医学统计学 03_2 参数估计
医学统计学复习重点

整理分析和2.计描述4.(集合)。
1.抽样随机2.分组随机3.实验顺序随机。
称全距,用离散系数,为标准差与均数只比,常:CV=s/x究,1.抽样研究2.个体变异。
系统误差:指数据搜集和测量过程中由于仪器不准确、造成观察结果呈倾向性的偏大或偏小,这种误差称为系统误差由于一些非人真实性(validity):观察值与真值的接近程度,受系统误差的影响( (reliabiliy)——也称精密度(precision)或重复性(repeatability)是直接用样本统计量作为对应的总体参数最常用的是95%10095有5在描述两变量间的关系时,若散点图呈直线趋势或有直线相关关系,可进行直线回归分析。
参数:根根据样本的分布特征而计算得到的1、★医学统计学工作基本步骤:统计设计;收集资料.;整理资料;分析资料2、★统计分析包括:统计描述、统计推断3、频数分布的两个重要特征:集中趋势和离散趋势4、正态分布的两个参数:均数;标准差。
5、★频数表的用途:揭示计量资料的分布类型;揭示计量资料的分布特征;便于发现特大值和特小值;便于进一步进行统计分析★常见的统计资料的类型有:计量资料;计数资料;等级资料7、★t检验的应用条件是:①正态分布:当样本含量较小时,要求样本来自正态总体。
②方差齐性:两样本均数比较时,要求两总体方差相等。
U检验的应用条件是:①大样本(如n>50);②小样本,σ已知且样本来自正态总体。
8、★.描述分类变量常用的指标有率、构成比、相对数。
9、率是指某种现象在一定条件下,实际发生的观察单位数与可能发生该现象的总观察单位数之比,常用来描述某种现象发生的频率大小或强度构成比是指一事物内部某一组成部分的观察单位数与该事物各组成部分的观察单位总数之比,常用来描述某一事物内部各组成部分所占的比重或分布。
10、★四格表卡方专用公式应用条件n≥40,且Tmin≥5 研究事物或现象间的线性关系用相关分析,研究事物或现象间的线性数量依存关系用回归分析。
医学统计学课件:参数估计

区间估计
定义
区间估计是在给定样本数据的情况下,以一定的概率保证未知参数落在某个区间 内。这个概率通常被称为置信度或置信水平。
方法
枢轴法、百分位数法和方差法等。枢轴法是利用样本分布的枢轴量来计算区间估 计,百分位数法是通过计算样本数据的百分位数来估计参数的区间,方差法则是 利用样本方差和样本均值之间的关系来计算区间估计。
非参数统计与参数统计的比较
非参数统计对于数据的分布假设更加稳健,对于 不同的数据分布形式适应性更强。
参数统计需要对总体分布的具体形式进行假设, 因此对于数据真实分布的偏离会相应增大。
在实际应用中,非参数统计方法常常可以提供更 加准确的推断结果。
非参数统计的应用范围
非参数统计在医学研究中被广泛应用 于生存分析、预后分析和相关数据的 统计分析。
03
贝叶斯参数估计
贝叶斯估计的概念
1
贝叶斯估计是一种利用数据信息对未知参数进 行推断的方法,基于概率统计理论。
2
它利用已知参数的先验分布和样本信息,推导 出后验分布,进而对未知参数进行估计。
3
贝叶斯估计广泛应用于医学、经济学、生物学 等领域。
贝叶斯估计的原理
基于贝叶斯定理,将样本信息与先验分布结合,推导出后验分布。 通过分析后验分布,对未知参数进行估计,得出贝叶斯估计值。
详细描述
在医学研究中,通过对总体数据的分布特 征进行分析,可以了解总体的集中趋势和 离散程度。同时,通过对总体数据中是否 存在影响因素进行分析,可以了解影响总 体参数的各种因素。此外,还可以研究总 体数据是否符合某种特定的分布模型。
医学图像数据的分析
总结词
医学图像数据分析是医学统计学中参数估计的新兴应 用领域,通过对医学图像数据进行分析,可以提取更 多有关患者病情和治疗效果的信息。
医学统计学教学课件》第四章参数估计基础(研究生)

介绍线性回归模型在最小二乘法估计中的使 用。
2 最小二乘估计
掌握最小二乘法估计法及其优势和不足。
置信区间
1 置信区间的概念和意义
了解置信区间的定义和在参数估计中的重要性。
2 构造置信区间
学习如何构造合适的置信区间。
3 置信区间的意义及应用
了解置信区间在统计决策中的作用。
样本量计算
1 样本容量的确定方法
点估计和区间估计
1 点估计
掌握点估计的概念、方法和性质。
2 区间估计
了解区间估计的定义、方法和性质。
极大似然估计
1 似然函数
理解似然函数在极大似然 估计中的作用。
2 极大似然估计
掌握使用极大似然估计法 进行参数估计的步骤和原 理。
3 举例
通过实际案例,了解极大 似然估计的应用。
最小二乘法估计
1 线性回归模型
医学统计学教学课件第四 章
本章将介绍医学统计学中的参数估计基础,包括参数估计的概念、点估计和 区间估计、极大似然估计、最小二乘法估计、置信区间和样本量计算。
参数估计的概念
1 什么是参数
了解医学统计学中的参数 及其定义。
了解参数估计中的误差来 源与影响因素。
掌握确定样本容量的常用方法。
3 相关性样本量计算
学习相关性研究中的样本量计算方法。
2 跨组设计的样本量计算
了解跨组设计中的样本量计算方法。
4 非劣效性试验的样本量计算
掌握非劣效性试验中的样本量计算方法。
总结
1 本章重点知识点回顾
总结本章重点内容和要点。
3 参考文献
列出本章学习所需的参考文献。
2 课后作业
医药应用统计-参数估计

19:46
第二节 区间估计
19:46
案例 4.3
设某药厂生产的某种药片直径 X 是
一随机变量,服从方差为 0.82 的正态分布。现从某日 生产的药片中随机抽取 9 片,测得其直径分别为(单 位:mm) 14.1,14.7,14.7,14.4,14.6,14.5,14.5,14.8, 14.2,
19:46
E ( X 1 ) , D( X 1 ) 2 即 X1 是 的无偏估计量;
再由前面例 4.1 知, X 也是 的无偏估计量,而由第 三章定理 3.1 知 D( X )= D( X ) =
2
n
22
因此 X 比 X1 更有效。
二、正态总体均值的区间估计 (一)方差 2 已知时总体均值 的区间估计 设总体 X 服从正态分布 N ( , 2 ) , X 1 , X 2 , , X n 是来自正态总体 X 的一个样本。考察总体均值 的 无偏估计——样本均值
1 n X Xi n i 1
偏估计量,若
ˆ ) < D( ˆ) D( 1 2
ˆ 更有效。 则称ˆ1比 2
19:46
例 4.2
设 X 1 , X 2 , X n 是来自总体 X 的一个
样本,证明样本均值
1 n X Xi n i 1
比总体均值 的另一无偏估计量 X1 更有效。
19:46
证:由于 X1 与总体 X 服从同一分布,则
ˆ 为 的无偏估计量。 则称
例 4.1
设 X 1 , X 2 , , X n 是来自总体 X 的一个样
1 n 本, 证明样本均值 X X i 是总体均值 的无偏估 n i 1
计量。
19:46
《医学统计学》第六章+参数估计与假设检验

2、该地所有人收缩压的均数可能在什么范围?
医学统计学(第7版)
三、总体均数的区间估计
(一)σ 已知
➢ 如果变量 X 服从均数为 μ、标准差为 的正态分布,则: z
服从标准正态分布。则:
P X 1.96
X 1.96
0.95
(二)σ 未知
1. t 分布
➢ 事实上,总体标准差 通常是未知的,这时我们可以用其估计量S代替 ,但
在这种情况下,( X ) / ( S /
n)
已不再服从标准正态分布,而是服从著名的 t 分布。
William Gosset
不同自由度的t分布图
医学统计学(第7版)
2. 可信区间的计算
S12 S22
n1 n2
2 ,v
医学统计学(第7版)
例题
➢ 例6-4 评价复方缬沙坦胶囊与缬沙坦胶囊对照治疗轻中度高血压的有效性,将102名患
者随机分为两组,其中试验组和对照组分别为54例和48例。经六周治疗后测量收缩压,
试验组平均下降15.77mmHg,标准差为13.17mmHg;对照组平均下降9.53mmHg,标准
样本率的标准差称为率的标准误(standard error of rate),可用来描述样
本率抽样误差的大小。率的标准误越小,则率的抽样误差越小,率的标
准误越大,则率的抽样误差越大。公式为:
p
(1 )
n
2. 率的标准误的估计
在一般情况下,总体率 π 往往是未知的,此时可用样本率 P 来估计总体
标准差与标准误的比较
标 准 差
标 准 误
医学统计学-参数估计

反复从该总体中随机抽取n=120的若干样本,用样本均
数作为观察值,称该120个样本指标值的频数分布为抽 样分布(sampling distribution)。
t分布、F分布、χ2分布等均为常见的抽样分布。
每次摸到红球的比例分别为12.5%,20.0%,35.5%,… 等,将其频率分布列于表4-2。
表4-2 总体概率为30%时的随机抽样结果(n=40)
红球比例(%)
样本频数
频率(%
10.0~
1
1
15.0~
2
2
20.0~
15
15
25.0~
23
23
30.0~
31
31
35.0~
20
20
40.0~
5
5
45.0~50.0
应总体概率间的差异,因而说明了率的抽样误差
大小。
=
p
1
n
s
=
p
p 1 p n=
pq n
四、二项分布和泊松分布的应用
(一)二项分布 1.二项分布的成立条件 2.二项分布的特征 3.二项分布的应用
(二)泊松分布 1.泊松分布的概率密度函数 2.泊松分布的特征 3.泊松分布的应用
(一) 二项分布(贝努利分布) (Bernoulli distribution)
0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 X
图D n=30,π=0.3
二项分布总体不同样本例数时的抽样分布
2.二项分布的特征
⑵二项分布的均数和标准差
医学统计学课件:参数估计

医学统计学课件:参数估计xx年xx月xx日contents •参数估计概述•参数估计方法•参数估计在医学中的应用•参数估计的优缺点•参数估计的相关计算•医学统计学的未来发展目录01参数估计概述定义与意义参数估计利用样本信息对总体参数进行推断和估计。
意义通过参数估计,利用样本信息对总体特征进行推断、解释和预测,为研究设计和医学实践提供重要依据。
参数估计与点估计的关系参数估计包括点估计和区间估计。
点估计:用样本统计量估计总体参数的方法,是参数估计的基础。
区间估计:在点估计的基础上,给出总体参数的估计区间,是参数估计的拓展。
确定研究问题和研究假设。
设计研究方案和收集数据。
对样本数据进行分析,得到样本统计量和样本信息。
根据样本统计量和样本信息,构造合适的统计量(点估计)或区间估计量(区间估计)。
对所构造的统计量或区间估计量进行假设检验,判断其是否具有统计意义和实际意义。
根据参数估计的结果,进行推断分析和决策。
参数估计的基本步骤02参数估计方法1点估计23点估计是一种对总体参数的数值近似,通常用一个单一的数值来表示。
定义常见的点估计方法包括最大似然估计和矩估计。
方法点估计的优点是简单、直观,但可能存在精度不足的问题。
特点03特点区间估计的优点是能够给出总体参数的精度范围,但可能存在精度不足的问题。
区间估计01定义区间估计是一种对总体参数的区间范围的估计,通常用一个置信区间来表示。
02方法基于样本统计量和样本容量的信息,利用置信区间的计算公式来得到总体参数的置信区间。
定义贝叶斯估计是一种基于贝叶斯定理的参数估计方法,通常将总体参数看作是一个随机变量。
方法首先需要建立一个关于总体参数的先验分布,然后结合样本信息进行后验分布的计算,最后利用后验分布进行参数的估计。
特点贝叶斯估计的优点是能够充分利用先验知识和样本信息,从而得到更加精确的参数估计结果。
但是,贝叶斯估计方法需要更多的主观判断和计算成本。
贝叶斯估计03参数估计在医学中的应用样本均数和标准差估计通过分析临床试验数据,可以估计治疗组和对照组的均数和标准差,从而了解治疗效果和病情变化情况。
医学统计学知识点梳理

医学统计学知识点梳理医学统计学:是用统计学原理和方法研究生物医学问题的一门学科。
他包括了研究设计、数据收集、整理、分析以及分析结果的正确解释和表达。
统计描述:用统计指标、统计图表对资料的数量特征及分布规律进行客观的描述和表达。
统计推断:在一定的置信度和概率保证下,用样本信息推断总体特征:①参数估计:用样本的指标去推断总体相应的指标②假设检验:由样本的差异推断总体之间是否可能存在的差异同质:一个总体中有许多个体,他们之所以共同成为人们研究的对象,必定存在共性,我们说一些个体处于同一总体,就是指他们大同小异,具有同质性。
总体(population)是根据研究目的确定的同质的观察单位的全体,更确切的说,是同质的所有观察单位某种观察值(变量值)的集合。
总体可分为有限总体和无限总体。
总体中的所有单位都能够标识者为有限总体,反之为无限总体。
样本:从总体中随机抽取部分观察单位,其测量结果的集合称为样本(sample)。
样本应具有代表性。
所谓有代表性的样本,是指用随机抽样方法获得的样本。
随机抽样:随机抽样(random sampling)是指按照随机化的原则(总体中每一个观察单位都有同等的机会被选入到样本中),从总体中抽取部分观察单位的过程。
随机抽样是样本具有代表性的保证。
变异:在自然状态下,个体间测量结果的差异称为变异(variation)。
变异是生物医学研究领域普遍存在的现象。
严格的说,在自然状态下,任何两个患者或研究群体间都存在差异,其表现为各种生理测量值的参差不齐。
(1)计量资料:对每个观察单位用定量的方法测定某项指标量的大小,所得的资料称为计量资料(measurement data)。
计量资料亦称定量资料、测量资料。
.其变量值是定量的,表现为数值大小,一般有度量衡单位。
(2)计数资料:将观察单位按某种属性或类别分组,所得的观察单位数称为计数资料(count data)。
计数资料亦称定性资料或分类资料。
医学统计学(参数估计)
1. 总体均数的估计
(1)z 分布法
①σ已知
z 分布法 t 分布
②σ未知,但n足够大,n>50
( x z/2· , x z/2 · ) s s x x
即( x ±z/2· ) s
x
(1)z分布 法
应用条件: 例题
σ已知,或σ未知但样本量较大并可计算出 x 及 Sx
调查某市400名成人,得到脉搏均数为72次/分, 标准差为6.4次/分,求95%和99%可信区间.
t
X S n
X SX
,
v n 1
2.t 分布的特征
(1)t分布是以0为中心,左右对称的单峰分布。
பைடு நூலகம்
(2)形似标准正态分布,与自由度有关。
(3)t分布是一簇曲线。
z=
x
x
x
/
~N(0,1)
n
t 分布(与z分布比较的特点)
t 分布示意图
3. t 界值表(附表7 P190)
解:13例中的近期有效人数服从二项分布。
由m=8,n-m=5,1-=0.95,查统计用表11,得p1= 0.316,p2=0.861,故近期有效总体率p的95%置信区间为 (0.316,0.861)。
2.总体率的置信区间
⑵ 正态近似法 当n足够大,并且np和 n(1-p)>5时,p的抽样分布近似正态分布,可 按照式4-9计算总体率的置信区间 (p-1.96
4. 置信区间和可信限
可信限(confidence limit,简记为CL)为两个点值; 置信区间是以上、下可信限为界的一个范围。
【习题】
研究生医学统计学-参数估计

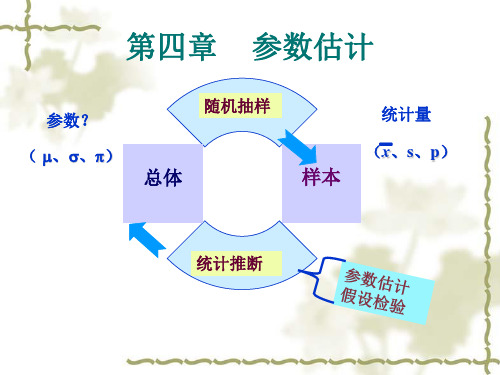
统计推断 如:总体均数 总体标准差 总体率 如:样本均数
x
样本标准差 S 样本率 P
统计推断:抽样研究中用样本统 计量来推论总体参数的过程。
– 参数估计: 用样本统计量来估计总体参数 (总体均数和总体概率)的大小。
– 假设检验:又称显著性检验,方法:均数z 检验 、t 检验、方差分析,2检验、秩和检 验等.
31.0~
34.0~ 40.0~ 合计
5
3 2 100
5.0
3.0 2.0 100.0
• 频率的抽样误差:样本频率与样本频率之间 或样本频率与总体概率之间的差异。
• 频率的标准误:即样本频率的标准差,表示 频率的抽样误差的指标
若X服从二项分布B(n,)
样本频率为 样本频率p的总体均数为 p=π, (1 ) 2 样本频率p的总体方差为 p n 样本频率p的标准差(率的标准误)
x
图d(n=30)
n=50 PERCENT 30
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 mm MIDPOINT
15 36 57 77 98 19
医药数理统计第3章:参数估计

1 n2
n i 1
D(
xi
)
2
n
样本均值 x 标准化后,定理
的结果可转化为:
Z
x / n
~
N (0, 1)
例如: x1,x2,...x10是来自N 5,1简单样本,x是
容量为10的样本均值,则x服从什么分布?并求:
(1)E(x );(2)D(x );(3)P(x 5)
答 : x服从N (5, 1 )的分布 10
临界值
2
(n)
2 0.025
(8)
17.535,
附表4-1
2 0.975
(10)
3.247,
附表4-2
2 0.1
(25)
34.382.
附表4-3
附表5只详列到 n=45 为止.
定理3.3
设x1, x2 ,...,xn是来自正态总体N (, 2 )的样本,
则对于其样本方差s2 , 有
(n 1)s2
的
样
本,
试
求P( s
2 2
1.666)的 概 率.
解
:
由定理3.3可知
:
(
n
1)s
2
2
~
2 (n 1)
所以P
(
s
2 2
1.666)
15s2
P( 2
151.666)
15s2
P( 2
24.99)
由定理3.3知 : 2
15s2
2
~
2(15)
又由上侧分位数的意义得知,当2 (15) 24.99时, 查表得 0.05
2 (n)分布的概率密度为
p(
x)
n
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
6
0.718 0.906 1.440 1.943 2.447 3.143 3.707 4.317 5.208 5.959
7
0.711 0.896 1.415 1.895 2.365 2.998 3.499 4.029 4.785 5.408
8
0.706 0.889 1.397 1.860 2.306 2.896 3.355 3.833 4.501 5.041
附表2 t 界值表
0.10 0.20 3.078 1.886 1.638 1.533 1.476
概 率,P 0.05 0.025 0.01 0.10 0.05 0.02 6.314 12.706 31.821 2.920 4.303 6.965 2.353 3.182 4.541 2.132 2.776 3.747 2.015 2.571 3.365
主要内容
点估计 区间估计 两个要素 均数可信区间的构建 正确理解可信区间的涵义
2015/3/6
2
统计推断的内容
参数估计
(parameter estimation)
假设检验
(hypothesis test)
2015/3/6
3
参数估计
• 由样本统计量估计总体参数
– 点估计(point estimation) – 区间估计(interval estimation)
概 率,P 0.05 0.025 0.01 0.10 0.05 0.02 6.314 12.706 31.821 2.920 4.303 6.965 2.353 3.182 4.541 2.132 2.776 3.747 2.015 25 0.0025 0.001 0.0005 0.01 0.005 0.002 0.001 63.657 127.321 318.309 636.619 9.925 14.089 22.327 31.599 5.841 7.453 10.215 12.924 4.604 5.598 7.173 8.610 4.032 4.773 5.893 6.869
25 70.9(次 / 分)
X
t0.05,24
s X
73.6 2.064 6.5 /
25 76.3(次 / 分)
即该地正常成年男子脉搏总体均数的95%可信区间为:
70.9~76.3(次/分) 。用该区间估计该地正常成年男子脉搏总
体均数的可信度为95%。
2015/3/6
16
例4.2
某 市 2001 年 120 名 7 岁 男 孩 身 高 均 数 为 123.62cm,标准差为4.75cm,计算该市7岁 男童总体均数90%的可信区间。
(n1
1)s12 (n2 1)s22 n1 n2 2
• 均数之差的标准误
s X1 X2
sC2
(
1 n1
1 n2
)
2015/3/6
22
计算
sC2
11 9.772 12 12.172 12 13 2
122.93
s X1 X2
122.93 ( 1 1 ) 4.439 12 13
9
0.703 0.883 1.383 1.833 2.262 2.821 3.250 3.690 4.297 4.781
10
0.700 0.879 1.372 1.812 2.228 2.764 3.169 3.581 4.144 4.587
21 22 23 24 25
2015/3/6
0.686
0.686 0.685 0.685 0.684
3.135
3.119 3.104 3.091 3.078
3.527
3.505 3.485 3.467 3.450
3.819
3.792 3.768 3.745 3.725
15
例4.1
本例自由度=12-1=24,经查表得t0.05,24=2.064,则
X
t0.05,24
s X
73.6 2.064 6.5 /
-t
0
t
0.005 0.0025 0.001 0.0005 0.01 0.005 0.002 0.001 63.657 127.321 318.309 636.619 9.925 14.089 22.327 31.599 5.841 7.453 10.215 12.924 4.604 5.598 7.173 8.610 4.032 4.773 5.893 6.869
X =144.07
s = 4.72 x1,x2,x3…x10
2015/3/6
6
点估计
• 直接用样本统计量作为总体参数的估计值
–方法简单,但未考虑抽样误差的大小 –在实际问题中,总体参数往往是未知的,但它们是固
定的值,并不是随机变量值。而样本统计量随样本的 不同而不同,属随机的。
2015/3/6
7
区间估计
9
0.703 0.883 1.383 1.833 2.262 2.821 3.250 3.690 4.297 4.781
10
0.700 0.879 1.372 1.812 2.228 2.764 3.169 3.581 4.144 4.587
11 12 13 14 15
2015/3/6
0.697 0.695 0.694 0.692 0.691
2015/3/6
19
均数之差可信区间的计算
正常组
1=?
肝炎组
2=? 1- 2 =?
均 数:273.18ug/dl 标准差:9.77ug/dl
2015/3/6
均 数: 231.86ug/dl 标准差:12.17ug/dl
X 1 X 2 41.32
20
与均数之差有关的抽样分布
“均数之差”与“均数之差的标准误”之比,
3.106 3.055 3.012 2.977 2.947 2.5758
3.497 3.428 3.372 3.326 3.286
4.025 3.930 3.852 3.787 3.733
4.437 4.318 4.221 4.140 4.073
18
例4.2
• n=120>100,标准正态分布代替t分布,u0.10=1.645
精确性
– 是指区间的大小(或长短)
兼顾可靠性、精确性
2015/3/6
9
均数的可信区间
• 基础:抽样误差理论 • 从正态分布总体中随机抽取一个样本,则
t
X s
~
t(n1)
X
t值接近于0的可能性较大,远离0的可能性较小, 出现太大的t值和太小的t值的可能性更小,根据t 分布的性质,t有95%可能在-t0.05,v到t0.05,v之间。
13
例4.1
• 随机抽取某地25名正常成年男子,测得该 样本的脉搏均数为73.6次/分,标准差为6.5 次/分,求该地正常成年男子脉搏总体均数 95%的可信区间。
2015/3/6
14
自由度
单侧 双侧
1
2
3
4
5
0.25 0.50 1.000 0.816 0.765 0.741 0.727
0.20 0.40 1.376 1.061 0.978 0.941 0.920
双侧t0.05,23 2.069
(271.18 231.86) 2.069 4.439 32.14, 50.50
2015/3/6
23
正确理解可信区间的涵义
• 可信区间一旦形成,它要么包含总体参数,要么不包 含总体参数,二者必居其一,无概率可言。所谓95% 的可信度是针对可信区间的构建方法而言的。
2015/3/6
17
自由度 n
单侧 双侧
1
2
3
4
5
0.25 0.50 1.000 0.816 0.765 0.741 0.727
0.20 0.40 1.376 1.061 0.978 0.941 0.920
附表2 t 界值表
0.10 0.20 3.078 1.886 1.638 1.533 1.476
2015/3/6
4
参数估计之一:点估计 • 用样本统计量作为总体参数的估计
例如: 用样本均数作为总体均数的一个估计
2015/3/6
5
点估计的缺陷
=?cm, =?cm
x1,x2,x3,x4…… N
X =143.37
s = 5.23 x1,x2,x3…x10
样本含量 n=10
X=142.72
s = 9.2473 x1,x2,x3…x10
2015/3/6
27
可信区间与参考值范围的区别
可信区间用于估计总体参数,总体参数只有一个 。 参考值范围用于估计变量值的分布范围,变量值可能很多
甚至无限 。 95%的可信区间中的95%是可信度,即所求可信区间包含
• 按一定的概率或可信度(1- )用一个区间估计总体 参数所在范围,这个范围称作可信度为1- 的可
信区间(confidence interval, CI),又称置信区间 。 这种估计方法称为区间估计。
2015/3/6
8
可信区间的两个要素
可信度(1-), 可靠性
– 一般取90%,95%。 – 可人为控制。
2015/3/6
-2 -1 0 1 2
25
正确理解可信区间的涵义
• 在区间估计中,总体参数虽未知,但却是 固定的值(且只有一个),而不是随机变 量值 。
2015/3/6
26
下列说法正确吗?
算得总有该该某体区区995参间间5%%数 包 有的的有 含总 9可599体 %信55% % 的参区的 的 可数间可 总 能在,能 体 包该则落 参 含区:在 数 总间该 内 。 体区 。 参间 数。 。 该区间包含总体参数,可信度为95%。