误差棒 标准差 标准误差
标准误差和标准偏差

标准误差和标准偏差标准误差和标准偏差是统计学中常用的两个概念,它们在数据分析和实证研究中扮演着重要的角色。
虽然它们都是衡量数据离散程度的指标,但其计算方法和应用领域有所不同。
本文将深入探讨标准误差和标准偏差的概念、计算方法和实际应用,希望能够为读者提供清晰的认识和理解。
标准误差(Standard Error,SE)是用来衡量样本均值与总体均值之间的差异程度的指标。
在统计学中,我们通常只能获得样本数据,而无法得知总体的真实数值。
因此,我们通过样本数据的均值来估计总体均值,标准误差就是衡量这一估计值的准确性的指标。
标准误差的计算公式为样本标准差除以样本容量的平方根,即SE = SD / √n,其中SD代表样本标准差,n代表样本容量。
标准误差越小,代表样本均值与总体均值之间的差异越小,估计值越准确。
标准偏差(Standard Deviation,SD)是用来衡量数据离散程度的指标,它描述了样本数据的离散程度或者分布的广度。
标准偏差的计算方法是先计算每个数据与均值的差值的平方和,然后除以样本容量再开方,即SD = √(Σ(xi x̄)² / n),其中xi代表每个数据,x̄代表样本均值,n代表样本容量。
标准偏差越大,代表数据的离散程度越大,分布越广。
在实际应用中,标准误差经常用于描述样本均值的稳定性和准确性,特别是在进行统计推断和假设检验时,标准误差的大小直接影响到推断结论的可靠性。
而标准偏差则常用于描述数据的离散程度和分布的广度,通过标准偏差可以直观地了解数据的变异程度,对比不同组别或不同变量的差异。
需要注意的是,标准误差和标准偏差都是统计学中常用的指标,但在实际应用中需要根据具体情况选择合适的指标。
如果我们关注的是样本均值的准确性和稳定性,那么应该关注标准误差;如果我们关注的是数据的离散程度和分布的广度,那么应该关注标准偏差。
在数据分析和实证研究中,正确理解和应用这两个指标,能够帮助我们更准确地描述数据特征,做出科学的推断和决策。
误差棒

误差棒方法1:在data中建立一列,然后设置为y+—误差列使用x,y,y+-一起作图就可以了方法2:在绘制好的图表窗口上,图表-添加误差列然后设置误差百分比或者自动计算标准变差 1. 计算标准偏差将所有数据输入Excel, 分别计算每组数据的平均值,待用。
将所有数据输入Excel,在“统计”类别中选择函数“STDEV A”(或者直接搜索“标准偏差”),然后分别计算每组数据的标准偏差(步骤如同计算平均值,不再叙述),待用2. 将X轴数据,平均值,标准偏差输入origin,然后选中标准偏差所在列--colomn--set as Y error , 然后选中所有数据--plot--special line/symbol--Y error。
STDEV• STDEV 函数假设它的自变量是某母群体的抽样样本。
如果您的观测数据代表整个母群体,则应该使用 STDEVP 函数来计算标准差。
•标准差的计算是采用不偏估计或 n-1 法。
• TRUE 和 FALSE 等逻辑值及文字,将被忽略。
当逻辑值和文字不许被忽略时,请使用工作表函数 STDEV A。
STDEV A• STDEV A 函数假设其自变量为母体的样本数据。
如果您的数据代表整个母体,则您应该用 STDEVP 函数来计算变异数。
void function(e,t){for(var n=t.getElementsByTagName("img"),a=+new Date,i=[],o=function(){this.removeEventListener&&this.removeEventListener("load",o,!1),i.push ({img:this,time:+new Date})},s=0;s< n.length;s++)!function(){var e=n[s];e.addEventListener?!plete&&e.addEventListener("load",o,!1):e.attachEvent&&e.atta chEvent("onreadystatechange",function(){"complete"==e.readyState&&o.call(e,o)})}();alog("spe ed.set",{fsItems:i,fs:a})}(window,document);•自变量若为 TRUE,则会被视为 1;若为 FALSE,则被视为 0 (零)。
怎样做误差棒

今天试验数据出来,想用误差棒表征一下实验数据,可问遍了整个实验室的人,竟然没有一个会的,失望,上网查才发现,有同样问题的人还真不少,倒是有回复的,可正所谓难的不会,会的不难,会做误差棒图的回复的非常笼统,根本不知道在说啥,于是,自个儿琢磨了半天,试了N-1次,终于做出漂亮的误差棒啦,贴在这里,希望对大家有用:1.计算标准偏差-. 将所有数据输入Excel, 分别计算每组数据的平均值,待用。
-. 将所有数据输入Excel,在“统计”类别中选择函数“STDEVA”(或者直接搜索“标准偏差”),然后分别计算每组数据的标准偏差(步骤如同计算平均值,不再叙述),待用2. 将X轴数据,平均值,标准偏差输入origin,然后选中标准偏差所在列--colomn--set as Y error , 然后选中所有数据--plot--specialline/symbol--Y error。
2.剩下的工作就驾轻就熟啦方法1:在data中建立一列,然后设置为y+—误差列使用x,y,y+-一起作图就可以了方法2:在绘制好的图表窗口上,图表-添加误差列然后设置误差百分比或者自动计算标准变差大唐太阳2010-04-08 16:29:12161.122.104.*1. 计算标准偏差-. 将所有数据输入Excel, 分别计算每组数据的平均值,待用。
-. 将所有数据输入Excel,在“统计”类别中选择函数“STDEVA”(或者直接搜索“标准偏差”),然后分别计算每组数据的标准偏差(步骤如同计算平均值,不再叙述),待用2. 将X轴数据,平均值,标准偏差输入origin,然后选中标准偏差所在列--colomn--set as Y error , 然后选中所有数据--plot--special l ine/symbol--Y error。
剩余的工作就自己完成吧^_^。
怎样做误差棒(精)

今天试验数据出来,想用误差棒表征一下实验数据,可问遍了整个实验室的人,竟然没有一个会的,失望,上网查才发现,有同样问题的人还真不少,倒是有回复的,可正所谓难的不会,会的不难,会做误差棒图的回复的非常笼统,根本不知道在说啥,于是,自个儿琢磨了半天,试了N-1次,终于做出漂亮的误差棒啦,贴在这里,希望对大家有用:1.计算标准偏差-. 将所有数据输入Excel, 分别计算每组数据的平均值,待用。
-. 将所有数据输入Excel,在“统计”类别中选择函数“STDEVA”(或者直接搜索“标准偏差”),然后分别计算每组数据的标准偏差(步骤如同计算平均值,不再叙述),待用2. 将X轴数据,平均值,标准偏差输入origin,然后选中标准偏差所在列--colomn--set as Y error , 然后选中所有数据--plot--specialline/symbol--Y error。
2.剩下的工作就驾轻就熟啦方法1:在data中建立一列,然后设置为y+—误差列使用x,y,y+-一起作图就可以了方法2:在绘制好的图表窗口上,图表-添加误差列然后设置误差百分比或者自动计算标准变差大唐太阳2010-04-08 16:29:12161.122.104.*1. 计算标准偏差-. 将所有数据输入Excel, 分别计算每组数据的平均值,待用。
-. 将所有数据输入Excel,在“统计”类别中选择函数“STDEVA”(或者直接搜索“标准偏差”),然后分别计算每组数据的标准偏差(步骤如同计算平均值,不再叙述),待用2. 将X轴数据,平均值,标准偏差输入origin,然后选中标准偏差所在列--colomn--set as Y error , 然后选中所有数据--plot--special l ine/symbol--Y error。
剩余的工作就自己完成吧^_^。
标准差 标准误差

标准差标准误差标准差和标准误差是统计学中最重要的两个概念之一。
它们都是衡量样本数据偏离均值的程度的指标。
然而,它们的计算方式和用途却不同,下面将会详细介绍这两个概念。
一、标准差标准差是用来衡量样本数据的变异程度的指标。
它的计算方式是,先计算每一个数据与均值的差,然后用这些差的平方和除以样本的大小,最后求平方根。
这个平均差的平方根就是标准差。
例如,我们有一组数据 {2, 4, 6, 8, 10}。
它的平均值是 6。
那么,计算标准差的方法如下:- 先计算每个数据与均值的差:2-6=-4, 4-6=-2, 6-6=0, 8-6=2, 10-6=4- 计算这些差的平方和:(-4)^2 + (-2)^2 + 0 + 2^2 + 4^2 = 36- 把这个平方和除以样本大小(5):36/5 = 7.2- 最后求平方根:√7.2 ≈ 2.684所以,这组数据的标准差是 2.684。
二、标准误差标准误差是用来给出样本均值与总体均值之间的差异的置信区间的指标。
它的计算方式是,把样本标准差除以样本大小的平方根。
这个值就是标准误差。
标准误差的计算公式是:SE = σ / √n其中,σ 表示总体标准差,n 表示样本大小。
例如,我们有一组样本数据 {2, 4, 6, 8, 10},它的样本均值是 6。
如果我们要估计它与总体均值的差异,而且总体标准差为 2。
那么,这个样本的标准误差的计算方法如下:- 先计算样本标准差:和上面的例子一样,这个样本的标准差是 2.684。
- 把样本标准差除以样本大小的平方根:2.684 / √5 ≈ 1.201所以,这个样本的标准误差是 1.201。
三、总结标准差和标准误差都是用来衡量样本数据的偏离程度的指标。
标准差是用来衡量样本数据的变异程度,而标准误差则是用来给出样本均值与总体均值之间的差异的置信区间的指标。
它们的计算基本相似,但目的和使用方法则不同。
在实际应用中,我们需要根据不同的需要选择合适的指标去进行分析和决策。
标准误差 标准偏差

标准误差与标准偏差:定义和区别
在统计学和数据分析中,标准误差(Standard Error)和标准偏差(Standard Deviation)是两个常用的概念,它们用于描述数据的离散程度和估计值的精确性。
尽管它们都与数据的分散程度有关,但它们的定义和应用有所不同。
1. 标准误差(Standard Error):
标准误差是用来估计样本统计量与总体参数之间的差异的度量。
它表示估计值的精确程度,并用于推断总体参数。
标准误差越小,表示样本统计量与总体参数越接近。
标准误差通常用样本标准偏差除以样本大小的平方根来计算。
2. 标准偏差(Standard Deviation):
标准偏差是用来衡量数据集内个体数据与其平均值之间的差异或离散程度的度量。
它描述了数据的分散程度,即数据点相对于平均值的散布情况。
标准偏差越大,表示数据的离散程度越高,数据点相对于平均值的差异越大。
区别:
-定义:标准误差用于估计样本统计量与总体参数之间的差异,而标准偏差用于衡量数据集内个体数据与其平均值之间的差异。
-目的:标准误差用于推断总体参数,评估估计值的精确性;标准偏差用于描述数据的分散程度,衡量数据点相对于平均值的差异。
-计算方法:标准误差通常通过样本标准偏差除以样本大小的平方根来计算;标准偏差是通过计算数据与其平均值之间的差异来得到。
在实际应用中,标准误差和标准偏差都是重要的统计指标,但它们的应用场景和解释略有不同。
标准误差更多用于推断总体参数和比较不同样本估计值之间的差异,而标准偏差则更多用于描述数据的离散程度和衡量数据点的差异性。
误差棒标准差还是标准误差

误差棒标准差还是标准误差在统计学和数据分析中,我们经常会遇到误差的概念。
误差是指测量值与真实值之间的差异,而误差的大小和分布对于数据的可靠性和可信度具有重要影响。
在描述数据的时候,我们经常会用到误差棒、标准差和标准误差这些概念。
那么,误差棒、标准差和标准误差到底有什么区别?在什么情况下应该使用它们呢?本文将对这些概念进行详细的解释和比较,帮助读者更好地理解它们的含义和用途。
首先,让我们来看看误差棒。
误差棒是一种用于表示样本均值估计的不确定性范围的方法。
误差棒通常用于绘制柱状图或折线图中,用来表示每个数据点的变异范围。
误差棒的长度可以根据数据的标准差或标准误差来确定。
标准差是用来衡量数据的离散程度的指标,它表示的是数据点相对于均值的分散程度。
标准误差则是用来衡量样本均值估计的精确程度的指标,它表示的是样本均值与总体均值之间的差异。
因此,误差棒的长度可以根据标准差或标准误差来确定,用来表示数据的变异程度和样本均值估计的精确程度。
那么,标准差和标准误差有什么区别呢?标准差是描述数据分布的离散程度的指标,它是数据点与均值之间的平均距离。
标准差越大,表示数据的离散程度越大,数据点之间的差异越大。
而标准误差是用来衡量样本均值估计的精确程度的指标,它是样本均值与总体均值之间的差异。
标准误差的计算方法是将标准差除以样本容量的平方根。
因此,标准误差的大小与样本容量有关,样本容量越大,标准误差越小,样本均值的估计越精确。
在实际应用中,我们应该如何选择使用误差棒、标准差和标准误差呢?如果我们想要表示数据的变异程度,可以使用误差棒,根据数据的标准差来确定误差棒的长度。
如果我们想要衡量样本均值估计的精确程度,可以使用标准误差,根据样本容量和标准差来确定标准误差的大小。
而标准差则可以用来描述数据的离散程度,帮助我们更好地理解数据的分布特征。
总的来说,误差棒、标准差和标准误差都是用来描述数据特征和样本均值估计精确程度的重要指标。
标准误差和标准偏差

标准误差和标准偏差标准误差和标准偏差是统计学中常用的两个概念,它们都是用来衡量数据的离散程度和稳定性的指标。
虽然它们都是用来衡量数据的离散程度,但是它们的计算方法和应用场景却有所不同。
本文将对标准误差和标准偏差进行详细介绍,以帮助读者更好地理解和运用这两个概念。
标准误差(Standard Error,SE)是用来衡量样本均值估计值与总体均值之间的偏差程度的一种指标。
在统计学中,我们往往通过样本数据来估计总体的参数,比如总体均值。
而样本均值与总体均值之间的差异是不可避免的,标准误差就是用来衡量这种差异的大小。
标准误差的计算公式为标准差除以样本容量的平方根,即SE = SD / √n,其中SD代表样本标准差,n代表样本容量。
标准误差的大小与样本容量成反比,样本容量越大,标准误差越小,估计结果越稳定。
标准误差通常用于构建置信区间和进行假设检验,它的大小直接影响到统计推断的准确性和可靠性。
标准偏差(Standard Deviation,SD)是用来衡量数据的离散程度的一种指标。
它表示数据点与平均值之间的平均偏差程度,是衡量数据分布的广泛程度的重要指标。
标准偏差的计算公式为每个数据点与平均值的差的平方和的平均值再开方,即SD = √(Σ(xi x̄)² / n),其中xi代表每个数据点,x̄代表平均值,n代表样本容量。
标准偏差的大小反映了数据的离散程度,标准偏差越大,数据的离散程度越高,反之亦然。
在实际应用中,标准偏差常常用来比较不同数据集之间的离散程度,以及评估数据的稳定性和可靠性。
标准误差和标准偏差都是用来衡量数据的稳定性和可靠性的重要指标,但是它们的计算方法和应用场景有所不同。
标准误差主要用于估计总体参数的稳定性和可靠性,通常与置信区间和假设检验相关;而标准偏差主要用于衡量数据的离散程度和稳定性,常用于比较不同数据集之间的差异。
在实际应用中,我们需要根据具体的问题和需求选择合适的指标,以便更准确地评估数据的稳定性和可靠性。
误差棒定义

误差棒定义
摘要:
1.误差棒的定义
2.误差棒的作用
3.误差棒的计算方法
4.误差棒的应用示例
正文:
误差棒是统计学中一种用来表示数据误差范围的工具。
它是一种可视化的表达方式,可以帮助我们更好地理解数据的不确定性。
误差棒的作用主要有两个。
一是可以清晰地表达出数据的误差范围,让我们对数据的精确度有一个直观的理解。
二是可以通过误差棒来比较不同数据之间的误差大小,为我们的数据分析提供更多的信息。
误差棒的计算方法是首先确定数据的均值和标准差,然后在均值上加减标准差的倍数,这个倍数通常是设为2,这样就可以得到一个包含大约95% 的数据的范围。
最后,将这个范围用一个竖线表示在均值旁边,这就是误差棒。
例如,如果我们有一个样本的均值是50,标准差是5,那么误差棒就是[45, 55],用一个竖线表示在50 的旁边。
这就表示,我们可以有95% 的信心,真实的数值会在45 到55 之间。
误差棒算法-概述说明以及解释

误差棒算法-概述说明以及解释1. 引言1.1 概述误差棒算法是一种用于衡量数据集合中的变化和不确定性的统计工具。
它通过计算数据集合的均值和标准误差来确定数据点的稳定性和可靠性。
误差棒算法在科学研究、统计分析和数据可视化中被广泛应用,可以帮助研究人员更准确地理解和解释数据的特征。
本文将从定义、应用和优缺点三个方面对误差棒算法进行深入探讨,以期能够为读者提供全面的了解和认识。
同时,也将对误差棒算法的未来发展进行展望,为相关领域的研究和实践提供指导和参考。
1.2 文章结构文章结构部分:本文分为引言、正文和结论三个部分。
引言部分将对误差棒算法进行概述,介绍文章的结构和目的,为读者提供文章内容的概要。
正文部分将详细讨论误差棒算法的定义、应用以及其优缺点,帮助读者深入了解这一算法的原理和作用。
结论部分将对文章进行总结,展望误差棒算法的未来发展,并得出结论。
1.3 目的本文的主要目的是介绍误差棒算法,讨论它的定义、应用以及优缺点。
通过对误差棒算法的深入探讨,旨在帮助读者了解该算法在数据分析和统计学中的重要作用,以及在实际应用中的优势和局限性。
同时,通过对误差棒算法的讨论,也能够为读者提供在相关领域进行数据处理和分析时的参考和指导。
最终,希望能够为读者提供全面和深入的了解,使其能够更好地应用误差棒算法解决问题并做出准确的推断和判断。
2. 正文2.1 误差棒算法的定义误差棒算法,又称为误差棒法或误差条法,是一种统计学中常用的方法,用于表示统计数据的不确定性范围。
它通常用于展示样本均值或统计量与总体参数之间的差异。
简单来说,误差棒是一种用于表示数据变异范围的图形表示方法。
在实际应用中,误差棒通常通过标准误差或置信区间来表示。
标准误差是指样本均值与总体参数之间的标准差,通常用于表示样本均值的不确定性。
而置信区间则是对总体参数的取值范围进行估计,通常用于表示总体参数的不确定性范围。
误差棒算法的核心思想是通过绘制误差棒图,以直观的形式展示数据的变异范围,从而帮助人们更好地理解统计数据的可信度和稳定性。
标准偏差标准误差的区别

标准偏差标准误差的区别标准偏差和标准误差是统计学中常用的两个概念,它们都是用来衡量数据的离散程度和数据的稳定性的。
虽然它们都是用来衡量数据的离散程度,但它们的计算方法和应用场景有所不同。
本文将对标准偏差和标准误差进行详细的比较和解释。
首先,让我们来了解一下标准偏差。
标准偏差是用来衡量一组数据的离散程度或者说是数据的波动程度的。
标准偏差越大,表示数据的波动程度越大,反之亦然。
标准偏差的计算方法是先计算每个数据与平均值的差值,然后将这些差值平方并求和,最后再除以数据的个数,最后再开平方。
标准偏差的单位和原始数据的单位是相同的。
接下来,让我们来了解一下标准误差。
标准误差是用来衡量样本均值与总体均值之间的离散程度的。
标准误差越小,表示样本均值与总体均值之间的离散程度越小,反之亦然。
标准误差的计算方法是将总体标准差除以样本容量的平方根。
标准误差的单位和原始数据的单位是相同的。
在比较标准偏差和标准误差的区别时,我们可以从以下几个方面进行比较。
首先是计算方法的不同。
标准偏差是通过计算每个数据与平均值的差值的平方和再开平方得到的,而标准误差是通过总体标准差除以样本容量的平方根得到的。
其次是应用场景的不同。
标准偏差主要用来衡量一组数据的离散程度,而标准误差主要用来衡量样本均值与总体均值之间的离散程度。
最后是解释的不同。
标准偏差是用来衡量数据的波动程度,而标准误差是用来衡量样本均值与总体均值之间的离散程度。
综上所述,标准偏差和标准误差都是用来衡量数据的离散程度的,但它们的计算方法和应用场景有所不同。
在实际应用中,我们需要根据具体的情况选择合适的指标来衡量数据的离散程度,以便更好地分析和解释数据。
希望本文对您有所帮助,谢谢阅读。
误差棒在荧光文献中的应用

误差棒在荧光文献中的应用
误差棒(error bars)在荧光文献中的应用主要是用于表示荧光
实验结果的可信度和变异范围。
具体包括:
1. 表示荧光强度的变异范围:误差棒可以用来表示荧光实验中测量结果的变异范围,通常使用标准差或标准误差来计算误差棒的长度。
这样一来,读者可以了解到不同实验重复测量之间的荧光强度差异。
2. 比较不同条件的荧光实验结果:误差棒可以用于比较不同实验条件下的荧光实验结果。
通过将不同条件的荧光强度的误差棒绘制在同一图上,可以比较两个或多个条件的结果之间的差异是否显著。
3. 显示荧光实验结果的统计显著性:误差棒可以用于显示荧光实验结果的统计显著性。
当两个条件的误差棒之间没有重叠时,表示两个条件的结果差异是显著的。
相反,如果两个条件的误差棒有重叠,那么结果差异可能是不显著的。
总之,误差棒在荧光文献中的应用主要是为了提供实验结果的可信度和变异范围,并进行结果比较和统计显著性判断。
标准误差和标准偏差

标准误差和标准偏差标准误差和标准偏差是统计学中常用的两个概念,它们在数据分析和推断中起着重要的作用。
本文将对标准误差和标准偏差进行详细介绍,并探讨它们在实际应用中的意义和用途。
标准误差(Standard Error,SE)是用来衡量样本均值估计值的精确度的指标。
在统计学中,我们通常通过样本数据来估计总体参数,比如总体均值。
由于样本数据只是总体的一个子集,因此样本均值与总体均值之间存在一定的差异。
标准误差就是衡量这种差异的指标。
标准误差的计算公式为标准差除以样本容量的平方根,即SE = σ/√n,其中σ代表总体标准差,n代表样本容量。
标准误差的大小与样本容量和总体标准差有关,样本容量越大,标准误差越小;总体标准差越小,标准误差越小。
标准误差的大小直接影响到样本均值的精确度,标准误差越小,样本均值的估计精度越高。
标准偏差(Standard Deviation,SD)是用来衡量数据的离散程度或者波动程度的指标。
标准偏差越大,代表数据的离散程度越大,反之则离散程度越小。
标准偏差的计算公式为各个数据与平均值的差的平方和的平均数的平方根,即SD = √(Σ(xi-μ)²/n),其中xi代表各个数据,μ代表平均值,n代表数据个数。
标准偏差的大小反映了数据的波动程度,数据的波动程度越大,标准偏差越大;数据的波动程度越小,标准偏差越小。
在实际应用中,标准偏差常常用来衡量数据的稳定性和一致性,数据的标准偏差越小,代表数据越稳定,反之则数据越不稳定。
标准误差和标准偏差在统计学和实验设计中有着广泛的应用。
在实际数据分析中,我们通常会计算样本均值的标准误差,以评估样本均值的估计精度;同时,我们也会计算数据的标准偏差,以衡量数据的稳定性和离散程度。
在实验设计中,我们可以利用标准误差和标准偏差来比较不同实验组之间的差异,从而得出科学合理的结论。
总之,标准误差和标准偏差是统计学中重要的两个概念,它们分别衡量了样本均值的估计精度和数据的离散程度。
误差棒 标准差 标准误差

标准差(Standard Deviation) 和标准误差(Standard Error)本文摘自Streiner DL.Maintaining standards: differences between the standard deviation and standarderror, and when to use each. Can J Psychiatry 1996; 41: 498–502.标准差(Standard Deviation)标准差,缩写为S.D., SD, 或者 s (就是为了把人给弄晕?),是描述数据点在均值(mean)周围聚集程度的指标。
如果把单个数据点称为“X i,” 因此“X1” 是第一个值,“X2” 是第二个值,以此类推。
均值称为“M”。
初看上去Σ(X i-M)就可以作为描述数据点散布情况的指标,也就是把每个X i与M的偏差求和。
换句话讲,是(单个数据点—数据点的平均)的总和。
看上去挺有逻辑性的,但是它有两个缺点。
第一个困难是:上述定义的结果永远是0。
根据定义,高出均值的和永远等于低于均值的和,因此它们相互抵消。
可以取差值的绝对值来解决(也就是说,忽略负值的符号),但是由于各种神秘兮兮的原因,统计学家不喜欢绝对值。
另外一个剔除负号的方法是取平方,因为任何数的平方肯定是正的。
所以,我们就有Σ(X i-M)2。
另外一个问题是当我们增加数据点后此等式的结果会随之增大。
比如我们手头有25个值的样本,根据前面公式计算出SD是10。
如果再加25个一模一样的样本,直觉上50个大样本的数据点分布情况应该不变。
但是我们的公式会产生更大的SD值。
好在我们可以通过除以数据点数量N来弥补这个漏洞。
所以等式就变成Σ(X i-M)2/N.根据墨菲定律,我们解决了两个问题,就会随之产生两个新问题。
第一个问题(或者我们应该称为第三个问题,这样能与前面的相衔接)是用平方表达偏差。
假设我们测量自闭症儿童的IQ。
标准差和标准误

标准误
• 所谓的标准误是指样本平均数的标准误 • 概念:样本平均数的标准误是指样本平均数与总体 平均数的误差,反映了样本平均数的离散程度。标 准误越小,说明样本平均数与总体平均数越接近。 反之,则样本平均数越离散。
• 样本平均数的计算公式:
s sx n
标准差和标准误的区别
1、意义不同:标准差(也称单数标准差)一 般用s表示,表示各观测值之间变异大小的指 标,反映了样本观测值 xi 对样本平均值 x 的离散程度。是数据精密度的衡量指标。而 标准误是一般用 s x表示,反映样本平均数对 总体平均数 的变异程度,从而反映抽样误 差的大小,是量度结果精密度的指标。 2、用途不同:标准差是最常用的统计量,一 般用于表示一组样本样本变量的分散程度, 标准误一般用于统计推断中,主要包括假设 检验和参数估计
• 随着样本容量(或测量次数)的增加,标准 差趋向某个稳定值,也就是样本标准差越来 越接近于总体标准差。标准误随着样本容量 (或测量次数)的增加逐渐减小,即样本平 均数越来越接近于总体平均数。故在实验中 经常采用适当增加样本容量减小标准误的方 法来减小试验误差。
• 标准误是标准差的 ,二者都是衡量样本变 量随机性的指标,只是从不同的角度来反映 误差。
• 标准差(standard deviation):作为随机误差的代 表,是随机误差绝对值的平均值。在国家计量技 术规范中,标准差的正式名称为标准偏差,用符 号σ表示,其他别名:总体标准差,母体标准差, 均方根误差,均方根偏差,均方误差,均方差, 单次测量标准差和理论标准差等
标准差
n 1 2 • 样本标准差的定义 s (xi表示一组样本样本变量的分散程度般用于表示一组样本样本变量的分散程度标准误一般用于统计推断中主要包括假设标准误一般用于统计推断中主要包括假设检验和参数估计检验和参数估计随着样本容量或测量次数的增加标准差趋向某个稳定值也就是样本标准差越来越接近于总体标准差
误差棒是怎么算出来的

误差棒是怎么算出来的
误差棒是以被测量的算术平均值为中点,在表示测量值大小的方向上画出的一个线段,线段长度的一半等于(标准或扩展)不确定度。
它表示被测量以某一概率(68%或95%)落在棒上。
误差棒计算如下:
1、选中需要绘制误差棒的Y列。
2、依次选择统计>描述统计>行统计>打开对话框。
3、输出量选择“均值”与“标准差”,点击确定。
4、可以看到输出为“均值”和“标准差”列。
5、选择X列和“均值”和“标准差”列,点击做“直线图”。
6、可以看到画出带误差棒的曲线图。
7、双击图,进行编辑,在线条选项框可以编辑线条和误差棒的粗细。
8、点击“垂直线”选项卡,勾选“n个点只显示一个点,其余跳过,n= ”选项,并输入n值(n值为抽点间距)。
9、可以得到误差棒密度减少的图。
关于误差棒画法
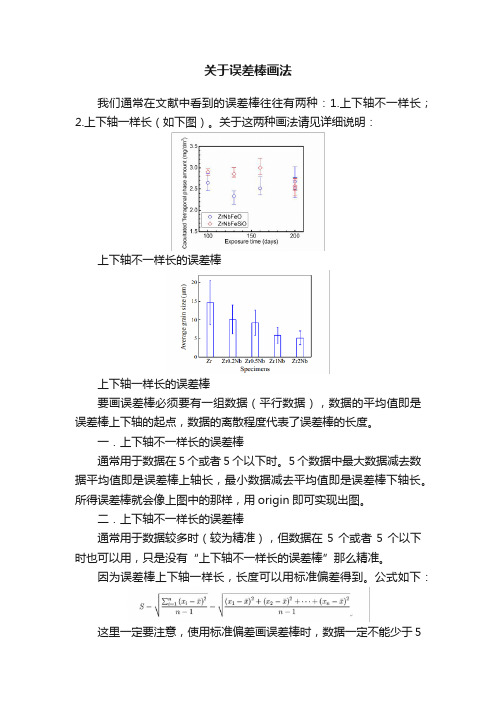
关于误差棒画法
我们通常在文献中看到的误差棒往往有两种:1.上下轴不一样长;
2.上下轴一样长(如下图)。
关于这两种画法请见详细说明:
上下轴不一样长的误差棒
上下轴一样长的误差棒
要画误差棒必须要有一组数据(平行数据),数据的平均值即是误差棒上下轴的起点,数据的离散程度代表了误差棒的长度。
一.上下轴不一样长的误差棒
通常用于数据在5个或者5个以下时。
5个数据中最大数据减去数据平均值即是误差棒上轴长,最小数据减去平均值即是误差棒下轴长。
所得误差棒就会像上图中的那样,用origin即可实现出图。
二.上下轴不一样长的误差棒
通常用于数据较多时(较为精准),但数据在5个或者5个以下时也可以用,只是没有“上下轴不一样长的误差棒”那么精准。
因为误差棒上下轴一样长,长度可以用标准偏差得到。
公式如下:
这里一定要注意,使用标准偏差画误差棒时,数据一定不能少于5
个。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
标准差(Standard Deviation) 和标准误差(Standard Error)本文摘自Streiner DL.Maintaining standards: differences between the standard deviation and standarderror, and when to use each. Can J Psychiatry 1996; 41: 498–502.标准差(Standard Deviation)标准差,缩写为S.D., SD, 或者 s (就是为了把人给弄晕?),是描述数据点在均值(mean)周围聚集程度的指标。
如果把单个数据点称为“X i,” 因此“X1” 是第一个值,“X2” 是第二个值,以此类推。
均值称为“M”。
初看上去Σ(X i-M)就可以作为描述数据点散布情况的指标,也就是把每个X i与M的偏差求和。
换句话讲,是(单个数据点—数据点的平均)的总和。
看上去挺有逻辑性的,但是它有两个缺点。
第一个困难是:上述定义的结果永远是0。
根据定义,高出均值的和永远等于低于均值的和,因此它们相互抵消。
可以取差值的绝对值来解决(也就是说,忽略负值的符号),但是由于各种神秘兮兮的原因,统计学家不喜欢绝对值。
另外一个剔除负号的方法是取平方,因为任何数的平方肯定是正的。
所以,我们就有Σ(X i-M)2。
另外一个问题是当我们增加数据点后此等式的结果会随之增大。
比如我们手头有25个值的样本,根据前面公式计算出SD是10。
如果再加25个一模一样的样本,直觉上50个大样本的数据点分布情况应该不变。
但是我们的公式会产生更大的SD值。
好在我们可以通过除以数据点数量N来弥补这个漏洞。
所以等式就变成Σ(X i-M)2/N.根据墨菲定律,我们解决了两个问题,就会随之产生两个新问题。
第一个问题(或者我们应该称为第三个问题,这样能与前面的相衔接)是用平方表达偏差。
假设我们测量自闭症儿童的IQ。
也许会发现IQ均值是75, 散布程度是100 个IQ点平方。
这IQ点平方又是什么东西?不过这容易处理:用结果的平方根替代,这样结果就与原来的测量单位一致。
所以上面的例子中的散布程度就是10个IQ点,变得更加容易理解。
最后一个问题是目前的公式是一个有偏估计,也就是说,结果总是高于或者低于真实的值。
解释稍微有点复杂,先要绕个弯。
在多数情况下,我们做研究的时候,更感兴趣样本来自的总体(population)。
比如,我们探查有年轻男性精神分裂症患者的家庭中的外现情绪(expressed emotion,EE)水平时,我们的兴趣点是所有满足此条件的家庭(总体),而不单单是哪些受研究的家庭。
我们的工作便是从样本中估计出总体的均值(mean)和SD。
因为研究使用的只是样本,所以这些估计会与总体的值未知程度的偏差。
理想情况下,计算SD的时候我们应当知道每个家庭的分值(score)偏离总体均值的程度,但是我们手头只有样本的均值。
根据定义,分值样本偏离样本均值的程度要小于偏离其他值,因此使用样本均值减去分值得到的结果总是比用总体均值(还不知道)减去分值要小,公式产生的结果也就偏小(当然N很大的时候,这个偏差就可以忽略)。
为了纠正这个问题,我们会用N-1除,而不是N。
总之,最后我们得到了修正的标准差的(估计)公式(称为样本标准差):顺带一下,不要直接使用此公式计算SD,会产生很多舍入误差(rounding error)。
统计学书一般会提供另外一个等同的公式,能获得更加精确的值。
现在我们完成了所有推导工作,这意味着什么呢?假设数据是正态分布的,一旦知道了均值和SD,我们便知道了分值分布的所有情况。
对于任一个正态分布,大概2/3(精确的是68.2%)的分值会落在均值-1 SD 和均值+1 SD之间,95.4%的在均值-2 SD 和均值+2 SD之间。
比如,大部分研究生或者职业院校的入学考试(GRE,MCAT,LSAT和其他折磨人的手段)的分数分布(正态)就设计成均值500,SD 100。
这意味68%的人得分在400到600之间,略超过95%的人在300到700之间。
使用正态曲线的概率表,我们就能准确指出低于或者高于某个分数的比例是多少。
相反的,如果我们想让5%的人淘汰掉,如果知道当年测试的均值和SD,依靠概率表,我们就能准确划出最低分数线。
总结一下,SD告诉我们分值围绕均值的分布情况。
现在我们转向标准误差(standard error)。
标准误差(Standard Error)前面我提到过大部分研究的目的是估计某个总体(population)的参数,比如均值和SD(标准方差)。
一旦有了估计值,另外一个问题随之而来:这个估计的精确程度如何?这问题看上去无解。
我们实际上不知道确切的总体参数值,所以怎么能评价估计值的接近程度呢?挺符合逻辑的推理。
但是以前的统计学家们没有被吓倒,我们也不会。
我们可以求助于概率:(问题转化成)真实总体均值处于某个范围内的概率有多大?(格言:统计意味着你不需要把话给说绝了。
)回答这个疑问的一种方法重复研究(实验)几百次,获得很多均值估计。
然后取这些均值估计的均值,同时也得出它的标准方差(估计)。
然后用前面提到的概率表,我们可估计出一个范围,包括90%或者95%的这些均值估计。
如果每个样本是随机的,我们就可以安心地说真实的(总体)均值90%或者95%会落在这个范围内。
我们给这些均值估计的标准差取一个新名字:均值的标准误差(the standard error of the mean),缩写是SEM,或者,如果不存在混淆,直接用SE代表。
但是首先得处理一个小纰漏:重复研究(实验)几百次。
现今做一次研究已经很困难了,不要说几百次了(即使你能花费整个余生来做这些实验)。
好在一向给力的统计学家们已经想出了基于单项研究(实验)确定SE的方法。
让我们先从直观的角度来讲:是哪些因素影响了我们对估计精确性的判断?一个明显的因素是研究的规模。
样本规模N越大,反常数据对结果的影响就越小,我们的估计就越接近总体的均值。
所以,N应该出现在计算SE公式的分母中:因为N越大,SE越小。
类似的,第二因素是:数据的波动越小,我们越相信均值估计能精确反映它们。
所以,SD应该出现在计算公式的分子上:SD越大,SE越大。
因此我们得出以下公式:(为什么不是N? 因为实际是我们是在用N除方差SD2,我们实际不想再用平方值,所以就又采用平方根了。
)所以,SD实际上反映的是数据点的波动情况,而SE则是均值的波动情况。
置信区间(Confidence Interval)前面一节,针对SE,我们提到了某个值范围。
我们有95%或者99%的信心认为真实值就处在当中。
我们称这个值范围为“置信区间”,缩写是CI。
让我们看看它是如何计算的。
看正态分布表,你会发现95%的区域处在-1.96SD和+1.96 SD 之间。
回顾到前面的GRE和MCAT的例子,分数均值是500,SD是100,这样95%的分数处在304和696之间。
如何得到这两个值呢?首先,我们把S D乘上1.96,然后从均值中减去这部分,便得到下限304。
如果加到均值上我们便得到上限696。
CI也是这样计算的,不同的地方是我们用SE替代SD。
所以计算95%的CI的公式是:95%CI= 均值± ( 1.96 x SE)。
选择SD, SE和CI好了,现在我们有SD, SE和CI。
问题也随之而来:什么时候用?选择哪个指标呢?很明显,当我们描述研究结果时,SD是必须报告的。
根据SD和样本大小,读者很快就能获知SE和任意的CI。
如果我们再添加上SE和CI,是不是有重复之嫌?回答是:“YES”和“NO”兼有。
本质上,我们是想告之读者通常数据在不同样本上是存在波动的。
某一次研究上获得的数据不会与另外一次重复研究的结果一模一样。
我们想告之的是期望的差异到底有多大:可能波动存在,但是没有大到会修改结论,或者波动足够大,下次重复研究可能会得出相反的结论。
某种程度上来讲,这就是检验的显著程度,P level 越低,结果的偶然性就越低,下次能重复出类似结果的可能性越高。
但是显著性检验,通常是黑白分明的:结果要么是显著的,要么不是。
如果两个实验组的均值差别只是勉强通过了P < 0.05的红线,也经常被当成一个很稳定的结果。
如果我们在图表中加上CI,读者就很容易确定样本和样本间的数据波动会有多大,但是我们选择哪个CI呢?我们会在图表上加上error bar(误差条,很难听),通常等同于1个SE。
好处是不用选择SE或者CI了(它们指向的是一样的东西),也无过多的计算。
不幸的这种方法传递了很少有用信息。
一个error bar (-1 SE,+1 SE )等同于68%的CI;代表我们有68%的信心真的均值(或者2个实验组的均值的差别)会落在这个范围内。
糟糕的是,我们习惯用95%,99% 而不是68%。
所以让忘记加上SE吧,传递的信息量太少了,它的主要用途是计算CI。
那么把error bar加长吧,用2个SE如何?这好像有点意思,2是1.96的不错估计。
有两方面的好处。
首先这个方法能显示95%的CI,比68%更有意义。
其次能让我们用眼睛检验差别的显著性(至少在2个实验组的情况下是如此)。
如果下面bar的顶部和上面bar的底部没有重叠,两个实验组的差异必定是显著的(5%的显著水平)。
因此我们会说,这2个组间存在显著差别。
如果我们做t-test,结果会验证这个发现。
这种方法对超过2个组的情况就不那么精确了。
因为需要多次比较(比如,组1和组2,组2和组3,组1和组3),但是至少能给出差别的粗略指示。
在表格中展示CI的时候,你应该给出确切的数值(乘以1.96而不是2)。
总结SD反映的是数据点围绕均值的分布状况,是数据报告中必须有的指标。
SE则反映了均值波动的情况,是研究重复多次后,期望得到的差异程度。
SE自身不传递很多有用的信息,主要功能是计算95%和99%的CI。
CI是显著性检验的补充,反映的是真实的均值或者均值差别的范围。
一些期刊已把显著性检验抛弃了,CI取而代之。
这可能走过头了。
因为这两种方法各有优点,也均会被误用。
比如,一项小样本研究可能发现控制组和实验组间的差别显著(0.05的显著水平)。
如果在结果展示加上CI,读者会很容易看到CI十分宽,说明对差别的估计是很粗糙的。
与之相反,大量鼓吹的被二手烟影响的人数,实际上不是一个均值估计。
最好的估计是0,它有很宽的CI,报道的却只是CI的上限。
总之,SD、显著性检验,95%或者99% 的CI,均应该加在报告中,有利于读者理解研究结果。
它们均有信息量,能相互补充,而不是替代。
相反,“裸”的SE的并不能告诉我们什么信息,多占据了一些篇幅和空间而已。