同源建模详细讲解整理版
5.5计算方法预测三级结构-02-同源建模法SWISS-MODEL

《生物信息学》第五章:蛋白质结构预测与分析(第二部分) 计算方法预测三级结构:同源建模法SWISS-MODEL预测蛋白质三级结构的首选方法是同源建模法(homolog modeling)。
该方法基于原理:相似的氨基酸序列对应着相似的蛋白质结构。
比如三个蛋白质,它们在序列水平上十分相似,解析出的结构也十分相似。
第四个蛋白质的序列和前面三个也高度相似,那么就可以比着前三个结构的样子“画”出第四个的样子。
所以同源建模法的关键就是找到一个好的模板。
好的模板要求,在序列水平上模板(template)要与目标(target)蛋白质具有超过30%的一致度。
同源建模法操作流程如下(图1):图1. 同源建模法操作流程1. 确定模板:找到与目标蛋白质同源的已知蛋白质结构作为模版(目标序列与模版序列间的一致度要≥30%)。
2. 序列比对:为目标序列与模板序列创建序列对比。
模板可以选取多个,通过做多序列比对,各取所长,让模板序列中与目标序列相似的片段尽可能多的覆盖整个目标序列,同时要尽量避免没有模板参考的断口。
3. 计算模型:通过序列比对,将目标序列里的氨基酸替换到模板结构里对应的氨基酸所在的空间位置上。
这一步通过同源建模软件来实现。
4.换模板或修正序列比对,重新构建模型,再次评估。
SWISS-MODEL()它能帮助完成上述步骤中从模板选取到创建序列比对,再到计算模型,以及最后的质量评估的全部过程。
你需要做的只是:输入目标序列,点Build Model(创建模型)(图2左)。
大约三到五分钟之后就会返回结果。
如果这种自动挡模式不能满足你的要求,可以通过点击Search For Templates切换成手动挡,以便指定模板。
也可以直接把做好的目标序列与模板序列之间的序列比对按照指定格式黏贴到输入框里,再点击Build Model(创建模型)(图2右)。
这时,SWISS-MODEL会根据输入的特定格式的序列比对,识别出哪个是目标序列,哪个是模板,并自动从PDB数据库下载模板结构,最后根据输入的比对计算结构模型。
蛋白质三级结构预测(swiss-model同源建模)
利用同源建模预测蛋白质的三级结构首先声明一下,以下纯属个人观点,方法步骤仅供参考,不可作为规范标准,结果出来之后请自行分析结果。
我用的是SWISS-MODEL同源建模的方法进行的蛋白质高级结构预测,其实这个方法是有限制条件的,不过作为一个选修课作业,我们不用深入探究,所以有时不够严谨,大家知道就行!对于一个未知结构的蛋白质,白质建立结构模型。
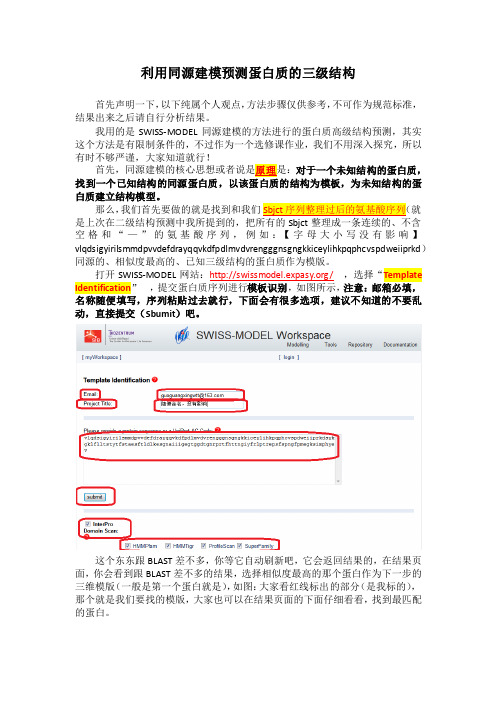
那么,我们首先要做的就是找到和我们空格和“—”的氨基酸序列,例如:【字母大小写没有影响】vlqdsigyirilsmmdpvvdefdrayqqvkdfpdlmvdvrengggnsgngkkiceylihkpqphcvspdweiiprkd)同源的、相似度最高的、已知三级结构的蛋白质作为模版。
打开SWISS-MODEL网站:/,选择“Template Identification,提交蛋白质序列进行模板识别,如图所示,注意:邮箱必填,名称随便填写,序列粘贴过去就行,下面会有很多选项,建议不知道的不要乱动,直接提交(Sbumit)吧。
这个东东跟BLAST差不多,你等它自动刷新吧,它会返回结果的,在结果页面,你会看到跟BLAST差不多的结果,选择相似度最高的那个蛋白作为下一步的三维模版(一般是第一个蛋白就是),如图:大家看红线标出的部分(是我标的),那个就是我们要找的模版,大家也可以在结果页面的下面仔细看看,找到最匹配的蛋白。
这里还有一点要作说明,就是上图标出的代码是PDB编号,前四个表示PDB- Code,最后一位表示Chain-ID,具体什么意思,大家有兴趣就去了解一些吧。
接下来,去NCBI串串门吧,在NCBI中搜索上面查到的蛋白的PDB号,一般输入前四位就行啦,注意:搜索蛋白库(Protein)。
找到以后,以FASTA格式显示。
接下来,我们再回到SWISS-MODEL,接下来就是重点和难点啦,在线提交序列进行同源建模分析,这个在线提交不是大家想象的那么容易,这个耗费了我大部分的时间,说到这里我就想画个圈圈诅咒它,大家注意啦~~~~~~~~~~~SWISS-MODEL 是一个自动化的蛋白质比较建模服务器,该服务器提供用户三种模式可选择:Automatic mode(简捷模式): 用于建模的氨基酸序列或是Swiss-Prot/TrEMBL (/sprot )编目号(accession)可以直接通过web界面提交。
Harmony 分析方法

目录完成一个分析 (5)Analytical解析法 (5)Custom用户自定义分析 (5)Decline常规递减分析 (5)FMB流动物质平衡法 (6)Forecast生产预测 (6)Gas AOF/TPC气体无阻流量/油管性能曲线 (6)Material Balance物质平衡 (7)Numerical数值法 (7)PSS ModelPSS模型 (7)Ratio Analysis比率分析 (8)Risk & Sensitivity风险和敏感性分析 (8)Type Well特征井 (8)Typecurve特征曲线 (8)Unconventional Reservoir非常规油气藏模块 (9)Volumetrics容量法 (9)完成一个解析法分析 (10)创建一个解析模型 (10)配置模型 (11)历史拟合 (11)生产预测 (11)模拟和测试设计 (11)模拟复杂多层系统 (11)建立用户自定义工作表 (12)完成一个递减分析 (13)传统递减分析 (14)致密气/页岩气递减分析 (15)完成一个流动物质平衡分析 (18)创建一个流动物质平衡分析 (19)单一油气藏的井组分析 (19)水侵的油气藏分析 (19)考虑压力对渗透率影响及岩石渗透率的物质平衡分析 (19)考虑页岩气吸附气的物质平衡分析 (19)创建一个预测工作表 (19)比率预测 (20)水油比预测 (22)自定义预测 (24)合并预测 (27)采用预测工作表 (29)完成一个气藏AOF/TPC 分析 (30)简单气体导流能力模型(C,n) (31)Forchheimer气体导流模型(LIT) (34)自定义导流分析 (35)气体油管性能曲线 (37)AOF/TPC处理选项 (38)概况窗口 (39)TPC 概况窗口 (39)AOF概况窗口 (40)工作点概况窗口 (40)完成一个物质平衡分析 (44)油的物质平衡(OMB) (44)创建一个油的物质平衡分析 (44)图,参数和数据展示 (46)气体物质平衡(GMB) (47)创建一个气体物质平衡分析 (48)视图和参数 (50)高级选项 (51)CBM物质平衡 (53)创建一CBM物质平衡分析 (53)King CBM 物质平衡分析 (54)Seidle CBM 物质平衡分析 (55)Jensen & Smith CBM物质平衡分析 (55)创建一个数值模型 (41)创建一个数值模型 (42)应用数值模型 (42)数值模型的局限性 (43)数值模型在F.A.S.T. RTA™ and F.A.S.T. CBM™中的不同 (43)完成一个压力梯度分析 (44)创建一个压力梯度分析 (56)数据诊断 (58)创建一个PSS 模型 (59)整合参数 (59)创建一个PSS 模型预测 (60)附加预测特性 (61)表皮随时间变化 (61)裂缝 (62)各向异性 (62)预测CO2生产 (63)负荷系数 (64)增速特性 (65)水体 (65)预测细节 (65)历史拟合 (66)完成一个历史拟合 (66)历史拟合方法 (66)历史拟合预测 (66)完成一个比率分析 (66)水油比(WOR) (67)含油率 (68)完成一个风险&敏感性分析 (69)风险分析 (69)参数标签栏 (70)视图类型 (74)相关性标签 (75)定义运行次数 (75)计算和结果标签栏 (76)百分数 (77)综合图表标签栏 (77)敏感性分析 (78)定义最高及最低限 (79)敏感性分析结论Sensitivity Results (80)计算 (81)完成一个监测分析 (81)霍尔图分析 (82)孔隙替代率(VRR)分析 (85)VRR 分析参数 (87)比较VRR模型 (88)完成一个特征井分析 (90)创建一个特征井分析 (91)在井面板中移除异常井 (93)设置初试日期与极值的偏移 (94)数据设置视图选项 (96)X-轴 (97)Y-轴 (97)其他 (98)完成一个特征曲线分析 (98)创建一个特征曲线分析 (99)共同特性 (99)模型 (99)吸附性、岩石力学性质、拟稳态水驱和多层井分析 (100)特征曲线图 (100)Agarwal-Gardner特征曲线分析 (101)边界流拟合 (102)瞬态流拟合 (102)Blasingame 特征曲线分析方法 (102)边界流拟合 (102)瞬态流拟合 (103)Fetkovich特征曲线分析方法 (103)边界流拟合 (103)瞬态流拟合 (104)时间重新初始化 (104)无因次压力积分(NPI)特征曲线分析方法 (105)边界流拟合 (106)瞬态流拟合 (106)瞬时特征曲线分析方法 (106)边界流拟合 (106)瞬态流拟合 (107)Wattenbarger 特征曲线分析方法 (107)边界流拟合 (107)瞬态流拟合 (107)创建一个非常规储藏模型 (108)创建一个非常规储藏分析 (108)视图和参数 (111)视图 (111)参数 (116)垂直和水平井 (117)常压和变压 (117)完成一个容量法分析 (118)油的容量法 (118)气体容量法 (120)CBM 容量法 (121)完成一个分析Analytical解析法Custom用户自定义分析Decline常规递减分析FMB流动物质平衡法Forecast生产预测Gas AOF/TPC气体无阻流量/油管性能曲线Material Balance物质平衡Numerical数值法PSS Model PSS模型Ratio Analysis比率分析Risk & Sensitivity风险和敏感性分析Type Well特征井特征曲线TypecurveUnconventional Reservoir非常规油气藏模块Volumetrics容量法完成一个解析法分析子标题:建立一个解析模型配置模型历史数据拟合预测模拟和测试设计模拟复杂多层系统解析法模型用于验证对于生产的解释和预测。
同源建模详细讲解-整理版

05
同源建模的案例分析
案例一:自然语言处理领域的应用
总结词
自然语言处理领域是同源建模的重要应用场景之一, 通过同源建模技术,可以更好地理解和处理自然语言 数据。
详细描述
在自然语言处理领域,同源建模技术被广泛应用于文本 分类、情感分析、机器翻译等方面。通过构建同源模型 ,可以更好地捕捉文本中的语义信息和上下文信息,提 高处理效率和准确性。例如,在文本分类中,同源建模 技术可以帮助我们更好地理解文本的主题和分类;在情 感分析中,同源建模技术可以更准确地判断文本的情感 倾向;在机器翻译中,同源建模技术可以提高翻译的准 确性和流畅性。
同源建模详细讲解整理版
04
同源建模的优缺点分析
目录
• 同源建模概述 • 同源建模的关键技术 • 同源建模的实现步骤 • 同源建模的优缺点分析 • 同源建模的案例分析 • 同源建模的未来发展与展望
优点分析
高效性
同源建模基于相似性原理,能够快速建立 模型,提高建模效率。
灵活性
同源建模适用于多种数据类型和场景,具 有较好的灵活性。
技术发展趋势
智能化
同源建模技术将进一步融合人工智能和机器学习算法,实 现建模过程的自动化和智能化,提高建模效率和精度。
精细化
随着计算能力和数据量的提升,同源建模将向更精细化的 方向发展,能够处理更复杂的模型和更高精度的数据。
多学科交叉
同源建模将进一步与物理学、数学、工程学等多个学科交 叉融合,拓展其应用领域和解决复杂问题的能力。
05
同源建模的案例分析
同源建模的基本原理
1 2 3
基于共同祖先的遗传信息
同源建模利用具有共同祖先的物种之间的遗传信 息,通过比较它们的基因和蛋白质序列,找出相 似性和差异性。
同源建模的实验报告(3篇)

第1篇一、实验目的1. 熟悉同源建模的基本原理和方法;2. 掌握同源建模的实验步骤和操作技巧;3. 通过同源建模预测蛋白质的三级结构,并验证预测结果的准确性。
二、实验原理同源建模是一种基于生物信息学的方法,利用已知蛋白质的三维结构作为模板,通过计算机模拟和计算,预测未知蛋白质的三维结构。
该方法基于以下两个原理:1. 蛋白质的结构由其氨基酸序列唯一决定,知道其一级序列,在理论上就可以获取其二级结构以及三级结构;2. 蛋白质的三级结构在进化中更稳定或者说更保守。
如果两个蛋白质的氨基酸序列有50%相同,那么约有90%的α-碳原子的位置偏差不超过3,这是同源模型化方法在结构预测方面成功的保证。
三、实验材料与仪器1. 实验材料:蛋白质序列、NCBI数据库、SwissModel在线平台、MOE软件;2. 实验仪器:计算机、网络连接。
四、实验步骤1. 收集蛋白质序列:在NCBI数据库中搜索目标蛋白质的序列,获取其一级结构信息。
2. 模板搜寻:使用SwissModel在线平台进行模板搜寻,寻找与目标蛋白质序列具有较高同源性的已知蛋白质结构作为模板。
3. 模型构建:根据模板蛋白质的三维结构,使用SwissModel在线平台构建目标蛋白质的三维结构模型。
4. 模型优化:使用MOE软件对模型进行优化,包括分子力学优化、能量最小化等。
5. 模型验证:通过比对实验结果和预测结构,验证同源建模的准确性。
6. 结果分析:分析预测结构的合理性,解释蛋白质的功能和作用机理。
五、实验结果与分析1. 模板搜寻:在SwissModel在线平台中,成功找到与目标蛋白质序列具有较高同源性的模板蛋白质。
2. 模型构建:根据模板蛋白质的三维结构,成功构建了目标蛋白质的三维结构模型。
3. 模型优化:使用MOE软件对模型进行优化,优化后的模型具有更低的能量。
4. 模型验证:通过比对实验结果和预测结构,验证同源建模的准确性。
预测结构在关键区域与实验结果基本一致。
udec中文说明

通用离散元用户指导(U D E C 3.1)山东科技大学2004.9目 录1 引 言 (1)1.1 总 论 (1)1.2 与其他方法的比较 (2)1.3 一般特性 (2)1.4 应用领域 (3)2 开始启动 (4)2.1 安装和启动程序 (4)2.1.7 内存赋值 (4)2.1.9 运行UDEC (5)2.1.10 安装测试程序 (5)2.2 简单演示-通用命令的应用 (5)2.3 概念与术语 (6)2.4 UDEC模型:初始块体的划分 (8)2.5 命令语法 (9)2.6 UDEC应用基础 (10)2.6.1 块体划分 (10)2.6.2 指定材料模型 (16)2.6.2.1 块体模型 (16)2.6.2.2 节理模型 (17)2.6.3 施加边界条件和初始条件 (19)2.6.4 迭代为初始平衡 (21)2.6.5 进行改变和分析 (24)2.6.6 保存或恢复计算状态 (25)2.6.7 简单分析的总结 (25)2.8 系统单位 (26)3 用UDEC求解问题 (27)3.1 一般性研究 (27)3.1.1 第1步:定义分析模型的对象 (28)3.1.2 第2步:产生物理系统的概念图形 (28)3.1.3 第3步:建造和运行简单的理想模型 (28)3.1.4 第4步:综合特定问题的数据 (29)3.1.5 第5步:准备一系列详细的运行模型 (29)3.1.6 第6步:进行模型计算 (29)3.1.7 第7步:提供结果和解释 (30)3.2 产生模型 (30)3.2.1 确定UDEC模型合适的计算范围 (30)3.2.2 产生节理 (32)3.2.2.1 统计节理组生成器 (32)3.2.2.2 VORONOI多边形生成器 (34)3.2.2.3 例子 (34)3.2.3 产生内部边界形状 (35)3.3 变形块体和刚体的选择 (38)3.4 边界条件 (42)3.4.1 应力边界 (42)3.4.1.1 施加应力梯度 (43)3.4.1.2 改变边界应力 (44)3.4.1.3 打印和绘图 (44)3.4.1.4 提示和建议 (45)3.4.2 位移边界 (46)3.4.3 真实边界-选择合理类型 (46)3.4.4 人工边界 (46)3.4.4.1 对称轴 (46)3.4.4.2 截取边界 (46)3.4.4.3 边界元边界 (49)3.5 初始条件 (50)3.5.1 在均匀介质中的均匀应力:无重力 (50)3.5.2 无节理介质中具有梯度变化的应力:均匀材料 (51)3.5.3 无节理介质中具有梯度变化的应力:非均匀材料 (51)3.5.4 具有非均匀单元的密实模型 (52)3.5.5 随模型变化的初始应力 (53)3.5.6 节理化介质的应力 (54)3.5.7 绘制应力等值线图 (55)3.6 加载与施工模拟 (57)3.7 选择本构模型 (62)3.7.1 变形块体材料模型 (63)3.7.2 节理材料模型 (64)3.7.3 合理模型的选择 (65)3.8 材料性质 (71)3.8.1 岩块性质 (71)3.8.1.1 质量密度 (71)3.8.1.2 基本变形性质 (71)3.8.1.3 基本强度性质 (72)3.8.1.4 峰后效应 (73)3.8.1.5 现场性质参数的外延 (77)3.8.2 节理性质 (80)3.9 提示和建议 (81)3.9.1 节理几何形状的选择 (81)3.9.2 设计模型 (81)3.9.3 检查模型运行时间 (82)3.9.4 对允许时间的影响 (82)3.9.5 单元密度的考虑 (83)3.9.6 检查模型响应 (83)3.9.7 检查块体接触 (83)3.9.8 应用体积模量和剪切模量 (83)3.9.9 选择阻尼 (84)3.9.10 给块体和节理模型指定模型和赋值 (84)3.9.11 避免圆角误差 (85)3.9.12 接触嵌入 (85)3.9.13 非联结块体 (86)3.9.14 初始化变量 (86)3.9.15 确定坍塌荷载 (86)3.9.16 确定安全系数 (86)3.10 解 释 (88)3.10.1 不平衡力 (88)3.10.2 块体/网格结点的速度 (88)3.10.3 块体破坏的塑性指标 (89)3.11 模拟方法 (89)3.11.1 有限数据系统模拟 (89)3.11.2 混沌系统的模拟 (90)3.11.3 局部化、物理的不稳定性和应力路径 (91)1 引言1.1 总论通用离散元程序(UDEC,Universal Distinct Element Code)是一个处理不连续介质的二维离散元程序。
discoverystudio讲义中文

建模模板同源建模的基本原理是,你映射的一个未知的蛋白质序列一种已知蛋白质的结构。
因此,如果你没有已知的蛋白质,或模板,你将无法建立模型。
模板的共同来源是蛋白质在结构生物信息学研究的实验室数据银行(目标)。
该网站RCSB是HTTP:/ /。
org /。
蛋白质数据库(PDB)可能是世界上领先的公共源三维生物分子数据(1)。
截至七月2006,超过37000项可在PDB。
每个月都有更多的人加入。
X射线衍射仪和其它固态技术占大多数的结构。
然而,超过5500的核磁共振结构还可用。
这些沉积的结构包括蛋白质,肽,核酸,碳水化合物,这些分子的配合物。
在发现工作室环境中工作的这些分子是一个关键的过程给你的建模工作。
这个练习如何准备一个PDB文件作为一个模板同源建模项目。
你将在课程中学习如何:•加载PDB文件直接从蛋白质数据银行,•生产和检验蛋白质报告,•清除晶体单元电池,•分裂分子,•删除不需要的组件,和保存已完成的文件。
1、开始发现工作室2制剂,684个晶体的水,和几个离子。
抑制剂是曲古抑菌素A,一个很好的研究组蛋白去乙酰化酶抑制剂(2)。
的结构。
3、检查蛋白质报告在深入了解蛋白质,我们应该花一点时间来看看有什么。
一种快连锁。
但我们要清楚我们几个非原子以及。
4、删除单元电池晶体单元单元在分子力学计算中的意义不大。
有时它只是更容易这个文件是由多个部分组成的。
我们可以通过层次结构查看组件其他练习窗口。
然而,我们实际上可以分开的组件的PDB文件更快的四的成分是蛋白质(1t64_a和1t64_b),配体(1t64_nonprotein),和结晶水(1t64_water)。
拆分命令的三个选项允许在如何处理对象的操作中有一定的灵活性。
所有打出的层次结构视图中所有链和非蛋白结构为独立的对象,并列出每个氨基酸序列为序列单独序列。
蛋白打出所有的蛋白链结构为独立的对象层次结构中的每个视图和列表的氨基酸序列为序列单独序列。
非蛋白打出配体,如为单独的对象的水域在层次视图其他非蛋白结构和列表的任何非蛋白多肽序列在序列视图分离的序列。
同源建模的基本流程

同源建模的基本流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!同源建模的基本流程。
1. 搜集序列数据。
收集目标蛋白质的氨基酸序列。
同源建模详细讲解-整理版

Verify_3D
•
78.74% of the residues had an averaged 3D-1D score > 0.2
ERRAT
•
Overall quality factor值越高越好,一般高解析度的晶体结构该值 可以达到95,而对于解析度一般的来说该值只能到91左右。本例 中的ERRAT值为68.280, 还需要继续优化改进。
如蛋白质和核酸)数据库, 内容包括由全世界生物学家和生物化 学家上传的蛋白质或核酸的X光晶体衍射或者NMR核磁共振结 构数据。
• 截止2013.包含的一级序列有2200W。
• 通过实验测定的蛋白质结构远远不能满足研究需要,于是蛋白
质结构预测就成为研究结构生物学的一个有效手段。
之后,又有SWIFT MODELLER,UCSF Chimera interface *注: 图形用户界面(Graphical User Interface,GUI)
Easymodeller 2.0
1、指定工作目录
2、输入氨基酸序列
3、加载模板信息(可指定加载某条链,可加载多模板)
4、多重序列比对(可编辑比对结果) 5、生成模型(自动Loop建模,手工Loop建模)
生成模型 模型优化 自动Loop建模
手动Loop建模
Manual Loop modeling
加载一个需要优化 的PDB模型
Loop优化的起始碱基 Loop优化的结束碱基
手动Loop建模 后模型的文件
Advanced Optimization Options
加载优化的模型 自动优化模型 生成分子动力学轨 迹(用VMD或 CHIMERA打开查看)
优化前
68.280
同源模建及其分析工具的研究进展

同源模建及其分析工具的研究进展蛋白质的三级结构预测可通过同源模建、折叠识别、从头预测等方法进行,但同源模建应用最广泛,且最成熟。
文章详述了同源模建的原理、方法步骤、常用工具,并对其应用前景进行了分析和讨论。
Abstract:Tertiary structure of proteins can be predicted by comparative modeling,fold recognition,de novo prediction methods,but comparative modeling is the most widely used and most matured methods. This paper describes the principles,process steps and common tools of comparative modeling,also its prospects are analyzed and discussed.Key words:Protein structure prediction;Comparative modeling;Analysis tools随着“人类基因组计划”的顺利完成,多种模式动植物基因序列的测定以及蛋白质工程技术的不断发展带来了大量的蛋白质一级结构的数据。
而传统的蛋白质结构研究的手段主要是X射线晶体衍射、核磁共振等,使用这些技术进行蛋白质三级结构的测定不仅成本较高,效率还相当低下,而且由于技术发展的局限,实验中还有许多问题没有解决。
截至2014年10月,TrEMBL中收录的蛋白质序列达到83955074条,SwissProt中经过手工修正的序列达546439条(http:///)[1]。
相比而言,PDB蛋白结构数据库(http:///pdb/home/home.do)[2]的结构数据只有103921个,相差巨大。
为了充分地理解蛋白是如何执行功能以及根据蛋白结构设计出更合理的药物,能否获得蛋白的结构甚至预测其结构就显得尤为重要,这些都使从理论上对一个已知序列的蛋白质的空间结构进行预测的问题变得日益紧迫和重要。
同源建模的可行性研究报告

同源建模的可行性研究报告一、引言同源建模是一种新兴的建模方法,旨在通过对不同数据源中的同源数据进行整合和建模,实现更加综合和全面的数据分析。
在信息化浪潮的推动下,各行各业的数据呈现出多样化和复杂化的特点,传统的数据建模方法已经难以满足日益增长的数据需求。
因此,同源建模作为一种新的数据建模方法,具有很大的发展潜力和价值。
本报告旨在对同源建模的可行性进行研究和分析,为同源建模的应用和推广提供理论支持和实践指导。
二、同源建模的概念和原理1. 同源建模的概念同源建模是指基于不同数据源中的同源数据进行数据整合和建模的方法。
所谓同源数据,是指来自不同数据源但具有相同含义和结构的数据。
同源建模旨在通过对同源数据的整合和建模,实现更加综合和全面的数据分析,从而为决策提供更加丰富和全面的信息支持。
2. 同源建模的原理同源建模的原理主要包括数据整合、特征提取和模型建立。
首先,需要对不同数据源中的同源数据进行整合,将其统一到一个数据源中。
然后,通过特征提取,将同源数据中的特征进行提取和筛选,以便进行后续的建模分析。
最后,基于整合后的同源数据,建立数据模型,进行数据分析和决策支持。
三、同源建模的应用场景同源建模的应用场景主要包括金融领域、医疗领域、互联网领域等。
具体应用场景如下:1. 金融领域:银行、证券、保险等金融机构需要对客户的各种数据进行分析和预测,以便进行风险评估和决策支持。
同源建模可以帮助金融机构对客户的不同数据进行整合和建模,实现更加全面和准确的风险评估。
2. 医疗领域:医疗机构需要对患者的临床数据、影像数据、基因数据等进行分析和诊断,以支持临床决策和治疗方案选择。
同源建模可以帮助医疗机构对不同数据源中的同源数据进行整合和建模,实现更加全面和准确的诊断和治疗支持。
3. 互联网领域:互联网企业需要对用户的行为数据、社交数据、消费数据等进行分析和预测,以支持产品设计和营销决策。
同源建模可以帮助互联网企业对不同数据源中的同源数据进行整合和建模,实现更加全面和准确的用户画像和预测分析。
ClC-0氯离子通道蛋白质空间结构的同源建模

ClC-0氯离子通道蛋白质空间结构的同源建模于涛;朱紫洪;郝栋梁;彭黎;张攀;徐号;郭旭【摘要】ClC型氯离子通道蛋白质在调节生命体的新陈代谢过程中起着重要作用。
在原有蛋白质ClC-ec1晶体结构的基础上,依据同源建模的原理,借助SWISS-MODEL网络服务器构建了一类重要氯离子通道蛋白质ClC-0的空间结构,同时对所得结构的合理性进行了分析。
通过衡量结构的Z-score值、分析结构的空间坐标波动性以及利用视图软件VMD将建模的ClC-0结构和模板结构进行比较,发现通过同源建模所得到蛋白质ClC-0的空间结构符合后续研究的要求,这在很大程度上方便了该类蛋白质的后续计算模拟研究。
%CIC-type chloride ion channel proteins play important role in regulating the metabolism process of biological system. On the base of CIC-ec1 crystal structure,in accordance with the principle of homology modeling,using SWISS-MODEL net server,constructed the spatial structure of a kind of CIC-0 chloride ion channel protein , and analyzed the reasonableness of the obtained structure. Through measuring the Z-score of the structure ,analyzing the fluctuation of space coordinates of the structure , and comparing the modeling CIC-0 structure with template structure,discovered that the spatial structure of CIC-0 protein by homology modeling complied withthe requirement of further study ,which makes the further simulation and computation be easy.【期刊名称】《江汉大学学报(自然科学版)》【年(卷),期】2015(000)002【总页数】5页(P111-115)【关键词】同源建模;氯离子通道蛋白质;SWISS-MODEL【作者】于涛;朱紫洪;郝栋梁;彭黎;张攀;徐号;郭旭【作者单位】江汉大学物理与信息工程学院,湖北武汉 430056;江汉大学物理与信息工程学院,湖北武汉 430056;江汉大学物理与信息工程学院,湖北武汉430056;江汉大学物理与信息工程学院,湖北武汉 430056;江汉大学物理与信息工程学院,湖北武汉 430056;江汉大学物理与信息工程学院,湖北武汉 430056;江汉大学物理与信息工程学院,湖北武汉 430056【正文语种】中文【中图分类】Q51;TP391.9离子通道是镶嵌在生物体细胞膜上一类重要的蛋白质微小孔道,它在生命体系的新陈代谢过程中扮演着极其重要的角色。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 之后,又有 , • *注: 图形用户界面( ,)
、指定工作目录 、输入氨基酸序列 、加载模板信息(可指定加载某条链,可加载多模板) 、多重序列比对(可编辑比对结果) 、生成模型(自动建模,手工建模) 、优化模型
多重序列比对
氨基酸序列
工作目录 提交模板序列
模型优化
模型生成
命令信息 显示窗口
• :包含大量的检测项,可以针对提交的蛋白结构与正常结构之间的 差异,产生一个非常长而且详细的报告。
• : 计算 范围之内,不同原子类型对之间形成的非键相互作用的数目 (侧链)。原子按照、、进行分类,所以有六种不同的相互作用类 型:、、、 、 、 。得分>比较好。
• :比较模型和氨基酸一级结构的关系,获得评价即可。
同源模建结果评价与改进策略
• 同源模建结果的评价 • 、 、、 、 • 的服务器包括了这五种常用的检测 • 其网址为: • 除外,也是一个常用的在线模型分析工具,其网址为:
• : 以中高分辨的晶体结构参数为参考,给出提交模型的一系列立体 化学参数(主链)。其输出的结果包括:拉氏图,主链的键长与键 角,二级结构图,平面侧链与水平面之间的背离程度等。
加载模板 ②
(文件)
多重序列比对 ④
生成模型
⑤
模型名称
模型名称
模板对齐 ③
⑥ 模型优化
自动建模
手动建模
加载一个需要优化 的模型
优化的起始碱基 优化的结束碱基
手动建模后模 型的文件
加载优化的模型 自动优化模型
生成分子动力学轨 迹(用或打开查看)
绘制模型的能量图
()
模型质量检验 • 模型提交服务器( )进行检验
生物 多聚态
推测相互作用界面
晶体或高浓度 溶液中蛋白质
的四级结构
晶胞堆积
折叠
进化 关系
突变、单核苷酸及 保守残基的分布
蛋白质配体 复合物
三维结构
不同基团的 相关性
表面残基暴露 与分子构成
形态和静 电属性
抗原位点 及表面修
饰
配体和功能 位点
催化簇结构功能—催 化机制
缝隙(酶活 性位点)
总结来说
三维结构
• 提交目标蛋白与模板蛋白的序列比对结果(等格式)
• 适用:、较高的相似性
•
、利用模式未必能找到最合适模板的情况
•
、使用者有目的的使用特定的模板蛋白
• (比如具有更为相似的活性位点结果,而不是更为相似的整体结 构)
邮箱 模型命名
比对后的序列
比对文件
• :项目模式 • 难以直接通过序列比对获得模板 • 需要人工插入调节(借助蛋白结构编辑软件) • 可以将前两种模式模建出的蛋白进行人为调整 • 适用:相似性不高
报告内容
、同源建模的基础结构生物学 、蛋白质结构预测之同源建模 、同源建模的基本步骤 、同源建模常用软件介绍在线服务器 、同源建模常用软件介绍 、模型质量检测
、结构生物学
结构生物学是以生物大分子特定空间结构、结构的特定 运动与生物学功能的关系为基础,来阐明生命现象及其应用的 科学。
以生物大分子三级结构的确定作为手段,研究生物大分 子的结构与功能关系,探讨生物大分子的作用机制和原理作为 研究目的。
功能 作用机制 分子间互作
功能注释 确认功能位点
指导实验 验证功能
设计和改造 蛋白
药物靶标 设计
结构生物学主要研究方法
射线晶体衍射()
多维核磁共振( )
晶体,准确度最高
高浓度水溶液 精确度≤
冷冻电子显微镜
细胞和细胞器
数据库
• 蛋白质数据库( )是一个生物大分子(如蛋白质和核酸)数据 库, 内容包括由全世界生物学家和生物化学家上传的蛋白质或 核酸的光晶体衍射或者核磁共振结构数据。
• :本部分主要需要的是拉氏图( ),可下载格式、格式以及格式 。落在核心区允许区最大允许区的碱基百分比大于的模型质量很好 。
•>
• 值越高越好,一般高解析度的晶体结构该值可以达到,而对于解 析度一般的来说该值只能到左右。本例中的值为, 还级结构。
• 、三级结构的保守型远远大于一级结构的保守型。 • 应用限制:模板蛋白和目标蛋白的序列一致性需要大于
同源建模的基本步骤
• 、模板蛋白搜索 • 数据库、(或) 、获取模板(一个或多个) • 、比对结果的校正 • 、主链生成 • 、环区建模 • 、模型优化 • 、合理性检测
• 截止,数据库已测结构的蛋白质,而该库中包含的一级序列有 。
• 通过实验测定的蛋白质结构远远不能满足研究需要,于是蛋白 质结构预测就成为研究结构生物学的一个有效手段。
蛋白质结构预测之同源建模
• 蛋白质结构预测方法: • 同源建模,折叠识别和从头计算。 • 同源建模基本原理: • 、一个蛋白质的结构由其氨基酸序列唯一的决定。由一级结构,
同源建模在线服务器
同源建模软件
图形化软件
• : 网址 • 非专业人士应用最为广泛的一个在线建模服务器。 • 特点:简单、自动化、对学术团队免费。
• :自动模式,可以称为是最傻瓜的方式 • 提交自己的氨基酸序列邮箱即可 • 适用:一致性较高时
邮箱 模型命名
氨基酸序列
登录号
• : 比对模式
•:
• *也可以下载本地安装包
• 评价:根据结果质量检验,该服务器应该是自动建模的软件里是结 果最详细的,二级结构、模型、配体结合位点等等。
• 缺点:计算结果时间比较长
•
结果需要进一步优化
: 同源二聚体建模 异源二聚体建模
识别可能的互作蛋白
•:
• 评价:自动建模预测服务程序,在目标模板比对这一步做出的结果 较好,且在预测序列与模板序列相似度差时有较好的模型预测效果 。
• 该软件由 开发,目前最新的版本是,可在下和运行,需要对应版 本的 (<)。完全免费。
• 主要功能包括:多聚体建模,二硫键建模,杂原子建模等(配体、 辅酶等)。自带一套模建结构后的优化、分析。
•! • 该软件完全是命令行模式,操作相对复杂,可控制的地方多。
• 对于习惯于的我们来说,操作不太方便。 • 于是。。。 • 印度 大学的一位牛人 为其编写了一个界面,即为 。,目前最新版
• : 与预先计算好的一系列标准体积之间的差别。用 来表示。作为一 个统计学值,可以显示模板蛋白质和待测蛋白之间的匹配程度,当 较低时,就意味着没有匹配搜索的结构
实例
• 以我研究的 的模型进行实例讲解:
数据库
寻找最合适模板 和()
多模板建模
检测模型质 量
模型优化
再次检验模 型
① ② ③
贴入序列 ①