fork系统调用
fork函数超详解及其用法

3. 进程控制上一页第30 章进程下一页3. 进程控制3.1. fork函数#include <sys/types.h>#include <unistd.h>pid_t fork(void);fork调用失败则返回-1,调用成功的返回值见下面的解释。
我们通过一个例子来理解fork是怎样创建新进程的。
例30.3. fork#include <sys/types.h>#include <unistd.h>#include <stdio.h>#include <stdlib.h>int main(void){pid_t pid;char *message;int n;pid = fork();if (pid < 0) {perror("fork failed");exit(1);}if (pid == 0) {message = "This is the child\n"; n = 6;} else {message = "This is the parent\n"; n = 3;}for(; n > 0; n--) {printf(message);sleep(1);}return 0;}$ ./a.outThis is the childThis is the parentThis is the childThis is the parentThis is the childThis is the parentThis is the child$ This is the childThis is the child这个程序的运行过程如下图所示。
图30.4. fork父进程初始化。
父进程调用fork,这是一个系统调用,因此进入内核。
内核根据父进程复制出一个子进程,父进程和子进程的PCB信息相同,用户态代码和数据也相同。
fork函数的基本介绍和应用

fork函数的基本介绍和应⽤从fork()函数的⾓度来看,⼀个进程⼤致包括以下三点:代码数据分配给进程的资源fork()函数通过系统调⽤,创建⼀个与原来进程⼏乎完全相同的进程,接⼊点从调⽤fork()函数处开始。
也就是两个进程在之后的步骤⾥可以做完全相同的事,但如果初始参数或者传⼊的变量不同,或者是判断条件不同,两个进程也可以做不太⼀样的事。
⼀个进程调⽤fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。
然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同,相当于孪⽣兄弟。
⼀个同学给我的例⼦:what happens when the follwing code executes?#include <stdio.h>#include <unistd.h>#include <sys/types.h>int main(void){pid_t childpid;pid_t mypid;mypid = getpid();childpid = fork();//此处开始进⾏fork接⼊if(childpid == -1){perror("Failed to fork");return1;}if(childpid == 0) //child codeprintf("I am child %ld,ID = %ld\n",(long)getpid(),(long)mypid);else//parent codeprintf("I am parent %ld,ID = %ld\n",(long)getpid(),(long)mypid);return0 ;}结果为:I am parent 14789,ID = 14789I am child 14790,ID = 14789ID即mypid,由于fork执⾏前就得到了值,所以在两个进程中都没有变化。
linux中fork的作用

linux中fork的作用在Linux中,fork(是一个非常重要的系统调用。
它的作用是创建一个新的进程,这个新的进程被称为子进程,而原始进程被称为父进程。
fork(系统调用会在父进程和子进程之间复制一份相同的当前执行状态,包括程序的代码、数据、堆栈以及其他相关资源。
当一个进程调用fork(时,操作系统会将当前的进程映像复制一份,包括进程的地址空间、文件描述符、信号处理器等。
然后操作系统会分配一个唯一的进程ID(PID)给子进程,父进程和子进程会分别返回子进程的PID和0。
子进程会从fork(调用的位置开始执行,而父进程则继续执行接下来的指令。
fork(的作用有以下几个方面:1. 多任务处理:通过fork(,一个进程可以生成多个子进程,每个子进程可以执行不同的任务。
这种多任务处理的能力是Linux操作系统的基石之一,它允许同时运行多个进程,从而提高系统的并发性和响应性能。
2. 进程间通信:fork(可以为不同的进程提供通信机制。
子进程可以通过进程间通信(IPC)机制与父进程进行数据交换,包括管道、消息队列、共享内存等。
这样实现了进程间的数据共享和协同工作。
3. 服务器模型:fork(在服务器模型中起到关键作用。
通过fork(,一个服务器进程可以创建多个子进程来处理客户端请求。
子进程在接收到请求后,可以独立地为客户端提供服务,这样能够极大地提高服务器的吞吐量和并发处理能力。
4. 资源管理:通过fork(,Linux可以对资源进行有效的管理。
当一个进程需要一个完全相同的副本来执行其他任务时,可以使用fork(来复制当前进程的状态。
这种状态的复制可以节省时间和资源,避免了重新加载和初始化的开销。
5. 守护进程创建:守护进程是在后台执行的长时间运行的进程,不依赖于任何终端。
通过调用fork(,父进程可以使自己成为一个后台进程,并终止自己,而子进程则变为一个孤儿进程并被init进程接管。
这样,守护进程就能够在系统启动后一直运行,提供服务。
fork的底层实现方式

fork的底层实现方式Fork是Unix系统中的一个重要概念,它可以创建一个新的进程,这个新的进程是原进程的一个副本。
在Unix系统中,每个进程都有一个唯一的进程ID,fork会为新的进程分配一个新的进程ID,并且这个新的进程会继承原进程的所有资源,包括代码段、数据段、堆栈、文件描述符等等。
那么,fork的底层实现方式是什么呢?在Unix系统中,fork是通过系统调用来实现的。
当一个进程调用fork时,操作系统会为新的进程创建一个新的进程控制块(PCB),并将原进程的PCB复制一份到新的进程的PCB中。
这样,新的进程就拥有了原进程的所有资源。
在fork的实现过程中,操作系统会为新的进程分配一个新的虚拟地址空间,并将原进程的虚拟地址空间复制一份到新的进程的虚拟地址空间中。
这个过程被称为“写时复制”(Copy-On-Write)。
也就是说,当新的进程需要修改某个资源时,操作系统会将这个资源从原进程的虚拟地址空间中复制一份到新的进程的虚拟地址空间中,然后再进行修改。
这样,就避免了资源的重复复制,提高了fork的效率。
除了资源的复制外,fork还需要进行一些其他的操作。
例如,新的进程需要拥有自己的进程ID、父进程ID、用户ID、组ID等等。
操作系统会为新的进程分配一个新的进程ID,并将原进程的进程ID作为新进程的父进程ID。
此外,新的进程还需要重新打开文件描述符、清空信号处理器等等。
总的来说,fork的底层实现方式是通过系统调用来实现的。
在实现过程中,操作系统会为新的进程创建一个新的进程控制块,并将原进程的所有资源复制一份到新的进程中。
为了提高效率,操作系统采用了“写时复制”的技术,避免了资源的重复复制。
此外,新的进程还需要进行一些其他的操作,例如重新打开文件描述符、清空信号处理器等等。
linux中的fork()函数
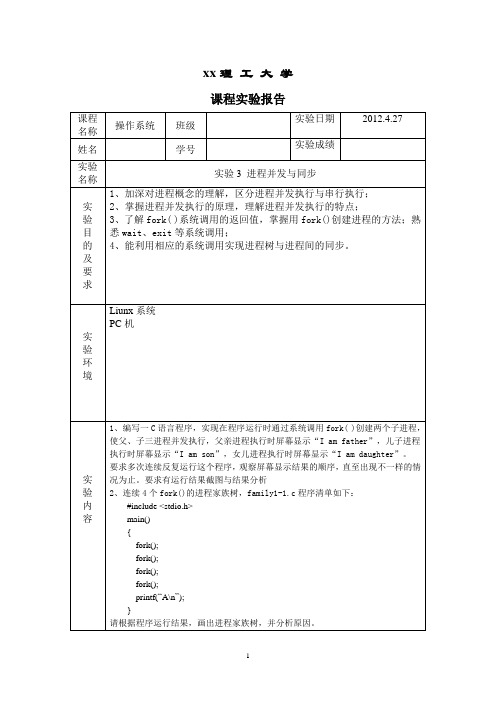
xx理工大学课程实验报告课程名称操作系统班级实验日期2012.4.27姓名学号实验成绩实验名称实验3 进程并发与同步实验目的及要求1、加深对进程概念的理解,区分进程并发执行与串行执行;2、掌握进程并发执行的原理,理解进程并发执行的特点;3、了解fork( )系统调用的返回值,掌握用fork()创建进程的方法;熟悉wait、exit等系统调用;4、能利用相应的系统调用实现进程树与进程间的同步。
实验环境Liunx系统PC机实验内容1、编写一C语言程序,实现在程序运行时通过系统调用fork( )创建两个子进程,使父、子三进程并发执行,父亲进程执行时屏幕显示“I am father”,儿子进程执行时屏幕显示“I am son”,女儿进程执行时屏幕显示“I am daughter”。
要求多次连续反复运行这个程序,观察屏幕显示结果的顺序,直至出现不一样的情况为止。
要求有运行结果截图与结果分析2、连续4个fork()的进程家族树,family1-1.c程序清单如下:#include <stdio.h>main(){fork();fork();fork();fork();printf(“A\n”);}请根据程序运行结果,画出进程家族树,并分析原因。
3、修改程序1,在父、子进程中分别使用wait、exit等系统调用“实现”其同步推进,父进程必须等待儿子进程与女儿进程结束,才可以输出消息。
写出相应的同步控制,并分析运行结果。
4、创建一个子进程,并给它加载程序,其功能是调用键盘命令“ls -l”,已知该键盘命令的路径与文件名为:/bin/ls。
父进程创建子进程,并加载./child2程序。
写出相应的程序代码并分析程序运行结果。
算法描述及实验步骤1.(1)父进程创建儿子进程,成功输出“I am son”,失败进入第二步。
(2)父进程失败,继续创建女儿进程,成功输出“I am daughter”,失败则输出“I am father”。
fork函数

父进程
父进程
#include <sys/types.h> main() 执 { 行 pid_t val; printf(“PID…); 分裂 val=fork(); if(val!=0) printf(“parent…”); else printf(“child…); }
main( ) { pid_t val; printf(“PID…); val=fork(); if(val!=0) printf(“parent…”); else printf(“child…); }
运行结果1 global=5,vari=4;
global=4,vari=5;
运行结果2
global=4,vari=5; global=5,vari=4
分析:子进程和父进程的数据段、堆栈段不同。子进程执 行语句“global++,vari—”时,只是对自己的数据段 进行了修改,并未影响到父进程的数据段,
exec()—执行一个文件的调用
子进程如何执行一个新的程序文本?
通过exec()调用族,加载新的程序文本
通过一个系统调用exec,子进程可以拥有自己的可 执行代码。即exec用一个新进程覆盖调用进程。 它的参数包括新进程对应的文件和命令行参数。成 功调用时,不再返回;否则,返回出错原因。 六种exec调用格式:各种调用的区别在于参数的处 理方法不同,常用的格式有:
void main(void) { printf(“Hello \n”); fork(); printf(“Bye \n”); }
运行结果 Hello Bye Bye
fork()调用例子(2)
#include<stdio.h> #Include<sys/types.h> #include<unistd.h> void main(void){ if (fork()==0) printf(“In the CHILD process\n”); else printf(“In the PARENT process\n”); }
fork()系统调用

fork系统调用分类:LINUX1.预备知识不妨简单理解为,一个进程表示的,就是一个可执行程序的一次执行过程中的一个状态。
操作系统对进程的管理,典型的情况,是通过进程表完成的。
进程表中的每一个表项,记录的是当前操作系统中一个进程的情况。
对于单 CPU的情况而言,每一特定时刻只有一个进程占用 CPU,但是系统中可能同时存在多个活动的(等待执行或继续执行的)进程。
一个称为“程序计数器(program counter, pc)”的寄存器,指出当前占用CPU的进程要执行的下一条指令的位置。
当分给某个进程的CPU时间已经用完,操作系统将该进程相关的寄存器的值,保存到该进程在进程表中对应的表项里面;把将要接替这个进程占用 CPU的那个进程的上下文,从进程表中读出,并更新相应的寄存器(这个过程称为“上下文交换(process context switch)”,实际的上下文交换需要涉及到更多的数据,那和fork无关,不再多说,主要要记住程序寄存器pc指出程序当前已经执行到哪里,是进程上下文的重要内容,换出 CPU的进程要保存这个寄存器的值,换入CPU的进程,也要根据进程表中保存的本进程执行上下文信息,更新这个寄存器)。
2.fork系统调用当你的程序执行到下面的语句:pid=fork();操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。
新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。
问题是怎么返回,在父子进程中就分道扬镳。
父进程继续执行,操作系统对fork的实现,使这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。
父子进程的说法

父子进程的说法
"父子进程"是指在操作系统中,由一个进程创建(通常是通过fork系统调用)的进程关系。
这种关系通常用于实现并发执行或并行计算,允许父进程和子进程在独立的执行空间中运行。
以下是关于父子进程的一些说明:
1.父进程:执行fork系统调用的进程称为父进程。
父进程在创建子进程后,通常会继续执行一些任务,或者等待子进程完成执行。
2.子进程:通过fork系统调用创建的新进程称为子进程。
子进程是父进程的副本,拥有独立的内存空间,但通常会继承父进程的代码段、数据段、文件描述符等信息。
3.进程独立性:父进程和子进程之间是相对独立的,它们可以并发执行,互不影响。
子进程的修改通常不会影响父进程,反之亦然。
4.通信机制:父子进程之间可以通过进程间通信(Inter-Process Communication,IPC)来进行数据交换。
常见的IPC方法包括管道、共享内存、消息队列等。
5.等待子进程:父进程通常会使用wait系统调用等待子进程的结束,并获取子进程的退出状态。
这样可以确保父进程在子进程执行完毕后进行进一步的处理。
在多进程的环境中,父子进程的概念非常重要,它们共同构成了并发执行的基础。
在Unix/Linux等操作系统中,fork系统调用是实现多进程的一种常见方式。
linux中fork的语法及用法

在Linux中,fork()函数是用于创建一个新进程的系统调用。
以下是fork()函数的语法和用法:
语法:
fork()`函数返回两次:一次是在父进程中,另一次是在新创建的子进程中。
在父进程中,fork()函数返回新创建子进程的进程ID(PID)。
在子进程中,fork()函数返回0。
如果fork()函数出现错误,它会返回一个负值,通常为-1。
用法:
1.在父进程中调用fork()函数,创建一个子进程。
2.父进程和子进程从fork()函数返回处开始执行。
3.父进程和子进程可以继续执行不同的代码路径,实现并行执行。
4.可以通过wait()或waitpid()函数等待子进程结束,以回收子进程的资
源。
示例:
在上述示例中,父进程和子进程分别打印不同的消息,并使用wait()函数等待子进程结束。
注意,在子进程中,我们使用return 0;语句来结束子进程的执行。
fork()函数的理解

对于刚刚接触Unix/Linux操作系统,在Linux下编写多进程的人来说,fork是最难理解的概念之一:它执行一次却返回两个值。
首先我们来看下fork函数的原型:#i nclude <sys/types.h>#i nclude <uni ST d.h>pid_t fork(void);返回值:负数:如果出错,则fork()返回-1,此时没有创建新的进程。
最初的进程仍然运行。
零:在子进程中,fork()返回0正数:在负进程中,fork()返回正的子进程的PID其次我们来看下如何利用fork创建子进程。
创建子进程的样板代码如下所示:pid_t child;if((child = fork())<0)/*错误处理*/else if(child == 0)/*这是新进程*/else/*这是最初的父进程*/fock函数调用一次却返回两次;向父进程返回子进程的ID,向子进程中返回0,这是因为父进程可能存在很多过子进程,所以必须通过这个返回的子进程ID来跟踪子进程,而子进程只有一个父进程,他的ID可以通过getppid取得。
下面我们来对比一下两个例子:第一个:#include <unistd.h>#include <stdio.h>int main(){pid_t pid;int count=0;pid = fork();printf( "This is first time, pid = %d\n", pid );printf( "This is sec ON d time, pid = %d\n", pid );count++;printf( "count = %d\n", count );if ( pid>0 ){printf( "This is the parent process,the child has the pid:%d\n", pid );}else if ( !pid ){printf( "This is the child Process.\n")}else{printf( "fork failed.\n" );}printf( "This is third time, pid = %d\n", pid );printf( "This is fouth time, pid = %d\n", pid );return 0;}运行结果如下:问题:这个结果很奇怪了,为什么printf的语句执行两次,而那句“count++;”的语句却只执行了一次接着看:#include <unistd.h>#include <stdio.h>int main(void){pid_t pid;int count=0;pid = fork();printf( "Now, the pid returned by calling fork() is %d\n", pid );if ( pid>0 ){printf( "This is the parent proc ESS,the child has the pid:%d\n", pid );printf( "In the parent process,count = %d\n", count );}else if ( !pid ){printf( "This is the child process.\n");printf( "Do your own things here.\n" );count ++;printf( "In the child process, count = %d\n", count );}else{printf( "fork failed.\n" );}return 0;}运行结果如下:现在来解释上面提出的问题。
Linux进程控制原语

Linux/UNIX进程控制原语Linux/UNIX进程控制原语-1 进程控制原语
(2)exec系统调用 系统调用 格式: 六种 六种) 格式:(六种)
int execl(path,arg0,arg1,…,argn,(char *)0)
char *path, *arg0, *arg1, …, *argn ; exec调用进程的正文段被指定的目标文件的正文段 调用进程的正文段被指定的目标文件的正文段 所覆盖,其属性的变化方式与fork成功后从父进程 所覆盖,其属性的变化方式与 成功后从父进程 那里继承属性的方式几乎是一样的。 那里继承属性的方式几乎是一样的。系统中绝大多 数命令都是通过exec来执行的,不但 来执行的, 数命令都是通过 来执行的 不但shell进程所 进程所 创建的子进程使用它来执行用户命令, 创建的子进程使用它来执行用户命令,shell进程本 进程本 身和它的祖先进程也是用exec来启动执行的。 来启动执行的。 身和它的祖先进程也是用 来启动执行的
(6)程序执行说明 (6)程序执行说明 该程序说明主进程创建了一个子程序后, 该程序说明主进程创建了一个子程序后,二 个进程并发执行的情况。 个进程并发执行的情况。 主进程在执行fork系统调用前是一个进程, 主进程在执行 系统调用前是一个进程, 系统调用前是一个进程 执行fork系统调用后,系统中又增加了一个与 系统调用后, 执行 系统调用后 原过程环境相同的子进程, 原过程环境相同的子进程,它们执行程序中 fork语句以后相同的程序,父和子进程 中都有 语句以后相同的程序, 语句以后相同的程序 自己的变量pid,但它们的值不同,它是 自己的变量 ,但它们的值不同,它是fork调 调 用后的返回值,父进程的pid为大于 的值, 为大于0的值 用后的返回值,父进程的 为大于 的值,它 代表新创建子进程的标识符,而子进程的pid为 代表新创建子进程的标识符,而子进程的 为 0。这样父子进程执行相同一个程序,但却执行 。这样父子进程执行相同一个程序, 不同的程序段。子进程执行if(pid= = 0)以后的 不同的程序段。子进程执行 以后的 大括号内的程序, 语句; 大括号内的程序,即execlp语句;而父进程执 语句 以后的大括号内的程序。 行else以后的大括号内的程序。 以后的大括号内的程序
fork

2)vfork()系统调用除了能保证用户空间内存不会被复制之外,它与fork几乎是完全相同的.vfork存在的问题是它要求子进程立即调用exec,
而不用修改任何内存,这在真正实现的时候要困难的多,尤其是考虑到exec调用有可能失败.
./test
count= 1
count= 1
Segmentation fault (core dumped)
分析:
通过将fork()换成vfork(),由于vfork()是共享数据段,为什么结果不是2呢,答案是:
vfork保证子进程先运行,在它调用 exec 或 exit 之后父进程才可能被调度运行.如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁.
示例代码:
#include <unistd.h>
#include <stdio.h>
int main(int argc, char ** argv )
{
int pid = fork();
if(pid == -1 )
{
// print("error!");
} else if( pid = =0 ) {
3)做最后的修改,在子进程执行时,调用_exit(),程序如下:
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
int main(void)
fork 用法

fork 用法fork 是一个系统调用,用于创建一个新的进程。
新的进程是原始进程(父进程)的一个副本,称为子进程。
这两个进程在几乎所有方面都是相同的,包括代码、数据和上下文。
在编程中,fork 通常用于创建一个新的进程,以便在子进程中执行不同的任务。
基本用法:#include <unistd.h>#include <stdio.h>int main() {pid_t pid = fork();if (pid == -1) {// 处理 fork 失败的情况perror("fork");return 1;}if (pid == 0) {// 子进程执行的代码printf("This is the child process (PID=%d)\n", getpid());} else {// 父进程执行的代码printf("This is the parent process (PID=%d), child PID=%d\n", getpid(), pid);}return 0;}注意事项:fork 返回两次,一次在父进程中返回子进程的PID,另一次在子进程中返回0。
在父子进程中的变量和状态是相互独立的,它们不会相互影响。
在fork 之后,通常会使用exec 函数族在子进程中加载新的程序。
父子进程的执行顺序和执行时间是不确定的,取决于操作系统的调度。
示例:在子进程中执行其他程序#include <unistd.h>#include <stdio.h>#include <sys/wait.h>int main() {pid_t pid = fork();if (pid == -1) {perror("fork");return 1;}if (pid == 0) {// 子进程中执行其他程序execl("/bin/ls", "ls", "-l", NULL);} else {// 等待子进程结束wait(NULL);printf("Parent process done.\n");}return 0;}这个例子中,父进程创建了一个子进程,子进程通过 execl 加载了 /bin/ls 程序。
fork实现原理

fork实现原理Fork 实现原理在操作系统中,fork 是基本的进程创建操作之一,它会复制当前进程的所有资源创建出一个新的进程。
在本文中,我们将探讨 fork 的实现原理。
1. fork 函数在 Unix 系统中,fork 的实现是通过系统调用来完成的。
用户程序调用 fork 函数之后,系统内核(kernel)会复制一份当前进程的所有资源并创建出一个新的进程,这个新的进程也称为子进程。
在父进程中,fork 函数会返回子进程的 PID(process ID),而在子进程中,它会返回 0。
2. 内存结构在 fork 函数被调用的时候,操作系统会将当前进程的虚拟地址空间复制一份给子进程。
这样,子进程就有了自己的独立内存空间,可以与父进程并行执行。
注意,这里只是指虚拟地址空间,物理内存并没有被复制。
操作系统会使用写时复制(Copy-on-write)技术,即在子进程需要修改内存中某个值时才会开辟新的物理内存空间,避免了大量的内存复制。
这种技术可以大大提高程序的运行效率。
3. 文件描述符和文件表文件描述符是一个整数,用来标识一个特定的文件或资源。
在 Unix系统中,每一个进程都有属于自己的文件表,其中存储了打开的文件列表以及文件的各种元信息。
在 fork 操作中,子进程会继承父进程的全部文件描述符和文件表。
这意味着在子进程中打开或关闭文件等操作都会影响父进程的文件,相当于父子进程共享文件。
4. 进程控制块进程控制块(Proc Control Block,PCB)是操作系统内部维护的一个数据结构,存储了进程的各种属性。
在 fork 后,子进程会获取一份父进程的 PCB,包括进程 ID、状态、优先级等信息。
这使得系统可以在同一个进程中对父子进程进行管理和调度。
5. 总结fork 是操作系统中基本的进程创建操作之一,在 Unix 系统中是通过系统调用实现的。
在 fork 实现中,操作系统会复制一份当前进程的虚拟地址空间、文件描述符以及进程控制块,并使用写时复制技术避免大量的内存复制。
操作系统 fork()

void main (void)
{
int x=5;
if( fork( ) )
{
x+=30;
printf ("%d\n",x);
}
else
printf("%d\n",x);
printf("%d\n",x);
}
1.2预测结果:
administrator@ubuntu:~/yanhong$ ./a.out
5
35
35
5
5
将第一个printf("%d\n",x);----printf("%d ",x);后得到B程序
B:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int y=9;
if( fork( ) )
{
x+=30;
printf ("%d\n",x);
}
else
{
printf("%d\n",y);
printf("%d\n",x);
}
printf("%d\n",x);
}
结果::
administrator@ubuntu:~/yanhong$ vi 4.c
administrator@ubuntu:~/yanhong$ cc 4.c
实验心得:
(一)对进程的理解:
一个进程包含三个元素:
linux创建进程的方法

linux创建进程的方法
在Linux系统中,创建进程的方法有多种,其中最常用的方法是使用fork()系统调用。
下面是详细的创建进程的步骤:
1. 导入头文件
在程序中导入头文件<unistd.h>,该头文件中包含了fork()系统调用的声明。
2. 调用fork()系统调用
使用fork()系统调用创建一个新的进程。
fork()系统调用会返回两次,一次在父进程中返回子进程的PID,另一次在子进程中返回0。
3. 判断进程类型
根据fork()系统调用的返回值判断当前进程是父进程还是子进程。
如果返回值大于0,则表示当前进程是父进程,返回值为子进程的PID;如果返回值为0,则表示当前进程是子进程。
4. 编写父进程代码
在父进程中编写需要执行的代码。
通常情况下,父进程会等待子进程执行完毕后再继续执行。
5. 编写子进程代码
在子进程中编写需要执行的代码。
通常情况下,子进程会执行一些与父进程不同的操作。
6. 退出进程
在进程执行完毕后,使用exit()系统调用退出进程。
在父进程中,可以使用wait()系统调用等待子进程执行完毕后再退出。
以上就是在Linux系统中创建进程的详细步骤。
需要注意的是,创建进程时需要
注意进程间的通信和同步问题,以确保程序的正确性和稳定性。
fork()的用法

fork()的用法
fork() 是一个用于创建新进程的系统调用。
具体来说,它会复制当前进程,然后创建一个与原进程几乎完全相同的新进程。
新进程(子进程)会继承父进程的所有资源,包括代码、数据和系统资源。
fork() 的基本用法如下:
1. 调用 fork() 函数,它会返回两次:一次是在父进程中,返回新创建子进程的 PID;另一次是在子进程中,返回 0。
2. 在父进程中,fork() 返回新创建子进程的 PID,可以通过这个 PID 对子进程进行操作。
3. 在子进程中,fork() 返回 0,可以通过返回值来区分当前是父进程还是子进程。
fork() 的常见用法包括:
1. 创建新的子进程:通过调用 fork() 函数,可以创建一个与原进程几乎完全相同的新进程。
新进程会继承父进程的所有资源,包括代码、数据和系统资源。
2. 实现多线程:fork() 可以用来实现多线程编程。
在每个线程中调用 fork() 函数,可以创建多个子进程,从而实现并发执行。
3. 实现并行计算:通过 fork() 函数创建多个子进程,每个子进程执行不同的任务,可以实现并行计算,提高程序的执行效率。
需要注意的是,fork() 函数的使用需要谨慎,因为它涉及到进程的创建和复制。
如果使用不当,可能会导致资源泄漏、竞争条件等问题。
因此,在使用fork() 函数时需要仔细考虑程序的逻辑和安全性。
操作系统常用系统调用

1.fork()功能:创建一个新的进程. 语法:#include #includepid_t fork(); 说明:本系统调用产生一个新的进程, 叫子进程, 是调用进程的一个复制品. 调用进程叫父进程, 子进程继承了父进程的几乎所有的属性:2.waitpid()功能:等待指定进程号的子进程的返回并修改状态语法:#include #includepid_t waitpid(pid,stat_loc,options) pid_t pid; int *stat_loc,options; 说明:当pid等于-1,options等于0时,该系统调用等同于wait().否则该系统调用的行为由参数pid和options决定. pid指定了一组父进程要求知道其状态的子进程: -1:要求知道任何一个子进程的返回状态. >0:要求知道进程号为pid值的子进程的状态.0) { waitpid(pid,&stat_loc,0);/*父进程等待进程号为pid的子进程的返回*/ }else { /*子进程的处理过程*/ exit(1);}/*父进程*/ printf("stat_loc is [ d]\n",stat_loc); /*字符串"stat_loc is [1]"将被打印出来*/3.exit()功能:终止进程. 语法:#include void exit(status) int status; 说明:调用进程被该系统调用终止.引起附加的处理在进程被终止前全部结束.返回值:无4.signal()功能:信号管理功能语法:#include void (*signal(sig,disp))(int) int sig; void (*disp)(int); void (*sigset(sig,disp))(int) int sig; void (*disp)(int); int sighold(sig) int sig; int sigrelse(sig) int sig; int sigignore(sig) int sig; int sigpause(sig) int sig; 说明:这些系统调用提供了应用程序对指定信号的简单的信号处理. signal()和sigset()用于修改信号定位.参数sig指定信号(除了SIGKILL和SIGSTOP,这两种信号由系统处理,用户程序不能捕捉到). disp指定新的信号定位,即新的信号处理函数指针.可以为SIG_IGN,SIG_DFL或信号句柄地址. 若使用signal(),disp是信号句柄地址,sig不能为SIGILL,SIGTRAP或SIGPWR,收到该信号时,系统首先将重置sig的信号句柄为SIG_DFL,然后执行信号句柄. 若使用sigset(),disp是信号句柄地址,该信号时,系统首先将该信号加入调用进程的信号掩码中,然后执行信号句柄.当信号句柄运行结束后,系统将恢复调用进程的信号掩码为信号收到前的状态.另外,使用sigset()时,disp为SIG_HOLD,则该信号将会加入调用进程的信号掩码中而信号的定位不变. sighold()将信号加入调用进程的信号掩码中. sigrelse()将信号从调用进程的信号掩码中删除. sigignore()将信号的定位设置为SIG_IGN. sigpause()将信号从调用进程的信号掩码中删除,同时挂起调用进程直到收到信号. 若信号SIGCHLD的信号定位为SIG_IGN,则调用进程的子进程在终止时不会变成僵死进程.调用进程也不用等待子进程返回并做相应处理. 返回值:调用成功则signal()返回最近调用signal()设置的disp的值. 否则返回SIG_ERR.例子一:设置用户自己的信号中断处理函数,以SIGINT信号为例: int flag=0; void myself() {flag=1;printf("get signal SIGINT\n"); /*若要重新设置SIGINT信号中断处理函数为本函数则执行以*下步骤*/ void (*a)(); a=myself;signal(SIGINT,a);flag=2;}main(){while (1) { sleep(2000); /*等待中断信号*/ if (flag==1) { printf("skip system call sleep\n"); exit(0);}if (flag==2) { printf("skip system call sleep\n"); printf("waiting for next signal\n"); }}}5.kill()功能:向一个或一组进程发送一个信号. 语法:#include #includeint kill(pid,sig); pid_t pid; int sig; 说明:本系统调用向一个或一组进程发送一个信号,该信号由参数sig指定,为系统给出的信号表中的一个.若为0(空信号)则检查错误但实际上并没有发送信号,用于检查pid的有效性. pid指定将要被发送信号的进程或进程组.pid若大于0,则信号将被发送到进程号等于pid 的进程;若pid等于0则信号将被发送到所有的与发送信号进程同在一个进程组的进程(系统的特殊进程除外);若pid小于-1,则信号将被发送到所有进程组号与pid绝对值相同的进程;若pid等于-1,则信号将被发送到所有的进程(特殊系统进程除外). 信号要发送到指定的进程,首先调用进程必须有对该进程发送信号的权限.若调用进程有合适的优先级则具备有权限.若调用进程的实际或有效的UID等于接收信号的进程的实际UID或用setuid()系统调用设置的UID,或sig等于SIGCONT同时收发双方进程的会话号相同,则调用进程也有发送信号的权限. 若进程有发送信号到pid指定的任何一个进程的权限则调用成功, 否则调用失败,没有信号发出.返回值:调用成功则返回0,否则返回-1. 例子:假设前一个例子进程号为324,现向它发一个SIGINT信号,让它做信号处理: kill((pid_t)324,SIGINT);6.alarm()功能:设置一个进程的超时时钟. 语法:#include unsigned int alarm(sec) unsigned int sec; 说明:指示调用进程的超时时钟在指定的时间后向调用进程发送一个SIGALRM信号.设置超时时钟时时间值不会被放入堆栈中,后一次设置会把前一次(还未到超时时间)冲掉. 若sec为0,则取消任何以前设置的超时时钟. fork()会将新进程的超时时钟初始化为0.而当一个进程用exec()族系统调用新的执行文件时,调用前设置的超时时钟在调用后仍有效. 返回值:返回上次设置超时时钟后到调用时还剩余的时间秒数. 例子:int flag=0; void myself() {flag=1;printf("get signal SIGALRM\n"); /*若要重新设置SIGALRM信号中断处理函数为本函数则执行*以下步骤*/ void (*a)(); a=myself;signal(SIGALRM,a);flag=2;}main(){alarm(100); /*100秒后发超时中断信号*/ while (1) { sleep(2000); /*等待中断信号*/ if (flag==1) { printf("skip system call sleep\n"); exit(0);}if (flag==2) { printf("skip system call sleep\n"); printf("waiting for next signal\n"); }}}7.system()功能:产生一个新的进程, 子进程执行指定的命令. 语法:#include #includeint system(string) char *string; 说明:本调用将参数string传递给一个命令解释器(一般为sh)执行, 即string被解释为一条命令, 由sh执行该命令.若参数string为一个空指针则为检查命令解释器是否存在. 该命令可以同命令行命令相同形式, 但由于命令做为一个参数放在系统调用中, 应注意编译时对特殊意义字符的处理. 命令的查找是按PATH环境变量的定义的. 命令所生成的后果一般不会对父进程造成影响. 返回值:当参数为空指针时, 只有当命令解释器有效时返回值为非零. 若参数不为空指针, 返回值为该命令的返回状态(同waitpid())的返回值. 命令无效或语法错误则返回非零值,所执行的命令被终止. 其他情况则返回-1. 例子:char command[81]; int i; for (i=1;i0) { wait((int *)0); /*父进程等待子进程的返回*/ }else { /*子进程处理过程*/ exit(0);}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
fork系统调用
(1) fork系统调用说明
fork系统调用用于从已存在进程中创建一个新进程,新进程称为子进程,而原进程称为父进程。
fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的进程号,而子进程中的返回值则返回 0。
因此,可以通过返回值来判定该进程是父进程还是子进程。
使用fork函数得到的子进程是父进程的一个复制品,它从父进程处继承了整个进程的地址空间,包括进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设定、进程优先级、进程组号、当前工作目录、根目录、资源限制、控制终端等,而子进程所独有的只有它的进程号、计时器等。
因此可以看出,使用fork系统调用的代价是很大的,它复制了父进程中的数据段和堆栈段里的绝大部分内容,使得fork系统调用的执行速度并不很快。
fork的返回值这样设计是有原因的,fork在子进程中返回0,子进程仍可以调用getpid函数得到自己的进程ID,也可以调用getppid函数得到父进程的进程ID。
在父进程中使用getpid函数可以得到自己的进程ID,然而要想得到子进程的进程ID,只有将fork的返回值记录下来,别无它法。
fork的另一个特性是所有由父进程打开的文件描述符都被复制到子进程中。
父、子进程中相同编号的文件描述符在内核中指向同一个file结构体,也就是说,file结构体的引用计数要增加。
由于代码段(加载到内存的执行码)在内存中是只读的,所以父子进程可共用代码段,而数据段和堆栈段子进程则完全从父进程复制拷贝了一份。
(2)父进程进行fork系统调用时完成的操作
假设id=fork(),父进程进行fork系统调用时,fork所做工作如下:
①为新进程分配task_struct任务结构体内存空间。
②把父进程task_struct任务结构体复制到子进程task_struct任务
结构体。
③为新进程在其内存上建立内核堆栈。
④对子进程task_struct任务结构体中部分变量进行初始化设置。
⑤把父进程的有关信息复制给子进程,建立共享关系。
⑥把子进程加入到可运行队列中。
⑦结束fork()函数,返回子进程ID值给父进程中栈段变量id。
⑧当子进程开始运行时,操作系统返回0给子进程中栈段变量id。
(3)fork调用时所发生的事情
下面代码是fork函数调用模板,fork函数调用后常与if-else语句结合使用使父子进程执行不同的流程。
假设下面代码执行时产生的是X进程,fork后产生子进程的是XX进程,XX进程的进程ID号为1000。
int pid ;
pid = fork();
if (pid < 0) {
perror("fork failed");
exit(1);
}
if (pid == 0) {
message = "This is the child/n";
} else {
message = "This is the parent/n";
}
调用fork前,内存中只有X进程,如图12-9所示,此时XX进程还没“出生”。