 754 Chaoyang, LN 421 Chaozhou, GD 768 Chengde, HEB 314 Chengdu, SC 28 Chenzhou, HN 735 Chifeng, NM 476 Chizhou, AH 566 Chongqing, CQ 23 Chuxiong, YN 878 Chuzhou, AH 550Dali, YN 872Dalian, LN 411 Dandong, LN 415 Daqing, HL 459 Datong, SX 352 Dazhou, SC 818 Delingha, QH 977 Deyang, SC 838 Dezhou, SD 534 Dingxi, GS 932 Dongguan, GD 769 Dongsheng, NM 477 Dongying, SD 546 Duyun, GZ 854Enshi, HB 718Ezhou, HB 711 Fangchenggang, GX 770 Foshan, GD 757 Fushun, LN 413 Fuxin, LN 418 Fuyang, AH 558 Fuzhou, FJ 591 Fuzhou, JX 794 Ganzhou, JX 797 GeErmu, QH 979 GeEr, XZ 897Gejiu, YN 873Gonghe, QH 974 GuangAn, SC 826 Guangyuan, SC 839 Guangzhou, GD 20 Guilin, GX 773 Guiyang, GZ 851 Guyuan, NX 954 Haikou, HQ 898 Hailaer, NM 470 Haiyan, QH 970 Hami, XJ 902 Handan, HEB 310 Hangzhou, ZJ 571 Hanzhong, SN 916 Harbin, HL 451 Hebi, HEN 392 Hechi, GX 778 Hefei, AH 551 Hegang, HL 468 Heihe, HL 456 Hengshui, HEB 318 Hengyang, HN 734 Hetian, XJ 903 Heyuan, GD 762 Heze, SD 530 Hezuo, GS 941 HuaiYin, JS 517 Huaibei, AH 561 Huaihua, HN 745 Huainan, AH 554 Huangchuan, HEN 397 Huanggang, HB 713 Huangshan, AH 559 Huangshi, HB 714 Huhehaote, NM 471 Huizhou, GD 752 Huludao, LN 429 Hunchun, JL 440 Huzhou, ZJ 572 JiAn, JX 796 Jiagedaqi, HL 457 Jiamusi, HL 454 Jiangmen, GD 750 Jiaozuo, HEN 391Jieyang, GD 663 Jilin, JL 432Jinan, SD 531 Jinchang, GS 935 Jincheng, SX 356 Jingdezhen, JX 798 Jinghong, YN 691 Jingmen, HB 724 Jingzhou, HB 716 Jinhua, ZJ 579 Jining, NM 474 Jining, SD 537 Jinzhou, LN 416 Jishou, HN 743 Jiujiang, JX 792 Jiuquan, GS 937 Jixi, HL 467 Kaifeng, HEN 378 Kaili, GZ 855 Kalamayi, XJ 990 Kangding, SC 836 Kashi, XJ 998 KuErle, XJ 996 Kuitun, XJ 992 Kunming, YN 871 Laiwu, SD 634 Langfang, HEB 316 Lanzhou, GS 931 Leshan, SC 833 Lhasa, XZ 891 Lianyungang, JS 518 Liaocheng, SD 635 Liaoyang, LN 419 Liaoyuan, JL 437 Lijiang, YN 888 Lincang, YN 883 Linfen, SX 357 Linhe, NM 478 Linxia, GS 930 Linyi, SD 539 Linzhi, XZ 894 Lishi, SX 358 Lishui, ZJ 578Liuku, YN 886 Liupanshui, GZ 858 Liuzhou, GX 772 Longyan, FJ 597 Loudi, HN 738 Luohe, HEN 395 Luoyang, HEN 379 Luxi, YN 692 Luzhou, SC 830 MaAnshan, AH 555 MaErkang, SC 837 Maoming, GD 668 Maqin, QH, 975 Meihekou, JL 448 Meizhou, GD 753 Mianyang, SC 816 Mudanjiang, HL 453 Naidong, XZ 893 Nanchang, JX 791 Nanchong, SC 817 Nanjing, JS 25 Nanning, GX 771 Nanping, FJ 599 Nantong, JS 513 Nanyang, HEN 377 Naqu, XZ 896 Neijiang, SC 832 Ningbo, ZJ 574 Ningde, FJ 593 Panjin, LN 427 Panzhihua, SC 812 PingAn, QH, 972 Pingdingshan, HEN 375 Pingliang, GS, 933 Pingxiang, JX 799 Putian, FJ 594 Puyang, HEN 393 Qingdao, SD 532 Qingyuan, GD 763 Qinhuangdao, HEB 335 Qinzhou, GX 777 Qiqihar, HL 452 Qitaihe, HL 464Qujing, YN 874 Quzhou, ZJ 570 Rikaze, XZ 892 Rizhao, SD 633 Sanmenxia, HEN 398 Sanming, FJ 598 Shanghai, SH 21 Shangqiu, HEN 370 Shangrao, JX 793 Shangzhou, SN 914 Shantou, GD 754 Shanwei, GD 660 Shaoguan, GD 751 Shaoxing, ZJ 575 Shaoyang, HN 739 Shenyang, LN 24 Shenzhen, GD 755 Shihezi, XJ 993 Shijiazhuang, HEB 311 Shiyan, HB 719 Shizuishan, NX 952 Shuangyashan, HL 469 Shunde, GD 765 Shuozhou, SX 349 Simao, YN 879 Siping, JL 434 Songyuan, JL 438 Suihua, HL 455 Suining, SC 825 Suizhou, HB 722 Suqian, JS 527 Suzhou, AH 557 Suzhou, JS 512 Tacheng, XJ 901 TaiAn, SD 538 Taiyuan, SX 351 Taizhou, JS 523 Taizhou, ZJ 576 Tangshan, HEB 315 Tianjin, TJ 22 Tianshui, GS 938 Tieling, LN 410 Tongchuan, SN 919Tongliao, NM 475 Tongling, AH 562 Tongren, GZ 856 Weifang, SD 536 Weihai, SD 631 Weinan, SN 913 Wenshan, YN 876 Wenzhou, ZJ 577 Wuhai, NM 473 Wuhan, HB 27 Wuhu, AH 553 Wulanhaote, NM 482 Wuxi, JS 510 Wuzhou, GX 774 XiAn, SN 29 Xiamen, FJ 592 Xiangfan, HB 710 Xiangtan, HN 732 Xianning, HB 715 Xiantao, HB 728 Xianyang, SN 910 Xiaogan, HB 712 Xichang, SC 834 Xilinhaote, NM 479 Xingtai, HEB 319 Xingyi, GZ 859 Xinxiang, HEN 373 Xinyang, HEN 376 Xinyu, JX 790 Xinzhou, SX 350 Xuancheng, AH 563 Xuchang, HEN 374 Xuzhou, JS 516 YaAn, SC 835 YanAn, SN 911 Yancheng, JS 515 Yangjiang, GD 662 Yangquan, SX 353 Yangzhou, JS 514 Yanji, JL 433 Yantai, SD 535 Yibin, SC 831 Yichang, HB 717Yichun, JX 795 Yingkou, LN 417 Yingtan, JX 701 Yiyang, HN 737 Yongzhou, HN 746 Yuci, SX 354 Yueyang, HN 730 Yulin, GX 775Yulin, SN 912 Yuncheng, SX 359 Yunfu, GD 766 Yuxi, YN 877 Zaozhuang, SD 632 Zhangjiajie, HN 744 Zhangjiakou, HEB 313 Zhangzhou, FJ 596 Zhanjiang, GD 759 Zhaoqing, GD 758 Zhaotong, YN 870 Zhengzhou, HEN 371 Zhenjiang, JS 511 Zhongdian, YN 887 Zhongshan, GD 760 Zhoukou, HEN 394 Zhoushan, ZJ 580 Zhuhai, GD 756 Zhumadian, HEN 396 Zhuzhou, HN 733 Zibo, SD 533 Zigong, SC 813 Zunyi, GZ 852。
区位码国标码机内码的转换公式

区位码国标码机内码的转换公式
区位码、国标码和机内码是用于汉字编码的三种不同方式。
每种方式
都有相应的转换公式。
1. 区位码(QW Code):
区位码是按照笔画的先后顺序给每个汉字编码的方式。
汉字的区位码
由两个数字组成,前一个数字表示汉字所在的汉字区的编码,后一个数字
表示汉字在该区的顺序编码。
转换公式如下:
区位码=(区码-16)*94+位码+161
2. 国标码(GB Code):
国标码是按照笔画的先后顺序给每个汉字编码的方式,与区位码相似。
汉字的国标码由两个数字组成,前一个数字表示汉字所在的编码区的编码,后一个数字表示汉字在该区的顺序编码。
转换公式如下:
国标码=(区码-16)*94+位码+161
3. 机内码(Internal Code):
机内码是计算机内部使用的编码方式,与区位码和国标码不同,它用
一个整数表示一个汉字。
机内码的转换公式如下:
机内码=(区码+128)*256+位码
需要注意的是,上述公式中的区码和位码应该是指汉字的区位码或国
标码的区码和位码,而不是指ASCII码或Unicode码。
这些转换公式可以用于不同编码间的转换。
例如,如果已知一个汉字
的区位码,可以通过区位码的转换公式将其转换为国标码或机内码。
同样
地,如果已知一个汉字的国标码或机内码,也可以通过相应的公式将其转换为区位码或其他编码。
总结:区位码国标码和机内码是用于汉字编码的三种不同方式,每种方式都有相应的转换公式。
在转换时需要根据公式将一个编码方式的值转换为另一种编码方式的值。
中文编码字符的几个实现级别

中文编码字符的几个实现级别中文编码字符的几个实现级别1. 概述中文编码字符实现级别指的是中文字符在计算机中的表示方式和存储形式。
随着技术的不断发展,中文编码字符的实现级别也在不断升级,以适应不同的应用场景和需求。
目前,常见的中文编码字符实现级别主要包括ASCII编码、Unicode编码和UTF-8编码等。
接下来,我们将对这几个实现级别进行深入探讨。
2. ASCII编码ASCII(American Standard Code for Information Interchange)编码是最早期的一种字符编码标准,最初只包括英文字母、数字和一些符号,共128个字符。
由于ASCII编码是按照7位二进制数来表示字符,因此无法表示中文字符,只能满足英文字符的需求。
随着中文字符的需求逐渐增加,ASCII编码已经不能满足实际应用需求。
3. Unicode编码为解决ASCII编码无法表示中文字符的问题,Unicode编码应运而生。
Unicode编码是一种全球化的字符编码标准,旨在为世界上所有的文字和符号设立统一的编码,以便跨语言、跨评台地进行文本处理、存储和显示。
Unicode编码涵盖了全球范围内几乎所有的字符,包括中文字符在内,为计算机系统提供了广泛的字符支持。
4. UTF-8编码UTF-8(Unicode Transformation Format - 8-bit)是Unicode编码的一种变体,它通过可变长度的编码方式,实现了对Unicode字符集的高效编码和解码。
UTF-8编码采用1-4个字节来表示一个字符,对于英文字符采用1个字节表示,对于中文字符通常采用3个字节表示。
由于它的高效性和兼容性,UTF-8编码在互联网领域得到了广泛应用,成为了当前最流行的字符编码方式。
5. 个人观点在我看来,随着全球化的发展和信息交流的日益频繁,Unicode编码和UTF-8编码已经成为了当今计算机系统中广泛采用的字符编码标准。
国字在unioncode的码位

国字在unioncode的码位
在Unioncode编码体系中,国字指的是中文汉字。
在Unioncode中,汉字的编码范围为4E00至9FFF,这个范围内包含了常见的中文汉字和部分生僻汉字。
下面将介绍一些国字在Unioncode中的码位情况。
首先,我们知道汉字的Unicode编码范围为4E00至9FFF,其中4E00是第一个汉字“一”的编码,9FFF是最后一个汉字“鿿”的编码。
这个范围内的码位被用来存储各种汉字字符。
在Unioncode中,每个字符都有一个唯一的码位,用来表示该字符在编码体系中的位置。
对于汉字来说,每个汉字都对应一个固定的码位,可以通过码位来唯一确定一个汉字的身份。
举例来说,汉字“中”的Unioncode码位为4E2D,汉字“国”的码位为56FD,汉字“字”的码位为5B57。
这些码位是固定不变的,不会因为不同的编码系统而发生变化。
除了常见的汉字,Unioncode还包含了一些生僻的汉字和特殊的汉字,它们的码位也在4E00至9FFF的范围内。
这些汉字的码位虽然不常用,但在特定的场合下仍然会被使用到。
总的来说,国字在Unioncode的码位范围是4E00至9FFF,这个范围内包含了大部分的中文汉字,每个汉字都有一个固定的码位,通过码位可以准确地表示一个汉字的身份。
在计算机中,汉字的码位被用来进行编码和解码,确保汉字能够在不同的系统中正确显示和传输。
Unioncode的码位体系为汉字的处理和传输提供了标准化的方法,使汉字的应用更加方便和可靠。
code25码 编码标准 -回复

code25码编码标准-回复代码25码(Code 25)编码标准,是一种离散字符编码方案,用于在条码和标签上的数据传输和识别。
25码编码标准由两个宽度相等的条和间隙组成,每个字符由5个单元组成,每个单元可以是条或者间隙。
本文将详细介绍25码编码标准的原理和应用。
第一步,我们先了解25码编码标准的基本结构和字符集。
25码编码标准由数字0-9和特殊字符*+-./组成。
其中,数字字符由5个单元的条/间隙组合表示,特殊字符有不同的表示方式。
在25码中,每个字符的起始和结束都有一个条作为起点和终点的标识。
接下来,我们介绍25码编码标准的字符表示方法。
对于数字0-9,每个字符使用5个单元的条/间隙组合表示,每个单元可以是短条(1)或者短间隙(0)。
例如,数字0的编码是00011,数字1的编码是10001,以此类推。
对于特殊字符,每个字符的编码方式不同,比如的编码是11010,-的编码是01100。
第三步,我们介绍25码编码标准的校验码。
校验码是为了验证条码的准确性而添加的,它能够帮助检测和修正输入错误。
25码编码标准中的校验码使用算法来计算得出。
校验码的计算通常基于字符的位置和权重,通过将字符和权重相乘,将结果相加,然后取余数得到校验码。
校验码可以在条码中加一个特殊字符来表示。
第四步,我们了解25码编码标准在实际应用中的应用情况。
25码编码标准广泛应用于零售业、物流和仓储管理等领域。
在零售业中,25码常用于商品标签上的条码,供销售员快速扫描和检查商品信息。
在物流和仓储管理中,25码用于标识存储和运输中的包裹和货物,以便跟踪和管理。
第五步,我们介绍25码编码标准的优点和缺点。
25码编码标准具有编码简单、可靠性高、扫描速度快的优点。
它适用于需要快速读取和识别的场景。
然而,25码编码标准的字符密度较低,占用空间较大,不能表示较大字符集,这是它的一个缺点。
最后,总结一下25码编码标准的重要性和应用前景。
25码编码标准是一种常用的条码编码标准,具有广泛的应用前景。
关于CRC码的基本知识

一、CRC码工作原理1. CRC校验原理CRC的英文全称为Cyclic Redundancy Check(Code),中文名称为循环冗余校验(码)。
它是一类重要的线性分组码,编码和解码方法简单,检错和纠错能力强,在通信领域广泛地用于实现差错控制。
CRC计算与普通的除法计算有所不同。
普通的除法计算是借位相减的,而CRC计算则是异或运算。
任何一个除法运算都需要选取一个除数,在CRC运算中我们称之为poly,而宽度W就是poly最高位的位置。
比如poly 1001的W是3,而不是4。
注意最高位总是1,当你选定一个宽度,那么你只需要选择低W各位的值。
假如我们想计算一个位串的CRC码,并要保证每一位都要被处理,因此我们需要在目标位串后面加上W个0。
CRC校验原理看起来比较复杂,因为大多数书上基本上是以二进制的多项式形式来说明的。
其实很简单的问题,其根本思想就是先在要发送的帧后面附加一个数(这个就是用来校验的校验码,但要注意,这里的数也是二进制序列的,下同),生成一个新帧发送给接收端。
当然,这个附加的数不是随意的,它要使所生成的新帧能与发送端和接收端共同选定的某个特定数整除(注意,这里不是直接采用二进制除法,而是采用一种称之为“模2除法”)。
到达接收端后,再把接收到的新帧除以(同样采用“模2除法”)这个选定的除数。
因为在发送端发送数据帧之前就已通过附加一个数,做了“去余”处理(也就已经能整除了),所以结果应该是没有余数。
如果有余数,则表明该帧在传输过程中出现了差错。
【说明】“模2除法”与“算术除法”类似,但它既不向上位借位,也不比较除数和被除数的相同位数值的大小,只要以相同位数进行相除即可。
模2加法运算为:1+1=0,0+1=1,0+0=0,无进位,也无借位;模2减法运算为:1-1=0,0-1=1,1-0=1,0-0=0,也无进位,无借位。
相当于二进制中的逻辑异或运算。
也就是比较后,两者对应位相同则结果为“0”,不同则结果为“1”。
VisualStudioCode运行程序时输出中文成乱码问题及解决方法
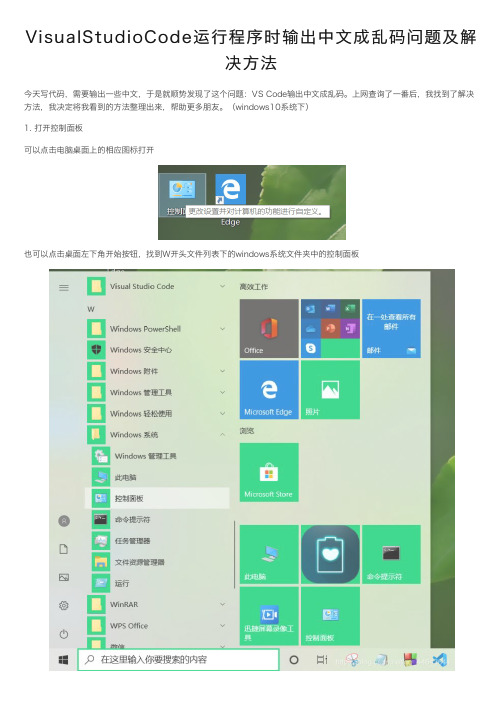
VisualStudioCode运⾏程序时输出中⽂成乱码问题及解决⽅法今天写代码,需要输出⼀些中⽂,于是就顺势发现了这个问题:VS Code输出中⽂成乱码。
上⽹查询了⼀番后,我找到了解决⽅法,我决定将我看到的⽅法整理出来,帮助更多朋友。
(windows10系统下)1. 打开控制⾯板可以点击电脑桌⾯上的相应图标打开也可以点击桌⾯左下⾓开始按钮,找到W开头⽂件列表下的windows系统⽂件夹中的控制⾯板2.选择时钟和区域下的更改⽇期、时间或数字格式3.点击管理,然后点选择更改系统区域设置4. 勾选Beta版:使⽤Unicode UTF-8提供全球语⾔⽀持,然后点击确定,并同意系统的重启请求重启电脑后就OK啦!知识点补充:Visual Studio Code 打开程序⽂件中⽂乱码解决⽅法使⽤Visual Studio Code打开程序⽂件后对应的中⽂乱码,造成这种现象的原因是⽂件的编码⽅式不同.可以通过调整打开⽂件的编码⽅式来解决Visual Studio Code打开中⽂乱码的问题.操作步骤如下:⾸先点击右下⾓当前的编码格式 ,本次实验中的编码⽅式为UTF-8点击编码⽅式后,Select Action输⼊框会⾃动弹出Reopen with Encoding和Save with Encoding,点击Reopen with Encoding进⼊编码⽅式选择列表.在弹出的列表中选择Simplified Chinese(GB2312),乱码问题应该解决.如果Visual Studio Code选择了Simplified Chinese(GB2312)编码⽅式依然乱码,可以尝试在上⽅的输⼊框中输⼊ GB ,这样就会显⽰出中⽂对应的编码⽅式.通过选择不同的编码⽅式来尝试解决Visual Studio Code乱码的问题.也可以通过安装Visual Studio Code插件 GBKtoUTF8来实现打开⽂件⾃动转码.但是当前测试中发现GBKtoUTF8存在⼀些Bug,偶尔⾃动将⼯程中当前打开的⽂件内容替换成其他⽂件的内容. 造成程序代码丢失.总结到此这篇关于Visual Studio Code运⾏程序时输出中⽂成乱码的⽂章就介绍到这了,更多相关Visual Studio Code运⾏程序中⽂乱码内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
code blocks中文输出乱码的解决方法

code blocks中文输出乱码的解决方法在 Code Blocks 中输出中文乱码的问题通常是由于编码问题引起的。
以下是几种可能的解决方法:1. 确保源文件的编码方式正确:在 Code Blocks 中,点击菜单栏的 `File -> Default Encoding...`,选择 `UTF-8` 或 `GBK`(根据你的需要)作为默认编码方式。
2. 添加以下代码到源文件顶部:在源文件的开头添加如下代码:```c++#pragma execution_character_set("utf-8")```这将告诉编译器使用 UTF-8 编码解释你的源代码。
3. 保存源文件为 UTF-8 编码:在 Code Blocks 中,点击菜单栏的 `File -> Save file As...`,选择 `UTF-8` 编码保存你的源文件。
4. 设置控制台编码:在 Code Blocks 中,点击菜单栏的`Settings -> Environment -> Encoding`,选择 `UTF-8` 或 `GBK`(根据你的需要)作为控制台编码方式。
5. 使用 `wprintf` 函数:如果以上方法仍然无效,可以尝试使用 `wprintf` 函数而不是 `printf` 函数进行中文输出。
例如:```c++#include <stdio.h>#include <locale.h>int main() {setlocale(LC_ALL, ""); // 设置环境为当前区域的默认环境wprintf(L"中文测试\n");return 0;}```这将使用宽字符版本的 `printf` 实现中文输出。
如果上述方法仍然不能解决问题,可能是由于操作系统或编写的代码中的其他问题导致。
你可以尝试在其他编程环境中进行测试,或者查阅 Code Blocks 官方文档或论坛等资源以获取更多帮助。
编码信息详解c获取中文编码(gbkgb2312)

编码信息详解,C#获取中文编码(GBK,GB2312)2011-01-26 21:28:45| 分类:C# | 标签:|字号大中小订阅以前在写C#代码时,感觉VS提供的没有系统默认的编码,现在发现虽然没有但可以通过如下方式获得中文编码信息(如GBK,GB2312),只需找到对应编码名称的codepage即可。
下面是微软编程提供的所有编码信息,包括编码名称,编码代码页标识符,编码说明,这对于编程转码相当有作用。
【C# Code】EncodingInfo[] info = Encoding.GetEncodings();Console.Write("编码名称" + "\t" + "编码代码页标识符" + "\t" + "编码说明" + "\n");for (int i = 0; i < info.Length; i++){Console.Write(info[i].Name + "\t\t" + info[i].CodePage + "\t\t\t" + info[i].DisplayName + "\n");}结果如下:编码名称|编码代码页标识符|编码说明IBM037|37|IBM EBCDIC (美国-加拿大)IBM437|437|OEM 美国IBM500|500|IBM EBCDIC (国际)ASMO-708|708|阿拉伯字符(ASMO-708)DOS-720|720|阿拉伯字符(DOS)ibm737|737|希腊字符(DOS)ibm775|775|波罗的海字符(DOS)ibm850|850|西欧字符(DOS)ibm852|852|中欧字符(DOS)IBM855|855|OEM 西里尔语ibm857|857|土耳其字符(DOS)IBM00858|858|OEM 多语言拉丁语IIBM860|860|葡萄牙语(DOS)ibm861|861|冰岛语(DOS)DOS-862|862|希伯来字符(DOS)IBM863|863|加拿大法语(DOS)IBM864|864|阿拉伯字符(864)IBM865|865|北欧字符(DOS)cp866|866|西里尔字符(DOS)ibm869|869|现代希腊字符(DOS)IBM870|870|IBM EBCDIC (多语言拉丁语2) windows-874|874|泰语(Windows)cp875|875|IBM EBCDIC (现代希腊语)shift_jis|932|日语(Shift-JIS)gb2312|936|简体中文(GB2312)ks_c_5601-1987|949|朝鲜语big5|950|繁体中文(Big5)IBM1026|1026|IBM EBCDIC (土耳其拉丁语5)IBM01047|1047|IBM 拉丁语1IBM01140|1140|IBM EBCDIC (美国-加拿大-欧洲) IBM01141|1141|IBM EBCDIC (德国-欧洲)IBM01142|1142|IBM EBCDIC (丹麦-挪威-欧洲) IBM01143|1143|IBM EBCDIC (芬兰-瑞典-欧洲) IBM01144|1144|IBM EBCDIC (意大利-欧洲)IBM01145|1145|IBM EBCDIC (西班牙-欧洲)IBM01146|1146|IBM EBCDIC (英国-欧洲)IBM01147|1147|IBM EBCDIC (法国-欧洲)IBM01148|1148|IBM EBCDIC (国际-欧洲)IBM01149|1149|IBM EBCDIC (冰岛语-欧洲)utf-16|1200|UnicodeunicodeFFFE|1201|Unicode (Big-Endian) windows-1250|1250|中欧字符(Windows) windows-1251|1251|西里尔字符(Windows) Windows-1252|1252|西欧字符(Windows) windows-1253|1253|希腊字符(Windows) windows-1254|1254|土耳其字符(Windows) windows-1255|1255|希伯来字符(Windows) windows-1256|1256|阿拉伯字符(Windows) windows-1257|1257|波罗的海字符(Windows) windows-1258|1258|越南字符(Windows)Johab|1361|朝鲜语(Johab)macintosh|10000|西欧字符(Mac)x-mac-japanese|10001|日语(Mac)x-mac-chinesetrad|10002|繁体中文(Mac)x-mac-korean|10003|朝鲜语(Mac)x-mac-arabic|10004|阿拉伯字符(Mac)x-mac-hebrew|10005|希伯来字符(Mac)x-mac-greek|10006|希腊字符(Mac)x-mac-cyrillic|10007|西里尔字符(Mac)x-mac-chinesesimp|10008|简体中文(Mac)x-mac-romanian|10010|罗马尼亚语(Mac)x-mac-ukrainian|10017|乌克兰语(Mac)x-mac-thai|10021|泰语(Mac)x-mac-ce|10029|中欧字符(Mac)x-mac-icelandic|10079|冰岛语(Mac)x-mac-turkish|10081|土耳其字符(Mac)x-mac-croatian|10082|克罗地亚语(Mac)utf-32|12000|Unicode (UTF-32)utf-32BE|12001|Unicode (UTF-32 Big-Endian) x-Chinese-CNS|20000|繁体中文(CNS)x-cp20001|20001|TCA 台湾x-Chinese-Eten|20002|繁体中文(Eten)x-cp20003|20003|IBM5550 台湾x-cp20004|20004|TeleText 台湾x-cp20005|20005|Wang 台湾x-IA5|20105|西欧字符(IA5)x-IA5-German|20106|德语(IA5)x-IA5-Swedish|20107|瑞典语(IA5)x-IA5-Norwegian|20108|挪威语(IA5)us-ascii|20127|US-ASCIIx-cp20261|20261|T.61x-cp20269|20269|ISO-6937IBM273|20273|IBM EBCDIC (德国)IBM277|20277|IBM EBCDIC (丹麦-挪威)IBM278|20278|IBM EBCDIC (芬兰-瑞典)IBM280|20280|IBM EBCDIC (意大利)IBM284|20284|IBM EBCDIC (西班牙)IBM285|20285|IBM EBCDIC (UK)IBM290|20290|IBM EBCDIC (日语片假名)IBM297|20297|IBM EBCDIC (法国)IBM420|20420|IBM EBCDIC (阿拉伯语)IBM423|20423|IBM EBCDIC (希腊语)IBM424|20424|IBM EBCDIC (希伯来语)x-EBCDIC-KoreanExtended|20833|IBM EBCDIC (朝鲜语扩展) IBM-Thai|20838|IBM EBCDIC (泰语)koi8-r|20866|西里尔字符(KOI8-R)IBM871|20871|IBM EBCDIC (冰岛语)IBM880|20880|IBM EBCDIC (西里尔俄语)IBM905|20905|IBM EBCDIC (土耳其语)IBM00924|20924|IBM 拉丁语1EUC-JP|20932|日语(JIS 0208-1990 和0212-1990)x-cp20936|20936|简体中文(GB2312-80)x-cp20949|20949|朝鲜语Wansungcp1025|21025|IBM EBCDIC (西里尔塞尔维亚-保加利亚语) koi8-u|21866|西里尔字符(KOI8-U)iso-8859-1|28591|西欧字符(ISO)iso-8859-2|28592|中欧字符(ISO)iso-8859-3|28593|拉丁语3 (ISO)iso-8859-4|28594|波罗的海字符(ISO)iso-8859-5|28595|西里尔字符(ISO)iso-8859-6|28596|阿拉伯字符(ISO)iso-8859-7|28597|希腊字符(ISO)iso-8859-8|28598|希伯来字符(ISO-Visual)iso-8859-9|28599|土耳其字符(ISO)iso-8859-13|28603|爱沙尼亚语(ISO)iso-8859-15|28605|拉丁语9 (ISO)x-Europa|29001|欧罗巴iso-8859-8-i|38598|希伯来字符(ISO-Logical)iso-2022-jp|50220|日语(JIS)csISO2022JP|50221|日语(JIS-允许1 字节假名)iso-2022-jp|50222|日语(JIS-允许1 字节假名- SO/SI) iso-2022-kr|50225|朝鲜语(ISO)x-cp50227|50227|简体中文(ISO-2022)euc-jp|51932|日语(EUC)EUC-CN|51936|简体中文(EUC)euc-kr|51949|朝鲜语(EUC)hz-gb-2312|52936|简体中文(HZ)GB18030|54936|简体中文(GB18030)x-iscii-de|57002|ISCII 梵文x-iscii-be|57003|ISCII 孟加拉语x-iscii-ta|57004|ISCII 泰米尔语x-iscii-te|57005|ISCII 泰卢固语x-iscii-as|57006|ISCII 阿萨姆语x-iscii-or|57007|ISCII 奥里雅语x-iscii-ka|57008|ISCII 卡纳达语x-iscii-ma|57009|ISCII 马拉雅拉姆语x-iscii-gu|57010|ISCII 古吉拉特语x-iscii-pa|57011|ISCII 旁遮普语utf-7|65000|Unicode (UTF-7)utf-8|65001|Unicode (UTF-8)想要使用某种编码时可以这样,Encoding Gbk =Encoding.GetEncoding(int codepage); 如果想使用gb2312 编码,则可以Encoding Gbk = Encoding.GetEncoding(936);下面就是一段GB2312编码的代码:byte[] dataArray = new byte[100];new Random().NextBytes(dataArray);Encoding Gbk = Encoding.GetEncoding(936);Console.WriteLine(Gbk.GetString(dataArray));依次类推~备注:(什么是编码代码页标识符)运行-cmd-顶部右键-属性-选项-当前代码页(可以发现大陆装的系统默认就是codpage是936 也即GBK)。
CODE39编码方式(中文)

CODE 39 编码方式CODE 39 背景资料Code 39,待开发的第一个字母数字的符号,是仍然被广泛使用,尤其是在非零售环境。
它是由美国国防部使用的标准条形码,是由卫生行业条码委员会(HIBCC)也可用于。
39码也被称为“3 9中的代码”和“美元3”。
一个典型的代码39条码是:Code 39是一个离散的,可变长度的符号。
这是自我检查,在一个单一的的打印缺陷,不能转置成另一种有效的字符的字符。
计算校验和位数由于39码是自我检查,校验位通常是没有必要的。
然而,在应用要求的精度非常高的水平的一个模43校验位数字可能会增加。
1. 要计算的可选校验数字,请按照下列步骤。
1。
以条形码的每个字符的值(0到42)。
启动和停止字符不包括在校验和计算。
2. 萨姆在步骤1中所描述的每个字符的每个值的值。
3. 43,从第2步划分的结果。
4. 在第3步师的其余部分将被追加到前停止字符的数据电文的校验字符。
编码符号一旦校验数字已计算,我们知道整个消息必须在酒吧和空间编码。
继续我们的例子中,我们会从零编码,Code 39条码使用我们在上面的例子:一个67位数的校验HI345678。
在下面的文本,我们将讨论通过条码的编码,考虑到数字“1”代表“暗”或“bar”,而“0”的条形码代表“轻”或“空间”部分条形码。
因此,数字1101代表一个双宽条(11),由一个单一的广阔的空间(0)单宽条(1),。
这将是印在条码:一个Code 39条码的架构一个Code 39条码具有以下结构:1。
一个起始字符- 星号(*)字符。
2。
从下表中的编码字符的任何数。
3。
一个可选的校验和数字计算上文所述,从下表编码。
4。
一个终止符,这是第二个星号字符。
CODE 39码的编码表此表显示了如何来编码每一个Code 39条码的数字。
请注意,“宽度编码”列的“N”和“W”为宽窄的表示,而“条码编码”列表示的条形码如何将实际编码所描述的上述“编码符号”。
记住,每个字符的开始和结束与酒吧,因而总是启动的“条码编码”和“1”结尾。
中文的ascii码表

中文的ascii码表中文的ASCII码表ASCII (American Standard Code for Information Interchange)码表是计算机中最基本、最常用的编码方式之一,它使用7位二进制数表示一个字符,最多可表示128个字符。
ASCII码表中包含了字母、数字、标点符号、控制字符等基本字符。
而对于中文字符,ASCII码表无法直接表示,需要采用其他编码方式。
一、 GB2312编码GB2312是中国大陆国家标准简体中文字符集,包含了一万多个汉字。
每个汉字编码占两个字节,第一个字节的范围是0xB0~0xF7,第二个字节的范围是0xA1~0xFE。
GB2312编码方式可以通过将两个字节按照顺序合并为一个整数进行表示。
比如汉字“中”在GB2312中的编码为0xD6D0。
二、 BIG5编码BIG5是台湾的汉字编码方式,它是目前最常见的繁体中文编码方式。
BIG5编码方式同样使用两个字节来表示一个汉字,第一个字节的范围是0x81~0xFE,第二个字节的范围是0x40~0x7E和0xA1~0xFE。
BIG5编码方式同样可以按照两个字节合并为一个整数进行表示,比如“中”字的BIG5编码为0xA440。
三、 UTF-8编码UTF-8是一种可变长度的字符编码方式,在Unicode中为每个字符分配了一个唯一的编号,然后采用不同长度的字节序列表示这些字符。
对于中文字符而言,UTF-8编码方式需要三个字节表示一个字符,第一个字节的前三位为111,后五位表示字符长度,第二个字节的前两位为10,后六位为字符码的高五位,第三个字节的前两位同样为10,后六位为字符码的低五位。
比如“中”字的UTF-8编码为0xE4B8AD。
四、GB18030编码GB18030是中国官方发布的通用字符集标准,它与GB2312码表相比增加了很多汉字和符号的编码,包括繁体中文和日文汉字。
GB18030编码方式同样采用两个字节来表示一个汉字,但是比GB2312码表多支持四个字节的编码方式。
中文的编码格式

中文的编码格式中文的编码格式在计算机领域中起到了至关重要的作用。
编码格式是将文字和符号转化为计算机可以识别和处理的二进制代码的规则和规范。
不同的中文编码格式对于中文字符的表示和存储方式不尽相同,因此深入了解中文的编码格式有助于我们更好地理解和应用中文字符。
一、ASCII编码ASCII(American Standard Code for Information Interchange)编码是最基础的字符编码格式之一,在ASCII编码中使用7位二进制来表示字符。
这种编码方式只能表示英文字符、数字和一些常见的符号,无法表示中文字符。
ASCII编码主要用于早期计算机系统,现在已经很少使用了。
二、GB2312编码GB2312编码是我国国家标准,是中国国家标准局于1980年发布的第一个中文字符集。
GB2312编码采用两个字节表示一个汉字,其中一部分是表示汉字的区位码,另一部分是表示区内位置的区位码。
GB2312编码主要包含了6,763个汉字和682个非汉字字符。
GB2312编码在解决中文字符表示的问题上具有一定的局限性,它只能支持有限的字符集合,因此在一些特殊的应用场景下并不适用。
随着计算机技术的发展,GB2312编码逐渐被更先进的编码格式取代。
三、GB18030编码GB18030是我国国家标准局于2000年发布的最新的中文字符编码标准。
它是在GB2312编码基础上的扩展,可以支持更多的汉字和非汉字字符。
GB18030采用1至4个字节来表示字符,具有更高的兼容性和灵活性。
GB18030编码已成为中文字符编码的主流标准,并被广泛应用于计算机软件、操作系统以及互联网等领域。
它的出现解决了之前字符编码标准的不足,使得中文字符的表示和处理更加便捷和可靠。
四、Unicode编码Unicode是一种全球范围内使用的字符编码标准,包含了世界各种语言的字符。
Unicode编码统一了字符表示,为各个语言的字符提供了唯一的编码。
中文电码文档

中文电码1. 什么是中文电码中文电码(Chinese telegraph code),是一种用数字编码来表示汉字的方法。
它广泛用于电信、电报、电传等场合,是传统电信技术与汉字书写相结合的产物。
使用中文电码,可以将汉字转换为数字编码,在通信中传输和处理汉字信息。
2. 中文电码的历史背景中文电码的发展与中国的电信业发展紧密相连。
最早的中文电码可以追溯到19世纪末,那时候电报业刚刚出现,人们迫切需要一种将汉字转换为数字编码的方法。
经过多次改进和演变,中文电码逐渐形成了今天我们所熟知的形式。
3. 中文电码的编码规则中文电码的核心是汉字和数字之间的对应关系。
每一个汉字都被赋予了一个唯一的数字编码,这个编码可以被用来表示和传输对应的汉字。
一般来说,中文电码按照拼音的声母和韵母进行编码,然后再加上声调信息。
具体的编码规则可以根据不同的标准和需求有所差异。
4. 中文电码的应用场景中文电码在通信技术和信息处理中起到了重要的作用。
它可以被用来在电报、电传等电信系统中传输汉字信息。
此外,中文电码还被广泛应用于计算机输入法和字符集编码中。
许多输入法和操作系统都采用了中文电码的编码规则,以便用户输入和处理汉字文本。
5. 中文电码的优缺点中文电码作为一种将汉字转换为数字编码的方法,具有一定的优点和缺点。
其主要优点有: - 可以有效地将汉字信息转换为数字形式,便于传输和处理; - 编码规则相对简单,容易理解和使用; - 在传统电信系统中得到了广泛应用,保持了较高的兼容性。
然而,中文电码也存在一些缺点,如: - 编码长度较长,影响了传输效率; - 受到字数限制,无法表示所有汉字。
6. 中文电码的发展趋势随着计算机和通信技术的不断发展,中文电码也在不断演变和改进。
新的编码规则和标准出现,既保留了传统的中文电码特点,又解决了一些问题。
例如,GB码、Unicode等编码标准为中文字符的传输和处理提供了更加全面和高效的解决方案。
7. 结论中文电码作为一种传统的汉字编码方式,发挥了重要的作用。
code在语言学中的释义

code在语言学中的释义code在语言学中可以指代多种含义。
其中一种常见的解释是指语言的编码系统。
在语言学中,我们知道每种语言都有一套独特的编码系统,通过这套系统,人们可以用特定的符号、声音或手势来表达思想、情感和意义。
这种编码系统称为语言的code。
不同的语言有不同的code,比如汉字是中文的code,字母表是英文的code。
通过这些code,人们可以将思想转化为具体的符号,以便进行交流和沟通。
code在语言学中还可以指代语言的规范和约定。
语言是人类社会交流的工具,为了确保交流的准确性和有效性,人们会约定一些规则和准则,这些规则和准则被称为语言的code。
比如,语法规则、词汇用法和语义解释等都是语言的code。
这些规范和约定使得语言的使用变得有条不紊,避免了交流中的歧义和混乱。
code还可以指代一种特定的语言变体或方言。
在语言学中,我们知道语言会随着时间和地域的变化而发展,并产生不同的变体或方言。
这些变体或方言被视为语言的不同code。
比如,汉语有普通话、粤语和四川话等不同的code;英语有英国英语、美国英语和澳大利亚英语等不同的code。
这些不同的code反映了社会和文化的多样性,丰富了语言的表达方式和交流方式。
在计算机科学和信息技术领域,code也有特定的含义。
在这个领域中,code指代一种特殊的语言,即编程语言。
编程语言是计算机和人类交流的工具,通过编写特定的code,人们可以告诉计算机如何执行特定的任务和操作。
编程语言有很多种,比如Java、Python 和C++等,它们都有自己的语法和规范,通过这些code,程序员可以编写出各种各样的软件和应用程序。
code在语言学中有多种含义,它可以指代语言的编码系统、语言的规范和约定,以及语言的不同变体和方言。
此外,在计算机科学和信息技术领域,code也指代一种特殊的语言,即编程语言。
这些不同的含义反映了code在语言学中的多样性和重要性。
通过理解和应用不同的code,我们可以更好地理解和使用语言,提高交流的效果和质量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CODE 39 编码方式
CODE 39 背景资料
Code 39,待开发的第一个字母数字的符号,是仍然被广泛使用,尤其是在非零售环境。
它是由美国国防部使用的标准条形码,是由卫生行业条码委员会(HIBCC)也可用于。
39码也被称为“3 9中的代码”和“美元3”。
一个典型的代码39条码是:
Code 39是一个离散的,可变长度的符号。
这是自我检查,在一个单一的的打印缺陷,不能转置成另一种有效的字符的字符。
计算校验和位数
由于39码是自我检查,校验位通常是没有必要的。
然而,在应用要求的精度非常高的水平的一个模43校验位数字可能会增加。
1. 要计算的可选校验数字,请按照下列步骤。
1。
以条形码的每个字符的值(0到42)。
启动和停止字符不包括在校验和计算。
2. 萨姆在步骤1中所描述的每个字符的每个值的值。
3. 43,从第2步划分的结果。
4. 在第3步师的其余部分将被追加到前停止字符的数据电文的校验字符。
编码符号
一旦校验数字已计算,我们知道整个消息必须在酒吧和空间编码。
继续我们的例子中,我们会从零编码,Code 39条码使用我们在上面的例子:一个67位数的校验HI345678。
在下面的文本,我们将讨论通过条码的编码,考虑到数字“1”代表“暗”或“bar”,而“0”的条形码代表“轻”或“空间”部分条形码。
因此,数字1101代表一个双宽条(11),由一个单一的广阔的空间(0)单宽条(1),。
这将是印在条码:
一个Code 39条码的架构
一个Code 39条码具有以下结构:
1。
一个起始字符- 星号(*)字符。
2。
从下表中的编码字符的任何数。
3。
一个可选的校验和数字计算上文所述,从下表编码。
4。
一个终止符,这是第二个星号字符。
CODE 39码的编码表
此表显示了如何来编码每一个Code 39条码的数字。
请注意,“宽度编码”列的“N”和“W”为宽窄的表示,而“条码编码”列表示的条形码如何将实际编码所描述的上述“编码符号”。
记住,每个字符的开始和结束与酒吧,因而总是启动的“条码编码”和“1”结尾。
.
CHECK VALUE ASCII
CHAR
WIDTH
ENCODING
BARCODE
ENCODING
CHECK
VALUE
ASCII
CHAR
WIDTH
ENCODING
BARCODE
ENCODING
00NNNWWNWNN10100110110122M WNWNNNNWN110110101001 11WNNWNNNNW11010010101123N NNNNWNNWW101011010011 22NNWWNNNNW10110010101124O WNNNWNNWN110101101001 33WNWWNNNNN11011001010125P NNWNWNNWN101101101001 44NNNWWNNNW10100110101126Q NNNNNNWWW101010110011 55WNNWWNNNN11010011010127R WNNNNNWWN110101011001 66NNWWWNNNN10110011010128S NNWNNNWWN101101011001 77NNNWNNWNW10100101101129T NNNNWNWWN101011011001 88WNNWNNWNN11010010110130U WWNNNNNNW110010101011 99NNWWNNWNN10110010110131V NWWNNNNNW100110101011 10A NNWWNNWNN11010100101132W WWWNNNNNN110011010101 11B NNWNNWNNW10110100101133X NWNNWNNNW100101101011
12C WNWNNWNNN11011010010134Y WWNNWNNNN110010110101 13D NNNNWWNNW10101100101135Z NWWNWNNNN100110110101 14E WNNNWWNNN11010110010136-NWNNNNWNW100101011011 15F NNWNWWNNN10110110010137.WWNNNNWNN110010101101 16G NNNNNWWNW10101001101138SPACE NWWNNNWNN100110101101 17H WNNNNWWNN11010100110139$NWNWNWNNN100100100101 18I NNWNNWWNN10110100110140/NWNWNNNWN100100101001 19J NNNNWWWNN10101100110141+NWNNNWNWN100101001001 20K WNNNNNNWW11010101001142%NNNWNWNWN101001001001 21L NNWNNNNWW101101010011n/a*NWNNWNWNN100101101101
如果Code 39条码与空间开始,该条形码将被追加到缓冲区以往任何代码39条码,系统将等待更多的条码(S)。
如果不启动与空间的一个Code39条码,条码将被追加到任何以前的39码条码和整个消息将被传递到应用程序。
换句话说,如果有额外的代码39条码的条码,它必须开始与空间如果条码是在消息的最后一个条码,它决不能与空间开始。
CODE 39码编码的例子
现在,我们将代码的例子中,我们上面使用,TEST8052。
在这种情况下,我们不会使用一个校
验位。
1。
起始字符(*):100101101101。
2。
数字“T”型:101011011001 enocded。
3。
该数字的“E”:110101100101 enocded。
4。
该数字的“S”:enocded为101101011001。
5。
数字“T”型:101011011001 enocded。
6。
数字“8”:110100101101 enocded。
7。
数字“0”:101001101101 enocded。
8。
数字“5”:为110100110101 enocded。
9。
数字“2”:101100101011 enocded。
10。
终止符(*):100101101101。
这是条形码已投入领域,反映了刚才提到的10个分类指数中,每个切片在下面的图形表示。
注:在上面的编码例如需要注意的是每个字符之间的字符间空间。
这是在10组件列表中没有列出,但有一个每个字符之间的字符间的空间。
这间的字符空间是在白色的空间分离的灰色地带
图形表示。
EXTENDED CODE 39(扩展CODE39)编码表
它是可能的,用39码的“全ASCII模式”,所有128个ASCII字符进行编码。
这是通过使用$/,%,并作为“转变为”字符+符号。
结合单个字符,如下表示要使用全ASCII字符的字符。