模式识别期末考试复习资料
模式识别复习题分解

《模式识别》试题库一、基本概念题1.1 模式识别的三大核心问题是:、、。
1.2、模式分布为团状时,选用聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利用两类方法处理多类问题的技术途径有:(1);(2);(3)。
其中最常用的是第个技术途径。
1.6 判别函数的正负和数值大小在分类中的意义是:,。
1.7 感知器算法。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
1.8 积累位势函数法的判别界面一般为。
(1)线性界面;(2)非线性界面。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW BSS S+1.10 作为统计判别问题的模式分类,在()情况下,可使用聂曼-皮尔逊判决准则。
1.11 确定性模式非线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 用作确定性模式非线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满足下列三个条件,都可作为势函数。
①();②( ); ③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越大,说明ωi 类模式与ωj 类模式的分布( )。
当ωi 类模式与ωj 类模式的分布相同时,J ij =( )。
1.14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
1.15 信息熵可以作为一种可分性判据的原因是: 。
1.16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
1.17 随机变量l(x )=p( x |ω1)/p( x |ω2),l( x )又称似然比,则E {l( x )|ω2}=( )。
模式识别期末试题及答案

模式识别期末试题及答案正文:模式识别期末试题及答案1. 选择题1.1 下列关于机器学习的说法中,正确的是:A. 机器学习是一种人工智能的应用领域B. 机器学习只能应用于结构化数据C. 机器学习不需要预先定义规则D. 机器学习只能处理监督学习问题答案:A1.2 在监督学习中,以下哪个选项描述了正确的训练过程?A. 通过输入特征和预期输出,训练一个模型来进行预测B. 通过输入特征和可能的输出,训练一个模型来进行预测C. 通过输入特征和无标签的数据,训练一个模型来进行预测D. 通过输入特征和已有标签的数据,训练一个模型来进行分类答案:D2. 简答题2.1 请解释什么是模式识别?模式识别是指在给定一组输入数据的情况下,通过学习和建模,识别和分类输入数据中的模式或规律。
通过模式识别算法,我们可以从数据中提取重要的特征,并根据这些特征进行分类、聚类或预测等任务。
2.2 请解释监督学习和无监督学习的区别。
监督学习是一种机器学习方法,其中训练数据包含了输入特征和对应的标签或输出。
通过给算法提供已知输入和输出的训练样本,监督学习的目标是学习一个函数,将新的输入映射到正确的输出。
而无监督学习则没有标签或输出信息。
无监督学习的目标是从未标记的数据中找到模式和结构。
这种学习方法通常用于聚类、降维和异常检测等任务。
3. 计算题3.1 请计算以下数据集的平均值:[2, 4, 6, 8, 10]答案:63.2 请计算以下数据集的标准差:[1, 3, 5, 7, 9]答案:2.834. 综合题4.1 对于一个二分类问题,我们可以使用逻辑回归模型进行预测。
请简要解释逻辑回归模型的原理,并说明它适用的场景。
逻辑回归模型是一种用于解决二分类问题的监督学习算法。
其基本原理是通过将特征的线性组合传递给一个非线性函数(称为sigmoid函数),将实数值映射到[0,1]之间的概率。
这个映射的概率可以被解释为某个样本属于正类的概率。
逻辑回归适用于需要估计二分类问题的概率的场景,例如垃圾邮件分类、欺诈检测等。
【模式识别】期末考试试卷01

《模式识别》期末考试试题(B )一、填空题(15个空,每空2分,共30分)1.基于机器学习的模式识别系统通常由两个过程组成, 即分类器设计和( )。
2.统计模式识别把( )表达为一个随机向量(即特征向量), 将模式类表达为由有穷或无穷个具有相似数值特性的模式组成的集合。
3.特征一般有两种表达方法:(1)将特征表达为数值;(2)将特征表达为( )。
4.特征提取是指采用( )实现由模式测量空间向特征空间的转变。
5.同一类模式类样本的分布比较集中,没有或临界样本很少,这样的模式类称为( )。
6.加权空间的所有分界面都通过( )。
7.线性多类判别: 若每两个模式类间可用判别平面分开, 在这种情况下,M 类有( )个判别函数,存在有不确定区域。
8.当取0-1损失函数时, 最小风险贝叶斯判决准则等价于( )判决准则。
9.Neyman-Pearson 决策的基本思想是( )某一错误率,同时追求另一错误率最小。
10.聚类/集群:用事先不知样本的类别,而利用样本的先验知识来构造分类器属于( )学习。
11.相似性测度、聚类准则和( )称为聚类分析的三要素。
12.K/C 均值算法使用的聚类准则函数是误差平方和准则,通过反复迭代优化聚类结果,使所有样本到各自所属类别的中心的( )达到最小。
13.根据神经元的不同连接方式,可将神经网络分为分层网络和相互连接型网络两大类。
其中分层网络可细分为前向网络、( )和层内互连前向网络三种互连方式。
14.神经网络的特性及能力主要取决于网络拓扑结构及( )。
15.BP 神经网络是采用误差反向传播算法的多层前向网络,其中,神经元的传输函数为S 型函数,网络的输入和输出是一种( )映射关系。
二、简答题(2题,每小题10分,共20分)1.两类问题的最小风险Bayes 决策的主要思想是什么? 2.已知一组数据的协方差矩阵为11/21/21⎡⎤⎢⎥⎣⎦,试问: (1)协方差矩阵中各元素的含义是什么? (2)K-L 变换的最佳准则是什么?(3)为什么说经K-L 变换后消除了各分量之间的相关性?三、 计算题(2题,每小题13分,共26分)1.已知有两类样本集,分别为ω1={x 1, x 2}={(1,2)T , (-1,0)T }; ω2={x 3, x 4} ={(-1,-2)T , (1,-1)T } 设初始权值w 1=(1,1,1)T , ρk =1,试用感知器固定增量法求判别函数,画出决策面。
模式识别期末复习总结

1、贝叶斯分类器贝叶斯分类器的定义:在具有模式的完整统计知识的条件下,按照贝叶斯决策理论进行设计的一种最优分类器。
贝叶斯分类器的分类原理:通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。
贝叶斯的公式:什么情况下使用贝叶斯分类器:对先验概率和类概率密度有充分的先验知识,或者有足够多的样本,可以较好的进行概率密度估计,如果这些条件不满足,则采用最优方法设计出的分类器往往不具有最优性质。
2、K近邻法kNN算法的核心思想:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
假设有N个已知样本分属c个类,考察新样本x在这些样本中的前K个近邻,设其中有个属于类,则类的判别函数就是决策规则:若则∈什么情况下使用K近邻法:kNN只是确定一种决策原则,在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,并不需要利用已知数据事先训练出一个判别函数,这种方法不需要太多的先验知识。
在样本数量不足时,KNN法通常也可以得到不错的结果。
但是这种决策算法需要始终存储所有的已知样本,并将每一个新样本与所有已知样本进行比较和排序,其计算和存储的成本都很大。
对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
3、PCA和LDA的区别Principal Components Analysis(PCA):uses a signal representation criterionLinear Discriminant Analysis(LDA):uses a signal classification criterionLDA:线性判别分析,一种分类方法。
它寻找线性分类器最佳的法线向量方向,将高维数据投影到一维空间,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。
模式识别期末试题

一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类(2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2)(3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A→01, A→ 0A1 , A→ 1A0 , B→BA , B→ 0}, A)(2)({A}, {0, 1}, {A→0, A→ 0A}, A)(3)({S}, {a, b}, {S → 00S, S → 11S, S → 00, S → 11}, S)(4)({A}, {0, 1}, {A→01, A→ 0A1, A→ 1A0}, A)9、影响层次聚类算法结果的主要因素有(计算模式距离的测度、(聚类准则、类间距离门限、预定的类别数目))。
10、欧式距离具有(1、2 );马式距离具有(1、2、3、4 )。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性11、线性判别函数的正负和数值大小的几何意义是(正(负)表示样本点位于判别界面法向量指向的正(负)半空间中;绝对值正比于样本点到判别界面的距离。
模式识别期末复习

模式识别期末复习1似然比决策准则为:若1221()()()()()p P l p P ωωωω=≥x x x ,则1ω∈x ;若1221()()()()()p P l p P ωωωω=≤x x x ,则2ω∈x 。
负对数似然比为[]()ln ()h l =-x x ,当()i p ωx 是均值向量为i μ和协方差矩阵为12=∑∑=∑的正态分布时:①试推导出()h x ,并指出其决策面规则; ②分析这种情况下的决策面类型。
解:①()()111112211()exp 2(2)T dp ωμμπ-⎛⎫=--∑- ⎪⎝⎭∑x x x ;()()122212211()exp 2(2)T dp ωμμπ-⎛⎫=--∑- ⎪⎝⎭∑x x x两边取自然对数()()111111ln ()ln 2ln 222Td p ωμμπ-=--∑---∑x x x ;()()122211ln ()ln 2ln 222Td p ωμμπ-=--∑---∑x x x[]()()()()()2111112211111111122211111211221210201()ln ()ln ()ln ()11221111222211()220 T TT T T T T T T T T T i i h l p p w w w ωωμμμμμμμμμμμμμμμμμ-------------=-=-=-∑---∑-⎛⎫⎛⎫=∑-∑+∑-∑-∑+∑ ⎪ ⎪⎝⎭⎝⎭=-∑-∑∑-∑--+-==∑Tx x x x x x x x x x x x x x x +=w w x w 1012T i i i μμ-=∑似然比决策准则为:若1221()()()()()p P l p P ωωωω=≥x x x ,则1ω∈x ;若1221()()()()()p P l p P ωωωω=≤x x x ,则2ω∈x即 若12()ln ()ln ()h P P ωω≤-x ,则1ω∈x ;若12()ln ()ln ()h P P ωω≥-x ,则2ω∈x ② 由上式所决定的决策面为超平面。
模式识别复习资料

(4)如果 Z j( k 1 ) Z j( k )j 1 ,2 , ,K ,则回到(2),将模式 样本逐个重新分类,重复迭代计算。
.
15
例2.3:已知20个模式样本如下,试用K-均值算法分类。
X1 0,0T X2 1,0T X3 0,1T X4 1,1T X5 2,1T X6 1,2T X7 2,2T X8 3,2T
x1
20
8 聚类准则函数Jj与K的关系曲线
上述K-均值算法,其类型数目假定已知为K个。当K未知时,
可以令K逐渐增加, 此时J j 会单调减少。最初减小速度快,但当 K 增加到一定数值时,减小速度会减慢,直到K =总样本数N 时,
Jj = 0。Jj-K关系曲线如下图:
Jj
曲线的拐点 A 对应着接近最优
④ 判断:
Zj(2)Zj(1)
j 1,2 ,故返回第②步。 .
17
② 从新的聚类中心得:
X 1: D D12||||X X11ZZ12((22))|||| X1S1(2) ┋
X 20:D D12||||X X2200Z Z12((22))|||| X20S2(2) 有: S 1 ( 2 ) { X 1 ,X 2 , ,X 8 } N 1 8
(2)将最小距离 3 对应的类 G1(0) 和G2 (0) 合并为1类,得 新的分类。
G 1( 1 2 ) G 1 ( 0 )G , 2 ( 0 ) G 3(1)G 3(0) G 4(1 )G 4(0 ) G 5(1)G 5(0) G 6(1 )G 6(0)
计算聚类后的距离矩阵D(1): 由D(0) 递推出D(1) 。
3)计算合并后新类别之间的距离,得D(n+1)。
4)跳至第2步,重复计算及合并。
模式识别复习题
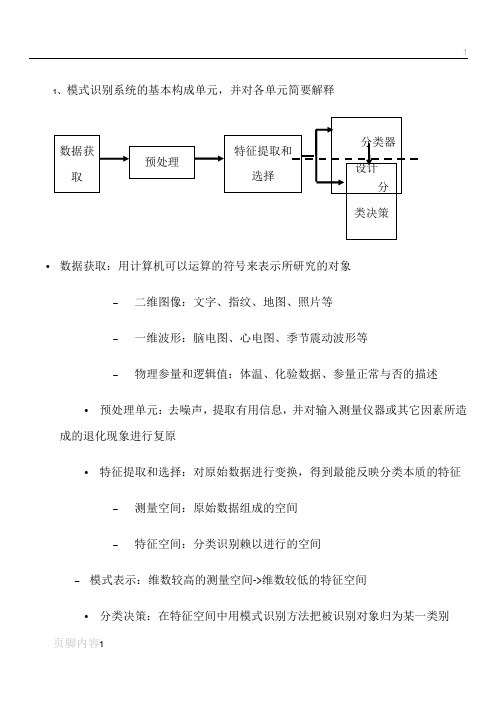
1、模式识别系统的基本构成单元,并对各单元简要解释•数据获取:用计算机可以运算的符号来表示所研究的对象–二维图像:文字、指纹、地图、照片等–一维波形:脑电图、心电图、季节震动波形等–物理参量和逻辑值:体温、化验数据、参量正常与否的描述•预处理单元:去噪声,提取有用信息,并对输入测量仪器或其它因素所造成的退化现象进行复原•特征提取和选择:对原始数据进行变换,得到最能反映分类本质的特征–测量空间:原始数据组成的空间–特征空间:分类识别赖以进行的空间–模式表示:维数较高的测量空间->维数较低的特征空间•分类决策:在特征空间中用模式识别方法把被识别对象归为某一类别–基本做法:在样本训练集基础上确定某个判决规则,使得按这种规则对被识别对象进行分类所造成的错误识别率最小或引起的损失最小2、写出K-均值聚类算法的基本步骤, 例子见布置的作业题.算法:第一步:选K 个初始聚类中心,z 1(1),z 2(1),…,z K (1),其中括号内的序号为寻找聚类中心的迭代运算的次序号。
聚类中心的向量值可任意设定,例如可选开始的K 个模式样本的向量值作为初始聚类中心。
第二步:逐个将需分类的模式样本{x}按最小距离准则分配给K 个聚类中心中的某一个z j (1)。
假设i=j 时,}K ,2,1i ,)k (z x min{)k (D i j =-=,则)k (S x j ∈,其中k 为迭代运算的次序号,第一次迭代k=1,S j 表示第j 个聚类,其聚类中心为z j 。
第三步:计算各个聚类中心的新的向量值,z j (k+1),j=1,2,…,K求各聚类域中所包含样本的均值向量:其中N j 为第j 个聚类域S j 中所包含的样本个数。
以均值向量作为新的聚类中心,可使如下聚类准则函数最小:在这一步中要分别计算K 个聚类中的样本均值向量,所以称之为K-均值算法。
第四步:若)k (z )1k (z j j ≠+,j=1,2,…,K ,则返回第二步,将模式样本逐个重新分类,重复迭代运算; 若)k (z )1k (z j j =+,j=1,2,…,K ,则算法收敛,计算结束。
模式识别期末复习

1.模式是值得具体的摸一个物体,比如,李论是学生,李论是模式,学生是模式类。
2P134页5.23在图像识别中,假定有灌木丛和坦克两种类型,分别用ω1和ω2表示,它们的先验概率分别为0.7和0.3,损失函数如表所示。
现在做了四次试验,获得四个样本的类概率密度如下::0.1,0.15,0.3, 0.6:0.8,0.7,0.55, 0.3(1)试用贝叶斯最小误判概率准则判决四个样本各属于哪个类型;(2)假定只考虑前两种判决,试用贝叶斯最小风险准则判决四个样本各属于哪个类型;(3)将拒绝判决考虑在内,重新考核四次试验的结果。
表类型损失判决ω1 ω2a1 (判为ω1) 0.5 2.0a2 (判为ω2) 4.0 1.0a3 (拒绝判决) 1.5 1.5解:(1)两类问题的Bayes最小误判概率准则为如果,则判,否则判。
由已知数据,q12=0.3/0.7=3/7,样本x1:∵ l12(x1)=0.1/0.8<q12=3/7 \ x1Îω2样本x2:∵ l12(x2)=0.15/0.7<q12=3/7 \ x2Îω2样本x3:∵ l12(x3)=0.3/0.55>q12=3/7 \ x3Îω1样本x4:∵ l12(x4)=0.6/0.3>q12=3/7 \ x4Îω1(2)不含拒绝判决的两类问题的Bayes最小风险判决准则为如果,则判,否则判。
由已知数据,q12=0.3´(2 - 1)/[0.7´(4 - 0.5)]=3/24.5,样本x1:∵ l12(x1)=1/8>q12=6/49 \ x1Îω1样本x2:∵ l12(x2)=3/14>q12=6/49 \ x2Îω1样本x3:∵ l12(x3)=6/11>q12=6/49 \ x3Îω1样本x4:∵ l12(x4)=6/3>q12=6/49 \ x4Îω1(3)含拒绝判决的两类问题的Bayes最小风险判决准则为其中条件风险:后验概率:记 (4.7-1)则,含拒绝判决的两类问题的Bayes最小风险判决准则为对四个样本逐一列写下表,用(4.7-1)式计算r(aj|x)。
模式识别期末复习笔记

模式识别期末复习笔记模式识别ch2 贝叶斯决策1.贝叶斯公式2.贝叶斯决策的特例a)先验概率相同(均匀先验概率):决策仅依赖于类条件概率密度b)类条件概率密度相同:决策仅依赖于先验概率3.计算题(医学测试⽅法)4.计算题(车⾝⾼低)5.贝叶斯决策的最优性a)最⼩化误差概率的⾓度i.每次均选择概率⼤的类做判断结果,因此错误概率永远是最⼩的b)最⼩化风险的⾓度i.每次均选择条件风险最⼩的结果,因此总风险最⼩6.对于两类分类问题,最⼩风险贝叶斯决策a)可以基于似然⽐进⾏决策b)p(x|ω1)p(x|ω2)≥λ12?λ22λ21?λ11p(ω2)p(ω1)则判断为1类,否则为2类c)似然⽐超过某个阈值(θ),那么可判决为ω1类7.0-1损失(误判是等价的):最⼩化风险就是最⼤化后验,也就是选择后验最⼤的a)最⼩化误差概率与最⼩化风险等价,即选择最⼤后验的分类,即满⾜最⼩误差概率,也满⾜最⼩风险8.先验概率未知时如何设计风险最⼩的分类器?a)使先验概率取任意值时的总风险的最坏情况尽可能⼩b)极⼩化极⼤准则:i.极⼩化指的是贝叶斯风险,因为它是总风险的最⼩值ii.极⼤化指的是使贝叶斯风险达到最⼤iii.贝叶斯风险是和先验有关的,其最⼤也就是其极值,就是导数等于0 的时候c)极⼩化极⼤风险是最坏的贝叶斯风险9.从最⼩化误差概率的意义上讲,贝叶斯是最优的;贝叶斯决策得到的总风险也是最⼩的10.判别函数a)对于两类分类,根据判别函数的正负进⾏类的判断;对于多类问题,两两组成两类问题b)两类问题下:g(x)=g1(x)?g2(x)i.若g(x)≥0,即g1(x)≥g2(x),则判断为1类,否则为2类c)g1(x),g2(x)的设计i.最⼩总风险贝叶斯分类器1.g1(x)=?R(α1|x),风险的相反数ii.最⼩误差概率贝叶斯分类器1. g 1(x )=p (ω1|x )2. g 1(x )=p (x|ω1)p (ω1)3. g 1(x )=log(p (x|ω1))+log(p (ω1))11.12. 计算题(决策边界为何下偏)ch3 参数估计1. 模式分类的途径(截图)2. 当可⽤数据很多以⾄于减轻了先验知识的作⽤时,贝叶斯估计可退化为最⼤似然估计。
模式识别期末考试题及答案

模式识别期末考试题及答案一、填空题1. 模式识别是研究通过_________从观测数据中自动识别和分类模式的一种学科。
答案:计算机算法2. 在模式识别中,特征选择的主要目的是_________。
答案:降低数据的维度3. 支持向量机(SVM)的基本思想是找到一个最优的超平面,使得两类数据的_________最大化。
答案:间隔4. 主成分分析(PCA)是一种_________方法,用于降低数据的维度。
答案:线性降维5. 隐马尔可夫模型(HMM)是一种用于处理_________数据的统计模型。
答案:时序二、选择题6. 以下哪种方法不属于模式识别的监督学习方法?()A. 线性判别分析B. 支持向量机C. 神经网络D. K-means聚类答案:D7. 在以下哪种情况下,可以使用主成分分析(PCA)进行特征降维?()A. 数据维度较高,且特征之间存在线性关系B. 数据维度较高,且特征之间存在非线性关系C. 数据维度较低,且特征之间存在线性关系D. 数据维度较低,且特征之间存在非线性关系答案:A8. 以下哪个算法不属于聚类算法?()A. K-meansB. 层次聚类C. 判别分析D. 密度聚类答案:C三、判断题9. 模式识别的目的是将输入数据映射到事先定义的类别中。
()答案:正确10. 在模式识别中,特征提取和特征选择是两个不同的概念,其中特征提取是将原始特征转换为新的特征,而特征选择是从原始特征中筛选出有用的特征。
()答案:正确四、简答题11. 简述模式识别的主要任务。
答案:模式识别的主要任务包括:分类、回归、聚类、异常检测等。
其中,分类和回归任务属于监督学习,聚类和异常检测任务属于无监督学习。
12. 简述支持向量机(SVM)的基本原理。
答案:支持向量机的基本原理是找到一个最优的超平面,使得两类数据的间隔最大化。
具体来说,SVM通过求解一个凸二次规划问题来确定最优超平面,使得训练数据中的正类和负类数据点尽可能远离这个超平面。
模式识别复习要点

复习要点绪论1、举出日常生活或技术、学术领域中应用模式识别理论解决问题的实例。
答:语音识别,图像识别,车牌识别,文字识别,人脸识别,通信中的信号识别;① 文字识别汉字已有数千年的历史,也是世界上使用人数最多的文字,对于中华民族灿烂文化的形成和发展有着不可磨灭的功勋。
所以在信息技术及计算机技术日益普及的今天,如何将文字方便、快速地输入到计算机中已成为影响人机接口效率的一个重要瓶颈,也关系到计算机能否真正在我过得到普及的应用。
目前,汉字输入主要分为人工键盘输入和机器自动识别输入两种。
其中人工键入速度慢而且劳动强度大;自动输入又分为汉字识别输入及语音识别输入。
从识别技术的难度来说,手写体识别的难度高于印刷体识别,而在手写体识别中,脱机手写体的难度又远远超过了联机手写体识别。
到目前为止,除了脱机手写体数字的识别已有实际应用外,汉字等文字的脱机手写体识别还处在实验室阶段。
②语音识别语音识别技术技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
近年来,在生物识别技术领域中,声纹识别技术以其独特的方便性、经济性和准确性等优势受到世人瞩目,并日益成为人们日常生活和工作中重要且普及的安验证方式。
而且利用基因算法训练连续隐马尔柯夫模型的语音识别方法现已成为语音识别的主流技术,该方法在语音识别时识别速度较快,也有较高的识别率。
③ 指纹识别我们手掌及其手指、脚、脚趾内侧表面的皮肤凹凸不平产生的纹路会形成各种各样的图案。
而这些皮肤的纹路在图案、断点和交叉点上各不相同,是唯一的。
依靠这种唯一性,就可以将一个人同他的指纹对应起来,通过比较他的指纹和预先保存的指纹进行比较,便可以验证他的真实身份。
一般的指纹分成有以下几个大的类别:环型(loop),螺旋型(whorl),弓型(arch),这样就可以将每个人的指纹分别归类,进行检索。
指纹识别基本上可分成:预处理、特征选择和模式分类几个大的步骤。
模式识别复习重点总结

模式识别复习重点总结(总16页)-CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除1.什么是模式及模式识别模式识别的应用领域主要有哪些模式:存在于时间,空间中可观察的事物,具有时间或空间分布的信息; 模式识别:用计算机实现人对各种事物或现象的分析,描述,判断,识别。
模式识别的应用领域:(1)字符识别;(2) 医疗诊断;(3)遥感; (4)指纹识别 脸形识别;(5)检测污染分析,大气,水源,环境监测; (6)自动检测;(7 )语声识别,机器翻译,电话号码自动查询,侦听,机器故障判断;(8)军事应用。
2.模式识别系统的基本组成是什么(1) 信息的获取:是通过传感器,将光或声音等信息转化为电信息;(2) 预处理:包括A\D,二值化,图象的平滑,变换,增强,恢复,滤波等, 主要指图象处理;(3) 特征抽取和选择:在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征;(4) 分类器设计:分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率最低。
把这些判决规则建成标准库;(5) 分类决策:在特征空间中对被识别对象进行分类。
3.模式识别的基本问题有哪些(1)模式(样本)表示方法:(a )向量表示;(b )矩阵表示;(c )几何表示;(4)基元(链码)表示;(2)模式类的紧致性:模式识别的要求:满足紧致集,才能很好地分类;如果不满足紧致集,就要采取变换的方法,满足紧致集(3)相似与分类;(a)两个样本x i ,x j 之间的相似度量满足以下要求: ① 应为非负值② 样本本身相似性度量应最大 ③ 度量应满足对称性④ 在满足紧致性的条件下,相似性应该是点间距离的 单调函数(b)用各种距离表示相似性(4)特征的生成:特征包括:(a)低层特征;(b)中层特征;(c)高层特征 (5) 数据的标准化:(a)极差标准化;(b)方差标准化4.线性判别方法(1)两类:二维及多维判别函数,判别边界,判别规则二维情况:(a )判别函数: ( ) (b )判别边界:(c )判别规则:n 维情况:(a )判别函数: 也可表示为: 32211)(w x w x w x g ++=为坐标向量为参数,21,x x w 12211......)(+++++=n n n w x w x w x w x g X W x g T =)(为增值模式向量。
模式识别复习题

模式识别复习题一、试问“模式”与“模式类”的含义。
如果一位姓王的先生是位老年人,试问“王先生”和“老头”谁是模式,谁是模式类?答:在模式识别学科中,我们把通过对具体的事物进行观测所得到的具有时间和空间分布的信息称为“模式”,而把模式所属的类别或同一类中模式的总体称为模式类。
就“模式”与“模式类”而言,模式类是一类事物的代表,概念或典型,而“模式”则是某一事物的具体体现,如“老头”是模式类,而王先生则是“模式”,是“老头”的具体化。
二、试从模式类与模式概念分析以下词之间的关系:王老头,王老太,王明(清华大学本科生),周强(年轻教师),老年人,老头,老太,年青人。
答:在模式识别学科中,我们把通过对具体的事物进行观测所得到的具有时间和空间分布的信息称为“模式”,而把模式所属的类别或同一类中模式的总体称为模式类。
模式类:老年人模式:王老太,老头,老太。
模式类:年青人模式:王明(清华大学本科生),周强(年轻教师)模式类:老头模式:王老头模式类:老太模式:王老太三、对一副道路图像,希望把道路部分划分出来,可以采用以下两种方法:1.在该图像中分别在道路部分与非道路部分画出一个窗口,把在这两个窗口中的象素数据作为训练集,用Fisher准则方法求得分类器参数,再用该分类器对整幅图进行分类。
2.将整幅图的每个象素的属性记录在一张数据表中,然后用某种方法将这些数据按它们的自然分布状况划分成两类。
因此每个象素就分别得到相应的类别号,从而实现了道路图像的分割。
试问以上两种方法哪一种是监督学习,哪个是非监督学习?并说明这两种学习方法的定义与它们间的区别。
答:第一种方法中标记了两类样本的标号,需要人手工干预训练过程,属于监督学习方法;第二种方法只是依照数据的自然分布,把它们划分成两类,属于非监督学习方法。
监督学习方法用来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
最新模式识别复习题

《模式识别》试题库一、基本概念题1.1 模式识别的三大核心问题是:、、。
1.2、模式分布为团状时,选用聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利用两类方法处理多类问题的技术途径有:(1);(2);(3)。
其中最常用的是第个技术途径。
1.6 判别函数的正负和数值大小在分类中的意义是:,。
1.7 感知器算法。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
1.8 积累位势函数法的判别界面一般为。
(1)线性界面;(2)非线性界面。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW BSS S+1.10 作为统计判别问题的模式分类,在()情况下,可使用聂曼-皮尔逊判决准则。
1.11 确定性模式非线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 用作确定性模式非线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满足下列三个条件,都可作为势函数。
①();②( ); ③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越大,说明ωi 类模式与ωj 类模式的分布( )。
当ωi 类模式与ωj 类模式的分布相同时,J ij =( )。
1.14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
1.15 信息熵可以作为一种可分性判据的原因是: 。
1.16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
1.17 随机变量l(x )=p( x |ω1)/p( x |ω2),l( x )又称似然比,则E {l( x )|ω2}=( )。
模式识别复习重点总结85199

1.什么是模式及模式识别?模式识别的应用领域主要有哪些?模式:存在于时间,空间中可观察的事物,具有时间或空间分布的信息; 模式识别:用计算机实现人对各种事物或现象的分析,描述,判断,识别。
模式识别的应用领域:(1)字符识别;(2) 医疗诊断;(3)遥感; (4)指纹识别 脸形识别;(5)检测污染分析,大气,水源,环境监测;(6)自动检测;(7 )语声识别,机器翻译,电话号码自动查询,侦听,机器故障判断; (8)军事应用。
2.模式识别系统的基本组成是什么?(1) 信息的获取:是通过传感器,将光或声音等信息转化为电信息;(2) 预处理:包括A \D,二值化,图象的平滑,变换,增强,恢复,滤波等, 主要指图象处理;(3) 特征抽取和选择:在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征;(4) 分类器设计:分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率最低。
把这些判决规则建成标准库; (5) 分类决策:在特征空间中对被识别对象进行分类。
3.模式识别的基本问题有哪些?(1)模式(样本)表示方法:(a)向量表示;(b)矩阵表示;(c)几何表示;(4)基元(链码)表示;(2)模式类的紧致性:模式识别的要求:满足紧致集,才能很好地分类;如果不满足紧致集,就要采取变换的方法,满足紧致集(3)相似与分类;(a)两个样本x i ,x j 之间的相似度量满足以下要求: ① 应为非负值② 样本本身相似性度量应最大 ③ 度量应满足对称性④ 在满足紧致性的条件下,相似性应该是点间距离的 单调函数(b)用各种距离表示相似性 (4)特征的生成:特征包括:(a)低层特征;(b)中层特征;(c)高层特征 (5) 数据的标准化:(a)极差标准化;(b)方差标准化4.线性判别方法(1)两类:二维及多维判别函数,判别边界,判别规则 二维情况:(a)判别函数: ( )(b)判别边界:g(x )=0; (c)判别规则:n 维情况:(a)判别函数:也可表示为:32211)(w x w x w x g ++=为坐标向量为参数,21,x x w 12211......)(+++++=n n n w x w x w x w x g X W x g T =)(为增值权向量,T T n n w w w w W ),,...,,(121=+(b)判别边界:g1(x ) =W TX =0 (c)判别规则:(2)多类:3种判别方法(函数、边界、规则)(A )第一种情况:(a)判别函数:M 类可有M 个判别函数(b) 判别边界:ωi (i=1,2,…,n )类与其它类之间的边界由 g i(x )=0确定(c)(B)第二种情况:(a)判别函数:有 M (M _1)/2个判别平面(b) 判别边界: (c )判别规则:(C)第三种情况:(a)判别函数: (b) 判别边界:g i (x ) =gj (x ) 或g i (x ) -gj (x ) =0(c)判别规则:5.什么是模式空间及加权空间,解向量及解区? (1)模式空间:由 构成的n 维欧氏空间;(2)加权空间:以为变量构成的欧氏空间; (3)解向量:分界面为H,W 与H 正交,W称为解向量; (4)解区:解向量的变动范围称为解区。
四川大学模式识别期末考试内容

2.一个典型的模式识别系统主要由哪几个部分组成
3.什么是后验概率?
系统在某个具体的模式样本X条件下位于某种类型的概率。
4.确定线性分类器的主要步骤
①采集训练样本,构成训练样本集。样本应该具有典型性
5.序贯分类方法,除了考虑分类造成的损失外,还考虑特征获取造成的代价,先用一部分特征分类,然后逐步加入性特征以减少分类损失,同时平衡总的损失,以求得最有效益。
十四、假设在某个地区细胞识别中正常(w1)和异常(w2)两类先验概率分别为P(w1)=0。9,P(w2)=0。1,现有一待识别的细胞,其观察值为x,从类条件概率密度分布曲线上查得 , ,并且已知 , , ,
分解法:把所有样本看做一类,逐级分解为每个样本一类。
10.特征抽取与特征选择的区别?
特征抽取:原始特征的数量可能很大,或者样本处于一个高维空间中,通过映射(或变换)的方法可以用低维空间来义上就是指一种变换。
特征选择:从一组特征中挑选出一些最有效的特征以达到降低特征空间维数的目的,这个过程叫特征选择。
试对该细胞x用一下两种方法进行分类:
1.基于最小错误率的贝叶斯决策;
2.基于最小风险的贝叶斯决策;
请分析两种结果的异同及原因。
答:1。
2。
十七、写出两类和多类情况下最小风险贝叶斯决策判别函数和决策面方程。
十八、请论述模式识别系统的主要组成部分及其设计流程,并简述各组成部分中常用方法的主要思想。
信息获取:通过测量、采样和量化,可以用矩阵或向量表示二维图像或以为波形。
离散K-L变换又称主成分分析(PCA),是一种基于目标统计特性的最佳正交变换,被广泛应用于数据压缩、特征降维等方面。
模式识别复习题参考

ω2: X2 =(1,1)T , X4 =(0,-2)T, X6 =(-2,0)T 给定初始增广权向量 w1=(1 1 1)T , C=1。
要求:用感知器算法求模式分类的解向量w。 7-8 参考: 用多类感知器算法求下列模式的判别函数:
x4: 1, 1, 0, 2, 0
x5: 3, 2, 1, 2, 1 x6: 4, 1, 1, 1, 0
5、设有 5 个 6 维模式样本如下,按最小/大距离准则进行聚类分析(距离度量采用欧氏距离)
x1: 0, 1,3, 1, 3, 4
x2: 3, 3, 3, 1,2,1 x3: 1, 0, 0, 0, 1,1
ω1: (-1 -1)T,ω2: (0 0)T,ω3: (1 1)T 解:采用一般化的感知器算法,将模式样本写成增广形式,即
x1 =(-1,-1,1)T , x2 = (0, 0,1)T , x3 = (1,1,1)T
取初始值 w1 = w2 = w3 = (0, 0, 0)T ,取 C = 1,则有
第四步:若 z j (k + 1) ≠ z j (k) ,j=1,2,…,K,则返回第二步,将模式样本逐个重新分类,重复迭代
运算;
若 z j (k + 1) = z j (k) ,j=1,2,…,K,则算法收敛,计算结束。
(2)选 k = 2 , z1(1) = x1, z2 (1) = x10 ,用 K-均值算法进行聚类分析
假设 i=j 时, D j (k) = min{ x − zi (k) ,i = 1,2,⋯K} ,则 x ∈ S j (k) ,其中 k 为迭代运算的次序号,
模式识别复习资料

(3)求R的特征值、特征矢量 的特征值、
| R − λI |= (25.4 − λ ) 2 − 252 = 0 ⇒ λ1 = 50.4, λ2 = 0.4 r r r 1 1 r 1 1 , t2 = Rt j = λ j t j , j = 1,2 ⇒ t1 = 1 2 2 − 1
解:利用Bayes公式 利用Bayes公式 Bayes p(x =阳| ω1)P(ω1) P(ω1 | x =阳 = )
p(x =阳 ) p(x =阳| ω1)P(ω1) = p(x =阳| ω1)P(ω1) + p(x =阳| ω2 )P(ω2 ) 0.95×0.005 = = 0.323 0.95×0.005 + 0.01×0.995
习题2.2 习题
给 定 x , 做 出 α 1决 策 和 α 2 决 策 的 风 险 分 别 为 : R (α 1 x ) = λ1 1 P (ω 1 x ) + λ1 2 P (ω 2 x ) R (α 2 x ) = λ 2 1 P ( ω 1 x ) + λ 2 2 P ( ω 2 x ) 最小风险的贝叶斯决策为:
患癌症者; 例:对一批人进行癌症普查,ω1 :患癌症者; 对一批人进行癌症普查, 正常人。 模式特征x= 化验结果), =1: ω2 :正常人。 模式特征x=x(化验结果),x=1: 阳性; =0:阴性。 阳性;x=0:阴性。 已知: 统计结果) 已知:(统计结果) 先验概率: )=0 先验概率:P(ω1)=0.005 )=1 )=0 P(ω2)=1-P(ω1)=0.995 条件概率: )=0 条件概率:p(x=阳|ω1)=0.95 )=0 p(x=阴|ω1)=0.05 )=0 p(x=阳|ω2)=0.01 呈阳性反映的人是否患癌症? 求:呈阳性反映的人是否患癌症?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实用文档文案大全题型:1.填空题5题2.名词解释4题3.问答题4题4.计算作图题3题5.综合计算题1题备注1:没有整理第一章和第六章,老师说不考的备注2:非线性判别函数相关概念P69概率相关定义、性质、公式P83以后最小错误率贝叶斯决策公式P85 最小风险贝叶斯P86 正态贝叶斯P90综合计算有可能是第六次作业一、填空题物以类聚人以群分体现的是聚类分析的基本思想。
模式识别分类:1.从实现方法来分模式识别分为监督分类和非监督分类;2.从理论上来分,有统计模式识别,统计模式识别,模糊模式识别,神经网络模式识别法聚类分析是按照不同对象之间的差异,根据距离函数的规律做模式分类的。
模式的特性:可观察性、可区分性、相似性模式识别的任务:一是研究生物体(包括人)是如何感知对象的,二是如何用计算机实现模式识别的理论和方法。
计算机的发展方向:1.神经网络计算机--模拟人的大脑思维;2.生物计算机--运用生物工程技术、蛋白分子作芯片;3.光计算机--用光作为信息载体,通过对光的处理来完成对信息的处理。
训练学习方法:监督学习、无监督学习(无先验知识,甚至类别数也未知)。
统计模式识别有:1.聚类分析法(非监督);2.判决函数法/几何分类法(监督);3.基于统计决策的概率分类法 - 以模式集在特征空间中分布的类概率密度函数为基础,对总体特征进行研究,以取得分类的方法数据的标准化目的:消除各个分量之间数值范围大小对算法的影响模式识别系统的基本构成:书P7聚类过程遵循的基本步骤:特征选择;近邻测度;聚类准则;聚类算法;结果验证;结果判定。
相似测度基础:以两矢量的方向是否相近作为考虑的基础,矢量长度并不重要。
确定聚类准则的两种方式:阈值准则,函数准则基于距离阈值的聚类算法——分解聚类:近邻聚类法;最大最小距离聚类法类间距离计算准则:1)最短距离法2)最长距离法 3)中间距离法4)重心法5)类平均距离法6)离差平方和法P24 系统聚类法——合并的思想用于随机模式分类识别的方法,通常称为贝叶斯判决。
BAYES 决策常用的准则:最小错误率;最小风险错误率的计算或估计方法:①按理论公式计算;②计算错误率上界;③实验估计。
填空实用文档文案大全1.名词解释相似性测度:衡量模式之间相似性的一种尺度明氏距离:P17当m=2时,明氏距离为欧氏距离。
当m=1时:绝对距离(曼哈顿距离)称为“街坊”距离感知器算法:就是通过训练样本模式的迭代和学习,产生线性(或广义线性)可分的模式判别函数。
梯度:P59 感知器P227 模糊度P182 清晰性P182 含混性近似性随机性》》》》》》》模式:对客体(研究对象)特征的描述(定量的或结构的),是取自客观世界的某一样本的测量值的集合(或综合)。
模式所指的不是事物本身,而是从事物获得的信息。
模式识别:确定一个样本的类别属性(模式类)的过程,即把某一样本归属于多个类型中的某个类型。
模式类:具有某些共同特性的模式的集合。
特征选择:在原始特征基础上选择一些主要特征作为判别用的特征。
特征提取:采用某种变换技术,得出数目上比原来少的综合特征作为分类用。
特征抽取:通过各种手段从原始数据中得出反映分类问题的若干特征(有时需进行数据标准化)特征空间:进行模式分类的空间。
特征向量:用 n 维列向量来表示一个(模式)样本,说明该样本具有 n 个数字特征 x= (x1 , x2 , …, xn)T 常称之为特征向量。
人工智能:是研究如何将人的智能转化为机器智能,或者是用机器来模拟或实现人的智能。
聚类分析:根据模式之间的相似性(相邻性)对模式进行分类,是一种非监督分类方法。
聚类准则:根据相似性测度确定的,衡量模式之间是否相似的标准。
即把不同模式聚为一类还是归为不同类的准则——同一类模式相似程度的标准或不同类模式差异程度的标准。
聚类准则函数:在聚类分析中,表示模式类内相似或类间差异性的函数。
相似度:衡量模式之间相似程度的尺度。
相似性测度:衡量模式之间相似性的一种尺度。
欧氏距离(简称距离):P15 马氏距离:P15明氏距离:P17当m=2时,明氏距离为欧氏距离。
当m=1时:绝对距离(曼哈顿距离)称为“街坊”距离汉明(Hamming)距离:P17判别函数:直接用来对模式进行分类的准则函数。
感知器算法:就是通过训练样本模式的迭代和学习,产生线性(或广义线性)可分的模式判别函数。
梯度:P59分类器的正确率:指分类器正确分类的项目占所有被分类项目的比率。
过拟合:高维空间训练形成的分类器,相当于在低维空间的一个复杂的非线性分类器,这种分类器过多的强调了训练名词解实用文档文案大全的准确率甚至于对一些错误/异常的数据也进行了学习,而正确的数据却无法覆盖整个特征空间。
为此,这样得到的分类器在对新数据进行预测时将会出现错误。
这种现象称之为过拟合,同时也是维数灾难的直接体现。
实用文档文案大全2.问答题统计模式识别的优缺点:主要优点:1)比较成熟2)能考虑干扰噪声等影响3)识别模式基元能力强主要缺点:1)对结构复杂的模式抽取特征困难2)不能反映模式的结构特征,难以描述模式的性质3)难以从整体角度考虑识别问题句法模式识别优缺点:主要优点:1)识别方便,可以从简单的基元开始,由简至繁。
2)能反映模式的结构特征,能描述模式的性质。
3)对图象畸变的抗干扰能力较强。
主要缺点:当存在干扰及噪声时,抽取特征基元困难,且易失误。
模糊模式识别优缺点:主要优点:由于隶属度函数作为样本与模板间相似程度的度量,故往往能反映整体的与主体的特征,从而允许样本有相当程度的干扰与畸变。
主要缺点:准确合理的隶属度函数往往难以建立,故限制了它的应用。
神经网络模式识别法优缺点:主要优点:可处理一些环境信息十分复杂,背景知识不清楚,推理规则不明确的问题。
允许样本有较大的缺损、畸变。
主要缺点:模型在不断丰富与完善中,目前能识别的模式类还不够多。
分类与聚类的区别:分类:用已知类别的样本训练集来设计分类器(监督学习), 由学习过程和识别过程两部分组成,且用于学习的样本类别是已知的。
聚类(集群):事先不知样本的类别,而利用样本的先验知识来构造分类器(无监督学习)。
马氏距离的优缺点:优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同;马氏距离还可以排除变量之间的相关性的干扰;满足距离的四个基本公理:非负性、自反性、对称性和三角不等式。
缺点:有可能夸大变化微小的变量的作用;协方差不易计算近邻聚类法优缺点:优点:计算简单(一种虽粗糙但快速的方法)。
局限性:问答实用文档文案大全聚类过程中,类的中心一旦确定将不会改变,模式一旦指定类后也不再改变。
聚类结果很大程度上依赖于第一个聚类中心的位置选择、待分类模式样本的排列次序、距离阈值T的大小以及样本分布的几何性质等。
最大最小距离算法(小中取大距离算法):算法思想:在模式特征矢量集中以最大距离原则选取新的聚类中心。
以最小距离原则进行模式归类,通常使用欧式距离。
层次聚类法(系统聚类法、分级聚类法): 思路:每个样本先自成一类,然后按距离准则逐步合并,减少类数。
动态聚类的基本步骤:建立初始聚类中心,进行初始聚类;计算模式和类的距离,调整模式的类别;计算各聚类的参数,删除、合并或分裂一些聚类;从初始聚类开始,运用迭代算法动态地改变模式的类别和聚类的中心使准则函数取得极值或设定的参数达到设计要求时停止。
ISODATA与K-均值算法比较:相似:聚类中心的位置均通过样本均值的迭代运算决定。
相异: K-均值算法的聚类中心个数不变;ISODATA的聚类中心个数变化。
ISODATA基本思路:(1)选择初始值——包括若干聚类中心及一些指标。
可在迭代运算过程中人为修改,据此将N个模式样本分配到各个聚类中心去。
(2)按最近邻规则进行分类。
(3)聚类后的处理:计算各类中的距离函数等指标,按照给定的要求,将前次获得的聚类集进行分裂或合并处理,以获得新的聚类中心,即调整聚类中心的个数。
(4)判断结果是否符合要求:符合,结束;不同聚类算法比较:线性判别函数的特点:实用文档文案大全形式简单,容易学习;用于线性可分的模式类。
分段线性判别函数特点:相对简单;能逼近各种形状的超曲面。
一维正态曲线的性质:(1)曲线在 x 轴的上方,与x轴不相交。
(2)曲线关于直线 x =μ对称。
(3)当 x =μ时,曲线位于最高点。
(4)当x<μ时,曲线上升;当x>μ时,曲线下降.并且当曲线向左、右两边无限延伸时,以x轴为渐近线,向它无限靠近。
(5)μ一定时,曲线的形状由σ确定。
σ越大,曲线越“矮胖”,表示总体的分布越分散;σ越小。
曲线越“瘦高”。
表示总体的分布越集中。
特征选择和提取的目的:经过选择或变换,组成识别特征,尽可能保留分类信息,在保证一定分类精度的前提下,减少特征维数,使分类器的工作既快又准确。
K-L变换进行特征提取的优缺点:优点:变换在均方误差最小的意义下使新样本集{X *}逼近原样本集{X}的分布,既压缩了维数又保留了类别鉴别信息。
变换后的新模式向量各分量相对总体均值的方差等于原样本集总体自相关矩阵的大特征值,表明变换突出了模式类之间的差异性。
C*为对角矩阵说明了变换后样本各分量互不相关,亦即消除了原来特征之间的相关性,便于进一步进行特征的选择。
缺点:对两类问题容易得到较满意的结果。
类别愈多,效果愈差。
需要通过足够多的样本估计样本集的协方差矩阵或其它类型的散布矩阵。
当样本数不足时,矩阵的估计会变得十分粗略,变换的优越性也就不能充分的地显示出来。
计算矩阵的本征值和本征向量缺乏统一的快速算法,给计算带来困难。
实用文档文案大全3.计算作图题最大最小距离算法(小中取大距离算法):计算按照P22的例2.1来最短距离准则进行系统聚类分类:P25例2.2层次聚类分析:(此处为例题)(1) 设全部样本分为6类(2) 作距离矩阵D(0) (3) 求最小元素(4) 把ω1, ω3合并ω7=(1,3);ω4, ω6合并ω8=(4,6)(5) 作距离矩阵D(1)(6) 若合并的类数没有达到要求,转(3), 否则停止(7) 求最小元素(8) ω8, ω5, ω2合并, ω9=(2,5,4,6)(9) 如无阈值要求,直至最后归为一类ω10K均值算法P28例2.3 判别函数:P40》第一种:例3.1&3.2P42此法将 M 个多类问题分成M个两类问题,识别每一类均需M个判别函数。
识别出所有的M类仍是这M个函数。
》第二种:P44例3.3&3.4每分离出一类,需要与I 有关的M-1个判决函数;要分开M类模式,共需M(M-1)/2个判决函数。
对三类问题需要3(3-1)/2=3个判决函数。