MySQL基本知识整理--数据库和表的操作
php_数据库面试题及答案(3篇)

第1篇1. 请简要介绍数据库的基本概念和分类。
答:数据库是按照数据结构来组织、存储和管理数据的仓库。
它包含一系列相互关联的数据集。
数据库分为关系型数据库和非关系型数据库两大类。
2. 什么是SQL?请列举几个常用的SQL语句。
答:SQL(Structured Query Language)是一种标准化的查询语言,用于管理关系型数据库。
常用的SQL语句包括:- SELECT:查询数据- INSERT:插入数据- UPDATE:更新数据- DELETE:删除数据- CREATE:创建数据库或表- DROP:删除数据库或表- ALTER:修改数据库或表结构3. 请解释以下SQL语句的含义:- SELECT FROM students WHERE age > 18;- INSERT INTO employees (name, age, salary) VALUES ('张三', 25, 5000);- UPDATE students SET age = 20 WHERE name = '李四';- DELETE FROM employees WHERE age = 30;答:- SELECT FROM students WHERE age > 18;:查询年龄大于18岁的学生信息。
- INSERT INTO employees (name, age, salary) VALUES ('张三', 25, 5000);向员工表插入一条记录,姓名为张三,年龄为25岁,薪资为5000元。
- UPDATE students SET age = 20 WHERE name = '李四';将姓名为李四的学生年龄修改为20岁。
- DELETE FROM employees WHERE age = 30;删除年龄为30岁的员工记录。
4. 什么是索引?请举例说明索引的作用。
MySql数据库培训教程PPT课件

mysql程序常用命令
数据举例
学生档案中的学生记录 (崔文华,男,1984,上海,计算机系,1990)
数据的形式不能完全表达其内容 数据的解释
语义:学生姓名、性别、出生年月、籍贯、所 在系别、入学时间
解释:崔文华是个大学生,1984年出生,上海 人,2003年考入计算机系
数据库
数据库(Database,简称DB)的定义: “按照数据结构来组织、存储和管理数据的仓库”
关系型数据库管理系统称为RDBMS,R指Relation
DBMS的作用
它对数据库进行统一的管理和控制,以保证数据库的ቤተ መጻሕፍቲ ባይዱ安全性和完整性。
DBMS的主要功能-For程序员
数据定义功能: 提供数据定义语言(DDL) 定义数据库中的数据对象
数据操纵功能: 提供数据操纵语言(DML) 操纵数据实现对数据库的基本操作 (查询、插入、删除和修改)
MySQL数据库
MySQL数据库
数据库概述 数据库基础知识 SQL语言 MySQL数据库基础操作
第一部分:数据库概述
• 数据库基本概念 • 什么是MySQL数据库 • MySQL基本操作
数据库基本概念
数据(Data) 数据库(Database) 数据库管理系统(DBMS) 数据库系统(DBS)
性能快捷、优化SQL语言 容易使用 多线程和可靠性 多用户支持 可移植性和开放源代码 遵循国际标准和国际化支持 为多种编程语言提供API
MySQL5特性
MySQL数据库对象

教学环节教师活动学生活动新课导入(5分钟)回顾旧识,根据“立生超市管理系统”项目建设进度,提问:1.用什么工具完成数据库的物理设计?2.如何查看MySQL数据库的组成对象?思考回答问题目标展示(5分钟) PPT展示本课题要完成的目标并适当解说观看了解新课教学(60分钟)活动一查看MySQL数据库的组成对象(20分钟) 在MySQL数据库管理系统中,每个数据库都由多个“组件”构成,它们各司其职、协同向运行系统提供高效的数据支撑服务。
一、操作演示:1.运行第三方客户端软件Navicat for mysql2.新建连接,如下图所示。
3.连接测试。
二、辅导答疑三、借助Navicat,讲述如下内容1.数据库的组成对象2.数据表的浏览和机构编辑3.安装文件夹下的data内容四、辅导答疑观察并思考连接数据库操作完成PPT上的“做一做”“查一查”听课、反思前面的自我操作完成PPT上的“填一填”练习活动二 MySQL数据库的常见对象及用途(20分钟)借助PPT,讲述:1.表(Table)表是数据表的简称,是MySQL数据库实际存储数据的地方。
数据库系统中的所有数据处理操作最终都是对数据表的操作。
在Navicat中演示表的相关操作。
辅导学生查看表2.视图(View)视图又称为虚表,它可以像数据表那样支持数据处理操作。
视图的数据可以来自一个或多个数据表,又把数据表称为基表。
在Navicat中演示视图的相关操作。
3.索引(Index)索引是一种根据数据表列(字段)建立排序的结构,它可以提高检索特定数据的速度。
在Navicat中演示索引的查看。
4.存储过程(Procedure)和函数(Function)存储过程是指存储在数据库中的用SQL语言编写的实现了杲种数据处理功能的程序模块。
使用存储过程可以简化数据库管理并提高数据处理的效率。
函数是有返回值的存储过程。
在Navicat中演示存储过和函数的创建方式。
5.触发器(Trigger)触发器是与存储过程类似的程序模块,但它是隶属于数据表的。
中等职业教材数据库应用基础(第三版)第一章笔记整理

中等职业教材数据库应用基础(第三版)第一章笔记整理根据你提供的信息,我整理了《中等职业教材数据库应用基础(第三版)》第一章的笔记如下:第一章:数据库基础知识1. 数据库概述- 数据库是一种组织和管理数据的系统,可以按照特定的结构和方式存储、检索和处理数据。
- 数据库管理系统(DBMS)是管理和操作数据库的软件。
2. 数据库的组成要素- 数据库的组成要素包括数据、数据库模型、数据库管理系统(DBMS)、数据库管理员和数据库应用程序。
3. 数据库模型- 数据库模型是描述和定义数据、数据结构、数据关系、数据操作和数据约束的方式。
- 常见的数据库模型包括层次模型、网状模型、关系模型、面向对象模型和面向文档模型。
4. 关系模型- 关系模型是最常用的数据库模型,采用表的形式表示数据,表之间通过关系建立联系。
- 表由行和列组成,每行表示一个记录,每列表示记录的一个属性。
5. 数据库管理系统(DBMS)- DBMS是管理和操作数据库的软件,提供数据定义语言(DDL)、数据操作语言(DML)和数据查询语言(DQL)等功能。
- 常见的DBMS包括Oracle、MySQL、SQL Server等。
6. 数据库管理员- 数据库管理员负责数据库的设计、安装、配置、维护和管理等工作。
- 数据库管理员还负责数据库的备份和恢复、性能优化和安全管理等工作。
7. 数据库应用程序- 数据库应用程序是使用数据库存储和处理数据的应用软件。
- 数据库应用程序可以通过编程语言(如Java、C#)或者数据库查询语言(如SQL)进行开发。
8. 数据库的基本操作- 数据库的基本操作包括创建数据库、创建表、插入数据、查询数据、更新数据和删除数据等操作。
上述内容是第一章《数据库基础知识》的笔记整理,主要介绍了数据库的概述、组成要素、模型、数据库管理系统、数据库管理员、数据库应用程序以及数据库的基本操作等相关知识点。
希望对你有帮助!。
高中必修一信息技术知识点

高中必修一信息技术知识点一、信息与信息技术。
1. 信息的概念。
- 信息是指数据、信号、消息中所包含的意义。
例如,交通信号灯的颜色(红、绿、黄)就是一种信息,它传达了车辆是否可以通行的意义。
- 信息具有载体依附性,它不能独立存在,必须依附于一定的载体,如文字、图像、声音等。
2. 信息技术的发展历程。
- 古代信息技术:包括语言的使用、文字的创造、印刷术的发明等。
语言是人类最早的信息交流方式,它使得信息能够在人与人之间传递;文字的出现则使信息可以被记录和保存;印刷术的发明提高了信息的复制效率,促进了知识的传播。
- 近代信息技术:以电信技术的发明为标志,如电报、电话等。
电报实现了远距离的文字信息传递,电话则让人们可以直接进行语音交流。
- 现代信息技术:以计算机和网络技术为核心。
计算机具有高速运算、大容量存储等特点,网络技术则使信息的传播更加便捷、快速,实现了全球范围内的信息共享。
3. 信息技术的发展趋势。
- 多元化:信息技术的表现形式越来越多样化,如多媒体技术将文字、图像、声音、视频等多种信息形式融合在一起。
- 网络化:互联网的普及使得信息的传播和共享更加方便,人们可以通过网络获取各种信息资源,进行在线交流、学习、工作等。
- 智能化:如人工智能技术的发展,智能机器人、语音识别、图像识别等应用不断涌现,使信息技术能够模拟人类的智能行为。
- 虚拟化:例如虚拟现实(VR)和增强现实(AR)技术,能够创建虚拟的环境或者将虚拟信息与现实世界相结合,给用户带来全新的体验。
二、信息的获取。
1. 信息获取的一般过程。
- 定位信息需求:明确自己需要什么样的信息,例如,要写一篇关于环境保护的论文,就需要获取与环境现状、污染治理措施、环保政策等相关的信息。
- 选择信息来源:信息来源有多种,包括文献型信息源(如书籍、报纸、杂志等)、口头型信息源(如与人交谈获取信息)、电子型信息源(如网站、数据库等)和实物型信息源(如产品样本、文物等)。
产品经理-10分钟带你了解数据库、数据仓库、数据湖、数据中台的区别与联系(一)

10分钟带你了解数据库、数据仓库、数据湖、数据中台的区别与联系(一)作为一名数据小白,在日常讲授和杂务工作中经常会接触到数据。
随着用户数据与金融业务数据的不断累加,数据管理与处理愈发重要。
本篇文章中,无名氏将一文说明数据库、数据仓库、数据湖、数据中台的区别与联系。
作为数据相关的产品小白,在日常学习工作中经常能或者听到大家在讨论数据库,数据仓库,数据集市,数据库数据湖还有最近比较火的数据中台,似乎这些名词都与数据存在着联系,查阅各类相关书籍,大部分书籍中的内容过于专业晦涩难懂。
那么这结合我积累的相关方面知识,向大家介绍一下上述这些名词的与联系,以及在各类企业及业务范围上的适用范围,如有不准确的地方,希望大家进行指正。
相信大部分有些许技术背景的都对数据库有一定的了解,数据库是“按照数据结构来组织、存储和管理数据的仓库”,一般分为“关系型数据库”与“非关系型数据库”。
1.关系型数据库实际上回顾过去的数据库一共有三种模型,即层次模型,网状模型,关系模型。
(1)首先层次模型的数据结构为树状结构,即是一种上下级的社团组织层级关系组织数据的一种方式:(2)带状模型的数据结构为网状网状结构,即将每个数据节点与其他很多节点都连接起来:(3)关系模型的数据结构可以看做是一个二维表格,任何数据都可以通过行号与列号来唯一确定:由于相比于层次模型和网状模型,关系模型理解和使用最简单,最终基于关系型最后数据库在各行各业应用了起来。
关系模型的数学方法第一卷涉及到关系,元组,属性,笛卡尔积,域等等令人头秃的高等数学术语,这里大家如果感兴趣可以看看相关的文献,我就不放出来催眠大家了,尽管数学原理比较复杂,但如果用事务平时学习工作的具体事务举例,就相对容易理解。
我们以某公司的员工信息表为例,该公司的员工信息可以用一个表格存起来。
并且定义如下:同时部门ID对应这另一个职能部门表:我们可以通过给定一个政府部门部门名称,查到一条部门的记录,根据部门ID,又可以记述查到该部门下的员工记录,这样三维的表格就通过ID映射建立了“一对多”的关系。
《数据库原理及应用》教案

06
数据库管理系统介绍与选 型建议
常见数据库管理系统介绍
关系型数据库管理系统(RDBMS)
如Oracle、MySQL、SQL Server等,以表格形式存储数据,提供SQL语言进行数据操作 和管理。
数据库完整性的重要性
确保数据的准确性和可信度,维护数据库的可靠性和稳定性。
数据库完整性威胁
包括数据输入错误、数据更新异常、并发操作冲突等。
数据库并发控制概述
1 2
并发控制的概念
在多个用户或进程同时访问数据库时,保证事务 的一致性和隔离性,防止相互干扰和数据不一致 。
并发控制的重要性
提高数据库系统的吞吐量和资源利用率,保证多 个用户或进程能够正确地共享数据库资源。
02ቤተ መጻሕፍቲ ባይዱ
数据库基本概念与数据模 型
数据库基本概念
数据库(Database)
数据库管理系统(DBMS)
存储在计算机内的、有组织的、可共享的 数据集合。
用于存储、检索、定义和管理大量数据的 软件。
数据库系统(DBS)
数据独立性
包括数据库、数据库管理系统、应用程序 、数据库管理员和用户等组成部分。
应用程序与数据的存储结构相互独立,使 得数据的逻辑结构和物理结构可以独立进 行修改。
非关系型数据库管理系统(NoSQL)
如MongoDB、Redis、Cassandra等,采用非表格形式存储数据,适用于大数据、高并 发等场景。
分布式数据库管理系统
如Hadoop、HBase、TiDB等,支持数据分布式存储和处理,适用于海量数据存储和分析 。
linux连接mysql命令

linux连接mysql命令linux连接mysql是最基本的操作之一,对于初学者来说我们可以通过命令来连接mysql,下面由店铺为大家整理了linux下连接mysql 命令的相关知识,希望对大家有所帮助!linux连接MYSQL命令格式: mysql -h主机地址 -u用户名 -p用户密码linux连接mysql命令实例1、连接到本机上的MYSQL找到mysql的安装目录,一般可以直接键入命令mysql -uroot -p,回车后提示你输密码,如果刚安装好MYSQL,超级用户root是没有密码的,故直接回车即可进入到MYSQL中了,MYSQL的提示符是:mysql>linux连接MYSQL命令实例2、连接到远程主机上的MYSQL假设远程主机的IP为:10.0.0.1,用户名为root,密码为123。
则键入以下命令:mysql -h10.0.0.1 -uroot -p123(注:u与root可以不用加空格,其它也一样)退出MYSQL命令exit (回车)附:linux下有关mysql数据库方面的操作必须首先登录到mysql中,有关操作都是在mysql的提示符下进行,而且每个命令以分号结束1、显示数据库列表。
show databases;2、显示库中的数据表:use mysql; //打开库show tables;3、显示数据表的结构:describe 表名;4、建库:create database 库名;GBK: create database test2 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;UTF8: CREATE DATABASE `test2` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;5、建表:use 库名;create table 表名(字段设定列表);6、删库和删表:drop database 库名;drop table 表名;7、将表中记录清空:delete from 表名;truncate table 表名;8、显示表中的记录:select * from 表名;9、编码的修改如果要改变整个mysql的编码格式:启动mysql的时候,mysqld_safe命令行加入--default-character-set=gbk如果要改变某个库的编码格式:在mysql提示符后输入命令alter database db_name default character set gbk;10.重命名表alter table t1 rename t2;11.查看sql语句的效率explain < table_name >例如:explain select * from t3 where id=3952602;12.用文本方式将数据装入数据库表中(例如D:/mysql.txt)mysql> LOAD DATA LOCAL INFILE "D:/mysql.txt" INTO TABLE MYTABLE;。
超经典MySQL练习50题,做完这些你的SQL就过关了
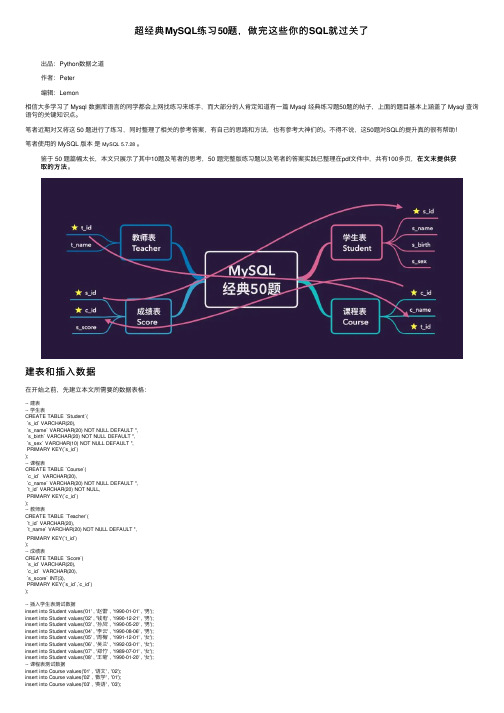
超经典MySQL练习50题,做完这些你的SQL就过关了出品:Python数据之道作者:Peter编辑:Lemon相信⼤多学习了 Mysql 数据库语⾔的同学都会上⽹找练习来练⼿,⽽⼤部分的⼈肯定知道有⼀篇 Mysql 经典练习题50题的帖⼦,上⾯的题⽬基本上涵盖了 Mysql 查询语句的关键知识点。
笔者近期对⼜将这 50 题进⾏了练习,同时整理了相关的参考答案,有⾃⼰的思路和⽅法,也有参考⼤神们的。
不得不说,这50题对SQL的提升真的很有帮助!笔者使⽤的 MySQL 版本是MySQL 5.7.28。
在⽂末提供获鉴于 50 题篇幅太长,本⽂只展⽰了其中10题及笔者的思考,50 题完整版练习题以及笔者的答案实践已整理在pdf⽂件中,共有100多页,在⽂末提供获取的⽅法。
取的⽅法建表和插⼊数据在开始之前,先建⽴本⽂所需要的数据表格:-- 建表-- 学⽣表CREATE TABLE `Student`(`s_id` VARCHAR(20),`s_name` VARCHAR(20) NOT NULL DEFAULT '',`s_birth` VARCHAR(20) NOT NULL DEFAULT '',`s_sex` VARCHAR(10) NOT NULL DEFAULT '',PRIMARY KEY(`s_id`));-- 课程表CREATE TABLE `Course`(`c_id` VARCHAR(20),`c_name` VARCHAR(20) NOT NULL DEFAULT '',`t_id` VARCHAR(20) NOT NULL,PRIMARY KEY(`c_id`));-- 教师表CREATE TABLE `Teacher`(`t_id` VARCHAR(20),`t_name` VARCHAR(20) NOT NULL DEFAULT '',PRIMARY KEY(`t_id`));-- 成绩表CREATE TABLE `Score`(`s_id` VARCHAR(20),`c_id` VARCHAR(20),`s_score` INT(3),PRIMARY KEY(`s_id`,`c_id`));-- 插⼊学⽣表测试数据insert into Student values('01' , '赵雷' , '1990-01-01' , '男');insert into Student values('02' , '钱电' , '1990-12-21' , '男');insert into Student values('03' , '孙风' , '1990-05-20' , '男');insert into Student values('04' , '李云' , '1990-08-06' , '男');insert into Student values('05' , '周梅' , '1991-12-01' , '⼥');insert into Student values('06' , '吴兰' , '1992-03-01' , '⼥');insert into Student values('07' , '郑⽵' , '1989-07-01' , '⼥');insert into Student values('08' , '王菊' , '1990-01-20' , '⼥');-- 课程表测试数据insert into Course values('01' , '语⽂' , '02');insert into Course values('02' , '数学' , '01');insert into Course values('03' , '英语' , '03');-- 教师表测试数据insert into Teacher values('01' , '张三');insert into Teacher values('02' , '李四');insert into Teacher values('03' , '王五');-- 成绩表测试数据insert into Score values('01' , '01' , 80);insert into Score values('01' , '02' , 90);insert into Score values('01' , '03' , 99);insert into Score values('02' , '01' , 70);insert into Score values('02' , '02' , 60);insert into Score values('02' , '03' , 80);insert into Score values('03' , '01' , 80);insert into Score values('03' , '02' , 80);insert into Score values('03' , '03' , 80);insert into Score values('04' , '01' , 50);insert into Score values('04' , '02' , 30);insert into Score values('04' , '03' , 20);insert into Score values('05' , '01' , 76);insert into Score values('05' , '02' , 87);insert into Score values('06' , '01' , 31);insert into Score values('06' , '03' , 34);insert into Score values('07' , '02' , 89);insert into Score values('07' , '03' , 98);题⽬1题⽬要求成绩⾼的学⽣的信息及课程分数查询'01'课程⽐'02'课程成绩⾼SQL实现-- ⽅法1selecta.*,b.s_score as 1_score,c.s_score as 2_scorefrom Student ajoin Score b on a.s_id = b.s_id and b.c_id = '01' -- 两个表通过学号连接,指定01left join Score c on a.s_id = c.s_id and c.c_id='02' or c.c_id is NULL -- 指定02,或者c中的c_id直接不存在-- 为NULL的条件可以不存在,因为左连接中会直接排除c表中不存在的数据,包含NULLwhere b.s_score > c.s_score; -- 判断条件-- ⽅法2:直接使⽤where语句selecta.*,b.s_score as 1_score,c.s_score as 2_scorefrom Student a, Score b, Score cwhere a.s_id=b.s_id -- 列出全部的条件and a.s_id=c.s_idand b.c_id='01'and c.c_id='02'and b.s_score > c.s_score; -- 前者成绩⾼第⼆种⽅法实现:第⼆种⽅法实现题⽬2题⽬要求查询'01'课程⽐'02'课程成绩低成绩低的学⽣的信息及课程分数(题⽬1是成绩⾼)SQL实现类⽐题⽬1的实现过程-- ⽅法1:通过连接⽅式实现selecta.*,b.s_score as 1_score,c.s_score as 2_scorefrom Student aleft join Score b on a.s_id=b.s_id and b.c_id='01' or b.c_id=NULL -- 包含NULL的数据join score c on a.s_id=c.s_id and c.c_id='02'where b.s_score < c.s_score;-- 通过where⼦句实现selecta.*,b.s_score as 1_score,c.s_score as 2_scorefrom Student a, Score b, Score cwhere a.s_id=b.s_idand a.s_id=c.s_idand a.s_id=c.s_idand b.c_id='01'and c.c_id='02'and b.s_score < c.s_score; -- 前者⽐较⼩题⽬3题⽬需求查询平均成绩⼤于等于60分的同学的学⽣编号和学⽣姓名和平均成绩SQL实现-- 执⾏顺序:先执⾏分组,再执⾏avg平均操作selectb.s_id,b.s_name,round(avg(a.s_score), 2) as avg_scorefrom Student bjoin Score aon b.s_id = a.s_idgroup by b.s_id -- 分组之后查询每个⼈的平均成绩having avg_score >= 60;-- 附加题:总分超过200分的同学selectb.s_id,b.s_name,round(sum(a.s_score),2) as sum_score -- sum求和from Student bjoin Score aon b.s_id=a.s_idgroup by b.s_idhaving sum_score > 200;附加题:总分超过200分的同学题⽬4题⽬要求查询平均成绩⼩于60分的同学的学⽣编号和学⽣姓名和平均成绩(包括有成绩的和⽆成绩的)SQL实现1-两种情况连接平均分⼩于60selectb.s_id,b.s_name,round(avg(a.s_score), 2) as avg_score -- round四舍五⼊函数from Student bjoin Score aon b.s_id = a.s_idgroup by b.s_id -- 分组之后查询每个⼈的平均成绩having avg_score < 60;结果为:没有成绩的同学:selecta.s_id,a.s_name,a.s_name,0 as avg_scorefrom Student awhere a.s_id not in ( -- 学⽣的学号不在给给定表的学号中 select distinct s_id -- 查询出全部的学号from Score);最后将两个部分的结果连起来即可:通过union⽅法SQL实现2-ifnull函数判断使⽤ifnull函数selectS.s_id,S.s_name,round(avg(ifnull(C.s_score,0)), 2) as avg_score -- ifnull 函数:第⼀个参数存在则取它本⾝,不存在取第⼆个值0 from Student Sleft join Score Con S.s_id = C.s_idgroup by s_idhaving avg_score < 60;使⽤null判断selecta.s_id,a.s_name,ROUND(AVG(b.s_score), 2) as avg_scorefrom Student aleft join Score b on a.s_id = b.s_idGROUP BY a.s_idHAVING avg_score < 60 or avg_score is null; -- 最后的NULL判断题⽬5题⽬需求查询所有同学的学⽣编号、学⽣姓名、选课总数、所有课程的总成绩SQL实现selecta.s_id,a.s_name,count(b.c_id) as course_number -- 课程个数,sum(b.s_score) as scores_sum -- 成绩总和from Student aleft join Score bon a.s_id = b.s_idgroup by a.s_id,a.s_name;题⽬6题⽬需求查询“李”姓⽼师的数量SQL实现select count(t_name) from Teacher where t_name like '李%'; -- 通配符这题怕是最简单的吧题⽬7题⽬需求查询学过张三⽼师张三⽼师授课的同学的信息SQL实现-- ⽅法1:通过张三⽼师的课程的学⽣来查找;⾃⼰的⽅法select * -- 3. 通过学号找出全部学⽣信息from Studentwhere s_id in (select s_id -- 2.通过课程找出对应的学号from Score Sjoin Course Con S.c_id = C.c_id -- 课程表和成绩表where C.t_id=(select t_id from Teacher where t_name='张三') -- 1.查询张三⽼师的课程);-- ⽅法2:通过张三⽼师的课程来查询select s1.*from Student s1join Score s2on s1.s_id=s2.s_idwhere s2.c_id in (select c_id from Course c where t_id=( -- 1. 通过⽼师找出其对应的课程select t_id from Teacher t where t_name='张三'))-- ⽅法3select s.* from Teacher tleft join Course c on t.t_id=c.t_id -- 教师表和课程表left join Score sc on c.c_id=sc.c_id -- 课程表和成绩表left join Student s on s.s_id=sc.s_id -- 成绩表和学⽣信息表where t.t_name='张三';⾃⼰的⽅法:⽅法2来实现:⽅法3实现:题⽬8题⽬需求找出没有学过张三⽼师课程的学⽣SQL实现select * -- 3. 通过学号找出全部学⽣信息from Studentwhere s_id not in ( -- 2.通过学号取反:学号不在张三⽼师授课的学⽣的学号中select s_idfrom Score Sjoin Course Con S.c_id = C.c_idwhere C.t_id=(select t_id from Teacher where t_name ='张三') -- 1.查询张三⽼师的课程);-- ⽅法2:select *where s1.s_id not in (select s2.s_id from Student s2 join Score s3 on s2.s_id=s3.s_id where s3.c_id in( select c.c_id from Course c join Teacher t on c.t_id=t.t_id where t_name='张三' ));-- ⽅法3select s1.*from Student s1join Score s2on s1.s_id=s2.s_idwhere s2.c_id not in (select c_id from Course c where t_id=( -- 1. 通过⽼师找出其对应的课程select t_id from Teacher t where t_name='张三'));⽅法2:题⽬9题⽬需求查询学过编号为01,并且学过并且学过编号为02课程的学⽣信息SQL实现-- ⾃⼰的⽅法:通过⾃连接实现select s1.*from Student s1where s_id in (select s2.s_id from Score s2join Score s3on s2.s_id=s3.s_idwhere s2.c_id='01' and s3.c_id='02');-- ⽅法2:直接通过where语句实现select s1.*from Student s1, Score s2, Score s3where s1.s_id=s2.s_idand s1.s_id=s3.s_idand s2.c_id=01 and s3.c_id=02;-- ⽅法3:两个⼦查询select sc1.s_idfrom (select * from Score s1 where s1.c_id='01') sc1,(select * from Score s1 where s1.c_id='02') sc2where sc1.s_id=sc2.s_id;-- 2.找出学⽣信息select *from Studentwhere s_id in (select sc1.s_id -- 指定学号是符合要求的from (select * from Score s1 where s1.c_id='01') sc1,(select * from Score s1 where s1.c_id='02') sc2where sc1.s_id=sc2.s_id);1. 先从Score表中看看哪些⼈是满⾜要求的:01-05同学是满⾜的通过⾃连接查询的语句如下:查询出学号后再匹配出学⽣信息:通过where语句实现:⽅法3的实现:题⽬10题⽬需求但是没有学过02课程的学⽣信息(注意和上⾯ 题⽬的区别)查询学过01课程,但是没有学过SQL实现⾸先看看哪些同学是满⾜要求的:只有06号同学是满⾜的错误思路1直接将上⾯⼀题的结果全部排出,导致那些没有学过01课程的学⽣也出现了:07,08select s1.*from Student s1where s_id not in ( -- 直接将上⾯⼀题的结果全部排出,导致那些没有学过01课程的学⽣也出现了:07,08select s2.s_id from Score s2join Score s3on s2.s_id=s3.s_idwhere s2.c_id='01' and s3.c_id ='02');错误思路2将上⾯题⽬中的02课程直接取反,导致同时修过01,02,03或者只修01,03的同学也会出现select s1.*from Student s1where s_id in (select s2.s_id from Score s2join Score s3on s2.s_id=s3.s_idwhere s2.c_id='01' and s3.c_id !='02' -- 直接取反是不⾏的,因为修改(01,02,03)的同学也会出现);正确思路https:///p/9abffdd334fa-- ⽅法1:根据两种修课情况来判断select s1.*from Student s1where s1.s_id in (select s_id from Score where c_id='01') -- 修过01课程,要保留and s1.s_id not in (select s_id from Score where c_id='02'); -- 哪些⼈修过02,需要排除!!!!!⽅法2:先把06号学⽣找出来select * from Student where s_id in (select s_idfrom Scorewhere c_id='01' -- 修过01课程的学号and s_id not in (select s_id -- 同时学号不能在修过02课程中出现 from Scorewhere c_id='02'));鉴于篇幅,本⽂只展⽰了50题中的10道题的答案以及笔者的实践⼼得。
数据处理与数据管理

数据处理与数据管理数据处理的基本目的是从大量的、可能是杂乱无章的、难以理解的数据中抽取并推导出对于某些特定的人们来说是有价值、有意义的数据。
以下是由店铺整理关于什么是数据处理的内容,希望大家喜欢数据处理的基本信息处理软件数据处理离不开软件的支持,数据处理软件包括:用以书写处理程序的各种程序设计语言及其编译程序,管理数据的文件系统和数据库系统,以及各种数据处理方法的应用软件包。
为了保证数据安全可靠,还有一整套数据安全保密的技术。
方式根据处理设备的结构方式、工作方式,以及数据的时间空间分布方式的不同,数据处理有不同的方式。
不同的处理方式要求不同的硬件和软件支持。
每种处理方式都有自己的特点,应当根据应用问题的实际环境选择合适的处理方式。
数据处理主要有四种分类方式①根据处理设备的结构方式区分,有联机处理方式和脱机处理方式。
②根据数据处理时间的分配方式区分,有批处理方式、分时处理方式和实时处理方式。
③根据数据处理空间的分布方式区分,有集中式处理方式和分布处理方式。
④根据计算机中央处理器的工作方式区分,有单道作业处理方式、多道作业处理方式和交互式处理方式。
数据处理对数据(包括数值的和非数值的)进行分析和加工的技术过程。
包括对各种原始数据的分析、整理、计算、编辑等的加工和处理。
比数据分析含义广。
随着计算机的日益普及,在计算机应用领域中,数值计算所占比重很小,通过计算机数据处理进行信息管理已成为主要的应用。
如测绘制图管理、仓库管理、财会管理、交通运输管理,技术情报管理、办公室自动化等。
在地理数据方面既有大量自然环境数据(土地、水、气候、生物等各类资源数据),也有大量社会经济数据(人口、交通、工农业等),常要求进行综合性数据处理。
故需建立地理数据库,系统地整理和存储地理数据减少冗余,发展数据处理软件,充分利用数据库技术进行数据管理和处理。
数据处理的相关信息数据处理用计算机收集、记录数据,经加工产生新的信息形式的技术。
医学信息技术基础教程-第4章数据库与数据管理技术基础-统稿_校对

第四章数据库与数据管理技术随着计算机和网络等信息技术在医药学领域深度应用,极大地推动了数据库技术在医药学领域的广泛应用。
尤其国家对公共卫生信息化和医疗改革的大力度建设投入,医院及其他医疗机构已经建立起数目众多的医院电子病历数据库、药品数据库、疾病数据库、新药数据库、生物数据库、医药文献数据库等具有医药特色数据库。
这些数据库支撑着数字化和网络化环境下的医学信息系统运作,是大型的网络数据库。
本章将以SQL Server 2008数据库管理系统为背景,介绍有关数据库的应用知识。
4.1 数据库基础知识人类的日常生活和社会生产每时每刻都产生大量的数据,数据已经成为一种需要被管理和加工的非常重要的资源。
如何科学地收集、整理、存储、加工和传输数据是人们长期以来十分关注的问题。
医药领域存在着大量的数据和数据处理的需求,因而数据库技术也成为了医药学领域专业学生必须了解和掌握的知识。
4.1.1海量数据与数据库系统在信息时代人们的生活和工作与信息密切相关。
数据作为信息社会的产物,大量地充塞人们的生活空间,网络银行、网上购物、电子政务、电子图书馆、医院看病等等,比比皆是数字的海洋,例如:一个医院一天的影像信息数据量为80GB ,一年约为30TB。
全球数字数据量每两年就翻一番,据2011年的统计,数据量达到了里程碑式的1.8万亿个G字节。
面对如此海量的数据,如何高效存储和管理数据是人们面临的挑战。
数据库技术产生于20世纪60年代末70年代初,是一种计算机辅助管理数据的方法,它研究如何科学地组织和存储数据,如何高效地获取和处理数据。
伴随计算机网络技术的发展、人们对数据的认识和使用需求,数据库技术从单机处理发展到联网处理,从集中式发展到分布式或到客户机/服务器处理,直到并行处理。
数据库(DataBase,简称DB):可以理解为存放数据的仓库。
它是长期储存在计算机外部存储设备上的一组相关数据的集合。
数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
计算机一级考试实操知识点整理

计算机一级考试实操知识点整理
1. 电脑硬件知识
- 计算机基本组成部分:主机、显示器、键盘、鼠标等
- 了解各硬件设备的作用和功能
- 掌握硬盘、内存、CPU等主要硬件组件的基本知识
2. 操作系统知识
- 熟悉Windows操作系统的基本操作和界面
- 掌握文件和文件夹的管理,包括创建、复制、剪切、删除等
操作
- 理解常见的操作系统错误提示和解决方法
- 了解计算机网络基本概念,如IP地址、子网掩码等
3. 常用办公软件知识
- 掌握Microsoft Office套件中的Word、Excel和PowerPoint等
软件的基本操作
- 熟悉常用的办公软件中的常见功能,如文本编辑、表格操作、图形绘制等
- 了解电子邮件的基本操作和常见邮件客户端
4. 网络基础知识
- 理解计算机网络的基本概念和组成
- 掌握网络连接和配置的基本操作,如网络设置、IP地址的获
取等
- 了解网络安全的基本知识和常见的网络攻击方式
5. 数据库知识
- 了解数据库的基本概念和常见的数据库管理系统,如MySQL、Oracle等
- 熟悉数据库的基本操作,如创建表、插入数据、查询数据等
- 掌握SQL语言的基本语法和常见操作
6. 软件开发知识
- 了解软件开发的基本流程和方法,如需求分析、设计、编码、测试等
- 掌握至少一种编程语言的基本语法和常见开发工具的使用
- 熟悉软件开发中常见的开发模型,如瀑布模型、敏捷开发等
以上是计算机一级考试实操的一些知识点整理,希望对您有所帮助。
3.3数据与系统-教科版(2019)高中信息技术必修一教学设计

三、实践活动(用时10分钟)
1. 分组讨论:学生们将分成若干小组,每组讨论一个与数据管理相关的实际问题。
2. 实验操作:为了加深理解,我们将进行一个简单的数据库操作实验。这个操作将演示如何创建数据库、输入数据和执行基本查询。
(6)参观考察:组织学生参观企业、科研机构等,了解数据与系统在实际工作中的应用,激发学生的学习兴趣和职业规划意识。
七、作业布置与反馈
一、作业布置
1. 知识点巩固:
(1)请简述数据与系统的概念及其关系。
(2)结合案例分析,说明数据管理系统的优势。
(3)列举三种常见的数据处理方法,并简要说明其原理。
2. 实践操作:
(4)项目导向学习:以项目为驱动,引导学生自主学习,培养他们的团队协作能力和实际操作能力。
2. 教学活动设计:
(1)角色扮演:组织学生扮演数据管理员、系统分析师等角色,模拟实际工作中数据与系统的应用场景,提高学生的实际操作能力。
(2)实验:设计相关实验,让学生动手操作,如数据整理、数据可视化等,巩固所学知识。
(4)网络资源:提供相关网站链接,引导学生自主学习,拓宽知识视野。
五、教学流程
一、导入新课(用时5分钟)
同学们,今天我们将要学习的是《数据与系统》这一章节。在开始之前,我想先问大家一个问题:“你们在日常生活中是否遇到过数据丢失或难以管理的情况?”比如,当你的电脑文件乱糟糟的时候,你是否感到困扰?这个问题与我们将要学习的内容密切相关。通过这个问题,我希望能够引起大家的兴趣和好奇心,让我们一同探索数据与系统的奥秘。
(3)项目研究:组织学生参与学校或社区的信息化项目,如校园一卡通系统、社区信息发布平台等,让学生在实际项目中锻炼自己的数据管理能力和团队协作能力。
3-数据库设计与开发教案
株洲职业技术学院教师授课教案课程名称服务软件外包授课课题数据库设计与应用授课专业班级中职培训班教学目标1. 会使用phpmyadmin管理mysql数据库2. 会使用sql语句创建表,修改记录、删除记录、新增记录、查询记录教学要点教学重点使用多个函数查询数据库信息教学难点函数的综合运用课型讲学做一体化教法与学法(教具)任务驱动、讲学做一体化,多媒体教学设备课后作业教学后记(教师课后填写)授课教师崔曙光备课时间2011年7月2日课堂案例1—数据库概念及范式【案例学习目标】【案例知识要点】【案例完成步骤】(1)数据库的基本概念1.1 数据(Data)与数据处理(Data Processing)(1)数据:是描述事物所使用的符号。
(2)数据的种类:文字、图形、图像和声音。
(3)计算机中的数据:临时性数据、永久性数据。
◆临时性数据:存放于计算机内存中,与程序仅有短时间的交互关系,随着程序的结束而消亡。
◆永久性数据:对系统起着长期持久的作用,数据库中处理的是持久性数据。
1.2 数据库(Database,DB)数据库是长期存储在计算机内、有组织的和可共享的数据集合。
1.3 数据库管理系统(DBMS)数据库管理系统(Database Management System,DBMS)是专门用于管理数据库的计算机系统软件。
数据库管理系统能够为数据库提供数据的定义、建立、维护、查询和统计等操作功能。
(2)数据库范式●第一范式:所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
●第二范式第二范式(2NF)就是非主属性完全依赖于主关键字。
●第三范式在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。
数据仓库中的数据及组织概述

30
3.1 数据仓库中的数据组织 3.2 数据仓库中数据的追加 3.3 数据仓库中的元数据
31
3.3数据仓库中的元数据
❖ 传统数据库中为了说明数据引入了数据字典的概念。 ❖ 数据字典是描述数据的数据。
32
3.3.1元数据的定义
❖ 元数据:是用来描述数据的数据。它描述和定位数 据组件、它们的来源及它们在数据仓库进程中的活 动;关于数据和操作的相关描述(输入、计算和输 出)。
33
3.3.1元数据的定义
❖ 其主要目标是提供数据资源的全面指南,使得数据 仓库管理员和开发人员可以方便地了解数据仓库中 有什么数据?数据在什么地方?它们来源于哪里, 以及数据仓库系统中是如何利用这些数据?如何管 理这些数据?
34
3.3.1元数据的定义
❖ 与元数据产生、存储有关的工具: ❖ 数据抽取工具:完成ETL操作。 ❖ 前端展现工具:实现把关系表映射成与业务相关的
每种商品每一天的销售数据。 ❖ 高度综合数据:记录每个顾客每月或每年的购物金
额,或每种商品每月或每年的销售数据。
16
1)数据粒度
❖ 数据粒度的确定是业务分析、硬件、软件的一个折中。 ❖ 在数据仓库中多重粒度是必不可少的
17
1)数据粒度
❖ 数据粒度是数据仓库的重要概念。存在两种形式, 形式二: ❖ 样本数据库,其粒度是根据采样率的高低来划分的。 ❖ 盖洛普民意测验是一种观点的民意测验,其特点是用简
40
1)MDC的OIM标准
❖ OIM标准的目的 ❖ 通过公共的元数据信息来支持不同工具和系统之间
数据的共享和重用。 ❖ 它涉及信息系统的各个阶段。 ❖ 采用UML描述。
41
2)OMG组织的CWM标准
数据收集与管理的基本原则与操作技巧

02
数据仓库将分散在各个业务系 统的数据进行整合、清洗和转 换,以多维度的形式存储数据 ,并提供查询和分析工具。
03
数据仓库适用于需要跨多个业 务系统进行综合分析的场景, 如企业级报表和决策支持系统 。
云存储
1
云存储(Cloud Storage)是一种通过网络将数 据存储在远程服务器上的方式,通常由第三方提 供商管理。
数据收集与管理的基 本原则与操作技巧
汇报人:
2023-12-27
目录
• 数据收集的基本原则 • 数据管理的基本原则 • 数据收集的方法与技巧 • 数据处理的常用工具与技术 • 数据存储的常用方式与技巧 • 数据应用的原则与技巧
01
数据收集的基本原则
准确性原则
总结词
确保数据的真实性和正确Байду номын сангаас是数据收集的首要原则。
非关系型数据库
01
非关系型数据库(NoSQL)采用键值对、文档、列
族或图形等形式来存储数据,无需固定的数据结构。
02
非关系型数据库的优势在于灵活性、可扩展性和高性
能,适用于大数据量和高并发的应用场景。
03
常见的非关系型数据库包括MongoDB、Cassandra
、Redis等。
数据仓库
01
数据仓库(Data Warehouse )是一个大型、集中式的存储 和管理数据的系统,用于支持 决策分析和报告。
VS
详细描述
数据可视化能够将复杂的数据以易于理解 的方式呈现,帮助用户更好地理解数据、 发现数据中的规律和趋势,以及进行数据 预测。常用的数据可视化工具包括Excel 、Tableau、Power BI等。
数据挖掘
总结词
2020年php面试题及答案(3篇)

第1篇一、前言随着互联网的快速发展,PHP作为一种开源的脚本语言,广泛应用于Web开发领域。
为了帮助大家更好地应对2020年的PHP面试,本文整理了一系列PHP面试题及答案,涵盖了PHP基础、面向对象编程、框架、数据库等方面。
希望对大家有所帮助。
二、PHP基础1. 请简述PHP的变量类型。
答:PHP变量类型包括整型(int)、浮点型(float)、布尔型(bool)、字符串型(string)、数组型(array)、对象型(object)、资源型(resource)和NULL。
2. 请解释PHP中的魔术方法。
答:魔术方法是PHP中的一种特殊方法,以两个下划线开头和结尾。
常用的魔术方法有__construct()、__destruct()、__get()、__set()、__isset()、__unset()、__call()、__callStatic()、__toString()等。
3. 请简述PHP中的常量。
答:常量是定义后不可改变的变量,使用define()函数定义。
常量名称区分大小写,并且不能以数字开头。
4. 请解释PHP中的类型转换。
答:PHP支持自动类型转换和显式类型转换。
自动类型转换是指编译器根据需要自动将一个变量转换为另一种类型;显式类型转换是指使用类型转换运算符将变量转换为指定类型。
5. 请简述PHP中的数据类型比较。
答:PHP中的数据类型比较遵循以下规则:数值型比较大小;字符串型比较字典序;布尔型比较为true或false;对象型比较引用。
三、面向对象编程1. 请简述面向对象编程的基本概念。
答:面向对象编程是一种编程范式,将数据(属性)和行为(方法)封装在一起,形成对象。
面向对象编程的基本概念包括:类、对象、封装、继承、多态。
2. 请解释PHP中的继承。
答:继承是指子类继承父类的属性和方法。
在PHP中,使用冒号(:)来指定父类。
3. 请简述PHP中的多态。
答:多态是指同一操作作用于不同的对象,可以有不同的解释和结果。
计算机信息技术基础

2024/1/25
5
发展历程回顾
2024/1/25
第一代计算机(1946-1957年)
采用电子管作为基本元件,体积大、功耗高、可靠性差。
第二代计算机(1958-1964年)
采用晶体管作为基本元件,体积缩小、功耗降低、可靠性提高。
第三代计算机(1965-1970年)
采用中、小规模集成电路作为基本元件,进一步提高了计算机的性能 和可靠性。
内存地址、指针等基本概念
2024/1/25
数据结构的类型,如数组、链表、栈、队列等
14
数据处理技术及应用领域
数据的收集、整理、分析、解释等处 理技术
数据挖掘、大数据等技术在商业、科 研等领域的应用
2024/1/25
数据库管理系统(DBMS)的基本概 念及操作
15
04
计算机网络基础知识普及
2024/1/25
演讲技巧与互动环节设计
了解并掌握演讲的基本技巧和方法,如语言表达、肢体语言等,同时善于设计互动环节, 如提问、讨论等,提高演讲效果和观众参与度。
33
07
数据库管理系统原理及应用
实践探讨
2024/1/25
34
数据库管理系统概述和原理介绍
2024/1/25
数据库管理系统(DBMS)定义
01
是一种软件,用于存储、检索、定义和管理大量数据,提供数
善于使用模板和向导
了解并学会使用Word中的模板和向导功能,可以快速创建符合规范 要求的文档,节省时间和精力。
2024/1/25
31
Excel数据处理和分析方法
2024/1/25
数据输入与整理
掌握Excel中数据输入的基本规则,如日期、数字、文本等 数据的输入方法,以及数据整理的技巧,如排序、筛选、 去重等。
idea mysql visio 的介绍

idea mysql visio 的介绍1. 引言1.1 概述引言部分将以介绍和概述的形式开篇,为读者提供对本篇文章主题以及涵盖内容的基本了解。
本文将着重介绍两种常用的软件工具,即Idea和MySQL,并进一步详细探讨它们各自的特点、功能以及使用场景。
此外,我们还将介绍Visio 这款流行的数据库管理工具,并对其应用领域、主要功能与特点进行阐述。
通过全面深入地了解这些工具,读者将能够更有效地应用于实际项目中。
1.2 文章结构为了使读者有条理地阅读本文并准确地获取所需信息,文章采用了明确的结构安排。
首先,我们将开始介绍Idea部分,包括入门指南、功能特点和使用场景。
然后,我们会转向MySQL,在此部分中,我们将详细说明数据库概述、特点与优势以及数据库管理工具。
最后一部分是关于Visio的介绍,我们会先给出一个概述和应用领域,在接下来的内容中重点介绍主要功能与特点,并分享使用该软件的方法与技巧。
通过这样清晰明了的结构设计,读者可以在不同层次上获得所需信息,或者有选择地阅读相关内容。
1.3 目的本文旨在为读者提供一个全面且详尽的概述,使他们能够更好地了解和熟悉Idea、MySQL和Visio这几款软件工具。
同时,我们也希望通过介绍它们各自的特点和优势,能够帮助读者在实际项目中作出明智的选择,并更加高效地完成开发任务。
此外,通过深入挖掘这些工具的使用场景、方法与技巧,我们也可以带领读者进一步扩展他们的技术知识和技能。
最后,本文还将对这些工具进行总结回顾,并展望未来的发展前景,以引发读者对新技术和工具的思考,并鼓励他们不断学习和创新。
以上就是“1. 引言”部分内容的详细撰写,请参考并整理到你的长文中。
2. Idea的介绍2.1 入门指南- Idea是一款由JetBrains公司推出的基于Java开发的集成开发环境(IDE),旨在提供全面的开发支持和工具集。
它支持多种编程语言,包括Java、Kotlin、Groovy等,并提供强大的代码编辑、调试和自动化测试功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MySQL数据库知识整理
/* MySQL服务操作 */
/* 打开数据库服务 */
net start mysql
/* 连接与断开服务 */
mysql -h 地址-P 端口-u 用户名-p 密码
/* 跳过权限验证登录MySQL */
mysqld --skip-grant-tables
/* 修改root密码 */
update er set password=password('xxx');
/* 显示正在运行的线程 */
SHOW PROCESSLIST
/* 数据库操作 */
/* 查看当前数据库 */
select database();
/* 显示当前时间、用户名、数据库版本 */
select now(), user(), version();
/* 创建库 */
create database[ if not exists] 数据库名数据库选项数据库选项:CHARACTER SET charset_name COLLATE collation_name
/* 查看已有库 */
show databases[ like 'pattern']
/* 查看当前库信息*/
show create database 数据库名
/* 修改库的选项信息 */
alter database 库名选项信息
/* 删除库 */
drop database[ if exists] 数据库名同时删除该数据库相关的目录及其目录内容
/* 数据表操作 */
/* 删除表*/
DROP TABLE[ IF EXISTS] 表名
/* 清空表数据 */
TRUNCATE [TABLE] 表名
/* 复制表结构 */
CREATE TABLE 表名 LIKE 要复制的表名
/* 复制表结构和数据 */
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
/* 检查表是否有错误 */
CHECK TABLE tbl_name [, tbl_name] ... [option]
/* 优化表 */
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] /* 修复表 */
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
/* 分析表 */
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name]。