DB数据库导入导出精修订
EXPDB_IMPDB导出数据库和导入数据库操作手册

EXPDB与IMPDB查找oracle的安装路径:echo $ORACLE_HOME;操作步骤:1.需要在数据库创建HEC_DUMP_DIR类似的directory(此命令需要dba权限,例如:在mastest数据库中,需要以masdemo用户身份登陆.)- -Create directory=》create or replace directory DUMP_DIR_TEST as '/u01/oracle/oracle_test';2.授权=》grant read,write on directory DUMP_DIR_TEST to HEC2DEV;3.导出(用su – oracle命令切换到oracle用户下面,执行下面的语句, schemas为当前用户)=》expdp hec2dev/hec2dev directory=DUMP_DIR_TESTdumpfile=hec2dev1102.dmp logfile=DUMP_DIR_TEST:hec2dev1102.log带版本号导出(从高版本导出,导入到低版本时需要带版本号,点击pl/sql的命令窗口或者sqlplus hec2dev/hec2dev@mastest,在最上面都会有版本号):=》expdp hec2dev/ hec2dev directory=DUMP_DIR_TESTdumpfile=autohec2test.dmp logfile=DUMP_DIR_TEST:autohec2test.logschemas=autohec2test version='10.2.0.1.0'可能出现的问题:(1)指定的Net服务名不正确。
解决方法:因为没有配置指定ORACLE_SID,可以用命令:echo $ORACLE_SID 进行查看是否指定了ORACLE_SID,若没有,可以通过命令:exportORACLE_SID=mastest(要导出数据库的sid)解决。
DB2数据导入导出及建库步骤2命令

文档编号:DB2数据导入导出及建库步骤2013年3月关于本文档说明:类型-创建(C)、修改(U)、删除(D)、增加(A);目录关于本文档 (2)DB2 数据导入导出及建库步骤 (4)一、数据库数据的导出 (4)二、编辑导出的数据 (4)三、数据库的创建 (5)四、数据库数据的导入 (5)五、数据库数据的备份与还原 (5)DB2 数据导入导出及建库步骤【说明:LISG为已有数据库,LISG为想要创建的数据库。
】一、数据库数据的导出1、启动DB2服务本地:db2cmd 远程:telnet2、连接数据库db2 connect to LISG user db2inst1 using db2adm273、重启数据库,断开所有连接db2stop forcedb2start4、导出表结构及函数db2look -d LISG-a -e -x -o 20130309.sql -i db2inst1 -w db2adm275、导出基础数据(需指定文件夹目录cd /home/db2inst1/20130309 )db2move LISG export -u db2inst1 -p db2adm27二、编辑导出的数据1、基础数据打tar包命令:进入上级目录,执行“tar -tvf 20130309.tar20130309 ”;2、将导出的建表语句、基础数据放到指定路径下,编辑导出的20130307.sql文件,按照“表结构\视图\函数\存储\RISKAMNT函数”排序。
去掉所有的双引号,更换表与函数的前缀名为想要用的用户名(如“DB2INST1”),去掉开头的connect 并且把所有存在blob字段的表空间(即create语句的IN 后面的表空间)改成新建pagesize 32 K 的表空间(LISG);3、将所有的创建function语句剪切到另一个function.sql文件中去(直接创建function可能会失败);4、编辑db2move.lst文件,将双引号去掉,更换前缀名为想要用的用户名(如“DB2INST1”);三、数据库的创建1、新建数据库LISGdb2 create database LISG using codeset utf-8 territory cn2、查看库信息db2 get db cfg for LISG3、创建缓冲池(连接到LISG后为LISG创建一个pagesize 为32k的缓冲池)db2 connect to LISG user db2inst1 using db2adm27db2 create bufferpool LISGBF immediate size 1000 pagesize 32K4、创建三个表空间,使用刚才建立的缓冲池,使用D:\DB2\LISG处的容器(自动新建)常规表空间:db2 create regular tablespace LISG pagesize 32K managed by system using ('D:\DB2\ LISG) bufferpool LISGBF系统临时表空间:db2 create system temporary tablespace LISG1 pagesize 32K managed by system using ('D:\DB2\ LISG1) bufferpool LISGBF用户临时表空间:db2 create user temporary tablespace LISG2 pagesize 32K managed by system using ('D:\DB2\ LISG2) bufferpool LISGBF四、数据库数据的导入1、连接数据库db2 connect to LISG user db2inst1 using db2adm272、导入表结构db2 –tvf 20130309.sql3、导入函数db2 –tvf function.sql4、导入基础数据db2move LISG load -u db2inst1 -p db2adm27五、数据库数据的备份与还原(一)数据库数据备份1、重启数据库,断开所有连接db2stop forcedb2start2、备份数据库db2 backup database LISG to ‘指定目录’(二)数据库数据还原(备注:当在同一台主机上还原一个新的数据库时产生容器共享冲突)1、重启数据库,断开所有连接db2stop forcedb2start2、删除数据库db2 drop database LISG3、重建数据库LISGdb2 create database LISG using codeset utf-8 territory cn4、查看库信息db2 get db cfg for LISG5、创建缓冲池(连接到LISG后为LISG创建一个pagesize 为32k的缓冲池)db2 connect to LISG user db2inst1 using db2adm27db2 create bufferpool LISGBF immediate size 1000 pagesize 32K6、创建三个表空间,使用刚才建立的缓冲池,使用D:\DB2\LISG处的容器(自动新建)db2 create regular tablespace LISG pagesize 32K managed by system using (/home/db2inst1/LISG/ LISG’)bufferpool LISGBFdb2 create system temporary tablespace LISG1 pagesize 32K managed by system using ('D:\DB2\ LISG1') bufferpool LISGBFdb2 create user temporary tablespace LISG2 pagesize 32K managed by system using ('D:\DB2\ LISG2') bufferpool LISGBF7、还原数据库【说明:备份的数据库(olddb) 与要还原的数据(newdb)名不相同: db2 restore db olddb into newdb 】db2 restore database LISG into LISG(from C:\Documents and Settings\Administrator)友情提示:范文可能无法思考和涵盖全面,供参考!最好找专业人士起草或审核后使用,感谢您的下载!。
DB数据库的导入和导出详解

本文件为您介绍DB2数据库中表结构的导入和导出的两种常用方法,供您参考选择,希望能够对您有所帮助。
方法一在控制中心的对象视图窗口中,选择所要导出表结构的数据表,按住Ctrl或Shift可多选,单击鼠标右键,选择->生成DDL即可。
方法二◆第一步:打开DB2的命令行工具,在DB2安装目录的BIN文件夹下新建一个文件夹data,并且进入该目录。
创建该目录: mkdir data进入该目录: cd data◆第二步:导出表结构,命令行如下:db2look -d dbname -e -a -x -i username -w password -o ddlfile.sql执行成功之后,你会在刚才新建的文件夹下找到该sql文件。
◆第三步:导出数据,命令行如下:db2move databasename export -u username -p password至此,导出数据结束。
2导出表中数据export to [path(例:D:"TABLE1.ixf)] of ixf select [字段(例: * or col1,col2,col3)] from TABLE1;export to [path(例:D:"TABLE1.del)] of del select [字段(例: * or col1,col2,col3)] from TABLE1;导入表的数据import from [path(例:D:"TABLE1.ixf)] of ixf insert into TABLE1;load from [path(例:D:"TABLE1.ixf)] of ixf insert into TABLE1;load from [path(例:D:"TABLE1.ixf)] of ixf replace into TABLE1; // 装入数据前,先删除已存在记录load from [path(例:D:"TABLE1.ixf)] of ixf restart into TABLE1; // 当装入失败时,重新执行,并记录导出结果和错误信息import from [path(例:D:"TABLE1.ixf)] of ixf savecount 1000 messages [path(例:D:"msg.txt)] insert into TABLE1;// 其中,savecount表示完成每1000条操作,记录一次.存在自增长字段的数据导入:load from [path(例:D:"TABLE1.ixf)] of ixf modified by identityignore insert into TABLE1;// 加入modified by identityignore.解除装入数据时,发生的检查挂起:SET INTEGRITY FOR TABLE1 CHECK IMMEDIATE UNCHECKED;命令只对数据通过约束检查的表有效,如果执行还不能解除,有必要检查数据的完整性,是否不符合约束条件,并试图重新整理数据,再执行装入操作.另外,对load和import,字面上的区别是:装入和导入,但仍未理解两者之间的区别.只是性能上load显然优于import.(load 需要更多的权限)。
DB数据库修改方法

DB数据库修改方法数据库的修改操作是指对数据库中的数据进行增、删、改的操作。
在数据库中,数据是以表的形式存放的,所以修改操作实际上是对表中数据的修改。
下面将介绍数据库中常用的修改方法。
1.插入数据:插入数据是将新的数据添加到数据库表中的操作。
可以使用SQL语句的INSERTINTO语句来实现。
INSERTINTO语句的基本语法如下:INSERT INTO table_name (column1, column2, ...) VALUES(value1, value2, ...);2.更新数据:更新数据是修改数据库表中已有数据的操作。
可以使用SQL语句的UPDATE语句来实现。
UPDATE语句的基本语法如下:UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;3.删除数据:删除数据是将数据库表中的数据删除的操作。
可以使用SQL语句的DELETE语句来实现。
DELETE语句的基本语法如下:DELETE FROM table_name WHERE condition;4.添加列:在数据库表中添加新的列或字段。
可以使用SQL语句的ALTERTABLE语句来实现。
ALTERTABLE语句的基本语法如下:ALTER TABLE table_name ADD column_name datatype;5.删除列:在数据库表中删除已有的列或字段。
可以使用SQL语句的ALTERTABLE语句来实现。
ALTERTABLE语句的基本语法如下:ALTER TABLE table_name DROP COLUMN column_name;6.修改列数据类型、长度等属性:在数据库表中修改已有的列的数据类型、长度等属性。
可以使用SQL 语句的ALTERTABLE语句来实现。
ALTERTABLE语句的基本语法如下:ALTER TABLE table_name MODIFY COLUMN column_name datatype; 7.修改表名:在数据库中修改表的名称。
数据库表导入与导出方法

数据库表导入与导出方法数据库表导入与导出方法SERVER、ACCESS、EXCEL数据转换,详细说明如下:一、SQL SERVER 和ACCESS的数据导入导出常规的数据导入导出:使用DTS向导迁移你的Access数据到SQL Server,你可以使用这些步骤: ○1在SQL SERVER企业管理器中的Tools(工具)菜单上,选择Data Transformation○2Services(数据转换服务),然后选择 czdImport Data(导入数据)。
○3在Choose a Data Source(选择数据源)对话框中选择Microsoft Access as the Source,然后键入你的.mdb数据库(.mdb 文件扩展名)的文件名或通过浏览寻找该文件。
○4在Choose a Destination(选择目标)对话框中,选择Microsoft OLE DB Prov ider for SQL Server,选择数据库服务器,然后单击必要的验证方式。
○5在Specify Table Copy(指定表格复制)或Query(查询)对话框中,单击Copy tables(复制表格)。
○6在Select Source Tables(选择源表格)对话框中,单击Select All(全部选定)。
下一步,完成。
Transact-SQL语句进行导入导出:1.在SQL SERVER里查询access数据:SELECT *FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0','Data Source="c:\DB.mdb";User ID=Admin;Password=')...表名2.将access导入SQL server在SQL SERVER 里运行:SELECT *INTO newtableFROM OPENDATASOURCE ('Microsoft.Jet.OLEDB.4.0','Data Source="c:\DB.mdb";User ID=Admin;Password=' )...表名3.将SQL SERVER表里的数据插入到Access表中在SQL SERVER 里运行:insert into OpenDataSource( 'Microsoft.Jet.OLEDB.4.0','Data Source=" c:\DB.mdb";User ID=Admin;Password=')...表名(列名1,列名2)select 列名1,列名2 from sql表实例:insert into OPENROWSET('Microsoft.Jet.OLEDB.4.0','C:\db.mdb';'admin';'', Test)select id,name from TestINSERT INTO OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\trade.mdb';'admin'; '', 表名)SELECT *FROM sqltablename二、SQL SERVER 和EXCEL的数据导入导出1、在SQL SERVER里查询Excel数据:SELECT *FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0','Data Source="c:\book1.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...[Sheet1$] 下面是个查询的示例,它通过用于Jet 的OLE DB 提供程序查询Excel 电子表格。
EXPDB_IMPDB导出数据库和导入数据库操作手册

EXPDB_IMPDB导出数据库和导入数据库操作手册EXPDP/IMPDP导出导入操作手册1.介绍EXPDP/IMPDP 是 Oracle 数据库中提供的一种工具,用于导出和导入数据库中的数据和对象。
通过使用 EXPDP 可以将数据库中的指定数据表、视图、程序、触发器等对象导出到一个二进制文件中,而使用 IMPDP 可以将这个导出的文件再导入到一个新的数据库中。
2.环境设置在使用 EXPDP/IMPDP 前,需要进行一些环境设置。
首先,确保数据库已经以归档模式运行,并且存在一个有效的备份策略。
其次,确认当前用户具备使用 EXPDP/IMPDP 的权限,可以通过以下语句进行授权:```GRANT EXP_FULL_DATABASE, IMP_FULL_DATABASE TO username;```其中,`username` 是需要授权的用户名。
3.导出数据库要导出数据库,可以使用以下命令:```expdp username/passwordconnect_stringDIRECTORY=directory_name DUMP LOG```其中,`username` 是要导出数据的用户名,`password` 是该用户的密码,`connect_string` 是连接数据库的字符串,`directory_name` 是导出文件所在的目录,`dump` 是导出文件的名称,`log` 是导出日志文件的名称。
4.导入数据库要导入数据库,可以使用以下命令:```impdp username/passwordconnect_stringDIRECTORY=directory_name DUMP LOG```其中,`username` 是要导入数据的用户名,`password` 是该用户的密码,`connect_string` 是连接数据库的字符串,`directory_name` 是导入文件所在的目录,`dump` 是导入文件的名称,`log` 是导入日志文件的名称。
DB数据库导入导出

DB数据库导⼊导出D B数据库导⼊导出⽂件排版存档编号:[UYTR-OUPT28-KBNTL98-UYNN208]D B2数据导⼊导出2012年3⽉12⽇编辑:徐彦⼀、环境操作系统:Redhat Linux AS( #1 SMP i686 i386 GNU/Linux)数据库版本:DB2 WorkGroup版 V9.7.0(数据库版本可通过连接数据库来查看,db2 connect to dbname)⼆、声明实例⽤户,默认为db2inst1Das⽤户,默认为dasusr1数据库安装⽬录($INSTHOME),默认为/opt/ibm/db2/实例安装⽬录($HOME),默认为/home/db2inst1/实例名:db2inst1数据库名:三、导出具体步骤导出对象结构建议单独创建⼀个数据导出⽬录,利于导出⽂件整理的清晰。
$ su – db2inst1# 切换⾄db2inst1⽤户$ cd /#为导出⽬录,例如/home/db2inst1/dbdmp(db2inst1要有相应的读写权限)$ db2 connect to# 连接⾄数据库$ db2look –d -e –a –l –o .sql# 导出数据库对象创建脚本例⼦:数据库名为meibof导出数据库数据(建议在⽬录下另建db2move的⽬录⽤来存放导出数据,因为db2move 命令会产⽣若⼲⽂件)db2move export(如果导出是发现有warning,在上⾯的命名后⾯加上 -aw参数)以数据库名为meibof为例:四、导⼊具体步骤建⽴新数据库$ su – db2inst1# 切换⾄db2inst1⽤户db2 create db (建议使⽤db2cc⼯具来进⾏创建数据库)创建名为meibof的数据库:执⾏.sql脚本创建数据库切换到放置.sql的⽬录db2 –tvf .sql(单次导⼊有可能丢失数据结构,建议连续执⾏3次,导⼊完成后,和开发⼈员确认数据库对象的数量,尤其是存储过程。
Oracle使用expdb、impdb解决导出、导入时的用户修改、表空间修改变更问题

Oracle使⽤expdb、impdb解决导出、导⼊时的⽤户修改、表空间修改变更问题对于Oracle的数据导出和导⼊,我们之前⼀直使⽤exp、imp来处理,但⽤imp在导⼊时经常会要求表空间⼀致,⽽博主今天恰恰就遇到了需要变更表空间和⽤户的情况,这在我们平常的业务场景中也会遇到,那么该如何处理呢?我们采⽤Oralce的 “数据泵” Data Dump来处理。
测试环境:Windows Server 2008 R2、Oracle11g⽬录1、数据泵(Data Dump)主要解决问题2、数据泵使⽤限制3、创建测试数据库4、导出源数据库5、导⼊⽬标数据库6、验证导⼊后表空间1、数据泵(Data Dump)主要解决问题①. ⽐imp/exp更加灵活,⽀持多种元数据过滤策略,多种导⼊、导出模式,如将A表空间B⽤户数据导⼊C表空间D⽤户下,则只需REMAP_SCHEMA即可②. 表空间占⽤和表空间变更问题,可使⽤REMAP_TABLESPACE来解决③. 空表问题,Oracle11g新的表并且表中⽆数据也为使⽤过则表的segment空间是不会分配的,这样在使⽤exp导出时空表便不会被导出,解决这个问题要么给空分配segment或直接使⽤expdp。
④. 效率问题。
普通情况下expdp/impdp⽐exp/imp效率要⾼,⾼多少博主没有测试,有兴趣的不妨验证下,@博主。
2、数据泵使⽤限制使⽤expdp、impdp有条件限制⼀是远程使⽤时必须配置好Database Link,因为expdp、impdp只能在服务端使⽤,不能再客户端使⽤;⼆是试⽤前要解决路径配置问题。
3、创建测试数据库创建源⽤户和表空间,为了便于操作我们给新创建⽤户授权的了dba权限,⼤家在本地使⽤时注意1. /*第1步:创建临时表空间 */2. create temporary tablespace test_source_temp3. tempfile 'D:\Oracle11g\oradata\test_source_temp.dbf'4. size 10m5. autoextend on6. next 1m maxsize unlimited7. extent management local;8.9. /*第2步:创建数据表空间 */10. create tablespace test_source11. logging12. datafile 'D:\Oracle11g\oradata\test_source.dbf'13. size 10m14. autoextend on15. next 1m maxsize unlimited16. extent management local;17.18. /*第3步:创建⽤户并指定表空间 */19. create user test_source identified by a12345620. default tablespace test_source21. temporary tablespace test_source_temp;22.23. /*第4步:给⽤户授予权限 */24. grant connect,resource,dba to test_source;创建两张测试表,⼀张基础数据类型,⼀张含clob、blob、date等复杂数据类型1. --表12. create table tab_13. (4. tab1_field1 number,5. tab1_field2 varchar2(20),6. tab1_field3 varchar2(10)9. insert into TAB_1 (tab1_field1, tab1_field2, tab1_field3) values (1, 'a12', 'a13');10. insert into TAB_1 (tab1_field1, tab1_field2, tab1_field3) values (2, '张22', '李23');11.12. --表213. create table TAB_214. (15. tab2_field1 NUMBER,16. tab2_field2 VARCHAR2(20),17. tab2_field3 DATE,18. tab2_field4 CLOB,19. tab2_field5 BLOB20. )21. --插⼊测试数据22. insert into TAB_2 (tab2_field1,tab2_field2,tab2_field3,tab2_field4,tab2_field5) values ('1','A12',SYSDATE,'测试1','C1');23. insert into TAB_2 (tab2_field1,tab2_field2,tab2_field3,tab2_field4,tab2_field5) values ('1','测试22',SYSDATE,'测试2','C2');24. insert into TAB_2 (tab2_field1,tab2_field2,tab2_field3,tab2_field4,tab2_field5) values ('1','嘿嘿32',SYSDATE,'测试3','C3');创建⽬标⽤户和表空间1. /*第1步:创建临时表空间 */2. create temporary tablespace test_target_temp3. tempfile 'D:\Oracle11g\oradata\test_target_temp.dbf'4. size 10m5. autoextend on6. next 1m maxsize unlimited7. extent management local;8.9. /*第2步:创建数据表空间 */10. create tablespace test_target11. logging12. datafile 'D:\Oracle11g\oradata\test_target.dbf'13. size 10m14. autoextend on15. next 1m maxsize unlimited16. extent management local;17.18. /*第3步:创建⽤户并指定表空间 */19. create user test_target identified by a12345620. default tablespace test_target21. temporary tablespace test_target_temp;22.23. /*第4步:给⽤户授予权限 */24. grant connect,resource,dba to test_target;4、导出源数据库这⾥需要注意:EXP和IMP是客户端⼯具程序,它们既可以在客户端使⽤,也可以在服务端使⽤。
数据库导入导出方法

1、在数据库新建一个表
1)在左边对象里选中“表”。
点上面“新建”选项。
2)出现一个对话框。
选“导入表”。
点“确定”。
3)出现对话框,选你要导入有Excel表。
4)导入后会出现“导入数据表向导”。
(1)选中“显示工作表”点“下一步”。
(2)选中“第一行包含列标题”点“下一步”。
(3)选中“新表中”点“下一步”。
(4)“下一步”。
(5)选中“不要主键”,点“下一步”
(6)“导入到表:”改表名,点完成。
5)左边“对象”选中“报表”,在右边点“”。
(1)在“表/查询”下选要导出的表名。
将下面“可用字段”里的选项。
按导出顺序依次选入“选定的字段”里,点“下一步”。
(2)点“下一步”,到报表布局方式,在“布局里”选“纵栏表”,方向选“纵向”。
点下一步。
(3)点“下一步”,选“修改报表设计”,点完成。
6)完成创建报表后会弹出报表修改的对话框。
(1)先删除页眉页脚。
(在表格处单击鼠标右键,点页眉页脚就可以删除。
)
(2)只留“主体”。
将主体中的字段调整到导出字段的大小,关闭报表保存。
7)选中报表,在工具栏里找到导出选择用WDRD导出。
(2)导出WORD后保存。
uxdb数据库常用命令

uxdb数据库常用命令UXDB数据库是一种常用的数据库,它具有丰富的命令,用于管理和操作数据库。
本文将介绍一些常用的UXDB数据库命令,帮助读者更好地了解和使用UXDB数据库。
1. 创建数据库命令在UXDB数据库中,我们可以使用"CREATE DATABASE"命令来创建一个新的数据库。
例如,我们可以使用以下命令创建一个名为"mydb"的数据库:CREATE DATABASE mydb;2. 创建表命令在UXDB数据库中,我们可以使用"CREATE TABLE"命令来创建一个新的表。
例如,我们可以使用以下命令创建一个名为"users"的表:CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT);3. 插入数据命令在UXDB数据库中,我们可以使用"INSERT INTO"命令向表中插入数据。
例如,我们可以使用以下命令向"users"表中插入一条新的记录:INSERT INTO users (id, name, age) VALUES (1, 'John', 25);4. 查询数据命令在UXDB数据库中,我们可以使用"SELECT"命令来查询表中的数据。
例如,我们可以使用以下命令查询"users"表中的所有记录:SELECT * FROM users;5. 更新数据命令在UXDB数据库中,我们可以使用"UPDATE"命令来更新表中的数据。
例如,我们可以使用以下命令将"users"表中id为1的记录的年龄更新为30:UPDATE users SET age = 30 WHERE id = 1;6. 删除数据命令在UXDB数据库中,我们可以使用"DELETE"命令来删除表中的数据。
数据库数据导入与导出的技巧与方法

数据库数据导入与导出的技巧与方法随着信息时代的来临,数据成为企业和个人生活中不可或缺的一部分。
有效地管理和处理数据变得至关重要。
数据库是存储和管理大量结构化数据的理想工具,它使得数据的访问、更新和分析变得更加高效和可靠。
然而,数据库的真正价值在于其数据的导入和导出功能。
数据的导入和导出是将现有的数据存储到数据库中或从数据库中提取数据的过程。
在本文中,我们将介绍一些数据库数据导入和导出的技巧和方法,帮助您更好地管理和利用您的数据。
一、导入数据的技巧与方法1. 使用数据库管理软件数据库管理软件(例如MySQL Workbench、Navicat等)通常提供了直观且易于使用的界面,使得数据导入过程更加简单。
这些软件通常具有导入向导,可以快速指导用户导入各种数据格式。
首先,您需要选择要导入的数据文件(如CSV、Excel等),然后选择目标数据表和字段映射关系。
最后,您可以预览和验证导入数据,并执行导入操作。
2. 使用SQL语句对于一些精通SQL语句的用户来说,使用SQL语句直接导入数据也是一个不错的选择。
您可以使用LOAD DATA INFILE语句将文本文件导入到数据库中,该语句可以根据指定的格式将文件中的数据导入到指定的数据表中。
此方式适用于大批量数据导入,速度较快且能够保留数据的完整性。
3. 使用ETL工具ETL(Extract Transform Load)工具是一种用于将数据从一个数据库(或文件)提取出来,然后经过一系列的清洗和转换处理后,再加载到另一个数据库(或文件)中的工具。
常见的ETL工具如Talend、Pentaho等。
这些工具提供了可视化的界面和强大的数据处理能力,能够满足复杂的数据导入需求。
二、导出数据的技巧与方法1. 使用数据库管理软件数据库管理软件往往也提供了数据导出的功能。
您可以选择要导出的数据表和字段,然后指定导出的格式(如CSV、Excel、SQL等),最后执行导出操作。
Step75.5下DB数据块导入导出及DB当前值存储为默认值报告
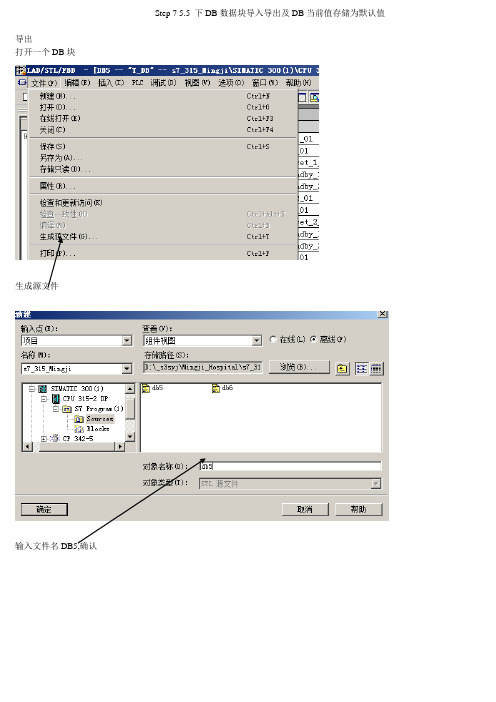
Step 7 5.5 下DB数据块导入导出及DB当前值存储为默认值
导出
打开一个DB块
生成源文件
输入文件名DB5,确认
Simatic manager
Source> DB5>右键>导出源文件
新建一个excel文件
导入外部数据
按教程操作,注意导入完成后
最后的;不能少,否则编译时候会出错.
Begain
End_data_block
之间的数据可以删除
增加减少数据到你想要的数据
另存为prn格式
保存的文件后缀名改一下.prn > .awl
Sources >插入新对象>外部文件选择刚才重命名的awl文件
注意DB号,每句结束的; 保存编译,没有出错的话,就导入导出完成.
DB块的初始值传送给CPU 作为实际值Simatic manager View >oline 打开DB块
先保存,再生成源文件
选中DB
导出到文件夹Excel导入外部数据
BEGIN END_DATA_BLOCK 之间是当前数据
复制到对应区域.
在另存为prn ,改名awl ,导入, 打开, 保存编译. 注意,数据要建立得整齐一些.否则删除多余的;吧.。
expdpimpdp数据库导入导出命令详解

expdpimpdp数据库导⼊导出命令详解⼀、创建逻辑⽬录,该命令不会在操作系统创建真正的⽬录,最好以system等管理员创建。
create directory dpdata1 as 'd:\test\dump';⼆、查看管理理员⽬录(同时查看操作系统是否存在,因为Oracle并不关⼼该⽬录是否存在,如果不存在,则出错)select * from dba_directories;三、给scott⽤户赋予在指定⽬录的操作权限,最好以system等管理员赋予。
grant read,write on directory dpdata1 to scott;四、导出数据1)按⽤户导expdp scott/tiger@orcl schemas=scott dumpfile=expdp.dmp DIRECTORY=dpdata1;2)并⾏进程parallelexpdp scott/tiger@orcl directory=dpdata1 dumpfile=scott3.dmp parallel=40 job_name=scott33)按表名导expdp scott/tiger@orcl TABLES=emp,dept dumpfile=expdp.dmp DIRECTORY=dpdata1;4)按查询条件导expdp scott/tiger@orcl directory=dpdata1 dumpfile=expdp.dmp Tables=emp query='WHERE deptno=20';5)按表空间导expdp system/manager DIRECTORY=dpdata1 DUMPFILE=tablespace.dmp TABLESPACES=temp,example;6)导整个数据库expdp system/manager DIRECTORY=dpdata1 DUMPFILE=full.dmp FULL=y;五、还原数据1)导到指定⽤户下impdp scott/tiger DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=scott;2)改变表的ownerimpdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp TABLES=scott.dept REMAP_SCHEMA=scott:system;3)导⼊表空间impdp system/manager DIRECTORY=dpdata1 DUMPFILE=tablespace.dmp TABLESPACES=example;4)导⼊数据库impdb system/manager DIRECTORY=dump_dir DUMPFILE=full.dmp FULL=y;5)追加数据impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=system TABLE_EXISTS_ACTION=append;----------------------------Expdp/Impdp的相关参数----------------------------EXPDP命令⾏选项1. ATTACH该选项⽤于在客户会话与已存在导出作⽤之间建⽴关联.语法如下ATTACH=[schema_name.]job_nameSchema_name⽤于指定⽅案名,job_name⽤于指定导出作业名.注意,如果使⽤ATTACH选项,在命令⾏除了连接字符串和ATTACH选项外,不能指定任何其他选项,⽰例如下:Expdp scott/tiger ATTACH=scott.export_job2. CONTENT该选项⽤于指定要导出的内容.默认值为ALLCONTENT={ALL | DATA_ONLY | METADATA_ONLY}当设置CONTENT为ALL 时,将导出对象定义及其所有数据.为DATA_ONLY时,只导出对象数据,为METADATA_ONLY时,只导出对象定义Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dumpCONTENT=METADATA_ONLY3. DIRECTORY指定转储⽂件和⽇志⽂件所在的⽬录DIRECTORY=directory_objectDirectory_object⽤于指定⽬录对象名称.需要注意,⽬录对象是使⽤CREATE DIRECTORY语句建⽴的对象,⽽不是OS ⽬录Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dump建⽴⽬录:CREATE DIRECTORY dump as ‘d:dump’;查询创建了那些⼦⽬录:SELECT * FROM dba_directories;4. DUMPFILE⽤于指定转储⽂件的名称,默认名称为expdat.dmpDUMPFILE=[directory_object:]file_name [,….]Directory_object⽤于指定⽬录对象名,file_name⽤于指定转储⽂件名.需要注意,如果不指定directory_object,导出⼯具会⾃动使⽤DIRECTORY选项指定的⽬录对象Expdp scott/tiger DIRECTORY=dump1 DUMPFILE=dump2:a.dmp5. ESTIMATE指定估算被导出表所占⽤磁盘空间分⽅法.默认值是BLOCKSEXTIMATE={BLOCKS | STATISTICS}设置为BLOCKS时,oracle会按照⽬标对象所占⽤的数据块个数乘以数据块尺⼨估算对象占⽤的空间,设置为STATISTICS时,根据最近统计值估算对象占⽤空间Expdp scott/tiger TABLES=emp ESTIMATE=STATISTICSDIRECTORY=dump DUMPFILE=a.dump6. EXTIMATE_ONLY指定是否只估算导出作业所占⽤的磁盘空间,默认值为NEXTIMATE_ONLY={Y | N}设置为Y时,导出作⽤只估算对象所占⽤的磁盘空间,⽽不会执⾏导出作业,为N时,不仅估算对象所占⽤的磁盘空间,还会执⾏导出操作. Expdp scott/tiger ESTIMATE_ONLY=y NOLOGFILE=y7. EXCLUDE该选项⽤于指定执⾏操作时释放要排除对象类型或相关对象EXCLUDE=object_type[:name_clause] [,….]Object_type⽤于指定要排除的对象类型,name_clause⽤于指定要排除的具体对象.EXCLUDE和INCLUDE不能同时使⽤Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dup EXCLUDE=VIEW8. FILESIZE指定导出⽂件的最⼤尺⼨,默认为0,(表⽰⽂件尺⼨没有限制)9. FLASHBACK_SCN指定导出特定SCN时刻的表数据FLASHBACK_SCN=scn_valueScn_value⽤于标识SCN值.FLASHBACK_SCN和FLASHBACK_TIME不能同时使⽤Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dmpFLASHBACK_SCN=35852310. FLASHBACK_TIME指定导出特定时间点的表数据FLASHBACK_TIME=”TO_TIMESTAMP(time_value)”Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dmp FLASHBACK_TIME=“TO_TIMESTAMP(’25-08-2004 14:35:00’,’DD-MM-YYYY HH24:MI:SS’)”11. FULL指定数据库模式导出,默认为NFULL={Y | N}为Y时,标识执⾏数据库导出.12. HELP指定是否显⽰EXPDP命令⾏选项的帮助信息,默认为N当设置为Y时,会显⽰导出选项的帮助信息.Expdp help=y13. INCLUDE指定导出时要包含的对象类型及相关对象INCLUDE = object_type[:name_clause] [,… ]14. JOB_NAME指定要导出作⽤的名称,默认为SYS_XXXJOB_NAME=jobname_string15. LOGFILE指定导出⽇志⽂件⽂件的名称,默认名称为export.logLOGFILE=[directory_object:]file_nameDirectory_object⽤于指定⽬录对象名称,file_name⽤于指定导出⽇志⽂件名.如果不指定directory_object.导出作⽤会⾃动使⽤DIRECTORY 的相应选项值.Expdp scott/tiger DIRECTORY=dump DUMPFILE=a.dmp logfile=a.log16. NETWORK_LINK指定数据库链名,如果要将远程数据库对象导出到本地例程的转储⽂件中,必须设置该选项.17. NOLOGFILE该选项⽤于指定禁⽌⽣成导出⽇志⽂件,默认值为N.18. PARALLEL指定执⾏导出操作的并⾏进程个数,默认值为119. PARFILE指定导出参数⽂件的名称PARFILE=[directory_path] file_name20. QUERY⽤于指定过滤导出数据的where条件QUERY=[schema.] [table_name:] query_clauseSchema ⽤于指定⽅案名,table_name⽤于指定表名,query_clause⽤于指定条件限制⼦句.QUERY选项不能与 CONNECT=METADATA_ONLY,EXTIMATE_ONLY,TRANSPORT_TABLESPACES等选项同时使⽤.Expdp scott/tiger directory=dump dumpfiel=a.dmpTables=emp query=’WHERE deptno=20’21. SCHEMAS该⽅案⽤于指定执⾏⽅案模式导出,默认为当前⽤户⽅案.22. STATUS指定显⽰导出作⽤进程的详细状态,默认值为023. TABLES指定表模式导出TABLES=[schema_name.]table_name[:partition_name][,…]Schema_name⽤于指定⽅案名,table_name⽤于指定导出的表名,partition_name⽤于指定要导出的分区名.24. TABLESPACES指定要导出表空间列表25. TRANSPORT_FULL_CHECK该选项⽤于指定被搬移表空间和未搬移表空间关联关系的检查⽅式,默认为N.当设置为Y时,导出作⽤会检查表空间直接的完整关联关系,如果表空间所在表空间或其索引所在的表空间只有⼀个表空间被搬移,将显⽰错误信息.当设置为N时, 导出作⽤只检查单端依赖,如果搬移索引所在表空间,但未搬移表所在表空间,将显⽰出错信息,如果搬移表所在表空间,未搬移索引所在表空间,则不会显⽰错误信息.26. TRANSPORT_TABLESPACES指定执⾏表空间模式导出27. VERSION指定被导出对象的数据库版本,默认值为COMPATIBLE.VERSION={COMPATIBLE | LATEST | version_string}为COMPATIBLE时,会根据初始化参数COMPATIBLE⽣成对象元数据;为LATEST时,会根据数据库的实际版本⽣成对象元数据.version_string ⽤于指定数据库版本字符串.调⽤EXPDP使⽤EXPDP⼯具时,其转储⽂件只能被存放在DIRECTORY对象对应的OS⽬录中,⽽不能直接指定转储⽂件所在的OS⽬录.因此,使⽤EXPDP⼯具时,必须⾸先建⽴DIRECTORY对象.并且需要为数据库⽤户授予使⽤DIRECTORY对象权限.-------------------------------------应⽤-------------------------------------Data Pump 反映了整个导出/导⼊过程的完全⾰新。
数据库管理软件数据导入导出要点总结

数据库管理软件数据导入导出要点总结一、导入导出概述数据库管理软件的导入导出功能是指将外部数据导入到数据库中,或将数据库中的数据导出到外部文件中。
在数据库管理过程中,数据的导入导出是一个非常重要的环节,它涉及到数据的安全性、数据的完整性以及数据的准确性。
因此,在进行数据导入导出时,需要遵循一定的要点和规范,以确保数据的有效性和可靠性。
二、数据导入要点总结1. 数据格式的匹配在进行数据导入前,需确保导入数据的格式与目标数据库的格式能够匹配,否则可能导致数据丢失或错误。
可以通过预处理数据、调整数据的结构并进行数据类型转换等方式来实现数据格式的匹配。
2. 数据清洗及筛选在导入数据之前,需要对数据进行清洗和筛选,剔除可能存在的无效数据和重复数据,以减少数据导入的时间和资源消耗。
同时,也可以根据需要筛选出特定的数据,并进行相应的数据处理。
3. 数据一致性的检查在进行数据导入之前,需要对目标数据库已有的数据进行一致性检查,确保导入的数据与已有数据的一致性。
可使用一致性检查工具对数据进行验证,比对数据的主键和外键,确保数据的完整性和正确性。
4. 数据备份和恢复在进行数据导入之前,务必先进行数据备份,以备数据导入过程中出现错误或数据丢失的情况。
同时,也要确保有相应的数据恢复计划和手段,以便在需要时能够恢复导入前的数据状态。
5. 导入速度和效率的优化数据导入过程中,可能会涉及大量的数据量和复杂的操作,导致耗时较长。
为提高导入速度和效率,可以采用批量导入方式,在数据导入前进行适当的数据分组和预处理,减少对数据库的访问次数,提高导入的效率。
三、数据导出要点总结1. 导出数据的选择在进行数据导出时,需根据需求选择导出的数据。
可以根据时间范围、条件过滤等方式选择导出的数据,以满足不同的业务需求。
2. 数据导出格式的选择根据导出数据的用途和需求,选择合适的导出格式。
常见的导出格式有CSV、Excel、文本文件等,可以根据数据的结构和研究目的选择合适的格式。
数据库技术中的数据导入与数据导出(四)

数据库技术中的数据导入与数据导出在数据库管理系统中,数据导入和数据导出是非常重要的操作,它们提供了将数据从一个数据库系统迁移到另一个数据库系统的途径,也提供了将数据用于其他应用程序的方式。
本文将对数据库技术中的数据导入和数据导出进行讨论。
一、数据导入数据导入是将外部数据存储到数据库中的过程。
在实际应用中,数据导入的需求非常普遍,比如将外部数据文件导入到数据库中进行统计分析和数据挖掘,或者将其他数据库系统中的数据导入到新的数据库系统中。
1. 导入数据的格式在数据导入的过程中,最常见的数据格式包括CSV(逗号分隔值)文件、Excel文件、XML文件和JSON文件等。
CSV文件是最常用的导入数据格式,它使用逗号或其他字符作为字段的分隔符,每行表示一个记录。
Excel文件可以存储多个工作表和复杂的数据结构,在导入数据时需要指定要导入的工作表和数据范围。
XML和JSON文件是用于存储结构化数据的格式,导入时需要解析文件并将数据转换为数据库表的形式。
2. 导入数据的方法在数据库技术中,有多种方法可以实现数据导入。
最常见的方法包括使用SQL语句、使用ETL工具和使用编程语言。
使用SQL语句导入数据是最简单和直接的方法。
可以使用LOAD DATA INFILE语句将CSV文件的数据导入到数据库表中,或使用INSERT INTO语句逐条插入数据。
ETL工具(抽取、转换和加载)是专门用于数据导入和数据转换的工具。
通过ETL工具,可以定义数据源、目标和转换规则,实现数据从源系统到目标系统的导入过程。
使用编程语言进行数据导入是最灵活和强大的方法。
通过编程语言,可以自定义数据导入的逻辑和流程,实现更复杂的数据转换和数据验证。
二、数据导出数据导出是将数据库中的数据存储到外部文件或其他数据库系统中的过程。
数据导出常用于数据备份、数据共享和数据集成等应用场景。
1. 导出数据的格式在数据导出的过程中,可以选择不同的数据格式来存储导出的数据。
数据库中的数据导入与导出工具及方法

数据库中的数据导入与导出工具及方法在数据库管理和数据分析领域,数据导入与导出是一项非常重要的工作。
数据库中存储着大量有价值的数据,而将这些数据导入或导出到其他系统或文件中,可以为企业决策和业务运营提供有力的支持。
本文将介绍数据库中常用的数据导入与导出工具及方法,帮助读者更好地进行数据处理和管理。
一、数据导入工具及方法1. SQL INSERT语句导入:对于小规模的数据导入,最简单的方法是使用SQL语句中的INSERT语句。
通过编写INSERT语句,我们可以将数据逐条插入到数据库表中。
这种方法适用于手动录入或者导入少量数据的情况,但对于大规模数据导入来说可能会比较繁琐。
2. 数据库管理工具导入:市面上有许多数据库管理工具,例如MySQL Workbench、Navicat 等,这些工具提供了直观的界面和功能强大的导入功能,可以快速导入大量数据。
用户只需选择数据源、目标表和数据文件,然后进行映射和校验,最后点击导入按钮即可完成数据导入操作。
3. 数据集成工具导入:数据集成工具如Talend、Kettle等提供了丰富的数据导入功能。
用户可以通过可视化拖拽、配置参数等方式,将数据从不同的源系统导入到目标数据库中。
这些工具通常支持各种数据源的连接,同时对数据的清洗和转换也提供了强大的功能,可以满足复杂数据导入的需求。
二、数据导出工具及方法1. SQL SELECT语句导出:类似于数据导入,我们可以使用SQL SELECT语句来导出特定的数据。
通过编写SELECT语句,并将结果保存为文本文件,我们可以实现数据的导出操作。
这种方法适用于导出少量数据或特定查询结果的情况。
2. 数据库管理工具导出:数据库管理工具提供了直观的导出功能,用户只需要选择数据源、目标文件格式和导出路径,然后点击导出按钮即可。
这些工具通常支持各种常见的文件格式,如CSV、Excel等,并可以设置数据分隔符、编码方式以及导出字段等参数。
3. 数据集成工具导出:数据集成工具也可以用于数据导出操作。
使用MongoDB命令工具导出、导入数据

使⽤MongoDB命令⼯具导出、导⼊数据Windows 10家庭中⽂版,MongoDB 3.6.3,前⾔在前⾯的测试中,已经往MongoDB的数据库中写⼊了⼀些数据。
现在要重新测试程序,数据库中的旧数据需要被清理掉,可是,⼜想保存之前写⼊的数据,于是,就需要导出数据(或备份)了——使⽤MongoDB提供的mongoexport命令。
顺便测试了导出操作的反向操作——导⼊数据,使⽤mongoimport命令。
注意,MongoDB的bin⽬录已经添加到Windows环境变量path中了。
那么,两个命令怎么使⽤呢?使⽤命令 + --help参数:可以查看帮助信息中的链接中更详细的信息mongoexport官⽂:/manual/reference/program/mongoexport/mongoimport官⽂:/manual/reference/program/mongoimport/操作操作1:导出数据将认证数据库globalnews下的数据全部导出到当前⽬录下的⽂件0713_news_bck.json中。
另外,mongoexport命令也可以使⽤的/uri选项的⽅式操作,可以对照使⽤帮助来操作。
D:\ws\mdb_backup>mongoexport /u reporter /p 111111 /authenticationDatabase globalnews /d globalnews /c news /o0713_news_bck.json2018-07-13T16:36:31.977+0800 connected to: localhost2018-07-13T16:36:32.046+0800 exported 363 records导出的数据⽂件:默认⽤json格式,也可以存储为csv格式或其它(甚⾄可以⾃定义?)说明,mongoexport导出的数据,就只是数据,是没有数据库、集合相关信息的。
数据库数据导入与导出的最佳实践的说明书

数据库数据导入与导出的最佳实践的说明书在当今信息技术高速发展的时代,数据对于企业和个人来说越来越重要。
数据库作为一种存储和管理数据的工具,扮演着重要的角色。
然而,随着数据量的不断增长,数据库的数据导入与导出变得越来越复杂和困难。
本文将为您介绍数据库数据导入与导出的最佳实践,帮助您高效地处理数据库中的数据。
一、导入数据1. 数据备份在进行数据库数据导入之前,首先要做的是对当前数据库进行备份。
备份可以保证数据的安全性,并且在出现问题时可以恢复到之前的状态。
备份过程应注意将备份文件存储到可靠的位置,以防意外数据丢失。
2. 导入工具选择选择适合的导入工具是一个关键的决策。
常见的数据库导入工具包括命令行工具、图形界面工具和脚本工具等。
根据需求和实际情况选择最适合的工具,确保导入过程顺利进行。
3. 数据格式准备在导入数据之前,需要准备好数据的格式。
数据的格式应与目标数据库的结构相匹配,包括表的字段和数据类型等。
如果数据格式不正确,将会导致导入错误或数据丢失的问题。
二、导出数据1. 导出方式选择选择合适的导出方式可以帮助您高效地导出数据。
常见的数据库导出方式包括命令行导出、图形界面导出和数据库备份等。
根据具体情况选择最适合的方式进行数据导出。
2. 导出范围确定在进行数据导出时,需要确定导出的范围。
可以选择导出全部数据,或者根据自定义条件进行筛选导出。
确保导出的数据范围准确无误,避免导出不完整或错误的数据。
3. 数据格式选择选择适合的数据格式进行导出也是非常重要的。
常见的数据格式包括CSV、Excel、JSON等。
根据导入数据库的要求和实际情况选择最合适的格式。
三、常见问题与解决方案1. 数据库版本不匹配在进行数据导入与导出时,可能会出现数据库版本不匹配的情况。
解决这个问题的方法是确保目标数据库的版本与导出数据的数据库版本兼容,或者进行版本转换。
2. 数据量过大当数据库中的数据量过大时,导入与导出的过程可能会非常耗时。
DB数据库修改方法

导出:首先打开DB数据库:1、点击“外部数据”
2、点击导出栏“Excel”
3、点击“浏览”选择导出文件存储目录,然后“确定”
4、出现此画面,直接关闭。
然后去存储路径打开导出的文件进行修改。
导入:打开DB数据库
1、点击“外部数据”
2、导入数据时应首先关闭打开的数据表:如下图:右击“CMES”点击“关闭”。
3、此时再点击导入栏的“Excel”
4、选择导入文件的存储路径,选中“将数据库导入当前的数据库表中(I)”
5、点击“确定”
6、选择“第一行包含列标题”然后点击“下一步”。
7、直接点击“下一步”
8、选择“不要主键”,点击“下一步”
9、直接点击“完成”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
D B数据库导入导出集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#DB2数据导入导出2012年3月12日编辑:徐彦一、环境操作系统:Redhat Linux AS( #1 SMP i686 i386 GNU/Linux)数据库版本:DB2 WorkGroup版 V9.7.0(数据库版本可通过连接数据库来查看,db2 connect to dbname)二、声明●实例用户,默认为db2inst1●Das用户,默认为dasusr1●数据库安装目录($INSTHOME),默认为/opt/ibm/db2/●实例安装目录($HOME),默认为/home/db2inst1/●实例名:db2inst1●数据库名:<dbname>三、导出具体步骤导出对象结构建议单独创建一个数据导出目录,利于导出文件整理的清晰。
$ su – db2inst1# 切换至db2inst1用户$ cd /<backupdir>#<backupdir>为导出目录,例如/home/db2inst1/dbdmp(db2inst1要有相应的读写权限)$ db2 connect to <dbname># 连接至数据库$ db2look –d <dbname> -e –a –l –o <dbname>.sql# 导出数据库对象创建脚本例子:数据库名为meibof导出数据库数据(建议在<backupdir>目录下另建db2move的目录用来存放导出数据,因为db2move命令会产生若干文件)db2move <dbname> export(如果导出是发现有warning,在上面的命名后面加上 -aw参数)以数据库名为meibof为例:四、导入具体步骤建立新数据库$ su – db2inst1# 切换至db2inst1用户db2 create db <dbname>(建议使用db2cc工具来进行创建数据库)创建名为meibof的数据库:执行<dbname>.sql脚本创建数据库切换到放置<dbname>.sql的目录db2 –tvf <dbname>.sql(单次导入有可能丢失数据结构,建议连续执行3次,导入完成后,和开发人员确认数据库对象的数量,尤其是存储过程。
)导入数据切换到放置db2move导出数据的目录db2move <dbname> load一致性检查原理:如果发现有表存在检查挂起状态(由于检查约束的原因),则输入命令如下db2 set integrity for immediate checked将其转换成正常状态。
首先利用 sql 语句得到要检查的表的执行语句主要命令:db2 "select 'db2 set integrity for <dbname>.'||TABNAME||' immediate checked' from w here TABSCHEMA='<SCHEMA>' and STATUS='C'"以数据库名meibof,SCHEMA名meibof为例:查出有14张表需要转换成正常状态。
在上一条语句末加上 > 把要添加的sql语句添加到脚本文件如下例:用vi文本编辑器打开脚本文件:1)在第一行加入连接数据库sql语句;2)在最后一行加入commit命令,db2 commit执行完后再次检查发现没有需要更正的:说明:如果还有需要更正的表,则反复执行上述操作。
五、附录用法db2look 版本db2look:生成 DDL 以便重新创建在数据库中定义的对象语法: db2look -d DBname [-e] [-u Creator] [-z Schema] [-t Tname1Tname2...TnameN] [-tw Tname] [-h] [-o Fname] [-a][-m] [-c] [-r] [-l] [-x] [-xd] [-f] [-fd] [-td x] [-noview] [-i userID] [-w password][-v Vname1 Vname2 ... VnameN][-wrapper WrapperName] [-server ServerName] [-nofed] db2look -d DBname [-u Creator] [-s] [-g] [-a] [-t Tname1Tname2...TnameN][-p] [-o Fname] [-i userID] [-w password]db2look [-h]-d: 数据库名称:这必须指定-e: 抽取复制数据库所需要的 DDL 文件此选项将生成包含 DDL 语句的脚本可以对另一个数据库运行此脚本以便重新创建数据库对象此选项可以和 -m 选项一起使用-u: 创建程序标识:若 -u 和 -a 都未指定,则将使用 $USER 如果指定了 -a 选项,则将忽略 -u 选项-z: 模式名:如果同时指定了 -z 和 -a,则将忽略 -z联合部分的模式名被忽略-t: 生成指定表的统计信息可以指定的表的数目最多为 30-tw: 为名称与表名的模式条件(通配符)相匹配的表生成 DDL 当指定了 -tw 选项时,-t 选项会被忽略-v: 只为视图生成 DDL,当指定了 -t 时将忽略此选项-h: 更详细的帮助消息-o: 将输出重定向到给定的文件名如果未指定 -o 选项,则输出将转到 stdout-a: 为所有创建程序生成统计信息如果指定了此选项,则将忽略 -u 选项-m: 在模拟方式下运行 db2look 实用程序此选项将生成包含 SQL UPDATE 语句的脚本这些 SQL UPDATE 语句捕获所有统计信息可以对另一个数据库运行此脚本以便复制初始的那一个当指定了 -m 选项时,将忽略 -p、-g 和 -s 选项-c: 不要生成模拟的 COMMIT 语句除非指定了 -m 或 -e,否则将忽略此选项将不生成 CONNECT 和 CONNECT RESET 语句省略了 COMMIT。
在执行脚本之后,需要显式地进行落实。
-r: 不要生成模拟的 RUNSTATS 语句缺省值为 RUNSTATS。
仅当指定了 -m 时,此选项才有效-l: 生成数据库布局:数据库分区组、缓冲池和表空间。
-x: 如果指定了此选项,则 db2look 实用程序将生成授权 DDL对于现有已授权特权,不包括对象的原始定义器-xd: 如果指定了此选项,则 db2look 实用程序将生成授权 DDL对于现有已授权特权,包括对象的原始定义器-f: 抽取配置参数和环境变量如果指定此选项,将忽略 -wrapper 和 -server 选项-fd: 为 opt_buffpage 和 opt_sortheap 以及其它配置和环境参数生成 db2fopt 语句。
-td: 将 x 指定为语句定界符(缺省定界符为分号(;))应该与 -e 选项一起使用(如果触发器或者 SQL 例程存在的话)-p: 使用明文格式-s: 生成 postscript 文件此选项将为您生成 postscript 文件当设置了此选项时,将除去所有 latex 和 tmp ps 文件所需的(非 IBM)软件:LaTeX 和 dvips注意:文件必须在 LaTeX 输入路径中 -g: 使用图形来显示索引的页访存对必须安装 Gnuplot,并且 <> 必须在您的 LaTeX 输入路径中还将随 LaTeX 文件一起生成 <> 文件-i: 登录到数据库驻留的服务器时所使用的用户标识-w: 登录到数据库驻留的服务器时所使用的密码-noview: 不要生成 CREATE VIEW ddl 语句-wrapper: 为适用于此包装器的联合对象生成 DDL生成的对象可能包含下列各项:包装器、服务器、用户映射、昵称、类型映射、函数模板、函数映射和索引规范-server: 为适用于此服务器的联合对象生成 DDL生成的对象可能包含下列各项:包装器、服务器、用户映射、昵称、类型映射、函数模板、函数映射和索引规范-nofed: 不要生成 Federated DDL如果指定此选项,将忽略 -wrapper 和 -server 选项LaTeX 排版:latex 以获得示例: db2look -d DEPARTMENT -u walid -e -o-- 这将生成由用户 WALID 创建的所有表和联合对象的 DDL 语句-- db2look 输出被发送到名为的文件中示例: db2look -d DEPARTMENT -z myscm1 -e -o-- 这将为模式名为 MYSCM1 的所有表生成 DDL 语句-- 还将生成 $USER 创建的所有联合对象的 DDL。
-- db2look 输出被发送到名为的文件中示例: db2look -d DEPARTMENT -u walid -m -o-- 这将生成 UPDATE 语句以捕获关于用户 WALID 创建的表/昵称的统计信息-- db2look 输出被发送到名为的文件中示例: db2look -d DEPARTMENT -u walid -e -wrapper W1 -o-- 这将生成由用户 WALID 创建的所有表的 DDL 语句-- 还将生成适用于包装器 W1 的用户 WALID 所创建所有联合对象的 DDL-- db2look 输出被发送到名为的文件中示例: db2look -d DEPARTMENT -u walid -e -server S1 -o-- 这将生成由用户 WALID 创建的所有表的 DDL 语句-- 还将生成适用于服务器 S1 的用户 WALID 所创建所有联合对象的 DDL-- db2look 输出被发送到名为的文件中用法db2move <database-name> <action> [<option> <value>]首先,您必须指定数据库名(想要移动的表所在的数据库)和要执行的操作(export 和 import 或 load)。
然后指定一个选项来定义操作的范围。
例如,可以将一个操作限制在特定的表(-tn)、表空间(-ts)、表创建者(-tc)或模式名(-sn)范围内。
指定表、表空间或表的创建者的一个子集只对export操作有效。
如果指定多个值,就必须使用逗号将其分隔开;在值列表项之间不允许有空格。