Hibernate中OneToMany映射讲解
hibernate核心,一对多,多对多映射讲解,看了就完全搞明白了

在many一方删除数据1
• 删除“五四大道”
inverse设为true,由many一方删除 从one一方去“删除”, Hibernate只是执行了 问题出在配置文件上 update语句。还是未删 没有配置set节点的inverse属性 除成功! 根本没有执行 Delete语句,数据 没有被删除!
– 配置Hibernate多对多关联,实现某OA系统项 目和人员对照关系的管理
本章目标
• 掌握单向many-to-one关联 • 掌握双向one-to-many关联 • 掌握many-to-many关联
实体间的关联
• 单向多对一
tblJd.getQx().getQxname();
• 单向一对多
TblJd jd = (TblJd)tblQx.getJds().get(0); jd.getJdname(); tblQx.getJds.add(jd);
小结
• 在租房系统中,房屋信息(Fwxx)与用户 (User)间也是多对一关系。如何配置映 射文件,使之可以通过下面的代码输出房 屋信息和发布该信息的用户名称? Fwxx fwxx = (Fwxx)super.get(Fwxx.class,1);
System.out.println( fwxx.getTitle() + "," + fwxx.getUser.getUname());
inverse是“反转”的意思,表示关联关系的控制权。 为true,表示由对方负责关联关系的添加和删除; 执行了delete语句, 为false,表示由自己负责维护关联关系。 删除成功
• 在many一方删除数据的正确做法:
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
jpa onetomany 用法

JPA(Java Persistence API)是一种Java持久化标准,它提供了一种将对象映射到数据库中的方式。
在JPA 中,@OneToMany注解用于表示一对多的关系。
@OneToMany注解通常用于在实体类之间建立一对多的关系。
它表示一个实体类中的对象与另一个实体类中的对象存在一对多的关系。
例如,一个班级与多个学生存在一对多的关系,一个学生只能属于一个班级。
以下是使用@OneToMany注解的示例:java复制代码@Entitypublic class Classroom {// ...@OneToMany(mappedBy = "classroom")private List<Student> students;// ...}@Entitypublic class Student {// ...@ManyToOne(fetch = ZY)@JoinColumn(name = "classroom_id")private Classroom classroom;// ...}在上面的示例中,Classroom实体类中有一个students属性,它是一个Student对象的列表。
该列表的一端通过mappedBy属性指定为Student类中的classroom属性。
这意味着Classroom实体类中的每个对象都与Student实体类中的多个对象相关联。
在Student实体类中,classroom属性是一个ManyToOne关联,它表示一个学生只能属于一个班级。
通过@JoinColumn注解指定了外键列的名称(classroom_id),该列用于将学生与班级关联起来。
需要注意的是,在使用@OneToMany注解时,需要在关联的另一端(Student类中的classroom属性)使用@ManyToOne注解来指定关联的另一方。
同时,还需要使用@JoinColumn注解来指定关联的外键列的名称。
one-to-many&many-to-one

Hibernate之one-to-many感悟:基于架构的设计,主要在于xml配置文件的编写原理:表中一对多的实现是在表中使用外键关联,也就是通过一张表的主键做为另一个表的外键来建立一对多关系。
在hibernate的pojo类中实现一对多关系的方法是在主控类中个设置一个集合属性来包含对方类的若干对象,而在另一个类中,只包含主控类的一个对象,从而实现一对多关系的建立。
例如:customer和order表,一个customer对应多个order(订单),则应该在Customer的pojo类中设置一个set来包含order的若干对象。
demo:1、数据库:create table `testdb`.`customer`(`cid` int not null auto_increment,`cname` varchar(20),primary key (`cid`));create unique index `PRIMARY` on `testdb`.`customer`(`cid`);create table `testdb`.`order`(`oid` int not null auto_increment,`odes` varchar(500),`cid` int,primary key (`oid`));create unique index `PRIMARY` on `testdb`.`order`(`oid`);注意,上面两个表在数据库中是相互独立的噢,因为这里所说的一对多是在hibernate层上讨论的,跟在数据库中创建主外键的关联不一样。
2、创建eclipse的hibernate支持3、创建两个表的hbm映射,并相应生成POJO类4、修改pojo类遵从刚才讨论的在hibernate层上实现一对多的原则:在主控类中个设置一个集合属性来包含对方类的若干对象,而在另一个类中,只包含主控类的一个对象,从而实现一对多关系的建立。
hibernate注解之@Onetomany、@Manytoone、@JoinColumn
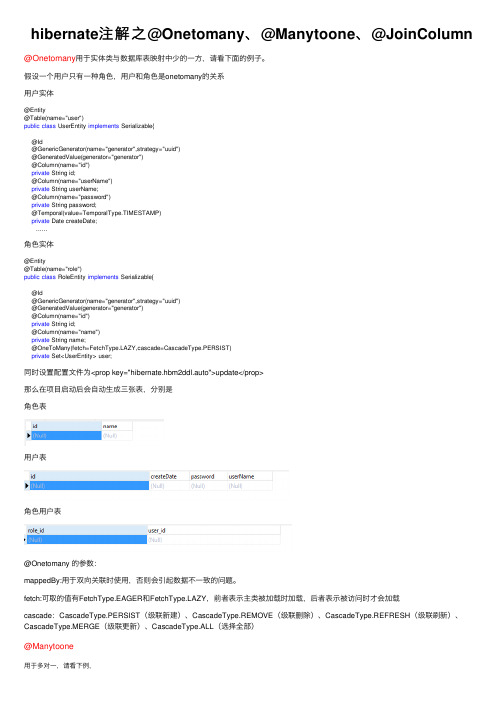
hibernate注解之@Onetomany、@Manytoone、@JoinColumn @Onetomany⽤于实体类与数据库表映射中少的⼀⽅,请看下⾯的例⼦。
假设⼀个⽤户只有⼀种⾓⾊,⽤户和⾓⾊是onetomany的关系⽤户实体@Entity@Table(name="user")public class UserEntity implements Serializable{@Id@GenericGenerator(name="generator",strategy="uuid")@GeneratedValue(generator="generator")@Column(name="id")private String id;@Column(name="userName")private String userName;@Column(name="password")private String password;@Temporal(value=TemporalType.TIMESTAMP)private Date createDate; ......⾓⾊实体@Entity@Table(name="role")public class RoleEntity implements Serializable{@Id@GenericGenerator(name="generator",strategy="uuid")@GeneratedValue(generator="generator")@Column(name="id")private String id;@Column(name="name")private String name;@OneToMany(fetch=ZY,cascade=CascadeType.PERSIST)private Set<UserEntity> user;同时设置配置⽂件为<prop key="hibernate.hbm2ddl.auto">update</prop>那么在项⽬启动后会⾃动⽣成三张表,分别是⾓⾊表⽤户表⾓⾊⽤户表@Onetomany 的参数:mappedBy:⽤于双向关联时使⽤,否则会引起数据不⼀致的问题。
manytoone注解

manytoone注解在Java开发中,我们经常会遇到需要处理多对一关系的情况。
为了简化开发过程,Hibernate框架提供了一个非常有用的注解——@ManyToOne。
这个注解可以帮助我们轻松地处理多对一关系,使得代码更加简洁和易于维护。
@ManyToOne注解的作用是将一个实体类与另一个实体类建立多对一的关系。
在数据库中,这种关系通常通过外键来实现。
通过使用@ManyToOne注解,我们可以在实体类中指定多对一关系的属性,并且告诉Hibernate框架如何映射到数据库中。
在使用@ManyToOne注解时,我们需要注意一些细节。
首先,我们需要在多对一关系的属性上添加@ManyToOne注解。
这个注解需要指定一个targetEntity属性,用于指定关联的实体类。
例如,如果我们有一个Order实体类和一个Customer实体类,我们可以在Order实体类中的customer属性上添加@ManyToOne注解,并指定targetEntity属性为Customer.class。
其次,我们需要在多对一关系的属性上添加@JoinColumn注解。
这个注解用于指定外键的名称和其他相关属性。
例如,我们可以使用@JoinColumn注解来指定外键的名称、是否可为空、是否唯一等。
除了@ManyToOne注解,Hibernate还提供了其他一些注解来帮助我们处理多对一关系。
例如,@JoinColumn注解可以用于指定外键的名称和其他相关属性。
@Fetch注解可以用于指定关联实体的加载策略。
@Cascade注解可以用于指定级联操作的行为。
使用@ManyToOne注解可以使我们的代码更加简洁和易于维护。
通过使用这个注解,我们可以将多对一关系的处理逻辑集中在实体类中,而不是分散在各个地方。
这样一来,我们可以更加方便地修改和扩展代码。
然而,尽管@ManyToOne注解非常有用,但我们在使用它时还是需要注意一些问题。
首先,我们需要确保多对一关系的属性在数据库中有对应的外键。
Hibernate注解

Hibernate注解常用的hibernate annotation标签如下:@Entity--注释声明该类为持久类。
@Table(name="promotion_info")--持久性映射的表(表名="promotion_info)。
@Column(name=”DESC”,nullable=false,length=512)--用于指定持久属性或字段的映射列。
@Id--注释可以表明哪种属性是该类中的独特标识符(即相当于数据表的主键)。
@GeneratedValue--定义自动增长的主键的生成策略。
@Transient--将忽略这些字段和属性,不用持久化到数据库。
@Temporal(TemporalType.TIMESTAMP)--声明时间格式。
@Enumerated--声明枚举@Version--声明添加对乐观锁定的支持@OneToOne--可以建立实体bean之间的一对一的关联@OneToMany--可以建立实体bean之间的一对多的关联@ManyToOne--可以建立实体bean之间的多对一的关联@ManyToMany--可以建立实体bean之间的多对多的关联@Formula--一个SQL表达式,这种属性是只读的,不在数据库生成属性(可以使用sum、average、max等)@OrderBy--Many端某个字段排序(List)下面是对以上常用Hibernate注解标签的详细介绍与举例:@Entity--注释声明该类为持久类。
将一个Javabean类声明为一个实体的数据库表映射类,最好实现序列化.此时,默认情况下,所有的类属性都为映射到数据表的持久性字段.若在类中,添加另外属性,而非映射来数据库的, 要用下面的Transient来注解.@Table(name="promotion_info")--持久性映射的表(表名="promotion_info).@T able是类一级的注解,定义在@Entity下,为实体bean映射表,目录和schema的名字,默认为实体bean的类名,不带包名.示例:@Entity@T able(name="CUST", schema="RECORDS")public class Customer { ... }@Column(name=”DESC”,nullable=false,length=512)--用于指定持久属性或字段的映射列。
Hibernate_映射配置文件详解

Prepared by TongGang
hibernate.cfg.xml的常用属性
• • • • • • • • • connection.url:数据库URL ername:数据库用户名 connection.password:数据库用户密码 connection.driver_class:数据库JDBC驱动 show_sql:是否将运行期生成的SQL输出到日志以供调试。取 show_sql 值 true | false dialect:配置数据库的方言,根据底层的数据库不同产生不 dialect 同的sql语句,Hibernate 会针对数据库的特性在访问时进行 优化。 hbm2ddl.auto:在启动和停止时自动地创建,更新或删除数据 hbm2ddl.auto 库模式。取值 create | update | create-drop resource:映射文件配置,配置文件名必须包含其相 mapping resource 对于根的全路径 connection.datasource :JNDI数据源的名称
• Class:定义一个持久化类 Class: • name (可选): 持久化类(或者接 (可选): 持久化类( 可选 口)的类名 • table (可选 - 默认是类的非全限 (可选 定名): 定名): 对应的数据库表名 • discriminator-value (可选 - 默 discriminator(可选 认和类名一样): 认和类名一样): 一个用于区分不 同的子类的值,在多态行为时使用。 同的子类的值,在多态行为时使用。 它可以接受的值包括 null 和 not null。 null。
Prepared by TongGang
Hibernate注释大全

)
public Set<Monkey> getTrainedMonkeys() {
...
}
@Entity
public class Monkey {
... //no bidir
用 cascading 实现传播持久化(Transitive persistence)
cascade 属性接受值为 CascadeType 数组,其类型如下:
? CascadeType.PERSIST: cascades the persist (create) operation to associated entities persist() is called or if the entity is managed 如果一个实体是受管状态,或者当 persist() 函数被调用时,触发级联创建(create)操作。
@SecondaryTable(name="Cat2", uniqueConstraints={
@UniqueConstraint(columnNames={"storyPart2"})})
})
public class Cat implements Serializable {
...
}
public class MyDao {
doStuff() {
Query q = s.getNamedQuery("night.moreRecentThan");
q.setDate( "date", aMonthAgo );
Hibernate基础知识详解

Hibernate基础知识详解<hibernate-mapping><class name="*.*.*" table="t_customer" catalog="***"><id name="id" column="c_id"><generator class="identity"/></id><property name="name" column="c_name" length="20"/><set name="orders" inverse="false" cascade="save-update"><key column="c_customer_id"/></set></class></hibernate-mapping>(1)统⼀声明包名,这样在<class>中就不需要写类的全名。
(2)关于<class>标签配置name 属性:类的全名称table 表的名称,可以省略,这时表的名称就与类名⼀致catalog 属性:数据库名称可以省略.如果省略,参考核⼼配置⽂件中 url 路径中的库名称(3)关于<id>标签,<id>是⽤于建⽴类中的属性与表中的主键映射。
name 类中的属性名称column 表中的主键名称 column 它也可以省略,这时列名就与类中属性名称⼀致length 字段长度type 属性指定类型<generator>它主要是描述主键⽣成策略。
详解Hibernatecascade级联属性的CascadeType的用法

详解Hibernatecascade级联属性的CascadeType的⽤法详解Hibernate cascade级联属性的CascadeType的⽤法cascade(级联)级联在编写触发器时经常⽤到,触发器的作⽤是当主控表信息改变时,⽤来保证其关联表中数据同步更新。
若对触发器来修改或删除关联表相记录,必须要删除对应的关联表信息,否则,会存有脏数据。
所以,适当的做法是,删除主表的同时,关联表的信息也要同时删除,在hibernate中,只需设置cascade属性值即可。
cascade表⽰级联操作,在hibernate配置注解@OneToOne,@OneToMany,@ManyToMany,@ManyToOne中的属性。
例如:@ManyToOne(cascade = CascadeType.REFRESH, optional = true)@JoinColumn(name = "user_id", unique = false)private UserBaseInfo userBaseInfo;配置多种级联,例如:@OneToOne(cascade = {CascadeType.REFRESH,CascadeType.PERSIST,CascadeType.MERGE}, optional = true)@JoinColumn(name = "user_id", unique = false)private UserBaseInfo userBaseInfo;CascadeType.PERSIST:级联新增(⼜称级联保存):对order对象保存时也对items⾥的对象也会保存。
对应EntityManager 的presist⽅法。
CascadeType.MERGE:级联合并(级联更新):若items属性修改了那么order对象保存时同时修改items⾥的对象。
对应EntityManager的merge⽅法。
hibernate的manytoone和onetomany用例 -回复

hibernate的manytoone和onetomany用例-回复Hibernate是一个Java的持久化框架,常用于开发数据访问层的代码。
它提供了一种简化数据库操作的方法,可以通过对象和关系数据库进行交互。
在Hibernate中,常用的关系映射包括many-to-one和one-to-many。
本文将通过详细讲解这两种关系映射的用例来帮助读者更好地理解和使用Hibernate。
首先,我们来了解一下many-to-one关系映射。
这种映射关系表示一个实体对象(通常是较"多"的一方)可以与另一个实体对象(通常是较"一"的一方)建立多对一的关系。
在关系数据库中,这种关系通过外键实现。
在Hibernate中,我们可以通过注解或XML配置来映射这种关系。
假设我们要建立一个简单的图书和作者的many-to-one关系映射。
一个作者可以写多本图书,而一本图书只能由一个作者所写。
我们先创建一个Author类和一个Book类。
Author类包含作者的姓名、年龄等属性,并与多个Book对象建立关联,通过"books"字段来表示与图书的关系。
Book 类包含图书的名字、出版日期等属性,并通过"author"字段与一个Author 对象建立关联,表示与作者的关系。
javapublic class Author {private Long id;private String name;private int age;private List<Book> books;省略getter和setter方法}public class Book {private Long id;private String name;private LocalDate publishDate;private Author author;省略getter和setter方法}在Author类中,我们可以使用OneToMany注解来建立与Book对象的关联,并通过设置cascade属性来实现级联操作。
hibernate annotation 双向 one-to-one 注解

环境:Hibernate 3.3.1Maven 3.0.4MySQL 5.5.13Myeclipse 8.6.1建表语句:DROP TABLE IF EXISTS `t_card`;CREATE TABLE `t_card` (`cardId` int(10) unsigned NOT NULL AUTO_INCREMENT,`cardNumber` char(18) NOT NULL,PRIMARY KEY (`cardId`)) ENGINE=InnoDB AUTO_INCREMENT=2DEFAULT CHARSET=gb2312; INSERT INTO `t_card` VALUES ('1', '440911************');DROP TABLE IF EXISTS `t_person`;CREATE TABLE `t_person` (`personId` int(10) unsigned NOT NULL AUTO_INCREMENT,`personName` varchar(15) NOT NULL,`cid` int(10) unsigned NOT NULL,PRIMARY KEY (`personId`)) ENGINE=InnoDB AUTO_INCREMENT=2DEFAULT CHARSET=gb2312; INSERT INTO `t_person` VALUES ('1', 'fancy', '1');Person.javapackage com.fancy.po;import javax.persistence.CascadeType;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.GenerationType;import javax.persistence.Id;import javax.persistence.JoinColumn;import javax.persistence.OneToOne;import javax.persistence.Table;/*** -----------------------------------------* @文件: Person.java* @作者: fancy* @邮箱: fancyzero@* @时间: 2012-6-10* @描述: 实体类* -----------------------------------------*//*** @Entity 声明一个类为实体Bean* @Table(name = "xx")指定实体类映射的表,如果表名和实体类名一致,可以不指定*/@Entity@Table(name = "t_person")public class Person {private Integer personId;private String personName;private Card card;/*** @Id 映射主键属性,这里采用uuid的主键生成策略* @GeneratedValue ——注解声明了主键的生成策略。
component

Component:组建映射在hibernate中,component是某个实体的逻辑组成部分,它与实体的根本区别是没有oid,component可以成为是值对象(DDD)采用component映射的好处:它实现了对象模型的细粒度划分,层次会更分明,复用率会更高2004年著名建模专家Eric Evans发表了他最具影响力的著名书籍:Domain-Driven Design –Tackling Complexity in the Heart of Software(中文译名:领域驱动设计2006年3月清华出版社译本,或称Domain Driven-Design architecture [Evans DDD])。
就是告诉我们如何做好业务层!并以领域驱动设计思想来选择和合适的框架。
User.javaprivate int id;private String name;private Contact contact;Contact.javaprivate String email;private String address;private String zipCode;private String contactTel;<hibernate-mapping><class name="er" table="t_user"><id name="id"><generator class="native"/></id><property name="name"/><component name="contact"><property name="email"/><property name="address"/><property name="zipCode"/><property name="contactT el"/></component></class></hibernate-mapping>public class ComponentMappingT est extends TestCase {public void testSave1() {Session session = null;try {session = HibernateUtils.getSession();session.beginTransaction();User user = new User();user.setName("张三");Contact contact = new Contact();contact.setAddress("xxxxx");contact.setEmail("***********");contact.setZipCode("1111111");contact.setContactTel("9999999999");user.setContact(contact);session.save(user);session.getTransaction().commit();}catch(Exception e) {e.printStackTrace();session.getTransaction().rollback();}finally {HibernateUtils.closeSession(session);}}}。
一对一关联查询注解@OneToOne的实例详解

⼀对⼀关联查询注解@OneToOne的实例详解 表的关联查询⽐较复杂,应⽤的场景很多,本⽂根据⾃⼰的经验解释@OneToOne注解中的属性在项⽬中的应⽤。
本打算⼀篇博客把增删改查写在⼀起,但是在改的时候遇到了⼀些问题,感觉挺有意思,所以写下第⼆篇专门讲修改。
⼀、单向@OneToOne实例详解假设⼀个场景,⼀个⼈只能领养⼀只宠物,根据⼈能够找到宠物,并且查看宠物的信息,关系是单向的。
创建⼈与宠物的数据表结构。
下载地址:创建实体。
Person.javapackage com.my.model;import java.io.Serializable;import javax.persistence.CascadeType;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.FetchType;import javax.persistence.ForeignKey;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.JoinColumn;import javax.persistence.OneToOne;import javax.persistence.Table;import org.hibernate.annotations.Cascade;import org.springframework.beans.factory.annotation.Autowired;@Entity@Table(name = "person")public class Person implements Serializable{@Id// id⾃动⽣成@GeneratedValue@Column(name = "id")private Long id;@Column(name = "name")private String name;//cascade:表的级联操作@OneToOne(fetch=ZY,cascade = CascadeType.ALL) //JPA注释:⼀对⼀关系//referencedColumnName:参考列名,默认的情况下是列表的主键//nullable=是否可以为空,//insertable:是否可以插⼊,//updatable:是否可以更新// columnDefinition=列定义,//foreignKey=外键@JoinColumn(name="pet_id",referencedColumnName="id",nullable=false)private Pet pet;@Overridepublic String toString() {return "Person [id=" + id + ", name=" + name + ", pet=" + pet + "]";}}Pet.javapackage com.my.model;import java.io.Serializable;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.Table;@Entity@Table(name = "pet")public class Pet implements Serializable{@Id// id⾃动⽣成@GeneratedValue@Column(name = "id")private Long id;@Column(name = "pet_name")private String petName;@Column(name = "pet_class")private String petClass;//省略set,get⽅法。
hibernate注解简介

@Entity
@Table(name="T_MODEL_PLANE")
public class ModelPlane {
private Long id;
private String name;
@Id
@Column(name="PLANE_ID")
传统上,Hibernate的配置依赖于外部 XML 文件:数据库映射被定义为一组 XML 映射文件,并且在启动时进行加载。创建这些映射有很多方法,可以从已有数据库模式或Java类模型中自动创建,也可以手工创建。无论如何,您最终将获得大量的 Hibernate 映射文件。此外,还可以使用工具,通过javadoc样式的注释生成映射文件,尽管这样会给您的构建过程增加一个步骤。
...
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate</artifactId>
<version>3.2.1.ga</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
hibernate 字段类型

文章标题:深度探讨 Hibernate 字段类型:从简单到复杂的全面评估在软件开发中,使用 Hibernate 是非常常见的,它是一个基于 Java的持久化框架,用于将对象映射到数据库中。
在使用 Hibernate 进行数据库操作时,了解各种字段类型的映射以及它们的特性和用途是非常重要的。
在本文中,我们将从简单到复杂,全面评估 Hibernate 中常见的字段类型,包括字符串、数字、日期、枚举等,并深入讨论它们的映射规则和最佳实践。
1. 字符串类型在 Hibernate 中,字符串类型是最常见的字段类型之一。
它通常用来映射数据库表中的 VARCHAR、CHAR 或 TEXT 等类型的字段。
在定义字符串类型的映射时,需要考虑数据库的字符集和长度限制。
另外,还可以使用 @Column 注解来指定字段的其他属性,如是否唯一、是否可为空等。
2. 数字类型除了字符串类型,数字类型也是数据库中常见的字段类型。
在Hibernate 中,可以使用 Integer、Long、Double 等包装类来映射数据库中的整型、长整型和浮点型字段。
需要注意的是,需要根据数据库中字段的精度和范围来选择合适的 Java 包装类,并且可以使用@Column 注解来指定数字的精度和小数点位数。
3. 日期类型日期类型在数据库和 Java 中都是非常重要的数据类型。
在 Hibernate 中,可以使用 Date、Time、Timestamp 等类来映射数据库中的日期和时间字段。
需要注意的是,Hibernate 提供了丰富的日期格式化和解析工具,并且可以使用 @Temporal 注解来指定日期字段的精度,如 DATE、TIME 或 TIMESTAMP。
4. 枚举类型枚举类型在 Hibernate 中也有很好的支持。
通过 @Enumerated 注解,可以将 Java 中的枚举类型映射到数据库表中的字段,并且可以指定枚举类的映射策略。
另外,还可以使用 @Convert 注解来定制枚举类型的映射规则,将枚举值存储为数据库中的特定类型。
Hibernate 实体类 注解 大全

@Column(name="BIRTH",nullable="false",columnDefinition="DATE")
public String getBithday() {
return birthday;
}
7、@Transient
public User getUser() {
return user;
}
9、@JoinColumn
可选
@JoinColumn和@Column类似,介量描述的不是一个简单字段,而一一个关联字段,例如.描述一个@ManyToOne的字段.
name:该字段的名称.由于@JoinColumn描述的是一个关联字段,如ManyToOne,则默认的名称由其关联的实体决定.
catalog:可选,表示Catalog名称,默认为Catalog("").
schema:可选,表示Schema名称,默认为Schema("").
3、@id
必须
@id定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键.置于getXxxx()前.
4、@GeneratedValue(strategy=GenerationType,generator="")
@Entity
//继承策略。另一个类继承本类,那么本类里的属性应用到另一个类中
@Inheritance(strategy = InheritanceType.JOINED )
@Table(name="INFOM_TESTRESULT")
public class TestResult extends IdEntity{}
hibernatetemplate常用删除方法

hibernatetemplate常用删除方法HibernateTemplate常用删除方法Hibernate作为一种常用的ORM框架之一,已经被广泛应用于企业级应用程序的开发中。
Hibernate的优点在于可以大大简化数据访问层的开发,同时也提供了丰富的API来支持数据的增删改查操作。
本文将重点介绍HibernateTemplate中常用的删除方法,以帮助开发人员更好地利用Hibernate进行数据操作。
按条件删除按条件删除是Hibernate中最常用的删除方法之一,它允许我们根据指定的条件删除数据库中的记录。
在HibernateTemplate中,我们可以使用以下方法来实现按条件删除:```javapublic int delete(String queryString, Object... values);```这个方法接收两个参数,第一个参数是要执行的HQL语句,第二个参数是一个可变参数数组,用于指定HQL语句中的参数值。
例如,我们可以使用以下代码删除名字为Tom的用户记录:```javaString hql = "delete from User where name=?";int result = hibernateTemplate.delete(hql, "Tom");```按主键删除按主键删除是另一种常用的删除方法,它允许我们根据指定的主键删除数据库中的记录。
在HibernateTemplate中,我们可以使用以下方法来实现按主键删除:```javapublic <T> int delete(Class<T> entityClass, Serializable id);```这个方法接收两个参数,第一个参数是实体类的Class对象,第二个参数是要删除的记录的主键值。
例如,我们可以使用以下代码删除主键值为1的用户记录:```javaint result = hibernateTemplate.delete(User.class, 1L);```批量删除批量删除是一种高效的删除方法,它允许我们一次性删除多条记录。
@ManyToOne和@OneToMany注解

@ManyToOne和@OneToMany注解(1)ManyToOne(多对⼀)单向:不产⽣中间表,但可以⽤@Joincolumn(name=" ")来指定⽣成外键的名字,外键在多的⼀⽅表中产⽣!(2)OneToMany(⼀对多)单向:会产⽣中间表,此时可以⽤@onetoMany @Joincolumn(name=" ")避免产⽣中间表,并且指定了外键的名字(别看 @joincolumn在⼀中写着,但它存在在多的那个表中)(3)OneToMany ,ManyToOne 双向(两个注解⼀起⽤的):如果不在@OneToMany中加mappedy属性就会产⽣中间表,此时通常在@ManyToOne的注解下再添上注解@Joincolumn(name=" ")来指定外键的名字(说明:多的⼀⽅为关系维护端,关系维护端负责外键记录的更新,关系被维护端没有权利更新外键记录)!(@OneToMany(mappedBy="⼀对多中,多中⼀的属性")出现mapby为被维护端|||默认为延迟加载)⽤例:@ManyToOne(fetch=ZY)@JoinColumn(name="child_id")private OrderChild orderChild;@OneToMany(mappedBy="orderChild",fetch=ZY,cascade={CascadeType.MERGE})@NotFound(action=NotFoundAction.IGNORE)//代表可以为空,允许为nullprivate List<OrderChildGoods> goodsList;hibernate中@ManyToOne默认是⽴即加载,@OneToMany默认是懒加载但是如果加上了@NotFound之后设置的fetch=ZY是不起作⽤的,也就是设置@NotFound后变为了⽴即加载eager。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<class name="Person" table="t_person"> <id name="id" type="integer" column="t_id"> <generator class="sequence"> <param name="sequence">hb_person_seq</param> </generator> </id> <property name="name" type="string" column="t_name"></property> <property name="age" type="integer" column="t_age"></property> <many-to-one name="team" class="Team" column="t_team_id"></many-toone> </class>
OneToMany映射(List)
之前,在一对多的映射中,one方使用Set集合去关联many方,我们都知 道Set集合是无序的,而我们现在有这样的需求:one方包含的many方的 对象需要为他们编号,让它们是有序的,可能大家立刻想到使用主键ID, 但是,一方面组件ID的作用并不是编号,它是起唯一标识对象的作用, 另一方面,我们在实际的项目中,很多时候都使用UUID机制来生成和控 制ID,你不可能拿那些值来标识对象吧?也就是说,我们这个时候要单 独拿一个字段来标识many方对象的编号,而该字段又不是主键ID,不能 使用序列,那么这个时候怎么办呢?我们使用one-to-many的list机制来、 实现。
保存
Team team=new Team(); team.setName("广州恒大"); Person p=new Person(); p.setName("可卿"); p.setAge(25); //要让p认识team,到时候外键才会有值 p.setTeam(team); //面向team做保存,同样要让team认识p team.getMembers().add(p); session.saveOrUpdate(team);
删除
删除要考虑的问题:是否级联删除 这里可分三种情况讨论: 1、没有设置cascade级联删除的情况 2、设置了cascade记录删除的情况 3、t_turn为空,外键不为空的情况。
案例描述: 假设现在有一个球队(Team),球队当中有球 员,球队和球员之间显然是一对多的关系, 现在我们一对多的list机制来实现为这些球员 编号,同时引入UUID机制。
UUID:Universally Unique Identifier,是指在一台机器上生 成的数字,它保证对在同一时空中的所有机器都是唯一的。 按照开放软件基金会(OSF)制定的标准计算,用到了以太网 卡地址、纳秒级时间、芯片IDxxx-xxxx-xxxx-xxxxxx-xxxxxxxxxx (8-4-4-4-12)
其中每个 x 是 0-9 或 a-f 范围内的一个十六进制的数字。
UUID的配置
<id name="id" type="string" column="t_id"> <generator class="uuid"></generator> </id>
UUID的优缺点
Hibernate在保存对象时,由hibernate生成一个UUID字符串 作为主键,保证了唯一性,但其并无任何业务逻辑意 义,只能作为主键,唯一缺点长度较大,32位(Hibernate 将UUID中间的“-”删除了)的字符串, 占用存储空间大,但是有两个很重要的优点,Hibernate在维 护主键时,不用去数据库查询,从而提高效率,而且它是跨 数据库的,以后切换数据库极其方便。
特点:uuid长度大,占用空间大,跨数据库,不用访问数据 库就生成主键值,所以效率高且能保证唯一性,移植非常方 便,推荐使用。
one-to-many(List)案例
public class Person { private int id; private String name; private int age; private Team team; }
public class Team { private int id; private String name; List<Person> members=new ArrayList<Person>(); }
<id name="id" type="integer" column="t_id"> <generator class="sequence"> <param name="sequence">hb_team_seq</param> </generator> </id> <property name="name" type="string" column="t_name"></property> <!-- 注意:这里不能有inverse。因为最后执行的更新语句,还要设置t_turn字 段的值。 也就是说,这个时候,one方不但要维护many方的外键t_team_id,还要 维护many方的t_turn字段,这是与set集合的本质区别,因此不能像在set集合 那里那样使用inverse。这里必须要执行update。 --> <list name="members" cascade="all"> <key column="t_team_id"></key> <list-index base="0" column="t_turn"></list-index> <one-to-many class="Person"/> </list>