mysql性能优化思维导图
mysql性能优化-慢查询分析、优化索引和配置

mysql性能优化-慢查询分析、优化索引和配置目录一、优化概述二、查询与索引优化分析1性能瓶颈定位Show命令慢查询日志explain分析查询profiling分析查询2索引及查询优化三、配置优化1) max_connections2) back_log3) interactive_timeout4) key_buffer_size5) query_cache_size6) record_buffer_size7) read_rnd_buffer_size8) sort_buffer_size9) join_buffer_size10) table_cache11) max_heap_table_size12) tmp_table_size13) thread_cache_size14) thread_concurrency15) wait_timeout一、优化概述MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候。
磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应用分布在网络上,那么查询量相当大的时候那么平瓶颈就会出现在网络上,我们可以用mpstat, iostat, sar和vmstat来查看系统的性能状态。
除了服务器硬件的性能瓶颈,对于MySQL系统本身,我们可以使用工具来优化数据库的性能,通常有三种:使用索引,使用EXPLAIN分析查询以及调整MySQL的内部配置。
二、查询与索引优化分析在优化MySQL时,通常需要对数据库进行分析,常见的分析手段有慢查询日志,EXPLAIN 分析查询,profiling分析以及show命令查询系统状态及系统变量,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
1 性能瓶颈定位Show命令我们可以通过show命令查看MySQL状态及变量,找到系统的瓶颈:Mysql> show status ——显示状态信息(扩展show status like ‘XXX’)Mysql> show variables ——显示系统变量(扩展show variables like ‘XXX’)Mysql> show innodb status ——显示InnoDB存储引擎的状态Mysql> show processlist ——查看当前SQL执行,包括执行状态、是否锁表等Shell> mysqladmin variables -u username -p password——显示系统变量Shell> mysqladmin extended-status -u username -p password——显示状态信息查看状态变量及帮助:Shell> mysqld –verbose –help [|more #逐行显示]比较全的Show命令的使用可参考: http://blog.php //18/慢查询日志慢查询日志开启:在配置文件f或my.ini中在[mysql d]一行下面加入两个配置参数log-slow-queries=/data/mysqldata/slow-query.loglong_query_time=2注:log-slow-queries参数为慢查询日志存放的位置,一般这个目录要有mysql的运行帐号的可写权限,一般都将这个目录设置为mysql的数据存放目录;long_query_time=2中的2表示查询超过两秒才记录;在f或者my.ini中添加log-queries-not-using-indexes参数,表示记录下没有使用索引的查询。
mysql性能优化精品PPT课件

目录索引
MySQL优化方式 MySQL技巧分享 MySQL函数
MySQL优化方式
MySQL优化方式
系统优化:硬件、架构 服务优化 应用优化
系统优化
使用好的硬件,更快的硬盘、大内存、多核CPU,专业的存 储服务器(NAS、SAN)
设计合理架构,如果 MySQL 访问频繁,考虑 Master/Slave 读写分离;数据库分表、数据库切片(分布式),也考虑使 用相应缓存服务帮助 MySQL 缓解访问压力
选项
max_connections query_cache_size sort_buffer_size
record_buffer table_cache
缺省值
100 0 (不打开)M 16M
16M 512
说明
MySQL服务器同时处理的数据库连接的最大数量
查询缓存区的最大长度,按照当前需求,一倍一倍 增加,本选项比较重要
每个线程的排序缓存大小,一般按照内存可以设置 为2M以上,推荐是16M,该选项对排序order by, group by起作用
每个进行一个顺序扫描的线程为其扫描的每张表分 配这个大小的一个缓冲区,可以设置为2M以上
为所有线程打开表的数量。增加该值能增加mysqld 要求的文件描述符的数量。MySQL对每个唯一打开 的表需要2个文件描述符。
8M
128M 0 256M
innodb_log_buffer_size
128K
8M
说明
InnoDB使用一个缓冲池来保存索引和原始数据, 这 里你设置越大,你在存取表里面数据时所需要的磁盘 I/O越少,一般是内存的一半,不超过2G,否则系 统会崩溃,这个参数非常重要
InnoDB用来保存 metadata 信息, 如果内存是4G, 最好本值超过200M
高性能MySQL(第4版)

精彩摘录
处理并发读/写访问的系统通常实现一个由两种锁类型组成的锁系统。这两种锁通常被称为共享锁(shared lock)和排他锁(exclusive lock),也叫读锁(read lock)和写锁(write lock)。
InnoDB目前处理死锁的方式是将持有最少行级排他锁的事务回滚(这是一种最容易回滚的近似算法)。
MySQL的客户端/服务器通信协议 查询状态 查询优化处理 查询执行引擎 将结果返回给客户端
UNION的限制 等值传递 并行执行 在同一个表中查询和更新
优化COUNT()查询 优化联接查询 使用WITH ROLLUP优化GROUP BY 优化LIMIT和OFFSET子句 优化SQL CALC FOUND ROWS 优化UNION查询
云上的机器类型 选择正确的机器类型 选择正确的磁盘类型 额外的建议
建立合规控制体系
什么是合规性
小结
服务组织控制类型2 萨班斯-奥克斯利法案 支付卡行业数据安全标准 健康保险可携带性和责任法案 联邦风险和授权管理计划 通用数据保护条例 Schrems II
机密信息管理 角色与数据分离 跟踪变更 备份和恢复过程
MySQL Enterprise Backup Percona XtraBackup mydumper mysqldump
逻辑SQL备份 文件系统快照 Percona XtraBackup
恢复逻辑备份 从快照中恢复 使用Percona XtraBackup进行恢复 原始文件恢复后启动MySQL
读书笔记
翻译的有点难读,讲的似乎懂了,似乎又没懂,要看的话,678章可以先看。 看的英文版,比第三版删减了一些东西,更加聚焦于开发需要的东西。 总体挺不错的,但是整体行文像是博客,有点底层逻辑和原理没有讲解,sql优化部分,缺少sql例子。 全面介绍mysql,dba必备。 读了几个章节,像重要的事物和索引,读起来感觉都是浅尝辄止,弃了。 买了纸质书,坦白的说要学基础知识第三版更合适,这本书适合怀旧。 该书基于MySQL8.0版本介绍的。 刚出版就上架了?不得不说,**读书有点东西。
千金良方:MySQL性能优化金字塔法则

2.1背景 2.2 MySQL 5.5.54的安装 2.3升级MySQL 5.5.54到MySQL 5.6.35 2.4升级注意事项
3.1快速安装MySQL 3.2数据目录结构 3.3 MySQL Server体系结构 3.4 MySQL中的存储引擎 3.5 InnoDB存储引擎体系结构 3.6 InnoDB存储引擎后台线程 3.7 MySQL前台线程
31.1环境配置 31.2问题现象 31.3诊断分析 31.4解决方案 31.5 MySQL最大连接数为214的源码解析 31.6 Linux资源限制 31.7本章小结
32.1环境配置 32.2问题现象 32.3诊断分析 32.4挂起时先做什么 32.5本章小结
33.1硬件和系统调优概览 33.2 CPU 33.3网络 33.4其他 33.5本章小结
10.1什么是information_schema 10.2 information_schema组成对象
11.1使用Server层的字典表查询相关的元数据信息 11.2使用InnoDB层的字典表查询相关的元数据信息
12.1 user 12.2 db 12.3 tables_priv 12.4 columns_priv 12.5 procs_priv 12.6 proxies_priv
48.1简介 48.2原理 48.3命令行选项 48.4实战演示
49.1简介 49.2原理 49.3命令行选项 49.4实战演示
50.1简介 50.2原理 50.3命令行选项 50.4实战演示
51.1闪回工具科普 51.2 binlog2sql 51.3 MyFlash
作者介绍
这是《千金良方:MySQL性能优化金字塔法则》的读书笔记模板,暂无该书作者的介绍。
MySQL基础快速入门知识总结(附思维导图)

MySQL基础快速⼊门知识总结(附思维导图)⽬录前⾔⼀.数据库基础知识1.什么是数据库2.数据库的分类3.数据库的常⽤语⾔4.数据库的常⽤操作⽅式5.MySQL的架构⼆.数据库的增删改查1.创建数据库2.查询数据库3.修改数据库4.删除数据库三.表的增删改查1.创建表2.查询表3.修改表4.删除表四.记录的增删改查1.插⼊记录2.查询记录(最常⽤)3.修改记录4.删除记录五.字段类型1.数字型1.1整数型1.2⼩数型2.⽂本型3.⽇期时间六.字段属性总结前⾔本⽂是我这段时间⾃学MySQL之后,⾃⼰总结的⼀些MySQL的⼊门基础知识.我⾃⼰⽤的是MySQL 5.7.⼀.数据库基础知识1.什么是数据库数据库是按照⼀定数据结构,进⾏组织,存储,管理数据的仓库数据的仓库,是⼀种对⼤量信息进⾏管理的⾼效解决⽅案.数据库系统DBS=数据库DB+数据库管理系统DBMS.2.数据库的分类数据库的分为关系型数据库和分关系型数据库.关系型:是建⽴在关系模型上的数据库,关系模型顾名思义就是⼆维表模型,⽤来记录实体和实体与实体信息之间的关系信息.常见的关系型数据库有Oracle ,MySQL ,SQL Server.⾮关系型数据库:不建⽴在关系模型上的数据库.主要有MongoDB Redis3.数据库的常⽤语⾔数据库系统DBS结构化查询语⾔SQL数据库DB数据库管理系统DBMS表table⾏row => 记录record列column => 字段field4.数据库的常⽤操作⽅式DOS命令:连接远程主机:mysql -h 主机名/IP地址 -P端⼝号 -u ⽤户名 -p 密码连接本机主机:mysql -u⽤户名 -p密码客户端(可视化软件):Navicat代码:Web⽹页:PHPMyAdmin5.MySQL的架构C/S架构:服务端管理和存储数据客户端发送操作请求⼆.数据库的增删改查1.创建数据库#创建数据库的语法create database `库名` charset=utf8/gbk;创建数据库前,需要先连接进数据库,可以⽤⾃⼰的本地数据库练习.2.查询数据库#查询所有数据库show databases;#按条件查询like ,其中%表⽰任意多个字符,-表⽰任意⼀个字符.create databases like '%-';#查询建库语句show create database;3.修改数据库#修改数据库(仅能修改选项,也就是字符集这些)alter database `库名` [新选项];4.删除数据库#删除数据库(语法很简单,但后果很严重.⼀般你也没有权限,哈哈.)drop database `库名`;三.表的增删改查1.创建表#创建表前,先指定数据库use `指定库名`;#创建表的create table `表名`(`字段1` 字段1类型字段1属性,...`字段N` 字段N类型字段N属性);[选项]其中的选项主要包括三⼤类:1. 字符集 charset=utf8 / GBK …2. 数据引擎 engine=innodb / mysiam3. 备注 comment='‘备注内容''其它的字段类型和字段属性,后⾯有详细写到.2.查询表#查询所有表show tables;#条件查询show tables like '%-';#查询表结构desc `表名`;#查询建表语句show create table `表名`;3.修改表#修改表选项alter table `表名` [新选项];#修改表名rename table `旧表命` to `新表名`;#修改表内的字段alter table `表名` change `旧字段名` `新字段名` 新字段类型; #添加新字段到字段末尾alter table `表名` add `新字段名` 类型属性;#添加字段到对应字段后alter table `表名` add `新字段名` 类型属性 after `对应字段` #添加字段到最前⾯alter table `表名` add `新字段名` 类型属性 first;4.删除表#如果表存在,则删除表,否则报错drop table [if exists] `表名`;四.记录的增删改查1.插⼊记录#插⼊记录insert into `表名`(`字段1`,...`字段`) values('值1',...,'值N');#当⼀次传⼊所有值时,可以省不写字段insert into `表名` values('值1',...,'值N');#当需⼀次传⼊多条记录时insert into `表名`(`字段1`,...`字段`) values('值1',...,'值N'),('值1',...,'值N'),...,('值1',...,'值N');#当需⼀次传⼊多条记录,且字段全传⼊时insert into `student` values(值列表1),(值列表2),(值列表n); 2.查询记录(最常⽤)#查询语法select [选型] 字段列表 as 别名 from `表名` where 条件表达式;1、条件表达式:逻辑运算符:and or not⽐较运算符:+ - * / < > = !=2、选项:all:查询所有,不写默认就是所有distinct:去重.重复指查询后的数据⾥,记录的所有字段全部相同,才认定为重复.as:别名.给查询后的字段设置⼀个别名,⽅便查阅.常见的聚合函数:count(),Max(),Min(),Sum(),avg()3、连表查询 join1.内连接 inner join#将参与连接的两个表中符合连接条件的记录查询出来,不符合的过滤掉.select * form `表1` inner join `表2` on 连接条件;2.左外连接 left Join#将参与连接的左表中即使不能匹配连接条件的记录也会查询出来,右表不符合的过滤掉select * from `表1` left join `表2` on 连接条件;3.右外连接 right join#将参与连接的右表中即使不能匹配连接条件的记录也会查询出来,左表不符合的过滤掉select * from `表1` right join `表2` on 连接条件;3.修改记录#语法update `表名` set `字段`='新值' where 条件表达式;4.删除记录#语法delete from `表名` where 条件表达式;五.字段类型1.数字型1.1整数型tinyint:占⽤⼀个字节,⼀共能表⽰256个数有符号:-128~127⽆符号:0~255int:占⽤4个字节有符号:-21亿~21亿⽆字符:0~42亿1.2⼩数型浮点数:float(M,D):单精度浮点数double(M,D):双精度浮点数定点数:decimal(M,D):数据不会丢失的⼩数类型,常⽤于记录货币2.⽂本型1. char(M):定长字符,M表⽰最⼤的字符数.优势为运算速度快.常⽤在255个字符内的固定长度的字符.如:⾝份证,电话号码等.2. varchar(M):变长字符,M表⽰最⼤的字符数.优势为节省空间.常⽤在255个字符以内,长度不确定的字符.3. text:常⽤在256个字符以上的⽂本中3.⽇期时间1. datetime:固定的⽇期时间2. timestamp:时间戳:当新增记录或更新记录时⾃动更新为当前系统时间,⽤于记录最后⼀次修改的时间或新插⼊记录的时间六.字段属性1. not null:设置该字段的值不能为空,不写就是默认可以为空2. default 默认值:设置⼀个默认值,没有数据传⼊就是使⽤默认值.有数据传⼊则使⽤传⼊的值3. comment:备注⽤汉字备注字段,⽅便后期维护4. unique key:唯⼀值该字段的值不能重复,但可以为空5. primary key 主键:⽤于唯⼀标识⼀条记录⼀个表最能只能有⼀个主键不能为空不能重复6. auto_increment ⾃动增长:在新插⼊记录时,⾃动在本字段最⼤值的基础上加1,条件本字段的类型必须为整数型.常与主键⼀起使⽤,但不是必须与主键⼀起使⽤.总结到此这篇关于MySQL基础快速⼊门知识总结的⽂章就介绍到这了,更多相关MySQL基础⼊门内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
Mysql基础学习脑图
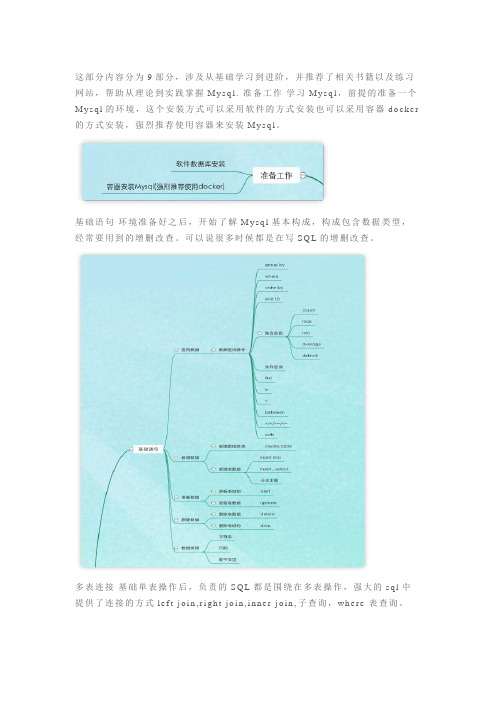
这部分内容分为9部分,涉及从基础学习到进阶,并推荐了相关书籍以及练习网站,帮助从理论到实践掌握M y s q l.准备工作学习M y s q l,前提的准备一个M y s q l的环境,这个安装方式可以采用软件的方式安装也可以采用容器d o c k e r 的方式安装,强烈推荐使用容器来安装M y s q l。
基础语句环境准备好之后,开始了解M y s q l基本构成,构成包含数据类型,经常要用到的增删改查。
可以说很多时候都是在写S Q L的增删改查。
多表连接基础单表操作后,负责的S Q L都是围绕在多表操作,强大的s q l中提供了连接的方式l e f t j o i n,r i g h t j o i n,i n n e r j o i n,子查询,w h e r e表查询。
索引索引可以说是数据库中强大的工具,它用来帮助提高程序的检索速度,在
程序对数据量大的情况下,索引发挥的作用越大。
事务事务是数据库中保持数据操作正确的序列,这些操作要么是执行成功,要
么执行失败。
而事务也有不能的隔离级别,用来保证多个事务操作的影响范围。
数据库引擎M y s q l中常用的数据库引擎有两个I n n o d b,M y I A S M,不同的操作
中对应的锁操作也不同。
高可用数据库高可用一般都是用主从,设计主从,读写分离,b i n l o g操作。