Mean Shift算法步骤
mean-shift算法公式

mean-shift算法公式Mean-shift算法是一种无参聚类算法,常用于图像分割、目标跟踪和模式识别等领域。
本文将详细介绍mean-shift算法的原理、公式和实际应用场景。
一、原理Mean-shift算法的核心思想是密度估计和质心漂移。
它基于高斯核函数,通过不断更新质心,最终将数据点分为不同的簇。
具体而言,我们要对每个数据点x_i进行密度估计,将其周围的点加权后求和得到密度估计值f(x_i)。
给定一个初始质心x_c,我们通过以下公式计算新质心x_c’:x_c' = \frac{\sum_{x_i \in B(x_c,r)} w(x_i) \times x_i}{\sum_{x_i \in B(x_c,r)} w(x_i)}B(x_c,r)表示以x_c为圆心,半径为r的区域,w(x_i)为高斯权重系数,可以写作w(x_i) = e ^ {-\frac{(x_i - x_c)^2}{2 \times \sigma^2}}\sigma是高斯核函数的标准差,控制窗口大小和权重降低的速度。
在计算新质心后,我们将其移动到新位置,即x_c = x_c’,然后重复以上步骤,直到质心不再改变或者达到预定的迭代次数为止。
最终,所有距离相近的数据点被归为同一簇。
算法的时间复杂度为O(nr^2),其中n为数据点数量,r为窗口半径。
可以通过调整r和\sigma来平衡速度和准确率。
二、公式1. 高斯核函数w(x_i) = e ^ {-\frac{(x_i - x_c)^2}{2 \times \sigma^2}}其中x_i和x_c是数据点和质心的位置向量,\sigma是高斯核函数的标准差。
该函数表示距离越大的数据点的权重越小,与质心距离越近的数据点的权重越大,因此可以有效估计密度。
2. 新质心计算公式x_c' = \frac{\sum_{x_i \in B(x_c,r)} w(x_i) \times x_i}{\sum_{x_i \in B(x_c,r)} w(x_i)}B(x_c,r)表示以x_c为圆心,半径为r的区域,w(x_i)为高斯权重系数。
经典Mean Shift算法介绍

经典Mean Shift算法介绍1无参数密度估计 (1)2核密度梯度估计过程 (3)3算法收敛性分析 (4)均值漂移(Mean Shift)是Fukunaga等提出的一种非参数概率密度梯度估计算法,在统计相似性计算与连续优化方法之间建立了一座桥梁,尽管它效率非常高,但最初并未得到人们的关注。
直到1995年,Cheng改进了Mean Shift算法中的核函数和权重函数,并将其应用于聚类和全局优化,才扩大了该算法的适用范围。
1997年到2003年,Comaniciu等将该方法应用到图像特征空间的分析,对图像进行平滑和分割处理,随后他又将非刚体的跟踪问题近似为一个Mean Shift最优化问题,使得跟踪可以实时进行。
由于Mean Shift算法完全依靠特征空间中的样本点进行分析,不需要任何先验知识,收敛速度快,近年来被广泛应用于模式分类、图像分割、以及目标跟踪等诸多计算机视觉研究领域。
均值漂移方法[4]是一种最优的寻找概率密度极大值的梯度上升法,提供了一种新的目标描述与定位的框架,其基本思想是:通过反复迭代搜索特征空间中样本点最密集的区域,搜索点沿着样本点密度增加的方向“漂移”到局部密度极大点。
基于Mean Shift方法的目标跟踪技术采用核概率密度来描述目标的特征,由于目标的直方图具有特征稳定、抗部分遮挡、计算方法简单和计算量小的特点,因此基于Mean Shift的跟踪一般采用直方图对目标进行建模;然后通过相似性度量,利用Mean Shift搜寻目标位置,最终实现目标的匹配和跟踪。
均值漂移方法将目标特征与空间信息有效地结合起来,避免了使用复杂模型描述目标的形状、外观及其运动,具有很高的稳定性,能够适应目标的形状、大小的连续变换,而且计算速度很快,抗干扰能力强,在解决计算机视觉底层任务过程中表现出了良好的鲁棒性和较高的实时处理能力。
1无参数密度估计目标检测与跟踪过程中,必须用到一定的手段对检测与跟踪的方法进行优化,将目标的表象信息映射到一个特征空间,其中的特征值就是特征空间的随机变量。
Mean Shift算法在彩色图像分割中的应用

Mean Shift算法在彩色图像分割中的应用摘要:Mean Shift算法是目前广泛应用于图像分割和计算机视觉中的方法。
论述了该算法应用在彩色图像分割中的原理及过程,并给出实验过程和结果。
关键词:Mean Shift算法;彩色图像分割;数字图像处理0 引言图像分割是图像分析、识别和理解的基础,是从图像处理到图像分析的一个关键步骤。
由于彩色图像提供了比灰度图像更为丰富的信息,彩色图像的分割在近几年越来越引起人们的重视,成为图像技术研究的热点之一。
Mean shift(均值漂移,MS)算法是一种有效的统计迭代算法,最早由Fukunaga在1975年提出。
直到1995年,Cheng改进了MS算法中的核函数和权重函数,并将其应用于聚类和全局优化,扩大了该算法的适用范围。
从1997年到2003年,Comaniciu将该方法应用到图像特征空间的分析,对图像进行平滑和分割处理,并证明了MS算法在满足一定条件下,可收敛到最近的一个概率密度函数的稳态点,因此,MS算法可用来检测概率密度函数中存在的模态。
由于MS算法完全依靠特征空间中的样本点进行分析,不需要任何先验知识,并且收敛速度快,近年来被广泛应用于图像分割和跟踪等计算机视觉领域。
1 Mean Shift算法1.1 Mean Shift算法原理定义:X代表一个d维的欧氏空间,x是该空间中的一个点,用一列向量表示.x的模为‖x‖2=x Tx.R表示实数域.如果一个函数K:K →R存在一个轮廓函数k:[0,∞]→R,即K(x)=c kk(‖x‖2)(1)其中c k>0为标准化常数,且满足:①k是非负的;②k是非增的,即如果a<b那么k(a)≥k(b);③k是分段连续的,并且∫0k(r)dr<∞.则称函数K(x)为核函数。
对概率密度函数f(x),设在d维空间X中有n个采样点x i,i=1,2,…,n,用定义的核函数K(x)和d×d的正对称带宽矩阵H,得到核密度估计表达式为(x)=∑ni=1ω(x i)|H i|-12 K(H-12i(x-x i))=∑ni=1c kωi|H i|-12k(‖x-x i‖2Hi)(2)其中:w(x i)≥0赋给采样点x i的权重,满足∑ω(x i)=1,简记为ωi.‖x-x i‖2H i=(x-x i)TH-1 i(x-x i).核函数K(x)决定了采样点x i与核中心点x之间的相似性度量,带宽矩阵H i决定了核函数的影响范围。
meanshift算法原理

meanshift算法原理
MeanShift(均值漂移)是一种非参数化的聚类算法,用于在数据集中发现数据点的密集区域。
它基于密度估计的原理,通过计算数据点的局部密度梯度来寻找数据点的聚集中心。
MeanShift 算法的原理如下:
1. 初始化:为每个数据点选择一个随机的聚集中心。
2. 密度估计:对于每个数据点,计算其与其他数据点之间的距离,并将距离定义为核函数的参数。
常用的核函数是高斯核函数。
3. 均值漂移:对于每个数据点,计算其局部密度梯度向量。
梯度向量的方向是从当前数据点指向密度更高的方向,梯度的大小代表密度的变化程度。
使用梯度向量来更新当前数据点的位置。
4. 更新聚集中心:将数据点移动到更新后的位置,并将其作为新的聚集中心。
5. 重复步骤2-4 直到满足停止条件(例如,聚集中心的移动小于某个阈值)。
MeanShift 算法的特点是不需要事先指定聚类的数量,它能够自动确定聚类的形状和数量。
它具有较好的收敛性和适应性,对于非凸形状的聚类问题也能有效地处理。
在应用中,MeanShift 算法可以用于图像分割、目标跟踪、图像压缩等领域。
它在计算复杂度上较高,但在一些特定的数据集和问题中表现出良好的效果。
meanshift算法简介

第28页/共35页
(5)若
,则停止;否则y0←y1转步骤②。
限制条件:新目标中心需位于原目标中心附近。
第29页/共35页
Meanshift跟踪结果
• 转word文档。
第30页/共35页
第13页/共35页
fh,K
x
2ck ,d n nhd 2 i1
xi x g
x xi h
2
2ck ,d h2cg ,d
cg ,d nhd
n i1 g
x xi h
2
n i1 xi g
n g
i1
x xi h
x xi h
2
2
x
基于核函数G(x)的 概率密度估计
就是要求 式最大,可以计算
的Mean Shift向量,这
样我们就可以得到候选区域中心 移向真实目标区域y的向量:
=
其中 值得注意的是,一般在一帧中找到目标的位置,需要Mean Shift算法从开始若干次迭代才能得到。
第27页/共35页
• 整个算法流程
①在当前帧以y0为起点,计算候选目标的特征{pu(y0)}u=1,2…..m;
Mean shift向量
第14页/共35页
•
用核函数G在 x点计算得到的Mean Shift向量 正比于归一化的用核函数K估计的概率密度的函数 的
梯度,归一化因子为用核函数G估计的x点的概率密度.因此Mean Shift向量 总是指向概率密度增加最大的方
向.
第15页/共35页
Mean shift向量的物理意义的什么呢?
均值偏移算法

均值偏移算法
均值偏移算法(Mean Shift algorithm)是一种基于密度的非参数化聚类算法,用于数据聚类和图像分割等任务。
它的原理是通过迭代地移动数据样本的均值位置,直到满足某个终止条件为止,从而实现聚类的目标。
算法步骤如下:
1. 初始化每个数据样本的均值位置,可以选择随机选取或者使用其他聚类算法的结果作为初始点。
2. 对于每个数据样本,计算它与所有其他样本之间的距离。
3. 根据一定的核函数,将距离较近的数据样本聚集到一个小区域中。
4. 通过计算每个聚类区域的均值,更新每个数据样本的均值位置。
5. 重复步骤2~4,直到均值位置不发生变化或者达到迭代次数的终止条件。
均值偏移算法有以下特点:
- 不需要指定聚类的数量,而是根据数据样本自身的分布情况进行聚类。
- 对于不规则形状和密度变化较大的数据集效果好。
- 对噪声数据敏感。
在图像分割中,均值偏移算法可以通过选择合适的颜色空间和核函数,将图像中的每个像素点聚类到相应的区域中,从而实现图像的分割。
MeanShift

§5-1Mean Shift 算法Mean Shift 算法是由Fukunaga 和Hosteler 于1975年提出的一种无监督聚类方法[109],Mean Shift 的含义是均值偏移向量,它使每一个点“漂移”到密度函数的局部极大值点。
但是再提出之初,Mean Shift 算法并没有得到广泛的重视,直到1995年,Cheng 等人对该算法进行了进一步的研究[110],提出了一般的表达形式并定义了一族核函数,从而扩展了该算法的应用领域,此后Mean Shift 算法逐步得到了人们的重视。
目前,Mean Shift 算法已广泛应用于目标跟踪[111~114]、图像分割与平滑[115~118]等领域,同时由于该算法具有简洁、能够处理目标变形等优点,也是目前目标跟踪领域的一个重要研究热点。
5-1-1 Mean Shift 算法原理Mean Shift 算法是一种基于密度梯度的无参数估计方法,从空间任意一点,沿核密度的梯度上升方向,以自适应的步长进行搜索,最终可以收敛于核密度估计函数的局部极大值处。
基本的Mean Shift 算法可以描述为:设{}()1,,i x i n = 为d 维空间R d 中含有n 个样本点的集合,在点x 处的均值偏移向量的基本形式可以由式(5.1)表示:1()()hh ix S M x xx k∈=-∑ (5.1)其中,S h 是R d 中满足式(5.2)的所有y 点集合,其形状为一个半径为h 的高维球区域。
k 为所有n 个样本点中属于高维球区域的点的数目。
(x i -x )为样本点相对于点x 的偏移向量。
根据式(5.1)的定义可知,点x 的均值偏移向量就是所有属于S h 区域中的样本点与点x 的偏移向量均值,而S h 区域中的样本点大多数是沿着概率密度梯度的方向,所以均值漂移向量的方向与概率密度梯度方向一致,图5.1为具体的示意图。
{}2():()()Th S x y y x y x h=--≤ (5.2)图5.1 Mean Shift 示意图 Fig.5.1 Mean Shift sketch map根据式(5.1)和图5.1可以看出,所有属于区域S h 中的样本点对于点x 的均值漂移向量贡献度相同,而与这些点与点x 间的距离无关。
MeanShift算法
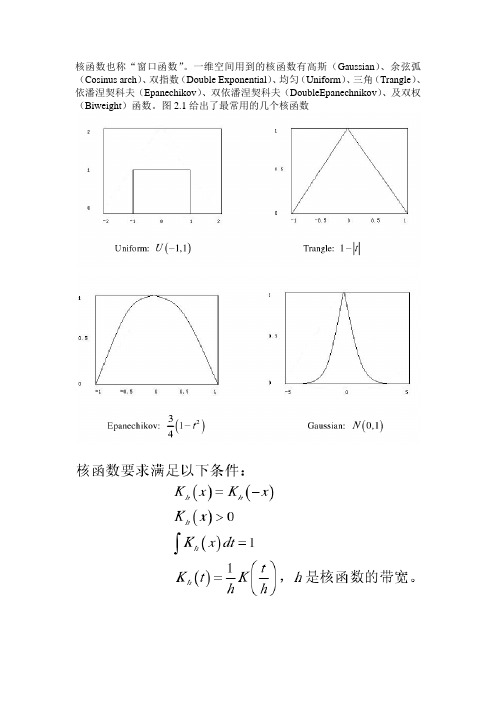
核函数也称“窗口函数”。
一维空间用到的核函数有高斯(Gaussian)、余弦弧(Cosinus arch)、双指数(Double Exponential)、均匀(Uniform)、三角(Trangle)、依潘涅契科夫(Epanechikov)、双依潘涅契科夫(DoubleEpanechnikov)、及双权(Biweight)函数。
图2.1给出了最常用的几个核函数给定一组一维空间的n个数据点集合令该数据集合的概率密度函数假设为f (x),核函数取值为,那么在数据点x处的密度估计可以按下式计算:上式就是核密度估计的定义。
其中,x为核函数要处理的数据的中心点,即数据集合相对于点x几何图形对称。
核密度估计的含义可以理解为:核估计器在被估计点为中心的窗口内计算数据点加权的局部平均。
或者:将在每个采样点为中心的局部函数的平均效果作为该采样点概率密度函数的估计值。
MeanShift实现:1.选择窗的大小和初始位置.2.计算此时窗口内的Mass Center.3.调整窗口的中心到Mass Center.4.重复2和3,直到窗口中心"会聚",即每次窗口移动的距离小于一定的阈值,或者迭代次数达到设定值。
meanshift算法思想其实很简单:利用概率密度的梯度爬升来寻找局部最优。
它要做的就是输入一个在图像的范围,然后一直迭代(朝着重心迭代)直到满足你的要求为止。
但是他是怎么用于做图像跟踪的呢?这是我自从学习meanshift以来,一直的困惑。
而且网上也没有合理的解释。
经过这几天的思考,和对反向投影的理解使得我对它的原理有了大致的认识。
在opencv中,进行meanshift其实很简单,输入一张图像(imgProb),再输入一个开始迭代的方框(windowIn)和一个迭代条件(criteria),输出的是迭代完成的位置(comp )。
这是函数原型:int cvMeanShift( const void* imgProb, CvRect windowIn,CvTermCriteria criteria, CvConnectedComp* comp )但是当它用于跟踪时,这张输入的图像就必须是反向投影图了。
MSA_计算公式

MSA_计算公式MSA(Mean Shift Algorithm)是一种非参数的聚类算法,主要用于数据点的聚类和密度估计。
它的计算公式是基于核密度估计和梯度上升的思想,通过迭代寻找数据点的局部最大密度区域,从而得到聚类结果。
1.数据点密度估计:对于给定的数据集,首先需要进行数据点的密度估计。
常用的方法是使用高斯核函数,计算每个数据点与其邻域内其他数据点的距离,并将距离作为权重计算密度。
具体公式如下:\[k(x_i, x_j) = \exp \left( -\frac{{\,x_i - x_j\,^2}}{{2h^2}} \right)\]其中,\(x_i\)和\(x_j\)是数据集中的两个数据点,\(h\)是高斯核函数的带宽。
2.梯度上升迭代:在数据点的密度估计完成后,需要进行梯度上升的迭代过程,找到局部最大密度区域。
具体公式如下:\[m(x) = \frac{\sum_{i=1}^{n} k(x, x_i) \cdotx_i}{\sum_{i=1}^{n} k(x, x_i)} - x\]其中,\(m(x)\)表示数据点\(x\)的梯度向量,\(k(x,x_i)\)表示数据点\(x\)与数据点\(x_i\)之间的权重,\(n\)表示数据集中的数据点数量。
3.密度最大化:通过迭代计算梯度向量,将数据点移动到局部最大密度区域。
具体公式如下:\[x_{t+1}=m(x_t)+x_t\]其中,\(x_{t+1}\)表示迭代后的数据点位置,\(x_t\)表示迭代前的数据点位置。
4.聚类结果:在迭代过程中,如果两个数据点的位置足够接近,则认为它们属于同一个聚类。
可以使用距离阈值来判断两个数据点是否属于同一个聚类。
MSA算法的优点是不需要预先指定聚类数量,且对于数据集的分布形状没有假设。
但是,该算法的计算复杂度较高,对数据点的数量和维度敏感。
因此,在实际应用中需要考虑算法的效率和可扩展性。
总结起来,MSA算法的计算公式主要包括数据点密度估计、梯度上升迭代、密度最大化和聚类结果。
均值移位算法

均值移位算法
均值移位算法(Mean Shift Algorithm)是一种非参数密度估计方法,主要用于聚类分析、图像分割等领域。
它的原理是通过不断的平移移
动中心点,使得样本点向密度最大的区域聚集,分析其核密度分布,
进而得出数据分割的结果。
均值移位算法具有以下优点:
1.不需要预先设定簇数目,能够自动进行聚类。
2.不受数据分布情况的影响。
3.不需要迭代,运算速度快。
但是,随着数据量增大,计算复杂度也会增大,因此需要合理设置核
函数的大小。
均值移位算法的应用范围广泛,包括:
1.图像分割:对图像进行聚类,得到图像中的颜色群体。
2.物体跟踪:通过对物体进行追踪,实现对物体的自动检测、跟踪等功能。
3.模式分类:将数据划分为不同的分类,识别数据中的模式。
4.聚类分析:对数据进行聚类,发现数据的内在规律。
5.异常检测:发现数据中的异常点,排除错误数据。
均值移位算法的实现包括以下步骤:
1.选择核函数和带宽。
2.初始化中心点和权值。
3.计算移动向量和权值更新。
4.重复步骤3,直到中心点不再发生明显变化,或达到设定的迭代次数。
在使用均值移位算法时,需要合理设置核函数的大小,以避免计算复
杂度过高。
同时,也要注意数据是否存在离群点,以及需要设置合理
的停止条件。
总之,均值移位算法是一种非常有用的聚类分析方法,可以应用于各
种领域。
尤其是在图像分割、物体跟踪等领域,均值移位算法具有突
出的优势,有着广泛的应用前景。
mean shift算法讲解

mean shift算法讲解Mean shift算法是一种无监督的聚类算法,它的主要思想是通过不断迭代寻找数据点的概率分布密度的众数,从而实现数据的聚类。
本文将详细介绍Mean shift算法的具体步骤和实现流程,并深入解析其原理和应用场景。
一、算法背景和基本原理Mean shift算法最初由Comaniciu和Meer于1992年提出,它是一种基于密度估计的聚类方法。
其核心思想是通过计算每个数据点周围的概率密度分布,不断调整数据点的位置直到达到局部极大值点(众数),从而实现数据点的聚集。
Mean shift算法的基本原理如下:1.初始化:选择一个合适的核函数和带宽,然后从数据集中选择一个数据点作为初始中心点。
2.密度估计:计算每个数据点周围的概率密度分布,以核函数和带宽作为参数。
3.均值偏移:根据密度估计结果,通过计算梯度的方向,将当前中心点移动到密度分布的局部极大值点。
4.收敛判断:判断当前中心点和移动后的中心点之间的距离,如果小于某个阈值,则认为算法收敛,结束迭代。
否则,将移动后的中心点作为新的中心点,重复步骤2-4直到收敛。
二、算法步骤详解下面将详细解释Mean shift算法的每一步骤。
1.初始化为了实现Mean shift算法,我们首先需要选择一个适当的核函数和带宽。
核函数可以是高斯核函数或者其他类型的核函数。
带宽决定了数据点的搜索半径,即计算密度估计的范围。
一个较小的带宽会导致聚类过于散乱,而一个较大的带宽会导致聚类过于集中。
因此,合适的带宽选择是非常重要的。
2.密度估计在第二步中,我们需要计算每个数据点周围的概率密度分布。
这可以通过核函数和带宽来实现。
对于给定的数据点xi,其密度估计可以表示为:f(xi)=1/N*ΣK(xi-xj)/h其中,N是数据点的总数,K是核函数,h是带宽。
该公式意味着每个数据点的密度估计值是通过计算该数据点和所有其他数据点之间的核函数和的平均值得到的。
3.均值偏移在第三步中,我们通过计算梯度的方向来将当前中心点移动到密度分布的局部极大值点。
mean-shift算法matlab代码

一、介绍Mean-shift算法Mean-shift算法是一种基于密度估计的非参数聚类算法,它可以根据数据点的密度分布自动寻找最优的聚类中心。
该算法最早由Dorin Comaniciu和Peter Meer在1999年提出,并被广泛应用于图像分割、目标跟踪等领域。
其原理是通过不断地将数据点向局部密度最大的方向移动,直到达到局部密度的最大值点,即收敛到聚类中心。
二、 Mean-shift算法的优势1. 无需事先确定聚类数量:Mean-shift算法不需要事先确定聚类数量,能够根据数据点的密度自动确定聚类数量。
2. 对初始值不敏感:Mean-shift算法对初始值不敏感,能够自动找到全局最优的聚类中心。
3. 适用于高维数据:Mean-shift算法在高维数据中仍然能够有效地进行聚类。
三、 Mean-shift算法的实现步骤1. 初始化:选择每个数据点作为初始的聚类中心。
2. 计算密度:对于每个数据点,计算其密度,并将其向密度增加的方向移动。
3. 更新聚类中心:不断重复步骤2,直至收敛到局部密度的最大值点,得到最终的聚类中心。
四、 Mean-shift算法的Matlab代码实现以下是一个简单的Matlab代码实现Mean-shift算法的示例:```matlab数据初始化X = randn(500, 2); 生成500个二维随机数据点Mean-shift算法bandwidth = 1; 设置带宽参数ms = MeanShift(X, bandwidth); 初始化Mean-shift对象[clustCent, memberships] = ms.cluster(); 执行聚类聚类结果可视化figure;scatter(X(:,1), X(:,2), 10, memberships, 'filled');hold on;plot(clustCent(:,1), clustCent(:,2), 'kx', 'MarkerSize',15,'LineWidth',3);title('Mean-shift聚类结果');```在代码中,我们首先初始化500个二维随机数据点X,然后设置带宽参数并初始化Mean-shift对象。
核函数带宽自适应的MeanShift跟踪算法

万方数据第6期陈昌涛等:核函数带宽自适应的Mean—Shift跟踪算法168l1Mean.Shift跟踪算法1.1Bhattacharyya系数通过,,l级核加权直方图来表示模板的颜色分布q。
如式(1):吼=c∑“o(石一%)/圳2]6(6(悲)一“)(1)其中:瓤(f=1,…,n)表示像素在目标模板中的位置,其中心位置设为算。
同时令b(氟)表示位置石。
处的像素颜色(对于灰度图像b(xi)为灰度等级),后为核函数框架,c为吼的归一化常数,h为带宽,跚,=置菇(2)同样令Y;(i=1,…,,1)表示像素在候选目标中的位置,其中心位置设为Y。
那么与计算模板颜色概率密度分布函数类似,得到候选目标的颜色分布P。
用Bhattacharyya系数P表示候选目标与模板目标之间的匹配程度Bj,如式(3)所示。
p(p(y),g)=∑、佤丽=-(3)得到的P越大,表示候选目标与模板目标越匹配,那么对应的中心,,越有可能是目标在当前帧中的位置。
1.2Mean—Shift目标跟踪用式(4)进行Mean-Shift迭代"1:姜y叫0罕II2】…蚤wig【II导≯II2】其中:儿(i=1,…,n)表示像素在候选目标中的位置,其初始中心位置设为%,毗=∑ ̄/再7i丐习祆面i了=可,在使用式(4)进行迭代前,,,初始化为Yo,每次迭代完成,用得到的新的Y替换,直至Y收敛到一个不变的值,从而找到最佳模式匹配位置,实现目标跟踪。
2基于Bhattacharyya系数的核带宽更新在Mean.Shift跟踪算法中,式(1)中使用的核函数为凸函数,如:后c”石II,={:,一“茗“2’:::|l季:c5,起到中心加权的作用,对目标边缘背景的影响有较好的抑制作用,保证了目标跟踪的稳定性和准确性。
由此,笔者受到启示,如果核函数为凹函数,如:……1)-∞“2’㈥季:(6)即对目标边缘起到增强作用,那么由此直方图与模板中心加权直方图计算Bhattacharyya系数与核带宽的更新有着一定的关系,下面将予以详细介绍。
均值平移算法

均值平移算法均值平移算法(Mean Shift Algorithm)是一种用于数据聚类和图像分割的非参数方法。
它的基本思想是通过迭代计算数据点的均值平移向量,将数据点移动到局部密度最大的区域,从而实现聚类的目的。
在介绍均值平移算法之前,先来了解一下聚类的概念。
聚类是指将具有相似特征的数据点分组到一起的过程。
在实际应用中,聚类可以用于图像分割、目标跟踪、无监督学习等领域。
而均值平移算法作为一种常用的聚类算法,具有以下特点:1. 非参数化:均值平移算法不需要事先指定聚类的个数,而是通过迭代计算数据点的均值平移向量,从而确定聚类的个数和位置。
2. 局部搜索:均值平移算法是一种局部搜索算法,它通过计算数据点的均值平移向量,将数据点移动到局部密度最大的区域。
这样可以保证聚类的准确性,并且能够处理非凸形状的聚类。
下面我们来详细介绍均值平移算法的原理和步骤:1. 初始化:首先选择一个合适的窗口大小和数据点的初始位置。
窗口大小决定了局部搜索的范围,而初始位置可以是随机选择的或者根据先验知识进行选择。
2. 计算均值平移向量:对于窗口内的每个数据点,计算它与其他数据点的距离,并将距离加权后的向量相加。
这个加权和即为均值平移向量。
3. 移动数据点:根据计算得到的均值平移向量,将数据点移动到局部密度最大的区域。
具体做法是将数据点沿着均值平移向量的方向移动一定的距离。
4. 更新窗口:更新窗口的位置,使其包含移动后的数据点。
然后回到第2步,继续计算均值平移向量,并移动数据点,直到满足停止条件。
均值平移算法的停止条件可以是迭代次数达到一定的阈值,或者数据点的移动距离小于一定的阈值。
在实际应用中,可以根据具体的情况选择合适的停止条件。
均值平移算法的优点是可以自动发现数据中的聚类,并且对于非凸形状的聚类效果好。
然而,它也有一些缺点,比如对于大规模数据的处理速度较慢,并且对于窗口大小的选择比较敏感。
总结一下,均值平移算法是一种常用的聚类算法,它通过迭代计算数据点的均值平移向量,将数据点移动到局部密度最大的区域,从而实现聚类的目的。
MSA计算方法

MSA计算方法MSA(Mean Shift Algorithm)是一种非参数无监督学习算法,广泛应用于数据聚类和图像分割等领域。
它的基本思想是寻找数据点的概率密度最大值,从而确定类别或划分区域。
MSA的计算过程主要包括以下几个步骤:1.数据点选择:从给定的数据集中选择一个数据点作为初始点。
2.窗口大小选择:选择一个合适的窗口大小。
窗口大小可以决定概率密度的计算范围。
如果窗口过小,可能导致过多的小尺度模式;如果窗口过大,可能导致尺度较大的模式被忽略。
3.密度计算:计算窗口内每个数据点的概率密度。
一种常用的计算方法是采用核函数,如高斯核函数,来确定每个数据点与初始点之间的距离。
4.密度最大值寻找:选择密度最大的数据点作为新的初始点。
5.迭代:重复步骤3和步骤4,直到初始点不再变化或达到预先设定的迭代次数。
6.数据点分类:将每个数据点分类到其最近的初始点。
分配完所有数据点后,完成一个聚类过程。
MSA的计算方法有一些优点和应用范围:1.无需预设类别:MSA是一个无监督学习算法,不需要预设数据类别,能自动进行聚类。
2.鲁棒性较强:MSA不受初始点的选择和窗口大小的变化影响,算法具有较好的鲁棒性。
3.适用于多种数据类型:MSA不仅适用于数值型数据,也适用于字符串型、图像型等多种数据类型。
4.可扩展性好:MSA可以通过调整参数实现不同的聚类要求,如聚类数目、分类精度等。
MSA算法的应用非常广泛,主要集中在以下几个领域:1.数据聚类:MSA可以用于将数据点划分为不同的类别,找出数据集中隐藏的结构和模式。
2.图像分割:MSA可以将图像划分为不同的区域,使得同一区域内的像素具有相似的特性。
3.移动目标跟踪:MSA可以根据目标的外观特征,实现对移动目标的实时跟踪。
4.目标识别:MSA可以用于在复杂背景下,区分目标和背景,提取目标的特征。
总之,MSA是一种非常有用的聚类算法,它通过寻找数据点的概率密度最大值,能够实现数据聚类、图像分割以及目标跟踪等应用。
高斯核函数mean-shift matlab

高斯核函数mean-shift matlab高斯核函数是一种常用的核函数,它广泛应用于图像处理、模式识别、机器学习等领域。
平均漂移(mean-shift)算法是一种基于高斯核函数的非参数密度估计方法,具有较强的适应性和鲁棒性。
平均漂移算法基于传统的核密度估计方法,但它不需要指定数据的概率分布函数。
相反,它使用核函数来估计密度函数。
核函数通常采用高斯核函数,如下所示:$$K(x) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{x^2}{2\sigma^2}}$$$x$表示一个样本点,$\sigma$表示高斯分布的标准差。
平均漂移算法通过迭代来寻找样本点的密度中心,即最高密度的点。
为了找到密度中心,要先选择一个起始点,并使用核函数来计算该点周围所有点的权值。
然后,根据所有点的权值计算权重平均值,以此平移当前点的位置。
不断迭代此过程,直到找到密度中心为止。
1. 选择一个起始点$x_0$。
2. 计算权重$w_i = K(||x_i-x_0||)$,其中$||\cdot||$表示欧几里得距离。
3. 计算权重平均值:$m(x_0) =\frac{\sum_{i=1}^n w_ix_i}{\sum_{i=1}^n w_i}$。
4. 将$x_0$平移到$m(x_0)$,即$x_0 = m(x_0)$。
5. 重复2~4步,直到$m(x_0)$与$x_0$之间的距离小于某个阈值或达到预定的最大迭代次数。
```matlabfunction [center, idx] = mean_shift(data, bandwidth, eps)[n, d] = size(data); % 数据维度center = zeros(n, d); % 每个数据点的密度中心converged = false(n, 1); % 每个数据点是否已经收敛idx = zeros(n, 1); % 数据点所属簇的标签for i = 1:nx = data(i, :); % 取出一个数据点cnt = 0;while ~converged(i) && cnt < 100 % 最多迭代100次cnt = cnt + 1;w = exp(-sum((data-repmat(x, n, 1)).^2, 2)/(2*bandwidth^2)); % 计算所有点的权重x_new = sum(repmat(w, 1, d).*data, 1) / sum(w); % 根据权重计算新的位置if norm(x_new - x) < eps % 如果位置变化很小,认为已经收敛center(i, :) = x_new;idx(i) = find(abs(w-max(w))<eps, 1); % 选择权重最大的簇作为标签converged(i) = true;elsex = x_new;endendend````data`表示数据样本,`bandwidth`表示高斯核函数的标准差,`eps`表示收敛判定的阈值。
Mean_Shift_算法概述

Mean Shift 概述Mean Shift 简介Mean Shift 这个概念最早是由Fukunaga等人[1]于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift是一个名词,它指代的是一个向量,但随着Mean Shift理论的发展,Mean Shift的含义也发生了变化,如果我们说Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束.然而在以后的很长一段时间内Mean Shift并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift的重要文献[2]才发表.在这篇重要的文献中,Yizong Cheng 对基本的Mean Shift算法在以下两个方面做了推广,首先Yizong Cheng定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift的适用范围.另外Yizong Cheng指出了Mean Shift可能应用的领域,并给出了具体的例子.Comaniciu等人[3][4]把Mean Shift成功的运用的特征空间的分析,在图像平滑和图像分割中Mean Shift都得到了很好的应用. Comaniciu等在文章中证明了,Mean Shift算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift算法可以用来检测概率密度函数中存在的模态.Comaniciu等人[5]还把非刚体的跟踪问题近似为一个Mean Shift最优化问题,使得跟踪可以实时的进行.在后面的几节,本文将详细的说明Mean Shift的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明.最后本文还将给出Mean Shift在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用.Mean Shift 的基本思想及其扩展基本Mean Shift给定d 维空间dR 中的n 个样本点i x ,i=1,…,n,在x 点的Mean Shift 向量的基本形式定义为:()()1i hh i x S M x x x k ∈≡-∑ (1)其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合,()()(){}2:Th S x y y x y x h ≡--≤ (2)k 表示在这n 个样本点i x 中,有k 个点落入h S 区域中.我们可以看到()i x x -是样本点i x 相对于点x 的偏移向量,(1)式定义的Mean Shift 向量()h M x 就是对落入区域h S 中的k 个样本点相对于点x 的偏移向量求和然后再平均.从直观上看,如果样本点i x 从一个概率密度函数()f x 中采样得到,由于非零的概率密度梯度指向概率密度增加最大的方向,因此从平均上来说, h S 区域内的样本点更多的落在沿着概率密度梯度的方向.因此,对应的, Mean Shift 向量()h M x 应该指向概率密度梯度的方向.图1,Mean Shift 示意图如上图所示, 大圆圈所圈定的范围就是h S ,小圆圈代表落入h S 区域内的样本点i h x S ∈,黑点就是Mean Shift 的基准点x ,箭头表示样本点相对于基准点x 的偏移向量,很明显的,我们可以看出,平均的偏移向量()h M x 会指向样本分布最多的区域,也就是概率密度函数的梯度方向.扩展的Mean Shift核函数首先我们引进核函数的概念.定义:X 代表一个d 维的欧氏空间,x 是该空间中的一个点,用一列向量表示. x 的模2T x x x =.R 表示实数域.如果一个函数:K X R →存在一个剖面函数[]:0,k R ∞→,即()2()K x k x=(3)并且满足:(1) k 是非负的.(2) k 是非增的,即如果a b <那么()()k a k b ≥. (3) k 是分段连续的,并且()k r dr ∞<∞⎰那么,函数()K x 就被称为核函数.举例:在Mean Shift 中,有两类核函数经常用到,他们分别是, 单位均匀核函数:1 if 1()0 if 1x F x x ⎧<⎪=⎨≥⎪⎩ (4)单位高斯核函数:2()xN x e-= (5)这两类核函数如下图所示.图2, (a) 单位均匀核函数 (b) 单位高斯核函数一个核函数可以与一个均匀核函数相乘而截尾,如一个截尾的高斯核函数为,()2if ()0 ifx e x N F x x ββλλλ-⎧<⎪=⎨≥⎪⎩ (6)图 3 显示了不同的,βλ值所对应的截尾高斯核函数的示意图.图3 截尾高斯核函数 (a) 11N F (b) 0.11N FMean Shift 扩展形式从(1)式我们可以看出,只要是落入h S 的采样点,无论其离x 远近,对最终的()h M x 计算的贡献是一样的,然而我们知道,一般的说来,离x 越近的采样点对估计x 周围的统计特性越有效,因此我们引进核函数的概念,在计算()h M x 时可以考虑距离的影响;同时我们也可以认为在这所有的样本点i x 中,重要性并不一样,因此我们对每个样本都引入一个权重系数.如此以来我们就可以把基本的Mean Shift 形式扩展为:()11()()()()()nHi i i i nHi i i Gx x w x x x M x Gx x w x ==--≡-∑∑ (7)其中: ()()1/21/2()H i i G x x HG H x x ---=-()G x 是一个单位核函数H 是一个正定的对称d d ⨯矩阵,我们一般称之为带宽矩阵()0i w x ≥是一个赋给采样点i x 的权重在实际应用的过程中,带宽矩阵H 一般被限定为一个对角矩阵221diag ,...,d H h h ⎡⎤=⎣⎦,甚至更简单的被取为正比于单位矩阵,即2H h I =.由于后一形式只需要确定一个系数h ,在Mean Shift 中常常被采用,在本文的后面部分我们也采用这种形式,因此(7)式又可以被写为:()11()()()()()ni i i i h ni i i x xG w x x x hM x x x G w x h ==--≡-∑∑ (8)我们可以看到,如果对所有的采样点i x 满足(1)()1i w x =(2) 1 if 1()0 if 1 x G x x ⎧<⎪=⎨≥⎪⎩则(8)式完全退化为(1)式,也就是说,我们所给出的扩展的Mean Shift 形式在某些情况下会退化为最基本的Mean Shift 形式.Mean Shift 的物理含义正如上一节直观性的指出,Mean Shift 指向概率密度梯度方向,这一节将证明Mean Shift 向量()h M x 是归一化的概率密度梯度.在本节我们还给出了迭代Mean Shift 算法的详细描述,并证明,该算法会收敛到概率密度函数的一个稳态点.概率密度梯度对一个概率密度函数()f x ,已知d 维空间中n 个采样点i x ,i=1,…,n, ()f x 的核函数估计(也称为Parzen 窗估计)为,11()ˆ()()ni i i n di i x x K w x h f x h w x ==-⎛⎫ ⎪⎝⎭=∑∑ (9)其中()0i w x ≥是一个赋给采样点i x 的权重()K x 是一个核函数,并且满足()1k x dx =⎰我们另外定义: 核函数()K x 的剖面函数()k x ,使得()2()K x kx=(10);()k x 的负导函数()g x ,即'()()g x k x =-,其对应的核函数()2()G x g x= (11)概率密度函数()f x 的梯度()f x ∇的估计为:()2'1212()ˆˆ()()()ni i i i nd i i x xx x k w x h f x f x h w x =+=⎛⎫--⎪ ⎪⎝⎭∇=∇=∑∑(12)由上面的定义, '()()g x k x =-,()2()G x gx =,上式可以重写为()()21212112112()ˆ()()()()2 ()()nii i i nd i i n i n i i i i i i n d n i i i i i x xx x G w x h f x h w x x x x x x x G w x G w x h h x x h h w x G w x h =+=====⎛⎫-- ⎪ ⎪⎝⎭∇=⎡⎤⎛⎫-⎡-⎤⎛⎫-⎢⎥ ⎪ ⎪ ⎪⎢⎥⎢⎥⎝⎭⎝⎭⎢⎥=⎢⎥-⎛⎫⎢⎥⎢⎥ ⎪⎢⎥⎝⎭⎢⎥⎣⎦⎣⎦∑∑∑∑∑∑ (13)上式右边的第二个中括号内的那一部分就是(8)式定义的Mean Shift 向量,第一个中括号内的那一部分是以()G x 为核函数对概率密度函数()f x 的估计,我们记做ˆ()G f x ,而(9)式定义的ˆ()f x 我们重新记做ˆ()Kf x ,因此(11)式可以重新写为: ˆ()f x ∇=ˆ()Kf x ∇=()22ˆ()G h f x M x h(14)由(12)式我们可以得出,()2ˆ()1ˆ2()Kh G f x M x h f x ∇=(15)(15)式表明,用核函数G 在x 点计算得到的Mean Shift 向量()h M x 正比于归一化的用核函数K 估计的概率密度的函数ˆ()Kf x 的梯度,归一化因子为用核函数G 估计的x 点的概率密度.因此Mean Shift 向量()h M x 总是指向概率密度增加最大的方向.Mean Shift 算法 算法步骤我们在前面已经指出,我们在提及Mean Shift 向量和Mean Shift 算法的时候指代不同的概念,Mean Shift 向量是名词,指的是一个向量;而Mean Shift 算法是动词,指的是一个迭代的步骤.我们把(8)式的x 提到求和号的外面来,可以得到下式,()11()()()()ni i i i h n i i i x xG w x x hM x x x x G w x h ==-=--∑∑(16)我们把上式右边的第一项记为()h m x ,即11()()()()()ni i i i h n i i i x xG w x x hm x x x G w x h ==-=-∑∑(17)给定一个初始点x ,核函数()G X , 容许误差ε,Mean Shift 算法循环的执行下面三步,直至结束条件满足, (1).计算()h m x (2).把()h m x 赋给x(3).如果()h m x x ε-<,结束循环;若不然,继续执行(1).由(16)式我们知道, ()()h h m x x M x =+,因此上面的步骤也就是不断的沿着概率密度的梯度方向移动,同时步长不仅与梯度的大小有关,也与该点的概率密度有关,在密度大的地方,更接近我们要找的概率密度的峰值,Mean Shift 算法使得移动的步长小一些,相反,在密度小的地方,移动的步长就大一些.在满足一定条件下,Mean Shift 算法一定会收敛到该点附近的峰值,这一收敛性由下面一小节给出证明.算法的收敛性证明我们用{}j y ,1,2,...j =来表示Mean Shift 算法中移动点的痕迹,由(17)式我们可写为,111()()()()ni ji ii j n i ji i x y G w x x h y x y G w x h=+=-=-∑∑, 1,2,...j = (18)与j y 对应的概率密度函数估计值ˆ()jf y 可表示为, 11()ˆ()()ni j i i K j n di i x y K w x h f y h w x ==-⎛⎫ ⎪⎝⎭=∑∑ (19)下面的定理将证明序列{}j y 和{}ˆ()jf y 的收敛性. 定理:如果核函数()K x 有一个凸的,单调递增的剖面函数,核函数()G x 由式(10)和(11)定义,则序列{}j y 和{}ˆ()jf y 是收敛的. 证明:由于n 是有限的,核函数()(0)K x K ≤,因此序列{}ˆ()jf y 是有界的,所以我们只需要证明{}ˆ()j f y 是严格递增的的,即要证明,对所有j=1,2,…如果1j jy y +≠,那么ˆ()j f y 1ˆ()j f y +< (20)不失一般性,我们可以假设0j y =,由(19)式和(10)式,我们可以得到1ˆ()j f y +ˆ()j f y -=221111 ()()n i j i ji ni d i i x y x y k k w x h h h w x +==⎡⎤⎛⎫⎛⎫--⎢⎥ ⎪ ⎪- ⎪ ⎪⎢⎥⎝⎭⎝⎭⎣⎦∑∑ (21) 由于剖面函数()k x 的凸性意味着对所有12,[0,)x x ∈∞且12x x ≠,有'2121()()()()k x k x k x x x ≥+-(22)因为'()()g x k x =-,上式可以写为,2112()()()()k x k x g x x x -≥-(23)结合(21)与(23)式,可以得到,1ˆ()j f y +ˆ()jf y -222111211 ()()ni j i j i i n i d i i x y g x y x w x h h w x ++=+=⎛⎫-⎡⎤⎪≥--⎢⎥⎣⎦ ⎪⎝⎭∑∑2211112112()()ni j T j i j i n i d i i x y g y x y w x h h w x +++=+=⎛⎫-⎡⎤⎪=-⎢⎥⎣⎦ ⎪⎝⎭∑∑12221211112()()()j n nT ii i i j i n d i i i i x x y x g w x y g w x h h h w x +++===⎡⎤⎛⎫⎛⎫=-⎢⎥ ⎪ ⎪ ⎪ ⎪⎢⎥⎝⎭⎝⎭⎣⎦∑∑∑(24)由(18)式我们可以得出,1ˆ()j f y +ˆ()jf y -2211211()n ij n i d i i x y g h hw x +=+=⎛⎫≥ ⎪ ⎪⎝⎭∑∑(25)由于剖面函数()k x 是单调递减的,所以求和项210nii x g h =⎛⎫>⎪ ⎪⎝⎭∑,因此,只要10j j y y +≠= (25)式的右边项严格大于零,即1ˆ()j f y +ˆ()jf y >.由此可证得,序列{}ˆ()j f y 收敛 为了证明序列{}j y 的收敛性,对于0j y ≠,(25)式可以写为1ˆ()j f y +ˆ()jf y -2211211()ni jj jn i d i i x y y y g hhw x +=+=⎛⎫- ⎪≥- ⎪⎝⎭∑∑(26) 现在对于标号j,j+1,…,j+m -1,对(26)式的左右两边分别求和,得到 ˆ()j m f y +ˆ()jf y -22111211...()ni j m j m j m ni d i i x y y y g h h w x +-++-=+=⎛⎫- ⎪≥-+ ⎪⎝⎭∑∑2211211()ni jj jn i d i i x y y y g hhw x +=+=⎛⎫- ⎪+- ⎪⎝⎭∑∑2211211...()j m j m j j n d i i y y y y M h w x ++--+=⎡⎤≥-++-⎢⎥⎣⎦∑2211()j m j n d i i y y M hw x ++=≥-∑(27)其中M 表示对应序列{}j y 的所有求和项21n i ji x y g h =⎛⎫-⎪ ⎪⎝⎭∑的最小值.由于{}ˆ()jf y 收敛,它是一个Cauchy 序列,(27)式意味着{}j y 也是一个Cauchy 序列,因此,序列{}j y 收敛.Mean Shift 的应用从前面关于Mean Shift 和概率密度梯度的关系的论述,我们可以清楚的看到,Mean Shift 算法本质上是一个自适应的梯度上升搜索峰值的方法,如下图所示,如果数据集{},1,...i x i n =服从概率密度函数f(x),给定一个如图初始点x ,Mean Shift 算法就会一步步的移动,最终收敛到第一个峰值点.从这张图上,我们可以看到Mean Shift 至少有如下三方面的应用:(1)聚类,数据集{},1,...i x i n =中的每一点都可以作为初始点,分别执行Mean Shift 算法,收敛到同一个点算作一类;(2)模态的检测,概率密度函数中的一个峰值就是一个模态,Mean Shift在峰值处收敛,自然可以找到该模态.(3)最优化,Mean Shift 可以找到峰值,自然可以作为最优化的方法,Mean Shift 算法进行最优化的关键是要把最优化的目标转化成Mean Shift 隐含估计的概率密度函数.图4.Mean Shift 算法示意图Mean Shift 算法在许多领域获得了非常成功的应用,下面简要的介绍一下其在图像平滑,图像分割以及物体跟踪中的应用,一来说明其强大的生命力,二来使对上文描述的算法有一个直观的了解.图像平滑与分割一幅图像可以表示成一个二维网格点上p 维向量,每一个网格点代表一个象素,1p =表示这是一个灰度图,3p =表示彩色图,3p >表示一个多谱图,网格点的坐标表示图像的空间信息.我们统一考虑图像的空间信息和色彩(或灰度等)信息,组成一个2p +维的向量(,)s r x x x =,其中s x 表示网格点的坐标,r x 表示该网格点上p 维向量特征.我们用核函数,s r h h K 来估计x 的分布, ,s r h h K 具有如下形式,22,2s rs r h h p s r sr C x x K k k h h h h ⎛⎫⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭⎝⎭ (28)其中,s r h h 控制着平滑的解析度,C 是一个归一化常数.我们分别用i x 和i z ,i =1,…,n 表示原始和平滑后的图像.用Mean Shift 算法进行图像平滑的具体步骤如下, 对每一个象素点, 1,初始化1j =,并且使,1i i y x =2,运用Mean Shift 算法计算,1i j y +,直到收敛.记收敛后的值为,i c y3.赋值(),,s ri i i c z x y =图5是原始图像,图中40⨯20白框区域被选中来更好的显示基于Mean Shift 的图像平滑步骤,图6显示了这一区域的平滑步骤,x, y 表示这一区域内的象素点的坐标,图6(a)在一个三维空间显示了各个象素点的灰度值,图6(b)显示各点的移动痕迹,黑点是最终收敛值,图6(c)显示了平滑后的各象素点的灰度值,图6(d)是继续分割后的结果.图5.原始图像图6.(a)原始图像的各象素点灰度值.(b)各象素点的Mean Shift移动路径.(c)平滑后的各象素点的灰度值.(d)分割后的结果图7显示了图5经过平滑后的结果,我们可以看到,草地上的草地纹理被平滑掉了,而图像中边缘仍然很好的保持着..图7平滑后的结果h h是非常重要的参数,人们可以根据解析度的在基于Mean Shift的图像平滑中,式(28)中的,s rh h会对最终的平滑结果有一定的影响,图7显示了这两个参数对平要求而直接给定,不同,s rh影响更大一些.滑结果的影响,我们可以看出,s图8,原始图和平滑后的图基于Mean Shift的图像分割与图像平滑非常类似,只需要把收敛到同一点的起始点归为一类,然后把这一类的标号赋给这些起始点,在图像分割中有时还需要把包含象素点太少类去掉,图6(d)显示分割后的灰度值.图8,显示了图5经过分隔后的结果图8,分割后的结果物体跟踪我们用一个物体的灰度或色彩分布来描述这个物体,假设物体中心位于0x ,则该物体可以表示为()21ˆi i s ns u i x xqC k b x u h δ=⎛⎫- ⎪⎡⎤=-⎣⎦ ⎪⎝⎭∑(29)候选的位于y 的物体可以描述为()21ˆ()hn s s i u h i i x ypy C k b x u h δ=⎛⎫-⎡⎤ ⎪=-⎣⎦ ⎪⎝⎭∑(30)因此物体跟踪可以简化为寻找最优的y ,使得ˆ()u py 与ˆu q 最相似. ˆ()u py 与ˆu q 的最相似性用Bhattacharrya 系数ˆ()y ρ来度量分布,即 []ˆ()(),mu y p y q ρρ=≡= (31)式(31)在ˆu p()0ˆy 点泰勒展开可得,[]1111(),(22m mu u u p y q p y ρ==≈∑ (32)把式(30)带入式,整理可得,[]2111(),22mnhii u i C y x p y q w k h ρ==⎛⎫-≈ ⎪ ⎪⎝⎭∑ (33)其中,1[()mi i u w b x u δ==-∑对式(33)右边的第二项,我们可以利用Mean Shift 算法进行最优化.在Comaniciu 等人的文章中,他们只用平均每帧图像只用4.19次Mean Shift 迭代就可以收敛,他们的结果很显示在600MHz 的PC 机上,他们的程序可以每秒处理30帧352⨯240象素的图像.下图显示了各帧需要的Mean Shift 迭代次数.图9,各帧需要的Mean Shift迭代次数下图显示了Comaniciu等人的跟踪结果图10,基于Mean Shift的物体跟踪结果结论本文回顾了Mean Shift的发展历史,介绍了它的基本思想,给出了具体的算法步骤,详细证明了它与梯度上升搜索法的联系,并给出Mean Shift算法的收敛性证明,最后给出了Mean Shift在图像平滑,图像分割以及实时物体跟踪中的具体应用,显示Mean Shift强大的生命力.参考文献[1]The Estimation of the Gradient of a Density Function, with Applications in Pattern Recognition (1975)[2]Mean shift, mode seeking, and clustering (1995)[3]Mean Shift: a robust approach toward feature space analysis (2002)[4]Real-time tracking of non-rigid objects using mean shift (2000)[5]Mean-shift Blob Tracking through Scale Space (2003)[6]An algorithm for data-driven bandwidth selection(2003)。
均值漂移算法 权重

均值漂移算法权重
均值漂移算法(Mean Shift Algorithm)是一种无参数的非监督学习算法,主要用于聚类和图像分割。
该算法通过在数据空间中寻找数据点密度的局部最大值来发现聚类中心。
均值漂移算法中没有显式的权重参数。
其核心思想是通过计算数据点周围的核密度估计,将每个点移动到其所在区域的密度最大值,直到收敛到局部极值。
这个过程会将数据点聚集在密度最大的区域,形成聚类中心。
在均值漂移算法中,数据点的移动是根据核密度估计的梯度进行的。
可以通过以下步骤来进行均值漂移:
1. 选择核函数:选择一个核函数,通常使用高斯核函数。
2. 确定带宽:确定用于估计核密度的带宽参数。
带宽的选择对算法的性能有很大影响。
3. 初始化数据点:将每个数据点初始化为数据空间中的某个位置。
4. 迭代更新:对于每个数据点,计算其周围数据点的加权平均,根据密度梯度更新数据点的位置,直到收敛为止。
需要注意的是,在均值漂移算法中,所有数据点对于密度估计的贡献是相等的,因此没有显式的权重。
带宽的选择对算法的性能和聚类结果有很大的影响,通常需要通过交叉验证等方法进行调整。
总体而言,均值漂移算法是一种灵活而强大的聚类算法,但在实际应用中需要仔细调整参数以获得最佳结果。
1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Mean Shift 算法步骤
把(8)式的x 提到求和号的外面来,可以得到下式,
()11
(
)()()()n
i i i i h n i i i x x
G w x x h
M x x x x G w x h ==-=--∑∑
(16)
把上式右边的第一项记为()h m x ,即
11
(
)()()()()n
i i i i h n i i i x x
G w x x h
m x x x G w x h ==-=-∑∑
(17)
给定一个初始点x ,核函数()G X , 容许误差ε,Mean Shift 算法循环的执行下面三步,直至结束条件满足, (1)计算()h m x (2)把()h m x 赋给x
(3)如果()h m x x ε-<,结束循环;若不然,继续执行(1).
由(16)式我们知道, ()()h h m x x M x =+,因此上面的步骤也就是不断的沿着概率密度的梯度方向移动,同时步长不仅与梯度的大小有关,也与该点的概率密度有关,在密度大的地方,更接近我们要找的概率密度的峰值,Mean Shift 算法使得移动的步长小一些,相反,在密度小的地方,移动的步长就大一些.在满足一定条件下,Mean Shift 算法一定会收敛到该点附近的峰值,这一收敛性由下面一小节给出证明。
4.3 传统的 Mean Shift 跟踪算法
Mean Shift 算法可以通过自动或半自动的方式来初始化被跟踪的目标。
半自动是指在初始帧,手动选定感兴趣的目标区域;自动方式是通过目标检测方法得到待跟踪的目标区域。
目标区域就是核函数的作用区域,其大小即为核函数的带宽(又名“尺度”)。
本文研究的是彩色视频,采用Mean Shift 算法跟踪目标时,目标特征通常选用目标的颜色特征。
实时处理需要满足低计算量的要求,可以将图像在某种颜色空间下的每个子空间划分为k 个相等的区间,即k 个bin 。
以RGB 空间为例,特征空间中总的bin 数应该是m=k3。
然后计算出图像的颜色
直方图,即为目标模型的描述。
后面视频图像里可能的目标区域的颜色直方图特征则为候选模型的描述。
核函数一般选Epanechikov 函数。
采用恰当的相似度函数来计算当前帧中候选模型和目标模型的相似度,利用求解相似度函数的最大值来获得Mean Shift 向量,即目标在当前帧中的偏移量,目标最终会在数次的迭代计算后收敛到真实位置,从而达到跟踪的目的。
1. 目标模型的描述
假设{x i }i=1,2,...,n 表示目标区域中的n 个像素且目标中心点坐标为x 0,则该目标区域所有像素点的概率分布密度为q u 。
()
2
1
ˆi i s n
s u i x x
q
C k b x u h δ=⎛⎫
- ⎪⎡⎤=-⎣
⎦ ⎪⎝
⎭
∑
(29)
式中k(x)为核函数,用以表示目标颜色直方图的权重,离x 0越近,权重越大。
h 为核函数带宽,b(x)为目标区域x i 的颜色特征。
δ(x)为1维delta 函数,用以判断x i 的索引值与特征值u 是否相等,相等时值为1,否则为0。
C 为归一化常数。
2
011
(||||)n
i i C x x k h ==
-∑ (2)
2. 候选目标模型的描述
初始帧以后目标的可能区域即为候选区域,令其中心位置为y ,区域像素用 {x i }i=1,2,...,n 表示,类比目标模型描述,候选目标模型的概率密度为: 候选的位于y 的物体可以描述为
()2
1
ˆ()h
n s s i u h i i x y
p
y C k b x u h δ=⎛⎫
-⎡⎤ ⎪=-⎣
⎦ ⎪⎝
⎭
∑
(30)
2
01
1
(||||)h n
i i C x x k h ==
-∑ (2) 3. 相似度函数
相似度函数用来衡量目标模型和候选目标模型两者的距离或相似程度。
Mean Shift 算法中使用 Bhattacharyya 系数(又称“巴氏系数”)作为相似度函数,Bhattacharyya 系数是对两个统计样本重叠量的近似计算,用来对两组样本的相
关性进行测量。
因此物体跟踪可以简化为寻找最优的y ,使得ˆ()u p
y 与ˆu q 最相似. ˆ()u p
y 与ˆu q 的最相似性用Bhattacharrya 系数ˆ()y ρ来度量分布,即
[
]ˆ()(),m
u y p y q ρ
ρ=≡= (31)
式(31)在ˆu p
()0ˆy 点泰勒展开可得,
[
]1111(),(22m m
u u u p y q p y ρ==≈∑
(32)
把式(30)带入式,整理可得,
[
]2
111(),22
m
n
h
i
i u i C y x p y q w k h ρ==⎛⎫
-≈ ⎪ ⎪⎝
⎭
∑ (33)
其中1[()m
i i u w b x u δ==-∑4. 目标定位
要寻找当前帧中目标的真实位置,即为要找到最大的候选区域。
首先在当前帧定位前一帧里目标的中心位置来作为当前帧的目标中心,以该点出发开始搜索最优的匹配区域,令其中心为y 。
假设目标候选区域的各特征分布密度为{p u (y)}u=1,2,...,m ,上一帧目标中心点坐标为y 0,则当前帧中跟踪目标的中心位置为y 1。
2011201m
i i i i m i i i y x x w g h y y x w g h ==⎛⎫
- ⎪ ⎪⎝⎭
=⎛⎫- ⎪ ⎪⎝⎭
∑∑ (3)
其中g(x)=-k ´(x),w i 为权重。
(b(x )u)m
i i u w ==- (4) 通过迭代计算y 1值,当前后两次迭代值小于某一个阈值时即可确定跟踪目标在当前帧的位置。
这样比一般的盲搜算法省时高效,通过若干次迭代后便可找到目标的真实位置。